转录组Denovo手册(无答案)
denovo-技术支持类-基因组denovo组装新技术

图1 10X Genomic linked-reads辅助基因组组装流程图表1 不同组装策略组装人的基因组大小和ScaffoldN50长度[1]随着技术的发展,越来越多的物种完成了基因组的测序工作。
但基于二代测序短读长的限制,制约了参考基因组的组装质量,从而影响了后续研究工作的开展。
如今,我们可以利用更多的新技术,如10X Genomics,BioNano,ChiCago等,将基因组组装结果进行完善,进一步构建出高质量的参考基因组。
10X Genomics linked-reads10X Genomics公司通过在序列中引入barcode序列,能够得到跨度在50-100Kb的linked reads信息,与二代测序数据相结合,在Scaffold 的组装上能够得到媲美三代测序的组装结果(表1)。
展开阅读10X Genomic linked-reads辅助基因组组装流程如下图所示:图2 光学图谱工作流程图表3 利用Chicago技术提升相应的指标图3 Chicago文库构建流程图[6]Chicago文库构建流程如下:基因组 de novo 组装新技术助力文章冲刺新高度[1] Mostovoy Y, Levy-Sakin M, Lam J, et al. A hybrid approach for de novo human genome sequence assembly and phasing[J]. Nature methods, 2016. 阅读原文>>/nmeth/journal/v13/n7/abs/nmeth.3865.html[2] Pendleton M, Sebra R, Pang A W C, et al. Assembly and diploid architecture of an individual human genome via single-molecule tech-nologies[J]. Nature methods, 2015. 阅读原文>>/s?wd=paperuri:(ac8d0768*******de9b67e959e5d924b)&filter=sc_long_sign&sc_ks_para=q%3DAssembly+and+diploid+architecture+of+an+individual +human+genome+via+single-molecule+technologies.&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_us=14004045691020250024[3] VanBuren R, Bryant D, Edger P P , et al. Single-molecule sequencing of the desiccation-tolerant grass Oropetium thomaeum[J]. Nature, 2015. 阅读原文>>/s?wd=paperuri:(4f4baa5f458c3598ebfa32b1017a4569)&filter=sc_long_sign&sc_ks_para=q%3DSingle-molecule+sequencing+of+the+desiccation-tolera nt+grass+Oropetium+thomaeum.&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_us=3671601047694710580[4] Dong Y, Xie M, Jiang Y, et al.Sequencing and automated whole-genome optical mapping of the genome of adomestic goat (Capra hircus). Nature biotechnology, 2013, 31(2): 135-141. 阅读原文>>/nbt/journal/v31/n2/full/nbt.2478.html [5] Zhang Q, Chen W, Sun L, et al. The genome of Prunus mume. Nature communications, 2012, 3: 1318. 阅读原文>>http://pubmedcentralcanada.ca/pmcc/articles/PMC3535359/[6] Bredeson J V, Lyons J B, Prochnik S E, et al. Sequencing wild and cultivated cassava and related species reveals extensive interspecific hybridization and genetic diversity[J]. Nature biotechnology, 2016, 34(5): 562-570. 阅读原文>>/s?wd=paperuri:(030555bb483ea9f72bf308bf22787f02)&filter=sc_long_sign&sc_ks_para=q%3DSequencing+wild+and+cultivated+cassava+and+related +species+reveals+extensive+interspecific+hybridization+and+genetic+diversity.&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_us=13838504648880517513[7] Putnam N H, O'Connell B L, Stites J C,et al. Chromosome-scale shotgun assembly using an in vitro method forlong-range linkage[J]. Genome research, 2016, 26(3): 342-350. 阅读原文>>/s?wd=paperuri:(4c8ec46542c7e21bfa15ae10f7a9f8bf)&filter=sc_long_sign&sc_ks_para=q%3DChromosome-scale+shotgun+assembly+using+an+in+vit ro+method+for+long-range+linkage.&tn=SE_baiduxueshu_c1gjeupa&ie=utf-8&sc_us=36575566455777547参考文献Chicago技术(体外Hi-C 技术)作为提供长距离连接数据的组装提升方法,Chicago技术不仅能够获得长序列连接信息,还能帮助组装提升到染色体水平,该技术使用效率高、操作简便、经济性强,并且产生的高质量文库能够更好地应用于后期组装或研究。
《Denovo技术介绍》PPT课件

DNA测序
Nanopore是对DNA链直接测序可以直接 测序同时直接检测碱基修饰。 获得DNA链上的甲基化修饰结果,较 PacBio更为准确有效
目录
Hi-C 技术
Hi-C技术,一种高通量染色体构象捕获技术(High-throughput chromosome conformation capture),可以实现单个样本辅助基因组组装,使基因组达到染色体水 平
《Denovo技术介绍》PPT课件
本课件仅供大家学习学习 学习完毕请自觉删除
谢谢 本课件仅供大家学习学习
学习完毕请自觉删除 谢谢
目录
什么是Denovo?
也叫从头测序。是指对基因组序列未知或没有近源物种基 因组信息的某接、组 装和注释,从而获得该物种完整的基因组序列图谱。
Pacific Bio 测序缺点
错误率高达12.5%,每读8个碱基,就有一个是读错的,错误类型多 为“插入”,即会多读一个碱基。测序错误是随机的,可以通过测序深 度的提高来校正。
目录
BioNano光学图 谱技术
技术原理
BioNano光学物理图谱技术,简而言之是利用单链酶切技术在DNA上 做荧光标记,再通过纳米孔道对长达几百kb的长链DNA单分子线性化,经 过高分辨率光学系统进行拍照,在较短时间获得更完整的基因图谱,在辅助 基因组组装和结构变异(structural variants,SV)检测等方面有广泛的应 用。
主要产品
人类基因组测序
动植物基因组测序 细菌基因组测序 真菌基因组测序 宏基因组测序
测序工具
一代测序-sanger 二代测序-illumina 三代测序PB/Bionano/nanopore
原理
优势
劣势
无参考基因的转录组分析
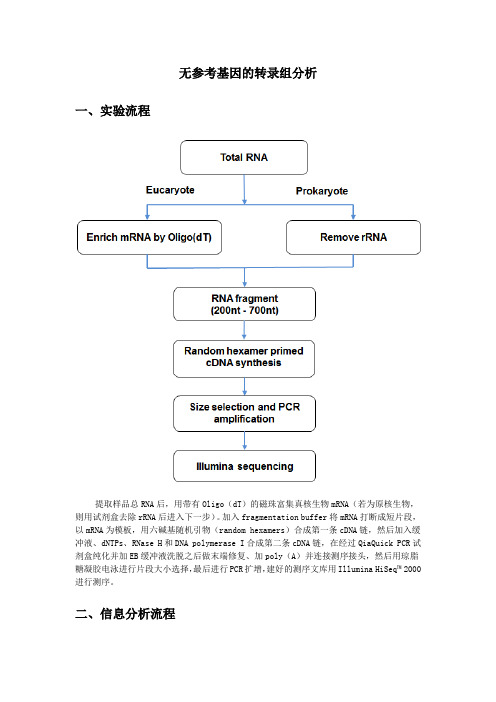
二、信息分析流程
1、产量统计
原始序列数据
测序得到的原始图像数据经 base calling 转化为序列数据,我们称之为 raw data 或 raw reads,结果以 fastq 文件格式存储,fastq 文件为用户得到的最原始文件,里面存储 reads 的序列以及 reads 的测序质量。在 fastq 格式文件中每个 read 由四行描述: \@FC61FL8AAXX:1:17:1012:19200#GCCAAT/1 CCACTGTCATGTGAACATCACAGAGACATTTCTTGA + bbbbbbbbbbbbbbbbbbbbbbbbbaaaaaaaaa_\\
y y
[1]
2 p(i | x) (当 p(i | x) 0.5 时)
i 0 i 0
或者
y y
2(1 p(i | x)) (当 p(i | x) 0.5 时)
i 0 i 0
其中
p(i | x) (
N2 i ) N1
( x i )! N x! y!(1 2 ) ( x i 1) N1
Clean Reads 数据
原始序列数据经过去除杂质后得到的数据。产量统计和后续信息分析分析都基于 Clean Reads。
测序产量统计表格示例
Samples
Total Reads
Total Nucleotides (nt)
Q20 percentage
N percentage
GC percentage *
基因注释到 GO 条目结果文件示例
GO 条目与 All-Unigene 对应结果文件示例
5、Unigene 代谢通路分析
KEGG 是系统分析基因产物在细胞中的代谢途径以及这些基因产物的功能的数据库,利 用 KEGG 可以进一步研究基因在生物学上的复杂行为。 根据 KEGG 注释信息我们能进一步得到 Unigene 的 Pathway 注释。
动植物基因组de novo常见问题

动植物基因组de novo常见问题基础知识1、什么是基因组de novo测序答:对某一物种进行高通量测序,利用高性能计算平台和生物信息学方法,在不依赖于参考基因组的情况下进行组装,从而绘制该物种的全基因组序列图谱。
2、普通基因组的定义答:单倍体,纯合二倍体或者杂合度<%,且重复序列含量<50%,GC 含量为35%到65%之间的二倍体。
3、复杂基因组的定义答:杂合率>%,重复序列含量>50%,GC含量处于异常的范围(GC 含量<35%或者GC含量>65%=的二倍体,多倍体。
诺禾致源对二倍体复杂基因组进一步细分为微杂合基因组(%<杂合率<%=、高杂合基因组(杂合率>%)以及高重复基因组(重复序列比例>50%)。
4、怎么查询基因组的大小答:查询植物基因组大小的网站:;查询动物基因组大小的网站:。
、5、基因组的项目周期6、基因组承诺的组装指标答:简单基因组:contig N50>20K,scaffold N50>500K;复杂基因组:contig N50>20K,scaffold N50>300K。
样品要求1、动植物基因组测序对取样有什么要求答:植物:需要黑暗无菌条件下培养的黄化苗、组培苗,基因组样本量500μg~1mg,越多越好。
选择纯合或杂合度尽可能小的样品(杂合度<%)。
动物:应选取肌肉、血液等含脂肪较少的部位取样,尽量选择同一个体取样,以减少个体差异性对后续拼接的影响。
基因组样本量500μg~1mg,越多越好。
样本的性别决定模式是XY型,则尽量选择雌性个体(XX型),如果是ZW型,则尽量选择雄性个体(ZZ型)。
2、全基因组测序对DNA样本有什么要求答:(1)样品需求量(单次):小片段文库,≥3μg;2Kb~5Kb大片段文库,≥20μg;10Kb~20Kb大片段文库,≥60μg;完成全基因组测序样品DNA量需求约为500μg~1mg;(2)样品浓度:对于小片段文库,≥50ng/μl,对于2Kb~5Kb 大片段文库,≥150ng/μl;对于10Kb~20Kb大片段文库,≥150ng/μl;(3)样品纯度:OD260/280=~;无蛋白质、RNA污染或肉眼可见杂质污染;(4)样品质量:基因组完整。
二代测序 denovo 流程

一、概述二代测序(Next Generation Sequencing, NGS)技术的广泛应用,使得基因组学研究取得了长足的进步。
其中,二代测序denovo流程是利用NGS技术对未知生物样本进行全基因组测序,并在此基础上进行基因组组装和注释的过程。
本文将对二代测序denovo流程进行深入探讨,从数据处理到基因组组装和注释等方面进行详细介绍。
二、数据处理在进行denovo全基因组测序之前,首先需要进行数据处理。
数据处理包括测序数据的质量控制、序列过滤和去除低质量序列等步骤。
在质量控制方面,可以利用软件对测序数据进行质量评估,筛选出高质量的测序数据用于后续分析。
针对测序数据中可能存在的接头序列和低质量碱基,需要进行序列过滤和去除低质量序列的处理,确保后续的组装和注释过程能够得到准确的结果。
三、基因组组装基因组组装是denovo流程中的关键步骤,主要是将测序得到的短序列reads进行拼接,重建成完整的基因组序列。
目前,常用的基因组组装算法包括SOAPdenovo、Velvet、ABySS等。
这些算法能够根据reads之间的重叠信息和kmers的频率进行拼接,得到较为完整的基因组序列。
对于大规模基因组的组装,还可以采用高通量测序技术辅助组装,如mate p本人r测序或二代测序测序辅助第三代测序(Hybrid Assembly)等方法。
四、基因组注释基因组注释是denovo流程中的另一个重要步骤,主要是对组装得到的基因组序列进行基因预测、基因功能注释和通路分析等。
在基因预测方面,可以利用软件对基因组序列进行Open Reading Frame (ORF)预测和基因预测,以确定基因的位置和编码序列。
在基因功能注释方面,可以利用生物信息学数据库和工具对基因进行功能和结构注释,帮助研究人员理解基因的生物学功能和作用。
为了进一步了解基因的生物学功能和相互作用,还可以进行通路分析,探究基因在生物体内的作用机制。
五、应用与发展二代测序denovo流程在生命科学研究中有着广泛的应用与发展前景。
大刍草苗期转录组RNA—Seq数据的denovo拼接

玉米 属 于 禾本 科 ( P o a c e a e ) 玉蜀黍属 ( Z e a ) , 玉 义上 包 括 了 mRNA、 n o n - c o d i n g RNA 等 ) , 进 而 推
蜀黍 属 又 被 划 分 成 5个 种 , 分别是 Z . d i p l o p e r e n — 断完整的基因结构, 确定选择性剪切事件 , 研究在不
比对研 究 。结 果 表 明 : 转 录组 测 序 共 得 到 了 4 6 . 4 G B的原始数据, 归并 整理后 获得长 7 6 b p的序 列 有
1 7 5 1 0 1 2 5 0 条, 经 质量控制 和 d e 舢l U o拼接后 , 共获得 了 5 8 1 4 7条大刍 草转 录本 , 其平均长 度为 1 3 3 5 b p 。比对 分 析发现其中 9 4 . 3 %的转录本和玉米 B 7 3自交系 的 c D NA序 列有较好 的匹配 , 与水 稻 匹配 的有 8 4 . 1 , 高粱
Z . ma y s s s p . me x i c a n a和 Z. ma y s s s p . ma y s聚在 本 ; 而 基 于 高 通 量 测 序 的 RNA— S e q技 术 则 可 以较
一
类, 后续 对 叶绿体 、 核糖 体 的研 究也 得 到 了相 似结 为全 面地 、 对 几乎 全部 的 R NA 转 录本 进行分 析 。 根据 所 研 究 的 物 种 是 否 有 参 考 基 因 组 信 息 , 的序 列拼 接 和 d e n O V O序 列 拼接 , 或 当基 因组 信 息
n i s 、 Z . p e r e n n i s 、 Z . 1 u x u r i a n s 、Z . n i c a r a g u e n s i s 和 同组 织 、 不 同发育 阶段 、 不 同实验 处 理 中的相关 基 因
SOAPdenovo_Readme

IntroductionSOAPdenovo is a novel short-read assembly method that can build a draft assembly for the human-sized genomes. The program is specially designed to assemble Illumina GA. It creates new opportunities for building reference sequences and carrying out accurate analyses of unexplored genomes in a cost effective way. SOAPdenovo是一种新型的short-read装配方法,可以建立一个de novo组装人l类大小的基因组草案。
这个程序是为装配Illumina测序 short reads特别设计的。
它以一种高效益的方式为建立参考序列和计算出精确的未知基因组创造了新的机会。
System RequirementSOAPdenovo aims for large plant and animal genomes, although it also works well on bacteria and fungi genomes. It runs on 64-bit Linux system with a minimum of 5G physical memory. For big genomes like human, about 150 GB memory would be required.SOAPdenovo虽然也能在细菌和真菌基因组也能很好的运行但它的目标是大的植物和动物的基因组。
它运行在最小内存5G的64位Linux系统上。
像人类的大基因组,大约需要150G内存。
无参转录组序列组装及实际操作
2019/11/29
实际操作
核心蛋白比对率评估:
• mkdir assemblyevaluation #创建结果存放目录 • vi cegmer.sh #生成脚本
2019/11/29
Trinity组装习题
请将以下真菌数据拷贝到自己的PMO下(自己任意命名一 个文件夹即可),根据本节所学习到的知识完成数据的组装, 并对各项指标做统计。 数据路径:/home/chenxi/Trinity/practice 数据量大小:每个样本数据大小1M
框移错误导 致的缺口以 及过早终止
的比例。
2019/11/29
组装评估
判断标准: ① 无外源物种污染。
② 比对率大于80%。
组装评估
物种近缘性 良好 CDS序列相 对完整 60%以上
注释比率 核心蛋白 比对率
80%以上
准确性
2019/11/29
Stop Codon比率20%以下
Trinity参数调整
cat /home/chenxi/Trinity/clean/ Sp.ds.right.fq /home/chenxi/Trinity/ clean/ Sp.hs.right.fq> /home/chenxi/Trinity/fq/reads_2.fq
2019/11/29
实际操作
• 生成组装的shell:vi triniy.sh
物种。 优点:不依赖任何的参考基因组。 缺点:假阳性问题。
2019/11/29
组装效果统计
2019/11/29
Trinity简介
• Trinity是一款高效且稳定的以RNA-Seq为基础从头组装 转录组的软件。
• Trinity包含三个独立的软件模块: a. Inchworm(C++) b. Chrysalis(C++) c. Butterfly(Java) • 通过有秩序的对大规模的RNA-seq reads 数据进行读取,
动植物Denovo测序知识大讲解

动植物Denovo测序知识⼤讲解⾼通量测序的技术开起我们探索动植物基因组奥秘的步伐,提到动植物基因组测序,这就不得不提⼀个概念——de novo测序。
那么什么是de nove测序呢,它与重测序有什么区别呢?De nove测序中Read、Contig和Scaffold等⼜代表什么呢?De nove测序中为什么要建不同⼤⼩⽚段的梯度⽂库?基因注释⼜是注释哪些内容?各位客官别急,且听⼩编给您细细讲来。
1De novo测序概念De novo是⼀个拉丁⽂,代表从头开始的意思,⽽de nove测序则是指在不需要任何参考序列的情况下对某⼀物种进⾏基因组测序,然后将测得的序列进⾏拼接、组装,从⽽绘制该物种的全基因组序列图谱。
由于⾼通量测序长度的限制,⽬前测序策略是先将基因组打断⼩的⽚段,然后再对测出序列⽚段进⾏拼接,最终得到物种的序列图谱如图1所⽰。
图1 ⾼通量测序模式图2De novo测序与重测序区别重测序概念:重测序是全基因组重新测序的简称,是指是对已知基因组序列的物种进⾏不同个体的基因组测序,并在此基础上对个体或群体进⾏差异性分析。
从概念上来看两者的区别在于de nove测序是对没有参考基因组的物种进⾏测序,⽽重测序是对已有基因组的物种进⾏测序,这只是它们区别很⼩的⼀部分。
从原理上来看de nove测序和重测序最根本的区别在于de nove测序需要对测序得到的Reads进⾏拼接组装,⽽重测序得到的数据则是没有组装的短的Reads序列。
值得注意的是,随着测序成本的降低以及组装算法的改进,de nove测序成本越来越低,⽬前来说de nove测序不只对于没有参考基因组物种进⾏测序,还可以对⼀些特有的亚种、品种以及变种等进⾏测序。
3Reads Conting Scaffold概念Reads:即我们通常说的读长的意思,它是指⾼通量测序平台直接产⽣的DNA序列。
Contig:是指Reads基于Overlap关系,拼接获得的长的序列;Scaffold:是指将获得的Contig根据⼤⽚段⽂库的Pair-end关系,将Contig进⼀步组装成更长的序列;关于三者之间的关系如图2所⽰,注意的是Contig是⽆Gap的连续的DNA序列,⽽Scaffold是存在Gap的DNA序列。
生工从零开始解读转录组测序第二版

生工从零开始解读转录组测序第二版本书着重介绍了转录组测序的概念、原理及基本方法。
这些年我们已经建立了很多新技术,包括各种抗体技术、限制性内切酶技术等等。
但是,在我们实际应用中发现,上述这些技术都有自身不足之处。
如限制性内切酶在大肠杆菌中只能将单链 DNA 切成双链,而抗体却可以利用一个个的片段特异性地与一个个 DNA 片断结合;限制性内切酶往往难以完全识别一条多链的 DNA,而抗体则具备对大量碱基进行高通量识别的能力……这些不足之处,导致目前限制性内切酶和抗体联用的方案效率低下,没有得到广泛应用。
因此,在细胞内,使用转录组测序,仍然是最好的选择。
转录组学是一门新兴的边缘交叉学科,它集中体现了当今生命科学领域里面最先进的研究手段和思想观点。
它把人类认知水平提升到了一个崭新的层次,为揭示生命活动的奥秘打开了一扇窗户。
同时也带给我们许多启迪:1.在生物医药产业界,转录组学正逐渐取代蛋白质组学,成为主流的研究热点。
2.转录组学作为一项非常精准的检验指标,其意义远超过蛋白质组学。
3.随着转录组学的快速发展,越来越多的疾病被确诊并治愈,这无疑会极大推动整个医疗卫生事业的发展。
4.由于转录组学的出现,让更多的临床试验设计者关注临床试验的伦理问题,促进了临床试验的规范化管理。
5.转录组学还引入了一套新的评价模型——“数据驱动”的评估框架,即以转录组学数据为依托,采用统计学方法,定量描述某一生物学过程或状态的表达情况,再根据预期的目标值,运用统计学软件,进行相应的统计分析,最终获得该生物学过程或状态的表征参数。
6.转录组学为后续的基础研究奠定了坚实的基础,尤其是在癌症早期筛查、药物靶向治疗、药物毒副反应监控、药物安全性评价等方面显示出巨大优势。
7.转录组学的诞生改写了人类对生命的认识历史,掀开了生命科学研究的新篇章!生物信息学是现代分子生物学、系统生物学和计算机科学相结合发展起来的一门综合性边缘学科。
生物信息学是一门研究人类生物学信息(基因、蛋白质)的形式、存储、加工、表达、传递、调控、功能和进化的学科。
无参转录组序列组装及实际操作
2019/11/29
Trinity使用—输入及输出
输入文件: fa或者fq文件
创建一个文件存放输出结果的目录:
mkdir assemble
框移错误导 致的缺口以 及过早终止
的比例。
2019/11/29
组装评估
判断标准: ① 无外源物种污染。
② 比对率大于80%。
组装评估
物种近缘性 良好 CDS序列相 对完整 60%以上
注释比率 核心蛋白 比对率
80%以上
准确性
2019/11/29
Stop Codon比率20%以下
Trinity参数调整
2019/11/29
实际操作
本地运行:sh triniy.sh
任务运行
本地挂起运行:nohup sh triniy.sh &
投递运行:qsub –cwd –l vf=10G –l p=5 triniy.sh
任务查看:qstat/qstat –j job_number/jobs
2019/11/29
full_cleanup
只保留组装结果文件,并以Trinity.fasta命 名。
group_pairs_distance 双端reads比对的最大长度(超过该长度认为 没有比对上)
min_kmer_cov
最小k-mer覆盖值。
2019/11/29
Trinity使用—任务及运行
生成组装任务脚本:vi trinity.sh
转录本数目过多,但是N50低,怎么办? 数据量太大,如何提高组装速度? 物种类型是真菌,参数需要注意什么?
SOAPdenovo的部分解释

来说说一个基因组是怎么来的吧(附:仅自己的看法)1.样品的采集、DNA的提取、上机这一部分就略去吧,体力+操作娴熟活,爆个小料,实验组的少堂兄刚和师姐去大理、丽江、临沧等好几个地方花费10天时间采回了一批样。
据说超累超累得活。
去之前还开玩笑说回来可能不认识他了。
或者极端情况是被野兽带走。
哈哈,可见样品的来之不易了吧?跳过。
此步骤过于血腥暴力。
不再展开:)2.测序的原理我们组采用的是Illumina/Solexa测序,它的基本原理是边合成变测序。
在Sanger等测序方法的基础上,通过技术创新,用不同颜色的荧光标记四种不同的dNTP,当DNA聚合酶合成互补链时,每添加一种dNTP就会释放出不同的荧光,根据捕捉的荧光信号并经过特定的计算机软件处理,从而获得待测DNA的序列信息。
3.操作流程(注:图片引自Elaine R. Mardis (2008) Next-Generation DNA Sequencing Methods Annu. Rev. Genomics Hum. Genet. 9:387–402)简要的表述一下上图测序的过程:1)测序文库的构建准备基因组DNA---随机变短化为几百碱基或更短的小片段---两头加上特定的接头若为转录组测序RNA片段---反转录---cDNA----片段化----加街头值得注意的是:我们这里片段的大小对于后面的数据分析有影响,可根据需要来选择。
对于基因组测序来说,通常会选择几种不同的片段大小,以便在组装的时候获得更多的信息。
2)锚定桥接带接头的DNA片段---变性---与通道上的引物刑场桥状结构---便于后续扩增3)预扩增添加dNTP 和Taq 酶----固相桥式PCR 扩增---变性---释放出互补的单链--通过--不断循环---获得上百万条成簇分布的双链待测片段4)单碱基延伸测序加入四种荧光标记的dNTP 、DNA 聚合酶以及接头引物进行扩增,在每一个测序簇延伸互补链时,每加入一个被荧光标记的dNTP就能释放出相对应的荧光,测序仪通过捕获荧光信号,并通过计算机软件将光信号转化为测序峰,从而获得待测片段的序列信息。
华大基因转录组结题报告(de novo)

公认 P value 为
时该基因表达差异极显著。
表 6 两个样品之间 Scaffold-gene 表达差异分析:(以结果表格的一部分示例)
2.1 实验流程说明........................................................... 3 2.2 信息分析流程说明....................................................... 3 三、 项目结果报告............................................................ 4 3.1 数据处理和质控报告..................................................... 4
三、 项目结果报告
3.1 数据处理和质控报告
3.1.1 原始测序数据产量
说明:测序的数据产量是合同的重要指标,按合同规定,1 个样品的测序产量(base pairs) 应不少于 1Gb ,该项工作的完成情况见下表:
表 1 测序数据统计结果 Strains Sample A Sample B
Total Reads 17,524,548 17,604,310
3.2.5 Scaffold-gene表达差异分析
说明:我们利用软件 soap 将不同样本中得到的 Reads 比对到 scaffold-gene 上,获得 scaffold 上 reads 的数目,然后计算 scaffold 在不同样本之间表达差异的 P value,一般
6
华大基因转录组分析(de novo)结题报告
结果已审阅,同意交付。
签名:
日期:
年月日
RNA denovo

RNA de novo 应用及分析报告作者:李娜娜部门:技术支持部日期:2014-05-16g y n e r g y G e G e n e r g y G e n e r G e n e r g y G e n e r g y G e n e r g y G e n e r g y G G e n e r g y G e n e r g y G e n e n e r g y G e n e r g y G e n e r g e r g y G e n e r g y G e n e r g y g y G e n e r g y G e n e r g y G e n e r g y G e n e r g y n e r g y G e n e rr g y G e G目录一、测序流程2二、案例介绍三、报告解读g y n e r g y G e G e n e r g y G e n e r G e n e r g y G e n e r g y G e n e r g y G e n e r g y G G e n e r g y G e n e r g y G e n e n e r g y G e n e r g y G e n e r g e r g y G e n e r g y G e n e r g y g y G e n e r g y G e n e r g y G e n e r g y G e n e r g y n e r g y G e n e rr g y G e G3RNA de novo 测序:对不依赖任何参考基因组的物种进行转录组测序。
2×100bp ,20~30M reads/sample 。
一、实验原理RNAseq-C01测序数据质量统计RNAseq-C02RNA-seq de novo 组装与统计RNAseq-C03编码蛋白框(ORF/CDS )预测RNAseq-C04Unigene 注释(GO 、KEGG 、COG 、蛋白结构域等)RNAseq-C05SSR 预测分析RNAseq-C06基因差异表达(两个样本以上)其它g y n e r g y G e G e n e r g y G e n e r G e n e r g y G e n e r g y G e n e r g y G e n e r g y G G e n e r g y G e n e r g y G e n e n e r g y G e n e r g y G e n e r g e r g y G e n e r g y G e n e r g y g y G e n e r g y G e n e r g y G e n e r g y G e n e r g y n e r g y G e n e rr g y G e G均一化cDNA 文库均一化cDNA 文库:通过特定处理降低高丰度的cDNA ,使得表达基因对应的cDNA 拷贝数相等或接近,以在后续的测序分析中得到的转录本更加完整,获得更多的转录本信息。
denovo-组装变异检测产品新升级

首页 科技服务 医学检测 科学与技术 市场与支持 加入我们 关于我们组装变异检测分析,是指对物种基因组进行组装,用组装后的序列进行变异检测分析。
从而得到更多、更准确的SNP,InDel,SV,CNV,Novel gene等变异信息。
组装变异检测对物种中高复杂的结构变异,具有非常高的灵敏性,能够更充分的挖掘出与农艺性状相关基因的变异,为开发相应的分子标记和功能基因研究奠定基础。
技术路线10X Genomics助力组装变异检测升级更全面的SV检测案例解析Linked Reads可有效提供跨度超过几十Kb甚至更长的信息,通过Barcode Overlap关系能够准确的区分单体型变异中不相邻的区域(图3)。
对人NA12878进行检测,通过Linked Reads发现6号染色体中存在一段长达70Kb的缺失(图4)。
同时,对人NA12878中以往发现的8个SV进行Phasing,发现在8个SV中,5个含有较高的Phasing值,3个具有较低的Phasing值(表2)。
对SV(已检测)进行孟德尔遗传分析,发现在NA12878(Mother)中的5个较高Phasing值的SV有3个遗传到了NA12882(Child),进一步研究发现当NA12882存在Deletion时,即对应相关的单体。
此外研究还通过探针序列验证了Phasing值较高的SV的准确性。
而对于Phasing值较低的3个SV,两个通过探针序列验证是假阳性,一个验证是确实存在SV,之所以分值较低是因为这个Deletion在三个个体中均存在(Father、Mother和Child)。
此结果说明利用Linked Reads检测大片段的SV具有较高的准确性。
图4 通过Linked Reads确定6号染色体存在70Kb的缺失表2 Linked Reads对8个SV进行PhasingChr.Location Phase blockBCsintersectingHap1BCsintersectingHap2P DeletedhaplotypeDeletioninheritedbyNA12882Phasingconsistentwithinheritance 1189704509–18978335950188502070574 4.90 × 10–131No YesYesYesYesYesYesYesYesYesYesYes3162512134–162626335190161712492257 6.10 × 10–1525104432113–10450367327098341819528 6.60 × 10–52678967194–79036419*310764666274577.00 × 10–81No678967194–79036419*31078967164502 6.10 × 10–131No839232074–39387229*39030957010450 5.70 × 10–141839232074–39387229*390393708004601599400881–997150152709834181997870.51FP No N/A1437631609–377712286203378120528Common Common N/A14106932640–10717493164010669287010130.68FP No N/ATwo breakpoints of the deletion are on different phase blocks.Low-scoring SV candidates2.80 × 10–140.11图3 通过Barcode Overlap关系可有效检测NA12878存在的结构变异78765000791650007876500079165000NA12878, Chr. 6: 78967194–79036419Barcode overlap013barcodes78765000791650007876500079165000NA12882, Chr. 6: 78967194–79036419Barcode overlap013阅读原文>>。
转录组测序

转录组测序今天我们来学习一些关于转录组测序的知识,从转录组的一些基本概念开始。
第一章Intron:内含子,间隔存在于真核生物细胞DNA中的序列,转录时存在于前体mRNA中,通过剪接过程被去除,最终不存在成熟的mRNA中。
Exon:外显子,真核生物DNA中的序列,与Intron对应,序列在剪接过程中不被去除,最终存在于成熟的mRNA分子中。
UTR:Untranslated regions,非翻译区,信使RNA分子两端的非编码片段。
5'-UTR从mRNA起点的甲基化鸟嘌呤核苷酸帽直至AUG起始密码子,3'-UTR从编码区末端的终止密码子直至PolyA尾的前端。
CDS:code DNA sequence,基因编码区域,mRNA序列中编码蛋白质的序列,以起始密码子开始以终止密码子结束的片段。
转录本(Transcript):基因通过转录形成的一种或多种可供编码蛋白质的成熟的mRNA。
可变剪切:从同一个mRNA前体出发,通过不同剪接方式、选择不同的剪接位点,产生不同的mRNA剪接异构体的过程,可以产生多个转录本。
融合基因:来自不同基因的外显子组合形成新的mRNA,最终产生与外显子来源基因表达产物不同的蛋白质。
start codon,起始密码子;stop codon,终止密码子转录组(Transcriptome):特定生物体在某种状态下所有基因转录产物的总和。
链特异性文库:鉴定真核生物的反义转录本或原核生物的ncRNA。
合成第二链cDNA时用dUTP代表dTTP,使得第二链cDNA上布满含dUTP的位点,然后用特异性识别尿嘧啶的酶消化第二链,得到只包含第一链cDNA信息的文库。
转录组:转录组被测序的物种已经有一个参考基因组。
在分析数据时,不需要拼接转录本,只需要将转录组测序数据与参考基因组进行比较,就可以确定每个基因的表达水平。
无转录组:转录组被测序的物种没有参考基因组,因此需要拼接转录组数据以获得样品中的转录本信息,然后对这些拼接的转录本进行功能注释,然后将转录组数据与拼接的转录本进行比较并计算其表达水平。
【分享】目前最好最完整的SOAPdenovo使用说明

【分享】目前最好最完整的SOAPdenovo使用说明转载于泛基因/article/26这是一份关于基因组组装软件SOAPdenovo的使用说明,内容包括了程序使用、参数的详细说明、参数如何调整、各个主要输出文件的格式说明等。
简介:SOAPdenovo(目前最新版是SOAPdenovo2)是利用一种新的组装短read的方法,它以kerm为节点单位,利用de Bruijn图的方法实现全基因组的组装,和其他短序列组装软件相比,它可以进行大型基因组比如人类基因组的组装,组装结果更加准确可靠,可以通过组装的结果非常准确地鉴别出基因组上的序列结构性变异,为构建全基因组参考序列和以低测序成本对未知基因组实施精确分析创造了可能。
程序的下载及安装:下载地址:安装:(a) 下载SOAPdenovo的压缩包(b) 解压缩(c)将得到可执行文件SOAPdenovo和一个配置文件的模板example.contig1 使用程序及参数:SOAPdenovo可以一步跑完,也可以分成四步单独跑一步跑完的脚本:./ SOAPdenovo all -s lib.cfg -K 29 -D 1 -o ant >>ass.log四步单独跑的脚本:./ SOAPdenovo pregraph -s lib.cfg -d 1 -K 29 -o ant >pregraph.log./ SOAPdenovo contig -g ant -D 1 -M 3 >contig.log./ SOAPdenovo map -s lib23.cfg -g ant >map.log./ SOAPdenovo scaff -g ant -F >scaff.log2 参数说明用法:/PathToProgram/SOAPdenovo all -s configFile [-K kmer -d KmerFreqCutOff -D EdgeCovCutoff -M mergeLevel -R -u -G gapLenDiff -L minContigLen -p n_cpu] -o Output-s STR 配置文件-o STR 输出文件的文件名前缀-g STR 输入文件的文件名前缀-K INT 输入的K-mer值大小,默认值23,取值范围 13-63 -p INT 程序运行时设定的线程数,默认值8-R 利用read鉴别短的重复序列,默认值不进行此操作-d INT 去除频数不大于该值的k-mer,默认值为0-D INT 去除频数不大于该值的由k-mer连接的边,默认值为1,即该边上每个点的频数都小于等于1时才去除-M INT 连接contig时合并相似序列的等级,默认值为1,最大值3。
Trinity进行转录组组装

##Trinity进行转录组组装mkdir trinity_denovocd trinity_denovoln -s /home/lenovo/TrinityNatureProtocolTutorial/1M_READS_sample/*.fq ./#将样本的reads合并在一起cat *.left.fq > reads.ALL.left.fqcat *.right.fq > reads.ALL.right.fq#运行trinity拼接Trinity --seqType fq --max_memory 10G --left reads.ALL.left.fq --right reads.ALL.right.fq --SS_lib_type RF --CPU 6 --normalize_reads --output trinity_denovo --bflyCalculateCPU &> trinity_denovo.log#查看Trinity.fasta的头几行head trinity_denovo/Trinity.fasta#拼接结果的统计/opt/biosoft/trinityrnaseq-2.1.1/util/TrinityStats.pl trinity_denovo/Trinity.fasta > trinity_denovo/Trinity.fasta.stats#查看统计结果less trinity_denovo/Trinity.fasta.stats# 提取最长的Unigeneextract_longest_isoforms_from_TrinityFasta.pl trinity_denovo/Trinity.fasta > trinity_denovo/unigene.longest.fasta##将reads比对到转录组对组装结果进行评估mkdir -p /home/lenovo/trinity_denovo/assessingcd /home/lenovo/trinity_denovo/assessingln -s /home/lenovo/trinity_denovo/trinity_denovo/Trinity.fasta ./ln -s /home/lenovo/trinity_denovo/reads.ALL.left.fqln -s /home/lenovo/trinity_denovo/reads.ALL.right.fq#构建数据库索引bowtie2-build Trinity.fasta Trinity#将reads比对到转录本并对结果文件排序bowtie2 --local --no-unal -x Trinity -q -1 reads.ALL.left.fq -2 reads.ALL.right.fq | samtools view -Sb - | samtools sort -no - - > Sorted.bam #查看结果文件samtools view Sorted.bam | less#给出BAM文件的比对结果的summarysamtools flagstat Sorted.bam#统计比对结果/opt/biosoft/trinityrnaseq-2.1.1/util/SAM_nameSorted_to_uniq_count_stats.pl Sorted.bam#将比对可视化tophat2 -o mapping_reads_ALL -p 4 --read-mismatches 2 -r 50 --library-type fr-firststrand Trinity reads.ALL.left.fq reads.ALL.right.fqsamtools index mapping_reads_ALL/accepted_hits.bamigv.sh###########################################使用tophat进行比对mkdir -p /home/lenovo/trinity_denovo/tophatcd /home/lenovo/trinity_denovo/tophatln -s /home/lenovo/TrinityNatureProtocolTutorial/1M_READS_sample/*.fq ./ln -s /home/lenovo/trinity_denovo/trinity_denovo/Trinity.fasta ./#用bowtie2建立Trinity.fasta的indexbowtie2-build Trinity.fasta genome#开始比对tophat2 -o mapping_Sp_ds -p 4 --read-mismatches 2 -r 50 --library-type fr-firststrand genome Sp.ds.1M.left.fq Sp.ds.1M.right.fqtophat2 -o mapping_Sp_hs -p 4 --read-mismatches 2 -r 50 --library-type fr-firststrand genome Sp.hs.1M.left.fq Sp.hs.1M.right.fq#查看samtools view -h mapping_Sp_ds/accepted_hits.bam | less#提取unique比对samtools view -h mapping_Sp_ds/accepted_hits.bam |awk '$1~/^@/||$5==50{print $0}' |samtools view -bhS - >Sp_ds.unique.bamsamtools view -h mapping_Sp_hs/accepted_hits.bam |awk '$1~/^@/||$5==50{print $0}' |samtools view -bhS - >Sp_hs.unique.bam #查看samtools view Sp_ds.unique.bam | less#建indexsamtools index Sp_ds.unique.bamsamtools index Sp_hs.unique.bam############################################比对reads评估表达量(每个样本都需要单独比对)mkdir exp_calcd exp_calln -s /home/lenovo/TrinityNatureProtocolTutorial/1M_READS_sample/*.fq ./ln -s /home/lenovo/trinity_denovo/trinity_denovo/Trinity.fasta ./#比对Sp.ds样本/opt/biosoft/trinityrnaseq-2.1.1/util/align_and_estimate_abundance.pl --transcripts Trinity.fasta --seqType fq --left Sp.ds.1M.left.fq --right Sp.ds.1M.right.fq --est_method RSEM --aln_method bowtie --trinity_mode --prep_reference --output_dir Sp_ds.RSEM#比对Sp.hs样本/opt/biosoft/trinityrnaseq-2.1.1/util/align_and_estimate_abundance.pl --transcripts Trinity.fasta --seqType fq --left Sp.hs.1M.left.fq --right Sp.hs.1M.right.fq --est_method RSEM --aln_method bowtie --trinity_mode --prep_reference --output_dir Sp_hs.RSEM#查看前几行head Sp_hs.RSEM/RSEM.Sp_hs.isoforms.results##差异表达分析(edgeR)mkdir -p /home/lenovo/trinity_denovo/diff_ecd /home/lenovo/trinity_denovo/diff_exp/ln -s ../exp_cal/Sp_ds.RSEM/*.results ./ln -s ../exp_cal/Sp_hs.RSEM/*.results ./#得到表达量matrix文件/opt/biosoft/trinityrnaseq-2.1.1/util/abundance_estimates_to_matrix.pl --est_method RSEM --out_prefix genes *.genes.results/opt/biosoft/trinityrnaseq-2.1.1/util/abundance_estimates_to_matrix.pl --est_method RSEM --out_prefix isoforms *.isoforms.results#查看head -n20 genes.counts.matrix##计算转录本和基因的TPM(以genes为例)mkdir count_matrixcd count_matrix/#计算genes的表达量/opt/biosoft/trinityrnaseq-2.1.1/util/misc/count_matrix_features_given_MIN_TPM_threshold.pl/home/lenovo/trinity_denovo/diff_exp/genes.TPM.not_cross_norm | tee genes.TPM.not_cross_norm.counts_by_min_TPM #用R图形化展示% R> data = read.table("genes.TPM.not_cross_norm.counts_by_min_TPM", header=T)> plot(data, xlim=c(-100,0), ylim=c(0,100000), t='b')# extract the data between 10 TPM and 100 TPM> filt_data = data[data[,1] > -100 & data[,1] < -10,]# perform a linear regression on this filtered subset of the data> fit = lm(filt_data[,2] ~ filt_data[,1])> print(fit)Call:lm(formula = filt_data[, 2] ~ filt_data[, 1])Coefficients:(Intercept) filt_data[, 1]9169.2 81.2# add the linear regression line to the plot>abline(fit, col='green', lwd=3)#使用edgeR进行差异表达分析/opt/biosoft/trinityrnaseq-2.1.1/Analysis/DifferentialExpression/run_DE_analysis.pl --matrix isoforms.counts.matrix --method edgeR --dispersion 0.1 --output edgeR#查看生成的edgeR文件夹ls -ltr edgeR/#查看head edgeR/isoforms.counts.matrix.RSEM.Sp_ds_vs_RSEM.Sp_hs.edgeR.DE_results#火山图evince edgeR/isoforms.counts.matrix.RSEM.Sp_ds_vs_RSEM.Sp_hs.edgeR.DE_results.MA_n_Volcano.pdfsed '1,1d' edgeR/isoforms.counts.matrix.RSEM.Sp_ds_vs_RSEM.Sp_hs.edgeR.DE_results | awk '{ if ($5 <= 0.05) print;}' | wc -l# 提取差异表达基因进行聚类分析和热图制作cd edgeR/opt/biosoft/trinityrnaseq-2.1.1/Analysis/DifferentialExpression/analyze_diff_expr.pl --matrix ../isoforms.TMM.EXPR.matrix -P 1e-3 -C 2wc -l diffExpr.P1e-3_C2.matrix#查看热图evince diffExpr.P1e-3_C2.matrix.log2.centered.genes_vs_samples_heatmap.pdf#根据聚类图提取子类/opt/biosoft/trinityrnaseq-2.1.1/Analysis/DifferentialExpression/define_clusters_by_cutting_tree.pl --Ptree 60 -R diffExpr.P1e-3_C2.matrix.RDataevince diffExpr.P1e-3_C2.matrix.RData.clusters_fixed_P_60/my_cluster_plots.pdf##使用TransDecoder预测蛋白编码区mkdir -p /home/lenovo/trinity_denovo/transdecodercd /home/lenovo/trinity_denovo/transdecoderln -s ../trinity_denovo/Trinity.fasta ./# transdecoder 常用方法mkdir transdecoder_simplecd transdecoder_simple#提取长度不小于指定值的ORF/opt/biosoft/TransDecoder-2.0.1/TransDecoder.LongOrfs -t ../Trinity.fasta #进行ORF预测/opt/biosoft/TransDecoder-2.0.1/TransDecoder.Predict -t ../Trinity.fasta。
无参考基因的转录组分析

无参考基因的转录组分析无参考基因的转录组分析是指在没有对应基因组序列的情况下,对生物体的转录组数据进行分析,从中获取信息并进行生物学研究。
在无参考基因组的情况下,无法直接对转录组数据进行比对和注释,因此需要采取一些策略和方法来解决这个问题。
1. 转录本组装:通过对转录组数据进行拼接,将转录本组装成单个完整序列,从而获得转录本信息。
这可以使用多个软件来实现,如Trinity、Cufflinks等。
通过对转录本进行定量分析,可以确定各个基因的表达水平。
2. 转录本定量:通过建立转录本的表达矩阵,可以对各个基因的表达水平进行比较和分析。
这可以使用软件如RSEM、eXpress等来完成。
3. 基因功能注释:虽然没有对应基因组序列,但可以利用已知物种的参考基因组信息来进行基因功能注释。
这可以使用一些在线数据库和工具,如Gene Ontology (GO)、KEGG、PANTHER等。
4. 差异表达基因筛选:通过比较不同样本组之间的转录本表达差异,可以筛选出差异表达基因。
这可以使用软件如DESeq2、edgeR等来完成。
5. 寻找新基因:在无参考基因组的情况下,还可以利用转录组数据寻找新基因。
这可以通过比对转录组序列到已知物种的参考基因组上,找出不在参考基因组上的序列,进而预测出新基因。
这可以使用软件如TransDecoder、CPC等来完成。
6.功能富集分析:通过对差异表达基因进行功能富集分析,可以了解这些基因在功能上的特点。
这可以使用一些在线工具和数据库,如DAVID、GSEA等。
7.转录因子分析:转录因子在调控基因的转录过程中起到重要的作用。
通过分析转录因子在转录组中的表达情况,可以了解其在调控过程中的参与情况。
这可以使用一些软件和数据库,如JASPAR、MEME等。
8. 代谢通路分析:通过对差异表达基因进行代谢通路分析,可以了解不同样本组之间在代谢水平上的差异。
这可以使用一些在线工具和数据库,如KEGG、MetaboAnalyst等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
对于初级分析的项目,只需要给合作伙伴提供过滤后的数据即可,所以会对过滤后的数 据做dt1h LReenagdt2h
N3Z5123 FUNzPTEARAA 503060871000;536871 5725.71;52. 99.9971;99. 75 75
确定的?我们所说的插入片段长度是指 括了 read1 和 read2 本身的长度?
read1
和
read2
之间没有测到的那一段的长度还是包
1112..什解么释是Soilnedxeax测测序序中,几进个行关in键de的x技测术序:的边主合要成目边的测是序什(么S?BS),可逆阻断技术和桥式 。 PCR
2.信息分析流程:
软件(Conesa, A., S. Gotz, et al. (2005). "Blast2GO: a universal tool for annotation, visualization 得到 的 and analysis in functional genomics research." Bioinformatics 21(18): 3674-6.) Unigene
Unigene
相似根性的据蛋KE白G,G从注而释得信到息该我U们n能ige进ne一的步蛋得白到功U能ni注ge释ne信的息P。athway 注释。
统计我,如们将下图Un所ig示en:e 和 COG 数据库进行比对,预测 Unigene 可能的功能并对其做功能分类
根据nr注释信息我们能得到GO功能注释。我们根据nr注释信息,使用 ( ) Blast2GO 2.3.5
本节问题: 1.Q20 是什么意思? 2.BMS 系统上给出的 Q20%值是如何计算出来的? 3.转录组暂时执行数据质量标准是怎样的?你有什么更好的建议(拿出自己的测试数据)? 4.在统计数据信息时,read1 和 read2 长度相等吗? 5.read每个碱基测序错误率的分布如何?read测序长度增加有什么好处?为什么SOAP比对 的时候允许 3’端有更多的错配? 6.如何根据 BMS 上的碱基频率分布图查找建库或测序失败的问题?
G得O到注每释个信U息nig。enBela的st2GGOO注已释被后其,我它们文用献引W用EG超O过软1件50(
次,是同行广泛认可的 Ye, J., L. Fang, et al.
G(2O00注6)释. 软"W件EG。O:
a web tool for plotting GO annotations." Nucleic Acids Res 34(Web Server issue):
2.3 功能注释
原理: 首 先 , 通 过 ( ) 将 blastx blast-2.2.18 Unigene 序 列 比 对 到 蛋 白 数 据 库
Swiss-Prot(ftp:///pub/databases/uniprot_datafiles_by_format/fasta/),
11..3 本 在建节库问过题程:中,我们是先对RNA进行片段化后合成cDNA还是先用RNA合成cDNA再对cDNA
进行片段化?为什么要这样做?
2. 3.
相名对词于解生释:物芯插片入,片华段大的测序有什么优势?
4. 5.
f名as词tq解文释件:中Praeiar-desn的d r格ea式ds是怎样的?
W293-7.)对所有 Unigene 做 GO 功能分类统计,从宏观上认识该物种的基因功能分布特征。
如下图所示:
本节问题: 1.用 blast 比对时,blast 格式的选择和 evalue 阈值的设定是怎样的? 2.为什么我们会去掉较短的组装序列,选用大于 200 的序列比对? 3.如何降低比对所用时间? 4.在 COG 图中,请问每个分类的参考数据库是什么? 5.介绍一下我们比对用的四大数据库。 67..Gbleanste和Onbtolalto这gy(两简个称比对GO软)件的有含何义区?别,各自的特点是什么? 98..流从程Nr中库对的b注las释t 比结对果得中到得的到mG0O格分式类的结结果果是是怎如样何一处个理过得程到,最用终到表了格哪格些式软的件结工果具文?件的? 10.何做选bl择astb比las对t 的的建第库一类步型工?作是工作是什么?blast能够实现哪几种可能的序列比对方式?如
3. A该da参pt数er属c于on建ta库mi问na题ti,ona%dap(t记er为污Ad染a影pte响r实%)际产量。 4. Q20% (高于 80%)
该参数反映总体质量情况,de novo 项目 Q20 都应高于 80%,如果低于 70%则会严重影 响组装。质量非常差的数据,加进去会使组装效果变得更差。 5.GC%:
转录组 De novo 流程工作手册 1.De novo 流程生物学原理
1.1 实验流程
提取样品总 RNA 后,用带有 Oligo(dT)的磁珠富集真核生物 mRNA(若为原核生 物,则用试剂盒去除 rRNA 后进入下一步)。加入 fragmentaion buffer 将 打断 mRNA 成链短,片然段后,加以入缓mR冲N液A、为d模N板TP,s、用R六N碱as基e H随机和引D物N(A rpaonldyommerhaesexaIm合er成s)第合二成条第一cD条NAcD链N,A 在接经测过序接Qi头aQ,ui然ck后P用CR琼试脂剂糖盒凝纯胶化电并泳加进行EB片缓段冲大液小洗选脱择之,后最做后末进端行修P复C、测序。 11..2R测aw序c质 lus控ters (16 万~18 万) 对于 De novo 测序,质量胜过产量,小片段(200-500bp)宜上 18 万尽量缩小波动范围, 如果超过 20 万或者低于 15 万,则会影响质量和产量(Q20%,GC%),cluster 密度越高,数据 产量越大,但相邻 cluster 之间的荧光信号易相互干扰,影响数据质量;反之,cluster 密 度越低,相邻 cluster 的荧光信号越容易识别,但数据产量也较低。 2. Basecall duplicate% 该参数属于 solexa-pipeline 自身问题,只影响实际产量。
Gene Indices clustering tools (TGICL): a software system for fast clustering of large EST
冗dat余aseUtns.i"gBeinoei。nf最orm后a,tic将s 1U9n(i5g):e6n5e1序-2列.)与做蛋进白一数步据序库列n拼r、接S和wi去ss冗-P余ro处t、理KE,GG得和到尽COG可做能b长la的s非tx
2原.1理数:据过滤: 测序得到的 reads,并不都是有效的,里面含有带接头的,重复的,测序质量很低的 , reads
数这据些处re理ads的会步影骤响:组装和后续分析,我们必须对下机的 reads 过滤,得到有效 reads. 1 去除含 adaptor 的 reads 2 去除 N 的比例大于 10%的 reads 3 去除低质量 reads(质量值 Q <= 5 的碱基数占整个 read 的 50%以上) 4 获得 Clean reads,后续分析都基于 Clean reads
由于 De novo 项目的 GC%在最开始一般不知道,所以要采取更加灵活的处理方式,而不 是值设和定标死准板差,的以标及准,每如个误l差an在e 的+-%GC为%离合差格,,现来在反一映般总是体3变5-化65情%。况可。以如通果过r计aw算c所lu有stelran浓e 平度上均 的过高或者试剂出现问题,会导致 GC%在 reads 尾部分叉,严重时需要截去 reads 尾部一段 长度的序列。 6.Insert size:
比间对的(比对ev结al果ue<有0矛.0盾00,01则),按取n比r、对S结wi果ss最-P好ro的t、蛋K白EG确G 定和 UCnOGig的en优e 先的级序确列定方向Un。ig如en果e 的不同序库列之方 向,跟以上四个库皆比不上的 Unigene 我们用软件 ESTScan(Iseli, Jongeneel et al. 1999) 预测其编码区并确定序列的方向。对于能确定序列方向的 Unigene 我们给出其从 5'到 3'方 向的序列,对于无法确定序列方向的 Unigene 我们给出组装软件得到的序列。 本节问题: 1.Kerm 的含义? 2.contig 的含义? 3.scaffold 的含义? 4.unigene 的含义? 5.N50 的计算? 6.聚类的标准是什么? 7.有两个 read,read1:ACCAGCA;read2:TCCAGCA 请按照 kerm=5,构建 De bruijn 图 8.用不同 K-mer 组装得到的结果有什么差异?能合并吗? 9.影响组装的因素一般有哪些? 10,评价转录组的组装效果的常用指标有哪些? 11.转录组组装与基因组组装相比有何特点,制约转录组组装的主要因素有哪些? 1123..为插什入么片补段洞长后度的的大sca小ffo对ld组还装要结做果一有次何聚影类响,?主要目的是什么?
2.2 组装:
原理: 使用短 reads 组装软件 SOAPdenovo(Li, R., H. Zhu, et al. (2009). "De novo assembly of
装hum。aSnOgAePndoemnoevsow首ith先m将as具siv有el一y p定ar长all度el sohvoertrlreaapd的seqrueeandcsing连."成G更en长om的e 片Re段s.),做这转些录通组过从r头ea组ds overlap 关系得到的不含 N 的组装片段我们称之称为 Contig。然后,我们将 reads 比对回 Contig,通过 paired-end reads 能确定来自同一转录本的不同 Contig 以及这些 Contig 之 间的距离,SOAPdenovo 将这些 Contig 连在一起,中间未知序列用 N 表示,这样就得到 Scaffold。进一步利用 paired-end reads 对 Scaffold 做补洞处理,最后得到含 N 最少,两 端不能再延长的序列,我们称之为 Unigene。如果同一物种做了多个样品测序,则不同样品 组装得到的 Unigene 可通过序列聚类软件 TGICL(Pertea, G., X. Huang, et al. (2003). "TIGR