用JAVA实现的Pascal语言的词法分析器
GPJ_Pascal集成开发坏境_词法分析_语法分析_语义分析和中间代码生成

第16卷 增刊3 广西工学院学报 V ol.16 Sup3 2005年10月 JO U RN A L OF GU AN G XI U N IV ERSIT Y OF T ECHNO L OG Y Oct.2005文章编号:1004-6410(2005)S3-0083-04GPJ_Pascal集成开发坏境——词法分析、语法分析、语义分析和中间代码生成计算机科学与技术 011班 2001041148 张 弦指导教师:原庆能摘 要:G PJ_Pascal是P ASCA L的一个子集。
G PJ_P ascal集成开发环境是编辑、编译和执行GP J_Pascal程序的平台,具有可视化的用户界面。
本文主要介绍了GP J_P ascal编译器的构造,其中,词法分析器扫描源程序,根据语言的词法规则,分解和识别出每个单词,同时进行词法检查;语法分析器以词法分析器生成的符号表为基础,验证单词符号串序列是否是语言文法的一个句子;在分析过程中,符号表被频繁地用来建立表项、查找表项、填充和引用表项;语法分析子程序采用了自上而下的递归子程序法,在语法分析的同时,也根据程序的语义生成有利于程序移植的相应三元式代码,并提供了出错处理的机制。
GP J_P ascal编译器总体结构完整、清晰,含义明确、易读、易理解,出错少,可靠性大,并易于对G PJ_Pascal的词法和语法进行扩充。
关 键 词:词法分析;语法分析;符号表;三元式Abstract:GPJ_Pascal is a subset of Pascal.GPJ_Pascal Integ rated Developm ent Env ir onm ent is a platform w ith a visual user's interface,and the GPJ_Pascal pro gram can be edited,co mpiled and perform ed.In the paper,the structure o f the GPJ_Pascal compiler is mainly intr oduced,the lexer can scan the sour ce prog ram acco rding to the m orphology rule o f lang uag e w hich can decompose and disting uish ev ery w or d,and car ry out mor pholog y inspection at the sam e tim e;the parser is the basis o f the sym bol table generated by verify ing w hether a w ord sym bo l string is a sentence of the lang uage gramm ar o r not;in analysis process,the item is utilized to establish,seek,fill and reference for m frequently;the parse subprog ram has adopted top-botto m recursiv e subprog ram law while parsing,it also gener ates the corresponding triple code according to the semantic, w hich is helpful for prog ram transplant,and offers mistaken handle m echanism.The overall structure of the GPJ_Pascal co mpiler is com plete,distinct,clear m eaning,easily r eading and understanding,co mpiling fewer m istakes,big reliability,and easily ex panding the morpholog y and g rammar.Key words:lex er;par ser;symbol table;triple一、课题分析GPJ_Pascal是PASCAL的一个子集,包含了Pascal大部分的语法成分,能满足一般的编程需要。
第三章 词法分析及词法分析程序 课后答案【khdaw_lxywyl】

课 后 答 案 网
第三章 词法分析及词法分析程序 1 试用某种高级语言编写一个 FORTRAN 源程序的预处理子程序,其功能是: 每调用它一次, 即把源程序中的一个完整语句送入扫描缓冲区。要求删去语句中的注释行;删去续行标记字 符,把语句中的各行连接起来,并在语句的末端加上语句结束符。此外,还要求此程序具有 组织源程序列表输出的功能。 2 画出用来识别如下三个关键字的状态转移图。 STEP STRING SWITCH 3 假定有一个猎人带着一只狼、一头山羊和一棵白菜来到一条河的左岸,拟摆渡过河,而岸 边只有一条小船,其 大小仅能装载人和其余三件东西中的一件,也就是说,每一次猎人只 能将随行者中的一件带到彼岸。若猎人将狼和山羊留在同一岸上而无人照管,那么,狼就会 将羊吃掉;如果猎人把山羊和白菜留在同一岸,山羊也会把白菜吃掉。现在,请你用状态转
试找出一个长度最小的输入串,使得:
h (1) 在识别此输入串的过程中,每一状态至少经历一次;
(2) 每一状态转换至少经历一次。 9 对于下列的状态转换矩阵:[]a[]bS[]A[]SA[]A[]BB[]B[]B(i) 初态:S
k 终态:B[][][]a[]bS[]A[]BA[]B[]AB[]B[]B(ii) 初态:S
26 指出下列 LEX 正规式所匹配的字符串:
. (1) "{" [^{]*"}"
(2) ^[^a-z][A-Z][0-9]$ (3) [^0-9]|[\r\n]
w (4) \′([^′\n]|\′\′)+\′
(5) \"([^"\n]|\\["\n])*\"
a 27 写出一个 LEX 正规式,它能匹配 C 语言的所有无符号整数 (例如:OX89ab,0123,45,
编译原理语法分析器(java完美运行版)

编译原理语法分析器(java完美运行版)第一篇:编译原理语法分析器 (java完美运行版)实验二语法分析器一、实验目的通过完成预测分析法的语法分析程序,了解预测分析法和递归子程序法的区别和联系。
使学生了解语法分析的功能,掌握语法分析程序设计的原理和构造方法,训练学生掌握开发应用程序的基本方法。
有利于提高学生的专业素质,为培养适应社会多方面需要的能力。
二、实验内容υ根据某一文法编制调试 LL(1)分析程序,以便对任意输入的符号串进行分析。
υ构造预测分析表,并利用分析表和一个栈来实现对上述程序设计语言的分析程序。
υ分析法的功能是利用LL(1)控制程序根据显示栈栈顶内容、向前看符号以及LL(1)分析表,对输入符号串自上而下的分析过程。
三、LL(1)分析法实验设计思想及算法υ模块结构:(1)定义部分:定义常量、变量、数据结构。
(2)初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体、数组、临时变量等);(3)控制部分:从键盘输入一个表达式符号串;(4)利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示错误信息。
四、实验要求1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等。
2、如果遇到错误的表达式,应输出错误提示信息。
3、对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG|—TG(3)G->ε(4)T->FS(5)S->*FS|/FS(6)S->ε(7)F->(E)(8)F->i 输出的格式如下:五、实验源程序LL1.java import java.awt.*;import java.awt.event.*;import javax.swing.*;import javax.swing.table.DefaultTableModel;import java.sql.*;import java.util.Vector;public class LL1 extends JFrame implements ActionListener { /****/private static final long serialVersionUID = 1L;JTextField tf1;JTextField tf2;JLabel l;JButton b0;JPanel p1,p2,p3;JTextArea t1,t2,t3;JButton b1,b2,b3;JLabel l0,l1,l2,l3,l4;JTable table;Statement sta;Connection conn;ResultSet rs;DefaultTableModel dtm;String Vn[]=null;Vector P=null;int firstComplete[]=null;//存储已判断过first的数据char first[][]=null;//存储最后first结果int followComplete[]=null;//存储已判断过follow的数据char follow[][]=null;//存储最后follow结果char select[][]=null;//存储最后select结果int LL=0;//标记是否为LL(1)String vt_tou[]=null;//储存VtObject shuju[][]=null;//存储表达式数据char yn_null[]=null;//存储能否推出空LL1(){ setLocation(100,0);setSize(700,780);tf1=new JTextField(13);tf2=new JTextField(13);l=new JLabel(“>>”);l0=new JLabel(“输入字符串:”);l1=new JLabel(“输入的文法”);l2=new JLabel(“ ”);l3=new JLabel(“分析的结”);l4=new JLabel(“预测分析”);//p1=new JPanel();p2=new JPanel();p3=new JPanel();t1=new JTextArea(24,20);t2=new JTextArea(1,30);t3=new JTextArea(24,40);b0=new JButton(“确定(S为开始)”);b1=new JButton(“ 判断文法”);为:果:表:b2=new JButton(“输入”);b3=new JButton(“清空”);table=new JTable();JScrollPane jp1=new JScrollPane(t1);JScrollPane jp2=new JScrollPane(t2);JScrollPane jp3=new JScrollPane(t3);p2.add(tf1);p2.add(l);p2.add(tf2);p2.add(b0);p2.add(b1);p2.add(l0);p2.add(l2);p2.add(jp2);p2. add(b2);p2.add(b3);p2.add(l1);p2.add(l3);p2.add(jp1);p2.add(jp3);p3.add(l4);p3.add(newJScrollPane(table));add(p2,“Center”);add(p3,“South”);b0.addActionListener(this);b1.addActionListener(this);b2.ad dActionListener(this);b3.addActionListener(this);setDefaultClose Operation(JFrame.EXIT_ON_CLOSE);table.setPreferredScrollable ViewportSize(new Dimension(660,200));setVisible(true);} public void actionPerformed(ActionEvent e){ if(e.getSource()==b0){ String a=tf1.getText();String b=tf2.getText();t1.append(a+'→'+b+'n');}if(e.getSource()==b1){ t3.setText(“");int Vnnum=0,k;Vn=new String[100];P=new Vector();String s[]=t1.getText().split(”n“);for(int i=0;ireturn;}if(s[i].charAt(0)<='Z'&&s[i].charAt(0)>='A'&&s[i].charAt(1)=='→'){ for(k=0;k=Vnnum){ Vn[Vnnum]=s[i].substring(0, 1);//存入Vn数据 Vnnum++;} P.add(s[i]);} else { t3.setText(”文法输入有误,请重新输入“);return;} } yn_null=new char[100];first=new char[Vnnum][100];int flag=0;String firstVn[]=null;firstComplete=new int[Vnnum];for(int i=0;Vn[i]!=null;i++)//依次求FIRST** { flag=0;firstVn=new String[20];if((flag=add_First(first[i],Vn[i],firstVn,flag))==-1)return;firstComplete[i]=1;} t3.append(”first集:“+”n“);//显示FIRST**for(inti=0;Vn[i]!=null;i++){ t3.append(”first(“+Vn[i]+”)={ “);for(int j=0;first[i][j]!='';j++){ t3.append(first[i][j]+” , “);} t3.append(”}“+”n“);}follow=new char[Vnnum][100];String followVn[]=null;followComplete=new int[Vnnum];for(int i=0;Vn[i]!=null;i++)//求FOLLOW** { flag=0;followVn=new String[20];if((flag=tianjiaFollow(follow[i],Vn[i],followVn,flag))==-1)return;followComplete[i]=1;} t3.append(”fol low集:“+”n“);//显示FOLLOW**for(inti=0;Vn[i]!=null;i++){ t3.append(”follow(“+Vn[i]+”)={ “);for(i nt j=0;follow[i][j]!='';j++){ t3.append(follow[i][j]+” , “);} t3.append(”}“+”n“);} select=new char[P.size()][100];for(int i=0;itianjiaSelect(select[i],(String)P.elementAt(i),flag);}t3.append(”select集:“+”n“);//显示SELECT**for(int i=0;ifor(int i=0;Vn[i]!=null;i++)//判断select交集是否为空{ intbiaozhi=0;char save[]=new char[100];for(int j=0;jif(t.substring(0,1).equals(Vn[i])){ for(k=0;select[j][k]!='';k++){ if(puanduanChar(save,select[j][k])){ save[biaozhi]=select[j][k];bia ozhi++;} else//当有交集时,不为LL(1)文法{ t3.append(”不是LL(1)文法!“+”n“);return;} } } } } char Vt[]=new char[100];int biaozhi=0;for(int i=0;i{ if(t.charAt(j)>'Z'||t.charAt(j)<'A'){ if(puanduanChar(Vt,t.cha rAt(j))){ Vt[biaozhi]=t.charAt(j);biaozhi++;} } } } if(puanduanChar(Vt,'#'))//若可推出空集,则将#加入Vt。
词法分析器flex中文手册

FLEX 中文手册这是flex手册的部分中文翻译,仅供参考•一些简单的例子•输入文件的格式•模式•如何匹配输入•动作•生成的扫描器•开始条件•文件结尾规则•与yacc一起使用一些简单的例子首先给出一些简单的例子,来了解一下如何使用flex。
下面的flex输入所定义的扫描器,用来将所有的“username”字符串替换为用户的登陆名字:%% username printf("%s", getlogin());默认情况下,flex扫描器无法匹配的所有文本将被复制到输出,所以该扫描器的实际效果是将输入文件复制到输出,并对每一个“username”进行展开。
在这个例子中,只有一个规则。
“username”是模式(pattern),“printf”是动作(action)。
“%%”标志着规则的开始。
这里是另一个简单的例子:int num_lines = 0, num_chars = 0;%% \n ++num_lines; ++num_chars; . ++num_chars;%% int main(void){yylex();printf("# of lines = %d, # of chars = %d\n", num_lines, num_chars);}该扫描器计算输入的字符个数和行数(除了最后的计数报告,并未产生其它输出)。
第一行声明了两个全局变量,“num_lines”和“num_chars”,可以在yylex()函数中和第二个“%%”后面声明的main()函数中使用。
有两个规则,一个是匹配换行符(“\n”)并增加行数和字符数,另一个是匹配所有不是换行符的其它字符(由正规表达式“.”表示)。
一个稍微复杂点的例子:/* scanner for a toy Pascal-like language */%{/* need this for the call to atof() below */#include <math.h>%}DIGIT [0-9] ID [a-z][a-z0-9]*%%{DIGIT}+ {printf( "An integer: %s (%d)\n", yytext,atoi( yytext ) );}{DIGIT}+"."{DIGIT}* {printf( "A float: %s (%g)\n", yytext,atof( yytext ) );}if|then|begin|end|procedure|function {printf( "A keyword: %s\n", yytext );}{ID} printf( "An identifier: %s\n", yytext );"+"|"-"|"*"|"/" printf( "An operator: %s\n", yytext );"{"[^}\n]*"}" /* eat up one-line comments */[ \t\n]+ /* eat up whitespace */. printf( "Unrecognized character: %s\n", yytext );%%int main(int argc, char **argv){++argv, --argc; /* skip over program name */if ( argc > 0 )yyin = fopen( argv[0], "r" );elseyyin = stdin;yylex();}这是一个类似Pascal语言的简单扫描器的初始部分,用来识别不同类型的标志(tokens)并给出报告。
词法分析器的实现与设计

题目:词法分析器的设计与实现一、引言................................ 错误!未定义书签。
二、词法分析器的设计 (3)2.1词的内部定义 (3)2.2词法分析器的任务及功能 (3)32.2.2 功能: (4)2.3单词符号对应的种别码: (4)三、词法分析器的实现 (5)3.1主程序示意图: (5)3.2函数定义说明 (6)3.3程序设计实现及功能说明 (6)错误!未定义书签。
77四、词法分析程序的C语言源代码: (7)五、结果分析: (12)摘要:词法分析是中文信息处理中的一项基础性工作。
词法分析结果的好坏将直接影响中文信息处理上层应用的效果。
通过权威的评测和实际应用表明,IRLAS是一个高精度、高质量的、高可靠性的词法分析系统。
众所周知,切分歧义和未登录词识别是中文分词中的两大难点。
理解词法分析在编译程序中的作用,加深对有穷自动机模型的理解,掌握词法分析程序的实现方法和技术,用c语言对一个简单语言的子集编制一个一遍扫描的编译程序,以加深对编译原理的理解,掌握编译程序的实现方法和技术。
Abstract:lexical analysis is a basic task in Chinese information processing. The results of lexical analysis will directly affect the effectiveness of the application of Chinese information processing. The evaluation and practical application show that IRLAS is a high precision, high quality and high reliability lexical analysis system. It is well known that segmentation ambiguity and unknown word recognition are the two major difficulties in Chinese word segmentation. The understanding of lexical analyse the program at compile, deepen of finite automata model for understanding, master lexical analysis program implementation method and technology, using C language subset of a simple language compilation of a scanned again compiler, to deepen to compile the principle solution, master compiler implementation method and technology.关键词:词法分析器?扫描器?单词符号?预处理Keywords: lexical analyzer word symbol pretreatment scanner一、引言运用C语言设计词法分析器,由指定文件读入预分析的源程序,经过词法分析器的分析,将结果写入指定文件。
编译原理填空选择

编译原理填空选择一、填空题:1-01.编译程序的工作过程一般可以划分为词法分析,语法分析,语义分析,之间代码生成,代码优化等几个基本阶段,同时还会伴有表格处理和出错处理 .1-02.若源程序是用高级语言编写的,目标程序是机器语言程序或汇编程序 ,则其翻译程序称为编译程序.1-03.编译方式与解释方式的根本区别在于是否生成目标代码.1-04.翻译程序是这样一种程序,它能够将用甲语言书写的程序转换成与其等价的用乙语言书写的程序 .1-05.对编译程序而言,输入数据是源程序 ,输出结果是目标程序 .1-06.如果编译程序生成的目标程序是机器代码程序,则源程序的执行分为两大阶段: 编译阶段和运行阶段 .如果编译程序生成的目标程序是汇编语言程序,则源程序的执行分为三个阶段: 编译阶段 , 汇编阶段和运行阶段.2-01.所谓最右推导是指:任何一步αTβ都是对α中最右非终结符进行替换的。
2-02.一个上下文无关文法所含四个组成部分是一组终结符号、一组非终结符号、一个开始符号、一组产生式。
2-03.产生式是用于定义语法成分的一种书写规则。
2-04.设G[S]是给定文法,则由文法G所定义的语言L(G)可描述为: L(G)={x│S x,x∈VT*} 。
2-05.设G是一个给定的文法,S是文法的开始符号,如果S x(其中x∈V*),则称x是文法的一个句型。
2-06.设G是一个给定的文法,S是文法的开始符号,如果S x(其中x∈VT*),则称x是文法的一个句子。
3-01.扫描器的任务是从源程序中识别出一个个单词符号。
4-01.语法分析最常用的两类方法是自上而下和自下而上分析法。
4-02.语法分析的任务是识别给定的终极符串是否为给定文法的句子。
4-03.递归下降法不允许任一非终极符是直接左递归的。
4-04.自顶向下的语法分析方法的关键是如何选择候选式的问题。
4-05.递归下降分析法是自顶向下分析方法。
4-06.自顶向下的语法分析方法的基本思想是:从文法的开始符号开始,根据给定的输入串并按照文法的产生式一步一步的向下进行直接推导,试图推导出文法的句子,使之与给定的输入串匹配。
Pascal语言的词法分析器

编译原理课程实验报告一、实验内容:1、编写Pascal 语言的词法分析器,可以手工编写,也可以利用LEX 工具生成。
2、编写一个LEX 源文件,使之生成可统计文本文件中字符、单词和行数,并能够报告统计结果的程序,其中单词定义为字母、数字串,标点、空格不计算为单词。
二、实现原理:1、词法分析器对输入的程序进行分析,将关键字,保留字与系统标识符分开,并对其属性进行说明。
建立数组,将单词读入,对单词进行判断,通过扫描对照关键字表来识别关键字。
2、字符计数识别空格,区分单词和其他符号,循环计数。
三、实验环境工具:Parser Generator 0.60 lex/yacc 编辑器平台:Windows Server 2003 Enterprise四、源程序:Pascal 标识符 Pascal 整数和实数1、词法分析器Pascal语言的词法分析器%{(* lexical analyzer for Pascal)%}%{(* 本程序通过扫描对照关键字表来识别关键字 *)(* 过程和函数定义 *)procedure commenteof;(* 检查并返回错误输入 *)beginwriteln('unexpected EOF inside comment at line ', yylineno);end(*commenteof*);function upper(str : String) : String;(* 将字符串转换为大写 *)var i : integer;beginfor i := 1 to length(str) dostr[i] := upCase(str[i]);upper := strend(*upper*);function is_keyword(id : string; var token : integer) : boolean;(* 检查 id 是否为 Pascal 关键字; 若是, 返回 token 中相应的 token number *)constid_len = 20;typeIdent = string[id_len];const(* Pascal 关键字表: *)(* 用 Pascal 关键字表: *)no_of_keywords = 39;keyword : array [1..no_of_keywords] of Ident = ('AND', 'ARRAY', 'BEGIN', 'CASE','CONST', 'DIV', 'DO', 'DOWNTO','ELSE', 'END', 'EXTERNAL', 'EXTERN','FILE', 'FOR', 'FORWARD', 'FUNCTION','GOTO', 'IF', 'IN', 'LABEL','MOD', 'NIL', 'NOT', 'OF','OR', 'OTHERWISE', 'PACKED', 'PROCEDURE','PROGRAM', 'RECORD', 'REPEAT', 'SET','THEN', 'TO', 'TYPE', 'UNTIL','VAR', 'WHILE', 'WITH');keyword_token : array [1..no_of_keywords] of integer = (_AND, _ARRAY, _BEGIN, _CASE,_CONST, _DIV, _DO, _DOWNTO,_ELSE, _END, _EXTERNAL, _EXTERNAL,(* EXTERNAL: 2 spellings (see above)! *) _FILE, _FOR, _FORWARD, _FUNCTION,_GOTO, _IF, _IN, _LABEL,_MOD, _NIL, _NOT, _OF,_OR, _OTHERWISE, _PACKED, _PROCEDURE,_PROGRAM, _RECORD, _REPEAT, _SET,_THEN, _TO, _TYPE, _UNTIL,_VAR, _WHILE, _WITH);var m, n, k : integer;beginid := upper(id);(* 二分法检索: *)m := 1; n := no_of_keywords;while m<=n dobegink := m+(n-m) div 2;if id=keyword[k] thenbeginis_keyword := true;token := keyword_token[k];exitendelse if id>keyword[k] thenm := k+1elsen := k-1end;is_keyword := falseend(*is_keyword*);%}NQUOTE [^']%{(* 规则部分 *)%}%%%{var c : char;kw : integer;%}[a-zA-Z]([a-zA-Z0-9])* if is_keyword(yytext, kw) then return(kw)elsereturn(IDENTIFIER);":=" return(ASSIGNMENT);'({NQUOTE}|'')+' return(CHARACTER_STRING);":" return(COLON);"," return(COMMA);[0-9]+ return(DIGSEQ);"." return(DOT);".." return(DOTDOT);"=" return(EQUAL);">=" return(GE);">" return(GT);"[" return(LBRAC);"<=" return(LE);"(" return(LPAREN);"<" return(LT);"-" return(MINUS);"<>" return(NOTEQUAL);"+" return(PLUS);"]" return(RBRAC);[0-9]+"."[0-9]+ return(REALNUMBER);")" return(RPAREN);";" return(SEMICOLON);"/" return(SLASH);"*" return(STAR);"**" return(STARSTAR);"->" |"^" return(UPARROW);"(*" |"{" beginrepeatc := get_char;case c of'}' : ;'*' : beginc := get_char;if c=')' then exit else unget_char(c)end;#0 : begincommenteof;exit;end;end;until falseend;[ \n\t\f] ;return(ILLEGAL);2、字符统计编写一个LEX源文件,使之生成可统计文本文件中字符、单词和行数,并能够报告统计结果的程序,其中单词定义为字母、数字串,标点、空格不计算为单词。
词法分析程序

词法分析程序⼀、词法分析程序功能:词法分析器的功能为输⼊源程序,按照构词规则分解成⼀系列单词符号。
单词是语⾔中具有独⽴意义的最⼩单位,包括关键字、标识符、运算符、界符和常量等(1) 关键字是由程序语⾔定义的具有固定意义的标识符。
例如,Pascal 中的begin,end,if,while都是保留字。
这些字通常不⽤作⼀般标识符。
(2) 标识符⽤来表⽰各种名字,如变量名,数组名,过程名等等。
(3) 常数常数的类型⼀般有整型、实型、布尔型、⽂字型等。
(4) 运算符如+、-、*、/等等。
(5) 界符如逗号、分号、括号、等等。
⼆、符号与种别码对照表三、代码实现:#include <stdio.h>#include <stdlib.h>#include <string.h>#define SIZE 100char prog[SIZE],ch,token[8];int p=0,syn,n,i;char *keyword[6]={"begin","then","if","while","do","end"};//定义关键字数组void scaner();void main(){int select=-1;p=0;printf("请输⼊源程序字符串(以'#'结束):\n");do{ch=getchar();prog[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(syn){case -1:printf("词法分析出错\n");break;default :printf("<%d,%s>\n",syn,token);break;}}while(syn!=0);printf("词法分析成功\n");getchar();}void scaner(){for(n=0;n<8;n++){token[n]='\0';}n=0;ch=prog[p++];while(ch==''){ch=prog[p++];}if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){do{token[n++]=ch;ch=prog[p++];}while((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')||(ch>='0'&&ch<='9'));syn=10;for(n=0;n<6;n++)//在六个关键字中对⽐{if(strcmp(token,keyword[n])==0)syn=n+1;}p--;}else if(ch>='0'&&ch<='9')//判断输⼊的是否为整数常数{p--;do{token[n++]=prog[p++];ch=prog[p];}while(ch>='0'&&ch<='9');syn=11;return;}else{switch(ch){case'+':syn=13;token[0]=ch;break;case'-':syn=14;token[0]=ch;break;case'*':syn=15;token[0]=ch;break;case'/':syn=16;token[0]=ch;break;case':':syn=17;token[0]=ch;ch=prog[p++];if(ch=='='){token[1]=ch;syn++;}else p--;break;case'<':syn=20;token[0]=ch;ch=prog[p++];if(ch=='>'){token[1]=ch;syn++;}else if(ch=='='){token[1]=ch;syn=syn+2;}else p--;break;case'>':syn=23;token[0]=ch;ch=prog[p++];if(ch=='='){token[1]=ch;syn++;}else p--;break;case'=':syn=25;token[0]=ch;break;case';':syn=26;token[0]=ch;break;case'(':syn=27;token[0]=ch;break;case')':syn=28;token[0]=ch;break;case'#':syn=0;token[0]=ch;break;default: printf("词法分析出错! 请检查是否输⼊⾮法字符\n");syn=-1;break; }}}四、程序运⾏结果截图:。
基于Pascal的编译器设计与实现

基于Pascal的编译器设计与实现一、引言编译器是一种将高级语言翻译成机器语言的程序,它在计算机科学领域扮演着至关重要的角色。
Pascal是一种结构化程序设计语言,由Niklaus Wirth于1968年设计并于1970年首次发布。
本文将探讨基于Pascal的编译器设计与实现,介绍编译器的基本原理、Pascal语言特性以及如何将Pascal代码转换为目标机器代码的过程。
二、编译器的基本原理编译器通常由词法分析器、语法分析器、语义分析器、中间代码生成器、优化器和代码生成器等模块组成。
其中,词法分析器负责将源代码转换成单词流,语法分析器将单词流转换成语法树,语义分析器检查语法树是否符合语义规则,中间代码生成器将语法树转换成中间代码,优化器对中间代码进行优化,最后由代码生成器将优化后的中间代码转换成目标机器代码。
三、Pascal语言特性Pascal是一种结构化程序设计语言,具有严格的语法规则和清晰的程序结构。
它支持过程和函数的定义,具有强大的数据类型系统和丰富的控制结构。
Pascal还提供了丰富的标准库函数,方便程序员进行开发。
四、基于Pascal的编译器设计在设计基于Pascal的编译器时,首先需要编写词法分析器和语法分析器来解析Pascal源代码。
词法分析器负责将源代码转换成单词流,而语法分析器则将单词流转换成抽象语法树。
接着需要实现语义分析器来检查抽象语法树是否符合Pascal语言规范,并生成中间代码。
最后通过优化器和代码生成器将中间代码转换成目标机器代码。
五、编译过程详解词法分析:词法分析阶段将源代码按照规定的单词规则进行划分,生成单词流。
语法分析:语法分析阶段将单词流转换成抽象语法树,检查源代码是否符合Pascal语言的语法规则。
语义分析:语义分析阶段检查抽象语法树是否符合Pascal语言的语义规则,并进行类型检查等操作。
中间代码生成:中间代码生成阶段将经过语义分析的抽象语法树转换成中间表示形式,如三地址码或者四元式。
java词法分析器实验报告

Java 词法分析器实验报告--07111101--奥特曼一.词法分析器功能概述:1.使用DFA实现词法分析器的设计;2.实现对Java源程序中注释和空格(空行)的过滤;3.利用两对半缓冲区从文件中逐一读取单词;4.词法分析结果属性字流存放在独立文件(c:\words.txt)中;5.统计源程序所有单词数以、错误单词数、单词所在的行数;6.具有报告词法错误和出错位置(源程序行号)的功能;二.源程序设计实现://程序大部分参照网络,自己做了小部分改动#include<iostream>#include<fstream>#include<cstdio>#include<cstdlib>#include<cstring>#include"const.h"using namespace std;char rbuf[RBUFSIZE]; //读文件缓冲区int rp; //读文件缓冲区指针char ch; //当前扫描到的字符int type; //单词的类型char sbuf[SBUFSIZE]; //单词字符串缓冲区int sp; //单词字符串缓冲区指针ifstream inFile; //输入文件ofstream outFile; //输出文件void clear_rbuf()//清空读文件缓冲区{int i;for(i=0;i<RBUFSIZE;i++)rbuf[i]='\0';rp=0;}void clear_sbuf()//清空单词字符缓冲区{int i;for(i=0;i<SBUFSIZE;i++)sbuf[i]='\0';sp=0;}void get_ch()//从读文件缓冲区得到下一个字符{ch=rbuf[rp];rp++;}void put_ch(char ch)//向字符缓冲区追加一个字符{sbuf[sp]=ch;sp++;}void get_type(char * msg)//得到单词类型{int i;for(i=0;i<TABLE_LENGTH;i++){if (!strcmp(msg, ATTR_MAP[i].keyword)){type=ATTR_MAP[i].type;return;}}return;}int digit(int base)//判断字符是否属于base进制并转换{char c=ch;int result;if (c>='0'&&c<='7')result = (int)(c - '0');else if(c>='8'&&c<='9'){if (base > 8)result=(int)(c-'0');elseresult = -1;}else if(c>='a'&&c<= 'f'){if (base>10)result=(int)(c-'a'+10);elseresult=-1;}else if (c>='A'&&c<='F'){if (base>10)result=(int)(c-'A'+10);elseresult=-1;}elseresult=-1;return result;}void scan_fraction()//扫描指数{while(digit(10)>=0){put_ch(ch);get_ch();}if(ch=='e'||ch=='E'){put_ch(ch);get_ch();if(ch=='+'||ch=='-'){put_ch(ch);get_ch();}while(digit(10)>=0){put_ch(ch);get_ch();}return;}return;}void scan_suffix() //扫描浮点数后缀{scan_fraction();if(ch=='f'||ch=='F'||ch=='d'||ch=='D'){put_ch(ch);get_ch();}type=T_FLOAT;return;}bool is_spectial(char &ch)//判断字符是否是特殊字符{if(ch=='!'||ch=='%'||ch=='&'||ch=='*'||ch=='?'||ch=='+'||ch=='-'||ch==':'||ch=='<'| |ch=='='||ch=='>'||ch=='^'||ch=='|'||ch=='~')return true;elsereturn false;}void scan_operator()//扫描运算符{while (is_spectial(ch)){put_ch(ch);get_ch();}get_type(sbuf);if(type==0)type=T_ERROR;return;}void scan_number(int radix)//扫描8、10、16进制数值{while(digit(radix)>=0){put_ch(ch);get_ch();}if(radix!=10&&ch=='.'){put_ch(ch);get_ch();type=T_ERROR;}else if(radix==10&&ch=='.'){put_ch('.');get_ch();if(digit(10)>=0)scan_suffix();}else if(radix==10&&(ch=='e'||ch=='E'||ch=='f'||ch=='F'||ch=='d'||ch=='D')) scan_suffix();else if(ch == 'l' || ch == 'L'){put_ch(ch);get_ch();type=T_INT;}else type=T_INT;return;}void skip_comment()//跳过注释内容{while(ch!='\0'){switch(ch){case'*':get_ch();if (ch=='/'){get_ch();return;}break;default:get_ch();break;}}}bool is_idchar(char &ch)//判断字符是否标识符首字符{return((ch>='0'&&ch<='9')||(ch>='A'&&ch<='Z')||(ch>='a'&&ch<='z')||ch=='$'||ch=='_');}void scan_ident()//搜索关键字、标识符{bool id_or_key = true;bool tem=true;//是否仍是标识符或关键字while(ch!=C_TAB&&ch!=C_FF&&ch!=C_CR&&ch!=C_LF&&ch!='\0') {if(is_idchar(ch)){put_ch(ch);get_ch();if(is_idchar(ch))continue;elseget_type(sbuf);if(type!=0)return;else{type=T_IDENTIFIER;return;}}}}void scan_char()//转义字符搜索字符{int oct = 0;int hex = 0;if(ch=='\\'){get_ch();if(ch=='\\')put_ch('\\');get_ch();if(ch=='\'')put_ch('\'');get_ch();if(ch=='\"')put_ch('\"');get_ch();if(ch=='b')put_ch('\b');get_ch();if(ch=='t')put_ch('\t');get_ch();if(ch=='n')put_ch('\n');get_ch();if(ch=='f')put_ch('\f');get_ch();if(ch=='r')put_ch('\r');get_ch();if('0'<=ch&&ch<='7'){oct=digit(8);get_ch();if('0'<=ch&&ch<='7'){oct=oct*8+digit(8);get_ch();if('0'<=ch&&ch<='7'){oct=oct*8+digit(8);get_ch();}}put_ch((char)oct);}if(ch=='u'){get_ch();if(('0'<=ch&&ch<='9')||('a'<=ch&&ch<='f')||('A'<=ch&&ch<='F')){hex=hex*16+digit(16);get_ch();if(('0'<=ch&&ch<='9')||('a'<=ch&&ch<='f')||('A'<=ch&&ch<='F')){hex=hex*16+digit(16);get_ch();if(('0'<=ch&&ch<='9')||('a'<=ch&&ch<='f')||('A'<=ch&&ch<='F')) {hex=hex*16+digit(16);get_ch();if(('0'<=ch&&ch<='9')||('a'<=ch&&ch<='f')||('A'<=ch&&ch<='F')){hex=hex*16+digit(16);get_ch();}}}}put_ch((char)hex);}}else{put_ch(ch);get_ch();}}void get_word()//获取下一个单词及属性{clear_sbuf();type=0;while (ch!='\0'){if((ch>='A'&&ch<='Z')||(ch>='a'&&ch<='z')||ch=='$'||ch=='_')//关键字、标识符{scan_ident();return;}else if(ch=='\'')//字符{get_ch();if(ch=='\''){type=T_ERROR;strcpy(sbuf,"''");get_ch();}else{scan_char();if(ch=='\''){type=T_CHAR;get_ch();}else type=T_ERROR;}return;}else if(ch=='\"')//字符串{get_ch();{type=T_ERROR;strcpy(sbuf,"\"\"");get_ch();}else{do{scan_char();}while(ch!='\"'&&ch!=C_TAB&&ch!=C_FF&&ch!=C_CR&&ch!=C_LF);if(ch=='\"'){type=T_STRING;get_ch();}else type=T_ERROR;}return;}else if(ch=='.')//.开头数字{put_ch(ch);get_ch();if(digit(10)>=0)scan_suffix();else type=T_BOUND;return;}else if(ch=='0')//0开头数字{put_ch('0');get_ch();if(ch=='x'||ch=='X'){put_ch(ch);get_ch();if(digit(16)>=0&&ch!='0')scan_number(16);}else if(digit(8)>=0&&ch!='0')scan_number(8);{put_ch('.');get_ch();if(digit(10)>=0)scan_suffix();}else if(ch==' '){get_ch();type=T_INT;}else type=T_ERROR;return;}else if('1'<=ch&&ch<='9')//1-9开头数字{scan_number(10);return;}else if((ch=='(')||(ch==')')||(ch=='[')||(ch==']'))//9个界限符中的8个{put_ch(ch);get_ch();type = T_BOUND;return;}else if(ch==','){put_ch(ch);get_ch();type = T_COMMA;return;}else if((ch=='{')||(ch=='}')){put_ch(ch);get_ch();type = T_BRACKET;return;}else if(ch==';'){put_ch(ch);get_ch();type = T_SEMICOLON;return;}else if(ch=='/')//注释、'/'运算符、 '/='运算符 {get_ch();if(ch=='/'){while(ch!=C_CR&&ch!=C_LF&&ch!='\0') get_ch();break;}else if(ch=='*'){get_ch();skip_comment();}else if(ch=='='){strcpy(sbuf, "/=");type=T_ASSIGN;get_ch();}else{strcpy(sbuf, "/");type=T_MULDIV;}return;}else if(is_spectial(ch))//特殊字符{scan_operator();return;}else get_ch();//间隔符}}void readfile(char * fn_in)//将源文件读入缓冲区{rp = 0;inFile.open(fn_in);if (!inFile.is_open())return;while(inFile.get(rbuf[rp]))rp++;inFile.close();rp = 0;}void writefile()//向输出文件写字符{sp = 0;outFile << "(0x" << hex << type << ") ";outFile << "[";while(sbuf[sp]!='\0'){outFile << sbuf[sp];sp++;}outFile << "]";outFile << endl;sp = 0;}int main(int argc, char * argv[]){char fn_in[NAMESIZE];char fn_out[NAMESIZE];cout << "Input the name of Java source file: ";cin >> fn_in;readfile(fn_in);cout << "Input name of testing result file: ";cin >> fn_out;outFile.open(fn_out);get_ch();while(ch!='\0'){get_word();if(strlen(sbuf)!=0)writefile();}outFile.close();cout << "The analysis has been completed!" << endl;system("pause");return 0;}三.程序执行流程a.首先从Java文件中读取半个缓冲区的字符串读入预处理缓冲区中,将缓冲区中的注释、空行、空格全部处理,最后预处理缓冲区里面只剩下单词、一个空格、换行;b.将预处理缓冲区里面的的数据分两次读入两对半缓冲区ScanBuffer中,送入词法分析器wordScanner进行逐个单词分析,由wordScanner调用相应的转换函数进行单词属性的分析。
基于Pascal的编程语言设计与实现

基于Pascal的编程语言设计与实现一、引言Pascal是一种结构化编程语言,由Niklaus Wirth于1968年至1969年间设计并实现。
它被广泛用于教学和软件开发领域,具有清晰的语法结构和强大的表达能力。
本文将探讨基于Pascal的编程语言设计与实现,包括语言特性、语法规则、编译器实现等方面的内容。
二、Pascal语言特性Pascal语言具有以下几个显著特点: 1. 结构化:Pascal是一种结构化编程语言,支持模块化、过程化的程序设计方法,有助于提高代码的可读性和可维护性。
2. 强类型:Pascal是一种强类型语言,要求在编译时进行类型检查,可以有效避免类型错误导致的程序异常。
3. 静态作用域:Pascal采用静态作用域规则,变量的作用域在编译时确定,有利于程序员理解代码逻辑和调试程序。
4. 结构体支持:Pascal提供了记录(record)类型,可以定义复杂的数据结构,方便处理多字段数据。
三、Pascal语法规则Pascal语言的语法规则包括关键字、标识符、常量、变量、运算符等内容。
下面是一个简单的Pascal程序示例:示例代码star:编程语言:pascalprogram HelloWorld;beginwriteln('Hello, World!');end.示例代码end 在上面的示例中,“program”是关键字,“HelloWorld”是标识符,“begin”和“end”表示程序块的开始和结束,“writeln”是输出函数,“‘Hello, World!’”是字符串常量。
四、基于Pascal的编程语言设计基于Pascal的编程语言设计需要考虑以下几个方面: 1. 语法扩展:可以在Pascal基础上扩展新的语法规则,如引入面向对象编程特性、Lambda表达式等。
2. 标准库增强:设计新的标准库函数和数据结构,提供更丰富的功能支持。
3. 工具链完善:开发相应的编译器、解释器和调试器,确保新语言可以被有效地编译和执行。
PASCAL语言、正规表达式

权
所 有
ELSE 向前指针前移一个位置;
PASCAL语言、正规表达式
15
改进方法
基本方法的缺点:
更新向前指针时要做二次测试
每半区带有结束标记的缓冲器
@
更新向前指针时只要做一次测试
李
文
生
… i f x = y t h eof e n j : = j + 2 ; eof eof
制
作
,
开始指针 向前指针
本章内容安排:
@
李
首先讨论用手工方式设计并实现词法分析器的方法和步骤
文 生
词法分析器的作用
制
源程序的输入与词法分析器的输出
作 ,
单词符号的描述及识别
词法分析器的设计与实现
版
然后介绍词法分析器的自动生成
权
所 有
软件工具LEX
PASCAL语言、正规表达式
3
2.1 词法分析器的作用
源程序由单词组成,单词是最小的语义单位
<id,指向标识符R在符号表中的入口的指针>
制 作
<mul_op, >
, <num,整数值60>
版 权 所 有
PASCAL语言、正规表达式
20
2.3 记号的描述和识别
识别单词是按照记号的模式进行的,一种 记号的模式匹配一类单词的集合。
正规表达式和正规文法是描述模式的重要
@
工具。
李
文
生
制
一、词法与正规文法
可以简化设计
可以改进编译器的效率
@
李 文
生 可以加强编译器的可移植性
制 作 ,
版 权 所 有
PASCAL语言、正规表达式
词法分析器

《编译原理》课程实验报告课程实验题目:词法分析器学院:计算机科学与技术班级:软件1503学号:04153094姓名:刘欣指导教师姓名:陈燕完成时间:词法分析定义:词法分析器的功能输入源程序,按照构词规则分解成一系列单词符号。
单词是语言中具有独立意义的最小单位,包括关键字、标识符、运算符、界符和常量等(1) 关键字是由程序语言定义的具有固定意义的标识符。
例如,Pascal 中的begin,end,if,while都是保留字。
这些字通常不用作一般标识符。
(2) 标识符用来表示各种名字,如变量名,数组名,过程名等等。
(3) 常数常数的类型一般有整型、实型、布尔型、文字型等。
(4) 运算符如+、-、*、/等等。
(5) 界符如逗号、分号、括号、等等。
输出:词法分析器所输出单词符号常常表示成如下的二元式:(单词种别,单词符号的属性值)单词种别通常用整数编码。
标识符一般统归为一种。
常数则宜按类型(整、实、布尔等)分种。
关键字可将其全体视为一种。
运算符可采用一符一种的方法。
界符一般用一符一种的方法。
对于每个单词符号,除了给出了种别编码之外,还应给出有关单词符号的属性信息。
单词符号的属性是指单词符号的特性或特征。
示例:比如如下的代码段:while(i>=j) i--经词法分析器处理后,它将被转为如下的单词符号序列:<while, _><(, _><id, 指向i的符号表项的指针><>=, _><id, 指向j的符号表项的指针><), _><id, 指向i的符号表项的指针><--, _><;, _>词法分析分析器作为一个独立子程序词法分析是编译过程中的一个阶段,在语法分析前进行。
词法分析作为一遍,可以简化设计,改进编译效率,增加编译系统的可移植性。
也可以和语法分析结合在一起作为一遍,由语法分析程序调用词法分析程序来获得当前单词供语法分析使用。
java程序编译的三个步骤

java程序编译的三个步骤Java程序编译的三个步骤可以分为词法分析、语法分析和代码生成。
下面将逐步介绍这三个步骤。
一、词法分析词法分析是将源代码转化为单词(Token)序列的过程。
在这个步骤中,编译器会对源代码进行扫描,并将其分解为最小的语法单元。
这些语法单元可以是关键字、运算符、标识符、常量等。
词法分析器会根据语言的语法规则,对源代码进行切割,生成一个个的Token。
例如,对于以下Java代码片段:```javaint a = 10;int b = 20;int c = a + b;System.out.println(c);```词法分析器将会将其分解为如下的Token序列:```int, a, =, 10, ;, int, b, =, 20, ;, int, c, =, a, +, b, ;, System.out, ., println, (, c, ), ;```二、语法分析语法分析是将词法分析生成的Token序列转化为抽象语法树(AST)的过程。
在这个步骤中,编译器会根据语法规则,对Token序列进行组织和分析,构建出程序的语法结构。
语法分析器会根据语言的语法规则,将Token序列转化为一棵语法树,以表示程序的逻辑结构。
例如,对于以下Java代码片段:```javaint a = 10;int b = 20;int c = a + b;System.out.println(c);```语法分析器将会构建出如下的语法树:```Program├── DeclarationStatement│ ├── Type: int│ ├── Identifier: a│ └── Literal: 10├── DeclarationStatement│ ├── Type: int│ ├── Identifier: b│ └── Literal: 20├── DeclarationStatement│ ├── Type: int│ ├── Identifier: c│ └── BinaryExpression│ ├── Identifier: a│ ├── Operator: +│ └── Identifier: b└── Expre ssionStatement└── MethodInvocation├── MethodInvocation│ └── Identifier: out├── Identifier: println└── Arguments└── Identifier: c```三、代码生成代码生成是将抽象语法树转化为目标平台的可执行代码的过程。
Java与自然语言处理利用Java实现文本分析技术

Java与自然语言处理利用Java实现文本分析技术Java与自然语言处理:利用Java实现文本分析技术自然语言处理(Natural Language Processing, NLP)是一门研究人类语言和计算机之间交互的科学领域。
它结合了人工智能、计算机科学和语言学的知识,致力于使计算机能够理解、解释和生成人类语言。
在当今信息爆炸的时代,文本分析技术尤为重要。
本文将介绍如何利用Java实现文本分析技术。
I. 文本预处理文本预处理是文本分析的基础工作,它包括词法分析、标注、分词和归一化等步骤。
Java提供了丰富的自然语言处理库,如OpenNLP、Stanford CoreNLP等,可以方便地实现这些预处理步骤。
以下是一个示例代码:```import opennlp.tools.tokenize.TokenizerME;import opennlp.tools.tokenize.TokenizerModel;import java.io.FileInputStream;import java.io.IOException;public class TextPreprocessing {public static void main(String[] args) throws IOException {FileInputStream modelFile = new FileInputStream("en-token.bin");TokenizerModel model = new TokenizerModel(modelFile);TokenizerME tokenizer = new TokenizerME(model);String text = "Hello, how are you? I'm fine, thank you.";String[] tokens = tokenizer.tokenize(text);for (String token : tokens) {System.out.println(token);}}}```以上代码使用了OpenNLP库中的TokenizerME类,将文本分割成单词并输出。
编译原理题库——选择题

编译原理a二、选择题(请在前括号内选择最确切的一项作为答案划一个勾,多划按错论)(每个4分,共40分)1.词法分析器的输出结果是_____。
A.( ) 单词的种别编码 B.( ) 单词在符号表中的位置C.( ) 单词的种别编码和自身值D.( ) 单词自身值2.正规式 M 1 和 M 2 等价是指_____。
A.( ) M1和M2的状态数相等 B.( ) M1和M2的有向边条数相等C.( ) M1和M2所识别的语言集相等D.( ) M1和M2状态数和有向边条数相等3.文法G:S→xSx|y所识别的语言是_____。
A.( ) xyx B.( ) (xyx)* C.( ) xnyxn(n≥0) D.( ) x*yx*4.如果文法G是无二义的,则它的任何句子α_____。
A.( )最左推导和最右推导对应的语法树必定相同B.( ) 最左推导和最右推导对应的语法树可能不同C.( ) 最左推导和最右推导必定相同D.( )可能存在两个不同的最左推导,但它们对应的语法树相同5.构造编译程序应掌握______。
A.( )源程序 B.( ) 目标语言C.( ) 编译方法 D.( ) 以上三项都是6.四元式之间的联系是通过_____实现的。
A.( ) 指示器B.( ) 临时变量C.( ) 符号表 D.( ) 程序变量7.表达式(┐A∨B)∧(C∨D)的逆波兰表示为_____。
A. ( ) ┐AB∨∧CD∨B.( ) A┐B ∨CD∨∧C.( ) AB∨┐CD∨∧ D.( ) A┐B∨∧CD∨8. 优化可生成_____的目标代码。
A.( ) 运行时间较短B.( ) 占用存储空间较小C.( ) 运行时间短但占用内存空间大D.( ) 运行时间短且占用存储空间小9.下列______优化方法不是针对循环优化进行的。
A. ( ) 强度削弱B. ( ) 删除归纳变量C. ( ) 删除多余运算D. ( ) 代码外提10.编译程序使用_____区别标识符的作用域。
词法分析实验报告(实验一)
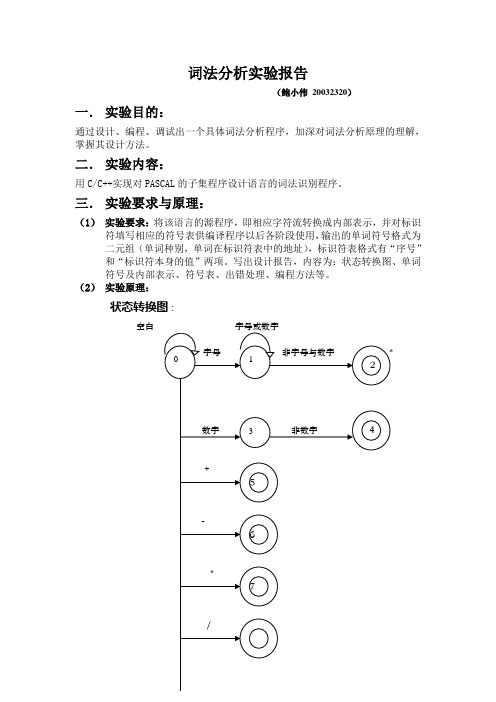
词法分析实验报告(鲍小伟20032320)一.实验目的:通过设计、编程、调试出一个具体词法分析程序,加深对词法分析原理的理解,掌握其设计方法。
二.实验内容:用C/C++实现对PASCAL的子集程序设计语言的词法识别程序。
三.实验要求与原理:(1)实验要求:将该语言的源程序,即相应字符流转换成内部表示,并对标识符填写相应的符号表供编译程序以后各阶段使用,输出的单词符号格式为二元组(单词种别,单词在标识符表中的地址),标识符表格式有“序号”和“标识符本身的值”两项。
写出设计报告,内容为:状态转换图、单词符号及内部表示、符号表、出错处理、编程方法等。
(2)实验原理:状态转换图:空白8923单词符号及内部表示:标志符表和常数表:void getchar();//将下一输入字符读到ch中,指针后移一字符位置void getbc();//保证ch是一个非空白字符void concat();//将ch连接到字符串stroken的末尾void retract();//置ch为空白字符,指针前移一字符位置int isdigit();//判断是否整数int isletter();//首字母的判断int reserve();//对stroken进行关键字表的查找,返回其编码值int insertid();//将stroken中的标识符插入符号表,返回在符号表中的位置int insertconst();//将stroken中的常数插入常数表,返回在常数表中的位置四.主要源代码:Scanner::Scanner(char str[], int n) //构造函数{strcpy(buffer, str);length = n;i = j = 0;}int Scanner::isdigit()//判断是否整数{if(ch>='0' && ch<='9')return 1;elsereturn 0;}int Scanner::isletter()//首字母的判断{if((ch>='a' && ch<='z') || (ch>='A' && ch<='Z'))return 1;elsereturn 0;}void Scanner::getchar() //将下一输入字符读到ch中,指针后移一字符位置{ch = buffer[i];i++;}void Scanner::getbc() //保证ch是一个非空白字符{while(ch == ' ')getchar();}void Scanner::concat() //将ch连接到字符串stroken的末尾{strtoken[j] = ch;j++;}void Scanner::retract() //置ch为空白字符,指针前移一字符位置{ch = ' ';i--;}int Scanner::reserve() //对stroken进行关键字表的查找,返回其编码值{int i, flag = 0;for(i=0; i<15; i++){if( strncmp(reservechar[i],strupr(strtoken), j) == 0 ){flag = 1;break;}}if(flag == 1) return i+1;else return 0;}int Scanner::insertid() //将stroken中的标识符插入符号表,返回在符号表中的位置{for(int a = 0; a < m; a++)for(int b = 0; b < x[a]; b++)if( strncmp(&id[a][0], strtoken, j) == 0 ){return m+1;break;}for(a = 0; a < j; a++)id[m][a] = strtoken[a];x[m] = j;m++;return m;}int Scanner::insertconst() //将stroken中的常数插入常数表,返回在常数表中的位置{for(int i = 0; i < j; i++)cst[n][i] = strtoken[i];y[n] = j;n++;return n;}void Scanner::scan(){while(i < length){j = 0;int code, value;strcpy(strtoken, " "); //置strtoken为空串getchar();getbc();if(isletter()) //如果打头的是字母{while(isletter() || isdigit()){concat();getchar();}retract();code = reserve();if(code == 0) //如果扫描到的是标识符{value = insertid();cout<<"<34,"<<value<<">"<<'\n';}else cout<<"<"<<code<<",*>"<<'\n'; //如果扫描到的是关键字}else if(isdigit()) //如果打头的是数字{while(isdigit()){concat();getchar();}retract();value = insertconst();cout<<"<33,"<<value<<">"<<'\n';}else if(ch == '+')cout<<"<16,*>"<<'\n';else if(ch == '-')cout<<"<17,*>"<<'\n';else if(ch == '*')cout<<"<18,*>"<<'\n';else if(ch == '/')cout<<"<19,*>"<<'\n';else if(ch == '=')cout<<"<20,*>"<<'\n';else if(ch == '<'){getchar();if(ch == '>')cout<<"<21,*>"<<'\n';else if(ch == '=')cout<<"<23,*>"<<'\n';else{retract();cout<<"<22,*>"<<'\n';}}else if(ch == '>'){getchar();if(ch == '=')cout<<"<25,*>"<<'\n';else{retract();cout<<"<24,*>"<<'\n';}}else if(ch == '.')cout<<"<26,*>"<<'\n';else if(ch == ',')cout<<"<27,*>"<<'\n';else if(ch == ';')cout<<"<28,*>"<<'\n';else if(ch == ':'){getchar();if(ch == '=')cout<<"<30,*>"<<'\n';else{retract();cout<<"<29,*>"<<'\n';}}else if(ch == '(')cout<<"<31,*>"<<'\n';else if(ch == ')')cout<<"<32,*>"<<'\n';else if(ch == '{'){while(ch != '}')getchar();}else cout<<"出错!"<<'\n';}}void main(void){fstream file;file.open("F:/20032320/20032320.txt", ios::in||ios::nocreate); //以只读方式打开file.unsetf(ios::skipws); //不跳过文本中的空格char buffer[100]; //缓冲区定义cout<<"扫描结果如下所示"<<'\n';while(file.getline(buffer, 100)){Scanner SS(buffer, strlen(buffer));SS.scan();}cout<<"标识符表如下:\n"<<"编号\t"<<"值\n";for(int i=0; i<m; i++){cout<<i+1<<'\t';for(int j=0; j<x[i]; j++)cout<<id[i][j];cout<<'\n';}cout<<"常数表如下:\n"<<"编号\t"<<"值\n";for(i=0; i<n; i++){cout<<i+1<<'\t';for(int j=0; j<y[i]; j++)cout<<cst[i][j];cout<<'\n';}}五.运行结果:程序的运行结果如下图所示:。
词法分析上机实习题

词法分析上机实习题对于如下文法所定义的PASCAL语言子集,试编写并上机调试一个词法分析程序:<程序>→PROGRAM <标识符>;<分程序>.<分程序>→<变量说明>BEGIN<语句表>END<变量说明>→V AR<变量表>:<类型>;| <空><变量表>→<变量表>,<变量> | <变量><类型>→INTEGER<语句表>→<语句表>;<语句> | <语句><语句>→<赋值语句> | <条件语句> | <WHILE语句> | <复合语句> | <过程定义> <赋值语句>→<变量>:=<算术表达式><条件语句>→IF<关系表达式>THEN<语句>ELSE<语句><WHILE语句>→WHILE<关系表达式>DO<语句><复合语句>→BEGIN<语句表>END<过程定义>→PROCEDURE<标识符><参数表>;BEGIN<语句表>END<参数表>→(<标识符表>)| <空><标识符表>→<标识符表>,<标识符> | <标识符><算术表达式>→<算术表达式>+<项> | <项><项>→<项>*<初等量> | <初等量><初等量>→(<算术表达式>)| <变量> | <无符号数><关系表达式>→<算术表达式><关系符><算术表达式><变量>→<标识符><标识符>→<标识符><字母> | <标识符><数学> | <字母><无符号数>→<无符号数><数字> | <数字><关系符>→= | < | <= | > | >= | <><字母>→A | B | C | ··· | X | Y | Z<数字>→0 | 1 | 2 | ··· | 8 | 9<空>→要求和提示:(1)单词的分类。
《编译原理》实验报告(用Java编写)

《编译原理》实验报告(用Java编写)学生姓名:学号:专业班级:实验类型:□验证□综合■设计□创新实验日期:实验成绩:实验1 词法分析程序的设计一、实验项目名称词法分析程序的设计二、实验目的掌握计算机语言的词法分析程序的开发方法。
三、实验基本原理编制一个能够分析三种整数、标识符、主要运算符和主要关键字的词法分析程序。
1、根据以下的正规式,编制正规文法,画出状态图;标识符<字母>(<字母>|<数字字符>)*十进制整数0 | ((1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)*)八进制整数0(1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)*十六进制整数0x(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)*运算符和界符+ - * / > < = ( ) ;关键字if then else while do2、根据状态图,设计词法分析函数int scan( ),完成以下功能:1)从文本文件中读入测试源代码,根据状态转换图,分析出一个单词,2)以二元式形式输出单词<单词种类,单词属性>其中单词种类用整数表示:0:标识符1:十进制整数2:八进制整数3:十六进制整数运算符和界符,关键字采用一字一符,不编码其中单词属性表示如下:标识符,整数由于采用一类一符,属性用单词表示运算符和界符,关键字采用一字一符,属性为空3、编写测试程序,反复调用函数scan( ),输出单词种别和属性。
四、主要仪器设备及耗材PC微机DOS操作系统或Windows 操作系统Turbo C 程序集成环境或Visual C++ 程序集成环境或Java五、实验步骤1、根据正规式,画出状态转换图;2、根据状态图,设计词法分析算法;3、采用C或C++语言,设计函数scan( ),实现该算法;4、编制测试程序(主函数main);5、调试程序:读入文本文件,检查输出结果。
计算机编译原理---词法分析器实验报告

编译原理实验报告书词法分析器目录1、摘要: (2)2、实验目的: (2)3、任务概述 (3)4、实验依据的原理 (3)5、程序设计思想 (5)6、实验结果分析 (7)7、总结 (9)1、摘要:本实验用C/C++高级语言编写词法分析程序,通过课堂上对词法分析器相关的背景知识的足够了解,清晰词法分析的过程,在脑海中形成词法分析的一般方案,根据方案一步步所要实现的目的,形成对词法分析器程序的模块划分和整体规划,最终实现一个词法分析器。
具体要求能够通过扫描源程序分析出单词符号,将相应字符流转换成内码。
2、实验目的:通过设计、调试词法分析程序,实现从源程序中分出各种单词的方法;熟悉词法分析程序所用的工具自动机,进一步理解自动机理论。
掌握文法转换成自动机的技术及有穷自动机实现的方法。
确定词法分析器的输出形式及标识符与关键字的区分方法。
加深对课堂教学的理解;提高词法分析方法的时间能力。
通过本实验,掌握从源程序文件中读取有效字符的方法和产生源程序的内部表示文件的方法以及掌握词法分析的实现方法,并可以成功的上机调试编出词法分析程序。
3、任务概述用C/C++实现对Pascal的子集程序设计语言的词法识别程序。
词法分析程序的主要工作为:(1)从源程序文件中读入字符。
(2)统计行数和列数用于错误单词的定位。
(3)删除空格类字符,包括回车、制表符空格。
(4)按拼写单词,并用(内码,属性)二元式表示。
(5)根据需要是否填写标识符表供以后各阶段使用。
4、实验依据的原理(1)词法分析器工作流程图图1 词法分析器工作流程图实现流程:从左至右逐个字符地对源程序进行扫描,产生一个个的单词符号,把作为字符串的源程序改造成为单词符号串的中间程序。
词法分析的功能是输入源程序,输出单词符号。
所依据的理论基础有有限自动机、正规式、正规文法。
(2)词法分析器的功能是输入源程序,输出单词符号,单词符号是一个程序语言的基本语法符号,一般分为五种:关键字、标识符、常数、运算符、界符五大类。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
import java.io.*;
public class WordAnalyse {
static char[] strbuf = new char[150];//定义一个数组,用以存放从文件读取来的字符串
int keywordIndex; //取关键字的类号
String[] keyWord = {"and","begin","const","div","do","else","end",
"function","if","integer","not","or","procedure","program",
"read","real","then","type","var","while","write"};
public static void main(String[] args) throws IOException {
WordAnalyse wa = new WordAnalyse();
wa.readFile("d:/pascal.txt");
System.out.println("******用JAVA实现的Pascal语言的词法分析器*********");
System.out.println("******The Result:******"+"\n");
wa.run();
System.out.println("\n"+"******Complete !******");
}
//从文件中把字符串读取到一个字符数组中
private void readFile(String url) throws IOException{
int ch,i=0;
FileReader fr = new FileReader(url);
while( (ch=fr.read())!=-1){
strbuf[i++]=(char)ch;
}
}
private boolean isLetter(char ch) {
if('a'<=ch&ch<='z'||'A'<=ch&ch<='Z')
return true;
else return false;
}
private boolean isDigit(char ch) {
if('0'<= ch&&ch<='9')
return true;
else return false;
}
private void run(){ //分析整个strbuf里的字符串
StringBuffer buf = new StringBuffer(); //定义一个缓冲区
for(int i=0; i<strbuf.length;i++){ //i既是循环变量,也是文件指针
//当读头读到space\enter\line的时候,忽略!
if(strbuf[i]==' '||strbuf[i]=='\t'||strbuf[i]=='\n')
i++;
if(isLetter(strbuf[i])) {
int k;
buf.delete(0, buf.length());
while(isLetter(strbuf[i])||isDigit(strbuf[i])) {
buf.append(strbuf[i]);
i++;
}
i--;
//查找buf里面的字符串是否为关键字
for(k =0; k<keyWord.length; k++){
if(new String(buf).equals(keyWord[k])){
keywordIndex = k;
System.out.println(buf + "\t\t" +keywordIndex);
break;
}
}
if(k>20)
System.out.println(buf + "\t\t" +21);
}
if(isDigit(strbuf[i])) { 1
buf.delete(0, buf.length());
while(isDigit(strbuf[i])){
buf.append(strbuf[i]);
i++;
}
i--;
System.out.println(buf + "\t\t" +22);
}
switch((char)strbuf[i]){
case',':System.out.println(strbuf[i] + "\t\t" + 23);break;
case';':System.out.println(strbuf[i] + "\t\t" + 24);break;
case'.':System.out.println(strbuf[i] + "\t\t" + 26);break;
case'(':System.out.println(strbuf[i] + "\t\t" + 27);break;
case')':System.out.println(strbuf[i] + "\t\t" + 28);break;
case'[':System.out.println(strbuf[i] + "\t\t" + 29);break;
case']':System.out.println(strbuf[i] + "\t\t" + 30);break;
case'+':System.out.println(strbuf[i] + "\t\t" + 34);break;
case'-':System.out.println(strbuf[i] + "\t\t" + 35);break;
case'=':System.out.println(strbuf[i] + "\t\t" + 38);break;
case':':{
buf.delete(0, buf.length());
buf.append(strbuf[i]);
i++;
if(strbuf[i]=='='){
buf.append(strbuf[i]);
System.out.println(buf + "\t\t" + 44);
} else{
System.out.println(buf + "\t\t" + 25); i++;
}
};break;
case'>':{
buf.delete(0, buf.length());
buf.append(strbuf[i]);
i++;
if(strbuf[i]=='='){
buf.append(strbuf[i]);
System.out.println(buf + "\t\t" + 43);
} else{
System.out.println(buf + "\t\t" + 40); i--;
}
};break;
case'<':{
buf.delete(0, buf.length());
buf.append(strbuf[i]);
i++;
if(strbuf[i]=='='){
buf.append(strbuf[i]);
System.out.println(buf + "\t\t" + 42); i++;
} else if(strbuf[i]=='>'){
buf.append(strbuf[i]);
System.out.println(buf + "\t\t" + 41); i++;
} else{
System.out.println(buf + "\t\t" + 39); i++;
}
};break;
}//switch结束
}
} 2 }。