大数据与数据挖掘之文本挖掘
大数据常见的9种数据分析手段

大数据常见的9种数据分析手段一、数据清洗数据清洗是指对原始数据进行预处理,去除重复数据、缺失数据和异常值,以保证数据的准确性和完整性。
常见的数据清洗手段包括去重、填充缺失值和异常值处理等。
1. 去重:通过对数据进行去重操作,去除重复的数据,以避免在后续分析过程中对同一数据进行重复计算,提高数据分析效率。
2. 填充缺失值:对于存在缺失数据的情况,可以使用插值法、均值法等方法对缺失值进行填充,以保证数据的完整性。
3. 异常值处理:对于异常值,可以通过箱线图、Z-Score等方法进行检测和处理,以排除异常值对数据分析结果的干扰。
二、数据预处理数据预处理是指对清洗后的数据进行进一步的处理,以满足后续数据分析的需求。
常见的数据预处理手段包括数据变换、数据归一化和数据离散化等。
1. 数据变换:通过对数据进行变换,可以将非线性关系转化为线性关系,提高数据分析的准确性。
常见的数据变换方法包括对数变换、指数变换和平方根变换等。
2. 数据归一化:对于不同量纲的数据,可以使用数据归一化方法将其转化为统一的范围,以消除不同量纲对数据分析的影响。
常见的数据归一化方法包括最小-最大归一化和Z-Score归一化等。
3. 数据离散化:将连续型数据转化为离散型数据,可以简化数据分析过程,提高计算效率。
常见的数据离散化方法包括等宽离散化和等频离散化等。
三、数据可视化数据可视化是将数据以图表等形式展示出来,使数据更加直观、易于理解和分析的过程。
常见的数据可视化手段包括柱状图、折线图、散点图和饼图等。
1. 柱状图:用于展示不同类别或变量之间的数量关系,可以直观地比较各类别或变量的大小。
2. 折线图:用于展示数据随时间或其他变量的变化趋势,可以观察到数据的趋势和周期性变化。
3. 散点图:用于展示两个变量之间的关系,可以观察到变量之间的相关性和趋势。
4. 饼图:用于展示不同类别或变量在整体中的占比情况,可以直观地比较各类别或变量的重要性。
数据挖掘技术在大数据分析中的应用

数据挖掘技术在大数据分析中的应用随着信息技术的飞速发展,数据量也越来越庞大,这就促使了数据挖掘技术的快速崛起。
数据挖掘技术是指从数据库中获取信息并进行分析、挖掘出有用的信息的过程。
在大数据分析中,数据挖掘技术发挥着越来越重要的作用。
本文将详细阐述数据挖掘技术在大数据分析中的应用。
一、数据挖掘技术与大数据分析数据挖掘技术是从大量数据中挖掘出有意义的信息,这些信息可以是隐含的、未知的或者新颖的。
而大数据分析是从海量数据中提取有效信息的过程,它可以使企业或组织更好地决策和实现业务目标。
数据挖掘技术和大数据分析有很大的关联,数据挖掘技术是大数据分析中的一项重要技术手段。
二、数据挖掘技术在大数据分析中的应用1.决策树决策树算法是数据挖掘中常用的一种分类算法,可以帮助企业或组织快速分析数据并做出决策。
例如,在金融领域,银行可以根据客户的数据(如年龄、职业、收入等)构建决策树,预测客户是否会逾期还款,从而及时采取措施,减少损失。
2.聚类聚类是将相似对象分组的过程,该过程可以帮助企业或组织快速分析客户群体和商品类型,挖掘出其中的规律和特点。
例如,在电商领域,企业可以通过聚类算法将消费者分为不同的群体,然后根据不同群体的喜好和偏好,向不同群体推荐不同的商品,从而提高销售额。
3.关联分析关联分析是指在数据集中挖掘高度相关的数据,以发现数据集中的规律和关系。
例如,在零售行业,企业可以对销售数据进行关联分析,挖掘出商品之间的关联性,以便更好地制定促销策略。
4.文本挖掘文本挖掘可以将大量的非结构化文本数据转化为结构化数据,并提取出其中的有用信息。
例如,在舆情分析中,可以通过文本挖掘技术快速分析大量的新闻和社交媒体数据,并了解公众对某一事件或话题的态度和看法。
三、数据挖掘技术在大数据分析中的优势1.快速准确大数据分析通常需要处理海量数据,使用传统的手动方法处理数据耗时费力且容易出错。
数据挖掘技术可以通过算法迅速地对海量数据进行处理,准确地提取出有用的信息。
数据挖掘的概念与技术介绍

数据挖掘的概念与技术介绍数据挖掘的概念与技术介绍数据挖掘是指从大量的数据中发现隐藏在其中的有价值的信息、模式和规律的过程。
随着互联网时代的到来,越来越多的数据被收集和存储,数据挖掘成为了从这些海量数据中获取洞察和知识的重要工具。
本文将围绕数据挖掘的概念和技术展开讨论,帮助读者深入理解数据挖掘的核心要素和方法。
一、数据挖掘的概念1.1 数据挖掘的定义数据挖掘是一种通过自动或半自动的方式,从大量的数据中发现有用的信息、模式和规律的过程。
通过应用统计学、机器学习和人工智能等技术,数据挖掘可以帮助人们从数据中进行预测、分析和决策。
1.2 数据挖掘的目标数据挖掘的主要目标是从数据中发现隐藏的模式和规律,并将这些知识应用于实际问题的解决。
数据挖掘可以帮助企业提高市场营销的效果、改进产品设计、优化生产过程等。
数据挖掘也被广泛应用于科学研究、金融风险分析、医学诊断等领域。
1.3 数据挖掘的流程数据挖掘的流程通常包括数据收集、数据预处理、模型构建、模型评估和模型应用等步骤。
其中,数据预处理是数据挖掘流程中非常重要的一环,它包括数据清洗、数据集成、数据变换和数据规约等子任务。
二、数据挖掘的技术2.1 关联规则挖掘关联规则挖掘是数据挖掘的一个重要技术,它用于发现数据集中的项之间的关联关系。
通过挖掘关联规则,可以发现数据中隐藏的有用信息,如购物篮分析中的“啤酒和尿布”现象。
2.2 分类与回归分类与回归是数据挖掘中常用的技术,它们用于对数据进行分类或预测。
分类是指根据已有的样本数据,建立分类模型,然后将新的数据实例分到不同的类别中。
回归则是根据数据的特征和已知的输出值,建立回归模型,然后预测新的数据实例的输出值。
2.3 聚类分析聚类分析是一种将数据分成不同的类别或簇的技术。
通过发现数据之间的相似性,聚类可以帮助人们理解数据的内在结构和特点。
聚类分析在市场细分、社交网络分析等领域具有广泛的应用。
2.4 异常检测异常检测是指从数据中识别出与大多数数据显著不同的样本或模式。
银行工作中的数据挖掘方法与案例分享

银行工作中的数据挖掘方法与案例分享在当今信息爆炸的时代,数据已经成为各行各业的重要资源。
银行作为金融行业的重要组成部分,也不例外。
银行拥有大量的客户数据、交易数据等,利用这些数据进行数据挖掘分析,可以帮助银行更好地了解客户需求、优化业务流程、提高风险控制能力等。
本文将介绍银行工作中常用的数据挖掘方法,并分享一些实际案例。
一、关联规则挖掘关联规则挖掘是一种常见的数据挖掘方法,它可以帮助银行发现不同变量之间的关联关系。
例如,银行可以利用关联规则挖掘分析客户的消费习惯,从而精准地推送相关产品和服务。
此外,关联规则挖掘还可以用于分析信用卡交易数据,帮助银行发现异常交易行为,提高风险控制能力。
案例分享:某银行利用关联规则挖掘分析信用卡交易数据,发现了一组异常交易行为。
这些交易都发生在深夜,并且金额较大,与持卡人平时的消费习惯明显不符。
通过进一步调查,银行发现这些交易是由盗刷者所为。
及时发现并阻止了这些异常交易,银行成功保护了客户的资金安全。
二、聚类分析聚类分析是一种常用的无监督学习方法,它可以将数据集中相似的样本归为一类。
在银行工作中,聚类分析可以帮助银行发现不同客户群体的特征和行为模式,为精准营销和定制化服务提供依据。
案例分享:某银行利用聚类分析对客户进行分群,发现了两个明显的客户群体:一类是年轻人,他们更倾向于使用移动支付和线上银行服务;另一类是中老年人,他们更喜欢传统的网点服务。
基于这一发现,银行针对不同客户群体推出了不同的产品和服务,提高了客户满意度和业务收入。
三、决策树算法决策树算法是一种常用的监督学习方法,它可以根据已有的数据建立决策树模型,用于预测和分类。
在银行工作中,决策树算法可以帮助银行进行风险评估和信用评级。
案例分享:某银行利用决策树算法对客户进行信用评级,根据客户的个人信息、财务状况等指标,预测客户的信用状况。
通过信用评级,银行可以更好地判断客户的还款能力,从而制定相应的贷款政策和利率。
文本挖掘理论概述

基金项目: 河南省科技攻关项目(0324220024)
22
福建电脑
2008 年第 9 期
词 。 虚 词 例 如 英 文 中 的 "a, the, of, for, with, in, at, ……", 中 文 中 的"的, 得, 地, ……"; 实词例如数据库会议上的论文中的"数据 库"一词, 视为非用词。
知 识 领 域 有 深 入 的 了 解 [4]。
3) 文本挖掘可以对大量文档集合的内容进行总结、分类、聚
类 .、关 联 分 析 以 及 利 用 文 档 进 行 趋 势 预 测 等 。
4) 解释与评估: 将挖掘得到的知识或者模式进行评价, 将符
合一定标准的知识或者模式呈现给用户。
3、Web 文本挖掘的一般处理过程 无 论 是 在 数 据 结 构 还 是 分 析 处 理 方 面 , Web 文 本 挖 掘 和 数
在机器学习中常 用 的 模 型 质 量 评 估 指 标 有 分 正 确 率 ( Clas- sification Accuracy) , 查 准 率 ( Precision) 与 查 全 率 ( Recall) , 查 准 率 与 查 全 率 的 几 何 平 均 数 , 信 息 估 值 ( Information Score) 兴 趣 性 ( Interestingness) 。其中兴趣性是一个主客观结合的评价指标。 4、结 论 和 展 望
对 Internet 上 的 文 本 数 据 进 行 文 本 挖 掘 可 以 看 作 是 一 种 机 器学习的过程。在机器学习中学习的结果是某种知识模型 M, 机 器学习的一个重要组成部分便是对产生的模型 M 进行评估。对 所获取的知识模式进行质量评价, 若评价的结果满足一定的要 求, 则存储知识模式, 否则返回到以前的某个环节分析改进后进 行 新 一 轮 的 挖 掘 工 作 [7]。
大数据中的文本分析技术及其应用实现

大数据中的文本分析技术及其应用实现近年来,数据处理技术不断发展,大数据的应用越来越广泛,并且逐渐成为各行业提高竞争力的关键之一。
然而,海量的数据并非一定是有用的,需要通过有效的分析方法来挖掘其中潜在的价值。
文本分析技术是其中的一种重要方法,它可以通过对海量文本数据的收集、清洗、处理、分析和探索,揭示其中蕴含的信息和规律,为商业、社会等领域提供有效的决策支持和业务创新。
一、文本分析技术的基本原理和方法文本分析是一种信息处理技术,它旨在对大量的非结构化文本数据进行自动化处理和分析。
文本数据是指非数字化的数据,例如文章、新闻、社交媒体评论、电子邮件、网页等等。
文本分析技术主要包括以下几个方面:1.文本预处理文本数据经常存在一些问题,例如缺少结构、包含多余信息、存在噪音、错别字、缩写、词形变化、专业术语等等。
为了让文本数据更加容易处理和分析,需要先对其进行预处理。
包括文本清洗、分词、词性标注、命名实体识别等等。
2.文本分类与聚类文本分类是指将一系列文本数据分为不同的类别或标签,这些类别或标签是根据文本内容和主题进行划分的。
聚类是指将相似的文本数据聚集在一起,形成一组集群。
这个过程主要使用分类算法、聚类算法等。
3.文本情感分析文本情感分析可以对文本内容进行情感判断,判断文本表达的情感是积极还是消极。
这个过程主要使用情感词典、机器学习等方法。
4.文本挖掘文本挖掘是指对文本数据进行深度分析,发掘其中的知识和规律,提供有价值的信息。
文本挖掘常用的方法包括主题模型、关联规则、序列模式等等。
二、文本分析技术的应用实现随着大数据技术的不断发展,文本分析技术也获得了广泛的应用。
下面从商业、社会等几个方面介绍其应用实践。
1.商业领域文本分析技术在商业领域的应用非常广泛,例如:(1)市场调查:对大量的消费者评论、社交媒体数据进行情感分析和主题分析,挖掘出消费者的需求和偏好,为产品的开发和市场的推广提供决策支持。
(2)投资决策:对各种信息来源(例如公司年报、新闻报道、社交媒体等)进行文本分类和情感分析,量化风险和预测股价等方面的趋势变化和风险等因素。
中文文本挖掘的流程与工具分析

中文文本挖掘的流程与工具分析1. 引言1.1 中文文本挖掘的重要性中文文本挖掘是信息技术领域中的一个重要研究方向,其重要性不言而喻。
随着互联网和大数据时代的到来,我们正面临着海量的中文文本数据,如新闻报道、社交媒体内容、科技论文等,这些数据蕴含着丰富的信息和知识,但要从中获取有用的信息并利用这些知识,却需要借助文本挖掘技术。
中文文本挖掘的重要性主要体现在以下几个方面:中文文本挖掘可以帮助我们快速有效地获取信息,对文本数据进行分析和理解。
通过文本挖掘技术,我们能够识别出文本中的关键信息、主题和情感等,从而更好地进行信息检索和知识发现。
中文文本挖掘可以帮助我们进行大规模文本数据的处理和管理,提高工作效率和数据利用率。
通过挖掘文本数据的隐藏信息和规律,我们可以更好地进行数据挖掘、决策支持和预测分析。
中文文本挖掘也可以应用于各行各业,如金融、医疗、电商等领域,为企业和组织提供智能化解决方案,提升竞争力和效益。
中文文本挖掘在当前信息社会中扮演着重要的角色,其应用前景广阔,对于推动信息技术的发展和社会进步具有重要意义。
1.2 中文文本挖掘的研究意义1. 语言信息处理:中文文本挖掘可以帮助我们更好地理解和处理汉语语言信息。
通过对大规模中文文本的分析和挖掘,可以揭示出中文语言的规律和特点,从而为自然语言处理领域的研究提供参考和支持。
2. 数据挖掘和知识发现:中文文本中蕴含着丰富的信息和知识,通过文本挖掘技术可以从中抽取出有用的信息,发现隐藏在文本背后的规律和模式,为决策和预测提供依据。
3. 情感分析和舆情监控:随着社交媒体和互联网的发展,中文文本中蕴含着大量的情感信息。
通过对中文文本的情感分析和舆情监控,可以及时发现和处理舆情事件,保护公众利益和社会稳定。
4. 文化遗产保护:中文文本记录了中华文化的宝贵遗产,通过文本挖掘技术可以对古籍文献进行数字化处理和保护,让更多人了解和学习中华传统文化。
中文文本挖掘不仅对语言信息处理和数据挖掘领域具有重要意义,也对社会舆情监控、文化遗产保护等领域有着广泛的应用前景和研究意义。
大数据与数据挖掘之文本挖掘(PPT 56张)

文档的向量空间模型
W权值计算方法TF-IDF
目前广泛采用TF-IDF权值计算方法来计算权重, TF-IDF的主 要思想是,如果某个词或短语在一篇文章中出现的频率TF 高,并且在其他文章中很少出现,则认为此词或者短语具 有很好的类别区分能力,适合用来分类。 TF词频(Term Frequency)指的是某一个给定的词语在该文件 中出现的次数。 IDF逆文档频率(Inverse Document Frequency)是全体文档数与 包含词条文档数的比值。如果包含词条的文档越少,IDF越 大,则说明词条具有很好的类别区分能力。 在完整的向量空间模型中,将TF和IDF组合在一起,形成TFIDF度量:TF-IDF(d,t)= TF(d,t)*IDF(t)
• (11)查词表,W不在词表中,将W最右边一个字去掉, 得到W="是三" • (12)查词表,W不在词表中,将W最右边一个字去掉, 得到W=“是”,这时W是单字,将W加入到S2中,S2=“计 算语言学/ 课程/ 是/ ”, • 并将W从S1中去掉,此时S1="三个课时"; • ������ ������ • (21)S2=“计算语言学/ 课程/ 是/ 三/ 个/ 课时/ ”,此时 S1=""。 • (22)S1为空,输出S2作为分词结果,分词过程结束。
停用词
• • • • 指文档中出现的连词,介词,冠词等并无太大意义的词。 英文中常用的停用词有the,a, it等 中文中常见的有“是”,“的”,“地”等。 停用词消除可以减少term的个数,降低存储空间。停用词 的消除方法: • (1)查表法:建立一个停用词表,通过查表的方式去掉 停用词。 • (2)基于DF的方法:统计每个词的DF,如果超过总文档 数目的某个百分比(如80%),则作为停用词去掉。
大数据与数据挖掘:探究大数据的应用价值和数据挖掘的算法

大数据与数据挖掘:探究大数据的应用价值和数据挖掘的算法摘要近年来,大数据技术迅猛发展,海量数据的产生和应用已成为社会发展的重要趋势。
大数据的应用价值与数据挖掘算法的不断完善,共同推进了各行各业的数字化转型,并催生了许多新兴产业。
本文将从大数据的应用价值和数据挖掘的算法两方面入手,探讨大数据时代数据分析的意义和发展方向。
关键词:大数据,数据挖掘,算法,应用价值,数据分析1. 大数据的应用价值大数据是指无法在一定时间内通过传统数据处理工具或方法进行采集、管理和处理的海量数据,其特点包括数据量大、种类繁多、生成速度快、价值密度低等。
随着互联网、物联网、移动通信等技术的快速发展,各行各业都积累了大量的数据,这些数据蕴藏着巨大的应用价值。
1.1 提升决策效率大数据能够提供更加全面、深入的洞察,帮助企业做出更明智的决策。
例如,通过分析用户行为数据,电商平台可以了解用户喜好,精准推荐商品,提升销售效率;通过分析交通数据,城市规划部门可以优化交通路线,缓解交通拥堵;通过分析医疗数据,医生可以更好地诊断病情,制定个性化的治疗方案。
1.2 创新产品和服务大数据为产品和服务的创新提供了新的思路。
例如,通过分析用户社交数据,社交平台可以开发更符合用户需求的个性化功能;通过分析用户购物数据,零售商可以开发更加精准的营销策略,创造更大的价值。
1.3 优化资源配置大数据可以帮助企业优化资源配置,提高效率。
例如,通过分析生产数据,制造企业可以优化生产流程,降低生产成本;通过分析库存数据,物流企业可以优化仓储管理,提高配送效率;通过分析能源数据,能源企业可以优化能源利用,降低能耗。
1.4 促进社会发展大数据在社会发展中也发挥着重要作用。
例如,通过分析犯罪数据,公安部门可以提高破案率,维护社会安全;通过分析环境数据,环境保护部门可以监测环境污染,制定环境保护政策;通过分析教育数据,教育部门可以了解教育现状,制定教育发展规划。
2. 数据挖掘的算法数据挖掘是通过分析大量数据,提取有价值的信息和知识的过程,其核心是利用各种算法来发现隐藏在数据中的规律和模式。
数据挖掘的算法和应用案例

数据挖掘的算法和应用案例数据挖掘是一种从大量数据中提取潜在模式和知识的过程。
它结合了统计学、人工智能和机器学习等多个领域的技术和方法,在各个行业和领域都有广泛的应用。
本文将介绍一些常见的数据挖掘算法和应用案例。
一、关联规则挖掘关联规则挖掘是寻找数据中项与项之间的关联关系。
这种技术广泛应用于市场营销、购物篮分析和推荐系统中。
以购物篮分析为例,通过挖掘顾客购买商品之间的关联规则,商家可以了解客户的购物习惯和喜好,从而进行更加精准的商品推荐和促销活动。
二、分类与回归分类与回归是一类有监督学习的数据挖掘算法,它用于将数据分为不同的类别或预测数据的数值。
在医疗领域中,可以利用分类算法对患者的病情进行预测和诊断。
例如,通过对患者的病历数据进行训练,建立一个分类模型,可以在未来的新病例中预测患者是否得某种疾病。
三、聚类分析聚类分析是一种无监督学习的数据挖掘算法,其目标是将相似的对象归为一类。
在市场细分和社交网络分析中,聚类分析被广泛应用。
例如,一家电商公司可以利用聚类分析将用户划分为不同的群体,然后针对不同群体的用户制定个性化的营销策略。
四、异常检测异常检测用于识别与普通模式不符的异常数据。
在金融领域,异常检测可以用于发现金融欺诈行为。
通过对历史交易数据进行异常检测,银行可以及时发现不寻常的交易模式,并采取相应措施保护客户的资金安全。
五、文本挖掘文本挖掘用于从大量的文本数据中提取有价值的信息和知识。
在舆情分析和情感分析中,文本挖掘被广泛应用。
例如,通过对社交媒体上用户的评论进行情感分析,可以了解用户对某个产品或事件的态度和观点。
六、推荐系统推荐系统是通过分析用户的历史行为和偏好,为用户提供个性化的推荐。
在电商和视频网站中,推荐系统能够根据用户的兴趣和喜好,为他们推荐符合其口味的商品或视频。
通过挖掘用户的行为数据,推荐系统可以不断优化推荐效果,提高用户满意度。
综上所述,数据挖掘算法在各个行业和领域都有广泛的应用。
文本挖掘技术综述

文本挖掘技术综述一、本文概述随着信息技术的快速发展,大量的文本数据在各个领域产生并积累,如何从海量的文本数据中提取出有用的信息成为了亟待解决的问题。
文本挖掘技术应运而生,它通过对文本数据进行处理、分析和挖掘,以揭示隐藏在其中的知识和模式。
本文旨在对文本挖掘技术进行全面的综述,从基本概念、主要方法、应用领域以及未来发展趋势等方面进行深入探讨,以期对文本挖掘技术的研究与应用提供有益的参考和启示。
本文将对文本挖掘技术的定义、特点、发展历程等基本概念进行阐述,帮助读者对文本挖掘技术有一个整体的认识。
接着,将重点介绍文本挖掘的主要方法,包括文本预处理、特征提取、文本分类、聚类分析、情感分析、实体识别等,并对各种方法的原理、优缺点进行详细的分析和比较。
本文还将探讨文本挖掘技术在不同领域的应用,如新闻推荐、舆情监控、电子商务、生物医学等,通过具体案例展示文本挖掘技术的实际应用效果。
同时,也将分析文本挖掘技术所面临的挑战和问题,如数据稀疏性、语义鸿沟、计算效率等,并探讨相应的解决方案和发展方向。
本文将对文本挖掘技术的未来发展趋势进行展望,随着、自然语言处理、深度学习等技术的不断发展,文本挖掘技术将在更多领域发挥重要作用,为实现智能化、个性化的信息服务提供有力支持。
本文将对文本挖掘技术进行全面而深入的综述,旨在为读者提供一个清晰、系统的文本挖掘技术知识框架,推动文本挖掘技术的进一步研究和应用。
二、文本挖掘的基本流程文本挖掘,作为数据挖掘的一个分支,专注于从非结构化的文本数据中提取有用的信息和知识。
其基本流程可以分为以下几个关键步骤:数据收集:需要收集并整理相关的文本数据。
这些数据可能来源于网络、数据库、文档、社交媒体等,涵盖了各种语言、格式和领域。
数据预处理:在得到原始文本数据后,需要进行一系列预处理操作,包括去除无关字符、标点符号,进行分词、词干提取、词性标注等。
这些操作的目的是将文本数据转化为适合后续处理的结构化形式。
大数据分析与挖掘 08大数据挖掘-非结构化

• 应用场景 • 全球多达80%的大数据是非结构化的,如博客、微博等内容,其次人类 的自然语言语气、语调、隐喻、反语等非常复杂,简单的数据分析模型 无法应对。
• 结构化数据的典型场景为:企业ERP、财务系统;医疗HIS数据库;教育 一卡通;政府行政审批;其他核心数据库等
• 非结构化数据,包括视频、音频、图片、图像、文档、文本等形式。典 型案例如医疗影像系统、教育视频点播、视频监控、国土GIS、设计院、 文件服务器(PDM/FTP)、媒体资源管理等。
• 3.文档主题生成模型(Latent Dirichlet Allocation, LDA):主要用于监测客户行为变化,它可以发现数 据的相似性以便进行分类和分组。LDA使用统计算法从非结构化数据抽取主题、概念和其他含义,它 不理解语法或者人类语言,而只是寻找模式。任何数量、类型非结构化的、半结构化和结构化源数据 都可以应用LDA监测模式来进行分析。
• 2.命名实体识别(Named Entity Extraction, NEE):基于自然语言处理,借鉴了计算机科学、人工智能 和语言学等学科,可以确定哪些部分可能代表如人、地点、组织、职称、产品、货币金额、百分比、 日期和事件等实体。NEE算法为每个标识的实体生成一个分数,该分数表明识别正确的概率。我们可 以视情况设定一个阈值,来达到我们的目的。
• 定义 • 结构化数据,即行数据,存储在数据库里,可以用二维表结构来逻辑表 达实现的数据; 非结构化数据,不方便用数据库二维逻辑表来表现的数据
• 存储格式的区别 • 关系数据库 — 结构定义不易改变,数据定长。 非结构化数据库 — 是指其字段长度可变,并且每个字段的记录又可以由 可重复或不可重复的子字段构成的数据库。
基于关联的分类方法 用信息检索技术等提取关键词,生成概念层次,利用关联分析对文档分类。
大数据分析平台中的文本挖掘技术使用教程

大数据分析平台中的文本挖掘技术使用教程随着大数据时代的到来,文本数据成为了一种非常重要的数据形式。
在大数据分析平台中,文本挖掘技术的使用变得越来越普遍。
本篇文章将为您提供一份文本挖掘技术在大数据分析平台中的使用教程。
一、什么是文本挖掘技术文本挖掘技术,也称为文本数据挖掘技术,是指从非结构化或半结构化的文本数据中,提取有价值的信息、模式或知识的过程。
它结合了自然语言处理、机器学习和统计分析等技术,可以帮助我们从海量的文本数据中发现隐藏的模式、关系和趋势。
在大数据分析平台中,文本挖掘技术可以应用于舆情分析、情感分析、主题建模、智能问答等场景。
二、文本挖掘技术的基本步骤1. 数据准备在使用文本挖掘技术之前,首先需要进行数据准备工作。
这包括数据清洗、去除噪声、标准化等步骤。
清洗数据是为了去除无效或重复的文本,以及处理一些特殊字符或格式。
而标准化数据可以将文本转换为特定的格式,便于后续的处理和分析。
2. 文本预处理文本预处理是文本挖掘中的重要步骤,其目的是将原始文本转换为可用于分析的结构化形式。
预处理包括分词、去除停用词、词干化和词向量化等步骤。
分词是将文本划分为词汇单位的过程,可以使用自然语言处理工具或开源的分词库来实现。
去除停用词是指去除对分析无意义的常见词汇,例如“的”、“是”等。
词干化可以将词语的变化形式转换为词干形式,以减少词汇的冗余。
而词向量化则是将文本转换为数值化的向量表示,常见的方法有词袋模型和词嵌入模型等。
3. 特征提取与选择在文本挖掘中,特征提取是指从文本中提取有用的特征,以便于后续的建模和分析。
常见的特征提取方法包括词频、TF-IDF、N-gram等。
词频是指统计每个词在文本中出现的频率,通过计算词频可以得到每个词的重要程度。
TF-IDF是一种用于评估词语在文本中重要程度的方法,它考虑了词频和逆文档频率的权衡。
N-gram是指连续N个词的组合,它可以捕捉到词语之间的语义关系。
4. 模型构建与训练在特征提取之后,可以选择适合的机器学习模型对文本进行分类、聚类、关联分析等任务。
大数据环境下文本信息挖掘系统设计

大数据环境下文本信息挖掘系统设计赵逸智;张云峰【摘要】The traditional text information mining technology system can carry out the systematic information mining for text information,but is easy to generate the data identification messy code of the system and data interference in the big data environ-ment. Aiming at these problems,a design scheme of text information mining system in big data environment is put forward. The data reducer is added on the hardware device of the system,which can filter the data,ensure the accuracy of data entered into the recognition stage,and improve the efficiency of data mining. The prime number matrix model is used in the process of infor-mation mining to mine the text information deeply. The Aprioirt computing method is optimized to ensure the priority recognition of text information,avoid the data chaos and data interference of the traditional method. In order to verify the effectiveness of text information mining system in large data environment,the contrast simulation experiment was designed. The experimental data verifies that the text information mining system in large data environment is effective,and can avoid the data chaos and data in-terference of the traditional methods.%传统文本信息挖掘技术系统能够对文本信息进行系统的信息挖掘,但是在大数据环境下容易产生系统的数据识别乱码以及数据干扰.针对上述问题,提出一种大数据环境下文本信息挖掘系统设计方案,在系统的硬件设备上增加数据简化器,通过数据简化器能够对数据进行一定的过滤筛选,保证数据进入识别阶段的准确率,同时促进了数据挖掘过程的效率,对文本信息挖掘的过程使用质数矩阵模型,通过建立的质数矩阵模型能够有效地对文本信息进行深层次的挖掘.同时优化了Aprioirt计算方法,保证了对文本信息的优先识别度,避免了传统方法中出现的数据混乱以及数据干扰问题.为了验证设计的大数据环境下文本信息挖掘系统的有效性,设计了对比仿真实验,通过实验数据的分析,有效地证明了设计的大数据环境下文本信息挖掘系统的有效性,避免了传统方法中出现的数据混乱以及数据干扰问题.【期刊名称】《现代电子技术》【年(卷),期】2018(041)001【总页数】4页(P125-128)【关键词】大数据环境;文本信息;关联密度;Aprioirt计算方法;挖掘系统【作者】赵逸智;张云峰【作者单位】北华航天工业学院,河北廊坊065000;北华航天工业学院,河北廊坊065000【正文语种】中文【中图分类】TN911.1-34;TP391伴随互联网时代的快速崛起,互联网的数据信息已经用海量来比拟[1-2]。
基于数据挖掘技术的网络文本分析研究

基于数据挖掘技术的网络文本分析研究网络文本分析,是指利用计算机技术对网络上的文本进行分析和挖掘,以发掘其中隐含的信息或规律。
而数据挖掘技术,则是其中最为基础和重要的技术之一。
本文将探讨基于数据挖掘技术的网络文本分析研究。
一、简述数据挖掘技术数据挖掘技术又称为知识发现和数据挖掘,是在大数据环境下对大规模数据进行分析、挖掘和处理的技术。
其目的是通过对数据的处理和分析,来寻找数据中隐含的规律、模式和知识,并对之进行应用和推理。
数据挖掘技术应用广泛,包括金融、医疗、电子商务等各个领域。
在网络分析领域中,数据挖掘技术也是重要的分析手段。
二、网络文本分析应用网络文本是指网络上出现的所有文字信息,比如新闻、博客、微博等等。
这些文本中蕴含着大量的信息,如情感、关键词等,如果能挖掘出来,可以为各种应用提供支持。
目前,在社交媒体、电商推荐、政治舆情等方面,都有着广泛的应用。
以社交媒体为例,网络文本中蕴含着人们对于某些话题、产品、事件等的情感和想法。
而对于企业营销而言,了解和分析用户的情感,可以更好地把握用户需求,优化产品和服务。
因此,在社交媒体营销中,对于网络文本的分析是非常重要的。
另一方面,网络文本分析可以帮助政府了解民意、把握舆情。
当今社会,大众媒体的普及,使得民众拥有自由的言论和表达权。
如果可以有效地对网络文本进行分析和挖掘,政府可以及时了解民意,更好地处理社会问题,提供更优质的公共服务。
三、文本数据挖掘的基本流程文本挖掘的基本流程包括:预处理、特征选择、模型构建及评估等步骤。
其中,文本数据预处理是非常重要的步骤,它包括分词、去停用词、去重等操作。
文本预处理后,需要进行特征选择,即从文本中提取有意义的关键特征。
在特征选择之后,需要对其进行建模,通常使用机器学习、神经网络等方法。
最后,需要对模型进行评估和测试,判断其在真实场景下的效果。
文本数据挖掘的主要难点在于文本的复杂性,特别是其中包含的主观性和多样性。
但随着机器学习和自然语言处理技术的发展,这些问题得到了很好的解决。
文本数据挖掘技术导论-第5章 文本聚类
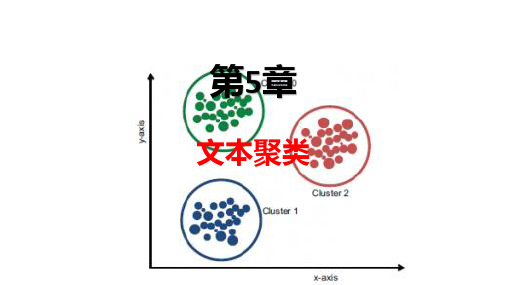
5.1 文本聚类概述
国内外研究现状与发展趋势 经过半个多世纪的研究,目前已经有了许多关于聚类分析的著作,聚类分析也
逐渐有了成熟的体系,并在数据挖掘方法中占据了重要的地位,现有的聚类分析方 法有以下五种,分别是划分式聚类算法、层次聚类算法、基于密度的聚类算法、基 于网格的聚类算法和基于模型的聚类算法。
5.2 文本聚类原理与方法
基于划分的方法 基于划分的方法就是给定一组未知的文档,然后通过某种方法将这些文档划分
成多个不同的分区,具体要求就是每个分区内文档尽可能的相似,而在不同分区的 文档差异性较大。给定一个含有n个文档的文本集,以及要生成的簇的数目k。每一 个分组就代表一个聚类,k<n。这k个分组满足下列条件:每一个分组至少包含一个 文档,每一个文档属于且仅属一个分组。对于给定的k,算法首先的任务就是将文 本集建成k个划分,以后通过反复迭代从而改变分组的重定位,使得毎一次改进之 后的分组方案都较前一次好。将文档在不同的划分间移动,直至满足一定的准则。 一个好的划分的一般准则是:在同一个簇中的文档尽可能“相似”,不同簇中的文 档则尽可能“相异”。
5.1 文本聚类概述
研究热点: (1)对于一些需要事先确定聚类数以及初始聚类中心的算法,如何优化这些超 参数的选取,从而提高算法的稳定性以及模型质量? (2)目前的许多聚类算法只适用于结构化数据,如何通过对现有算法进行改进 使其同样适用于非结构化数据? (3)随着大数据时代的来临,数据的体量变得越来越大,如何对现有算法进行 改进从而使得算法更加高效稳定? (4)现有的某些算法对于凸形球状的文档集有良好的聚类效果,但是对于非凸 文档集的聚类效果较差,如何改进现有算法从而提高算法对不同文档集的普适性?
由于中文文档没有词的边界,所以一般先由分词软件对中文文档进行分词,然 后再把文档转换成向量,通过特征抽取后形成样本矩阵,最后再进行聚类,文本聚 类的输出一般为文档集合的一个划分。
文本挖掘的统计专业人才需求分析

文本挖掘的统计专业人才需求分析文本挖掘(Text Mining)是一个涉及自然语言处理、机器学习、统计分析等多学科的交叉领域,近年来受到越来越多的关注。
随着大数据时代的到来,文本挖掘技术在商业、金融、医疗等领域的应用越来越广泛,而这也需要越来越多的专业人才来支持这一领域的发展。
本报告将对文本挖掘领域的统计专业人才需求进行分析。
一、文本挖掘在各行业的应用文本挖掘技术在各行各业都有广泛应用。
其中,金融行业的应用主要是通过对投资者情绪进行分析,来预测股票市场的涨跌情况。
医疗行业中,文本挖掘技术可以用于自动化实验结果的分析,还可以对大量医疗文件进行归类和筛选,有助于医生更快速地做出诊断和治疗决策。
在商业领域中,文本挖掘常常被用来分析消费者需求和趋势,从而指导企业的市场策略和产品设计。
二、文本挖掘的专业技能要求文本挖掘涉及到自然语言处理、机器学习、数据挖掘、统计分析等多个领域,因此对人才的专业技能要求也比较高。
以下是针对统计专业人才的一些具体技能要求:1.熟练应用各种统计分析方法,如聚类分析、分类分析、回归分析等,以及各种可视化工具,如R语言、Python等;2.能够对大量文本数据进行处理和分析,理解文本数据的特殊性质,如文本数据的无序性、多义性等;3.熟悉常见的自然语言处理技术,如词频统计、词性标注、命名实体识别、情感分析等;4.掌握机器学习的基本理论和方法,如决策树/随机森林、朴素贝叶斯、支持向量机等;5.具有一定的编程能力,能够熟练使用SQL、Java、Python等编程语言。
三、统计专业人才的需求分析根据招聘网站上的数据,我们可以看出,文本挖掘领域对统计专业人才的需求较为稳定。
虽然与其他专业(如计算机、数学)相比,统计专业人才的招聘量相对较少,但求职市场上的需求与供应相对较平衡。
此外,根据不同的公司和领域,对统计专业人才的需求也有所不同。
包括以下方面:1.行业领域:不同行业内的文本挖掘技术的应用重点各有不同,因此在不同行业内的职位需求也会有所差别。
大数据常见的9种数据分析手段

大数据常见的9种数据分析手段一、数据清洗与预处理数据清洗与预处理是大数据分析的第一步,它包括去除重复数据、处理缺失值、处理异常值、处理噪声等。
常见的数据清洗与预处理手段有:1. 去除重复数据:通过对数据集进行去重操作,去除重复的记录,确保数据集的惟一性。
2. 处理缺失值:对于缺失的数据,可以选择删除含有缺失值的记录,或者使用插值法进行填充。
3. 处理异常值:通过统计分析和可视化分析等方法,识别和处理异常值,以避免对后续分析产生影响。
4. 处理噪声:通过滤波等方法,去除数据中的噪声,提高数据的质量和准确性。
二、数据可视化数据可视化是将数据以图表、图象等形式展示出来,匡助人们更直观地理解数据的特征和规律。
常见的数据可视化手段有:1. 条形图:用于比较不同类别的数据大小。
2. 折线图:用于展示数据随时间变化的趋势。
3. 散点图:用于展示两个变量之间的关系。
4. 饼图:用于展示各个部份占总体的比例。
5. 热力图:用于展示数据在空间上的分布情况。
三、数据挖掘数据挖掘是通过发现数据中的隐藏模式、规律和关联性,从大数据中提取有价值的信息。
常见的数据挖掘手段有:1. 关联规则挖掘:通过分析数据中的项集之间的关联关系,发现频繁项集和关联规则。
2. 聚类分析:将数据集中的对象划分为若干个类别,使得同一类别内的对象相似度较高,不同类别之间的相似度较低。
3. 分类分析:通过对已有数据集进行训练,建立分类模型,对新数据进行分类预测。
4. 预测分析:通过对历史数据的分析,预测未来的趋势和结果。
四、文本挖掘文本挖掘是从大规模的文本数据中提取实用信息的过程。
常见的文本挖掘手段有:1. 文本分类:将文本数据按照一定的标准进行分类,如情感分类、主题分类等。
2. 文本聚类:将相似的文本数据会萃到一起,形成一个类别。
3. 关键词提取:从文本中提取出关键词,用于后续的分析和处理。
4. 文本摘要:通过对文本内容的分析,提取出文本的核心信息,生成简洁的摘要。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• (4)查词表,W不在词表中,将W最右边一个字去掉,得 到W="课程是三";
• (5)查词表,W不在词表中,将W最右边一个字去掉,得 到W="课程是";
• (11)查词表,W不在词表中,将W最右边一个字去掉,得 到W="是三"
• S1="计算语言学课程是三个课时" • 设定最大词长MaxLen= 5 • S2= " "
• (1)S2=“”;S1不为空,从S1左边取出候选子串
• W="计算语言学";
• (2)查词表,“计算语言学”在词表中,将W加入到S2中 ,S2=“计算语言学/ ”,并将W从S1中去掉,此时S1="课 程是三个课时";
•
• 以上式子中 是该词在文件中的出现次数,而分母则是在 文件中所有字词的出现次数之和。
IDF度量
•逆向文件频率(inverse document frequency,IDF)是一个 词语普遍重要性的度量。某一特定词语的IDF,可以由总文 件数目除以包含该词语之文件的数目,再将得到的商取对数 得到:
预处理
• 把中文的汉字序列切分成有意义的词,就是中文分 词,也称为切词。
• “我是一个学生”分词的结果是:我是一个学生。 • 和平民主
– 和平、民主;和、平民、主
• 提高人民生活水平
– 提高、高人、人民、民生、生活、活水、水平
• 大学生活象白纸
– 大学、生活、象、白纸 – 大学生、活象、白纸
最大匹配分词法
• 向量空间模型将文档表达为一个矢量,看作向量空间中的 一个点。
文档的向量空间模型
W权值计算方法TF-IDF
目前广泛采用TF-IDF权值计算方法来计算权重, TF-IDF 的主要思想是,如果某个词或短语在一篇文章中出现的频 率TF高,并且在其他文章中很少出现,则认为此词或者短 语具有很好的类别区分能力,适合用来分类。
大数据与数据挖掘-文本挖掘
1、文本挖掘概述
文本挖掘的背景
• 数据挖掘大部分研究主要针对结构化数据,如关系的、事 务的和数据仓库数据。
• 现实中大部分数据存储在文本数据库中,如新闻文章、 研究论文、书籍、WEB页面等。
• 存放在文本数据库中的数据是半结构化数据,文档中可能 包含结构化字段,如标题、作者、出版社、出版日期 等, 也包含大量非结构化数据,如摘要和内容等。
• (12)查词表,W不在词表中,将W最右边一个字去掉,得 到W=“是”,这时W是单字,将W加入到S2中,S2=“计算 语言学/ 课程/ 是/ ”,
• 并将W从S1中去掉,此时S1="三个课时";
• ������ ������
• (21)S2=“计算语言学/ 课程/ 是/ 三/ 个/ 课时/ ” ,此时S1=""。
停用词。 • (2)基于DF的方法:统计每个词的DF,如果超过总文档
数目的某个百分比(如80%),则作为停用词去掉。
文档建模
• 特征表示是指以一定的特征项如词条或描 述来代表文档信息。
• 特征表示模型有多种,常用的有布尔逻辑 型、向量空间型等
• 向量空间模型中,将每个文本文档看成是一组词条(T1, T2,T3,…,Tn)构成,对于每一词条Ti,根据其在文档 中的重要程度赋予一定的权值,可以将其看成一个n维坐 标系,W1,W2,…,Wn为对应的坐标值,因此每一篇文档 都可以映射为由一组词条矢量构成的向量空间中的一点, 对于所有待挖掘的文档都用词条特征矢量(T1,W1;T2, W2;T3,W3;…;Tn,Wn)表示。
• (22)S1为空,输出S2作为分词结果,分词过程结束。
停用词
• 指文档中出现的连词,介词,冠词等并无太大意义的词。 • 英文中常用的停用词有the,a, it等 • 中文中常见的有“是”,“的”,“地”等。 • 停用词消除可以减少term的个数,降低存储空间。停用词
的消除方法: • (1)查表法:建立一个停用词表,通过查表的方式去掉
• 概括地讲,如果一个查询包含关键词 w1,w2,...,wN, 它们在一篇特定网页中的词频分 别是: TF1, TF2, ..., TFN。 (TF: term frequency)。 那么,这个查询和该网页的相关性 就是:TF1 + TF2 + ... + TFN。
• 词“的”站了总词频的 80% 以上,它对确定网页的主题 几乎没有用。在度量相关性时不应考虑它们的频率。删除 后,上述网页的相似度就变成了0.007,其中“大数据” 贡献了 0.002,“应用”贡献了 0.005。 “应用”是个 很通用的词,而“大数据”是个很专业的词,后者在相关 性排名中比前者重要。因此我们需要给汉语中的每一个词 给一个权重,这个权重的设定必须满足下面两个条件:
TF词频(Term Frequency)指的是某一个给定的词语在该文 件中出现的次数。
IDF逆文档频率(Inverse Document Frequency)是全体文 档数与包含词条文档数的比值。如果包含词条的文档越少, IDF越大,则说明词条具有很好的类别区分能力。
在完整的向量空间模型中,将TF和IDF组合在一起,形 成TF-IDF度量:TF-IDF(d,t)= TF(d,t)*IDF(t)
TF度量
• 在一份给定的文件里,词频(term frequency,TF)指的 是某一个给定的词语在该文件中出现的频率。这个数字是 对词数(term count)的归一化,以防止它偏向长的文件。 (同一个词语在长文件里可能会比短文件有更高的词数, 而不管该词语重要与否。)对于在某一特定文件里的词 语 来说,它的重要性可表示为:
文本挖掘概念
• 文本挖掘旨在通过识别和检索令人感兴趣 的模式,进而从数据源中抽取有用的信息。 文本挖掘的数据源是文本集合,令人感兴 趣的模式不是从形式化的数据库记录里发 现,而是从非结构化的数据中发现。
文本挖掘的过程
• 预处理 • 文档建模 • 相似性计算 • 信息检索 • 文本分类 • 文本聚类 • 模型评价
•|D|:语料库中的文件总数
•:
包含词语的文件数目(即的文件数目)如
果该词语不在语料库中,就会导致被除数为零,因此一
般情况下使用
关键词与网页的相关性计算
• 在某个一共有一千词的网页中“大数据”、“的” 和“应用”分别出现了 2 次、35 次 和 5 次, 那么它们的词频就分别是 0.002、0.035 和 0.005。三个数相加,其和 0.042 就是相应网页 和查询“大数据的应用” 相关性的一个简单的度 量。