分布式技术架构介绍共25页文档
分布式体系结构

分布式体系结构一、分布式计算分布式计算是指将计算任务分布在多个计算机上进行处理,以实现计算效率的提高和计算成本的降低。
分布式计算系统通常由一组相互连接的计算机组成,这些计算机协同工作,共同完成计算任务。
在分布式计算中,不同的计算机可以运行不同的操作系统和编程语言,这使得分布式计算具有高度的灵活性和可扩展性。
二、分布式存储分布式存储是指将数据存储在多个计算机上,以实现数据的高可用性和可扩展性。
与传统的中心式存储相比,分布式存储具有更高的可靠性和灵活性。
在分布式存储系统中,数据被分散存储在多个节点上,这使得数据备份和恢复更加容易和可靠。
同时,分布式存储也便于数据的扩展和维护。
三、分布式数据库分布式数据库是指将数据库系统建立在多个计算机上,以实现数据的分布式存储和处理。
与传统的集中式数据库相比,分布式数据库具有更高的可扩展性和可靠性。
在分布式数据库中,数据被分散存储在多个节点上,这使得数据备份和恢复更加容易和可靠。
同时,分布式数据库也便于数据的扩展和维护。
四、分布式网络分布式网络是指将网络结构建立在多个计算机上,以实现网络的分布式管理和控制。
与传统的中心式网络相比,分布式网络具有更高的可靠性和灵活性。
在分布式网络中,不同的计算机可以运行不同的操作系统和协议栈,这使得分布式网络具有高度的灵活性和可扩展性。
五、分布式安全分布式安全是指为分布式系统提供安全保障的技术和方法。
在分布式系统中,由于计算和数据是分布的,因此安全问题也呈现出分布式的特点。
为了保证分布式系统的安全性,需要采取一系列的安全措施和技术手段,如身份认证、访问控制、加密传输等。
六、分布式管理分布式管理是指对分布式系统进行管理和维护的技术和方法。
在分布式系统中,由于计算和数据是分布的,因此管理问题也呈现出分布式的特点。
为了保证分布式系统的稳定性和可靠性,需要采取一系列的管理措施和技术手段,如监控、日志、故障排除等。
七、分布式监控分布式监控是指对分布式系统进行监控和优化的技术和方法。
分布式系统架构原理

分布式系统架构原理今天来聊聊分布式系统架构原理。
你有没有见过那种大型的物流中心呀?里面有好多的仓库、好多的工人还有各种各样的运输车辆。
这就有点像分布式系统呢。
在一个大的电商购物节的时候,海量的订单涌来,如果只靠一个小仓库能处理得过来吗?根本不可能嘛。
这时候就需要很多个仓库联动起来,各自承担一部分任务,来确保所有订单能尽快处理,这个就是分布式系统解决问题的一个生活场景写照啦。
分布式系统架构呢,简单来讲就是把一个大的任务分解成好多小任务,让分布在不同地方的许多小系统(就像那些小仓库)一起执行。
打个比方,这就像盖房子,一个人盖一栋房子可能要花好长时间,那要是找好多人呢,每个人负责一块地方,砖头砌墙的砌墙,房子很快就盖好啦。
这里头有个重要的原理就是数据的分布与一致性。
比如说,我们把东西存到不同的仓库(不同的存储节点),要是我在一个仓库存了些新货物,别的仓库要能很快知道有这么个情况,不然就乱套了。
这时候就引出了像分布式锁、一致性哈希这样的技术。
这些东西可不好理解哦,老实说,我一开始也不明白为啥要有这么复杂的概念。
以分布式锁为例来解释下。
好比我们在图书馆只有一本特受欢迎的书(资源),好多人都想借阅,那这时候就得给这本书上把锁,一次就让一个人借,其他人就得等着。
在分布式系统里,如果很多节点都要访问修改同一条数据,就得用这个分布式锁来避免冲突。
分布式系统架构在实际应用里超级广泛,像大型互联网公司的搜索引擎服务,面对全球海量的用户搜索请求,就是靠分布式系统把这些任务分散到世界各地的服务器上处理。
不过呢,在做分布式系统架构的时候也有注意事项,像网络延迟、节点故障这些因素都会影响整体系统的性能,我们得小心应对。
说到这里,你可能会问了:那如果在处理过程中节点不断增加或者减少怎么办呢?这就涉及到了系统的扩展性原理了。
分布式系统要能轻松应对节点的动态变化,就得做好架构设计,比如采用一些动态分配任务的算法之类的。
我自己在学习这些内容的时候,真的是觉得既有趣又充满挑战。
分布式体系结构范文

分布式体系结构范文分布式体系结构是一种在计算机系统中使用多个计算机或处理器进行协同工作的体系结构。
它可以提供更高的灵活性、可扩展性和容错性,同时还能提供更好的性能和资源利用率。
本文将介绍分布式体系结构的定义、特点、优势和应用,并探讨其在实际应用中的挑战和解决方案。
一、定义和特点:1.节点自治:每个节点都有自己的处理能力和资源,可以独立地执行任务和决策。
2.通信协作:节点之间通过网络进行通信和协作,共同完成任务。
3.分布式控制:系统的控制逻辑被分布在不同的节点上,每个节点都可以参与决策和控制过程。
4.可扩展性:可以根据需求增加或减少节点数量,以适应不断变化的工作负载。
5.容错性:系统可以容忍节点故障或通信故障,并具备自愈能力。
二、优势和应用:1.性能提升:通过利用多个节点的处理能力,可以提高任务的响应速度和吞吐量。
2.资源利用率提高:每个节点可以独立地执行任务,充分利用系统的资源。
3.可扩展性强:可以根据需求增加或减少节点数量,满足不断变化的工作负载。
4.容错性强:系统可以容忍节点故障或通信故障,并具备自愈能力。
5.灵活性提高:每个节点都可以独立地执行任务和决策,系统具有更高的灵活性。
分布式体系结构在许多领域有广泛的应用,如云计算、大数据分析、物联网等。
在云计算中,分布式体系结构可以提供弹性计算和资源共享的能力。
在大数据分析中,可以利用分布式体系结构进行并行计算和数据处理。
在物联网中,分布式体系结构可以实现设备之间的协作和数据共享。
三、挑战和解决方案:1.容错机制:通过使用冗余节点和数据备份等手段,可以提高系统的容错性和可靠性。
2.通信优化:通过优化网络拓扑结构、选择合适的通信协议等,可以减少通信延迟和带宽消耗。
3. 一致性协议:通过使用分布式一致性协议,如Paxos、Raft等,可以确保分布式系统中的数据一致性。
4.负载均衡:通过使用负载均衡算法,可以将任务均匀地分配给各个节点,提高系统的性能和资源利用率。
分布式控制系统的体系结构PPT课件

4. 管理级
• 厂级管理计算机,或是若干个机组的管理计算 机。
• 使用者:厂长、经理、总工程师、值长等行政 管理或运行管理人员。
• 主要任务:监测企业各部分的运行情况,利用 历史数据和实时数据预测可能发生的各种情况, 从企业全局利益出发辅助企业管理人员进行决 策,帮助企业实现其规划目标。
Network)
第1页/共24页
ቤተ መጻሕፍቲ ባይዱ 分布控制系统典型结构
第2页/共24页
分布控制系统典型结构
第3页/共24页
1.现场级
• 现场级设备:传感器、变送器和执行器 现场级的信息传递方式: (1)传统的4~20mA 模拟量传输方式 (2)现场总线的全数字量传输方式 (3)在4~20mA模拟量信号上,叠加上调制 后的数字量信号的混合传输方式 现场信息传递方式发展方向:以现场总线为基 础的全数字传输
1.分布式控制系统的结构分为哪几层?各层设备有哪些? 2.怎样理解分布式控制系统的分散方式? 3.层次分散型和水平分层型的特点是什么? 4.何为分级递阶控制结构?
第23页/共24页
感谢您的欣赏!
第24页/共24页
些。
第17页/共24页
3. 地理分散
• 分布式控制系统的安装布置方式:
• 地理集中式——把所有的基本控制单元集中在 中央控制室或附近的电子设计室内;
• 地理分散式——把基本控制单元安装在被控生 产过程的附近,即在整个厂房内分散布置。
第18页/共24页
2.2.2 DCS的体系结构
• 体系结构:分级递阶控制结构——分布式控制系 统在水平和垂直方向都是分层(级)的。
AC 800F
HSE
FIO 100
FF-H1
分布式计算架构介绍

一致性与复制
Web 代理缓存:一致性哈希缓存 Web 宿主系统的复制:虚拟主机复制 Web 应用程序的复制:SVN 的复制
安全性
考虑到因特网的开放特性,设计一个保护客户和服务器免遭各种攻击的安全体 系结构是非常重要的。Web中的大部分安全问题与建立客户和服务器之前的安全信 道有关。在Web中建立一条安全信道的主要方法是使用安全套接字(Secure Socket Layer,SSL),该协议最初由Netscape提出。尽管SSL从未被正式标准化,当 大多数Web客户和服务器都支持它。 摘自《分布式原理与范式》第二版
进程
最重要的Web客户端进程是一种称为Web浏览器(Web browser)的软件, 他通过从服务器获取Web页面并把他们显示在用户的屏幕上来允许用户访问这些页 面。浏览器一般提供带有超链接的界面,用户只需单击一次超链接来访问它。
另一个常用的客户端进程是web代理(Web proxy).起初,这种进程用于允许浏 览器处理不同于HTTP的应用协议,例如要从一个FTP服务器上请求文件,浏览器可 以发送一个HTTP请求给本地FTP代理,后者将获取文件并把它嵌入在一个HTTP响应 消息中返回给浏览器
同步
Web文档的分布式创作是通过单独的协议(即WebDAV)处理的。WebDAV代 表Web分布式创作和版本控制(Web distributed authoring and cersioning),他提 供一种简单的方式来锁定共享文档,可以在远程Web服务器上创建、删除、复制和 移动文档。 摘自《分布式原理与范式》第二版
分布式计算架构介绍
大型网站技术框架的应用
为什么要运用分布式计算
web服务器的架构及其优点 Web服务器分布式技术的体现
为什么要使用运用分布式计算
分布式架构概述
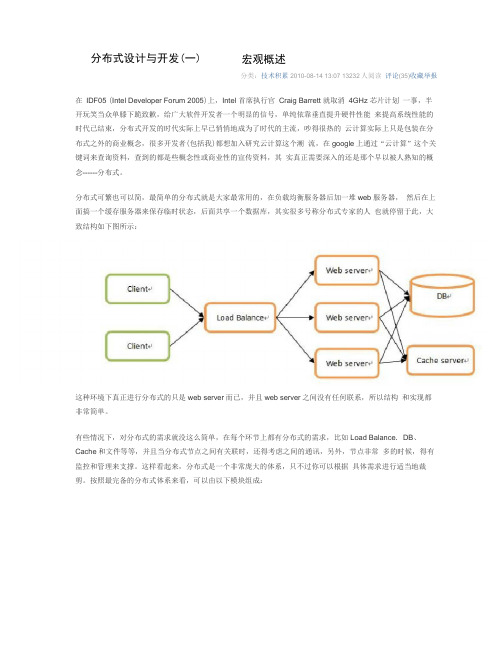
分布式设计与开发(一) 宏观概述分类:技术积累2010-08-14 13:07 13232人阅读评论(35)收藏举报在IDF05 (Intel Developer Forum 2005)上,Intel 首席执行官Craig Barrett 就取消4GHz 芯片计划一事,半开玩笑当众单膝下跪致歉,给广大软件开发者一个明显的信号,单纯依靠垂直提升硬件性能来提高系统性能的时代已结束,分布式开发的时代实际上早已悄悄地成为了时代的主流,吵得很热的云计算实际上只是包装在分布式之外的商业概念,很多开发者(包括我)都想加入研究云计算这个潮流,在google上通过“云计算”这个关键词来查询资料,查到的都是些概念性或商业性的宣传资料,其实真正需要深入的还是那个早以被人熟知的概念------分布式。
分布式可繁也可以简,最简单的分布式就是大家最常用的,在负载均衡服务器后加一堆web服务器,然后在上面搞一个缓存服务器来保存临时状态,后面共享一个数据库,其实很多号称分布式专家的人也就停留于此,大致结构如下图所示:这种环境下真正进行分布式的只是web server而已,并且web server之间没有任何联系,所以结构和实现都非常简单。
有些情况下,对分布式的需求就没这么简单,在每个环节上都有分布式的需求,比如Load Balance. DB、Cache和文件等等,并且当分布式节点之间有关联时,还得考虑之间的通讯,另外,节点非常多的时候,得有监控和管理来支撑。
这样看起来,分布式是一个非常庞大的体系,只不过你可以根据具体需求进行适当地裁剪。
按照最完备的分布式体系来看,可以由以下模块组成:分布式任务处理服务:负责具体的业务逻辑处理分布式节点注册和查询:负责管理所有分布式节点的命名和物理信息的注册与查询,是节点之间联系的桥梁分布式DB :分布式结构化数据存取分布式Cache :分布式缓存数据(非持久化)存取分布式文件:分布式文件存取网络通信:节点之间的网络数据通信监控管理:搜集、监控和诊断所有节点运行状态分布式编程语言:用于分布式环境下的专有编程语言,比如Elang 、Scala分布式算法:为解决分布式环境下一些特有问题的算法,比如解决一致性问题的Paxos 算法 因此,若要深入研究云计算和分布式,就得深入研究以上领域,而这些领域每一块的水都很深,都需 要很底层的知识和技术来支撑,所以说,对于想提升技术的开发者来说,以分布式来作为切入点是非 常好的,可以以此为线索,探索计算机世界的各个角落。
分布式系统架构 技术栈详解

分布式系统架构技术栈详解分布式系统架构是一种通过将系统的不同组件分布在不同的节点上来实现高可用性、可伸缩性和容错性的系统设计方法。
它是一种将任务分解成多个子任务,并通过网络进行通信和协作的系统架构。
在分布式系统架构中,技术栈是指用于构建和管理分布式系统的各种技术和工具的集合。
下面将介绍几个常用的技术栈。
1. 分布式存储技术:分布式存储技术是分布式系统中的核心技术之一。
它将数据分布到多个节点上,实现数据的高可用性和容错性。
常见的分布式存储技术包括分布式文件系统(如HDFS)、分布式数据库(如Cassandra和MongoDB)等。
2. 分布式计算技术:分布式计算技术用于将计算任务分布到多个节点上并进行并行计算。
常见的分布式计算技术包括MapReduce(如Hadoop)和Spark等。
这些技术通过将大规模的计算任务分解成多个小任务,并在多个节点上并行执行,从而实现高效的计算。
3. 分布式消息队列技术:分布式消息队列技术用于在分布式系统中实现异步通信和解耦。
它通过提供可靠的消息传递机制来实现系统间的解耦和异步通信。
常见的分布式消息队列技术包括Kafka和RabbitMQ等。
4. 分布式缓存技术:分布式缓存技术用于在分布式系统中提高数据访问性能。
它将数据缓存在多个节点上,以减轻数据库的负载和提高系统的响应速度。
常见的分布式缓存技术包括Redis和Memcached等。
5. 分布式服务框架技术:分布式服务框架技术用于实现分布式系统中的服务调用和管理。
它提供了服务注册、发现和负载均衡等功能,简化了分布式系统的开发和维护。
常见的分布式服务框架技术包括Dubbo和Spring Cloud等。
以上是几个常用的分布式系统架构技术栈。
在实际应用中,根据具体的需求和场景,还可以选择其他技术和工具来构建和管理分布式系统。
分布式系统架构的设计和实现是一个复杂而关键的任务,需要综合考虑系统的可靠性、性能和可扩展性等方面的需求。
分布式系统架构模式

分布式系统架构模式1. 简介分布式系统是由多个相互协作的计算机节点组成的系统,这些节点通过网络连接进行通信和协调。
分布式系统架构模式是一组在设计分布式系统时常用的模式或者范例,用于解决常见的设计问题,优化系统性能和可靠性。
2. 模式列表以下是常见的分布式系统架构模式:2.1. 微服务架构微服务架构将一个大型应用拆分为一系列更小、更自治、更具弹性的服务。
每个服务都有自己独立的数据库,并可以独立部署、扩展和维护。
微服务之间通过轻量级通信机制进行交互。
2.2. 负载均衡负载均衡模式用于在集群中分配用户请求,以平衡各个节点上的资源负载。
负载均衡器可以使用多种策略来选择目标节点,例如轮询、随机等。
2.3. 分片分片模式将数据按照某种规则划分为多个片段,并将每个片段存储在不同的存储节点上。
这样可以实现数据水平拆分,提高吞吐量和可扩展性。
2.4. 异步消息传递异步消息传递模式用于在分布式系统中解耦发送者和接收者之间的时序关系。
发送者将消息发送到消息队列,而不需要等待接收者的响应。
接收者可以按照自己的速度处理消息,并通过回调机制返回结果。
2.5. 缓存缓存模式用于加速数据访问,减少对后端资源的依赖。
在分布式系统中,常见的缓存方案有分布式内存缓存和分布式数据库缓存。
3. 模式优势与注意事项以下是各个模式的优势和使用注意事项:3.1. 微服务架构•优势:增强系统灵活性、可扩展性和可维护性;允许团队独立开发、部署和扩展各个微服务。
•注意事项:增加了系统复杂性;要求良好的服务设计、通信协议和监控机制。
3.2. 负载均衡•优势:提高系统吞吐量和可用性;确保节点资源平衡利用。
•注意事项:引入了负载均衡器作为单点故障;需选择适当的负载均衡策略。
3.3. 分片•优势:提高系统扩展性和吞吐量;减少单个节点的存储负担。
•注意事项:增加了数据一致性和分片迁移等问题;数据查询需要跨多个分片进行处理。
3.4. 异步消息传递•优势:解耦发送者和接收者;提高系统性能和可伸缩性。
分布式技术架构介绍

•
系统架构更加清晰,代码质量提高,利于升级和
维护,稳定性高
•
网站初期或者规模较小,整体上容易 把控
•
服务层利用分布式系统的架构实现HA的功能
•
适用大型网站系统的场景中
服务框架
应 用 A 应 用 B 应 用 C 应 用 D 应 用 E 应 用 F 应 用 G 应用1 (服务调用者) 应用2 (服务调用者) 服务框架
价值、专业、分享、快乐
分布式技术架构介绍
目录 • • • • •
CONTENTS 网站架构的演变 分布式服务框架 分布式数据访问层 云计算服务 大数据
改变传统IT架构的束缚
网站架构的演变
一. 从一台单机的交易网站开始
文件
应用程序 数据库 应用服务器
• 应用程序、数据库、文件等都放在一台服务器上
• •
数据库 拆分阶段
• •
需要保证数据的一致性、实时性、事务性 业务逻辑划分的较清晰,结构化数据
五. 数据库读写分离
负载均衡器 应用服务器 订单 负载均衡器 用户 商品 订单 用户 应用服务器 商品
应用服 务器 数据库 分布式缓存 集群 商品表 用户表
数据复制
数据库
主从库 数据同步
商品表
用户表 订单表 从库(读)
二. 应用与数据分离
应用服务器 订单 应用服务器 用户 商品
数据库服务器 商品表 数据库 服务器
数据库
用户表
订单表
• 单机负载告警,将应用程序和数据分离 • 应用系统一台服务器,数据库和文件各一台服务器
三. 应用服务器集群化
负载均衡器 应用服务器 负载均衡器 订单 用户 商品 订单 应用服务器 用户 商品
分布式架构设计技术方案

分布式架构设计技术方案一、为啥要搞分布式架构呢?咱就说现在这互联网啊,那流量就像洪水猛兽似的。
你要是整一个单体架构,就好比让一个小瘦子去扛一座山,迟早得被压垮。
所以呢,分布式架构就像是找一群小伙伴来一起分担这个压力。
比如说电商网站,双11的时候那订单量蹭蹭往上涨,如果是单体架构,服务器估计得直接冒烟,但是分布式架构就不一样了,各个组件分工合作,就像一个超级战队,轻松应对。
二、分布式架构的核心组件。
1. 服务拆分。
这就好比把一个大蛋糕切成好几块。
把整个系统按照功能或者业务逻辑拆分成一个个小的服务。
比如说一个电商系统,可以拆分成用户服务(管用户注册、登录啥的)、商品服务(商品的信息管理)、订单服务(订单的创建、查询等)。
这样每个服务都可以独立开发、部署和扩展。
就像每个小伙伴负责自己擅长的事情,而不是眉毛胡子一把抓。
2. 消息队列。
这可是个神奇的东西,就像一个超级邮差。
比如说在电商系统里,当用户下单了,订单服务处理完订单创建,得通知库存服务减库存吧。
要是直接调用,万一库存服务正忙呢,那就麻烦了。
这时候消息队列就闪亮登场了。
订单服务把减库存这个消息扔到消息队列里,库存服务有空了就去消息队列里取这个消息来处理,就像邮差把信件安全地送到目的地一样,而且还保证了各个服务之间的松散耦合。
3. 分布式数据库。
传统的数据库就像一个小仓库,分布式数据库呢,那就是好多小仓库组成的大仓库群。
数据分散存放在不同的节点上。
这有啥好处呢?首先是容量大了啊,能装更多的数据。
其次呢,还能提高读写性能。
就像有好多条路可以去存放和获取数据,而不是都挤在一条路上。
比如说一些大型社交网站,用户数据超级多,分布式数据库就能轻松应对。
4. 缓存。
缓存就像是一个聪明的小助手。
有些数据是经常被访问的,比如说电商网站上的热门商品信息。
每次都从数据库里去拿,多慢啊。
这时候就在靠近用户的地方设置一个缓存,就像在你家门口放一个小盒子,第一次从数据库拿了热门商品信息后就放在这个缓存小盒子里,下次再有人访问这个热门商品信息,直接从缓存里拿就好了,那速度,就像火箭一样快。
分布式系统架构与技术

分布式系统架构与技术随着互联网的不断发展,大量的数据和应用被分散到不同的地方进行处理和存储,分布式系统便应运而生。
什么是分布式系统?分布式系统是由多个自治计算机组成的系统, 它们在网络中相互协作实现共同的任务。
这些计算机通常是物理隔离的, 但是它们又能通过网络连接进行通信和数据传输。
分布式系统能够提供高可用性、高性能、高伸缩性以及更大的容错能力。
对于大规模的并行计算、大型互联网应用、数据挖掘等领域,都需要分布式系统提供支持。
分布式系统的架构和技术分布式系统的架构一般采用客户端/服务器的模式:客户端:分布式系统的用户界面,由计算机硬件和软件组成,用户通过客户端与分布式系统进行交互。
服务器:分布式系统的核心,由一组集群、网格或云服务器组成,完成数据存储、计算和管理等核心任务。
常见的分布式系统技术包括:1. RPC(Remote Procedure Call,远程过程调用)RPC是在分布式系统中实现远程过程调用的一种技术。
它基本的实现原理是:客户端向服务器发送调用请求,服务器接收到请求后执行指定的过程并返回结果给客户端。
RPC技术的优点在于可以使得客户端与服务端感受不到中间的传输和远程处理过程,使得程序设计更简单、易维护。
2. 消息队列消息队列是一种异步通信机制,可以实现多个分布式系统异步通信和协作。
消息队列将消息存储在一个队列中,等到处理时再进行处理。
这种技术非常适合需要高可用性、高并发、高吞吐量的场景,如高负载网站、电商系统,金融交易系统等。
3. 分布式缓存分布式缓存使用内存存储来缓存数据,可以提高数据访问的响应速度,减轻后端系统压力。
同时,还可以提高系统的可伸缩性和可用性。
常见的分布式缓存实现包括Redis、Memcache等。
4. 负载均衡负载均衡是分布式系统中非常重要的技术。
它能够根据服务器的负载情况动态地分配用户请求,从而保证每台服务器的负载均衡。
常见的负载均衡技术包括基于DNS的负载均衡、基于软件的LVS负载均衡、硬件负载均衡等。
分布式架构详解

分布式架构详解分布式架构是指将一个系统的不同功能模块分布在不同的计算机或服务器上,通过网络进行通信和协调,共同完成系统的任务。
相比于传统的单机架构,分布式架构具有高并发、高可扩展性、高可用性等优势,能够更好地满足现代应用对性能和可靠性的要求。
在分布式架构中,一个系统通常由多个服务组成,每个服务负责完成某个特定的功能。
这些服务可以分布在不同的物理机器或虚拟机上,通过网络协议进行通信和交互。
服务之间通过接口规范定义了彼此之间的通信方式和数据格式。
通过这种方式,不同的服务可以并行工作,提高系统的处理能力。
为了保证分布式架构的高可用性,通常会使用负载均衡技术来均衡不同服务节点的负载,防止某个节点成为系统的瓶颈。
常用的负载均衡算法有轮询法、权重法、哈希法等。
负载均衡器可以根据预定义的规则将客户端请求分发到不同的服务节点,从而实现负载均衡。
在分布式架构中,数据同步和数据一致性是一个非常重要的问题。
由于数据分布在不同的节点上,在进行数据操作时需要确保所有节点的数据一致性。
为了解决这个问题,分布式系统引入了一致性协议,如Paxos、Raft等。
这些协议可以保证分布式系统中的数据一致性,确保不同节点上的数据在进行操作时保持同步。
另外,分布式架构还可以通过消息队列来实现服务之间的异步通信。
消息队列可以将消息存储在队列中,供其他服务消费,从而实现服务之间的解耦。
通过消息队列,不同的服务可以并行处理消息,提高系统的处理能力和吞吐量。
分布式架构还需要考虑容错和故障恢复的问题。
由于系统的不可靠性,任何一个节点都有可能发生故障。
为了保证系统的继续运行,分布式系统通常会采用冗余备份的方式。
当一个节点发生故障时,系统可以自动切换到备份节点,从而保证系统的可用性。
总结来说,分布式架构是一种将系统的不同功能模块分布在不同的计算机或服务器上,通过网络进行通信和协调的架构方式。
分布式架构具有高并发、高可扩展性、高可用性等优势,能够更好地满足现代应用对性能和可靠性的要求。
分布式架构方案

分布式架构方案在当今数字化时代,分布式架构方案已经成为许多企业和组织的首选。
分布式架构是一种将系统拆分成多个独立的组件,这些组件可以在不同的物理位置上运行,并通过网络进行通信和协调的技术架构。
它的出现可以帮助解决传统单一架构所面临的诸多问题,如性能瓶颈、可扩展性和高可用性。
本文将探讨分布式架构方案的原理、常见的架构模式和一些应用案例。
一、分布式架构的原理分布式架构的核心原则是将系统拆分成多个独立的组件,每个组件可以独立地运行和扩展。
这些组件通过网络进行通信和协调,以共同完成系统的功能。
这种拆分和分布可以带来许多好处,其中包括:1. 高性能和可扩展性:分布式架构可以将系统的负载分散到多个组件上,从而实现更好的性能和处理能力。
当系统需求增加时,可以简单地增加更多的组件来扩展系统的性能。
2. 高可用性和容错性:通过将系统分布到多个组件上,即使某个组件出现故障或中断,其他组件依然可以正常运行。
这种冗余设计可以提高系统的可用性和鲁棒性。
3. 地理分布和跨越:分布式架构使得系统可以部署在不同的物理位置上。
这对于需要处理大规模数据或服务用户分布在不同地理位置上的应用非常重要。
二、常见的分布式架构模式在实践中,有许多常见的分布式架构模式被广泛应用。
下面介绍其中一些常见的模式:1. 客户端-服务器架构:这是最简单的分布式架构模式,其中客户端向服务器发送请求,服务器处理请求并返回响应。
这种模式在Web应用程序中被广泛应用,如网站和移动应用。
2. 消息队列:消息队列模式用于在不同的组件之间传递和处理消息。
发送者将消息发送到队列,接收者从队列中获取并处理消息。
这种模式可以有效地解耦系统的不同组件,提高系统的可伸缩性和可靠性。
3. 微服务架构:微服务架构是一种将大型系统拆分成多个较小、自治的服务的架构模式。
每个服务都可以独立地开发、部署和扩展,通过API进行通信和协调。
这种模式可以提高开发效率和可扩展性。
4. 数据分片:当系统处理大规模数据时,数据分片模式可以将数据分割成多个片段,并将每个片段分配给不同的组件处理。
分布式架构设计原理

分布式架构设计原理分布式架构呢,简单说就是把一个大的系统拆成好多小的部分,让它们分散在不同的地方运行。
为啥要这么干呢?就好比一个人干活太累了,找一群小伙伴来帮忙一样。
比如说,一个大型的电商网站,如果所有的功能都在一台服务器上,那这台服务器可就惨了,要处理海量的订单、用户登录、商品展示啥的,肯定会累趴下。
但是把这些功能分到不同的服务器上,就像分工明确的小团队,各自负责一块,效率就蹭蹭地上去了。
那这些小部分之间怎么交流呢?这就涉及到网络通信啦。
就像小伙伴之间要聊天传递信息一样,分布式系统里的各个组件也得互相说话。
不过这可不像咱们平常聊天那么简单。
这里面得有一套规则,也就是协议。
比如说HTTP协议,就像是大家都懂的一种通用语言,不同的组件用这个语言来发送请求和接收响应。
在分布式架构里,数据的存储也很有讲究。
不能像把所有东西都塞在一个小抽屉里那样。
得有专门的数据库来存储数据,而且可能还不止一个数据库呢。
有时候为了提高数据读取的速度,还会做数据的缓存。
这就好比你把常用的东西放在手边的小盒子里,要用的时候直接拿,不用每次都跑到大仓库(数据库)里去找。
比如说,用户经常查看的热门商品信息,就可以缓存起来,下次再有人看的时候,一下子就能显示出来,速度超快。
说到这儿,不得不提一下分布式系统的容错性。
这就像一群小伙伴里,有一两个小伙伴生病(出故障)了,整个团队不能就散伙了呀。
分布式系统得有办法应对这种情况。
它会有备份,有冗余。
就像有替补队员一样。
如果一台服务器坏了,其他的服务器可以顶上,保证系统还能正常运行。
这就给系统穿上了一层厚厚的铠甲,让它不那么容易被打倒。
还有负载均衡呢。
这就像是一个聪明的小管家,看着哪个服务器比较闲,就把新的任务分配给它。
不能让有的服务器忙得要死,有的服务器却在那儿闲着没事干。
就像在一个团队里,要让每个人的工作量都比较均衡,这样大家都能愉快地工作,整个系统的效率也能达到最高。
另外,分布式架构的扩展性也超棒。
Java分布式应用技术架构介绍

Java分布式应⽤技术架构介绍分布式架构的演进系统架构演化历程-初始阶段架构初始阶段的⼩型系统应⽤程序、数据库、⽂件等所有的资源都在⼀台服务器上通俗称为LAMP特征:应⽤程序、数据库、⽂件等所有的资源都在⼀台服务器上。
描述:通常服务器操作系统使⽤linux,应⽤程序使⽤PHP开发,然后部署在Apache上,数据库使⽤Mysql,汇集各种免费开源软件以及⼀台廉价服务器就可以开始系统的发展之路了。
系统架构演化历程-应⽤服务和数据服务分离好景不长,发现随着系统访问量的再度增加,webserver机器的压⼒在⾼峰期会上升到⽐较⾼,这个时候开始考虑增加⼀台webserver特征:应⽤程序、数据库、⽂件分别部署在独⽴的资源上。
描述:数据量增加,单台服务器性能及存储空间不⾜,需要将应⽤和数据分离,并发处理能⼒和数据存储空间得到了很⼤改善。
系统架构演化历程-使⽤缓存改善性能特征:数据库中访问较集中的⼀⼩部分数据存储在缓存服务器中,减少数据库的访问次数,降低数据库的访问压⼒。
描述:系统访问特点遵循⼆⼋定律,即80%的业务访问集中在20%的数据上。
缓存分为本地缓存和远程分布式缓存,本地缓存访问速度更快但缓存数据量有限,同时存在与应⽤程序争⽤内存的情况。
系统架构演化历程-使⽤应⽤服务器集群在做完分库分表这些⼯作后,数据库上的压⼒已经降到⽐较低了,⼜开始过着每天看着访问量暴增的幸福⽣活了,突然有⼀天,发现系统的访问⼜开始有变慢的趋势了,这个时候⾸先查看数据库,压⼒⼀切正常,之后查看webserver,发现apache阻塞了很多的请求,⽽应⽤服务器对每个请求也是⽐较快的,看来是请求数太⾼导致需要排队等待,响应速度变慢特征:多台服务器通过负载均衡同时向外部提供服务,解决单台服务器处理能⼒和存储空间上限的问题。
描述:使⽤集群是系统解决⾼并发、海量数据问题的常⽤⼿段。
通过向集群中追加资源,提升系统的并发处理能⼒,使得服务器的负载压⼒不再成为整个系统的瓶颈。
分布式技术架构介绍
应用
应用
数据库
数据库
数据库 缓存阶段
应用服务器集群
集群阶段
数据库服务器集群
数 据 库
缓存
特点
•
应用 程序
问题
经历了应用和数据拆分和集群、缓存等阶段 千级强并发,万级弱并发(在线用户),十万级用户 大型企业ERP、供应链、大型企业HR、办公OA、核 心业务系统 • • • • • 中央集中式部署架构,小型机和FC共享存储场景较多, 水平扩展有瓶颈(应用和数据的扩展能力都很差) 有热备和故障恢复机制,但数据集中存储,安全风险高 大量的事务、锁检测导致数据库访问瓶颈 基础设施率用低,成本高 追求单节点的稳定性
服务框架 服务1 (服务提供者)
服务框架 服务2 (服务提供者)
服务框架 服务3 (服务提供者)
放的服务列表;
• 应用与服务实现负载均衡,通过随机、轮询、权 重等策略;
消息中间件
• 既然应用拆分了,形成了服务层,应用由紧
应用 A
1
应用 B
2
应用 C
2
耦合变为松耦合,那么应用之间、服务之间、
应用与服务之间如何通讯? • • • 应用解耦 异步通讯、操作的异步 有些场景中,利用消息系统确保分布式数据
•
系统架构更加清晰,代码质量提高,利于升级和
维护,稳定性高
•
网站初期或者规模较小,整体上容易 把控
•
服务层利用分布式系统的架构实现HA的功能
•
适用大型网站系统的场景中
服务框架
应 用 A 应 用 B 应 用 C 应 用 D 应 用 E 应 用 F 应 用 G 应用1 (服务调用者) 应用2 (服务调用者) 服务框架
• •
分布式架构介绍

1. 使用Redis有哪些好处?(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找与操作的时间复杂度都是O(1) (2) 支持丰富数据类型,支持string,list,set,sorted set,hash(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除2. redis相比memcached有哪些优势?(1) memcached所有的值均是简单的字符串,Redis作为其替代者,支持更为丰富的数据类型(2) redis的速度比memcached快很多(3) redis可以持久化其数据3. redis常见性能问题与解决方案:(1) Master最好不要做任何持久化工作,如RDB内存快照与AOF日志文件(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次(3) 为了主从复制的速度与连接的稳定性,Master与Slave最好在同一个局域网内(4) 尽量避免在压力很大的主库上增加从库(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3…这样的结构方便解决单点故障问题,实现Slave对Master的替换。
如果Master挂了,可以立刻启用Slave1做Master,其他不变。
4. MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据相关知识:redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
redis 提供6种数据淘汰策略:voltile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰no-enviction(驱逐):禁止驱逐数据5. Memcache与Redis的区别都有哪些?1)、存储方式Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。
分布式架构详解

分布式架构详解随着互联网的迅猛发展,越来越多的应用场景需要处理海量数据和高并发请求。
而单机架构往往无法满足这些需求,因此分布式架构应运而生。
分布式架构是指将一个应用系统划分为多个子系统,分别部署在不同的服务器上,并通过网络进行通信和协作,以实现高性能、高可用和可扩展的系统。
分布式架构的核心思想是将一个复杂的问题分解为多个简单的子问题,并通过协作完成整体任务。
每个子系统负责处理一部分业务逻辑,通过消息传递、远程调用等方式进行通信,最终协同工作,提供完整的功能。
在分布式架构中,常见的组件包括:负载均衡器、分布式缓存、分布式数据库等。
负载均衡器用于将请求分发到多个服务器上,以实现负载均衡和高可用。
分布式缓存用于存储频繁访问的数据,以减轻数据库的压力。
分布式数据库则将数据分片存储在多个节点上,提高数据存取的并发能力和处理能力。
在分布式架构中,节点之间的通信是关键。
常见的通信方式包括:同步调用、异步调用和消息队列。
同步调用是指调用方等待被调用方返回结果后才继续执行,适用于实时性要求较高的场景。
异步调用是指调用方不等待被调用方返回结果,而是继续执行自己的逻辑,被调用方将结果回调给调用方,适用于实时性要求不高的场景。
消息队列则是将消息发送到队列中,由消费者异步消费,适用于解耦和削峰填谷的场景。
分布式架构的优点在于可扩展性和高可用性。
由于系统可以通过增加节点来扩展性能,因此可以满足不断增长的用户需求。
同时,由于系统的各个组件部署在不同的服务器上,即使某个节点发生故障,系统仍然可以继续提供服务,提高了系统的可用性。
然而,分布式架构也面临一些挑战和问题。
首先,节点之间的通信增加了系统的复杂性,需要考虑网络延迟、数据一致性等因素。
其次,分布式环境下的故障和并发问题更加复杂,需要引入分布式事务、分布式锁等机制来保证数据的一致性和可靠性。
此外,分布式架构的设计和开发需要更高的技术水平和复杂度,对开发人员的要求更高。
总结起来,分布式架构是为了解决大规模数据处理和高并发请求而提出的一种架构模式。
分布式架构设计方案

分布式架构设计方案一、引言随着互联网和云计算的快速发展,分布式架构设计方案成为了现代软件系统开发中不可忽视的关键要素。
本文将介绍分布式架构概念、设计原则以及常用的分布式架构模式,并提供一个实际的分布式架构设计方案,以供参考。
二、分布式架构概述分布式架构是指将一个软件系统的不同功能模块或组件分布在多台服务器上,以实现高性能、高可靠性和可扩展性的设计方案。
它能够将系统负载分散到不同节点上,提高并发处理能力,并提供容错机制以保证系统的高可用性。
三、分布式架构设计原则1. 服务解耦:将系统拆分为独立的服务,每个服务负责特定的业务功能,通过接口进行通信,实现解耦和独立部署。
2. 异步通信:采用消息队列等异步通信方式,降低系统耦合度,提高系统的可扩展性和可靠性。
3. 水平扩展:通过水平扩展增加系统的处理能力,将负载均衡在不同的节点上,提高系统的性能和可用性。
4. 数据分区:将数据按照一定的规则进行分区存储,降低单一节点的负载压力,并提高系统的数据处理能力。
5. 容错设计:采用冗余备份和自动容错机制,保证系统的高可用性和数据的安全性。
四、常用的分布式架构模式1. 服务化架构:将系统拆分为多个微服务,每个微服务负责特定的业务功能,并通过RESTful API等方式进行通信。
2. 分层架构:将系统按照不同的职责和功能划分为多个层次,包括展示层、业务逻辑层、数据访问层等,实现功能模块的独立发展。
3. 多层缓存架构:通过在不同节点上设置缓存层,提高数据的读取速度和系统的响应性能。
4. 数据库分库分表架构:将数据库按照一定的规则进行分片存储,提高系统的数据存储能力和查询性能。
5. 分布式消息队列架构:采用消息队列作为通信中介,实现系统间的解耦和异步通信。
五、分布式架构设计方案示例为了让读者更好地理解分布式架构设计方案的实际应用,本文以一个电子商务系统为例,提供以下设计方案:1. 服务化架构:将系统拆分为用户服务、商品服务、订单服务等多个微服务,每个微服务可以独立部署和扩展。