如何在SAS中实现R×C列联表的两两比较
多个样本及其两两比较的秩和检验SAS程序

多个样本及其两两比较的秩和检验SAS程序多个样本及其两两比较的秩和检验SAS程序广东医学院预防医学教研室(524023)丁元林孔丹莉秩和检验是医学实践中较为常用的一大类非参数统计方法,目前国内几本较具权威性SAS专著11,22,均介绍了秩和检验的一些SAS程序,宇氏132也作了进一步的探讨和总结,但对于不同资料类型和特征的多个样本比较的秩和检验SAS程序阐述得不够全面,而且几乎未涉及到两两比较的SAS程序,但实际工作者往往对两两比较的结果更为感兴趣。
为此,本文结合实例,根据常见类型资料的特点,给出了多个样本及其两两比较的秩和检验SAS程序。
11成组设计的原始数据多个样本及其两两比较这种类型资料一般为成组设计的定量资料,但各个样本的总体呈偏态分布或方差不齐,且未整理成其他形式(如频数表),检验其总体分布是否相同的常用秩和检验方法是Kruska-l Wallis法,在SAS软件中实现的过程步有以下三种:NPAR1WAY过程、FREQ 过程以及RANK和ANOVA两过程的结合。
各个样本两两比较一般可通过RANK和ANOVA两过程的结合,采用M EANS语句来实现。
对文献142第139页表1中的数据进行Kruska-l Wallis检验及两两比较的SAS程序如下: /*以下为建立数据库*/data dy1;do group=1to3;input x@@;output;end;cards;918016014101211211910162102121310 214215141031121814184113111516510 3171516519319211671441624101316710;/*以下为调用F REQ过程*/proc fr eq;t ables group*x/scores=rank cmh2noprint;/*以下为调用N PAR1WAY过程*/proc npar1way w ilcoxon;class group;v ar x;/*以下为调用RA NK过程*/proc rank data=dy1out=a;v ar x;ranks r;/*以下为调用A NOV A过程*/proc anova;class group;model r=group;means group/lsd;r un;以上程序中调用FREQ过程产生的第二个CMH 统计量、NPAR1WAY过程产生的卡方统计量以及ANOVA过程产生的R2与T 总之积,即为为Kruska-l Wallis检验结果。
多个样本及其两两比较的秩和检验SAS程序

/ / !以下为调用 3 N 5 O 过程! ; & ’ ! $ ’ & @ + # @ # + >’ ( @ # ) A ; B " ’ ! C AB / / !以下为调用 5 4 8 9 过程! ; & ’ ! & # . C+ # @ # # ’ ( @ B ) ; P # & E ; B " ’ ! C AB ; & # . C $ & / / !以下为调用 : ; < 过程! ; & ’ ! " *+ # @ # B ) % ; ! " # $ $ @ & , # @ B " ’ ! C / ; * ’ + , " & @ & , # @ B " ’ ! C $ $ > / ; " $ * , # . $ @ & , # @ $ @ + , & & + 2 K K ) ; & ( .
!
以上程序中调用 8 6 9 : 过程产生的第二个 T =U 统计 量、 4 5 " 6 ( 2" 7 过程产生的卡方统计量以及
$与 即为为 * " 4 ; < " 过程产生的 6 " + , . / 0 1 总 之积, 检验结果。 过程步中的 规定 2 / 0 0 3 " 4 ; < " = 9 "#43; (R / 3 0 I B G B F D D AR ; I 0 / + B , C D ; S / + G / / !以下为调用 6 " 4 * 过程! ; + B I + / F .? / @ / E ? (B , @ E / D A ; ; S / + G + / F . + / / !以下为调用 " 4 ; < " 过程! 万方数据 ; + B I / F B S / D
R×C列联表资料的统计分析

定量变量:年龄、红细胞
二值变量:性别(男、女)
多值名义变量:药物类型(A、B、C)、血型 (A、B、AB、O)
多值有序变量:疗效(痊愈、显效、好转、无 效)、临床诊断(Ⅰ级、Ⅱ级、Ⅲ级)、CT诊断 (Ⅰ级、Ⅱ级、Ⅲ级)
双向无序的RC表
药物 类型 A B C 血型: A 8 7 10
胆汁质
13 15 9
抑郁质
7 10 8
粘液质
14 13 15
二、双向无序RC表的统计分析
第一步,建立检验假设。
H0: 3个专业学生的气质类型构成(频数分布) 相同 H1: 3个专业学生的气质类型构成(频数分布) 不全相同 a0.05。
二、双向无序RC表的统计分析
第二步,计算检验统计量。
2
二、双向无序RC表的统计分析
原因变量为二值变量,结果变量为多值 名义变量的2C表
表 12 满族与回族居民血型的频数分布 民族 满族 回族 合计 例数 血型:A 442 369 811 B 483 384 867 O 416 487 903 AB 172 115 287 合计 1513 1355 2868
双向有序且属性不同RC表的统计方法
对于双向有序且属性不同的RC表资料应根据具 体的分析目来确定分析方法:
第一个分析目的,只关心各组结果变量取值之间的差别是
否具有统计学意义,此时,原因变量的有序性就变得无关 紧要了,可将此时的“双向有序RC列联表资料”视为 “结果变量为有序变量的单向有序RC列联表资料”,可 以选用的统计分析方法有秩和检验、Ridit分析和有序变 量的logistic回归分析
双向有序且属性不同RC表的统计方法
第四个分析目的,希望考察各行上的频数分布 是否相同,此时,将此资料视为双向无序的 RC列联表资料,可根据资料具备的前提条件, 2 选用一般 检验或 Fisher精确检验。若P<0.05, 不能认为两有序变量之间有相关关系,而只能 认为各行上的频数分布不同
【宝典】R×C列联表(分类数据)的统计分析方法选择与SPSS实现

【宝典】R×C列联表(分类数据)的统计分析方法选择与SPSS实现分类资料在医学统计中很常见,有些统计学书上称为计数资料,比如(有效、无效),(发病、不发病),(男、女),血型(A、B、O、AB)等等。
分类资料一般根据频数整理成列联表的形式,一般的列联表多是二维的(也称行列表,或R×C列联表,高维列联表下次讨论),列联表根据变量是否有序可以分为双向无序、单项有序、双向有序列联表,统计方法是不同的,分析如下:一、双向无序列联表(一)成组四格表是指行、列变量均为无序的列联表,例如要研究吸烟和肺癌之间的关系,行变量为是否吸烟:吸烟、不吸烟,列变量为肺癌发病:发病,不发病,如下表:发生肺癌未发生肺癌吸烟a b不吸烟 c d对于这种数据,我们的统计目的是分析行列变量的独立性,即:肺癌发病是否与吸烟有关,可选用的方法有以下两种:1、Pearson卡方检验:基于卡方分布,H0为行、列变量相互独立,SPSS中“分析->描述性统计->交叉表”可实现。
四格表使用条件:专用公式①样本总数大于40;②各个单元格理论值均大于5。
校正公式:①样本总数大于40;②理论值1<T<5;Fisher确切概率法:①样本总数小于40,或T<1,无需选择,软件自动计算成组四格表Fisher。
2、Fisher精确概率:基于超几何分布,当数据不满足Pearson卡方检验时使用。
SPSS 中“分析->描述性统计->交叉表”可实现。
注意SPSS仅提供了2×2表的精确概率,需要计算R×C列联表的精确概率,可以选择精确按钮中的蒙特卡罗近似法实现。
(一)成组R×C表(双向无序)A型B型O型AB型A地区 a b c dB地区 e f j hC地区i j k l1.Pearson卡方检验条件:不能有任何一个格子的理论频数T<1,同时1<T<5的格子数不能超过总格子数的1/5.如若不符合:可以增加研究样本量(通常少用);对理论频数较小的行或者列进行合并或者删除;采用R×C表的Fisher确切概率法(通常采用蒙特卡洛近似法)2.R×C表Fisher确切概率法操作:分析—描述—交叉表—设置好行列变量—点击精确—选择蒙特卡洛。
r语言 三组间两两比较方法

在R语言中,有多种方法可以进行三组间的两两比较。
以下是一些常见的方法:1. t检验(pairwise.t.test):当数据满足正态性和方差齐性假设时,可以使用t检验来进行两两比较。
该函数会对每对组进行t检验,计算出每对之间的差异显著性水平和置信区间。
```Rpairwise.t.test(data$group, data$value, p.adjust.method = "bonferroni")```2. 方差分析(ANOVA):如果数据不满足t检验的假设条件,可以使用方差分析来进行两两比较。
可以使用ANOVA函数进行方差分析,然后使用posthoc函数进行多重比较。
```Rmodel <- aov(value ~ group, data = data)posthoc <- TukeyHSD(model)```3. 非参数检验(Kruskal-Wallis检验):当数据不满足正态性和方差齐性假设时,可以使用非参数方法进行两两比较,如Kruskal-Wallis检验。
可以使用kruskal.test函数进行Kruskal-Wallis检验,然后使用pairwise.wilcox.test函数进行多重比较。
```Rkruskal.test(value ~ group, data = data)pairwise.wilcox.test(data$value, data$group, p.adjust.method = "bonferroni")```这些方法都可以用于进行三组间的两两比较,具体应该根据数据的性质和实验设计来选择合适的方法。
在进行多重比较时,通常需要考虑到多重比较校正以控制错误率。
常见的多重比较校正方法包括Bonferroni校正、Holm校正等。
RC列联表资料的统计分析与SAS软件实现

一、调查问卷数据导入SPSS中。数据导入后,可以在SPSS主界面的 数据视图中查看数据。
二、进行列联表分析
1、打开列联表分析对话框
1、打开列联表分析对话框
在SPSS主菜单中,选择“分析”>“表”>“列联表”。这将打开列联表分析 对话框。
2、选择变量
2、选择变量
3、SAS实现
在这个示例中,mydata是包含RC列联表资料的数据集名称,var1和var2是需 要进行卡方检验的两个分类变量。chisq选项告诉PROC FREQ过程执行卡方检验。 运行这个过程后,将会生成一个包含卡方统计量、自由度和p值的输出表。
3、SAS实现
案例分析 为了更好地说明RC列联表资料的统计分析和SAS软件实现,让我们以一个实际 案例为例。在这个案例中,我们有一份包含两个分类变量的RC列联表资料,目的 是检验这两个变量之间的关联性。我们将分别使用Excel和SAS进行分析。
2、统计方法
2、统计方法
对于RC列联表资料,常用的统计方法包括卡方检验、Fisher精确检验、对数 似然比检验等。这些方法可以用来检验两个分类变量之间的独立性,以及判断某 种关联的存在性。根据分析目的和数据特点,选择合适的统计方法是非常重要的。
3、SAS实现
3、SAS实现
在SAS软件中,可以使用PROC FREQ和PROC LOGISTIC等过程来对RC列联表资 料进行统计分析。PROC FREQ过程可以用来进行频数统计和独立性检验,而PROC LOGISTIC过程则可以用来进行关联性分析和效应估计。下面是一个使用PROC FREQ进行卡方检验的示例代码:
三、解读结果
1、频率表
1、频率表
频率表展示了每个变量的单独频率以及不同变量组合的频率。通过查看频率 表,可以了解不同变量之间的关系。
(仅供参考)如何在SAS中实现R×C列联表的两两比较
A14-如何在SAS中实现R×C列联表的两两比较内容来自网络,侵删在分析R×C列联表时,在卡方检验有统计意义的情况下常常需要做进一步的多重比较。
可以采用的方法为1)卡方分割(具体见本人另外一篇文章《R×C行列表卡方值分割的概念及运用》)将原表卡方值分割成独立的子卡方值,分割后的子卡方值和对应的自由度相加会和原表的卡方值和自由度相等。
2)或者采用彼此之间非独立的两两比较。
但是两两比较的卡方值和对应的自由度相加不会等于原表卡方值和自由度,所以此类比较不能称为卡方分割法。
尽管后者更为灵活但需要调整多重比较的次数以避免增加第一类错误。
本文将具体讲解如何在SAS中实现R×C列联表的两两比较。
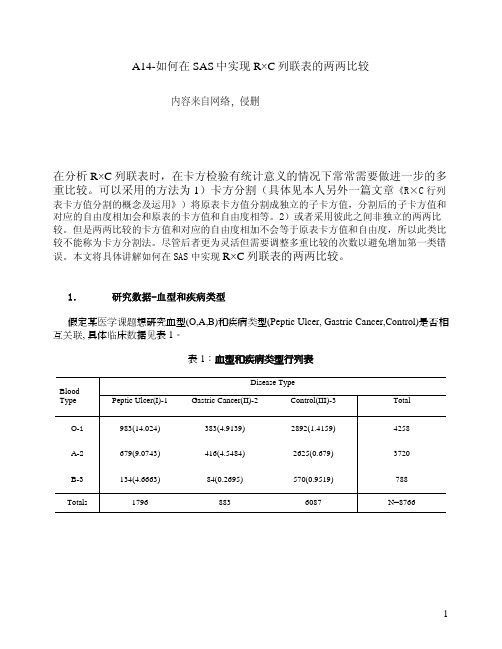
1.研究数据-血型和疾病类型假定某医学课题想研究血型(O,A,B)和疾病类型(Peptic Ulcer, Gastric Cancer,Control)是否相互关联, 具体临床数据见表1。
表1:血型和疾病类型行列表Disease TypeBloodType Peptic Ulcer(I)-1 Gastric Cancer(II)-2 Control(III)-3 Total O-1983(14.024)383(4.9139)2892(1.4159)4258A-2679(9.0743)416(4.5484)2625(0.679)3720B-3134(4.6663)84(0.2695)570(0.9519)788Totals17968836087N=87662.初步分析我们先用SAS/PROC FREQ 和PROC CORRESP 先对数据做初步的分析,来判断行列变量之间的关系。
CELLCHI2 选项是计算按公式2-1计算每个单元格在总体值的组成。
2χij ijijji E OE C 2,)(-=(2-1)proc freq data=paper14;weight count;table r*c/chisq cellchi2nopercent;run;proc corresp data=paper14;weight count;les r, c;tabrun;表2 – 卡方检验结果Table of r by cr cFrequencyCell Chi-SquareRow PctCol Pct 123Total198314.02423.0954.733834.91398.9943.3728921.415967.9247.51425826799.074318.2537.814164.548411.1847.1126250.67970.5643.12372031344.666317.017.46840.269510.669.515700.951972.349.36788Total 179688360878766 Statistics for Table of r by cStatistic DF Value Prob ------------------------------------------------------ Chi-Square 4 40.5434 <.0001 Likelihood Ratio Chi-Square 4 40.6401 <.0001 Mantel-Haenszel Chi-Square 1 21.0035 <.0001 Sample Size = 8766从表2中可以看出第1行(血型O)的卡方检验分值在所有行中所占比重最高((14.024+4.9139+1.4159)/40.5434≈50%);第1列(Peptic Ulcer(I))的卡方检验分值在所有列中所占比重最高((14.024+9.0743+4.6663)/40.5434≈68.5%)。
如何用SAS软件正确分析生物医学科研资料XX. R × C列联表资料的统计分析与SAS软件实现(三)

如何用SAS软件正确分析生物医学科研资料XX. R × C列联表资料的统计分析与SAS软件实现(三)王琪;胡良平;柳伟伟【摘要】生物统计学是生物学领域科学研究和实际工作中必不可少的工具,在分子生物学迅速发展的今天,生物统计学更显示出了它的重要性。
实验设计与数据统计分析是现代生物学的基石,是生物学研究者检验假说、寻找模式、建立生物学理论的有利工具,也是生物学研究者探索微观和宏观生物世界的必备基础知识。
对于每天甚至是每时每刻涌现的大量的、以天文数字计量的分子遗传数据,必须借助统计学知识加以分析处理,才能从中获得有意义的信息。
“生物多样性数据分析”是开展生物多样性研究的一个重要方面,数据分析能力的高低极大地影响着我们对各种生态学现象认识的深度和广度。
现在,电子计算机的普及使得生物统计分析过程大大简化,生物统计分析软件包的普及将生物统计学从统计学家的书本里解放了出来,简化了生物统计分析过程,使之成为生物学研究者的常用工具。
本刊特邀军事医学科学院生物医学统计学咨询中心主任胡良平教授,以“如何用 SAS 软件正确分析生物医学科研资料”为题,撰写系列统计学讲座,希望该系列讲座能对生物医学科研工作者有所帮助。
【期刊名称】《中国医药生物技术》【年(卷),期】2012(000)006【总页数】3页(P469-471)【作者】王琪;胡良平;柳伟伟【作者单位】100850 北京,军事医学科学院生物医学统计学咨询中心;100850 北京,军事医学科学院生物医学统计学咨询中心;100850 北京,军事医学科学院生物医学统计学咨询中心【正文语种】中文XX. R × C列联表资料的统计分析与SAS软件实现(三)编者按生物统计学是生物学领域科学研究和实际工作中必不可少的工具,在分子生物学迅速发展的今天,生物统计学更显示出了它的重要性。
实验设计与数据统计分析是现代生物学的基石,是生物学研究者检验假说、寻找模式、建立生物学理论的有利工具,也是生物学研究者探索微观和宏观生物世界的必备基础知识。
【VIP专享】SAS相关分析与CORR过程

Kendall相关系数
(3)数据集选项:
outp=SAS-data-set; 要求该过程创建一个存放 Pearson相关系数的新的数据集,使用该选项须同 时使用Pearson选项;
outs=SAS-data-set; 要求该过程创建一个存放 Spearman相关系数的新的数据集,使用该选项须 同时使用Spearman选项
该语句要求系统执行相关过程。
当该语句没有选择项时,表示该过程对输入数 据集中所有数值变量计算Pearson的乘积矩相关系 数和显著性概率,以及单变量的统计量。
(1)数据集选项:
data=SAS-data-set;
proc corr <option-list>;
(2)有关相关类型的选项:
Pearson的积矩相关系数;
var 语句
该语句列出要计算相关系数的变量。 如:proc corr;
var a b c; 上例说明,将计算a和b,a和c,b和c三对变量间的 相关系数。
with 语句
为了得到变量间特殊组合的相关系数,该语句与 var语句一起使用。 由var语句列出的变量放在输出相关阵的上方,而 由with语句列出的变量竖在相关阵的左边。 例如:proc corr;
var a b c; with x y z; 该语句意味着x,y,z分别与a,b,c做相关分析。
partial 语句
该语句给出计算Pearson偏相关, Spearman的偏等级相关等。
相关关系的度量
1、对于两个连续型变量,常用Pearson积矩相关系 数度量,其计算公式如下:
rxy xi x yi y Nhomakorabea2
2
xi x yi y
SPSS超详细操作:卡方检验(R×C列联表)

SPSS超详细操作:卡⽅检验(R×C列联表)医咖会之前推送过⼀些卡⽅检验相关的⽂章,包括:卡⽅检验(2x2)、卡⽅检验(2xC)、配对卡⽅检验、分层卡⽅检验等。
今天我们再和⼤家分享⼀下,如何⽤SPSS来做RxC列联表的卡⽅检验。
⼀、问题与数据研究者拟分析购房⼈与购房类型的关系,共招募了在过去12个⽉中有过购房记录的333位受试者,收集了购房⼈类型(buyer_type)和房屋类型(property_type)的变量信息。
其中研究对象类型按照单⾝男性(single male)、单⾝⼥性(single female)、已婚两⼈(married couple)和多⼈家庭(family)分类;房屋类型按照楼房(flat)、平房(bungalow)、独栋别墅(detached house)和联排别墅(terrace)分类,部分数据如下图。
其中,Individual scores for each paticipant(左图)列出了每⼀个研究对象的情况,⽽Total count data (frequencies)(右图)则是对相同情况研究对象的数据进⾏了汇总。
⼆、对问题的分析研究者想分析多种购房⼈类型与多种房屋类型的关系,建议使⽤卡⽅检验(R×C),但需要先满⾜3项假设:假设1:存在两个⽆序多分类变量,如本研究中购房⼈类型和房屋类型均为⽆序分类变量。
假设2:具有相互独⽴的观测值,如本研究中各位研究对象的信息都是独⽴的,不会相互⼲扰。
假设3:样本量⾜够⼤,最⼩的样本量要求为分析中的任⼀期望频数⼤于5。
本研究数据符合假设1和假设2,那么应该如何检验假设3,并进⾏卡⽅检验(R×C)呢?三、SPSS操作1. 数据加权如果数据是汇总格式(如上图中的Total count data),则在进⾏卡⽅检验之前,需要先对数据加权。
如果数据是个案格式(如上图中的Individual scores for each paticipant),则可以跳过“数据加权”步骤,直接进⾏卡⽅检验的SPSS操作。
SPSS列联表分析

例3: 以下是胃癌真菌病因研究中3种食物样品的真菌检出率,比较3种食物真菌检出率有无差异.
本例中SPSS提示没有理论频数小于5,且最小的理论频数为8.00,故直接选择Pearson 卡方结果,即χ2=22.841,P<0.001,提示三种食物中真菌检出率不同.此时还需要进一步考虑三种食物真菌检出率到底谁与谁之间的差异存在统计学意义,这里就需要用到卡方分割,通俗讲就是把RC列联表拆分成若干个四个表分别进行χ2检验,进而判断不同组两两比较差异是否用统计学意义,但是因为多组比较可能会增加犯I类错误概率,所以还需要对χ2检验的P值进行校正.常用Bonferroni法进行校正,本例中需要进行3次两两比较,校正的检验水准α=0.05/比较次数=0.05/3=0.0167,即当两两比较P<0.0167才能认为差异有统计学意义.
Kappa一致性检验
1、Kappa检验旨在评价两种方法是否存在一致性,或者是同一个研究者先后两次的诊断结果 2、Kappa检验会利用列联表的全部数据 3、Kappa检验可计算Kappa值用于评价一致性大小
配对χ2检验(McNemar检验)
1、配对χ2检验主要确定两种方法诊断结果是否有差别 2、配对χ2检验只利用“不一致“数据,如表中b和c 3、配对χ2检验只能给出两种方法差别是否具有统计学意义的判断
无效 疗效=1
好转 疗效=2
显效 疗效=3
治愈 疗效=4
合计
有效率%
甲法
24
26ห้องสมุดไป่ตู้
72
186
308
92.2
乙法
20
16
24
32
92
78.3
丙法
20
22
14
22
(仅供参考)如何在SAS中实现R×C列联表的两两比较
A14-如何在SAS中实现R×C列联表的两两比较内容来自网络,侵删在分析R×C列联表时,在卡方检验有统计意义的情况下常常需要做进一步的多重比较。
可以采用的方法为1)卡方分割(具体见本人另外一篇文章《R×C行列表卡方值分割的概念及运用》)将原表卡方值分割成独立的子卡方值,分割后的子卡方值和对应的自由度相加会和原表的卡方值和自由度相等。
2)或者采用彼此之间非独立的两两比较。
但是两两比较的卡方值和对应的自由度相加不会等于原表卡方值和自由度,所以此类比较不能称为卡方分割法。
尽管后者更为灵活但需要调整多重比较的次数以避免增加第一类错误。
本文将具体讲解如何在SAS中实现R×C列联表的两两比较。
1.研究数据-血型和疾病类型假定某医学课题想研究血型(O,A,B)和疾病类型(Peptic Ulcer, Gastric Cancer,Control)是否相互关联, 具体临床数据见表1。
表1:血型和疾病类型行列表Disease TypeBloodType Peptic Ulcer(I)-1 Gastric Cancer(II)-2 Control(III)-3 Total O-1983(14.024)383(4.9139)2892(1.4159)4258A-2679(9.0743)416(4.5484)2625(0.679)3720B-3134(4.6663)84(0.2695)570(0.9519)788Totals17968836087N=87662.初步分析我们先用SAS/PROC FREQ 和PROC CORRESP 先对数据做初步的分析,来判断行列变量之间的关系。
CELLCHI2 选项是计算按公式2-1计算每个单元格在总体值的组成。
2χij ijijji E OE C 2,)(-=(2-1)proc freq data=paper14;weight count;table r*c/chisq cellchi2nopercent;run;proc corresp data=paper14;weight count;les r, c;tabrun;表2 – 卡方检验结果Table of r by cr cFrequencyCell Chi-SquareRow PctCol Pct 123Total198314.02423.0954.733834.91398.9943.3728921.415967.9247.51425826799.074318.2537.814164.548411.1847.1126250.67970.5643.12372031344.666317.017.46840.269510.669.515700.951972.349.36788Total 179688360878766 Statistics for Table of r by cStatistic DF Value Prob ------------------------------------------------------ Chi-Square 4 40.5434 <.0001 Likelihood Ratio Chi-Square 4 40.6401 <.0001 Mantel-Haenszel Chi-Square 1 21.0035 <.0001 Sample Size = 8766从表2中可以看出第1行(血型O)的卡方检验分值在所有行中所占比重最高((14.024+4.9139+1.4159)/40.5434≈50%);第1列(Peptic Ulcer(I))的卡方检验分值在所有列中所占比重最高((14.024+9.0743+4.6663)/40.5434≈68.5%)。
多组等级资料比较的秩和检验及组间两两比较的SAS实现

多组等级资料比较的秩和检验及组间两两比较的SAS实现郭志武【摘要】目的探讨多组等级资料的秩和检验及组间两两比较的SAS实现.方法结合实例介绍多组等级资料Kruskal-Wallis H检验和两两比较Nemenyi检验的计算方法和步骤,通过编制SAS程序一次性完成Kruskal-Wallis H检验和Nemenyi 检验.结果运行SAS程序得到可靠结果.结论编制SAS程序可以有效实现多组等级资料的秩和检验及组间两两比较.【期刊名称】《中国医院统计》【年(卷),期】2018(025)003【总页数】2页(P233-234)【关键词】等级资料;秩和检验;两两比较;SAS【作者】郭志武【作者单位】518033 深圳市中医院【正文语种】中文多组独立样本等级资料是临床常见的资料类型。
针对多组独立样本等级资料比较的假设检验通常采用Kruskal-Wallis H检验,若检验结果具有统计学意义,则可以进一步采用Nemenyi检验进行组间两两比较[1]。
Kruskal-Wallis H检验利用通用的统计软件可以完成,但Nemenyi检验却不能直接从统计软件包的集成功能或模块中完成,需要另外编写自定义程序。
刘伟等采用SPSS菜单操作结合编程实现了Nemenyi检验[2],本文通过编制SAS程序一次性完成Kruskal-Wallis H检验和Nemenyi检验。
1 方法与步骤参考文献[1]已详细介绍了Kruskal-Wallis H检验和Nemenyi检验的原理、方法和步骤。
本文只针对多组独立样本的等级资料结合实例介绍计算方法和步骤。
文献[1]第131页实例如下:4种疾病患者痰液内嗜酸性粒细胞的检查结果见表1。
问4种疾病患者痰液内嗜酸性粒细胞有无差别?表1 4种疾病患者痰液内嗜酸性粒细胞比较嗜酸性粒细胞(1)支气管扩张(2)肺水肿(3)肺癌(4)病毒性呼吸道感染(5)合计(6)秩范围(7)平均秩(8)-0353111~116+25751912~3021 ++95332031~5040.5+++62201051~6055.5Ri739.5 436.5 409.5 244.5 ni17 15 17 11 60Ri 43.5029.1024.0922.23(1)首先进行Kruskal-Wallis H检验检验统计量H按以下公式计算:(1)式中,ni为各样本例数,N为样本总例数(N=∑ni),Ri为各样本秩和。
R×C表资料的

R×C表资料的R×CR×C表⼜称为⾏×列表, 其检验⽤于多个样本率的⽐较、两个或多个构成⽐的⽐较、以及双向⽆序分类资料的关联性检验。
基本数据有三种情况:①多个样本率⽐较时,有R⾏2列,称为R×2表;②两个样本的构成⽐⽐较时,有2⾏R列,称2×R表;③多个样本的构成⽐⽐较,以及双向⽆序分类资料关联性检验时,有R⾏C列,称为R×C表。
2、⾏×列表资料的卡⽅检验⾏×列表资料的卡⽅检验⽤于多个率或多个构成⽐的⽐较。
1)专⽤公式:r⾏c列表资料卡⽅检验的卡⽅值=2)应⽤条件:要求每个格⼦中的理论频数T均⼤于5或1但在使⽤时须注意,简化计算公式只有在所有Tij均⼤于5的情况下使⽤。
若出现⼀个理论数⼩于1的格⼦,或1处理的⽅法继续观察,适当扩⼤样本量。
②将邻近有意义的(或性质相同)分类进⾏合并,以适当增加频数,满⾜计算公式的应R×C 表的分类及其检验⽅法的选择R×C表可分为双向⽆序、单向有序、双向有序属性相同和双向有序属性不同4类。
1.双向⽆序R×C表R×C表中两个分类变量皆为⽆序分类变量。
对于该类资料:①若研究⽬的为多个样本率(或构成⽐)⽐较,可⽤⾏×列表资料的检验;②若研究⽬的为分析两个分类变量之间有⽆关联性以及关系的密切程度时,可⽤⾏×列表资料的检验以及Pearson列联系数进⾏分析。
2.单向有序R×C表①R×C表分组变量(如年龄)是有序的,⽽指标变量(如传染病的类型)是⽆序的;研究⽬的通常是多个构成⽐的⽐较,如分析不同年龄组传染病的构成情况;此时可⽤⾏×列表资料的检验分析。
3.双向有序属性相同的R×C表R×C表中的两分类变量皆为有序且属性相同。
实际上是2×2配对设计的扩展,即⽔平数≥3的诊断试验配伍设计,如⽤两种检测⽅法对同⼀批样品的测定结果。
sas卡方检验编程语句分析

结果
实际频数 理论频数
结果解释
本例n>40且各格子的期望值均大于5, 因而选用Chi-Square的2统计量及其显 著性水平,即2=39.927,P=0.0001, 拒绝H0,认为内科疗法对两种类型胃溃 疡的治愈率差别有统计学意义,一般类 型的治愈率高于特殊型。
例2 某省三地区花生黄曲霉素B1污染率比较
地区 未污染 污染 合计 污染率(%)
甲
乙 丙 合计
6
30 8 44
23
14 3 40
29
44 11 84
79.3
31.8 27.3 47.6
程序1:一般输入方法
data ex2; input r c count@@; cards; 1 1 6 1 2 23 2 1 30 2 2 14 3 1 8 3 2 3 ;
此部分结果是普通四格表2检验的结果, 不适于配对2检验使用。
1960年Cohen等提出用Kappa值作为评价判断的一致性 程度的指标。当两个诊断完全一致时,Kappa值为1。当 观测一致率大于期望一致率时,Kappa值为正数,且 Kappa值越大,说明一致性越好。当观察一致率小于期望 一致率时,Kappa值为负数,这种情况一般来说比较少见。 根据边缘概率的计算,Kappa值的范围值应在-1~1之间。 Kappa≥0.75两者一致性较好;0.75>Kappa≥0.4两者 一致性一般;Kappa<0.4两者一致性较差。
结果
本例各格子期望值均大于5,选用ChiSquare的2统计量及其显著水平,即2=17.907, P=0.0001,按=0.05的检验水准拒受H0,认为 三地花生黄曲霉素B1污染率有差别。源自配对设计的2检验(SAS程序)
200名已确诊的血吸虫患者,治 疗前经皮试法及粪检法检查,结果 如下表,问两种检查方法的结果有 无差别?
一元析因设计分析两两比较的sas程序设计

一元析因设计分析两两比较的sas程序设计
SAS程序设计步骤:
1. 导入数据:使用SAS的数据提取功能,从关系数据库或文本文件中提取数据,并将其导入到SAS的数据集中。
2. 数据清理:使用SAS的数据清理功能,清理数据,确保数据的准确性和可用性。
3. 建立变量:使用SAS的变量建立功能,建立用于分析的变量,以便进行两两比较。
4. 运行分析:使用SAS的分析功能,运行两两比较分析,以获得有关变量之间的比较结果。
5. 结果报告:使用SAS的报告功能,创建有关两两比较分析结果的报告,以供查看和分析。
SAS的卡方检验(正式)

四格表卡方检验的SAS程序
• NOROW不给出列联表中各格的行百分数。 • NOCOL不给出列联表中各格的列百分数。 • NOCUM不给出频数表的累积频数和累积百分数。 • NOPRINT不给出表格,但给出CHISQ、MEASURES或
CMH等语句所指定的统计量。 • Trend指令系统对2×C频数表的C个百分率进行
• FREQ过程的语句基本格式如下: Proc freq data= order= ; Table 分类变量*分类变量/ <Ooptions>; Weight 变量; Run;
四格表卡方检验的SAS程序
• DATA=数据集:规定PROC FREQ语句使用的数据集; • ORDER=FREQ,按频数递减顺序排列;ORDER=
四格表资料
• 定性指标分为有序的(如:疗效分为“治愈、显效、好转 、无效、死亡”)和名义的(如:血型分为“O、A、B、 AB”型)2类,对于每1个受试者来说,有序指标的观 测结果只能是该有序指标若干等级中的1级(如某人的疗 效为“显效”);名义指标的观测结果只能是该名义指标 若干标志中的1个(如某人的血型为B型),显然,无法 像处理定量指标那样去直接分析定性指标,故这类资料常 被整理成列联表的形式后再进行分析。
概述
• 前面已介绍了两个率比较的检验,在观察例数不 够大或拟对多个率进行比较时,检验就不适宜了 ,因为直接对多个样本率作两两间的检验有可能 增加第一类误差。2检验可解决此类问题。
• 卡方检验是用途很广的一种假设检验方法,这里 我们主要学习它在分类资料统计推断中的应用, 包括:两个率或两个构成比比较的卡方检验;多 个率或多个构成比比较的卡方检验以及分类资料 的相关分析等。
Cochran-Armitage趋势检验; • WEIGHT语句:通常每个观察值提供数值1给频数计数,
13.4.2 行列均为顺序变量的相关检验的SAS程序_SAS统计分析与应用从入门到精通_[共6页]
![13.4.2 行列均为顺序变量的相关检验的SAS程序_SAS统计分析与应用从入门到精通_[共6页]](https://img.taocdn.com/s3/m/d406e5518762caaedc33d463.png)
231行×列表分析 第 13 章同R ×C 表资料。
对于双向有序属性不同R ×C 表资料,有3种分析目的,所以也就有3种相应的统计分析方法。
其一,只关心试验分组变量取不同水平时,有序的结果变量之间的差别是否有显著性意义,采用单向有序列联表的分析方法。
其二,希望研究两个有序变量之间是否有相关关系,就需要运用定性资料的相关分析方法,包括Spearman 秩相关分析和典型相关分析。
其三,如果两个有序变量之间有相关关系,需要迚一步研究两个变量之间是否呈直线变化关系,这就需要迚行线性趋势检验。
对于和双向有序属性相同R ×C 表资料,研究的目的通常是分析两种检测方法的一致性,此时宜用一致性检验(或称Kappa 检验),也可以用特殊模型分析方法(可用SAS 软件)。
一致性检验见四栺表的一致性检验。
与处理配对设计2×2表资料的思路一样,除了对方表资料作一致性检验外,还可以对两种检测方法的检测结果不一致部分作比较,此时称为“对称性检验”(在分析配对设计2×2表资料时,叫做McNemar's Test )。
13.4.1 行列均为顺序变量的相关检验介绍变量虽然是有序的,但毕竟还不是定量的,需要给有序变量的各等级赋值,方可迚行相关分析。
最简单的赋值法是按顺序赋给秩次(即得分),即给行变量的等级赋值1,2,…,R 和给列变量的等级赋值1,2,…,C 。
这样(X,Y)的不同取值就有R×C 对,表中的R×C 个频数就是这R×C 对取值所对应的频数,然后计算Spearman 秩相关系数,幵作显著性检验,这是比较粗糙的分析方法。
Spearman 秩相关分析比较粗糙,这是因为它给有序变量的等级赋值过于简单,不能最大限度地获得有序变量之间的相关信息。
而典型相关分析是在使有序变量的相关达到极大的前提下给有序变量的各等级赋值,就是对于表的边缘(指“行合计”与“列合计”)设法产生一双变量正态,从而迚行相关分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
A14-如何在SAS中实现R×C列联表的两两比较内容来自网络,侵删在分析R×C列联表时,在卡方检验有统计意义的情况下常常需要做进一步的多重比较。
可以采用的方法为1)卡方分割(具体见本人另外一篇文章《R×C行列表卡方值分割的概念及运用》)将原表卡方值分割成独立的子卡方值,分割后的子卡方值和对应的自由度相加会和原表的卡方值和自由度相等。
2)或者采用彼此之间非独立的两两比较。
但是两两比较的卡方值和对应的自由度相加不会等于原表卡方值和自由度,所以此类比较不能称为卡方分割法。
尽管后者更为灵活但需要调整多重比较的次数以避免增加第一类错误。
本文将具体讲解如何在SAS中实现R×C列联表的两两比较。
1.研究数据-血型和疾病类型假定某医学课题想研究血型(O,A,B)和疾病类型(Peptic Ulcer, Gastric Cancer,Control)是否相互关联, 具体临床数据见表1。
表1:血型和疾病类型行列表Disease TypeBloodType Peptic Ulcer(I)-1 Gastric Cancer(II)-2 Control(III)-3 Total O-1983(14.024)383(4.9139)2892(1.4159)4258A-2679(9.0743)416(4.5484)2625(0.679)3720B-3134(4.6663)84(0.2695)570(0.9519)788Totals17968836087N=87662.初步分析我们先用SAS/PROC FREQ 和PROC CORRESP 先对数据做初步的分析,来判断行列变量之间的关系。
CELLCHI2 选项是计算按公式2-1计算每个单元格在总体值的组成。
2χij ijijji E OE C 2,)(-=(2-1)proc freq data=paper14;weight count;table r*c/chisq cellchi2nopercent;run;proc corresp data=paper14;weight count;les r, c;tabrun;表2 – 卡方检验结果Table of r by cr cFrequencyCell Chi-SquareRow PctCol Pct 123Total198314.02423.0954.733834.91398.9943.3728921.415967.9247.51425826799.074318.2537.814164.548411.1847.1126250.67970.5643.12372031344.666317.017.46840.269510.669.515700.951972.349.36788Total 179688360878766 Statistics for Table of r by cStatistic DF Value Prob ------------------------------------------------------ Chi-Square 4 40.5434 <.0001 Likelihood Ratio Chi-Square 4 40.6401 <.0001 Mantel-Haenszel Chi-Square 1 21.0035 <.0001 Sample Size = 8766从表2中可以看出第1行(血型O)的卡方检验分值在所有行中所占比重最高((14.024+4.9139+1.4159)/40.5434≈50%);第1列(Peptic Ulcer(I))的卡方检验分值在所有列中所占比重最高((14.024+9.0743+4.6663)/40.5434≈68.5%)。
这表明第1行和第1列与其他行列相比有显著不同。
同时,在图1中行1和列1很明显地远离其他行列。
这说明了表1中的行列表行变量(血型)和列变量(疾病类型)并非相互独立(Pearson 检验的P 值<0.0001)。
2χ那么如何运用统计检验来说明血型O 和Peptic Ulcer(I)与其他组存在有统计意义的区别?下面讨论如何运用两两比较来回答这个问题。
3. 在SAS PROC FREQ 中实现两两比较具体做法是:1) 从R×C 行列表中行变量中任取两不同的行和原行列表的列变量组成新的2×C 子行列表,共有⎪⎪次。
分别计算各子表的2χ值。
⎭⎫⎝⎛2R2) 从R×C 行列表中列变量中任取两不同的列和原行列表的行变量组成新的R×2子行列表,共有⎪⎪次。
分别计算各子表的2χ值。
⎭⎫⎝⎛2C3) 最后作根据比较次数做Bonferroni adjustment 。
a)如果只做行变量之间的比较,共⎪⎪次; b)如果只做列变量之间的比较,共 ⎪⎪次;c)如果都做比较,则⎪⎪⎭+次;⎭⎫⎝⎛2R ⎭⎫ ⎝⎛2C ⎫ ⎝⎛2R ⎪⎪⎭⎫⎝⎛2C表1-血型和疾病类型数据的两两比较的SAS 程序如下:proc freq data =paper14; where r in (1,2); weight count; table r*c/chisq ; run ;proc freq data =paper14; where r in (1,3); weight count; table r*c/chisq ; run ;proc freq data =paper14; where r in (2,3); weight count; table r*c/chisq ; run ;proc freq data =paper14; weight count;where c in (1,2); table r*c/chisq ; run ;proc freq data =paper14; weight count;where c in (1,3); table r*c/chisq ; run ;proc freq data =paper14; weight count;where c in (2,3); table r*c/chisq ; run ;6 个子表对应的卡方检验,原P-值,Bonferroni法矫正后的P-值如下:Obs comparison DF Value Raw_P1 12 33.7632 <.00012 2 2 14.9892 0.00063 3 2 1.0091 0.60384 4 2 30.5817 <.00015 5 2 29.6973 <.00016 6 2 5.6361 0.0597Test Raw Bonferroni1 <.0001 <.00012 0.0006 0.00333 0.6038 1.00004 <.0001 <.00015 <.0001 <.00016 0.0597 0.3583即使对原P-值进行保守的Bonferroni法矫正后,检验1,2和4,5都保持了统计意义。
这说明血型O与其他两个行组及Peptic Ulcer(I)与其他两个列组均存在有统计意义的差别。
4.在SAS PROC GENMOD中实现两两比较作为一个有意义的补充,我们也可以在log-linear模型下对行列变量进行上述的两两比较。
不过所得出的卡方为likelihood ratio Chi-square而不是Pearson Chi-square。
原表PROC FREQ 输出的LR卡方检验的结果如下:Obs comparison DF Value Raw_P1 12 33.9019 <.00012 2 2 15.6836 0.00043 3 2 1.0179 0.60114 4 2 30.6379 <.00015 5 2 29.7964 <.00016 6 2 5.6387 0.0596SAS/PROC GENMOD的程序和结果如下:proc genmod data=paper14;class r c;model count=r c r*c / dist=poisson type3;contrast"comparision1: O vs A across Cancer Type"r*c 1 -10 -110,r*c 10 -1 -101;contrast"comparison2: O vs B across Cancer Type"r*c 1 -10000 -110,r*c 10 -1000 -101;contrast"comparison3: A vs B across Cancer Type"r*c 0001 -10 -110,r*c 00010 -1 -101;contrast"comparision4: Peptic Ulcer vs Gastric Cancer across Blood type"r*c 1 -10 -110000 ,r*c 1 -10000 -110 ;contrast"comparision5: Peptic Ulcer vs Control across Blood type"r*c 10 -1 -101000,r*c 10 -1000 -101;contrast"comparison6: Gastric Cancer vs Control Group across Blood type"r*c 01 -10 -11000,r*c 01 -10000 -11;run;Contrast ResultsChi-Contrast DF Square Pr > ChiSq comparision1: O vs A across Cancer Type 2 33.90 <.0001 comparison2: O vs B across Cancer Type 2 15.68 0.0004 comparison3: A vs B across Cancer Type 2 1.02 0.6011 comparision4: Peptic Ulcer vs Gastric Cancer across Blood type 2 30.64 <.0001comparision5: Peptic Ulcer vs Control across Blood type 2 29.80 <.0001 comparison6: Gastric Cancer vs Control Group across Blood type 2 5.64 0.0596SAS/PROC FREQ 和 SAS/PROC GENMOD 的结果一致。