如何测试搜索引擎的索引量大小
搜索引擎的实验报告

一、实验目的1. 了解搜索引擎的基本原理和功能。
2. 评估不同搜索引擎的性能,包括搜索速度、准确性、相关性等。
3. 分析搜索引擎的优缺点,为实际应用提供参考。
二、实验环境1. 操作系统:Windows 102. 浏览器:Chrome3. 搜索引擎:百度、谷歌、必应、搜狗三、实验内容1. 搜索速度测试2. 搜索准确性测试3. 搜索相关性测试4. 搜索引擎优缺点分析四、实验步骤1. 搜索速度测试(1)分别打开百度、谷歌、必应、搜狗四个搜索引擎。
(2)在搜索框中输入相同的关键词,如“搜索引擎”。
(3)记录每个搜索引擎的搜索结果出现时间。
(4)比较四个搜索引擎的搜索速度。
2. 搜索准确性测试(1)在搜索框中输入关键词“搜索引擎”。
(2)分析搜索结果中与关键词相关的内容,判断搜索结果的准确性。
(3)比较四个搜索引擎的搜索准确性。
3. 搜索相关性测试(1)在搜索框中输入关键词“搜索引擎”。
(2)分析搜索结果中与关键词相关的内容,判断搜索结果的相关性。
(3)比较四个搜索引擎的搜索相关性。
4. 搜索引擎优缺点分析(1)分析四个搜索引擎在搜索速度、准确性、相关性等方面的优缺点。
(2)结合实际应用场景,总结各搜索引擎的适用范围。
五、实验结果与分析1. 搜索速度测试结果(1)百度:搜索结果出现时间为2秒。
(2)谷歌:搜索结果出现时间为1.5秒。
(3)必应:搜索结果出现时间为2.5秒。
(4)搜狗:搜索结果出现时间为2秒。
从实验结果可以看出,谷歌的搜索速度最快,其次是百度,搜狗和必应的搜索速度相对较慢。
2. 搜索准确性测试结果(1)百度:搜索结果中约80%与关键词相关。
(2)谷歌:搜索结果中约85%与关键词相关。
(3)必应:搜索结果中约75%与关键词相关。
(4)搜狗:搜索结果中约80%与关键词相关。
从实验结果可以看出,谷歌和百度的搜索准确性较高,其次是搜狗,必应的搜索准确性相对较低。
3. 搜索相关性测试结果(1)百度:搜索结果中约70%与关键词相关。
es查询索引数据量语句

es查询索引数据量语句ES(Elasticsearch)是一个开源的分布式搜索和分析引擎,它使用倒排索引来快速检索大量数据。
在ES中,可以使用查询语句来获取索引中的数据量。
下面将详细介绍如何使用ES查询索引数据量的语句。
ES查询索引数据量的语句是通过发送HTTP请求到ES服务器来实现的。
具体的语句如下:```GET /索引名/_count```其中,`索引名`是你要查询的索引的名称。
通过发送这个请求,ES 会返回一个包含索引中文档数量的响应。
下面是一个具体的示例,假设我们要查询名为`my_index`的索引中的数据量:```GET /my_index/_count```发送这个请求后,ES会返回一个类似下面的响应:```{"count" : 1000,"_shards" : {"total" : 5,"successful" : 5,"skipped" : 0,"failed" : 0}}```在这个响应中,`count`字段表示索引中的文档数量,这里是1000。
`_shards`字段提供了关于分片的信息,包括总分片数、成功的分片数、跳过的分片数和失败的分片数。
需要注意的是,如果你的索引非常大,查询数据量可能会花费一些时间。
此外,如果你的索引被分片到多个节点上,查询结果可能会稍有不同,因为每个节点上的数据量可能不完全相同。
以上就是使用ES查询索引数据量的语句的详细介绍。
通过发送这个请求,你可以方便地获取索引中的数据量信息。
如果你需要进一步扩展和深入分析索引中的数据,ES还提供了更多强大的查询和聚合功能,可以根据具体需求进行使用。
搜索引擎测试方法

搜索引擎测试方法
搜索引擎测试是一个多方面的过程,它旨在评估搜索引擎的性能、准确性和用户体验。
下面列举了一些常见的搜索引擎测试方法:
1. 查询测试:使用一系列常见、多样化的查询来测试搜索引擎的响应速度、搜索结果的准确性和完整性。
可以考虑包含不同的关键词、短语、问题等,以确保搜索引擎能够正确解释和返回相关的结果。
2. 评估搜索结果的相关性:通过比较搜索结果与预期相关结果的准确程度来评估搜索引擎的相关性。
可以使用人工标记或专家判断来评估搜索结果的相关性。
3. 垂直搜索测试:针对特定领域或主题进行搜索引擎测试,以评估搜索结果的垂直特化程度和相关性。
这涉及到针对特定领域的查询和评估。
4. 用户体验测试:通过用户反馈、问卷调查和用户行为分析来评估搜索引擎的用户体验。
这包括搜索结果的布局、页面加载速度、相关性提示、过滤选项等。
5. 性能测试:测试搜索引擎在处理各种工作负载情况下的响应速度和性能。
可以使用负载测试工具模拟多个并发用户来评估搜索引擎的性能瓶颈。
6. 语言和地区测试:测试搜索引擎在不同语言和地区的搜索结果的准确性和相关性。
这涉及到使用不同的语言和地区设置进行搜索,以评估搜索引擎在全球范
围内的适应能力。
这些都是常见的搜索引擎测试方法,具体的方法和工具可以根据需要和资源的可用性进行选择和定制。
百度索引量工具升级:可查看子目录收录量
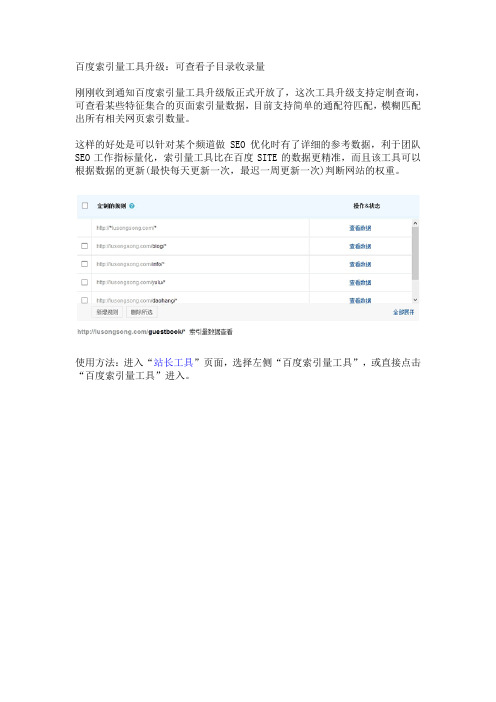
百度索引量工具升级:可查看子目录收录量
刚刚收到通知百度索引量工具升级版正式开放了,这次工具升级支持定制查询,可查看某些特征集合的页面索引量数据,目前支持简单的通配符匹配,模糊匹配出所有相关网页索引数量。
这样的好处是可以针对某个频道做SEO优化时有了详细的参考数据,利于团队SEO工作指标量化,索引量工具比在百度SITE的数据更精准,而且该工具可以根据数据的更新(最快每天更新一次,最迟一周更新一次)判断网站的权重。
使用方法:进入“站长工具”页面,选择左侧“百度索引量工具”,或直接点击“百度索引量工具”进入。
网络基础 搜索引擎的查询技巧

网络基础搜索引擎的查询技巧搜索引擎为用户查找信息提供了极大的方便,你只需输入几个关键词,任何想要的资料都会从世界各个角落汇集到你的电脑前。
然而如果操作不当,搜索效率也是会大打折扣的。
比方说你本想查询某方面的资料,可搜索引擎返回的却是大量无关的信息。
这种情况责任通常不在搜索引擎,而是因为你没有掌握提高搜索精度的技巧。
下面将从9个方面进行介绍,来提高信息检索的效率。
●简单查询在搜索引擎中输入关键词,然后点击“搜索”就行了,系统很快会返回查询结果,这是最简单的查询方法,使用方便,但是查询的结果却不准确,可能包含着许多无用的信息。
●双引号用(" ")给要查询的关键词加上双引号(半角,以下要加的其它符号同此),可以实现精确的查询,这种方法要求查询结果要精确匹配,不包括演变形式。
例如在搜索引擎的文字框中输入“电传”,它就会返回网页中有“电传”这个关键字的网址,而不会返回诸如“电话传真”之类网页。
●使用加号(+)在关键词的前面使用加号,也就等于告诉搜索引擎该单词必须出现在搜索结果中的网页上,例如,在搜索引擎中输入“+电脑+电话+传真”就表示要查找的内容必须要同时包含“电脑、电话、传真”这三个关键词。
●使用减号(-)在关键词的前面使用减号,也就意味着在查询结果中不能出现该关键词,例如,在搜索引擎中输入“电视台-中央电视台”,它就表示最后的查询结果中一定不包含“中央电视台”。
●通配符(*和?)通配符包括星号(*)和问号(?),前者表示匹配的数量不受限制,后者匹配的字符数要受到限制,主要用在英文搜索引擎中。
例如输入“computer*”,就可以找到“computer、computers、computerised、computerized”等单词,而输入“comp?ter”,则只能找到“computer、compater、competer”等单词。
●使用布尔检索所谓布尔检索,是指通过标准的布尔逻辑关系来表达关键词与关键词之间逻辑关系的一种查询方法,这种查询方法允许我们输入多个关键词,各个关键词之间的关系可以用逻辑关系词来表示。
搜索引擎的主要性能评价指标

搜索引擎的主要性能评价指标1.搜索引擎建立索引的方法数据库中的索引一般是按照倒排文档的文件格式存放的,在建立倒排索引的时候,不同的搜索引擎有不同的选项。
有些搜索引擎对于信息页面建立全文索引:而有些只建立摘要部分,或者是段落前面部分的索引。
还有些搜索引擎,如Google建立索引的时候,同时还考虑超文本的不同标记所表示的不同含义,如粗体、大字体显示的东西往往比较重要:放在"锚"链接中的信息往往是它所指向页面的信息的概括,所以用它来作为所指向的页面的重要信息。
Google、Infbseek还在建立索引的过程中收集页面中的超链接。
这些超链接反映了收集到的信息之间的空间结构,利用这些结果可以提高页面相关度判别的准确度。
由于索引不同,在检索信息时产生的结果会不同。
2.搜索引擎的受欢迎程度搜索引擎的受欢迎程度体现了用户对搜索引擎的偏爱程度,知名度高、性能稳定和搜索质量好的搜索引擎很受用户的青睐。
搜索引擎的受欢迎程度也会随着它的知名度和服务水平的变化而动态地变化。
搜索引擎的服务水平与它所收集的信息量、信息的新颖度和查询的精确度相关。
随着各种新的搜索技术的出现,智能化的、支持多媒体检索的搜索引擎将越来越受到用户的欢迎。
3.搜索引擎的检索功能搜索引擎所支持的检索功能的多少及其实现的程度,直接决定了检索效果的好坏,所以网络检索工具除了要支持诸如布尔检索、邻近检索、截词检索、字段检索等基本的检索功能之外,更应该根据网上信息资源的变化,及时地应用新技术、新方法,提高高级检索功能。
另外,由于中文信息持有的编码不统一问题,所以如果搜索引擎能够实现不同内码之间的自动转换,用户就能全面检索大陆及港台地区乃至全世界的中文信息。
这样不但可以提高搜索引擎的质量,而且会得到用户的支持。
4.搜索引擎的检索效果检索效果可以从响应时间、查全率、查准率和相关度方面来衡量。
响应时间是用户输入检索式开始查询到检出结果的时间:查全率是指一次要求搜索结果中符合用户要求的数目与用户查询相关的总数之比:查准率是指一次搜索结果集中符合用户要求的数目与该词搜索结果总数之比:相似度是指用户查询与搜索结果之间相似度的一种度量二查准率是一个复杂的概念,一方面表示搜索引擎对搜索结果的排序,另一方面却体现了搜索引擎对垃圾网页的抗干扰能力。
搜索引擎的测试方法

搜索引擎的测试方法
搜索引擎的测试方法可以分为以下几种:
1. 人工测试:由人工观察和评估搜索结果的准确性、相关性、多样性等。
这可以通过让测试者根据给定的查询词搜索并评估结果的正确性和有用性来完成。
2. 自动测试:使用自动化工具和技术,对搜索引擎的各项指标进行测试和评估。
这可能涉及到使用爬虫来抓取搜索结果,然后使用评估算法分析和比较结果。
3. 用户反馈:通过用户反馈和意见收集来评估搜索引擎的质量。
这可以通过收集用户对搜索结果的意见、投诉、建议等来实现。
4. 对比测试:将搜索引擎与其他类似的搜索引擎进行比较测试,比较它们在查询结果、速度、多样性等方面的表现。
5. 用户行为分析:通过分析用户的搜索行为和点击行为来评估搜索引擎的质量。
这可以通过收集和分析用户点击、翻页、放弃、重新搜索等操作来实现。
无论采用哪种测试方法,都需要考虑一些关键指标,例如搜索结果的准确性、相关性、排序算法的效果、搜索速度、搜索结果的多样性等。
同时,还可以根据具体需求和场景,自定义一些测试方法和指标。
如何进行检测网站搜索引擎_检测网站搜索引擎用哪些方法

如何进行检测网站搜索引擎_检测网站搜索引擎用哪些方法大家应该了解到了为什么有些人做长尾关键词非常简单,有些人做长尾关键词却非常痛苦,主要还是因为网站的整体权重所致。
下面由店铺为大家整理的检测网站搜索引擎方法,希望大家喜欢!检测网站搜索引擎方法一、了解网站权重正常否,是否被降权:1、最直接看网站是否被降权的方式,就是看搜索引擎是否给予这个网站流量。
当搜索引擎将某网站降权,则一个流量都不会给它,所以利用查看该网站的关键词百名内是否有排名就可以断定。
2、检索该网站首页的整个标题,首页也应该在第一位,如下图:注:当搜索整个标题也看不到网站首页时,90%都可证明该网站已被降权了。
(就算爱站上查询百度权重1,也是没有任何意义的)二、检测内页权重:对于一般内容页的标题组合为“文章标题”+“网站名称”的,如果搜索该页的整个标题时,也在第一位,说明这个网站的内页权重也还不错,已经比较适合利用内容页做长尾关键词了。
如果搜索文章页的标题(不含网站名)就能在第一位,说明该站内页权重很好,此时做竞争不大的长尾关键词就非常好做了,只要有收录,基本就会有一定排名。
而大量的长尾关键词也获得了排名,就会让权重更为提升,首页的主关键词也就排的更为稳固。
提升搜索引擎及用户的友好度一,避免过长的篇幅造成网页体积巨大也让用户感觉很难理解。
我们做一个专题确实就是想通过这么一个页面让用户了解更多我们想跟他们表达的信息,于是在很多的时候我们的专题页可能做得非常长,有的甚至超过十多屏内容。
这样不管是对于用户还是搜索引擎,要等这个网页加载完毕需要很长时间,有的甚至需要数十秒时间,这样谁都没有这样的耐心。
再者,就算用户是一个非常有耐心的人,看到十多屏的内容都头疼,虽然解释得很具体,但反而让人感觉很费解。
其实我们只需要几屏的内容即可,向用户表达一个总体信息即可,这样反而可以让用户一眼扫过去就知道我们在干什么,如果他们感兴趣自然会继续浏览这个页面上的外链页面,因为这个时候已经知道要做什么了。
搜索引擎的测试

首先,整个测试计划分为线下测试与线上测试。线下与线上测 试都要分功能测试与性能测试。 一、线下功能测试分为两个部分: 搜索引擎本身的功能测试, 嵌套在前台应用中的功能测试。
二、线下性能测试也分为两个部分: 直接对搜索引擎进行加压的性能测试 通过前台应用进行加压的性能测试:
• 手工测试
• 自动化测试
自动化测试 自动化测试是软件测试发展的一个必然趋 势。随着软件技术的不断发展,测试工具也 , 得到长足的发展,人们开始利用测试工具来 帮助自己做一些重复性的工作。软件测试的 一个显著特点是重复性,重复让人产生厌倦 的心理,重复使工作量倍增,因此人们想到 用工具来解决重复的问题。
搜索引擎测试的难点 衡量搜索引擎系统功能质量方面有2大指标,查询率、查准 率。 性能方面从吞吐率、响应时间、系统资源消耗等多方面综合 考虑。 搜索引擎应用参与运作的角色划分:分发请求/合并查询结 果的merger,以及查询服务的searcher.
搜索引擎漏洞测试:全球最大的软件测试公 司uTest周四宣布了最新搜索引擎漏洞测试结 果。测页面下载速度、实 时相关性和有效性对搜索引测试,其实就是功能回归了,使用预发 布环境来跑回归,手工或者自动化随便,这是不能缺少的。 四、线上的性能测试,这个也是使用预发布环境,分流 线上的一部分压力到这里,观察线上与预发布环境中的各服 务器的情况,如果是第一次发布,线上没有流量,那么就自 己来模拟,或者靠运营来宣传了。记录下服务器的各性能指 标,
手工测试 手工测试有其不可替代的地方,因为人具有很强的 判断能力,而工具没有。手工测试不可替代的地方 至少包括以下几点。 测试用例的设计:测试人员的经验和对错误的判断 能力是工具不可替代的。 界面和用户体验测试:人类的审美观和心理体验是 工具不可模拟的。 正确性的检查:人们对是非的判断、逻辑推理能力 是工具不具备的。
电子商务搜索引擎性能测试报告

电子商务搜索引擎性能测试报告Ⅰ. 引言随着电子商务行业的蓬勃发展,搜索引擎在提供高效和准确搜索结果方面扮演了重要角色。
为了保证电子商务搜索引擎的稳定性和性能,本文对某搜索引擎进行了性能测试并报告测试结果。
Ⅱ. 测试目的我们的测试旨在评估该电子商务搜索引擎的性能、吞吐量和响应时间,并提供一个准确的指标来评估其是否能够满足用户的需求。
Ⅲ. 测试环境我们在以下环境中进行了性能测试:- 服务器配置:8核 Intel Xeon 处理器,32GB RAM- 操作系统:Linux CentOS 7- 数据库:MySQL 8.0- 浏览器:Google ChromeⅣ. 测试方法1. 压力测试:我们模拟了不同并发用户数下的搜索请求,测试服务器在不同负载下的性能表现。
并发用户数量分别是100、500、1000和5000,持续时间为1小时。
2. 吞吐量测试:我们通过在固定时间内发送大量搜索请求,测试服务器每秒可以处理的请求总数。
3. 响应时间测试:我们记录并分析了服务器在不同负载下的平均响应时间和最大响应时间。
Ⅴ. 测试结果1. 压力测试结果:- 并发用户数为100时,搜索引擎响应时间平均为0.5秒,最大响应时间为1秒;搜索成功率为99.5%。
- 并发用户数为500时,搜索引擎响应时间平均为1秒,最大响应时间为2秒;搜索成功率为98.8%。
- 并发用户数为1000时,搜索引擎响应时间平均为2秒,最大响应时间为3秒;搜索成功率为95.2%。
- 并发用户数为5000时,搜索引擎响应时间平均为5秒,最大响应时间为8秒;搜索成功率为81.3%。
2. 吞吐量测试结果:- 在测试时间内,服务器能够处理的请求总数为:100用户/秒、500用户/秒、1000用户/秒和5000用户/秒。
3. 响应时间测试结果:- 不同负载下的平均响应时间逐渐增加,最大响应时间也相应延长。
Ⅵ. 结论基于我们的测试结果,可以得出以下结论:1. 在较小的并发用户数下,该电子商务搜索引擎表现良好,响应时间较快,搜索成功率高。
搜索引擎优化评估的指标

随着对互联网网站搜索引擎优化的需求不断增加,优化评估也开始受到越来越多广大网站经营者的重视。
搜索引擎优化评估是网站经营过程中一个至关重要的环节,有助于网站经营者在不断优化网站过程中更好地把握当前状况,更好地把握未来发展。
搜索引擎优化评估主要包括以下五大指标:
1.搜索引擎的发现率:反映搜索引擎对网站的发现情况,反映网站是否能够被搜索引擎发现和收录,从而体现网站的关键词优化水平;
2.搜索引擎抓取频率:反映搜索引擎对网站的抓取情况,可以了解搜索引擎对网站的抓取速度以及搜索引擎对网站的收录的频率;
3.关键词排名:反映搜索引擎对网站在特定关键词下的排名,可以体现网站优化效果;
4.页面流量统计:可以统计网站的访客来源,从而了解搜索引擎在访客来源中所占比例;
5.网站效果统计:统计网站的转化率,浏览深度或拜访时长,从而可以反映网站的优化效果。
总而言之,搜索引擎优化评估的指标便是上述五项,把握这些指标,网站经营者可以更方便和快捷地制定有效的优化策略。
对于没有搜索引擎优化经验的网站经营者,可以利用技术服务平台的技术支持,了解搜索引擎优化的基本内容,针对不同的网站制定具体的优化方案,将网站经营的提升到一个新的层次。
Oracle:如何计算索引的大小

Oracle:如何计算索引的⼤⼩上次因为创建索引失败,原因是TEMP临时表空间满,经过测试,索引创建需要的临时表空间⼤概是索引的⼤⼩,所以在执⾏alter index index_name rebuild online nologging parallel 5语句前,要计算出创建索引需要的临时段的⼤⼩。
实验如下:SQL> select * from v$version;BANNER----------------------------------------------------------------Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - ProdPL/SQL Release 10.2.0.1.0 - ProductionCORE 10.2.0.1.0 ProductionTNS for Linux: Version 10.2.0.1.0 - ProductionNLSRTL Version 10.2.0.1.0 - ProductionSQL> create table test (name varchar2(4000));Table created.SQL> begin2 for i in 1..10000 loop3 insert into test values(i);4 end loop;5 commit;6 end;7 /PL/SQL procedure successfully completed.SQL> select sum(bytes)/1024 kb from user_extents2 where segment_name='TEST';KB----------192SQL> select sum(bytes)/1024 kb from user_extents2 where segment_name='IX_NAME';KB----------256索引⽐表⼤!实验到了这⾥不得不说⼀下rowid这个伪列。
查看mysql库大小,表大小,索引大小

查看mysql库⼤⼩,表⼤⼩,索引⼤⼩说明:通过MySQL的 information_schema 数据库,可查询数据库中每个表占⽤的空间、表记录的⾏数;该库中有⼀个 TABLES 表,这个表主要字段分别是:TABLE_SCHEMA : 数据库名TABLE_NAME:表名ENGINE:所使⽤的存储引擎TABLES_ROWS:记录数DATA_LENGTH:数据⼤⼩INDEX_LENGTH:索引⼤⼩其他字段请参考MySQL的⼿册,查看⼀个表占⽤空间的⼤⼩,那就相当于是数据⼤⼩ + 索引⼤⼩。
查看所有库的⼤⼩mysql>use information_schema;Database changedmysql>select concat(round(sum(DATA_LENGTH/1024/1024),2),'MB') as data from TABLES;+----------+| data |+----------+|104.21MB |+----------+1 row in set (0.11 sec)查看指定库的⼤⼩mysql>select concat(round(sum(DATA_LENGTH/1024/1024),2),'MB') as data from TABLES where table_schema='jishi';+---------+| data |+---------+|26.17MB |+---------+1 row in set (0.01 sec)查看指定库的指定表的⼤⼩mysql>select concat(round(sum(DATA_LENGTH/1024/1024),2),'MB') as data from TABLES where table_schema='jishi'and table_name='a_ya';+--------+| data |+--------+|0.02MB |+--------+1 row in set (0.00 sec)查看指定库的索引⼤⼩mysql>SELECT CONCAT(ROUND(SUM(index_length)/(1024*1024), 2), ' MB') AS'Total Index Size'FROM TABLES WHERE table_schema ='jishi';+------------------+| Total Index Size |+------------------+|0.94 MB |+------------------+1 row in set (0.01 sec)查看指定库的指定表的索引⼤⼩mysql>SELECT CONCAT(ROUND(SUM(index_length)/(1024*1024), 2), ' MB') AS'Total Index Size'FROM TABLES WHERE table_schema ='test'and table_name='a_yuser';+------------------+| Total Index Size |+------------------+|21.84 MB |+------------------+1 row in set (0.00 sec)mysql> show create table test.a_yuser\G;***************************1. row ***************************Table: a_yuserCreate Table: CREATE TABLE `a_yuser` (`email` varchar(60) NOT NULL DEFAULT'',`user_name` varchar(60) NOT NULL DEFAULT'',KEY `cc` (`email`(5)),KEY `ccb` (`user_name`(5)),KEY `ccbc` (`email`(5),`user_name`(5))) ENGINE=MyISAM DEFAULT CHARSET=utf81 row in set (0.00 sec)ERROR:No query specifiedmysql>select count(*) from test.a_yuser;+----------+|count(*) |+----------+|1073607|+----------+1 row in set (0.00 sec)查看⼀个库中的情况mysql>SELECT CONCAT(table_schema,'.',table_name) AS'Table Name', CONCAT(ROUND(table_rows/1000000,4),'M') AS'Number of Rows', CONCAT(ROUND(data_length/(1024*1024*1024),4),'G') AS'Data Size', CONCAT(ROUND +---------------+----------------+-----------+------------+---------+|Table Name |Number of Rows | Data Size |Index Size | Total |+---------------+----------------+-----------+------------+---------+| test.a_br |0.4625M |0.0259G |0.0171G |0.0431G || test.a_skuclr |0.7099M |0.0660G |0.0259G |0.0919G || test.a_yuser |1.0736M |0.0497G |0.0213G |0.0710G || test.test |0.0000M |0.0000G |0.0000G |0.0000G |+---------------+----------------+-----------+------------+---------+4 rows in set (0.13 sec)参考⽹址:/question/12_3673/s/blog_4c197d420101fbl9.html。
数据库索引的性能测试与评估方法(五)

数据库索引的性能测试与评估方法引言:数据库索引是提高查询速度的重要手段,它能够快速定位到数据所在的位置。
然而,在设计和使用索引时,如何评估和测试其性能表现至关重要。
本文将介绍数据库索引的性能测试与评估方法,以帮助开发人员更好地优化和调整索引。
一、基准测试基准测试是评估索引性能的重要手段。
通过构建具有典型查询负载的测试数据集,可以模拟真实生产环境中的工作负载,从而观察索引在不同负载下的表现。
1. 数据生成首先,需要生成一份适当大小的测试数据集。
可以选择一个已有的数据库表作为基础,复制其结构并填充数据。
可以使用现有工具或自行编写脚本来实现。
2. 查询负载根据实际应用场景,设计一组典型的查询语句作为查询负载。
包括各种复杂度的查询语句,包括单表查询、跨表查询、带聚合函数查询等等。
3. 测试环境搭建一套与生产环境相似的测试环境,包括硬件设备和软件配置。
确保测试环境的稳定性和可重复性。
4. 测试过程在测试环境中执行查询负载,记录每个查询的执行时间和资源消耗情况。
可以使用性能测试工具来自动执行测试脚本,并收集性能指标。
5. 结果分析根据收集到的执行时间和资源消耗情况,可以分析并比较不同索引的性能表现。
可以观察到某些索引在特定查询下的优势和劣势,从而进行优化和调整。
二、查询计划查询计划是数据库在执行查询语句时的执行策略。
通过了解查询计划,可以发现索引的使用情况和性能问题,从而进行优化。
1. 解释执行计划使用数据库提供的解释执行计划功能,可以查看查询语句在执行时的具体执行计划。
可以观察到查询是如何从索引或全表扫描中选择的,从而判断索引是否起到了预期的作用。
2. 优化执行计划在测试过程中,可以尝试优化查询语句的执行计划,比如调整查询条件的顺序、重写复杂的查询语句等。
观察优化后的执行计划和性能变化,可以评估索引的优化效果。
三、性能监控性能监控是实时观察数据库索引性能的手段。
通过监控关键指标,可以及时发现性能问题并进行调整。
数据库索引的性能测试与评估方法(八)

数据库索引的性能测试与评估方法数据库索引是一种用于提高数据库查询效率的关键技术,可以极大地加快数据检索的速度。
然而,在实际应用中,如何评估和测试数据库索引的性能成为一个重要的问题。
本文将介绍一些常用的数据库索引性能测试与评估方法,帮助读者更好地理解和应用数据库索引技术。
一、数据生成与导入在进行数据库索引性能测试之前,首先需要生成大规模的测试数据并将其导入到目标数据库。
通常,可以使用数据生成工具自动生成测试数据,如Faker、Mockaroo等。
这些工具可以根据特定规则生成逼真的数据,模拟真实应用场景。
导入数据时,可以使用数据库自带的导入功能,或者编写脚本进行批量导入。
二、测试方案设计在进行数据库索引性能测试时,需要设计合理的测试方案。
以下是一些常用的测试方案设计思路:1. 单一索引测试选择一个单一的索引进行测试,不考虑其他索引的影响。
通过查询具有高选择性的列,如主键或唯一键,评估该索引在查询性能上的表现。
2. 复合索引测试选择一个复合索引进行测试,测试该索引在多列组合查询时的性能。
通过模拟多个查询条件,评估复合索引在综合查询性能上的表现。
3. 多索引测试选择多个索引进行测试,并模拟多个查询场景,评估多个索引对查询性能的综合影响。
可以通过调整查询条件的选择性以及索引的命中率,观察不同索引组合的查询效果。
三、性能指标评估在进行数据库索引性能测试时,需要关注以下几个重要的性能指标:1. 查询响应时间查询响应时间是衡量索引性能的重要指标之一。
通过记录查询开始和结束的时间戳,计算查询执行时间,以评估索引的查询效率。
2. 查询执行计划查询执行计划可以提供索引使用情况的详细信息,包括索引的选择、索引的扫描方式等。
通过分析查询执行计划,可以评估索引的使用是否合理,是否存在性能瓶颈。
3. 索引命中率索引命中率是衡量索引性能的重要指标之一。
可以通过观察索引的读取次数和查询次数的比例,计算索引的命中率。
如果索引的命中率较低,可能需要优化索引设计或调整查询条件。
搜索引擎评估

搜索引擎评估搜索引擎评估搜索引擎是人们获取信息的重要工具,而搜索引擎的质量直接影响到用户能否快速、准确地找到所需信息。
因此,对搜索引擎的评估显得尤为重要。
本文将从搜索结果质量、搜索速度和用户体验三方面对搜索引擎进行评估。
首先,搜索结果质量是评估搜索引擎的重要指标之一。
搜索引擎的主要任务是根据用户输入的关键词,返回与之相关的结果。
因此,搜索引擎的搜索结果应该尽可能的与用户的意图相匹配,且排在前面的结果更具权威性和准确性。
搜索结果质量的评估可以通过衡量搜索引擎返回的结果的相关性、权威性和准确性来进行。
相关性可以通过用户点击率和停留时间来衡量,高点击率且长停留时间的结果意味着搜索结果与用户需求的匹配度高。
权威性可以通过评估搜索结果中的网站信誉和可信度来进行。
准确性则可通过评估搜索结果中是否存在拼写错误、错误的关键词匹配等来进行。
其次,搜索速度是衡量搜索引擎质量的另一个重要指标。
现代社会的快节奏要求搜索引擎能够快速返回搜索结果。
搜索引擎的速度取决于其搜索算法的设计和处理能力。
搜索引擎评估可通过对搜索过程中的响应时间进行衡量来进行,响应时间越短,搜索引擎的速度越快。
最后,用户体验是评估搜索引擎的重要方面之一。
搜索引擎应该为用户提供良好的搜索体验,包括用户界面设计、搜索建议和搜索策略等。
用户界面设计应简洁、清晰,方便用户操作。
搜索建议可以提供用户输入关键词时的提示和自动补全功能,以提高用户搜索的精确度。
搜索策略可以通过为用户提供各类筛选和排序功能来帮助用户进一步找到自己需要的信息。
综上所述,对搜索引擎进行评估涉及搜索结果质量、搜索速度和用户体验三个方面。
评估搜索引擎的质量需要综合考虑这些指标,以期为用户提供更好的搜索服务。
通过评估搜索引擎的质量,可以指导搜索引擎的改进和优化,提高其搜索效果和用户满意度。
搜索引擎评判的基本指标

搜索引擎评判的基本指标互联网技术的日益成熟,网络的普及,搜索引擎越来越成为广大网民不可或缺的工具了。
以至于某企业老总说,“目前门户网站的核心技术就是搜索引擎”。
怎么来评价一个搜索引擎的好坏,我认为因该从以下几个方面来考虑,尽管这种想法书卷气十足,但是我想至少可以在优化算法,设计用户界面上有点意义。
1.查全率:它是指检索列出的结果的数据与实际网络中拥有的与检索关键词相关的数据量地差别或说差距。
从理论上讲没有那个搜索引擎能够含盖所有的网络信息,但是每个搜索引擎有尽可能的扩展自己的数据库以求,信息覆盖更全面。
查全率=检索出的相关信息数量/系统中所有的相关信息量注:实际数据库中所有的相关信息量实际上是一个理论概念,并没有人也没有办法去确切的统计到底会有多少与某一个关键词相关的信息。
所以这个概念只供理论研究用。
对于用户来说,看到的最直观的是检索反馈结果多少,所以,对某一个关键词来说,反馈的结果愈多当然是查全率越高。
实际这是不完全正确的。
2.查准率:实际反应的是检索反馈的结果与用户检索关键词之间的匹配程度。
这对网民来说也是至关重要的,查准率=检出的有用的资料/检索反馈的结果的总量对于一个拥用户来说,如果就某一个关键词检索出来的结果全然没用,准确率极低,那么将无疑是最大的伤害,所以搜索引擎必须想尽办法提高检索的匹配程度。
提高检索结果与关键词的匹配程度有两种实现方法,其一就是有自己的独特的[匹配方法,比如Google的Page Ranking 技术等,其二就是提供高级检索功能,即提供用户自定义逻辑检索。
3.响应速度:用户能够快速的得到反馈结果。
搜索引擎的实用性来看,必须保证用户可以很快地得到查询结果。
一般情况下,库容量越大,响应速度越慢。
4.检库容量:搜索引擎必须要有相当大的库容量才具有一定的代表性和实用性。
可以说搜索引擎可搜索的库容量大小是搜索引擎质量标志的第一要素。
库容量的大小取决于工作方式。
采用“机器人检索”方式的搜索引擎的库容量一般要远大于“人工分类”方式的搜索引擎。
分布式搜索中节点索引量大小估计算法

分布式搜索中节点索引量大小估计算法
吴晟;李星
【期刊名称】《计算机应用》
【年(卷),期】2008(28)9
【摘要】分布式搜索是解决对深层网络搜索的有效方案,各节点的索引量大小是分布式搜索引擎描述选择节点的重要参数.为了解决在非合作环境中估算节点索引量大小的问题,提出并实现了基于高频词汇再采样的高频再采样算法和基于文档捕获概率不同假设的异概捕获算法.高频再采样算法在随机采样后基于样本集中的高频词汇进行再采样;而异概捕获算法则利用Logistic函数和条件似然方法估算节点的索引量大小.通过真实网络数据的实验结果表明,这些算法优于已有的采样-再采样与捕获-再捕获算法.
【总页数】4页(P2345-2348)
【作者】吴晟;李星
【作者单位】清华大学,电子工程系,北京,100084;清华大学,电子工程系,北
京,100084
【正文语种】中文
【中图分类】TP393.09
【相关文献】
1.元搜索引擎原理在实现分布式虚拟联合目录中的应用研究 [J], 欧阳剑;李冠盛
2.搜索引擎中混合型分布式索引组织策略 [J], 陈伟;刘康苗;卜佳俊;陈纯;张利军
3.MapReduce在分布式搜索引擎中的应用 [J], 吴文忠;易平
4.ElasticSearch分布式搜索引擎在天文大数据检索中的应用研究∗ [J], 陈亚杰;王锋;邓辉;刘应波
5.ElasticSearch分布式搜索引擎在地名地址检索中的应用 [J], 张哲; 刘云鹤; 王乃生
因版权原因,仅展示原文概要,查看原文内容请购买。
搜索引擎的主要性能评价指标

根据建立搜索引擎评价指标体系的若干原则,我们认为可以建立以下搜索引擎主要性能评价指标,它包含以下几个部分:
1.搜索引擎索引库的相关评价指标索引数据库的构成是搜索引擎检索性能优劣的基础,由此我们把它摆在评价指标的第一部分来考虑。
搜索引擎索引库的评价指标应该包括索引标引数量、标引的文件种类、标引深度和更新频率等方面。
由于索引标引数量我们难以检测,可以通过本文后面提到的“相关查全率”来间接反映,故这里把它剔除。
索引标引深度内含几方面的内容,如全面索引或部分索引、是否考虑超文本的不同标记所表示的不同含义和是否收集页面中的超链接等,而且索引数据库标引的深度直接影响检索效果,所以我们把它细分为三方面。
2 .搜索引擎检索功能的相关指标搜索引擎检索功能的评价指标主要包括:基本检索、高级检索、目录式浏览检索和其他功能检索。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
如何测试搜索引擎的索引量大小(前篇)
背景知识:搜索引擎的质量指标一般包括相关性(Relevance)、时效性(Freshness)、全面性(Comprehensiveness)和可用性(Usability)等四个方面,今天我们要谈的索引量就属于完整性指标的范畴。
首先需要注意的是,对于搜索引擎,网页的索引量和抓取量是不同的概念。
搜索引擎的网页抓取数量一般都要远大于索引量,因为抓取的网页中包括很多内容重复或者作弊等质量不高的网页。
搜索引擎需要根据算法从抓取的网页当中取其精华,去其糟粕,挑选出有价值的网页进行索引。
因此,对用户而言,搜索引擎的索引量大小才更有意义。
其次,无限制增大索引量并不一定能保证搜索质量的提升。
一方面,在全面性指标中,除索引量外,还需要考虑到收录网页的质量和不同类型网页的分布。
另一方面,搜索引擎的质量指标体系要保证四方面的均衡发展,不是依靠单个指标的突破就可以改善的。
目前包括雅虎中国在内的主流中文搜索引擎的网页索引量都在20 亿量级,基本上可以满足用户的日常查询需求。
然而,由于从外部无法直接测算出搜索引擎网页索引量的绝对值大小,很多搜索引擎服务商喜欢对外夸大自己的收录网页数,作为市场噱头。
从1998年开始,Krishna Bharat和Andrei Broder就开始研究,如何通过第三方来客观比较不同搜索引擎索引量的大小。
8年后,在今年5月份的WWW2006大会上,来自以色列的Ziv Bar-Yossef和Maxim Gurevich由于这方面的出色研究成果夺得了大会唯一的最佳论文奖。
他们的研究算出了主流英文搜索引擎的索引量相对大小:雅虎是Google的1.28倍,Google是MSN的1.36倍。
他们是如何算出这些数字的呢?下面我们将为搜索引擎爱好者介绍这个算法,以及探讨在中文搜索引擎上是如何应用的。
概述
搜索引擎的索引量或称覆盖率对搜索结果的相关性、时效性和找到率都具有深远的影响。
出于市场运作的考虑,各大互联网搜索引擎不时对外公布自己索引的文档数量,然而这些数据往往不同程度地被加入了一些水份,可信度上有一个问号。
因此,如何通过搜索引擎的公共接口,也就是通常所说的搜索框,比较客观、准确地测试它的索引量就成为了一个令人关注的问题。
图1 对搜索引擎的索引采样
每一个搜索引擎的索引都覆盖了互联网上全部文档的一个子集。
如果我们把测试作为对这个集合的采样,那么问题的关键就在于如何实现一个近似的等概率随机采样(uniform. search engine url sampler),参见图1。
具体地说,假定一个搜索引擎S总共索引了|D|个文档,那么我们希望采样得到某一个具体文档的概率是1/|D|。
一旦实现了通过搜索框对索引的等概率随机采样,我们就可以在统计意义上比较有把握地估计搜索引擎索引量的相对大小。
如下图所示:
图2 比较搜索引擎索引的相对大小
我们先对引擎S1随机采样N1个url。
然后,通过url查询获知引擎S2索引了其中的N12个url,而没有索引另外N10个。
换句话说,N1 = N10+N12 。
同样地,如果我们对引擎S2随机采样N2个url,发现其中N21被S1收录而N20没有收录,N2=N20+N21。
那么我们可以估计S1与S2的相对大小为:
|D1|/|D2|
≌(N12+N10) / (N12+N12N20/N21)
=(N1N21)/(N2N12)
=N21/N12 (如果N1══N2)
如何测试搜索引擎的索引量大小(后篇)
搜索引擎索引的等概率随机采样:
对于搜索引擎等概率随机采样的研究已经有了相当长的历史,具体的背景文献我们不准备在这里一一探讨。
我们希望通过对Bar-Yossef等人最近工作的介绍,把一种比较客观、科学的测试方法推介给读者。
我们也会探讨他们的方法对于中文索引的局限性和一些解决方案。
图3 一个简化的搜索引擎索引
图3给出了一个简化了的搜索引擎索引示例,假定关键字“news”将返回4个结果:、、和。
首先我们给出一组定义
● 关键字搜索结果集合:results(q) = { 搜索关键字q所返回的全部结果文档之集合}
● 文档关键字集合:queries(x) = { 所有能返回文档x的搜索关键字之集合}
● 搜索关键字池P:一组理论上能够覆盖所有文档的搜索关键字集合
o 例如图3中P= {news, bbc, maps, google}
● 关键字搜索结果量:card(q) = |results(q)|,搜索关键字q所返回的全部结果文档之数量
o 例如图3中card(“news”) = 4,card(“bbc”) = 3
● 文档匹配度:deg(x) = |queries(x)| ,全体能够匹配文档x的搜索关键字数量
o 例如图3中deg() = 1,deg() = 2
当我们通过搜索框对搜索引擎的索引进行采样,所获得的结果实际上偏向于匹配度高的文档。
对于图3所示的搜索引擎,如果我们从搜索关键字池P = {news, bbc, maps, google}中任意选取一个关键字,然后在所得搜索结果中任意选取一个文档,那么选到某一个具体文档的概率与它的匹配度成正比,例如,p() = 2/13 ,p() = 1/13
因此,通过关键字对搜索引擎的索引进行采样,实际上是对文档匹配度概率分布在作随机抽样。
具体地说,如果相对于一个给定的搜索关键字池P,该索引的全部文档匹配度的总和为deg(D) = ∑x∈Ddeg(x),那么通过搜索框对引擎采样获取具体一个文档x的概率是deg(x)/ deg(D)。
如何通过对文档匹配度分布的随机抽样而获得我们所期望的等概率随机采样呢?这正是Bar-Yossef 等人工作的主要成果所在:他们采用蒙特卡罗仿真(Monte Carlo Simulation)算法实现了这一点
● 目标分布π(x) :D上的等概率随机分布, π(x) = 1/|D|
● 实际采样分布p(x) :D上的文档匹配度随机分布,p(x) = deg(x) / ∑x'∈Ddeg(x')
● 偏差权值: w(x) = π(x)/p(x) ∝1/deg(x)
采样过程,参见图4
● 选定一个搜索关键字池P
● 随机选取q ∈P
● 在搜索结果中随机选取一个文档x ∈results(q)
● 计算该文档对P 的匹配度deg(x)
● 产生一个0~1的随机数r,如果r ≤ 1/deg(x)保留该文档,否则放弃
● 重复上述过程直到获得N个有效采样点
图4 通过蒙特卡罗仿真(Monte Carlo Simulation)算法实现对索引的等概率随机采样
问题和讨论
上述算法在数学上非常严谨优美,但是在具体的实现过程中仍然有相当多的困难,尤其是对于中文搜索引擎,有一些特殊的问题需要探讨。
● 搜索关键字池P的选取
P选择的条件是(1)要保证p(x) = 0,即索引中文档不匹配任何一个关键字q ∈P的概率足够小。
如果这个概率太高,测试只能局限于索引的一小部分,测试的结果就失去了意义。
(2)关键字搜索结果量card(q)最好要比较小,这样可以尽可能地避免搜索结果超过搜索引擎允许返回结果的上限。
作者提出的方案是通过抓取和分析一个大型的网上文库,例如维基百科全书,选择其中所有的英文单词的集合或者所有K个相连单词的集合作为P。
这对于没有分词问题的英文而言是容易实现的,但对于汉语等需要分词的语种,这个方法似乎并不很合适。
我们建议直接采用GBK字库中的全部字符,或者采用中文分词标准中所有词汇的集合。
● 如何计算文档对P的匹配度deg(x)?
文档匹配度deg(x)必须离线计算,通过查询获得是不现实的。
对英文文档来说,只要计算文档中覆盖了多少个关键字q ∈P。
但是对中文而言,不同引擎包含了不同的搜索逻辑,例如四个汉字以下的搜索通常采取词组搜索,长搜索词有些引擎可能采取与或逻辑。
不同引擎对于汉语分词的处理也有较大的差异。
在索引文档时,有些引擎可能考虑了繁简汉字的转换。
所有这些都会对匹配度产生一定程度的影响。
实际上,匹配度deg(x)的计算并不一定要十分精确,一些近似处理是可以接受的,只要误差不至于太大。
我们建议用GBK字库的单个汉字集合作为P,这样可以避免分词的差异。
而此时文档的匹配度就是一个文档包含不同GBK字符的个数。
● 搜索引擎对搜索最大返回结果的限制。
这一点Bar-Yossef 等人的文章中有比较详细的讨论,他们认为这个限制对于测试结果的影响并不太大。
● 该算法的计算复杂度比较高。
从计算量上考虑,由于deg(x)一般都比较大,因此搜索结果文档被放弃的比例较高,如何进一步改进算法的复杂度是一个值得探讨的问题。