计量经济学课后习题
计量经济学(庞浩)第二版课后习题答案

2.7 设销售收入X 为解释变量,销售成本Y 为被解释变量。
现已根据某百货公司某年12个月的有关资料计算出以下数据:(单位:万元) 2()425053.73tXX -=∑ 647.88X = 2()262855.25tY Y -=∑ 549.8Y =()()334229.09tt XX Y Y --=∑(1) 拟合简单线性回归方程,并对方程中回归系数的经济意义作出解释。
(2) 计算可决系数和回归估计的标准误差。
(3) 对2β进行显著水平为5%的显著性检验。
(4) 假定下年1月销售收入为800万元,利用拟合的回归方程预测其销售成本,并给出置信度为95%的预测区间。
练习题2.7参考解答:(1)建立回归模型: i i i u X Y ++=21ββ用OLS 法估计参数: 222()()334229.09ˆ0.7863()425053.73i i i i i iX X Y Y x y X X x β--====-∑∑∑∑ 12ˆˆ549.80.7863647.8866.2872Y X ββ=-=-⨯= 估计结果为: ˆ66.28720.7863i iY X =+ 说明该百货公司销售收入每增加1元,平均说来销售成本将增加0.7863元。
(2)计算可决系数和回归估计的标准误差 可决系数为:22222222222ˆˆˆ()0.7863425053.73262796.990.999778262855.25262855.25i i iiiiy x x Ry yyββ===⨯===∑∑∑∑∑∑由 2221i ie ry=-∑∑ 可得222(1)i i e R y =-∑∑222(1)(10.999778)262855.2558.3539ii eR y =-=-⨯=∑∑回归估计的标准误差: ˆ 2.4157σ===(3) 对2β进行显著水平为5%的显著性检验*222^^22ˆˆ~(2)ˆˆ()()t t n SE SE βββββ-==-^22.4157ˆ()0.0037651.9614SE β====*2^2ˆ0.7863212.51350.0037ˆ()t SE ββ===查表得 0.05α=时,0.025(122) 2.228t -=<*212.5135t = 表明2β显著不为0,销售收入对销售成本有显著影响.(4) 假定下年1月销售收入为800万元,利用拟合的回归方程预测其销售成本,并给出置信度为95%的预测区间。
计量经济学第二版课后习题1-14章中文版答案汇总

第四章习题 1.(1)22ˆ=TSR estScore T =520.4-5.82×22=392.36 (2)ΔTestScore=-5.82×(23-19)=-23.28即平均测试成绩所减少的分数回归预测值为23.28。
(3)core est S T =βˆ0 +βˆ1×CS =520.4-5.82×1.4=395.85 (4)SER 2=∑=-n i u n 1ˆ21i 2=11.5 ∴SSR=∑=ni u1ˆi2=SER 2×(n-2)=11.5×(100-2)=12960.5R 2=T SS ESS =1-T SSSSR =0.08∴TSS=SSR ÷(1-R 2)=12960.5÷(1-0.08)=14087.5=21)(Y ∑=-ni iY∴s Y 2=1-n 121)(Y ∑=-ni iY =14087.5÷(100-1)≈140.30∴s Y ≈11.93 2. (1)①70ˆ=Height eight W =-99.41+3.94×70=176.39 ②65ˆ=Height eight W =-99.41+3.94×65=156.69 ③74ˆ=Height eight W=-99.41+3.94×74=192.15(2)ΔWeight=3.94×1.5=5.91(3)1inch=2.54cm,1lb=0.4536kg①eight Wˆ(kg)=-99.41×0.4536+54.24536.0×94.3Height(cm)=-45.092+0.7036×Height(cm)②R 2无量纲,与计量单位无关,所以仍为0.81③SER=10.2×0.4536=4.6267kg 3.(1)①系数696.7为回归截距,决定回归线的总体水平②系数9.6为回归系数,体现年龄对周收入的影响程度,每增加1岁周收入平均增加$9.6 (2)SER=624.1美元,其度量单位为美元。
计量经济学(庞皓_第二版)课后习题及答案
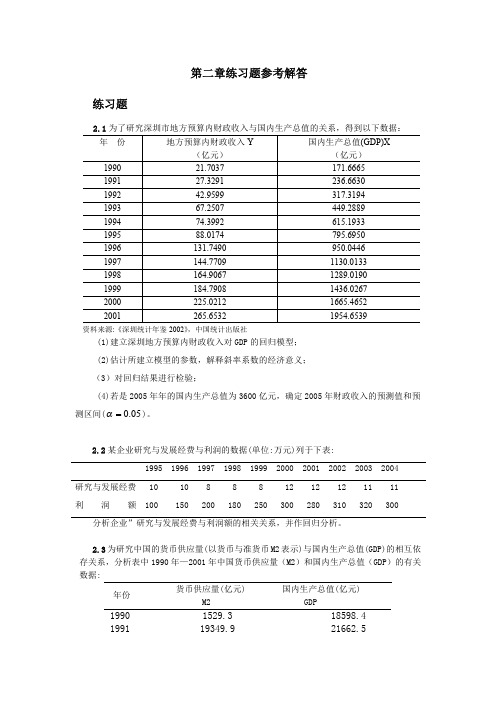
76.6
0.85
美国(US Airways)航空公司
75.7
0.68
联合(United)航空公司
73.8
0.74
美洲(American)航空公司
72.2
0.93
德尔塔(Delta)航空公司
71.2
0.72
美国西部(Americawest)航空公司
70.8
1.22
1资料来源:(美)David R.Anderson 等《商务与经济统计》,第 405 页,机械工业出版社
2 i
=
3134543
XiYi = 1296836
∑Yi2 = 539512
(1)作销售额对价格的回归分析,并解释其结果。 (2)回归直线未解释的销售变差部分是多少?
2.9 表中是中国 1978 年-1997 年的财政收入 Y 和国内生产总值 X 的数据:
中国国内生产总值及财政收入
单位:亿元
年份பைடு நூலகம்
国内生产总值 X
测区间(α = 0.05 )。
练习题参考解答
练习题 2.1 参考解答 1、建立深圳地方预算内财政收入对 GDP 的回归模型,建立 EViews 文件,利用地方预 算内财政收入(Y)和 GDP 的数据表,作散点图
可看出地方预算内财政收入(Y)和 GDP 的关系近似直线关系,可建立线性回归模型:
Yt = β1 + β 2GDPt + ut
取α = 0.05 , Yf 平均值置信度 95%的预测区间为:
∑ ^
^
Yf m tα 2 σ
1 n
+
(X f
− X )2 xi2
GDP2005 = 3600 时
计量经济学课后习题答案

计量经济学课后习题答案业产值C 某年某地区20个乡镇工业产值的合计数D 某年某地区20个乡镇各镇工业产值⒋同一统计指标按时间顺序记录的数据列称为【 B 】A 横截面数据B 时间序列数据C 修匀数据D原始数据⒌回归分析中定义【 B 】A 解释变量和被解释变量都是随机变量B 解释变量为非随机变量,被解释变量为随机变量C 解释变量和被解释变量都是非随机变量D 解释变量为随机变量,被解释变量为非随机变量二、填空题⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。
⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。
计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。
⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。
⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒等关系。
三、简答题⒈什么是计量经济学?它与统计学的关系是怎样的?计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。
计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。
计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。
可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。
例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。
反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。
计量经济学 课后练习题答案解析
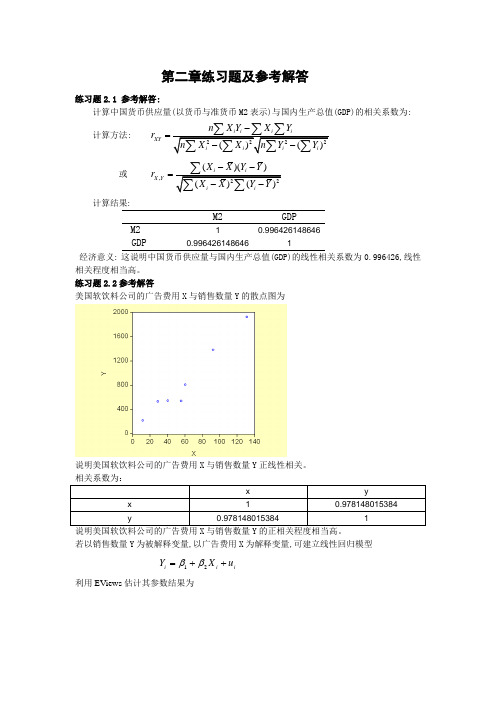
第二章练习题及参考解答练习题2.1 参考解答:计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为:计算方法: XY n X Y X Y r -=或,()()X Y X X Y Y r --=计算结果:M2GDPM2 10.996426148646GDP0.9964261486461经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性相关程度相当高。
练习题2.2参考解答美国软饮料公司的广告费用X 与销售数量Y 的散点图为说明美国软饮料公司的广告费用X 与销售数量Y 正线性相关。
相关系数为:说明美国软饮料公司的广告费用X 与销售数量Y 的正相关程度相当高。
若以销售数量Y 为被解释变量,以广告费用X 为解释变量,可建立线性回归模型 i i i u X Y ++=21ββ 利用EViews 估计其参数结果为经t 检验表明, 广告费用X 对美国软饮料公司的销售数量Y 确有显著影响。
回归结果表明,广告费用X 每增加1百万美元, 平均说来软饮料公司的销售数量将增加14.40359(百万箱)。
练习题2.3参考解答:1、 建立深圳地方预算内财政收入对GDP 的回归模型,建立EViews 文件,利用地方预算内财政收入(Y )和GDP 的数据表,作散点图可看出地方预算内财政收入(Y )和GDP 的关系近似直线关系,可建立线性回归模型: t t t u GDP Y ++=21ββ 利用EViews 估计其参数结果为即 ˆ20.46110.0850t tY GDP =+ (9.8674) (0.0033)t=(2.0736) (26.1038) R 2=0.9771 F=681.4064经检验说明,深圳市的GDP 对地方财政收入确有显著影响。
20.9771R =,说明GDP 解释了地方财政收入变动的近98%,模型拟合程度较好。
模型说明当GDP 每增长1亿元时,平均说来地方财政收入将增长0.0850亿元。
李子奈计量经济学课后习题解答

(一)基本知识类题型 1-1. 什么是计量经济学? 1-2. 简述当代计量经济学发展的动向。 1-3. 计量经济学方法与一般经济数学方法有什么区别? 1-4.为什么说计量经济学是经济理论、数学和经济统计学的结合?试述三者之关系。 1-5.为什么说计量经济学是一门经济学科?它在经济学科体系中的作用和地位是什么? 1-6.计量经济学的研究的对象和内容是什么?计量经济学模型研究的经济关系有哪两个基 本特征? 1-7.试结合一个具体经济问题说明建立与应用计量经济学模型的主要步骤。 1-8.建立计量经济学模型的基本思想是什么? 1-9.计量经济学模型主要有哪些应用领域?各自的原理是什么? 1-10.试分别举出五个时间序列数据和横截面数据,并说明时间序列数据和横截面数据有和 异同? 1-11.试解释单方程模型和联立方程模型的概念,并举例说明两者之间的联系与区别。 1-12.模型的检验包括几个方面?其具体含义是什么? 1-13.常用的样本数据有哪些? 1-14.计量经济模型中为何要包括随机误差项?简述随机误差项形成的原因。 1-15.估计量和估计值有何区别?哪些类型的关系式不存在估计问题? 1-16.经济数据在计量经济分析中的作用是什么? 1-17.下列假想模型是否属于揭示因果关系的计量经济学模型?为什么?
3ห้องสมุดไป่ตู้
答:计量经济学的研究对象是经济现象,是研究经济现象中的具体数量规律(或者说,计量 经济学是利用数学方法, 根据统计测定的经济数据, 对反映经济现象本质的经济数量关系进 行研究) 。计量经济学的内容大致包括两个方面:一是方法论,即计量经济学方法或理论计 量经济学;二是应用,即应用计量经济学;无论是理论计量经济学还是应用计量经济学,都 包括理论、方法和数据三种要素。 计量经济学模型研究的经济关系有两个基本特征:一是随机关系;二是因果关系。 1-7.答: 1-8.答:计量经济学方法,就是定量分析经济现象中各因素之间的因果关系。所以,第一 步, 要根据经济理论分析所研究的经济现象, 找出经济现象之间的因果关系及相互间的联系, 把问题作为被解释变量,把影响问题的主要因素作为解释变量,把非主要因素归入随机项; 第二步, 要按照它们之间的行为关系选择适当的数学形式描述这些变量之间的关系, 一般是 用一组数学上彼此独立、互不矛盾、完整有解的方程组表示。在建立理论模型的时,要求理 论模型在参数估计、模型检验的过程中不断得到修正,以便得到一个较好的、能够解释过去 的、反映客观经济规律的数学模型。此外,还可以通过散电图或模拟的方法,选择一个拟合 效果较好的数学模型。 1-9.答:计量经济学模型主要有以下几个方面的用途:①结构分析,即研究一个或几个经 济变量发生变化及结构参数的变动对其他变量以至整个经济系统产生何种的影响; 其原理是 弹性分析、乘数分析与比较静力分析。②经济预测,即用其进行中短期经济的因果预测;其 原理是模拟历史,从已经发生的经济活动中找出变化规律;③政策评价,即利用计量经济模 型定量分析政策变量变化对经济系统运行的影响,是对不同政策执行情况的“模拟仿真” 。 ④检验与发展经济理论, 即利用计量经济模型和实际统计资料实证分析某个理论假说的正确 与否;其原理是如果按照某种经济理论建立的计量经济模型可以很好地拟合实际观察数据, 则意味着该理论是符合客观事实的,否则则表明该理论不能说明客观事实。 1-10.答:时间序列数据的例子如:改革开放以来 25 年中的 GDP、居民人均消费支出、人 均可支配收入、 零售物价指数、 固定资产投资等; 横截面数据的例子如: 2003 年各省的 GDP、 该年各工业部门的销售额、 该年不同收入的城镇居民消费支出、 该年不同城镇居民的可支配 收入、该年各省的固定资产投资等。这两类数据都是反映经济规律的经济现象的数量信息, 不同点:时间序列数据是含义、口径相同的同一指标按时间先后排列的统计数据列;而横截 面数据是一批发生在同一时间截面上不同统计单元的相同统计指标组成的数据列。 1-11.答:如果模型系统只包含一个方程,即只研究单一的经济活动过程,揭示其因素之间
计量经济学课后习题答案

计量经济学练习题第一章导论一、单项选择题⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】A 总量数据B 横截面数据C平均数据 D 相对数据⒉横截面数据是指【A 】A 同一时点上不同统计单位相同统计指标组成的数据B 同一时点上相同统计单位相同统计指标组成的数据C 同一时点上相同统计单位不同统计指标组成的数据D 同一时点上不同统计单位不同统计指标组成的数据⒊下面属于截面数据的是【D 】A 1991-2003年各年某地区20个乡镇的平均工业产值B 1991-2003年各年某地区20个乡镇的各镇工业产值C 某年某地区20个乡镇工业产值的合计数D 某年某地区20个乡镇各镇工业产值⒋同一统计指标按时间顺序记录的数据列称为【B 】A 横截面数据B 时间序列数据C 修匀数据D原始数据⒌回归分析中定义【 B 】A 解释变量和被解释变量都是随机变量B 解释变量为非随机变量,被解释变量为随机变量C 解释变量和被解释变量都是非随机变量D 解释变量为随机变量,被解释变量为非随机变量二、填空题⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。
⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。
计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。
⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。
⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒等关系。
三、简答题⒈什么是计量经济学?它与统计学的关系是怎样的?计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。
计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。
《计量经济学教程(第二版)》习题解答课后习题答案

《计量经济学(第二版)》习题解答第一章1.1 计量经济学的研究任务是什么?计量经济模型研究的经济关系有哪两个基本特征? 答:(1)利用计量经济模型定量分析经济变量之间的随机因果关系。
(2)随机关系、因果关系。
1.2 试述计量经济学与经济学和统计学的关系。
答:(1)计量经济学与经济学:经济学为计量经济研究提供理论依据,计量经济学是对经济理论的具体应用,同时可以实证和发展经济理论。
(2)统计数据是建立和评价计量经济模型的事实依据,计量经济研究是对统计数据资源的深层开发和利用。
1.3 试分别举出三个时间序列数据和横截面数据。
1.4 试解释单方程模型和联立方程模型的概念,并举例说明两者之间的联系与区别。
1.5 试结合一个具体经济问题说明计量经济研究的步骤。
1.6 计量经济模型主要有哪些用途?试举例说明。
1.7 下列设定的计量经济模型是否合理,为什么?(1)ε++=∑=31i iiGDP b a GDPε++=3bGDP a GDP其中,GDP i (i =1,2,3)是第i 产业的国内生产总值。
答:第1个方程是一个统计定义方程,不是随机方程;第2个方程是一个相关关系,而不是因果关系,因为不能用分量来解释总量的变化。
(2)ε++=21bS a S其中,S 1、S 2分别为农村居民和城镇居民年末储蓄存款余额。
答:是一个相关关系,而不是因果关系。
(3)ε+++=t t t L b I b a Y 21其中,Y 、I 、L 分别是建筑业产值、建筑业固定资产投资和职工人数。
答:解释变量I 不合理,根据生产函数要求,资本变量应该是总资本,而固定资产投资只能反映当年的新增资本。
(4)ε++=t t bP a Y其中,Y 、P 分别是居民耐用消费品支出和耐用消费品物价指数。
答:模型设定中缺失了对居民耐用消费品支出有重要影响的其他解释变量。
按照所设定的模型,实际上假定这些其他变量的影响是一个常量,居民耐用消费品支出主要取决于耐用消费品价格的变化;所以,模型的经济意义不合理,估计参数时可能会夸大价格因素的影响。
计量经济学课后习题1-8章

计量经济学课后习题1-8章计量经济学课后习题总结第一章绪论1、什么事计量经济学?计量经济学就是把经济理论、经济统计数据和数理统计学与其他数学方法相结合,通过建立经济计量模型来研究经济变量之间相互关系及其演变的规律的一门学科。
2、计量经济学的研究方法有那几个步骤?(1)建立模型:包括模型中变量的选取及模型函数形式的确定。
(2)模型参数的估计:通过搜集相关是数据,采用不同的参数估计方法,进行模型参数估计。
(3)模型参数的检验:包括经济检验、以及统计学方面的检验。
(4)经济计量模型的应用:经济预测、经济结构分析、经济政策评价。
3、经济计量模型有哪些特点?经济计量模型是一个代数的、随即的数学模型,它可以是线性或非线性(对参数而言)形式。
4、经济计量模型中的数据有哪几种类型(1)定量数据:时间序列数据、截面数据、面板数据(2)定型数据:虚拟变量数据第二章一元线性回归模型1、什么是相关关系?它有那几种类型?(书上没有确切的答案)(1)相关关系:当一个或几个相互联系的变量取一定的数值时,与之相对应的另一变量的值虽然不确定,但它仍按某种规律在一定的范围内变化。
变量间的这种相互关系,称为具有不确定性的相关关系(2)相关关系的种类1.按相关程度分类:(1)完全相关:一种现象的数量变化完全由另一种现象的数量变化所确定。
在这种情况下,相关关系便称为函数关系,因此也可以说函数关系是相关关系的一个特例。
(2)不完全相关:两个现象之间的关系介于完全相关和不相关之间(3)不相关:两个现象彼此互不影响,其数量变化各自独立2.按相关的方向分类:(1)正相关:两个现象的变化方向相同(2)负相关:两个现象的变化方向相反3.按相关的形式分类(1)线性相关:两种相关现象之间的关系大致呈现为线性关系(2)非线性相关:两种相关现象之间的关系并不表现为直线关系,而是近似于某种曲线方程的关系4.按相关关系涉及的变量数目分类(1)单相关:两个变量之间的相关关系,即一个因变量与一个自变量之间的依存关系(2)复相关:多个变量之间的相关关系,即一个因变量与多个自变量的复杂依存关系(3)偏相关:当研究因变量与两个或多个自变量相关时,如果把其余的自变量看成不变(即当作常量),只研究因变量与其中一个自变量之间的相关关系,就称为偏相关。
计量经济学(庞皓)_课后习题答案
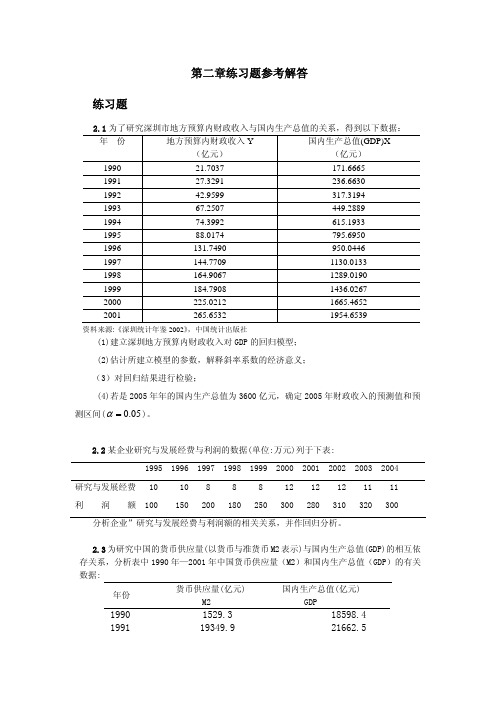
Yf 个别值置信度 95%的预测区间为:
∑ ^
^
Yf m tα 2 σ
1+
1 n
+
(X f
− X )2 xi2
即
480.884 m 2.228× 7.5325×
1+ 1 + 7195337.357 12 3293728.494
= 480.884 m 30.3381 (亿元)
练习题 2.3 参考解答 计算中国货币供应量(以货币与准货币 M2 表示)与国内生产总值(GDP)的相关系数为
列1
列2
列1
1
列 2 0.979213
1
这说明中国货币供应量与国内生产总值(GDP)的先行相关系数为 0.979213,线性相关程度
比较高。
练习题 2.5 参考解答 美国各航空公司航班正点到达比率和每 10 万名乘客投诉次数的散点图为
由图形看出航班正点到达比率和每 10 万名乘客投诉次数呈现负相关关系,计算线性相关系数 为-0.882607。
1.60
16
11.33
根据上表资料:
红利(元) 0.80 1.94 3.00 0.28 0.84 1.80 1.21 1.07
(1)建立每股帐面价值和当年红利的回归方程;
(2)解释回归系数的经济意义;
(3)若序号为 6 的公司的股票每股帐面价值增加 1 元,估计当年红利可能为多少?
2.5 美国各航空公司业绩的统计数据公布在《华尔街日报 1999 年年鉴》(The Wall Street
449.2889
1994
74.3992
615.1933
1995
88.0174
795.6950
《计量经济学》第三版课后题答案李子奈

封面作者:Pan Hongliang仅供个人学习第一章绪论参考重点:计量经济学的一般建模过程第一章课后题(1.4.5)1.什么是计量经济学?计量经济学方法与一般经济数学方法有什么区别?答:计量经济学是经济学的一个分支学科,是以揭示经济活动中客观存在的数量关系为内容的分支学科,是由经济学、统计学和数学三者结合而成的交叉学科。
计量经济学方法揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。
4.建立与应用计量经济学模型的主要步骤有哪些?答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和—致性;(3)估计模型参数;(4)检验模型,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。
5.模型的检验包括几个方面?其具体含义是什么?答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。
在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型的预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。
第二章经典单方程计量经济学模型:一元线性回归模型参考重点:1.相关分析与回归分析的概念、联系以及区别?2.总体随机项与样本随机项的区别与联系?3.为什么需要进行拟合优度检验?4.如何缩小置信区间?(P46)由上式可以看出(1).增大样本容量。
(新)计量经济学课后习题答案汇总

计量经济学练习题第一章导论一、单项选择题⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】A 总量数据B 横截面数据C平均数据 D 相对数据⒉横截面数据是指【A 】A 同一时点上不同统计单位相同统计指标组成的数据B 同一时点上相同统计单位相同统计指标组成的数据C 同一时点上相同统计单位不同统计指标组成的数据D 同一时点上不同统计单位不同统计指标组成的数据⒊下面属于截面数据的是【D 】A 1991-2003年各年某地区20个乡镇的平均工业产值B 1991-2003年各年某地区20个乡镇的各镇工业产值C 某年某地区20个乡镇工业产值的合计数D 某年某地区20个乡镇各镇工业产值⒋同一统计指标按时间顺序记录的数据列称为【B 】A 横截面数据B 时间序列数据C 修匀数据D原始数据⒌回归分析中定义【 B 】A 解释变量和被解释变量都是随机变量B 解释变量为非随机变量,被解释变量为随机变量C 解释变量和被解释变量都是非随机变量D 解释变量为随机变量,被解释变量为非随机变量二、填空题⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。
⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分析三大支柱。
⒊经典计量经济学的最基本方法是回归分析。
计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。
⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。
⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒等关系。
三、简答题⒈什么是计量经济学?它与统计学的关系是怎样的?计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。
计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。
计量经济学课后习题

计量经济学课后习题第二章――第12题作者:黎敏题目――下表是中国内地2007年各地区税收Y和国内生产总值GDP的统计资料。
单位:亿元地区Y GDP地区Y GDP北京1435.79353.3湖北4349230.7天津438.45050.4湖南410.79200河北618.313709.5广东2415.531084.4山西430.55733.4广西282.75955.7内蒙古347.96091.1海南881223.3辽宁815.711023.5重庆294.54122.5吉林237.45284.7四川62910505.3黑龙江3357065贵州211.92741.9上海1975.512188.9云南378.64741.3江苏1894.825741.2西藏11.7342.2浙江1535.418780.4陕西355.55465.8安徽401.97364.2甘肃142.12702.4福建5949249.1青海43.3783.6江西281.95500.3宁夏58.8889.2山东1308.425965.9新疆220.63523.2河南62515012.5要求:以手工和运用Eviews软件(或其他软件);(1)作出散点图,建立税收随国内生产总值GDP变化的亿元线性回归方程,并解释斜率的经济意义;(2)对所建立的回归方程进行检验;(3)若2008年某地区国内生产总值为8500亿元,求该地区税收收入的预测值及预测区间。
解答(1)散点图如图所示:模型建立我们假设拟建立如下回归模型:根据Eviews 软件对表中数据进行回归分析的计算结果可得:斜率的经济意义:国内生产总值GDP 每增加1亿元,国内税收增加0.071亿元。
μββ++=P 10GD Y ()()91.99F 0.760359.90.120.071GDP0.6312==+=R Y i --(2)进行模型检验:从回归估计的结果看,模型拟合较好。
,表明国内税收变化76.03%可由国内生产总值GDP 的变化来解释。
计量经济学(庞皓)_课后习题答案
Yˆ2005 = −3.611151 + 0.134582 × 3600 = 480.884 (亿元)
区间预测:
∑ 平均值为:
xi2
=
σ
2 x
(n
−1)
=
587.26862
× (12
−1)
=
3793728.494
( X f 1 − X )2 = (3600 − 917.5874)2 = 7195337.357
1.138
18
2.98
1.092
试建立曲线回归方程 yˆ = a ebx ( Yˆ = ln a + b x )并进行计量分析。
2.7 为研究美国软饮料公司的广告费用 X 与销售数量 Y 的关系,分析七种主要品牌软饮
料公司的有关数据2(见表 8-1)
表 8-1
美国软饮料公司广告费用与销售数量
品牌名称
449.2889
1994
74.3992
615.1933
1995
88.0174
795.6950
1996
131.7490
950.0446
1997
144.7709
1130.0133
1998
164.9067
1289.0190
1999
184.7908
1436.0267
2000
225.0212
1665.4652
2 i
=
3134543
∑Yi2 = 539512
(1)作销售额对价格的回归分析,并解释其结果。 (2)回归直线未解释的销售变差部分是多少?
∑ XiYi = 1296836
2.9 表中是中国 1978 年-1997 年的财政收入 Y 和国内生产总值 X 的数据:
计量经济学习题及全部答案

计量经济学习题及全部答案Newly compiled on November 23, 2020《计量经济学》习题(一)一、判断正误1.在研究经济变量之间的非确定性关系时,回归分析是唯一可用的分析方法。
( ) 2.最小二乘法进行参数估计的基本原理是使残差平方和最小。
( )3.无论回归模型中包括多少个解释变量,总离差平方和的自由度总为(n -1)。
( ) 4.当我们说估计的回归系数在统计上是显着的,意思是说它显着地异于0。
( ) 5.总离差平方和(TSS )可分解为残差平方和(ESS )与回归平方和(RSS )之和,其中残差平方和(ESS )表示总离差平方和中可由样本回归直线解释的部分。
( ) 6.多元线性回归模型的F 检验和t 检验是一致的。
( )7.当存在严重的多重共线性时,普通最小二乘估计往往会低估参数估计量的方差。
( )8.如果随机误差项的方差随解释变量变化而变化,则线性回归模型存在随机误差项的自相关。
( )9.在存在异方差的情况下,会对回归模型的正确建立和统计推断带来严重后果。
( ) 10...DW 检验只能检验一阶自相关。
( ) 二、单选题1.样本回归函数(方程)的表达式为( )。
A .i Y =01i i X u ββ++B .(/)i E Y X =01i X ββ+C .i Y =01ˆˆi i X e ββ++D .ˆi Y =01ˆˆi X ββ+ 2.下图中“{”所指的距离是( )。
A .随机干扰项B .残差C .i Y 的离差D .ˆi Y 的离差 3.在总体回归方程(/)E Y X =01X ββ+中,1β表示( )。
A .当X 增加一个单位时,Y 增加1β个单位B .当X 增加一个单位时,Y 平均增加1β个单位C .当Y 增加一个单位时,X 增加1β个单位D .当Y 增加一个单位时,X 平均增加1β个单位 4.可决系数2R 是指( )。
A .剩余平方和占总离差平方和的比重B .总离差平方和占回归平方和的比重C .回归平方和占总离差平方和的比重D .回归平方和占剩余平方和的比重 5.已知含有截距项的三元线性回归模型估计的残差平方和为2i e ∑=800,估计用的样本容量为24,则随机误差项i u 的方差估计量为( )。
计量经济学第三版-课后习题答案

计量经济学第三版-课后习题答案*************************************************************** ******************************************************************* ********************??第一章绪论(一)基本知识类题型1-1.什么是计量经济学?1-3.计量经济学方法与一般经济数学方法有什么区别?它在经济学科体系中的作用和地位是什么?1-6.计量经济学的研究的对象和内容是什么?计量经济学模型研究的经济关系有哪两个基本特征?1-7.试结合一个具体经济问题说明建立与应用计量经济学模型的主要步骤。
1-9.计量经济学模型主要有哪些应用领域?各自的原理是什么?1-12.模型的检验包括几个方面?其具体含义是什么?1-17.下列假想模型是否属于揭示因果关系的计量经济学模型?为什么?⑴ S t=112.0+0.12R t其中S t为第t年农村居民储蓄增加额(亿元)、R t为第t年城镇居民可支配收入总额(亿元)。
⑵ S t-1=4432.0+0.30R t其中S t-1为第(t-1)年底农村居民储蓄余额(亿元)、R t为第t年农村居民纯收入总额(亿元)。
1-18.指出下列假想模型中的错误,并说明理由:(1)RS t=8300.0-0.24RI t+112.IV t其中,RS t为第t年社会消费品零售总额(亿元),RI t为第t年居民收入总额(亿元)(城镇居民可支配收入总额与农村居民纯收入总额之和),IV t为第t年全社会固定资产投资总额1(亿元)。
(2)C t=180+1.2Y t其中,C、Y分别是城镇居民消费支出和可支配收入。
(3)ln Y t=1.15+1.62 ln K t-0.28ln L t其中,Y、K、L分别是工业总产值、工业生产资金和职工人数。
1-19.下列假想的计量经济模型是否合理,为什么?(1)GDP=α+∑βi GDP i+ε其中,GDP i(i=1,2,3)是第i产业的国内生产总值。
计量经济学(数字教材版)课后习题参考答案

课后习题参考答案第二章教材习题与解析1、 判断下列表达式是否正确:y i =β0+β1x i ,i =1,2,⋯ny ̂i =β̂0+β̂1x i ,i =1,2,⋯nE(y i |x i )=β0+β1x i +u i ,i =1,2,⋯n E(y i |x i )=β0+β1x i ,i =1,2,⋯nE(y i |x i )=β̂0+β̂1x i ,i =1,2,⋯ny i =β0+β1x i +u i ,i =1,2,⋯ny ̂i =β̂0+β̂1x i +u i ,i =1,2,⋯n y i =β̂0+β̂1x i +u i ,i =1,2,⋯n y i =β̂0+β̂1x i +u ̂i ,i =1,2,⋯n y ̂i =β̂0+β̂1x i +u ̂i ,i =1,2,⋯n答案:对于计量经济学模型有两种类型,一是总体回归模型,另一是样本回归模型。
两类回归模型都具有确定形式与随机形式两种表达方式:总体回归模型的确定形式:X X Y E 10)|(ββ+= 总体回归模型的随机形式:μββ++=X Y 10样本回归模型的确定形式:X Y 10ˆˆˆββ+= 样本回归模型的随机形式:e X Y ++=10ˆˆββ 除此之外,其他的表达形式均是错误的2、给定一元线性回归模型:y =β0+β1x +u (1)叙述模型的基本假定;(2)写出参数β0和β1的最小二乘估计公式;(3)说明满足基本假定的最小二乘估计量的统计性质; (4)写出随机扰动项方差的无偏估计公式。
答案:(1)线性回归模型的基本假设有两大类,一类是关于随机误差项的,包括零均值、同方差、不序列相关、满足正态分布等假设;另一类是关于解释变量的,主要是解释变量是非随机的,如果是随机变量,则与随机误差项不相关。
(2)12ˆi iix yxβ=∑∑,01ˆˆY X ββ=- (3)考察总体的估计量,可从如下几个方面考察其优劣性:1)线性性,即它是否是另一个随机变量的线性函数; 2)无偏性,即它的均值或期望是否等于总体的真实值;3)有效值,即它是否在所有线性无偏估计量中具有最小方差;4)渐进无偏性,即样本容量趋于无穷大时,它的均值序列是否趋于总体真值; 5)一致性,即样本容量趋于无穷大时,它是否依概率收敛于总体的真值;6)渐进有效性,即样本容量趋于无穷大时,它在所有的一致估计量中是否具有最小的渐进方差。
计量经济学课后习题答案

第一章1.计量经济学是一门什么样的学科?答:计量经济学的英文单词是Econometrics,本意是“经济计量”,研究经济问题的计量方法,因此有时也译为“经济计量学”。
将Econometrics译为“计量经济学”是为了强调它是现代经济学的一门分支学科,不仅要研究经济问题的计量方法,还要研究经济问题发展变化的数量规律。
可以认为,计量经济学是以经济理论为指导,以经济数据为依据,以数学、统计方法为手段,通过建立、估计、检验经济模型,揭示客观经济活动中存在的随机因果关系的一门应用经济学的分支学科。
2.计量经济学与经济理论、数学、统计学的联系和区别是什么?答:计量经济学是经济理论、数学、统计学的结合,是经济学、数学、统计学的交叉学科(或边缘学科)。
计量经济学与经济学、数学、统计学的联系主要是计量经济学对这些学科的应用。
计量经济学对经济学的应用主要体现在以下几个方面:第一,计量经济学模型的选择和确定,包括对变量和经济模型的选择,需要经济学理论提供依据和思路;第二,计量经济分析中对经济模型的修改和调整,如改变函数形式、增减变量等,需要有经济理论的指导和把握;第三,计量经济分析结果的解读和应用也需要经济理论提供基础、背景和思路。
计量经济学对统计学的应用,至少有两个重要方面:一是计量经济分析所采用的数据的收集与处理、参数的估计等,需要使用统计学的方法和技术来完成;一是参数估计值、模型的预测结果的可靠性,需要使用统计方法加以分析、判断。
计量经济学对数学的应用也是多方面的,首先,对非线性函数进行线性转化的方法和技巧,是数学在计量经济学中的应用;其次,任何的参数估计归根结底都是数学运算,较复杂的参数估计方法,或者较复杂的模型的参数估计,更需要相当的数学知识和数学运算能力,另外,在计量经济理论和方法的研究方面,需要用到许多的数学知识和原理。
计量经济学与经济学、数学、统计学的区别也很明显,经济学、数学、统计学中的任何一门学科,都不能替代计量经济学,这三门学科简单地合起来,也不能替代计量经济学。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
4.产生模型设定偏误的主要原因是什么?模型设定偏误的后果以及检验方法有哪些?
答:产生模型设定偏误的原因主要有:模型制定者不熟悉相应的理论知识;对经济问题本身认识不够或不熟悉前人的相关工作:模型制定者手头没有相关变量的数据;解释变量无法测量或数据本身存在测量误差。
模型设定偏误的后果有:(1)如果遗漏了重要的解释变量,会造成OLS估计量在小样本下有偏,在大样本下非一致;对随机干扰项的方差估计也是有偏的。(2)如果包含了无关的解释变量,尽管OLS估计量具有无偏性与一致性,但不具有最小方差性。(3)如果选择了错误的函数形式,则后果是全方位的,不但会造成估计的参数具有完全不同的经济意义,而且估计结果也不同。
1.为什么要建立联立方程计量经济学模型?联立方程计量经济学模型适用于什么样的经济现象?
答:经济现象是极为复杂的,其中诸因素之间的关系,在很多情况下,不是单一方程所能描述的那种简单的单向因果关系,而是相互依存,互为因果的,这时,就必须用联立的计量经济学方程才能描述清楚。
所以与单方程适用于单一经济现象的研究相比,联立方程计量经济学模型适用于描述复杂的经济现象,即经济系统。
在一元线性回归分析中,二者具有等价作用,因为二者都是对共同的假设——解释变量的参数等于零一一进行检验。
1.回归模型中引入虚拟变量的作用是什么?有哪几种基本的引入方式?它们各适合用于什么情况?
答:在模型中引入虚拟变量,主要是为了寻找某(些)定性因素对解释变量的影响。
加法方式与乘法方式是最主要的引入方式。
3.一元线性回归模型的基本假设主要有哪些?违背基本假设的模型是否不可以估计?
答:线性回归模型的基本假设有两大类:一类是关于随机干扰项的,包括零均值,同方差,不序列相关,满足正态分布等假设;另一类是关于解释变量的,主要有:解释变量是非随机的,若是随机变量,则与随机干扰项不相关。实际上,这些假设都是针对普通最小二乘法的。
用工具变量法估计的参数,一般情况下,在小样本下是有偏的,但在大样本下是渐近无偏的。如果选取的工具变量与方程随机干扰项完全不相关,那么其参数估计量是无偏估计量。对于间接最小二乘法,对简化式模型应用普通最小二乘法得到的参数估计量具有线性性、无偏性、有效性。通过多数关系体系计算得到结构方程的结构参数估计量在小样本下是有偏的,在大样本下是渐近无偏的。采用二阶段最小二乘法得到结构方程的结构参数估计量在小样本下是有偏的,在大样本下是渐近无偏的。
前者主要适用于定性因素对截距项产生影响的情况,后者主要适用于定性因素对斜率项产生影响的情况。除此外,还可以加法与乘法组合的方式引入虚拟变量,这时可测度定性因素对截距项与斜率项同时产生影响的情况。
3.滞后变量模型有哪几种类型?分布滞后模型使用OLS方法存在哪些问题?
答:滞后变量模型有分布滞后模型和自回归模型两大类,前者只有解释变量及其滞后变量作为模型的解释变量,不包含被解释变量的滞后变量作为模型的解释变量;而后者则以当期解释变量与被解释变量的若干期滞后变量作为模型的解释变量。分布滞后模型有无限期的分布滞后模型和有限期的分布滞后模型;自回归模型又以Coyck模型、自适应预检验和F检验有何不同?在一元线性回归分析中二者是否有等价作用?(见课本P70)
答:在多元线性回归分析中,t检验常被用作检验回归方程中各个参数的显著性,而F检验则被用作检验整个回归关系的显著性。各解释变量联合起来对被解释变量有显著的线性关系,并不意味着每一个解释变量分别对被解释变量有显著的线性关系。
在违背这些基本假设的情况下,普通最小二乘估计量就不再是最佳线性无偏估计量,因此使用普通最小二乘法进行估计己无多大意义。但模型本身还是可以估计的,尤其是可以通过最大似然法等其他原理进行估计。
假设1. 解释变量X是确定性变量,不是随机变量;
假设2. 随机误差项m具有零均值、同方差和不序列相关性:
4.如何缩小置信区间?(P46)
由上式可以看出(1).增大样本容量。样本容量变大,可使样本参数估计量的标准差减小;同时,在同样置信水平下,n越大,t分布表中的临界值越小。(2)提高模型的拟合优度。因为样本参数估计量的标准差和残差平方和呈正比,模型的拟合优度越高,残差平方和应越小。
1.为什么计量经济学模型的理论方程中必须包含随机干扰项?
对模型设定偏误的检验方法有:检验是否含有无关变量,可以使用t检验与F检验完成:检验是否有相关变量的遗漏或函数形式设定偏误,可以使用残差图示法,Ramsey提出的RESET检验来完成。
10.简述约化建模理论与传统理论的异同点?
答:Hendry的约化建模理论的核心是“从一般到简单”的建模思想,即首先提出一个包括各种因素在内的“一般”模型,然后再通过观测数据,利用各种检验对模型进行检验并化简,最后得到一个相对简单的模型。传统建模理论的主导思想是“从简单到复杂”的建模思想,它首先提出一个简单的模型,然后从各种可能的备选变量中选择适当的变量进入模型,最后得到一个与数据拟合较好的较为复杂的模型。
从二者的主要联系上看,它们都以对经济现象的解释为目标,以已有的经济理论为建模依据,以对数据的拟合程度作为模型优劣的重要的判定标准之一,也都有若干检验标推。
从二者的主要区别上看,传统的建模理论往往更依赖于某种单一的经济理论,旧“从一般到简单”的建模理论则更注重将各种不同经济理论纳入到最初的“一般”模型中,甚至更多地是从直觉和经验来建立“一般”的模型;尽管两者都有若干种检验标准,但约化建模理论从实践上有更大量的诊断性检验来看每一步建模的可行性,或寻找改善模型的路径:与传统建模实践中存在的过渡“数据开采”问题相比,由于约化建模理论的初估模型是一个包括所有可能变量的“一般”模型,因此也就避免了过度的“数据开采”问题;另外,由于初始模型的“一般”性,所有研究者在建模的初期往往有着相同的“起点”,因此,在相同的约化程序下,最后得到的最终模型也应该是相同的。而传统建模实践中对同一经济问题往往有各种不同经济理论来解释,如果不同的研究者采用不同的经济理论建模,得到的最终模型也会不同。当然,由于约化建模理论有更多的检验,使得建模过程更复杂,相比之下,传统建模方法则更加“灵活”。
5.模型的检验包括几个方面?其具体含义是什么?
答:模型的检验主要包括:经济意义检验、统计检验、计量经济学检验、模型的预测检验。在经济意义检验中,需要检验模型是否符合经济意义,检验求得的参数估计值的符号与大小是否与根据人们的经验和经济理论所拟订的期望值相符合;在统计检验中,需要检验模型参数估计值的可靠性,即检验模型的统计学性质;在计量经济学检验中,需要检验模型的计量经济学性质,包括随机扰动项的序列相关检验、异方差性检验、解释变量的多重共线性检验等;模型的预测检验主要检验模型参数估计量的稳定性以及对样本容量变化时的灵敏度,以确定所建立的模型是否可以用于样本观测值以外的范围。
E(mi)=0 i=1,2, …,n
Var (mi)=sm2 i=1,2, …,n
Cov(mi, mj)=0 i≠j i,j= 1,2, …,n
假设3. 随机误差项m与解释变量X之间不相关:
Cov(Xi, mi)=0 i=1,2, …,n
假设4. m服从零均值、同方差、零协方差的正态分布
mi~N(0, sm2 ) i=1,2, …,n
假设5. 随着样本容量的无限增加,解释变量X的样本方差趋于一有限常数。即
e(xi-x上面横)2/n →Q, n→正无穷
假设6. 回归模型是正确设定的
1.多元线性回归模型的基本假设是什么?在证明最小二乘估计量的无偏性和有效性的过程中,哪些基本假设起了作用?
2.联立方程计量经济学模型的识别状况可以分为几类?其含义各是什么?
答:联立方程计量经济学模型的识别状况可以分为可识别和不可识别,可识别又分为恰好识别和过度识别。
如果联立方程计量经济学模型中某个结构方程不具有确定的统计形式,则称该方程为不可识别,或者根据参数关系体系,在已知简化式参数估计值时,如果不能得到联立方程计量经济学模型中某个结构方程的确定的结构参数估计值,称该方程为不可识别。如果一个模型中的所有随机方程都是可以识别的,则认为该联立方程计量经济学模型系统是可以识别的。反过来,如果一个模型系统中存在一个不可识别的随机方程,则认为该联立方程汁量经济学模型系统是不可以识别的。如果某一个随机方程具有唯一一组参数估计量,称其为恰好识别;如果某一个随机方程具有多组参数估计量,称其为过度识别。
1.什么是计量经济学?计量经济学方法与一般经济数学方法有什么区别?
答:计量经济学是经济学的一个分支学科,是以揭示经济活动中客观存在的数量关系为内容的分支学科,是由经济学、统计学和数学三者结合而成的交叉学科。
计量经济学方法揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述;一般经济数学方法揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。
4.建立与应用计量经济学模型的主要步骤有哪些?
答:建立与应用计量经济学模型的主要步骤如下:(1)设定理论模型,包括选择模型所包含的变量,确定变量之间的数学关系和拟定模型中待估参数的数值范围;(2)收集样本数据,要考虑样本数据的完整性、准确性、可比性和—致性;(3)估计模型参数;(4)检验模型,包括经济意义检验、统计检验、计量经济学检验和模型预测检验。
答:多元线性回归模型的基本假定仍然是针对随机干扰项与针对解释变量两大类的假设。针对随机干扰项的假设有:零均值,同方差,无序列相关且服从正态分布。针对解释量的假设有;解释变量应具有非随机性,如果后随机的,则不能与随机干扰项相关;各解释变量之间不存在(完全)线性相关关系。