深度优先搜索和广度优先搜索的深入讨论
深度优先搜索和广度优先搜索的深入讨论

一、深度优先搜索和广度优先搜索的深入讨论(一)深度优先搜索的特点是:(1)从上面几个实例看出,可以用深度优先搜索的方法处理的题目是各种各样的。
有的搜索深度是已知和固定的,如例題2-4, 2-5, 2-6;有的是未知的,如例题2-7、例题2-8;有的搜索深度是有限制的,但达到目标的深度是不定的。
但也看到,无论问题的内容和性质以及求解要求如何不同,它们的程序结构都是相同的, 即都是深度优先算法(一)和深度优先算法(二)中描述的算法结构,不相同的仅仅是存储结点数据结构和产生规则以及输出要求。
(2)深度优先搜索法有递归以及非递归两种设计方法。
一般的,当搜索深度较小、问题递归方式比较明显时,用递归方法设计好,它可以使得程序结构更简捷易懂。
当搜索深度较大时,如例题2-5、2-6。
当数据量较大时,由于系统堆栈容量的限制,递归容易产生溢出,用非递归方法设计比较好。
(3)深度优先搜索方法有广义和狭义两种理解。
广义的理解是,只要最新产生的结点(即深度最大的结点)先进行扩展的方法,就称为深度优先搜索方法。
在这种理解情况下,深度优先搜索算法有全部保留和不全部保留产生的结点的两种情况。
而狭义的理解是,仅仅只保留全部产生结点的算法。
本书取前一种广义的理解。
不保留全部结点的算法属于一般的回溯算法范畴。
保留全部结点的算法,实际上是在数掲库中产生一个结点之间的搜索树,因此也属于图搜索算法的范畴。
(4)不保留全部结点的深度优先搜索法,由于把扩展望的结点从数据库中弹出删除,这样,一般在数据库中存储的结点数就是深度值,因此它占用的空间较少,所以,当搜索树的结点较多,用其他方法易产生内存溢出时,深度优先搜索不失为一种有效的算法。
(5)从输出结果可看岀,深度优先搜索找到的第一个解并不一定是最优解。
例如例題2-8得最优解为13,但第一个解却是17。
如果要求出最优解的话,一种方法将是后面要介绍的动态规划法,另一种方法是修改原算法:把原输出过程的地方改为记录过程,即记录达到当前目标的路径和相应的路程值,并与前面已记录的值进行比较,保留其中最优的,等全部搜索完成后,才把保留的最优解输出。
深度优先算法和广度优先算法的时间复杂度

深度优先算法和广度优先算法的时间复杂度深度优先算法和广度优先算法是在图论中常见的两种搜索算法,它们在解决各种问题时都有很重要的作用。
本文将以深入浅出的方式从时间复杂度的角度对这两种算法进行全面评估,并探讨它们在实际应用中的优劣势。
1. 深度优先算法的时间复杂度深度优先算法是一种用于遍历或搜索树或图的算法。
它从图中的某个顶点出发,沿着一条路径一直走到底,直到不能再前进为止,然后回溯到上一个节点,尝试走其他的路径,直到所有路径都被走过为止。
深度优先算法的时间复杂度与图的深度有关。
在最坏情况下,深度优先算法的时间复杂度为O(V+E),其中V表示顶点的数量,E表示边的数量。
2. 广度优先算法的时间复杂度广度优先算法也是一种用于遍历或搜索树或图的算法。
与深度优先算法不同的是,广度优先算法是从图的某个顶点出发,首先访问这个顶点的所有邻接节点,然后再依次访问这些节点的邻接节点,依次类推。
广度优先算法的时间复杂度与图中边的数量有关。
在最坏情况下,广度优先算法的时间复杂度为O(V+E)。
3. 深度优先算法与广度优先算法的比较从时间复杂度的角度来看,深度优先算法和广度优先算法在最坏情况下都是O(V+E),并没有明显的差异。
但从实际运行情况来看,深度优先算法和广度优先算法的性能差异是显而易见的。
在一般情况下,广度优先算法要比深度优先算法快,因为广度优先算法的搜索速度更快,且能够更快地找到最短路径。
4. 个人观点和理解在实际应用中,选择深度优先算法还是广度优先算法取决于具体的问题。
如果要找到两个节点之间的最短路径,那么广度优先算法是更好的选择;而如果要搜索整个图,那么深度优先算法可能是更好的选择。
要根据具体的问题来选择合适的算法。
5. 总结和回顾本文从时间复杂度的角度对深度优先算法和广度优先算法进行了全面评估,探讨了它们的优劣势和实际应用中的选择。
通过对两种算法的时间复杂度进行比较,可以更全面、深刻和灵活地理解深度优先算法和广度优先算法的特点和适用场景。
深度优先算法和广度优先算法的时间复杂度

深度优先算法和广度优先算法都是图搜索中常见的算法,它们具有不同的特点和适用场景。
在进行全面评估之前,让我们先来了解一下深度优先算法和广度优先算法的基本概念和原理。
### 1. 深度优先算法(Depth-First Search, DFS)深度优先算法是一种用于遍历或搜索树或图的算法。
其核心思想是从起始顶点出发,沿着一条路径直到末端,然后回溯,继续搜索下一条路径,直到所有路径都被探索。
在实际应用中,深度优先算法常常通过递归或栈来实现。
### 2. 广度优先算法(Breadth-First Search, BFS)广度优先算法也是一种用于遍历或搜索树或图的算法。
其核心思想是从起始顶点出发,依次遍历该顶点的所有相邻顶点,然后再以这些相邻顶点作为起点,继续遍历它们的相邻顶点,以此类推,直到所有顶点都被遍历。
在实际应用中,广度优先算法通常通过队列来实现。
### 3. 深度优先算法和广度优先算法的时间复杂度在实际应用中,我们经常需要对算法的时间复杂度进行分析。
针对深度优先算法和广度优先算法,它们的时间复杂度并不相同。
- 深度优先算法的时间复杂度:O(V + E),其中V为顶点数,E为边数。
在最坏的情况下,如果采用邻接矩阵来表示图的话,深度优先算法的时间复杂度为O(V^2);如果采用邻接表来表示图的话,时间复杂度为O(V + E)。
- 广度优先算法的时间复杂度:O(V + E),其中V为顶点数,E为边数。
无论采用邻接矩阵还是邻接表表示图,广度优先算法的时间复杂度都是O(V + E)。
### 4. 个人理解和观点在实际应用中,我们在选择使用深度优先算法还是广度优先算法时,需要根据具体的问题场景来进行选择。
如果要寻找图中的一条路径,或者判断两个节点之间是否存在路径,通常会选择使用深度优先算法;如果要寻找最短路径或者进行层次遍历,通常会选择使用广度优先算法。
深度优先算法和广度优先算法都是非常重要的图搜索算法,它们各自适用于不同的场景,并且具有不同的时间复杂度。
深度优先搜索和广度优先搜索

二、 重排九宫问题游戏
在一个 3 乘 3 的九宫中有 1-8 的 8 个数及一个空格随机摆放在其中的格子里。如下面 左图所示。现在要求实现这样的问题:将该九宫调整为如下图右图所示的形式。调整规则是: 每次只能将与空格(上,下或左,右)相临的一个数字平移到空格中。试编程实现。
|2|8 |3|
|1|2|3|
from = f; to = t; distance = d; skip = false; } } class Depth { final int MAX = 100; // This array holds the flight information. FlightInfo flights[] = new FlightInfo[MAX]; int numFlights = 0; // number of entries in flight array Stack btStack = new Stack(); // backtrack stack public static void main(String args[]) {
下面是用深度优先搜索求解的程序:
// Find connections using a depth-first search. import java.util.*; import java.io.*; // Flight information. class FlightInfo {
String from; String to; int distance; boolean skip; // used in backtracking FlightInfo(String f, String t, int d) {
int dist; FlightInfo f; // See if at destination. dist = match(from, to); if(dist != 0) {
深度优先搜索和广度优先搜索

深度优先搜索和⼴度优先搜索 深度优先搜索和⼴度优先搜索都是图的遍历算法。
⼀、深度优先搜索(Depth First Search) 1、介绍 深度优先搜索(DFS),顾名思义,在进⾏遍历或者说搜索的时候,选择⼀个没有被搜过的结点(⼀般选择顶点),按照深度优先,⼀直往该结点的后续路径结点进⾏访问,直到该路径的最后⼀个结点,然后再从未被访问的邻结点进⾏深度优先搜索,重复以上过程,直⾄所有点都被访问,遍历结束。
⼀般步骤:(1)访问顶点v;(2)依次从v的未被访问的邻接点出发,对图进⾏深度优先遍历;直⾄图中和v有路径相通的顶点都被访问;(3)若此时图中尚有顶点未被访问,则从⼀个未被访问的顶点出发,重新进⾏深度优先遍历,直到图中所有顶点均被访问过为⽌。
可以看出,深度优先算法使⽤递归即可实现。
2、⽆向图的深度优先搜索 下⾯以⽆向图为例,进⾏深度优先搜索遍历: 遍历过程: 所以遍历结果是:A→C→B→D→F→G→E。
3、有向图的深度优先搜索 下⾯以有向图为例,进⾏深度优先遍历: 遍历过程: 所以遍历结果为:A→B→C→E→D→F→G。
⼆、⼴度优先搜索(Breadth First Search) 1、介绍 ⼴度优先搜索(BFS)是图的另⼀种遍历⽅式,与DFS相对,是以⼴度优先进⾏搜索。
简⾔之就是先访问图的顶点,然后⼴度优先访问其邻接点,然后再依次进⾏被访问点的邻接点,⼀层⼀层访问,直⾄访问完所有点,遍历结束。
2、⽆向图的⼴度优先搜索 下⾯是⽆向图的⼴度优先搜索过程: 所以遍历结果为:A→C→D→F→B→G→E。
3、有向图的⼴度优先搜索 下⾯是有向图的⼴度优先搜索过程: 所以遍历结果为:A→B→C→E→F→D→G。
三、两者实现⽅式对⽐ 深度优先搜索⽤栈(stack)来实现,整个过程可以想象成⼀个倒⽴的树形:把根节点压⼊栈中。
每次从栈中弹出⼀个元素,搜索所有在它下⼀级的元素,把这些元素压⼊栈中。
并把这个元素记为它下⼀级元素的前驱。
“八”数码问题的宽度优先搜索与深度优先搜索

“八”数码问题的宽度优先搜索与深度优先搜索我在观看视频和查看大学课本及网上搜索等资料才对“八”数码问题有了更进一步的了解和认识。
一、“八”数码问题的宽度优先搜索步骤如下:1、判断初始节点是否为目标节点,若初始节点是目标节点则搜索过程结束;若不是则转到第2步;2、由初始节点向第1层扩展,得到3个节点:2、3、4;得到一个节点即判断该节点是否为目标节点,若是则搜索过程结束;若2、3、4节点均不是目标节点则转到第3步;3、从第1层的第1个节点向第2层扩展,得到节点5;从第1层的第2个节点向第2层扩展,得到3个节点:6、7、8;从第1层的第3个节点向第2层扩展得到节点9;得到一个节点即判断该节点是否为目标节点,若是则搜索过程结束;若6、7、8、9节点均不是目标节点则转到第4步;4、按照上述方法对下一层的节点进行扩展,搜索目标节点;直至搜索到目标节点为止。
二、“八”数码问题的深度优先搜索步骤如下:1、设置深度界限,假设为5;2、判断初始节点是否为目标节点,若初始节点是目标节点则搜索过程结束;若不是则转到第2步;3、由初始节点向第1层扩展,得到节点2,判断节点2是否为目标节点;若是则搜索过程结束;若不是,则将节点2向第2层扩展,得到节点3;4、判断节点3是否为目标节点,若是则搜索过程结束;若不是则将节点3向第3层扩展,得到节点4;5、判断节点4是否为目标节点,若是则搜索过程结束;若不是则将节点4向第4层扩展,得到节点5;6、判断节点5是否为目标节点,若是则搜索过程结束;若不是则结束此轮搜索,返回到第2层,将节点3向第3层扩展得到节点6;7、判断节点6是否为目标节点,若是则搜索过程结束;若不是则将节点6向第4层扩展,得到节点7;8、判断节点7是否为目标节点,若是则结束搜索过程;若不是则将节点6向第4层扩展得到节点8;9、依次类推,知道得到目标节点为止。
三、上述两种搜索策略的比较在宽度优先搜索过程中,扩展到第26个节点时找到了目标节点;而在深度优先搜索过程中,扩展到第18个节点时得到了目标节点。
广度优先搜索(BFS)与深度优先搜索(DFS)的对比及优缺点

⼴度优先搜索(BFS)与深度优先搜索(DFS)的对⽐及优缺点 深搜,顾名思义,是深⼊其中、直取结果的⼀种搜索⽅法。
如果深搜是⼀个⼈,那么他的性格⼀定倔得像头⽜!他从⼀点出发去旅游,只朝着⼀个⽅向⾛,除⾮路断了,他绝不改变⽅向!除⾮四个⽅向全都不通或遇到终点,他绝不后退⼀步!因此,他的姐姐⼴搜总是嘲笑他,说他是个⼀根筋、不撞南墙不回头的家伙。
深搜很讨厌他姐姐的嘲笑,但⼜不想跟⾃⼰的亲姐姐闹⽭盾,于是他决定给姐姐讲述⾃⼰旅途中的经历,来改善姐姐对他的看法。
他成功了,⽽且只讲了⼀次。
从那以后他姐姐不仅再没有嘲笑过他,⽽且连看他的眼神都充满了赞赏。
他以为是⾃⼰路上的各种英勇征服了姐姐,但他不知道,其实另有原因…… 深搜是这样跟姐姐讲的:关于旅⾏呢,我并不把⽬的地的风光放在第⼀位,⽽是更注重于沿路的风景,所以我不会去追求最短路,⽽是把所有能通向终点的路都⾛⼀遍。
可是我并不知道往哪⾛能到达⽬的地,于是我只能每到⼀个地⽅,就向当地的⼈请教各个⽅向的道路情况。
为了避免重复向别⼈问同⼀个⽅向,我就给⾃⼰规定:先问北,如果有路,那就往北⾛,到达下⼀个地⽅的时候就在执⾏此规定,如果往北不通,我就再问西,其次是南、东,要是这四个⽅向都不通或者抵达了终点,那我回到上⼀个地⽅,继续探索其他没去过的⽅向。
我还要求⾃⼰要记住那些帮过他的⼈,但是那些给我帮倒忙的、让我⽩费⼒⽓的⼈,要忘记他们。
有了这些规定之后,我就可以⼤胆的往前⾛了,既不⽤担⼼到不了不⽬的地,也不⽤担⼼重复⾛以前的路。
哈哈哈……深搜优缺点优点1、能找出所有解决⽅案2、优先搜索⼀棵⼦树,然后是另⼀棵,所以和⼴搜对⽐,有着内存需要相对较少的优点缺点1、要多次遍历,搜索所有可能路径,标识做了之后还要取消。
2、在深度很⼤的情况下效率不⾼ ⼴搜,顾名思义,是多管齐下、⼴撒⽹的⼀种搜索⽅法 如果⼴搜是⼀个⼈,那么她⼀定很贪⼼,⽽且喜新厌旧!她从⼀点出发去旅游,先把与起点相邻的地⽅全部游览⼀遍,然后再把与她刚游览过的景点相邻的景点全都游览⼀边……⼀直这样,直⾄所有的景点都游览⼀遍。
广度优先搜索和深度优先搜索有何区别

广度优先搜索和深度优先搜索有何区别在计算机科学和算法领域中,广度优先搜索(BreadthFirst Search,简称 BFS)和深度优先搜索(DepthFirst Search,简称 DFS)是两种常见且重要的图或树的遍历算法。
它们在解决各种问题时都有着广泛的应用,但在搜索策略和特点上存在着显著的差异。
让我们先来了解一下广度优先搜索。
想象一下你正在一个迷宫中,你从入口开始,先探索与入口相邻的所有房间,然后再依次探索这些相邻房间相邻的房间,以此类推。
这就是广度优先搜索的基本思路。
广度优先搜索是以逐层的方式进行的。
它首先访问起始节点,然后依次访问起始节点的所有邻接节点,接着再访问这些邻接节点的邻接节点,就像在平静的湖面上泛起的层层涟漪。
这种搜索方式确保在访问更深层次的节点之前,先访问同一层次的所有节点。
在实现广度优先搜索时,通常会使用一个队列(Queue)数据结构。
将起始节点入队,然后循环取出队列头部的节点,并将其未访问过的邻接节点入队,直到队列为空。
这种方式保证了搜索的顺序是按照层次进行的。
广度优先搜索的一个重要应用是在寻找最短路径问题上。
因为它先访问距离起始节点近的节点,所以如果存在最短路径,它往往能够更快地找到。
例如,在地图导航中,要找到从一个地点到另一个地点的最短路线,广度优先搜索就可能是一个不错的选择。
接下来,我们看看深度优先搜索。
如果说广度优先搜索是逐层展开,那么深度优先搜索就像是一个勇敢的探险家,沿着一条路径一直走下去,直到走到尽头或者无法继续,然后才回溯并尝试其他路径。
深度优先搜索通过递归或者使用栈(Stack)来实现。
从起始节点开始,不断深入访问未访问过的邻接节点,直到无法继续,然后回溯到上一个未完全探索的节点,继续探索其他分支。
深度优先搜索在探索复杂的树形结构或者处理递归问题时非常有用。
比如在检查一个表达式是否合法、遍历一个复杂的文件目录结构等方面,深度优先搜索能够发挥其优势。
深度优先和广度优先比较

深度优先和⼴度优先⽐较区别:1)⼆叉树的深度优先遍历的⾮递归的通⽤做法是采⽤栈,⼴度优先遍历的⾮递归的通⽤做法是采⽤队列。
2)深度优先遍历:对每⼀个可能的分⽀路径深⼊到不能再深⼊为⽌,⽽且每个结点只能访问⼀次。
要特别注意的是,⼆叉树的深度优先遍历⽐较特殊,可以细分为先序遍历、中序遍历、后序遍历。
具体说明如下:先序遍历:对任⼀⼦树,先访问根,然后遍历其左⼦树,最后遍历其右⼦树。
中序遍历:对任⼀⼦树,先遍历其左⼦树,然后访问根,最后遍历其右⼦树。
后序遍历:对任⼀⼦树,先遍历其左⼦树,然后遍历其右⼦树,最后访问根。
⼴度优先遍历:⼜叫层次遍历,从上往下对每⼀层依次访问,在每⼀层中,从左往右(也可以从右往左)访问结点,访问完⼀层就进⼊下⼀层,直到没有结点可以访问为⽌。
3)深度优先搜素算法:不全部保留结点,占⽤空间少;有回溯操作(即有⼊栈、出栈操作),运⾏速度慢。
⼴度优先搜索算法:保留全部结点,占⽤空间⼤;⽆回溯操作(即⽆⼊栈、出栈操作),运⾏速度快。
通常深度优先搜索法不全部保留结点,扩展完的结点从数据库中弹出删去,这样,⼀般在数据库中存储的结点数就是深度值,因此它占⽤空间较少。
所以,当搜索树的结点较多,⽤其它⽅法易产⽣内存溢出时,深度优先搜索不失为⼀种有效的求解⽅法。
⼴度优先搜索算法,⼀般需存储产⽣的所有结点,占⽤的存储空间要⽐深度优先搜索⼤得多,因此,程序设计中,必须考虑溢出和节省内存空间的问题。
但⼴度优先搜索法⼀般⽆回溯操作,即⼊栈和出栈的操作,所以运⾏速度⽐深度优先搜索要快些深度优先:前序遍历:35,20,15,16,29,28,30,40,50,45,55中序遍历:15,16,20,28,29,30,35,40,45,50,55后序遍历:16,15,28,30,29,20,45,55,50,40,35⼴度优先遍历:35 20 40 15 29 50 16 28 30 45 55代码:package www.hhy;import java.beans.beancontext.BeanContextChild;import java.util.*;class Binarytree {class TreeNode{int value;TreeNode left;TreeNode right;public TreeNode(int value) {this.value = value;}}//⽤递归创建⼆叉树public int i = 0;TreeNode creatTesttree(String s){TreeNode root = null;if (s.charAt(i)!='#') {root = new TreeNode(s.charAt(i));i++;root.left = creatTesttree(s);root.right = creatTesttree(s);}else{i++;}return root;}//⼆叉树的前序遍历递归void binaryTreePrevOrder(TreeNode root){if(root==null){return;}System.out.println(root.value+" ");binaryTreePrevOrder(root.left);binaryTreePrevOrder(root.right);}//⼆叉树的中序遍历递归void binaryTreeInOrder(TreeNode root){if(root==null){return;}binaryTreeInOrder(root.left);System.out.println(root.value+" ");binaryTreeInOrder(root.right);}//⼆叉树的后续遍历递归void binaryTreePostOrder(TreeNode root){if(root==null){return;}binaryTreePostOrder(root.left);binaryTreePostOrder(root.right);System.out.println(root.value+" ");}//层序遍历void binaryTreeLevelOrder(TreeNode root,int level){if(root ==null||level<1){return;}if(level==1){System.out.print(root.value+" ");}binaryTreeLevelOrder(root.left,level-1);binaryTreeLevelOrder(root.right,level-1);}void BTreeLevelOrder(TreeNode root){if (root == null)return;int dep = getHeight(root);for (int i = 1; i <= dep; i++){binaryTreeLevelOrder(root,i);}}//⼆叉树的层序遍历⾮递归void binaryTreeLevelOrder(TreeNode root) {Queue<TreeNode> queue = new LinkedList<>();if(root != null) {queue.offer(root);//LinkedList offer add}while (!queue.isEmpty()) {//1、拿到队头的元素把队头元素的左右⼦树⼊队 TreeNode cur = queue.poll();System.out.print(cur.value+" ");//2、不为空的时候才能⼊队if(cur.left != null) {queue.offer(cur.left);}if(cur.right != null) {queue.offer(cur.right);}}}//⼆叉树的前序遍历⾮递归void binaryTreePrevOrderNonR(TreeNode root){Stack<TreeNode> stack = new Stack<>();TreeNode cur = root;TreeNode top = null;while (cur != null || !stack.empty()) {while (cur != null) {stack.push(cur);System.out.print(cur.value + " ");cur = cur.left;}top = stack.pop();cur = top.right;}System.out.println();}//⼆叉树的中序遍历⾮递归void binaryTreeInOrderNonR(TreeNode root){Stack<TreeNode> stack = new Stack<>();TreeNode cur = root;TreeNode top = null;while (cur != null || !stack.empty()) {while (cur != null) {stack.push(cur);cur = cur.left;}top = stack.pop();System.out.print(top.value+" ");cur = top.right;}System.out.println();}//⼆叉树的后序遍历⾮递归void binaryTreePostOrderNonR(TreeNode root) {Stack<TreeNode> stack = new Stack<>();TreeNode cur = root;TreeNode prev = null;while (cur != null || !stack.empty()) {while (cur != null) {stack.push(cur);cur = cur.left;}cur = stack.peek();//L D//cur.right == prev 代表的是 cur的右边已经打印过了if(cur.right == null || cur.right == prev) {stack.pop();System.out.println(cur.value);prev = cur;cur = null;}else {cur = cur.right;}}}//⼆叉树的节点个数递归int getSize(TreeNode root){if(root==null){return 0;}return getSize(root.left)+getSize(root.right)+1;}//⼆叉树的叶⼦节点的个数递归int getLeafSize(TreeNode root){if(root==null){return 0;}if(root.left==null && root.right==null){return 1;}return getLeafSize(root.left)+getLeafSize(root.right); }//⼆叉树得到第K层结点的个数int getKlevelSize(TreeNode root ,int k){if(root==null){return 0;}if(k == 1){return 1;}return getKlevelSize(root.left,k-1)+getKlevelSize(root.right,k-1);}//⼆叉树查找并返回该结点递归// 查找,依次在⼆叉树的根、左⼦树、// 右⼦树中查找 value,如果找到,返回结点,否则返回 nullTreeNode find(TreeNode root, int value){if(root == null) {return null;}if(root.value == value){return root;}TreeNode ret = find(root.left,value);if(ret != null) {return ret;}ret = find(root.right,value);if(ret != null) {return ret;}return null;}//⼆叉树的⾼度int getHeight(TreeNode root){if(root==null){return 0;}int leftHeight = getHeight(root.left);int rightHeight = getHeight(root.right);return leftHeight>rightHeight ? leftHeight+1:rightHeight+1;}//判断⼀个树是不是完全⼆叉树public int binaryTreeComplete(TreeNode root) {Queue<TreeNode> queue = new LinkedList<TreeNode>();if(root != null) {queue.add(root);//offer}while(!queue.isEmpty()) {TreeNode cur = queue.peek();queue.poll();if(cur != null) {queue.add(cur.left);queue.add(cur.right);}else {break;}}while(!queue.isEmpty()) {TreeNode cur = queue.peek();if (cur != null){//说明不是满⼆叉树return -1;}else{queue.poll();}}return 0;//代表是完全⼆叉树}//检查两棵树是否是相同的,如果两棵树结构相同,并且在结点上的值相同,那么这两棵树是相同返回true public boolean isSameTree(TreeNode p,TreeNode q){if((p==null&&q!=null)||(p!=null&&q==null)){}if(p==null && q==null){return true;}if(p.value!=q.value){return false;}return isSameTree(p.left,q.left)&&isSameTree(p.right,q.left);}//检查是否为⼦树public boolean isSubTree(TreeNode s,TreeNode t){if(s==null||t==null){return false;}if(isSameTree(s,t)){return true;}else if (isSubTree(s.left,t)){return true;}else if(isSubTree(s.right,t)){return true;}else{return false;}}//1.判断是否为平衡⼆叉树,左右⼦树的⾼度之差不超过 "1"(⼤根本⾝是平衡⼆叉树,左右⼦树也必须是平衡⼆叉树) // 时间复杂度为n^2//2.求复杂度为O(n)的解法public boolean isBanlanced(TreeNode root){if(root==null){return true;}else{int leftHeight = getHeight(root.left);int rightHeight = getHeight(root.right);return Math.abs(leftHeight-rightHeight)<2&&isBanlanced(root.left)&&isBanlanced(root.right);}}//判断是否为对称⼆叉树public boolean isSymmetric(TreeNode root){if(root==null){return true;}return isSymmetric(root.left,root.right);}public boolean isSymmetric(TreeNode lefttree,TreeNode righttree){if((lefttree==null && righttree!=null)||(lefttree!=null && righttree ==null)){return false;}if(lefttree == null && righttree == null){return true;}return lefttree.value == righttree.value && isSymmetric(lefttree.left,righttree.right)&& isSymmetric(lefttree.right,righttree.left);}//⼆叉树创建字符串⾮递归写法public String tree2str(TreeNode t){StringBuilder sb = new StringBuilder();tree2strchild(t,sb);return sb.toString();}public void tree2strchild(TreeNode t ,StringBuilder sb){if (t==null){}sb.append(t.value);if (t.left!=null){sb.append("(");tree2strchild(t.left,sb);sb.append(")");}else {if (t.right==null){}}}//⼆叉树字符串递归写法public String CreateStr(TreeNode t){if(t==null){return "";}if(t.left==null&&t.right==null){return t.value+"";}if(t.left==null){return t.value+"()"+"("+CreateStr(t.right)+")";}if(t.right==null){return t.value+"("+CreateStr(t.left)+")";}return t.value+"("+CreateStr(t.left)+")"+"("+CreateStr(t.right)+")";}public int rob(TreeNode root) {if (root == null) return 0;return Math.max(robOK(root), robNG(root));}private int robOK(TreeNode root) {if (root == null) return 0;return root.value + robNG(root.left) + robNG(root.right);}private int robNG(TreeNode root) {if (root == null) return 0;return rob(root.left) + rob(root.right);}//⼆叉树的公共祖先public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { if(root==null){return null;}if(root==p||root==q){return root;}TreeNode leftTree = lowestCommonAncestor(root.left,p,q);//p||q nullTreeNode rightTree = lowestCommonAncestor(root.right,p,q);//p||q null//3if(leftTree!=null && rightTree!=null){return root;}//左边找到else if (leftTree!=null ){return leftTree;}//右边找到else if(rightTree!=null){return rightTree;}//都没找到的情况下return null;}//⼆叉搜索树,若他的左⼦树不为空,左⼦树上的所有节点都⼩于根节点,//如果他的右⼦树不为空,右⼦树上的所有节点都⼤于根节点//最终他的中序排列都是有序结果//输⼊⼀棵⼆叉搜索树,将该⼆叉搜索树转换成⼀个排序的双向链表。
浅析深度优先和广度优先遍历实现过程、区别及使用场景

浅析深度优先和⼴度优先遍历实现过程、区别及使⽤场景⼀、什么是深度/⼴度优先遍历? 深度优先遍历简称DFS(Depth First Search),⼴度优先遍历简称BFS(Breadth First Search),它们是遍历图当中所有顶点的两种⽅式。
这两种遍历⽅式有什么不同呢?我们来举个栗⼦: 我们来到⼀个游乐场,游乐场⾥有11个景点。
我们从景点0开始,要玩遍游乐场的所有景点,可以有什么样的游玩次序呢?1、深度优先遍历 第⼀种是⼀头扎到底的玩法。
我们选择⼀条⽀路,尽可能不断地深⼊,如果遇到死路就往回退,回退过程中如果遇到没探索过的⽀路,就进⼊该⽀路继续深⼊。
在图中,我们⾸先选择景点1的这条路,继续深⼊到景点7、景点8,终于发现⾛不动了: 于是,我们退回到景点7,然后探索景点10,⼜⾛到了死胡同。
于是,退回到景点1,探索景点9: 按照这个思路,我们再退回到景点0,后续依次探索景点2、3、5、4、发现相邻的都玩过了,再回退到3,再接着玩6,终于玩遍了整个游乐场: 具体次序如下图,景点旁边的数字代表探索次序。
当然还可以有别的排法。
像这样先深⼊探索,⾛到头再回退寻找其他出路的遍历⽅式,就叫做深度优先遍历(DFS)。
这⽅式看起来很像⼆叉树的前序遍历。
没错,其实⼆叉树的前序、中序、后序遍历,本质上也可以认为是深度优先遍历。
2、⼴度优先遍历 除了像深度优先遍历这样⼀头扎到底的玩法以外,我们还有另⼀种玩法:⾸先把起点相邻的⼏个景点玩遍,然后去玩距离起点稍远⼀些(隔⼀层)的景点,然后再去玩距离起点更远⼀些(隔两层)的景点… 在图中,我们⾸先探索景点0的相邻景点1、2、3、4: 接着,我们探索与景点0相隔⼀层的景点7、9、5、6: 最后,我们探索与景点0相隔两层的景点8、10: 像这样⼀层⼀层由内⽽外的遍历⽅式,就叫做⼴度优先遍历(BFS)。
这⽅式看起来很像⼆叉树的层序遍历。
没错,其实⼆叉树的层序遍历,本质上也可以认为是⼴度优先遍历。
深度优先和广度优先算法

深度优先和广度优先算法深度优先和广度优先算法深度优先遍历和广度优先遍历是两种常用的图遍历算法。
它们的策略不同,各有优缺点,可以在不同的场景中使用。
一、深度优先遍历深度优先遍历(Depth First Search,DFS)是一种搜索算法,它从一个顶点开始遍历,尽可能深地搜索图中的每一个可能的路径,直到找到所有的路径。
该算法使用栈来实现。
1. 算法描述深度优先遍历的过程可以描述为:- 访问起始顶点v,并标记为已访问; - 从v的未被访问的邻接顶点开始深度优先遍历,直到所有的邻接顶点都被访问过或不存在未访问的邻接顶点; - 如果图中还有未被访问的顶点,则从这些顶点中任选一个,重复步骤1。
2. 算法实现深度优先遍历算法可以使用递归或者栈来实现。
以下是使用栈实现深度优先遍历的示例代码:``` void DFS(Graph g, int v, bool[] visited) { visited[v] = true; printf("%d ", v);for (int w : g.adj(v)) { if(!visited[w]) { DFS(g, w,visited); } } } ```3. 算法分析深度优先遍历的时间复杂度为O(V+E),其中V是顶点数,E是边数。
由于该算法使用栈来实现,因此空间复杂度为O(V)。
二、广度优先遍历广度优先遍历(Breadth First Search,BFS)是一种搜索算法,它从一个顶点开始遍历,逐步扩展到它的邻接顶点,直到找到所有的路径。
该算法使用队列来实现。
1. 算法描述广度优先遍历的过程可以描述为:- 访问起始顶点v,并标记为已访问; - 将v的所有未被访问的邻接顶点加入队列中; - 从队列头取出一个顶点w,并标记为已访问; - 将w的所有未被访问的邻接顶点加入队列中; - 如果队列不为空,则重复步骤3。
2. 算法实现广度优先遍历算法可以使用队列来实现。
深度优先算法与广度优先算法的比较

深度优先算法与广度优先算法的比较深度优先算法以深度为优先,从一个节点开始,逐个遍历其邻居节点直至最深处,然后回溯到上一个节点,再继续遍历其他分支。
它是通过栈来实现的,先进后出的特性决定了深度优先算法是一个递归算法。
深度优先算法在过程中,不需要记住所有的路径,只需要记住当前路径上的节点即可。
对于树而言,深度优先算法通常沿着左子树一直深入,直到最深的叶节点,然后再回溯到前一个节点继续右子树的遍历。
广度优先算法以广度为优先,从一个节点开始,逐层遍历其所有邻居节点,然后再遍历下一层的节点,直至遍历完所有节点。
它是通过队列来实现的,先进先出的特性决定了广度优先算法是一个非递归算法。
广度优先算法在过程中,需要记住每一层的节点,并且按照先进先出的顺序进行遍历。
对于树而言,广度优先算法会先遍历根节点,然后是根节点的子节点,再然后是子节点的子节点,按照层次逐层遍历。
以下是深度优先算法和广度优先算法的比较:1.方式:深度优先算法通过一条路径一直遍历到最深处,然后回溯到上一个节点,再继续遍历其他分支。
广度优先算法逐层遍历,先遍历当前层的节点,再遍历下一层的节点。
2.存储结构:深度优先算法使用栈进行遍历,而广度优先算法使用队列进行遍历。
3.内存占用:深度优先算法只需要记住当前路径上的节点,所以内存占用较小。
而广度优先算法需要记住每一层的节点,所以内存占用较大。
4.时间效率:深度优先算法通常适用于解决单个解或路径的问题,因为它首先深入其中一个分支,整个分支再回溯,因此它可能会浪费一些时间在不必要的路径上。
而广度优先算法通常适用于解决最短路径或最小步数的问题,因为它遍历一层后再遍历下一层,所以找到的解很可能是最优解。
5.应用场景:深度优先算法适用于解决迷宫问题、拓扑排序和连通性等问题。
广度优先算法适用于解决最短路径、社交网络中的人际关系、图的遍历和等问题。
总结起来,深度优先算法和广度优先算法都有各自的特点和适用场景。
深度优先算法适合解决单个解或路径的问题,而广度优先算法适合解决最短路径或最小步数的问题。
深度优先搜索和广度优先搜索的区别

深度优先搜索和⼴度优先搜索的区别1、深度优先算法占内存少但速度较慢,⼴度优先算法占内存多但速度较快,在距离和深度成正⽐的情况下能较快地求出最优解。
2、深度优先与⼴度优先的控制结构和产⽣系统很相似,唯⼀的区别在于对扩展节点选取上。
由于其保留了所有的前继节点,所以在产⽣后继节点时可以去掉⼀部分重复的节点,从⽽提⾼了搜索效率。
3、这两种算法每次都扩展⼀个节点的所有⼦节点,⽽不同的是,深度优先下⼀次扩展的是本次扩展出来的⼦节点中的⼀个,⽽⼴度优先扩展的则是本次扩展的节点的兄弟点。
在具体实现上为了提⾼效率,所以采⽤了不同的数据结构。
4、深度优先搜索的基本思想:任意选择图G的⼀个顶点v0作为根,通过相继地添加边来形成在顶点v0开始的路,其中每条新边都与路上的最后⼀个顶点以及不在路上的⼀个顶点相关联。
继续尽可能多地添加边到这条路。
若这条路经过图G的所有顶点,则这条路即为G的⼀棵⽣成树;若这条路没有经过G的所有顶点,不妨设形成这条路的顶点顺序v0,v1,......,vn。
则返回到路⾥的次最后顶点v(n-1).若有可能,则形成在顶点v(n-1)开始的经过的还没有放过的顶点的路;否则,返回到路⾥的顶点v(n-2)。
然后再试。
重复这个过程,在所访问过的最后⼀个顶点开始,在路上次返回的顶点,只要有可能就形成新的路,知道不能添加更多的边为⽌。
5、⼴度优先搜索的基本思想:从图的顶点中任意第选择⼀个根,然后添加与这个顶点相关联的所有边,在这个阶段添加的新顶点成为⽣成树⾥1层上的顶点,任意地排序它们。
下⼀步,按照顺序访问1层上的每⼀个顶点,只要不产⽣回路,就添加与这个顶点相关联的每个边。
这样就产⽣了树⾥2的上的顶点。
遵循同样的原则继续下去,经有限步骤就产⽣了⽣成树。
广度优先和深度优先算法

广度优先和深度优先算法
广度优先算法和深度优先算法是常见的图遍历算法。
广度优先算法又称为宽度优先搜索,它从起点开始,逐层遍历图,直到找到目标节点为止。
在遍历过程中,每一层的节点按照从左到右的顺序依次被访问,因此也称为层次遍历。
广度优先算法通常借助队列来实现。
深度优先算法则是从起点开始,沿着一条路径一直走到底,直到不能再走为止,然后回退到上一个节点,继续探索下一条路径。
深度优先算法采用栈结构实现,因为需要回溯,所以每次访问完一个节点后,需要将该节点从栈中弹出。
广度优先算法和深度优先算法各有优缺点。
广度优先算法能够保证找到的解一定是最优解,但在搜索深度较大的图时,需要维护大量的节点,因此空间复杂度较高。
而深度优先算法则不需要维护过多的节点,但不能保证找到的解一定是最优解。
在选择算法时,需要根据实际情况进行权衡。
- 1 -。
深度优先搜索和广度优先搜索

深度优先搜索和广度优先搜索深度优先搜索(DFS)和广度优先搜索(BFS)是图论中常用的两种搜索算法。
它们是解决许多与图相关的问题的重要工具。
本文将着重介绍深度优先搜索和广度优先搜索的原理、应用场景以及优缺点。
一、深度优先搜索(DFS)深度优先搜索是一种先序遍历二叉树的思想。
从图的一个顶点出发,递归地访问与该顶点相邻的顶点,直到无法再继续前进为止,然后回溯到前一个顶点,继续访问其未被访问的邻接顶点,直到遍历完整个图。
深度优先搜索的基本思想可用以下步骤总结:1. 选择一个初始顶点;2. 访问该顶点,并标记为已访问;3. 递归访问该顶点的邻接顶点,直到所有邻接顶点均被访问过。
深度优先搜索的应用场景较为广泛。
在寻找连通分量、解决迷宫问题、查找拓扑排序等问题中,深度优先搜索都能够发挥重要作用。
它的主要优点是容易实现,缺点是可能进入无限循环。
二、广度优先搜索(BFS)广度优先搜索是一种逐层访问的思想。
从图的一个顶点出发,先访问该顶点,然后依次访问与该顶点邻接且未被访问的顶点,直到遍历完整个图。
广度优先搜索的基本思想可用以下步骤总结:1. 选择一个初始顶点;2. 访问该顶点,并标记为已访问;3. 将该顶点的所有邻接顶点加入一个队列;4. 从队列中依次取出一个顶点,并访问该顶点的邻接顶点,标记为已访问;5. 重复步骤4,直到队列为空。
广度优先搜索的应用场景也非常广泛。
在求最短路径、社交网络分析、网络爬虫等方面都可以使用广度优先搜索算法。
它的主要优点是可以找到最短路径,缺点是需要使用队列数据结构。
三、DFS与BFS的比较深度优先搜索和广度优先搜索各自有着不同的优缺点,适用于不同的场景。
深度优先搜索的优点是在空间复杂度较低的情况下找到解,但可能陷入无限循环,搜索路径不一定是最短的。
广度优先搜索能找到最短路径,但需要保存所有搜索过的节点,空间复杂度较高。
需要根据实际问题选择合适的搜索算法,例如在求最短路径问题中,广度优先搜索更加合适;而在解决连通分量问题时,深度优先搜索更为适用。
深度优先遍历算法和广度优先遍历算法实验小结

深度优先遍历算法和广度优先遍历算法实验小结一、引言在计算机科学领域,图的遍历是一种基本的算法操作。
深度优先遍历算法(Depth First Search,DFS)和广度优先遍历算法(Breadth First Search,BFS)是两种常用的图遍历算法。
它们在解决图的连通性和可达性等问题上具有重要的应用价值。
本文将从理论基础、算法原理、实验设计和实验结果等方面对深度优先遍历算法和广度优先遍历算法进行实验小结。
二、深度优先遍历算法深度优先遍历算法是一种用于遍历或搜索树或图的算法。
该算法从图的某个顶点开始遍历,沿着一条路径一直向前直到不能再继续前进为止,然后退回到上一个节点,尝试下一个节点,直到遍历完整个图。
深度优先遍历算法通常使用栈来实现。
以下是深度优先遍历算法的伪代码:1. 创建一个栈并将起始节点压入栈中2. 将起始节点标记为已访问3. 当栈不为空时,执行以下步骤:a. 弹出栈顶节点,并访问该节点b. 将该节点尚未访问的邻居节点压入栈中,并标记为已访问4. 重复步骤3,直到栈为空三、广度优先遍历算法广度优先遍历算法是一种用于遍历或搜索树或图的算法。
该算法从图的某个顶点开始遍历,先访问起始节点的所有相邻节点,然后再依次访问这些相邻节点的相邻节点,依次类推,直到遍历完整个图。
广度优先遍历算法通常使用队列来实现。
以下是广度优先遍历算法的伪代码:1. 创建一个队列并将起始节点入队2. 将起始节点标记为已访问3. 当队列不为空时,执行以下步骤:a. 出队一个节点,并访问该节点b. 将该节点尚未访问的邻居节点入队,并标记为已访问4. 重复步骤3,直到队列为空四、实验设计本次实验旨在通过编程实现深度优先遍历算法和广度优先遍历算法,并通过对比它们在不同图结构下的遍历效果,验证其算法的正确性和有效性。
具体实验设计如下:1. 实验工具:使用Python编程语言实现深度优先遍历算法和广度优先遍历算法2. 实验数据:设计多组图结构数据,包括树、稠密图、稀疏图等3. 实验环境:在相同的硬件环境下运行实验程序,确保实验结果的可比性4. 实验步骤:编写程序实现深度优先遍历算法和广度优先遍历算法,进行多次实验并记录实验结果5. 实验指标:记录每种算法的遍历路径、遍历时间和空间复杂度等指标,进行对比分析五、实验结果在不同图结构下,经过多次实验,分别记录了深度优先遍历算法和广度优先遍历算法的实验结果。
数据结构与算法(13):深度优先搜索和广度优先搜索
2.2.2 有向图的广广度优先搜索
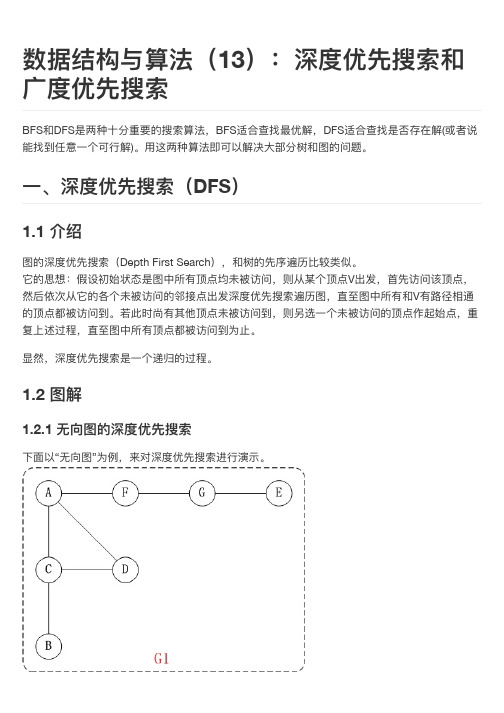
下面面以“有向图”为例例,来对广广度优先搜索进行行行演示。还是以上面面的图G2为例例进行行行说明。
第1步:访问A。 第2步:访问B。 第3步:依次访问C,E,F。 在访问了了B之后,接下来访问B的出边的另一一个顶点,即C,E,F。前 面面已经说过,在本文文实现中,顶点ABCDEFG按照顺序存储的,因此会先访问C,再依次访 问E,F。 第4步:依次访问D,G。 在访问完C,E,F之后,再依次访问它们的出边的另一一个顶点。还是按 照C,E,F的顺序访问,C的已经全部访问过了了,那么就只剩下E,F;先访问E的邻接点D,再访 问F的邻接点G。
if(mVexs[i]==ch)
return i;
return -1;
}
/* * 读取一一个输入入字符
*/
private char readChar() {
char ch='0';
do {
try {
ch = (char)System.in.read();
} catch (IOException e) {
数据结构与算法(13):深度优先搜索和 广广度优先搜索
BFS和DFS是两种十十分重要的搜索算法,BFS适合查找最优解,DFS适合查找是否存在解(或者说 能找到任意一一个可行行行解)。用用这两种算法即可以解决大大部分树和图的问题。
一一、深度优先搜索(DFS)
1.1 介绍
图的深度优先搜索(Depth First Search),和树的先序遍历比比较类似。 它的思想:假设初始状态是图中所有顶点均未被访问,则从某个顶点V出发,首首先访问该顶点, 然后依次从它的各个未被访问的邻接点出发深度优先搜索遍历图,直至至图中所有和V有路路径相通 的顶点都被访问到。若此时尚有其他顶点未被访问到,则另选一一个未被访问的顶点作起始点,重 复上述过程,直至至图中所有顶点都被访问到为止止。 显然,深度优先搜索是一一个递归的过程。
深度优先算法与广度优先算法

深度优先算法与⼴度优先算法深度优先搜索和⼴度优先搜索,都是图形搜索算法,它两相似,⼜却不同,在应⽤上也被⽤到不同的地⽅。
这⾥拿⼀起讨论,⽅便⽐较。
⼀、深度优先搜索深度优先搜索属于图算法的⼀种,是⼀个针对图和树的遍历算法,英⽂缩写为DFS即Depth First Search。
深度优先搜索是图论中的经典算法,利⽤深度优先搜索算法可以产⽣⽬标图的相应拓扑排序表,利⽤拓扑排序表可以⽅便的解决很多相关的图论问题,如最⼤路径问题等等。
⼀般⽤堆数据结构来辅助实现DFS算法。
其过程简要来说是对每⼀个可能的分⽀路径深⼊到不能再深⼊为⽌,⽽且每个节点只能访问⼀次。
基本步奏(1)对于下⾯的树⽽⾔,DFS⽅法⾸先从根节点1开始,其搜索节点顺序是1,2,3,4,5,6,7,8(假定左分枝和右分枝中优先选择左分枝)。
(2)从stack中访问栈顶的点;(3)找出与此点邻接的且尚未遍历的点,进⾏标记,然后放⼊stack中,依次进⾏;(4)如果此点没有尚未遍历的邻接点,则将此点从stack中弹出,再按照(3)依次进⾏;(5)直到遍历完整个树,stack⾥的元素都将弹出,最后栈为空,DFS遍历完成。
⼆、⼴度优先搜索⼴度优先搜索(也称宽度优先搜索,缩写BFS,以下采⽤⼴度来描述)是连通图的⼀种遍历算法这⼀算法也是很多重要的图的算法的原型。
Dijkstra单源最短路径算法和Prim最⼩⽣成树算法都采⽤了和宽度优先搜索类似的思想。
其别名⼜叫BFS,属于⼀种盲⽬搜寻法,⽬的是系统地展开并检查图中的所有节点,以找寻结果。
换句话说,它并不考虑结果的可能位置,彻底地搜索整张图,直到找到结果为⽌。
基本过程,BFS是从根节点开始,沿着树(图)的宽度遍历树(图)的节点。
如果所有节点均被访问,则算法中⽌。
⼀般⽤队列数据结构来辅助实现BFS算法。
基本步奏(1)给出⼀连通图,如图,初始化全是⽩⾊(未访问);(2)搜索起点V1(灰⾊);(3)已搜索V1(⿊⾊),即将搜索V2,V3,V4(标灰);(4)对V2,V3,V4重复以上操作;(5)直到终点V7被染灰,终⽌;(6)最短路径为V1,V4,V7.作者:安然若知链接:https:///p/bff70b786bb6来源:简书简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
深度优先搜索和广度优先搜索的比较和应用场景

深度优先搜索和广度优先搜索的比较和应用场景在计算机科学中,深度优先搜索(DFS)和广度优先搜索(BFS)是两种常用的图搜索算法。
它们在解决许多问题时都能够发挥重要作用,但在不同的情况下具有不同的优势和适用性。
本文将对深度优先搜索和广度优先搜索进行比较和分析,并讨论它们在不同应用场景中的使用。
一、深度优先搜索(DFS)深度优先搜索是一种通过遍历图的深度节点来查找目标节点的算法。
它的基本思想是从起始节点开始,依次遍历该节点的相邻节点,直到到达目标节点或者无法继续搜索为止。
如果当前节点有未被访问的相邻节点,则选择其中一个作为下一个节点继续进行深度搜索;如果当前节点没有未被访问的相邻节点,则回溯到上一个节点,并选择其未被访问的相邻节点进行搜索。
深度优先搜索的主要优势是其在搜索树的深度方向上进行,能够快速达到目标节点。
它通常使用递归或栈数据结构来实现,代码实现相对简单。
深度优先搜索适用于以下情况:1. 图中的路径问题:深度优先搜索能够在图中找到一条路径是否存在。
2. 拓扑排序问题:深度优先搜索能够对有向无环图进行拓扑排序,找到图中节点的一个线性排序。
3. 连通性问题:深度优先搜索能够判断图中的连通分量数量以及它们的具体节点组合。
二、广度优先搜索(BFS)广度优先搜索是一种通过遍历图的广度节点来查找目标节点的算法。
它的基本思想是从起始节点开始,先遍历起始节点的所有相邻节点,然后再遍历相邻节点的相邻节点,以此类推,直到到达目标节点或者无法继续搜索为止。
广度优先搜索通常使用队列数据结构来实现。
广度优先搜索的主要优势是其在搜索树的广度方向上进行,能够逐层地搜索目标节点所在的路径。
它逐层扩展搜索,直到找到目标节点或者遍历完整个图。
广度优先搜索适用于以下情况:1. 最短路径问题:广度优先搜索能够在无权图中找到起始节点到目标节点的最短路径。
2. 网络分析问题:广度优先搜索能够在图中查找节点的邻居节点、度数或者群组。
三、深度优先搜索和广度优先搜索的比较深度优先搜索和广度优先搜索在以下方面有所不同:1. 搜索顺序:深度优先搜索按照深度优先的顺序进行搜索,而广度优先搜索按照广度优先的顺序进行搜索。
数据结构之的遍历深度优先搜索和广度优先搜索的实现和应用

数据结构之的遍历深度优先搜索和广度优先搜索的实现和应用深度优先搜索和广度优先搜索是数据结构中重要的遍历算法,它们在解决各种问题时起着关键作用。
本文将介绍深度优先搜索和广度优先搜索的实现方法以及它们的应用。
一、深度优先搜索的实现和应用深度优先搜索(Depth First Search,DFS)是一种用于图或树的遍历算法。
它的基本思想是从起始节点开始,一直沿着某一分支深入直到不能再深入为止,然后回溯到前一个节点,再沿另一分支深入,直到遍历完所有节点。
深度优先搜索可以通过递归或者栈来实现。
在实现深度优先搜索时,可以采用递归的方式。
具体的实现步骤如下:1. 创建一个访问数组,用于标记节点是否已经被访问过。
2. 从起始节点开始,将其标记为已访问。
3. 遍历当前节点的邻接节点,对于每个邻接节点,如果该节点未被访问过,则递归调用深度优先搜索函数。
4. 重复步骤3,直到所有节点都被访问过。
深度优先搜索的应用非常广泛,以下是几个常见的应用场景:1. 图的连通性判断:深度优先搜索可以用于判断图中的两个节点是否连通。
2. 拓扑排序:深度优先搜索可以用于对有向无环图进行拓扑排序,即按照一种特定的线性顺序对节点进行排序。
3. 岛屿数量计算:深度优先搜索可以用于计算给定矩阵中岛屿的数量,其中岛屿由相邻的陆地单元组成。
二、广度优先搜索的实现和应用广度优先搜索(Breadth First Search,BFS)是一种用于图或树的遍历算法。
它的基本思想是从起始节点开始,逐层遍历,先访问当前节点的所有邻接节点,然后再依次访问下一层的节点,直到遍历完所有节点。
广度优先搜索可以通过队列来实现。
在实现广度优先搜索时,可以采用队列的方式。
具体的实现步骤如下:1. 创建一个访问数组,用于标记节点是否已经被访问过。
2. 创建一个空队列,并将起始节点入队。
3. 当队列不为空时,取出队首节点,并标记为已访问。
4. 遍历当前节点的邻接节点,对于每个邻接节点,如果该节点未被访问过,则将其入队。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、深度优先搜索和广度优先搜索的深入讨论(一)深度优先搜索的特点是:(1)从上面几个实例看出,可以用深度优先搜索的方法处理的题目是各种各样的。
有的搜索深度是已知和固定的,如例题2-4,2-5,2-6;有的是未知的,如例题2-7、例题2-8;有的搜索深度是有限制的,但达到目标的深度是不定的。
但也看到,无论问题的内容和性质以及求解要求如何不同,它们的程序结构都是相同的,即都是深度优先算法(一)和深度优先算法(二)中描述的算法结构,不相同的仅仅是存储结点数据结构和产生规则以及输出要求。
(2)深度优先搜索法有递归以及非递归两种设计方法。
一般的,当搜索深度较小、问题递归方式比较明显时,用递归方法设计好,它可以使得程序结构更简捷易懂。
当搜索深度较大时,如例题2-5、2-6。
当数据量较大时,由于系统堆栈容量的限制,递归容易产生溢出,用非递归方法设计比较好。
(3)深度优先搜索方法有广义和狭义两种理解。
广义的理解是,只要最新产生的结点(即深度最大的结点)先进行扩展的方法,就称为深度优先搜索方法。
在这种理解情况下,深度优先搜索算法有全部保留和不全部保留产生的结点的两种情况。
而狭义的理解是,仅仅只保留全部产生结点的算法。
本书取前一种广义的理解。
不保留全部结点的算法属于一般的回溯算法范畴。
保留全部结点的算法,实际上是在数据库中产生一个结点之间的搜索树,因此也属于图搜索算法的范畴。
(4)不保留全部结点的深度优先搜索法,由于把扩展望的结点从数据库中弹出删除,这样,一般在数据库中存储的结点数就是深度值,因此它占用的空间较少,所以,当搜索树的结点较多,用其他方法易产生内存溢出时,深度优先搜索不失为一种有效的算法。
(5)从输出结果可看出,深度优先搜索找到的第一个解并不一定是最优解。
例如例题2-8得最优解为13,但第一个解却是17。
如果要求出最优解的话,一种方法将是后面要介绍的动态规划法,另一种方法是修改原算法:把原输出过程的地方改为记录过程,即记录达到当前目标的路径和相应的路程值,并与前面已记录的值进行比较,保留其中最优的,等全部搜索完成后,才把保留的最优解输出。
二、广度优先搜索法的显著特点是:(1)在产生新的子结点时,深度越小的结点越先得到扩展,即先产生它的子结点。
为使算法便于实现,存放结点的数据库一般用队列的结构。
(2)无论问题性质如何不同,利用广度优先搜索法解题的基本算法是相同的,但数据库中每一结点内容,产生式规则,根据不同的问题,有不同的内容和结构,就是同一问题也可以有不同的表示方法。
(3)当结点到跟结点的费用(有的书称为耗散值)和结点的深度成正比时,特别是当每一结点到根结点的费用等于深度时,用广度优先法得到的解是最优解,但如果不成正比,则得到的解不一定是最优解。
这一类问题要求出最优解,一种方法是使用后面要介绍的其他方法求解,另外一种方法是改进前面深度(或广度)优先搜索算法:找到一个目标后,不是立即退出,而是记录下目标结点的路径和费用,如果有多个目标结点,就加以比较,留下较优的结点。
把所有可能的路径都搜索完后,才输出记录的最优路径。
(4)广度优先搜索算法,一般需要存储产生的所有结点,占的存储空间要比深度优先大得多,因此程序设计中,必须考虑溢出和节省内存空间得问题。
(5)比较深度优先和广度优先两种搜索法,广度优先搜索法一般无回溯操作,即入栈和出栈的操作,所以运行速度比深度优先搜索算法法要快些。
总之,一般情况下,深度优先搜索法占内存少但速度较慢,广度优先搜索算法占内存多但速度较快,在距离和深度成正比的情况下能较快地求出最优解。
因此在选择用哪种算法时,要综合考虑。
决定取舍。
二、基本搜索算法比较和搜索算法的优化搜索算法是利用计算机的高性能来有目的的穷举一个问题的部分或所有的可能情况,从而求出问题的解的一种方法。
搜索过程实际上是根据初始条件和扩展规则构造一棵解答树并寻找符合目标状态的节点的过程。
所有的搜索算法从其最终的算法实现上来看,都可以划分成两个部分──控制结构和产生系统,而所有的算法的优化和改进主要都是通过修改其控制结构来完成的。
现在主要对其控制结构进行讨论,因此对其产生系统作如下约定:FunctionExpendNode(Situation:Tsituation;ExpendWayNo:Integer):TSituation;表示对给出的节点状态Sitution采用第ExpendWayNo种扩展规则进行扩展,并且返回扩展后的状态。
(本文所采用的算法描述语言为类Pascal。
)第一部分基本搜索算法一、回溯算法回溯算法是所有搜索算法中最为基本的一种算法,其采用了一种“走不通就掉头”思想作为其控制结构,其相当于采用了先根遍历的方法来构造解答树,可用于找解或所有解以及最优解。
具体的算法描述如下:(略)范例:一个M*M的棋盘上某一点上有一个马,要求寻找一条从这一点出发不重复的跳完棋盘上所有的点的路线。
评价:回溯算法对空间的消耗较少,当其与分枝定界法一起使用时,对于所求解在解答树中层次较深的问题有较好的效果。
但应避免在后继节点可能与前继节点相同的问题中使用,以免产生循环。
二、深度搜索与广度搜索深度搜索与广度搜索的控制结构和产生系统很相似,唯一的区别在于对扩展节点选取上。
由于其保留了所有的前继节点,所以在产生后继节点时可以去掉一部分重复的节点,从而提高了搜索效率。
这两种算法每次都扩展一个节点的所有子节点,而不同的是,深度搜索下一次扩展的是本次扩展出来的子节点中的一个,而广度搜索扩展的则是本次扩展的节点的兄弟节点。
在具体实现上为了提高效率,所以采用了不同的数据结构.三、初探队与广度优先搜索:1、队的定义:队是特殊的线性表之一,它只允许在队的一端插入,在队的另一端删除。
插入一端叫队尾(T),删除一端叫队首(H),没有任何元素的队叫做空队。
队列遵循"先进先出"原则,排队购物、买票等,就是最常见的队。
2、队的基本操作:(1)队的描述:type queue=array[1..100] of integer;var a:queue; {定义数组}h,d:integer; {队首、队尾指针}(2)初始化(图1):procedure start;beginh:=1; d:=1;end;(3)入队操作(图2):procedure enter;beginread(s); {读入数据}inc(d); {队尾加一}a[d]:=s;end;(4)出队操作(图3):procedure out;begininc(h); {队首加一}a[h]:=0;end;广度优先搜索类似于树的按层次遍历的过程。
它和队有很多相似之处,运用了队的许多思想,其实就是对队的深入一步研究,它的基本操作和队列几乎一样。
第二部分搜索算法的优化一、双向广度搜索广度搜索虽然可以得到最优解,但是其空间消耗增长太快。
但如果从正反两个方向进行广度搜索,理想情况下可以减少二分之一的搜索量,从而提高搜索速度。
范例:移动一个只含字母A和B的字符串中的字母,给定初始状态为(a)表,目标状态为(b)表,给定移动规则为:只能互相对换相邻字母。
请找出一条移动最少步数的办法。
(a)(b)问题分析:从初始状态和目标状态均按照广度优先搜索扩展接点,当达到以下状态时,出现相交点,如图(c),接点序号表示生成顺序。
双向扩展结点:(c)(d)顺序扩展的第8个子结点与逆序扩展得到的第4个子结点就是交互点,问题的最佳路径如图(e)→→→→(e)利用双向搜索对广度搜索算法的改进:1、添加一张节点表,作为反向扩展表。
2、在while循环体中在正向扩展代码后加入反向扩展代码,其扩展过程不能与正向过程共享一个for循环。
3、在正向扩展出一个节点后,需在反向表中查找是否有重合节点。
反向扩展时与之相同。
对双向广度搜索算法的改进:略微修改一下控制结构,每次while循环时只扩展正反两个方向中节点数目较少的一个,可以使两边的发展速度保持一定的平衡,从而减少总扩展节点的个数,加快搜索速度。
二、分支定界分支定界实际上是A*算法的一种雏形,其对于每个扩展出来的节点给出一个预期值,如果这个预期值不如当前已经搜索出来的结果好的话,则将这个节点(包括其子节点)从解答树中删去,从而达到加快搜索速度的目的。
范例:在一个商店中购物,设第I种商品的价格为Ci。
但商店提供一种折扣,即给出一组商品的组合,如果一次性购买了这一组商品,则可以享受较优惠的价格。
现在给出一张购买清单和商店所提供的折扣清单,要求利用这些折扣,使所付款最少。
问题分析:显然,折扣使用的顺序与最终结果无关,所以可以先将所有的折扣按折扣率从大到小排序,然后采用回溯法的控制结构,对每个折扣从其最大可能使用次数向零递减搜索,设A为已打完折扣后优惠的价格,C为当前未打折扣的商品零售价之和,则其预期值为A+a*C,其中a为下一个折扣的折扣率。
如当前已是最后一个折扣,则a=1。
对回溯算法的改进:1、添加一个全局变量BestAnswer,记录当前最优解。
2、在每次生成一个节点时,计算其预期值,并与BestAnswer比较。
如果不好,则调用回溯过程。
三、A*算法A*算法中更一般的引入了一个估价函数f,其定义为f=g+h。
其中g为到达当前节点的耗费,而h表示对从当前节点到达目标节点的耗费的估计。
其必须满足两个条件:1、h必须小于等于实际的从当前节点到达目标节点的最小耗费h*。
2、f必须保持单调递增。
A*算法的控制结构与广度搜索的十分类似,只是每次扩展的都是当前待扩展节点中f值最小的一个,如果扩展出来的节点与已扩展的节点重复,则删去这个节点。
如果与待扩展节点重复,如果这个节点的估价函数值较小,则用其代替原待扩展节点,具体算法描述如下:范例:一个3*3的棋盘中有1-8八个数字和一个空格,现给出一个初始态和一个目标态,要求利用这个空格,用最少的步数,使其到达目标态。
问题分析:预期值定义为h=|x-dx|+|y-dy|。
估价函数定义为f=g+h。
<Type>Node(节点类型)=RecordSitutation:TSituation(当前节点状态);g:Integer;(到达当前状态的耗费)h:Integer;(预计的耗费)f:Real;(估价函数值)Last:Integer;(父节点)End<Var>List(节点表):Array[1..Max(最多节点数)] of Node(节点类型);open(总节点数):Integer;close(待扩展节点编号):Integer;New-S:Tsituation;(新节点)<Init>List<-0;open<-1;close<-0;List[1].Situation<- 初始状态;<Main Program>While (close<open(还有未扩展节点)) and(open<Max(空间未用完)) and(未找到目标节点) doBeginBeginclose:=close+1;For I:=close+1 to open do (寻找估价函数值最小的节点) Beginif List[i].f<List[close].f thenBegin交换List[i]和List[close];End-If;End-For;End;For I:=1 to TotalExpendMethod do(扩展一层子节点)BeginNew-S:=ExpendNode(List[close].Situation,I)If Not (New-S in List[1..close]) then(扩展出的节点未与已扩展的节点重复)BeginIf Not (New-S in List[close+1..open]) then(扩展出的节点未与待扩展的节点重复)Beginopen:=open+1;List[open].Situation:=New-S;List[open].Last:=close;List[open].g:=List[close].g+cost;List[open].h:=GetH(List[open].Situation);List[open].f:=List[open].h+List[open].g;End-IfElse BeginIf List[close].g+cost+GetH(New-S)<List[same].f then(扩展出来的节点的估价函数值小于与其相同的节点)BeginList[same].Situation:= New-S;List[same].Last:=close;List[same].g:=List[close].g+cost;List[same].h:=GetH(List[open].Situation);List[same].f:=List[open].h+List[open].g;End-If;End-Else;End-IfEnd-For;End-While;对A*算法的改进--分阶段A*:当A*算法出现数据溢出时,从待扩展节点中取出若干个估价函数值较小的节点,然后放弃其余的待扩展节点,从而可以使搜索进一步的进行下去。