算符优先文法
编译原理实验4算符优先算法

一、实验目的与任务算术表达式和赋值语句的文法可以是(你可以根据需要适当改变):S→i=EE→E+E|E-E|E*E|E/E|(E)|i根据算符优先分析法,将赋值语句进行语法分析,翻译成等价的一组基本操作,每一基本操作用四元式表示。
二、实验涉及的相关知识点算符的优先顺序。
三、实验内容与过程如参考C语言的运算符。
输入如下表达式(以分号为结束):(1)a = 10;(2)b = a + 20;注:此例可以进行优化后输出(不作要求):(+,b,a,20)(3)c=(1+2)/3+4-(5+6/7);四、实验结果及分析(1)输出:(=, a,10,-)(2)输出:(=,r1,20,-)(+,r2,a,r1)(=,b,r2,-)(3)输出:(+,r1,1,2) (/,r2,r1,3) (/,r3,6,7) (+,r4,5,r3,) (+,r5,r2,4) (-,r6,r5,r4) (=,c,r6,-)五、实验有关附件(如程序、附图、参考资料,等)......h == '#') o][Peek(n0).No];if(r == '<') h == 'E'&& Peek(1).ch == '#' && Token[ipToken].ch == '#')return TRUE;elsereturn FALSE;}h){k = TRUE; h == 'E'){n ++;}return n;}词结束(遇到“#”号),无法移进,需要规约,返回:1词没有结束,需判断是否可以移进栈单词<=单词:移进后返回:2栈单词>单词:不能移进,需要规约,返回:1单词没有优先关系:出错,返回:-1int MoveIn(){SToken s,t; h = '#';Token[TokenNumber].No = O_NUL;return TRUE; h = '+';Token[TokenNumber].No = O_PLUS;GetChar();break;case '-':Token[TokenNumber].ch = '-';Token[TokenNumber].No = O_MINUS;GetChar();break;case '*':Token[TokenNumber].ch = '*';Token[TokenNumber].No = O_TIMES;GetChar();break;case '/':Token[TokenNumber].ch = '/';Token[TokenNumber].No = O_SLASH;GetChar();break;case '(':Token[TokenNumber].ch = '(';Token[TokenNumber].No = O_L_PAREN;GetChar();break;case ')':Token[TokenNumber].ch = ')';Token[TokenNumber].No = O_R_PAREN;GetChar();break;default:if(ch >= '0' && ch <= '9') h = 'i';Token[TokenNumber].No = O_IDENT;}else{return ! MakeErr("表达式中含有非法字符。
5.2-算符优先分析-简单介绍

结论: 对于二义性的表达式文法,我们可以直 结论: 对于二义性的表达式文法,
观地给出运算符之间的优先关系, 观地给出运算符之间的优先关系,使得输入串 的归约过程可以唯一确定. i1+i2*i3的归约过程可以唯一确定. 对任意给定的一个文法, 对任意给定的一个文法, 如何计算算符之间的优先关系? 如何计算算符之间的优先关系?
算符优先分析 语法树的框架 N N i + N i
规范归约过程
步骤 符号栈 1 2 3 4 5 6 7 8 9 10 # #i #F #T #E #E+ #E+i #E+F #E+T #E 剩余 动作 输入串 i+i# 移进 +i# +i# +i# +i# i# # # 归约 归约 归约 移进 移进 归约 归约 F→i F→i T→F T→F E→T E→T
; ; ( ) a + # ( ) a + #
课后思考: 课后思考:
1.给出输入串#(a+a)#的算符优先分析过程 1.给出输入串#(a+a)#的算符优先分析过程 给出输入串#(a+a)# 2.#(a+a)# 是文法的句子吗? 2.#(a& 语法分析 5.1 自下而上分析基本问题 5.2 算符优先分析 5.3 LR分析 分析 5.4 YACC
5.2 算符优先分析
5.2.1 算符优先文法及优先表构造 5.2.2 算符优先分析算法
优先分析法
• 根据某种优先关系确定 “可归约串 . 根据某种优先关系 优先关系确定 可归约串 可归约串” • 简单优先分析法 *
• 算符文法的两个限制
• 上下文无关文法 • 不含空产生式
补充例: 补充例:表达式文法
算符优先_实验报告

一、实验目的1. 理解算符优先分析法的原理和过程。
2. 掌握算符优先分析法的实现方法。
3. 通过实验加深对自底向上语法分析方法的理解。
二、实验内容1. 算符优先分析法原理介绍算符优先分析法是一种自底向上的语法分析方法,它通过比较相邻算符的优先次序来识别句型中的句柄,进而执行归约。
该方法的核心是确立文法的终结符之间的优先关系。
2. 实验步骤(1)判断文法是否为OG文法:OG文法要求所有产生式右部至少有一个终结符。
(2)判断文法是否为OPG文法:计算FIRSTVT集、LASTVT集,并构建算符优先矩阵。
(3)对句子进行分析:根据分析表判断句子是否为文法的句子。
(4)实现程序:从文件和键盘读取输入,将结果输出到指定文件和屏幕,并具有一致性。
3. 实验数据(1)文法:g[e]:e->e+t|t(2)测试句子:12+t, t+12, 12+13t, 12+t13三、实验过程1. 判断文法是否为OG文法根据给定的文法,我们可以看到所有产生式右部至少有一个终结符,因此该文法为OG文法。
2. 判断文法是否为OPG文法,并构建算符优先矩阵(1)计算FIRSTVT集FIRSTVT(e) = {t}FIRSTVT(t) = {t}(2)计算LASTVT集LASTVT(e) = {t}LASTVT(t) = {t}(3)构建算符优先矩阵| + - ( ) t e $+ > - - - > > -- > - - - > > -> > > > > > >( > > > > > > >) - - - - - - -t - - - - - - -e - - - - - - -$ - - - - - - -3. 对句子进行分析(1)分析句子“12+t”根据分析表,我们可以得到以下分析过程:12+t -> 12+t -> 12+t -> t -> t(2)分析句子“t+12”根据分析表,我们可以得到以下分析过程:t+12 -> t+12 -> t+12 -> t+12 -> t+12 -> t -> t (3)分析句子“12+13t”根据分析表,我们可以得到以下分析过程:12+13t -> 12+13t -> 12+13t -> 12+13t -> 12+13t -> t -> t(4)分析句子“12+t13”根据分析表,我们可以得到以下分析过程:12+t13 -> 12+t13 -> 12+t13 -> 12+t13 -> 12+t13 -> t13 -> t13 -> t13 -> t -> t四、实验结果1. 测试句子“12+t”分析结果:正确2. 测试句子“t+12”分析结果:正确3. 测试句子“12+13t”分析结果:正确4. 测试句子“12+t13”分析结果:正确五、实验总结通过本次实验,我们深入了解了算符优先分析法的原理和实现方法。
算符优先文法分析

算符优先文法分析1.问题描述基于算符优先分析法的语法分析程序要求:(1)输入已知文法,生成文法矩阵,判断该文法是否是算符优先文法。
(2)用程序自动生成该文法的算符优先关系矩阵。
(3)对人工输入的句型或句子,分析该句型或句子是否合法,能否用已知文法推出。
(4)具有通用性。
所开发的程序可适用于不同的文法和任意输入串,且能判断该文法是否为算符优先文法。
(5)有运行实例。
对于输入的文法和符号串,所编制的语法分析程序应能正确判断此串是否为文法的句子,并要求输出分析过程。
2.算符优先分析法2.1算符优先文法定义:设有不含空串的一文法G,如果G中没有形如G>……BC……的产生式,其中B和C为非终结符,且对任意两个终结符a,b之间之多只有<,>,=,三种关系的一种成立,则称G是一个算符优先文法。
非终结符的FIRSTVT集合和LASTVT集合FIRSTVT(B)={b|B→b…或B→Cb…}LASTVT(B)={b|B→…a或B→…aC}2.2算符优先矩阵算符优先关系矩阵,判断输入是否满足已知文法的依据。
根据非终结符的FIRSTVT集合和LASTVT集合产生。
1.“=”关系若A→…ab…或A→…aBb…,则a=b;2.“〈⋅”关系若A→…aB…,对每一个b属于FIRSTVT(B),有a〈⋅b;3.“⋅〉”关系若A→…Bb…,对每一个a属于LASTVT(B),有a⋅〉 b。
2.3如何规约在分析过程中,利用分析栈存放已识别的那部分句型,而句型的其余部分由剩余输入串组成,通过比较栈顶符号和下一个输入符号之间的关系,可以判别栈顶符号是否为句柄尾符号。
如果是句柄尾,则沿栈顶向下,在栈内寻找句柄头(利用关系)。
由关系和关系之间包括的符号串就是句柄,然后把它们弹出栈,并代之以归约后的非终结符。
这样就完成了一次归约过程。
2.4算符优先分析方法的局限性由于算符优先分析法去掉了单非终结符之间的归约,尽管在分析过程中,当决定是否为句柄时采取一些检查措施,但仍难完全避免把错误的句子得到正确的归约。
算符优先文法实验报告

《编译原理》课程实验报告实验名称:算符优先文法姓名学号:地点:教师院系:计算机与通信工程学院专业:计算机科学与技术09-2一.实验目的设计、编制并调试一个算符优先法分析程序,加深对算符优先法分析原理的理解。
二.实验内容算术表达式的文法:(1).E → E +T | E -T | T(2).T → T * F | T / F | F(3).F → i |(E)转化后的文法:(1).E → E +T(2).E → E -T(3).E → T(4).T → T * F(5).T →T / F(6).T →F(7).F → i(8).F →(E)根据表达式的文法,首先计算每个非终结符的FIRSTVT和LASTVT:执行算法逐条扫描文法规则,从而构造出文法的算符优先关系表如图所示用算符优先分析法法对该文法进行分析,在每次归约成功后则输出四元式。
四元式形式如下:(op,arg1,arg2,result)其中op是运算符,arg1,arg2分别是第一和第二个运算对象,当op是一目运算时,常常将运算对象定义为arg1.例如,表达式-C和赋值语句X=a的四元式可分别表示为(i)(@,C,-,T)(j)(=,a,-,X)三.源代码:#include<stdio.h>#include<string.h>#include<stdlib.h>#define MAXSIZE 64#define N -10typedef char datatype;typedef struct{datatype data[MAXSIZE];int top;}seqstack;seqstack OPR;seqstack OPT;char *p;int matrix[7][7]={{N,-1,-1,-1,-1,N,1},{N,1,-1,-1,-1,1,1},{N,1,1,-1,-1,1,1},{1,1,1,N,N,1,1},{N,-1,-1,-1,-1,0,N},{N,1,1,N,N,1,1},{-1,N,N,-1,N,N,0}}; int row,line;int count=1;int compare(char m,char n){switch(m){case '=':row=0;break;case '+':row=1;break;case '*':row=2;break;case 'i':row=3;break;case '(':row=4;break;case ')':row=5;break;case '$':row=6;break;default: return -100;break;}switch(n){case '=':line=0;break;case '+':line=1;break;case '*':line=2;break;case 'i':line=3;break;case '(':line=4;break;case ')':line=5;break;case '$':line=6;break;default: return -100;break;}return matrix[row][line];}void OPRsetnull(){OPR.top=-1;}bool OPRempty(){if(OPR.top>=0)return false;elsereturn true;}void OPRpush(char x){if(OPR.top==MAXSIZE-1)printf("上溢!");else {OPR.top++;OPR.data[OPR.top]=x;}}datatype OPRpop(){if(OPRempty()){printf("下溢!");return NULL;}else{OPR.top--;return(OPR.data[OPR.top+1]);}}datatype OPRtop(){if(OPRempty()){return NULL;}elsereturn(OPR.data[OPR.top]); }void OPTsetnull(){OPT.top=-1;}bool OPTempty(){if(OPT.top>=0)return false;elsereturn true;}void OPTpush(char x){if(OPT.top==MAXSIZE-1)printf("上溢!");else{OPT.top++;OPT.data[OPT.top]=x;}}datatype OPTpop(){if(OPTempty()){printf("下溢!");return NULL;}else{OPT.top--;return(OPT.data[OPT.top+1]);}}datatype OPTtop(){if(OPTempty()){return NULL;}else return(OPT.data[OPT.top]);}void output(char opt,char op1,char op2,int num){if(op1=='i'&&op2=='i') printf("(%c,%c,%c,t%d)\n",opt,op1,op2,num);if(op1!='i'&&op2=='i') printf("(%c,t%d,%c,t%d)\n",opt,op1,op2,num);if(op2!='i'&&op1=='i') printf("(%c,%c,t%d,t%d)\n",opt,op1,op2,num);if(op1!='i'&&op2!='i') printf("(%c,t%d,t%d,t%d)\n",opt,op1,op2,num); }void scan(){char opt;char op1,op2;if(*p=='$') OPTpush(*p);p++;while(*p!='$'){if(*p=='i') OPRpush(*p);else {opt=OPTtop();P: switch(compare(opt,*p)){case -1: OPTpush(*p); break;case N: break;case 0: OPTpop(); break;case 1: op1=OPRpop();op2=OPRpop();output(opt,op1,op2,count);OPRpush(count);count++;opt=OPTpop();opt=OPTtop();goto P; break;}}p++;}while(!OPTempty()&&!OPRempty()&&(OPTtop()!='$')){ op1=OPRpop();op2=OPRpop();opt=OPTpop();if(opt!='='){output(opt,op1,op2,count);OPRpush(char(count));count++;}if(opt=='=') printf("(%c,t%d, ,i)\n",opt,count-1);}}void main(){int d;OPRsetnull();OPTsetnull();char ch[]="$i=i*(i*(i+i))*i$";printf("分析语句:");printf("%s\n",ch);p=ch;scan();}四.实验步骤调试程序的结果:。
算符优先分析编译原理-PPT

算符优先分析算法
1 k:= 1; S [ k ] := “#”
2 repeat read 下一符号到a;
3
if S[ k ] Vt then j := k else j := k-1;
4
while S[ j ] > a do
5
{ repeat
6
Q := S[ j ];
7
if S[ j-1] Vt then j := j-1
则
a>#
(认为存在#S#)
8
算符优先文法OPG定义
在 OG文法 G 中,若任意两个终结符间至多 有一种算符优先关系存在,则称G 为算符优先 文法(OPG)。
注意:允许b>c, c>b; 不允许 b>c, b<c, b=c中任两个 同时存在。 b=c 不一定 c = b。 例1中:“(” = “)”,“)”<>“(”。
11
大家有疑问的,可以询问和交流
可以互相讨论下,但要小声点
(0)E’→#E# (1) E→E+T (2) E→T (3) T→T*F (4) T→F (5) F→PF|P (6) P→(E) (7) P→i
1)‘=’关系 由产生式(0)和(6),得 #=#, ( = )
2)‘<’关系 找形如A→…aB…得产生式 #E:则 #<FIRSTVT(E) +T: 则 +<FIRSTVT(T) *F: 则 *<FIRSTVT(F) F: 则 <FIRSTVT(F) (E: 则 (<FIRSTVT(E)
P→(E)|i
+ * ( ) i#
+>< << >< >
算符优先算法

算符优先算法1. 算符优先算法简介算符优先算法(Operator Precedence Parsing)是一种用于解析和计算表达式的方法。
它通过定义运算符之间的优先级和结合性来确定表达式的计算顺序,从而实现对表达式的准确解析和计算。
在算符优先算法中,每个运算符都被赋予一个优先级,表示其与其他运算符之间的优先关系。
根据这些优先级规则,可以将一个表达式转化为一个操作符和操作数构成的序列,并按照一定的顺序进行计算。
2. 算符优先文法在使用算符优先算法进行解析时,需要定义一个文法来描述运算符之间的关系。
这个文法称为算符优先文法。
一个典型的算符优先文法由以下三部分组成:1.终结符:表示可以出现在表达式中的基本元素,例如数字、变量名等。
2.非终结符:表示可以出现在表达式中但不能作为最终结果输出的元素,例如运算符。
3.产生式:描述了如何将非终结符转化为终结符或其他非终结符。
通过定义合适的产生式规则,可以建立起非终结符之间的优先关系。
这些优先关系决定了表达式中运算符的计算顺序。
3. 算符优先表算符优先表(Operator Precedence Table)是算符优先算法的核心数据结构之一。
它用于存储运算符之间的优先级和结合性信息。
一个典型的算符优先表由以下几部分组成:1.终结符集合:包含所有可能出现在表达式中的终结符。
2.非终结符集合:包含所有可能出现在表达式中的非终结符。
3.优先关系矩阵:用于存储运算符之间的优先关系。
矩阵中每个元素表示两个运算符之间的关系,例如“<”表示左运算符优先级低于右运算符,“>”表示左运算符优先级高于右运算符。
“=”表示两个运算符具有相同的优先级。
通过使用算符优先表,可以根据当前输入字符和栈顶字符来确定下一步应该进行的操作,例如移进、规约等。
4. 算法流程下面是一个简化版的算法流程:1.初始化输入串、操作数栈和操作符栈。
2.从输入串中读取一个字符作为当前输入字符。
3.如果当前输入字符为终结符,则进行移进操作,将其压入操作数栈,并读取下一个输入字符。
简单优先和算符优先分析方法

简单优先和算符优先分析方法简单优先分析(Simple Precedence Parsing)和算符优先分析(Operator Precedence Parsing)是两种常用的自底向上的语法分析方法。
它们是基于符号优先级的理念,通过比较符号之间的优先级关系,来进行语法分析。
1.简单优先分析简单优先分析是一种自底向上的语法分析方法,它利用一个优先级表来确定符号之间的优先关系。
简单优先分析的算法如下:(1)将输入串和符号栈初始化为空。
(2)从输入串中读入第一个输入符号a。
(3)将a与栈顶的符号进行比较:a.如果a的优先级大于栈顶符号的优先级,将a推入符号栈,并读入下一个输入符号。
b.如果a的优先级小于栈顶符号的优先级,将栈中的符号做规约操作,直到栈顶的符号优先级不小于a。
然后,将a推入符号栈。
c.如果a和栈顶符号优先级相等,栈顶的符号出栈,并将a推入符号栈。
(4)重复步骤(3)直到输入串为空。
(5)如果符号栈中只有一个符号且为文法的开始符号,则分析成功。
简单优先分析的优先级表一般由语法规则和符号之间的优先关系组成。
我们可以通过构造优先级关系表来实现简单优先分析。
2.算符优先分析算符优先分析是一种自底向上的语法分析方法,它也是基于符号优先级的理念,但是相对于简单优先分析,算符优先分析更加灵活,并且允许处理左递归的文法。
算符优先分析的算法如下:(1)将输入串和符号栈初始化为空。
(2)从输入串中读入第一个输入符号a。
(3)将a与栈顶的符号进行比较:a.如果a的优先级大于栈顶符号的优先级,将a推入符号栈,并读入下一个输入符号。
b.如果a的优先级小于栈顶符号的优先级,将栈中的符号做规约操作,直到栈顶的符号优先级不小于a。
然后,将a推入符号栈。
c.如果a和栈顶符号优先级相等,根据符号栈中符号的类型执行相应的操作(如归约、移进等)。
(4)重复步骤(3)直到输入串为空。
(5)如果符号栈中只有一个符号且为文法的开始符号,则分析成功。
编译原理5.2.1-12-3-算符优先文法

语法制导翻译的实现
E -> E + T | T T -> T - S | S S -> S * F | F
语法制导翻译的实现
F -> ( E ) | id
其中,E表示表达式,T表示项,S表示子表达式,F表示因子。根据这些语法规则和语义动作,可以编写语法分析程序来分析 算术表达式,并生成相应的目标代码。
WENKU DESIGN
WENKU
REPORTING
https://
构造算符优先关系
表
根据运算符的优先级和结合性, 构造一个算符优先关系表,用于 确定运算符之间的优先级关系。
添加括号
在构造算符优先关系表时,可能 需要添加括号来改变某些表达式 的优先级。
构造算符优先文法
定义文法规则
根据算符优先关系表,定义文法规则,使得每个运算符都有对应 的产生式。
消除左递归
确保文法规则中没有左递归,以避免语法分析时出现无限循环。
主要任务
02
编译原理的主要任务包括词法分析、语法分析、语义分析、中
间代码生成、代码优化和目标代码生成等。
应用
03
编译原理不仅应用于编译器设计,还广泛应用法的基本概念
定义与特点
定义
算符优先文法是一种形式文法,它通 过规定运算符的优先级和结合性来生 成语言的句子。
展望
进一步研究
算符优先文法虽然简洁且易于实 现,但在某些复杂语言描述方面 可能存在局限性。未来可以深入 研究算符优先文法的扩展方法, 以更好地适应各种语言结构的描 述需求。
应用领域拓展
算符优先文法不仅在编译原理中 有应用,还可以拓展到自然语言 处理、形式化验证等领域。未来 可以探索算符优先文法在这些领 域的应用,以实现更广泛的技术 创新。
算符优先文法课程设计

算符优先文法课程设计一、课程目标知识目标:1. 学生能理解算符优先文法的基本概念,掌握算符优先级的原则。
2. 学生能运用算符优先文法对算术表达式进行正确的解析和计算。
3. 学生了解算符优先文法在计算机科学中的应用和重要性。
技能目标:1. 学生能够运用算符优先文法设计简单的计算器程序,实现对算术表达式的计算。
2. 学生能够通过分析算术表达式,准确地判断算符的优先级,并进行相应的计算。
3. 学生能够运用所学知识解决实际问题,提高编程和逻辑思维能力。
情感态度价值观目标:1. 学生培养对计算机科学和程序设计的兴趣,激发探索精神。
2. 学生在学习过程中,培养合作、交流和问题解决的积极态度。
3. 学生通过算符优先文法的学习,认识到数学与计算机科学的紧密联系,增强学科交叉融合的意识。
课程性质分析:本课程为计算机科学相关学科,通过讲解算符优先文法,使学生掌握计算机处理算术表达式的基本原理。
学生特点分析:学生处于具备一定数学基础和逻辑思维能力的年级,对新鲜事物充满好奇,但可能对编程和算法尚感陌生。
教学要求:1. 教师应注重理论与实践相结合,让学生在实际操作中掌握算符优先文法。
2. 教师应引导学生主动思考,提高学生分析问题和解决问题的能力。
3. 教师关注学生的情感态度,鼓励学生积极参与课堂讨论,培养合作精神。
二、教学内容1. 算符优先文法基本概念:算符、优先级、结合性。
2. 算符优先级的判定方法:算术表达式中算符的优先级判断。
3. 算符优先文法的应用:设计简单计算器程序,实现算术表达式的计算。
4. 算符优先文法的算法实现:递归下降分析法、算符栈方法。
5. 实例分析:分析常见算术表达式的算符优先文法应用,总结规律。
6. 编程实践:编写计算器程序,实现对算术表达式的解析和计算。
教学内容安排和进度:第一课时:算符优先文法基本概念,结合教材第一章第一节。
第二课时:算符优先级的判定方法,结合教材第一章第二节。
第三课时:算符优先文法的应用,结合教材第二章第一节。
第5-1 算符优先文法
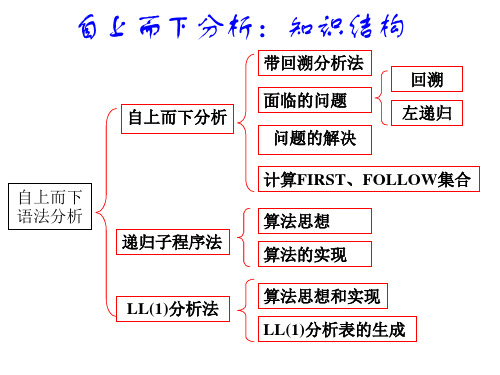
自上而下语法分析复习内容(No.3)
• 12.预测分析表的构造算法:
– 对每一条产生式A→α,先求出右部符号串α的 FIRST集,若FIRST(α)包含ε,则再求左部非终结符 A的FOLLOW(A)集;然后,对属于FIRST(α)或 FOLLOW(A)的终结符a填表元素 M[A,a]为 “A→α”。
如果文法G是无二义的,那么,规范推导 (最右推导)的逆过程必是规范归约(最左归约)。
对于规范句型来说,句柄的后面不会出现非 终结符号(句柄的后面只能出现终结符号)。
abbcde aAbcde aAde aABe S
修剪语法树
S
a A A b c B d e
b
二义性文法规范归约过程中右句型的句柄可能不唯一。 例如,文法 G[E]:
算符文法的定义 设G是一个文法,如果G中不存在形如A及 A→BC的产生式 (其中A,B,CVN ,, (VN VT)*),即 G中没有右部为或右部具有相邻非终结符号的产生式, 则称G为算符文法(OG文法)。 G[E]: E→E+E|E-E|E*E|E/E|EE|(E)|-E|id 是算符文法。 E→EAE|(E)|-E|id A→+|-|*|/| 不是算符文法(因右部EAE具有相邻的非终结符号)。
E T F
T|E+T F|T*F i|(E)
• ∵ E * F*i2+i3 ,且F i1 • ∴ i1是句型i1*i2+i3相对于非 终结符F的短语,也是相对 于规则F→i的直接短语 • ∵ E * T*i2+i3 ,且T + i1 • ∴ i1是句型i1*i2+i3相对于非 终结符T的短语。
(2)FIRST(S)={a,} FIRST(S')={,ε} FIRST(T)={} FIRST(T')={,ε} FOLLOW(S)={#} FOLLOW(S')={#} FOLLOW(T)={,#} FOLLOW(T')={,#}
编译原理5:算符优先关系表构造

1) 定义FIRSTVT集 和 LASTVT集
FIRSTVT(P) = {a | P a••• 或 P Qa•••}
注意: 在算符文法中, 一个非终结符推导出的
首个算符的位置要么是第一个, 要么是第二个
LASTVT(P) = {a | P
•••a 或 P
•••aQ}
2) 根据 FIRSTVT集 和 LASTVT集 计算三种优先关系
由FIRSTVT(P)结点到结点a用箭弧连接
3.对每个形如P→Q … 的产生式,
由FIRSTVT(P)到FIRSTVT(Q)用箭弧连接 经箭弧有路径能到达的终结符结点a , 则有a FIRSTVT(P)
4.对每个非终结符的FIRSTVT(P) ,
FIRSTVT(E’)
FIRSTVT(E) FIRSTVT(T)
(0) E'→#E# (1) E→E+T (2) E→T (3) T→T*F (4) T→F (5) F→P↑F (6) F→P (7) P→(E)
P→…ab… P→…aQb… # #
P→…aR… # + *
P→…Rb… # + * ↑ )
FIRSTVT(E) LASTVT(E) FIRSTVT(T) LASTVT(E) FIRSTVT(F) LASTVT(T) LASTVT(P)
(0) E'→#E# (1) E→E+T (2) E→T (3) T→T*F (4) T→F (5) F→P↑F (6) F→P (7) P→(E) (8) P→i
#
+
FIRSTVT(F)
*
FIRSTVT(P)
↑ ( i
4) 构造优先关系表
FOR 每个产生式 PX1 X2 ……Xn DO FOR i:=1 TO n-1 DO IF Xi 和 X i+1 均为终结符 THEN 置 Xi X i+1 IF Xi 和 X i+2 均为终结符, X i+1 为非终结符 , i ≤n-2, THEN 置 Xi X i+2 IF Xi为终结符, 但X i+1 为非终结符 THEN FOR FIRSTVT(X i+1 )中的每个a DO 置 Xi a IF Xi为非终结符, 但X i+1 为终结符 THEN FOR LASTVT(X i )中的每个a DO 置 a X i+1
算符优先文法的构造

算符优先⽂法的构造算符优先⽂法的构造算符优先⽂法属于⾃底向上的⽂法分析,需要不断的进⾏移进-规约操作,让⼀个输⼊的句⼦通过不断的移进-规约,最终变成⽂法的开始符号。
在移进-规约的过程中我们需要知道先对什么进⾏规约,得有个先后关系,故需要构造⽂法的算符优先表,来帮助规约分析时的规约对象。
构造FirstVT集和LastVT集FirstVT和LastVT分别代表某个⾮终结符所产⽣的句型中第⼀个和最后⼀个终结符的集合。
具体产⽣规则如下:Firstvt找Firstvt的三条规则:如果要找A的Firstvt,A的候选式中出现:A->a.......,即以终结符开头,该终结符⼊FirstvtA->B.......,即以⾮终结符开头,该⾮终结符的Firstvt⼊A的FirstvtA->Ba.....,即先以⾮终结符开头,紧跟终结符,则终结符⼊FirstvtLastvt找Lastvt的三条规则:如果要找A的Lastvt,A的候选式中出现:A->.......a,即以终结符结尾,该终结符⼊LastvtA->.......B,即以⾮终结符结尾,该⾮终结符的Lastvt⼊A的LastvtA->.....aB,即先以⾮终结符结尾,前⾯是终结符,则终结符⼊Firstvt构造算符优先表算符优先关系表即确定各个终结符的优先关系,以便之后寻找最左素短语。
算符优先表分以下⼏种情况:E->...aBc...和E->...ac...,在产⽣式中存在类似关系的终结符优先级相等,即a和c的优先级相等。
E->Ab,在产⽣式中存在⼀个⾮终结符在前⼀个终结符在后的情况,则A的LastVT集合中的终结符优先级都⾼于终结符b的优先级E->aB,在产⽣式中存在⼀个终结符在前和⼀个⾮终结符在后的情况,则B的FirstVT集合中的终结符优先级都⾼于终结符a的优先级其实⼤⽩话说起来就遵循⼀种就⾏:就是产⽣式中哪些终结符⼀起能规约成左部⾮终结符,则两者优先级相等,⽽终结符和⾮终结符在同⼀个产⽣式中,⾮终结符的终结符集合需要先规约成⾮终结符,所以那些⾮终结符的终结符的优先级要⾼于与⾮终结符在同⼀产⽣式中的终结符寻找待规约串寻找规约串即寻找最左素短语。
第六章 算符优先分析文法

E’→#E# E→E+T|T T→T*F|F F→P↑F|P P→(E)|i ( )
直接看产生式的右部, 直接看产生式的右部,若出现了 →…ab ab…或 →…a A → ab 或A → aBb,则a=b
25
求 < 关系
• 求出每个非终结符B的FIRSTVT(B) 求出每个非终结符 的 • 若A→…aB…,则∀b∈FIRSTVT(B),a<b , ∈ , E’→#E# FIRSTVT(E’) ={#} E→E+T|T FIRSTVT(E) ={+,*,↑, ( , i } T→T*F|F FIRSTVT(T) ={*,↑, ( , i } F→P↑F|P FIRSTVT(F) ={↑, ( , i } P→(E)|i ( ) FIRSTVT(P) ={ ( , i } E’→#E#且P→(E)则{#,(}<FIRSTVT(E) → E#且P→(E)则{#,( FIRSTVT(E) # < + , # <* ,#<↑ , #< (,# <I, (< +,( <*, (<↑ , (<( ,( <i
16
如果Ab或 如果 或(bA)出现在算符文法的句型γ中, )出现在算符文法的句型γ 其中A∈ , 其中 ∈VN, b ∈ VT,则γ中任何含 的短语必 , 中任何含b的短语必 含有A。 含有 。
* S => γ =abAβ
γ中含b的短语不含有 。 中含 的短语不含有A。 不含有
S a BB AB β b
当且仅当G中含有形如A 的产生式, a > b当且仅当G中含有形如A→…Bb…的产生式, B 的产生式 + 且B+ …a或B⇒…aC 。 ⇒ a a 所以不是算符优先文法。 所以不是算符优先文法。 21
第四章_2 算符优先分析法
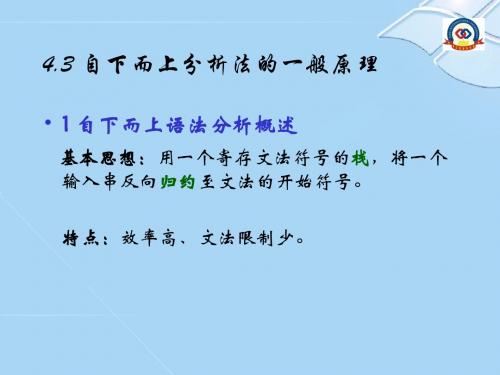
1 自下而上语法分析概述
• 移进-归约过程实例。 例4.11 设有文法G[A]: (1)A → aBcDe (2)B → b (3)B → Bb (4)D → d 对输入串abbcde$的移进-归约分析过程
对输入串abbcde$移进-归约分析过程: 步骤 0 1 2 3 4 5 6 7 8 9 10 符号栈 $ $a $ab $aB $aBb $aB $aBc $aBcd $aBcD $aBcDe $A 输入串 abbcde$ bbcde$ bcde$ bcde$ cde$ cde$ de$ e$ e$ $ $ 动作
动作
移进 归约 移进 移进 归约 归约 接受
4.4.6 算符优先分析法的局限性
• 1 一般语言的文法很难满足算符优先文法的条 件,仅在表达式局部中应用; • 2 由于忽略非终结符在归约过程中的作用,可 能导致对错误的句子得到正确的归约。
例4.13 设有算符优先文法 A → A;D|D D → D(E)|F F → a|(A) E → E+A|A 写出输入串(a+a)$的算符优先分析过程。 $ 该文法的算符优先关系表为:
结论:算符优先文法是无二义的。
4.4.3 算符优先关系表的构造
• 1 FIRSTVT集、 LASTVT集 + FIRSTVT(A)={b|A ⇒ b… 或 + A ⇒ Bb… ,b ∈ VT,B ∈ VN} 即:非终结符A往下推导所有可能出现的首个 算符的集合. LASTVT(A)={a|A ⇒ …a + A ⇒ …aB, a ∈ VT,B ∈ VN} 即:非终结符A往下推导所有可能出现的最后 一个算符的集合.
4.4.4 算符优先分析算法的设计
对4.12中的文法G[E]: E → E+T|T T → T*F|F F →(E)|id 写出输入串id+id$的算符优先分析过程。
算符优先分析法

算符优先分析过程
输入串 i +i * i 的分析过程: E 结论:输入串合法
E +T
T T*F
FF
i
i
i
下推栈
# #i
#F
#F+ #F+i #F+F #F+F* #F+F*i #F+F*F #F+T #E
输入串
i+i*i#
+i*i#
+i*i#
i*i# *i# *i# i# # # # #
查分析表
#<i i>+
ABC
• 11.我会打断别人的话。
ABC
• 12.我会换个角度将心比心来看别人的做法。 A B C
• 13.我能委婉地表达我的建议或反对的观点。 A B C
• 14.交谈时,我会注视对方的眼睛。
ABC
• 15.我很注意人们无意间身体姿态所流露的心情。 A B C
• 16.别人跟我讲话时,我会东张西望。
实例
求下述文法G的算符优先关系表:
E→E+T│T
T→T*F│F
E
F→(E)│i
T
F
考察 E→E+T 中的:E 和 +,+ 和 T 考察 T→T*F 中的:T 和 *,* 和 F 考察 F→(E) 中的:( 和 E,( 和 ),E 和 ) 考察 #E# 中的:# 和 E,# 和 #,E 和 #
一、留给别人良好的第一印象
• 怎样才能给对方留下良好的第一印象呢? • (1)发挥自己的长处。尺有所短,寸有所长。如果你发挥自己的长处,别
人就会喜欢跟你在一起,并愿意同你合作。所以,与人交往,要充满自信, 并尽可能地发挥自己的长处。 • (2)适应不同的场合。懂得与人交往的人,会因场合不同而改变自己的表 现。一成不变的状态会使人显得没有朝气,从而不会给人留下美好印象。 不管是与人亲密地倾谈,还是发表演说,都要在保持言行一致的前提下, 因时因地地有所变化。 • (3)放松心情。要想别人喜欢你,就要使别人在与你相处时感到轻松自在。 这种氛围只有你自己表现得轻松自如才能创造出来。因此,遇事时自己的 心理要尽量放松。学会幽默,不要总是神色严峻,或做出一副苦闷的样子。 • (4)善于使用眼神。不管是跟一个人还是跟一百个人说话,一定要记住用 眼睛望着对方。进入坐满人的房间时,应自然地举目四顾,微笑着用目光 照顾到所有的人。这会使你显得轻松自若。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
编译原理实验代码:对于任意给定的文法,判断其是否是算符优先文法。
代码如下:#include<iostream>#include<stdlib.h>#include <fstream>#define row 50#define col 50#define SIZE 50using namespace std;//两个重要结构体的定义//FIRSTVT表或LASTVT表中一个表项(A,a)结构体的初始化typedef struct{char nonterm; //非终结符char term; //终结符}StackElement;//存放(A,a)的栈的初始化typedef struct{StackElement *top;StackElement *bottom;int stacksize;}stack;//初始化(A,a)栈void InitStack(stack &S){S.bottom = new StackElement[SIZE];if(!S.bottom)cout<<"存储空间分配失败!"<<endl;S.top = S.bottom;S.stacksize = SIZE;}//判断(A,a)栈是否为空bool ifEmpty(stack S){if(S.top==S.bottom) return true; //如果栈为空,则返回true else return false; //否则不为空,返回false}//插入栈顶(A,a)元素void Insert(stack &S,StackElement e){if(S.top-S.bottom>=S.stacksize)cout<<"栈已满,无法插入!"<<endl;else{S.top->nonterm=e.nonterm;S.top->term=e.term;S.top++;}}//弹出栈顶(A,a)元素StackElement Pop(stack &S){StackElement e;e.nonterm = '\0';e.term = '\0';if(S.top==S.bottom){cout<<"栈为空,无法进行删除操作!"<<endl;return e;}else{S.top--;e.nonterm=S.top->nonterm;e.term=S.top->term;return e;}}//终结符与非终结符的判断函数(布尔类型)bool TerminalJud(char c){if(c>='A'&&c<='Z') return false; //非终结符返回false //else if(c>='a'&&c<='z') return false;else return true; //终结符返回true}//判断非终结符在first表中是否已存在bool ItemJud(char first[][col],int frist_len,char C){for(int i=0;i<frist_len;i++){if(first[i][0]==C)return true; //如果first表中已存在此非终结符,则返回true }return false;}//读文件函数int readfile(char sen[][col]){char addr[50];cout<<"请输入要读文件的地址(\\用\\\\表示):"<<endl;cin>>addr;ifstream fin;fin.open(addr,ios::in);if(!fin){cout<<"Cannot open file!\n"<<endl;}int i,mm,l,z,k,j;char D[100][100];for(i=0;!fin.eof();i++){fin>>D[i];cout<<D[i]<<endl;}k=0;//cout<<i<<" iiii"<<endl;//cout<<k<<endl;//for(j=0;j<i;j++)//cout<<D[j]<<"ggg"<<endl;for(z=0;z<i;z++){mm=0;l=0;for(j=0;j<=strlen(D[z]);j++){if(D[z][j]=='|'){sen[k][l]='\0';mm=1;k++;sen[k][0]=D[z][0];sen[k][1]='-';sen[k][2]='>';l=3;j++;}if(mm==0){sen[k][l]=D[z][j];l++ ;}if(mm==1){sen[k][l]=D[z][j];l++ ;}}k++;}//cout<<k<<" kkkkkk"<<endl;//for(i=0;i<k;i++)//cout<<sen[i]<<endl;return k;}//FIRSTVT表和LASTVT表中表项(非终结符)的初始化void ItemInit(char sen[][col],char first[][col],char last[][col],int sen_len,int &frist_len){int i;frist_len=1;first[0][0]=sen[0][0];last[0][0]=sen[0][0];for(i=1;i<sen_len;i++){if(TerminalJud(sen[i][0])==false &&ItemJud(first,frist_len,sen[i][0])==false) //k是当前first和last表的长度{first[frist_len][0]=sen[i][0];last[frist_len][0]=sen[i][0];frist_len++;}}}void FirstVt(char sen[][col],char first[][col],int sen_len,int frist_len) // frist_len 是first 表的行数sen_len是产生式的个数{StackElement DFS,record[SIZE];//StackElement char nonterm; //非终结符char term; //终结符stack Operator; //创建存放(A,a)的栈StackElement*top; StackElement *bottom; int stacksize;InitStack(Operator);int i,j,r=0;for(i=0;i<sen_len;i++) //第一次扫描,将能直接得出的first(A,a)放进栈中{for(j=3;sen[i][j]!='\0';j++){if(TerminalJud(sen[i][j])==true) //遇到的第一个终结符压入{int exist=0;DFS.nonterm=sen[i][0];DFS.term=sen[i][j];for(int i1=0;i<r;i++){if(record[i1].nonterm==sen[i][0]&&record[i1].term==sen[i][j]){exist=1;break;}record[r].nonterm=sen[i][0];record[r].term=sen[i][j];if(exist==0){Insert(Operator,DFS);//A-aB A-aC (A,a)压栈两次?record[r].nonterm=sen[i][0];record[r].term=sen[i][j];r++;}break;}}}int location[col]; //辅助数组,用来记录first表中放入终结符的位置for(i=0;i<frist_len;i++)location[i]=1;while(!ifEmpty(Operator)){int exist=0; //标志位,记录即将入栈的元素是否已经存在StackElement IDElement,DElement;DElement=Pop(Operator); //弹出栈顶元素for(i=0;i<frist_len;i++){if(first[i][0]==DElement.nonterm){int n=location[i];first[i][n]=DElement.term; //将终结符填入相应的first表中location[i]++;break;}}for(j=0;j<sen_len;j++){if(sen[j][3]==DElement.nonterm) //找出能推出当前非终结符的产生式的左部{IDElement.nonterm=sen[j][0];IDElement.term=DElement.term;//判断将要放进栈里的元素曾经是否出现过,若没有,才压入栈for(int r0=0;r0<r;r0++) //r记录record数组中的元素个数{if(record[r0].nonterm==IDElement.nonterm &&record[r0].term==IDElement.term)exist=1;break;}}if(exist==0){Insert(Operator,IDElement);record[r].nonterm=IDElement.nonterm;record[r].term=IDElement.term;r++;}}}}}void LastVt(char sen[][col],char last[][col],int sen_len,int frist_len) //firstvt 表与lastvt表行数一样first_len表示last 表的行数{int i,j,i1,j1;char c,record[row][col]={'\0'};for(i=0;i<sen_len;i++){for(j=0;sen[i][j]!='\0';j++){record[i][j]=sen[i][j];}j=j-1;for(i1=3,j1=j;i1<j1;i1++,j1--) //做翻转,就可以用求first的方法求last{c=record[i][i1];record[i][i1]=record[i][j1];record[i][j1]=c;}}//forFirstVt(record,last,sen_len,frist_len);}//判断非终结符在term表中是否已存在bool TermTableJud(char term[col],int term_len,char C)for(int i=0;i<term_len;i++){if(term[i]==C)return true; //如果first表中已存在此非终结符,则返回1}return false;}//构造算符优先关系表bool OpPriotable(char sen[][col],char first[][col],char last[][col],char opTable[][col],int sen_len,int first_len,int &opTable_len){int i,j,term_len=0;int i2,i3,opr,opc;char c1,c2,c3;char term[SIZE]={'\0'};for(i=0;i<sen_len;i++) //一维数组term记录关系表中存在的所有终结符{for(j=3;sen[i][j]!='\0';j++){if(TerminalJud(sen[i][j])==true)if(TermTableJud(term,term_len,sen[i][j])==false) //term_len记录term表的长度{term[term_len]=sen[i][j];term_len++;}}} //得到终结符表for(i=0;i<term_len+1;i++) //给优先关系表赋初值,都等于空for(j=0;j<term_len+1;j++)opTable[i][j]=' ';for(i=1;i<term_len+1;i++) //设置优先关系表的表头{opTable[i][0]=term[i-1];opTable[0][i]=term[i-1];}opTable[i][0]='$';opTable[0][i]='$';for(i=0;i<sen_len;i++) //找等于关系{for(j=4;sen[i][j]!='\0';j++)if(TerminalJud(sen[i][j-1])==true&&TerminalJud(sen[i][j])==true){c1=sen[i][j-1];c2=sen[i][j];for(opr=1;opr<term_len+1;opr++) //在opTable表中找到该存入的行标opr{if(opTable[opr][0]==c1)break;}for(opc=1;opc<term_len+1;opc++) //在opTable表中找到该存入的列标j2{if(opTable[0][opc]==c2)break;}if(opTable[opr][opc]!=' '){if(opTable[opr][opc]!='='){cout<<"不是算符优先文法!"<<endl;return false;}}else{opTable[opr][opc]='=';}}}for(j=5;sen[i][j]!='\0';j++){if(TerminalJud(sen[i][j-2])==true&&TerminalJud(sen[i][j-1])==false&&Ter minalJud(sen[i][j])==true){c1=sen[i][j-2];c2=sen[i][j];for(opr=1;opr<term_len+1;opr++) //在opTable表中找到该存入的行标opr{if(opTable[opr][0]==c1)break;}for(opc=1;opc<term_len+1;opc++) //在opTable表中找到该存入的列标opc{if(opTable[0][opc]==c2)break;}if(opTable[opr][opc]!=' ') //表示存在多种关系不满足条件{if(opTable[opr][opc]!='='){cout<<"不是算符优先文法!"<<endl;return false;}}else{opTable[opr][opc]='=';}}//if}//for(j)}//for(i)for(i=0;i<sen_len;i++) //找小于关系{for(j=3;sen[i][j]!='\0';j++){if(TerminalJud(sen[i][j])==true&&TerminalJud(sen[i][j+1])==false){c1=sen[i][j]; //c1记录终结符c2=sen[i][j+1]; //c2记录非终结符for(opr=1;opr<term_len+1;opr++) //在opTable表中找到该存入的行标opr{if(opTable[opr][0]==c1)break;}for(opc=0;opc<first_len;opc++) //找出非终结符在first表中的列标opc {if(first[opc][0]==c2)break;for(i2=1;first[opc][i2]!='\0';i2++){c3=first[opc][i2];for(i3=1;i3<term_len+1;i3++)if(opTable[0][i3]==c3){if(opTable[opr][i3]!=' '){if(opTable[opr][i3]!='<'){cout<<"不是算符优先文法!"<<endl;return false;}}else{opTable[opr][i3]='<';}break;}}}}}for(i=0;i<sen_len;i++) //找大于关系{for(j=3;sen[i][j]!='\0';j++){if(TerminalJud(sen[i][j])==false&&sen[i][j+1]!='\0'&&TerminalJud(sen[i][j +1])==true){c1=sen[i][j]; //c1记录非终结符c2=sen[i][j+1]; //c2记录终结符for(opr=1;opr<term_len+1;opr++) //在opTable表中找到该存入的列标j1{if(opTable[0][opr]==c2)break;for(opc=0;opc<first_len;opc++) //找出非终结符在last表中的行标j2 {if(last[opc][0]==c1)break;}for(i2=1;last[opc][i2]!='\0';i2++){c3=last[opc][i2];for(i3=1;i3<term_len+1;i3++)if(opTable[i3][0]==c3){if(opTable[i3][opr]!=' '){if(opTable[i3][opr]!='>'){cout<<"不是算符优先文法!"<<endl;return false;}}else{opTable[i3][opr]='>';}break;}}}}}opTable_len=term_len+1;return true;}//判断两算符优先关系并给出类型供构造分析表int RelationshipJud(char c1,char c2,char opTable[][col],int opTable_len) {int i,j;for(i=1;i<opTable_len;i++){if(opTable[i][0]==c1)break;}for(j=1;j<opTable_len;j++){if(opTable[0][j]==c2)break;}if(opTable[i][j]=='<')return 1;else if(opTable[i][j]=='=')return 2;else if(opTable[i][j]=='>')return 3;else return 4;}//判断输入串是不是优先文法bool PrioGramJud(char sen[][col],int sen_len){int i,j;for(i=0;i<sen_len;i++){for(j=4;sen[i][j]!='\0';j++)//gfhgfhggggggggggggggggggggggggggggggggg ggggggggggggggggggg{if(TerminalJud(sen[i][j-1])==false&&TerminalJud(sen[i][j])==false){cout<<"输入的不是算符文法!"<<endl;return false;}}}return true;}//开始分析输入串void InputAnalyse(char opTable[][col],char string[col],intopTable_len) //opTable_len是opTable表的长度{char a,Q,S[SIZE]={'\0'}; //S是分析栈char cho1,cho2;int i,j,relation;int k=0;S[k]='#';cho2='y';cout<<"\t\t\t\t分析过程如下:"<<endl;cout<<"-----------------------------------------------------------------------------"<<endl;//cout<<" 栈\t当前字符\t优先关系\t移进或规约"<<endl;//cout<<"分析过程如下:"<<endl;cout.width(10);cout<<"栈";cout.width(15);cout<<"当前字符";cout.width(20);cout<<"剩余符号串";cout.width(15);cout<<"优先关系";cout.width(15);cout<<"移进或规约"<<endl;char* p;p=string;p++;for(i=0;string[i]!='\0'&&cho2=='y';i++,p++){a=string[i]; //读入当前字符cho1='n'; //可否接受while(cho1=='n'){if(TerminalJud(S[k])==true) j=k; //规约使栈内有非终结符else j=k-1;relation=RelationshipJud(S[j],a,opTable,opTable_len);if(relation==3) //S[j]>a{//cout<<" "<<S<<"\t"<<" "<<a<<"\t\t >\t\t";cout.setf(ios::left);cout.width(10);cout<<S;cout.unsetf(ios::left);cout.width(15);cout<<a;cout.width(20);cout<<p;cout.width(15);cout<<">";do{Q=S[j];if(TerminalJud(S[j-1])==true) j=j-1;else j=j-2;}while(RelationshipJud(S[j],Q,opTable,opTable_len)!=1);//cout<<" "<<S[j]<<"归约"<<endl;cout.width(11);cout<<S[j];cout.width(4);cout<<"归约"<<endl;k=j+1;S[k]='N';for(int l=k+1;l<SIZE;l++){S[l]='\0';}}else if(relation==1) //S[j]<a{cho1='y';//cout<<" "<<S<<"\t"<<" "<<a<<"\t\t <\t\t 移进"<<endl;cout.setf(ios::left);cout.width(10);cout<<S;cout.unsetf(ios::left);cout.width(15);cout<<a;cout.width(20);cout<<p;cout.width(15);cout<<"<";cout.width(15);cout<<"移进"<<endl;k=k+1;S[k]=a;}else if(relation==2) //S[j]=a{cho1='y';//cout<<" "<<S<<"\t"<<" "<<a<<"\t\t =\t\t";cout.setf(ios::left);cout.width(10);cout<<S;cout.unsetf(ios::left);cout.width(15);cout<<a;cout.width(20);cout<<p;cout.width(15);cout<<"=";cout.width(15);if(RelationshipJud(S[j],'#',opTable,opTable_len)==2) {cout<<" 接受"<<endl;break;}else{cout<<" 移进"<<endl;k=k+1;S[k]=a;}}else{cho1='y';//cout<<" "<<S<<"\t"<<a<<"\t\t出错"<<endl;cout<<S<<" "<<a<<" 出错"<<endl;cout<<"对不起!字符串有错!"<<endl;cho2='n';break;}}//while}//for}//int main(){char choice='y';while(choice=='y'){system("cls");charsen[row][col]={'\0'},first[row][col]={'\0'},last[row][col]={'\0'},opTable[row ][col]={'\0'};char string[col];int i,k,p,q;p=readfile(sen);if(PrioGramJud(sen,p)==true){ItemInit(sen,first,last,p,q); //j记录FIRSTVT和LASTVT表的长度FirstVt(sen,first,p,q);cout<<"\t\t各非终结符FIRSTVT集"<<endl;cout<<"------------------------------------------------"<<endl;for(i=0;i<p;i++){for(int h=0;h<col;h++)cout<<first[i][h]<<" ";cout<<endl;}// cout<<endl;LastVt(sen,last,p,q);cout<<"\t\t各非终结符LASTVT集"<<endl;cout<<"-------------------------------------------------"<<endl;for(i=0;i<p;i++){for(int h=0;h<col;h++)cout<<last[i][h]<<" ";cout<<endl;}// cout<<endl;int flag=0 ,j;if(OpPriotable(sen,first,last,opTable,p,q,k)==true) //k记录opTable表的长度{for(i=1;i<=k;i++){flag=0;for(j=0;j<p;j++){for(int h=0;h<col;h++){if(last[j][h]==opTable[i][0]){opTable[i][k]='>';flag=1;break;}}if(flag=1) break;}}for(i=1;i<=k;i++){flag=0;for(j=0;j<p;j++){for(int h=0;h<=col;h++){if(first[j][h]==opTable[0][i]){opTable[k][i]='<';flag=1;break;}}if(flag=1) break;}}opTable[k][k]='=';cout<<"\t\t优先关系表:"<<endl;cout<<"----------------------------------------------"<<endl;for(i=0;i<=k;i++){for(int h=0;h<=k;h++)cout<<opTable[i][h]<<" ";cout<<endl;}// cout<<endl;cout<<"请输入要分析的串,以$结束:"<<endl;cin>>string;InputAnalyse(opTable,string,k); //k是opTable表的长度}}cout<<"是否继续?y/n"<<endl;cin>>choice;}system("pause");}。