keil解决中文乱码设置
中文乱码解决方案

中文乱码解决方案一、引言随着全球化进程的加速,跨国交流和跨文化交流变得越来越频繁。
作为全球最大的人口国家之一,中国在国际交流中发挥着重要的作用。
然而,在跨文化交流的过程中,我们常常会遇到一个共同的问题,即中文乱码。
中文乱码是指在计算机系统中,由于编码方式不兼容或设置错误,导致中文字符无法正确显示的现象。
本文将介绍一些常见的中文乱码问题以及解决方案。
二、常见中文乱码问题及原因1. 网页中出现乱码在浏览网页时,我们经常会遇到中文乱码的问题,这主要是由于网页编码方式不兼容或设置错误所引起的。
常见的编码方式包括UTF-8、GBK、GB2312等,如果网页编码方式与浏览器设置的编码方式不一致,就会导致中文字符无法正确显示。
2. 文本文件打开后乱码当我们使用文本编辑器打开一个文本文件时,如果文件的编码方式与编辑器的默认编码方式不一致,就会导致文件内容显示为乱码。
常见的文本文件编码方式有UTF-8、GBK、GB2312等。
3. 数据库中存储的中文乱码在数据库中存储中文信息时,如果数据库的编码方式设置不正确,就会导致存储的中文字符显示为乱码。
常见的数据库编码方式有UTF-8、GBK、GB2312等。
三、中文乱码解决方案1. 网页中文乱码解决方案(1)设置浏览器编码方式:在浏览器的设置选项中,找到编码方式(通常在“字符编码”、“编码”或“语言”选项下),将其设置为与网页编码方式一致的选项,如将编码方式设置为UTF-8。
(2)手动指定网页编码:如果网页上没有明确设置编码方式的选项,可以尝试在浏览器地址栏中手动添加编码方式,如在URL后面添加“?charset=utf-8”。
2. 文本文件乱码解决方案(1)使用支持多种编码方式的文本编辑器:选择一个支持多种编码方式的文本编辑器,如Notepad++、Sublime Text等。
在打开文本文件时,可以手动选择文件的编码方式来正确显示内容。
(2)重新保存文件:将文本文件另存为选项,选择正确的编码方式,再重新打开文件即可解决乱码问题。
开发过程遇到的中文乱码问题如何解决

开发过程遇到的中文乱码问题如何解决1.数据库编码不一致导致乱码解决方法:首先查看数据库编码,输入:show variables like "%char%";确认编码一致,如果不一致,可输入:SET character_set_client='utf8';SET character_set_connection='utf8';SET character_set_results='utf8';也可设置成gbk编码;也可以在安装Mysql目录下修改my.ini文件default-character-set=utf-82.jsp页面乱码问题在myeclipse中jsp的默认编码为ISO-8859-8;只需在页面头部修改为<%@page pageEncoding="UTF-8" contentType="text/html; charset=UTF-8" %>在JSP页面头部加入下面这句话,告诉浏览器应该调用UTF-8的字符集。
<meta http-equiv="Content-Type"content="text/html; charset=utf-8 "/>3.jsp连接数据库存入中文乱码在数据库连接时jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncodin g=utf-8如果使用框架连接则把头文件都修改成UTF-8编码即可4.在使用struts2可使用过滤器:先变写一个过滤器package com.oumyye.util;import java.io.IOException;import javax.servlet.Filter;import javax.servlet.FilterChain;import javax.servlet.FilterConfig;import javax.servlet.ServletException;import javax.servlet.ServletRequest;import javax.servlet.ServletResponse;public class CharacterEncodingFilter implements Filter{protected String encoding = null;protected FilterConfig filterConfig = null;public void init(FilterConfig filterConfig) throws ServletExc eption {this.filterConfig = filterConfig;this.encoding = filterConfig.getInitParameter("encoding") ; } public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { if (encoding != null) { request.setCharacterEncoding(encoding) ; response.setContentType("text/html; charset="+encoding); } chai n.doFilter(request, response); } public void destroy() { this.enc oding = null; this.filterConfig = null;}}在web.xml中配置<?xml version="1.0" encoding="UTF-8"?><web-app xmlns:xsi="/2001/XMLSchema-instance" xm lns="/xml/ns/javaee" xmlns:web="http://java.su /xml/ns/javaee/web-app_2_5.xsd" xsi:schemaLocation="http://j /xml/ns/javaee /xml/ns/javaee/web-a pp_3_0.xsd" version="3.0"><display-name>0001web</display-name><!-- 中文编码过滤器 --><filter><filter-name>CharacterEncodingFilter</filter-name><filter-class>com.oumyye.util.CharacterEncodingFilter</fi lter-class><init-param><param-name>encoding</param-name><param-value>UTF-8</param-value></init-param></filter><filter-mapping><filter-name>CharacterEncodingFilter</filter-name><url-pattern>/*</url-pattern><dispatcher>REQUEST</dispatcher><dispatcher>FORWARD</dispatcher></filter-mapping>在表单中只能使用post传值,此方法对于get无效。
keil 切换编码中文乱码的一种手动解决方法 -回复

keil 切换编码中文乱码的一种手动解决方法-回复在Keil中遇到编码问题时,出现中文乱码是很常见的情况。
中文乱码的出现主要是由于编码方式不匹配所致,这篇文章将介绍一种手动解决方法来切换Keil的编码以解决中文乱码问题。
第一步:确认编码方式首先,我们需要确认当前Keil的编码方式。
在Keil中,可以通过打开一个文本文件来确认当前的编码方式。
在菜单栏中选择"File" -> "Open",然后在弹出的对话框中选择一个中文文件并打开。
如果文件正常显示中文内容,则说明Keil的编码方式与该文件相匹配;如果出现乱码,则需要进行后续的切换编码操作。
第二步:打开设置在Keil的菜单栏中选择"Project" -> "Options for Target"。
在打开的对话框中选择"C/C++" 选项卡,然后点击"Language Extensions" 选项。
第三步:切换编码方式在"Language Extensions" 选项卡中,可以看到"Character Encoding" 的设置。
一般情况下,Keil默认使用的是"US ASCII" 编码方式,而中文需要使用"GB2312" 或者"UTF-8" 编码方式。
我们可以尝试依次选择这两种编码方式,然后点击"OK" 按钮保存设置。
第四步:重新打开文件完成编码方式的切换后,需要重新打开中文文件来查看是否解决了中文乱码问题。
按照第一步的方法打开一个中文文件,如果文件能够正常显示中文内容,则说明切换编码方式成功;如果还是出现乱码,可以尝试重新选择其他编码方式进行设置。
其他注意事项:- 在切换编码方式之前,建议备份项目文件,以免操作错误导致文件损坏或丢失。
单片机的中文显示处理技巧

单片机的中文显示处理技巧单片机作为嵌入式系统中的重要组成部分,其在各个领域的应用日益广泛。
在很多情况下,我们需要通过单片机实现中文的显示,因此掌握单片机的中文显示处理技巧是非常必要的。
本文将介绍几种常见的单片机中文显示处理技巧,旨在帮助读者更好地理解和应用。
一、汉字的编码问题在开始讨论单片机的中文显示处理技巧之前,我们首先需要了解汉字的编码方式。
目前最常用的汉字编码方式是GB2312和Unicode。
GB2312采用两个字节表示一个汉字,而Unicode则采用更多的字节,可以覆盖更多的字符。
在单片机中,我们通常会采用GB2312编码方式进行中文字符的表示和处理。
二、字库的引入和使用为了实现单片机的中文显示,我们需要一个字库,即包含了各种中文字符的数据表。
我们可以从官方渠道或者其他第三方资源中获取相应的字库。
在实际应用中,我们可以将字库编译为数组或者独立的数据文件,并将其导入到单片机的存储器中。
然后,我们可以通过访问相应的地址来获取并显示中文字符。
三、液晶显示屏的使用技巧在实际应用中,我们通常会使用液晶显示屏来实现单片机的中文显示。
下面是几个液晶显示屏使用中的注意事项:1. 设置字符显示模式:液晶显示屏中一般包含有字符发生器,我们可以通过设置字符显示模式来选择使用汉字编码还是英文字母编码。
2. 设置显示位置:在使用液晶显示屏显示汉字之前,我们需要设置显示位置,即将显示的汉字写入指定的坐标位置。
3. 字符的显示方式:液晶显示屏通常有多种显示方式,例如点阵式显示和字符行显示等。
我们可以根据实际需求选择合适的显示方式。
四、中文字符串的处理技巧除了显示单个中文字符之外,有时候我们还需要处理中文字符串。
在处理中文字符串时,我们需要注意以下几点:1. 字符串的存储方式:中文字符串通常会占用更多的存储空间,因此在设计程序时需要合理安排存储,以免出现内存溢出等问题。
2. 字符串的显示方式:在液晶显示屏上显示中文字符串时,我们可以选择逐个显示字符,也可以选择将整个字符串作为一个整体进行显示。
中文乱码解决方法

中文乱码解决方法
1.使用正确的字符编码
2.转换文件编码格式
如果你打开一个文本文件或者网页时发现中文显示为乱码,可能是由
于文件的编码格式不正确导致的。
你可以尝试将文件的编码格式转换为正
确的格式。
Windows操作系统中可以使用记事本打开文件,另存为时选择
正确的编码方式即可。
Mac和Linux系统可以使用终端命令行工具进行转换,具体方法可以参考相关操作系统的文档和教程。
3.选择正确的字体
有时候中文显示为乱码是由于缺乏相应的字体文件所致。
当你打开一
个文档或者网页时,如果使用的字体不包含中文字符,那么中文可能会显
示为乱码或者方块。
解决方法是选择适合的字体。
一般来说,宋体、微软
雅黑、黑体等字体都包含了常用的中文字符,并且具有良好的兼容性。
4.更新操作系统和应用程序
乱码问题有时也可能是由于操作系统或者应用程序的bug导致的。
这
些bug可能会导致字符编码不正确或者字体渲染错误。
为了解决这类问题,建议你及时更新操作系统和应用程序的版本,以获取最新的修复和改进。
5.检查网络连接和网页编码
6.使用专业的文本处理工具
总结:
中文乱码问题可能由多种原因引起,包括字符编码不一致、文件格式不正确、字体缺失等。
解决方法包括使用正确的编码方式、转换文件的编码格式、选择合适的字体、更新操作系统和应用程序、检查网络连接和网页编码、使用专业的文本处理工具等。
通过以上方法,相信大家能够有效地解决中文乱码问题,提高中文字符的显示质量。
关于KEIL uv3 for arm的背景的颜色和字体的设置和恢复的解决方法

一般我们都是在KEIL下用C编程的,所以可以设置 ARM: Editor C Files,如果开发其他如C++的,可以选择其他相关项进行编辑设置。
我自己设置了一下KEIL 中ARM: Editor C Files的背景颜色,字体等,结果搞的乱七八糟,想恢复到最初状态,找了一下UV3的安装目录,发现了恢复的方法
关于KEIL uv3 for arm的背景的颜色和字体的设置和恢复的解决方法
2011-11-24 15:43:23| 分类: 转载 |字号 订阅
TAG: KEIL FOR ARM;字体;背景;颜色;恢复;KEIL UVISION3,keil的底色如guation -> Colors & Fonts
注:如果改的是其他项的内容,也可用同样的方法找到相关的文件进行修改。
现在给大家分享一下:
恢复方法:
到UV3的安装目录下:
如 C:\Keil\uv3,找到 CARMC_Default.INI文件,用记事本打开,将里面的内容全部复制下来,再找到 CARMC.ini文件,将其打开,用刚才复制的内容将CARMC.ini中的所有内容全部
覆盖掉,保存,关闭。
重新启动keil uvision3,就可以了。
web解决中文乱码问题的代码

web解决中文乱码问题的代码- 什么是中文乱码问题?中文乱码问题是指在网页或者其他文本编辑器中,中文字符无法正确显示,而出现乱码的情况。
这种情况通常是由于编码格式不一致或者不正确导致的。
- 为什么会出现中文乱码问题?中文乱码问题通常是由于以下原因导致的:1. 编码格式不一致或者不正确;2. 网页或者文本编辑器的编码设置不正确;3. 中文字符集不支持当前的编码格式。
- 如何解决中文乱码问题?解决中文乱码问题可以采用以下方法:1. 修改网页或者文本编辑器的编码设置,将编码格式设置为UTF-8或者GBK;2. 在网页的<head>标签内添加<meta charset="UTF-8">;3. 在文本编辑器中选择正确的编码格式,如UTF-8或者GBK;4. 将中文字符转换为Unicode编码,再进行显示;5. 使用专门的中文乱码解决工具进行解决。
- 代码示例以下是一段解决中文乱码问题的代码示例:```html<!DOCTYPE html><html><head><meta charset="UTF-8"><title>中文乱码问题解决示例</title></head><body><h1>中文乱码问题解决示例</h1><p>以下是一段中文文本:</p><p>这是一段中文文本,如果编码格式设置不正确,就会出现乱码的情况。
</p></body></html>```在上面的代码中,我们在<head>标签内添加了<metacharset="UTF-8">,这样就可以将编码格式设置为UTF-8,从而解决中文乱码问题。
中文乱码的解决方法

中文乱码的解决方法在进行中文文本处理过程中,可能会遇到乱码的情况,这主要是由于使用了不兼容的编码格式或者在数据传输过程中出现了错误。
下面是一些解决中文乱码问题的方法:1.使用正确的编码方式2.修改文件编码如果已经打开了一个包含乱码的文本文件,可以通过修改文件编码方式来解决问题。
例如,在记事本软件中,可以尝试选择“另存为”功能,并将编码方式改为UTF-8,然后重新保存文件,这样就可以解决乱码问题。
3.检查网页编码当浏览网页时遇到乱码问题,可以在浏览器的“查看”或“选项”菜单中找到“编码”选项,并将其设置为正确的编码方式(例如UTF-8),刷新网页后,乱码问题通常会得到解决。
5.使用转码工具如果已经得知文件的原始编码方式但无法通过其他方式解决乱码问题,可以尝试使用一些转码工具来将文件以正确的编码方式转换。
例如,iconv是一款常用的转码工具,可以在命令行界面下使用。
6.检查数据传输过程在进行数据传输时,特别是在网络传输中,可能会出现数据传输错误导致中文乱码。
可以检查数据传输过程中的设置和参数,确保传输过程中不会造成乱码问题。
7.检查数据库和应用程序设置在进行数据库操作和应用程序开发时,也可能会出现中文乱码问题。
可以检查数据库和应用程序的设置,确保正确地处理和显示中文字符。
8.清除特殊字符和格式有时候,中文乱码问题可能是由于文本中存在特殊字符或格式导致的。
可以尝试清除文本中的特殊字符和格式,然后重新保存或传输文件,看是否能够解决乱码问题。
总结起来,解决中文乱码问题的关键是了解文件的编码方式,并确保在处理过程中使用相同的编码方式。
此外,要注意数据传输过程中的设置和参数,以及数据库和应用程序的设置,确保正确地处理和显示中文字符。
最后,如果以上方法仍然无法解决乱码问题,可以尝试使用专业的转码工具来转换文件的编码方式。
直接在Keil下仿真的T9拼音输入法(完整版)

/*看到论坛上有人发T9拼音输入法,好多人感兴趣啊!呵呵,也把我很久以前的程序找出来重新编译了一下,特点是直接在Keil下仿真,切换到串口窗口就可以直接看到结果。
希望大家喜欢哦仿真步骤如下:1、把3个帖子的内容分别保存为51t9py.c,51t9py_indexa.h,5py_mb.h,放在同一目录下,将51t9py.c加入工程编译2、由于Keil的模拟串口是单字节显示,汉字显示为乱码,所以要加挂RICHWIN或RichView这种会重新刷新显示的中文平台,或手工刷新屏幕,所以请先到/dl/chinese.htm 下载RichView,安装运行3、在Keil环境下可以直接按“Ctrl+F5”键仿真,按“F5”全速运行,切换到在串口依次输入: //64*.6 426***.5 98*.7 936.3 586.1 4826*.1 9464*.7 64*.6试试:-)4、按键对应(根据我自己的手机设置的,全部在PC的小键盘操作): //Num /:上一拼音?*:下一拼音 //7:pqrs 8:tuv 9:wxyz -:前翻页 //4:ghi 5:jkl 6:mno +:后翻页 //1:? 2:abc 3:def 回车键:输入状态和选字状态切换 //0:? .和空格及回车键:输入状态和选字状态切换 //*///请把这个帖子的内容保存为51t9py.c//--------------------------------------------------------------------------//// 源程序大公开 //// (c) Copyright 2001-2003 xuwenjun //// All Rights Reserved //// V1.00 ////--------------------------------------------------------------------------////标题: T9拼音输入法模块 ////文件名: 51t9py.c ////版本: V1.00 ////修改人: 徐文军 E-mail:xuwenjun@ ////日期: 05-4-8 ////描述: T9拼音输入法模块 ////声明: //// 以下代码仅免费提供给学习用途,但引用或修改后必须在文件中声明出处. // // 如用于商业用途请与作者联系. E-mail:xuwenjun@ //// 有问题请mailto xuwenjun@ 欢迎与我交流! ////--------------------------------------------------------------------------////老版本: 无老版本文件名: ////创建人: 徐文军 E-mail:xuwenjun@ ////日期: 02-11-05 ////描述: //// 1、很久以前的程序,根据网友张凯、李强的51py输入法子程序改编, // // 增加索引、完善主程序、测试程序,使之在Keil下直接仿真 //// 2、在Keil环境下可以直接按“Ctrl+F5”键仿真,切换到在串口依次输入: //// 64*.6 426***.5 98*.7 936.3 586.1 4826*.1 9464*.7 64*.6试试:-) //// 3、由于Keil的模拟串口是单字节显示,汉字显示为乱码,所以要加挂 //// RICHWIN或RichView这种会重新刷新显示的中文平台,或手工刷新屏幕 // // (RichView可以到/dl/chinese.htm 下载) //// 4、按键对应(根据我自己的手机设置的,全部在PC的小键盘操作): //// Num /:上一拼音?*:下一拼音 //// 7:pqrs 8:tuv 9:wxyz -:前翻页 //// 4:ghi 5:jkl 6:mno +:后翻页 //// 1:? 2:abc 3:def 回车键:输入状态和选字状态切换 //// 0:? .和空格及回车键:输入状态和选字状态切换 ////--------------------------------------------------------------------------//#include<string.h>#include<stdio.h>#include"PY_mb.h"//#include"51t9_MB.h"#include"51t9py_indexa.h"#define CNTLQ 0x11#define CNTLS 0x13#define DEL 0x7F#define BACKSPACE 0x08#define CR 0x0D#define LF 0x0Aunsigned char cpt9PY_Mblen;struct t9PY_index code * cpt9PY_Mb[16];unsigned char t9PY_ime(char *strInput_t9PY_str){struct t9PY_index *cpHZ,*cpHZedge,*cpHZTemp;unsigned char i,j,cInputStrLength;cpt9PY_Mblen=0; //完全匹配组数j=0; //j为匹配最大值cInputStrLength=strlen(strInput_t9PY_str); //输入拼音串长度//if(*strInput_t9PY_str=='\0')return(0); //如果输入空字符返回0//cpHZ=&(t9PY_index2[0]); //查首字母索引//cpHZedge=t9PY_index2+sizeof(t9PY_index2)/sizeof(t9PY_index2[0]);// strInput_t9PY_str++; //指向拼音串第二个字母//while(cpHZ < cpHZedge) //待查询记录条数{for(i=0;i<cInputStrLength;i++){if(*(strInput_t9PY_str+i)!=*((*cpHZ).t9PY_T9+i)) //检查字符串匹配 {if (i+1 > j){j=i+1; //j为匹配最大值cpHZTemp=cpHZ;}break; //发现字母串不配,退出//}}if((i==cInputStrLength) && (cpt9PY_Mblen<16)) //字母串全配,最多8组 {cpt9PY_Mb[cpt9PY_Mblen]=cpHZ;cpt9PY_Mblen++;}cpHZ++;}if(j!=cInputStrLength) //不完全匹配输出最多匹配的1组cpt9PY_Mb[0]=cpHZTemp;return (cpt9PY_Mblen); //输出完全匹配组数,0为无果而终//}char * t9PY_ime_mb(char *strInput_t9PY_str){if(t9PY_ime(strInput_t9PY_str) > 0)return ((*(cpt9PY_Mb[0])).PY_mb);elsereturn (PY_mb_space);}void t9PY_Test(void){bit PYEnter=0;bit HZok=0;unsigned char temp;// unsigned char temp2;unsigned char t9PYn=0;char idata inline[16]={0x00};idata char chinese_word[3]=" ";char tempchar,Add=0,i=0;struct t9PY_index *cpTemp;// cpTemp=t9PY_index2;// printf ("\n按键/:上一拼音*:下一拼音 .和空格及回车键:输入状态和选字状态切换\n"); // printf ("请按键:2-abc 3-def 4-ghi 5-jkl 6-mno 7-pqrs 8-tuv 9-wxyz \n"); //while(!HZok){tempchar=getchar();switch (tempchar){// case '0':case '1':case '2':case '3':case '4':case '5':case '6':case '7':case '8':case '9':if (~PYEnter){inline[i]=tempchar;i++;Add=0;t9PY_ime(inline);}break;case '/':if (t9PYn >0) t9PYn --;break;case '*':t9PYn ++;if (t9PYn >=cpt9PY_Mblen) t9PYn --;break;case '-':if (Add >= 12) Add -= 12;break;case '=':case '+':if (Add < strlen((*cpTemp).PY_mb) -12 )Add += 12;break;case BACKSPACE:if (i>0) i--;inline[i]=0x00;Add=0;t9PY_ime(inline);// cpTemp=cpt9PY_Mb[t9PYn];break;// case '\n':case '.': //输入状态和选字状态切换case ' ':case '\n':PYEnter ^=1;break;default :// HZok=1;break;}printf (" \r");if (PYEnter){printf ("选");cpTemp=cpt9PY_Mb[t9PYn];if((cpTemp != PY_mb_space) && (tempchar>='1') && (tempchar<='9'))HZok=1;t9PYn=0;printf (" \r");// printf ("%s\n",inline);chinese_word[0]=*((*cpTemp).PY_mb+Add+(tempchar-'1')*2); chinese_word[1]=*((*cpTemp).PY_mb+Add+(tempchar-'1')*2+1); printf (chinese_word);printf ("\n");}else{// printf ((*(cpTemp)).PY);printf (":");printf ((*cpTemp).PY_mb+Add);// printf ("\n拼音1 2 3 4 5 6 7 8 9\r");}}else{printf ("拼");for (temp=t9PYn;temp<cpt9PY_Mblen;temp++){cpTemp=cpt9PY_Mb[temp];// temp2=((strlen((*(cpTemp)).PY_mb)-Add)/2);// printf ("%2bd:%02bd:",temp,temp2);printf (":");printf ((*(cpTemp)).PY);// printf ((*(cpTemp)).PY_mb+Add);// printf ("\n");}// printf ("\n");}}//-----以下为测试程序---------------------------------------------------------------------//#include <REG52.H>#include <stdio.h>#ifdef MONITOR51 /* Debugging with Monitor-51 needs */char code reserve [3] _at_ 0x23; /* space for serial interrupt if */#endif /* Stop Exection with Serial Intr. *//* is enabled */void main (void) {char input_string[]="98";/*------------------------------------------------Setup the serial port for 1200 baud at 16MHz.------------------------------------------------*/#ifndef MONITOR51SCON = 0x50; /* SCON: mode 1, 8-bit UART, enable rcvr */TMOD |= 0x20; /* TMOD: timer 1, mode 2, 8-bit reload */TH1 = 250; /* TH1: reload value for 9600 baud @ 11.0592MHz */ TR1 = 1; /* TR1: timer 1 run */TI = 1; /* TI: set TI to send first char of UART */#endif/*------------------------------------------------Note that an embedded program never exits (becausethere is no operating system to return to). Itmust loop and execute forever.------------------------------------------------*/// printf ("Hello World\n"); /* Print "Hello World" */printf ("\n");printf ("%s\n",input_string);printf (t9PY_ime_mb(input_string));printf ("按键对应:(全部在PC的小键盘操作)\n");printf (" /-上一拼音*-下一拼音\n");printf ("7-pqrs 8-tuv 9-wxyz --前翻页\n");printf ("4-ghi 5-jkl 6-mno +-后翻页\n");printf ("1-无效 2-abc 3-def 回车键-输入状态和选字状态切换\n");printf ("0-无效 .和空格及回车键-输入状态和选字状态切换\n\n");while(1){t9PY_Test();}}//请把这个帖子的内容保存为51t9py_indexa.h//--------------------------------------------------------------------------//// 源程序大公开 //// (c) Copyright 2001-2003 xuwenjun //// All Rights Reserved //// V1.00 ////--------------------------------------------------------------------------////标题: T9拼音输入法索引 ////文件名: 51t9py_indexa.h ////版本: V1.00 ////修改人: 徐文军 E-mail:xuwenjun@ ////日期: 05-4-8 ////描述: T9拼音输入法索引 ////声明: //// 以下代码仅免费提供给学习用途,但引用或修改后必须在文件中声明出处. // // 如用于商业用途请与作者联系. E-mail: xuwenjun@ //// 有问题请mailto xuwenjun@欢迎与我交流! ////--------------------------------------------------------------------------////老版本: 无老版本文件名: ////创建人: 徐文军 E-mail:xuwenjun@ // //日期: 02-11-05 ////描述: ////--------------------------------------------------------------------------//struct t9PY_index{char code *t9PY_T9;char code *PY;char code *PY_mb;};/*"拼音输入法查询码表,T9数字字母索引表(index)"*/struct t9PY_index code t9PY_index2[] ={{"","",PY_mb_space},{"2","a",PY_mb_a},{"3","e",PY_mb_e},{"4","i",PY_mb_space},{"6","o",PY_mb_o},{"8","u",PY_mb_space},{"8","v",PY_mb_space},{"24","ai",PY_mb_ai},{"26","an",PY_mb_an},{"26","ao",PY_mb_ao},{"22","ba",PY_mb_ba},{"24","bi",PY_mb_bi},{"26","bo",PY_mb_bo},{"28","bu",PY_mb_bu},{"22","ca",PY_mb_ca},{"23","ce",PY_mb_ce},{"24","ci",PY_mb_ci},{"28","cu",PY_mb_cu},{"32","da",PY_mb_da},{"34","di",PY_mb_di},{"38","du",PY_mb_du}, {"36","en",PY_mb_en}, {"37","er",PY_mb_er}, {"32","fa",PY_mb_fa}, {"36","fo",PY_mb_fo}, {"38","fu",PY_mb_fu}, {"42","ha",PY_mb_ha}, {"42","ga",PY_mb_ga}, {"43","ge",PY_mb_ge}, {"43","he",PY_mb_he}, {"48","gu",PY_mb_gu}, {"48","hu",PY_mb_hu}, {"54","ji",PY_mb_ji},{"58","ju",PY_mb_ju},{"52","ka",PY_mb_ka}, {"53","ke",PY_mb_ke}, {"58","ku",PY_mb_ku}, {"52","la",PY_mb_la},{"53","le",PY_mb_le},{"54","li",PY_mb_li},{"58","lu",PY_mb_lu},{"58","lv",PY_mb_lv},{"62","ma",PY_mb_ma}, {"63","me",PY_mb_me}, {"64","mi",PY_mb_mi}, {"66","mo",PY_mb_mo}, {"68","mu",PY_mb_mu}, {"62","na",PY_mb_na}, {"63","ne",PY_mb_ne}, {"64","ni",PY_mb_ni},{"68","nv",PY_mb_nv}, {"68","ou",PY_mb_ou}, {"72","pa",PY_mb_pa}, {"74","pi",PY_mb_pi}, {"76","po",PY_mb_po}, {"78","pu",PY_mb_pu}, {"74","qi",PY_mb_qi}, {"78","qu",PY_mb_qu}, {"73","re",PY_mb_re}, {"74","ri",PY_mb_ri},{"78","ru",PY_mb_ru}, {"72","sa",PY_mb_sa}, {"73","se",PY_mb_se}, {"74","si",PY_mb_si}, {"78","su",PY_mb_su}, {"82","ta",PY_mb_ta}, {"83","te",PY_mb_te}, {"84","ti",PY_mb_ti},{"88","tu",PY_mb_tu}, {"92","wa",PY_mb_wa}, {"96","wo",PY_mb_wo}, {"98","wu",PY_mb_wu}, {"94","xi",PY_mb_xi}, {"98","xu",PY_mb_xu}, {"92","ya",PY_mb_ya}, {"93","ye",PY_mb_ye}, {"94","yi",PY_mb_yi}, {"96","yo",PY_mb_yo}, {"98","yu",PY_mb_yu}, {"92","za",PY_mb_za}, {"93","ze",PY_mb_ze},{"98","zu",PY_mb_zu},{"264","ang",PY_mb_ang}, {"224","bai",PY_mb_bai}, {"226","ban",PY_mb_ban}, {"226","bao",PY_mb_bao}, {"234","bei",PY_mb_bei}, {"236","ben",PY_mb_ben}, {"243","bie",PY_mb_bie}, {"246","bin",PY_mb_bin}, {"224","cai",PY_mb_cai}, {"226","can",PY_mb_can}, {"226","cao",PY_mb_cao}, {"242","cha",PY_mb_cha}, {"243","che",PY_mb_che}, {"244","chi",PY_mb_chi}, {"248","chu",PY_mb_chu}, {"268","cou",PY_mb_cou}, {"284","cui",PY_mb_cui}, {"286","cun",PY_mb_cun}, {"286","cuo",PY_mb_cuo}, {"324","dai",PY_mb_dai}, {"326","dan",PY_mb_dan}, {"326","dao",PY_mb_dao}, {"343","die",PY_mb_die}, {"348","diu",PY_mb_diu}, {"368","dou",PY_mb_dou}, {"384","dui",PY_mb_dui}, {"386","dun",PY_mb_dun}, {"386","duo",PY_mb_duo}, {"326","fan",PY_mb_fan}, {"334","fei",PY_mb_fei},{"368","fou",PY_mb_fou}, {"424","gai",PY_mb_gai}, {"426","gan",PY_mb_gan}, {"426","gao",PY_mb_gao}, {"434","gei",PY_mb_gei}, {"436","gen",PY_mb_gan}, {"468","gou",PY_mb_gou}, {"482","gua",PY_mb_gua}, {"484","gui",PY_mb_gui}, {"486","gun",PY_mb_gun}, {"486","guo",PY_mb_guo}, {"423","hai",PY_mb_hai}, {"426","han",PY_mb_han}, {"426","hao",PY_mb_hao}, {"434","hei",PY_mb_hei}, {"436","hen",PY_mb_hen}, {"468","hou",PY_mb_hou}, {"482","hua",PY_mb_hua}, {"484","hui",PY_mb_hui}, {"486","hun",PY_mb_hun}, {"486","huo",PY_mb_huo}, {"542","jia",PY_mb_jia},{"543","jie",PY_mb_jie},{"546","jin",PY_mb_jin},{"548","jiu",PY_mb_jiu},{"583","jue",PY_mb_jue}, {"586","jun",PY_mb_jun}, {"524","kai",PY_mb_kai}, {"526","kan",PY_mb_kan}, {"526","kao",PY_mb_kao}, {"536","ken",PY_mb_ken},{"582","kua",PY_mb_kua}, {"584","kui",PY_mb_kui},{"586","kun",PY_mb_kun}, {"586","kuo",PY_mb_kuo}, {"524","lai",PY_mb_lai},{"526","lan",PY_mb_lan},{"526","lao",PY_mb_lao},{"534","lei",PY_mb_lei},{"543","lie",PY_mb_lie},{"546","lin",PY_mb_lin},{"548","liu",PY_mb_liu},{"568","lou",PY_mb_lou},{"583","lue",PY_mb_lue},{"586","lun",PY_mb_lun},{"586","luo",PY_mb_luo},{"624","mai",PY_mb_mai}, {"626","man",PY_mb_man}, {"626","mao",PY_mb_mao}, {"634","mei",PY_mb_mei}, {"636","men",PY_mb_men}, {"643","mie",PY_mb_mie}, {"646","min",PY_mb_min}, {"648","miu",PY_mb_miu}, {"668","mou",PY_mb_mou}, {"624","nai",PY_mb_nai},{"626","nan",PY_mb_nan}, {"626","nao",PY_mb_nao}, {"634","nei",PY_mb_nei},{"636","nen",PY_mb_nen}, {"643","nie",PY_mb_nie},{"646","nin",PY_mb_nin},{"683","nue",PY_mb_nue}, {"686","nuo",PY_mb_nuo}, {"724","pai",PY_mb_pai}, {"726","pan",PY_mb_pan}, {"726","pao",PY_mb_pao}, {"734","pei",PY_mb_pei}, {"736","pen",PY_mb_pen}, {"743","pie",PY_mb_pie}, {"746","pin",PY_mb_pin}, {"768","pou",PY_mb_pou}, {"742","qia",PY_mb_qia}, {"743","qie",PY_mb_qie}, {"746","qin",PY_mb_qin}, {"748","qiu",PY_mb_qiu}, {"783","que",PY_mb_que}, {"786","qun",PY_mb_qun}, {"726","ran",PY_mb_ran}, {"726","rao",PY_mb_rao}, {"736","ren",PY_mb_ren}, {"768","rou",PY_mb_rou}, {"784","rui",PY_mb_rui}, {"786","run",PY_mb_run}, {"786","ruo",PY_mb_ruo}, {"724","sai",PY_mb_sai}, {"726","sao",PY_mb_sao}, {"726","san",PY_mb_san}, {"736","sen",PY_mb_sen}, {"742","sha",PY_mb_sha}, {"743","she",PY_mb_she}, {"744","shi",PY_mb_shi}, {"748","shu",PY_mb_shu},{"784","sui",PY_mb_sui}, {"786","sun",PY_mb_sun}, {"786","suo",PY_mb_suo}, {"824","tai",PY_mb_tai},{"826","tan",PY_mb_tan}, {"826","tao",PY_mb_tao}, {"843","tie",PY_mb_tie},{"868","tou",PY_mb_tou}, {"884","tui",PY_mb_tui},{"886","tun",PY_mb_tun}, {"886","tuo",PY_mb_tuo}, {"924","wai",PY_mb_wai}, {"926","wan",PY_mb_wan}, {"934","wei",PY_mb_wei}, {"936","wen",PY_mb_wen}, {"942","xia",PY_mb_xia}, {"943","xie",PY_mb_xie}, {"946","xin",PY_mb_xin}, {"948","xiu",PY_mb_xiu}, {"983","xue",PY_mb_xue}, {"986","xun",PY_mb_xun}, {"926","yan",PY_mb_yan}, {"926","yao",PY_mb_yao}, {"946","yin",PY_mb_yin}, {"968","you",PY_mb_you}, {"983","yue",PY_mb_yue}, {"986","yun",PY_mb_yun}, {"924","zai",PY_mb_zai}, {"926","zan",PY_mb_zan}, {"926","zao",PY_mb_zao}, {"934","zei",PY_mb_zei},{"942","zha",PY_mb_zha},{"943","zhe",PY_mb_zhe},{"944","zhi",PY_mb_zhi},{"948","zhu",PY_mb_zhu},{"968","zou",PY_mb_zou},{"984","zui",PY_mb_zui},{"986","zun",PY_mb_zun},{"986","zuo",PY_mb_zuo},{"2264","bang",PY_mb_bang}, {"2364","beng",PY_mb_beng}, {"2426","bian",PY_mb_bian}, {"2426","biao",PY_mb_biao}, {"2464","bing",PY_mb_bing}, {"2264","cang",PY_mb_cang}, {"2364","ceng",PY_mb_ceng}, {"2424","chai",PY_mb_chai}, {"2426","chan",PY_mb_chan}, {"2426","chao",PY_mb_chao}, {"2436","chen",PY_mb_chen}, {"2468","chou",PY_mb_chou}, {"2484","chuai",PY_mb_chuai}, {"2484","chui",PY_mb_chui}, {"2484","chun",PY_mb_chun}, {"2486","chuo",PY_mb_chuo}, {"2664","cong",PY_mb_cong}, {"2826","cuan",PY_mb_cuan}, {"3264","dang",PY_mb_dang}, {"3364","deng",PY_mb_deng}, {"3426","dian",PY_mb_dian}, {"3426","diao",PY_mb_diao}, {"3464","ding",PY_mb_ding},{"3826","duan",PY_mb_duan}, {"3264","fang",PY_mb_fang}, {"3364","feng",PY_mb_feng}, {"4264","gang",PY_mb_gang}, {"4364","geng",PY_mb_geng}, {"4664","gong",PY_mb_gong}, {"4824","guai",PY_mb_guai},{"4826","guan",PY_mb_guan}, {"4264","hang",PY_mb_hang}, {"4364","heng",PY_mb_heng}, {"4664","hong",PY_mb_hong}, {"4823","huai",PY_mb_huai},{"4826","huan",PY_mb_huan}, {"5426","jian",PY_mb_jian},{"5426","jiao",PY_mb_jiao},{"5464","jing",PY_mb_jing},{"5826","juan",PY_mb_juan},{"5264","kang",PY_mb_kang}, {"5364","keng",PY_mb_keng}, {"5664","kong",PY_mb_kong}, {"5824","kuai",PY_mb_kuai},{"5826","kuan",PY_mb_kuan}, {"5264","lang",PY_mb_lang},{"5366","leng",PY_mb_leng},{"5426","lian",PY_mb_lian},{"5426","liao",PY_mb_liao},{"5464","ling",PY_mb_ling},{"5664","long",PY_mb_long},{"5826","luan",PY_mb_luan},{"6264","mang",PY_mb_mang}, {"6364","meng",PY_mb_meng},{"6426","miao",PY_mb_miao}, {"6464","ming",PY_mb_ming}, {"6264","nang",PY_mb_nang}, {"6364","neng",PY_mb_neng}, {"6426","nian",PY_mb_nian}, {"6426","niao",PY_mb_niao}, {"6464","ning",PY_mb_ning}, {"6664","nong",PY_mb_nong}, {"6826","nuan",PY_mb_nuan}, {"7264","pang",PY_mb_pang}, {"7364","peng",PY_mb_peng}, {"7426","pian",PY_mb_pian}, {"7426","piao",PY_mb_piao}, {"7464","ping",PY_mb_ping}, {"7426","qian",PY_mb_qian}, {"7426","qiao",PY_mb_qiao}, {"7464","qing",PY_mb_qing}, {"7826","quan",PY_mb_quan}, {"7264","rang",PY_mb_rang}, {"7364","reng",PY_mb_reng}, {"7664","rong",PY_mb_rong}, {"7826","ruan",PY_mb_ruan}, {"7264","sang",PY_mb_sang}, {"7364","seng",PY_mb_seng}, {"7424","shai",PY_mb_shai}, {"7426","shan",PY_mb_shan}, {"7426","shao",PY_mb_shao}, {"7436","shen",PY_mb_shen}, {"7468","shou",PY_mb_shou}, {"7482","shua",PY_mb_shua}, {"7484","shui",PY_mb_shui},{"7486","shuo",PY_mb_shuo}, {"7664","song",PY_mb_song}, {"7826","suan",PY_mb_suan}, {"8264","tang",PY_mb_tang}, {"8364","teng",PY_mb_teng}, {"8426","tian",PY_mb_tian},{"8426","tiao",PY_mb_tiao},{"8464","ting",PY_mb_ting},{"8664","tong",PY_mb_tong}, {"8826","tuan",PY_mb_tuan}, {"9264","wang",PY_mb_wang}, {"9364","weng",PY_mb_weng}, {"9426","xian",PY_mb_xiao}, {"9426","xiao",PY_mb_xiao}, {"9464","xing",PY_mb_xing}, {"9826","xuan",PY_mb_xuan}, {"9264","yang",PY_mb_yang}, {"9464","ying",PY_mb_ying}, {"9664","yong",PY_mb_yong}, {"9826","yuan",PY_mb_yuan}, {"9264","zang",PY_mb_zang}, {"9364","zeng",PY_mb_zeng}, {"9424","zhai",PY_mb_zhai}, {"9426","zhan",PY_mb_zhan}, {"9426","zhao",PY_mb_zhao}, {"9436","zhen",PY_mb_zhen}, {"9468","zhou",PY_mb_zhou}, {"9482","zhua",PY_mb_zhua}, {"9484","zhui",PY_mb_zhui}, {"9486","zhun",PY_mb_zhun}, {"9486","zhuo",PY_mb_zhuo},{"9826","zuan",PY_mb_zuan},{"24264","chang",PY_mb_chang},{"24364","cheng",PY_mb_cheng},{"24664","chong",PY_mb_chong},{"24826","chuan",PY_mb_chuan},{"48264","guang",PY_mb_guang},{"48264","huang",PY_mb_huang},{"54264","jiang",PY_mb_jiang},{"54664","jiong",PY_mb_jiong},{"58264","kuang",PY_mb_kuang},{"54264","liang",PY_mb_liang},{"64264","niang",PY_mb_niang},{"74264","qiang",PY_mb_qiang},{"74664","qiong",PY_mb_qiong},{"74264","shang ",PY_mb_shang}, {"74364","sheng",PY_mb_sheng},{"74824","shuai",PY_mb_shuai},{"74826","shuan",PY_mb_shuan},{"94264","xiang",PY_mb_xiang},{"94664","xiong",PY_mb_xiong},{"94264","zhang",PY_mb_zhang},{"94364","zheng",PY_mb_zheng},{"94664","zhong",PY_mb_zhong},{"94824","zhuai",PY_mb_zhuai},{"94826","zhuan",PY_mb_zhuan},{"248264","chuang",PY_mb_chuang}, {"748264","shuang",PY_mb_shuang}, {"948264","zhuang",PY_mb_zhuang}, };码表发不上来,请自己到网络上寻找py_mb.h -。
修改Keil C程序代码字体为微软雅黑及Keil C光标定位不准的解决办法

修改Keil C程序代码字体为微软雅黑及Keil C光标定位不准的解决办法修改keil C程序代码字体:常规设置:在keil C的菜单栏中,点击Edit,选择最下面的onfiguration...,进入之后点击Colors&Fonts标签,然后选中自己想要修改字体的项目,比如C 文件的程序代码,那么我们选择8051:Editor C Files,然后再在它的右边窗口选中Text,修改旁边的字体即可。
上面的常规设置人人都会,但是,这里面只有几个字体,如果我们不喜欢这些字体想把C语言程序代码和汇编语言程序代码的字体换成其他字体呢?例如微软雅黑,方法也是有的:进入keil C的安装目录,在UV3目录下面用记事本打开A51.ini(这是汇编语言代码的)和C51.ini(这是C语言代码的),将[Font]FaceName =XXXXSize =12Italic =0Bold =0中FaceName=XXXX后面的字体名字修改为自己系统里面已经安装存在的字体名字即可,例如修改为FaceName=微软雅黑。
当然,字体大小,斜体,加粗这些也是可以修改的,修改Size=12后面的数字就是字体大小,修改Italic=0为1就是变成斜体,修改Bold=0为1就是字体加粗。
更多东西可以自己揣摩A51.ini和C51.ini里面的代码。
重新打开keil C看看程序代码,是不是变成有雅黑字体了呢?雅黑字体看起来更舒服。
当然,还有,很多人会发现,keil C经常出现光标没法准确定位位置,这个对不准位置的问题也还是很好解决的,方法就是用记事本打开keil C安装目录下面的TOOLS.ini,在[UV2]ORGANIZATION="xhu"NAME="chuan", "huang"EMAIL="xhu"BOOK0=UV3\RELEASE_NOTES.HTM("uVision Release Notes",GEN)添加一行代码“ANSI=1”即可。
Keil C51汉字显示的bug问题

Keil C51汉字显示的bug问题(0xFD问题)Keil C51汉字显示的bug问题一、缘起这两天改进MCU的液晶显示方法,采用“即编即显”的思路,编写了一个可以直接显示字符串的程序。
如程序调用disstr("我是你老爸");液晶屏上就会显示“我是你老爸”。
二、问题但是,花了1天多时间辛辛苦苦改好的程序后,却发现有些汉字显示有问题。
比如:P1:在第一行显示“实时参数”,第二行显示“工作状态”,实际上“工作状态”却重复显示了,除了在正确的地方显示外,还在“实时参数”后显示了。
P2:"正"字后若有":",则都显示成乱码。
如果后面没有":",则"正"字可正确显示,但是后面却显示了后面的一行字。
P3:"过"字总显示乱码;三、求索通过调试发现,上述汉字显示不正常的时候,是因为在字库中找不到匹配的汉字。
可是,自建的字库中明明有这些汉字,而且"数","正"字在后面无字符的时候是显示正确的啊!问题找了好久,怀疑传参类型不对,汉字查找可能溢出等,反复修改,总是无法解决问题,而且从现象来思考,都不应该是这些问题。
今日灵光一现:为什么不在传递字符串后显示该字符串的变量值呢?经过详细研究,西文字符在传递时应该是ACSII值,一个字节,数值小于128;而汉字传递的是其机内码,分高低2个字节,2个字节都大于127,当然并小于256。
字符串传递参数值一显示,可不得了。
其惊人之处有:1."数","正","过"正确显示时其传参值为:0xca00,0xd500,0xb900;而其正确的机内码应该是:0xca fd,0xd5fd,0xb9fd。
看来其低位字节被无情忽视。
2."数","正","过"单独显示正确,但是后面带一个字符或汉字就显示乱码了。
乱码处理方法

乱码处理方法
以下是 6 条关于乱码处理方法:
1. 哎呀,要是遇到乱码,咱可以试试换个编码格式呀!就像你穿衣服不搭调,那就换一件试试看嘛,比如从 UTF-8 换到 GBK 啥的。
比如你打开一个文档,全是乱码,这时候赶紧去调调编码格式呀!
2. 嘿,别忘了检查一下你的字体设置呀!有时候字体不对也会出现乱码呢。
这就好像走路走歪了路,得及时调整方向呀!比如说你在某个软件里看到的字全是乱七不糟的,那很可能就是字体的问题啦,赶紧去瞅瞅!
3. 你知道吗,重新安装相关软件也可能解决乱码问题哟!这就好比生病吃药,有时候得下点猛药才能治好嘛。
像我上次那个软件出现乱码,我把它卸了重装,立马就好啦!
4. 哇塞,清理一下缓存和临时文件也很重要呀!这就跟收拾房间一样,把垃圾清理掉,才能更清爽呀。
你想想,要是电脑里乱七八糟的东西太多,它能不出现乱码嘛。
比如说电脑用久了开始出乱码,那就赶紧清理一下呀!
5. 呀,有时候更新一下驱动程序也能行呢!这就跟给车子升级零件一样,让它跑得更顺畅嘛。
如果电脑显示有乱码,是不是驱动有点跟不上啦,赶紧去更新试试呗!
6. 注意哦,还可能是文件本身损坏导致的乱码呢!这就好像一个苹果烂了一块,会影响整体呀。
像有时候下载的文件一打开全是乱码,很有可能就是文件在下载过程中受损啦!
总之,遇到乱码不要慌,试试这些方法,说不定就能解决啦!。
解决keil不能设置字体和颜色的问题
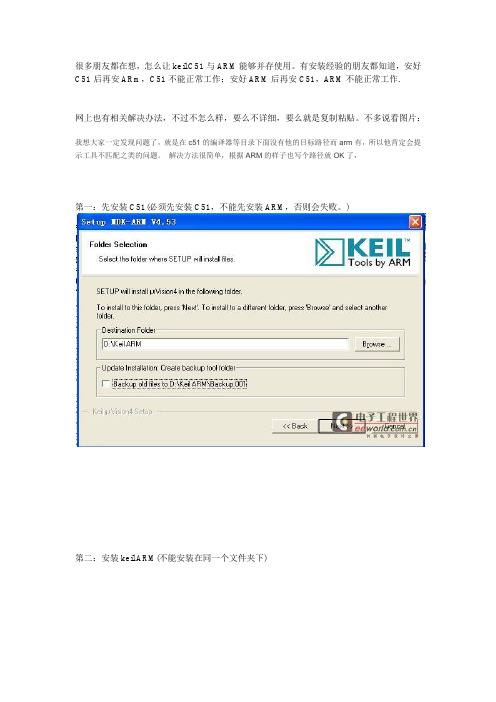
很多朋友都在想,怎么让keil C51与ARM能够并存使用。
有安装经验的朋友都知道,安好C51后再安ARm,C51不能正常工作;安好ARM后再安C51,ARM不能正常工作.网上也有相关解决办法,不过不怎么样,要么不详细,要么就是复制粘贴。
不多说看图片:我想大家一定发现问题了,就是在c51的编译器等目录下面没有他的目标路径而arm有,所以他肯定会提示工具不匹配之类的问题。
解决方法很简单,根据ARM的样子也写个路径就OK了,第一:先安装C51(必须先安装C51,不能先安装ARM,否则会失败。
)第二:安装keil ARM(不能安装在同一个文件夹下)我当前安装的是mdk arm4.53第三:打开keil c51和keil arm 两个文件夹,分别找到tools.ini分别打开两个“tools.ini”,将keil C51文件夹下的tools.ini文件中[C51]段复制到keil ARM中tools.ini文件的最后;将keil ARM文件夹下的tools.ini文件中[ARM]段复制到keil C51中tools.ini文件的最后:tools.ini -->keil ARM[UV2]ORGANIZATION="小川电子工作室"NAME="小川电子工作室", "小川电子工作室"EMAIL="paulhyde@"ARMSEL=1BOOK0=UV4\RELEASE_NOTES.HTM("uVision Release Notes",GEN)[ARM]PATH="D:\Keil ARM\ARM\"VERSION=4.50PATH1="C:\Program Files\arm-none-eabi-gcc-4_6\"TOOLPREFIX=arm-none-eabi-CPUDLL0=SARM.DLL(TDRV0,TDRV5,TDRV6,TDRV10) # Drivers for ARM7/9 devices CPUDLL1=SARMCM3.DLL(TDRV1,TDRV2,TDRV3,TDRV4,TDRV5,TDRV7,TDRV8,TDR V9,TDRV11,TDRV12,TDRV13) # Drivers for Cortex-M devicesCPUDLL2=SARMCR4.DLL(TDRV7) # Drivers for Cortex-R4 devicesBOOK0=HLP\RELEASE_NOTES.HTM("Release Notes",GEN)BOOK1=HLP\ARMTOOLS.chm("Complete User's Guide Selection",C)BOOK2=HLP\RL_RELEASE_NOTES.HTM("RL-ARM Release Notes",GEN)BOOK3=CMSIS\index.html("CMSIS Documentation",GEN)TDRV0=BIN\UL2ARM.DLL("ULINK2/ME ARM Debugger")TDRV1=BIN\UL2CM3.DLL("ULINK2/ME Cortex Debugger")TDRV2=BIN\AGDIRDI.DLL("RDI Interface Driver")TDRV3=BIN\ABLSTCM.dll("Altera Blaster Cortex Debugger")TDRV4=BIN\lmidk-agdi.dll("Stellaris ICDI")TDRV5=Signum\SigUV3Arm.dll("Signum Systems JTAGjet")TDRV6=Segger\JLTAgdi.dll("J-LINK / J-TRACE")TDRV7=Segger\JL2CM3.dll("Cortex-M/R J-LINK/J-Trace")TDRV8=STLink\ST-LINKIII-KEIL.dll ("ST-Link (Deprecated Version)")TDRV9=BIN\ULP2CM3.DLL("ULINK Pro Cortex Debugger")TDRV10=BIN\ULP2ARM.DLL("ULINK Pro ARM Debugger")TDRV11=NULink\Nu_Link.dll("NULink Debugger")TDRV12=SiLabs\SLAB_CM_Keil.dll("SiLabs UDA Debugger")TDRV13=STLink\ST-LINKIII-KEIL_SWO.dll ("ST-Link Debugger")DELDRVPKG0=ULINK\UninstallULINK.exe("ULINK Pro Driver V1.0")LIC0=ZB48T-RRRXD-GJE6P-M4J11-65JI1-GHTPNBOOK4=Signum\Docs\SigUV3Arm.htm("Signum Systems JTAGjet Driver Documentation",GEN)[ARMADS]PATH="D:\Keil ARM\ARM\"PATH1="BIN40\"CPUDLL0=SARM.DLL(TDRV0,TDRV5,TDRV6,TDRV10) # Drivers for ARM7/9 devices CPUDLL1=SARMCM3.DLL(TDRV1,TDRV2,TDRV3,TDRV4,TDRV5,TDRV7,TDRV8,TDR V9,TDRV11,TDRV12,TDRV13) # Drivers for Cortex-M devicesCPUDLL2=SARMCR4.DLL(TDRV7) # Drivers for Cortex-R4 devicesBOOK0=HLP\RELEASE_NOTES.HTM("Release Notes",GEN)BOOK1=HLP\ARMTOOLS.chm("Complete User's Guide Selection",C)BOOK2=HLP\RL_RELEASE_NOTES.HTM("RL-ARM Release Notes",GEN)BOOK3=CMSIS\index.html("CMSIS Documentation",GEN)BOOK4=Signum\Docs\SigUV3Arm.htm("Signum Systems JTAGjet Driver Documentation",GEN)TDRV0=BIN\UL2ARM.DLL("ULINK2/ME ARM Debugger")TDRV1=BIN\UL2CM3.DLL("ULINK2/ME Cortex Debugger")TDRV2=BIN\AGDIRDI.DLL("RDI Interface Driver")TDRV3=BIN\ABLSTCM.dll("Altera Blaster Cortex Debugger")TDRV4=BIN\lmidk-agdi.dll("Stellaris ICDI")TDRV5=Signum\SigUV3Arm.dll("Signum Systems JTAGjet")TDRV6=Segger\JLTAgdi.dll("J-LINK / J-TRACE")TDRV7=Segger\JL2CM3.dll("Cortex-M/R J-LINK/J-Trace")TDRV8=STLink\ST-LINKIII-KEIL.dll ("ST-Link (Deprecated Version)")TDRV9=BIN\ULP2CM3.DLL("ULINK Pro Cortex Debugger")TDRV10=BIN\ULP2ARM.DLL("ULINK Pro ARM Debugger")TDRV11=NULink\Nu_Link.dll("NULink Debugger")TDRV12=SiLabs\SLAB_CM_Keil.dll("SiLabs UDA Debugger")TDRV13=STLink\ST-LINKIII-KEIL_SWO.dll ("ST-Link Debugger") RTOS0=Dummy.DLL("Dummy")RTOS1=VARTXARM.DLL ("RTX Kernel")DELDRVPKG0=ULINK\UninstallULINK.exe("ULINK Pro Driver V1.0") [C51]PATH="D:\Keil C51\C51\"VERSION=V9.06BOOK0=HLP\Release_Notes.htm("Release Notes",GEN)BOOK1=HLP\C51TOOLS.chm("Complete User's Guide Selection",C) TDRV0=BIN\MON51.DLL ("Keil Monitor-51 Driver")TDRV1=BIN\ISD51.DLL ("Keil ISD51 In-System Debugger")TDRV2=BIN\MON390.DLL ("MON390: Dallas Contiguous Mode") TDRV3=BIN\LPC2EMP.DLL ("LPC900 EPM Emulator/Programmer") TDRV4=BIN\UL2UPSD.DLL ("ST-uPSD ULINK Driver")TDRV5=BIN\UL2XC800.DLL ("Infineon XC800 ULINK Driver")TDRV6=BIN\MONADI.DLL ("ADI Monitor Driver")TDRV7=BIN\DAS2XC800.DLL ("Infineon DAS Client for XC800") TDRV8=BIN\UL2LPC9.DLL ("NXP LPC95x ULINK Driver")RTOS0=Dummy.DLL("Dummy")RTOS1=RTXTINY.DLL ("RTX-51 Tiny")RTOS2=RTX51.DLL ("RTX-51 Full")LIC0=EXTEV-PIY1M-WN1AF-6K3HK-DRA7Y-FBXVWkeil-->c51[UV2]ORGANIZATION="小川工作室"NAME="王川北", "111"EMAIL="111"BOOK0=UV4\RELEASE_NOTES.HTM("uVision Release Notes",GEN) [C51]PATH="D:\Keil C51\C51\"VERSION=V9.06BOOK0=HLP\Release_Notes.htm("Release Notes",GEN)BOOK1=HLP\C51TOOLS.chm("Complete User's Guide Selection",C) TDRV0=BIN\MON51.DLL ("Keil Monitor-51 Driver")TDRV1=BIN\ISD51.DLL ("Keil ISD51 In-System Debugger")TDRV2=BIN\MON390.DLL ("MON390: Dallas Contiguous Mode")TDRV3=BIN\LPC2EMP.DLL ("LPC900 EPM Emulator/Programmer")TDRV4=BIN\UL2UPSD.DLL ("ST-uPSD ULINK Driver")TDRV5=BIN\UL2XC800.DLL ("Infineon XC800 ULINK Driver")TDRV6=BIN\MONADI.DLL ("ADI Monitor Driver")TDRV7=BIN\DAS2XC800.DLL ("Infineon DAS Client for XC800")TDRV8=BIN\UL2LPC9.DLL ("NXP LPC95x ULINK Driver")RTOS0=Dummy.DLL("Dummy")RTOS1=RTXTINY.DLL ("RTX-51 Tiny")RTOS2=RTX51.DLL ("RTX-51 Full")LIC0=8V02Z-JIX83-09VG9-4M1JI-YKSD6-5KBQ3[ARM]PATH="D:\Keil ARM\ARM\"VERSION=4.50PATH1="C:\Program Files\arm-none-eabi-gcc-4_6\"TOOLPREFIX=arm-none-eabi-CPUDLL0=SARM.DLL(TDRV0,TDRV5,TDRV6,TDRV10) # Drivers for ARM7/9 devices CPUDLL1=SARMCM3.DLL(TDRV1,TDRV2,TDRV3,TDRV4,TDRV5,TDRV7,TDRV8,TDR V9,TDRV11,TDRV12,TDRV13) # Drivers for Cortex-M devicesCPUDLL2=SARMCR4.DLL(TDRV7) # Drivers for Cortex-R4 devicesBOOK0=HLP\RELEASE_NOTES.HTM("Release Notes",GEN)BOOK1=HLP\ARMTOOLS.chm("Complete User's Guide Selection",C)BOOK2=HLP\RL_RELEASE_NOTES.HTM("RL-ARM Release Notes",GEN)BOOK3=CMSIS\index.html("CMSIS Documentation",GEN)BOOK4=Signum\Docs\SigUV3Arm.htm("Signum Systems JTAGjet Driver Documentation",GEN)TDRV0=BIN\UL2ARM.DLL("ULINK2/ME ARM Debugger")TDRV1=BIN\UL2CM3.DLL("ULINK2/ME Cortex Debugger")TDRV2=BIN\AGDIRDI.DLL("RDI Interface Driver")TDRV3=BIN\ABLSTCM.dll("Altera Blaster Cortex Debugger")TDRV4=BIN\lmidk-agdi.dll("Stellaris ICDI")TDRV5=Signum\SigUV3Arm.dll("Signum Systems JTAGjet")TDRV6=Segger\JLTAgdi.dll("J-LINK / J-TRACE")TDRV7=Segger\JL2CM3.dll("Cortex-M/R J-LINK/J-Trace")TDRV8=STLink\ST-LINKIII-KEIL.dll ("ST-Link (Deprecated Version)")TDRV9=BIN\ULP2CM3.DLL("ULINK Pro Cortex Debugger")TDRV10=BIN\ULP2ARM.DLL("ULINK Pro ARM Debugger")TDRV11=NULink\Nu_Link.dll("NULink Debugger")TDRV12=SiLabs\SLAB_CM_Keil.dll("SiLabs UDA Debugger")TDRV13=STLink\ST-LINKIII-KEIL_SWO.dll ("ST-Link Debugger")DELDRVPKG0=ULINK\UninstallULINK.exe("ULINK Pro Driver V1.0")LIC0=UJWBS-LNGB0-8FWIE-5N2GJ-UKXD9-NTBGM[ARMADS]PATH="D:\Keil ARM\ARM\"PATH1="BIN40\"CPUDLL0=SARM.DLL(TDRV0,TDRV5,TDRV6,TDRV10) # Drivers for ARM7/9 devices CPUDLL1=SARMCM3.DLL(TDRV1,TDRV2,TDRV3,TDRV4,TDRV5,TDRV7,TDRV8,TDR V9,TDRV11,TDRV12,TDRV13) # Drivers for Cortex-M devicesCPUDLL2=SARMCR4.DLL(TDRV7) # Drivers for Cortex-R4 devicesBOOK0=HLP\RELEASE_NOTES.HTM("Release Notes",GEN)BOOK1=HLP\ARMTOOLS.chm("Complete User's Guide Selection",C)BOOK2=HLP\RL_RELEASE_NOTES.HTM("RL-ARM Release Notes",GEN)BOOK3=CMSIS\index.html("CMSIS Documentation",GEN)BOOK4=Signum\Docs\SigUV3Arm.htm("Signum Systems JTAGjet Driver Documentation",GEN)TDRV0=BIN\UL2ARM.DLL("ULINK2/ME ARM Debugger")TDRV1=BIN\UL2CM3.DLL("ULINK2/ME Cortex Debugger")TDRV2=BIN\AGDIRDI.DLL("RDI Interface Driver")TDRV3=BIN\ABLSTCM.dll("Altera Blaster Cortex Debugger")TDRV4=BIN\lmidk-agdi.dll("Stellaris ICDI")TDRV5=Signum\SigUV3Arm.dll("Signum Systems JTAGjet")TDRV6=Segger\JLTAgdi.dll("J-LINK / J-TRACE")TDRV7=Segger\JL2CM3.dll("Cortex-M/R J-LINK/J-Trace")TDRV8=STLink\ST-LINKIII-KEIL.dll ("ST-Link (Deprecated Version)")TDRV9=BIN\ULP2CM3.DLL("ULINK Pro Cortex Debugger")TDRV10=BIN\ULP2ARM.DLL("ULINK Pro ARM Debugger")TDRV11=NULink\Nu_Link.dll("NULink Debugger")TDRV12=SiLabs\SLAB_CM_Keil.dll("SiLabs UDA Debugger")TDRV13=STLink\ST-LINKIII-KEIL_SWO.dll ("ST-Link Debugger")RTOS0=Dummy.DLL("Dummy")RTOS1=VARTXARM.DLL ("RTX Kernel")DELDRVPKG0=ULINK\UninstallULINK.exe("ULINK Pro Driver V1.0")。
keil uvision5 编译汉字3字节

keil uvision5 编译汉字3字节摘要:1.Keil Uvision5 编译器简介2.汉字在Keil Uvision5中的表示方法3.编译汉字时出现的问题及解决方法4.实战案例:编译一个包含汉字的程序正文:Keil Uvision5 是一款由德国Keil公司开发的集成开发环境(IDE),广泛应用于嵌入式系统开发。
在我国,许多工程师使用该编译器进行汉字编程。
下面将介绍如何在Keil Uvision5中编译汉字,以及在编译过程中可能遇到的问题及解决方法。
1.Keil Uvision5 编译器简介Keil Uvision5 集成开发环境集成了C/C++编译器、调试器、仿真器等功能,支持多种处理器架构,如ARM、MIPS等。
对于汉字编程,我们首先需要了解如何在Keil Uvision5中正确表示和编译汉字。
2.汉字在Keil Uvision5中的表示方法在Keil Uvision5中,汉字可以通过Unicode编码进行表示。
Unicode编码是一种字符编码标准,它为每个字符分配一个唯一的编码值。
常见的Unicode编码有UTF-8、UTF-16等。
在C/C++编程中,我们可以使用Unicode字符串来表示汉字。
在Keil Uvision5中编写汉字程序时,需要在代码文件的开头添加以下预处理指令:```c#include <stdio.h>#include <string.h>#include <unicode/ucnv.h>```其中,<unicode/ucnv.h>是Keil Uvision5自带的Unicode转换头文件。
3.编译汉字时出现的问题及解决方法在编译汉字程序时,可能会遇到以下问题:(1)编译器不支持Unicode字符串:部分编译器不支持Unicode字符串,导致汉字程序无法正常编译。
为了解决这个问题,我们可以将Unicode字符串转换为UTF-8编码的字符串,然后再进行操作。
keil 切换编码中文乱码的一种手动解决方法

一、引言在使用keil进行编码时,有时会遇到中文乱码的问题,这给我们的编程工作带来了不便。
本文将介绍一种手动解决keil切换编码中文乱码问题的方法,希望能够帮助到大家。
二、问题分析1. 中文乱码问题的原因在keil中,中文乱码可能是由于编码格式不一致所导致的。
不同的编码格式会导致中文字符的显示出现问题,从而影响程序的编写和阅读。
2. 解决方法针对keil切换编码中文乱码问题,我们可以通过手动调整编码格式来解决。
接下来将介绍具体的操作步骤。
三、操作步骤1. 打开keil软件,找到需要解决中文乱码的文件。
2. 点击菜单栏中的“文件”选项,选择“另存为”。
3. 在另存为窗口中,找到“编码”选项,点击下拉箭头选择“UTF-8”编码格式。
4. 点击“保存”按钮,将文件保存为UTF-8编码格式。
5. 关闭原文件,重新打开刚才保存的文件,此时中文乱码的问题应该得到了解决。
通过以上操作步骤,我们可以实现keil切换编码中文乱码问题的解决。
四、注意事项1. 在进行编码格式转换时,建议先备份原文件,以防操作失误导致文件损坏。
2. 在保存文件时,确保选择了正确的编码格式,否则可能会导致文件内容损坏或者乱码问题未能解决。
3. 如果以上操作仍未能解决中文乱码问题,可以考虑使用其他编辑工具来处理文件编码格式,或者寻求专业人士的帮助。
五、总结通过本文介绍的方法,我们可以手动解决keil切换编码中文乱码问题,从而提高编程效率和便利性。
在日常使用keil过程中,如果遇到类似问题,可以尝试以上方法进行处理,相信会对大家带来帮助。
六、结语希望本文介绍的内容能够对大家解决keil编码中文乱码问题有所帮助,也希望大家能够在使用keil软件时更加顺利地进行编程工作。
谢谢大家的阅读!中文乱码问题在使用keil进行编码的过程中是一个很常见的困扰,特别是对于初学者来说。
在编程过程中,我们经常需要使用中文注释或者中文命名变量,但是由于不同的编码格式,导致中文字符显示出现问题,给我们的编程工作带来了很大的不便。
程序中的汉字变乱码的解决方法

程序中的汉字变乱码的解决方法汉字出现乱码有好几种情况,大致可分成四类:网页、文本、文档和文件乱码。
第一类是由于港台的繁体中文大五码(BIG5)与大陆简体中文(GB2312)不通用造成的;第二类是系统(菜单、桌面、提示框)显示乱码,这是注册表中有关字体的部分设置不当引起的;第三类是各种应用程序(包括游戏)本来显示中文的地方出现乱码,形成原因比较复杂,有第二类的乱码原因,也可能是软件用到的中文动态链接库被英文动态链接库覆盖造成的;最后一类是邮件乱码。
(一)、网页、文本和文档文件乱码的消除网页乱码是浏览器(如IE等)对HTML网页解释时形成的。
如果在网页的代码中有形如:〈HTML〉〈HEAD〉〈META CONTENT=“text/html;charset=ISO-8859-1”〉〈/HEAD〉……〈/HTML〉的语句,浏览器在显示此页时,就会出现乱码。
因为浏览器会将此页语种辨认为“欧洲语系”。
解决的办法是将语种“ISO-8859-1”改为GB2312,如果是繁体网页则改为BIG5。
另一种解决办法是不修改网页代码,事先为浏览器安装多语言支持包(例如在安装IE时要安装多语言支持包),这样在浏览网页出现乱码时,就可以在浏览器中选择菜单栏下的“查看”/“编码”/“自动选择”/简体中文(GB2312),如为繁体中文则选择“查看”/“编码”/“自动选择”/繁体中文(BIG5),其它语言依此类推选择相应的语系,这样可消除网页乱码现象。
还有一种解决办法是利用多内码显示平台来转换内码。
常用多内码显示平台有:“南极星”、“四通利方”、“MagicWin 98等等。
网页无乱码保存的方法是:用浏览器打开网页时,在“查看”/“编码”中选择“自动选择”,存盘时保存类型选“web页”,编码选择“UNICOD”,这样保存过的网页再次打开时,在浏览器菜单“查看”、“编码”中不管选择简体中文(GB2312)、简体中文(HZ)还是UNICODE(UTF-8)或繁体中文(BIG5),最终显示都不会出现乱码。
程序中的汉字变乱码的解决方法

程序中的汉字变乱码的解决方法汉字出现乱码有好几种情况,大致可分成四类:网页、文本、文档和文件乱码。
第一类是由于港台的繁体中文大五码(BIG5)与大陆简体中文(GB2312)不通用造成的;第二类是系统(菜单、桌面、提示框)显示乱码,这是注册表中有关字体的部分设置不当引起的;第三类是各种应用程序(包括游戏)本来显示中文的地方出现乱码,形成原因比较复杂,有第二类的乱码原因,也可能是软件用到的中文动态链接库被英文动态链接库覆盖造成的;最后一类是邮件乱码。
(一)、网页、文本和文档文件乱码的消除网页乱码是浏览器(如IE等)对HTML网页解释时形成的。
如果在网页的代码中有形如:〈HTML〉〈HEAD〉〈META CONTENT=“text/html;charset=ISO-8859-1”〉〈/HEAD〉……〈/HTML〉的语句,浏览器在显示此页时,就会出现乱码。
因为浏览器会将此页语种辨认为“欧洲语系”。
解决的办法是将语种“ISO-8859-1”改为GB2312,如果是繁体网页则改为BIG5。
另一种解决办法是不修改网页代码,事先为浏览器安装多语言支持包(例如在安装IE时要安装多语言支持包),这样在浏览网页出现乱码时,就可以在浏览器中选择菜单栏下的“查看”/“编码”/“自动选择”/简体中文(GB2312),如为繁体中文则选择“查看”/“编码”/“自动选择”/繁体中文(BIG5),其它语言依此类推选择相应的语系,这样可消除网页乱码现象。
还有一种解决办法是利用多内码显示平台来转换内码。
常用多内码显示平台有:“南极星”、“四通利方”、“MagicWin 98等等。
网页无乱码保存的方法是:用浏览器打开网页时,在“查看”/“编码”中选择“自动选择”,存盘时保存类型选“web页”,编码选择“UNICOD”,这样保存过的网页再次打开时,在浏览器菜单“查看”、“编码”中不管选择简体中文(GB2312)、简体中文(HZ)还是UNICODE(UTF-8)或繁体中文(BIG5),最终显示都不会出现乱码。
keil中数组赋值汉字的编码格式

《深度解析keil中数组赋值汉字的编码格式》近年来,随着我国的科技发展和经济全球化的进程,对于中文字符编码的需求越来越迫切。
作为一名软件开发人员,我们常常会在使用keil进行编程时遇到需要对数组进行赋值的情况,而在涉及到中文字符编码时,就会出现一些诡异的问题,这就需要我们对keil中数组赋值汉字的编码格式进行深入探讨和分析。
让我们简要地回顾一下中文字符的编码方式。
在我国,中文字符有多种编码方式,比较常见的有GB2312、GBK、UTF-8等。
而在keil中,一般常使用Unicode编码进行字符的表示。
当我们需要在keil中对数组进行赋值时,就需要考虑到中文字符的编码格式与Unicode之间的转换和兼容性问题。
在keil中,对数组赋值中涉及到中文字符编码格式的问题,主要有两种常见的情形。
一种是直接在代码中使用中文字符进行赋值,另一种是将中文字符存储在外部文件中,再通过编码方式进行读取和赋值。
这两种情形在涉及到编码格式时,都需要我们对具体的编码方式进行细致的分析和处理。
对于第一种情况,当我们直接在代码中使用中文字符进行赋值时,就需要考虑到keil对于中文字符的内部表示方式。
一般来说,keil采用的是Unicode编码,因此我们需要保证在代码中使用的中文字符能够正确地被转换成Unicode编码进行存储和使用。
这就需要我们对ICU (International Components for Unicode)库进行合理地使用和配置,以确保中文字符能够被正确地解析和处理。
在进行数组赋值时,需要注意到Unicode编码下中文字符所占用的字节数,以避免出现截断或溢出的情况。
而对于第二种情况,当我们需要从外部文件中读取中文字符进行数组赋值时,就需要考虑到文件的编码格式与keil中Unicode编码之间的转换和兼容性问题。
一般来说,我们可以通过使用特定的编码库或者工具,将外部文件中的中文字符转换成Unicode编码进行存储和使用。
QtEmbedded下汉字显示成乱码问题的解决:

Qt/Embedded下汉字显示成乱码问题的解决:本人通过一段时间的研究,查资料和实验,解决了在Qt/Embedded下汉字显示为乱码的问题。
假设我们在Linux环境下,安装Qte及Qtopia的目录是/usr/local/qt_x86, QT环境建立后,在该目录下则有qt-2.3.7及qtopia-1.7.0目录(假设我们用的版本是qt-emdedded-2.3.7和qtopia-free-1.7.0)。
问题的现象是:执行应用程序后,汉字显示成乱码或小方块。
问题原因及解决办法:1、编译qte库时,对中文textcode的支持未编译进去。
解决办法:在已经创建好的Qte及Qtopia环境下,我们要修改/usr/local/qt_x86/qt/src/tools目录下的qconfig-qpe.h文件,将包含CODECS 的行注释掉(3行),然后重新编译Qte, 编译后的QT库就能够对中文textcode的支持了。
Qte默认的字体是Helvetica, 没有中文。
所以在自己的应用程序中指定一个Qte自带的中文字体unifont,这样就可以了。
后面附一段自己实验成功的程序。
编译自己的应用程序时,环境变量设置如下: (当前目录为/usr/local/qt_x86)export QTDIR=$PWD/qtexport QPEDIR=$PWD/qtopiaexport TMAKEDIR=$PWD/tmakeexport TMAKEPA TH=$TMAKEDIR/lib/qws/linux-generic-g++export PA TH=$QTDIR/bin:$QPEDIR/bin:$TMAKEDIR/bin:$PA TH源程序如下:study3-4.cpp#include <qapplication.h>//#include <qwidget.h>#include <qpushbutton.h>#include <qfont.h>#include <qlabel.h>#include <qtextcodec.h>class MyMainWindow:public QWidget{public:MyMainWindow();private:QPushButton *b1;QLabel *label;};MyMainWindow::MyMainWindow(){qApp->setDefaultCodec( QTextCodec::codecForName("GBK") );setGeometry( 100, 100, 200, 170);b1=new QPushButton( tr("按钮"), this );b1->setGeometry(20, 20, 100, 80);b1->setFont(QFont("unifont", 16, QFont::Bold) );label = new QLabel( this );//label->setText( tr("中文标签" ) );label->setGeometry( 20, 110, 180, 50 );label->setText( tr("这是第一行\n这是第二行" ));label->setFont(QFont("unifont", 16, QFont::Bold) );label->setAlignment( AlignCenter );}int main(int argc, char **argv){QApplication a(argc, argv);MyMainWindow w;a.setMainWidget( &w);w.show();a.exec();}工程文件如下://study3-4.proTEMPLA TE = appLANGUAGE = C++CONFIG += qt warn_on releaseSOURCES += study3-4.cpp。