SPSS—单样本T检验
spss单一样本的T检验

spss单一样本的T检验SPSS是一款广泛使用的统计软件,可以用于各种统计分析,包括单一样本的T 检验。
下面是关于如何使用SPSS进行单一样本的T检验的详细步骤和解释。
一、目的单一样本的T检验主要用于比较一个样本的平均值与已知的或预设的数值,或者用于比较一个样本与已知的或预设的数值之间的差异。
这种检验通常用于检验一个样本是否显著地不同于已知的或预设的数值。
二、步骤1.打开SPSS软件,点击“分析”菜单,然后选择“比较平均值”>“独立样本T检验”。
2.在弹出的对话框中,将左侧的“独立样本T检验”选项卡中的“变量”字段拖到右侧的“变量”框中。
3.在“独立样本T检验”选项卡下方的“组”字段中输入已知的或预设的数值。
4.点击“确定”按钮,SPSS将计算并显示T检验的结果。
三、结果解释单一样本的T检验的结果通常包括T值和p值。
T值是计算出的统计量,而p 值是观察到的数据与零假设之间的不一致程度。
如果p值小于选择的显著性水平(通常为0.05),则可以拒绝零假设,认为样本平均值与已知的或预设的数值之间存在显著差异。
四、注意事项1.单一样本的T检验的前提是数据符合正态分布。
如果数据不符合正态分布,可以使用非参数检验,例如Mann-Whitney U检验或Wilcoxon符号秩检验。
2.在使用单一样本的T检验时,需要明确知道或预设的数值是什么,以及为什么要比较这个数值。
如果不知道或预设的数值是什么,或者比较的目的不明确,那么这种检验可能会没有意义或者导致错误的结论。
3.单一样本的T检验只能告诉我们一个样本的平均值与已知的或预设的数值之间的差异是否显著,但不能告诉我们这种差异的实际意义或影响。
因此,在解释结果时需要谨慎,并考虑实际应用背景。
4.在进行单一样本的T检验时,需要确保数据的质量和准确性。
如果数据存在缺失、异常值或错误,将会对结果产生影响。
在进行统计分析前,需要对数据进行清洗和预处理。
5.在进行单一样本的T检验时,需要考虑变量的类型和测量尺度。
论文中的SPSS独立样本t检验与Mann-Whitney秩和检验

论文中的SPSS独立样本t检验与Mann-Whitney秩和检验因为有正态分布这个条件,所以使用t检验有时候会因为数据非正态从而采用非参数秩和检验方法,或在一个研究中,同时使用t检验和秩和检验。
===回顾性分析AIS患者108例,将患者分为预后良好组(79例)和预后不良组(29例),采集患者的基本资料,于入院24h内采集静脉血,测定RDW及其他血液学指标。
并记录入院时NIHSS评分及mRS评分,于患者发病后3个月时采用mRS量表对患者进行预后评分。
研究目的:探讨红细胞分布宽度(RDW)对急性缺血性卒中(AIS)患者静脉溶栓预后的预测作用。
核心方法:采用多因素 Logistic回归分析方程分析危险因素,及受试者工作特征曲线(ROC) 分析RDW 对患者溶栓结局的预测作用。
t检验:基线分析时采用t检验。
===统计学分析:采用SPSS 22.0统计软件包。
计数资料用例数(%)表示,两组符合正态分布的计量资料用(均值±标准差)表示,组间比较采用两独立样本t检验,偏态分布的计量资料用中位数和四分位距M(P25,P75)]表示,组间比较采用秩和检验。
应用多因素Logistic回归方程分析危险因素及受试者工作特征曲线(ROC)分析RDW对rt-PA溶栓治疗AIS患者预后的预测价值。
以P<0.05为差异有统计学意义。
这段文字是描述论文中数据分析方法的,这里注意,满足正态则t检验,非正态则秩和检验。
===上面这个三线表是常见的格式,适用于t检验,卡方检验,方差分析等检验方法统计分析结果的呈现和报告。
上面这段文字是对基线特征分析的结果描述,特点是言简意赅。
===上文主要分享t检验,后面的logistic回归、roc曲线分析,大家可以自行阅读原论文。
论文原文引用信息:梁安心,&汤颖.(2023).红细胞分布宽度对急性缺血性卒中患者静脉溶栓预后的预测作用.中国脑血管病杂志,15(2),5.==全文完==。
spss数据统计分析(复习)

均值:方差检验(【单样本T检验】1.从某厂第一季度生产的电子元件中抽取了部分样品测量他们的电阻(单位:欧姆),数据资料在“小测1.sav”中。
按质量规定,元件的额定电阻为0.140欧姆,假定元件的电阻服从正态分布。
判断这批产品的质量是否合格。
从上表单样本数据统计量表中可以得测试电阻值的样品有35个,均值为0.1423,标准差为0.00426,均值标准误为0.00072从单样本检验表中可以看出:t统计量的值为3.174,自由度为34,均值差值为0.00229,95%的置信区间(0.0008,0.0037),相伴概率为0.003,远小于显著性水平0.05,说明假设成立,也就是说这批产品的质量与0.140欧姆有显著性差异,说明这批产品的质量是不合格的。
【独立样本T检验】2、甲乙两台测时仪同时测量两靶间子弹飞行的时间,测量结果在“小测2.sav”中,假定两台仪器测量的结果服从正态分布,设显著性水平为0.05,问两台仪器的测量结果有无显著差异Levene检验主要用来检验原假设条件是否成立,(即:假设方差相等和方差不相等两种情况)如果SIG>0.05,证明假设成立,不能够拒绝原假设,如果SIG<0.05,证明假设不成立,拒绝原假设。
在组数据统计表中可以得到第1组有6个样本,均值为12.8883,标准差是0.72256,均值标准误为0.29498;第二组有7个样本,均值是13,标准差是0.5870均值标准误是0.22189;在独立样本检验表中可以得出F 的统计量的值为1.028,相伴概况为0,332,远大于显著性水平0.05,说明这两组数据的方差之间不存在显著差别,所以适合采用独立样本T检验。
t的统计量为-0.772,自由度为11,95%的置信区间,(01.07881,0.51834),相伴概率为0.456,远大于显著性水平0.05,假设成立,不能拒绝原假设,说明这2台仪器的测试结果没有显著性差异。
SPSS-t检验

数据输入
1)启动SPSS,进入定义变量工作表,分别命名 两变量:组别、鱼产量。其中组别1表示A料,组 别2表示B料。
2)进入数据视图工作表,输入数据
统计பைடு நூலகம்析
Analyze---compare mean----indendent samples T test
Test variable(输入):产鱼量
2、选择检验方法和计算检验统计量 因为总体标准差σ未知,所以采用t检验。 Analyze →Compare Means→One-Sample T Test出现如下对话框:
•把x移入到Test Variable(s) 的变量列表; •在Test Value后输入需要 比较的总体均数20; •OK
3、根据检验统计量的结果做出统计推断 基本统计量信息:
T检验
(一)单个总体均数的t检验 (二)独立样本成组t检验 (三)成对样本t检验
(一)单个总体均数的t检验
计算公式
样本平均数与总体平均数差异显著性检验
例:成虾的平均体重为21克,在配合饲料中添加 0.5%的酵母培养物饲养成虾时,随机抽取16只对 虾,体重为20.1、21.6、22.2、23.1、20.7、19.9、 21.3、21.4、22.6、22.3、20.9、21.7、22.8、 21.7、21.3、20.7。试检验添加添加0.5%的酵母 培养物是否提高了成虾体重。
从结果中可以看出,统计量t=3.056,P=0.012<α=0.05,因此拒 绝H0,接收H1,即用该方法测量所得结果与标准浓度值有所不 同。认为该方法测量结果所对应总体均数μ与标准浓度μ0间的差 异有统计学意义。
(二)独立样本成组t检验
独立样本:又称非配对样本或成组样本。是指一组数据与另一 组数据没有任何关系,也就是说,两样本资料是相互独立的。 两组的样本容量尽可能相同,可以提高检验的精确度。其均 数差异显著性的t检验,又分为两总体方差相等(方差齐性)和 方差不等两种检验方法。
spss均值检验(均数分析单样本t检验独立样本t检验)

在统计学中,我们往往从样本的特性推知随机变量总体的特性。
但由于总体中个体之间存在差异,样本的统计量和总体的参数之间往往会有误差。
因此,均值不相等的样本未必来自不同分布的总体,而均值相等的样本未必来自有相同分布的总体。
也就是说,如何从样本均值的差异推知总体的差异,这就是均值比较的内容。
SPSS提供了均值比较过程,在主菜单栏单击“Analyze”菜单下的“Compare Means”项,该项下有5个过程,如图4-1。
平均数比较Means过程用于统计分组变量的的基本统计量。
这些基本统计量包括:均值(Mean)、标准差(Standard Deviation)、观察量数目(Number of Cases)、方差(Variance)。
Means过程还可以列出方差表和线性检验结果。
[例子]调查了棉铃虫百株卵量在暴雨前后的数量变化,统计暴雨前和暴雨后的统计量,其数据如下:暴雨前 110 115 133 133 128 108 110 110 140 104 160 120 120暴雨后 90 116 101 131 110 88 92 104 126 86 114 88 112该数据保存在“DATA4-1.SAV”文件中。
1)准备分析数据在数据编辑窗口输入分析的数据,如图4-2所示。
或者打开需要分析的数据文件“DATA4-1.SAV”。
图4-2 数据窗口2)启动分析过程在SPSS主菜单中依次选择“Analyze→Compare Means→Means”。
出现对话框如图4-3。
图4-3 Means设置窗口3)设置分析变量从左边的变量列表中选中“百株卵量”变量后,点击变量选择右拉按钮,该变量就进入到因子变量列表“Dependent List:”框里,用户可以从左边变量列表里选择一个或多个变量进行统计。
从左边的变量列表中选中“调查时候”变量,点击“Independent List”框左边的右拉按钮,该变量就进入分组变量“IndependentList”框里,用户可以从左边变量列表里选择一个或多个分组变量。
SPSS抽样误差和t检验

抽样误差和t 检验Sampling error and t test一、目的要求(一)掌握抽样误差的定义,单样本t 检验、配对t 检验和两样本t 检验的计算及在SPSS 中的实现 (二)熟悉三种t 检验的适用条件二、预习纲要(一)t 检验的前提条件1.样本来自正态总体;2.两样本均数比较时,两样本总体方差齐性;3.各样本之间相互独立。
(二)抽样误差定义由个体变异产生的,抽样造成样本统计量与总体参数的差异,称为抽样误差。
通常用标准误说明均数抽样误差的大小。
(三)计算公式 1.标准误 nS S x =2.样本均数与总体均数比较 xS x t ||μ-=3.配对资料的比较 dS d t |0|-=4.两样本均数比较 )(2121||x x S x x t --=三、例题(一)样本均数与总体均数比较(One-Sample T Test 过程)【例1】随机抽取某地区20名成年男子,测得其脉搏(次/分)如下:75 73 73 76 79 63 81 80 76 70 897577828176806779661.数据的录入本例只有一个变量脉搏,其变量名为pulse ,依次输入上述的20个脉搏测量值,结果如图4.1图4.1 单样本t检验数据录入格式2.统计分析选择Analyze---Compare Means---One Sample T Test…命令项,弹出One Sample T Test对话框,将左侧变量列表中的变量pulse选入右侧的Test Variable(s):栏中。
在Test V alue栏中键入待比较的总体均值72(图4.2),最后点击OK钮。
图4.2 One Sample T Test对话框3.结果的输出及解释:首先输出的是变量pulse的基本统计指标,一共有20例样本,样本均值为75.900,标准差为6.121,标准误为1.3686。
其次输出的是单样本比较的统计指标,t=2.850,自由度为19,双侧P值=0.010,P<0.05,不能认为该地成年男子的脉搏为72次/分。
spss T检验

Std. Error Mean 193.13
t 4.207
df 7
Sig. (2-tailed) .004
正正正正组 维维素E缺缺组
812.50
结论:相关系数=0.584,P(sig.)=0.129,认为两配对变量无相 关关系。t=4.207,df=7,P=0.004<0.05,故可认为不同正正的大 百鼠肝中维维素A含量有统计意义。
脉脉
10
One-Sample Test Test Value = 72 95% Confidence Interval of the Difference Lower Upper -8.84 -.36
脉脉
t -2.453
df 9
Sig. (2-tailed) .037
Mean Difference -4.60
T检验:样本均数与总体均数的比较
问题:正正人的脉脉麻均72次/分,现测得10例某病患者的脉脉(次/分): 54,67,68,78,70,66,67,70,65,69,试问此病患者与正正人有无 显著性差别?
检验变量
检验值
One-Sample Statistics N Mean 67.40 Std. Deviation 5.93 Std. Error Mean 1.87
Mean Difference 119.725
结论:因t=-264.848,df=109,双侧概率P〈0.0005,两均数之 〈 差=119.725,差值的95%可信区间为118.829-120.621。因此该 市7岁男童的95%可信区间为118.829-120.621cm。
独立样本T检验 ( tow-sample t-test for independent samples )
SPSS统计实验单双样本t检验

单样本T检验
班级
期末成
绩
1 87 1 96 1 80 1 90 1 88 1 70 1 67 1 7
2 1 70 1 75 1 86
检验班级1的期末平均成绩是否达到80.
表中可看出均值=80.09,均值大于80
上表是对均值为80的显著性检验:T统计量=0.031,双侧检验P值=0.976大于显著性水平0.05,即表明接受原假设,没有显著性差异。
在95%的置信区间下的取值范围为(-6.50,6.68).综合分析可知班级1的期末平均成绩达到80.
两个样本T检验
班级
期末成
绩
1 87 1 96 1 80 1 90 1 88 1 70 1 67 1 7
2 1 70 1 75
1 86
2 77 2 68 2 65 2 61 2 9
3 2 88 2 80 2 85 2 85 2 80 2 96
计算两个班级期末成绩的平均成绩,标准差,最高分和最低分来比较两个班级间成绩有无明显差异。
两个班级期末成绩的均值为79.95,标准差为10.330,最高分为96,最低分为61,置信区间下限为75.37,上限为84.53。
上表为班级1,2在均值,置信度,标准差、中位数和最大、最小值等各项指标的对比情况:从表中可看出1班与2班的各项指标都很接近,1班略大于2班。
方差齐性检验的F值=0.018,P值=0.895,T检验在方差相等与不等两种情况下的T值都为0.06,P值都为0.952,都大于给定的显著性水平a=0.05,即两个班的成绩没有显著性差异。
spss软件进行T检验方法

小 结
SPSS中“Analyze”菜单中的“Compare Means”可用于均值检验,其子菜单中的 “One-sample T test”用于单一样本T检验; “Independent-samples T test”用于两独立 样本T检验;“Baired-samples T test”用于 两配对样本T检验。
SPSS将自动计算T值,由于该统计量服从 n−1个自由度的T分布,SPSS将根据T分布表给 出t值对应的相伴概率值。如果相伴概率值小 于或等于用户设想的显著性水平,则拒绝H0, 认为两总体均值之间存在显著差异。相反,相 伴概率大于显著性水平,则不拒绝H0,可以 认为两总体均值之间不存在显著差异。
4.1 Means过程 4.1.1 统计学上的定义和计算公式
定义:Means过程是SPSS计算各种基本描 述统计量的过程。与第3章中的计算某一样本 总体均值相比,Means过程其实就是按照用户 指定条件,对样本进行分组计算均数和标准差, 如按性别计算各组的均数和标准差。
用户可以指定一个或多个变量作为分组变 量。如果分组变量为多个,还应指定这些分组 变量之间的层次关系。层次关系可以是同层次 的或多层次的。同层次意味着将按照各分组变 量的不同取值分别对个案进行分组;多层次表 示将首先按第一分组变量分组,然后对各个分 组下的个案按照第二组分组变量进行分组。
78.00
89.00 87.00 76.00 56.00 76.00 89.00 89.00 99.00 89.00 88.00 98.00 78.00 89.00
78.00
87.00 89.00 97.00 76.00 100.00 89.00 89.00 89.00 98.00 78.00 78.00 89.00 68.00
spss独立样本t检验

spss中有关独立样本T检验的详细介绍包含操作过程和结果分析分析>比较平均值3.独立样本T检验独立样本T检验类似于单样本T检验,不过独立样本T检验的内容比单样本T检验要复杂的多,特别是对其结果的分析,而独立样本T检验被使用的情况也比单样本T检验更广泛(因此也可以看到网络上关于独立样本T检验的文章远比关于单样本T检验的文章多)对比:二者都是将数据的平均值进行比较,不同之处在于单样本T检验是将一个样本与某一特定值进行对比,而独立样本T检验是对多个样本之间的平均值进行对比。
独立样本是指进行对比的多个样本之间是相互独立、互不干扰的,通过独立样本T检验我们可以判断多个样本之间的平均值是否可以认为是相等的。
没有什么比举个例子更容易理解独立样本T检验的用途了:假如我们有两个样本,分别是来自农村和城市两个不同地方的人们的身高数据,我们的目的是探讨农村和城市的差异会不会给当地的人们带来身高上的影。
这时我们算出城市的人群的平均身高为168.38cm,而农村的人们的平均身高为164.58cm,二者差了3.8cm,那我们是否就可以认为这3.8cm就可以很好的说明农村和城市的人们身高有差异呢?那如果是差了3cm呢?如果是差了1cm呢?这种时候就不可以单靠感觉来评判了,而是应该使用独立样本T检验来帮助我们判断得出结论检验变量——需要进行平均值比较的数据分组变量——用于区分不同样本的变量选项——选择置信区间百分比以及缺失值的处理方法对于分组变量我们操作时需要注意一下,在我们选入了分组变量后,我们必须要对其进行定义组操作,因为SPSS无法自行判断如何通过分组变量对数据进行分组点击定义组我们有两种分类的方法,分别是使用指定的值与分割点,指定值就是将所有分类变量等于该输入的数值的样本划分为一组,分割点就是以该输入的数值为分割点划分出大于和小于该值的两组进行比较,这些都是很简单的,不多废话了~~接下来就是重头戏了——对结果的分析简洁解释:得到结果后,首先将独立样本检验表格中莱文方差等同性检验的显著性数值与0.05进行比较大于0.05,两组假定等方差,看第一行数据的显著性(双尾)数值,如果大于0.05,两组差异不显著;如果小于0.05,两组差异显著;小于0.05,两组不假定等方差,看第二行数据的显著性(双尾)数值,如果大于0.05,两组差异不显著;如果小于0.05,两组差异显著。
单样本t检验

SPSS比较均独立样本T检验案例解析

SPSS-比较均值-独立样本T检验案例解析2011-08-26 14:55在使用SPSS进行单样本T检验时,很多人都会问,如果数据不符合正太分布,那还能够进行T检验吗?而大样本,我们一般会认为它是符合正太分布的,在鈡型图看来,正太分布,基本左右是对称的,一般具备两个参数,数学期望和标准方差,即:N(p, Q)如果你的样本数非常少,一般需要进行正太分布检验,检验的方法网上很多,我就不说了下面以“雄性老鼠和雌性老鼠分别注射了某种毒素,经过观察分析,进行随机取样,查看最终老鼠是否活着。
问题:很多人认为,雄性老鼠和雌性老鼠分别注射毒液后,雌性老鼠存活下来的数量会比雄性老鼠多?我们将通过进行统计分析来认证这个假设是否成立。
下面进行参数设置:a 代表:雄性老鼠b代表:雌性老鼠tim 代表:生存时间,即指经过多长时间后,去查看结果0 代表:结果死亡1 代表:结果活着随机抽取的样本,如下所示:打开SPSS- 分析---检验均值---独立样本T检验,如下图所示:将你要分析的变量,移入右边的框内,再将你要进行分组的变量移入“分组变量”框内,“组别group()里面的两个参数,不能够随意设置,必须要跟样本里面的数字一致点击确定后,分析结果,如下所示:从组统计量可以看出,雄性老鼠的存活下来的均值为0.73,但是雌性老鼠存活下来的均值为1.00,很明显,雌性老是存活下来的个数明显比雄性老鼠多,但是一般我们不看这个结果,为什么?因为样本不够大,如果将样本升至10000个?也许这个均值将会发生变化,不具备统计学意义,我们一般只看独立样本检验的结果。
独立样本检验,提供了两种方法:levene检验和均值T检验两种方法Levene检验主要用来检验原假设条件是否成立,(即:假设方差相等和方差不相等两种情况)如果SIG>0.05,证明假设成立,不能够拒绝原假设,如果SIG<0.05,证明假设不成立,拒绝原假设。
进行levene检验结果判断是第一步,从上图,可以看出 sig<0.05 方差相等的假设不成立,所以看第二行,方差不相等的情况sig=0.082>0.05 即说明 P 值大于显著性水平,不应该拒绝原假设:即指:雌性老鼠和雄性老鼠在注射毒液后,存活下来的个数没有显著的差异本次分析的结果,不支持,很多人认为的:雄性老鼠和雌性老鼠分别注射毒液后,雌性老鼠存活下来的数量会比雄性老鼠多的结论。
用SPSS进行单样本T检验(One -Sample T Test)

用SPSS进行单样本T检验(One -Sample T Test)在《0-1总体分布下的参数假设检验示例一(SPSS实现)》中,我们简要介绍了用SPSS 检验二项分布的参数。
今天我们继续看看如何用SPSS进行单样本T检验(One -Sample T Test)。
看例子:例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)?分析:此检验的假设是:H0:该市五年级学生的400米平均成绩是仍为100秒。
H1:该市五年级学生的400米平均成绩是不为100秒。
打开SPSS,读入数据从结果中可以判断:1、p=0.287>0.05,在5%的显著性水平上,不能拒绝假设H0。
2、95%的置信区间端点一正一负,必然覆盖总体均值。
应该接受零假设(假设H0)。
这个结论出乎很多人的意料,因为样本均值明显下降了,105.38500000000003。
实际上,那是因为有一个样本值为400秒,从而造成错觉的缘故。
再看一个更有趣的例子。
例1:已知去年某市小学五年级学生400米的平均成绩是100秒,今年该市抽样测得60个五年级学生的400米成绩(数据见后面文件“CH6参检1小学生400米v提高B.sav”),试检验该市五年级学生的400米平均成绩是否应为100秒(有无提高或下降)?同上,打开SPSS,读入数据,结果:从结果中判断:t统计值的显著性概率为0.005小于1%,在1%犯错误的水平上拒绝零假设。
可以认为,今年该市五年级学生的400米平均成绩明显下降了。
t检验使用条件及在SPSS中地应用

t检验使用条件及在SPSS中的应用t检验是对均值的检验,有三种用途,分别对应不同的应用场景:1)单样本t检验(One Sample T Test):对一组样本,检验相应总体均值是否等于某个值;2)相互独立样本t检验(Independent-Sample T Test):利用来自某两个总体的独立样本,推断两个总体的均值是否存在显著性差异;3)配对样本t检验:是采用配对设计方法观察以下几种情形,1,两个同质受试对象分别接受两种不同的处理;2,同一受试对象接受两种不同的处理;3,同一受试对象处理前后。
下文将分别介绍三种t检验的使用条件以及在SPSS中的实现。
一、单样本t检验1.1简介1)单样本t检验的目的利用来自某总体的样本数据,推断该总体的均值是否与指定的检验值之间存在显著性差异,它是对总体均值的检验。
2)单样本t检验的前提样本来自的总体应服从和近似服从正态分布,且只涉及一个总体。
如果样本不符合正态分布或不清楚总体分布的形状,就不能用单样本t检验,而要改用单样本的非参数检验。
3)单样本t检验的步骤a)提出假设单样本t检验需要检验总体的均值是否与指定的检验值之间存在显著性差异,为此,,提出假设:给定检验值μH0:μ= μ(原假设,null hypothesis)H1:μ≠μ(备择假设,alternative hypothesis,)b)选择检验统计量属于总体均值和方差都未知的检验采用t统计量:t =X ̅−μ0S ̂√n ⁄,其中,X ̅和S ̂分别为样本均值和方差,t 的自由度为n-1SPSS 中还将显示均值标准误差,计算公式为S ̂√n⁄,即t 统计量的分母部分。
c) 计算统计量的观测值和概率将样本均值、样本方差、μ0带入t 统计量,得到t 统计量的观测值,查t 分布界值表计算出概率P 值。
d) 给出显著性水平α,作出统计判断给出显著性水平α,与检验统计量的概率P 值作比较。
当检验统计量的概率值小于显著性水平时,则拒绝原假设,认为总体均值与检验值μ0之间有显著性差异;反之,如果检验统计量的概率值大于显著性水平,则接受原假设,认为总体均值与检验值μ0之间没有显著性差异。
单样本t检验-SPSS教程
单样本t检验-SPSS教程一、问题与数据某研究者拟开展一项健康调查,在开展该研究之前,他想了解所招募的40名研究对象的体重指数BMI是否具有代表性。
根据既往研究报道,目标人群的BMI 均值为24kg/m²。
该研究者想知道他招募的研究对象的BMI均值是否也为24kg/m²。
部分数据图1。
图1 部分数据二、对问题分析研究者拟分析样本均值与总体均值是否不同,即判断招募研究对象的BMI均值与总体人群BMI均值24之间是否有差异。
针对这种情况,可以使用单样本t 检验,但需要先满足4项假设:假设1:观测变量为连续变量,如本研究中的BMI为连续变量。
假设2:观测值相互独立,如本研究中各位研究对象的信息都是独立的,不存在相互干扰作用。
假设3:观测变量不存在显著的异常值。
假设4:观测变量接近正态分布。
假设1和假设2取决于研究设计和数据类型,本研究数据符合假设1和假设2。
那么应该如何检验假设3和假设4,并进行单样本t检验呢?三、SPSS操作3.1 检验假设3:观测变量不存在显著的异常值在主界面点击Analyze→Descriptive Statistics→Explore,在Explore对话框中,将变量BMI选入Dependent List。
在Display模块内点击Plots。
如图2。
图2 Explore点击Plots,出现Explore: Plots对话框,保留Boxplots内系统默认选项Factor levels together,在Descriptive内取消选择Stem-and-leaf,在下方勾选Normality plots with tests。
点击Continue→OK。
如图3。
图3 Explore: Plots经上述操作,SPSS输出箱式图,研究者可根据箱式图判断数据中是否存在异常值。
如图4。
图4 箱式图SPSS中,数据点与箱子边缘的距离大于1.5倍箱身长度,则定义为异常值,以圆点(°)表示;与箱子边缘的距离大于3倍箱身长度,则定义为极端值,以星号(*)表示。
SPSS数据分析 第四章 t检验

3. 被称为观察到的(或实测的)显著性水平
4. 决策规则:若p值<, 拒绝 H0
双侧检验的P 值
/2
拒绝H0
1/2 P 值
/2
拒绝H0
1/2 P 值
临界值 0
临界值
Z
计算出的样本统计量
计算出的样本统计量
左侧检验的P 值
抽样分布
拒绝H0
P值
异较大。其图形如下:
f(t)
ν─>∞(标准正态曲线)
ν=5
ν=1
-5.0
-4.0
-3.0
-2.0
-1.0
0.0
1.0
2.0
3.0
4.0
5.0
t
图3-3 不同自由度下的t 分布图
3.特征:
① 单峰分布,以 0 为中心,左右对称; ② 自由度 越小,则 t 值越分散,t 分布的峰部
越矮而尾部翘得越高; ③当 逼近, SX 逼近 X , t 分布逼近 u 分布,故标
解:研究者想收集证据予以证明的 假设应该是“生产过程不正常”。 建立的原假设和备择假设为
H0 : 10cm H1 : 10cm
【例】某品牌洗涤剂在它的产品说明书中声称: 平均净含量不少于500克。从消费者的利益出发, 有关研究人员要通过抽检其中的一批产品来验 证该产品制造商的说明是否属实。试陈述用于 检验的原假设与备择假设
行比较
3. 作出决策
双侧检验:统计量的绝对值 > 临界值,拒 绝H0
左侧检验:统计量 < 临界值,拒绝H0 右侧检验:统计量 > 临界值,拒绝H0
利用 P 值 进行决策
什么是P 值?
独立样本的T检验

独⽴样本的T检验独⽴样本的T检验(independent-samples T Test)对于相互独⽴的两个来⾃正态总体的样本,利⽤独⽴样本的T 检验来检验这两个样本的均值和⽅差是否来源于同⼀总体。
在SPSS 中,独⽴样本的T检验由“Independent-Sample T Test”过程来完成。
例:双语教师的英语⽔平有⾼低之分,他们(她们)所教的学⽣对双语教学的态度是否有显著差异?例题分析:——研究⽬的:寻找差异——⾃变量:双语教师的英语⽔平(ordinal data等级变量),有两个⽔平:;level1低⽔平,level2 ⾼⽔平——因变量:学⽣的双语教学态度(interval data等距变量)SPSS操作步骤·Analyze→Compare Means→Independent Samples T Test·Click the 双语教学态度to the column of “Test Variable(s)” andthe 教师英语⽔平分组to the column of “Grouping variable”·Click the button of “Define Groups…” and put the group numbers“1” and “3” into Group 1 and Group 2, and “Continue” back, then“OK”.结果在论⽂中的呈现⽅式独⽴样本T检验结果显⽰,双语教师的英语⽔平不同,其所教学⽣对双语教学的态度有显著差异(t=-3,249, df=72, p<0.05)。
双语教师英语⽔平较低所教的学⽣,他们对双语教学态度的得分也显著低于英语⽔平较⾼的双语教师所教的学⽣(MD=-0.65)。
这可能是因为……练习:⽂科⽣和理科⽣对双语教学的态度是否有显著差异?配对样本T检验(Paired-samples T Test)配对样本T检验,⽤于检验两个相关的样本(配对资料)是否来⾃具有相同均值的总体。
独立样本T检验SPSS操作步骤
独立样本T检验SPSS操作
例如:男生和女生之间的学业自我效能感有没有统计学意义上的差异
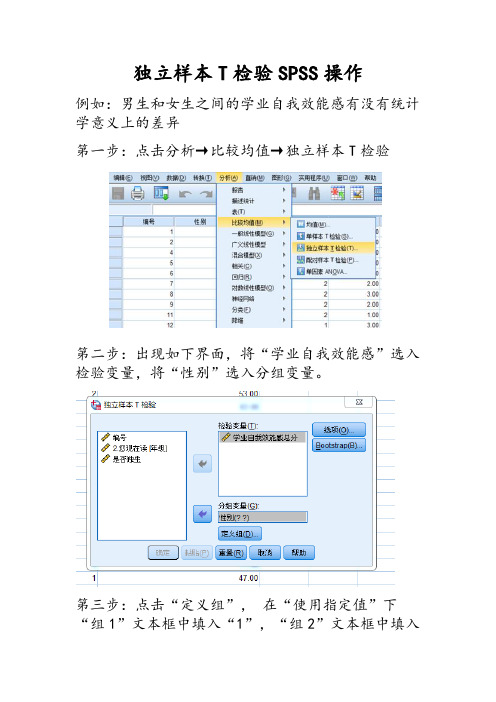
第一步:点击分析→比较均值→独立样本T检验
第二步:出现如下界面,将“学业自我效能感”选入检验变量,将“性别”选入分组变量。
第三步:点击“定义组”,在“使用指定值”下“组1”文本框中填入“1”,“组2”文本框中填入
“2”(因为数据中“1”代表男生,“2”代表女生),然后点击“继续”。
第四步:点击“确定”,出现得到T检验的结果。
第五步:分析结果。
第一张表的名字叫组统计量,实际上这个性别就是男性组和女性组,即按照不同的组别进行分组。
统计出男性组和女性组每一组的均值和标准差。
一列数据是可以选择用均值和标准差来表示的,均值表示的是这一组的学业自我效能感分数的一个均衡状态,标准差反映的就是同学们得分与这个均衡状态的这个偏离程度。
男性和女性在均值上的差异是否具有统计学意义,我们还需要继续考察独立样本T检验的表。
假设方差相等,看F和F对应的显著性水平,要看显著性水平是不是小于0.05,判断方差是否齐性。
若这个数小于0.05,说明假设方差相等的可能性小
于0.05,小概率事件发生,拒绝原假设,即假设方
差不相等,看第二行的数据t和t对应的显著性水平。
如果方差齐性,也就是sig值大于0.05,就看第一
行的数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、被调查学生对“云窗的打分值”总体平均值的推断:
1、以71个被调查学生为样本做T 检验
由表a 可知,71个观测的平均值为71.21,标准差为15,120,均值标准误为1.794。
表b 中,第二列是t 统计量的观测值为0.675,第三列是自由度n-1=70,第四列是t 统计量观测值的双尾概率p 值,第五列是样本均值与检验值的差(1.211),即t 统计量的分子部分,他除以表a 的均值标准误(1.794)后得到t 统计量的观测值0.675,第六列和第七列是总体均值与检验值差的95%的置信区间,为(67.63,74.79)。
对于研究的问题应采用双尾检验,因此比较
2α和2
p
,即比较α和p 。
由于p 大于α(0.05),因此不能拒绝零假设,认为被调查学生对“云窗的打分值”总体平均值没有显著差异。
有95%的把握认为总体均值在 67.63~74.79 分之间。
70分包含在置信区间内,也证实了上述推断。
2、被调查学生对“云窗的打分值”的重抽样自举
表c
Bootstrap 指定
采样方法简单箱图
样本数1000
置信区间度95.0%
置信区间类型百分位
由表c可知,自举过程执行1000次,随机数种子指定为默认值2000000,采样方法为简单箱图。
中均值的重抽样自举均值与实际样本均值的差为-0.12,1000个均值的标准差为1.82,由此得到的均值95%的置信区间为(67.18,74.46)
表e中没有给出双尾检验的概率p值,但是从检验的结果可知有95%的把握认为总体均值在
67.184~74.463之间。
70包含在置信区间内。
用更大的样本量再一次说明了被调查学生对“云窗的打分值”总体平均值没有显著差异。