试验设计与统计分析8
试验设计与统计分析

广东药学院自编教材试验设计与统计分析卫生统计学教研室2014.8第一章绪论在医药卫生、食品等专业研究领域,常需要开展大量的试验来确定或验证研究者在科研过程中提出的科学假设,例如临床上研究某种新的降糖药的疗效时,研究者需要将研究对象(如糖尿病患者)随机地分组,使其中一组患者服用研究中的该降糖药,另一组患者服用传统的降糖药,进而比较两组药物的疗效。
但在具体的试验实施之前,研究者需要面对很多问题,如试验中试验对象应如何选择和分组?如何在试验过程中避免服用不同试验药物对试验对象心理产生影响,继而影响到最终疗效的判断?选择什么样的指标可更好的反映药物疗效?样本量需要多少?试验数据应如何收集以及运用何种统计方法进行分析等等问题。
因为研究过程中研究结果会受到诸多因素影响,如研究对象的年龄、性别和病情可能影响药物疗效,如果不采取科学的方法使这些因素在比较组间分布均衡,就不能得到令人信服的结论。
因此为使科学研究在消耗最少人力和物力的情况下,最大限度地减少误差,获得科学可靠的结论,需要在研究开始之前对整个试验过程做出精心安排,制定详细具体的试验实施方案,即进行试验设计(experimental design)。
一个科学合理的试验设计,可以达到事半功倍的效果,是试验获得成功的关键。
一、试验设计的基本要素医学试验包括三个基本要素:即处理因素、试验对象和试验效应。
如研究某降糖新药的疗效,处理因素为降糖新药及比较的传统降糖药;研究者需用糖尿病患者作为试验对象;试验效应是能反映药物疗效的指标,如患者空腹血糖或餐后血糖的下降。
处理因素作用于试验对象后产生试验效应(图1),三个要素缺一不可,因此试验设计时要先明确三个基本要素,再制定详细的研究计划。
1. 处理因素处理因素(treatment)是指研究者根据研究目的施加于试验对象,以考察其试验效应的因素。
如临床上研究降糖药的疗效,降糖药即为处理因素。
在试验过程中处理因素的状态称为水平(level),如比较降糖新药和传统降糖药的疗效,则称该处理因素有两个水平。
实验设计与统计分析心得

实验设计与统计分析心得统计学专业认识实习报告心得体会本人系福州大学统计学专业的一名学生,于2005年6月27日——7月8日到福建省统计局科研所认识实习,在两周的时间里,我所做的每一项工作都是以前从来没有做过的,在领导和同事的耐心帮助下,我学习到了很多实用的、有价值的东西,在积累了一些实际工作经验的同时也更深刻的理解到了统计理论知识体系,为今后的学习奠定了坚实基础。
在认识实习期里,我所做的工作内容比较具体、感受和体会也比较多。
下面,我仅把实习期里的主要情况做一下汇报。
如有不妥之处,欢迎给予批评和指正。
一、福建省统计局科研所介绍科研所是统计局内部的一个重要职能部门,而统计科研涉及的领域也十分广阔,包括统计基础理论研究、统计应用研究和统计信息技术研究。
同时在政府统计工作中,对政府和社会关心的有关经济、社会、科技、资源与环境等重大问题,都需要从统计的角度进行分析研究,得出结论,提出建议。
“十五”期间,国家统计科技研究的重点是统计观念的创新、统计方法的创新、统计手段的创新以及统计体制的创新。
要积极组织、指导重大课题研究,统计科研所每年要完成一项以上具有重要影响的课题。
统计杂志是展示优秀科技成果的重要窗口,是科技成果转化为生产力的重要媒介。
要加强对统计杂志的领导和支持,不断提高杂志的质量,增加发行量,扩大影响力,努力创办一流杂志。
科研所的主要职能有五点,具体包括:1.拟订全省统计科研计划和科研制度,并组织实施;2.组织协调本局及全省各地区、各部门的统计科研工作;3.承担统计科研课题,负责向国家统计局和省直有关部门进行统计科研课题的申报立项及管理工作;4.承担全省统计科研成果的评审、选优、奖励工作,并推荐优秀成果参加国家和省级评奖;5.拟订省统计学会章程,负责省统计学会日常工作,履行省统计学会秘书处的职责。
根据国务院有关文件精神,国家和各地统计科研所作为非营利性社会公益类科研机构,只能加强,不能削弱。
统计科研所担负着从事统计科学研究、进行科研管理(组织统计科技交流、发布课题指南、课题立项、成果评奖等)、编辑出版统计杂志等重要职能。
实验设计与统计分析技术

实验设计与统计分析技术实验设计是探究事物本质的基础,好的实验设计可以提高实验的可靠性。
而统计分析则是对实验结果进行演绎和验证的重要手段。
在实验科学中,实验设计和统计分析技术的巧妙运用可以有效提高实验准确性和数据的可靠程度。
一、实验设计实验设计是指为了达到某种目的,通过有目的地干预自变量,比较受试者对干预后的因变量所产生的反应差异,从而达到推断因果关系的有效研究方案。
好的实验设计应该具备以下几个方面的要素:1.目的明确:实验设计必须要有一个明确的目的,例如验证一个假设、探索一个现象或寻找因果关系等。
2.随机性:实验设计需要随机分配受试者,以消除可能存在的干扰因素。
3.对照组设计:实验设计中需要使用对照组,以进行比较分析。
4.操作性:实验设计需要操作,即干预自变量。
5.可再现性:实验设计结果需要可再现,即能够得到可靠的结果。
二、统计分析实验数据的统计分析是实验设计后的重要环节。
以实验数据为基础,使用统计方法对实验数据进行分析,以便对实验所做的科学结论进行验证的技术就是统计技术。
统计方法的基本作用是根据样本的信息来推断总体的情况,以便得到尽可能准确的结论。
常用的统计方法有:1.描述性统计:通过对数据进行整理、分析和描述来简洁地展现数据的基本特征。
2.参数估计:从样本中得到的统计量来推断总体参数的值,如均值、方差等。
3.假设检验:通过对样本数据和总体数据的关系进行分析,判断样本数据是否可以反映总体数据的规律性。
4.回归分析:通过建立数学模型来描述因变量和自变量之间的关系,并进行相关性分析。
5.方差分析:主要用于不同组之间的比较,通过比较组内和组间的方差来推断样本或总体之间的差异。
总之,实验设计和统计分析技术的巧妙运用可以大大提高实验结果的可靠程度和准确性。
在今后的实验科研工作中,我们应该注重实验设计的合理性,并充分利用统计技术对实验数据进行分析和验证。
临床试验的研究设计与统计分析

临床试验的研究设计与统计分析临床试验是评估新药、新治疗方法或医疗器械安全性和疗效的关键环节,它对于指导临床决策和提高患者治疗效果具有重要意义。
本文将重点介绍临床试验的研究设计以及统计分析的相关方法和技巧。
一、临床试验研究设计1. 研究类型选择根据研究目的和数据获取方式,临床试验研究设计可分为观察性研究和干预性研究。
观察性研究主要通过观察人群的暴露与结果之间的关系,探索潜在的危险因素和保护因素。
干预性研究则通过对人群进行干预,评估干预措施的效果。
常见的干预性研究设计包括随机对照试验、非随机对照试验和自身对照试验。
2. 样本容量计算样本容量的确定是保证试验结果的可靠性和有效性的关键步骤。
通过样本容量计算,可以估算出适当的样本规模,以减少随机误差和提高统计检验的可靠性。
样本容量计算需考虑试验的研究问题、预计的效应大小、显著性水平、统计检验的类型等因素。
3. 随机化设计随机化是临床试验中的重要原则,它能够降低实验组与对照组之间的混杂因素的影响,提高试验结果的可靠性。
常见的随机化设计包括简单随机化、分层随机化和区组随机化等。
在随机化设计中,应根据试验的目的和实际情况选择适当的随机化方法。
4. 平行设计与交叉设计在干预性临床试验中,研究设计可以采用平行设计或交叉设计。
平行设计将受试者随机分配至实验组和对照组,在不同组中接受不同的干预措施;交叉设计则是将受试者分为不同顺序接受不同干预措施,并在每个干预阶段测量结果。
二、临床试验统计分析1. 描述性统计分析试验数据的描述性统计分析是对试验数据的基本特征进行总结和描述。
如平均数、标准差、中位数、分位数等。
通过描述性统计分析,可以了解试验数据的分布情况、集中趋势和离散程度,为进一步的推断性统计分析提供基础。
2. 推断性统计分析推断性统计分析是基于样本数据对总体进行推断,判断样本间差异是否代表总体间的差异。
常见的推断性统计分析包括假设检验和置信区间估计。
假设检验用于验证研究假设是否成立,置信区间估计则用于评估参数估计的精度。
试验设计与统计分析教案(西南大学)
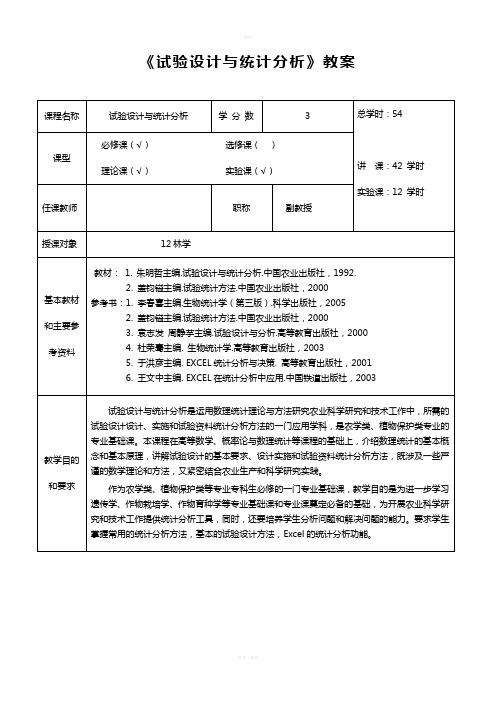
《试验设计与统计分析》教案
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)
《试验设计与统计分析》教案(章节备课)。
试验设计及其统计分析

实验问题的合理解释(3)
• 或许会有人有疑问。 • 因为他的测量从来没有在夜间进行,甚至,在正午以外的
时间也没有进行过。 • 所以, (1)我们还不能认为这个实验已经完整地回答了问题。如
果在晚上进行测量,这个模型就被质疑了。
(2)有限的结论:天空在正午是蓝色的。
6. 如何用实验结论来描绘现实?
假设与模型
定义术语
• 实验是根据问题或假说来进行的。 • 以“天空是什么颜色的?为例来讨论如何设计实验。 • 首先需要定义术语: (1)定义颜色为“可见光” (2)定义“天空”。例如,仪器是指向正上方还是指向水 平线的?还是其它。
时间进程
• 在时间上进行多次测量叫做时间进程。可以用于了解任何 特定的点上的测量是否具有代表性,以及在不同的条件下 系统是否会发生基础性变化。
• 每5min测量一次。 • 在时间进程实施之前,科学家已对“天空是什么颜色的?”
预言了一个简单的答案。随着时间进程的发展,发现天空 不只是一个颜色;相反,它在时时变化着。因此,科学家 不能仅仅给出一个简单的结论来。而是,需要建立一个适 应这些数据的新模型。
• 连续测量7天。
重复
对照
• 首先需要有一个“仪器对照”,保证相应的波长是可以被 测量到的。需要阳性对照和阴性对照。
(1)提出一系列问题,如天空是蓝色的?绿色的?黄色的? 红色的?
(2)测量中午时所有可见光的波长。 (3)得出结论:天空是蓝色的。
实验问题的合理解释(2)
• 天空真的是蓝色吗? (1)连续测量。30天,27天是蓝色,3天是灰色的(阴天) (2)显著性检验:差异显著 (3)认为,“天空是蓝色的”正确。
例:用A1、A2 、 A3三种饲料喂鸡,每种饲料饲喂30只鸡。一 个月后称重。该如何操作?
正交试验设计及其统计析

05
结论
正交试验设计的优势与局限性
高效
通过合理地减少试验次数,提高试验 效率。
全面
能够全面地探索各个因素之间的交互 作用。
正交试验设计的优势与局限性
• 可靠:基于统计理论,结果具有较高的可 靠性。
正交试验设计的优势与局限性
适用范围有限
适用于因素数量和水平数目不太多的情况。
对数据要求较高
需要大量的数据进行分析,且数据质量要高。
促进科学决策
通过正交试验设计和统计分析,能够 为企业或研究机构提供科学依据,促 进科学决策和优化方案制定。
02
正交试验设计的基本原理
正交表的选择与设计
正交表的选择
交互作用和误差控制
根据试验因素的数量、水平数和试验 次数,选择合适的正交表。
考虑因素间的交互作用和误差控制, 确保试验结果的准确性和可靠性。
试验因素和水平的确定
明确试验目的,确定试验因素和水平, 确保试验结果具有实际意义。
Hale Waihona Puke 试验方案的制定试验操作步骤
根据正交表,确定每个试验方案的试验操作步骤。
数据记录
预先设计好数据记录表格,以便准确记录每个试 验方案下的数据。
试验重复
考虑试验的重复性,以提高结果的稳定性和可靠 性。
试验结果的收集
数据整理
方差分析
方差分析的原理
方差分析用于检验各因素对试验指标 的影响是否显著,通过比较各因素的 方差贡献,判断其对试验指标的影响 程度。
方差分析的应用
在正交试验设计中,方差分析可用于 确定显著影响因素,并进一步优化试 验条件。
回归分析
回归分析的原理
回归分析通过建立数学模型描述各因素与试验指标之间的数量关系,并预测不同因素水平下试验指标 的变化趋势。
试验设计与统计分析 教学大纲

山西农业大学信息学院《试验设计与统计分析》教学大纲课程名称:试验设计与统计分析Experiment Design and Statistical Analysis课程编码:105011课程类别:专业基础课学时/学分:48学时/3学分适用专业:资环、环科等专业一、前言1、课程性质《试验设计与统计分析》,是数理统计学在生物科学领域的应用,主要涉及科学研究中的试验设计、抽样观测和统计推断,是一门应用数学。
课程还同时融入国际权威的SAS统计分析,通过上机处理试验实例的数据,巩固和加深理解所学统计原理及方法。
课程不仅讨论如何科学地设计试验,而且还讨论如何科学地收集数据、整理数据、分析数据、解释数据和做出结论,是从事科学研究必不可少的基础知识。
《试验设计与统计分析》是资环、环科专业的一门专业基础必修课程。
2、教学目标通过课堂讲授、课下作业和上机数据处理三个环节的教学过程,使学生掌握基本的试验设计与统计分析方法,掌握试验数据处理的程式步骤和技能。
3、教学要求针对试验设计与统计分析的学科特点,结合专业的性质,讲授课程时理论与方法并重,力图把统计原理讲解的清晰易懂,使学生了解典型内容的基本原理和方法,理解统计方法的理论背景,掌握一些基本技能,从而培养学生分析解决实际问题的能力。
4、先修课程高等数学、线性代数、概率论等二、课程内容绪论教学内容及总体要求:掌握:(1)试验设计与统计分析的概念、特点;(2)总体与样本、样本含量、参数与统计量的概念;(3)统计分析的基本要求。
了解:(1)试验设计与统计分析的作用及其主要内容;(2)试验设计与统计分析的发展概况;(3)错误与误差、准确性与精确性的概念。
教学目标:通过学习,使学生掌握试验设计与统计分析的概念、特点;总体与样本、样本含量、参数与统计量的概念;统计分析的基本要求。
教学方式方法建议:课堂讲授、课堂讨论学时:2学时一、试验在科学研究中的作用二、试验研究的一般程式及过程三、试验设计与统计分析的涵义四、试验设计与统计分析的必要性五、课程特点与学习方法六、常用术语和基本概念思考题:1、总体与样本、样本含量、参数与统计量的概念;2、统计分析的基本要求第一章田间试验设计(6学时)第一节田间试验设计基础1、田间试验设计概述2、试验设计中的基本概念第二节田间试验的种类1、按试验性质分类2、按因子多少分类第三节田间试验的特点和要求一、田间试验的特点二、田间试验的基本要求第四节试验误差与土壤差异一、田间试验的误差二、试验地的土壤差异三、试验地的选择和培养第五节田间试验设计原则一、重复二、随机排列三、局部控制第六节试验小区的控制技术一、试验小区的面积二、小区的形状三、重复次数四、对照区的设置五、保护行的设置六、重复区和小区的排列第七节常用的试验设计方法一、完全随机设计二、随机区组设计三、拉丁方设计四、巢式设计五、裂区设计掌握:(1)试验设计的概念、特点和基本要求、试验方案的拟定;(2)试验设计的基本原则、作用及其相互关系;(3)完全随机试验设计、随机区组设计的概念及其方法、特点和试验结果的统计分析方法;(4)试验研究中样本含量的估计。
试验设计与统计分析中的常见问题

6.试验数据的综合分析
(1)单因素试验数据的综合分析
有了单因素试验数据,可得到以下分析结果:
①通过方差分析得到因素对指标影响的显著性。
②通过回归分析得到因素对指标的影响规律。
③利用回归方程可得到最佳的参数水平及其指标值。
三、统计分析问题
(2)双因素试验数据的综合分析 有了双因素试验数据,可得到以下分析结果: ①通过方差分析得到因素及其交互作用对指标影响的 显著性。
“试验设计与统计分析”中的常见问题 四、写论文问题 1.题目要有吸引人眼球的地方 (1)试验手段先进,如:用流化床干燥大枣 (2)研究方法先进,如:用二次通用旋转组合 设计方法进行大枣干燥的研究,或大枣干燥工 艺参数的优化等。 (3)研究内容新颖,即无人进行过研究,如: 狗对牡丹花的看法。
四、写论文问题
“试验设计与统计分析”中的常见问题 三、统计分析问题 常用的统计分析方法有:方差分析,多重比较, 极差分析,回归分析,相关分析等。能得到的 分析结果如下:
三、统计分析问题 1.方差分析
以单因素试验为例,试验结果如下表。
重复次数
因素水平
1
x11 x21 … xi1
2
x12 x22 … …
…
… … … …
②通过方差分析得到因素及其交互作用对指标影响的 显著性。 ③对符合条件的正交试验数据,可进行回归分析。
三、统计分析问题
(4)多指标的参数优化
即找到一组最佳参数组合,使所有指标都较好的过程。
对于正交试验数据,可采用综合平衡法或加权综合评 分法。
对于回归试验数据,可采用加权综合评分法或主目标 优化法。
二、试验设计问题 5.回归试验
回归试验的目的是为了得到好的回归方程。有用的是 得到二次回归方程,可得到最佳参数组合。常采用二 次通用旋转组合设计,其优点是:利用回归方程预报 精度高,试验次数少。因为二次通用旋转组合设计各 因素都取5个水平,且试验点在编码空间分布合理 (分布在距中心点距离不等的3个球面上,且有星号 臂r控制回归方程的精度)。而BOX法设计,各因素 都取3个水平,分布在2个球面上,且无星号臂r控制, 回归成二次方程,不是也得是。因此,若是实际应用, 建议采用二次通用旋转组合设计。
试验设计与统计分析SAS实践教程(王玉顺)章 (8)

Pr > F < 0.0001
R2 = 0.9849
回归参数 截距 X X*X
X*X*X
表 8-7 多项式回归参数估计及其 t 检验
估计值
标准误
t值
-0.36505 0.31316
1.10922 0.42673
-0.33 0.73
0.10902
0.04295
2.54
-0.00378
0.00117
-3.22
第8单元 回归试验统计分析
proc nlin best=5 data=sasuser.IR72 method=marquardt converge=1e-8; parms k=1 to 100 by 10 a=1 to 100 by 10 b=1 to 100 by 10; bounds k>=1e-30,a>=1e-30,b>=1e-30; /*设置回归参数非负*/ model y=k/(1+a*exp(-b*x)); /*设定回归模型*/ der.k=1/(1+a*exp(-b*x)); /*设定 k 的偏导数*/ der.a=-k*exp(-b*x)/(1+a*exp(-b*x))**2; /*设定 a 的偏导数*/ der.b=k*x*a*exp(-b*x)/(1+a*exp(-b*x))**2; /*设定 b 的偏导数*/ output out=file p=EY r=ERROR; /*计算估计值、残差并输出*/
第8单元 回归试验统计分析 (6) 程序的输出结果如图8-1所示。
图8-1 试验观测和多项式拟合曲线
第8单元 回归试验统计分析 8.2.3 可线性化非线性回归
【例8-3】 为例8-2问题拟合一个抛物线方程Y2 = a + bX, 并做回归分析。
实验设计与统计分析

1.重复(replication)
定义:在试验中,将一个处理实施在两个或 两个以上的试验单位上,称为处理有重复。如 用某种饲料喂4头猪,就说这个处理(饲料)有4 次重复。 作用:
(1)估计误差
_
y 单个观测值是无法估计误差的大小。只有 获得多个观测值,才可以根据这些观测值之间 的差异来估计试验误差。 24
试验设计基本原则:
重复试验以降低结果的机会变异。
随机化安排指定的处理。
控制隐藏变量对反应的效应。
统计显著性(Statistical Significance)。
若观察的效果太大,在概率分布上极不可能发生,
称为该效应统计显著。
试验设计三原则的关系及作用
重复 随机化
无偏误差估计 估计误差
43
第三节 随机区组设计及其统计分析
一、 随机区组设计 二、随机区组设计试验结果的统计分析
一、随机区组设计
1.特点:使用了田间试验设计三个原则,并根据“局
部控制”的原则,将试验地按肥力程度划分为等于
重复数的区组,一区组安排一重复,区组内各处理
二是受误差影响不容易发现试验效应的规律。
16
3、试验方案中应包括对照水平或处理(check, CK)
对照是试验中比较处理效应的基准。
品种比较试验中常统一规定同生态区内使用对 照品种。
17
4、注意比较间的唯一差异性原则,才能正确
解析出试验因素的效应。唯一差异性原则:
为保证试验结果的严格可比性,除了试验因
素设置不同的水平外,其余因素或其他所有
条件均应保持一致,以排除非试验因素对试
验结果的干扰,这样的比较结果才能可靠。
如在对小麦进行叶面喷施P肥的试验中,可能
田间试验与统计分析 第八章 多因素试验设计与统计分析

两因素随机区组试验 总变异=区组间+处理间(A因素+B因素+ AXB互作)+误差
两因素裂区试验 总变异=区组间+处理间( A因素+B因素+ AXB互作)+主区 误差+副区误差
激素2
63
激素3
64
激素4
62
激素5
61
组(B)
II
III
IV
62
61
60
65
68
65
61
61
60
67
63
61
65
62
64
62
62
65
例2:两因素完全随机试验 -组合内有重复观察值
肥料 重复
土壤种类
施用A1、A2、A3三 种类
种肥料于B1、B2、
B1
B2
B3
B3 三 种 土 壤 , 以 A1 1
区组I 8 7 6 9 7 8 7 8 10 70 7.78
区组II 8 7 5 9 9 7 7 7 9 68 7.56
区组III T
8
24
6
20
6
17
8
26
6
22
6
21
6
20
8
23
9
28
63
201
7
平均 8 6.7 5.7 8.7 7.3 7 6.7 7.7 9.3
7.4
按品种和密度作两向分组整理成下表2: 表2 品种A和密度B的两向表
试验设计与统计分析

一、裂区设计
主区 完全随机
随机区组
拉丁方排列
副区 随机区组 拉丁方排列
一、裂区设计
有一肥料与品种试验,共6个品种,分别用1、2、 3、4、5、6表示,肥料用量有3个水平,分别用高、 中、低表示,试设计裂区试验。3次重复。
第二步,将主区因素A(肥料)的3个水平(高、 中、低)独立随机地排列在每个区组的3个主区中。
第三步,将各区组的每个主区划分为6个副区。
第四步,将副区因素B(品种)的6个水平1、2、 3、4、5、6品种独立随机地排列在每个主区的6个副 区中,即得裂区设计的田间排列。
152541243
Ⅰ
634362651
一、裂区设计
二因素试验:施肥(A,3个水平)、修剪(B,4个水平) 对第一个因素(施肥)要求有较大的试验面积,对第二个 因素(修剪)有较小的试验面积 按因素对试验面积的要求不同分成主因素和副因素。
A因素 B因素
一、裂区设计
在一个区组上,先按第一个因素(主因素或主处理)的水平
数划分主因素的试验小区,主因素的小区称为主区或整区,用
(4)多重比较—耕翻期×施氮量
同一绿肥耕翻时期内不同施氮水平的比较
s
aib1 aib2
2se2b
dfeb=12
0.634
LSD0.05=1.38
n
LSD0.01=1.94
施氮量
B3 B4 B2 B1
A1 早耕翻 差异显著性
平均产量 5% 1%
22.0
aA
18.9
bB
15.2
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
定性指标 不能用数量表示的指标称为定性指标或质量指 标。如色泽、风味、口感、手感等等。食品的 感官指标多为定性指标。
在试验设计中,根据试验目的的不同,可以用一个试验指标 (单指标试验) ,也可以同时用两个或两个以上的试验指标(多指 标试验)。
合理选用试验指标
过简, 难以全面准确地评价试验结果,功亏一篑 过繁琐, 增加许多不必要的浪费
可同时考虑多个试验因素和多个试验水平 经济有效的方法
第三节 试验设计的基本原则
食品试验设计的三个基本原则 重复原则(replication)
随机原则(random) 局部控制原则(local control)
1、重复原则(replication) 定义:是指试验中每种处理至少进行2次以上。
表 完全随机化单因素试验顺序(括号内数字为试验顺序编号)
水平
A1 A2 A3 86(14) 46(8) 32(3) 76(12) 70(1) 51(9)
试验结果与顺序
25(2) 36(5) 34(4) 37(6) 78(13) 38(7) 69(11) 57(10) 91(15)
二、多因素完全随机设计
在同一试验方案中包含2个或2个以上的试验因素,各个 因素都分为不同水平,其他试验条件均应严格控制一致。 处理组合(treatment combination)是各供试因素水平数 的乘积。 目的明确各试验因素的相对重要性和相互作用,从中评选 出1个或几个最优处理组合。
多因素试验的效率常高于单因素试验 二因 素试 验
即分时间分环境控制条件因素,使之对各试验处理的 影响达到最大程度的一致 区组内相对均匀一致,安排全套处理 区组间可有差异 区组数 = 重复次数
作用:降低误差
曲种:甲乙丙丁 每个2次重复
食品试验设计三个基本原则的关系及其作用示意图 重 复
随
机
局部控制
无偏的试验 误差估计
降低试验误差
因素 微生物菌种
水平 4个菌种 8个配方 4个水平 8个水平
处理或组合 4个处理 8个处理 3个处理 15个处 5个处理 理组合
培养基
3个菌种 3个水平 菌种、培养基 5个培养基配方 5个水平
试验单位(Experimental Unit)
在试验中能接受不同试验处理的试验载体叫做试验单位,也 称为试验单元。
因素A与B的ab个组合个重复n次,进行试验时,这ab n=N次试验的先 后顺序完全按随机方式确定,这就是两因素等重复完全随机设计方法。 [例]为提高粒粒橙饮料中汁胞的悬浮稳定性,研究了果汁pH值(A)、魔芋精粉 浓度(B)两个因素的不同水平组合对果汁黏度的影响。果汁pH值取3.5,4.0, 4.5三个水平,魔芋精粉浓度(%)取0.1,0.15,0.2三个水平,每个水平组合重 复2次,进行完全随机化试验。试验指标为果汁黏度(CP),越高越好。 表 两因素等重复完全随机试验顺序 处 理 A1B1 A1B1 A1B2 A1B2 A1B3 试验顺序 12 15 5 8 10 处 理 A1B3 A2B1 A2B1 A2B2 A2B2 试验顺序 1 7 2 18 3 处 理 A2B3 A2B3 A3B1 A3B1 A3B2 试验顺 序 13 16 14 17 6 处 理 A3B2 A3B3 A3B3 试验顺序 11 4 9
三、试验设计方法 完全随机设计 随机区组设计 正交试验设计
回归正交设计 回归正交旋转设计 ………………….
第二节 试验设计的一些基本概念
一、试验因素与水平
试验指标(Experimental index)
在试验设计中,根据试验的目的而选定的用来衡量或 考核试验效果的指示性状,称为试验指标。
作用:与重复相结合,能提供无偏的试验误差估计值。
2人测定豆奶蛋白质含量 方法一
重复1
1-1 1-2 3-1 3-2 5-1
重复2
2-2 2-1 4-1 4-2 5-2
重复1
1-1 2-1 3-1 4-1 5-1
重复2
1-2 2-2 3-2 4-2 5-2
方法二
3、局部控制(local control) 定义:将整个试验环境分成若干个相对最为一致的小环境, 再在小环境内设置成套处理。
部分实施(fractional enforcement)
全面试验(overall experiment)
在试验设计中,为了获得全面试验信息,正确地判断试验因 素及其各级交互作用对试验指标的影响,对所选取的试验因素 的所有水平组合全部实施1次以上的试验称为全面试验。
能够获得全面的试验信息,无一遗漏,各因素及各
第六节 常用抽样方法及其抽样误差
随机抽样
抽样误差(见前面章节)
第七节 样本含量的确定
在假设性检验中,统计意义不显著的结果, 可能由两方面造成的:
可能两组间没有方法来证明这种结果。
确定样本大小的原则:
数理统计学已证明误差的大小与重复次数的平方根成反 比,重复多,则误差小。如:四次重复的试验误差将只 有二次重复的同类试验的1/(2)1/2。
作用三:更准确地估计处理效应
单一重复所得的数值易受影响 多次重复所估计的处理效应比单个数值更为可靠,使处 理间的比较更为有效
2、随机原则(random) 定义:是指在试验中,每一个处理及每一个重复都有同等 的机会被安排在某一特定空间和时间环境中,以消 除某些处理或其重复可能占有的“优势”或“劣势”, 保证试验条件在空间和时间上的均匀性,避免任何 主观成见。 方法:抽签法、计算器(机)、随机数字表等。
同时测定5个鸡蛋蛋壳的强度 每种工艺重复加工4次
作用: 估计试验误差 降低试验误差,提高试验的精确度 更准确地估计处理效应
1、重复原则(replication) 作用一:估计试验误差
试验误差是客观存在的 只能由同一处理的几个重复间的差异估得
作用二:降低试验误差,提高试验的精确度
曲 种:甲、乙、丙3个 发酵时间:长、中、短3种 共有3×3= 9 个处理组合
明确二个试验因素的作用 检测3个曲种对各种发酵时间是否有不同反应,从中选出 最优处理组合
部分实施(fractional enforcement)
从全部试验处理中选取部分有代表性的处理进行试验,如正 交试验设计和中心旋转设计。
缺点
对试验环境条件要求较高,必须相当均匀
用途
可用于实验室实验
完 全 随 机 设 计
单因素完全随机设计
两因素完全随机设计
一、单因素完全随机设计
[例] 在无酒精啤酒的研究中,为了解麦芽汁的浓度对发酵液中 双乙酸生成量的影响,在发酵温度7OC,二氧化碳压力 0.6kg/cm2,发酵时间6d的试验条件下,选定麦芽汁浓度(%)为 6(A1),10(A2),12(A3)3个水平,每个水平重复5次,进行完全 随机设计,寻找适宜的麦芽汁浓度。 本试验中a=3,r=5,共进行35=15次试验。 抽签法 随机数字表
品生产、科研工作者经常遇到的现实问题,又是其必备
的基本功。
2、试验设计的任务 1、在研究工作之前,根据研究项目的需要,以概率论
试 验 设 计 的 任 务
与数理统计原理为理论基础,结合专业知识和实践 经验,经济、科学、合理地安排试验; 2、有效地控制试验误差干扰;
3、力求用较少的人力、物力、财力和时间,最大限度
实际设计过程中,难以做到!因此必须兼顾可变因素
试验方案的分类 供试因素(或因子)数 单因素试验 (single-factor experiment) 多因素试验 (multiple-factor experiment)
试 验 方 案 的 种 类
全面试验 (overall experiment)
在研究增稠剂种类、pH值和杀菌条件对豆奶稳定性的影响时,可只
选用豆奶的稳定性作为试验指标。 在研究不同吸附剂去除甜橙汁中苦味物质的效果时,可同时选用苦
味物质的去除率、维生素C的损失率、可溶性固性物质损失率作为
试验指标,综合考虑确定哪种吸附剂合适。
因素(Factor)
试验中,凡对试验指标可能产生影响的原因或要素,都称为 因素或因子。
统计推断
提高精确度
第四节 试验计划与方案
第五节 完全随机设计
完全随机设计 设计特点
将各处理随机分配到各个试验单元中(试验处理的试验顺序是 随机安排的) 每一处理的重复数可以相等或不相等 试验材料的随机分组 单因素或多因素试验皆可应用
优点
对试验单元的安排灵活机动,任一处理可安排在任一单元上 设计分析简便
质量水平(定性,具有质的区别)。如供试的不同曲种
数量水平(定量,具有量的差异)。如不同pH值
因素
增稠剂 用量 5种 用量
pH值
杀菌 温度 8个 温度
发酵 时间 3 个时 间长度
曲种
水平
6个值
4个 曲种
试验处理(treatment)和处理组合(treatment combination)
试验因素的不同水平称为试验处理。而各因素不同水平的组合, 称为处理组合。
在考察加热时间和加热温度对果胶酶活性影响时,果胶 酶活性是试验指标。
在考察贮藏方式对苹果果肉硬度的影响时,果肉硬 度就是试验指标。
定量指标
试 验 指 标
能用数量表示的指标称为定量指标或数量指标。 如食品的糖度、酸度、pH值、提汁率、糖化 度、吸光度、合格率等等。食品的理化指标及 由理化指标计算得到的特征值多为定量指标。
地获得丰富而可靠的资料; 4、充分地利用和科学地分析所获取的试验信息; 5、能明确回答研究项目所提出的问题和尽快获得最优 方案的目的。
二、试验设计的作用
可分清试验因素对试验指标影响的大小顺序,找出主要 因素,抓住主要矛盾。