GREENPLUM介绍之数据库管理(七)- 配置数据库高可用性之master镜像
如何设置高可用数据库服务器

如何设置高可用数据库服务器互联网的快速发展推动了大量数据的产生和存储,因此数据库服务器的高可用性显得尤为重要。
高可用数据库服务器可以确保数据库系统在面对硬件故障或网络中断等意外情况时仍能提供持续可靠的服务。
本文将介绍一些关键的设置和策略,帮助您搭建高可用的数据库服务器。
一、数据库服务器的冗余设置为了确保数据库系统的高可用性,首先需要进行服务器的冗余设置。
这意味着至少需要两台数据库服务器来提供冗余服务。
一台服务器作为主服务器,负责处理所有的读写请求,而另外一台服务器则作为备用服务器,监控主服务器的状态,并在主服务器发生故障时接管其职责。
为了实现这一设置,您可以考虑使用数据库复制技术。
数据库复制可以将主服务器上的数据同步到备用服务器上,确保备用服务器上的数据与主服务器上的数据保持一致。
当主服务器发生故障时,备用服务器可以立即切换为主服务器,继续提供服务。
二、实现高可用的网络架构除了服务器的冗余设置,高可用的数据库服务器还需要支持高可用的网络架构。
为了确保网络的可靠性,您可以考虑使用双机房部署。
将主服务器和备用服务器分别部署在不同的机房,通过跨机房的网络连接实现数据的同步和故障切换。
这样即使一台机房发生故障,另一台机房仍然可以继续提供服务。
此外,还可以考虑使用虚拟IP地址(VIP)技术来实现故障切换。
虚拟IP地址可以自动漂移到备用服务器上,确保在主服务器故障时,备用服务器可以立即接管主服务器的职责。
通过这种方式,可以实现数据库服务的无缝切换,减少业务中断的时间。
三、监控和故障转移要确保高可用数据库服务器的可靠性,监控和故障转移是必不可少的。
监控系统可以实时监测主服务器和备用服务器的状态,一旦发现主服务器出现故障,可以立即触发故障切换。
在故障发生时,需要及时进行故障转移,确保备用服务器可以立即接管主服务器的职责。
可以通过一些自动化的脚本或工具来实现故障转移的自动化,减少人工干预的时间和成本。
同时,为了保证数据库的数据完整性和一致性,还需要设置定期的数据备份和恢复策略。
greenplum 学习笔记

一般地,greenplum的每个segment节点对应一个网口NIC,一个物理CPU,一个磁盘控制器,以便同机器的多个segment之间互不影响。
greenplum的备份,提供了gp_dump做并行备份,master和segment节点同时执行备份操作,另外gp_crondump会定期执行备份操作;支持PostgreSQL的pg_dump和pg_dumpall命令,但是其将所有的数据写成一个文件保存在master上,使用受限。
(在白皮书的第21章节备份与恢复有详细描述)在master节点的$MASTER_DATA_DIRECTORY目录下,pg_hba.conf文件保存了主机远程访问策略;postgresql.conf文件配置了数据库运行的参数。
greenplum数据库的启动gpstart,关闭gpstop,重启gpstop -r,强制关闭gpstop -f ,修改参数后不重启DB加载参数gpstop -u ,仅启动mastergpstart -m;在master节点修改postgresql.conf文件,想所有segment同时修改postgresql.conf文件的操作是:gpssh -f ~/seg_hosts "echo 'parameter=value' | cat - >> /gpdata/p*/*/postgresql.conf"--------------------------------------------------------------------------------------------------------------用greenplum实现mapreduce:INPUT部分将输入拆分成(key,value)对儿,送给MAP部分;MAP部分将其生成新的(key,output_list)对儿,然后送给reduce部分;由reduce部分安照key分组运算得到结果。
Greenplum安装部署参考手册

Greenplum安装部署参考手册V1.02016年3月目录第一章硬件环境部署 (2)1.1 服务器与机柜 (2)1.2 网络部署 (2)1.2.1服务器网络连接 (2)1.2.2网卡绑定(bond)推荐模式 (3)1.3 raid及文件系统规划 (3)1.3.1 Master服务器配置 (3)1.3.2 Segment服务器配置 (4)第二章 GP软件环境部署 (5)2.1 操作系统环境安装部署 (5)2.2.1 BIOS设置开启超线程 (5)2.2.2 安装操作系统基础包 (5)2.2.3 安装系统语言 (5)2.2.4 安装系统工具包 (6)2.2.5 开发语言连接驱动 (8)2.2.6 时区配置 (8)2.2.7 文件系统和分区配置 (9)2.2.8 网卡配置 (10)2.2.9 操作系统安全配置 (11)2.2.10 操作系统用户组和用户 (13)2.2.11 网络IP配置 (14)2.2.12 对外服务VIP设置 (15)2.2.13 集群NTP服务时钟同步配置 (15)2.2.14 ssh服务参数调整 (15)2.2 操作系统参数设置 (15)2.3 数据库系统安装部署 (18)Greenplum软件安装 (18)数据库初始化 (21)2.4 数据库参数设置 (23)2.5 基准性能测试 (24)2.6 后续工作 (24)第一章硬件环境部署1.1服务器与机柜服务器器与机柜的摆放应需要充分考虑机器散热的问题,不建议每个机柜都完全放满。
1.2网络部署1.2.1服务器网络连接Greenplum集群内部各节点服务器通过独立的万兆以太网交换机连接,交换机为集群内部私有,配置两台,两台交换机直连,以双活方式工作。
每台集群内部服务器需配置两个万兆网口,每个网口连接一个交换机,同时两个万兆网口以mode4 方式邦定,配置一个IP。
如下图所示,每台服务器的第一张网卡都连接到一台交换机上,同理另一张网卡都连接到另一台交换机上。
GreenPlum数据库详细安装过程

目录1.1.GreenPlum数据库概述........................................1.2.GreenPlum数据库架构原理....................................2.SUSELinuxEnterprise1164-bit操作系统安装过程.....................2.1.初始化阶段 .................................................2.2.系统分区 ...................................................2.3.软件选择和系统任务 .........................................2.4.语言选择 ...................................................2.5.Kdump设置..................................................2.6.安装过程 ...................................................3.配置网卡IP......................................................4.GreenPlum中Master配置过程......................................4.1.建立gpadmin用户 ...........................................4.2.关闭防火墙 .................................................4.3.启动FTP....................................................4.4.使用FlashXP上传GreenPlum数据 .............................4.5.使用putty.exe工具配置GreenPlum数据库 .....................4.6.GreenPlum数据库配置详情....................................GrennPlum数据库的初始化...............................修改GreenPlum数据库账户的权限........................附录A...............................................................附录B...............................................................1.概述1.1.GreenPlum数据库概述1.2.GreenPlum数据库架构原理本系统中GreenPlum由一个主节点(master)和四个从节点(segment)构成,主节点和从节点由一台千兆交换机进行连接。
greenplum集群原理

greenplum集群原理
Greenplum是一种基于PostgreSQL的开源数据仓库系统,设计用于处理大规模数据集。
它使用MPP(大规模并行处理)架构,将数据分散到多个节点上,并使用这些节点进行并行查询处理,以提高查询性能。
Greenplum集群的基本原理是将数据分散到多个节点上,每个节点都有自己的存储和计算资源。
这种分布式架构允许多个节点同时处理查询,从而显著提高了大规模数据的查询性能。
在Greenplum集群中,有一个主节点(Master)和多个工作节点(Segment)。
主节点负责管理集群中的所有节点,协调查询请求并分发数据。
工作节点负责存储数据和执行查询操作。
当客户端发送查询请求时,主节点首先将查询计划分发给工作节点。
每个工作节点执行查询计划并返回结果给主节点。
主节点再将这些结果合并并返回给客户端。
Greenplum集群还具有强大的数据并行处理能力。
它将查询分成多个子任务,并将这些子任务分发给多个工作节点。
这些工作节点可以并行处理子任务,并在执行过程中自动进行数据分片和负载均衡。
这使得Greenplum集群能够高效地处理大规模数据集,提高查询性能。
PostgreSQL中的高可用性解决方案

PostgreSQL中的高可用性解决方案在现代的数据应用中,高可用性(High Availability,HA)是一个至关重要的因素。
在数据库领域,PostgreSQL提供了一些高可用性的解决方案,可以帮助用户实现数据的持续可用性和系统的可靠性。
本文将介绍一些常用的PostgreSQL高可用性解决方案。
1. 数据复制(Replication)数据复制是一种常见的高可用性解决方案,它通过将数据从主服务器复制到一个或多个备用服务器,实现数据的冗余存储和故障恢复能力。
PostgreSQL提供了多种数据复制方法,包括基于日志的物理复制(Physical Replication)和基于逻辑复制(Logical Replication)。
1.1 基于日志的物理复制基于日志的物理复制是PostgreSQL内置的一种数据复制方法,它通过复制主服务器上的事务日志(WAL),将变更的数据块物理复制到备用服务器。
这种方法可以实现快速的数据复制和故障切换,但对备用服务器的版本和配置要求较高。
1.2 基于逻辑复制基于逻辑复制是PostgreSQL 9.4及以上版本中引入的一种数据复制方法。
它通过解析和应用主服务器上的逻辑变更(例如INSERT、UPDATE、DELETE语句),将变更的数据逻辑复制到备用服务器。
这种方法相对灵活,可以实现不同版本和配置的备用服务器。
2. 流复制(Streaming Replication)流复制是PostgreSQL中一种基于日志的物理复制方法,它通过流式传输事务日志(WAL)来实现数据的持续复制和故障切换。
流复制要求主服务器和备用服务器之间有稳定的网络连接,并且备用服务器必须实时接收并应用主服务器上的更改。
2.1 同步流复制同步流复制是一种高可用性的方法,它确保主服务器上的事务在提交后,备用服务器立即应用并确认。
这种方法可以提供零数据丢失和最小的故障恢复时间,但对网络延迟和性能要求较高。
数据库管理技术的高可用性实现方法

数据库管理技术的高可用性实现方法在当今信息化的时代,数据库已经成为了企业和组织日常工作不可或缺的一部分。
然而,数据库管理系统的可用性一直是个值得关注的问题。
为了确保数据库系统的平稳运行和数据的安全性,高可用性的实现是非常必要的。
本文将介绍一些常用的数据库管理技术的高可用性实现方法,以帮助读者了解和应用这些技术来提高数据库系统的可用性。
1. 数据库复制数据库复制是一种常用的高可用性实现方法。
它通过将主库的数据复制到一个或多个备库来实现数据的冗余存储和高可用性。
当主库出现故障时,备库可以立即接管主库的工作,保证系统的可用性。
数据库复制可以采用同步复制或异步复制的方式。
同步复制要求备库必须与主库保持实时同步,确保数据的一致性;而异步复制则可以有一定的延迟,提高了数据同步的效率。
2. 数据库集群数据库集群是一种将多个数据库服务器连接起来形成一个逻辑上的整体,从而提高数据库系统的可用性和性能的方法。
数据库集群通常由主节点和多个从节点组成。
主节点负责处理用户提交的写请求,而从节点则用来处理读请求。
当主节点发生故障时,从节点中的一个会自动晋升为新的主节点。
数据库集群的好处在于它提供了水平扩展的能力,可以根据需要增加或减少节点的数量,以适应不同规模的应用需求。
3. 数据库备份与恢复数据库备份与恢复是一种保证数据安全和高可用性的重要手段。
通过定期对数据库进行备份,可以在数据库发生故障时快速恢复数据,减少系统停机时间。
在选择备份方案时,需要考虑到数据库的大小、备份的频率和备份的存储位置等因素。
同时,还需要测试备份和恢复的过程,以确保备份数据的完整性和可用性。
4. 数据库监控和故障检测数据库监控是保证数据库高可用性的关键环节之一。
通过对数据库系统的实时监控,可以及时发现故障和异常,采取相应的措施来预防和解决问题。
数据库监控可以包括对数据库性能指标的监测、对数据库资源的监控和对数据库操作的审计等。
同时,也可以通过故障检测来及时发现数据库中的硬件故障和软件故障,并采取相应的措施来修复。
GreenPlum安装笔记_计算机软件及应用_IT计算机_专业资料

2015/6/13 22:51 GP架构_1与GreenPlum类似的产品:IBM NITIZA(国内没人用)Terndata2007年被EMC收购GreenPlum国外市场:纳斯达克,skypeGreenPlum国内市场:阿里,民生银行,深发展银行,电信业(MPP架构)MPP架构:海量并行处理Massively Parallel Processingshare nothing 模式,每一个节点不进行资源共享,集群中每个节点有独立的CPU、内存、存储、总线等。
SMP架构:symmetric mass processing 对称多处理系统:耦合的多处理系统,共享总线、内存、IO资源,传统的ORCKLE,DB2是非常典型的产品ORACLE_RAC 处于半共享状态,各节点连接共享存储,所以不能算MPPGreenPlum 基于PostGreSQL8.2 之前在国内使用比较少,在国外使用广泛。
Mysql与PostGreSQL地位同等,但mysql被Oracle收购之后没落。
GreenPlum 在函数、dataloading、存储过程等继承了PostGreSQLGP增加BI和数据仓库的支持:A、外部表、并行加载(优势明显)B、资源队列管理的优化,对角色、用户、组进行资源优化分配,管理。
C、GP在查询优化器的增强、分布支持、分区表、执行计划的优化、空间回收、数据分析,简化调优,架构时对称、数据分布均匀的话,可以免去调优Master Host:访问系统的入口,所有请求都需要从Master Host访问,正常来讲,管理员也不可以直接访问SegmentHost ,系统中只允许直接访问MasterHost ,单独操作SegmentHost 影响一致性和完整性。
数据监听进程(PostGres):监听用户请求。
处理所有用户连接。
建立执行计划,通过网络层分发给SegmentHost。
协调整个处理过程,保证SegmentHost处理结果侧一致和同步。
greenplum gdfdist使用手册

greenplum gdfdist使用手册Greenplum GDFDist 使用手册概述Greenplum GDFDist 是一个用于在 Greenplum 数据库集群中进行分布式数据传输和加载的工具。
它提供了高效、可靠和并行的数据传输功能,能够加速数据导入和导出的过程。
本手册将向您介绍 GDFDist 的安装和配置方法,并提供一些常见的使用示例。
安装和配置1. 安装 GDFDistGDFDist 是作为 Greenplum 数据库分发功能的一部分提供的。
在安装 Greenplum 数据库时,GDFDist 已经被自动包括在内。
确保已正确安装 Greenplum 数据库版本来使用 GDFDist。
2. 配置 GDFDist在开始使用 GDFDist 之前,需要进行一些配置。
打开 Greenplum 数据库配置文件(通常位于 `$MASTER_DATA_DIRECTORY/gpseg-1/postgresql.conf`),找到以下配置项,并根据需要进行修改: - `gp_external_enable`:确保该配置项的值为 `on`,以启用外部表和 GDFDist 功能。
- `gp_external_max_segs`:根据您的集群规模和性能需求,适当调整此配置项的值。
它控制了能使用 GDFDist 进行数据传输的并行进程数量。
完成配置后,重新加载Greenplum 数据库配置文件以使更改生效。
使用示例以下是一些常见的 GDFDist 使用示例,展示了不同场景下如何高效地使用数据传输功能。
1. 从本地文件导入数据到 Greenplum 数据库使用 `COPY` 命令结合 GDFDist,可以将本地文件中的数据快速导入到 Greenplum 数据库中。
示例命令如下:```COPY my_table FROM PROGRAM 'gdfdist -F text -b my_file.txt' WITH (FORMAT CSV, HEADER);```在上述命令中,`my_table` 是指目标表的名称,`my_file.txt` 是指本地文件的路径名。
MySQL数据库的高可用性解决方案与部署

MySQL数据库的高可用性解决方案与部署随着互联网的迅猛发展,数据成为了企业最重要的资产之一。
而MySQL作为一种常用的关系型数据库,广泛应用于各个领域。
然而,由于数据库的单点故障可能导致业务中断,高可用性的需求变得尤为重要。
本文将重点讨论MySQL数据库的高可用性解决方案与部署。
一、高可用性的概念介绍高可用性(High Availability)指的是系统具有持续稳定运行的能力,即在面对硬件故障、软件问题或计划外的维护等情况下,仍然能够正常提供服务。
对于MySQL数据库而言,实现高可用性的关键在于确保数据库的持久性和可用性。
二、MySQL高可用性解决方案1. 主从复制(Master-Slave Replication)主从复制是MySQL中最为常见的高可用性解决方案之一。
通过配置一个主数据库(Master)和一个或多个从数据库(Slave),将主数据库的写操作同步到从数据库上。
在主数据库发生故障时,可以快速切换到从数据库,从而实现数据库的高可用性。
2. 主主复制(Master-Master Replication)与主从复制相比,主主复制可以实现双向的数据同步。
即每个节点既可以接受写操作,又可以读取数据。
这种解决方案在分布式系统中广泛应用,能够提高系统的并发性能和容错能力。
但需要注意的是,主主复制可能引发数据冲突和一致性问题,需要谨慎配置。
3. MHA(Master High Availability)MHA是由Mixi开发的一种自动化MySQL高可用性解决方案。
它基于主从复制原理,通过监控主库的状态来实现主从切换。
当主库出现故障时,MHA可以自动将从库切换为新的主库,并通知其他从库更改复制源。
MHA具有自动切换、故障检测和自动配置等特点,能够提供高可用性的MySQL服务。
4. Galera ClusterGalera Cluster是一个基于同步复制原理的MySQL高可用性解决方案,通过多个节点之间的同步复制来保证数据的一致性。
greeplumn介绍

Greenplum是一个基于开源PostgreSQL的分布式数据库,采用shared-nothing架构,即主机、操作系统、内存、存储都是每台服务器独立自我控制,不存在共享。
Greenplum本质上是一个关系型数据库集群,实际上是由多个独立的数据库服务组合而成的一个逻辑数据库。
与Oracle的RAC不同,这种数据库集群采取的是MPP(Massively Parallel Processing)架构。
Greenplum最大的特点就是基于低成本的开放平台基础上提供强大的并行数据计算性能和海量数据管理能力。
这个能力主要指的是并行计算能力,是对大任务、复杂任务的快速高效计算。
Greenplum内部使用udp网络,但是Greenplum会对数据包进行校验,因此可靠性等同于TCP。
greenplum原理

greenplum原理Greenplum是一种基于分布式架构的开源数据仓库系统,它是PostgreSQL的一个分支,用于处理大规模数据分析和处理任务。
下面是Greenplum的一些原理:1、分布式架构:Greenplum采用分布式架构,可以将数据分布在多个节点上,并通过并行处理来提高性能。
每个节点都可以独立处理查询请求,并通过分布式存储系统来协作完成数据读写操作。
2、数据分片:Greenplum支持对表进行数据分片,将数据划分为多个小的片段,然后分布在不同的节点上。
这样可以提高查询效率和并行处理能力。
数据分片可以是水平分片(将数据按照某个字段进行哈希)或垂直分片(将不同的表或列划分为不同的片段)。
3、并行查询:Greenplum支持并行查询,可以将一个查询任务划分为多个子任务,然后在多个节点上同时执行。
这样可以加速查询速度,提高系统性能。
4、数据倾斜:在Greenplum中,数据可能会在某些节点上分布不均匀,导致某些节点的负载较重,而其他节点的负载较轻。
这种现象称为数据倾斜。
为了解决这个问题,Greenplum支持动态负载均衡,可以自动检测负载不均衡的情况,并将数据重新分配到负载较轻的节点上。
5、数据复制:Greenplum支持数据复制,可以将数据在多个节点上进行备份,以提高数据的可用性和容错性。
当一个节点发生故障时,系统可以自动切换到其他可用的节点上继续执行查询任务。
6、数据压缩:Greenplum支持对数据进行压缩,以减少存储空间和提高读写性能。
常见的压缩算法包括Run-length Encoding(RLE)和Delta Encoding(Delta)。
总的来说,Greenplum通过分布式架构、数据分片、并行查询、动态负载均衡、数据复制和数据压缩等技术,实现了高性能、高可用性和可扩展性的数据仓库系统。
数据库的高可用性解决方案

数据库的高可用性解决方案一、简介在当今信息时代,数据库承担着各种应用系统中重要的数据存储和管理功能。
而数据库的高可用性成为了企业和组织所面临的一项重要挑战。
本文将介绍数据库的高可用性解决方案,旨在为读者提供相关的知识和参考。
二、数据库的高可用性需求数据库的高可用性是指数据库能够在遇到故障或异常情况时,保持系统的持续可用性,确保数据库和数据的可靠性、可用性、一致性和完整性。
在现代化的应用系统中,数据库的停机和数据丢失都将带来巨大的损失,因此高可用性已成为企业和组织的重要需求。
三、主备复制(Master-Slave Replication)方案主备复制方案是实现数据库高可用性的常见解决方案之一。
该方案通过将主数据库和一个或多个备数据库进行数据同步,保证备数据库中的数据与主数据库保持一致,当主数据库出现故障时,备数据库将自动切换为主数据库继续提供服务。
主备复制方案主要步骤如下:1. 配置主备数据库:在主数据库和备数据库上安装数据库软件,配置主库和从库的相关参数。
2. 启动主备复制:主数据库将日志记录发送到备数据库,备数据库进行日志重放,确保数据同步。
3. 监测主数据库故障:通过心跳机制或监控系统实时监测主数据库的状态,一旦主数据库发生故障,将自动启动备数据库。
4. 切换为主数据库:备数据库接管主数据库的角色,成为新的主数据库,提供服务。
四、数据库集群(Database Cluster)方案数据库集群方案也是常见的实现高可用性的方案之一。
该方案通过在多个节点上运行数据库软件,将数据分布在不同的节点上,实现数据的冗余和负载均衡,从而提高整个系统的可用性和性能。
数据库集群方案主要步骤如下:1. 配置数据库集群:安装数据库软件并配置集群节点,确保节点之间可以相互通信和同步数据。
2. 数据分片:将数据按照某种规则分散到不同的节点上,确保数据的冗余和负载均衡。
3. 故障检测与容错:通过心跳检测或监控系统实时监测节点的状态,一旦节点发生故障,自动将其从集群中剔除。
greenplum 语法

greenplum 语法Greenplum是一个分布式数据库管理系统,它支持SQL语言进行数据的查询、插入、更新和删除等操作。
本文将介绍Greenplum的基本语法和常用操作。
一、基本语法1. 创建数据库CREATE DATABASE dbname;2. 删除数据库DROP DATABASE dbname;3. 连接数据库c dbname;4. 创建表格CREATE TABLE tablename (column1 datatype,column2 datatype,column3 datatype,.....);5. 删除表格DROP TABLE tablename;6. 插入数据INSERT INTO tablename (column1, column2, column3, ....)VALUES (value1, value2, value3, .....);7. 查询数据SELECT column1, column2, ....FROM tablenameWHERE condition;8. 更新数据UPDATE tablenameSET column1 = value1, column2 = value2, ....WHERE condition;9. 删除数据DELETE FROM tablenameWHERE condition;二、常用操作1. 聚合函数聚合函数用于对数据进行计算,包括SUM、AVG、COUNT、MAX和MIN等。
SELECT SUM(column) FROM tablename;2. 排序排序用于对数据进行排序,包括ASC(升序)和DESC(降序)。
SELECT column1, column2, ....FROM tablenameORDER BY column1 ASC;3. 分组分组用于将数据按照某个字段进行分组,可以配合聚合函数进行计算。
SELECT column1, SUM(column2)FROM tablenameGROUP BY column1;4. 联结联结用于将两个或多个表格中的数据进行联合。
Greenplum服务器配置参数

Greenplum服务器配置参数Greenplum服务器配置参数⒈硬件配置⑴ CPU配置⑵内存配置⑶磁盘配置⑷网络配置⒉操作系统配置⑴操作系统版本⑵内核参数⑶文件系统配置⒊ Greenplum数据库配置⑴数据库初始化参数⑵数据目录配置⑶日志配置⑷和连接池配置⑸查询优化器配置⑹并行度配置⑺磁盘空间管理配置⒋ Greenplum集群配置⑴主节点配置⑵备节点配置⑶分布式配置⑷高可用配置⒌安全性配置⑴访问控制配置⑵数据加密配置⑶账号权限配置⒍监控和调优配置⑴系统监控配置⑵自动化调优配置⑶审计日志配置⒎高可用和容错配置⑴节点故障恢复配置⑵数据备份和恢复配置⑶手动主备切换配置⑷故障自动转移配置⒏性能优化配置⑴数据分区和表分区配置⑵查询缓存配置⑶并行查询配置⑷数据统计配置⒐系统维护和升级配置⑴集群维护配置⑵系统升级配置⑶定期备份配置⒑附件本文档涉及的附件详见附件目录。
1⒈法律名词及注释1⑴ Greenplum:Greenplum是一款用于大数据分析的并行数据库管理系统,以开源方式发布。
1⑵ CPU:中央处理器,计算机的核心部件之一,负责处理核心的计算任务。
1⑶内存:计算机中用于存储数据和指令的部件,辅助CPU进行高速数据读写。
1⑷磁盘:计算机用于存储数据的物理设备,可长期保存数据。
1⑸网络:计算机之间互联的方式,用于数据传输和通信。
1⑹操作系统:管理和控制计算机硬件与软件资源的系统软件。
1⑺数据库:用于存储和管理数据的系统。
1⑻分布式系统:由多个计算机节点组成的系统,节点之间通过网络通信。
1⑼高可用:系统在出现故障时仍能保持正常运行的能力。
1⑴0 账号权限:控制用户对系统资源的访问权限。
1⑴1 节点故障恢复:当一个节点发生故障时,系统自动将其恢复到正常状态。
1⑴2 数据备份和恢复:保护数据安全的措施,避免数据丢失。
1⑴3 自动化调优:系统根据负载情况自动对系统进行性能优化。
1⑴4 审计日志:记录系统操作和事件的日志,用于追踪和审查。
数据库高可用性方案汇总
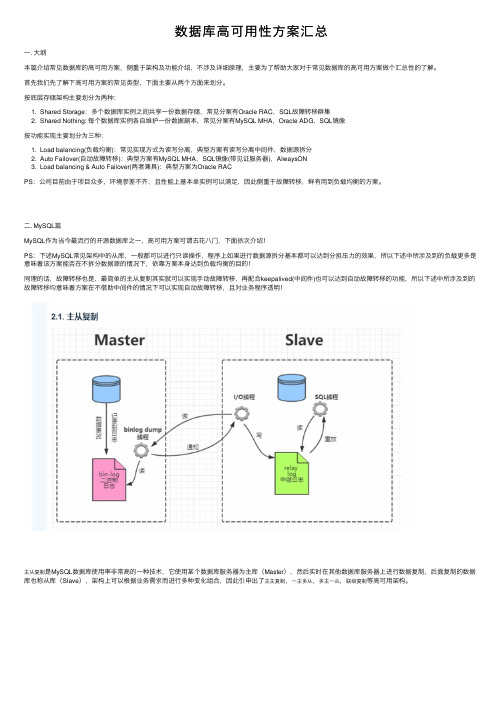
数据库⾼可⽤性⽅案汇总⼀. ⼤纲本篇介绍常见数据库的⾼可⽤⽅案,侧重于架构及功能介绍,不涉及详细原理,主要为了帮助⼤家对于常见数据库的⾼可⽤⽅案做个汇总性的了解。
⾸先我们先了解下⾼可⽤⽅案的常见类型,下⾯主要从两个⽅⾯来划分。
按底层存储架构主要划分为两种:1. Shared Storage:多个数据库实例之间共享⼀份数据存储,常见分案有Oracle RAC,SQL故障转移群集2. Shared Nothing: 每个数据库实例各⾃维护⼀份数据副本,常见分案有MySQL MHA,Oracle ADG,SQL镜像按功能实现主要划分为三种:1. Load balancing(负载均衡):常见实现⽅式为读写分离,典型⽅案有读写分离中间件,数据源拆分2. Auto Failover(⾃动故障转移):典型⽅案有MySQL MHA,SQL镜像(带见证服务器),AlwaysON3. Load balancing & Auto Failover(两者兼具):典型⽅案为Oracle RACPS:公司⽬前由于项⽬众多,环境参差不齐,且性能上基本单实例可以满⾜,因此侧重于故障转移,鲜有⽤到负载均衡的⽅案。
⼆. MySQL篇MySQL作为当今最流⾏的开源数据库之⼀,⾼可⽤⽅案可谓五花⼋门,下⾯依次介绍!PS:下述MySQL常见架构中的从库,⼀般都可以进⾏只读操作,程序上如果进⾏数据源拆分基本都可以达到分担压⼒的效果,所以下述中所涉及到的负载更多是意味着该⽅案能否在不拆分数据源的情况下,依靠⽅案本⾝达到负载均衡的⽬的!同理的话,故障转移也是,最简单的主从复制其实就可以实现⼿动故障转移,再配合keepalived(中间件)也可以达到⾃动故障转移的功能,所以下述中所涉及到的故障转移均意味着⽅案在不借助中间件的情况下可以实现⾃动故障转移,且对业务程序透明!主从复制是MySQL数据库使⽤率⾮常⾼的⼀种技术,它使⽤某个数据库服务器为主库(Master),然后实时在其他数据库服务器上进⾏数据复制,后⾯复制的数据库也称从库(Slave),架构上可以根据业务需求⽽进⾏多种变化组合,因此引申出了主主复制,⼀主多从,多主⼀从,联级复制等⾼可⽤架构。
greenplumd的reorgnize

greenplumd的reorgnize
Greenplum Database 是一个分布式数据库管理系统,它提供了高性能、高可用性和可扩展性的数据存储和处理功能。
在 Greenplum 中,表是存储数据的基本单位,每个表都由一个或多个段(Segment)组成,每个段都存储在单独的节点上。
当表的数据量较大时,需要对其进行分区以提高查询性能和数据管理效率。
在 Greenplum 中,reorgnize 是一个用于重新组织表的命令。
它主要用于重新组织表的物理存储结构,以提高查询性能和数据管理效率。
下面是一个示例:
```sql
REORGANIZE TABLE my_table;
```
上述命令将重新组织名为 my_table 的表的物理存储结构。
在执行该命令之前,需要确保表的数据已经备份,并且表的所有查询和更新操作都已经停止。
在执行 reorgnize 命令时,Greenplum 会根据表的结构和数据分布情况,重新组织表的物理存储结构。
这可能包括合并分裂的段、移动数据从一个节点到另一个节点、重新分配数据等操作。
这些操作可以提高查询性能和数据管理效率,但也需要一些时间和资源来完成。
总之,reorgnize 命令是 Greenplum 中用于重新组织表物理存储结构的重要命令。
它可以帮助提高查询性能和数据管理效率,但也需要谨慎操作并确保备份数据的完整性和一致性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
master,保证原primary
master故障时最后提交的事务可以正常提交,并且使用相同的端口接入用户新的连接请
求。
启用standby master的流程非常简单,既可以在初始化时启用standby
new_standby_hostname 在该工具调用完成之后,可以用gpstate检查状态$ gpstate -
f,新的primary segment应该是active的状态,如果有新加standby master,standby
master状态时passive。 Master instance = Active Master instance standby =
master接受用户连接请求,standby master通过gpsyncagent进程(运行在standby
master上)利用事务日志保持与primary
master的同步。由于master上不存放任何用户数据,存放在其中的表不会频繁更新,因
此同步是实时的。standby
master所在主机除了复制进程外,没有正式master服务运行。当primary出现故障,sta
master是不同步的,应该进一步检查detail_state和error_message列中的信息,判断
侍獠脑颍⒔薪饩觥M瓿晌侍獾木勒螅ü饔胓pinitstandby可以重新同
步standby master。 $ gpinitstandby -s standby_master_hostname -n
在系统工作的过程中,standby
master节点也可能出现数据同步故障,比如网络问题,导致gpsyncagent出现同步故障
没Э赡芪薹笆备兄K訢BA应该定期检查gp_master_mirroring中的信息,如果
⑾謘t
andby
Passive 在完成,新primary master激活之后,应该在其上运行analyze命令。比如 $
psql dbname -c 'ANALYZE;' 如果没有在激活时,添加新的standby
master,事后也可以通过gpinitstandby的调用添加新的standby master.
/gpdata /gpdata应该是standby master的数据目录。一旦完成激活,standby
master的身份转化成primary master。如果在激活的时候,想配置一个新的standby
master可以通过-c选项实现。 $ gpactivatestandby -d /gpdata -c
s参数指定standby用的主机名即可。也可以使用gpinitstandby工具去添加standby
master。DBA需要从处于工作状态的primary master节点上调用这个工具,使用-
s参数,后面跟上standby的主机名。比如 gpinitstandby -s mdw2 如果遇到primary
master(gpinitsystem),也可以对存在的系统添加standby
master(gpinitstandby)。无论哪种方式,首先要准备standb初始化时,添加standby
master,仅需要在gpinitsystem命令上使用-
GREENPLUM介绍之数据库管理(七)- 配置数据库高可用性之master镜像
master镜像是通过把primary master对应的standby
master放置到不同的物理主机实现的。正常情况下只有primary
standby出现故障,由于到目前为止,EMC还没有提供自己的cluster,因此,如果不使用
谌降腸luster的情况下,DBA需要手工激活standby master进行master
failover,这个过程通过调用gpactivatestandby命令实现 $ gpactivatestandby -d