第二讲 线性分类器
线性分类器及python实现

线性分类器及python实现以下内容参考CS231n。
上⼀篇关于分类器的⽂章,使⽤的是KNN分类器,KNN分类有两个主要的缺点:空间上,需要存储所有的训练数据⽤于⽐较。
时间上,每次分类操作,需要和所有训练数据⽐较。
本⽂开始线性分类器的学习。
和KNN相⽐,线性分类器才算得上真正具有实⽤价值的分类器,也是后⾯神经⽹络和卷积神经⽹络的基础。
线性分类器中包括⼏个⾮常重要的部分:权重矩阵W,偏差向量b评分函数损失函数正则化最优化权重矩阵W (Weights)可以理解为所有分类对应的模版向量w组成的矩阵,模版就是分类期望成为的样⼦。
训练数据可以理解为是N维空间中的⼀个向量v,v和W中每个模版做点积,点积越⼤,表⽰两个向量的夹⾓越⼩,也就越接近。
点积最⼤的模版w,就是v所对应的分类。
W不是⼀直不变的。
它会随着对损失函数最优化的过程,不断的调整。
偏差向量b (bias vector) b是不是可以理解为,如果不设置b,那所有的分类线都要通过原点,那其实就起不到分类的作⽤了?参考下图?三条线都通过原点,是⽆法对数据做分类的。
W和b分别对直线做旋转和平移。
评分函数(score function) 之所以是线性分类器,就是因为评分函数使⽤线性⽅程计算分数。
后⾯的神经⽹络会对线性函数做⾮线性处理。
下图直观的展⽰了分类器的线性。
损失函数(loss function)如何判断当前的W和b是否合适,是否能够输出准确的分类?通过损失函数,就可以计算预测的分类和实际分类之间的差异。
通过不断减⼩损失函数的值,也就是减少差异,就可以得到对应的W和b。
Python实现数据预处理# 每⾏均值mean_image = np.mean(X_train, axis=0)# second: subtract the mean image from train and test data# 零均值化,中⼼化,使数据分布在原点周围,可以加快训练的收敛速度X_train -= mean_imageX_val -= mean_imageX_test -= mean_imageX_dev -= mean_image处理b的技巧# third: append the bias dimension of ones (i.e. bias trick) so that our SVM# only has to worry about optimizing a single weight matrix W.# 技巧,将bias加到矩阵中,作为最后⼀列,直接参与矩阵运算。
作业2-线性分类器

end; for i=1:N1 x(1,i)=x1(1,i); x(2,i)=x1(2,i); y(i)=1; end; for i=(N1+1):(N1+N2) x(1,i)=x2(1,(i-N1)); x(2,i)=x2(2,(i-N1)); y(i)=-1; end; svm_struct=svmtrain(x,y,'Showplot',true); % 调用 svmtrain 函数对样本进行分类 % 分别创建训练样本矩阵和标号矩阵
x1(1,i)=-1.7+1.1*randn(1); x1(2,i)= 1.6+0.9*randn(1); x1(3,i)= 1; end; N2=400; for i=1:N2 x2(1,i)= 1.3+1.0*randn(1); x2(2,i)=-1.5+0.8*randn(1); x2(3,i)= 1; % 2 类400个训练样本,2维正态分布 % 1 类440个训练样本,2维正态分布
算法 2.
w(1)=rand(1); %对w 赋任意初值 w(2)=rand(1); w(3)=rand(1); p=0.001; %设置步长大小,一般在0~1 之间取值 for j=1:100 %j 为迭代次数,共迭代100 次 k=0; %k 是记录两类的样本误分类点的次数 n(j)=j; %n 记录迭代次数 for i=1:N1 xe=x1(:,i); %将1 类的各个样本值取出来,存入xe 中 if(w*xe<0) %1 类的迭代修正判断条件 w=w+p*xe'; %1 类的迭代修正公式,每次只修正一个样本的 %固定增量法 k=k+1; %记录1 类的误分类点总次数 end; end; for i=1:N2 xe=x2(:,i); %将2 类的各个样本值取出来,存入xe 中 if(w*xe>0) %2 类的迭代修正判断条件 w=w-p*xe'; %2 类的迭代修正公式,每次只修正一个样本的 %固定增量法 k=k+1; %记录1、2 类的误分类点总次数 end; end; en(j)=k; %en 记录每一次迭代中误分类点总次数 end; subplot(2,2,1); plot(n,en); %画图,横坐标为迭代次数,纵坐标为每次迭代 的误分类点总次数画图 t1=-5:1:5; %t1 范围是-5~5,步长为1 t2=(-w(1)*t1-w(3))/w(2); %求决策面 subplot(2,2,2);
LDA(线性判别分类器)学习笔记

LDA(线性判别分类器)学习笔记Linear Discriminant Analysis(线性判别分类器)是对费舍尔的线性鉴别⽅法(FLD)的归纳,属于监督学习的⽅法。
LDA的基本思想是将⾼维的模式样本投影到最佳鉴别⽮量空间,以达到抽取分类信息和压缩特征空间维数的效果,投影后保证模式样本在新的⼦空间有最⼤的类间距离和最⼩的类内距离,即模式在该空间中有最佳的可分离性。
因此,它是⼀种有效的特征抽取⽅法。
使⽤这种⽅法能够使投影后模式样本的类间散布矩阵最⼤,并且同时类内散布矩阵最⼩。
就是说,它能够保证投影后模式样本在新的空间中有最⼩的类内距离和最⼤的类间距离,即模式在该空间中有最佳的可分离性。
预备知识协⽅差与协⽅差矩阵协⽅差协⽅差分为随机变量的协⽅差和样本的协⽅差。
随机变量的协⽅差跟数学期望、⽅差⼀样,是分布的⼀个总体参数。
协⽅差是对两个随机变量联合分布线性相关程度的⼀种度量。
两个随机变量越线性相关,协⽅差越⼤,完全线性⽆关,协⽅差为零。
定义如下。
$$cov\left(X,Y\right)=E\left[\left(X-E\left[X\right])(Y-E\left[Y\right]\right)\right]$$因为变量尺度不同,所以不能⽤若⼲协⽅差的⼤⼩作为相关性强弱的⽐较。
因此引⼊相关系数,本质上是对协⽅差进⾏归⼀化。
$$\eta=\frac{cov\left(X,Y \right )}{\sqrt{var\left(X \right )\cdot var\left(Y \right )}}$$取值范围[-1,1]。
样本的协⽅差对于现有的m个样本,每个样本均具有n维属性,每⼀维属性我们都可以将其看作是⼀个随机变量。
每⼀个样本$x_j =\left[x_{1j} ,...,x_{nj}\right ]$。
那么我们就可以考察样本集中,两个随机变量(两属性)间的线性关系。
计算和随机变量的协⽅差⼀致。
线性分类器值感知机算法和最小均方误差算法

线性分类器之感知机算法和最小平方误差算法1.问题描述对所提供的的数据“data1.m ”,分别采用感知机算法、最小平方误差算法设计分类器,分别画出决策面,并比较性能,并且讨论算法中参数设置的影响2.方法叙述2.1感知机算法1.假设已知一组容量为N 的样本集1y ,2y ,…,N y ,其中N y 为d 维增广样本向量,分别来自1ω和2ω类。
如果有一个线性机器能把每个样本正确分类,即存在一个权向量a ,使得对于任何1ω∈y ,都有y a T >0,而对一任何2ω∈y ,都有y a T<0,则称这组样本集线性可分;否则称线性不可分。
若线性可分,则必存在一个权向量a ,能将每个样本正确分类。
2.基本方法:由上面原理可知,样本集1y ,2y ,…,N y 是线性可分,则必存在某个权向量a ,使得⎪⎩⎪⎨⎧∈<∈>21y ,0y ,0ωωj j Ti i T y a y a 对一切对一切 如果我们在来自2ω类的样本j y 前面加上一个负号,即令j y =—j y ,其中2ω∈j y ,则也有y a T >0。
因此,我们令⎩⎨⎧∈∈='21y ,-y ,ωωj ji i n y y y 对一切对一切那么,我们就可以不管样本原来的类型标志,只要找到一个对全部样本ny '都满足y a T >0,N n ,,3,2,1⋯⋯=的权向量a 就行了。
此过程称为样本的规范化,ny '成为规范化增广样本向量,后面我们用y 来表示它。
我们的目的是找到一个解向量*a ,使得N n y a n T ,...,2,1,0=>为此我们首先考虑处理线性可分问题的算法。
先构造这样一个准则函数)()(y∑∈=ky Tp y aa J γδ式中kγ是被权向量a 错分类的样本集合。
y δ的取值保证因此()a J p 总是大于等于0。
即错分类时有0≤y a T (1ω∈y ),0≥y a T(2ω∈y ),此时的y δ分别为-1,1。
模式识别之二次和线性分类器课件

线性分类器利用训练数据集学习得到 一个线性函数,该函数可用于对新数 据进行分类。分类决策边界是一个超 平面,将不同类别的数据分隔开来。
线性分类器数学模型
线性函数
优化目标
正则化
线性分类器使用的线性函数通 常表示为权重向量和特征向量 的内积加上偏置项,即y = w^Tx + b,其中y是预测类别 ,w是权重向量,x是特征向量 ,b是偏置项。
模式识别之二课次件和线性分类器
contents
目录
• 引言 • 二次分类器原理 • 线性分类器原理 • 二次与线性分类器比较 • 二次和线性分类器应用案例 • 总结与展望
01
引言
模式识别概述
模式
01
在感知或观察事物时,人们所发现的事物之间规律性的关系或
特征。
模式识别
02
利用计算机对输入的信号进行分类或描述,以实现自动识别目
01
深度学习在模式识别 中的应用
深度学习技术为模式识别提供了新的 解决方案,能够自动提取数据的深层 特征,提高识别精度。
02
多模态数据融合
利用多模态数据融合技术,将不同来 源、不同类型的数据进行融合,提高 模式识别的性能和鲁棒性。
03
迁移学习在模式识别 中的应用
迁移学习技术可以将在一个任务上学 到的知识迁移到另一个任务上,从而 加速模型训练,提高识别效率。
自然语言处理领域应用案例
1 2
文本分类
通过训练二次和线性分类器,对文本进行分类, 如新闻、广告、评论等,提高信息处理的效率。
情感分析
利用分类器对文本中的情感进行识别和分析,为 企业了解用户需求、改进产品提供参考。
3
机器翻译
结合分类器对源语言进行识别和转换,实现不同 语言之间的自动翻译,促进跨语言交流。
模式识别:线性分类器

模式识别:线性分类器一、实验目的和要求目的:了解线性分类器,对分类器的参数做一定的了解,理解参数设置对算法的影响。
要求:1. 产生两类样本2. 采用线性分类器生成出两类样本的分类面3. 对比线性分类器的性能,对比参数设置的结果二、实验环境、内容和方法环境:windows 7,matlab R2010a内容:通过实验,对生成的实验数据样本进行分类。
三、实验基本原理感知器基本原理:1.感知器的学习过程是不断改变权向量的输入,更新结构中的可变参数,最后实现在有限次迭代之后的收敛。
感知器的基本模型结构如图1所示:图1 感知器基本模型其中,X输入,Xi表示的是第i个输入;Y表示输出;W表示权向量;w0是阈值,f是一个阶跃函数。
感知器实现样本的线性分类主要过程是:特征向量的元素x1,x2,……,xk是网络的输入元素,每一个元素与相应的权wi相乘。
,乘积相加后再与阈值w0相加,结果通过f函数执行激活功能,f为系统的激活函数。
因为f是一个阶跃函数,故当自变量小于0时,f= -1;当自变量大于0时,f= 1。
这样,根据输出信号Y,把相应的特征向量分到为两类。
然而,权向量w并不是一个已知的参数,故感知器算法很重要的一个步骤即是寻找一个合理的决策超平面。
故设这个超平面为w,满足:(1)引入一个代价函数,定义为:(2)其中,Y是权向量w定义的超平面错误分类的训练向量的子集。
变量定义为:当时,= -1;当时,= +1。
显然,J(w)≥0。
当代价函数J(w)达到最小值0时,所有的训练向量分类都全部正确。
为了计算代价函数的最小迭代值,可以采用梯度下降法设计迭代算法,即:(3)其中,w(n)是第n次迭代的权向量,有多种取值方法,在本设计中采用固定非负值。
由J(w)的定义,可以进一步简化(3)得到:(4)通过(4)来不断更新w,这种算法就称为感知器算法(perceptron algorithm)。
可以证明,这种算法在经过有限次迭代之后是收敛的,也就是说,根据(4)规则修正权向量w,可以让所有的特征向量都正确分类。
李飞飞机器视觉课程笔记:第2课K最近邻与线性分类器

李飞飞机器视觉课程笔记:第2课K最近邻与线性分类器Lecture 2:Image Classification pipeline1.Image Classification(图⽚分类):a core task in Computer Vision(计算机视觉中的核⼼部分) 图像分类的基本任务就是⽐如将狗、猫和飞机等区分开来,在这之前我们先要将图⽚转换为⼀张巨⼤的数字表单,然后从所有种类中,给这个表单选定⼀个标签。
图⽚分类是计算机视觉中的最基本的⼀部分,⽐如计算机视觉中的物体检测就是在这个基础上进⾏细⼩的改动,所以学会图⽚分类,其他⼯作就是⼩菜⼀碟了。
⽐如⼀张图⽚,它在计算机看来就是⼀张巨⼤的数字表单,可以⼤致由⼀个300*100*3的三位数组表⽰,这⾥的3来⾃于图⽚红绿蓝三⾊道,所以图⽚的全部数字都是处于0~255之间的,这些数字反映的是亮度以及每个单点三基⾊的权值,所以难度在于,当你想要处理这表单中数以百万计的数字,并对其分类,如猫类,这个问题是相当复杂的。
此外,通过调整相机旋转、调亮度、光线等操作,还有图⽚对象的形变(Deformation,⽐如猫的不同姿势),对象被遮掩(Occlusion,只可以看到10%),同类演变(Intraclass variation)等相当多的⼲扰,⼀个物体可以完全不同,但是要在姿势改变时候,依旧识别出这些猫来,就是我们的算法可以解决这些所有问题。
An image classifier(图⽚分类器)是什么样⼦的呢?我们构建⼀个三维空间,将x轴上的值定位种类标签值,但是没有⼀种显⽰的⽅式来实现识别猫或者其他类别的算法代码,在数据结构中的简单算法⽐如冒泡排序(bubble sort)等算法的变体中,并没有哪种可以⽤来检测猫。
我们要做的是检测并勾画出图⽚的边界,按照边界形状与连接⽅式进⾏分类,这会让你学习到这类东西的“样本集合”,我们可以尽量找到他们的各种形态,⽐如我们看到任何像猫的⽿朵,我们便认为检测到猫,或者如果我们检测到猫的某些结构特征,⼀定程度上,我们可以认为检测到猫了,你也可以设定⼀些别的规则,但是问题在于,如果我现在要识别船或者⼈,就得回到画板去想“船和⼈的边界和明显特征是什么”,显然这是不可扩展的分类⽅法。
模式识别-2-线性判别函数与线性分类器设计

x2
2
X 是 n 维空间的一个向量
1
模式识别问题就是根据模式X的 n个特征来判别模式属于 ω1 ,ω2 , … , ωm类中的那一类。 例如右上图:三类的分类问题,它 们的边界线就是一个判别函数
x1
边界
3
用判别函数进行模式分类,取决两个因素:
判别函数的几何性质:线性与非线性 判别函数的参数确定:判别函数形式+参数
因此,三个判别边界为:
g 1 ( x ) x1 x 2 0 g 2 ( x ) x1 x 2 5 0 g (x) x 1 0 2 3
作图如下:
5
g1 ( x) 0 g 2 (x) 0 g (x) 0 3
必须指出,如果某个X使二个以上的判别函数 gi(x) >0 。 则此模式X就无法作出确切的判决。如图中 IR1,IR3, IR4区域。
另一种情况是IR2区域,判别函数都为负值。IR1,IR2, IR3,IR4。都为不确 定区域。
5
g1 ( x) 0 g 2 (x) 0 g (x) 0 3
第二章 线性判别函数与线性 分类器设计
• • • • 判别函数 线性判别函数 线性判别函数的性质 线性分类器设计
– – – – 梯度下降法—迭代法 感知器法 最小平方误差准则(MSE法)---非迭代法 Fisher分类准则
§ 2.1 判别函数
假设对一模式X已抽取n个特征, 表示为:
X ( x 1 , x 2 , x 3 ,..., x n )
12
2
1
g 23 ( x ) 0
判别函数: g ij ( x ) W ij 判别边界: g ij ( x ) o 判别条件:
线性分类器算法原理及应用

线性分类器算法原理及应用随着人工智能技术的发展,机器学习已成为各行各业的热门话题,许多人也开始关注和了解各种机器学习算法。
其中,线性分类器算法是一种应用较为广泛的算法,本文将为大家介绍它的原理及应用。
一、线性分类器算法的基础知识1.1 算法简介线性分类器算法是一种常见的机器学习算法,主要用于二分类问题(即将数据分为两类)。
它的基本原理是利用线性函数将数据进行分类,其中具体的分类依据是判断某个数据点是否在计算后大于或小于一个阈值。
1.2 基本公式在线性分类器算法中,一个线性函数的基本公式如下所示:Y = b + w1X1 + w2X2 + … + wnXn其中,Y表示样本的类别,b表示偏置项,w1~wn表示权值,X1~Xn表示输入数据的特征值。
当Y大于某个阈值时该样本被归为一类,小于则归为另一类。
1.3 适用场景线性分类器算法适用于多种分类问题,如判断一封邮件是否为垃圾邮件、一个人是否会违约等。
它的应用非常广泛,并且准确率较高。
二、线性分类器算法的实现步骤2.1 数据处理在使用线性分类器算法前,我们需要对数据进行预处理。
首先,需要清洗数据,去除异常值和缺失值等。
然后,对数据进行标准化处理,将数据归一化,避免数据范围的差异性对结果的影响。
2.2 模型训练训练模型是线性分类器算法的核心步骤。
在训练模型前,我们需要将数据集分为训练集和测试集,以验证模型的准确率。
训练模型的过程就是不断调整权值和偏置项,根据损失函数来确定误差,并利用优化算法进行调整。
常见的优化算法包括随机梯度下降法和牛顿法等。
2.3 模型评估模型评估是判断模型是否准确的重要步骤。
在评估模型时,我们需要将测试集输入模型中,通过预测值与实际值的比较来确定模型的准确率。
模型的评估应基于多个指标,如精度、召回率、F1值等。
通过综合考虑这些指标来评估模型的准确性。
三、线性分类器算法应用案例3.1 垃圾邮件分类垃圾邮件是我们在日常生活和工作中难以避免的问题。
线性分类器

中心问题:
1.存在一个间隔,满足
tic
Yd = svmSim(svm,Xt); %测试输出
t_sim = toc;
Yd = reshape(Yd,rows,cols);
%画出二维等值线图
contour(x1,x2,Yd,[0 0],'m'); %分类面
hold off;
3.3支持向量机实验结果参见下图:
评价三种方法的方法???
for i=1:N
if((X(i,:)*w)*y(i)<0)
mis_clas=mis_clas+1;
gradi=gradi+rho*(-y(i)*X(i,:))';
end
end
w=w-rho*gradi;%最后推到的那个公式
end
s(1)=1.6; t(1)=-s(1)*w(1)/w(2)-w(3)/w(2);
s(2)=11.2; t(2)=-s(2)*w(1)/w(2)-w(3)/w(2);%确定直线需要的两个点
figure(2)
plot(X(1:45,1),X(1:45,2),'*',X(46:100,1),X(46:100,2),'o',s,t);%绘制分界线
axis([0,12,0,8]);
1.3感知器算法实验结果参见下图
其中是第次迭代的权向量估计,并且是一系列的正实数。但是在这里必须注意:不连续的点除外。从感知机代价的定义以及有小点可以得到,
线性分类器的分类原理

线性分类器的分类原理线性分类器是一种常用的机器学习算法,主要用于将输入数据分成两个或多个不同的类别。
其分类原理基于线性方程和决策边界的概念。
线性分类器假设输入数据是由各个特征的线性组合得到的,即特征的权重与特征值的乘积之和。
假设我们有一个二维数据集,其中每个样本有两个特征,可以表示为X = {(x_1, y_1), (x_2, y_2), ..., (x_n, y_n)}。
线性分类器的目标是找到一个超平面,将不同类别的数据样本正确地分开。
假设有两个类别(标签为-1和+1),我们的目标是找到一个可行的分割超平面,定义为wx + b = 0,其中w 是特征权重向量,x 是特征向量,b 是偏置值。
对于特征向量x = (x_1, x_2, ..., x_m),权重向量w = (w_1, w_2, ..., w_m) 和偏置b,线性分类器的输出为:f(x) = sign(wx + b)将数据样本代入分割超平面,通过wx + b 的符号来判断其所属的类别。
如果wx + b 大于0,则样本属于标签+1 的类别,反之,则属于标签-1 的类别。
因此,分割超平面实质上是一个决策边界,将数据样本投影到不同的区域中。
为了找到一个最优的分割超平面,我们需要定义一个损失函数。
这个损失函数衡量了分类器预测和实际标签之间的差异。
常用的损失函数是合页损失(HingeLoss),其定义为:L(w, b) = max(0, 1 - y(wx + b))其中y 为样本的实际标签。
当样本的预测值和真实标签相符时,合页损失为0,表示分类正确;当预测值和真实标签不同时,损失函数不为0,表示分类错误。
我们的目标是最小化损失函数,找到最优的权重向量w 和偏置b,以使得分类器能够尽可能准确地对新样本进行分类。
为了实现分类器的训练,我们可以使用梯度下降算法或其他优化算法来最小化损失函数。
梯度下降算法的基本思想是通过计算损失函数对权重向量和偏置的梯度,并根据梯度的方向来更新权重和偏置的值。
计算机视觉-线性分类器

计算机视觉-线性分类器线性分类器CIFAR10数据集。
图像类型:⼆进制图像(⾮⿊即⽩,⾮0即1)、灰度图像(像素值0-255)、彩⾊图像(RGB,每⼀个通道都是255个像素值)。
⼤多数分类算法都要求输⼊向量。
将图像转换成向量的⽅法有很多,最直接简单的⽅法就是将图像矩阵转换成向量(⼀次排列每⼀个像素点的RGB就得到了向量)。
线性分类器:为什么从线性分类器开始?形式简单、易于理解;最重要的是线性分类器可以通过层级结构(神经⽹络)或者⾼维映射(⽀持向量机)可以组合成为功能强⼤的⾮线性模型。
线性分类器是神经⽹络的基础。
线性分类器是⽀持向量机的基础。
⼩样本情况下,⽀持向量机是绝对的王者;在⼤样本情况下,神经⽹络是绝对的王者。
将X向量转换为类别标签。
每⼀个类别都有⾃⼰的参数W和偏置b。
这⾥是假设1000个样本分为10类,这这10类样本就各⾃有各⾃的W和b。
决策规则:如果fi(x)>fj(x),i≠j,则决策输⼊图像x属于第i类。
也就是某⼀个类别x在第i类的打分⽐第j类的打分⾼的话,那么就将它归属于第i个类别。
损失函数:损失函数是⼀个函数,⽤于度量给定分类器的预测值与真实值的不⼀致程度,其输出通常是⼀个⾮负实值。
损失函数的输出值可以作为反馈信号来对分类器参数进⾏调整,以降低当前实例对应的损失值,从⽽提升分类器的分类效果。
正则项:因为不⽌存在⼀个权重W能够使得损失函数L=0,因此,在多个权重值之间做出选择时就需要⽤到正则项。
超参数:在开始学习过程之前设置的参数;超参数⼀般都会对模型性能有着重要的影响。
使⽤L2正则项:R(W)=求和(Wi^2),选择正则损失最⼩的那个权重W值。
L2正则损失对⼤数值权值进⾏惩罚,喜欢分散权值,⿎励分类器将所有维度的特征都⽤起来,⽽不是强烈的依赖其中少数⼏维特征。
L2正则过程中会选择尽量多的考虑到所有的维度特征,⽽不是简单依赖于其中某⼀个或⼏个特征就得出结果,避免了某个重要维度出现损伤的情况下导致整体出错。
SVM入门(二三)线性分类器

SVM入门(二三)线性分类器SVM入门(二)线性分类器Part 1线性分类器(一定意义上,也可以叫做感知机) 是最简单也很有效的分类器形式.在一个线性分类器中,可以看到SVM形成的思路,并接触很多SVM的核心概念.用一个二维空间里仅有两类样本的分类问题来举个小例子。
如图所示C1和C2是要区分的两个类别,在二维平面中它们的样本如上图所示。
中间的直线就是一个分类函数,它可以将两类样本完全分开。
一般的,如果一个线性函数能够将样本完全正确的分开,就称这些数据是线性可分的,否则称为非线性可分的。
什么叫线性函数呢?在一维空间里就是一个点,在二维空间里就是一条直线,三维空间里就是一个平面,可以如此想象下去,如果不关注空间的维数,这种线性函数还有一个统一的名称——超平面(Hyper Plane)!实际上,一个线性函数是一个实值函数(即函数的值是连续的实数),而我们的分类问题(例如这里的二元分类问题——回答一个样本属于还是不属于一个类别的问题)需要离散的输出值,例如用1表示某个样本属于类别C1,而用0表示不属于(不属于C1也就意味着属于C2),这时候只需要简单的在实值函数的基础上附加一个阈值即可,通过分类函数执行时得到的值大于还是小于这个阈值来确定类别归属。
例如我们有一个线性函数g(x)=wx+b我们可以取阈值为0,这样当有一个样本x i需要判别的时候,我们就看g(x i)的值。
若g(x i)>0,就判别为类别C1,若g(x i)<0,则判别为类别C2(等于的时候我们就拒绝判断,呵呵)。
此时也等价于给函数g(x)附加一个符号函数sgn(),即f(x)=sgn [g(x)]是我们真正的判别函数。
关于g(x)=wx+b这个表达式要注意三点:一,式中的x不是二维坐标系中的横轴,而是样本的向量表示,例如一个样本点的坐标是(3,8),则x T=(3,8) ,而不是x=3(一般说向量都是说列向量,因此以行向量形式来表示时,就加上转置)。
线性分类器 (Linear Classifiers)

第三章 线性分类器 (Linear Classifiers)我们看到,在一定条件下,基于概率或概率密度的分类器设计问题,即基于后验概率或类条件概率密度的分类器设计问题,或用Bayes 决策理论设计的分类器可转化为线性分类器。
线性分类器的特点是结构简单,计算工作量小,缺点是在很多情况下分类正确率不够高。
3.1 线性判别函数和决策超平面(Linear DiscriminantFunctions and Decision Hyperplanes)我们先考虑两类问题和线性判别函数。
设特征空间维数为m ,即x ∈R m ,一个超平面决策方程可写为())1.3(0:0=+=w l πT x w x这里,w =(w 1,w 2,⋯,w m )T 为权值向量,w 0为阈值(bias)。
如果x 1、x 2两个点均在超平面π上,则有)2.3(00201=+=+w w T T x w x w或())3.3(021=-x x w T显然,w 与x 1-x 2垂直。
有时,人们称w 为超平面π的法矢量。
将(3.1)展开得())4.3(0:002211==++++=∑=mi i i m m x w w x w x w x w l π x这里,x 0=1。
平面π在坐标轴上的截距为)5.3(0ii w w θ-=x 110w图3.1a 线性分类器决策超平面示意图1x 11图3.1b 线性分类器决策超平面示意图2图3.1给出了线性分类器决策超平面示意图。
根据该图,坐标原点到决策平面π的Euclid 距离为)6.3(202222100w w w w w w d m=+++=特征空间任意一点x =(x 1,x 2,⋯,x m )T 到决策平面π的Euclid 距离为()())7.3(,22222102211w x x l w w w w x w x w x w x w πd mm m i i =+++++++++=特别需要注意的是,π1: l (x )=w 1x 1+w 2x 2+⋯+w m x m +w 0=0与π2: l (x )= -w 1x 1-w 2x 2-⋯-w m x m -w 0=0所决定的平面完全相同,但它们的决策区域却是完全相反的。
第二讲 线性分类器
G x w1 x1 w2 x2
若令
x x1 , x2 ,
T
wn xn w0
, xn ,即模式对应的特征向量 , wn ,称为权向量
T
w = w1 , w2 ,
则判别函数可写为
G x wT x w0
对于任一模式 x ,若 G ( x)>0 ,可判别 x ∈ ω 1 ;若 G (x )<0 ,可判别 x∈ ω 2 ; 若 G (x )= 0 ,则不能判别 x 所属的类别。 此时决策边界方程为
图 3 线性判别函数
在判别函数中,特别 要注意函数名下标所对应的类别和判别函数正负
第 2 页 自动化学院 模式识别与智能系统研究所 高琪 gaoqi@
《模式识别》讲义 2011 版:第二讲
线性分类器
号之间的关系。 一般来说, 当判别函数 Gij ( x ) 对某个特征向量 x 取得正值时, x 对应的模式应当有可能归于类 i ,而不会归于类 j 。
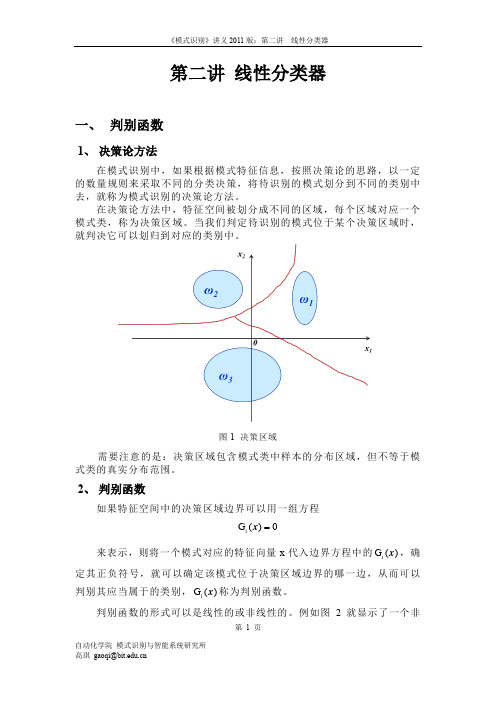
图 1 决策区域
需要注意的是:决策区域包含模式类中样本的分布区域,但不等于模 式类的真实分布范围。
2、 判别函数
如果特征空间中的决策区域边界可以用一组方程
Gi ( x) 0
来表示,则将一个模式对应的特征向量 x 代入边界方程中的 Gi ( x ) ,确 定其正负符号,就可以确定该模式位于决策区域边界的哪一边,从而可以 判别其应当属于的类别, Gi ( x ) 称为判别函数。 判别函数的形式可以是线性的或非线性的。例如图 2 就显示了一个非
图 9 多类问题――绝对可分
此时分类决策规则可以用判定表表示为:
G1 ( x )>0 G2 ( x )>0 G3 ( x )>0 分类决策 T F F x∈ ω1 F T F x∈ ω2 F F T x∈ ω3 T T F IR1 T F T IR2 F T T IR3 F F F IR4
线性分类器

如果 y(x) ≥ 0 ,则 x 分属于 C1 类,反之属于 C2 类。并且定义一个新的变量 t ,如果样
位于决策面上的两点 xA 和 xB ,由于 y(xA ) = y(xB ) = 0 ,因此有 wT (xA − xB ) = 0 ,故 w
与位于决策面里的所有向量正交,即 w 与决策面垂直(或说 w 为决策面的法向量)。也就是
说 w 决定决策面的方向。类似地,如果 x 为位于位于决策面上的一个点,则 y(x) = 0 ,且
注意,对于二类分类问题可以采用 1.1 节或 1.2 节中任一方法。
1.3 判别式参数求解
1.3.1 最小平方和法
考虑一个通用 K 类分类问题,特征向量采用 K 选 1 的编码方式表示。每个类 Ck 用线性
模型表示如下:
yk (x) = wk Tx + wk 0
(1.8)
其中 k = 1, , K 。将这 K 模型组合起来以向量形式表示为:
∑ ∑ ∑ mi
=
1 Ni
y∈ϒi
y
=
1 Ni
wTx
x∈Ci
=
w
T
⎛ ⎜
⎝
1 Ni
⎞ x⎟ = ⎠ x∈Ci
wTmi
这样式(1.21)的分子变为
( ) ( ) m1 − m2 2 = wTm1 − wTm2 2
= wT (m1 − m2 ) (m1 − m2 )T w = wTSbw
下面推导式(1.21)中分母与 w 的关系:
阵
T
,其第
n
行为向量
t
n
T
,并定义矩阵
X
,其第
n
行为向量
T
xn
。则目标函数为平方和函
线性分类器及非线性分类器-OK

线性分类器及⾮线性分类器-OK第⼆章统计模式识别(⼀)(⼏何分类法)⽬录统计分类的基本思想模板匹配法及其数学描述模式的相似性度量及距离分类法⼏何分类法(线性可分时)⼏何分类法(线性不可分时)⼩结1. 统计分类的基本思想模式与模式识别简单模式与复杂模式–分类–描述或分析模式识别的公理性假设,蕴含–可描述性–可分性–凝聚性–特征独⽴性–模式相似性统计分类的基本思想b公设⼀:可描述性存在⼀个有代表性的样本集可供使⽤,以便获得⼀个问题范围。
公设⼆:可分性⼀个“简单”模式,具有表征其类别的类属性特征。
{(),,()}i kf fω=??LX X统计分类的基本思想c公设三:凝聚性⼀个类的模式,其特征在特征空间中组成某种程度上的⼀个集群区域,不同类的特征组成的区域是彼此分离的。
备注:公设三中的特征是模式分类和识别的核⼼问题。
统计分类的基本思想d公设四:特征独⽴性⼀个“复杂”模式具有简单的组成部分,它们之间存在确定的关系。
模式被分解成这些组成部分,且它们有⼀个确定的⽽不是任意的结构。
公设五:模式相似性如果两个模式的特征或其简单的组成部分仅有微⼩差别,则称两个模式是相似的。
统计分类的基本思想e⼏点说明–相似性的区别是通过度量距离来定义的;–“微⼩差别”ó距离测度⼩于某个给定的阈值;–简单模式,具有量化的特征值(向量)举例1–A 模式:(4, yellow, 4 wheels)–B 模式:(4, green, 4 wheels)–C 模式:(4, yellow, 4 oars)Q. Wang8讲义:模式识别导论第⼆章:统计模式识别(⼀)统计分类的基本思想g线性判别分类的基本⽅法–将样本的各类特征向量定位于特征空间后设法找出分界线(n=2时)或分界⾯(n>2时)。
–把特征空间分割成若⼲区域,每个区域对应于⼀个类别–对于⼀个未知类别的模式落在那个区域,就被分到那个类别中。
注意:12(,,,)T n X x x x =L 特征维数增加,分类的复杂度提⾼;样本的类别增多,分类的复杂度也提⾼。
一文带你读懂线性分类器

一文带你读懂线性分类器一文带你读懂线性分类器什么是线性分类器?在有监督学习中,最主要的两种学习任务是回归(regression)和分类(classification),而其中线性回归和线性分类最为常见。
线性回归是预测某一个具体的值,而线性分类是数据所属类别进行预测。
这里,我们主要关注线性分类问题。
一般来说,几乎 80% 机器学习任务可以看作是某种分类问题。
分类,即给定一个输入的集合,分类器致力于预测每一个类别的概率。
类别标记(也被称为应变量或依赖变量)是一个离散的值,表示某个类别。
1. 如果数据中的 Label 只有两个类别,那么就属于二分类问题,相应的分类器被称为二分类器。
2. 多分类器解决 Label 种类多于两种类别的分类问题。
譬如,预测顾客是否会进行二次购买便是一个典型的二分类问题。
而识别图片中出现动物则是属于多分类问题,因为实际情况中动物有很多种。
本文的理论部分主要关注于二分类问题。
未来我们也会推出关于多分类的内容,敬请期待!二分类器是如何工作的?在前面的教程中你已经了解到函数由两类变量组成,一个应变量和一组特征(自变量)。
在线性回归中,应变量是一个没有范围的实数。
主要目标是通过最小化均方误差来预测其值。
对于二分类任务,标签可以有两个可能的整数值。
在大多数情况下,要么是[0,1]要么是[1,2]。
例如,如果目标是预测客户是否会购买产品。
标签可为如下:Y = 1(客户购买了产品)Y = 0 (客户没有购买产品)该模型使用特征X将每个客户分类到他最有可能的所属类别,即是潜在购买者,或否。
成功的概率用逻辑回归计算。
该算法将根据特征X计算出一个概率,并在该概率大于50%时预测成功。
概率的算式如下:θ是权重的集合,x是特征,b是偏差该函数可进一步分为两部分:线性模型逻辑函数线性模型你已经熟悉了计算权重的方法。
权重计算使用点积:θ^ Tx + bY是所有特征x_i的线性函数。
如果模型没有特征,则预测结果为偏差b。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
线性分类器
第二讲 线性分类器
一、 判别函数
1、 决策论方法
在模式识别中,如果根据模式特征信息,按照决策论的思路,以一定 的数量规则来采取不同的分类决策,将待识别的 模式划分到不同的类别中 去,就称为模式识别的决策论方法。 在决策论方法中,特征空间被划分成不同的区域,每个区域对应一个 模式类,称为决策区域。当我们判定待识别的模式位于某个决策区域时, 就判决它可以划归到对应的类别中。
第 1 页 自动化学院 模式识别与智能系统研究所 高琪 gaoqi@
《模式识别》讲义 201别函数,当 G( x )>0 时,可判别模式 x ∈ ω 1 ;当 G (x )<0 时,可判别 x ∈ ω2。
图 2 非线性判别函数
非线性判别函数的处理比较复杂,如果决策区域边界可以用线性方程 来表达,则决策区域可以用超平面来划分,无论在分类器的学习还是分类 决策时都比较方便。例如图 3 中的特征空间可以用两个线性判别函数来进 行分类决策: 当 G21 (x )>0 时, x ∈ ω 2 ; 当 G13 (x )<0 时, x ∈ ω 3 ; 当 G21 (x )<0 且 G13 ( x)>0 时, x ∈ ω 1 。
T
将其写成 n+1 维增广形式,即
Gij x wT x
x x1 , x2 , w = w1 , w2 , , xn ,1 ,即 n+1 维增广特征向量
T
, wn , w0 ,即 n+1 维增广权向量
T
此时分类决策规则为:
若Gij x 0, 则x i ; 若Gij x 0, 则x j ;
G x wT x w0 0
为 n 维超平面。对于决策边界上的任意线段,其起点 x 1 和终点 x 2 都在 该超平面上,即满足
G x wT x1 w0 wT x2 w0 0
即
wT ( x2 x1 ) 0
由此可见,权向量与决策边界超平面正交(垂直) ,其方向指向 ω 1 类 一边,而
G x wT x w0 0
设模式 x 距离决策边界的距离为 r ,则向量 x 可以表示为其在决策边界上的 投影点所代表的向量 x p 和向量 r
w 的和,即 w x xp r w w
图 12 线性判别函数的几何意义
代入判别函数中,得
G x wT x w0 wT ( x p r
3、 线性可分性和广义线性判别函数
一个模式识别问题是否线性可分( linearly separable ) ,取决于是否有可 能找到一个超平面来分离开两个相邻的类别。如果每个类别的分布范围本 身是全连通的单一凸集,且互不重叠,则这两个类别一定是线性可分的。 因此,线性不可分的情况有可能包含两种情况: ( 1 ) 至少有一个类别的分布范围是凹的, 且其凸包和另一个类别的分 布范围重叠;
图 3 线性判别函数
在判别函数中,特别 要注意函数名下标所对应的类别和判别函数正负
第 2 页 自动化学院 模式识别与智能系统研究所 高琪 gaoqi@
《模式识别》讲义 2011 版:第二讲
线性分类器
号之间的关系。 一般来说, 当判别函数 Gij ( x ) 对某个特征向量 x 取得正值时, x 对应的模式应当有可能归于类 i ,而不会归于类 j 。
如果给定一个分好类的样本集, 则其中每个样本对应的增广特征向量都是已 知的,此时要设计一个线性分类器可以实现两个类的分类决策,就是要求解出一 个能使得样本集内所有样本都能划分到正确的类别中的增广权向量 w , 这就是线 性分类器的设计目标。 ( 2) 求解条件 假设用于学习的样本集中有 l 个样本,其中有 li 个属于 i 类,对应的特
三、 线性分类器设计
1、 线性分类器设计思路
( 1) 设计目标 对于任意两个类之间,都可以使用一个线性判别函数来进行区分,决 策边界方程为:
Gij x wT x w0 0
其中
x x1 , x2 , , xn ,即模式对应的特征向量
T
w = w1 , w2 ,
, wn ,称为权向量
G( x) ( x a)( x b) x 2 (a b) x ab y1 (a b) y2 ab
在 2 维空间 Y 中,决策区域的边界是一条直线,线性不可分问题转换成为 了一个线性可分问题。判别函数
G( y) y1 (a b) y2 ab
称为广义线性判别函数。 在 Y 空间中决策区域边界是一条直线,两个模式类上的点分布于一条抛物 线上,分别位于决策线的两边。
。则增广权向量 w 应当满足
Gij ( x (1) ) w T x (1) 0 G ( x (2) ) w T x (2) 0 ij (l ) T (l ) Gij ( x i ) w x i 0 G ( y (1) ) w T y (1) 0 ij (2) T (2) Gij ( y ) w y 0 Gij ( y (l j ) ) w T y ( l j ) 0
G x w1 x1 w2 x2
若令
x x1 , x2 ,
T
wn xn w0
, xn ,即模式对应的特征向量 , wn ,称为权向量
T
w = w1 , w2 ,
则判别函数可写为
G x wT x w0
对于任一模式 x ,若 G ( x)>0 ,可判别 x ∈ ω 1 ;若 G (x )<0 ,可判别 x∈ ω 2 ; 若 G (x )= 0 ,则不能判别 x 所属的类别。 此时决策边界方程为
图 9 多类问题――绝对可分
此时分类决策规则可以用判定表表示为:
G1 ( x )>0 G2 ( x )>0 G3 ( x )>0 分类决策 T F F x∈ ω1 F T F x∈ ω2 F F T x∈ ω3 T T F IR1 T F T IR2 F T T IR3 F F F IR4
可以发现,绝对可分的情况存在许多分类不确定的区域。 ( 2) 两两可分 当每两个模式类之间都可以用一个判别函数来区分,称为两两可分。 此时若有 m 个模式类,就有 m(m-1)/2 个判别函数。
第 9 页 自动化学院 模式识别与智能系统研究所 高琪 gaoqi@
《模式识别》讲义 2011 版:第二讲
线性分类器
征向量分别为 x (1) , x (2) ,
,对应的特征向量分别为 , x (li ) ;有 l j 个属于 j 类,
y
(1)
, y (2) ,
,y
(l j )
当样本数 l n 时,该不等式方程组为不定的,没有有意义的解;当样本 l n 时,该不等式方程组为适定或超定的,有无穷多个解,但是这些解有一定的 分布区域,称为解区域。
图 13 线性分类器设计的解区域
如果 i 和 j 两类线性不可分,则解区域不存在。 思考: 增广权向量有几个未知数?至少需要几个样本才能求解? ( 3) 设计思路 如果用于学习的训练样本集是线性可分的,则一定有无穷多个解向量 w 满足判别函数不等式方程组,设计出的线性分类器也有无穷多个,因此,求取线 性分类器的设计结果一定是一个寻找最优解的过程。 一般设计思路是:
图 7 将一维线性不可分问题转化为二维线性可分问题
思考: 对于二维异或问题,能转化为高维的线性可分问题吗?
第 4 页 自动化学院 模式识别与智能系统研究所 高琪 gaoqi@
《模式识别》讲义 2011 版:第二讲
线性分类器
二、 线性分类器
1、 两类问题
当两类线性可分时,判别函数可写为
有一类线性不可分问题,可将其映射到另一个高维空间中,转化为一 个线性可分问题。例如一维特征空间中的线性不可分问题:
图 6 一维线性不可分问题
显然,可设定判别函数为
G( x) ( x a)( x b)
当 G (x )>0 时,可判别模式 x ∈ ω 1 ;当 G (x )<0 时,可判别 x ∈ ω 2 。此时 的判别函数为非线性判别函数。 令 y1 x 2 , y2 x ,此时原始 1 维特征空间映射到 2 维的特征空间中,判别 函数转化为:
图 4 包含凹区域的线性不可分情况
( 2 ) 一个类别的分布范围由两个以上不连通的区域构成, 这一类里最 典型的就是异或( XOR )问题;
图 5 异或( XOR )问题
第 3 页 自动化学院 模式识别与智能系统研究所 高琪 gaoqi@
《模式识别》讲义 2011 版:第二讲
线性分类器
第 6 页 自动化学院 模式识别与智能系统研究所 高琪 gaoqi@
《模式识别》讲义 2011 版:第二讲
线性分类器
图 10 多类问题――两两可分
此时分类决策规则可以用判定表表示为:
G12 ( x )>0 G23 ( x )>0 G31 ( x )>0 分类决策 T * F x∈ ω1 F T * x∈ ω2 * F T x∈ ω3 F F F IR
x k , 当Gk x max[Gi (x)]
1i m
第 7 页 自动化学院 模式识别与智能系统研究所 高琪 gaoqi@
《模式识别》讲义 2011 版:第二讲
线性分类器
3、 线性判别函数的几何意义
当一个模式位于线性决策边界上时,该模式与决策边界的距离为 0 , 对应的判别函数值也为 0 。直观地可以发现,当一个模式距离决策边界越 远时,判别函数的绝对值也应当越大,也就是说判别函数是模式 到决策超 平面距离远近的一种度量。 那么判别函数的几何意义究竟如何呢?下面以二类问题为例来进行分 析。如果判别函数 G x 可以将两类分开,则决策边界方程为: