层次分析法例题(1)
(完整word版)层次分析法例题

某物流企业需要采买一台设备,在采买设备时需要从功能、价格与可保护性三个角度进行议论,考虑应用层次解析法对 3 个不同样品牌的设备进行综合解析议论和排序,从中选出能实现物流规划总目标的最优设备,其层次构造以以下列图所示。
以 A 表示系统的总目标,判断层中B1表示功能,B2表示价格, B3表示可保护性。
C1,C2,C3表示备选的3种品牌的设备。
目A判断功能 B1价格B2性B3方案品 C1品C2品C3采次构解题步骤:1、标度及描述人们定性区分事物的能力习惯用 5个属性来表示,即同样重要、稍微重要、较强重要、强烈重要、绝对重要,当需要较高精度时,可以取两个相邻属性之间的值,这样就获取 9个数值,即 9个标度。
为了便于将比较判判断量化,引入1~9比率标度方法,规定用1、3、5、7、9分别表示依照经验判断,要素 i 与要素 j对照:同样重要、稍微重要、较强重要、强烈重要、绝对重要,而 2、4、6、8表示上述两判断级之间的折衷值。
度13579 2、4、6、8倒数定〔比要素i 与 j 〕要素 i 与 j 同重要要素 i 与 j 稍微重要要素 i 与 j 重要要素 i 与 j 烈重要要素 i 与 j 重要两个相判断要素的中要素 i 与 j 比得判断矩 a ij,要素j与i对照的判断 a ji=1/a ij注: a ij表示要素 i与要素 j 相重要度之比,且有下述关系:a ij =1/a ji; a ii=1 ; i,j=1 , 2,⋯,n然,比越大,要素 i 的重要度就越高。
2、成立判断矩阵A判断矩 是 次解析法的根本信息,也是 行 重 算的重要依照。
依照 构模型,将 中各要素两两 行判断与比 ,构造判断矩 :●判断矩 A比 )如表 1所示;●判断矩 B 1 ●判断矩 B 2 ●判断矩 B 3示。
B (即相 于物流系 目 ,判断 各要素相 重要性C (相 功能,各方案的相 重要性比 )如表 2 所示; C(相 价格,各方案的相 重要性比 )如表 3 所示;C(相 可 性,各方案的相 重要性比)如表 4 所表1判断矩 A BAB 1B 2 B 3B 1 1 1/3 2 B 2 3 1 5 B 31/21/51表 2 判断矩B1CB 1C 1C 2 C 3C 1 1 l/3 1/5 C 2 3 1 1/3 C 35 3 1表 3 判断矩 B 2-CB 2C 1C 2C3C 1 1 27 C 2 1/2 1 5 C 31/71/51表4 判断矩 B3CB 3C 1C 2 C 3C 1 1 3 l/7 C 2l/3 1 1/9 C 379 13、 算各判断矩 的特色 、特色向量及一致性 指一般来 ,在AHP 法中 算判断矩 的最大特色 与特色向量, 必不需要 高的精度,用求和法或求根法可以 算特色 的近似 。
(完整版)层次分析法例题

(完整版)层次分析法例题-CAL-FENGHAI-(2020YEAR-YICAI)_JINGBIAN实验目的:熟悉有关层次分析法模型的建立与计算,熟悉Matlab 的相关命令。
实验准备:1. 在开始本实验之前,请回顾教科书的相关内容;2. 需要一台准备安装Windows XP Professional 操作系统和装有Matlab 的计算机。
实验内容及要求试用层次分析法解决一个实际问题。
问题可参考教材P296第4大题。
实验过程:某物流企业需要采购一台设备,在采购设备时需要从功能、价格与可维护性三个角度进行评价,考虑应用层次分析法对3个不同品牌的设备进行综合分析评价和排序,从中选出能实现物流规划总目标的最优设备,其层次结构如下图所示。
以A 表示系统的总目标,判断层中1B 表示功能,2B 表示价格,3B 表示可维护性。
1C ,2C ,3C 表示备选的3种品牌的设备。
解题步骤:1、标度及描述人们定性区分事物的能力习惯用5个属性来表示,即同样重要、稍微重要、较强重要、强烈重要、绝对重要,当需要较高精度时,可以取两个相邻属性之间的值,这样就得到9个数值,即9个标度。
为了便于将比较判断定量化,引入1~9比率标度方法,规定用1、3、5、7、9分别表示根据经验判断,要素i 与要素j 相比:同样重要、稍微重要、较强重要、强烈重要、绝对重要,而2、4、6、8表示上述两判断级之间的折衷值。
5 因素i 与j 较强重要设备采购层次结构图2、4、6、8两个相邻判断因素的中间值倒数 因素i 与j 比较得判断矩阵a ij ,则因素j 与i 相比的判断为a ji =1/a ij注:a ij 表示要素i 与要素j 相对重要度之比,且有下述关系:a ij =1/a ji ;a ii =1; i ,j=1,2,…,n显然,比值越大,则要素i 的重要度就越高。
2、构建判断矩阵A判断矩阵是层次分析法的基本信息,也是进行权重计算的重要依据。
层次分析法现代汉语例题

层次分析法是一种决策分析方法,通常用于多个方案或因素之间进行比较和排序。
以下是一个使用层次分析法的现代汉语例题:
假设你是一名公司的采购主管,你需要从三个供应商(A、B、C)中选择一家供应商品质最好、价格最优、售后服务最好的供应商。
你将使用层次分析法来进行决策。
解题步骤:
制定目标层次:选择最优供应商
确定判断准则:商品质量、价格、售后服务
构建层次结构模型:将目标层次下的判断准则放在下一层,形成层次结构模型
刻画判断矩阵:采用1~9的比较尺度,对每两个判断准则进行比较,得到判断矩阵
求出权重向量:对判断矩阵进行归一化处理,计算出每个判断准则的权重
计算一致性指标:检查矩阵的一致性程度,得出一致性指标
计算最终权重:根据层次结构模型和权重向量,计算出每个供应商的最终权重
进行灵敏度分析:分析每个判断准则的变化对结果的影响程度
得出决策结果:综合考虑判断准则的权重和灵敏度分析的结果,得出选择最优供应商的决策结果
以上是一个基本的层次分析法的应用例题,具体细节需要根据实际情况进行调整和处理。
层次分析法例题详解

层次分析法例题详解
例题:假设一家公司想要改善客户满意度,以下是几项建议:
A. 增加客户服务
B. 提高产品质量
C. 提高客户服务质量
层次分析法:
1.首先,将上述三项建议放入一个表格中,比较它们之间的关系。
建议 | 增加客户服务 | 提高产品质量 | 提高客户服务质量
------|-----------------|------------------|------------------------
关系 | 相关 | 相关 | 直接相关
2.然后,根据上表的关系,将建议分类:
A. 增加客户服务和提高客户服务质量:这两项建议直接相关,可以归为一类,即增加客户服务和提高客户服务质量。
B. 提高产品质量:这一项建议与其他两项建议相关,但不属
于同一类别,可以独立归类。
3.最后,根据分类的结果,提出有效的解决方案:
A. 增加客户服务和提高客户服务质量:可以采取措施增加客
户服务人员的数量,同时提高客户服务质量,如培训客服人员,
提升服务水平。
B. 提高产品质量:可以采取措施改善产品质量,如改进生产流程,提高材料质量,以及实施质量控制等。
层次分析法例题

某物流企业需要采购一台设备,在采购设备时需要从功能、价格与可维护性三个角度进行评价,考虑应用层次分析法对3个不同品牌的设备进行综合分析评价和排序,从中选出能实现物流规划总目标的最优设备,其层次结构如下图所示;以A 表示系统的总目标,判断层中1B 表示功能,2B 表示价格,3B 表示可维护性;1C ,2C ,3C 表示备选的3种品牌的设备;解题步骤:1、标度及描述人们定性区分事物的能力习惯用5个属性来表示,即同样重要、稍微重要、较强重要、强烈重要、绝对重要,当需要较高精度时,可以取两个相邻属性之间的值,这样就得到9个数值,即9个标度;为了便于将比较判断定量化,引入1~9比率标度方法,规定用1、3、5、7、9分别表示根据经验判断,要素i 与要素j 相比:同样重要、稍微重要、较强重ij a ij =1/a ji ;a ii =1; i,j=1,2,…,n目标层判断层 方案层 图 设备采购层次结构图显然,比值越大,则要素i 的重要度就越高;2、构建判断矩阵A判断矩阵是层次分析法的基本信息,也是进行权重计算的重要依据; 根据结构模型,将图中各因素两两进行判断与比较,构造判断矩阵:●判断矩阵B A -即相对于物流系统总目标,判断层各因素相对重要性比较如表1所示;●判断矩阵C B -1相对功能,各方案的相对重要性比较如表2所示; ●判断矩阵C B -2相对价格,各方案的相对重要性比较如表3所示; ●判断矩阵C B -3相对可维护性,各方案的相对重要性比较如表4所 示;B A -C B -1C B -3一般来讲,在AHP 法中计算判断矩阵的最大特征值与特征向量,必不需要较高的精度,用求和法或求根法可以计算特征值的近似值;●求和法1将判断矩阵A 按列归一化即列元素之和为1:b ij = a ij /Σa ij ; 2将归一化的矩阵按行求和:c i =Σb ij i=1,2,3….n ; 3将c i 归一化:得到特征向量W =w 1,w 2,…w n T ,w i =c i /Σc i ,W 即为A 的特征向量的近似值; 4求特征向量W 对应的最大特征值: ●求根法1计算判断矩阵A 每行元素乘积的n 次方根;nnj iji aw ∏==1i =1, 2, …,n2将i w 归一化,得到∑==ni iii ww w 1;W =w 1,w 2,…w n T 即为A 的特征向量的近似值;3求特征向量W 对应的最大特征值:1判断矩阵B A -的特征根、特征向量与一致性检验 ①计算矩阵B A -的特征向量;计算判断矩阵B A -各行元素的乘积i M ,并求其n 次方根,如3223111=⨯⨯=M ,874.0311==M W ,类似地有,466.2322==M W ,464.0333==M W ;对向量Tn W W W W ],,,[21 =规范化,有类似地有684.02=W ,122.03=W ;所求得的特征向量即为: ②计算矩阵B A -的特征根类似地可以得到948.12=AW ,3666.03=AW ; 按照公式计算判断矩阵最大特征根: ③一致性检验;实际评价中评价者只能对A 进行粗略判断,这样有时会犯不一致的错误;如,已判断C 1比C 2重要,C 2比C 3较重要,那么,C 1应该比C 3更重要;如果又判断C 1比C 3较重要或同等重要,这就犯了逻辑错误;这就需要进行一致性检验;根据层次法原理,利用A 的理论最大特征值λmax 与n 之差检验一致性; 一致性指标:计算002.0133004.31max =--=--=n nCI λ<,1.0003.0<==RI CI CR ,查同阶平均随机一致性指标表5所示知58.0=RI ,一般认为CI<、 CR<时,判断矩阵的一致性可以接受,否则重新两两进行比较;1类似于第1步的计算过程,可以得到矩阵C B -1的特征根、特征向量与一致性检验如下:T W ]637.0,258.0,105.0[=,039.3max =λ,1.0033.0<=CR3判断矩阵C B -2的特征根、特征向量与一致性检验类似于第1步的计算过程,可以得到矩阵刀:—C 的特征根、特征向量与一致性检验如下:T W ]075.0,333.0,592.0[=,014.3max =λ,1.0012.0<=CR 4判断矩阵C B -3的特征根、特征向量与一致性检验类似于第1步的计算过程,可以得到矩阵C B -3的特征根、特征向量与一致性检验如下:T W ]785.0,066.0,149.0[=,08.3max =λ,1.0069.0<=CR 4、层次总排序获得同一层次各要素之间的相对重要度后,就可以自上而下地计算各级要素对总体的综合重要度;设二级共有m 个要素c 1, c 2,…,c m ,它们对总值的重要度为w 1, w 2,…, w m ;她的下一层次三级有p 1, p 2,…,p n 共n 个要素,令要素p i 对c j 的重要度权重为v ij ,则三级要素p i 的综合重要度为:方案C 1的重要度权重=×+×+×= 方案C 2的重要度权重=×+×+×=方案C 3的重要度权重=×+×0. 075+×=依据各方案综合重要度的大小,可对方案进行排序、决策; 层次总排序如表6所示;由表5可以看出,3种品牌设备的优劣顺序为:1C ,3C ,2C ,且品牌1明显优于其他两种品牌的设备;。
层次分析法练习参考标准答案

层次分析法练习参考答案————————————————————————————————作者:————————————————————————————————日期:2page3层次分析法练习练习一、市政工程项目建设决策问题提出市政部门管理人员需要对修建一项市政工程项目进行决策,可选择的方案是修建通往旅游区的高速路(简称建高速路)或修建城区地铁(简称建地铁)。
除了考虑经济效益外,还要考虑社会效益、环境效益等因素,即是多准则决策问题,试运用层次分析法建模解决。
1、建立递阶层次结构在市政工程项目决策问题中,市政管理人员希望通过选择不同的市政工程项目,使综合效益最高,即决策目标是“合理建设市政工程,使综合效益最高”。
为了实现这一目标,需要考虑的主要准则有三个,即经济效益、社会效益和环境效益。
但问题绝不这么简单。
通过深入思考,决策人员认为还必须考虑直接经济效益、间接经济效益、方便日常出行、方便假日出行、减少环境污染、改善城市面貌等因素(准则),从相互关系上分析,这些因素隶属于主要准则,因此放在下一层次考虑,并且分属于不同准则。
假设本问题只考虑这些准则,接下来需要明确为了实现决策目标、在上述准则下可以有哪些方案。
根据题中所述,本问题有两个解决方案,即建高速路或建地铁,这两个因素作为措施层元素放在递阶层次结构的最下层。
很明显,这两个方案于所有准则都相关。
将各个层次的因素按其上下关系摆放好位置,并将它们之间的关系用连线连接起来。
同时,为了方便后面的定量表示,一般从上到下用A 、B 、C 、D 。
代表不同层次,同一层次从左到右用1、2、3、4。
代表不同因素。
这样构成的递阶层次结构如下图。
目标层A准则层B准则层C合理建设市政工程,经济效社会效环境效直接经济效益 (C1)间接带动效益(C2)方便日常出行(C3)方便假日出行(C4)减少环境污染(C5)改善城市面貌(C6)page4措施层D图1 递阶层次结构示意图2、构造判断矩阵并请专家填写征求专家意见,填写后的判断矩阵如下:表2 判断矩阵表A B1 B2 B3 B1 C1 C2 B2 C3 C4 B3 C5 C6 B1 1 1/3 1/3C1 1 1 C3 1 3 C5 1 3 B2 1 1 C2 1 C4 1 C6 1 B3 1 C1 D1 D2 C2 D1 D2 C3 D1 D2 C4 D1 D2D1 1 5 D1 1 3 D1 1 1/5 D1 1 7 D2 1 D2 1 D2 1 D2 1 C5 D1 D2 C6 D1 D2D1 1 1/5 D1 1 1/3 D21D213、计算权向量及检验计算所得的权向量及检验结果见下:表4 层次计算权向量及检验结果表A 单(总)排序权值B1 单排序权值 B2 单排序权值 B3 单排序权值 B1 0.1429 C1 0.5000 C3 0.7500 C5 0.7500 B2 0.4286 C2 0.5000 C4 0.2500 C6 0.2500 B3 0.4286 CR 0.0000CR 0.0000CR 0.0000CR0.0000建高速建地铁page5C1 单排序权值 C2 单排序权值 C3 单排序权值 C4 单排序权值 D1 0.8333 D1 0.7500 D1 0.1667 D1 0.8750 D2 0.1667 D2 0.2500 D2 0.8333 D2 0.1250 CR 0.0000CR 0.0000CR 0.0000CR 0.0000C5 单排序权值 C6 单排序权值 D1 0.1667 D1 0.2500 D2 0.8333 D2 0.7500 CR 0.0000CR0.0000可以看出,所有单排序的C.R.<0.1,认为每个判断矩阵的一致性都是可以接受的。
层次分析法(1)

综上,层次分析法的基本步骤
1)建立层次分析结构模型 (建立层次结构图)
深入分析实际问题,将有关因素自上而下分层(目标— 准则或指标—方案或对象),上层受下层影响,而层内 各因素基本上相对独立。
2)构造成对比较阵
用成对比较法和1~9尺度,构造各层对上一层每一因素的 成对比较阵。
3)计算权向量并作一致性检验
对每一成对比较阵计算最大特征根和特征向量,作一致性 检验,若通过,则特征向量为权向量。
4)计算组合权向量(作组合一致性检验*)
组合权向量可作为决策的定量依据。
五 判断矩阵的近似计算方法
通过前面的介绍,我们知道,在层次分析方法 中,最根本的计算任务是求解判断矩阵的最大特征根 及其所对应的特征向量。这些问题当然可以用线性代 数知识去求解,并且能够利用计算机求得任意高精度 的结果。但事实上,在层次分析法中,判断矩阵的最 大特征根及其对应的特征向量的计算,并不需要追求 太高的精度。这是因为判断矩阵本身就是将定性问题 定量化的结果,允许存在一定的误差范围。因此,我 们常常用近似算法求解判断矩阵的最大特征根及其所 对应的特征向量。 三种方法:幂法、和积法和方根法
(3)科学考察和实践表明,1~9的比例标度已完全能区分 引起人们感觉差别的事物的各种属性。
显然,任何判断矩阵都应满足:
bij>0 ,bii = 1,bij = 1/bji,i,j = 1,2,…,n
因此,对于这样的判断矩阵来说, 作n(n-1)/2 次
两两判断就可以了。
判断过程中的问题
1、合理选择咨询对象;(专长及熟悉的领域)
=
=nW
即n是A的一个特征根,每只西瓜的重量是A对应于特 征根n的特征向量的各个分量。
很自然,我们会提出一个相反的问题,如果事先不知道 每只西瓜的重量,也没有衡器去称量,我们如能设法得到 判断矩阵(比较每两只西瓜的重量是最容易的),能否导 出西瓜的重量呢?显然是可以的,在判断矩阵具有完全一 致的条件下,我们可以通过解特征值问题
经典层次分析法分析及实例教程

当CR 0.1 时,认为层次总排序通过一致性检验。到
此,根据最下层(决策层)的层次总排序做出最后决策。
层次分析法的基本步骤归纳如下
1.建立层次结构模型 该结构图包括目标层,准则层,方案层。
2.构造成对比较矩阵 从第二层开始用成对比较矩阵和1~9尺度。
3.计算单排序权向量并做一致性检验 对每个成对比较矩阵计算最大特征值及其对应的特征向量, 利用一致性指标、随机一致性指标和一致性比率做一致性 检验。若检验通过,特征向量(归一化后)即为权向量; 若不通过,需要重新构造成对比较矩阵。
一般分为三层,最上面为目标层,最下面为方案层,中 间是准则层或指标层。 例1 的层次结构模型
买钢笔
目标层
质颜价外实 量色格形用
准则层
可供选择的笔
方案层
例2 层次结构模型
选择 旅游地
景
费
居
饮
旅
色
用
住
食
途
苏州、杭州、 桂林
目标层Z 准则层A 方案层B
若上层的每个因素都支配着下一层的所有因素,或被下一层所 有因素影响,称为完全层次结构,否则称为不完全层次结构。
A 4 7
2 3
1 3
1 5
2
1
1
1
1
3
1
1
3 5
1 2 5
B1
1 2
1
2
1 5
1 2
1
1
B2
3
1 3 1
1 18 3
8 3 1
1 1 3
B3
1 1
1 1
3
3 3 1
1 3 4
B4
1 3
1
1
层次分析法例题

二、AHP 求解层次分析法(Analytic Hierarchy Process )是一种定量与定性相结合的多目标决策分析法,将决策者的经验给予量化,这在对目标(因素)结构复杂且缺乏必要数据的情况下较为实用。
(一)、建立递阶层次结构目标层:最优生鲜农产品流通模式。
准则层:方案的影响因素有:1c 自然属性、2c 经济价值、3c 基础设施、5c 政府政策。
方案层:设三个方案分别为:1A 农产品产地一产地批发市场一销地批发市场一消费者、2A 农产品产地一产地批发市场一销地批发市场一农贸市场一消费者、3A 农业合作社一第三方物流企业一超市一消费者(本文假设农产品的生产地和销地不在同一个地区)。
。
图3—1 递阶层次结构(二)、构造判断(成对比较)矩阵所谓判断矩阵昰以矩阵的形式来表述每一层次中各要素相对其上层要素的相对重要程度。
为了使各因素之间进行两两比较得到量化的判断矩阵,引入1~9的标度,见表3—1.目标层:准则层:方案层:表3—1 标度值为了构造判断矩阵,作者对6个专家进行了咨询,根据专家和作者的经验,四个准则下的两两比较矩阵分别为:(三)、层次单排序及其一致性检验层次单排序就是把本层所有要素针对上一层某一要素,排出评比的次序,这种次序以相对的数值大小来表示。
对应于判断矩阵最大特征根λmax的特征向量,经归一化(使向量中各元素之和等于1)后记为W。
W的元素为同一层次因素对于上一层次因素某因素相对重要性的排序权值,这一过程称为层次单排序。
能否确认层次单排序,需要进行一致性检验,所谓一致性检验是指对A确定不一致的允许范围。
a,则λ比n 大的越多,A 的不一致性越严重。
用最大特征值对由于λ连续的依赖于ij应的特征向量作为被比较因素对上层某因素影响程度的权向量,其不一致程度越大,引起的判断误差越大。
因而可以用λ―n数值的大小来衡量 A 的不一致程度。
用一致性指标进行检验:max 1nCI n λ-=-。
其中max λ是比较矩阵的最大特征值,n 是比较矩阵的阶数。
(完整word版)层次分析法例题
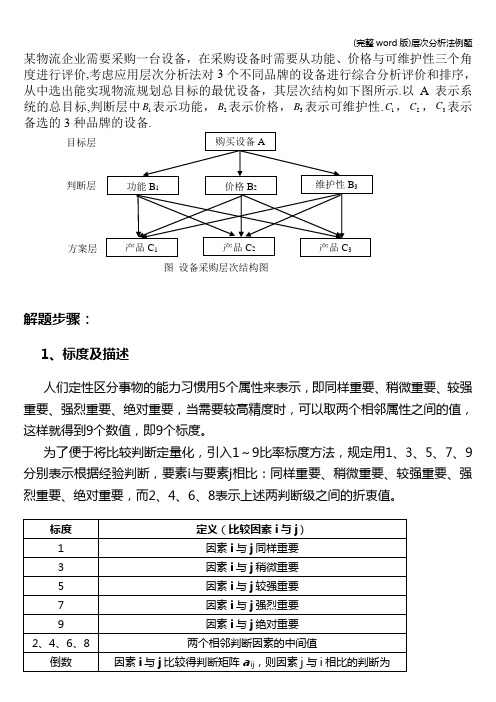
某物流企业需要采购一台设备,在采购设备时需要从功能、价格与可维护性三个角度进行评价,考虑应用层次分析法对3个不同品牌的设备进行综合分析评价和排序,从中选出能实现物流规划总目标的最优设备,其层次结构如下图所示.以A 表示系统的总目标,判断层中1B 表示功能,2B 表示价格,3B 表示可维护性.1C ,2C ,3C 表示备选的3种品牌的设备.解题步骤:1、标度及描述人们定性区分事物的能力习惯用5个属性来表示,即同样重要、稍微重要、较强重要、强烈重要、绝对重要,当需要较高精度时,可以取两个相邻属性之间的值,这样就得到9个数值,即9个标度。
为了便于将比较判断定量化,引入1~9比率标度方法,规定用1、3、5、7、9分别表示根据经验判断,要素i 与要素j 相比:同样重要、稍微重要、较强重要、强烈重要、绝对重要,而2、4、6、8表示上述两判断级之间的折衷值。
目标层判断层方案层 图 设备采购层次结构图注:a ij表示要素i与要素j相对重要度之比,且有下述关系:a ij=1/a ji ;a ii=1;i,j=1,2,…,n显然,比值越大,则要素i的重要度就越高.2、构建判断矩阵A判断矩阵是层次分析法的基本信息,也是进行权重计算的重要依据。
根据结构模型,将图中各因素两两进行判断与比较,构造判断矩阵:●判断矩阵BA-(即相对于物流系统总目标,判断层各因素相对重要性比较)如表1所示;●判断矩阵CB-1(相对功能,各方案的相对重要性比较)如表2所示;●判断矩阵CB-2(相对价格,各方案的相对重要性比较)如表3所示;●判断矩阵CB-3(相对可维护性,各方案的相对重要性比较)如表4所示。
表1判断矩阵BA-表2 判断矩阵CB-1表3 判断矩阵2表4判断矩阵C B-33、计算各判断矩阵的特征值、特征向量及一致性检验指标一般来讲,在AHP 法中计算判断矩阵的最大特征值与特征向量,必不需要较高的精度,用求和法或求根法可以计算特征值的近似值。
层次分析法例题.docx

某物流企业需要采购一台设备,在采购设备时需要从功能、价格与可维护性三个角度进行评价,考虑应用层次分析法对 3 个不同品牌的设备进行综合分析评价和排序,从中选出能实现物流规划总目标的最优设备,其层次结构如下图所示。
以 A 表示系统的总目标,判断层中B1表示功能,B2表示价格, B3表示可维护性。
C1,C2,C3表示备选的3种品牌的设备。
目A判断功能 B1价格B2性B3方案品1品 C品3C2C采次构解题步骤:1、标度及描述人们定性区分事物的能力习惯用 5个属性来表示,即同样重要、稍微重要、较强重要、强烈重要、绝对重要,当需要较高精度时,可以取两个相邻属性之间的值,这样就得到 9个数值,即 9个标度。
为了便于将比较判断定量化,引入1~9比率标度方法,规定用1、3、5、7、9分别表示根据经验判断,要素 i 与要素 j 相比:同样重要、稍微重要、较强重要、强烈重要、绝对重要,而 2、4、6、8表示上述两判断级之间的折衷值。
度定(比因素 i 与 j )1因素 i 与 j 同重要3因素 i 与 j 稍微重要5因素 i 与 j 重要7因素 i 与 j 烈重要9因素 i 与 j 重要2、 4、 6、 8两个相判断因素的中倒数因素 i 与 j 比得判断矩 a ij,因素 j 与 i 相比的判断 a ji =1/ a ij注: a ij表示要素 i 与要素 j 相重要度之比,且有下述关系:a ij =1/a ji;a ii =1; i , j=1 ,2,⋯, n 然,比越大,要素 i 的重要度就越高。
2、构建判断矩阵A判断矩阵是层次分析法的基本信息,也是进行权重计算的重要依据。
根据结构模型,将图中各因素两两进行判断与比较,构造判断矩阵:●判断矩阵 A B( 即相对于物流系统总目标,判断层各因素相对重要性比较 ) 如表 1所示;●判断矩阵 B 1 C ( 相对功能,各方案的相对重要性比较 ) 如表 2 所示;●判断矩阵 B 2 C( 相对价格,各方案的相对重要性比较 ) 如表 3 所示;●判断矩阵 B 3 C( 相对可维护性, 各方案的相对重要性比较 ) 如表 4 所示。
层次分析法例题

二、求解层次分析法()是一种定量与定性相结合的多目标决策分析法,将决策者的经验给予量化,这在对目标(因素)结构复杂且缺乏必要数据的情况下较为实用。
(一)、建立递阶层次结构目标层:最优生鲜农产品流通模式。
准则层:方案的影响因素有:c自然属性、2c经济价值、3c基础1设施、c政府政策。
5方案层:设三个方案分别为:A农产品产地一产地批发市场一销1地批发市场一消费者、A农产品产地一产地批发市场一销地批发2市场一农贸市场一消费者、A农业合作社一第三方物流企业一超3市一消费者(本文假设农产品的生产地和销地不在同一个地区)。
图3—1 递阶层次结构(二)、构造判断(成对比较)矩阵所谓判断矩阵昰以矩阵的形式来表述每一层次中各要素相对其上层要素的相对重要程度。
为了使各因素之间进行两两比较得到量化的判断矩阵,引入1~9的标度,见表3—1.表3—1 标度值目标准则方案为了构造判断矩阵,作者对6个专家进行了咨询,根据专家和作者的经验,四个准则下的两两比较矩阵分别为:(三)、层次单排序及其一致性检验层次单排序就是把本层所有要素针对上一层某一要素,排出评比的次序,这种次序以相对的数值大小来表示。
对应于判断矩阵最大特征根λ的特征向量,经归一化(使向量中各元素之和等于1)后记为W 。
W 的元素为同一层次因素对于上一层次因素某因素相对重要性的排序权值,这一过程称为层次单排序。
能否确认层次单排序,需要进行一致性检验,所谓一致性检验是指对A 确定不一致的允许范围。
由于λ 连续的依赖于ij a ,则λ 比n 大的越多,A 的不一致性越严重。
用最大特征值对应的特征向量作为被比较因素对上层某因素影响程度的权向量,其不一致程度越大,引起的判断误差越大。
因而可以用 λ―n 数值的大小来衡量 A 的不一致程度。
用一致性指标进行检验:max 1nCI n λ-=-。
其中max λ是比较矩阵的最大特征值,n 是比较矩阵的阶数。
CI 的值越小,判断矩阵越接近于完全一致。
层次分析法例题

某物流企业需要采购一台设备,在采购设备时需要从功能、价格与可维护性三个角度进行评价,考虑应用层次分析法对3个不同品牌的设备进行综合分析评价和排序,从中选出能实现物流规划总目标的最优设备,其层次结构如下图所示。
以A 表示系统的总目标,判断层中1B 表示功能,2B 表示价格,3B 表示可维护性。
1C ,2C ,3C 表示备选的3种品牌的设备。
解题步骤:1、标度及描述人们定性区分事物的能力习惯用5个属性来表示,即同样重要、稍微重要、较强重要、强烈重要、绝对重要,当需要较高精度时,可以取两个相邻属性之间的值,这样就得到9个数值,即9个标度。
为了便于将比较判断定量化,引入1~9比率标度方法,规定用1、3、5、7、9分别表示根据经验判断,要素i 与要素j 相比:同样重要、稍微重要、较强重要、强烈重要、绝对重要,而2、4、6、8表示上述两判断级之间的折衷值。
目标层判断层方案层图 设备采购层次结构图注:a ij表示要素i与要素j相对重要度之比,且有下述关系:a ij=1/a ji ;a ii=1;i,j=1,2,…,n显然,比值越大,则要素i的重要度就越高。
2、构建判断矩阵A判断矩阵是层次分析法的基本信息,也是进行权重计算的重要依据。
根据结构模型,将图中各因素两两进行判断与比较,构造判断矩阵:●判断矩阵BA-(即相对于物流系统总目标,判断层各因素相对重要性比较)如表1所示;●判断矩阵CB-1(相对功能,各方案的相对重要性比较)如表2所示;●判断矩阵CB-2(相对价格,各方案的相对重要性比较)如表3所示;●判断矩阵CB-3(相对可维护性,各方案的相对重要性比较)如表4所示。
表1判断矩阵BA-表2 判断矩阵CB-1表3 判断矩阵B2-C表4判断矩阵C B-33、计算各判断矩阵的特征值、特征向量及一致性检验指标一般来讲,在AHP 法中计算判断矩阵的最大特征值与特征向量,必不需要较高的精度,用求和法或求根法可以计算特征值的近似值。
层次分析题汇总

(一)用层次分析法分析下列句子的结构层次,并标明每层的结构关系。
1、她很爱看香山的红叶。
|主|谓||状|中||动|宾||动|宾||定|中|2、这本书的再次出版是我们意料中的事情。
|主|谓||定|中||动|宾||定|中|状|中||定|中||量词|短语||定|中|3、暴虐的李逵杀了许多无辜的百姓。
|主|谓||定|中||动|宾||定|中||定|中|4、他是我们班成绩最优秀的学生。
|主|谓||动|宾||主|谓||定|中||状|中||主|谓||定|中||状|中||量词|短语||介词|短语|12、他青年时期积极投入文化运动。
|主|谓||状|中||定|中||状|中||动|宾||定|中|13.大家都在默默祈祷和平的到来。
|主|谓||状|中||状|中||状|中||动|宾||定|中|14、《说文解字》对于探究上古汉语词义系统具有极其重要的价值。
|主|谓||状|中||介词|短语||动|宾||动|宾||定|中||定|中||状|中||定|中|(注:上古汉语是固定短语)15、鲁迅在一篇文章里,主张打落水狗。
16、在世界各地,保护环境的呼声都很高。
17、举行国庆阅兵有助于提升中国的形象和扩大中国的影响。
18、铃木是我们班口语最好的学生|主||谓||动||宾||定||中||定||中||定||中||主||谓|19、那些科学家已经设计好了解决这个问题的方案。
|主||谓||定||中||状||中心语||动||宾||动||补||述||宾||定||中|20、我没见过这样勇敢的年轻人。
2122232425262728(二)分析下列多重复句。
用“│”、“‖”、“Ⅲ”等分别表示第一、二、三重,在切分线下面标明关系。
(在原句划分即可)1、成功的基础是奋斗,||奋斗的收获是成功,|所以,只有知艰而进和奋斗不已,||才能走上成功的高峰。
并列因果条件2、生活是一张网,‖哪里都觉得有约束和限制,|||同时哪里都觉得有漏洞和机会,│所以,我们应该学会戴着镣铐跳舞,‖而非解说并列因果并列奢望绝对的自由。
关于层次分析法的例题与解.

旅游业发展水平评价问题摘要为了研究比较两个旅游城市Q、Y的旅游业发展水平,建立层次分析法]3[数学模型,对两个旅游城市Q、Y的旅游业发展水平进行了评价.首先,通过对题目中的图1、表1进行了分析与讨论,根据层次分析法,建立了目标层A、准则层B和子准则层C、方案层D四个层次,通过同一层目标之间的重要性的两两比较,得出判断矩阵,利用]1[MATLAB编程对每个判断矩阵进行求解.其次,用MATLAB软件算出决策组合向量,再比较决策组合向量的大小,由“决策组合向量最大”为目标,得出城市Y的决策组合向量为0.4325,城市Q组合向量为0.5675.最后,通过城市Q旅游业发展水平与旅游城市Y旅游业发展水平的决策组合向量比较,得出城市Q的旅游业发展水平较高.关键词层次分析法MATLAB旅游业发展水平决策组合向量1.问题重述本文要求分析QY,两个旅游城市旅游业发展水平,并且给出了两个城市各方面因素的对比,如城市规模与密度,经济条件,交通条件,生态环境条件,宣传与监督,旅游规格,空气质量,城市规模,人口密度,人均GDP,人均住房面积,第三产业增加值占GDP比重,税收GDP,外贸依存度,市内外交通,人均拥有绿地面积,污水集中处理率,环境噪音,国内外旅游人数,理赔金额,立案数量,A级景点数量,旅行社数量,星级饭店数量.建立数学模型进行求解.2.问题分析本文要求分析QY,两个城市的分析Y,两个旅游城市旅游业发展水平,在对Q中,发现需要考虑因素较多,第一、城市规模与密度,包括城市规模与人口密度.第二、经济条件,包括外贸依存度,人均GDP,人均住房面积,第三产业增加值占GDP比重,税收GDP.第三、交通条件,包括市内外交通.第四,生态环境条件包括空气质量,人均绿地面积,污水处理能力,环境噪音.第五、宣传与监督,包括国内外旅游人数,游客投诉立案件数.第六、旅游规格,包括A级景点个数,旅行社个数,星级饭店个数,这就涉及到层次分析法来估算各个指标的权重,评出最优方案.具体内容如下:(1)本文选择了对QY,两个旅游城市旅游业发展水平有影响的19个指标作为评价要素,指标规定如下:城市规模:城市的人口数量.人口密度:单位面积土地上居住的人口数.是反映某一地区范围内人口疏密程度的指标.人口影响城市规模.人口密度越大城市规模也就越大.人均GDP:即人均国内生产总值.人均城建资金:即用于城市建设的资金总投入.第三产业增加值:增加值率指在一定时期内单位产值的增加值.即第三产业增加值越高越能带动城市经济的发展.税收GDP:税收是国家为实现其职能,凭借政治权力,按照法律规定,通过税收工具强制地、无偿地征收参与国民收入和社会产品的分配和再分配取得财政收入的一种形式.外贸依存度:即城市对于外贸交易的依赖程度.市内交通:即城市市区交通情况.市外交通:即城市郊区交通情况.市内交通与市外交通对于城市交通条件具有同等的重要性.空气质量:即城市总体空气质量情况.空气质量越好对于城市生态环境就越好.人均绿地面积:即反应城市绿化面积以及人口密度的比值关系.污水处理能力:城市污水处理水平.环境噪音:城市环境噪音情况.国内外旅客人数:国内外来旅客一年总人数.人数越多说明宣传与监督就越好.理赔金额:即立案后需要赔付的资金数.立案件数:即在旅游时发生违法事件后公安部立案的件数.A 级景点数量:即A 级景点的个数.A 级景点越多,越能带动旅行社数量以及星级饭店数量,则旅游规格越大.旅行社数量:即旅行社的个数.星级饭店数量:即星级饭店在旅游景点的个数.(2)用层次分析法建立模型,根据判断矩阵,利用MATLAB 软件,算出每个判断矩阵的特征向量W 、最大特征根c 、一次性指标CI ,再结合随机一次性指标,得出每个指标的特征向量.(3)用(2)得出的数据,运用MATLAB 软件算出两个城市的决策组合向量,做比较.3.模型假设1.假设两个城市Q 、Y 的人口流动不大.2.假设两个城市Q 、Y 的各项指标短期内不会发生太大的改变.4.符号说明A : 表示目标层;j B : 表示准则层第j 个指标的名称)6,,2,1( =j ;i C : 表示子准则层第i 个指标的名称()19,,2,1 =i ; q D : 表示方案层第q 个指标的名称()2,1=q ;1w : 表示准则层对目标层的特征向量组成的矩阵; 2w : 表示子准则层对准则层的特征向量组成的矩阵; 3w : 表示方案层对子准则层的特征向量组成的矩阵;CI : 表示一次性指标;CR : 表示随机一次性指标; Z : 表示决策组合向量.5.模型建立与求解5.1 根据层次分析法分析以及题目中的图1可以建立如下表5-1的层次分析结构,并构造两两比较判断矩阵在递阶层次结构中,设上一层元素B 为准则层,所支配的下一层元素为1C ……19C ,要确定元素1C ……n C 对于准则层B 相对的重要性即权重,可分为两种情况:(1)如果1C 2C ……n C 对B 的重要性可定量,其权重可直接确定; (2)如果问题复杂,1C 2C ……n C 对B 的重要性无法直接定量,而是一些定性的,确定权重用两两比较方法.(3)其方法是,对于准则层C ,元素i C 和j C 哪一个更重要,重要多少,按1-9比例标度对重要性程度赋值.表5-2中列出了1-9标度的含义.对于准则B ,n 个元素之间相对重要性的比较得到一个两两比较判断矩阵P =()mxn ij P ,表示其中ij P 表示i P 和j P 对B 的影响之比,显然ij P >0,ij P =ijP 1,ij P =1,由ij P 的特点,P 称为正互反矩阵.通过两两判断矩阵用方根法求出他们的最大特征根和特征向量,求法如下: 1. 判断矩阵每一行元素的乘积,其中ij n1j 1p m =∏=,i =1,2…,n .2. 计算i m 的n 次方根_i w ,_i w =n i m .3. 对向量Tn w w w ⎪⎭⎫ ⎝⎛=__1,...,归一化,即∑==n j ji w 1__i w w ,则Tn w w w ⎪⎭⎫⎝⎛=__1,...,为所求的特征向量.4. 计算判断矩阵的最大特征跟m ax λ,()∑==n1max i iinw pw λ,式中()i pw 表示pw 的第i 个元素.5. 定义⎪⎭⎫ ⎝⎛--=1max n n CI CI λ为矩阵A 的一致性指标,为了确定A 的不一致性程度的容许范围,需要找出衡量A 的一致性指标CI 的标准.引入随机一致性指标RI .平均随机一致性指标RI 是这样得到的;对于固定的n ,随机构造正互反矩阵A ,其中ij a 是从1,2,……9,91......31,21中随机抽取的,这样的A 是最不一致的,取充分大的样子(500个样本)得到A 的最大特征跟的平均值m ax λ,定义⎪⎭⎫ ⎝⎛--=1max n n RI λ,对于不同的n 得出随机一致性指标RI 的数值如下表5-3表中n =1,2时RI =0,是因为1,2阶的正互反矩阵总是一致阵.令RICICR =,称CR 为一致性比率,当CR <0.1时,本文认为判断矩阵具有满意的一致性,否则就需要调整判断矩阵,使之具有满意的一致性.最后通过计算得出下表5-4(其中n B 表示准则层的特征向量中的第n 个数值,in C 表示指标层的特征向量第n 个准则对第j 个指标的数值)层次总排序一致性检验的方法j n1CI c CI j j ∑==j n 1c RI RI j j ∑==RICI CR =若1.0CR时,所以认为判断矩阵具有满意的一致性,否则就需要调整判断.矩阵,使之具有满意的一致性.5.2根据层次分析法求出各个指标的权重依据题目中的表1分析,对本题做出其中一种假设:(1)经济条件和交通条件重要性相当,生态环境条件最重要,旅游规格、宣传与监督、城市规模与密度依次次之.(2)在城市规模与密度中,城市人口比人口密度重要一点.(3)在经济条件中,第三产业增加值GDP第一重要,其次是人均GDP,税收GDP、外贸依存度、人均城建资金依次次之.(4)在交通条件中,市内交通和市外交通的重要性相当.(5)在生态环境条件中,空气质量第一重要,其次是人均绿地面积,污水处理能力、环境噪音依次次之.(6)在宣传与监督中,国内外旅游人数第一重要,理赔金额、游客投诉立案件数重要性相当.(7)在旅游规格中,A级景点个数第一重要,星级饭店个数、旅行社个数依次次之.(8)对于城市规模,城市Q比城市Y的重要性小一些;对于人口密度,城市Y比城市Q的重要性明显重要;对于人均GDP,城市Q比城市Y的重要性稍重要;对于人均城建资金,城市Q比城市Y的重要性稍微重要;对于第三产业增加值GDP,城市Q比城市Y的重要性小一些;对于税收GDP,城市Q比城市Y的重要性稍小一点;对于外贸依存度,城市Q比城市Y的重要性稍重要;对于市内交通,城市Y比城市Q的重要性稍重要一点;对于市外交通,城市Y比城市Q的重要性比稍重要小一点;归于空气质量,城市Q比城市Y的重要性相当;对于人均绿地面积,城市Y比城市Q的重要性稍重要;对于污水处理能力,城市Y比城市Q的重要性稍重要一些;对于环境噪音,城市Q比城市Y的重要性相当;对于国内外旅游人数,城市Q比城市Y的重要性稍重要;对于理赔金额,城市Q比城市Y的重要性稍重要一些;对于游客投诉立案件数,城市Q比城市Y的重要性稍重要;对于A级景点个数,城市Y比城市Q的重要性稍重要小一些;对于旅行社个数,城市Y比城市Q的重要性稍重要小一些;对于星级饭店个数,城市Q比城市Y的重要性相当.根据上述分析,按1-9比例标度对准则层对目标层、子准层对准则层、目标层对子准则层的重要程度进行赋值,构造准则层对目标层的判断矩阵、子准则层对准则层的判断矩阵、方案层对子准则层的判断矩阵.准则层()6,,2,1 =j B j 对目标层A 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=12312121321141313123412252321114232111431215141411A 利用MATLAB 软件(附录1)求得 最大特征值0719.6max =λ特征向量⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=1219.00753.03422.02057.02057.00492.01w一致性检验比率1.00116.0<=CR所以矩阵满足一致性检验.子准则层21,C C 对准则层1B 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=131311B利用MATLAB 软件(附录2)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 子准则层76543,,,,C C C C C 对准则层2B 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=121412312131321431522131511413221412B 利用MATLAB 软件(附录3)求得 最大特征值0681.5max =λ特征向量⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=0973.01599.04185.00618.02625.0w一致性检验比率1.00152.0<=CR所以矩阵满足一致性检验.子准则层98,C C 对准则层3B 的判断矩阵⎥⎦⎤⎢⎣⎡=11113B 利用MATLAB 软件(附录4)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 子准则层13121110,,,C C C C 对准则层4B 的判断矩阵⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎣⎡=1121311121312212133214B 利用MATLAB 软件(附录5)求得最大特征值0104.4max =λ特征向量⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡=1409.01409.02628.04554.0w 一致性检验比率1.00038.0<=CR所以矩阵满足一致性检验.子准则层161514,,C C C 对准则层5B 的判断矩阵⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=1221211212215B 利用MATLAB 软件(附录6)求得最大特征值0536.3max =λ特征向量⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=3108.01958.04934.0w 一致性检验比率1.00462.0<=CR所以矩阵满足一致性检验.子准则层191817,,C C C 对准则层6B 的判断矩阵⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎣⎡=1221211312316B 利用MATLAB 软件(附录7)求得最大特征值0092.3max =λ特征向量⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=2970.01634.05396.0w 一致性检验比率1.00079.0<=CR所以矩阵满足一致性检验.方案层对子准则层的判断矩阵 方案层21,D D 对子准则层1C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=122111C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层2C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=155112C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎢⎣=1667.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层3C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=133113C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层4C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=144114C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层5C 的判断矩阵:⎥⎥⎦⎤⎢⎢⎣⎡=122115C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎢⎣=3333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层6C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=133116C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层7C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=141417C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层8C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=155118C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎢⎣=8333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层9C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=122119C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层10C 的判断矩阵⎥⎦⎤⎢⎣⎡=111110C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层11C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1313111C利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=7500.02500.0w因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层12C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1414112C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2000.08000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层13C 的判断矩阵⎥⎦⎤⎢⎣⎡=111113C 利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层14C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331114C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验.2115⎥⎥⎦⎤⎢⎢⎣⎡=1441115C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=8000.02000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层16C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331116C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=2500.07500.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层17C 的判断矩阵⎥⎥⎦⎤⎢⎢⎣⎡=1331117C利用MATLAB 软件(附录8)求得最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验.2118⎥⎥⎦⎤⎢⎢⎣⎡=1221118C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=6667.03333.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 方案层21,D D 对子准则层19C 的判断矩阵:⎥⎦⎤⎢⎣⎡=111119C 利用MATLAB 软件(附录8)求得 最大特征值2max =λ特征向量为⎥⎦⎤⎢⎣⎡=5000.05000.0w 因为当2=n 时,0=RI ,2阶的正反矩阵总是一致性,所以满足一致性检验. 通过准则层()6,,2,1 =j B j 对目标层A 的判断矩阵、子准则层()19,,2,1 =i C i 对准则层()6,,2,1 =j B j 的判断矩阵得出特征向量,建立层次总表5-5层次总排序一致性检验如下:0073.061==∑=j j j CI B CI65274.0j 61j j ==∑=RI B RI0111.065274.00073.0===RI CI CR 由于1.00111.0<=CR ,所以认为层次总排序的结果具有满意的一致性,因此不需要重新调整判断矩阵的元素取值.5.3 利用MATLAB 进行决策组合向量的运算(附录9)⋅⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡=⋅⋅=Tw w w Z 2970.0001634.0000005396.00000003108.0000001958.0000004934.00000001409.0000001409.0000002628.0000004554.00000005000.0000005000.00000000973.000001599.0000004185.0000000618.0000002625.00000002500.0000007500.0132⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡5000.05000.06667.03333.06667.03333.02500.07500.08000.02000.02500.07500.05000.05000.02000.08000.07500.02500.05000.05000.06667.03333.01667.08333.08000.02000.02500.07500.06667.03333.02000.08000.02500.07500.08333.01667.03333.06667.0⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡⋅1219.00753.03422.02057.02057.00492.0 Z ⎥⎦⎤⎢⎣⎡=5675.04325.0 比较Z 值大小可知,12Z Z >,表明城市Q 的旅游发展也水平最高,城市Y 的旅游业发展水平次之,所以城市Q 的旅游发展也水平高.6模型的评价优点:(1) 本文选择了计算比较简单的层次分析法,经过计算得到了相应的综合发展旅游业的估计值,为城市旅游业的发展提供了依据.(2) 使用了MATLAB 软件,减少了计算工作量,大大降低了运算的困难.缺点:判断的结果具有一定的主观性,不能比较切实的结合当地的具体情况,做出科学的决策方案.7参考文献[1] 姜启源等,数学建模(第四版)北京:高等教育出版社.2011年[2] 马莉,数学实验与建模,北京:清华大学出版2010年[3] 王莲芬,层次分析法引论,北京:中国人民大学出版社,1990年附录:附录1x=[1 1/4 1/4 1/5 1/2 1/3;4 1 1 1/2 3 2;4 1 1 1/2 3 2;5 2 2 1 4 3;2 1/3 1/3 1/4 1 1/2;3 1/2 1/2 1/3 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-6)/5 %一致性指标CR=CI/1.24 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =6.0719W =0.04920.20570.20570.34220.07530.1219B =0.04670.21410.21410.29180.08810.1452CI =0.0144CR =0.0116C =0.2146附录2:>> x=[1 3;1/3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250附录3:x=[1 4 1/2 2 3;1/4 1 1/5 1/3 1/2;2 5 1 3 4;1/2 3 1/3 1 2;1/3 2 1/4 1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-5)/4 %一致性指标CR=CI/1.12 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =5.0681W =0.26250.06180.41850.15990.0973B =0.27340.05940.36640.18730.1135CI =0.0170CR =0.0152C =0.2698附录4:x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000附录5:x=[1 2 3 3;1/2 1 2 2;1/3 1/2 1 1;1/3 1/2 1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-4)/3 %一致性指标CR=CI/0.90 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =4.0104W =0.45540.26280.14090.1409B =0.43950.27870.14090.1409CI =0.0035CR =0.0038C =0.3131附录6:x=[1 2 2;1/2 1 1/2;1/2 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-3)/2 %一致性指标CR=CI/0.58 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =3.0536W =0.49340.19580.3108B =0.46060.18790.3515CI =0.0268CR =0.0462C =0.3733附录7:x=[1 3 2;1/3 1 1/2;1/2 2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-3)/2 %一致性指标CR=CI/0.58 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =3.0092W =0.53960.16340.2970B =0.51990.16200.3181CI =0.0046CR =0.0079C =0.4015附录8:% 目标层Q,Y对子准则层C1的赋值>> x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C2的赋值x=[1 5;1/5 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.83330.1667B =0.83330.1667CI =CR =NaNC =0.7222End% 目标层Q,Y对子准则层C3的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C4的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.80000.2000B =0.80000.2000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C5的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.66670.3333B =0.66670.3333CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C6的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C7的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.20000.8000B =0.20000.8000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C8的赋值x=[1 5;1/5 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.16670.8333B =0.16670.8333CI =CR =NaNC =0.7222End% 目标层Q,Y对子准则层C9的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C10的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =NaNC =0.5000% 目标层Q,Y对子准则层C11的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.25000.7500B =0.25000.7500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C12的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =W =0.80000.2000B =0.80000.2000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C13的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000% 目标层Q,Y对子准则层C14的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C15的赋值x=[1 4;1/4 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.20000.8000B =0.20000.8000CI =CR =NaNC =0.6800End% 目标层Q,Y对子准则层C16的赋值x=[1 1/3;3 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.75000.2500B =0.75000.2500CI =CR =NaNC =0.6250End% 目标层Q,Y对子准则层C17的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C18的赋值x=[1 2;1/2 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.33330.6667B =0.33330.6667CI =CR =NaNC =0.5556End% 目标层Q,Y对子准则层C19的赋值x=[1 1;1 1];[V,D]=eig(x);%c=max(diag(D)) %最大特征根位置f=find(diag(D)==max(diag(D))); %求lamda(最大特征根)位置----其中:diag 为矩阵对角线上的元素W=V(:,f)/sum(V(:,f)) %归一特征向量B=x/sum(x) %计算权向量CI=(c-2)/1 %一致性指标CR=CI/0 %一致性比率,要小于0.1C=sum(B.*W) %组合权重运算结果:c =2W =0.50000.5000B =0.50000.5000CI =CR =NaNC =0.5000附录9:% 最终组合权向量:x=[0.75 0 0 0 0 0;0.25 0 0 0 0 0;0 0.2625 0 0 0 0;0 0.0618 0 0 0 0;0 0.4185 0 0 0 0;0 0.1599 0 0 0 0;0 0.0973 0 0 0 0;0 0 0.5 0 0 0;0 0 0.5 0 0 0;0 0 0 0.4554 0 0;0 0 0 0.2628 0 0;0 0 0 0.1409 0 0;0 0 0 0.1409 0 0;0 0 0 0 0.4934 0;0 0 0 0 0.1958 0;0 0 0 0 0.3108 0;0 0 0 0 0 0.5396;0 0 0 0 0 0.1634;0 0 0 0 0 0.2970]x =0.7500 0 0 0 0 00.2500 0 0 0 0 00 0.2625 0 0 0 00 0.0618 0 0 0 00 0.4185 0 0 0 00 0.1599 0 0 0 00 0.0973 0 0 0 00 0 0.5000 0 0 00 0 0.5000 0 0 00 0 0 0.4554 0 00 0 0 0.2628 0 00 0 0 0.1409 0 00 0 0 0.1409 0 00 0 0 0 0.4934 00 0 0 0 0.1958 00 0 0 0 0.3108 00 0 0 0 0 0.53960 0 0 0 0 0.16340 0 0 0 0 0.2970y=[0.0492;0.2057;0.2057;0.3422;0.0753;0.1219]y =0.04920.20570.20570.34220.07530.1219z=x*y运算结果:z =0.03690.01230.05400.01270.08610.03290.02000.10290.10290.15580.08990.04820.04820.03720.01470.02340.06580.01990.0362a=[0.3333 0.8333 0.75 0.2 0.3333 0.75 0.2 0.1667 0.3333 0.5 0.25 0.8 0.5 0.75 0.2 0.75 0.3333 0.3333 0.5;0.6667 0.1667 0.25 0.8 0.6667 0.250.8 0.8333 0.6667 0.5 0.75 0.2 0.5 0.25 0.8 0.25 0.6667 0.6667 0.5]a =Columns 1 through 70.3333 0.8333 0.7500 0.2000 0.3333 0.7500 0.20000.6667 0.1667 0.2500 0.8000 0.6667 0.2500 0.8000Columns 8 through 140.1667 0.3333 0.5000 0.2500 0.8000 0.5000 0.75000.8333 0.6667 0.5000 0.7500 0.2000 0.5000 0.2500Columns 15 through 190.2000 0.7500 0.3333 0.3333 0.50000.8000 0.2500 0.6667 0.6667 0.5000c=a*z运算结果:c =0.43250.5675。
层次分析法例题 (1)

资料范本本资料为word版本,可以直接编辑和打印,感谢您的下载层次分析法例题 (1)地点:__________________时间:__________________说明:本资料适用于约定双方经过谈判,协商而共同承认,共同遵守的责任与义务,仅供参考,文档可直接下载或修改,不需要的部分可直接删除,使用时请详细阅读内容层次分析法在最优生鲜农产品流通中的应用班级(一)、建立递阶层次结构目标层:最优生鲜农产品流通模式。
准则层:方案的影响因素有:自然属性、经济价值、基础设施、政府政策。
方案层:设三个方案分别为:农产品产地一产地批发市场一销地批发市场一消费者、农产品产地一产地批发市场一销地批发市场一农贸市场一消费者、农业合作社一第三方物流企业一超市一消费者(本文假设农产品的生产地和销地不在同一个地区)。
方案层:G:最优生鲜农产品流通模式自然属性基础设施经济价值政府政策目标层:准则层:图3—1 递阶层次结构(二)、构造判断(成对比较)矩阵所谓判断矩阵昰以矩阵的形式来表述每一层次中各要素相对其上层要素的相对重要程度。
为了使各因素之间进行两两比较得到量化的判断矩阵,引入1~9的标度,见表为了构造判断矩阵,作者对6个专家进行了咨询,根据专家和作者的经验,四个准则下的两两比较矩阵分别为:(三)、层次单排序及其一致性检验层次单排序就是把本层所有要素针对上一层某一要素,排出评比的次序,这种次序以相对的数值大小来表示。
对应于判断矩阵最大特征根λmax的特征向量,经归一化(使向量中各元素之和等于1)后记为W。
W的元素为同一层次因素对于上一层次因素某因素相对重要性的排序权值,这一过程称为层次单排序。
能否确认层次单排序,需要进行一致性检验,所谓一致性检验是指对A确定不一致的允许范围。
由于λ 连续的依赖于,则λ 比n 大的越多,A 的不一致性越严重。
用最大特征值对应的特征向量作为被比较因素对上层某因素影响程度的权向量,其不一致程度越大,引起的判断误差越大。
层次分析法(2012)

n
可见,判断矩阵A-C具有满意的一致性。故有:
(1)着眼于提高企业的技术水平(C2) (2)改善职工的物质文化生活(C3) (3)调动职工的生产积极性(C1)
21
0.6372 0.2583 0.1042
(2)判断矩阵C1- P 如该厂认为:针对准则C1,有:P1最重要,P2很重要,P4重
C2
C3
W
0.1111 0.1304 0.0769 0.1042 0.5556 0.6522 0.6923 0.6372 0.3333 0.2174 0.2308 0.2583
1 1/ 5 1/ 3
AW=
0.1042 0.6372 0.2583
=
0.3177 1.9331 0.7833
5
1
3 1
3 1/ 3
ห้องสมุดไป่ตู้
P5:引进 新设备
判断矩阵C2- P
C2 P2 P3 P4
P2
1 7 3 5
P3
P4
P5
1/5 3 1/3 1
W
0.055 0.564
1/7 1/3 1 5 1/5 1/3 1 3
0.118
0.263
P5
max 4.117
RI 0.90
CI 0.039 CR 0.043<0.10
• 使用AHP,判断矩阵A的一致性很重要,但要求所 有判断都有完全的一致性不大可能。因此,一般只 要求A具有满意的一致性,此时λmax稍大于矩阵阶 数n,其余特征根接近零。这时,基于AHP得出的 结论才基本合理。为使所有判断保持一定程度上的 一致,AHP步骤中需要进行一致性检验。
10
判断矩阵是针对上一层次某因素而言,本层次与 之有关的各因素之间的相对重要性的数量表示。这是 将定性判断转变为定量表示的一个过程。 设准则层中因素Ck 与下一层P中的因素P1,P2,…,Pn 有关,则构造的判断矩阵如下表:
层次分析法例题

某物流企业需要采购一台设备,在采购设备时需要从功能、价格与可维护性三个角度进行评价,考虑应用层次分析法对3个不同品牌的设备进行综合分析评价和排序,从中选出能实现物流规划总目标的最优设备,其层次结构如下图所示。
以A 表示系统的总目标,判断层中1B 表示功能,2B 表示价格,3B 表示可维护性。
1C ,2C ,3C 表示备选的3种品牌的设备。
、9分ij a ij =1/a ji ;a ii =1;i ,j=1,2,…,n显然,比值越大,则要素i 的重要度就越高。
2、构建判断矩阵A判断矩阵是层次分析法的基本信息,也是进行权重计算的重要依据。
根据结构模型,将图中各因素两两进行判断与比较,构造判断矩阵:●判断矩阵B A -(即相对于物流系统总目标,判断层各因素相对重要性比较)如表1所示;●判断矩阵C B -1(相对功能,各方案的相对重要性比较)如表2所示; ●判断矩阵C B -2(相对价格,各方案的相对重要性比较)如表3所示; ●判断矩阵C B -3(相对可维护性,各方案的相对重要性比较)如表4所 示。
表1判断矩阵B A -3●求和法1)将判断矩阵A 按列归一化(即列元素之和为1):b ij =a ij /Σa ij ; 2)将归一化的矩阵按行求和:c i =Σb ij (i=1,2,3….n ); 3)将c i 归一化:得到特征向量W =(w 1,w 2,…w n )T ,w i =c i /Σc i , W 即为A 的特征向量的近似值;4)求特征向量W 对应的最大特征值: ●求根法1)计算判断矩阵A 每行元素乘积的n 次方根;n nj iji aw ∏==1(i=1,2,…,n)2)将i w 归一化,得到∑==ni iii ww w 1;W =(w 1,w 2,…w n )T 即为A 的特征向量的近似值;3)求特征向量W 对应的最大特征值:(1)判断矩阵B A -的特征根、特征向量与一致性检验 ①计算矩阵B A -的特征向量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
层次分析法在最优生鲜农产品流通中的应用
班级
(一)、建立递阶层次结构
目标层:最优生鲜农产品流通模式。
准则层:方案的影响因素有:1c 自然属性、2c 经济价值、3c 基础设施、5c 政府政策。
方案层:设三个方案分别为:1A 农产品产地一产地批发市场一销地批发市场一消费者、2A 农产品产地一产地批发市场一销地批发市场一农贸市场一消费者、3A 农业合作社一第三方物流企业一超市一消费者(本文假设农产品的生产地和销地不在同一个地区)。
。
图3—1 递阶层次结构
(二)、构造判断(成对比较)矩阵
所谓判断矩阵昰以矩阵的形式来表述每一层次中各要素相对其上层要素的相对重要程度。
为
目标层:
准则层:
方案层:
了使各因素之间进行两两比较得到量化的判断矩阵,引入1~9的标度,见表
为了构造判断矩阵,作者对6个专家进行了咨询,根据专家和作者的经验,四个准则下的两两比较矩阵分别为:
(三)、层次单排序及其一致性检验
层次单排序就是把本层所有要素针对上一层某一要素,排出评比的次序,这种次序以相对的数值大小来表示。
对应于判断矩阵最大特征根λmax的特征向量,经归一化(使向量中各元素之和等于1)后记为W。
W的元素为同一层次因素对于上一层次因素某因素相对重要性的排序权值,这一过程称为层次单排序。
能否确认层次单排序,需要进行一致性检验,所谓一致性检验是指对A确定不一致的允许范围。
a,则λ比n 大的越多,A 的不一致性越严重。
用最大特征值对由于λ连续的依赖于
ij
应的特征向量作为被比较因素对上层某因素影响程度的权向量,其不一致程度越大,引起的判断误差越大。
因而可以用λ―n数值的大小来衡量 A 的不一致程度。
用一致性指标进行检验:max 1
n
CI n λ-=
-。
其中max λ是比较矩阵的最大特征值,n 是比较矩
阵的阶数。
CI 的值越小,判断矩阵越接近于完全一致。
反之,判断矩阵偏离完全一致的程度越大。
(四)、层次总排序及其一致性检验
)0(273.0104.0056.0567.0092.1418.0224.0266.2222.0316.0353.0201
.0074.0105.0118.0121
.0037.0053.0059.0075
.0667.0526.0470.0603
.0136131121121113581
W
A =⎪⎪⎭⎪⎪
⎬⎫⎪⎪⎩⎪⎪⎨⎧−−−→−⎪⎪
⎭
⎪
⎪⎬
⎫
⎪⎪⎩⎪⎪⎨⎧−−−−→−⎪⎪⎭⎪⎪⎬⎫⎪⎪⎩⎪⎪⎨
⎧−−−−−−→−⎪⎪⎭⎪⎪⎬⎫⎪⎪⎩⎪⎪⎨
⎧=归一化按行求和列向量归一化
()T
AW 273.0,104.0,056.0,567.0073
.4273.0110.1104.0422.0056.0225.0567.0354.241110.1422.0225.0354.2273.0104.0056.0567.0136311121612118135
81)0(max )0()
0(==⎪⎭
⎫
⎝⎛+++=⎪⎪⎭⎪⎪⎬
⎫⎪⎪⎩⎪⎪⎨⎧=⎪⎪⎭⎪⎪⎬⎫⎪⎪⎩⎪⎪⎨⎧⎪⎪⎭⎪⎪⎬⎫⎪⎪⎩⎪⎪⎨⎧=ωλ
同理可计算出判断矩阵
⎪⎭⎪⎬
⎫
⎪⎩⎪⎨⎧=⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧=⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧=⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧=179711391111117121921,1811811931,189811313114321B B B B ,
对应的最大特征值与特征向量依次为:
.
776.0155.0069.0,083.3;
058.0347.0595.0,024.3;054.0306.0640.0,216.3;786.0146.0068.0,111.34)1(max )4(3)1(max )3(2)1(max )2(1)1(max )1(⎪⎭
⎪
⎬⎫⎪⎩⎪⎨⎧==⎪⎭⎪
⎬⎫
⎪⎩⎪⎨⎧==⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧==⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧==ωλωλωλωλ用一致性指标进行检验:max 1
n
CI n λ-=
-,
RI CI
CR =
(1)对于判断矩阵A ,λmax =4.073,RI=0.90
1
.0027.090.0024.0024.0144
073.4<====--=
RI CI CR CI 表示A 的不一致程度在容许范围内,此时可用A 的特征向量代替权向量。
(2)同理,对于判断矩阵B 1,B 2,B 3,B 4利用上述原理均通过一致性检验。
利用层次结构图绘出从目标层到方案层的计算结果:
⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧⎪⎭
⎪⎬⎫
⎪⎩⎪⎨⎧⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧776.0155.0069.0,058.0347.0595.0,054.0306.0640.0,786.0146.0068.0
目标层:
准则层:
()
⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧==776.0058.0054.0786.0155.0347.0306.0146.0069.0595.0640.0068.0,,,4)1(3)1(2)1(1)1()1(ωωωωω
⎪⎭
⎪⎬⎫⎪⎩⎪⎨⎧=⎪⎪⎭⎪⎪⎬⎫
⎪⎪⎩⎪⎪⎨⎧⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧==667.0178.0155.0273.0104.0056.0567.0776.0058.0054.0786.0155.0347.0306.0146.0069.0595.0640.0068.0)
0()1(ωωω
决策结果:是首选方案A 3,其次是方案A 2,再次是方案A 1.。