算法设计与分析C++语言描述(陈慧南版)课后答案
(陈慧南 第3版)算法设计与分析——第3章课后习题答案

第三章课后习题姓名:赵文浩学号:16111204082 班级:2016级计算机科学与技术3-2 在如下图所示的二叉搜索树上完成下列运算及随后的伸展操作,画出每次运算加伸展操作后的结果伸展树。
5030601040201585 70901)搜索80从图中可以看出,元素80不存在,因此伸展结点应为搜索过程中遇到的最后一个结点,即70,伸展过程如下图所示:503060104020158570905030601040201585709050301040201585907060状态1状态2状态32)插入80元素80插入后的状态以及将元素8作为伸展结点的伸展过程如下图所示:5030601040201585 709080插入元素80后50306010402015857090805030601040201585709080变换1变换25030601040201585908070变换33)删除30首先,将元素30结点伸展至根结点,然后删除根结点30,并将结点20(左边最大的结点、右边最小的结点)作为伸展结点,伸展过程如下图所示:3010402015709050856030102015709085605040102070908560504015709085605040变换1将30作为根结点删除结点30并变换将20作为伸展结点伸展至根节点102015。
(陈慧南 第3版)算法设计与分析——第6章课后习题答案

⑥ 选择作业 1,则 X 6, 2,3,5,1 。将其按照期限 di 非减次序排列可
得:
ID
di
5
1
6
2
3
3
1
3
2
4
作业5
作业3 作业2
-1
0
1
2
3
4
作业6 作业1(冲突)
该集合无可行排序,因此 X 6, 2,3,5,1 不可行, X 6, 2,3,5 ;
3
⑦ 选择作业 0,则 X 6, 2,3,5, 0 。将其按照期限 di 非减次序排列
可得:
ID
di
5
1
0
1
6
2
3
3
2
4
作业5
作业3 作业2
-1
0
1
2
3
4
作业0(冲突)作业6
该集合无可行排序,因此 X 6, 2,3,5, 0 不可行,X 6, 2,3,5 ;
⑧ 选择作业 4,则 X 6, 2,3,5, 4 。将其按照期限 di 非减次序排列
可得:
ID
Hale Waihona Puke di516
12,5,8,32, 7,5,18, 26, 4,3,11,10, 6 。请给出最优存储方案。
解析:首先将这 13 个程序按照程序长度非降序排列,得:
程序 ID
9 8 1 5 12 4 2 11 10 0 6 7 3
程序长度 ai 3 4 5 5 6 7 8 10 11 12 18 26 32
根据定理可知,按照程序编号存放方案如下:
解析:已知 Prim 算法时间复杂度为 O n2 ,受顶点 n 影响;
Kruskal 算法时间复杂度为 O m logm ,受边数 m 影响;
数据结构-C语言描述(第三版)(陈慧南)章 (11)

第11章 内 排 序
First 12
q 21
p 33
sorted
…
55
unsorted
26
42
…
(a)
First
③
q
p
sorted
unsorted
12
21
33
…
55
26
42
…
① ②
(b)
图11-3 链表的直接插入排序 (a) 插入26前;(b) 插入26后
第11章 内 排 序
与顺序表的直接插入排序一样,链表上的直接插入排序算 法首先将第一个记录视为只有一个记录的有序子序列,将第二 个记录插入该有序子序列中,再插入第三个记录,……,直到 插入最后一个记录为止。每趟插入,总是从链表的表头开始搜 索适当的插入位置。程序11-3中,指针p指示表中与待插入的 记录比较的结点,q指示p的前驱结点。指针sorted总是指向单链 表中已经有序的部分子表的尾部,而指针unsorted指向sorted的 后继结点,即待插入的记录结点,见图11-3(a)。如果待插入的 记录小于第一个记录,则应将其插在最前面。请注意,下面的 while循环总会终止。
1)
n(n 4
1)
(n
1)
O(n 2
)
(11-5)
AM(n)
n1
i1
i 2
2
1 2
n 1 i1
i+2(n
1)
n(n 1) 4
2(n
1)
O(n 2
)
(11-6)
第11章 内 排 序
2.链表上的直接插入排序
直接插入排序也可以在链表上实现。程序11-3是在单 链表上的直接插入排序算法的C语言程序。单链表采用程序 11-1中描述的单链表结构类型。在单链表表示下,将一个 记录插入到一个有序子序列中,搜索适当的插入位置的操作 可从链表的表头开始。图11-3中,从11到55之间的记录已 经有序,现要插入26。我们从表头开始,将26依次与12、21 和33比较。直到遇到大于或等于26的记录33为止,将26插在 21与33之间。该插入操作如图11-3(b)所示。
数据结构-C语言描述(第三版)(陈慧南)章 (6)

第6章 树 例如,设有序表为(21, 25, 28, 33, 36, 43),若要在表中 查找元素36,通常的做法是从表中第一个元素开始,将待查元素 与表中元素逐一比较进行查找,直到找到36为止。粗略地说,如 果表中每个元素的查找概率是相等的,则平均起来,成功查找一 个元素需要将该元素与表中一半元素作比较。如果将表中元素组 成图6-3所示的树形结构,情况就大为改观。我们可以从根结点 起,将各结点与待查元素比较,在查找成功的情况下,所需的最 多的比较次数是从根到待查元素的路径上遇到的结点数目。当表 的长度n很大时,使用图6-3所示的树形结构组织表中数据,可 以很大程度地减少查找所需的时间。为了查找36,我们可以让36 与根结点元素28比较,36比28大,接着查右子树,查找成功。显 然,采用树形结构能节省查找时间。
第6章 树
E
E
A
F
B
G
CD
LJ
M
N
T1
X
YZ
U T2
B
F
A
DC
G
JL
T3 N
M
(a)
(b)
图6-2 树的例子
(a) 树T1和T2组成森林;(b) 树T3
第6章 树
6.2 二 叉 树
二叉树是非常重要的树形数据结构。很多从实际问题中抽 象出来的数据都是二叉树形的,而且许多算法如果采用二叉树 形式解决则非常方便和高效。此外,以后我们将看到一般的树 或森林都可通过一个简单的转换得到与之相应的二叉树,从而 为树和森林的存储及运算的实现提供了有效方法。
第6章 树
图6-1描述了欧洲部分语言的谱系关系,它是一个后裔图, 图中使用的描述树形结构数据的形式为倒置的树形表示法。在 前几章中,我们学习了多种线性数据结构,但是一般来讲,这 些数据结构不适合表示如图6-1所示的层次结构的数据。为了 表示这类层次结构的数据,我们采用树形数据结构。在本章中 我们将学习多种不同特性的树形数据结构,如一般树、二叉树、 穿线二叉树、堆和哈夫曼树等。
(陈慧南 第3版)算法设计与分析——第7章课后习题答案

③ 其余元素
w[0][2] q[2] p[2] w[0][1] 15
k 1: c[0][0] c[1][2] c[0][2] min k 2 : c[0][1] c[2][2] w[0][2] 22 r[0][2] 2
17000
s[0][2]
0
m[1][3]
min
k k
1: m[1][1] m[2][3] 2 : m[1][2] m[3][3]
p1 p2 p4 p1 p3 p4
10000
s[1][3]
2
m[1][3]
min
k k
0 : m[0][0] m[1][3] 1: m[0][1] m[2][3]
第七章课后习题
姓名:赵文浩 学号:16111204082 班级:2016 级计算机科学与技术 7-1 写出对图 7-19 所示的多段图采用向后递推动态规划算法求解时的计算过程。
3
1
3
1
6
5
0
2
6
6
3
4
4 6
5
2
7
8
3
2
8
5
2
7
解析:
V 5 cost(5,8) 0 d (5,8) 8
V4
cos t(4, 6) minc(6,8) cos t(5,8) 7 cos t(4, 7) minc(7,8) cos t(5,8) 3
k 1: c[0][0] c[1][3] c[0][3] min k 2 : c[0][1] c[2][3] w[0][3] 25
算法设计与分析-课后习题集答案

(2)当 时, ,所以,可选 , 。对于 , ,所以, 。
(3)由(1)、(2)可知,取 , , ,当 时,有 ,所以 。
11. (1)当 时, ,所以 , 。可选 , 。对于 , ,即 。
(2)当 时, ,所以 , 。可选 , 。对于 , ,即 。
(3)因为 , 。当 时, , 。所以,可选 , ,对于 , ,即 。
第二章
2-17.证明:设 ,则 。
当 时, 。所以, 。
第五章
5-4.SolutionType DandC1(int left,int right)
{while(!Small(left,right)&&left<right)
{int m=Divide(left,right);
所以n-1<=m<=n (n-1)/2;
O(n)<=m<=O(n2);
克鲁斯卡尔对边数较少的带权图有较高的效率,而 ,此图边数较多,接近完全图,故选用普里姆算法。
10.
T仍是新图的最小代价生成树。
证明:假设T不是新图的最小代价生成树,T’是新图的最小代价生成树,那么cost(T’)<cost(T)。有cost(T’)-c(n-1)<cost(t)-c(n-1),即在原图中存在一颗生成树,其代价小于T的代价,这与题设中T是原图的最小代价生成树矛盾。所以假设不成立。证毕。
13.template <class T>
select (T&x,int k)
{
if(m>n) swap(m,n);
if(m+n<k||k<=0) {cout<<"Out Of Bounds"; return false;}
(陈慧南 第3版)算法设计与分析——第1章课后习题答案

第一章课后习题
姓名:赵文浩 学号:16111204082 班级:2016 级计算机科学与技术
1-4 证明等式 gcd(m,n)=gcd(n mod m, m) 对每对正整数 m 和 n,m>0 都成立。
1-13 写一个递归算法和一个迭代算法计算二项式系数:
#include<stdio.h> int Coef_recursive(int n,int m);//递归算法 int Coef_iteration(int n,int m);//迭代算法 int Factorial(int n);//计算 n 的阶乘 int main() { int n,m;
1-12 试用归纳法证明程序 1-7 的排列产生器算法的正确性。
证明:主函数中,程序调用 perm(a,0,n),实现排列产生器。 ① 当 n=1 时,即数组 a 中仅包含一个元素。函数内 k=0,与(n-1)=0 相等,因此函 数内仅执行 if(k==n-1)下的 for 语句块,且只执行一次。即将 a 数组中的一个元 素输出,实现了对一个元素的全排列。因此当 n=1 时,程序是显然正确的; ② 我们假设程序对于 n=k-1 仍能够满足条件, 将 k-1 个元素的全排列产生并输出; ③ 当 n=k 时,程序执行 else 下语句块的内容。首先执行 swap(a[0],a[0]),然后执 行 Perm(a,1,n),根据假设②可知,该语句能够产生以 a[0]为第一个元素,余下 (k-1)个元素的全排列; 然后再次执行 swap(a[0],a[0]), 并进行下一次循环。 此时 i=1, 即在本次循环中, 先执行 swap(a[0],a[1]), 将第二个元素与第一个元素互换, 下面执行 Perm(a,1,n), 根据假设②可知, 该语句产生以 a[1]为第一个元素, 余下(k-1)个元素的全排列; 以此类推,该循环每一次将各个元素调到首位,通过执行语句 Perm(a,1,n)以及 基于假设②,能够实现产生 k 个元素的全排列。 因此 n=k 时,程序仍满足条件。 ④ 综上所述,该排列器产生算法是正确的,证毕。
(陈慧南 第3版)算法设计与分析——第2章课后习题答案

g n
(1) f n 20n logn , g n n+ log 3 n
f n 20n logn 21n , g n n+ log 3 当 n 3 时, logn n log3 n 2n n 因此
因此可取 n0 3, c
1 ,当 2
n 足 够 大 时 , a f (n b) c f (n) 恒 成 立 。 所 以 符 合 主 定 理 的 情 况 3 , 因 此
T (n) (n)
(2) a 5, b 4, f n cn 2
解析: nlogb a nlog4 5 n1.161 ,则 f (n) c n2 (nlogb a ) ,其中可取 =0.9 。
n0 3, c 1 ,当 n n0 时, f n g n ,所以 f n = g n
(5) f (n) n 2n g (n) 3n 当 n 1 时 , 有 f (n) n 2n 3n g (n) , 因 此 可 取 n0 1, c 1 , 当 n n0 时 ,
第二章课后习题
姓名:赵文浩 学号:16111204082 班级:2016 级计算机科学与技术
2-10 试用定义证明下列等式的正确性 (1) 5n 2 8n 2 O n 2 证明: 当 n 1 时, f (n) 5n 2 8n 2 5n 2 。 因此可选取 n0 1, c 5 。 当 n n0 时, f (n) 5n 2 8n 2 5n 2 ,因此 5n 2 8n 2 O n 2 (2) 5n 2 8n 2 n 2 证 明 : f (n) 5n 2 8n 2 5n 2 (8n 2) 。 当 n 4 时 , 8n 2 2n2 即 :
算法分析与设计(陈慧南,电子科技出版社)复习资料

《算法分析与设计C》复习总成绩=平时成绩(30%)+考试成绩(70%)考试时间:2015年06月28日(16:00-17:50)试卷题型:一、 选择题(每空2分,共20分)二、 填空题(每空2分,共20分)三、 证明题(每题5分,共10分)四、 问答题(每题10分,共50分)第一章 算法求解基础算法的概念算法特征(输入、输出、确定性、可行性、有穷性)——掌握每种特征的含义、算法和程序的区别描述算法的方法(自然语言、流程图、伪代码、程序设计语言)欧几里德算法(辗转相除法)——递归/迭代程序实现及其变形常见算法种类——精确算法、启发式算法、近似算法、概率算法第二章 算法分析基础算法复杂度——运行一个算法所需的时间和空间。
好算法的四个特征(正确性、简明性、效率、最优性)正确性vs健壮性vs可靠性最优性——算法(最坏情况下)的执行时间已达到求解该类问题所需时间的下界。
影响程序运行时间的因素(程序所依赖的算法、问题规模和输入数据、计算机系统性能)算法的渐近时间复杂度 ——数量级上估计(Ο、Ω、Θ)最好、最坏、平均时间复杂度——定义——课后习题2-8(通过考察关键操作的执行次数)时间复杂度证明——课后习题2-10,2-13,2-17算法按时间复杂度分类:多项式时间算法、指数时间算法多项式时间算法:O(1)<O(logn)<O(n)<O(nlogn)<O(n2)<O(n3) 指数时间算法:O(2n)<O(n!)<O(n n)第五章 分治法分治法——求解的基本要素:将一个难以直接求解的复杂问题分解成若干个规模较小、相互独立但类型相同的子问题,然后求解这些子问题;如果这些子问题还比较复杂而不能直接求解,还可以继续细分,直到子问题足够小,能够直接求解为止;最后将子问题的解组合成原始问题的解。
这种问题求解策略称为分治法。
分治法很自然的导致一个递归算法。
平衡子问题思想递归算法的时间复杂度分析:递推式T(n)=aT(n/b)+cn k,T(1)=c——递推式中每部分的含义——求解得到算法的渐近时间复杂度(分三种情况)——改进思路求最大最小元二分搜索算法框架对半搜索——程序实现——对半搜索二叉判定树(树的构成)——对半搜索二叉判定树性质(左右子树结点数、树高等)——对半搜索的时间复杂度分析(搜索成功/失败、最好/最坏/平均)。
(陈慧南 第3版)算法设计与分析——第5章课后习题答案

(3) 分析算法的时间复杂度 上述算法的时间复杂度为 n 2
(2) 编写 C 程序实现这一算法;
#include<iostream> #include<cstdio> #include<cmath> #include<algorithm> using namespace std; #define N 1000 struct point { double x; double y; }p1[N],pxSmall[N],pxLarge[N]; double Distance (point a , point b); double min (double a , double b); bool Compare_Y (point a , point b); bool Compare_X (point a , point b); double minDistance (int l, int r); int main() { int n ; double D ; cin>>n;
int main() { int n, x, *a; cin >> n; a = new int[n]; for (int i = 0; i < n; i++) cin >> a[i]; cin >> x; if (Triple_search(a, 0, n - 1, x) == -1) cout << "NotFound!" << endl; else cout << Triple_search(a, 0, n - 1, x) << endl; delete []a; return 0; } int Triple_search(int a[], int l, int r, int x) { if (l <= r) { int m1 = l + (r-l)/3; int m2 = l + (r-l)*2/3; if (a[m2]<x) return Triple_search(a, m2 + 1, r, x); else if (a[m1] < x && a[m2] > x) return Triple_search(a, m1 + 1, m2 - 1, x); else if (a[m1] > x) return Triple_search(a, l, m1 - 1, x); else if (a[m1] == x) return m1; else if (a[m2] == x) return m2; } return -1; }
数据结构-C语言描述(第三版)(陈慧南)章 (4)

AD
n1 i0
1 n
(n
i
1)
n i 1
1 (n n
i)
n 1 2
第4章 线性表和数组
从上式来看,在顺序表中插入和删除元素,平均约需移动 表中的一半元素。Insert函数和Remove函数的平均时间复杂度均 为O(n)。
函数Retrieve的实现是比较容易的,由于顺序表可以随机存 取,所以无需搜索,便可立即获得位置pos处的元素,由语句 *x=lst.Elements[pos] 实现之。此函数的时间复杂度为O(1)。
第4章 线性表和数组
4.1.3 线性表的链接表示
使用第2章介绍的单链表、循环链表或双向链表存储 线性表称为线性表的链接存储表示。在本节中我们以不带 表头结点的单链表为例讨论线性表的链接表示的实现。我 们同样可以使用循环链表和双向链表实现线性表,也可以 使用带表头结点的链表实现线性表。在4.2节(多项式的算 术运算)中我们将介绍使用带表头结点的循环链表的线性 表应用实例。
第4章 线性表和数组
*x=lst.Elements[pos]; return TRUE; } BOOL Replace(List *lst, int pos, T x) {
if ( pos<0 || pos>=lst->Size){ printf("Out of Bounds"); return FALSE; } lst->Elements[pos]=x; return TRUE; }
第4章 线性表和数组
若线性表已满,则返回TRUE,否则返回FALSE。 int Size(List lst) 返回线性表的长度。 BOOL Insert(List *lst, int pos, T x) 若线性表未满且0≤pos≤n,则原表中位置在pos及pos之后的所有元素后 移一个位置,元素x插在位置pos处,并且函数返回TRUE;否则函数返回 FALSE。 BOOL Remove(List *lst, int pos, T* x) 若线性表非空且0≤pos<n,则位置pos处的元素复制到参数*x,从原表 中移去该元素,表中pos之后的所有元素前移一个位置,并且函数返回 TRUE;否则函数返回FALSE。
数据结构与算法分析—c语言描述 课后答案

Solutions Manual
Mark Allen Weiss Florida International University
Preface Included in this manual are answers to most of the exercises in the textbook Data Structures and Algorithm Analysis in C, second edition, published by Addison-Wesley. These answers reflect the state of the book in the first printing. Specifically omitted are likely programming assignments and any question whose solution is pointed to by a reference at the end of the chapter. Solutions vary in degree of completeness; generally, minor details are left to the reader. For clarity, programs are meant to be pseudo-C rather than completely perfect code. Errors can be reported to weiss@fi. Thanks to Grigori Schwarz and Brian Harvey for pointing out errors in previous incarnations of this manual.
算法设计与分析书后参考答案

参考答案第1章一、选择题1. C2. A3. C4. C A D B5. B6. B7. D 8. B 9. B 10. B 11. D 12. B二、填空题1. 输入;输出;确定性;可行性;有穷性2. 程序;有穷性3. 算法复杂度4. 时间复杂度;空间复杂度5. 正确性;简明性;高效性;最优性6. 精确算法;启发式算法7. 复杂性尽可能低的算法;其中复杂性最低者8. 最好性态;最坏性态;平均性态9. 基本运算10. 原地工作三、简答题1. 高级程序设计语言的主要好处是:(l)高级语言更接近算法语言,易学、易掌握,一般工程技术人员只需要几周时间的培训就可以胜任程序员的工作;(2)高级语言为程序员提供了结构化程序设计的环境和工具,使得设计出来的程序可读性好,可维护性强,可靠性高;(3)高级语言不依赖于机器语言,与具体的计算机硬件关系不大,因而所写出来的程序可移植性好、重用率高;(4)把复杂琐碎的事务交给编译程序,所以自动化程度高,发用周期短,程序员可以集中集中时间和精力从事更重要的创造性劳动,提高程序质量。
2. 使用抽象数据类型带给算法设计的好处主要有:(1)算法顶层设计与底层实现分离,使得在进行顶层设计时不考虑它所用到的数据,运算表示和实现;反过来,在表示数据和实现底层运算时,只要定义清楚抽象数据类型而不必考虑在什么场合引用它。
这样做使算法设计的复杂性降低了,条理性增强了,既有助于迅速开发出程序原型,又使开发过程少出差错,程序可靠性高。
(2)算法设计与数据结构设计隔开,允许数据结构自由选择,从中比较,优化算法效率。
(3)数据模型和该模型上的运算统一在抽象数据类型中,反映它们之间内在的互相依赖和互相制约的关系,便于空间和时间耗费的折衷,灵活地满足用户要求。
(4)由于顶层设计和底层实现局部化,在设计中出现的差错也是局部的,因而容易查找也容易纠正,在设计中常常要做的增、删、改也都是局部的,因而也都容易进行。
数据结构-C语言描述(第三版)(陈慧南)章 (12)

第12章 文件和外排序
1) 串行处理文件 串行处理文件(图12-2)是无序的,对这样的文件按关键字 值的搜索只能采取顺序搜索的方法进行,即从文件的第一个记 录开始,依次将待查关键字值与文件中的记录的关键字值进行 比较,直到成功找到该记录,或直到文件搜索完毕,搜索失败 为止。因此通常搜索时间比较长。
一般情况下,设l和u分别是搜索范围内的最小块号和最大 块号,L和H分别是该搜索范围内的最小关键字值和最大关键字 值,则下一次读入内存的块号i为:
i
1
K-L H-L
(u
1)
(12-2)
第12章 文件和外排序
这时:
若K<Li,则下一次被搜索的块号的范围为[l, i-1],并且新的 H将是Li;
若Li≤K≤Hi,则i即为所求的块,可在该块中去搜索待查关键字 值K;
对于无法事先知道记录被访问频率的应用,可以按第7章介 绍的自组织线性表的方式组织成自组织文件。具体方法有:计 数方法(count)、移至开头法(Move-To-Front)和互换位置法 (Transposition)。
第12章 文件和外排序
(2) 顺序处理文件 顺序处理文件已按关键字值排序。有序表上的各种搜索方 法原则上都可以用于顺序处理文件的搜索,如顺序搜索和二分 搜索等。但是由于文件是外存上的数据结构,在考虑算法时, 必须尽量减少访问外存的次数,因此顺序处理文件的搜索算法 有自己的特点。下面介绍顺序处理文件上的分块插值搜索。
第12章 文件和外排序
文件是存在外存储器上的。为了有效分配外存空间,我 们可以将多个扇区构成一个簇(cluster)。簇是文件的最小分配 单位。簇的大小由操作系统决定。文件管理器(file manager)是 操作系统的一部分,它负责记录一个文件由哪些簇组成。 UNIX操作系统按扇区分配文件空间,并称之为块(block)。为 了与逻辑文件和文件的逻辑记录相对应,文件存储器上的文 件称为物理文件(physical file),一簇或块(物理块)中的信息称 为物理记录。用户读/写的记录是指逻辑记录,查找该逻辑记 录所在的物理块是操作系统的职责。
(陈慧南 第3版)算法设计与分析——第8章课后习题答案

姓名:赵文浩 学号:16111204082 班级:2016 级计算机科学与技术
Байду номын сангаас
8-3 重新定义函数 Place(), 使得它或者返回下一个合法的列号或返回-1 表示没有 不冲突的列号,并按这种做法改写程序 8-4 的 Place 和 NQeens 函数。 解析:
8-4 图 8-4 所示的两个可行解是对称的。观察表明,n-皇后问题的解的确存在这 种对偶性。修改算法 NQueens,令 x[0] 1, 2, 些解。 解析: 为了解决对称性的冲突,只需在第一层时,遍历一半的列号即可。 改写后的程序如下:
8-6 设 有 子 集 和 数 问 题 的 实 例 W (w0, w1,
, w6) (5,7,10,12,15,18, 20) 和
M 35 。 求 W 中元素之和等于 M 的所有子集。 画出对于这一实例由 SumOfSub 算
法实际生成的那部分状态空间树。
解析: 构造的状态空间树如图所示:
{ cin>>m1>>m2; a[m1][m2]=1; a[m2][m1]=1; } } void PrintGraph() { int i,j; cout<<"创建的邻接矩阵为:"<<endl; for(i=0;i<V;i++) { for(j=0;j<V;j++) cout<<a[i][j]<<" "; cout<<endl; } } void NextValue(int k,int m,int *x) { int j; do { x[k]=(x[k]+1)%(m+1); if(!x[k]) return; for(j=0;j<k;j++) if(a[k][j]&&x[k]==x[j]) break; if(j==k) return; }while(1); } void mColoring(int k,int m,int *x) { int i; do { NextValue(k,m,x); if(!x[k]) break; if(k==V-1) { flag=1; for(i=0;i<V;i++) cout<<x[i]<<" "; cout<<endl; }
算法设计与分析 C 语言描述课后答案 陈慧南版湖北汽车工业学院

2i1T 2 2 i 1 n log n 2n 4n 2n i 2 2i1 4 2n log n log n 1 i 2 i 1 n
2n 2n log 2 n 2n log n log 2 n 3log n 2 n n log 2 n n log n
if(a[mid]<b[i]) left=mid; else if(a[mid]>b[i]) right=mid; else {cnt=mid; break;} }while(left<right-1) if(a[left]<b[i]) cnt=left; elsecnt=left-1; if(k>cnt) { if(cnt>0) { for(j=0;j<cnt;j++) { temp[j]=a[r]; r++; } left=cnt; k-=cnt; } else { temp[j]=b[i]; left=0; k--; } } else { for(j=0;j<k;j++) { temp[j]=a[r]; r++; } left=cnt; k-=cnt; return temp[k-1]; } } } } 第六章 1.由题可得:
E log n , n 1 I n E 2n n E 成功搜索的平均时间复杂度为 As n 1 log n 。 n n n 其中, I 是二叉判定树的内路径长度, E 是外路径长度,并且 E I 2n 。 Au n
2-10. ( 1 ) 当 n 1 时 , 5n 2 8n 2 5n 2 , 所 以 , 可 选 c 5 , n0 1 。 对 于 n n0 ,
南邮陈慧南版数据结构课后习题答案

}
65
if (p==root) root=root->lchild;
else q->rchild=p->lchild;
37
e=p->element;
25
delete p;
return true;
14
32
}
7.8 以下列序列为输入,从空树开始构造AVL搜索树。 (1)A,Z,B,Y,C,X (2)A,V,L,T,R,E,I,S,O,K
解:1 调用9.4中的函数InDg计算各个顶点的入度; 2 利用拓扑排序算法依次删去入度为0的顶点发出的边,若最后还
有入度不为0顶点,则该有向图存在有向回路,返回真值。
template <class T>
void LinkedGraph<T>::InDg(ENode<T> *a[],int n,int ind[])
int i,j,top=-1; //top为栈顶元素的下标 ENode<T> *p; for(i=0; i<n; i++)
if(!InDegree[i]) {
时间复杂度。
template <class E,class K>
bool BSTree<E,K>::Delete(E&e)
{ BTNode<E> *p=root,*q=p;
if (!p) return flse;
25
37
91
while (p->rchild)
{ q=p;
14
56
p=p->rchild;
if(!visited[i]) DFS1(i,visited,parent); delete []visited, []parent; }
(陈慧南 第3版)算法设计与分析——第4章课后习题答案
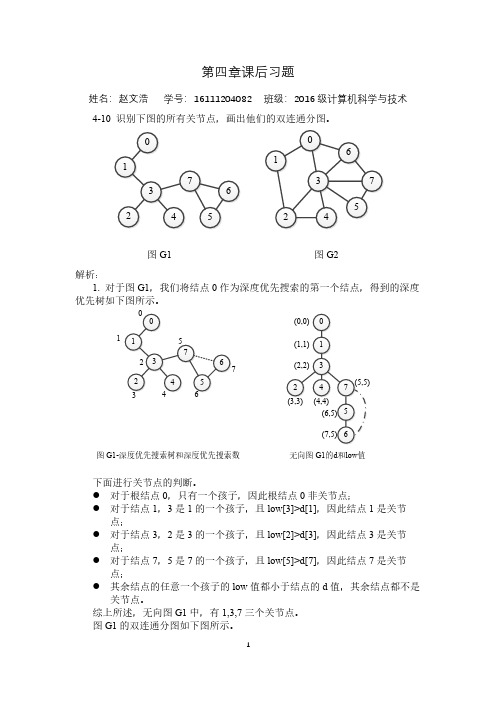
点; 其余结点的任意一个孩子的 low 值都小于结点的 d 值,其余结点都不是
关节点。 综上所述,无向图 G1 中,有 1,3,7 三个关节点。 图 G1 的双连通分图如下图所示。
1
7
0
6
3
1 2
1
的一个孩子且low3d1因此结点1是关节的一个孩子且low2d3因此结点3是关节的一个孩子且low5d7因此结点7是关节其余结点的任意一个孩子的low值都小于结点的d值其余结点都不是关节点
第四章课后习题
姓名:赵文浩 学号:16111204082 班级:2016 级计算机科学与技术 4-10 识别下图的所有关节点,画出他们的双连通分图。
3
5
7 3
3
4
图 G1的双连通分图
2. 对于图 G2,我们仍将结点 0 作为深度优先搜索的第一个结点,得到的深 度优先树如下图所示。
(0,0) 0
11
0 0
33
5 6
6 7
22
57 4 4
(1,0) 1
(2,0) 2
(3,0) 3
(4,2) 4
6 (5,0)
7 (6,3)
5 (7,3)
图 G2-深度优先搜索树和深度优先搜索数
无向图 G2的d和low值
下面进行关节点判断。 无向图 G2 的所有结点的任意一个孩子的 low 值都小于结点的 d 值,因此无 向图 G2 中不存在关节点。因此,该无向图的双连通图即为它本身,如下图所 示。
0 6
1
3
7
5
2
4
图 G2的双连通分图
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一章15P1-3. 最大公约数为1。
快1414倍。
主要考虑循环次数,程序1-2的while 循环体做了10次,程序1-3的while 循环体做了14141次(14142-2循环)若考虑其他语句,则没有这么多,可能就601倍。
第二章32P2-8.(1)画线语句的执行次数为log n ⎡⎤⎢⎥。
(log )n O 。
划线语句的执行次数应该理解为一格整体。
(2)画线语句的执行次数为111(1)(2)16jnii j k n n n ===++=∑∑∑。
3()n O 。
(3)画线语句的执行次数为。
O 。
(4)当n 为奇数时画线语句的执行次数为(1)(3)4n n ++, 当n 为偶数时画线语句的执行次数为 2(2)4n +。
2()n O 。
2-10.(1) 当 1n ≥ 时,225825n n n -+≤,所以,可选 5c =,01n =。
对于0n n ≥,22()5825f n n n n =-+≤,所以,22582()n n n -+=O 。
(2) 当 8n ≥ 时,2222582524n n n n n -+≥-+≥,所以,可选 4c =,08n =。
对于0n n ≥,22()5824f n n n n =-+≥,所以,22582()n n n -+=Ω。
(3) 由(1)、(2)可知,取14c =,25c =,08n =,当0n n ≥时,有22212582c n n n c n ≤-+≤,所以22582()n n n -+=Θ。
2-11. (1) 当3n ≥时,3log log n n n <<,所以()20log 21f n n n n =+<,3()log 2g n n n n =+>。
可选 212c =,03n =。
对于0n n ≥,()()f n cg n ≤,即()(())f n g n =O 。
注意:是f (n )和g (n )的关系。
(2) 当 4n ≥ 时,2log log n n n <<,所以 22()/log f n n n n =<,22()log g n n n n =≥。
可选 1c =,04n =。
对于 0n n ≥,2()()f n n cg n <≤,即 ()(())f n g n =O 。
(3)因为 log log(log )()(log )nn f n n n ==,()/log log 2n g n n n n ==。
当 4n ≥ 时,log(log )()n f n nn =≥,()log 2n g n n n =<。
所以,可选 1c =,04n =,对于0n n ≥,()()f n cg n ≥,即 ()(())f n g n =Ω。
第二章 2-17. 证明:设2i n =,则 log i n =。
()22log 2n T n T n n ⎛⎫⎢⎥=+ ⎪⎢⎥⎣⎦⎝⎭2222log 2log 222n n n T n n ⎡⎤⎛⎫⎢⎥⎛⎫=+⨯⨯+⎢⎥ ⎪ ⎪⎢⎥⎣⎦⎝⎭⎝⎭⎣⎦()2222log log22log 2n T n n n n ⎛⎫⎢⎥=+-+ ⎪⎢⎥⎣⎦⎝⎭22222log 22n T n n n ⎛⎫⎢⎥=+⨯- ⎪⎢⎥⎣⎦⎝⎭2322222log 22log 2222n n n T n n n ⎡⎤⎛⎫⎢⎥=+⨯⨯+⨯-⎢⎥ ⎪⎢⎥⎣⎦⎝⎭⎣⎦ ()3322log log422log 22n T n n n n n ⎛⎫⎢⎥=+-+⨯- ⎪⎢⎥⎣⎦⎝⎭33232log 242n T n n n n ⎛⎫⎢⎥=+⨯-- ⎪⎢⎥⎣⎦⎝⎭=()22log 24212k k n T kn n n n n k ⎛⎫⎢⎥=+----- ⎪⎢⎥⎣⎦⎝⎭()()()12221log 2422i T i n n n n n i -=+------()()()1242log log 121i n n n i i n -=⨯+---- ()2222log 2log log 3log 2n n n n n n n n =+---+ 2log log n n n n =+当2n ≥ 时,()22log T n n n ≤。
所以,()()2log T n n n =O 。
第五章5-4. SolutionType DandC1(int left,int right) {while(!Small(left,right)&&left<right) { int m=Divide(left,right); if(x<P(m) right=m -1; else if(x>P[m]) left=m+1; else return S(P) } }5-7. template <class T>int SortableList<T>::BSearch(const T&x,int left,int right) const {if (left<=right) { int m=(right+left)/3; if (x<l[m]) return BSearch(x,left,m -1); else if (x>l[m]) return BSearch(x,m+1,right); else return m; } return -1; }第五章 9.426351701234567-10证明:因为该算法在成功搜索的情况下,关键字之间的比较次数至少为log n ⎢⎥⎣⎦,至多为log 1n +⎢⎥⎣⎦。
在不成功搜索的情况下,关键字之间的比较次数至少为log 1n +⎢⎥⎣⎦,至多为log 2n +⎢⎥⎣⎦。
所以,算法的最好、最坏情况的时间复杂度为()log n Θ。
假定查找表中任何一个元素的概率是相等的,为1n,那么, 不成功搜索的平均时间复杂度为()()log 1u EA n n n ==Θ+, 成功搜索的平均时间复杂度为()()21log s I n E n n EA n n n n n+-+===-=Θ。
其中,I 是二叉判定树的内路径长度,E 是外路径长度,并且2E I n =+。
12.(1)证明:当或或时,程序显然正确。
当n=right -left+1>2时,程序执行下面的语句: int k=(right -left+1)/3; StoogeSort(left,right -k); StoogeSort(left+k,right); StoogeSort(left,right -k);①首次递归StoogeSort(left,right -k);时,序列的前2/3的子序列有序。
②当递归执行StoogeSort(left+k,right);时,使序列的后2/3的子序列有序,经过这两次递归排序,使原序列的后1/3的位置上是整个序列中较大的数,即序列后1/3的位置上数均大于前2/3的数,但此时,前2/3的序列并不一定是有序的。
③再次执行StoogeSort(left,right -k);使序列的前2/3有序。
经过三次递归,最终使序列有序。
所以,这一排序算法是正确的。
(2)最坏情况发生在序列按递减次序排列。
()()010T =T =,()21T =,()2313n n ⎛⎫T =T +⎪⎝⎭。
设322in ⎛⎫= ⎪⎝⎭,则log 1log31n i -=-。
()2431331139n n n ⎡⎤⎛⎫⎛⎫T =T +=T ++ ⎪ ⎪⎢⎥⎝⎭⎝⎭⎣⎦49319n ⎛⎫=T ++ ⎪⎝⎭=122333313i ii i n --⎡⎤⎛⎫=T +++++⎢⎥ ⎪⎝⎭⎢⎥⎣⎦()31322i i-=T +()31322i =- log 1log31312222n n --=⨯⨯- log3log313n-≤⨯log3log31n -⎛⎫=O ⎪ ⎪⎝⎭冒泡排序最坏时间复杂度为()2n O ,队排序最坏时间复杂度为()log n n O ,快速排序最坏时间复杂度为()log n n O 。
所以,该算法不如冒泡排序,堆排序,快速排序。
13. template <class T> select (T&x,int k) { if(m>n) swap(m,n); if(m+n<k||k<=0) {cout<<"Out Of Bounds"; return false;} int *p=new temp[k]; int mid,left=0,right=n -1,cnt=0,j=0,r=0; for(int i=0;i<m;i++) { while(k>0) { do { mid=(left+right)/2;if(a[mid]<b[i]) left=mid; else if(a[mid]>b[i]) right=mid; else {cnt=mid; break;} }while(left<right -1) if(a[left]<b[i]) cnt=left; else cnt=left -1; if(k>cnt) { if(cnt>0) { for(j=0;j<cnt;j++) { temp[j]=a[r]; r++; } left=cnt; k -=cnt; } else { temp[j]=b[i]; left=0; k --; } } else { for(j=0;j<k;j++) { temp[j]=a[r]; r++; } left=cnt; k -=cnt; return temp[k -1]; }}} }第六章1.由题可得:012345601234561051576183,,,,,,,,,,,,2357141p p p p p p p w w w w w w w ⎛⎫⎛⎫=⎪ ⎪⎝⎭⎝⎭,所以,最优解为()01234562,,,,,,,1,,1,0,1,1,13x x x x x x x ⎛⎫= ⎪⎝⎭,最大收益为211051561835533+⨯++++=。
8.第六章6-9.普里姆算法。
因为图G 是一个无向连通图。
所以n -1<=m<=n (n -1)/2; O(n)<=m<=O(n 2);克鲁斯卡尔对边数较少的带权图有较高的效率,而()()1.992m n n =O ≈O ,此图边数较多,接近完全图,故选用普里姆算法。
6-10.T 仍是新图的最小代价生成树。
证明:假设T 不是新图的最小代价生成树,T’是新图的最小代价生成树,那么cost(T’)<cost(T)。