正则表达式教程
js正则表达式详细教程

js正则表达式详细教程//校验是否全由数字组成[code] function isDigit(s) { var patrn=/^[0-9]{1,20}$/; if (!patrn.exec(s)) return false return true } [/code]//校验登录名:只能输⼊5-20个以字母开头、可带数字、“_”、“.”的字串[code] function isRegisterUserName(s) { var patrn=/^[a-zA-Z]{1}([a-zA-Z0-9]|[._]){4,19}$/; if (!patrn.exec(s)) return false return true } [/code]//校验⽤户姓名:只能输⼊1-30个以字母开头的字串[code] function isTrueName(s) { var patrn=/^[a-zA-Z]{1,30}$/; if (!patrn.exec(s)) return false return true } }} //校验密码:只能输⼊6-20个字母、数字、下划线 [code] function isPasswd(s) { var patrn=/^(\w){6,20}$/; if (!patrn.exec(s)) return false return true } [/code]//校验普通电话、传真号码:可以“+”开头,除数字外,可含有“-”[code] function isTel(s) { //var patrn=/^[+]{0,1}(\d){1,3}[ ]?([-]?(\d){1,12})+$/; var patrn=/^[+]{0,1}(\d){1,3}[ ]?([-]?((\d)|[ ]) {1,12})+$/; if (!patrn.exec(s)) return false return true } [/code]//校验⼿机号码:必须以数字开头,除数字外,可含有“-”[code] function isMobil(s) { var patrn=/^[+]{0,1}(\d){1,3}[ ]?([-]?((\d)|[ ]){1,12})+$/; if (!patrn.exec(s)) return false return true } [/code]//校验邮政编码[code] function isPostalCode(s) { //var patrn=/^[a-zA-Z0-9]{3,12}$/; var patrn=/^[a-zA-Z0-9 ]{3,12}$/; if (!patrn.exec(s)) return false return true } [/code]//校验搜索关键字[code] function isSearch(s) { var patrn=/^[^`~!@#$%^&*()+=|\\\][\]\{\}:;'\,.<>/?]{1}[^`~!@$%^&()+=|\\\] [\]\{\}:;'\,.<>?]{0,19}$/; if (!patrn.exec(s)) return false return true } function isIP(s) //by zergling { var patrn=/^[0-9.]{1,20}$/; if (!patrn.exec(s)) return false return true } [/code]正则表达式[code] "^\\d+$" //⾮负整数(正整数 + 0) "^[0-9]*[1-9][0-9]*$" //正整数 "^((-\\d+)|(0+))$" //⾮正整数(负整数 + 0) "^-[0-9]*[1-9][0-9]*$" //负整数 "^-?\\d+$" //整数 "^\\d+(\\.\\d+)?$" //⾮负浮点数(正浮点数 + 0) "^(([0-9]+\\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\\.[0-9]+)|([0-9]*[1-9][0-9]*))$" //正浮点数 "^((-\\d+(\\.\\d+)?)|(0+(\\.0+)?))$" //⾮正浮点数(负浮点数 + 0) "^(-(([0-9]+\\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\\.[0-9]+)|([0-9]*[1-9][0-9]*)))$" //负浮点数 "^(-?\\d+) (\\.\\d+)?$" //浮点数 "^[A-Za-z]+$" //由26个英⽂字母组成的字符串 "^[A-Z]+$" //由26个英⽂字母的⼤写组成的字符串 "^[a-z]+$" //由26个英⽂字母的⼩写组成的字符串 "^[A-Za-z0-9]+$" //由数字和26个英⽂字母组成的字符串"^\\w+$" //由数字、26个英⽂字母或者下划线组成的字符串 "^[\\w-]+(\\.[\\w-]+)*@[\\w-]+(\\.[\\w-]+)+$" //email地址"^[a-zA-z]+://(\\w+(-\\w+)*)(\\.(\\w+(-\\w+)*))*(\\?\\S*)?$" //url "^[A-Za-z0-9_]*$" [/code]正则表达式使⽤详解简介简单的说,正则表达式是⼀种可以⽤于模式匹配和替换的强有⼒的⼯具。
正则表达式30分钟入门教程——堪称网上能找到的最好的正则式入门教程

正则表达式30分钟⼊门教程——堪称⽹上能找到的最好的正则式⼊门教程本教程堪称⽹上能找到的最好正则表达式⼊门教程本⽂⽬标30分钟内让你明⽩正则表达式是什么,并对它有⼀些基本的了解,让你可以在⾃⼰的程序或⽹页⾥使⽤它。
如何使⽤本教程最重要的是——请给我30分钟,如果你没有使⽤正则表达式的经验,请不要试图在30秒内⼊门——除⾮你是超⼈ :)别被下⾯那些复杂的表达式吓倒,只要跟着我⼀步⼀步来,你会发现正则表达式其实并没有想像中的那么困难。
当然,如果你看完了这篇教程之后,发现⾃⼰明⽩了很多,却⼜⼏乎什么都记不得,那也是很正常的——我认为,没接触过正则表达式的⼈在看完这篇教程后,能把提到过的语法记住80%以上的可能性为零。
这⾥只是让你明⽩基本的原理,以后你还需要多练习,多使⽤,才能熟练掌握正则表达式。
除了作为⼊门教程之外,本⽂还试图成为可以在⽇常⼯作中使⽤的正则表达式语法参考⼿册。
就作者本⼈的经历来说,这个⽬标还是完成得不错的——你看,我⾃⼰也没能把所有的东西记下来,不是吗?⽂本格式约定:专业术语元字符/语法格式正则表达式正则表达式中的⼀部分(⽤于分析) 对其进⾏匹配的源字符串对正则表达式或其中⼀部分的说明本⽂右边有⼀些注释,主要是⽤来提供⼀些相关信息,或者给没有程序员背景的读者解释⼀些基本概念,通常可以忽略。
正则表达式到底是什么东西?字符是计算机软件处理⽂字时最基本的单位,可能是字母,数字,标点符号,空格,换⾏符,汉字等等。
字符串是0个或更多个字符的序列。
⽂本也就是⽂字,字符串。
说某个字符串匹配某个正则表达式,通常是指这个字符串⾥有⼀部分(或⼏部分分别)能满⾜表达式给出的条件。
在编写处理字符串的程序或⽹页时,经常会有查找符合某些复杂规则的字符串的需要。
正则表达式就是⽤于描述这些规则的⼯具。
换句话说,正则表达式就是记录⽂本规则的代码。
很可能你使⽤过Windows/Dos下⽤于⽂件查找的通配符(wildcard),也就是*和?。
易语言正则表达式简明教程

正则表达式(regular expression)前言正则表达式是烦琐的,但是强大的,学会之后的应用会让你除了提高效率外,会给你带来绝对的成就感。
只要认真去阅读这些资料,加上应用的时候进行一定的参考,掌握正则表达式不是问题。
索引1._引子2._正则表达式的历史3._正则表达式定义3.1_普通字符3.2_非打印字符3.3_特殊字符3.4_限定符3.5_定位符3.6_选择3.7_后向引用4._各种操作符的运算优先级5._全部符号解释6._部分例子7._正则表达式匹配规则7.1_基本模式匹配7.2_字符簇7.3_确定重复出现--------------------------------------------------------------------------------1. 引子目前,正则表达式已经在很多软件中得到广泛的应用,包括*nix(Linux, Unix等),HP 等操作系统,PHP,C#,Java等开发环境,以及很多的应用软件中,都可以看到正则表达式的影子。
正则表达式的使用,可以通过简单的办法来实现强大的功能。
为了简单有效而又不失强大,造成了正则表达式代码的难度较大,学习起来也不是很容易,所以需要付出一些努力才行,入门之后参照一定的参考,使用起来还是比较简单有效的。
例子: ^.+@.+\\..+$这样的代码曾经多次把我自己给吓退过。
可能很多人也是被这样的代码给吓跑的吧。
继续阅读本文将让你也可以自由应用这样的代码。
注意:这里的第7部分跟前面的内容看起来似乎有些重复,目的是把前面表格里的部分重新描述了一次,目的是让这些内容更容易理解。
2. 正则表达式的历史正则表达式的“祖先”可以一直上溯至对人类神经系统如何工作的早期研究。
Warren McCulloch 和 Walter Pitts 这两位神经生理学家研究出一种数学方式来描述这些神经网络。
1956 年, 一位叫 Stephen Kleene 的数学家在 McCulloch 和 Pitts 早期工作的基础上,发表了一篇标题为“神经网事件的表示法”的论文,引入了正则表达式的概念。
正则表达式,匹配中文语句

正则表达式是一种用于匹配和操作文本模式的工具。
它使用特定的语法规则来定义搜索模式,以便在文本中查找符合这些规则的文本片段。
以下是一些常见的正则表达式语法和示例:
匹配单个字符:
匹配任意单个字符:.
匹配特定字符:例如,[abc] 将匹配字符a、b 或c。
匹配数字和字母:
匹配任意数字:\d
匹配任意字母或数字:\w
匹配任意字母:\p{L}
匹配重复字符或数字:
重复一次或多次:+
重复零次或多次:*
重复特定次数:例如,{3} 表示重复三次。
匹配特定模式:
匹配以特定字符开头的字符串:^abc 表示匹配以"abc" 开头的字符串。
匹配以特定字符结尾的字符串:abc$ 表示匹配以"abc" 结尾的字符串。
匹配包含特定字符的字符串:例如,[a-z]+ 表示匹配包含一个或多个小写字母的字符串。
转义特殊字符:
使用反斜杠() 来转义特殊字符,例如,\d 表示匹配实际的反斜杠字符而不是特殊含义。
下面是一些示例,演示如何使用正则表达式来匹配中文字符:
匹配单个中文字符:[\u4e00-\u9fa5]
匹配多个中文字符:[\u4e00-\u9fa5]+
匹配以中文字符开头的字符串:^[\u4e00-\u9fa5]
匹配以中文字符结尾的字符串:[\u4e00-\u9fa5]$
请注意,正则表达式的语法可能因语言和工具而异,上述示例适用于大多数常见的情况。
在使用正则表达式时,请务必参考相关文档或工具的语法规范以确保正确使用。
布尔正则表达式教程_概述说明以及解释

布尔正则表达式教程概述说明以及解释1. 引言1.1 概述布尔正则表达式是一种用于处理字符串模式匹配的强大工具。
它能够根据用户定义的规则,对输入的文本进行搜索、替换和验证操作。
不同于传统的正则表达式,布尔正则表达式具有更丰富的逻辑运算符和特殊字符,使得匹配过程更加灵活和精确。
1.2 布尔正则表达式简介布尔正则表达式是由布尔运算符、特殊字符和普通字符组成的字符串模式。
布尔运算符包括与(&&)、或(||)、非(!)等,用于实现多条件的逻辑判断。
特殊字符主要用于表示一些通用或特定格式的文本模式,如数字、字母、空格等。
普通字符则是指除了特殊字符外的其他文本内容。
1.3 目的本篇教程旨在帮助读者全面理解并掌握布尔正则表达式,并通过详细解释和示例说明来讲解其基础知识、使用方法以及高级应用技巧。
同时,我们还将探讨布尔正则表达式在实际场景中的应用,并给出相应的建议和展望。
以上是“1. 引言”部分的内容,它主要对布尔正则表达式进行了概述、简介以及阐明了本篇文章的目的。
2. 布尔正则表达式基础知识2.1 什么是布尔正则表达式布尔正则表达式,又称为布尔模式匹配,是一种用于字符串匹配和处理的工具。
它通过使用特定的语法规则来定义一个模式,并通过该模式来判断目标字符串是否与之匹配。
其中,"布尔"表示结果只有两种可能性:匹配或不匹配。
2.2 基本语法规则- 字符匹配:普通字符可以直接用于匹配相同的字符。
- 单个字符通配符:点号(`.`)表示可以匹配除换行符外的任何单个字符。
- 字符类:方括号(`[]`)内可列出多个字符,表示可以匹配其中任意一个字符。
- 字符范围:在字符类中可以使用连字符(`-`)指定范围,如`[a-z]` 表示小写字母。
- 反义字符类:在方括号内插入`^` 表示反义,即需要排除的字符集合。
- 重复次数控制:- `*` 表示前一个元素可以出现0次或更多次;- `+` 表示前一个元素可以出现1次或更多次;- `?` 表示前一个元素可以出现0次或1次;- `{m}` 表示前一个元素必须出现m次;- `{m,}` 表示前一个元素至少出现m次;- `{m,n}` 表示前一个元素至少出现m次,最多出现n次。
正则表达式两个或两个以上的空格

正则表达式:两个或两个以上的空格正则表达式是一种用于匹配、查找和替换文本的模式。
在文本处理中,经常会遇到需要匹配空格的情况,而正则表达式则能够很好地解决这个问题。
本文将从浅入深,以“两个或两个以上的空格”为主题,探讨正则表达式的相关知识,并共享个人观点和理解。
1. 什么是正则表达式?正则表达式是一种用于描述、匹配、查找甚至替换字符串的模式。
它由普通字符(例如字母、数字)和特殊字符(称为元字符)组成。
在正则表达式中,空格通常表示为空格字符或者使用特殊元字符来表示。
接下来,我们将深入探讨如何使用正则表达式来匹配“两个或两个以上的空格”。
2. 匹配两个空格在正则表达式中,想要匹配两个空格,可以使用如下的模式:\s{2}。
其中,\s表示空白字符(包括空格、制表符和换行符),{2}表示匹配前面的元素两次。
\s{2}表示匹配两个连续的空白字符。
3. 匹配两个以上的空格如果想要匹配两个以上的空格,可以使用如下的模式:\s{2,}。
其中,{2,}表示匹配前面的元素至少两次。
\s{2,}表示匹配至少两个连续的空白字符。
4. 应用举例举个简单的例子来说明上述的正则表达式如何应用于真实的文本匹配。
假设我们有一段文本:“Hello world”,那么正则表达式\s{2}将匹配到“Hello world”中的两个空格;而正则表达式\s{2,}将匹配到“Hello world”中的两个以上的空格。
5. 总结与回顾通过本文的介绍,我们了解了如何使用正则表达式来匹配“两个或两个以上的空格”。
正则表达式能够帮助我们很好地处理文本中的空格,提高文本处理的效率。
使用正则表达式也需要结合实际情况进行灵活运用,以达到最佳的匹配效果。
6. 个人观点与理解我个人认为,正则表达式是文本处理中非常有用的工具之一。
对于匹配空格这样的简单任务,正则表达式能够快速、准确地完成。
但是需要注意的是,正则表达式在复杂匹配时可能会变得复杂难懂,需要谨慎使用。
webstorm正则表达式用法教程

webstorm正则表达式用法教程WebStorm中的正则表达式(Regular Expression)是一种强大的文本处理工具,它使用特定的模式来匹配、查找、替换文本中的字符序列。
下面是一个WebStorm中使用正则表达式的简单教程:1.打开WebStorm并创建或打开一个项目:首先,启动WebStorm并打开你希望在其中使用正则表达式的项目。
2.打开查找/替换功能:在WebStorm中,你可以通过按Ctrl+F (在Mac上为Cmd+F)来打开“查找”对话框。
如果你想在找到的内容上进行替换,可以同时按Ctrl+R(在Mac上为Cmd+R)打开“替换”对话框。
3.启用正则表达式:在“查找”或“替换”对话框中,你会看到一个名为“正则表达式”(Regex)的复选框。
勾选这个复选框以启用正则表达式功能。
4.编写正则表达式:在“查找”或“替换”字段中,你可以开始编写你的正则表达式。
正则表达式由一系列特殊字符和模式组成,用于匹配文本中的特定模式。
例如,.匹配任何单个字符(除了换行符),*匹配前面的字符0次或多次,\d匹配任何数字等。
5.测试正则表达式:在编写正则表达式时,你可以通过点击“查找下一个”按钮来测试你的表达式是否按预期工作。
如果表达式匹配到文本,那么匹配的文本将会被高亮显示。
6.替换文本:如果你希望替换匹配到的文本,可以在“替换为”字段中输入你想要替换成的文本,然后点击“替换”或“替换全部”按钮。
7.关闭查找/替换对话框:完成查找和替换操作后,你可以点击对话框上的“关闭”按钮来关闭它。
请注意,正则表达式的语法和用法可能非常复杂,需要一些时间来学习和实践。
如果你对正则表达式的具体语法或用法有疑问,我建议你查阅相关的文档或教程,或者向有经验的开发者寻求帮助。
正则表达式菜鸟教程

正则表达式菜鸟教程1.常见元字符
代码说明
.匹配换⾏符以外的任意字符
\w匹配字母或数字或下划线或汉字
\s匹配任意的空⽩符
**前⾯的内容可以
\d匹配数字可以连续重复使⽤任意次以使整个表达式得到匹配
\b匹配单词的开始或结束
^匹配字符串的开始
$匹配字符串的结束
2.重复
代码\语法说明
*重复零次或更多次
+重复⼀次或更多次
重复零次或⼀次
{n}重复n次
{n,}重复n次或更多次
{n,m}重复n到m次
3.转义字符\
4.字符类
⽅括号[]列出要匹配的字符,⽐如[aue],匹配其中的任何⼀个。
指定⼀个字符的范围,⽐如[1-9],[a-zA-Z]。
5.分枝条件
表⽰有⼏种规则,只要匹配其中的⼀个就可以。
⽤ | 将不同的规则分开。
6.分组
重复多个字符。
⽤()将其包起来叫做⼦表达式,就可以指定这个⼦表达式的重复次数了。
正则表达式入门教程

正则表达式入门教程以下内容经正则表达式学习网授权≈正则表达式是什么?≈在使用电脑进行各种文字处理的时候,我们有时需要查找和匹配一些特殊的字符串,如邮箱地址、验证用户输入的密码是否包含了大小写字母和数字,查找HTML源文档中的所有web地址等等,这时我们就可以使用到正则表达式。
正则表达式本身是一个“字符串”,通过这个“字符串”去描述字符组成规则。
如abbb、abbbb、abbbbb这三个字符串包都是以a字母开头a后面有一个b字母,而且b字母重复了3到5次。
用正则表达式来描述就是ab{3,5},b{3,5}表示b字符重复3到5次。
如果我们想匹配ababab这样的字符串,ab重复了3次,用正则表达式表示就是(ab){3},圆括号()是正则表达式中的分组。
大家如果想亲自感受正则表达式的使用效果,可以打开正则表达式测试系统。
如以上实例所展示的,正则表达式为人们提供了一种简单易用的字符处理工具。
它在目前主流的文字处理软件中都提供了良好的支持(不仅是编程软件,还有文字处理软件Uedit32、EditPlus,网页采集软件火车头等等),它具有很强的通用性,学好它,我们可以达一变应万变的效果。
≈正则表达式详解≈像{},()这种在正则表达式中,具有特殊含义的字符称为元字符(metacharacter)。
元字符是组成正则表达式的基本元素,在正则表达式经常使用的元字符不是很多,概念容易理解。
大家只要花30来分钟学完我们的教程基本上就可以完全掌握。
为了您能更快速的掌握正则表达式,我们为您推荐一款方便的正则表达式在线测试工具“RegExr”,(RegExr由免费提供)。
保留字符匹配字符本身匹配字符数量匹配字符位置分组匹配表达式选项保留字符(返回目录)在正则表达式中,有一些字符在正则表达式中具有特殊含义被称保留字符,如*表示前一个元素可以重复零次或多次,要匹配“*”字符本身使用\*,半角句号.匹配除了换行符外的所有字符,要匹配“.”使用\.。
Emeditor正则表达式教程

EmEdit or 正则表达式应用专题1在工作中,经常用到Em Edito r来编辑纯文本文档。
最近接触了正则表达式,感受到其功能非常强大。
我现在想要实现这样一个功能,还没有比较好的解决办法:在一篇中英文混排的文档中,删除中文字符(包括标点)之间的空格,但英文单词之间及英文单词与字母之前的空格不能删除;仅删除全角或半角空格,不删除制表符。
求高人试一下。
以下是一些比较有用的正则表达式:^[\t]*\n这个正则表达式代表所有的空行,指含有零个或零个以上空格或制表符、以换行符结尾、不含其它字符的行。
(^|(?<=中国)).*?(?=中国|$)用正则表达式匹配特定字符串外的所有字符。
指除“中国”外的所有其它字符,类似于反选功能。
^[ \t]+查找以上字符,并替换为空,可删除行首空白(包括全半角空格和制表符)。
[ \t]+$查找以上字符,并替换为空,可删除行末空白(包括全半角空格和制表符)。
^[ \t]+|[ \t]+$ 查找以上正则表达式,并替换为空,可删除行首和行末所有空白(包括全半角空格和制表符)。
匹配中文字符的正则表达式: [\u4e00-\u9fa5]评注:匹配中文还真是个头疼的事,有了这个表达式就好办了匹配双字节字符(包括汉字在内):[^\x00-\xff]评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)匹配空白行的正则表达式:\n\s*\r评注:可以用来删除空白行匹配HTM L标记的正则表达式:< (\S*?)[^>]*>.*?|<.*? />评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力匹配首尾空白字符的正则表达式:^\s*|\s*$评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式匹配Em ail地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*评注:表单验证时很实用匹配网址UR L的正则表达式:[a-zA-z]+://[^\s]*评注:网上流传的版本功能很有限,上面这个基本可以满足需求匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$评注:表单验证时很实用匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}评注:匹配形式如 0511-4405222 或 021-87888822匹配腾讯QQ号:[1-9][0-9]{4,}评注:腾讯QQ号从10000开始匹配中国邮政编码:[1-9]\d{5}(?!\d)评注:中国邮政编码为6位数字匹配身份证:\d{15}|\d{18}评注:中国的身份证为15位或18位匹配ip地址:\d+\.\d+\.\d+\.\d+评注:提取ip地址时有用匹配特定数字:^[1-9]\d*$//匹配正整数^-[1-9]\d*$ //匹配负整数^-?[1-9]\d*$ //匹配整数^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$//匹配正浮点数^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$//匹配负浮点数^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$//匹配浮点数^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非负浮点数(正浮点数 + 0)^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$//匹配非正浮点数(负浮点数 +0)评注:处理大量数据时有用,具体应用时注意修正匹配特定字符串:^[A-Za-z]+$//匹配由26个英文字母组成的字符串^[A-Z]+$//匹配由26个英文字母的大写组成的字符串^[a-z]+$//匹配由26个英文字母的小写组成的字符串^[A-Za-z0-9]+$//匹配由数字和26个英文字母组成的字符串^\w+$//匹配由数字、26个英文字母或者下划线组成的字符串评注:最基本也是最常用的一些表达式^.*John.*$ 匹配包括“John”的整行。
jmeter正则表达式教程(3)

jmeter正则表达式教程(3)正则表达式:⽹上没有找到详细简单的,⾃⼰描述下不要介意;正则表达式⽤于提取相应数据中的代码、⽂本等数据,利⽤正则表达式,提取响应数据,移植到下⼀线程组的参数中,从⽽进⾏测试。
⼀、解释:解释很多,但是最关键(1)注释不多说,随便⾃⼰喜欢(2)Apply to:默认即可(3)要检查的字段:主体等选择,⼀般我们选择主体,即服务器返回给我们的页⾯主体信息(4)引⽤名称:即参数名称,这个⾃⼰定义,在后⾯时可⽤(5)正则表达式:正则表达式中()括起来的部分就是要提取的。
.代表任意字符,+代表出现任意次,后⾯加?. 最后就是这个(.+?)(6)模板:$1$代表只有⼀组数据(7)匹配数字:0代表随机取值,1代表全部取值,通常情况下填0,如果在LR中,取出的值是⼀个数组,还得处理⼀下,LR11版本⽤⼀个随机的函数就可以不⽤写⼤段的代码来处理数组(8)缺省值:如果参数没有取得到值,那默认给⼀个值让它取引⽤名称:即参数名称,这个⾃⼰定义,在后⾯时可⽤模板:⽤$$引⽤起来,如果在正则表达式中有多个提取表达式(多个括号括起来的东东),则可以是$1$,$2$等等,表⽰解析到的第⼏个值给str,正则表达式的提取模式,值从1开始,值0对应的是整个匹配的表达式如对于表达式s(.*) 值0对应str,值1对应tr匹配数字(0代表随机):0代表随机,-1代表所有,其余正整数代表将在已提取的内容中,第⼏个匹配的内容$x$ 相当于正则表达式的第⼏个需求匹配数字相当于需求在响应数据的位置(因为数据内可能有多个需求)⼀个符合要求的正则表达式:name = "file" value = "(.+?)">。
():封装了待返回的匹配字符串。
.:匹配任何字符串。
+:⼀次或多次。
:不要太贪婪,在找到第⼀个匹配项后停⼆、启动jmeter,打开测试计划,先执⾏⼀次,查看结果树找到需要提取的信息;在需要提取的请求内添加正则表达式提取器(后置处理器中)三、填写正则表达式内容;红框内是要提取的例⼦,确定好要提取的东西,然后进⾏填写正则表达式;四、运⾏线程组提取;我们正则表达式提取的内容是正确的。
正则表达式使用工具教程

正则表达式使用工具教程正则表达式-教程正则表达式是烦琐的,但是它是强大的,在八爪鱼中,学会正则表达式的应用能让你的数据展示更加规范化,所提取数据字段表达更加精准。
合理的运用正则,除了提升你的数据展示规范、字段表达精准之外,还会给你带来绝对的成就感。
只要认真阅读本教程,结合八爪鱼正则表达式工具实战应用,掌握正则表达式是非常容易的。
内容列表:11.1正则表达式-简介11.2正则表达式-简单示例11.3-正则表达式-八爪鱼正则工具11.4正则表达式-语法11.5正则表达式-正则表达式及简单应用11.1正则表达式-简介正则表达式(Regular Expression),按英文直译是“规范化表达”,其作用是将复杂模糊的源数据通过正则表达式转化为简单直观的目标数据。
例如:“150ABCD”“一百五ABCD”“One hundred and fiftyABCD”分析思考过程:以上字符串中,我们的源文本数据分别为:““150ABCD”、“一百五ABCD”、“One hundred and fiftyABCD”假设我们要提取目标数据为:字符串中以数字开头的数据那么我们约束条件为:只取字符串中以数字开头的源数据将此约束条件转化为正则表达式为:[0-9](.+)\b其中,[0-9]的语义为开头1位为0-9开头,中间间隔以通配符“.”代替,(.+)语义为字符串长度不做限定,\b的语义为,匹配一个边界。
正则后的目标数据:“150ABCD”通过这个简单例子,我们大致了解到了为什么要用正则与正则所能实现的效果,讲通俗点就是,正则只是将我们的意愿(提取字符串中以数字开头的数据)以表达式的形式展现出来([0-9](.+)\b),并最终通过表达式匹配到所需要的目标数据(“150ABCD”),所以灵活运用正则,可以通过简单的方法实现强大的功能。
为什么要在八爪鱼中使用正则?在八爪鱼采集数据过程中,受限于网页HTML结构的原因,部分目标数据并不能单独提取出来,这时需要简单的搜索与替换操作来提取与预期搜索结果匹配的确切文本,除此之外,对数据要求精准规范的用户,还能通过正则表达式测试所提取数据字符串的模式、替换文本、基于匹配模式从字符串中提取子字符串等操作。
正则表达式口诀及教程

. 匹配除 "\n" 之外的任何单个字符。要匹配包括 ’\n’ 在内的任何字符,请使用象 ’[.\n]’ 的模式。
(pattern) 匹配pattern 并获取这一匹配。
(?:pattern) 匹配pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。
实在多得排不下,横杠请来帮个忙; ([1-5])
尖头放进中括号,反义定义威力大; ([^a]指除“a”外的任意字符 )
1竖作用可不小,两边正则互替换; (键盘上与“\”是同一个键)
1竖能用很多次,复杂定义很方便;
园括号,用途多;
反向引用指定组,数字排符对应它; (“\b(\w+)\b\s+\1\b”中的数字“1”引用前面的“(\w+)”)
"^[A-Za-z]+$" //由26个英文字母组成的字符串
"^[A-Z]+$" //由26个英文字母的大写组成的字符串
"^[a-z]+$" //由26个英文字母的小写组成的字符串
"^[A-Za-z0-9]+$" //由数字和26个英文字母组成的字符串
"^\w+$" //由数字、26个英文字母或者下划线组成的字符串
\t 匹配一个制表符。等价于 \x09 和 \cI。
\v 匹配一个垂直制表符。等价于 \x0b 和 \cK。
\w 匹配包括下划线的任何单词字符。等价于’[A-Za-z0-9_]’。
\W 匹配任何非单词字符。等价于 ’[^A-Za-z0-9_]’。
\xn 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。
正则表达式入门教程(VBA)

正则表达式入门教程(VBA)正则表达式入门教程(VBA)[日期:2011-08-25] 来源:作者:admin [字体:大中小] 引言正则表达式(regular expression)就是用一个“字符串”来描述一个特征,然后去验证另一个“字符串”是否符合这个特征。
比如表达式“ab+” 描述的特征是“一个'a' 和任意个'b' ”,那么'ab', 'abb', 'abbbbbbbbbb' 都符合这个特征。
正则表达式可以用来:(1)验证字符串是否符合指定特征,比如验证是否是合法的邮件地址。
(2)用来查找字符串,从一个长的文本中查找符合指定特征的字符串,比查找固定字符串更加灵活方便。
(3)用来替换,比普通的替换更强大。
正则表达式学习起来其实是很简单的,不多的几个较为抽象的概念也很容易理解。
之所以很多人感觉正则表达式比较复杂,一方面是因为大多数的文档没有做到由浅入深地讲解,概念上没有注意先后顺序,给读者的理解带来困难;另一方面,各种引擎自带的文档一般都要介绍它特有的功能,然而这部分特有的功能并不是我们首先要理解的。
文章中的每一个举例,都可以点击进入到测试页面进行测试。
闲话少说,开始。
1. 正则表达式规则1.1 普通字符字母、数字、汉字、下划线、以及后边章节中没有特殊定义的标点符号,都是"普通字符"。
表达式中的普通字符,在匹配一个字符串的时候,匹配与之相同的一个字符。
举例1:表达式"c",在匹配字符串"abcde" 时,匹配结果是:成功;匹配到的内容是:"c";匹配到的位置是:开始于2,结束于3。
(注:下标从0开始还是从1开始,因当前编程语言的不同而可能不同)举例2:表达式"bcd",在匹配字符串"abcde" 时,匹配结果是:成功;匹配到的内容是:"bcd";匹配到的位置是:开始于1,结束于4。
regexp_replace 正则表达式的用法

regexp_replace 正则表达式的用法正则表达式是一种用来匹配、查找和替换文本中特定模式的工具。
它是基于字符组成的字符串,使用一些特殊字符和语法来描述目标模式。
在很多编程语言和文本处理工具中,正则表达式被广泛应用于数据处理、文本编辑、字符串匹配等各种应用场景。
在正则表达式中,中括号[] 用来定义一个字符类,也称为字符集或字符范围。
它表示一个字符集合,可以包含多个字符。
正则表达式将会匹配这些字符类中的任意一个字符。
使用中括号的语法如下:- [abc]:匹配字符a、b 或c- [a-z]:匹配任意小写字母- [A-Z]:匹配任意大写字母- [0-9]:匹配任意数字- [^abc]:匹配除了字符a、b、c 以外的任意字符- [^a-z]:匹配除了小写字母以外的任意字符通过上述语法,正则表达式能够灵活地匹配不同的字符集合。
下面将逐步介绍中括号在正则表达式中的应用。
1. 匹配单个字符:最简单的用法是通过中括号匹配单个字符。
例如,正则表达式[abc] 会匹配"a"、"b" 或"c" 中的任意一个字符。
例子:匹配所有的元音字符。
表达式:[aeiou]输入字符串:"Hello, World! This is a test."匹配结果:"o", "o", "i", "i", "i", "a", "e"2. 匹配字符范围:使用连字符"-" 可以定义一个字符范围。
例如,正则表达式[a-z] 会匹配任意小写字母。
例子:匹配所有的小写字母。
表达式:[a-z]输入字符串:"Hello, World! This is a test."匹配结果:"e", "l", "l", "o", "o", "r", "l", "d", "h", "i", "s", "i", "s", "a", "t", "e", "s", "t"3. 排除字符:在中括号中使用插入符号"^" 可以排除某些字符。
《易语言“正则表达式”教程》

《易语言“正则表达式”教程》本文改编自多个文档,因此如有雷同,不是巧合。
“正则表达式”的应用范围越来越广,有了这个强大的工具,我们可以做很多事情,如搜索一句话中某个特定的数据,屏蔽掉一些非法贴子的发言,网页中匹配特定数据,代码编辑框中字符的高亮等等,这都可以用正则表达式来完成。
本书分为四个部分。
第一部分介绍了易语言的正则表达式支持库,在这里,大家可以了解第一个正则表达式的易语言程序写法,以及一个通用的小工具的制作。
第二部分介绍了正则表达式的基本语法,大家可以用上述的小工具进行试验。
第三部分介绍了用易语言写的正则表达式工具的使用方法。
这些工具是由易语言用户提供的,有的工具还带有易语言源码。
他们是:monkeycz、零点飞越、寻梦。
第四部分介绍了正则表达式的高级技巧。
目录《易语言“正则表达式”教程》 (1)目录 (1)第一章易语言正则表达式入门 (3)一.与DOS下的通配符类似 (3)二.初步了解正则表达式的规定 (3)三.一个速查列表 (4)四.正则表达式支持库的命令 (5)4.1 第1个正则表达式程序 (5)4.2 第2个正则表达式例程 (7)4.3 第3个例程 (8)4.4 一个小型的正则工具 (9)第二章揭开正则表达式的神秘面纱 (11)引言 (12)一. 正则表达式规则 (12)1.1 普通字符 (12)1.2 简单的转义字符 (13)1.3 能够与“多种字符”匹配的表达式 (14)1.4 自定义能够匹配“多种字符”的表达式 (16)1.5 修饰匹配次数的特殊符号 (17)1.6 其他一些代表抽象意义的特殊符号 (20)二. 正则表达式中的一些高级规则 (21)2.1 匹配次数中的贪婪与非贪婪 (21)2.2 反向引用\1, \2... (23)2.3 预搜索,不匹配;反向预搜索,不匹配 (24)三. 其他通用规则 (25)四. 其他提示 (27)第三章正则表达式工具与实例 (28)一.正则表达式支持库 (29)1.1 “正则表达式”数据类型 (29)1.2 “搜索结果”数据类型 (30)二.正则表达式实用工具 (30)2.1 一个成品工具 (30)2.2 易语言写的工具 (33)三.应用实例 (34)3.1 实例1 (34)3.2 实例2 (36)3.3 实例3 (37)3.4 实例4 (37)第四章正则表达式话题 (38)引言 (38)一. 表达式的递归匹配 (38)1.1匹配未知层次的嵌套 (38)1.2 匹配有限层次的嵌套 (39)二. 非贪婪匹配的效率 (40)2.1效率陷阱的产生 (40)2.2效率陷阱的避免 (41)附录: (42)一.17种常用正则表达式 (42)第一章易语言正则表达式入门一.与DOS下的通配符类似其实,所谓的“正则表达式”,是大家一直在使用的,记得吗?在搜索文件时,会使用一种威力巨大的武器——DOS通配符——“?”和“*”。
正则表达式教程之重复匹配详解

正则表达式教程之重复匹配详解本⽂实例讲述了正则表达式教程之重复匹配。
分享给⼤家供⼤家参考,具体如下:注:在所有例⼦中正则表达式匹配结果包含在源⽂本中的【和】之间,有的例⼦会使⽤Java来实现,如果是java本⾝正则表达式的⽤法,会在相应的地⽅说明。
所有java例⼦都在JDK1.6.0_13下测试通过。
⼀、有多少个匹配前⾯⼏篇讲的都是匹配⼀个字符,但是⼀个字符或字符集合要匹配多次,应该怎么做呢?⽐如要匹配⼀个电⼦邮件地址,⽤之前说到的⽅法,可能有⼈会写出像\w@\w\.\w这样的正则表达式,但这个只能匹配到像a@b.c这样的地址,明显是不正确的,接下来就来看看如何匹配电⼦邮件地址。
⾸先要知道电⼦邮件地址的组成:以字母数字或下划线开头的⼀组字符,后⾯跟@符号,再后⾯是域名,即⽤户名@域名地址。
不过这也跟具体的邮箱服务提供商有关,有的在⽤户名中也允许.字符。
1、匹配⼀个或多个字符要想匹配同⼀个字符(或字符集合)的多次重复,只要简单地给这个字符(或字符集合)加上⼀个+字符作为后缀就可以了。
+匹配⼀个或多个字符(⾄少⼀个)。
如:a匹配a本⾝,a+将匹配⼀个或多个连续出现的a;[0-9]+匹配多个连续的数字。
注意:在给⼀个字符集合加上+后缀的时候,必须把+放在字符集合的外⾯,否则就不是重复匹配了。
如[0-9+]这样就表⽰数字或+号了,虽然语法上正确,但不是我们想要的了。
⽂本:Hello, mhmyqn@ or mhmyqn@ is my email.正则表达式:\w+@(\w+\.)+\w+结果:Hello, 【mhmyqn@】 or 【mhmyqn@】 is my email.分析:\w+可以匹配⼀个或多个字符,⽽⼦表达式(\w+\.)+可匹配像.这样的字符串,⽽最后不会是.字符结尾,所以后⾯还会有⼀个\w+。
像mhmyqn@这样的邮件地址也会匹配到。
2、匹配零个或多个字符匹配零个或多个字符使⽤元符*,它的⽤法和+完全⼀样,只要把它放在⼀下字符或字符集合的后⾯,就可以匹配该字符(或字符集合)连续出现零次或多次。
python正则表达式re.search()的基本使用教程
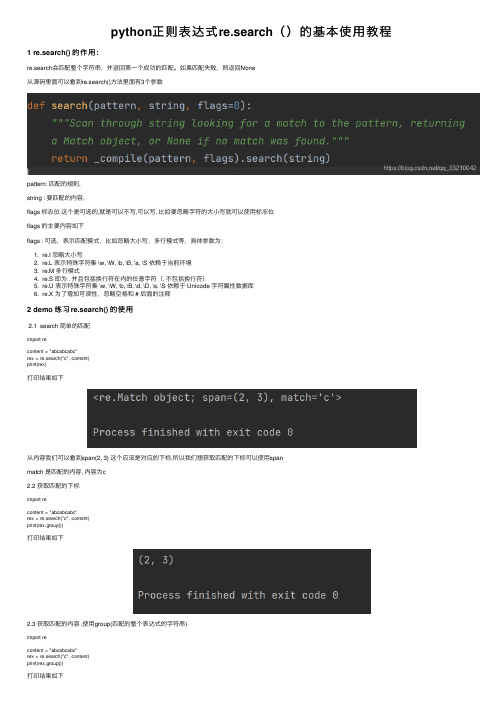
python正则表达式re.search()的基本使⽤教程1 re.search() 的作⽤:re.search会匹配整个字符串,并返回第⼀个成功的匹配。
如果匹配失败,则返回None从源码⾥⾯可以看到re.search()⽅法⾥⾯有3个参数pattern: 匹配的规则,string : 要匹配的内容,flags 标志位这个是可选的,就是可以不写,可以写, ⽐如要忽略字符的⼤⼩写就可以使⽤标志位flags 的主要内容如下flags : 可选,表⽰匹配模式,⽐如忽略⼤⼩写,多⾏模式等,具体参数为:1. re.I 忽略⼤⼩写2. re.L 表⽰特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境3. re.M 多⾏模式4. re.S 即为 . 并且包括换⾏符在内的任意字符(. 不包括换⾏符)5. re.U 表⽰特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库6. re.X 为了增加可读性,忽略空格和 # 后⾯的注释2 demo 练习re.search() 的使⽤2.1 search 简单的匹配import recontent = "abcabcabc"rex = re.search("c", content)print(rex)打印结果如下从内容我们可以看到span(2, 3) 这个应该是对应的下标,所以我们想获取匹配的下标可以使⽤spanmatch 是匹配的内容, 内容为c2.2 获取匹配的下标import recontent = "abcabcabc"rex = re.search("c", content)print(rex.group())打印结果如下2.3 获取匹配的内容 ,使⽤group(匹配的整个表达式的字符串)import recontent = "abcabcabc"rex = re.search("c", content)print(rex.group())打印结果如下注意group 和span 不能同时使⽤, 否则会报错2.4 使⽤标志位忽略匹配的⼤⼩写import recontent = "abcabcabc"rex = re.search("C", content, re.I)print(rex.group())打印结果如下这⾥使⽤⼤写字母C 忽略⼤⼩写之后也能匹配到c 2.5 使⽤search 匹配字符串⾥⾯的数组import recontent = "abc123abc"rex = re.search("\d+", content)print(rex.group())打印结果2.6 search 结合compile 使⽤import recontent = "abc123abc"rex_content = pile("\d+")rex = rex_content.search(content)print(rex.group())打印结果2.7 group 的使⽤import recontent = "abc123def"rex_compile = pile("([a-z]*)([0-9]*)([a-z]*)")rex = rex_compile.search(content)print(rex.group())print(rex.group(0)) # group()和group(0) ⼀样匹配的是整体print(rex.group(1)) # 匹配第⼀个⼩括号的内容print(rex.group(2)) # 匹配第⼆个⼩括号的内容print(rex.group(3)) # 匹配第三个⼩括号的内容打印结果group() ⼩括号⾥⾯不⽌有数字,可以是⾃定的内容如下content = "zhangsanfeng108le"rex_compile = pile("(?P<name>[a-z]*)(?P<age>[0-9]*)")rex_content = rex_compile.search(content)print(rex_content.group())print(rex_content.group("name")) # 这⾥效果等同于group(1)print(rex_content.group("age")) # 这⾥效果等同于group(2)打印结果如下总结到此这篇关于python正则表达式re.search()基本使⽤的⽂章就介绍到这了,更多相关python正则表达式re.search()内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
正则表达式学习要点:1.什么是正则表达式2.创建正则表达式3.获取控制4.常用的正则假设用户需要在HTML 表单中填写姓名、地址、出生日期等。
那么在将表单提交到服务器进一步处理前,JavaScript 程序会检查表单以确认用户确实输入了信息并且这些信息是符合要求的。
一.什么是正则表达式正则表达式(regular expression)是一个描述字符模式的对象。
ECMAScript 的RegExp 类表示正则表达式,而String 和RegExp 都定义了使用正则表达式进行强大的模式匹配和文本检索与替换的函数。
正则表达式主要用来验证客户端的输入数据。
用户填写完表单单击按钮之后,表单就会被发送到服务器,在服务器端通常会用PHP、 等服务器脚本对其进行进一步处理。
因为客户端验证,可以节约大量的服务器端的系统资源,并且提供更好的用户体验。
二.创建正则表达式创建正则表达式和创建字符串类似,创建正则表达式提供了两种方法,一种是采用new运算符,另一个是采用字面量方式。
1.两种创建方式var box = new RegExp('box'); //第一个参数字符串var box = new RegExp('box', 'ig'); //第二个参数可选模式修饰符模式修饰符的可选参数参数含义i 忽略大小写g 全局匹配m 多行匹配var box = /box/; //直接用两个反斜杠var box = /box/ig; //在第二个斜杠后面加上模式修饰符2.测试正则表达式RegExp 对象包含两个方法:test()和exec(),功能基本相似,用于测试字符串匹配。
test()方法在字符串中查找是否存在指定的正则表达式并返回布尔值,如果存在则返回true,不存在则返回false。
exec()方法也用于在字符串中查找指定正则表达式,如果exec()方法执行成功,则返回包含该查找字符串的相关信息数组。
如果执行失败,则返回null。
RegExp 对象的方法方法功能test 在字符串中测试模式匹配,返回true 或falseexec 在字符串中执行匹配搜索,返回结果数组/*使用new 运算符的test 方法示例*/var pattern = new RegExp('box', 'i'); //创建正则模式,不区分大小写var str = 'This is a Box!'; //创建要比对的字符串alert(pattern.test(str)); //通过test()方法验证是否匹配/*使用字面量方式的test 方法示例*/var pattern = /box/i; //创建正则模式,不区分大小写var str = 'This is a Box!';alert(pattern.test(str));/*使用一条语句实现正则匹配*/alert(/box/i.test('This is a Box!')); //模式和字符串替换掉了两个变量/*使用exec 返回匹配数组*/var pattern = /box/i;var str = 'This is a Box!';alert(pattern.exec(str)); //匹配了返回数组,否则返回nullPS:exec 方法还有其他具体应用,我们在获取控制学完后再看。
3.使用字符串的正则表达式方法除了test()和exec()方法,String 对象也提供了4 个使用正则表达式的方法。
String 对象中的正则表达式方法方法含义match(pattern) 返回pattern 中的子串或nullreplace(pattern, replacement) 用replacement 替换patternsearch(pattern) 返回字符串中pattern 开始位置split(pattern) 返回字符串按指定pattern 拆分的数组/*使用match 方法获取获取匹配数组*/var pattern = /box/ig; //全局搜索var str = 'This is a Box!,That is a Box too';alert(str.match(pattern)); //匹配到两个Box,Boxalert(str.match(pattern).length); //获取数组的长度/*使用search 来查找匹配数据*/var pattern = /box/ig;var str = 'This is a Box!,That is a Box too';alert(str.search(pattern)); //查找到返回位置,否则返回-1PS:因为search 方法查找到即返回,也就是说无需g 全局/*使用replace 替换匹配到的数据*/var pattern = /box/ig;var str = 'This is a Box!,That is a Box too';alert(str.replace(pattern, 'Tom')); //将Box 替换成了Tom/*使用split 拆分成字符串数组*/var pattern = / /ig;var str = 'This is a Box!,That is a Box too';alert(str.split(pattern)); //将空格拆开分组成数组RegExp对象的静态属性属性短名含义input $_ 当前被匹配的字符串lastMatch $& 最后一个匹配字符串lastParen $+ 最后一对圆括号内的匹配子串leftContext $` 最后一次匹配前的子串multiline $* 用于指定是否所有的表达式都用于多行的布尔值rightContext $' 在上次匹配之后的子串/*使用静态属性*/var pattern = /(g)oogle/;var str = 'This is google!';pattern.test(str); //执行一下alert(RegExp.input); //This is google!alert(RegExp.leftContext); //This isalert(RegExp.rightContext); //!alert(stMatch); //googlealert(stParen); //galert(RegExp.multiline); //falsePS:Opera 不支持input、lastMatch、lastParen 和multiline 属性。
IE 不支持multiline 属性。
所有的属性可以使用短名来操作RegExp.input 可以改写成RegExp['$_'],依次类推。
但RegExp.input 比较特殊,它还可以写成RegExp.$_。
RegExp对象的实例属性属性含义global Boolean 值,表示g 是否已设置ignoreCase Boolean 值,表示i 是否已设置lastIndex 整数,代表下次匹配将从哪里字符位置开始multiline Boolean 值,表示m 是否已设置Source 正则表达式的源字符串形式/*使用实例属性*/var pattern = /google/ig;alert(pattern.global); //true,是否全局了alert(pattern.ignoreCase); //true,是否忽略大小写alert(pattern.multiline); //false,是否支持换行alert(stIndex); //0,下次的匹配位置alert(pattern.source); //google,正则表达式的源字符串var pattern = /google/g;var str = 'google google google';pattern.test(str); //google,匹配第一次alert(stIndex); //6,第二次匹配的位PS:以上基本没什么用。
并且lastIndex 在获取下次匹配位置上IE 和其他浏览器有偏差,主要表现在非全局匹配上。
lastIndex 还支持手动设置,直接赋值操作。
三.获取控制正则表达式元字符是包含特殊含义的字符。
它们有一些特殊功能,可以控制匹配模式的方式。
反斜杠后的元字符将失去其特殊含义。
字符类:单个字符和数字元字符/元符号匹配情况. 匹配除换行符外的任意字符[a-z0-9] 匹配括号中的字符集中的任意字符[^a-z0-9] 匹配任意不在括号中的字符集中的字符\d 匹配数字\D 匹配非数字,同[^0-9]相同\w 匹配字母和数字及_\W 匹配非字母和数字及_字符类:空白字符元字符/元符号匹配情况\0 匹配null 字符\b 匹配空格字符\f 匹配进纸字符\n 匹配换行符\r 匹配回车字符\t 匹配制表符\s 匹配空白字符、空格、制表符和换行符\S 匹配非空白字符字符类:锚字符元字符/元符号匹配情况^ 行首匹配$ 行尾匹配\A 只有匹配字符串开始处\b 匹配单词边界,词在[]内时无效\B 匹配非单词边界\G 匹配当前搜索的开始位置\Z 匹配字符串结束处或行尾\z 只匹配字符串结束处字符类:重复字符元字符/元符号匹配情况x? 匹配0 个或1 个xx* 匹配0 个或任意多个xx+ 匹配至少一个x(xyz)+ 匹配至少一个(xyz)x{m,n} 匹配最少m 个、最多n 个x字符类:替代字符元字符/元符号匹配情况this|where|logo 匹配this 或where 或logo 中任意一个字符类:记录字符元字符/元符号匹配情况(string) 用于反向引用的分组\1 或$1 匹配第一个分组中的内容\2 或$2 匹配第二个分组中的内容\3 或$3 匹配第三个分组中的内容/*使用点元字符*/var pattern = /g..gle/; //.匹配一个任意字符var str = 'google';alert(pattern.test(str));/*重复匹配*/var pattern = /g.*gle/; //.匹配0 个一个或多个var str = 'google'; //*,?,+,{n,m}alert(pattern.test(str));/*使用字符类匹配*/var pattern = /g[a-zA-Z_]*gle/; //[a-z]*表示任意个a-z 中的字符var str = 'google';alert(pattern.test(str));var pattern = /g[^0-9]*gle/; //[^0-9]*表示任意个非0-9 的字符var str = 'google';alert(pattern.test(str));var pattern = /[a-z][A-Z]+/; //[A-Z]+表示A-Z 一次或多次var str = 'gOOGLE';alert(pattern.test(str));/*使用元符号匹配*/var pattern = /g\w*gle/; //\w*匹配任意多个所有字母数字_ var str = 'google';alert(pattern.test(str));var pattern = /google\d*/; //\d*匹配任意多个数字var str = 'google444';alert(pattern.test(str));var pattern = /\D{7,}/; //\D{7,}匹配至少7 个非数字var str = 'google8';alert(pattern.test(str));/*使用锚元字符匹配*/var pattern = /^google$/; //^从开头匹配,$从结尾开始匹配var str = 'google';alert(pattern.test(str));var pattern = /goo\sgle/; //\s 可以匹配到空格var str = 'goo gle';alert(pattern.test(str));var pattern = /google\b/; //\b 可以匹配是否到了边界var str = 'google';alert(pattern.test(str));/*使用或模式匹配*/var pattern = /google|baidu|bing/; //匹配三种其中一种字符串var str = 'google';alert(pattern.test(str));/*使用分组模式匹配*/var pattern = /(google){4,8}/; //匹配分组里的字符串4-8 次var str = 'googlegoogle';alert(pattern.test(str));var pattern = /8(.*)8/; //获取8..8 之间的任意字符var str = 'This is 8google8';str.match(pattern);alert(RegExp.$1); //得到第一个分组里的字符串内容var pattern = /8(.*)8/;var str = 'This is 8google8';var result = str.replace(pattern,'<strong>$1</strong>'); //得到替换的字符串输出document.write(result);var pattern = /(.*)\s(.*)/;var str = 'google baidu';var result = str.replace(pattern, '$2 $1'); //将两个分组的值替换输出document.write(result);贪婪惰性+ +?? ??* *?{n} {n}?{n,} {n,}?{n,m} {n,m}?/*关于贪婪和惰性*/var pattern = /[a-z]+?/; //?号关闭了贪婪匹配,只替换了第一个var str = 'abcdefjhijklmnopqrstuvwxyz';var result = str.replace(pattern, 'xxx');alert(result);var pattern = /8(.+?)8/g; //禁止了贪婪,开启的全局var str = 'This is 8google8, That is 8google8, There is 8google8'; var result = str.replace(pattern,'<strong>$1</strong>'); document.write(result);var pattern = /8([^8]*)8/g; //另一种禁止贪婪var str = 'This is 8google8, That is 8google8, There is 8google8'; var result = str.replace(pattern,'<strong>$1</strong>'); document.write(result);/*使用exec 返回数组*/var pattern = /^[a-z]+\s[0-9]{4}$/i;var str = 'google 2012';alert(pattern.exec(str)); //返回整个字符串var pattern = /^[a-z]+/i; //只匹配字母var str = 'google 2012';alert(pattern.exec(str)); //返回googlevar pattern = /^([a-z]+)\s([0-9]{4})$/i; //使用分组var str = 'google 2012';alert(pattern.exec(str)[0]); //google 2012alert(pattern.exec(str)[1]); //googlealert(pattern.exec(str)[2]); //2012/*捕获性分组和非捕获性分组*/var pattern = /(\d+)([a-z])/; //捕获性分组var str = '123abc';alert(pattern.exec(str));var pattern = /(\d+)(?:[a-z])/; //非捕获性分组var str = '123abc';alert(pattern.exec(str));/*使用分组嵌套*/var pattern = /(A?(B?(C?)))/; //从外往内获取var str = 'ABC';alert(pattern.exec(str));/*使用前瞻捕获*/var pattern = /(goo(?=gle))/; //goo 后面必须跟着gle 才能捕获var str = 'google';alert(pattern.exec(str));/*使用特殊字符匹配*/var pattern = /\.\[\/b\]/; //特殊字符,用\符号转义即可var str = '.[/b]';alert(pattern.test(str));/*使用换行模式*/var pattern = /^\d+/mg; //启用了换行模式var str = '1.baidu\n2.google\n3.bing';var result = str.replace(pattern, '#');alert(result);四.常用的正则1.检查邮政编码var pattern = /[1-9][0-9]{5}/; //共6 位数字,第一位不能为0 var str = '224000';alert(pattern.test(str));2.检查文件压缩包var pattern = /[\w]+\.zip|rar|gz/; //\d\w_表示所有数字和字母加下划线var str = '123.zip'; //\.表示匹配.,后面是一个选择alert(pattern.test(str));3.删除多余空格var pattern = /\s/g; //g 必须全局,才能全部匹配var str = '111 222 333';var result = str.replace(pattern,''); //把空格匹配成无空格alert(result);4.删除首尾空格var pattern = /^\s+/; //强制首var str = ' goo gle ';var result = str.replace(pattern, '');pattern = /\s+$/; //强制尾result = result.replace(pattern, '');alert('|' + result + '|');var pattern = /^\s*(.+?)\s*$/; //使用了非贪婪捕获var str = ' google ';alert('|' + pattern.exec(str)[1] + '|');var pattern = /^\s*(.+?)\s*$/;var str = ' google ';alert('|' + str.replace(pattern, '$1') + '|'); //使用了分组获取5.简单的电子邮件验证var pattern = /^([a-zA-Z0-9_\.\-]+)@([a-zA-Z0-9_\.\-]+)\.([a-zA-Z]{2,4})$/;var str = '@';alert(pattern.test(str));var pattern = /^([\w\.\-]+)@([\w\.\-]+)\.([\w]{2,4})$/;var str = '@';alert(pattern.test(str));。