数学建模 SPSS 典型相关分析
典型相关分析的spss操作流程

典型相关分析的spss操作流程1.首先,打开SPSS软件并创建一个新的数据文件。
First, open the SPSS software and create a new data file.2.导入你要进行典型相关分析的数据到SPSS中。
Import the data for canonical correlation analysis into SPSS.3.确保数据变量的命名和类型是正确的。
Make sure the data variable names and types are correct.4.确认数据的缺失值情况,并进行适当的处理。
Check for missing values in the data and handle them appropriately.5.选择“分析”菜单中的“相关”选项。
Select the "Correlate" option from the "Analysis" menu.6.选择“典型相关”作为分析的方法。
Choose "Canonical Correlation" as the method for analysis.7.将想要进行分析的自变量和因变量添加到对应的框中。
Add the predictor and criterion variables to their respective boxes for analysis.8.确定是否需要进行变量的标准化处理。
Decide if standardization of variables is needed.9.点击“OK”开始进行典型相关分析。
Click "OK" to start the canonical correlation analysis.10.解释典型相关分析的结果和统计显著性。
Interpret the results and statistical significance of the canonical correlation analysis.11.对典型相关分析的结果进行图表展示。
如何在SPSS中实现典型相关分析

如何在SPSS中实现典型相关分析什么是典型相关分析?典型相关分析是指对于两个变量集合,分别找出它们的主成分,使得两个主成分之间相关系数最大,称为典型相关分析,也叫双重主成分分析。
典型相关分析可用于研究两个变量集合之间的联系,特别是当变量集合具有相关结构时,可发现更深入的联系。
SPSS中如何实现典型相关分析?1.打开数据文件:首先要打开SPSS软件,然后点击“文件”选项卡,从下拉菜单中选择“打开”命令。
在弹出的打开文件对话框中选择自己的典型相关分析数据文件并打开。
2.设置典型相关分析:点击“分析”选项卡,在下拉菜单中选择“典型相关”命令。
在弹出的对话框中选择两组变量集合并输入相关变量的名称,然后点击“确定”按钮。
3.进行典型相关分析:在弹出的典型相关分析结果窗口中,SPSS会输出典型相关系数矩阵和变量权重矩阵,以及典型变量的相关性和累积方差贡献等信息。
4.结果解释:通过观察典型相关系数矩阵和变量权重矩阵,可发现两个变量集合之间的相关性状况。
同时,通过观察典型变量的相关性和累积方差贡献,获取变量集合对联结的贡献度和对典型变量的解释能力。
典型相关分析的应用实例举例来说,假设我们想研究人的身体状况与心理健康之间的关系。
我们将人的身体状况因素归为一组变量集(如身高、体重、BMI指数等),将人的心理健康因素归为另一组变量集(如焦虑得分、抑郁得分、快乐得分等),然后进行典型相关分析。
结果显示,两组变量集之间存在强关联,其中第一对典型变量是身高、体重、BMI指数、焦虑得分和抑郁得分;第二对典型变量是快乐得分、嗜睡得分和心境得分。
这些变量集代表两方面不同的人类特征。
因此我们可以得到人类身体和心理健康之间的关系非常密切。
典型相关分析是一种用于寻找两组变量集合之间关联的有用工具。
在SPSS中实现典型相关分析,需要首先打开数据文件,然后选择指定变量集合并进行典型相关分析。
最后通过观察典型相关系数矩阵、变量权重矩阵、典型变量的相关性和累积方差贡献等指标,来解释变量集合之间的关联状况。
SPSS典型相关分析案例

SPSS典型相关分析案例典型相关分析(Canonical Correlation Analysis,CCA)是一种统计方法,用于研究两组变量之间的相关性。
它可以帮助研究人员了解两组变量之间的关系,并提供有关这些关系的详细信息。
在SPSS中,可以使用典型相关分析来探索两个或多个变量之间的关系,并进一步理解这些变量如何相互影响。
下面我们将介绍一个典型相关分析的案例,以展示如何在SPSS中执行该分析。
案例背景:假设我们有一个医学研究数据集,包含30名患者的多个生物标记物和他们的疾病严重程度评分。
我们希望了解这些生物标记物与疾病严重程度之间的关系,并查看是否可以建立一个线性模型来预测疾病严重程度。
以下是执行这个案例的步骤:第1步:准备数据首先,我们需要准备数据,确保所有变量都是数值型。
在SPSS中,我们可以通过检查数据集的描述性统计信息或查看变量视图来做到这一点。
第2步:导入数据在SPSS中,我们可以通过选择菜单中的"File"选项,然后选择"Open"来导入数据集。
我们应该选择包含待分析数据的文件,并确保正确指定变量的类型。
第3步:执行典型相关分析要执行典型相关分析,我们可以选择菜单中的"Analyze"选项,然后选择"Canonical Correlation"。
在弹出的对话框中,我们应该选择我们希望研究的生物标记物变量和疾病严重程度评分变量。
然后,我们可以选择一些选项,如方差-协方差矩阵、相关矩阵和判别系数,并点击"OK"执行分析。
第4步:解释结果完成分析后,SPSS将提供几个输出表。
我们应该关注典型相关系数和标准化典型系数,以了解两组变量之间的关系。
我们可以使用这些系数来解释生物标记物如何与疾病严重程度相关联,并找到最重要的变量。
此外,我们还可以使用SPSS提供的其他统计结果来进一步解释模型的效果和预测能力。
SPSS相关分析案例讲解

相关分析一、两个变量的相关分析:Bivariate 1.相关系数的含义相关分析是研究变量间密切程度的一种常用统计方法。
相关系数是描述相关关系强弱程度和方向的统计量,通常用r 表示。
①相关系数的取值范围在-1和+1之间,即:–1≤r ≤ 1。
②计算结果,若r 为正,则表明两变量为正相关;若r 为负,则表明两变量为负相关。
③相关系数r 的数值越接近于1(–1或+1),表示相关系数越强;越接近于0,表示相关系数越弱。
如果r=1或–1,则表示两个现象完全直线性相关。
如果=0,则表示两个现象完全不相关(不是直线相关)。
④3.0<r ,称为微弱相关、5.03.0<≤r ,称为低度相关、8.05.0<≤r ,称为显著(中度)相关、18.0<≤r ,称为高度相关⑤r 值很小,说明X 与Y 之间没有线性相关关系,但并不意味着X 与Y 之间没有其它关系,如很强的非线性关系。
⑥直线相关系数一般只适用与测定变量间的线性相关关系,若要衡量非线性相关时,一般应采用相关指数R 。
2.常用的简单相关系数(1)皮尔逊(Pearson )相关系数皮尔逊相关系数亦称积矩相关系数,1890年由英国统计学家卡尔•皮尔逊提出。
定距变量之间的相关关系测量常用Pearson 系数法。
计算公式如下:∑∑∑===----=ni ni i ini i iy y x xy y x xr 11221)()())(( (1)(1)式是样本的相关系数。
计算皮尔逊相关系数的数据要求:变量都是服从正态分布,相互独立的连续数据;两个变量在散点图上有线性相关趋势;样本容量30≥n 。
(2)斯皮尔曼(Spearman )等级相关系数Spearman 相关系数又称秩相关系数,是用来测度两个定序数据之间的线性相关程度的指标。
当两组变量值以等级次序表示时,可以用斯皮尔曼等级相关系数反映变量间的关系密切程度。
它是根据数据的秩而不是原始数据来计算相关系数的,其计算过程包括:对连续数据的排秩、对离散数据的排序,利用每对数据等级的差额及差额平方,通过公式计算得到相关系数。
SPSS相关分析实例操作步骤-SPSS做相关分析

SPSS相关分析实例操作步骤-SPSS做相关分析SPSS(Statistical Product and Service Solutions)是目前在工业、商业、学术研究等领域中广泛应用的统计学软件包之一。
Correlation是SPSS的一个功能模块,可以用于分析两个或多个变量之间的关系。
下面是SPSS进行相关分析的具体步骤:1. 打开SPSS软件,选择“变量视图”(Variable View),输入相关的变量名,包括数字型变量和分类变量。
2. 进入“数据视图”(Data View),输入数据,并保存数据集。
3. 打开菜单栏中的“分析”(Analyze),选择“相关”(Correlate),再选择“双变量”(Bivariate)。
4. 在双变量窗口中,选择包含需要分析的变量的变量名,并将其移至右侧窗口中的变量框(Variables)。
5. 如果需要控制其他变量的影响,可以选择“控制变量”(Options)。
6. 点击“确定”(OK)按钮后,SPSS将输出结果,并将其显示在输出窗口中。
相关系数(Correlation Coefficient)介于-1和1之间,可以用来衡量两个变量之间的线性关系的强度。
7. 如果需要对结果进行图形化展示,可以选择“图”(Plots),并选择适当的图形类型。
需要注意的是,进行相关分析时需要确保变量之间存在线性关系。
如果变量之间存在非线性关系,建议使用其他统计方法进行分析。
同时,SPSS进行相关分析的结果只能描述变量之间的关系,不能用于说明因果关系。
以上是SPSS做相关分析的具体步骤,希望能对大家进行SPSS 数据分析有所帮助。
SPSS典型相关分析结果解读

Correlations for Set-1Y1Y2Y3Y1 1.0000.9983.5012Y2.9983 1.0000.5176Y3.5012.5176 1.0000第一组变量间的简单相关系数Correlations for Set-2X1X2X3X4X5X6X7X8X9X10X11X12X13 X1 1.0000-.3079-.7700-.7068-.6762-.7411-.7466-.5922-.1948-.1285-.2650-.9070-.6874 X2-.3079 1.0000-.0117.0103-.0613-.0283-.0140.3333.4161.3810.3831.1098-.0640 X3-.7700-.0117 1.0000.9905.9860.9973.9990.5892.0421-.0196.2492.9515.9903 X4-.7068.0103.9905 1.0000.9910.9935.9952.5634.0249-.0367.2476.9120.9953 X5-.6762-.0613.9860.9910 1.0000.9887.9912.5717.0363-.0277.2475.8972.9926 X6-.7411-.0283.9973.9935.9887 1.0000.9985.5563.0142-.0453.2210.9355.9950 X7-.7466-.0140.9990.9952.9912.9985 1.0000.5795.0319-.0298.2441.9390.9945 X8-.5922.3333.5892.5634.5717.5563.5795 1.0000.7097.6540.8990.6619.5138 X9-.1948.4161.0421.0249.0363.0142.0319.7097 1.0000.9922.8520.1350-.0228 X10-.1285.3810-.0196-.0367-.0277-.0453-.0298.6540.9922 1.0000.8184.0752-.0801 X11-.2650.3831.2492.2476.2475.2210.2441.8990.8520.8184 1.0000.3093.1840 X12-.9070.1098.9515.9120.8972.9355.9390.6619.1350.0752.3093 1.0000.9040 X13-.6874-.0640.9903.9953.9926.9950.9945.5138-.0228-.0801.1840.9040 1.0000Correlations Between Set-1and Set-2X1X2X3X4X5X6X7X8X9X10X11X12X13 Y1-.7542-.0147.9995.9940.9892.9989.9998.5788.0334-.0280.2426.9430.9937 Y2-.7280-.0234.9965.9958.9954.9977.9988.5859.0485-.0136.2573.9285.9949 Y3-.4485.2952.5096.4955.5230.4760.5048.9695.7610.7071.9073.5449.4500Canonical Correlations1 1.0002 1.0003 1.000第一对典型变量的典型相关系数为CR1=1.....二三Test that remaining correlations are zero:维度递减检验结果降维检验Wilk's Chi-SQ DF Sig.1.000.000.000.0002.000.00024.000.0003.000103.48911.000.000此为检验相关系数是否显著的检验,原假设:相关系数为0,每行的检验都是对此行及以后各行所对应的典型相关系数的多元检验。
数学建模__SPSS_典型相关分析

数学建模__SPSS_典型相关分析典型相关分析(Canonical Correlation Analysis)是一种多变量统计方法,用于分析两组变量之间的关系。
在典型相关分析中,我们尝试找到两组变量之间的线性组合,使得这些线性组合之间的相关性最大化。
典型相关分析可以帮助研究者理解两组变量之间的关系,并发现潜在的相关结构。
典型相关分析适用于有两组或多组相关变量的研究。
典型相关分析既可以用于预测模型的建立,也可以用于变量选择和降维。
下面我们将介绍典型相关分析的基本原理、步骤和应用。
典型相关分析的基本原理是寻找两个组合线性关系,使得两个组合相互之间具有最大的相关性。
在典型相关分析中,我们将一个变量集作为自变量,另一个变量集作为因变量,然后寻找这两个变量集之间的最佳线性组合。
典型相关分析的步骤如下:1.收集数据:首先需要收集自变量和因变量的数据。
这些数据可以是观察数据、实验数据或调查数据。
2.数据预处理:在进行典型相关分析之前,我们需要对数据进行预处理。
这包括缺失数据处理、异常值检测和变量归一化等步骤。
3.计算相关系数:接下来,我们需要计算自变量和因变量之间的相关系数。
这可以通过计算皮尔逊相关系数、斯皮尔曼相关系数或肯德尔相关系数来实现。
4.计算典型变量:通过应用典型相关分析模型,我们可以计算出一组自变量和一组因变量的典型变量。
典型变量是自变量和因变量的线性组合,它们具有最大的相关性。
5.进行相关性检验:在典型相关分析中,我们常常需要进行相关性的显著性检验。
这可以通过计算典型相关系数的显著性水平来实现。
6.结果解释和应用:最后,根据典型相关分析的结果,我们可以解释自变量和因变量之间的关系,并根据这些结果进行应用和决策。
典型相关分析的应用非常广泛。
例如,在金融领域,典型相关分析可以帮助分析公司的财务指标与市场指标之间的关系。
在医学研究中,典型相关分析可以用于分析不同变量对医疗结果的影响。
在社会科学研究中,典型相关分析可以帮助分析人们的行为和态度之间的关系。
SPSS 软件应用 相关分析举例
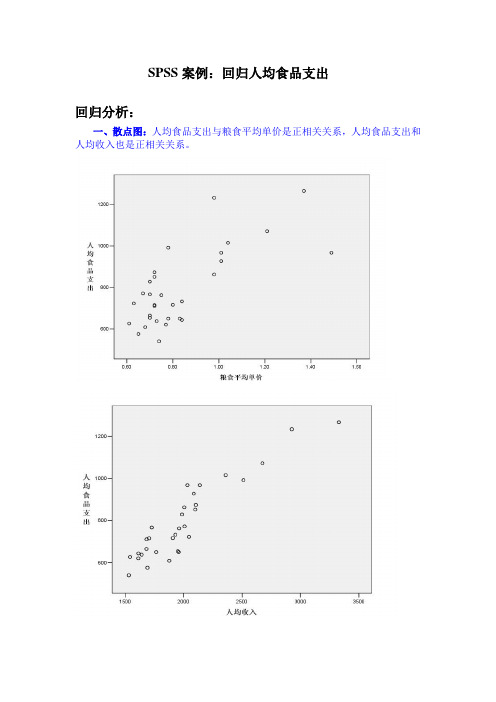
SPSS案例:回归人均食品支出回归分析:一、散点图:人均食品支出与粮食平均单价是正相关关系,人均食品支出和人均收入也是正相关关系。
二、相关性分析:人均食品支出与粮食平均单价的相关系数为0.730,为显著相关,假设检验t检验,sig(2-tailed)=0小于双侧检验的显著水平0.01,所以推翻原假设,人均食品支出与粮食平均单价线性相关。
人均食品支出与人均收入的相关系数为0.921,为显著相关,假设检验t检验,sig(2-tailed)=0小于双侧检验的显著水平0.01,所以推翻原假设,人均食品支出与人均收入线性相关。
三、(1)方程中的自变量列表(方法是进入)(2 )模型拟合概述:可以从表中看出,自变量和因变量之间的相关系数为0.940,拟合线性回归的确定性系数为0.883,经调整后的确定性系数为0.875,标准误的估计为2.766。
这里的R,R^2的值反映两变量的共变量比率高,模型与数据的拟合程度好。
Durbin-Watson=2.766>2,所以他们三者的关系程度显著。
四、方差分析:回归平方和为915129.1,残差平方和为120679.8,总平方和为1035809,对应的F统计量的值为106.164,显著性水平小于0.05,可以认为所建立的回归方程有效。
因为sig=0小于0.05,所以推翻原假设的多个自变量同时为0的假设,所以自变量不同时为0.五、回归系数:非标准化的回归系数X1的估计值为213.423,标准误为73.278,标准化的回归系数为0.243,回归系数显著性检验t统计量的值为2.913,对应显著性水平Sig.=0.007<0.05,可以认为粮食平均单价对人均食品输出有显著影响。
X2的估计值为0.352,标准误为0.038,标准化的回归系数0.767,回归系数显著性检验t统计量的值为9.185,对应显著性水平Sig.=0.000<0.05,可以认为人均收入对人均食品输出有显著影响。
SPSS典型相关分析

表6
第18页/共23页
表7
从这两个表中可以看出,V1主要和变量hed相关 (0.99329),而V2主要和led(0.92484)及net (0.75305)相关;W1主要和变量arti(0.99696)及 man(0.92221)相关,而W2主要和com(0.81123) 相关;这和它们的典型系数是一致的。
表1 相关性的若干检验
第12页/共23页
表2给出了特征根(Eigenvalue),特征根所占的百分比 (Pct)和累积百分比(Cum. Pct)和典型相关系数(Canon Cor)及其平方(Sq. Cor)。看来,头两对典型变量(V, W) 的累积特征根已经占了总量的99.427%。它们的典型相 关系数也都在0.95之上。
第14页/共23页
表3 未标准化系数 表4 标准化系数
第15页/共23页
可以看出,头一个典型变量V1相应于前面第一个(也是最 重要的)特征值,主要代表高学历变量hed;而相应于前面 第二个(次要的)特征值的第二个典型变量V2主要代表低 学历变量led和部分的网民变量net,但高学历变量在这里起 负面作用。 从表4中可以得到第一变量的头三个典型变量V1、 V2、V3中的V1 和V2的表达式:
12.3 典型相关分析的实例分析
例12.1为研究业内人士和观众对于一些电视节目的观点 的关系,对某地方30个电视节目做了问卷调查并给出 了平均评分。观众评分来自低学历(led)、高学历(hed) 和网络(net)调查三种,它们形成第一组变量;而业内人 士分评分来自包括演员和导演在内的艺术家(arti)、发 行(com)与业内各部门主管(man)三种,形成第二组变 量。参加图12.1,数据间TV.Sav。
SPSS典型相关分析结果解读

SPSS典型相关分析结果解读
典型相关分析是SPSS的一种统计分析方法,用于检验两变量之间的线性关系。
它的结果包括Pearson积差相关系数、Spearman等级相关系数以及Kendall tau-b相关系数。
a. Pearson积差相关系数:Pearson积差相关系数是最常用的相关分析指标,该系数介于-1~+1之间,表示两个变量之间的线性关系强度。
当其值接近1时,表明两个变量之间呈正相关;当其值接近-1时,表明两个变量之间呈负相关;而当其值接近0时,表明两个变量之间没有显著相关性。
b. Spearman等级相关系数:Spearman等级相关系数也是一种常用的相关分析指标,用于检验两个变量之间的非线性关系,通常情况下,该指标的取值范围在-1~+1之间,其余与Pearson积差相关系数的解释原理相同。
c. Kendall tau-b相关系数:Kendall tau-b相关系数也是一种常用的相关分析指标,用于检验两个变量之间的非线性关系,其取值范围也是-1~+1,当取值为正时,表明两个变量之间存在正相关性;当取值为负时,表明两个变量之间存在负相关性;而当取值为0时,表明两个变量之间没有显著相关性。
用SPSS进行相关分析的典型案例

数据预处理
缺失值处理
对于缺失值,可以采用删除缺失样本、均值插补、多重插补等方法进行处理。在本案例中,由于缺失值较少,采用删 除缺失样本的方法进行处理。
异常值处理
对于异常值,可以采用箱线图、散点图等方法进行识别和处理。在本案例中,通过箱线图发现存在少数极端异常值, 采用删除异常样本的方法进行处理。
数据标准化
06
典型案例三:经济学领域 应用
案例背景介绍
研究目的
探讨某国经济增长与失业率之间的关系 。
VS
数据来源
采用某国统计局发布的年度经济数据,包 括GDP增长率、失业率等指标。
SPSS操作步骤详解
1. 数据导入与整理 将原始数据导入SPSS软件。 对数据进行清洗和整理,确保数据质量和准确性。
SPSS操作步骤详解
显著性检验
观察相关系数旁边的显著性水平 (p值),判断相关关系是否具有 统计显著性。通常情况下,p值小 于0.05被认为具有统计显著性。
结果讨论
结合相关系数和显著性检验结果 ,讨论社会经济地位与心理健康 之间的关系。例如,可以探讨不 同教育水平或职业对心理健康的 影响,以及这种关系在不同人群 中的差异。
关注SPSS输出的显著性检验结果。如 果P值小于设定的显著性水平(如 0.05),则认为药物剂量与症状改善 程度之间的相关性是显著的,即两变 量之间存在统计学意义的关联。
结合专业背景和实际情境,对结果进 行解释和讨论。例如,如果药物剂量 与症状改善程度呈正相关且相关性显 著,可以认为增加药物剂量有助于改 善患者症状。同时,需要注意结果的 局限性和可能的影响因素,以便为医 学实践提供有价值的参考信息。
提出政策建议或未来研究方向,以促进经济增长和降 低失业率。
SPSS典型相关分析及结果解释

SPSS典型相关分析及结果解释SPSS 11.0 - 23.0典型相关分析1方法简介如果要研究一个变量和一组变量间的相关,则可以使用多元线性回归,方程的复相关系数就是我们要的东西,同时偏相关系数还可以描述固定其他因素时某个自变量和应变量间的关系。
但如果要研究两组变量的相关关系时,这些统计方法就无能为力了。
比如要研究居民生活环境与健康状况的关系,生活环境和健康状况都有一大堆变量,如何来做?难道说做出两两相关系数?显然并不现实,我们需要寻找到更加综合,更具有代表性的指标,典型相关(Canonical Correlation)分析就可以解决这个问题。
典型相关分析方法由Hotelling提出,他的基本思想和主成分分析非常相似,也是降维。
即根据变量间的相关关系,寻找一个或少数几个综合变量(实际观察变量的线性组合)对来替代原变量,从而将二组变量的关系集中到少数几对综合变量的关系上,提取时要求第一对综合变量间的相关性最大,第二对次之,依此类推。
这些综合变量被称为典型变量,或典则变量,第1对典型变量间的相关系数则被称为第1典型相关系数。
一般来说,只需要提取1~2对典型变量即可较为充分的概括样本信息。
可以证明,当两个变量组均只有一个变量时,典型相关系数即为简单相关系数;当一组变量只有一个变量时,典型相关系数即为复相关系数。
故可以认为典型相关系1数是简单相关系数、复相关系数的推广,或者说简单相关系数、复相关系数是典型相关系数的特例。
2引例及语法说明在SPSS中可以有两种方法来拟合典型相关分析,第一种是采用Manova过程来拟合,第二种是采用专门提供的宏程序来拟合,第二种方法在使用上非常简单,而输出的结果又非常详细,因此这里只对它进行介绍。
该程序名为Canonical correlation.sps,就放在SPSS的安装路径之中,调用方式如下:INCLUDE 'SPSS所在路径\Canonical correlation.sps'.CANCORR SET1=第一组变量的列表/SET2=第二组变量的列表.在程序中首先应当使用include命令读入典型相关分析的宏程序,然后使用cancorr名称调用,注意最后的“.”表示整个语句结束,不能遗漏。
spss典型相关分析

spss典型相关分析【SPSS典型相关分析】导言:典型相关分析是一种常用的统计方法,旨在研究两个不同变量集之间的关联程度。
通过典型相关分析,可以定量地了解两组变量之间的相互影响,从而更好地理解它们之间的关系。
本文将介绍SPSS软件在典型相关分析中的操作流程,并通过一个具体案例来展示对结果的解释和分析。
一、概述典型相关分析是一种多元回归技术,用于研究两组变量集之间的关系。
它通过构建线性组合(典型变量),从而发现两组变量之间的最大相关。
典型相关分析包含两个主要步骤:提取典型变量和解释典型变量。
二、SPSS操作流程1. 数据准备首先,需要确保所用数据集完整、无缺失值,并且变量之间没有共线性。
可以使用SPSS软件导入需要分析的数据集。
2. 创建数据文件在SPSS软件中,通过点击“文件”并选择“新建”来创建新的数据文件。
3. 导入数据在新的数据文件中,通过点击“文件”并选择“打开”来导入待分析的数据集。
在弹出的窗口中,选择所需导入的数据文件并点击“打开”。
4. 进行典型相关分析在SPSS软件中,点击“分析”并选择“典型相关”进行分析。
5. 设置变量在典型相关分析的窗口中,将两组变量逐一添加到相应的文字框中。
6. 运行分析确认所设置的变量无误后,点击“确定”运行分析。
7. 结果解释得出结果后,可以通过SPSS软件中提供的表格和图形等形式进行结果的解释和展示。
三、案例展示为了更好地理解典型相关分析的操作流程和结果解释,以下是一个具体案例的分析。
案例描述:研究人员想要了解大学生的学习成绩和心理健康之间的关系,他们收集了大学生的学习成绩(包括各科目的成绩和平均绩点)和心理健康指标(包括抑郁程度、压力水平和自尊水平)的数据。
分析步骤:1. 数据准备:研究人员清洗数据并确保数据集完整和无缺失值。
他们还进行了变量之间的相关性分析,以排除共线性。
2. 创建数据文件:研究人员在SPSS软件中创建了新的数据文件,命名为“大学生学习与心理健康”。
SPSS 典型相关分析案例

SPSS典型相关分析是一种通过分析一组变量与另一组变量之间的相关性来解释对方变量
差异的统计方法。
在企业管理和人力资源管
理领域,这种方法常被用来研究员工工作满
意度与各种因素的关系,并制定相关的管理
策略。
以下是一个SPSS典型相关分析的案例。
假设我们有一个样本,由100名员工组成,我们想要研究员工工作满意度与以下9个因
素之间的关系:薪酬、晋升机会、培训机会、福利、工作环境、工作内容、工作压力、同
事关系和公司文化。
在进行典型相关分析之前,我们需要将这些变量进行预处理,即去
除不需要的变量、处理缺失值和异常值等。
然后,我们进入SPSS软件,点击“Analyze”菜单下的“Canonical Correlation”命令,在打开的对话框中选择所有9个因素和员工
满意度作为“Variable(s)”并点击“OK”按钮。
SPSS会自动给出相应的结果,包括典型相关系数、方差解释比、典型相关变量等。
假设结果表明第一个典型相关系数为0.70,方差解释比为49%,前三个典型相关变量分别是薪酬、晋升机会和工作内容。
这意味着
这三个变量与员工工作满意度的关系最为密切,可以通过调整这些变量来提高员工的工
作满意度。
具体的建议可以根据调查结果和
实际情况制定,比如提高薪酬水平、加强晋升机会和职业发展支持、改善工作环境等。
(完整版)SPSS双变量相关性分析

数学建模SPSS双变量相关性分析
关键词:数学建模相关性分析SPSS
摘要:在数学建模中,相关性分析是很重要的一部分,尤其是在双变量分析时,要根据变量之间的联系建立评价指标,并且通过这些指标来进行比对赋值而做出评价结果。
本文由数学建模中的双变量分析出发,首先阐述最主要的三种数据分析:Pearson系数,Spearman系数和Kendall系数的原理与应用,再由实际建模问题出发,阐述整个建模过程和结果。
r s=
∑(P i−P ave)(Q i−Q ave)√∑(P i−P ave)2(Q i−Q ave)2
在SPSS中打开数据,点击:分析—>相关—>双变量,打开对话窗口,选择需要分析的两个变量、Spearman秩相关系数分析以及双侧检验。
需要说明两点:
(1)因各体重与各体质数据之间的相关性正负未知,需选用双侧检验;
(2)除了数据满足非正态分布以外,Spearman秩相关系数分析还需要数据分级,以计算秩。
但在SPSS中程序会自动生成秩,无需再手动分级。
注意要保证总体相关系数ρ与样本相关系数r保持一致,还须考虑Sig值。
由数据,Sig<0.5表示接受原假设,即Rho>|r|。
Sig<0.5则拒绝原假设,两者不相关。
而r值则代表了正负相关性,以及相关性大小。
结果见表。
数学建模spss时间预测,心得总结及实例
《一周总结,底稿供参考》我们通过案例来说明:假设我们拿到一个时间序列数据集:某男装生产线销售额。
一个产品分类销售公司会根据过去10 年的销售数据来预测其男装生产线的月销售情况。
现在我们得到了10年120个历史销售数据,理论上讲,历史数据越多预测越稳定,一般也要24个历史数据才行!大家看到,原则上讲数据中没有时间变量,实际上也不需要时间变量,但你必须知道时间的起点和时间间隔。
当我们现在预测方法创建模型时,记住:一定要先定义数据的时间序列和标记!这时候你要决定你的时间序列数据的开始时间,时间间隔,周期!在我们这个案例中,你要决定季度是否是你考虑周期性或季节性的影响因素,软件能够侦测到你的数据的季节性变化因子。
定义了时间序列的时间标记后,数据集自动生成四个新的变量:YEAR、QUARTER、MONTH 和DATE(时间标签)。
接下来:为了帮我们找到适当的模型,最好先绘制时间序列。
时间序列的可视化检查通常可以很好地指导并帮助我们进行选择。
另外,我们需要弄清以下几点:•此序列是否存在整体趋势?如果是,趋势是显示持续存在还是显示将随时间而消逝?•此序列是否显示季节变化?如果是,那么这种季节的波动是随时间而加剧还是持续稳定存在?这时候我们就可以看到时间序列图了!我们看到:此序列显示整体上升趋势,即序列值随时间而增加。
上升趋势似乎将持续,即为线性趋势。
此序列还有一个明显的季节特征,即年度高点在十二月。
季节变化显示随上升序列而增长的趋势,表明是乘法季节模型而不是加法季节模型。
此时,我们对时间序列的特征有了大致的了解,便可以开始尝试构建预测模型。
时间序列预测模型的建立是一个不断尝试和选择的过程。
spss提供了三大类预测方法:1-专家建模器,2-指数平滑法,3-ARIMA指数平滑法指数平滑法有助于预测存在趋势和/或季节的序列,此处数据同时体现上述两种特征。
创建最适当的指数平滑模型包括确定模型类型(此模型是否需要包含趋势和/或季节),然后获取最适合选定模型的参数。
SPSS数据分析—典型相关分析

我们已经知道,两个随机变量间的相关关系可以用简单相关系数表示,一个随机变量和多个随机变量的相关关系可以用复相关系数表示,而如果需要研究多个随机变量和多个随机变量间的相关关系,则需要使用典型相关分析。
典型相关分析由于研究的是两组随机变量之间的相关关系,因此也属于一种多元统计分析方法,多元统计分析方法基本上都有降维的思想,典型相关分析也不例外,它借用主成分分析的思想,在多个变量中提取少数几个综合变量,将研究多个变量间的相关关系转换为研究几个综合变量的相关关系。
典型相关分析首先在每组变量中寻找线性组合,使其具有最大相关性,然后再继续寻找在每组中寻找线性组合,使其在和第一次寻找的线性组合不相关的条件下,具有最大相关性,如此继续,直到两组变量的相关性被提取完为止,这些被提取的变量就是综合变量,也称为典型变量,第一对典型变量之间的相关系数称为第一典型相关系数,和其他多元分析一样,一般提取2-3对典型变量,就可以充分概括样本信息。
看一个例子我们现在想分析体力与运动能力的关系,随机抽取了38人,收集了与体力有关的7项指标,与运动能力有关的5项指标,数据如下SPSS对于典型相关分析没有专门的过程,而是需要调用专门的宏程序来加以完成,该程序名为Canonical correlation.sps,在按照SPSS的时候默认安装在Sample文件夹中相应的程序为:INCLUDE 'E:\Program Files\IBM\SPSS\Statistics\21\Samples\Simplified Chinese\Canonical correlation.sps'.CANCORR SET1=X1 to X7/ SET2=Y1 to Y5 .首先通过include命令读取宏程序,然后用cancorr调用程序主体并进行变量指定。
数学建模:spss统计分析

SPSS
第1节 描述统计
设变量X有一组观测数据x1,,x2 ,…,xn ,常 用的描述统计量有: (1)中心趋势:平均值、中位数、众数、和 (2)离中趋势:方差、标准差、最大最小值、 极差 (3)百分位数:四分位数、 给定间距的等间距分位数 (4)分布度统计量:偏态度、峰态度
自回归曲线图
高低图
交互相关图
序列图
频谱图
误差线图
SPSS
第3节 参数检验与置信区间
例4 某糖厂用自动包装机装糖,其装糖量服从正态分布,且
每包标准重量为100kg.某天开工后,需对打包机工作进行鉴 定,测得9包糖的重量(kg)为:数据例4.sav
(1)这天打包机的工作是否正常?( 0.05 ) (2)求这天打包机平均装糖重量的置信区间
临界值F
值
F值
SPSS
一维方差分析步骤
1、编辑数据文件:定义两个数值型变量,一个为 因素变量(也成为分组变量)fodder(饲 料),要求是数值型变量,有四个不同水平1, 2,3,4;一个为观测变量weight(体重), 输入数据。保存为:例5.sav
2、选择统计方法:Analyze→Compare Means →One-Way ANOVA 将weight送入因变量列框,将 fodder送入因子(因素)框,点击“确定” 3、输出结果:sig.=0.000<0.05,认为不同饲料对猪 体重增加的作用有显著不同。
Means菜单详解
1 Means过程 求分类变量的综合描述统计量,目的在于比较 2 One-Samples T Test过程 检验单个变量的均值是否与给定的常数之间存在差异。 3 Independent-Samples T Test过程 检验两个不相关的样本来自具有相同均值的总体,例如想知 道购买某产品的顾客与不购买该产品的顾客的平均收入是否相 同。 4 Paired-Samples T Test过程 检验两个相关的样本是否来自具有相同均值的总体。常用与 被观测对象在实验前后是否有差异。 5 One-Way ANOVA过程 单因素方差分析,在下节介绍。
SPSS数据分析实用教程14 典型相关分析

典型相关分析方法最早由Hotelling于1935年提 出,他分析了算术速度和能力与阅读速度与能 力之间的相关程度。典型相关变量与原始的变 量之间的关系可以用下图来说明:
典型相关分析的功能
典型相关分析的主要思想是把两组变量之间的 相关性问题转换为两个单一的变量之间的相关 性问题来讨论
确定变量之间是否存在相关关系 根据一个或几个变量的值,预测或者控制另一个变 量的取值 进行因素分析
基本思想是把两个随机向量X 和Y之间的相关 问题,转化为两个综合变量U和V之间的相关 问题进行讨论,其中U和V分别为X和Y的线性 组合,即U=a'X,V=b'y。
对产品特性的市场价格(第1组)和这些产品的产量的 分析 某种产品的各种性能(第1组)和这种产品的各种物理 、化学特性的关系的分析 一年级大学生入学后的各科考试成绩(第1组)和其高 考时各科的考试成绩等的分析
第一、二组变量的相关系数矩阵
第一组变量和第二组变量的交叉相 关系数矩阵
典Байду номын сангаас相关系数
典型相关的显著性检验
第一组变量的冗余分析
第二组变量的冗余分析
作业
INCLUDE后面引号里面的内容为文件“Canonical correlation.sps”,其 路径要用户电脑中SPSS安装路径下面的“Canonical correlation.sps”所 在的路径来代替
Correlations for Set-1 OldLengt OldWidth OldLengt 1.0000 .7346 OldWidth .7346 1.0000
案例分析
典型相关分析SPSS例析

典型相关分析典型相关分析(Canonical correlation )又称规则相关分析,用以分析两组变量间关系的一种方法;两个变量组均包含多个变量,所以简单相关和多元回归的解惑都是规则相关的特例。
典型相关将各组变量作为整体对待,描述的是两个变量组之间整体的相关,而不是两个变量组个别变量之间的相关。
典型相关与主成分相关有类似,不过主成分考虑的是一组变量,而典型相关考虑的是两组变量间的关系,有学者将规则相关视为双管的主成分分析;因为它主要在寻找一组变量的成分使之与另一组的成分具有最大的线性关系。
典型相关模型的基本假设:两组变量间是线性关系,每对典型变量之间是线性关系,每个典型变量与本组变量之间也是线性关系;典型相关还要求各组内变量间不能有高度的复共线性。
典型相关两组变量地位相等,如有隐含的因果关系,可令一组为自变量,另一组为因变量。
典型相关会找出一组变量的线性组合**=i i j j X a x Y b y =∑∑与 ,称为典型变量;以使两个典型变量之间所能获得相关系数达到最大,这一相关系数称为典型相关系数。
i a 和j b 称为典型系数。
如果对变量进行标准化后再进行上述操作,得到的是标准化的典型系数。
典型变量的性质每个典型变量智慧与对应的另一组典型变量相关,而不与其他典型变量相关;原来所有变量的总方差通过典型变量而成为几个相互独立的维度。
一个典型相关系数只是两个典型变量之间的相关,不能代表两个变量组的相关;各对典型变量构成的多维典型相关,共同代表两组变量间的整体相关。
典型负荷系数和交叉负荷系数典型负荷系数也称结构相关系数,指的是一个典型变量与本组所有变量的简单相关系数,交叉负荷系数指的是一个典型变量与另一组变量组各个变量的简单相关系数。
典型系数隐含着偏相关的意思,而典型负荷系数代表的是典型变量与变量间的简单相关,两者有很大区别。
重叠指数如果一组变量的部分方差可以又另一个变量的方差来解释和预测,就可以说这部分方差与另一个变量的方差之间相重叠,或可由另一变量所解释。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
典型相关分析
在对经济问题的研究和管理研究中,不仅经常需要考察两个变量之间的相关程度,而且还经常需要考察多个变量与多个变量之间即两组变量之间的相关性。
典型相关分析就是测度两组变量之间相关程度的一种多元统计方法。
典型相关分析计算步骤
(一)根据分析目的建立原始矩阵 原始数据矩阵
⎥
⎥⎥⎥⎥⎦⎤
⎢⎢⎢⎢⎢⎣
⎡nq n n np
n n q
p
q p y y y x x x y y y x x x y y y x x x
2
1
2
1222
21
22211121111211
(二)对原始数据进行标准化变化并计算相关系数矩阵
R = ⎥⎦
⎤
⎢
⎣⎡2221
1211
R R R R 其中11R ,22R 分别为第一组变量和第二组变量的相关系数阵,12R = 21
R '为第一组变量和第二组变量的相关系数
(三)求典型相关系数和典型变量
计算矩阵=A 111-R 12R 122-R 21R 以及矩阵=B 122-R 21R 1
11-R 12R 的特征值和特征向量,分
别得典型相关系数和典型变量。
(四)检验各典型相关系数的显著性
第五节 利用SPSS 进行典型相关分析
第一步,录入原始数据,如下表:X1 X2 X3 X4 X5 分别代表多孩率、综合节育率、初中及以上受教育程度的人口比例、人均国民收入和城镇人口比例。
研究人口出生与教育程度、生活水平等的相关。
1、点击“Files→New→Syntax”打开如下对话框。
2、输入调用命令程序及定义典型相关分析变量组的命令。
如图
输入时要注意“Canonical correlation.sps”程序所在的根目录,注意变量组的格式和空格。
第三步,执行程序。
用光标选择这些命令,使其图黑,再点击运行键,即可得到所有典型相关分析结果。
输出结果1
输出结果2
主要结果的解释:
第一组变量相关系数
Correlations for Set-1
X1 X2
X1 1.0000 -.7610
X2 -.7610 1.0000
第二组变量相关系数
Correlations for Set-2
X3 X4 X5
X3 1.0000 .7712 .8488
X4 .7712 1.0000 .8777
X5 .8488 .8777 1.0000
第一组与第二组变量之间的相关系数
Correlations Between Set-1 and Set-2
X3 X4 X5
X1 -.5418 -.4528 -.4534
X2 .2929 .2528 .2447
典型相关系数
Canonical Correlations
1 .578
2 .025
维度递减检验结果(降维检验)
Test that remaining correlations are zero:
Wilk's Chi-SQ DF Sig.
1 .666 10.584 6.000 .102
2 .999 .017 2.000 .992
标准化典型系数—第一组
Standardized Canonical Coefficients for Set-1 1 2
X1 -1.319 .797
X2 -.486 1.463
粗系数—第一组(没有标准化的,作者注)
Raw Canonical Coefficients for Set-1
1 2
X1 -.131 .079
X2 -.091 .275
_
标准化典型系数—第二组
Standardized Canonical Coefficients for Set-2
1 2
X3 .997 -.261
X4 .292 2.075
X5 -.274 -1.743
粗系数—第二组(没有标准化的,作者注)
Raw Canonical Coefficients for Set-2
1 2
X3 .086 -.023
X4 .000 .002
X5 -.017 -.107
典型负载系数(结构相关系数:典型变量与原始变量之间的相关系数)第一组Canonical Loadings for Set-1
1 2
X1 -.949 -.316
X2 .517 .856
交叉负载系数(某一组中的典型变量与另外一组的原始变量之间的相关系数)—第一组原始变量
Cross Loadings for Set-1
1 2
X1 -.548 -.008
X2 .299 .022
典型负载系数(结构相关系数:典型变量与原始变量之间的相关系数)第二组Canonical Loadings for Set-2
1 2
X3 .990 -.140
X4 .821 .344
X5 .829 -.143
交叉负载系数(某一组中的典型变量与另外一组的原始变量之间的相关系数)—第二组原始变量
Cross Loadings for Set-2
1 2
X3 .572 -.004
X4 .474 .009
X5 .479 -.004
Redundancy Analysis:(冗余分析)
(第一组原始变量总方差中由本组变式代表的比例)
Proportion of Variance of Set-1 Explained by Its Own Can. Var. Prop Var
CV1-1 .584
CV1-2 .416
(第一组原始变量总方差中由第二组的变式所解释的比例)
Proportion of Variance of Set-1 Explained by Opposite Can.Var. Prop Var
CV2-1 .195
CV2-2 .000
(第二组原始变量总方差中由本组变式代表的比例)
Proportion of Variance of Set-2 Explained by Its Own Can. Var. Prop Var
CV2-1 .780
CV2-2 .053
(第二组原始变量总方差中由第一组的变式所解释的比例)
Proportion of Variance of Set-2 Explained by Opposite Can. Var. Prop Var
CV1-1 .261
CV1-2 .000
------ END MATRIX -----
另外,在数据表中还输出了以下结果:
s1_cv001:第一组的第一个典型变量;
s2_cv001:第二组的第一个典型变量;
s1_cv002:第一组的第二个典型变量;
s2_cv002:第二组的第二个典型变量;。