最新C语言链表排序
c语言中linklist类型

c语言中linklist类型LinkList类型是C语言中常用的数据结构之一,它是一种线性链表的实现方式。
在计算机科学中,链表是一种常见的数据结构,用于存储和操作一系列元素。
链表由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。
链表中的第一个节点称为头节点,最后一个节点称为尾节点。
链表可以根据需要动态地增加或删除节点,相比于数组,链表的大小可以根据实际需求进行调整。
链表的实现可以使用不同的方式,其中最常见的是单向链表。
在单向链表中,每个节点只有一个指针,指向下一个节点。
这种实现方式简单且高效,适用于大多数场景。
除了单向链表,还有双向链表和循环链表等其他实现方式。
链表的优点是可以快速在任意位置插入或删除节点,而无需移动其他节点。
这是由于链表中的节点通过指针相互连接,而不是像数组那样连续存储。
另外,链表的大小可以根据需要进行动态调整,而数组的大小是静态的。
这使得链表在处理动态数据集合时非常有用。
然而,链表也有一些缺点。
首先,访问链表中的任意节点都需要从头节点开始遍历,直到找到目标节点。
这导致了链表的访问时间复杂度为O(n),而数组的访问时间复杂度为O(1)。
其次,链表需要额外的内存空间来存储指针信息,这会占用更多的存储空间。
在C语言中,可以使用结构体来定义链表节点,例如:```typedef struct Node {int data;struct Node *next;} Node;typedef struct LinkedList {Node *head;Node *tail;} LinkedList;```上述代码定义了一个包含数据和指针的节点结构体Node,以及一个包含头节点和尾节点指针的链表结构体LinkedList。
通过这样的定义,可以方便地进行链表的操作,比如插入、删除和遍历等。
链表的插入操作可以分为三步:创建新节点、修改指针、更新链表的头尾指针。
例如,插入一个新节点到链表末尾的代码如下:```void insert(LinkedList *list, int data) {Node *newNode = (Node *)malloc(sizeof(Node));newNode->data = data;newNode->next = NULL;if (list->head == NULL) {list->head = newNode;list->tail = newNode;} else {list->tail->next = newNode;list->tail = newNode;}}```链表的删除操作也类似,可以分为三步:找到目标节点、修改指针、释放内存。
sort函数参数和头文件c语言 -回复

sort函数参数和头文件c语言-回复关于sort函数参数和头文件的讨论在C语言中,sort函数广泛应用于数组或链表的排序操作。
它是一个快速且高效的排序算法,可以根据用户定义的比较函数将元素按照指定的顺序进行排列。
本文将详细介绍sort函数的参数和头文件,以帮助读者更好地理解和使用这一功能强大的函数。
首先,我们需要知道sort函数的基本用法和功能。
sort函数被定义在C 标准库中的<unistd.h>头文件中,因此在使用之前,我们需要在代码中引入这个头文件。
同时,为了使用sort函数,我们还需要了解它的参数和原型。
sort函数的原型如下:cvoid sort(void *base, size_t num, size_t size, int (*cmp_func)(const void *, const void *));下面我们一步一步解释每个参数的作用和含义。
1. base:这个参数是指向要排序数组或链表的指针。
在排序算法中,sort函数会根据用户提供的比较函数来比较这些元素的大小,并对它们进行排序。
要确保指针指向的内存区域足够容纳要排序的元素。
2. num:这个参数表示要排序的元素的数量。
sort函数会根据用户提供的比较函数,将这些元素按照指定的顺序进行排列。
要确保这个参数的值和实际要排序的元素数量一致,否则可能导致排序结果不正确。
3. size:这个参数表示要排序元素的大小,以字节为单位。
sort函数会根据这个参数来确定每个元素的大小,从而进行正确的排序。
要确保这个参数的值和实际要排序的元素大小一致,否则可能导致排序结果不正确。
4. cmp_func:这个参数是一个指向比较函数的指针。
sort函数会调用这个函数,来比较要排序的元素的大小。
比较函数需要满足以下条件:- 它需要返回一个整数值,根据这个返回值来确定两个元素的大小关系。
如果返回值小于0,表示第一个元素小于第二个元素;如果返回值大于0,表示第一个元素大于第二个元素;如果返回值等于0,表示两个元素相等。
c语言递归反转链表

在C语言中,递归反转链表的代码实现相对简洁。
下面是一个实现链表反转的递归函数示例:#include <stdio.h>#include <stdlib.h>// 定义链表节点结构体typedef struct ListNode {int val;struct ListNode *next;} ListNode;// 递归函数,用于反转链表ListNode* reverseList(ListNode* head) {// 递归的基准情况:如果链表为空或者只有一个节点,返回原节点if (head == NULL || head->next == NULL) {return head;}// 递归地反转剩下的链表部分ListNode* newHead = reverseList(head->next);// 将当前节点的next指向null(因为它现在是链表的最后一个节点)head->next->next = head;head->next = NULL;// 返回新的头节点return newHead;}// 辅助函数,用于创建链表ListNode* createList(int[] values, int size) {ListNode* head = NULL;for (int i = size - 1; i >= 0; --i) {ListNode* newNode = malloc(sizeof(ListNode));newNode->val = values[i];newNode->next = head;head = newNode;}return head;}// 打印链表void printList(ListNode* head) {while (head != NULL) {printf("%d ", head->val);head = head->next;}printf("\n");}int main() {int values[] = {1, 2, 3, 4, 5};int size = sizeof(values) / sizeof(values[0]);ListNode* originalHead = createList(values, size);printf("Original list: ");printList(originalHead);ListNode* reversedHead = reverseList(originalHead);printf("Reversed list: ");printList(reversedHead);// 释放链表内存ListNode* current = originalHead;while (current != NULL) {ListNode* temp = current;current = current->next;free(temp);}return 0;}这段代码首先定义了一个链表节点结构体ListNode。
[转载整理]C语言链表实例
![[转载整理]C语言链表实例](https://img.taocdn.com/s3/m/0aca427eb94ae45c3b3567ec102de2bd9605debe.png)
[转载整理]C语⾔链表实例 C语⾔链表有单链表、双向链表、循环链表。
单链表由数据域和指针域组成,数据域存放数据,指针域存放该数据类型的指针便于找到下⼀个节点。
双链表则含有头指针域、数据域和尾指针域,域单链表不同,双链表可以从后⼀个节点找到前⼀个节点,⼆单链表则不⾏。
循环链表就是在单链表的基础上,将头结点的地址指针存放在最后⼀个节点的指针域⾥以,此形成循环。
此外还有双向循环链表,它同时具有双向链表和循环链表的功能。
单链表如:链表节点的数据结构定义struct node{int num;struct node *p;} ;在此链表节点的定义中,除⼀个整型的成员外,成员p是指向与节点类型完全相同的指针。
※在链表节点的数据结构中,⾮常特殊的⼀点就是结构体内的指针域的数据类型使⽤了未定义成功的数据类型。
这是在C中唯⼀规定可以先使⽤后定义的数据结构。
链表实例代码:1// 原⽂地址 /wireless-dragon/p/5170565.html2 #include<stdio.h>3 #include<stdlib.h>4 #include<string.h>56 typedef int elemType;//定义存⼊的数据的类型可以是int char78 typedef struct NODE{ //定义链表的结构类型9 elemType element;10struct NODE *next;11 }Node;1213/************************************************************************/14/* 以下是关于线性表链接存储(单链表)操作的19种算法 */1516/* 1.初始化线性表,即置单链表的表头指针为空 */17/* 2.创建线性表,此函数输⼊负数终⽌读取数据*/18/* 3.打印链表,链表的遍历*/19/* 4.清除线性表L中的所有元素,即释放单链表L中所有的结点,使之成为⼀个空表 */20/* 5.返回单链表的长度 */21/* 6.检查单链表是否为空,若为空则返回1,否则返回0 */22/* 7.返回单链表中第pos个结点中的元素,若pos超出范围,则停⽌程序运⾏ */23/* 8.从单链表中查找具有给定值x的第⼀个元素,若查找成功则返回该结点data域的存储地址,否则返回NULL */24/* 9.把单链表中第pos个结点的值修改为x的值,若修改成功返回1,否则返回0 */25/* 10.向单链表的表头插⼊⼀个元素 */26/* 11.向单链表的末尾添加⼀个元素 */27/* 12.向单链表中第pos个结点位置插⼊元素为x的结点,若插⼊成功返回1,否则返回0 */28/* 13.向有序单链表中插⼊元素x结点,使得插⼊后仍然有序 */29/* 14.从单链表中删除表头结点,并把该结点的值返回,若删除失败则停⽌程序运⾏ */30/* 15.从单链表中删除表尾结点并返回它的值,若删除失败则停⽌程序运⾏ */31/* 16.从单链表中删除第pos个结点并返回它的值,若删除失败则停⽌程序运⾏ */32/* 17.从单链表中删除值为x的第⼀个结点,若删除成功则返回1,否则返回0 */33/* 18.交换2个元素的位置 */34/* 19.将线性表进⾏冒排序 */35363738/*注意检查分配到的动态内存是否为空*/3940414243/* 1.初始化线性表,即置单链表的表头指针为空 */44void initList(Node **pNode)45 {46 *pNode=NULL;47 printf("initList函数执⾏,初始化成功\n");48 }4950/* 2.创建线性表,此函数输⼊负数终⽌读取数据*/51 Node *creatList(Node *pHead)52 {53 Node *p1,*p2;54 p1=p2=(Node *)malloc(sizeof(Node));55if(p1 == NULL || p2 ==NULL)57 printf("内存分配失败\n");58 exit(0);59 }60 memset(p1,0,sizeof(Node));6162 scanf("%d",&p1->element);63 p1->next=NULL;6465while(p1->element >0) //输⼊的值⼤于0则继续,否则停⽌66 {67if(pHead == NULL)//空表,接⼊表头68 {69 pHead=p1;70 }71else72 {73 p2->next=p1;74 }7576 p2=p1;77 p1=(Node *)malloc(sizeof(Node));7879if(p1==NULL||p2==NULL)80 {81 printf("内存分配失败\n");82 exit(0);83 }84 memset(p1,0,sizeof(Node));85 scanf("%d",&p1->element);86 p1->next=NULL;87 }88 printf("CreatList函数执⾏,链表创建成功\n");89return pHead;90 }9192/* 3.打印链表,链表的遍历*/93void printList(Node *pHead)94 {95if(NULL==pHead)96 {97 printf("PrintList函数执⾏,链表为空\n");98 }99else100 {101while(NULL!=pHead)102 {103 printf("%d\n",pHead->element);104 pHead=pHead->next;105 }106 }107108 }109110111/* 4.清除线性表L中的所有元素,即释放单链表L中所有的结点,使之成为⼀个空表 */ 112void clearList(Node *pHead)113 {114 Node *pNext;115116if(pHead==NULL)117 {118 printf("clearList函数执⾏,链表为空\n");119return;120 }121while(pHead->next!=NULL)122 {123 pNext=pHead->next;124free(pHead);125 pHead=pNext;126 }127 printf("clearList函数执⾏,链表已经清除!\n");128129 }130131/* 5.返回链表的长度*/132int sizeList(Node *pHead)133 {134int size=0;135136while(pHead!=NULL)137 {138 size++;139 pHead=pHead->next;141 printf("sizelist函数执⾏,链表长度为%d\n",size);142return size;143 }144145/* 6.检查单链表是否为空,若为空则返回1,否则返回0 */146int isEmptyList(Node *pHead)147 {148if(pHead==NULL)149 {150 printf("isEmptylist函数执⾏,链表为空!\n");151return1;152 }153154else155 printf("isEmptylist函数执⾏,链表⾮空!\n");156return0;157158 }159160/* 7.返回链表中第post节点的数据,若post超出范围,则停⽌程序运⾏*/161int getElement(Node *pHead,int pos)162 {163int i=0;164if(pos<1)165 {166 printf("getElement函数执⾏,pos值⾮法!");167return0;168 }169if(pHead==NULL)170 {171 printf("getElement函数执⾏,链表为空!");172 }173174while (pHead!=NULL)175 {176 ++i;177if(i==pos)178 {179break;180 }181 pHead=pHead->next;182 }183if(i<pos)184 {185 printf("getElement函数执⾏,pos值超出链表长度\n");186return0;187 }188 printf("getElement函数执⾏,位置%d中的元素为%d\n",pos,pHead->element);189190return1;191 }192193//8.从单⼀链表中查找具有给定值x的第⼀个元素,若查找成功后,返回该节点data域的存储位置,否则返回NULL 194 elemType *getElemAddr(Node *pHead,elemType x)195 {196if(NULL==pHead)197 {198 printf("getEleAddr函数执⾏,链表为空");199return NULL;200 }201if(x<0)202 {203 printf("getEleAddr函数执⾏,给定值x不合法\n");204return NULL;205 }206while((pHead->element!=x)&&(NULL!=pHead->next))//判断链表是否为空,并且是否存在所查找的元素207 {208 pHead=pHead->next;209 }210if(pHead->element!=x)211 {212 printf("getElemAddr函数执⾏,在链表中没有找到x值\n");213return NULL;214 }215else216 {217 printf("getElemAddr函数执⾏,元素%d的地址为0x%x\n",x,&(pHead->element));218 }219return &(pHead->element);220221 }222223224/*9.修改链表中第pos个点X的值,如果修改成功,则返回1,否则返回0*/225int modifyElem(Node *pNode,int pos,elemType x)226 {227 Node *pHead;228 pHead=pNode;229int i=0;230if(NULL==pHead)231 {232 printf("modifyElem函数执⾏,链表为空\n");233return0;234 }235236if(pos<1)237 {238 printf("modifyElem函数执⾏,pos值⾮法\n");239return0;240 }241242while(pHead!= NULL)243 {244 ++i;245if(i==pos)246 {247break;248 }249 pHead=pHead->next;250 }251252if(i<pos)253 {254 printf("modifyElem函数执⾏,pos值超出链表长度\n");255return0;256 }257 pNode=pHead;258 pNode->element=x;259 printf("modifyElem函数执⾏,修改第%d点的元素为%d\n",pos,x);260261return1;262263 }264265/* 10.向单链表的表头插⼊⼀个元素 */266int insertHeadList(Node **pNode,elemType insertElem)267 {268 Node *pInsert;269 pInsert=(Node *)malloc(sizeof(Node));270if(pInsert==NULL) exit(1);271 memset(pInsert,0,sizeof(Node));272 pInsert->element=insertElem;273 pInsert->next=*pNode;274 *pNode=pInsert;275 printf("insertHeadList函数执⾏,向表头插⼊元素%d成功\n",insertElem);276return1;277 }278279/* 11.向单链表的末尾添加⼀个元素 */280int insertLastList(Node *pNode,elemType insertElem)281 {282 Node *pInsert;283 Node *pHead;284 Node *pTmp;285286 pHead=pNode;287 pTmp=pHead;288 pInsert=(Node *)malloc(sizeof(Node));289if(pInsert==NULL) exit(1);290 memset(pInsert,0,sizeof(Node));291 pInsert->element=insertElem;292 pInsert->next=NULL;293while(pHead->next!=NULL)294 {295 pHead=pHead->next;296 }297 pHead->next=pInsert;298 printf("insertLastList函数执⾏,向表尾插⼊元素%d成功!\n",insertElem);299return1;300 }301302/* 12.向单链表中第pos个结点位置插⼊元素为x的结点,若插⼊成功返回1,否则返回0*/ 303int isAddPos(Node *pNode,int pos,elemType x)304 {305 Node *pHead;306 pHead=pNode;307 Node *pTmp;308int i=0;309310if(NULL==pHead)311 {312 printf("AddPos函数执⾏,链表为空\n");313return0;314 }315316if(pos<1)317 {318 printf("AddPos函数执⾏,pos值⾮法\n");319return0;320 }321322while(pHead!=NULL)323 {324 ++i;325if(i==pos)326break;327 pHead=pHead->next;328 }329330if(i<pos)331 {332 printf("AddPos函数执⾏,pos值超出链表长度\n");333return0;334 }335336 pTmp=(Node *)malloc(sizeof(Node));337if(pTmp==NULL) exit(1);338 memset(pTmp,0,sizeof(Node));339 pTmp->next=pHead->next;340 pHead->next=pTmp;341 pTmp->element=x;342343 printf("AddPos函数执⾏成功,向节点%d后插⼊数值%d\n",pos,x); 344return1;345 }346347/* 13.向有序单链表中插⼊元素x结点,使得插⼊后仍然有序 */348int OrrderList(Node *pNode,elemType x)349 {350//注意如果此数值要排到⾏尾要修改本代码351 Node *pHead;352 pHead=pNode;353 Node *pTmp;354355if(NULL==pHead)356 {357 printf("OrrderList函数执⾏,链表为空\n");358return0;359 }360361if(x<1)362 {363 printf("OrrderList函数执⾏,x值⾮法\n");364return0;365 }366367while(pHead!=NULL)368 {369if((pHead->element)>=x)370break;371 pHead=pHead->next;372 }373374375if(pHead==NULL)376 {377 printf("OrrderList函数查找完毕,该函数中没有该值\n");378return0;379 }380381382 pTmp=(Node *)malloc(sizeof(Node));383if(pTmp==NULL) exit(1);384 memset(pTmp,0,sizeof(Node));385 pTmp->next=pHead->next;386 pHead->next=pTmp;387 pTmp->element=x;388389 printf("OrrderList函数成功插⼊数值%d\n",x);390return1;391 }392393/*14.从单链表中删除表头结点,并把该结点的值返回,若删除失败则停⽌程序运⾏*/ 394int DelHeadList(Node **pList)395 {396 Node *pHead;397 pHead=*pList;398if(pHead!=NULL)399 printf("DelHeadList函数执⾏,函数⾸元素为%d删除成功\n",pHead->element); 400else401 {402 printf("DelHeadList函数执⾏,链表为空!");403return0;404 }405 *pList=pHead->next;406return1;407 }408409/* 15.从单链表中删除表尾结点并返回它的值,若删除失败则停⽌程序运⾏ */410int DelLastList(Node *pNode)411 {412 Node *pHead;413 Node *pTmp;414415 pHead=pNode;416while(pHead->next!=NULL)417 {418 pTmp=pHead;419 pHead=pHead->next;420 }421 printf("链表尾删除元素%d成功!\n",pHead->element);422free(pHead);423 pTmp->next=NULL;424return1;425 }426427/* 16.从单链表中删除第pos个结点并返回它的值,若删除失败则停⽌程序运⾏ */ 428int DelPos(Node *pNode,int pos)429 {430 Node *pHead;431 pHead=pNode;432 Node *pTmp;433434int i=0;435436if(NULL==pHead)437 {438 printf("DelPos函数执⾏,链表为空\n");439return0;440 }441442if(pos<1)443 {444 printf("DelPos函数执⾏,pos值⾮法\n");445return0;446 }447448while(pHead!=NULL)449 {450 ++i;451if(i==pos)452break;453 pTmp=pHead;454 pHead=pHead->next;455 }456457if(i<pos)458 {459 printf("DelPos函数执⾏,pos值超出链表长度\n");460return0;461 }462 printf("DelPos函数执⾏成功,节点%d删除数值%d\n",pos,pHead->element); 463 pTmp->next=pHead->next;464free(pHead);465return1;466 }467468/* 17.从单链表中删除值为x的第⼀个结点,若删除成功则返回1,否则返回0 */469int Delx(Node **pNode,int x)470 {471 Node *pHead;472 Node *pTmp;473 pHead=*pNode;474int i=0;475476if(NULL==pHead)477 {478 printf("Delx函数执⾏,链表为空");479return0;480 }481if(x<0)482 {483 printf("Delx函数执⾏,给定值x不合法\n");484return0;485 }486while((pHead->element!=x)&&(NULL!=pHead->next))//判断链表是否为空,并且是否存在所查找的元素487 {488 ++i;489 pTmp=pHead;490 pHead=pHead->next;491 }492if(pHead->element!=x)493 {494 printf("Delx函数执⾏,在链表中没有找到x值\n");495return0;496 }497if((i==0)&&(NULL!=pHead->next))498 {499 printf("Delx函数执⾏,在链表⾸部找到此元素,此元素已经被删除\n");500 *pNode=pHead->next;501free(pHead);502return1;503 }504 printf("Delx函数执⾏,⾸个为%d元素被删除\n",x);505 pTmp->next=pHead->next;506free(pHead);507return1;508 }509510/* 18.交换2个元素的位置 */511int exchange2pos(Node *pNode,int pos1,int pos2)512 {513 Node *pHead;514int *pTmp;515int *pInsert;516int a;517int i=0;518519if(pos1<1||pos2<1)520 {521 printf("DelPos函数执⾏,pos值⾮法\n");522return0;523 }524525 pHead=pNode;526while(pHead!=NULL)527 {528 ++i;529if(i==pos1)530break;531 pHead=pHead->next;532 }533534if(i<pos1)535 {536 printf("DelPos函数执⾏,pos1值超出链表长度\n");537return0;538 }539540 pTmp=&(pHead->element);541 i=0;542 pHead=pNode;543while(pHead!=NULL)544 {545 ++i;546if(i==pos2)547break;548 pHead=pHead->next;549 }550551if(i<pos2)552 {553 printf("DelPos函数执⾏,pos2值超出链表长度\n");554return0;555 }556557 pInsert=&(pHead->element);558 a=*pTmp;559 *pTmp=*pInsert;560 *pInsert=a;561562 printf("DelPos函数执⾏,交换第%d个和第%d个pos点的值\n",pos1,pos2); 563return1;564 }565566int swap(int *p1,int *p2)567 {568int a;569if(*p1>*p2)570 {571 a=*p1;572 *p1=*p2;573 *p2=a;574 }575return0;576 }577578/* 19.将线性表进⾏冒泡排序 */579int Arrange(Node *pNode)580 {581 Node *pHead;582 pHead=pNode;583584int a=0,i,j;585586if(NULL==pHead)587 {588 printf("Arrange函数执⾏,链表为空\n");589return0;590 }591592while(pHead!=NULL)593 {594 ++a;595 pHead=pHead->next;596 }597598 pHead=pNode;599for(i=0;i<a-1;i++)600 {601for(j=1;j<a-i;j++)602 {603 swap(&(pHead->element),&(pHead->next->element));604 pHead=pHead->next;605 }606 pHead=pNode;607 }608 printf("Arrange函数执⾏,链表排序完毕!\n");609return0;610 }611612int main()613 {614 Node *pList=NULL;615int length=0;616617 elemType posElem;618619 initList(&pList);620 printList(pList);621622 pList=creatList(pList);623 printList(pList);624625 sizeList(pList);626 printList(pList);627628 isEmptyList(pList);629630631 posElem=getElement(pList,3);632 printList(pList);633634 getElemAddr(pList,5);635636 modifyElem(pList,4,1);637 printList(pList);638639 insertHeadList(&pList,5);640 printList(pList);641642 insertLastList(pList,10);643 printList(pList);644645 isAddPos(pList,4,5); 646 printList(pList);647648 OrrderList(pList,6);649 printList(pList);650651 DelHeadList(&pList); 652 printList(pList);653654 DelLastList(pList);655 printList(pList);656657 DelPos(pList,5);658 printList(pList);659660 Delx(&pList,5);661 printList(pList);662663 exchange2pos(pList,2,5); 664 printList(pList);665666 Arrange(pList);667 printList(pList);668669 clearList(pList);670return0;671 }。
C语言八大排序算法
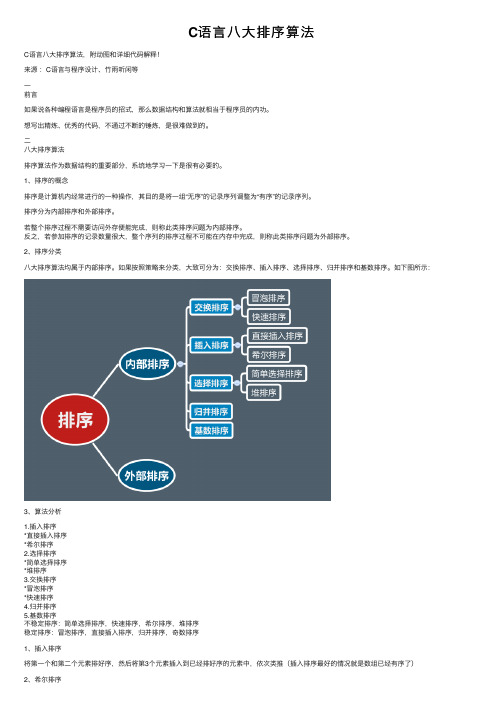
C语⾔⼋⼤排序算法C语⾔⼋⼤排序算法,附动图和详细代码解释!来源:C语⾔与程序设计、⽵⾬听闲等⼀前⾔如果说各种编程语⾔是程序员的招式,那么数据结构和算法就相当于程序员的内功。
想写出精炼、优秀的代码,不通过不断的锤炼,是很难做到的。
⼆⼋⼤排序算法排序算法作为数据结构的重要部分,系统地学习⼀下是很有必要的。
1、排序的概念排序是计算机内经常进⾏的⼀种操作,其⽬的是将⼀组“⽆序”的记录序列调整为“有序”的记录序列。
排序分为内部排序和外部排序。
若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序。
反之,若参加排序的记录数量很⼤,整个序列的排序过程不可能在内存中完成,则称此类排序问题为外部排序。
2、排序分类⼋⼤排序算法均属于内部排序。
如果按照策略来分类,⼤致可分为:交换排序、插⼊排序、选择排序、归并排序和基数排序。
如下图所⽰:3、算法分析1.插⼊排序*直接插⼊排序*希尔排序2.选择排序*简单选择排序*堆排序3.交换排序*冒泡排序*快速排序4.归并排序5.基数排序不稳定排序:简单选择排序,快速排序,希尔排序,堆排序稳定排序:冒泡排序,直接插⼊排序,归并排序,奇数排序1、插⼊排序将第⼀个和第⼆个元素排好序,然后将第3个元素插⼊到已经排好序的元素中,依次类推(插⼊排序最好的情况就是数组已经有序了)因为插⼊排序每次只能操作⼀个元素,效率低。
元素个数N,取奇数k=N/2,将下标差值为k的数分为⼀组(⼀组元素个数看总元素个数决定),在组内构成有序序列,再取k=k/2,将下标差值为k的数分为⼀组,构成有序序列,直到k=1,然后再进⾏直接插⼊排序。
3、简单选择排序选出最⼩的数和第⼀个数交换,再在剩余的数中⼜选择最⼩的和第⼆个数交换,依次类推4、堆排序以升序排序为例,利⽤⼩根堆的性质(堆顶元素最⼩)不断输出最⼩元素,直到堆中没有元素1.构建⼩根堆2.输出堆顶元素3.将堆低元素放⼀个到堆顶,再重新构造成⼩根堆,再输出堆顶元素,以此类推5、冒泡排序改进1:如果某次冒泡不存在数据交换,则说明已经排序好了,可以直接退出排序改进2:头尾进⾏冒泡,每次把最⼤的沉底,最⼩的浮上去,两边往中间靠16、快速排序选择⼀个基准元素,⽐基准元素⼩的放基准元素的前⾯,⽐基准元素⼤的放基准元素的后⾯,这种动作叫分区,每次分区都把⼀个数列分成了两部分,每次分区都使得⼀个数字有序,然后将基准元素前⾯部分和后⾯部分继续分区,⼀直分区直到分区的区间中只有⼀个元素的时候,⼀个元素的序列肯定是有序的嘛,所以最后⼀个升序的序列就完成啦。
数据结构C语言版_链式基数排序

{
int j,p;
for(j=0;j<RADIX;++j)for(p=r[0].next;p;p=r[p].next)
{
// ord将记录中第i个关键字映射到[0..RADIX-1]
keys=083 otheritems=10 next=0
第1趟收集后:
930 063 083 184 505 278 008 109 589 269
第2趟收集后:
505 008 109 930 063 269 278 083 184 589
第3趟收集后:
008 063 083 109 184 269 278 505 589 930
// L是采用静态链表表示的顺序表。对L作基数排序,使得L成为按关键字
// 自小到大的有序静态链表,L.r[0]为头结点。
void RadixSort(SLList *L)
{
int i;
ArrType f,e;
for(i=0;i<(*L).recnum;++i)
(*L).r[i].next=i+1;
; // 找下一个非空子表
if(f[j])
{
// 链接两个非空子表
r[t].next=f[j];
t=e[j];
}
}
r[t].next=0; // t指向最后一个非空子表中的最后一个结点
}
// 按链表输出静态链表
void printl(SLList L)
print(l);
链表排序(冒泡、选择、插入、快排、归并、希尔、堆排序)

链表排序(冒泡、选择、插⼊、快排、归并、希尔、堆排序)这篇⽂章分析⼀下链表的各种排序⽅法。
以下排序算法的正确性都可以在LeetCode的这⼀题检测。
本⽂⽤到的链表结构如下(排序算法都是传⼊链表头指针作为参数,返回排序后的头指针)struct ListNode {int val;ListNode *next;ListNode(int x) : val(x), next(NULL) {}};插⼊排序(算法中是直接交换节点,时间复杂度O(n^2),空间复杂度O(1))class Solution {public:ListNode *insertionSortList(ListNode *head) {// IMPORTANT: Please reset any member data you declared, as// the same Solution instance will be reused for each test case.if(head == NULL || head->next == NULL)return head;ListNode *p = head->next, *pstart = new ListNode(0), *pend = head;pstart->next = head; //为了操作⽅便,添加⼀个头结点while(p != NULL){ListNode *tmp = pstart->next, *pre = pstart;while(tmp != p && p->val >= tmp->val) //找到插⼊位置{tmp = tmp->next; pre = pre->next;}if(tmp == p)pend = p;else{pend->next = p->next;p->next = tmp;pre->next = p;}p = pend->next;}head = pstart->next;delete pstart;return head;}};选择排序(算法中只是交换节点的val值,时间复杂度O(n^2),空间复杂度O(1))class Solution {public:ListNode *selectSortList(ListNode *head) {// IMPORTANT: Please reset any member data you declared, as// the same Solution instance will be reused for each test case.//选择排序if(head == NULL || head->next == NULL)return head;ListNode *pstart = new ListNode(0);pstart->next = head; //为了操作⽅便,添加⼀个头结点ListNode*sortedTail = pstart;//指向已排好序的部分的尾部while(sortedTail->next != NULL){ListNode*minNode = sortedTail->next, *p = sortedTail->next->next;//寻找未排序部分的最⼩节点while(p != NULL){if(p->val < minNode->val)minNode = p;p = p->next;}swap(minNode->val, sortedTail->next->val);sortedTail = sortedTail->next;}head = pstart->next;delete pstart;return head;}};快速排序1(算法只交换节点的val值,平均时间复杂度O(nlogn),不考虑递归栈空间的话空间复杂度是O(1))这⾥的partition我们参考(选取第⼀个元素作为枢纽元的版本,因为链表选择最后⼀元素需要遍历⼀遍),具体可以参考这⾥我们还需要注意的⼀点是数组的partition两个参数分别代表数组的起始位置,两边都是闭区间,这样在排序的主函数中:void quicksort(vector<int>&arr, int low, int high){if(low < high){int middle = mypartition(arr, low, high);quicksort(arr, low, middle-1);quicksort(arr, middle+1, high);}}对左边⼦数组排序时,⼦数组右边界是middle-1,如果链表也按这种两边都是闭区间的话,找到分割后枢纽元middle,找到middle-1还得再次遍历数组,因此链表的partition采⽤前闭后开的区间(这样排序主函数也需要前闭后开区间),这样就可以避免上述问题class Solution {public:ListNode *quickSortList(ListNode *head) {// IMPORTANT: Please reset any member data you declared, as// the same Solution instance will be reused for each test case.//链表快速排序if(head == NULL || head->next == NULL)return head;qsortList(head, NULL);return head;}void qsortList(ListNode*head, ListNode*tail){//链表范围是[low, high)if(head != tail && head->next != tail){ListNode* mid = partitionList(head, tail);qsortList(head, mid);qsortList(mid->next, tail);}}ListNode* partitionList(ListNode*low, ListNode*high){//链表范围是[low, high)int key = low->val;ListNode* loc = low;for(ListNode*i = low->next; i != high; i = i->next)if(i->val < key){loc = loc->next;swap(i->val, loc->val);}swap(loc->val, low->val);return loc;}};快速排序2(算法交换链表节点,平均时间复杂度O(nlogn),不考虑递归栈空间的话空间复杂度是O(1))这⾥的partition,我们选取第⼀个节点作为枢纽元,然后把⼩于枢纽的节点放到⼀个链中,把不⼩于枢纽的及节点放到另⼀个链中,最后把两条链以及枢纽连接成⼀条链。
c语言有序单链表的二路归并算法

c语言有序单链表的二路归并算法C语言有序单链表的二路归并算法一、引言有序单链表是一种常见的数据结构,其中的元素按照一定的顺序排列。
当需要将两个有序单链表合并为一个有序单链表时,可以使用二路归并算法。
本文将介绍使用C语言实现有序单链表的二路归并算法的原理和步骤。
二、算法原理二路归并算法是一种常见的排序算法,它通过将两个有序链表合并为一个有序链表的方式来实现排序。
算法的基本思想是通过比较两个链表中的元素大小,将较小的元素添加到新的链表中,直到将两个链表全部合并为止。
三、算法步骤下面是使用C语言实现有序单链表的二路归并算法的详细步骤:1. 定义两个指针,分别指向两个有序单链表的头结点;2. 创建一个新的链表,用于存储合并后的有序链表;3. 循环比较两个链表中的元素大小,将较小的元素添加到新链表中,并将指针后移;4. 当其中一个链表遍历完毕时,将另一个链表中剩余的元素添加到新链表的末尾;5. 返回新链表的头结点,即为合并后的有序单链表。
四、代码实现下面是使用C语言实现有序单链表的二路归并算法的示例代码:```c#include <stdio.h>#include <stdlib.h>// 定义链表结点typedef struct Node {int data;struct Node* next;} Node;// 创建有序链表Node* createList(int arr[], int size) {Node* head = NULL;Node* tail = NULL;for (int i = 0; i < size; i++) {Node* newNode = (Node*)malloc(sizeof(Node));newNode->data = arr[i];newNode->next = NULL;if (head == NULL) {head = newNode;tail = newNode;} else {tail->next = newNode;tail = newNode;}}return head;}// 合并两个有序链表Node* mergeList(Node* list1, Node* list2) { if (list1 == NULL) {return list2;}if (list2 == NULL) {return list1;}Node* head = NULL;Node* tail = NULL;while (list1 != NULL && list2 != NULL) { if (list1->data <= list2->data) {if (head == NULL) {head = list1;tail = list1;} else {tail->next = list1;tail = list1;}list1 = list1->next;} else {if (head == NULL) {head = list2;tail = list2;} else {tail->next = list2;tail = list2;}list2 = list2->next;}}if (list1 != NULL) {tail->next = list1;}if (list2 != NULL) {tail->next = list2;}return head;}// 打印链表void printList(Node* head) { Node* p = head;while (p != NULL) {printf("%d ", p->data); p = p->next;}printf("\n");}int main() {int arr1[] = {1, 3, 5};int arr2[] = {2, 4, 6};Node* list1 = createList(arr1, sizeof(arr1) / sizeof(int));Node* list2 = createList(arr2, sizeof(arr2) / sizeof(int));printf("链表1:");printList(list1);printf("链表2:");printList(list2);Node* mergedList = mergeList(list1, list2);printf("合并后的链表:");printList(mergedList);return 0;}```五、算法分析有序单链表的二路归并算法的时间复杂度为O(n),其中n为两个链表的总长度。
c语言中索引排序 -回复

c语言中索引排序-回复C语言中索引排序是指对数组或者其他数据结构中的元素进行排序操作。
在进行排序时,我们常常需要使用索引来访问数组中的元素。
索引排序可以根据不同的需求,调整数组中元素的顺序,以达到我们想要的结果。
为了更好地理解索引排序的概念和实现方式,我们需要先了解数组和索引的基本定义和用法。
在C语言中,数组是一种用来存储相同类型元素的连续内存空间。
可以通过索引来访问数组中的元素,索引从0开始,依次递增。
例如,对于一个整型数组arr,可以使用arr[0]来访问第一个元素,arr[1]访问第二个元素,以此类推。
在解决实际问题时,我们可能会遇到需要对数组中的元素进行排序的情况。
排序可以根据元素的大小或其他特定的规则来改变数组中元素的顺序。
很多排序算法都是基于索引操作实现的,下面我们将逐步介绍一些常见的索引排序算法。
首先是冒泡排序算法,它是一种简单直观的排序算法。
冒泡排序算法通过多次遍历数组,每次比较相邻元素的大小,并根据排序规则交换位置,从而实现排序的目的。
在实现过程中,我们可以使用两重循环来遍历数组并比较元素大小。
通过这种方式可以实现索引排序,使得数组中的元素按照升序或降序排列。
其次是选择排序算法,它通过重复选择待排序的元素中的最小值或最大值,并将其放置在已排序的部分的末尾,从而实现排序的目的。
在实现选择排序时,我们可以使用一重循环来遍历数组并选择最小值或最大值的索引。
然后通过交换元素的位置,将最小值或最大值放置到已排序部分的末尾。
通过多次迭代,直到所有元素都按照排序规则排列。
另一种常见的索引排序算法是插入排序算法。
插入排序算法通过将数组中的元素逐个插入到已排序的序列中,从而实现排序的目的。
在实现插入排序时,我们可以使用一重循环来遍历数组并选择待插入的元素。
通过与已排序的元素逐个比较,找到插入位置,并通过交换位置的方式完成插入操作。
通过多次迭代,直到所有元素都按照排序规则排列。
最后是快速排序算法,它是一种常用的高效排序算法。
c语言链表的实用场景

c语言链表的实用场景链表是一种常用的数据结构,适用于许多实际场景。
在C语言中,链表通常通过指针来实现。
下面我将介绍一些常见的使用场景,以展示链表的实际应用。
1.数据库数据库中通常需要存储大量的数据,并进行高效的增删改查操作。
链表可以用于实现数据库中的表,每个节点表示一行数据,通过指针连接各行数据。
这样的设计可以简化数据的插入和删除操作,同时支持动态内存分配。
2.文件系统文件系统是操作系统中重要的组成部分,负责管理文件和目录的存储和组织。
链表可以被用来维护文件和目录的层次结构。
每个节点表示一个文件或目录,在节点中存储文件名和其他属性,并通过指针连接父节点和子节点,实现树状的文件系统结构。
3.缓存管理缓存是提高数据读写性能的一种机制,通常使用链表来实现。
链表的头节点表示最近访问的数据,越往后的节点表示越早被访问的数据。
当需要插入新数据时,链表头部的节点会被替换为新的数据,实现了最近访问数据的缓存功能。
4.链表排序链表排序是常见的问题,主要通过链表节点之间的指针修改来实现。
排序算法可以按照节点的值进行比较和交换,从而实现链表的排序功能。
链表排序应用于许多场景,如订单排序、学生成绩排序等。
5.模拟表达式求值在编译器和计算器中,链表可以用于构建和求解表达式。
每个节点表示表达式的一个操作数或操作符,通过指针连接节点,形成表达式树。
然后可以使用树来求解表达式的值,或者进行优化和转换。
6.链表图结构链表可以用于构建图结构,每个节点表示图的一个顶点,通过指针连接顶点之间的边。
链表图结构可以用于实现路由算法、网络拓扑结构、社交网络等。
7.线性代数运算链表可以用来实现向量和矩阵等线性代数结构。
每个节点表示矩阵的一个元素,通过指针连接不同元素之间的关系。
链表可以用于矩阵乘法、矩阵求逆等运算。
8.垃圾回收在编程中,动态内存分配往往需要手动管理内存的释放。
链表可以用来管理动态分配的内存块,通过指针连接各个内存块,并进行有效的垃圾回收。
冒泡排序链表c语言

冒泡排序链表c语言冒泡排序是一种简单而常用的排序算法,它可以用于对链表进行排序。
在本文中,我们将介绍如何使用C语言实现冒泡排序链表,并解释算法的原理和步骤。
让我们来了解一下冒泡排序的基本原理。
冒泡排序通过多次遍历待排序的元素,比较相邻的两个元素的大小,并根据需要交换它们的位置。
通过这样的比较和交换,最大(或最小)的元素会逐渐“冒泡”到列表的末尾(或开头),从而实现排序。
在链表中实现冒泡排序的思路与数组类似,但需要注意的是,我们无法像数组那样通过下标直接访问链表中的元素。
因此,在链表中进行元素比较和交换时,我们需要修改节点之间的连接关系。
下面是使用C语言实现冒泡排序链表的步骤:1. 遍历链表,确定链表的长度。
这一步是为了确定需要进行多少次排序遍历。
2. 写一个循环,循环次数为链表的长度减1。
每次循环都进行一次完整的遍历和排序。
3. 在每次遍历中,从链表的头部开始,比较相邻节点的值。
如果前一个节点的值大于后一个节点的值,则交换它们的位置。
4. 重复步骤3,直到遍历到链表的倒数第二个节点。
这样可以确保在每次遍历后,链表的最后一个节点都是当前遍历范围内的最大(或最小)值。
5. 重复步骤2和步骤3,直到完成所有的排序遍历。
此时,链表中的元素已经按照从小到大(或从大到小)的顺序排列好了。
以下是冒泡排序链表的C语言代码实现:```c#include <stdio.h>// 定义链表节点的结构体typedef struct Node {int data;struct Node* next;} Node;// 冒泡排序链表的函数void bubbleSortList(Node* head) {if (head == NULL || head->next == NULL) {return;}int len = 0;Node* cur = head;while (cur != NULL) {len++;cur = cur->next;}for (int i = 0; i < len - 1; i++) {cur = head;for (int j = 0; j < len - i - 1; j++) {if (cur->data > cur->next->data) { int temp = cur->data;cur->data = cur->next->data; cur->next->data = temp;}cur = cur->next;}}}// 打印链表的函数void printList(Node* head) {Node* cur = head;while (cur != NULL) {printf("%d ", cur->data);cur = cur->next;}printf("\n");}int main() {// 创建链表Node* head = (Node*)malloc(sizeof(Node)); Node* node1 = (Node*)malloc(sizeof(Node)); Node* node2 = (Node*)malloc(sizeof(Node)); Node* node3 = (Node*)malloc(sizeof(Node)); head->data = 3;node1->data = 2;node2->data = 4;node3->data = 1;head->next = node1;node1->next = node2;node2->next = node3;node3->next = NULL;// 打印排序前的链表printf("排序前的链表:");printList(head);// 对链表进行冒泡排序bubbleSortList(head);// 打印排序后的链表printf("排序后的链表:");printList(head);return 0;}```在上面的代码中,我们首先定义了一个链表节点的结构体,其中包含一个整型数据成员和一个指向下一个节点的指针成员。
C语言链表的排序

C语言链表的排序/某==========================功能:选择排序(由小到大)返回:指向链表表头的指针==========================某//某选择排序的基本思想就是反复从还未排好序的那些节点中,选出键值(就是用它排序的字段,我们取学号num为键值)最小的节点,依次重新组合成一个链表。
head存储的是第一个节点的地址,head->ne某t存储的是第二个节点的地址;任意一个节点p的地址,只能通过它前一个节点的ne某t来求得。
单向链表的选择排序图示:---->[1]---->[3]---->[2]...---->[n]---->[NULL](原链表)head1->ne某t3->ne某t2->ne某tn->ne某t---->[NULL](空链表)firttail---->[1]---->[2]---->[3]...---->[n]---->[NULL](排序后链表)firt1->ne某t2->ne某t3->ne某ttail->ne某t图10:有N个节点的链表选择排序1、先在原链表中找最小的,找到一个后就把它放到另一个空的链表中;2、空链表中安放第一个进来的节点,产生一个有序链表,并且让它在原链表中分离出来(此时要注意原链表中出来的是第一个节点还是中间其它节点);3、继续在原链表中找下一个最小的,找到后把它放入有序链表的尾指针的ne某t,然后它变成其尾指针;某/tructtudent某SelectSort(tructtudent某head){tructtudent某firt;/某排列后有序链的表头指针某/tructtudent 某tail;/某排列后有序链的表尾指针某/tructtudent某p_min;/某保留键值更小的节点的前驱节点的指针某/tructtudent某min;/某存储最小节点某/tructtudent某p;/某当前比较的节点某/firt=NULL;while(head!=NULL)/某在链表中找键值最小的节点。
c语言符号的优先级排序表

c语言符号的优先级排序表在C语言中,符号的优先级是确定表达式中各个符号执行顺序的一种方式。
了解符号的优先级对于正确理解和编写C代码非常重要。
本文将介绍C语言中常见的符号,并提供一个符号的优先级排序表,以帮助读者更好地理解C语言的语法规则。
1. 括号:( )括号具有最高的优先级,它们用于改变默认的执行顺序,将一个表达式的某一部分置于其他操作之前执行。
括号可以用于控制运算符的优先级。
2. 单目运算符:++,--,-(负号),!(逻辑非),~(按位取反),&(取地址)单目运算符具有较高的优先级。
它们作用于一个操作数,并按照给定的规则执行运算。
3. 算术运算符:*,/,%(取模),+,-(加法和减法)算术运算符具有较高的优先级,按照从左到右的顺序执行计算。
4. 移位运算符:<<(左移),>>(右移)移位运算符的优先级较低,它们用于将二进制数左移或右移指定的位数。
5. 关系运算符:>,<,>=,<=,==,!=关系运算符的优先级较低,它们用于比较两个操作数之间的关系,返回布尔值。
6. 逻辑运算符:&&(逻辑与),||(逻辑或)逻辑运算符的优先级较低,它们用于将多个条件连接起来,并根据逻辑运算的结果返回布尔值。
7. 按位与运算符:&按位与运算符的优先级较低,它们用于对两个操作数的每个对应位执行按位与运算。
8. 按位异或运算符:^按位异或运算符的优先级较低,它们用于对两个操作数的每个对应位执行按位异或运算。
9. 按位或运算符:|按位或运算符的优先级较低,它们用于对两个操作数的每个对应位执行按位或运算。
10. 三目运算符:? :三目运算符的优先级较低,它们用于根据条件选择要执行的操作。
11. 赋值运算符:=,+=,-=,*=,/=,%=赋值运算符的优先级较低,它们用于将值分配给变量,并将结果保存在操作数中。
了解符号的优先级对于正确理解和编写C代码至关重要。
数据结构c++顺序表、单链表的基本操作,查找、排序代码

} return 0; }
实验三 查找
实验名称: 实验3 查找 实验目的:掌握顺序表和有序表的查找方法及算法实现;掌握二叉排序 树和哈希表的构造和查找方法。通过上机操作,理解如何科学地组织信 息存储,并选择高效的查找算法。 实验内容:(2选1)内容1: 基本查找算法;内容2: 哈希表设计。 实验要求:1)在C++系统中编程实现;2)选择合适的数据结构实现查 找算法;3)写出算法设计的基本原理或画出流程图;4)算法实现代码 简洁明了;关键语句要有注释;5)给出调试和测试结果;6)完成实验 报告。 实验步骤: (1)算法设计 a.构造哈希函数的方法很多,常用的有(1)直接定址法(2)数字分析法;(3) 平方取中法;(4)折叠法;( 5)除留余数法;(6)随机数法;本实验采用的是除 留余数法:取关键字被某个不大于哈希表表长m的数p除后所得余数为哈 希地址 (2)算法实现 hash hashlist[n]; void listname(){ char *f; int s0,r,i; NameList[0].py="baojie"; NameList[1].py="chengቤተ መጻሕፍቲ ባይዱoyang"; ……………………………… NameList[29].py="wurenke"; for(i=0;i<q;i++){s0=0;f=NameList[i].py; for(r=0;*(f+r)!='\0';r++) s0+=*(f+r);NameList[i].k=s0; }} void creathash(){int i;
v[k-1]=v[k]; nn=nn-1; return ; } int main() {sq_LList<double>s1(100); cout<<"第一次输出顺序表对象s1:"<<endl; s1.prt_sq_LList(); s1.ins_sq_LList(0,1.5); s1.ins_sq_LList(1,2.5); s1.ins_sq_LList(4,3.5); cout<<"第二次输出顺序表对象s1:"<<endl; s1.prt_sq_LList(); s1.del_sq_LList(0); s1.del_sq_LList(2); cout<<"第三次输出顺序表对象s1:"<<endl; s1.prt_sq_LList(); return 0; } 运行及结果:
c语言常见排序算法

常见的C语言排序算法有以下几种:
1. 冒泡排序(Bubble Sort):比较相邻的元素,如果前一个元素大于后一个元素,则交换它们的位置,重复这个过程直到整个序列有序。
2. 插入排序(Insertion Sort):将未排序的元素逐个插入到已排序序列中的正确位置,直到整个序列有序。
3. 选择排序(Selection Sort):每次从未排序的元素中选择最小的元素,将其放到已排序序列的末尾,重复这个过程直到整个序列有序。
4. 快速排序(Quick Sort):选择一个基准元素,将序列分成两部分,一部分小于等于基准元素,一部分大于基准元素,然后对两部分递归地进行快速排序。
5. 归并排序(Merge Sort):将序列分成两部分,分别对两部分进行归并排序,然后将两个有序的子序列合并成一个有序的序列。
6. 堆排序(Heap Sort):将序列构建成一个最大堆,然后将堆顶元素与堆末尾元素交换,重复这个过程直到整个序列有序。
7. 希尔排序(Shell Sort):将序列按照一定的间隔分成若干个子序列,对每个子序列进行插入排序,然后逐渐减小间隔直到间隔为1,最后对整个序列进行插入排序。
8. 计数排序(Counting Sort):统计序列中每个元素出现的次数,然后按照元素的大小顺序将它们放入一个新的序列中。
9. 基数排序(Radix Sort):按照元素的个位、十位、百位等依次进行排序,直到所有位数都排完为止。
以上是常见的C语言排序算法,每种算法都有其特点和适用场景,选择合适的排序算法可以提高排序效率。
数据结构c语言版上机报告单链表

数据结构C语言版上机报告:单链表序在数据结构课程中,单链表是一个重要的概念,也是C语言中常用的数据结构之一。
本次报告将深入探讨单链表的基本概念、操作方法以及应用场景,帮助读者更深入地理解和掌握这一数据结构。
一、概述1.1 单链表的定义单链表是一种线性表,它由一系列节点组成,每个节点包含两部分:数据域和指针域。
数据域用于存储数据元素,指针域用于指向下一个节点,通过指针将这些节点串联在一起,形成一个链表结构。
1.2 单链表的特点单链表具有以下特点:(1)动态性:单链表的长度可以动态地增加或减少,不需要预先分配固定大小的空间。
(2)插入和删除操作高效:在单链表中进行插入和删除操作时,只需要修改指针的指向,时间复杂度为O(1)。
(3)随机访问效率低:由于单链表采用链式存储结构,无法通过下标直接访问元素,需要从头节点开始依次遍历,时间复杂度为O(n)。
1.3 单链表的基本操作单链表的基本操作包括:创建、插入、删除、查找等。
这些操作是使用单链表时常常会涉及到的,下面将逐一介绍这些操作的具体实现方法和应用场景。
二、创建2.1 头插法和尾插法在C语言中,可以通过头插法和尾插法来创建单链表。
头插法是将新节点插入到链表的头部,尾插法是将新节点插入到链表的尾部,这两种方法各有优缺点,可以根据具体应用场景来选择。
2.2 应用场景头插法适合于链表的逆序建立,尾插法适合于链表的顺序建立。
三、插入3.1 在指定位置插入节点在单链表中,插入节点需要考虑两种情况:在链表头部插入和在链表中间插入。
通过对指针的操作,可以实现在指定位置插入节点的功能。
3.2 应用场景在实际应用中,经常会有需要在指定位置插入节点的情况,比如排序操作、合并两个有序链表等。
四、删除4.1 删除指定节点在单链表中,删除节点同样需要考虑两种情况:删除头节点和删除中间节点。
通过对指针的操作,可以实现删除指定节点的功能。
4.2 应用场景在实际应用中,经常会有需要删除指定节点的情况,比如删除链表中特定数值的节点等。
C语言动态链表的排序(从小到大)2021.07.14

C语⾔动态链表的排序(从⼩到⼤)2021.07.14 //现在的主要问题是,排序的列表中不能出现0,原因是与NULL冲突。
#include <stdio.h>#include <stdlib.h>#define MAX 999999typedef struct LNode//重命名struct LNode为LNode{int data;LNode* next;//在结构体中可以直接使⽤新名字LNode}LNode;void CreateLinklist(LNode*& head){printf("请输⼊数字创建链表,以9999结束。
\n");head = (LNode*)malloc(sizeof(LNode));head->next = nullptr;LNode* flag;flag = head;int t;scanf_s("%d", &t);while (t != 9999){flag->data = t;flag->next = (LNode*)malloc(sizeof(LNode));flag = flag->next;scanf_s("%d", &t);}flag->next = nullptr;flag = head;}void printLinklist(LNode* p){if (p->data == NULL)printf("链表为空。
\n");else{printf("链表的结构为:\n");while (p->next != nullptr){printf("%d", p->data);p = p->next;if (p->next != nullptr)printf(" -> ");}}}void CopyLinklist(LNode*& head, LNode* b){head = (LNode*)malloc(sizeof(LNode));head->next = nullptr;LNode* flag;flag = head;while (b->next != nullptr){flag->data = b->data;flag->next = (LNode*)malloc(sizeof(LNode));flag = flag->next;b = b->next;}flag->next = nullptr;flag = head;}void sort(LNode*& headA, LNode* p){LNode* copy;CopyLinklist(copy, p);headA = (LNode*)malloc(sizeof(LNode));headA->next = nullptr;LNode* flagA;LNode* flagB;LNode* flagC;flagA = headA;flagB = copy;flagC = copy;int g;int num = 0;while (copy->next != nullptr){copy = copy->next;num++;}printf("该排序链表共有%d个结点。
C语言三种基本排序方法

C语言三种基本排序方法
一、选择排序法。
选择排序法的第一层循环从起始元素开始选到倒数第二个元素,主要是在每次进入的第二层循环之前,将外层循环的下标赋值给临时变量,接下来的第二层循环中,如果发现有比这个最小位置处的元素更小的元素,则将那个更小的元素的下标赋给临时变量,最后,在二层循环退出后,如果临时变量改变,则说明,有比当前外层循环位置更小的元素,需要将这两个元素交换。
二、冒泡排序法。
冒泡排序算法的运作如下:(从后往前)比较相邻的元素。
如果第一个比第二个大,就交换他们两个。
对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。
在这一点,最后的元素应该会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
三、插入排序法。
所谓插入排序法,就是检查第i个数字,如果在它的左边的数字比它大,进行交换,这个动作一直继续下去,直到这个数字的左边数字比它还要小,就可以停止了。
插入排序法主要的回圈有两个变数:i和j,每一次执行这个回圈,就会将第i个数字放到左边恰当的位置去。
插入排序的基本思想是:每步将一个待排序的纪录,按其关
键码值的大小插入前面已经排序的文件中适当位置上,直到全部插入完为止(分为直接插入法和折半插入法)。
C语言-链表

NWPU—CC—ZhangYanChun
13
┇
void main( )
{┇
for(i=1; i<=N; i++)
/*建立链表*/
{┇
}
for(i=1; i<=N; i++)
/*输出链表*/
{ if(i==1) p1=head;
/*p1指向首节点*/
else p1=p1->next; /*p1指向下一节点*/
第第9十页,一共2章8页。 结构体与共用体
NWPU—CC—ZhangYanChun
10
3) 重复第2步,建立并链接多个节点直至所需长
度,将末尾节点的next成员赋值0。
head
1048 p1 1370 p1
2101
2304
1012
2918
89.5
90
85
操作:
1370
1012
NULL
pp22
p2
p1=(struct student *)malloc(len);
成功,返回存储块起始指针,该指针类型为
void *;否则返回空指针(NULL)。
内存释放函数原形:void free(void *p); 功能:释放p所指向的内存块。
包含文件:malloc.h、stdlib.h中均有其原型声明。
C 程序设计
第第4十页,一共2章8页。 结构体与共用体
NWPU—CC—ZhangYanChun
第第5十页,一共2章8页。 结构体与共用体
NWPU—CC—ZhangYanChun
6
6) 链表的类型
单链表:每个节点只有一个指向后继节点的指针 双向链表:每个节点有两个用于指向其它节点的指针;
【数据结构】C语言判断链表是否为空,计算链表长度及链表排序算法

【数据结构】C语⾔判断链表是否为空,计算链表长度及链表排序算法今天继续学习了链表,这次是检测链表是否为空,计算链表长度,这都是蛮简单的,最后就是给链表排序,这⾥的链表排序是当然是最简单的冒泡排序。
还是希望和新⼿⼀起学习,希望得到⼤⽜指点······这次代码还是基于上次这个⽂章中的代码,直接在这上⾯写的,添加的,检测是否为空函数,计算链表长度函数,和链表排序函数,好了,上代码了。
/*链表创建,遍历,检测是否为空,计算链表长度,排序编译环境:VC++ 6.0编译系统:windows XP SP3*/#include <stdio.h>#include <stdlib.h>#include <malloc.h>// 定义链表中的节点typedef struct node{int member; // 节点中的成员struct node *pNext; // 指向下⼀个节点的指针}Node,*pNode;// 函数声明pNode CreateList(); // 创建链表函数void TraverseList(pNode ); // 遍历链表函数bool Is_Empty(pNode); // 判断链表是否为空int LengthList(pNode); // 计算链表长度函数void Sort_List(pNode); // 链表排序函数int main(){pNode pHead = NULL; // 定义初始化头节点,等价于 struct Node *pHead == NULLint flag; // 存放链表是否为空的标志,int Len;pHead = CreateList(); // 创建⼀个⾮循环单链表,并将该链表的头结点的地址付给pHeadTraverseList(pHead); // 调⽤遍历链表函数if (Is_Empty(pHead) == true) // 判断列表是否为空{return0;}Len = LengthList(pHead); // 调⽤计算链表长度函数printf("链表长度: %d 个节点。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
==========================功能:选择排序(由小到大)返回:指向链表表头的指针==========================*//*选择排序的基本思想就是反复从还未排好序的那些节点中,选出键值(就是用它排序的字段,我们取学号num为键值)最小的节点,依次重新组合成一个链表。
我认为写链表这类程序,关键是理解:head存储的是第一个节点的地址,head->next存储的是第二个节点的地址;任意一个节点p的地址,只能通过它前一个节点的next来求得。
单向链表的选择排序图示:---->[1]---->[3]---->[2]...---->[n]---->[NULL](原链表)head 1->next 3->next 2->next n->next---->[NULL](空链表)firsttail---->[1]---->[2]---->[3]...---->[n]---->[NULL](排序后链表)first 1->next 2->next 3->next tail->next图10:有N个节点的链表选择排序1、先在原链表中找最小的,找到一个后就把它放到另一个空的链表中;2、空链表中安放第一个进来的节点,产生一个有序链表,并且让它在原链表中分离出来(此时要注意原链表中出来的是第一个节点还是中间其它节点);3、继续在原链表中找下一个最小的,找到后把它放入有序链表的尾指针的next,然后它变成其尾指针;*/struct student *SelectSort(struct student *head){struct student *first; /*排列后有序链的表头指针*/struct student *tail; /*排列后有序链的表尾指针*/struct student *p_min; /*保留键值更小的节点的前驱节点的指针*/struct student *min; /*存储最小节点*/struct student *p; /*当前比较的节点*/first = NULL;while (head != NULL) /*在链表中找键值最小的节点。
*/{/*注意:这里for语句就是体现选择排序思想的地方*/for (p=head,min=head; p->next!=NULL; p=p->next) /*循环遍历链表中的节点,找出此时最小的节点。
*/{if (p->next->num < min->num) /*找到一个比当前min小的节点。
*/{p_min = p; /*保存找到节点的前驱节点:显然p->next的前驱节点是p。
*/min = p->next; /*保存键值更小的节点。
*/}}/*上面for语句结束后,就要做两件事;一是把它放入有序链表中;二是根据相应的条件判断,安排它离开原来的链表。
*//*第一件事*/if (first == NULL) /*如果有序链表目前还是一个空链表*/{first = min; /*第一次找到键值最小的节点。
*/tail = min; /*注意:尾指针让它指向最后的一个节点。
*/}else /*有序链表中已经有节点*/{tail->next = min; /*把刚找到的最小节点放到最后,即让尾指针的next指向它。
*/tail = min; /*尾指针也要指向它。
*/}/*第二件事*/if (min == head) /*如果找到的最小节点就是第一个节点*/{head = head->next; /*显然让head指向原head->next,即第二个节点,就OK*/}else /*如果不是第一个节点*/{p_min->next = min->next; /*前次最小节点的next指向当前min的next,这样就让min离开了原链表。
*/}}if (first != NULL) /*循环结束得到有序链表first*/{tail->next = NULL; /*单向链表的最后一个节点的next应该指向NULL*/}head = first;return head;}/*==========================功能:直接插入排序(由小到大)返回:指向链表表头的指针==========================*//*直接插入排序的基本思想就是假设链表的前面n-1个节点是已经按键值(就是用它排序的字段,我们取学号num为键值)排好序的,对于节点n在这个序列中找插入位置,使得n插入后新序列仍然有序。
按照这种思想,依次对链表从头到尾执行一遍,就可以使无序链表变为有序链表。
单向链表的直接插入排序图示:---->[1]---->[3]---->[2]...---->[n]---->[NULL](原链表)head 1->next 3->next 2->next n->next---->[1]---->[NULL](从原链表中取第1个节点作为只有一个节点的有序链表)head图11---->[3]---->[2]...---->[n]---->[NULL](原链表剩下用于直接插入排序的节点)first 3->next 2->next n->next图12---->[1]---->[2]---->[3]...---->[n]---->[NULL](排序后链表)head 1->next 2->next 3->next n->next图13:有N个节点的链表直接插入排序1、先在原链表中以第一个节点为一个有序链表,其余节点为待定节点。
2、从图12链表中取节点,到图11链表中定位插入。
3、上面图示虽说画了两条链表,其实只有一条链表。
在排序中,实质只增加了一个用于指向剩下需要排序节点的头指针first罢了。
这一点请读者务必搞清楚,要不然就可能认为它和上面的选择排序法一样了。
*/struct student *InsertSort(struct student *head){struct student *first; /*为原链表剩下用于直接插入排序的节点头指针*/struct student *t; /*临时指针变量:插入节点*/struct student *p; /*临时指针变量*/struct student *q; /*临时指针变量*/first = head->next; /*原链表剩下用于直接插入排序的节点链表:可根据图12来理解。
*/head->next = NULL; /*只含有一个节点的链表的有序链表:可根据图11来理解。
*/while (first != NULL) /*遍历剩下无序的链表*/{/*注意:这里for语句就是体现直接插入排序思想的地方*/for (t=first, q=head; ((q!=NULL) && (q->num < t->num)); p=q, q=q->next); /*无序节点在有序链表中找插入的位置*//*退出for循环,就是找到了插入的位置*//*注意:按道理来说,这句话可以放到下面注释了的那个位置也应该对的,但是就是不能。
原因:你若理解了上面的第3条,就知道了。
*/first = first->next; /*无序链表中的节点离开,以便它插入到有序链表中。
*/if (q == head) /*插在第一个节点之前*/{head = t;}else /*p是q的前驱*/{p->next = t;}t->next = q; /*完成插入动作*//*first = first->next;*/}return head;}/*==========================功能:冒泡排序(由小到大)返回:指向链表表头的指针==========================*//*直接插入排序的基本思想就是对当前还未排好序的范围内的全部节点,自上而下对相邻的两个节点依次进行比较和调整,让键值(就是用它排序的字段,我们取学号num为键值)较大的节点往下沉,键值较小的往上冒。
即:每当两相邻的节点比较后发现它们的排序与排序要求相反时,就将它们互换。
单向链表的冒泡排序图示:---->[1]---->[3]---->[2]...---->[n]---->[NULL](原链表)head 1->next 3->next 2->next n->next---->[1]---->[2]---->[3]...---->[n]---->[NULL](排序后链表)head 1->next 2->next 3->next n->next图14:有N个节点的链表冒泡排序任意两个相邻节点p、q位置互换图示:假设p1->next指向p,那么显然p1->next->next就指向q,p1->next->next->next就指向q的后继节点,我们用p2保存p1->next->next指针。
即:p2=p1->next->next,则有:[ ]---->[p]---------->[q]---->[ ](排序前)p1->next p1->next->next p2->next图15[ ]---->[q]---------->[p]---->[ ](排序后)图161、排序后q节点指向p节点,在调整指向之前,我们要保存原p的指向节点地址,即:p2=p1->next->next;2、顺着这一步一步往下推,排序后图16中p1->next->next要指的是p2->next,所以p1->next->next=p2->next;3、在图15中p2->next原是q发出来的指向,排序后图16中q的指向要变为指向p的,而原来p1->next是指向p的,所以p2->next=p1->next;4、在图15中p1->next原是指向p的,排序后图16中p1->next要指向q,原来p1->next->next (即p2)是指向q的,所以p1->next=p2;5、至此,我们完成了相邻两节点的顺序交换。