高性能计算集群(HPC CLUSTER)
高性能计算(HPC).
如何做好HPC的销售工作之应用 篇
•3、计算数学 主要应用软件:Gaussian 了解用户研究方向:科研基础软件 了解关键词:需要CPU高主频,并行效果差 CPU选型:advanced 内存选型:1、根据CPU 2、不需要大内存 硬盘选型:I/O量大,SAS 网络选型:不建议跨节点,需跨节点选择IB
如何做好HPC的销售工作之应用 篇ห้องสมุดไป่ตู้
•1、计算物理
•主要应用软件:VASP 了解用户研究方向:物理计算方向有金属、半导体、绝缘体 了解关键词:Kpoint 4X4X4 8X8X8 CPU选型:advanced 内存选型:1、根据CPU 2、CPU及Kpoint 硬盘选型:I/O量小,SATA 网络选型:跟进Kpoint 软件线性比:高
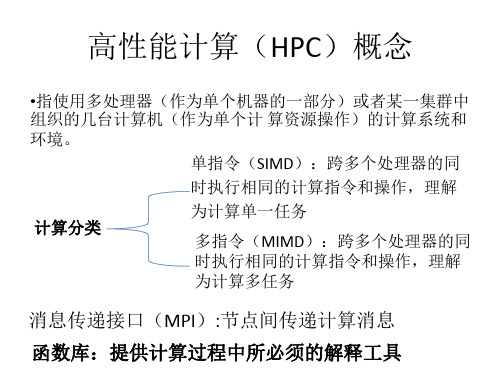
高性能计算(HPC)概念
•指使用多处理器(作为单个机器的一部分)或者某一集群中 组织的几台计算机(作为单个计 算资源操作)的计算系统和 环境。 单指令(SIMD):跨多个处理器的同 时执行相同的计算指令和操作,理解 为计算单一任务 计算分类 多指令(MIMD):跨多个处理器的同 时执行相同的计算指令和操作,理解 为计算多任务
消息传递接口(MPI):节点间传递计算消息
函数库:提供计算过程中所必须的解释工具
高性能计算(HPC)机组成
• • • • 1、计算子系统(可包含CPU、GPU、多路子节点) 2、网络子系统(管理网络;计算网络(Ethernet、IB)) 3、存储子系统(本地存储、并行存储) 4、管理子系统(对整个高性能计算平台运行性能进行实时
• 2、了解我们能为用户做什么
a) 机群硬件系统搭建 b) 机群软件系统安装
如何做好HPC的销售工作
•Linpack 理论峰值计算 什么是Linpack?
HPC高性能计算 hp

HPC介绍
作用? 1、计算节点:运行并行计算程序,是HPC的主 体结构; 2、管理节点:安装有集群管理软件,作为主节 点为整个HPC系统进行系统监控、管理和作 业调度,还负责对系统一次性安装操作系统及 应用软件;
HPC介绍
3、登陆节点:用来承接用户接入HPC系统,运 行并行计算的主题程序,对程序进行编译和调 试,划分任务和数据,分配给计算节点,并且 对任务进行回收和汇总; 4、I/O节点:用来连接后台大容量数据,将所 有数据共享给整个系统,负责数据的读取和存 储调用;
HPC介绍
HPC的特点有哪些呢? 1、先进性:并行计算是目前业界较为先进的计 算体系,是融合了计算、存储、网络和软件于 一体的系统,是一个成熟的产品和技术。 2、高性能:融合了业界最先进的产品,刀片服 务器、高速Infiniband网络、光纤网络及相关 设备于一体。
HPC介绍
3、扩展性:采用刀片技术特性,用户可以根本 自己的需求增减服务器数量,灵活的改变 HPC系统的性能,扩展系统的计算和存储能 力。 4、环保特性:刀片服务器是一个系统集合体, 不同于机架式服务器,它可以充分利用刀片机 箱的电源、风扇资源,确保减少耗电量、空间 等。
HPC(高性能计算)介绍
HPC介绍
HPC概述 HPC的软硬件配置 HPC的应用环境及案例
HPC介绍
什么是高性能计算? HPC是High Proformance Compute的缩写。 它是计算科学的一个分支,用以解决复杂的科 学计算或者数值计算。由多台服务器构成的一 种松散耦合的机群,为用户提供高性能计算、 专业的应用程序等服务。
HPC介绍
5、计算网络:一般采用Infiniband网络,常用 40Gb,高带宽低延时的特性满足计算节点之 间的消息传递要求。 6、千兆网络:是整个系统中的骨干网络,用户 操作系统的部署,软件的安装、监控等。
高性能计算集群方案

高性能计算集群方案引言高性能计算(High Performance Computing,HPC)是指利用大规模的计算机群集,通过并行计算方法解决复杂科学、工程和商业问题的一种计算模式。
为了提高计算效率,构建一个高性能计算集群是非常重要的。
本文将介绍一种高性能计算集群方案,该方案包括硬件设备的选择、软件平台的搭建以及集群管理的方法。
硬件设备选择搭建高性能计算集群的第一步是选择适合的硬件设备。
在选择硬件设备时,需要考虑以下几个因素:1. 处理器高性能计算集群的处理器是关键的硬件组成部分。
在选择处理器时,需要考虑其计算能力、核心数量、功耗以及成本等因素。
目前,常见的选择包括Intel Xeon、AMD EPYC等。
2. 内存集群的内存容量直接影响到计算任务的并行性和数据处理能力。
需要根据具体需求选择适当的内存容量,一般建议每个节点的内存容量应满足最大计算任务的内存需求。
3. 网络高性能计算集群需要使用高速网络进行节点间的数据通信。
目前常用的网络技术包括以太网(Ethernet)、InfiniBand等。
网络的带宽、延迟以及可扩展性都是选择网络技术时需要考虑的因素。
4. 存储对于高性能计算集群来说,快速的存储系统对于数据读写的效率至关重要。
可以选择使用固态硬盘(SSD)作为主存储,同时使用磁盘阵列(RAID)进行数据备份和冗余。
软件平台搭建搭建高性能计算集群的第二步是搭建软件平台。
软件平台需要提供集群管理、作业调度以及并行计算等功能。
1. 集群管理软件集群管理软件可以协调和控制集群中的各个节点。
常见的集群管理软件有Slurm、OpenPBS等,可以根据实际需求选择合适的软件。
2. 作业调度软件为了提高集群资源的利用率,需要使用作业调度软件进行任务调度和节点分配。
常见的作业调度软件有Torque、Moab等,根据需求选择合适的软件。
3. 并行计算软件高性能计算集群需要支持并行计算,因此需要安装相应的并行计算软件。
HPLinux高性能集群解决方案-1102

HPLinux高性能集群解决方案-1102前言高性能计算集群(HPCC-High Performance Computing Cluster)是计算机科学的一个分支,以解决复杂的科学计算或数值计算问题为目的,是由多台节点机(服务器)构成的一种松散耦合的计算节点集合。
为用户提供高性能计算、网络请求响应或专业的应用程序(包括并行计算、数据库、Web)等服务。
相比起传统的小型机,集群系统有极强的伸缩性,可通过在集群中增加或删减节点的方式,在不影响原有应用与计算任务的情况下,随时增加和降低系统的处理能力。
还可以通过人为分配的方式,将一个大型集群系统分割为多个小型集群分给多个用户使用,运行不同的业务与应用。
集群系统中的多台节点服务器系统通过相应的硬件及高速网络互连,由软件控制着,将复杂的问题分解开来,分配到各个计算节点上去,每个集群节点独立运行自己的进程,这些进程之间可以彼此通信(通常是利用MPI -消息传递接口),共同读取统一的数据资源,协同完成整个计算任务,以多台计算节点共同运算的模式来换取较小的计算时间。
根据不同的计算模式与规模,构成集群系统的节点数可以从几个到上千个。
对于以国家政府、军方及大型组织机构来讲,节点数目可以达到数千甚至上万。
而随着HPCC 应用的普及,中小规模的高性能计算集群也慢慢走进中小型用户的视野,高性能计算集群系统的部署,极大地满足了此类用户对复杂运算的能力的需求,大大拓展了其业务范围,为中小型用户的成长提供支持。
本次方案研究适合于中小规模用户的典型系统:基于32个计算节点和In ?niBand 高速网络的Linux 集群。
惠普Linux 高性能集群方案方案描述此次方案中,高性能计算集群系统的节点由HP BladeSystem 刀片服务器搭建,节点间通过InfiniBand 高速网络相连,管理、登录和存储节点由HP ProLiant机架式服务器构成,存储节点通过SAN 交换机外挂HPStorageWorks 磁盘阵列来存储大容量数据。
ibm计算机集群技术

高可扩展性集群技术
计算机集群技术
• 在OSI七层协议模型中的第二(数据链路层)、 第三(网络层)、第四(传输层)、第七层 (应用层)都有相应的负载均衡策略(算 法),在数据链路层上实现负载均衡的原理 是根据数据包的目的MAC地址选择不同的路 径;在网络层上可利用基于IP地址的分配方式 将数据流疏通到多个节点;而传输层和应用 层的交换(Switch),本身便是一种基于访问 流量的控制方式,能够实现负载均衡。
高可扩展性集群技术
计算机集群技术
• 在Web负载均衡群集的设计中,网络拓扑被设 计为对称结构。在对称结构中每台服务器都 具备等价的地位,都可以单独对外提供服务。 通过负载算法,分配设备将外部发送来的请 求均匀分配到对称结构中的每台服务器上, 接收到连接请求的服务器都独立回应客户的 请求。 如下图所示。
高性能计算集群技术
计算机集群技术
应用程序是否可以"并行化"? --HPC Cluster对于可以并行化的应用程序最为 有效 • 要实现并行计算,您需要:
– 支持并行运算的硬件架构; – 支持并行计算的应用程序; – 使应用能够并行执行的软件工具,如编译器,API 等等。
高性能计算集群技术
计算机集群技术
计算机集群技术
高可用性集群技术
高可用性集群技术
计算机集群技术
• 高可用性集群,英文原文为High Availability Cluster, 简称HA Cluster,是指以减少服务中 断(宕机)时间为目的的服务器集群技术。
高可用性集群技术
计算机集群技术
• 可用性是指一个系统保持在线并且可供访问, 有很多因素会造成系统宕机,包括为了维护 而有计划的宕机以及意外故障等,高可用性 方案的目标就是使宕机时间以及故障恢复时 间最小化,可以容忍的宕机时间明确的说明 方案的全面性、复杂性和成本
HPC高性能计算技术交流

IBM Technical Support Center
© 2006 IBM Corporation
Linux Cluster
HPC 常见行业
生命科学研究
蛋白质分子是非常复杂的链,实际上可以表示为无数个 3D 图形。实际上,在将蛋白质放到某 种溶液中时,它们会快速“折叠”成自己的自然状态。不正确的折叠会导致很多疾病,例如 Alzheimer 病;因此,对于蛋白质折叠的研究非常重要。 科学家试图理解蛋白质折叠的一种方 式是通过在计算机上进行模拟。实际上,蛋白质的折叠进行得非常迅速(可能只需要 1 微 秒),不过这个过程却非常复杂,这个模拟在普通的计算机上可能需要运行 10 年。这个领域 只不过是诸多业界领域中很小的一个,但是它却需要非常强大的计算能力。 业界中其他领域包括制药建模、虚拟外科手术训练、环境和诊断虚拟化、完整的医疗记录数据 库以及人类基因项目。
© 2006 IBM Corporation
Linux Cluster
Infiniband
Infiniband 对比私有协议互联
– 支持10Gb/sec 已经超过5年 – 2004年6月到2006年6月间,在TOP500中增长率300% – 私有协议技术每年在TOP500减少50% – 低延迟 – 服务器CPU卸载
震动图中包含有大陆和洋底内部特性的详细信息,对这些数据进行分析可以帮助我 们探测石油和其他资源。即便对于一个很小的区域来说,也有数以 TB 计的数据需 要重构;这种分析显然需要大量的计算能力。这个领域对于计算能力的需求是如此 旺盛,以至于超级计算机大部分都是在处理这种工作。
其他地理学方面的研究也需要类似的计算能力,例如用来预测地震的系统,用于安
高性能计算集群的配置与使用教程

高性能计算集群的配置与使用教程高性能计算(High Performance Computing,HPC)集群是一种强大的计算工具,能够处理大规模的数据和执行复杂的计算任务。
本文将介绍高性能计算集群的配置和使用方法,并为您提供详细的教程。
1. 配置高性能计算集群配置高性能计算集群需要以下几个步骤:1.1 硬件要求选择适合的硬件设备是配置高性能计算集群的第一步。
您需要选择性能强大的服务器,并确保服务器之间能够互相通信。
此外,还需要大容量的存储设备来存储数据和计算结果。
1.2 操作系统安装选择合适的操作系统安装在每个服务器上。
常用的操作系统有Linux和Windows Server,其中Linux被广泛使用于高性能计算集群。
安装操作系统后,您还需要配置网络设置、安装必要的软件和驱动程序。
1.3 服务器网络连接为了保证高性能计算集群的正常工作,需要配置服务器之间的网络连接。
您可以选择以太网、光纤等网络连接方式,并确保每个服务器都能够互相访问。
1.4 集群管理软件安装为了方便管理和控制高性能计算集群,您需要安装相应的集群管理软件。
常用的集群管理软件有Hadoop、Slurm和PBS等。
这些软件可以帮助您管理任务队列、分配资源和监控集群的运行状态。
2. 使用高性能计算集群配置完高性能计算集群后,您可以开始使用它进行计算任务。
以下是使用高性能计算集群的一般步骤:2.1 编写并提交任务首先,您需要编写计算任务的代码。
根据您的需求,可以选择编写Shell脚本、Python脚本或其他编程语言的代码。
编写完毕后,您需要将任务提交到集群管理软件中。
2.2 监控任务状态一旦任务提交成功,您可以使用集群管理软件提供的监控功能来跟踪任务的状态。
您可以查看任务的进度、资源使用情况和错误信息等。
2.3 调整任务与资源如果您发现任务需要更多的计算资源或运行时间,您可以根据需要调整任务的资源配置。
集群管理软件通常提供了资源调整的功能,您可以根据任务的实际情况进行调整。
高性能计算集群

高性能计算集群高性能计算集群(HPC_CLUSTER)是一种由大量计算节点组成的集群系统,用于处理高性能计算任务。
该集群通常由多个节点组成,每个节点都具有较高的计算和存储能力,通过网络进行连接和通信。
HPC_CLUSTER集群拥有强大的计算能力和高效的并行计算能力,可用于处理大数据分析、科学计算、物理模拟、天气预报、生物信息学等应用场景。
HPC_CLUSTER集群的核心组件包括计算节点、存储节点、网络和管理系统。
计算节点是集群的主要计算资源,每个计算节点通常由多个处理器或多核处理器组成,可同时执行多个并行任务。
存储节点负责存储集群的数据,通常采用分布式文件系统或对象存储系统来实现数据的共享和高可用性。
网络是连接集群节点的基础设施,通常使用高速网络如InfiniBand、以太网等来实现节点之间的通信。
管理系统负责集群的资源管理、任务调度和监控等工作,确保集群的性能和稳定性。
HPC_CLUSTER集群的性能关键在于其并行计算能力。
通过将任务分解为多个子任务,并在多个计算节点上并行执行,集群能够更快地完成大规模计算任务。
集群通常使用消息传递接口(MPI)等并行编程模型来实现任务的分发和结果的收集。
并行计算还可以通过任务的负载均衡机制来优化,确保每个计算节点的负载均衡,以提高集群的整体性能。
另外,HPC_CLUSTER集群还需要具备高可用性和容错性。
由于集群规模大且节点众多,节点故障是不可避免的。
集群需要具备自动故障检测和恢复机制,以保证集群的稳定性和可用性。
此外,集群还可以使用冗余配置和数据备份等策略来防止数据丢失和系统崩溃。
HPC_CLUSTER集群的管理与维护需要专业的人员来完成。
管理人员需要负责集群的部署、配置和维护,并监控集群的性能和状态。
他们还需要根据任务的需求进行资源调度和任务分发,以最大限度地利用集群的计算资源。
对于大规模集群,管理系统通常提供图形界面或命令行界面,方便管理员进行操作和管理。
HPC高性能计算集群实施指导手册

HPC高性能计算集群实施指导手册目录1、基本系统参数设置.........................................................................................................- 1 -1.1、ulimit系统进程资源限制 ...................................................................................- 1 -1.2、关闭selinux服务 ................................................................................................- 1 -1.3、配置本地yum源.................................................................................................- 1 -2、NIS服务配置 ..................................................................................................................- 2 -2.1、NIS服务器端的配置 ...........................................................................................- 2 -2.2、NIS客户端的配置管理 .......................................................................................- 4 -2.3、NIS客户端的属性设置 .......................................................................................- 6 -3、NFS配置 .........................................................................................................................- 8 -3.1、NFS软件包安装 ..................................................................................................- 8 -3.2、编辑NFS服务器配置文件..................................................................................- 8 -3.3、启动服务..............................................................................................................- 8 -3.4、在客户端中挂载NFS服务器中的共享目录......................................................- 9 -4、配置Kdump服务 ...........................................................................................................- 9 -4.1、Kdump安装 .........................................................................................................- 9 -4.2、Kdump配置 ...................................................................................................... - 10 -4.3、安装分析转存储文件所需的rpm包 .............................................................. - 11 -5、配置Rsyslog服务........................................................................................................ - 11 -5.1 服务端配置......................................................................................................... - 11 -5.2、客户端配置....................................................................................................... - 12 -5.3、日志轮询服务logrotate................................................................................... - 13 -1、基本系统参数设置1.1、ulimit系统进程资源限制修改/etc/security/limits.conf文件,添加如下内容:* soft memlock unlimited* hard memlock unlimited* soft stack unlimited* hard stack unlimited1.2、关闭selinux服务运行如下命令修改/etc/selinux/config文件,关闭selinuxsed -i s/=enable/=disabled/g /etc/selinux/configsed -i s/=enforcing/=disabled/g /etc/selinux/config可以使用以下命令查看selinux服务状态sestatus1.3、配置本地yum源上传对应操作系统的ISO文件到/public/sourecode目录将操作系统ISO文件挂载到/mnt目录mount –t iso9660 –o loop /public/sourcecode/xxx.iso /mnt创建/public/sourcecode/yum目录,并将安装盘内容拷贝到这个目录cp –rp /mnt/Packages/* /public/sourcecode/yum创建yum源配置文件/etc/yum.repo.d/Local.repo,内容如下:生成yum本地缓存,命令如下:yum makecache2、NIS服务配置2.1、NIS服务器端的配置NIS软件包安装查看系统中是否已经安装下列三个软件:ypserv NIS服务器软件, 一般默认是不安装的,需要安装yp-tools 提供对NIS服务器的查询和管理软件ypbind NIS客户端需要使用软件包rpm –qa | grep ^yp安装ypserv前需要利用rpm –qa | grep portmap 命令(6.0之后的版本使用rpcbind)确认portmap(rpcbind)已经安装。
宝德HPC高性能计算服务器集群系统简介

宝德HPC高性能计算服务器集群系统简介HPC高性能计算服务器集群系统是高性能计算和高可用技术有机结合的性能强大、高可用的集群系统。
在实际应用中,许多科学研究和商业企业的计算问题都可以通过HPC系统来解决。
HPC可以在下列领域能够帮助开发和研究人员进行建模和模拟,同时,以最快的速度计算出模拟的结果,为下一步开发和最终结构的确定提供及时可靠的依据:⎫⎫天气预报气象⎫制药企业的药理分析⎫科研人员的大型科学计算问题⎫石油勘探中对石油储量的分析⎫航空航天企业的设计和模拟⎫化工企业中对分子结构的分析计算⎫制造业中的CAD/CAM系统和模拟试验分析⎫银行和金融业对经济情况的分析生物/生命科学中生物分子研究和基因工程计算宝德HPC系统由高性能并行计算应用系统,集群控制节点、通信库以及管理服务器,数据库存储系统,各节点操作系统,节点通信系统,各计算节点,以及系统运行环境等组成。
★高性能计算应用系统各种并行计算的应用程序,针对不同的应用对象和问题而设计的软件系统。
★集群控制节点、通信库及管理服务器集群控制节点是HPC的核心设备,担任着运行主控程序和作业分发的任务。
其上的集群管理软件是整个高性能计算系统的管理者。
HPC控制节点通过集群控制、管理及通讯库将整个系统紧密联系在一起。
同时,还要负责初始化集群节点、在所需数量的节点上安装应用程序、并监视集群节点和互连的当前运行状况。
★数据库存储系统数据库存储系统是高性能计算的后端存储系统,与主控节点相连,高性能计算的结果通过主控节点统一送到该系统进行集中存储。
该系统可以一个RAID存储阵列柜,也可以是一个存储网络,如SAN等。
★节点操作系统因为Linux操作系统具有开放源码、容易整合和再开发的特点,所以在HPC Cluster中被普遍采纳,占到操作系统的80%以上的比例。
而Windows NT受其自身的封闭环境阻碍,Linux 有大量的集群系统可供选择,适合于不同的用途和需要,保证系统可适应最新的工具,有较高的可用性。
HPC高性能计算系列二之联想Intellegent+Cluster解决方案

14% - 16%
19% - 21%
调试 到投产
集成,配置和测试 上架, 线缆连接,网络连接 软件 集成,配置和应用测试 集成配置和测试中间件 应用部署和安装
45% 45% 29%
Implement
Configure/test
74 – 93
74 – 80
12%
10% - 11%
Cluster & HA
Intel Xeon Phi
nVIDIA
Mellanox Infiniband
NeXtScale
x86 平台
7
iDataPlex dx360 M4 System x3550/x3650
FlexSystem X3750 M4/x3850
Intelligent Cluster 大大降低HPC项目的风险
Intelligent Cluster具有更好的用户体验 ---- 降低销售风险和售后服务费用,提升服务质量 1. 在投标前,系统配置及方案经过专家验证,确保方案可行; 2. 在交付用户前,整机系统经过严格的测试,避免到达用户现场后出现更换故障部件的情况,有利于增 强System x产品高质量形象; 3. 由中国本地工厂服务团队提供的专业上架及布线服务,确保系统具有良好整洁的外观,提升用户体验 (见下图); 4. 整机系统到达用户现场后可以直接加电,仅需要少量甚至不需要集成商参与,可以减少系统实施所产 生的外部费用; 5. 集群系统部署及辅助用户业务安装的工作基本可以远程实现,不需要或短时间在用户现场工作,从而 降低LBS或GTS的内部实施费用
Customer Benefits
LENOVO Intelligent Cluster
$ €¥£
帮助您的应用快速上线
高性能计算集群(HPC_CLUSTER)

高性能计算集群(HPC CLUSTER)1.1什么是高性能计算集群?简单地说,高性能计算(High-Performance Computing)是计算机科学的一个分支,它致力于开发超级计算机,研究并行算法和开发相关软件。
高性能集群主要用于处理复杂的计算问题,应用在需要大规模科学计算的环境中,如天气预报、石油勘探与油藏模拟、分子模拟、基因测序等。
高性能集群上运行的应用程序一般使用并行算法,把一个大的普通问题根据一定的规则分为许多小的子问题,在集群内的不同节点上进行计算,而这些小问题的处理结果,经过处理可合并为原问题的最终结果。
由于这些小问题的计算一般是可以并行完成的,从而可以缩短问题的处理时间。
高性能集群在计算过程中,各节点是协同工作的,它们分别处理大问题的一部分,并在处理中根据需要进行数据交换,各节点的处理结果都是最终结果的一部分。
高性能集群的处理能力与集群的规模成正比,是集群内各节点处理能力之和,但这种集群一般没有高可用性。
1.2高性能计算分类高性能计算的分类方法很多。
这里从并行任务间的关系角度来对高性能计算分类。
1.2.1高吞吐计算(High-throughput Computing)有一类高性能计算,可以把它分成若干可以并行的子任务,而且各个子任务彼此间没有什么关联。
因为这种类型应用的一个共同特征是在海量数据上搜索某些特定模式,所以把这类计算称为高吞吐计算。
所谓的Internet计算都属于这一类。
按照Flynn的分类,高吞吐计算属于SIMD(Single Instruction/Multiple Data,单指令流-多数据流)的范畴。
1.2.2分布计算(Distributed Computing)另一类计算刚好和高吞吐计算相反,它们虽然可以给分成若干并行的子任务,但是子任务间联系很紧密,需要大量的数据交换。
按照Flynn的分类,分布式的高性能计算属于MIMD (Multiple Instruction/Multiple Data,多指令流-多数据流)的范畴。
高性能计算集群

⾼性能计算集群,英⽂原⽂为High Performance Computing Cluster,简称HPC Cluster,是指以提⾼科学计算能⼒为⽬的计算机集群技术。
HPC Cluster是⼀种并⾏计算(Parallel Processing)集群的实现⽅法。
并⾏计算是指将⼀个应⽤程序分割成多块可以并⾏执⾏的部分并指定到多个处理器上执⾏的⽅法。
⽬前的很多计算机系统可以⽀持SMP(对称多处理器)架构并通过进程调度机制进⾏并⾏处理,但是SMP技术的可扩展性是⼗分有限的,⽐如在⽬前的Intel架构上最多只可以扩展到8颗CPU。
为了满⾜哪些"计算能⼒饥渴"的科学计算任务,并⾏计算集群的⽅法被引⼊到计算机界。
著名的"深蓝"计算机就是并⾏计算集群的⼀种实现。
由于在某些廉价⽽通⽤的计算平台(如Intel+Linux)上运⾏并⾏计算集群可以提供极佳的性能价格⽐,所以近年来这种越来越受到⽤户的青睐。
⽐如壳牌⽯油(Shell)所使⽤的由IBM xSeries组成的1024节点的Linux HPC Cluster是⽬前世界上计算能⼒最强的计算机之⼀。
HPC Cluster向⽤户提供⼀个单⼀计算机的界⾯。
前置计算机负责与⽤户交互,并在接受⽤户提交的计算任务后通过调度器(Scheduler)程序将任务分配给各个计算节点执⾏;运⾏结束后通过前置计算机将结果返回给⽤户。
程序运⾏过程中的进程间通信(IPC)通过专⽤进⾏。
HPC Cluster中使⽤的服务器通常可以分为⽤户节点、节点、存贮节点和计算节点四种。
它们的⾓⾊分别是: ⽤户节点: 提供⽤户界⾯的计算机。
它从⽤户那⾥接受任务,运⾏调度器(在本地或独⽴的"控制节点"上)将任务分派到其它计算机,并将运算结果返回给⽤户。
管理节点: 提供管理功能的计算机。
它应该能够使管理员从这⼀计算机对集群中的任意⼀台计算机进⾏监视和操作,并处理集群中所有计算机的⽇志和报警信息。
hpc名词解释(一)

hpc名词解释(一)HPC相关名词1. HPC(High Performance Computing)HPC,即高性能计算,是指利用多个计算机或计算资源进行协同工作,以达到解决复杂问题的目的。
它通常涉及大量的数据处理、复杂的算法和高度并行化的计算任务。
2. 超级计算机(Supercomputer)超级计算机是一种具有巨大计算能力的计算机系统,广泛应用于天气预报、物理模拟、基因组学研究等领域。
它通常基于并行计算的原理,拥有大量的处理器和内存,并采用高速互联网络来实现高效的数据传输。
3. 并行计算(Parallel Computing)并行计算是指将计算任务分割成多个子任务,由多个处理器或计算节点同时进行计算,以提高计算速度和效率。
它可以通过多线程、多进程或分布式计算等方式实现。
4. 集群(Cluster)集群是由多个相互连接的计算节点组成的计算机系统,用于同时处理大规模的计算任务。
每个计算节点都具有自己的计算能力和存储资源,并通过高速网络进行通信和协调。
5. GPU(Graphics Processing Unit)GPU,即图形处理器,是一种专门用于处理图形和并行计算的硬件设备。
它的并行计算能力相比于传统的中央处理器(CPU)更强大,因此在HPC中常被用于加速计算任务,如深度学习、物理模拟等。
6. MPI(Message Passing Interface)MPI是一种编程接口标准,用于在并行计算中实现不同节点之间的数据通信和同步。
它提供了一系列的函数和库,可以用于分布式内存系统的并行计算。
7. 云计算(Cloud Computing)云计算是一种利用网络进行资源共享和服务交付的计算模式。
在HPC中,云计算可以提供弹性的资源分配和灵活的计算能力,以满足不同规模和需求的计算任务。
8. 数据并行(Data Parallelism)数据并行是一种并行计算的方式,它将数据划分成多个部分,由不同的处理器或计算节点并行处理各自的数据。
高性能计算(HPC)

可扩展性
总结词
高性能计算系统的可扩展性是指其随着规模扩大而性能提升的能力。
详细描述
可扩展性是高性能计算系统的一个重要评价指标。为了实现可扩展性,需要解决如何有效地将任务分配给多个处 理器核心、如何实现高效的节点间通信以及如何管理大规模系统的资源等问题。这需要采用先进的并行计算框架、 资源管理和调度算法等技术。
02
HPC系统架构
硬件架构
处理器架构
使用多核处理器和加速器(如GPU、FPGA)以提 高计算性能。
存储架构
采用高速缓存、分布式文件系统、内存数据库等 技术,提高数据访问速度。
网络架构
使用高速InfiniBand、以太网或定制网络技术,实 现节点间高速通信。
软件架构
01
并行计算框架
使用MPI、OpenMP、CUDA等 并行计算框架,实现任务和数据 的并行处理。
使用如Fortran、C/C、Python等语言进行高性能计 算应用程序开发。
性能优化技术
采用向量化、自动并行化、内存优化等技术,提高高 性能计算应用程序性能。
03
HPC应用案例
气候模拟
1
气候模拟是高性能计算的重要应用之一,通过模 拟大气、海洋、陆地等复杂系统的相互作用,预 测未来气候变化趋势。
05
HPC未来展望
异构计算
异构计算是指利用不同类型处理器(如CPU、GPU、FPGA等)协同完成 计算任务的技术。随着处理器技术的不断发展,异构计算在HPC中越来 越受到重视。
异构计算能够充分发挥不同类型处理器的优势,提高计算性能和能效。 例如,GPU适合于并行计算,而CPU则擅长控制和调度。通过合理地组
性能瓶颈
总结词
随着处理器性能的不断提升,高性能计算系统在内存带宽、 I/O性能以及处理器间通信等方面出现了性能瓶颈。
如何构建高性能计算集群

如何构建高性能计算集群构建高性能计算集群(HPC)是为了满足大规模科学计算、模拟和分析等计算需求的目标。
在构建高性能计算集群时,需要考虑硬件和软件两个方面的因素。
本文将从这两个方面介绍如何构建高性能计算集群。
硬件方面的因素:1.处理器选择:选择适合高性能计算的处理器,如基于x86架构的多核处理器或者图形处理器(GPU),因为它们具有较强的计算能力和并行处理能力。
2.内存和存储:为了充分发挥计算能力,需要具备足够的内存和存储能力。
选择高速的内存和存储设备,如DDR4内存和SSD硬盘来提高数据访问速度。
3. 网络架构:选择高性能的网络设备和拓扑结构,如以太网和InfiniBand等。
通过使用高速网络连接节点之间的通信,可以减小节点之间的延迟,提高集群的整体性能。
4.散热和供电:高性能计算集群需要大量的能量供应和散热设备来保证运行的稳定性。
选择高效的散热设备和稳定的电源来提高集群的稳定性和持续运行能力。
软件方面的因素:1. 操作系统选择:选择适合高性能计算工作负载的操作系统。
常用的操作系统包括Linux发行版,如CentOS、Ubuntu等。
这些操作系统具有较好的稳定性和易于管理的特点。
2. 集群管理软件:选择适用于高性能计算集群的管理软件,如Slurm、OpenPBS等。
这些管理软件可以帮助统一管理集群,调度任务,分配资源等,提高集群的运行效率。
3. 并行编程模型和库:选择适合高性能计算的并行编程模型和库,如MPI、OpenMP等。
这些编程模型和库可以帮助开发者更好地利用集群的并行计算能力,实现高效的并行计算。
4. 容器技术:使用容器技术,如Docker或Singularity等,可以方便地构建、部署和管理计算环境。
容器可以提高应用程序的可移植性和灵活性,降低集群维护的复杂性。
此外,为了构建高性能计算集群,还需要考虑以下几个方面的问题:1.网络拓扑结构的设计:选择适合集群规模和工作负载的网络拓扑结构,如树状结构、环形结构、胖树结构等。
hpc集群搭建手册

hpc集群搭建手册一、概述高性能计算集群(HPC)是一种用于处理大规模并行计算的硬件和软件架构。
通过将多个计算节点连接在一起,HPC集群可以实现高效的数据传输和计算能力。
本手册将指导您完成HPC集群的搭建过程。
二、硬件需求1.计算节点:每个计算节点应包含至少一块高性能GPU或CPU,并配备足够的内存和存储空间。
根据需要,可以配置多个计算节点以实现更高的计算能力。
2.网络设备:为了实现节点之间的通信,需要配置高速网络交换机和连接线。
建议使用以太网或InfiniBand等高速网络技术。
3.存储设备:为了存储数据和程序,需要配置高性能的存储系统,如SSD或高性能网络存储。
4.管理节点:用于监控和管理整个集群的节点。
5.散热设备:根据计算节点的数量和功耗,需要配置适当的散热设备,以确保稳定运行。
三、软件配置1.操作系统:选择适合HPC集群的操作系统,如Linux发行版。
建议使用稳定且具有良好支持的操作系统版本。
2.集群管理软件:选择适合的集群管理软件,如HTCondor、PBS、Torque等。
这些软件可以帮助您自动化作业调度和管理集群资源。
3.编译器和库:安装适合HPC集群的编译器和数学库,如GCC、CUDA、OpenMPI等。
这些工具可以帮助您编写高效的并行程序。
4.监控工具:选择适合的监控工具,如Nagios、Zabbix等。
这些工具可以帮助您监控集群的状态和性能。
四、网络配置1.配置网络连接:确保所有节点之间的网络连接稳定且具有足够的带宽。
测试网络延迟和吞吐量以确保满足性能要求。
2.配置无盘启动:为了方便管理,可以考虑配置无盘启动,使计算节点从管理节点获取操作系统和软件。
3.配置VLAN和IP地址:为每个节点分配唯一的IP地址,并配置VLAN以实现节点之间的隔离和安全通信。
五、存储配置1.配置存储设备:根据需要选择适当的存储设备,并确保其具有足够的容量和性能。
2.配置文件系统:选择适合HPC集群的文件系统,如NFS、GPFS等,并进行相应的配置和优化。
典型 hpc 的基本原理

典型 hpc 的基本原理
HPC(High Performance Computing),也称大规模计算,是指使用大量集成的计算机系统和高性能网络,来处理海量或高复杂度数据集,以快速解决问题的一种计算技术。
HPC的基本原理包括以下几个方面:
1. 并行计算:HPC建立在并行计算的基础上,通过将一个任务分解成多个子任务,并在多个处理器核心上同时执行这些子任务,以加快计算速度。
并行计算的核心思想是同时处理多个任务,以减少总体计算时间。
2. 分布式计算:HPC通常采用分布式计算技术,即将一个大型任务分解成多个小任务,并在不同的计算机节点上同时执行这些小任务。
分布式计算可以有效地利用多台计算机的资源,实现大规模计算。
3. 网格计算:网格计算是一种基于互联网的分布式计算方式,它将地理上分布的各种计算资源(包括高性能计算机、数据存储设备、软件和信息等)集成为一个虚拟的超级计算机,通过高性能网络进行连接,实现资源共享和协同工作。
4. 集群计算:集群计算是一种基于高性能计算机集群的并行计算技术。
它将多台高性能计算机连接在一起,通过并行执行和协同工作,实现大规模科学计算和工程模拟。
5. 云计算:云计算是一种基于互联网的计算方式,它通过虚拟化技术将各种硬件资源(如服务器、存储设备和数据库等)集成为一个虚拟的云,并通过
网络对外提供服务。
云计算可以提供弹性的、可伸缩的、按需付费的计算服务,使得用户可以随时随地访问数据和应用程序。
总的来说,HPC通过并行计算、分布式计算、网格计算、集群计算和云计算等技术,实现了大规模科学计算和工程模拟的高效运行。
高性能计算平台(HPC)简介 - 通用

高性能计算平台(HPC)简介SHPC概念简介HPC技术架构HPC应用分析123HPC案例实践4HPC面临挑战5普通计算—传统列车高性能计算—高铁列车 高性能计算好比“高铁列车”,除了车头,每节车厢都有动力,所以算得快。
普通计算好比“传统列车”,只有车头有动力,所以算得慢。
高性能计算(High Performance Computing),通过软件和网络将多台独立的计算机组建成为一个统一系统,通过将一个大规模计算任务进行分割并分发至内部各个计算节点上来实现对中大规模计算任务的支持。
目标:提高大规模应用问题的求解速度,包括但不限于工程仿真、材料科学、生命医药等领域。
l 计算性能强大l 具有海量级存储空间l 高速数据通讯l 完整的软件基础平台软件部分:集群管理软件、作业调度软件、并行存储软件,并行环境,操作系统,行业应用软件硬件部分:服务器、网络、存储数据中心服务部分:专业售后服务,专业应用调优、开发服务,专业设计咨询服务生命科学气象预报数值计算石油勘探生物物理汽车设计药物设计航空航天国防军事云计算中心/省市计算中心异构集群芯片设计基因信息影视渲染船舶制造高性能计算机是一个国家综合实力的体现HPC行业应用HPC超级计算快速发展我国超级计算系统研制过去十年,我国在顶尖超算系统研制处于国际领先行列我国超级计算系统部署情况2023.062022.11过去十年,我国超算系统部署数量处于国际领先行列我国应用情况(以入围ACM Gordon Bell Prize为例)2014地震模拟2016大气动力框架相场模拟海浪模拟地震模拟气候模拟20172018图计算框架量子模拟人造太阳第一性原理过去十年,依托我国顶尖超算系统,大规模并行应用设计和研制方面取得显著进步2021获得国际超算最高奖ACM Gordon Bell奖CPU计算节点硬件平台软件平台应用场景GPU计算节点整机柜产品并行文件存储高性能计算管理平台基础设施管理平台高性能计算行业应用大内存服务器通用服务器气象海洋生命科学物理化学材料科学工业仿真高能物理石油勘探动漫渲染天文遥感基础设施数据中心高密服务器HGX机型PCIe机型整机柜服务器高速网络InfiniBand网络RoCE网络全闪存储混闪存储集群管理集群调度作业提交精细计费应用特征分析平台系统环境微模块数据中心(MDC)液冷MDC 风液式解决方案操作系统编译器并行环境数学库HPC全栈方案架构HPC集群软硬件层次架构SAAS 并行环境PAAS 节点X86机架异构节点X86刀片Gauss Fluent Vasp Wien2k 基础设施供电系统(UPS&PDU)机房机柜系统(水冷/风冷)空调系统(精密空调)……Material studio Matlab 异构开发并行开发集群管理平台网络IB/OPA 千/万兆以太网络KVM IPMIIAAS 存储存储服务器IB/FC 存储阵列集群软件操作系统Linux(RedHat,CentOS…)Windows Server 编译环境环境工具并行文件系统调试工具应用软件应用开发……并行化应用模式应用结点间通讯系统与控制内部互连计算单元处理器,物理层设计,硬件管理Linux, Windows 操作系统与配置管理 操作系统中间件通讯函数库 (MPI, DVSM, PVM, etc) 集群控制与管理编译器,函数库,性能分析与调试工具开发工具作业管理批作业序列与调度,集群监控,系统扩展工具用户, ISV’s 软件工具 HPC 增值供应商 平台与网络供应商供电系统,制冷系统,机房环境基础架构机房方HPC集群硬件拓扑图通用计算——双路计算机架(高密度)、刀片通用计算——胖节点异构节点虚拟工作站区满足所有应用的可视化需求管理登陆机架高速计算网络并行存储区:满足所有应用的共享存储需求KVM、机柜、供电等附属设施CPU Memory I/O Channel ...CPU Memory I/O Channel CPU Memory I/O Channel CPUMemoryI/O Channel CPU Memory I/O Channel 网 络集群(Cluster):将多台计算机组织起来,通过网络连接在一起,进行协同工作,来模拟一台功能更强大的计算机,叫做集群。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
高性能计算集群(HPC CLUSTER)1.1什么是高性能计算集群?简单的说,高性能计算(High-Performance Computing)是计算机科学的一个分支,它致力于开发超级计算机,研究并行算法和开发相关软件。
高性能集群主要用于处理复杂的计算问题,应用在需要大规模科学计算的环境中,如天气预报、石油勘探与油藏模拟、分子模拟、基因测序等。
高性能集群上运行的应用程序一般使用并行算法,把一个大的普通问题根据一定的规则分为许多小的子问题,在集群内的不同节点上进行计算,而这些小问题的处理结果,经过处理可合并为原问题的最终结果。
由于这些小问题的计算一般是可以并行完成的,从而可以缩短问题的处理时间。
高性能集群在计算过程中,各节点是协同工作的,它们分别处理大问题的一部分,并在处理中根据需要进行数据交换,各节点的处理结果都是最终结果的一部分。
高性能集群的处理能力与集群的规模成正比,是集群内各节点处理能力之和,但这种集群一般没有高可用性。
1.2 高性能计算分类高性能计算的分类方法很多。
这里从并行任务间的关系角度来对高性能计算分类。
1.2.1 高吞吐计算(High-throughput Computing)有一类高性能计算,可以把它分成若干可以并行的子任务,而且各个子任务彼此间没有什么关联。
因为这种类型应用的一个共同特征是在海量数据上搜索某些特定模式,所以把这类计算称为高吞吐计算。
所谓的Internet计算都属于这一类。
按照Flynn的分类,高吞吐计算属于SIMD(Single Instruction/Multiple Data,单指令流-多数据流)的范畴。
1.2.2 分布计算(Distributed Computing)另一类计算刚好和高吞吐计算相反,它们虽然可以给分成若干并行的子任务,但是子任务间联系很紧密,需要大量的数据交换。
按照Flynn的分类,分布式的高性能计算属于MIMD (Multiple Instruction/Multiple Data,多指令流-多数据流)的范畴。
1.3高性能计算集群系统的特点可以采用现成的通用硬件设备或特殊应用的硬件设备,研制周期短;可实现单一系统映像,即操作控制、IP登录点、文件结构、存储空间、I/O空间、作业管理系统等等的单一化;高性能(因为CPU处理能力与磁盘均衡分布,用高速网络连接后具有并行吞吐能力);高可用性,本身互为冗余节点,能够为用户提供不间断的服务,由于系统中包括了多个结点,当一个结点出现故障的时候,整个系统仍然能够继续为用户提供服务;高可扩展性,在集群系统中可以动态地加入新的服务器和删除需要淘汰的服务器,从而能够最大限度地扩展系统以满足不断增长的应用的需要;安全性,天然的防火墙;资源可充分利用,集群系统的每个结点都是相对独立的机器,当这些机器不提供服务或者不需要使用的时候,仍然能够被充分利用。
而大型主机上更新下来的配件就难以被重新利用了。
具有极高的性能价格比,和传统的大型主机相比,具有很大的价格优势;1.4 Linux高性能集群系统当论及Linux高性能集群时,许多人的第一反映就是Beowulf。
起初,Beowulf只是一个著名的科学计算集群系统。
以后的很多集群都采用Beowulf类似的架构,所以,实际上,现在Beowulf已经成为一类广为接受的高性能集群的类型。
尽管名称各异,很多集群系统都是Beowulf集群的衍生物。
当然也存在有别于Beowulf的集群系统,COW和Mosix就是另两类著名的集群系统。
1.4.1 Beowulf集群简单的说,Beowulf是一种能够将多台计算机用于并行计算的体系结构。
通常Beowulf系统由通过以太网或其他网络连接的多个计算节点和管理节点构成。
管理节点控制整个集群系统,同时为计算节点提供文件服务和对外的网络连接。
它使用的是常见的硬件设备,象普通PC、以太网卡和集线器。
它很少使用特别定制的硬件和特殊的设备。
Beowulf集群的软件也是随处可见的,象Linux、PVM和MPI。
1.4.2 COW集群象Beowulf一样,COW(Cluster Of Workstation)也是由最常见的硬件设备和软件系统搭建而成。
通常也是由一个控制节点和多个计算节点构成。
COW和Beowulf的主要区别在于:COW中的计算节点主要都是闲置的计算资源,如办公室中的桌面工作站,它们就是普通的PC,采用普通的局域网进行连接。
因为这些计算节点白天会作为工作站使用,所以主要的集群计算发生在晚上和周末等空闲时间。
而Beowulf中的计算节点都是专职于并行计算,并且进行了性能优化。
Beowulf采用高速网(InfiniBand, SCI, Myrinet)上的消息传递(PVM 或MPI)进行进程间通信(IPC)。
因为COW中的计算节点主要的目的是桌面应用,所以它们都具有显示器、键盘和鼠标等外设。
而Beowulf的计算节点通常没有这些外设,对这些计算节点的访问通常是在管理节点上通过网络或串口线实现的。
1.4.3 Mosix集群实际上把Mosix集群放在高性能集群这一节是相当牵强的,但是和Beowulf等其他集群相比,Mosix集群确实是种非常特别的集群,它致力于在Linux系统上实现集群系统的单一系统映象SSI(Single System Image)。
Mosix集群将网络上运行Linux的计算机连接成一个集群系统。
系统自动均衡节点间的负载。
因为Mosix是在Linux系统内核中实现的集群,所以用户态的应用程序不需要任何修改就可以在Mosix集群上运行。
通常用户很少会注意到Linux和Mosix的差别。
对于他来说,Mosix集群就是运行Linux的一台PC。
尽管现在存在着不少的问题,Mosix始终是引人注目的集群系统2 如何架构高性能计算集群在搭建高性能计算集群(HPC CLUSTER)之前,我们首先要根据具体的应用需求,在节点的部署、高速互连网络的选择、以及集群管理和通讯软件,三个方面作出配置。
2. 1节点的部署根据功能,我们可以把集群中的节点划分为6种类型:用户节点(User Node)控制节点(Control Node)管理节点(Management Node)存储节点(Storage Node)安装节点(Installation Node)计算节点(Compute Node)虽然由多种类型的节点,但并不是说一台计算机只能是一种类型的节点。
一台计算机所扮演的节点类型要由集群的实际需求和计算机的配置决定。
在小型集群系统中,用户节点、控制节点、管理节点、存储节点和安装节点往往就是同一台计算机。
下面我们分别解释这些类型节点的作用。
2.1. 1用户节点(User Node)用户节点是外部世界访问集群系统的网关。
用户通常登录到这个节点上编译并运行作业。
用户节点是外部访问集群系统强大计算或存储能力的唯一入口,是整个系统的关键点。
为了保证用户节点的高可用性,应该采用硬件冗余的容错方法,如采用双机热备份。
至少应该采用RAID(Redundant Array of Independent Disks)技术保证用户节点的数据安全性。
2.1.2 控制节点(Control Node)控制节点主要承担两种任务: 为计算节点提供基本的网络服务,如DHCP、DNS和NFS; 调度计算节点上的作业,通常集群的作业调度程序(如PBS)应该运行在这个节点上。
通常控制节点是计算网络中的关键点,如果它失效,所有的计算节点都会失效。
所以控制节点也应该有硬件冗余保护。
2.1.3 管理节点(Management Node)管理节点是集群系统各种管理措施的控制节点。
管理网络的控制点,监控集群中各个节点和网络的运行状况。
通常的集群的管理软件也运行在这个节点上。
2.1.4 存储节点(Storage Node)如果集群系统的应用运行需要大量的数据,还需要一个存储节点。
顾名思义,存储节点就是集群系统的数据存储器和数据服务器。
如果需要存储TB级的数据,一个存储节点是不够的。
这时候你需要一个存储网络。
通常存储节点需要如下配置:ServerRAID保护数据的安全性; 高速网保证足够的数据传输速度。
2.1.5 安装节点(Installation Node)安装节点提供安装集群系统的各种软件,包括操作系统、各种运行库、管理软件和应用。
它还必须开放文件服务,如FTP或NFS。
2.1.6 计算节点(Computing Node)计算节点是整个集群系统的计算核心。
它的功能就是执行计算。
你需要根据你的需要和预算来决定采用什么样的配置。
理想的说,最好一个计算节点一个CPU。
但是如果考虑到预算限制,也可以采用SMP。
从性价比角度说,两个CPU的SMP优于3或4个CPU的SMP机器。
因为一个计算节点的失效通常不会影响其他节点,所以计算节点不需要冗余的硬件保护。
2.1.7 集群中节点的部署虽然由多种类型的节点,但并不是说一台计算机只能是一种类型的节点。
一台计算机所扮演的节点类型要由集群的实际需求和计算机的配置决定。
在小型集群系统中,用户节点、控制节点、管理节点、存储节点和安装节点往往就是同一台计算机,这台计算机通常成为主节点(Master Node)。
在这种情况下,集群就是由多个计算节点和一个主节点构成。
在大型的集群系统中如何部署这些节点是个比较复杂的问题,通常要综合应用需求,拓扑结构和预算等因素决定。
2.2 高速互连网络网络是集群最关键的部分.它的容量和性能直接影响了整个系统对高性能计算(HPC)的适用性。
根据我们的调查,大多数高性能科学计算任务都是通信密集型的,因此如何尽可能的缩短节点间的通信延迟和提高吞吐量是一个核心问题。
2.2.1快速以太网快速以太网是运行于UTP或光缆上的100Mb/S的高速局域网的总称。
由于TCP/IP运行时对CPU的占用较多,并且理论上的传输速度和延迟都比较差,现在我们在HPC集群中计算网络的选择上基本不考虑这个方案了。
2.2.2千兆以太网(Giganet)Giganet 是用于Linux 平台的虚拟接口(VI) 体系结构卡的第一家供应商,提供cLAN 卡和交换机。
VI 体系结构是独立于平台的软件和硬件系统,它由Intel 开发,用于创建群集。
它使用自己的网络通信协议在服务器之间直接交换数据,而不是使用IP,并且它并不打算成为WAN 可路由的系统。
Giganet 产品当前可以在节点之间提供 1 Gbps 单向通信,理论最小延迟为7 微秒,实测延迟为50-60微秒左右,并且运行时对CPU的占用也比较大。
2.2.3 IEEE SCIIEEE 标准SCI 的延迟更少(理论值1.46微秒, 实测值3-4微秒),并且其单向速度可达到10Gb/秒, 与InfiniBand 4X的理论值一样。