Python2.x 中文乱码问题解决方法
python中文乱码的解决方法

python中⽂乱码的解决⽅法乱码原因:源码⽂件的编码格式为utf-8,但是window的本地默认编码是gbk,所以在控制台直接打印utf-8的字符串当然是乱码了!解决⽅法:1、print mystr.decode('utf-8').encode('gbk')2、⽐较通⽤的⽅法:import systype = sys.getfilesystemencoding()print mystr.decode('utf-8').encode(type)1. Python中列表或字典输出乱码的解决⽅法问题: Python中的列表(list)或字典包含中⽂字符串,直接使⽤print会出现以下的结果:#打印字典dict = {'name': '张三'}print dict>>>{'name': ' e5 bc a0 e4 b8 89'}#打印列表list = [{'name': '张三'}]print list>>>[{'name': ' e5 bc a0 e4 b8 89'}]解决⽅案:使⽤以下⽅法进⾏输出:import json#打印字典dict = {'name': '张三'}print json.dumps(dict, encoding="UTF-8", ensure_ascii=False)>>>{'name': '张三'}#打印列表list = [{'name': '张三'}]print json.dumps(list, encoding="UTF-8", ensure_ascii=False)>>>[{'name': '张三'}]2. Python2.7的UnicodeEncodeError: ‘ascii' codec can't encode异常错误#重置编码格式import sysreload(sys)sys.setdefaultencoding('utf-8')以上就是python中⽂乱码的解决⽅法的详细内容,更多关于python乱码的资料请关注其它相关⽂章!。
中文乱码解决方案

中文乱码解决方案一、引言随着全球化进程的加速,跨国交流和跨文化交流变得越来越频繁。
作为全球最大的人口国家之一,中国在国际交流中发挥着重要的作用。
然而,在跨文化交流的过程中,我们常常会遇到一个共同的问题,即中文乱码。
中文乱码是指在计算机系统中,由于编码方式不兼容或设置错误,导致中文字符无法正确显示的现象。
本文将介绍一些常见的中文乱码问题以及解决方案。
二、常见中文乱码问题及原因1. 网页中出现乱码在浏览网页时,我们经常会遇到中文乱码的问题,这主要是由于网页编码方式不兼容或设置错误所引起的。
常见的编码方式包括UTF-8、GBK、GB2312等,如果网页编码方式与浏览器设置的编码方式不一致,就会导致中文字符无法正确显示。
2. 文本文件打开后乱码当我们使用文本编辑器打开一个文本文件时,如果文件的编码方式与编辑器的默认编码方式不一致,就会导致文件内容显示为乱码。
常见的文本文件编码方式有UTF-8、GBK、GB2312等。
3. 数据库中存储的中文乱码在数据库中存储中文信息时,如果数据库的编码方式设置不正确,就会导致存储的中文字符显示为乱码。
常见的数据库编码方式有UTF-8、GBK、GB2312等。
三、中文乱码解决方案1. 网页中文乱码解决方案(1)设置浏览器编码方式:在浏览器的设置选项中,找到编码方式(通常在“字符编码”、“编码”或“语言”选项下),将其设置为与网页编码方式一致的选项,如将编码方式设置为UTF-8。
(2)手动指定网页编码:如果网页上没有明确设置编码方式的选项,可以尝试在浏览器地址栏中手动添加编码方式,如在URL后面添加“?charset=utf-8”。
2. 文本文件乱码解决方案(1)使用支持多种编码方式的文本编辑器:选择一个支持多种编码方式的文本编辑器,如Notepad++、Sublime Text等。
在打开文本文件时,可以手动选择文件的编码方式来正确显示内容。
(2)重新保存文件:将文本文件另存为选项,选择正确的编码方式,再重新打开文件即可解决乱码问题。
完美解决Python2操作中文名文件乱码的问题

完美解决Python2操作中⽂名⽂件乱码的问题Python2默认是不⽀持中⽂的,⼀般我们在程序的开头加上#-*-coding:utf-8-*-来解决这个问题,但是在我⽤open()⽅法打开⽂件时,中⽂名字却显⽰成了乱码。
我先给⼤家说说Python中的编码问题,Python中的字符串的⼤概分为为str和Unicode两种形式,其中str常⽤的编码类型为utf-8,gb2312,gbk等等,Python使⽤Unicode作为编码的基础类型。
str记录的是字节数组,只是某种编码的存储格式,终于输出到⽂件或是打印出来是什么格式,完全取决于其解码的编码将他解码成什么样⼦;Unicode是⼀种类似于符号集的抽象编码,它只规定了符号的⼆进制代码,却没有规定这个⼆进制代码该如何存储,也就是它只是⼀种内部表⽰,不能直接保存,所以存储时需要规定⼀种存储形式,⽐如utf-8等。
Python中有编码转换的函数有:decode(char_set) 实现char_set解码成Unicodeencode(char_set) 实现Unicode编码成char_set查看Python⽂档会发现:open(filename, 'w')这个⽅法中,filename这个参数必须是Unicode编码的参数。
我之前加上#-*-coding:utf-8-*-将编码设置为utf-8,当调⽤这个⽅法往⾥传参数时,需要将这个变量filename解码成Unicode。
⽐如filename='中⽂.txt',使⽤open()时,这样写open(filename.decode('utf-8'), 'w'),这样创建的中⽂⽂件名就没有乱码问题了。
以上就是⼩编为⼤家带来的完美解决Python2操作中⽂名⽂件乱码的问题全部内容了,希望⼤家多多⽀持~。
python避免中文乱码的代码

python避免中文乱码的代码Python是一种非常流行的编程语言,但是在处理中文字符时,很容易出现乱码的情况。
这是因为Python默认使用的编码方式是ASCII码,而中文字符需要使用UTF-8等编码方式才能正确显示。
为了避免中文乱码,我们需要在代码中进行一些设置。
1. 设置文件编码方式在Python代码文件的开头,添加以下代码:```python# -*- coding: utf-8 -*-```这行代码告诉Python解释器,该文件使用UTF-8编码方式。
这样,Python就能正确地读取和处理中文字符了。
2. 使用Unicode字符串在Python中,字符串可以使用两种方式表示:普通字符串和Unicode字符串。
普通字符串使用ASCII码表示,而Unicode字符串使用UTF-8等编码方式表示。
为了避免中文乱码,我们可以使用Unicode字符串来表示中文字符。
例如:```pythons = u'你好,世界!'```这里的u表示该字符串是Unicode字符串,可以正确地表示中文字符。
3. 使用encode和decode方法如果我们已经有了一个普通字符串,但是其中包含中文字符,我们可以使用encode方法将其转换为Unicode字符串,再进行处理。
例如:```pythons = '你好,世界!'s_unicode = s.encode('utf-8')```这里的encode方法将普通字符串s转换为Unicode字符串s_unicode,使用的编码方式是UTF-8。
如果我们已经有了一个Unicode字符串,但是需要将其转换为普通字符串,可以使用decode方法。
例如:```pythons_unicode = u'你好,世界!'s = s_unicode.decode('utf-8')```这里的decode方法将Unicode字符串s_unicode转换为普通字符串s,使用的编码方式是UTF-8。
中文乱码解决方法

中文乱码解决方法
1.使用正确的字符编码
2.转换文件编码格式
如果你打开一个文本文件或者网页时发现中文显示为乱码,可能是由
于文件的编码格式不正确导致的。
你可以尝试将文件的编码格式转换为正
确的格式。
Windows操作系统中可以使用记事本打开文件,另存为时选择
正确的编码方式即可。
Mac和Linux系统可以使用终端命令行工具进行转换,具体方法可以参考相关操作系统的文档和教程。
3.选择正确的字体
有时候中文显示为乱码是由于缺乏相应的字体文件所致。
当你打开一
个文档或者网页时,如果使用的字体不包含中文字符,那么中文可能会显
示为乱码或者方块。
解决方法是选择适合的字体。
一般来说,宋体、微软
雅黑、黑体等字体都包含了常用的中文字符,并且具有良好的兼容性。
4.更新操作系统和应用程序
乱码问题有时也可能是由于操作系统或者应用程序的bug导致的。
这
些bug可能会导致字符编码不正确或者字体渲染错误。
为了解决这类问题,建议你及时更新操作系统和应用程序的版本,以获取最新的修复和改进。
5.检查网络连接和网页编码
6.使用专业的文本处理工具
总结:
中文乱码问题可能由多种原因引起,包括字符编码不一致、文件格式不正确、字体缺失等。
解决方法包括使用正确的编码方式、转换文件的编码格式、选择合适的字体、更新操作系统和应用程序、检查网络连接和网页编码、使用专业的文本处理工具等。
通过以上方法,相信大家能够有效地解决中文乱码问题,提高中文字符的显示质量。
中文乱码的解决方法

中文乱码的解决方法在进行中文文本处理过程中,可能会遇到乱码的情况,这主要是由于使用了不兼容的编码格式或者在数据传输过程中出现了错误。
下面是一些解决中文乱码问题的方法:1.使用正确的编码方式2.修改文件编码如果已经打开了一个包含乱码的文本文件,可以通过修改文件编码方式来解决问题。
例如,在记事本软件中,可以尝试选择“另存为”功能,并将编码方式改为UTF-8,然后重新保存文件,这样就可以解决乱码问题。
3.检查网页编码当浏览网页时遇到乱码问题,可以在浏览器的“查看”或“选项”菜单中找到“编码”选项,并将其设置为正确的编码方式(例如UTF-8),刷新网页后,乱码问题通常会得到解决。
5.使用转码工具如果已经得知文件的原始编码方式但无法通过其他方式解决乱码问题,可以尝试使用一些转码工具来将文件以正确的编码方式转换。
例如,iconv是一款常用的转码工具,可以在命令行界面下使用。
6.检查数据传输过程在进行数据传输时,特别是在网络传输中,可能会出现数据传输错误导致中文乱码。
可以检查数据传输过程中的设置和参数,确保传输过程中不会造成乱码问题。
7.检查数据库和应用程序设置在进行数据库操作和应用程序开发时,也可能会出现中文乱码问题。
可以检查数据库和应用程序的设置,确保正确地处理和显示中文字符。
8.清除特殊字符和格式有时候,中文乱码问题可能是由于文本中存在特殊字符或格式导致的。
可以尝试清除文本中的特殊字符和格式,然后重新保存或传输文件,看是否能够解决乱码问题。
总结起来,解决中文乱码问题的关键是了解文件的编码方式,并确保在处理过程中使用相同的编码方式。
此外,要注意数据传输过程中的设置和参数,以及数据库和应用程序的设置,确保正确地处理和显示中文字符。
最后,如果以上方法仍然无法解决乱码问题,可以尝试使用专业的转码工具来转换文件的编码方式。
中文乱码解决方案

中文乱码解决方案中文乱码问题是指在使用计算机软件或操作系统时,中文字符显示为乱码或其他非预期字符的情况。
中文乱码问题通常出现在以下几种情况下:1.编码不一致:中文乱码问题最常见的原因是编码不一致。
计算机中使用的编码方式有很多种,如UTF-8、GB2312、GBK等。
如果文件的编码方式与软件或操作系统的默认编码方式不一致,就会导致中文乱码。
解决该问题的方法是将文件的编码方式转换为与软件或操作系统一致的方式。
2.字体显示问题:中文乱码问题还可能与字体显示有关。
如果计算机中没有安装支持中文的字体,或字体文件损坏,就会导致中文字符显示为乱码或方框。
解决该问题的方法是通过安装正确的字体文件或修复字体文件来解决。
3.网页编码问题:在浏览网页时,如果网页的编码方式与浏览器的默认编码方式不一致,也会导致中文乱码。
解决该问题的方法是在浏览器中手动设置网页编码方式,或在网页头部指定正确的编码方式。
4.数据传输问题:中文乱码问题还可能与数据传输有关。
在进行数据传输时,如果数据的编码方式与传输协议或接收端的要求不一致,就会导致中文乱码。
解决该问题的方法是在数据传输的过程中进行编码转换,或在接收端进行适当的解码操作。
下面是一些常用的解决中文乱码问题的方法:3.设置浏览器编码方式:在浏览器的设置中,可以手动指定网页的编码方式。
可以尝试不同的编码方式,找到正确的方式显示中文字符。
4.检查数据传输设置:如果中文乱码问题是在数据传输过程中出现的,可以检查传输的设置是否一致。
比如,在进行数据库连接时,可以设置数据库的编码方式与应用程序的编码方式一致。
5.使用专业工具:如果以上方法无法解决中文乱码问题,可以考虑使用专业的中文乱码解决工具。
这些工具可以自动检测和修复中文乱码问题,提高处理效率。
总结起来,解决中文乱码问题需要确定问题的原因,然后采取相应的方法进行修复。
在处理中文乱码问题时,尽量使用标准的编码方式和字体文件,避免使用非标准或自定义的编码方式。
linux python中文乱码解决方法-概述说明以及解释

linux python中文乱码解决方法-概述说明以及解释1.引言1.1 概述概述部分是文章引言的一部分,它的目的是提供一个简要的介绍,概括文章的主题和内容。
在“Linux Python中文乱码解决方法”这篇长文中,概述部分可以包括以下内容:概述:随着Linux和Python的广泛应用,中文乱码问题也逐渐成为了许多开发者和用户的关注焦点。
在日常的Linux和Python编程过程中,我们经常会遇到中文乱码的情况,这不仅给我们的工作带来了不便,还可能影响程序的正确执行。
因此,解决Linux和Python中文乱码问题成为了一个重要的任务。
本文将从两个方面详细介绍Linux 和Python 中文乱码问题的原因和解决方法。
首先,我们将探讨Linux 系统中的中文乱码问题,分析其产生的原因和对应的解决方法。
其次,我们将深入探讨Python 编程语言中出现的中文乱码问题,解释其中的原因,并提供相应的解决方案。
通过本文的阐述,读者将能够更好地理解和解决在Linux 和Python 中遇到的中文乱码问题。
总结:在本文的结论部分,我们将总结我们在解决Linux 和Python 中文乱码问题的过程中所采用的方法和技巧。
我们将讨论这些方法的有效性和适用性,并提供一些建议,帮助读者在实际的工作和学习中更好地解决中文乱码问题。
通过本文提供的解决方案,读者将能够提高工作效率,避免中文乱码带来的困扰,并更好地利用Linux 和Python 进行程序开发和日常使用。
通过本文的阅读和理解,读者将对Linux 和Python 中文乱码问题有更清晰的认识,并能够运用相应的解决方法,提高工作效率和代码质量。
同时,本文还为解决其他编程语言或操作系统中出现的中文乱码问题提供了一个思路和参考。
文章结构部分的内容:1.2 文章结构本文将分为三个主要部分:引言、正文和结论。
- 引言部分将概述整篇文章的主要内容和目的,以便读者能够了解文章的背景和意义。
Python解决中文乱码
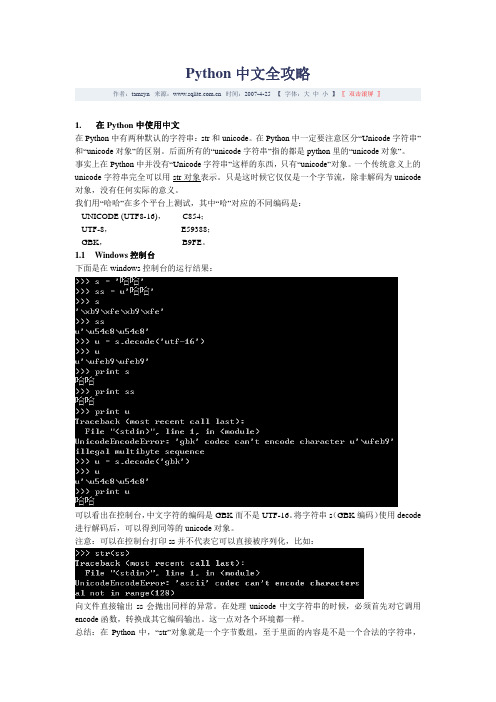
Python中文全攻略作者:tamsyn 来源: 时间:2007-4-25 【字体:大中小】〖双击滚屏〗1.在Python中使用中文在Python中有两种默认的字符串:str和unicode。
在Python中一定要注意区分“Unicode字符串”和“unicode对象”的区别。
后面所有的“unicode字符串”指的都是python里的“unicode对象”。
事实上在Python中并没有“Unicode字符串”这样的东西,只有“unicode”对象。
一个传统意义上的unicode字符串完全可以用str对象表示。
只是这时候它仅仅是一个字节流,除非解码为unicode 对象,没有任何实际的意义。
我们用“哈哈”在多个平台上测试,其中“哈”对应的不同编码是:UNICODE (UTF8-16),C854;UTF-8,E59388;GBK,B9FE。
1.1Windows控制台下面是在windows控制台的运行结果:可以看出在控制台,中文字符的编码是GBK而不是UTF-16。
将字符串s(GBK编码)使用decode 进行解码后,可以得到同等的unicode对象。
注意:可以在控制台打印ss并不代表它可以直接被序列化,比如:向文件直接输出ss会抛出同样的异常。
在处理unicode中文字符串的时候,必须首先对它调用encode函数,转换成其它编码输出。
这一点对各个环境都一样。
总结:在Python中,“str”对象就是一个字节数组,至于里面的内容是不是一个合法的字符串,以及这个字符串采用什么编码(gbk, utf-8, unicode)都不重要。
这些内容需要用户自己记录和判断。
这些的限制也同样适用于“unicode”对象。
要记住“unicode”对象中的内容可绝对不一定就是合法的unicode字符串,我们很快就会看到这种情况。
总结:在windows的控制台上,支持gbk编码的str对象和unicode编码的unicode对象。
AbaqusPython二次开发中文乱码终极解决方法

AbaqusPython二次开发中文乱终极解决方法
大家在用Python对Abaqus进行二次开发的时候,经常会遇到中文乱码的问题,此外,高版本Abaqus还会出现中文路径乱码问题。之前,公众号也推送过1篇文章来解决这个问题,以往主要是通过修改Abaqus安装目录下的Locale.txt文件来实现,但实际效果不佳,上述方法仅能解决中文路径和插件菜单中的乱码问题,中文GUI界面或者执行过程中的中文消息提示仍是乱码。以至于近些年在开发插件时一直采用英文界面和英文信息提示。
python遇到问题及解决方案

python遇到问题及解决方案
目录
1. 问题描述
1.1 安装问题
1.2 代码运行问题
1.3 常见报错问题
2. 解决方案
2.1 检查安装环境
2.2 修正代码错误
2.3 查找报错原因并解决
问题描述
在使用Python进行编程时,常常会遇到各种各样的问题,包括
安装问题、代码运行问题以及常见的报错问题。
这些问题可能会让人
感到困惑,但只要有合适的解决方案,就能够轻松地解决这些问题。
安装问题
当你在安装Python时遇到问题时,首先需要检查你的安装环境。
确保你选择了正确的Python版本,并且在安装过程中没有出现任何错
误信息。
如果安装过程中出现了问题,可以尝试重新下载安装程序,
或者查找相关的解决方案。
代码运行问题
在编写和运行Python代码时,可能会遇到一些错误或者程序无
法正常运行的情况。
这时候需要仔细检查代码,修正可能存在的错误,并确保代码逻辑正确。
同时,可以尝试使用调试工具或者打印输出来
定位问题所在。
常见报错问题
在运行Python代码时,有时候会出现各种各样的报错信息,如
语法错误、模块未找到等。
这时候需要查看报错信息的具体内容,分
析可能的原因,并采取相应的措施来解决问题。
可能需要查找相关的
文档或者向社区寻求帮助。
解决方案
针对不同的问题,可以采取不同的解决方案。
首先需要对问题进行仔细分析,然后有针对性地采取相应的措施来解决问题。
最重要的是保持耐心和对问题的持续探索,相信你一定能够克服各种困难,顺利地完成Python编程任务。
【Python】解决Python脚本在cmd命令行窗口运行时,中文乱码问题

搜索得知,中文windows默认的输出编码为gbk ,与脚本中定义的UTF-8不一样,所以出现了解码失败的情况
解决方法
有如下两种方法可以解决这个问题
方法一
我们可以通过先把中文解码为unicode,然后在转化为gbk来解决这个问题:
修改后运行结果:
方法二
当然,我们也可以通过改变cmd命令行窗口的输出格式来解决这个问题, chcp 65001 就是换成UTF-8代码页 chcp 936 可以换回默认的GBK
偏暗的原因是相机或者手机的raw格式为了保留住照片的更多细节对于曝光的控制都是非常保守的
【 Python】解决 Python脚本在 cmd命令行窗口运行时,中文乱码 问题
问题描述
python2.X,代码中指定了UTython3不存在该问题
运行结果:
但是这样就降低了脚本的兼容性,在其他环境运行的时候可能还会出现这样的错误, 而且可能会影响其他脚本运行,所以推荐使用第一种方法
程序中的汉字变乱码的解决方法

程序中的汉字变乱码的解决方法汉字出现乱码有好几种情况,大致可分成四类:网页、文本、文档和文件乱码。
第一类是由于港台的繁体中文大五码(BIG5)与大陆简体中文(GB2312)不通用造成的;第二类是系统(菜单、桌面、提示框)显示乱码,这是注册表中有关字体的部分设置不当引起的;第三类是各种应用程序(包括游戏)本来显示中文的地方出现乱码,形成原因比较复杂,有第二类的乱码原因,也可能是软件用到的中文动态链接库被英文动态链接库覆盖造成的;最后一类是邮件乱码。
(一)、网页、文本和文档文件乱码的消除网页乱码是浏览器(如IE等)对HTML网页解释时形成的。
如果在网页的代码中有形如:〈HTML〉〈HEAD〉〈META CONTENT=“text/html;charset=ISO-8859-1”〉〈/HEAD〉……〈/HTML〉的语句,浏览器在显示此页时,就会出现乱码。
因为浏览器会将此页语种辨认为“欧洲语系”。
解决的办法是将语种“ISO-8859-1”改为GB2312,如果是繁体网页则改为BIG5。
另一种解决办法是不修改网页代码,事先为浏览器安装多语言支持包(例如在安装IE时要安装多语言支持包),这样在浏览网页出现乱码时,就可以在浏览器中选择菜单栏下的“查看”/“编码”/“自动选择”/简体中文(GB2312),如为繁体中文则选择“查看”/“编码”/“自动选择”/繁体中文(BIG5),其它语言依此类推选择相应的语系,这样可消除网页乱码现象。
还有一种解决办法是利用多内码显示平台来转换内码。
常用多内码显示平台有:“南极星”、“四通利方”、“MagicWin 98等等。
网页无乱码保存的方法是:用浏览器打开网页时,在“查看”/“编码”中选择“自动选择”,存盘时保存类型选“web页”,编码选择“UNICOD”,这样保存过的网页再次打开时,在浏览器菜单“查看”、“编码”中不管选择简体中文(GB2312)、简体中文(HZ)还是UNICODE(UTF-8)或繁体中文(BIG5),最终显示都不会出现乱码。
python中文乱码问题深入分析

python中⽂乱码问题深⼊分析在本⽂中,以'哈'来解释作⽰例解释所有的问题,“哈”的各种编码如下:1. UNICODE (UTF8-16),C854;2. UTF-8,E59388;3. GBK,B9FE。
⼀直以来,python中的中⽂编码就是⼀个极为头⼤的问题,经常抛出编码转换的异常,python中的str和unicode到底是⼀个什么东西呢?在python中提到unicode,⼀般指的是unicode对象,例如'哈哈'的unicode对象为u'\u54c8\u54c8'⽽str,是⼀个字节数组,这个字节数组表⽰的是对unicode对象编码(可以是utf-8、gbk、cp936、GB2312)后的存储的格式。
这⾥它仅仅是⼀个字节流,没有其它的含义,如果你想使这个字节流显⽰的内容有意义,就必须⽤正确的编码格式,解码显⽰。
例如:对于unicode对象哈哈进⾏编码,编码成⼀个utf-8编码的str-s_utf8,s_utf8就是是⼀个字节数组,存放的就是' e5 93 88 e5 93 88',但是这仅仅是⼀个字节数组,如果你想将它通过print语句输出成哈哈,那你就失望了,为什么呢?因为print语句它的实现是将要输出的内容传送了操作系统,操作系统会根据系统的编码对输⼊的字节流进⾏编码,这就解释了为什么utf-8格式的字符串“哈哈”,输出的是“鍝堝搱”,因为 ' e5 93 88 e5 93 88'⽤GB2312去解释,其显⽰的出来就是“鍝堝搱”。
这⾥再强调⼀下,str记录的是字节数组,只是某种编码的存储格式,⾄于输出到⽂件或是打印出来是什么格式,完全取决于其解码的编码将它解码成什么样⼦。
这⾥再对print进⾏⼀点补充说明:当将⼀个unicode对象传给print时,在内部会将该unicode对象进⾏⼀次转换,转换成本地的默认编码(这仅是个⼈猜测)⼆、str和unicode对象的转换str和unicode对象的转换,通过encode和decode实现,具体使⽤如下:将GBK'哈哈'转换成unicode,然后再转换成UTF8三、Setdefaultencoding如上图的演⽰代码所⽰:当把s(gbk字符串)直接编码成utf-8的时候,将抛出异常,但是通过调⽤如下代码:import sysreload(sys)sys.setdefaultencoding('gbk')后就可以转换成功,为什么呢?在python中str和unicode在编码和解码过程中,如果将⼀个str直接编码成另⼀种编码,会先把str解码成unicode,采⽤的编码为默认编码,⼀般默认编码是anscii,所以在上⾯⽰例代码中第⼀次转换的时候会出错,当设定当前默认编码为'gbk'后,就不会出错了。
彻底搞懂python中文乱码问题(深入分析)

彻底搞懂python中⽂乱码问题(深⼊分析)前⾔曾⼏何时 Python 中⽂乱码的问题困扰了我很多很多年,每次出现中⽂乱码都要去⽹上搜索答案,虽然解决了当时遇到的问题但下次出现乱码的时候⼜会懵逼,究其原因还是知其然不知其所以然。
现在有的⼩伙伴为了躲避中⽂乱码的问题甚⾄代码中不使⽤中⽂,注释和提⽰都⽤英⽂,我曾经也这样⼲过,但这并不是解决问题,⽽是逃避问题,今天我们⼀起彻底解决 Python 中⽂乱码的问题。
基础知识ASCII很久很久以前,有⼀群⼈,他们决定⽤8个可以开合的晶体管来组合成不同的状态,以表⽰世界上的万物。
他们看到8个开关状态是好的,于是他们把这称为”字节“。
再后来,他们⼜做了⼀些可以处理这些字节的机器,机器开动了,可以⽤字节来组合出很多状态,状态开始变来变去。
他们看到这样是好的,于是它们就这机器称为”计算机“。
开始计算机只在美国⽤。
⼋位的字节⼀共可以组合出256(2的8次⽅)种不同的状态。
他们把其中的编号从0开始的32种状态分别规定了特殊的⽤途,⼀但终端、打印机遇上约定好的这些字节被传过来时,就要做⼀些约定的动作。
遇上0×10, 终端就换⾏,遇上0×07, 终端就向⼈们嘟嘟叫,例好遇上0x1b, 打印机就打印反⽩的字,或者终端就⽤彩⾊显⽰字母。
他们看到这样很好,于是就把这些0×20以下的字节状态称为”控制码”。
他们⼜把所有的空格、标点符号、数字、⼤⼩写字母分别⽤连续的字节状态表⽰,⼀直编到了第127号,这样计算机就可以⽤不同字节来存储英语的⽂字了。
⼤家看到这样,都感觉很好,于是⼤家都把这个⽅案叫做 ANSI的”Ascii”编码(American Standard Code for Information Interchange,美国信息互换标准代码)。
当时世界上所有的计算机都⽤同样的ASCII⽅案来保存英⽂⽂字。
GB2312后来,就像建造巴⽐伦塔⼀样,世界各地的都开始使⽤计算机,但是很多国家⽤的不是英⽂,他们的字母⾥有许多是ASCII⾥没有的,为了可以在计算机保存他们的⽂字,他们决定采⽤ 127号之后的空位来表⽰这些新的字母、符号,还加⼊了很多画表格时需要⽤下到的横线、竖线、交叉等形状,⼀直把序号编到了最后⼀个状态255。
[python]中文乱码问题
![[python]中文乱码问题](https://img.taocdn.com/s3/m/85ce232acdbff121dd36a32d7375a417866fc126.png)
[python]中⽂乱码问题乱码产⽣的原因乱码产⽣的根本原因是字节流转换字符前后不⼀致导致。
只要掌握了这个核⼼,就能解决乱码问题。
python2中使⽤了⼀些“trick”(没有区分字符和字节流),所以理解起来有些困难。
在python中遇到没有指定为unicode的string,就理解为字节流!字节流,没有编码,只有字节,所以在转换字符时经常会出现乱码。
源⽂件编码、字符串编码在python中有2个地⽅的编码要注意,源⽂件的编码、字符串的编码,只要设置正确了就不会出现乱码。
源⽂件编码在源⽂件的第⼀⾏或者第⼆⾏⼀定要声明⽂件的编码⽅式并且与⽂件编码⼀致,通常会将源⽂件保存为utf8,声明也是utf8,如1# coding=utf8或1#coding:utf8如果不指定源码⽂件编码格式,⽂件中包含⾮ascii字符就会出现错误。
SyntaxError: Non-ASCII character ‘\xe4’ in file test_encoding.py on line 3, but no encoding declared; see /dev/peps/pep-0263/ for details这是因为,如果不指定源⽂件编码,python解释器会按照默认的字符集ascii来解码⽂件,由于中⽂不属于ascii字符集,所以会出错。
字符串编码字符串编码分两种情况,指定了unicode:在字符串前边加u,如u'你好' ,这种情况不会出现乱码;没指定unicode:普通字符串的写法,如'你好' ,这种情况字符串的编码与源⽂件编码⼀致;当字符串编码与控制台编码不⼀致时,就会出现乱码,这是因为python中的字符串就是字节数组,由于没有声明为unicode,所以按照windows terminal的默认编码gbk来解码(从字节数组转为字符),utf8的字节数组转为gbk的字符,肯定是不兼容的,所以出现了乱码。
pythonrequests库,请求返回中文乱码问题的解决

pythonrequests库,请求返回中⽂乱码问题的解决python 中的requests库,进⾏请求,发现⼀直使⽤的 r.text ,返回的内容,看不懂。
如下图所⽰:经查阅资料,发现 requests库,r.text返回的是decode处理后的Unicode型的数据,r.content 返回的是bytes ⼆进制的原始数据。
如果headers 没有charset字符集指定的编码⽅式,r.text 会调⽤chardet 来计算字符集。
查看response的headers,如下:⽽标准的response响应,是返回如下:HTTP权威指南中,显⽰如果HTTP响应中Content-Type字段没有指定charset,则默认页⾯是'ISO-8859-1'编码。
这种处理英⽂没问题,⼀遇到中⽂,就会出现乱码。
解决:1.清楚该站的字符集编码,可以使⽤r.encoding='xxx'模式,然后再r.text()会根据设定的字符集进⾏转换后输出。
返回中⽂应该可以正常查看。
代码如下:r.encoding='utf-8'print(r.text),2. fiddler抓包,显⽰response已经 encoded了,让decode请求后的响应response,先获取bytes ⼆进制类型数据,再指定encoding,即可。
如:bytes=r.contentprint(bytes.decode(encoding="utf-8"))3.使⽤apparent_encoding可获取程序真实编码r.encoding = r.apparent_encodingprint(r.text)也可以正常查看response中的中⽂。
此⽂,记录⼀下⾃⼰学习过程中遇到的坑。
详细更多资料,可查看下⾯两篇⽂章,看后清楚很多。
查阅资料链接:。
解决python2.x文件读写编码问题

解决python2.x文件读写编码问题解决python2.x⽂件读写编码问题转⽂:python2.X版本在处理中⽂⽂件读写时经常会遇到乱码或者是UnicodeError错误,正如下⽂的程序所⽂:#coding=utf-8# test.txt是⽂个以gbk2312编码(简体中⽂windows系统中的默认⽂本编码)的⽂本⽂件# ⽂本写⽂with open('test.txt', 'a') as f:f.write('test') # 正常写⽂f.write('测试') # 正常写⽂,乱码f.write(u’测试') # 写⽂错误,触发UnicodeEncodeError异常# ⽂本读取with open('test.txt') as f:for line in f:print line, type(line) # 输出test娴嬭瘯, <type 'str'>由于脚本源⽂件中的字符为utf-8编码,⽂⽂本⽂档中的字符为gb2312编码,所以以str类型字符串直接写⽂⽂件,此时str字符串的编码与⽂件编码不同,导致乱码。
直接str类型参数传递给write⽂法容易导致乱码问题,直接传递Unicode类型字符串作为write的参数,会导致UnicodeEncodeError错误,这是因为python2在写⽂unicode字符串时会⽂动尝试转码为ascii编码,⽂ascii编码并不能处理中⽂。
知道了问题的根源,⽂先想到的解决⽂法就是对源字符串按照⽂件进⽂编码,保证编码正确。
# 解决⽂法1with open('test.txt', 'w') as f:f.write('测试'.decode('utf-8').encode('gb2312'))f.write(u'测试‘.ecode('gb2312')如果是str类型的字符串,需要使⽂decode(因为我在脚本中设定#coding=utf8,所以使⽂decode(‘utf-8’))将其改变为python内部使⽂的Unicde 编码然后使⽂encode转换成对应的编码类型。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Python2.x中文乱码问题解决方法
Python中乱码问题是一个很头痛的问题。
在Python3中,对中文进行了全面的支持,但在Python2.x中需要进行相关的设置才能使用中文。
否则会出现乱码
【问题原因】
在Python2.x中主要是字符编码的问题,处理不好的话,会导致乱码。
Python默认采取的ASCII编码,字母、标点和其他字符只使用一个字节来表示,但对于中文字符来说,一个字节满足不了需求。
代码如下:
>>> import sys
>>> sys.getdefaultencoding()
'ascii'
为了能在计算机中表示所有的中文字符,中文编码采用两个字节表示。
如果中文编码和ASCII混合使用的话,就会导致解码错误,从而才生乱码。
而CMD下默认的编码方式为:GBK,所以就造成了上面的乱码!
采用两个字节的中文编码标准有:GB2312、GBK、BIG5等。
【处理办法】
为了将各种不同的语言包含在统一的字符集中,满足国际间的信息交流,国际上制订了UNICODE字符集,包含了世界上所有语言字符,这些字符具有唯一的编码,通过使用UNICODE字符集可以满足跨语言的文字处理,避免乱码的产生。
i) 交互式命令中:一般不会出现乱码,无需做处理
ii) py脚本文件中:跨字符集必须做设置,否则乱码。
首先在开头一句添加:
代码如下:
# coding = utf-8
# 或
# coding = UTF-8
# 或
# -*- coding: utf-8 -*-
其次需将文件保存为UTF-8的格式!
上面那一句仅仅是告诉Python编译器:脚本中包含了非ASCII字符,并未进行转换。
如果要将字符编码从默认的ASCII改为UTF-8,需要在保存的时候选择保存为UTF-8格式。
如果是用NODEPAD打开,【另存为】-->UTF-8即可
如果是用IDLE打开,【Options】-> 【Configure IDLE】->【General】
上面的设置,可以保证IDLE,运行F5,能正常输出中文。
【编码解码】
在开头添加了# -*- coding: utf-8 -*-并将文件保存为UTF-8格式,仍然不能保证能输出正常输出中文,
不同的编辑器,如VIM,IDLE,Eclipse使用的输出编码都是不一致的。
所以,在一个地方能正常输出中文,在另外一个地方就未必。
所以还必须做编码解码设置!
encode:编码
decode:解码
必须保证编码、解码的对象是同一个。
比如说UTF-8方式编码,必须再用UTF-8进行解码即可。
所以最终解决办法,还必须先按原先的方式解码,再按控制台格式重新编码:比如CMD 默认是GBK方式
则必须使用如下方式:
正确输出结果:
【其他说明】
1.在Python3中,对中文的支持非常全面,源文件默认保存为UTF-8的编码,这样一来,不但可以在源代码中使用中文,而且变量名也可以使用中文,比如说: 代码如下:
>>> 中国= 'Chinese'
>>> print(中国)
Chinese
2.在Python3中,不需要来回的编解码,并且字符串对象也没有decode和encode 方法。