hadoop学习之hadoop完全分布式集群安装
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu_CentOS

Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS本教程讲述如何配置Hadoop 集群,默认读者已经掌握了Hadoop 的单机伪分布式配置,否则请先查看Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置。
本教程由厦门大学数据库实验室出品,转载请注明。
本教程适合于原生Hadoop 2,包括Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,保证按照步骤来,都能顺利安装并运行Hadoop。
另外有Hadoop安装配置简略版方便有基础的读者快速完成安装。
为了方便新手入门,我们准备了两篇不同系统的Hadoop 伪分布式配置教程。
但其他Hadoop 教程我们将不再区分,可同时适用于Ubuntu 和CentOS/RedHat 系统。
例如本教程以Ubuntu 系统为主要演示环境,但对Ubuntu/CentOS 的不同配置之处、CentOS 6.x 与CentOS 7 的操作区别等都会尽量给出注明。
环境本教程使用Ubuntu 14.04 64位作为系统环境,基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1,Hadoop 2.4.1 等。
本教程简单的使用两个节点作为集群环境: 一个作为Master 节点,局域网IP 为192.168.1.121;另一个作为Slave 节点,局域网IP 为192.168.1.122。
准备工作Hadoop 集群的安装配置大致为如下流程:1.选定一台机器作为Master2.在Master 节点上配置hadoop 用户、安装SSH server、安装Java 环境3.在Master 节点上安装Hadoop,并完成配置4.在其他Slave 节点上配置hadoop 用户、安装SSH server、安装Java 环境5.将Master 节点上的/usr/local/hadoop 目录复制到其他Slave 节点上6.在Master 节点上开启Hadoop配置hadoop 用户、安装SSH server、安装Java 环境、安装Hadoop 等过程已经在Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置中有详细介绍,请前往查看,不再重复叙述。
hadoop核心组件概述及hadoop集群的搭建

hadoop核⼼组件概述及hadoop集群的搭建什么是hadoop? Hadoop 是 Apache 旗下的⼀个⽤ java 语⾔实现开源软件框架,是⼀个开发和运⾏处理⼤规模数据的软件平台。
允许使⽤简单的编程模型在⼤量计算机集群上对⼤型数据集进⾏分布式处理。
hadoop提供的功能:利⽤服务器集群,根据⽤户的⾃定义业务逻辑,对海量数据进⾏分布式处理。
狭义上来说hadoop 指 Apache 这款开源框架,它的核⼼组件有:1. hdfs(分布式⽂件系统)(负责⽂件读写)2. yarn(运算资源调度系统)(负责为MapReduce程序分配运算硬件资源)3. MapReduce(分布式运算编程框架)扩展:关于hdfs集群: hdfs集群有⼀个name node(名称节点),类似zookeeper的leader(领导者),namenode记录了⽤户上传的⼀些⽂件分别在哪些DataNode上,记录了⽂件的源信息(就是记录了⽂件的名称和实际对应的物理地址),name node有⼀个公共端⼝默认是9000,这个端⼝是针对客户端访问的时候的,其他的⼩弟(跟随者)叫data node,namenode和datanode会通过rpc进⾏远程通讯。
Yarn集群: yarn集群⾥的⼩弟叫做node manager,MapReduce程序发给node manager来启动,MapReduce读数据的时候去找hdfs(datanode)去读。
(注:hdfs集群和yarn集群最好放在同⼀台机器⾥),yarn集群的⽼⼤主节点resource manager负责资源调度,应(最好)单独放在⼀台机器。
⼴义上来说,hadoop通常指更⼴泛的概念--------hadoop⽣态圈。
当下的 Hadoop 已经成长为⼀个庞⼤的体系,随着⽣态系统的成长,新出现的项⽬越来越多,其中不乏⼀些⾮ Apache 主管的项⽬,这些项⽬对 HADOOP 是很好的补充或者更⾼层的抽象。
《hadoop基础》课件——第三章 Hadoop集群的搭建及配置

19
Hadoop集群—文件监控
http://master:50070
20
Hadoop集群—文件监控
http://master:50070
21
Hadoop集群—文件监控
http://master:50070
22
Hadoop集群—任务监控
http://master:8088
23
Hadoop集群—日志监控
http://master:19888
24
Hadoop集群—问题 1.集群节点相关服务没有启动?
1. 检查对应机器防火墙状态; 2. 检查对应机器的时间是否与主节点同步;
25
Hadoop集群—问题
2.集群状态不一致,clusterID不一致? 1. 删除/data.dir配置的目录; 2. 重新执行hadoop格式化;
准备工作:
1.Linux操作系统搭建完好。 2.PC机、服务器、环境正常。 3.搭建Hadoop需要的软件包(hadoop-2.7.6、jdk1.8.0_171)。 4.搭建三台虚拟机。(master、node1、node2)
存储采用分布式文件系统 HDFS,而且,HDFS的名称 节点和数据节点位于不同机 器上。
2、vim编辑core-site.xml,修改以下配置: <property>
<name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
Hadoop集群的搭建方法与步骤

Hadoop集群的搭建方法与步骤随着大数据时代的到来,Hadoop作为一种分布式计算框架,被广泛应用于数据处理和分析领域。
搭建一个高效稳定的Hadoop集群对于数据科学家和工程师来说至关重要。
本文将介绍Hadoop集群的搭建方法与步骤。
一、硬件准备在搭建Hadoop集群之前,首先要准备好适合的硬件设备。
Hadoop集群通常需要至少三台服务器,一台用于NameNode,两台用于DataNode。
每台服务器的配置应该具备足够的内存和存储空间,以及稳定的网络连接。
二、操作系统安装在选择操作系统时,通常推荐使用Linux发行版,如Ubuntu、CentOS等。
这些操作系统具有良好的稳定性和兼容性,并且有大量的Hadoop安装和配置文档可供参考。
安装操作系统后,确保所有服务器上的软件包都是最新的。
三、Java环境配置Hadoop是基于Java开发的,因此在搭建Hadoop集群之前,需要在所有服务器上配置Java环境。
下载最新版本的Java Development Kit(JDK),并按照官方文档的指引进行安装和配置。
确保JAVA_HOME环境变量已正确设置,并且可以在所有服务器上运行Java命令。
四、Hadoop安装与配置1. 下载Hadoop从Hadoop官方网站上下载最新的稳定版本,并将其解压到一个合适的目录下,例如/opt/hadoop。
2. 编辑配置文件进入Hadoop的安装目录,编辑conf目录下的hadoop-env.sh文件,设置JAVA_HOME环境变量为Java的安装路径。
然后,编辑core-site.xml文件,配置Hadoop的核心参数,如文件系统的默认URI和临时目录。
接下来,编辑hdfs-site.xml文件,配置Hadoop分布式文件系统(HDFS)的相关参数,如副本数量和数据块大小。
最后,编辑mapred-site.xml文件,配置MapReduce框架的相关参数,如任务调度器和本地任务运行模式。
Hadoop集群搭建步骤

Hadoop集群搭建步骤1.先建⽴⼀台虚拟机,分配内存2G,硬盘20G,⽹络为nat 模式,设置⼀个静态的ip 地址: 例如设定3台机器的ip 为192.168.63.167(master) 192.16863.168(slave1) 192.168.63.169 (slave2)2.修改第⼀台主机的⽤户名3.复制master⽂件两次,重命名为slave1和slave2,打开虚拟机⽂件,然后按照同样的⽅法设置两个节点的ip和主机名4.建⽴主机名和ip的映射5.查看是否能ping通,关闭防⽕墙和selinux 配置6.配置ssh免密码登录在root⽤户下输⼊ssh-keygen -t rsa ⼀路回车秘钥⽣成后在~/.ssh/⽬录下,有两个⽂件id_rsa(私钥)和id_rsa.pub(公钥),将公钥复制到authorized_keys并赋予authorized_keys600权限同理在slave1和slave2节点上进⾏相同的操作,然后将公钥复制到master节点上的authoized_keys检查是否免密登录(第⼀次登录会有提⽰)7..安装JDK(省去)三个节点安装java并配置java环境变量8.安装MySQL(master 节点省去)9.安装SecureCRT或者xshell 客户端⼯具,然后分别链接上 3台服务器12.搭建集群12.1 集群结构三个结点:⼀个主节点master两个从节点内存2GB 磁盘20GB12.2 新建hadoop⽤户及其⽤户组⽤adduser新建⽤户并设置密码将新建的hadoop⽤户添加到hadoop⽤户组前⾯hadoop指的是⽤户组名,后⼀个指的是⽤户名赋予hadoop⽤户root权限12.3 安装hadoop并配置环境变量由于hadoop集群需要在每⼀个节点上进⾏相同的配置,因此先在master节点上配置,然后再复制到其他节点上即可。
将hadoop包放在/usr/⽬录下并解压配置环境变量在/etc/profile⽂件中添加如下命令12.4 搭建集群的准备⼯作在master节点上创建以下⽂件夹/usr/hadoop-2.6.5/dfs/name/usr/hadoop-2.6.5/dfs/data/usr/hadoop-2.6.5/temp12.5 配置hadoop⽂件接下来配置/usr/hadoop-2.6.5/etc//hadoop/⽬录下的七个⽂件slaves core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml hadoop-env.sh yarn-env.sh配置hadoop-env.sh配置yarn-env.sh配置slaves⽂件,删除localhost配置core-site.xml配置hdfs-site.xml配置mapred-site.xml配置yarn-site.xml将配置好的hadoop⽂件复制到其他节点上12.6 运⾏hadoop格式化Namenodesource /etc/profile13. 启动集群。
hadoop分布式环境搭建实验总结

hadoop分布式环境搭建实验总结Hadoop分布式环境搭建实验总结一、引言Hadoop是目前最流行的分布式计算框架之一,它具有高可靠性、高扩展性和高效性的特点。
在本次实验中,我们成功搭建了Hadoop分布式环境,并进行了相关测试和验证。
本文将对实验过程进行总结和归纳,以供参考。
二、实验准备在开始实验之前,我们需要准备好以下几个方面的内容:1. 硬件环境:至少两台具备相同配置的服务器,用于搭建Hadoop 集群。
2. 软件环境:安装好操作系统和Java开发环境,并下载Hadoop 的安装包。
三、实验步骤1. 安装Hadoop:解压Hadoop安装包,并根据官方文档进行相应的配置,包括修改配置文件、设置环境变量等。
2. 配置SSH无密码登录:为了实现集群间的通信,需要配置各个节点之间的SSH无密码登录。
具体步骤包括生成密钥对、将公钥分发到各个节点等。
3. 配置Hadoop集群:修改Hadoop配置文件,包括core-site.xml、hdfs-site.xml和mapred-site.xml等,设置集群的基本参数,如文件系统地址、数据存储路径等。
4. 启动Hadoop集群:通过启动NameNode、DataNode和ResourceManager等守护进程,使得集群开始正常运行。
可以通过jps命令来验证各个进程是否成功启动。
5. 测试Hadoop集群:可以使用Hadoop自带的例子程序进行测试,如WordCount、Sort等。
通过执行这些程序,可以验证集群的正常运行和计算能力。
四、实验结果经过以上步骤的操作,我们成功搭建了Hadoop分布式环境,并进行了相关测试。
以下是我们得到的一些实验结果:1. Hadoop集群的各个节点正常运行,并且能够相互通信。
2. Hadoop集群能够正确地处理输入数据,并生成期望的输出结果。
3. 集群的负载均衡和容错能力较强,即使某个节点出现故障,也能够继续运行和处理任务。
hadoop学习笔记(一、hadoop集群环境搭建)

Hadoop集群环境搭建1、准备资料虚拟机、Redhat6.5、hadoop-1.0.3、jdk1.62、基础环境设置2.1配置机器时间同步#配置时间自动同步crontab -e#手动同步时间/usr/sbin/ntpdate 1、安装JDK安装cd /home/wzq/dev./jdk-*****.bin设置环境变量Vi /etc/profile/java.sh2.2配置机器网络环境#配置主机名(hostname)vi /etc/sysconfig/network#修第一台hostname 为masterhostname master#检测hostname#使用setup 命令配置系统环境setup#检查ip配置cat /etc/sysconfig/network-scripts/ifcfg-eth0#重新启动网络服务/sbin/service network restart#检查网络ip配置/sbin/ifconfig2.3关闭防火墙2.4配置集群hosts列表vi /etc/hosts#添加一下内容到vi 中2.5创建用户账号和Hadoop部署目录和数据目录#创建hadoop 用户/usr/sbin/groupadd hadoop#分配hadoop 到hadoop 组中/usr/sbin/useradd hadoop -g hadoop#修改hadoop用户密码Passwd hadoop#创建hadoop 代码目录结构mkdir -p /opt/modules/hadoop/#修改目录结构权限拥有者为为hadoopchown -R hadoop:hadoop /opt/modules/hadoop/2.6生成登陆密钥#切换到Hadoop 用户下su hadoopcd /home/hadoop/#在master、node1、node2三台机器上都执行下面命令,生成公钥和私钥ssh-keygen -q -t rsa -N "" -f /home/hadoop/.ssh/id_rsacd /home/hadoop/.ssh#把node1、node2上的公钥拷贝到master上scp /home/hadoop/.ssh/ id_rsa.pub hadoop@master:/home/hadoop/.ssh/node1_pubkey scp /home/hadoop/.ssh/ id_rsa.pub hadoop@master:/home/hadoop/.ssh/node2_pubkey#在master上生成三台机器的共钥cp id_rsa.pub authorized_keyscat node1_pubkey >> authorized_keyscat node2_pubkey >> authorized_keysrm node1_pubkey node2_pubkey#吧master上的共钥拷贝到其他两个节点上scp authorized_keys node1: /home/hadoop/.ssh/scp authorized_keys node1: /home/hadoop/.ssh/#验证ssh masterssh node1ssh node2没有要求输入密码登陆,表示免密码登陆成功3、伪分布式环境搭建3.1下载并安装JAVA JDK系统软件#下载jdkwget http://60.28.110.228/source/package/jdk-6u21-linux-i586-rpm.bin#安装jdkchmod +x jdk-6u21-linux-i586-rpm.bin./jdk-6u21-linux-i586-rpm.bin#配置环境变量vi /etc/profile.d/java.sh#手动立即生效source /etc/profile3.2 Hadoop 文件下载和安装#切到hadoop 安装路径下cd /opt/modules/hadoop/#从 下载Hadoop 安装文件wget /apache-mirror/hadoop/common/hadoop-1.0.3/hadoop-1.0.3.tar.gz#如果已经下载,请复制文件到安装hadoop 文件夹cp hadoop-1.0.3.tar.gz /opt/modules/hadoop/#解压hadoop-1.0.3.tar.gzcd /opt/modules/hadoop/tar -xvf hadoop-1.0.3.tar.gz#配置环境变量vi /etc/profile.d/java.sh#手动立即生效source /etc/profile3.3配置hadoop-env.sh 环境变量#配置jdk。
hadoop2.2安装
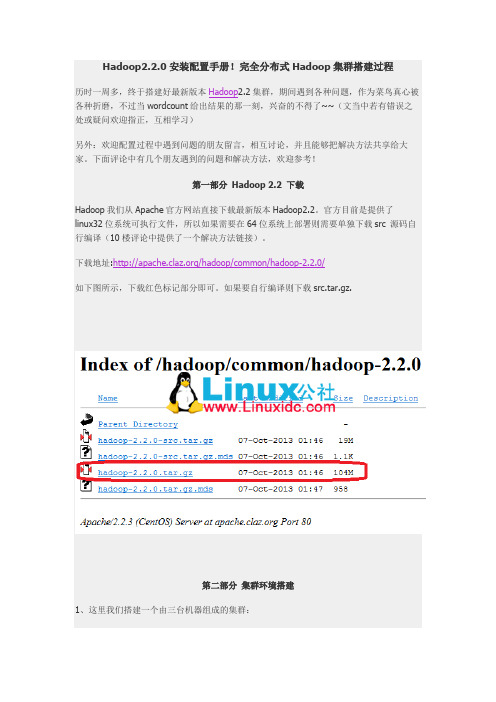
Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程历时一周多,终于搭建好最新版本Hadoop2.2集群,期间遇到各种问题,作为菜鸟真心被各种折磨,不过当wordcount给出结果的那一刻,兴奋的不得了~~(文当中若有错误之处或疑问欢迎指正,互相学习)另外:欢迎配置过程中遇到问题的朋友留言,相互讨论,并且能够把解决方法共享给大家。
下面评论中有几个朋友遇到的问题和解决方法,欢迎参考!第一部分Hadoop 2.2 下载Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。
官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译(10楼评论中提供了一个解决方法链接)。
下载地址:/hadoop/common/hadoop-2.2.0/如下图所示,下载红色标记部分即可。
如果要自行编译则下载src.tar.gz.第二部分集群环境搭建1、这里我们搭建一个由三台机器组成的集群:192.168.0.1 hduser/passwd cloud001 nn/snn/rm CentOS6 64bit192.168.0.2 hduser/passwd cloud002 dn/nm Ubuntu13.04 32bit192.168.0.3 hduser/passwd cloud003 dn/nm Ubuntu13.0432bit1.1 上面各列分别为IP、user/passwd、hostname、在cluster中充当的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager)1.2 Hostname可以在/etc/hostname中修改(ubuntu是在这个路径下,RedHat稍有不同)1.3 这里我们为每台机器新建了一个账户hduser.这里需要给每个账户分配sudo的权限。
hadoop集群搭建步骤

hadoop集群搭建步骤Hadoop集群搭建步骤Hadoop是一个开源的分布式计算框架,被广泛应用于大数据处理。
搭建Hadoop集群可以提供高可用性、高性能的分布式计算环境。
下面将介绍Hadoop集群的搭建步骤。
1. 硬件准备需要准备一组具有较高性能的服务器作为集群中的节点。
这些服务器需满足一定的硬件要求,包括处理器、内存和存储空间等。
通常情况下,建议使用至少3台服务器来搭建一个最小的Hadoop集群。
2. 操作系统安装在每台服务器上安装合适的操作系统,例如CentOS、Ubuntu等。
操作系统应该是最新的稳定版本,并且需要进行基本的配置,如网络设置、安装必要的软件和工具等。
3. Java环境配置Hadoop是基于Java开发的,因此需要在每台服务器上安装Java 开发环境。
确保安装的Java版本符合Hadoop的要求,并设置好相应的环境变量。
4. Hadoop安装和配置下载Hadoop的最新稳定版本,并将其解压到指定的目录。
然后,需要进行一些配置来启动Hadoop集群。
主要的配置文件包括hadoop-env.sh、core-site.xml、hdfs-site.xml和mapred-site.xml等。
在hadoop-env.sh文件中,可以设置一些全局的环境变量,如Java路径、Hadoop日志目录等。
在core-site.xml文件中,配置Hadoop的核心设置,如Hadoop的文件系统类型(HDFS)和默认的文件系统地址等。
在hdfs-site.xml文件中,配置HDFS的相关设置,如副本数量、数据块大小等。
在mapred-site.xml文件中,配置MapReduce的相关设置,如任务调度方式、任务跟踪器地址等。
5. 配置SSH免密码登录为了实现集群中各节点之间的通信,需要配置SSH免密码登录。
在每台服务器上生成SSH密钥,并将公钥添加到所有其他服务器的授权文件中,以实现无需密码即可登录其他服务器。
Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐血整理)

Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐⾎整理)系统:Centos 7,内核版本3.10本⽂介绍如何从0利⽤Docker搭建Hadoop环境,制作的镜像⽂件已经分享,也可以直接使⽤制作好的镜像⽂件。
⼀、宿主机准备⼯作0、宿主机(Centos7)安装Java(⾮必须,这⾥是为了⽅便搭建⽤于调试的伪分布式环境)1、宿主机安装Docker并启动Docker服务安装:yum install -y docker启动:service docker start⼆、制作Hadoop镜像(本⽂制作的镜像⽂件已经上传,如果直接使⽤制作好的镜像,可以忽略本步,直接跳转⾄步骤三)1、从官⽅下载Centos镜像docker pull centos下载后查看镜像 docker images 可以看到刚刚拉取的Centos镜像2、为镜像安装Hadoop1)启动centos容器docker run -it centos2)容器内安装java下载java,根据需要选择合适版本,如果下载历史版本拉到页⾯底端,这⾥我安装了java8/usr下创建java⽂件夹,并将java安装包在java⽂件下解压tar -zxvf jdk-8u192-linux-x64.tar.gz解压后⽂件夹改名(⾮必需)mv jdk1.8.0_192 jdk1.8配置java环境变量vi ~/.bashrc ,添加内容,保存后退出export JAVA_HOME=/usr/java/jdk1.8export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/libexport PATH=$PATH:${JAVA_HOME}/bin使环境变量⽣效 source ~/.bashrc验证安装结果 java -version这⾥注意,因为是在容器中安装,修改的是~/.bashrc⽽⾮我们使⽤更多的/etc/profile,否则再次启动容器的时候会环境变量会失效。
hadoop完全分布式搭建步骤

Hadoop是一个开源的分布式计算框架,它能够处理大规模数据的存储和处理。
本文将介绍如何搭建Hadoop完全分布式集群。
一、准备工作1. 安装Java环境:Hadoop需要Java环境的支持,因此需要先安装Java环境。
2. 下载Hadoop:从官网下载Hadoop的最新版本。
3. 配置SSH:Hadoop需要通过SSH进行节点之间的通信,因此需要配置SSH。
二、安装Hadoop1. 解压Hadoop:将下载好的Hadoop压缩包解压到指定目录下。
2. 配置Hadoop环境变量:将Hadoop的bin目录添加到系统的PATH环境变量中。
3. 修改Hadoop配置文件:进入Hadoop的conf目录,修改hadoop-env.sh文件和core-site.xml 文件。
4. 配置HDFS:修改hdfs-site.xml文件,设置NameNode和DataNode的存储路径。
5. 配置YARN:修改yarn-site.xml文件,设置ResourceManager和NodeManager的地址和端口号。
6. 配置MapReduce:修改mapred-site.xml文件,设置JobTracker和TaskTracker的地址和端口号。
7. 格式化HDFS:在NameNode所在的节点上执行格式化命令:hadoop namenode -format。
8. 启动Hadoop:在NameNode所在的节点上执行启动命令:start-all.sh。
三、验证Hadoop集群1. 查看Hadoop进程:在NameNode所在的节点上执行jps命令,查看Hadoop进程是否启动成功。
2. 查看Hadoop日志:在NameNode所在的节点上查看Hadoop的日志文件,确认是否有错误信息。
3. 访问Hadoop Web界面:在浏览器中输入NameNode的地址和端口号,访问HadoopWeb界面,确认Hadoop集群是否正常运行。
hadoop安装指南(非常详细,包成功)

➢3.10.2.进程➢JpsMaster节点:namenode/tasktracker(如果Master不兼做Slave, 不会出现datanode/TasktrackerSlave节点:datanode/Tasktracker说明:JobTracker 对应于NameNodeTaskTracker 对应于DataNodeDataNode 和NameNode 是针对数据存放来而言的JobTracker和TaskTracker是对于MapReduce执行而言的mapreduce中几个主要概念,mapreduce整体上可以分为这么几条执行线索:jobclient,JobTracker与TaskTracker。
1、JobClient会在用户端通过JobClient类将应用已经配置参数打包成jar文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker创建每个Task(即MapTask和ReduceTask)并将它们分发到各个TaskTracker服务中去执行2、JobTracker是一个master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。
一般情况应该把JobTracker部署在单独的机器上。
3、TaskTracker是运行在多个节点上的slaver服务。
TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。
TaskTracker都需要运行在HDFS的DataNode上3.10.3.文件系统HDFS⏹查看文件系统根目录:Hadoop fs–ls /。
Hadoop完全分布式详细安装过程

Hadoop详细安装过程一、本文思路1、安装虚拟化PC工具VMware,用于支撑Linux系统。
2、在VMware上安装Ubuntu系统。
3、安装Hadoop前的准备工作:安装JDK和SSH服务。
4、配置Hadoop。
5、为了方便开发过程,需安装eclipse。
6、运行一个简单的Hadoop程序:WordCount.java注:在win7系统上,利用虚拟工具VMware建立若干个Linux系统,每个系统为一个节点,构建Hadoop集群。
先在一个虚拟机上将所有需要配置的东西全部完成,然后再利用VMware 的克隆功能,直接生成其他虚拟机,这样做的目的是简单。
二、所需软件1、VMware:VMware Workstation,直接百度下载(在百度软件中心下载即可)。
2、Ubuntu系统:ubuntu-15.04-desktop-amd64.iso,百度网盘:/s/1qWxfxso注:使用15.04版本的Ubuntu(其他版本也可以),是64位系统。
3、jdk:jdk-8u60-linux-x64.tar.gz,网址:/technetwork/java/javase/downloads/jdk8-downloads-2133151.html注:下载64位的Linux版本的jdk。
4、Hadoop:hadoop-1.2.1-bin.tar.gz,网址:/apache/hadoop/common/hadoop-1.2.1/注:选择1.2.1版本的Hadoop。
5、eclipse:eclipse-java-mars-1-linux-gtk-x86_64.tar.gz,网址:/downloads/?osType=linux注:要选择Linux版本的,64位,如下:6、hadoop-eclipse-plugin-1.2.1.jar,这是eclipse的一个插件,用于Hadoop的开发,直接百度下载即可。
三、安装过程1、安装VMware。
Hadoop集群搭建详细简明教程

Linux 操作系统安装
利用 vmware 安装 Linux 虚拟机,选择 CentOS 操作系统
搭建机器配置说明
本人机器是 thinkpadt410,i7 处理器,8G 内存,虚拟机配置为 2G 内存,大家可以 按照自己的机器做相应调整,但虚拟机内存至少要求 1G。
会出现虚拟机硬件清单,我们要修改的,主要关注“光驱”和“软驱”,如下图: 选择“软驱”,点击“remove”移除软驱:
选择光驱,选择 CentOS ISO 镜像,如下图: 最后点击“Close”,回到“硬件配置页面”,点击“Finsh”即可,如下图: 下图为创建all or upgrade an existing system”
执行 java –version 命令 会出现上图的现象。 从网站上下载 jdk1.6 包( jdk-6u21-linux-x64-rpm.bin )上传到虚拟机上 修改权限:chmod u+x jdk-6u21-linux-x64-rpm.bin 解压并安装: ./jdk-6u21-linux-x64-rpm.bin (默认安装在/usr/java 中) 配置环境变量:vi /etc/profile 在该 profile 文件中最后添加:
选择“Skip”跳过,如下图:
选择“English”,next,如下图: 键盘选择默认,next,如下图:
选择默认,next,如下图:
输入主机名称,选择“CongfigureNetwork” 网络配置,如下图:
选中 system eth0 网卡,点击 edit,如下图:
选择网卡开机自动连接,其他不用配置(默认采用 DHCP 的方式获取 IP 地址), 点击“Apply”,如下图:
Hadoop2.7.3+Hbase-1.2.6完全分布式安装部署

Hadoop2.7.3+Hbase-1.2.6完全分布式安装部署Hadoop安装部署基本步骤:1、安装jdk,配置环境变量。
jdk可以去⽹上⾃⾏下载,环境变量如下:编辑 vim /etc/profile ⽂件,添加如下内容:export JAVA_HOME=/opt/java_environment/jdk1.7.0_80(填写⾃⼰的jdk安装路径)export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport PATH=$PATH:$JAVA_HOME/bin输⼊命令,source /etc/profile 使配置⽣效分别输⼊命令,java 、 javac 、 java -version,查看jdk环境变量是否配置成功2、linux环境下,⾄少需要3台机⼦,⼀台作为master,2台(以上)作为slave。
这⾥我以3台机器为例,linux⽤的是CentOS 6.5 x64为机器。
master 192.168.172.71slave1 192.168.172.72slave2 192.168.172.733、配置所有机器的hostname和hosts。
(1)更改hostname,可以编辑 vim /etc/sysconfig/network 更改master的HOSTNAME,这⾥改为HOSTNAME=master 其它slave为HOSTNAME=slave1、HOSTNAME=slave2 ,重启后⽣效。
或者直接输: hostname 名字,更改成功,这种⽅式⽆需重启即可⽣效, 但是重启系统后更改的名字会失效,仍是原来的名字 (2)更改host,可以编辑 vim /etc/hosts,增加如下内容: 192.168.172.71 master 192.168.172.72 slave1 192.168.172.73 slave2 hosts可以和hostname不⼀致,这⾥为了好记就写⼀致了。
Hadoop分布式详细安装步骤

Hadoop分布式详细安装步骤版本:0.20.2准备工作:由于Hadoop要求所有主机上hadoop的部署目录结构要相同,并且都有一个相同的用户名的帐户。
二台机器上是这样的:都有一个coole的帐户,主目录是/home/coole两台机器(内存应在512以上,否则可能会出现计算极度缓慢的情况):一台机器名:master IP:211.87.239.181一台机器名:slave IP:211.87.239.182每台都建coole用户如果是ubuntu,为了便于用coole帐号修改系统设置和访问系统文件,推荐把coole也设为sudoers(有root 权限的用户),具体做法是用已有的sudoer登录系统,执行sudo visudo –f /etc/sudoers,并在此文件中添加以下一行:mapred ALL=(ALL) ALL一、更改主机名:1、修改/etc/sysconfig/networkNETWORKING=yesHOSTNAME=yourname (在这修改hostname,把yourname换成你想用的名字)NISDOMAIN=修改后机器211.87.239.181中/etc/sysconfig/network文件内容为:NETWORKING=yesHOSTNAME=master修改后机器211.87.239.182中/etc/sysconfig/network文件内容为:NETWORKING=yesHOSTNAME=slave2、最后在终端下执行:# hostname ***** (*****为修改后的hostname,即你想用的名字)例如#hostname master特别提示:各处修改的名字要保持一致,否则会出现问题。
3、修改每台机器的/etc/hosts,保证每台机器间都可以通过机器名解析配置etc/hosts文件,以root 身份打开/etc/hosts文件。
Master/slave做同样修改。
hadoop安装实验总结

hadoop安装实验总结Hadoop安装实验总结一、引言Hadoop是一个开源的分布式计算平台,用于存储和处理大规模数据集。
在本次实验中,我们将介绍Hadoop的安装过程,并总结一些注意事项和常见问题的解决方法。
二、安装过程1. 确定操作系统的兼容性:Hadoop支持多种操作系统,包括Linux、Windows等。
在安装之前,我们需要确认所使用的操作系统版本与Hadoop的兼容性。
2. 下载Hadoop软件包:我们可以从Hadoop的官方网站或镜像站点上下载最新的稳定版本的Hadoop软件包。
确保选择与操作系统相对应的软件包。
3. 解压缩软件包:将下载的Hadoop软件包解压缩到指定的目录下。
可以使用命令行工具或图形界面工具进行解压缩操作。
4. 配置环境变量:为了方便使用Hadoop命令行工具,我们需要配置环境变量。
在Linux系统中,可以编辑.bashrc文件,在其中添加Hadoop的安装路径。
在Windows系统中,可以通过系统属性中的环境变量设置来配置。
5. 配置Hadoop集群:在Hadoop的安装目录下,找到conf文件夹,并编辑其中的配置文件。
主要包括core-site.xml、hdfs-site.xml 和mapred-site.xml等。
根据实际需求,配置Hadoop的相关参数,如文件系统路径、副本数量、任务调度等。
6. 格式化文件系统:在启动Hadoop之前,需要先格式化文件系统。
使用命令行工具进入Hadoop的安装目录下的bin文件夹,并执行格式化命令:hadoop namenode -format。
7. 启动Hadoop集群:在命令行工具中输入启动命令:start-all.sh(Linux)或start-all.cmd(Windows)。
Hadoop集群将会启动并显示相应的日志信息。
8. 验证Hadoop集群:在启动Hadoop集群后,我们可以通过访问Hadoop的Web界面来验证集群的运行状态。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
hadoop学习之hadoop完全分布式集群安装注:本文的主要目的是为了记录自己的学习过程,也方便与大家做交流。
转载请注明来自:/ab198604/article/details/8250461要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个hadoop分布式集群了。
说来简单,但是应该怎么做呢?不急,本文的主要目的就是让新手看了之后也能够亲自动手实施这些过程。
由于本人资金不充裕,只能通过虚拟机来实施模拟集群环境,虽然说是虚机模拟,但是在虚机上的hadoop的集群搭建过程也可以使用在实际的物理节点中,思想是一样的。
也如果你有充裕的资金,自己不介意烧钱买诸多电脑设备,这是最好不过的了。
也许有人想知道安装hadoop集群需要什么样的电脑配置,这里只针对虚拟机环境,下面介绍下我自己的情况:CPU:Intel酷睿双核 2.2Ghz内存: 4G硬盘: 320G系统:xp老实说,我的本本配置显然不够好,原配只有2G内存,但是安装hadoop集群时实在是很让人崩溃,本人亲身体验过后实在无法容忍,所以后来再扩了2G,虽然说性能还是不够好,但是学习嘛,目前这种配置还勉强可以满足学习要求,如果你的硬件配置比这要高是最好不过的了,如果能达到8G,甚至16G内存,学习hadoop表示无任何压力。
说完电脑的硬件配置,下面说说本人安装hadoop的准备条件:1 安装Vmware WorkStation软件有些人会问,为何要安装这个软件,这是一个VM公司提供的虚拟机工作平台,后面需要在这个平台上安装linux操作系统。
具体安装过程网上有很多资料,这里不作过多的说明。
2 在虚拟机上安装linux操作系统在前一步的基础之上安装linux操作系统,因为hadoop一般是运行在linux平台之上的,虽然现在也有windows版本,但是在linux上实施比较稳定,也不易出错,如果在windows安装hadoop集群,估计在安装过程中面对的各种问题会让人更加崩溃,其实我还没在windows 上安装过,呵呵~在虚拟机上安装的linux操作系统为ubuntu10.04,这是我安装的系统版本,为什么我会使用这个版本呢,很简单,因为我用的熟^_^其实用哪个linux系统都是可以的,比如,你可以用centos, redhat, fedora等均可,完全没有问题。
在虚拟机上安装linux的过程也在此略过,如果不了解可以在网上搜搜,有许多这方面的资料。
3 准备3个虚拟机节点其实这一步骤非常简单,如果你已经完成了第2步,此时你已经准备好了第一个虚拟节点,那第二个和第三个虚拟机节点如何准备?可能你已经想明白了,你可以按第2步的方法,再分别安装两遍linux系统,就分别实现了第二、三个虚拟机节点。
不过这个过程估计会让你很崩溃,其实还有一个更简单的方法,就是复制和粘贴,没错,就是在你刚安装好的第一个虚拟机节点,将整个系统目录进行复制,形成第二和第三个虚拟机节点。
简单吧!~~很多人也许会问,这三个结点有什么用,原理很简单,按照hadoop集群的基本要求,其中一个是master结点,主要是用于运行hadoop 程序中的namenode、secondorynamenode和jobtracker任务。
用外两个结点均为slave结点,其中一个是用于冗余目的,如果没有冗余,就不能称之为hadoop了,所以模拟hadoop集群至少要有3个结点,如果电脑配置非常高,可以考虑增加一些其它的结点。
slave结点主要将运行hadoop程序中的datanode和tasktracker任务。
所以,在准备好这3个结点之后,需要分别将linux系统的主机名重命名(因为前面是复制和粘帖操作产生另两上结点,此时这3个结点的主机名是一样的),重命名主机名的方法:Vim /etc/hostname通过修改hostname文件即可,这三个点结均要修改,以示区分。
以下是我对三个结点的ubuntu系统主机分别命名为:master, node1, node2基本条件准备好了,后面要干实事了,心急了吧,呵呵,别着急,只要跟着本人的思路,一步一个脚印地,一定能成功布署安装好hadoop 集群的。
安装过程主要有以下几个步骤:一、配置hosts文件二、建立hadoop运行帐号三、配置ssh免密码连入四、下载并解压hadoop安装包五、配置namenode,修改site文件六、配置hadoop-env.sh文件七、配置masters和slaves文件八、向各节点复制hadoop九、格式化namenode十、启动hadoop十一、用jps检验各后台进程是否成功启动十二、通过网站查看集群情况下面我们对以上过程,各个击破吧!~~一、配置hosts文件先简单说明下配置hosts文件的作用,它主要用于确定每个结点的IP地址,方便后续master结点能快速查到并访问各个结点。
在上述3个虚机结点上均需要配置此文件。
由于需要确定每个结点的IP地址,所以在配置hosts 文件之前需要先查看当前虚机结点的IP地址是多少,可以通过ifconfig命令进行查看,如本实验中,master结点的IP地址为:如果IP地址不对,可以通过ifconfig命令更改结点的物理IP地址,示例如下:通过上面命令可以将IP改为192.168.1.100。
将每个结点的IP地址设置完成后,就可以配置hosts文件了,hosts文件路径为;/etc/hosts,我的hosts文件配置如下,大家可以参考自己的IP地址以及相应的主机名完成配置二、建立hadoop运行帐号即为hadoop集群专门设置一个用户组及用户,这部分比较简单,参考示例如下:sudo groupadd hadoop //设置hadoop用户组sudo useradd –s /bin/bash –d /home/zhm –m zhm –g hadoop –G admin //添加一个zhm用户,此用户属于hadoop用户组,且具有admin 权限。
sudo passwd zhm //设置用户zhm登录密码su zhm //切换到zhm用户中上述3个虚机结点均需要进行以上步骤来完成hadoop运行帐号的建立。
三、配置ssh免密码连入这一环节最为重要,而且也最为关键,因为本人在这一步骤裁了不少跟头,走了不少弯路,如果这一步走成功了,后面环节进行的也会比较顺利。
SSH主要通过RSA算法来产生公钥与私钥,在数据传输过程中对数据进行加密来保障数据的安全性和可靠性,公钥部分是公共部分,网络上任一结点均可以访问,私钥主要用于对数据进行加密,以防他人盗取数据。
总而言之,这是一种非对称算法,想要破解还是非常有难度的。
Hadoop集群的各个结点之间需要进行数据的访问,被访问的结点对于访问用户结点的可靠性必须进行验证,hadoop采用的是ssh的方法通过密钥验证及数据加解密的方式进行远程安全登录操作,当然,如果hadoop 对每个结点的访问均需要进行验证,其效率将会大大降低,所以才需要配置SSH免密码的方法直接远程连入被访问结点,这样将大大提高访问效率。
OK,废话就不说了,下面看看如何配置SSH免密码登录吧!~~(1)每个结点分别产生公私密钥。
键入命令:以上命令是产生公私密钥,产生目录在用户主目录下的.ssh目录中,如下:Id_dsa.pub为公钥,id_dsa为私钥,紧接着将公钥文件复制成authorized_keys文件,这个步骤是必须的,过程如下:用上述同样的方法在剩下的两个结点中如法炮制即可。
(2)单机回环ssh免密码登录测试即在单机结点上用ssh进行登录,看能否登录成功。
登录成功后注销退出,过程如下:注意标红圈的指示,有以上信息表示操作成功,单点回环SSH登录及注销成功,这将为后续跨子结点SSH远程免密码登录作好准备。
用上述同样的方法在剩下的两个结点中如法炮制即可。
(3)让主结点(master)能通过SSH免密码登录两个子结点(slave)为了实现这个功能,两个slave结点的公钥文件中必须要包含主结点的公钥信息,这样当master就可以顺利安全地访问这两个slave结点了。
操作过程如下:如上过程显示了node1结点通过scp命令远程登录master结点,并复制master的公钥文件到当前的目录下,这一过程需要密码验证。
接着,将master结点的公钥文件追加至authorized_keys文件中,通过这步操作,如果不出问题,master结点就可以通过ssh远程免密码连接node1结点了。
在master结点中操作如下:由上图可以看出,node1结点首次连接时需要,“YES”确认连接,这意味着master结点连接node1结点时需要人工询问,无法自动连接,输入yes后成功接入,紧接着注销退出至master结点。
要实现ssh免密码连接至其它结点,还差一步,只需要再执行一遍ssh node1,如果没有要求你输入”yes”,就算成功了,过程如下:如上图所示,master已经可以通过ssh免密码登录至node1结点了。
对node2结点也可以用同样的方法进行,如下图:Node2结点复制master结点中的公钥文件Master通过ssh免密码登录至node2结点测试:第一次登录时:第二次登录时:表面上看,这两个结点的ssh免密码登录已经配置成功,但是我们还需要对主结点master也要进行上面的同样工作,这一步有点让人困惑,但是这是有原因的,具体原因现在也说不太好,据说是真实物理结点时需要做这项工作,因为jobtracker有可能会分布在其它结点上,jobtracker有不存在master结点上的可能性。
对master自身进行ssh免密码登录测试工作:至此,SSH免密码登录已经配置成功。
四、下载并解压hadoop安装包关于安装包的下载就不多说了,不过可以提一下目前我使用的版本为hadoop-0.20.2,这个版本不是最新的,不过学习嘛,先入门,后面等熟练了再用其它版本也不急。
而且《hadoop权威指南》这本书也是针对这个版本介绍的。
注:解压后hadoop软件目录在/home/zhm/hadoop下五、配置namenode,修改site文件在配置site文件之前需要作一些准备工作,下载java最新版的JDK软件,可以从oracle官网上下载,我使用的jdk软件版本为:jdk1.7.0_09,我将java的JDK解压安装在/opt/jdk1.7.0_09目录中,接着配置JAVA_HOME宏变量及hadoop路径,这是为了方便后面操作,这部分配置过程主要通过修改/etc/profile文件来完成,在profile文件中添加如下几行代码:然后执行:让配置文件立刻生效。