字符取模
威尔取模软件GBK字库GB2312字库说明书

威尔取模软件使用介绍(V1.0)一、简介1.1 界面介绍二、我要取几个汉字的字模2.1 取模2.1.1 打开软件2.1.2 在中文字符集文本框中输入要取模的文字,比如“欢迎使用威尔取模软件”,如下图所示。
2.1.3 选择要取模的字体,比如我要取宋体的字模,就选择宋体。
如下图所示。
此处列出的是系统安装的所有字体,如果要取自己下载的字体的模,请先安装该字体。
2.1.4 添加我要取模的字号,宽度,高度等信息。
点击添加按钮,打开添加窗口,如下图所示。
在字号,宽度,高度框中输入你要取模的文字大小。
比如我要取16*16的点阵,就在宽度和高度中输入16、16。
然后计算字号,字号=0.75*宽度。
输入12。
点击添加。
点击添加以后回到主界面,你会发现主界面字号列表框里面就多了一种你刚刚添加的字号了。
这时候点击你刚刚添加的字号选中它,然后再在预览框中输入一个汉字,看看效果。
2.1.5 如果效果不错可以跳过这一步。
如果效果不好有以下两种情况。
1.文字太大或者太小,如下图两种情况所示。
这时候就需要重新设置字号了。
增大或者减小字号。
2.字符不居中,如下图所示。
这时候调节右下方的位置调整滑块,将文字调节居中,如下图所示。
2.1.6 选择要生成C语言格式还是二进制文件格式。
如果是C语言格式,还可以选择是否生成数组的数组名。
2.1.7 假如我只要取我刚刚设置的16*16点阵字体,那么就要选择“取选中字号”,并选中16*16那一列。
如下图所示。
2.1.8 假如我只要取中文字模,那么就勾上取模中文,同时去掉取模英文的勾,如下图所示。
2.1.9 好了,所有设置妥当,可以开始取模啦。
点击“开始取模”。
如果选择的是C语言格式则取模完成后自动弹出结果窗口,如下图所示。
三、我要取整个GBK字库或者GB2312字库的字模3.1 取模3.1.1 打开软件3.1.2 假如我要取整个GBK字库的字模,那么点击右侧“GBK字库”按钮,自动输入GBK字符集所有文字。
JAVA大数类—基础操作(加减乘除、取模、四舍五入、设置保留位数)

JAVA⼤数类—基础操作(加减乘除、取模、四舍五⼊、设置保留位数)当基础数据类型长度⽆法满⾜需求时可以使⽤⼤数类 构造⽅法接受字符串为参数1 BigInteger bInt = new BigInteger("123123");2 BigDecimal bDouble = new BigDecimal("123123.123123124"); 基础操作(取模使⽤divideAndRemainder⽅法,返回的数组第⼆个元素为余数): BigDecimal在做除法时必须设定传⼊精度(保留多少位⼩数),否则会出现异常:ng.ArithmeticException: Non-terminating decimal expansion; no exact representable decimal result。
除法还有两个接受不同数量参数的⽅法: 接受两个参数的⽅法: @param divisor value by which this {@code BigDecimal} is to be divided. 传⼊除数 @param roundingMode rounding mode to apply. 传⼊round的模式 三个参数的⽅法: @param divisor value by which this {@code BigDecimal} is to be divided. 传⼊除数 @param scale scale of the {@code BigDecimal} quotient to be returned. 传⼊精度 @param roundingMode rounding mode to apply. 传⼊round的模式 round模式为⼩数取舍模式: BigDecimal.ROUND_UP:最后⼀位如果⼤于0,则向前进⼀位,正负数都如此。
手把手教你光立方取模软件的使用(以字符R为例)

手把手教你光立方取模软件的使用
(以字符R为例)
1、3D8光立方取模软件的视图分为:正视图,侧视图和俯视图,取模时只需要在你想要的视图上操作即可,不必管其他视图的变化
代表光立方的三视图分别是:正视图,侧视图和俯视图
2、用鼠标点击8*8的小方格,白色代表点亮,灰色代表熄灭,数据会显示在下面的hex显示区内
3、将R顺时针旋转180度,将旋转后的图形以白点的形式绘制在正视图的第一个8*8方框内(旋转是为了使图形数据与程序一致)
在正视图中点亮一个“R”的字符
4、找到hex文本框里第八行的第三到六的数据,这四个数据即为有效数据。
(图形不同获得的数据大小不同,总之除零以外的数据都是有效的)
”R”的数据显示在hex数据区内
5、用keil打开程序,找到名为ZIMO.H的文件。
在ZIMO.H里定义了一个名为table_id的数组,用hex文本框里的四个数据替换其中一组,点击保存并编译。
6、打开stc下载软件,如stc-isp-15xx-v6.61。
单片机型号选择stc12c5a60s2,点击“打开程序文件”到你程序文件夹得hex文件里添加后缀为.hex的文件。
7、将下载线一端插在电脑上一端用杜邦线插在spi下载口上(注意:上有标号不要差错)打开电源,点击下载软件的“下载”然后再重启一次电源,当提示操作成功时程序就下载完成了,。
c语言字符串提取数字的各位数字

c语言字符串提取数字的各位数字C语言是一种广泛应用于计算机编程的语言,它具有高效、灵活、可移植等特点。
在C语言中,字符串是一种常见的数据类型,它由一系列字符组成。
在处理字符串时,有时需要提取其中的数字,并将其各位数字分离出来。
本文将介绍C语言中提取数字的各位数字的方法。
首先,我们需要了解C语言中字符串和数字的表示方式。
在C语言中,字符串是由一系列字符组成的数组,以'\0'结尾。
而数字则可以表示为整型或浮点型。
在提取数字的各位数字时,我们需要将字符串转换为数字类型,然后进行分离。
C语言提供了一些函数可以将字符串转换为数字类型,如atoi、atof、strtol等。
其中,atoi函数可以将字符串转换为整型,atof函数可以将字符串转换为浮点型,strtol函数可以将字符串转换为长整型。
这些函数的使用方法如下:```cint atoi(const char *str); // 将字符串转换为整型double atof(const char *str); // 将字符串转换为浮点型long int strtol(const char *str, char **endptr, int base); // 将字符串转换为长整型```其中,str参数为要转换的字符串,endptr参数为指向转换后剩余字符串的指针,base参数为转换时使用的进制。
例如,当base为10时,表示使用十进制进行转换。
接下来,我们可以使用取模和除法运算来分离数字的各位数字。
例如,对于一个整数n,我们可以使用以下代码来分离其各位数字:```cint digit;while(n > 0){digit = n % 10; // 取出个位数字n /= 10; // 去掉个位数字// 对digit进行处理}```对于浮点数,我们可以先将其转换为整型,然后再进行分离。
例如,对于一个浮点数f,我们可以使用以下代码来分离其各位数字:```cint n = (int)f; // 将浮点数转换为整型int digit;while(n > 0){digit = n % 10; // 取出个位数字n /= 10; // 去掉个位数字// 对digit进行处理}```需要注意的是,当浮点数f为负数时,我们需要先将其取绝对值,然后再进行转换和分离。
AscII码字模提取方法
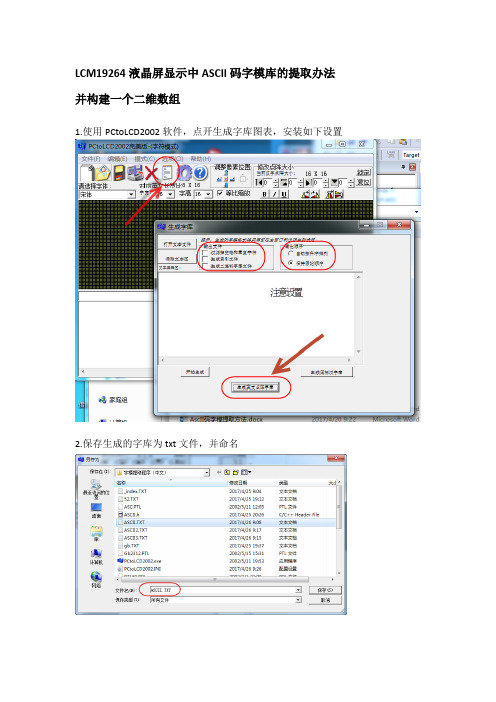
LCM19264液晶屏显示中ASCII码字模库的提取办法并构建一个二维数组
1.使用PCtoLCD2002软件,点开生成字库图表,安装如下设置
2.保存生成的字库为txt文件,并命名
3.打开刚刚生成的TXT文件,里面的每一行代表一个ASCII码的字码。
注意:31以上(包括31为不可见字符,我们不需要)
4. 在keil下新建文件Ascii.h,用了保存ASCII码字模Ascii.h文件内内容如下
以上声明了一个二维数组nAscii[][] ,并使用Code关键字将数组定义在Flash空间内,二维数组的第二位大小为16 ,此值为一个Ascii码字模的大小。
5. 将第3步文件中的可见字符复制到Ascii.h文件内的二维数组nAscii[][16] 中。
最后内容如下。
取模运算

数去除这个自然数,若该自然数能被整除,则说明其非素数。
C++实现功能函数:
/* 函数名:IsPrime
函数功能:判别自然数 n 是否为素数。 输入值:int n,自然数 n 返回值:bool,若自然数 n 是素数,返回 true,否则返回 false */
bool IsPrime(unsigned int n) {
<!--[if !supportLineBreakNewLine]--> <!--[endif]--> 基本性质: (1)若 p|(a-b),则 a≡b (% p)。例如 11 ≡ 4 (% 7), 18 ≡ 4(% 7) (2)(a % p)=(b % p)意味 a≡b (% p) (3)对称性:a≡b (% p)等价于 b≡a (% p) (4)传递性:若 a≡b (% p)且 b≡c (% p) ,则 a≡c (% p) 运算规则: 模运算与基本四则运算有些相似,但是除法例外。其规则如下:
说明: 1. 同余式: 正整数 a,b 对 p 取模,它们的余数相同,记做 a ≡ b % p 或者 a ≡ b (mod p)。 2. n % p 得到结果的正负由被除数 n 决定,与 p 无关。 例 如 : 7%4 = 3 , -7%4 = -3 , 7%-4 = 3 , -7%-4 = -3 。
取模运算
取模运算即模运算
模 运 算 即 求 余 运 算 。“模 ” 是 “Mod”的 音 译 ,模 运 算 多 应 用
于程序编写中。 Mod 的含义为求余。模运算在数论和程序设计中都有着广泛的应用,
从 奇 偶 数 的 判 别 到 素 数 的 判 别 ,从 模 幂 运 算 到 最 大 公 约 数 的 求 法 ,从 孙 子 问 题 到 凯 撒
c语言中%用法

在 C 语言中,百分号%是一个运算符,主要用于格式化输出和进行取模运算。
以下是%在 C 语言中的常见用法:
1. 格式化输出(printf 函数):
printf函数中%用于指定格式化输出的内容。
例如,%d表示输出整数,%f表示输出浮点数,%s表示输出字符串等。
2. 取模运算:
%用于进行取模运算,即求余数。
它返回除法运算的余数。
3. 格式化输入(scanf 函数):
scanf函数中也可以使用%来指定输入数据的格式。
4. 预处理器中的宏定义:
在预处理器中,%也可以用于宏定义的参数替换。
这只是%在 C 语言中的一些常见用法。
具体使用时,要根据上下文和具体情况来理解和使用%。
在格式化输出和输入中,%后面通常会跟随格式说明符,而在取模运算中,%用于表示取模操作。
字符取模原理

字符取模原理字符取模原理解析什么是字符取模字符取模是一种常见的编程技巧,用于判断字符串中某个字符在另一个字符集合中是否存在。
利用字符取模可以快速判断某个字符是否包含在一个字符串中,以及计算出字符在字符串中的位置。
字符取模的原理字符取模的原理基于ASCII码表,每个字符都对应一个唯一的ASCII码,范围从0到127。
通过将字符串中的字符与字符集合进行比较,可以根据字符的ASCII码判断字符是否存在于字符集合中。
字符取模的步骤1.将字符串和字符集合转换为ASCII码形式。
2.遍历字符串中的每个字符,并获取字符的ASCII码。
3.检查字符ASCII码是否包含在字符集合的ASCII码范围内。
4.如果包含,则表示字符存在于字符集合中;否则,表示字符不存在于字符集合中。
字符取模的示例以下是一个使用字符取模技巧判断字符串中是否包含某个字符的示例代码:def is_character_exists(string, character):# 获取字符集合的ASCII码character_set = set(ord(c) for c in string)# 获取字符的ASCII码char_ascii = ord(character)# 判断字符是否存在于字符集合中if char_ascii in character_set:return Trueelse:return False字符取模的优势和适用场景字符取模是一种高效的算法,可以快速判断一个字符是否存在于字符串中。
相比于遍历字符串逐个比较字符的方法,字符取模可以大大提高执行效率。
字符取模适用于以下场景: - 判断字符串中是否包含某个特定的字符。
- 在字符串中查找某个字符并获取其位置。
- 对字符串中的字符进行去重操作。
总结字符取模是一种利用字符的ASCII码进行快速判断字符是否存在于字符串中的编程技巧。
它遵循将字符串和字符集合转换为ASCII码,通过比较字符的ASCII码范围来判断字符是否存在的原理。
OLED模块使用说明

7.6 系统显示设计控制系统显示常用的显示器件有数码管、LCD、OLED等。
OLED即有机发光二极管(Organic Light Emitting Diode),其同时具备自发光,不需背光源、对比度高、制程较简单等优异之特性,被认为是下一代的平面显示器新兴应用技术。
本节主要介绍OLED的工作原理、底层驱动代码编写以及如何通过取模软件显示任何自己想要显示的文字或者图片。
7.6.1 OLED显示原理如图4所示为0.96寸OLED显示模块,其分辨率为128*64,采用4线SPI接口方式,模块的接口定义如表1所示。
图4 0.96寸OLED显示模块种并行接口方式、3线或4线SPI接口方式、IIC接口方式。
这里介绍OLED模块4线SPI 通信方式,只需4根通信线就能实现对OLED模块的显示控制,这4根线为:D0、D1、DC、CS。
如图5所示为4线SPI写操作时序图,在4线SPI模式下,每个数据长度均为8位,也即为1个字节。
每次发送该字节数据前,如果该字节数据为指令号,则将DC管脚拉低;如果该字节数据为普通数据,则将DC管脚置高。
在SCLK上升沿,数据从SDIN移入SSD1306,并且高位在前。
SSD1306的显存总共为128*64bit大小,SSD1306将这些显存分为8页,其对应关系如表2所示。
可见OLED水平像素分为128段,即SEG0~SEG127;垂直像素平分为8页,也即垂直方向每8个像素点为1页。
从而可见,在确定显示的位置后,通过往显存中写入一个字节数据,则相应的SEG将按照数据进行显示,位数据为1时,相应像素点被点亮,位数据为0时,相应的像素点熄灭。
图5 4线SPI写操作时序图令较多,具体的可以参考相关手册,这里介绍如表3所示几个比较常用的指令。
命令,随后发送的一个字节为要设置的对比度的值。
这个值设置得越大屏幕就越亮。
第二个命令为 0XAE/0XAF。
0XAE 为关闭显示命令; 0XAF 为开启显示命令。
汉字取模原理

汉字的取模原理手工取模原理(详解)因本人这个取模原理也搞了一天,网上也没有现成的资料,包括纵向和横向取模,对照网上各位所说慢慢摸索,最终把原理搞清楚,最后写出来给大家参照一下。
这里,我们先以英文和中文来说明,说明前我们先统一标准。
标准1:显示大小为16*16,显示的像素为1,不显示的为0。
标准2:显示大小为16*16,显示的像素为0,不显示的为1.有的显示要“字节倒序”,主要是显示器的要求不一样。
这里我们用标准1.解说以下图片:1.英文”A”字的取模,我们这里采用横向,横向取模为“高位在左”,方式是按单片机的内存每一位的排列,排列方式为“7.6.5.4.3.2.1.0”,显示的为1,不显示的为0,这里文字大小采用小4,占用像素为8*16。
1.1.我们按图把要显示的字用“1”填起来,图片显示为用1做的“A”,再把没有显示的用“0”填起来。
1.2.我们从Y轴的16行到Y轴第1行,一行一行的取,取8位二进制码,每行方向从左到右取数,再把二进制码用“8421”码转换成16进制码,分别是。
二进制汇编十六进制C语言十六进制Y轴第16行00000000B 00H 0X00Y轴第15行00000000B 00H 0X00Y轴第14行00000000B 00H 0X00Y轴第13行00010000B 10H 0X10Y轴第12行00010000B 10H 0X10Y轴第11行00011000B 18H 0X18Y轴第10行00101000B 28H 0X28Y轴第9行00101000B 28H 0X28Y轴第8行00100100B 24H 0X24Y轴第7行00111100B 3CH 0X3CY轴第6行01000100B 44H 0X44Y轴第5行01000010B 42H 0X42Y轴第4行01000010B 42H 0X42Y轴第3行11100111B 0E7H 0XE7Y轴第2行00000000B 00H 0X00Y轴第1行00000000B 00H 0X00整理汇编为; DB 00H,00H,00H,10H,10H,18H,28H,28H,24H,3CH,44H,42H,42H,0E7H,00H,00H1.3.英文的纵向取模,纵向取模的高位在下。
取模软件的使用

取模软件的使用
现在推荐款取模软件,一款对文字取模,另一款针对图片取模
21122Crtl ENTER .文字取模软件使用步骤:
.在此界面下输入"普中"个汉字
.然后+键,即可出现点阵字符在窗口中央1
33C C A51.选择取模方式,如果是语言,选择语言格式,如何是汇编语言,现则格式
将这些进制数据复
制到相应的例程中,
建立一个数组16
例程采用此模式设置字大小
2.取模软件的相关参数设置
18TFT
.寸的采用字节倒序
完
图片取模
,要根据自己对要显示图片大小填
入合适数字
图片取模软件使用要点:
点击保存后可以看到下面的进制数,把这数据复制到程序中,然后通过驱动程序把数据传到彩屏中,即可完成图像显示.16。
取模失败的原因分析及处理

取模失败的常见场景
01
除数为0
在进行取模运算时,如果除数为0,会导致取模失败,因为除数不能为0。
02
被除数为负数
在进行取模运算时,如果被除数为负数,也会导致取模失败,因为负数
无法被取模。
03
数据类型不匹配
在进行取模运算时,如果被除数和除数的数据类型不匹配,可能会导致
取模失败。例如,将浮点数进行取模运算,可能会得到不正确的结果。
取模算法优化
优化取模算法
根据具体的应用场景和需求,选择合适的取模算法,如快速取模算法、扩展欧几里得算法等,以提高 取模的效率和准确性。
异常处理
在取模过程中,对可能出现的异常情况进行预处理,如溢出、下溢等,以避免因异常情况导致取模失 败。
取模算法优化
优化取模算法
根据具体的应用场景和需求,选择合适的取模算法,如快速取模算法、扩展欧几里得算法等,以提高 取模的效率和准确性。
取模数不正确
总结词
取模数设置错误或不符合取模运算规 则。
详细描述
在进行取模运算时,取模数的设置不 正确,例如取模数为0或非整数,或者 取模数的符号与被除数的符号不一致 。
取模算法错误
总结词
取模算法实现错误或不符合预期。
详细描述
在进行取模运算时,使用的取模算法实现有误,例如在实现取模运算时没有正 确处理负数的情况,导致结果不准确。
取模失败的原因分析及 处理
目录
Contents
• 取模失败概述 • 取模失败的原因分析 • 取模失败的处理方法 • 取模失败的预防措施 • 取模失败的案例分析
目录
Contents
• 取模失败概述 • 取模失败的原因分析 • 取模失败的处理方法 • 取模失败的预防措施 • 取模失败的பைடு நூலகம்例分析
c语言百分号d没有双引号使用案例

c语言百分号d没有双引号使用案例(实用版)目录1. C 语言简介2. 百分号(%)在 C 语言中的用法3. 使用案例:没有双引号的情况4. 总结正文1. C 语言简介C 语言是一种广泛使用的计算机编程语言,由 Dennis Ritchie 在贝尔实验室开发。
C 语言的特点是功能强大,执行效率高,跨平台,可移植性强。
C 语言被广泛应用于操作系统、嵌入式系统、硬件驱动、游戏开发等领域。
2. 百分号(%)在 C 语言中的用法在 C 语言中,百分号(%)是一个特殊的字符,用于表示取模(modulo)运算。
取模运算符(%)的两边必须是整数,其功能是求余数。
例如,7 % 3 = 1,表示 7 除以 3 的余数是 1。
3. 使用案例:没有双引号的情况在 C 语言中,双引号(" ")用于表示字符串。
当需要表示一个没有双引号的字符串时,我们可以使用普通字符(如字母、数字、下划线等)组成字符串,或者使用一些特定的字符作为字符串的边界。
例如,我们可以使用一个下划线(_)作为字符串的边界,表示一个没有双引号的字符串:```c#include <stdio.h>int main() {char str[] = "hello_world";printf("%s", str);return 0;}```在这个例子中,我们使用一个数组存储字符串,并通过`printf`函数将其输出到屏幕上。
4. 总结本篇文章介绍了 C 语言的基本知识,重点讲解了百分号(%)的用法,并通过一个没有双引号的使用案例进行了演示。
字符取模原理

字符取模原理字符取模原理是指将一个字符转化为对应的ASCII码,再对某个数值取模的过程。
在计算机中,字符是以ASCII码的形式存储和表示的。
ASCII码是一个由128个字符组成的编码系统,每个字符对应一个唯一的数值。
在字符取模原理中,首先需要将字符转化为对应的ASCII码。
ASCII 码表中,每个字符都有一个唯一的数值表示。
例如,字符'A'的ASCII码为65,字符'a'的ASCII码为97。
通过查表或使用编程语言中的函数,可以将一个字符转化为对应的ASCII码。
接下来,需要选择一个数值作为取模的基数。
取模的基数可以是任意整数,常见的有10、100、256等。
选择不同的基数会对结果产生不同的影响。
然后,将字符的ASCII码与基数进行取模运算。
取模运算的结果是一个非负整数,范围从0到基数-1。
例如,如果基数为10,字符'A'的ASCII码65对10取模的结果是5,字符'a'的ASCII码97对10取模的结果是7。
通过字符取模原理,我们可以实现一些有趣的功能。
例如,可以根据字符的ASCII码判断字符的类型。
在ASCII码中,数字字符的范围是48到57,大写字母字符的范围是65到90,小写字母字符的范围是97到122。
通过对字符的ASCII码进行取模运算,可以判断字符属于哪个范围,从而确定字符的类型。
字符取模原理还可以用于实现简单的加密算法。
通过对字符的ASCII码进行取模运算,可以将原文中的字符转化为一系列新的字符。
只有知道取模的基数和算法,才能还原出原始的字符。
这样可以增加信息的安全性,防止未经授权的人查看或修改数据。
除了上述应用,字符取模原理还可以用于生成随机数。
通过对字符的ASCII码进行取模运算,可以得到一个随机的非负整数。
通过在取模运算之前,对字符进行加密或者加盐处理,可以进一步增加随机性,生成更加安全的随机数。
字符取模原理是将字符转化为对应的ASCII码,再对某个数值取模的过程。
字符取模原理

字符取模原理字符取模原理是计算机科学中的一个重要概念,它在数据处理和编程中有着广泛的应用。
本文将介绍字符取模原理的基本概念、应用场景以及相关的注意事项。
一、概念字符取模是指将字符转换为对应的数值,一般使用ASCII码或Unicode码来表示字符。
在计算机中,每个字符都有一个唯一的编码值,通过这个编码值可以对字符进行处理和操作。
字符取模的原理是通过对字符的编码值进行取模运算,将其映射到一个特定的范围内,得到一个与字符相关的数值。
二、应用场景1. 字符映射:字符取模可用于将字符映射到特定的索引或位置,常用于编码表、字典等数据结构的实现。
例如,可以使用字符取模将字母映射到26个英文字母的索引位置,方便进行字母表的排序和查找。
2. 散列函数:字符取模可以作为散列函数的一种实现方式,将字符串映射到一个固定大小的散列表中。
通过对字符串的每个字符进行取模运算,可以将字符串均匀地散列到散列表的不同位置,提高散列算法的效率和均匀性。
3. 数据分片:在分布式系统中,字符取模可以用于将数据分片到不同的节点上。
通过对数据的某个唯一标识(如用户ID、订单ID等)进行取模运算,可以将数据均匀地分配到不同的节点上,实现数据的负载均衡和并行处理。
4. 循环队列:字符取模还可以用于实现循环队列。
通过对队列的下标进行取模运算,可以将队列的头尾连接起来,实现循环利用队列空间的效果。
循环队列常用于缓冲区的实现,提高数据读写的效率。
三、注意事项1. 取模运算的基数要与映射范围的大小相匹配,以保证映射结果的准确性。
例如,如果要将字符映射到0-25的范围内,可以使用取模运算基数为26。
2. 字符取模的结果可能存在冲突,即不同的字符可能映射到相同的数值。
为了避免冲突,可以采用更复杂的映射算法,如哈希函数,或者增加冲突解决的策略,如链表法、开放寻址法等。
3. 字符取模的性能与映射范围的大小有关,映射范围越大,冲突的可能性越小,但计算开销也会增加。
awk 取模函数

awk 取模函数在awk中,取模函数(modulo function)用来计算两个数相除的余数。
通常表示为“a % b”,表示a除以b所得的余数。
在awk中,取模函数的使用非常灵活,可以用于各种场景。
下面将介绍一些常见的用法。
1. 判断奇偶性通过取模函数可以判断一个数是奇数还是偶数。
如果一个数除以2的余数为0,则表示它是偶数;如果余数为1,则表示它是奇数。
例如,我们可以使用取模函数来判断一个数是否为偶数:```awk 'BEGIN{num=10; if(num % 2 == 0) print num"是偶数"; else print num"是奇数"}'```输出结果为:10是偶数2. 分割字符串取模函数还可以用于分割字符串。
我们可以将一个长字符串按照指定的长度进行分割,并将分割后的子字符串打印出来。
例如,我们可以使用取模函数将一个字符串按照3个字符为一组进行分割:```awk 'BEGIN{str="abcdefghi"; len=3; for(i=1; i<=length(str); i+=len) print substr(str, i, len)}'```输出结果为:abcdefghi3. 生成序列取模函数还可以用于生成序列。
我们可以通过取模函数将一个数从1递增到指定的值,并将生成的序列打印出来。
例如,我们可以使用取模函数生成从1到10的序列:```awk 'BEGIN{end=10; for(i=1; i<=end; i++) print i}'```输出结果为:123456789104. 分组统计取模函数还可以用于分组统计。
我们可以通过取模函数将一组数据按照指定的范围进行分组,并统计每个分组中的数据个数。
例如,我们可以使用取模函数将一组数按照10为一组进行分组,并统计每个分组中的数的个数:```awk 'BEGIN{nums="1 2 3 4 5 6 7 8 9 10 11 12 13 14 15"; split(nums, arr); for(i=1; i<=length(arr); i++) group[int((arr[i]-1)/10)]++; for(i in group) print "第"i"组有"group[i]"个数"}'```输出结果为:第0组有10个数第1组有5个数总结:通过本文介绍,我们了解了awk中取模函数的一些常见用法。
大数加法取模

大数加法取模大数加法取模指的是两个大数相加后取模运算。
大数加法是指两个超过计算机能够表示的整数范围的数字相加,取模运算是指将一个数除以另一个数后得到的余数。
实现大数加法取模的一种常见方法是将两个大数转化为字符串,然后逐位相加,并逐位求模。
具体步骤如下:1. 将两个大数转化为字符串,并取得字符串的长度。
2. 从字符串的末尾开始,逐位相加,并将相加的结果和上一位的进位相加。
3. 计算当前位的余数,并将余数存储在结果字符串的末尾。
4. 计算当前位的进位,并将进位存储在下一位的运算中使用。
5. 重复步骤2-4直到两个大数的所有位都相加完成。
6. 最后得到的结果字符串即为相加后的结果。
7. 对结果字符串再次取模,得到最终的取模结果。
以下是一个使用Python实现大数加法取模的示例代码:```pythondef addMod(num1, num2, mod):result = []carry = 0len1 = len(num1)len2 = len(num2)while len1 > 0 or len2 > 0:digit1 = int(num1[len1-1]) if len1 > 0 else 0digit2 = int(num2[len2-1]) if len2 > 0 else 0sum = carry + digit1 + digit2carry = sum // 10result.append(str(sum % 10))len1 -= 1len2 -= 1if carry > 0:result.append(str(carry))result.reverse()result_str = ''.join(result)mod_result = int(result_str) % modreturn mod_result# Example usage:num1 = "12345678901234567890"num2 = "98765432109876543210"mod = 1000000007result = addMod(num1, num2, mod)print(result)```在这个示例中,我们将num1和num2分别赋值为两个大数的字符串表示形式,mod赋值为取模的数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
汉字字符图片取模
12864纵向取模,字节倒序。
直接关系到编程的方法。
(a)数字1 (8*16)(b) 纵向取模,字节倒序(c) 纵向取模
图1:纵向取模
图1(b)采用纵向取模,字节倒序的方式进行取模。
那么生产的字模的表格为:
从第一列开始,取上面的8位,倒序读,0x00;接着取第二列上面的8位,倒序读,0x10;接着取第三列上面的8位,倒序读,0x10;接着取第四列上面的8位,倒序读,0xf8;接着取第五列上面的8位,倒序读,0x00;……
直到这8列上半部分8位都取完,再从先半部分开始,自下而上(倒序),自左往右取完8列。
所以:/*-- 文字: 1 --*/
/*-- 宋体12; 此字体下对应的点阵为:宽x高=8x16 --*/
0x00,0x10,0x10,0xF8,0x00,0x00,0x00,0x00,0x00,0x20,0x20,0x3F,0x20,0x20,0x00,0x00
图1(c):纵向取模,方式如图。
/*-- 文字: 1 --*/
/*-- 宋体12; 此字体下对应的点阵为:宽x高=8x16 --*/
0x00,0x08,0x08,0x1F,0x00,0x00,0x00,0x00,0x00,0x04,0x04,0xFC,0x04,0x04,0x00,0x00
(a) 横向取模(b) 横向取模,字节倒序
图2:横向取模
横向取模:
/*-- 文字: 北--*/
/*-- 宋体12; 此字体下对应的点阵为:宽x高=16x16 --*/
0x04,0x40,0x04,0x40,0x04,0x40,0x04,0x44,0x04,0x48,0x7C,0x50,0x04,0x60,0x04,0x40, 0x04,0x40,0x04,0x40,0x04,0x40,0x04,0x42,0x1C,0x42,0xE4,0x42,0x44,0x3E,0x04,0x00
横向取模,字节倒序:
/*-- 文字: 北--*/
/*-- 宋体12; 此字体下对应的点阵为:宽x高=16x16 --*/
0x20,0x02,0x20,0x02,0x20,0x02,0x20,0x22,0x20,0x12,0x3E,0x0A,0x20,0x06,0x20,0x02, 0x20,0x02,0x20,0x02,0x20,0x02,0x20,0x42,0x38,0x42,0x27,0x42,0x22,0x7C,0x20,0x00。