使用XGBOOST进行机器学习实验报告
基于HMM-XGBoost的股价预测

基于HMM-XGBoost的股价预测基于HMM-XGBoost的股价预测摘要:股票市场中的预测一直备受研究者们的关注。
传统的预测方法往往受到多个因素的影响,从而难以取得准确预测结果。
本文提出了一种新的股价预测方法,基于隐马尔可夫模型(Hidden Markov Model,HMM)与XGBoost算法的结合。
通过利用HMM模型对股票市场的状态进行建模,结合XGBoost算法对多个特征进行综合分析,并通过训练预测模型来预测未来股价的变化。
实验证明,该方法相比传统方法在股价预测中取得了更好的效果。
1. 引言股票市场一直以来都是投资者们关注的焦点之一,而准确预测股价的变化对投资者来说尤为重要。
传统的股价预测方法主要基于技术分析和基本面分析,但是这些方法往往受到市场的复杂性、不确定性因素以及人为因素的影响,很难取得准确的预测结果。
因此,寻找一种能够更准确地预测股价变化的方法一直是股票市场中的研究热点。
2. 方法本文提出了一种基于HMM-XGBoost的股价预测方法。
该方法主要分为两个步骤:建模和预测。
2.1 建模首先,我们使用HMM模型对股票市场的状态进行建模。
HMM是一种经典的统计模型,可以用于对序列数据进行建模和预测。
我们将股票市场的状态划分为多个隐含状态,如上涨、下跌和震荡等。
通过对历史股价数据进行分析和训练,我们可以得到一个初始的HMM模型。
然后,我们使用Baum-Welch算法不断迭代优化该模型,以适应不同市场的变化。
2.2 预测在建模完成后,我们将使用XGBoost算法对多个特征进行综合分析,以辅助HMM模型进行预测。
XGBoost是一种基于梯度提升决策树的机器学习算法,在特征选择和模型优化方面具有优势。
我们将历史股价数据中的多个特征作为输入,通过训练XGBoost模型来预测未来股价的变化趋势。
3. 实验设计与结果为了验证该方法的有效性,我们选取了某股票市场的历史股价数据作为实验样本。
首先,我们将数据集划分为训练集和测试集。
《2024年基于改进XGBoost算法的山羊运动行为分类识别研究》范文

《基于改进XGBoost算法的山羊运动行为分类识别研究》篇一一、引言随着人工智能技术的不断发展,动物行为识别与分类已成为一个重要的研究领域。
山羊作为常见的家畜之一,其运动行为的研究对于提高养殖效率、保障动物福利具有重要意义。
然而,传统的山羊运动行为分类方法往往存在准确率低、鲁棒性差等问题。
为了解决这些问题,本文提出了一种基于改进XGBoost算法的山羊运动行为分类识别方法,旨在提高分类准确性和鲁棒性。
二、相关研究背景近年来,机器学习和深度学习在动物行为识别领域得到了广泛应用。
其中,XGBoost算法作为一种高效的梯度提升决策树算法,在多个领域取得了显著成果。
然而,在山羊运动行为分类方面,传统的XGBoost算法仍存在一定局限性,如对数据特征的选择和处理的不足等。
因此,本文旨在通过改进XGBoost算法,提高山羊运动行为的分类识别效果。
三、改进XGBoost算法的提出针对传统XGBoost算法在山羊运动行为分类方面的不足,本文提出以下改进措施:1. 数据预处理:通过分析山羊运动数据的特性,对原始数据进行清洗、归一化等预处理操作,以提高数据的可用性和质量。
2. 特征选择与处理:结合山羊运动行为的实际特点,选择合适的特征并进行特征降维和编码处理,以减少模型的复杂度和过拟合现象。
3. 参数优化:通过交叉验证和网格搜索等方法,对XGBoost 算法的参数进行优化,以提高模型的性能和泛化能力。
四、实验设计与实现1. 数据集:采用公开的山羊运动行为数据集进行实验,包括不同环境下的山羊运动数据。
2. 实验环境:使用Python编程语言和相应的机器学习库进行实验。
3. 模型训练与测试:将预处理后的数据集划分为训练集和测试集,使用改进的XGBoost算法进行模型训练和测试。
4. 性能评估:采用准确率、召回率、F1值等指标对模型的性能进行评估。
五、实验结果与分析经过实验验证,本文提出的改进XGBoost算法在山羊运动行为分类方面取得了显著效果。
极限梯度提升模型的训练-概述说明以及解释

极限梯度提升模型的训练-概述说明以及解释1.引言1.1 概述概述极限梯度提升模型(Extreme Gradient Boosting, XGBoost)是一种基于梯度提升决策树(Gradient Boosting Decision Tree, GBDT)算法的机器学习模型。
它在许多数据科学竞赛和实际应用中都表现出了出色的性能。
XGBoost模型的主要优势在于它具备高可扩展性、高效性和准确性。
通过在训练过程中采用了多种技术手段,XGBoost能够有效地处理高维特征和大规模数据集,并且在模型精度方面具有较强的竞争力。
本文将详细介绍极限梯度提升模型的训练方法和原理。
首先,我们将介绍梯度提升决策树算法的基本原理,包括梯度下降和决策树的概念。
然后,我们将阐述XGBoost模型的训练过程,包括损失函数的定义、模型的初始化和迭代优化算法。
最后,我们将探讨极限梯度提升模型在实际应用中的一些典型领域,如金融风控、推荐系统和医疗诊断等。
通过本文的阅读,读者将能够深入了解极限梯度提升模型的训练方法和原理,掌握XGBoost模型在实际应用中的优势和不足,并能够运用该模型解决实际问题。
希望本文能对机器学习和数据科学领域的研究者和从业者提供有益的参考和指导。
1.2 文章结构文章结构:本文主要包括引言、正文和结论三个部分。
引言部分主要是对本篇文章的概述,介绍了极限梯度提升模型的训练这一主题的背景和意义。
其中,概述部分会简要介绍极限梯度提升模型,包括其基本原理和训练过程。
文章结构部分将会列出本文的章节结构,并对各章节的内容进行简要说明。
正文部分主要分为三个章节:极限梯度提升模型的基本原理、极限梯度提升模型的训练过程和极限梯度提升模型的应用领域。
其中,极限梯度提升模型的基本原理章节将详细介绍该模型的基本概念、工作原理和数学原理等内容。
极限梯度提升模型的训练过程章节将详细说明该模型的训练方法和步骤,包括特征选择、参数设置、模型调优等方面的内容。
使用XGBOOST进行机器学习实验报告精品PPT课件

4.设计实验,并使用XGBOOST进行实验。
我们使用 XGBoost 对 Kaggle 上的数据竞赛”Santander Customer Satisfaction”进行了预测。 该项目的目的是通过银行客户的历史数据训练 一个模型来预测客户对银行的满意度,数据集上包含超过 300 个属性, 经过仔细分析,我们认为其中的属性包含了存款,贷款,国籍,年龄等 等。所有的属性都是匿名的并且包含了许多空值。我们的处理思路如下:
• 1. 读取数据,观察数据特征,发现可能有常量列和重复列。 • 2. 消除常量列,29 列数据被删除,这些属性值可能是永远为 0,或者永远为 1。 • 3. 消除重复列,数据中只有两列重复。 • 4. 首先使用随机森林进行训练,训练的目标不是得到最终结果,而是期望得到
每个属性 特征的重要性,为我们后面进行特征选择做准备。
2.XGBOOST的介绍
• XGBoost 算法可以有效的解决这个问题,相对于 Adaboost,XGBoost 采
用了二阶泰勒展开以使算法可以更快的收敛到全局最优。同时, XGBoost 采用 C++进行实现,运算速度 和精度都得到了大大的提升,在 实践中,XGBoost 赢得了多次机器学习竞赛的冠军,在 Kaggle 也是最火 的工具包之一。
• # 我们采用默认的阈值 1e-5 进行特征选
择,那么将从 306 个特征中选出 193 个。
• # 下面进行特征选择
Байду номын сангаас
• test = fs.transform(test) • print(X_train.shape, X_test.shape, test.shape)
基于XGBoost_机器学习模型的信用评分卡与基于逻辑回归模型的对比

第 42 卷第 6 期2023年 11 月Vol.42 No.6Nov. 2023中南民族大学学报(自然科学版)Journal of South-Central Minzu University(Natural Science Edition)基于XGBoost机器学习模型的信用评分卡与基于逻辑回归模型的对比张利斌,吴宗文(中南民族大学经济学院,武汉430074)摘要分别基于逻辑回归模型和XGBoost机器学习模型构建了信用评分卡,比较了两种模型在个人信用评分上的表现,指出XGBoost机器学习模型在“AUC、KS、F1和Accuracy值”上表现更加优秀.首先,从数据的包容性、可解释性以及模型的准确性方面对两个模型进行了对比;其次,使用住房贷款违约风险预测的竞赛数据,分别构建了基于逻辑回归模型和XGBoost机器学习模型的信用评分卡,并使用了AUC、KS、F1和Accuracy来评估这两个模型的分类效果和预测准确程度;最后,通过对比两个模型的评估结果,分析了XGBoost机器学习模型相较于逻辑回归模型更加优秀的原因.结论指出:XGBoost机器学习模型在测试集上的AUC、KS、F1和Accuracy值比逻辑回归模型分别提升了19.9%、17.5%、15.4%和11.9%,其原因在于XGBoost机器学习模型纳入了更多的维度信息、更加科学的缺失值处理方式以及考虑了正则化项的算法原理.关键词逻辑回归模型;XGBoost机器学习模型;信用评分卡中图分类号TP181;F832.51 文献标志码 A 文章编号1672-4321(2023)06-0846-07doi:10.20056/ki.ZNMDZK.20230616Credit scoring card based on XGBoost machine learning modelCompared with logistic regression modelZHANG Libin,WU Zongwen(School of Economics, South-Central Minzu University, Wuhan 430074, China)Abstract A credit scoring card based on logistic regression model and XGBoost machine learning model are constructed respectively. The performance of the two models are compared in personal credit scoring,and it is pointed out that XGBoost machine learning model performs better in “AUC, KS, F1 and Accuracy values”. Firstly, a comparative analysis of the two models is made from the aspects of data inclusiveness, interpretability and model accuracy. Secondly, using the competition data of housing loan default risk prediction,credit scoring cards based on logistic regression model and XGBoost machine learning model are constructed respectively, and AUC, KS, F1 and Accuracy are used to evaluate the classification effect and prediction accuracy of the two models. Finally,by comparing the evaluation results of the two models,the reason why XGBoost machine learning model is better than logistic regression model is analyzed. The conclusion points out that the values of AUC, KS, F1 and Accuracy of XGBoost machine learning model in the test set are increased by 19.9%, 17.5%, 15.4% and 11.9% respectively compared with logistic regression model. The reason is that XGBoost machine learning model includes more dimensional information, more scientific missing value processing method and better algorithm principle considering regularization term.Keywords logistic regression model; XGBoost machine learning model; credit score card在金融风控领域,如何根据贷款客户的基本信息和行为数据等,利用一定的分类模型,将贷款客户区分为违约客户和非违约客户,从而减少贷款机构的信用风险,是金融贷款机构孜孜不倦的追求.收稿日期2022-03-15作者简介张利斌(1973-),男,教授,博士,研究方向:产业经济学,E-mail:*****************基金项目中南民族大学研究生创新基金项目资助项目(3212021sycxjj195)第 6 期张利斌,等:基于XGBoost机器学习模型的信用评分卡与基于逻辑回归模型的对比当前有两种主流分类模型——统计学模型和机器学习模型.逻辑回归模型是最常用的统计学模型,其优点主要体现在:第一,理论基础成熟,适合二分类问题[1];第二,可解释性较强,易于理解[2];第三,模型训练时间短[3].缺点主要体现在:第一,容易产生过拟合,泛化能力弱[4];第二,特征空间很大时,分类性能不好[5].近年来,XGBoost机器学习模型在分类问题中表现优秀,受到越来越多风控人员的青睐,其优点主要体现在:第一,计算复杂度低,运行速度快,准确度高[6];第二,可处理数据量大[7].缺点主要体现在:第一,建模过程不透明,模型较难解释[8];第二,理论基础不够成熟,布置上线较困难[9].在分类模型的评价方面,当前学者主要使用AUC、KS、F1和Accuracy值等来评价逻辑回归模型和XGBoost机器学习模型的效果,并指出XGBoost 机器学习模型比逻辑回归模型在AUC、KS、F1和Accuracy值上表现更加优秀,但是并未解释更加优秀的原因.本文拟从维度信息的损失程度、缺失值的处理方式以及模型的算法原理三方面来解释其中的原因.1 模型对比1.1 逻辑回归模型逻辑回归模型[10]是线性回归模型的改进,是一种“广义的线性回归模型”,该模型是分类问题中最常用的统计学模型.逻辑回归模型的一般形式见式(1)所示,如下:f(x)=11+e-()β0+β1x1+β2x2+⋯+βn x n,(1)其中,β0~βn为模型的估计参数,x1~x n为模型的变量.在金融风控领域,以贷款客户的违约与否作为逻辑回归模型的因变量,一般称为“非违约客户”和“违约客户”,用0或1来表示,即f(x)<0.5为0;f(x)>0.5为1.1.2 XGBoost机器学习模型XGBoost机器学习模型[11]比传统的GBDT (Gradient Boosting Decision Tree,以下简称GBDT)更加进步的原因在于:传统的GBDT只利用了一阶的导数信息,而XGBoost机器学习模型对损失函数进行了二阶的泰勒展开,求得模型最优解的效率更高.具体如下:将XGBoost机器学习模型进行t次迭代之后,此时的目标函数为:L()t=∑i=1n l()yiyit-1+f t(x i)+Ω(f t),(2)将目标函数进行泰勒二阶展开可得:L t≈∑i=1néëêêùûúúl()yi,y i(t-1)+g i f t(x i)+12h i f2t()x i+Ω(f t),(3)gi=∂y(t-1)l(y t,y∧(t-1))为每个样本的一阶导数,12h i=12∂2y(t-1)l(y i,y∧(t-1))为每个样本的二阶导数.1.3 模型优缺点逻辑回归模型和XGBoost机器学习模型的优缺点如表1所示.相较于XGBoost机器学习模型,逻辑回归模型更加方便实现,并且可解释强;XGBoost 机器学习模型在处理大数据时精度更高,并且可以有效防止过拟合.2 实证分析本文的实证分析思路如下:首先,分别运用逻辑回归模型和XGBoost机器学习模型来构建信用评分卡,并运用AUC、KS、F1和Accuracy这四个指标评估模型的效果.其次,从维度信息的损失程度、缺失值的处理方式以及模型的算法原理三个方面对比两个模型,分析XGBoost机器学习模型比逻辑回归表1 逻辑回归模型和XGBoost机器学习模型的优缺点Tab. 1 Advantages and disadvantages of logistic regression model and XGboost machine learning model模型逻辑回归模型XGBoost机器学习模型优点适用于二分类问题简单易理解,可解释性强训练速度快精度高能有效处理缺失值能有效防止过拟合缺点对自变量的多重共线性表现敏感特征空间很大时,分类性能不好容易产生过拟合,分类精度不高建模不透明,不易理解处理低偏差、高方差的数据效果不好847第 42 卷中南民族大学学报(自然科学版)模型更加优秀的原因.2.1 逻辑回归模型2.1.1 数据介绍实验数据来自于kaggle 官网(https ://www./c/home -credit -default -risk/overview )的住房贷款违约风险预测的竞赛数据.本文的实验数据集包括20000个训练数据和5000个测试数据,其中实验数据集共有121列,包括个人基本信息、所在地区情况、借贷信息状况以及公司相关状况等.本文为更好地解释实证部分,将实验数据集的英文变量翻译为中文变量,如表2所示.2.1.2 数据预处理(1) 无效值处理原始数据表中的SK_ID_CURR 变量在实际建模中的用处不大,且包含用户的隐私信息,故需直接删除.(2) 缺失值处理根据jupyter 分析软件可得,121个变量中共有65个有缺失值.其中,共有57个变量的缺失比例大于10%,将其直接删除,对剩余的缺失变量做相应的填充处理,具体处理方式如表3所示.2.1.3 入模变量筛选对逻辑回归模型来说,入模变量的选择至关重要.本文选择WOE 分箱、IV 值筛选法以及相关性检测相结合的方法筛选入模变量,具体思路如下:首先,根据变量的阈值以及业务趋势进行WOE 分箱;其次,根据WOE 分箱计算变量的IV 值,筛选IV 值大于0.3的变量(IV 值大于0.3有较高的预测能力);最后,对IV 值大于0.3变量进行相关性检测,剔除相关性大于0.5中IV 值较小的那个变量.一般来说,建立逻辑回归模型只需选择10~12个变量[12].本文选择IV 值排名靠前且通过相关性检测的11个变量作为入模变量,具体如表4所示.2.1.4 逻辑回归模型的建立根据SPSS 软件,确定x 1~x 11各变量的估计参数,从而建立逻辑回归模型,具体表达式如(4)式所示:f (x )=11+e -()-1.132+0.535x1+0.462x 2+0.769x 3+0.713x 4+0.976x 5+0.875x 6+0.568x 7+0.760x 8+0.375x 9+0.179x 10+0.268x 11,(4)表2 变量解释表Tab. 2 Variable interpretation英文变量名称TARGETNAME_EDUCATION_TYPE AMT_INCOME_TOTAL DAYS_EMPLOYED DAYS_BIRTH FLAG_OWN_REALTYREGION_RATING_CLIENTREG_CITY_NOT_WORK_CITYFLAG_OWN_CAR FLAG_MOBILNAME_INCOME_TYPENAME_FAMILY_STATUSREGION_RATING_CLIENT_W_CITYCODE_GENDER AMT_CREDITNAME_HOUSING_TYPEDEF_30_CNT_SOCIAL_CIRCLE…DEF_60_CNT_SOCIAL_CIRCLE REG_CITY_NOT_LIVE_CITY BASEMENTAREA_AVG ORGANIZATION_TYPE中文变量名称违约情况教育程度收入就业年数年龄不动产拥有情况所在地区评级常驻地址和工作地址匹配情况车辆情况家庭电话提供情况收入类型家庭状况所在城市的评级性别贷款金额住房情况违约60天的天数…违约30天的天数常驻地址和联系地址匹配情况房屋的面积大小公司的组织情况解释0:正常还款;1:违约客户受教育程度客户的年总收入申请人就业年数客户申请贷款时的年龄Y :有;N :没有1:最高;2:中等;3:较差1:相同;0:不相同(城市级别匹配)Y :有;N :没有1:有;0:没有客户的收入类型客户的家庭状况1:最高;2:中等;3:较差F :女;M :男客户的贷款金额客户的住房情况(租房or 与父母同住)客户违约30天的次数…客户违约60天的次数1:相同;0:不相同(城市级别匹配)客户居住房屋的面积大小客户工作的组织类型848第 6 期张利斌,等:基于XGBoost 机器学习模型的信用评分卡与基于逻辑回归模型的对比其中x i (i =1⋯11)为11个入模变量;f (x )为预测结果.2.1.5 信用评分卡的建立根据传统的信用评分机制,可以制作信用评分卡,标准的信用评分卡如表5所示.表中,A 、B 为假设的基础分值,本文设为500和50,θ0~θn 为x 1~x n 的估计参数,ω11~ωnk n为x 1~x n 各分量的WOE 值.根据评分转换原理,计算出11个入模变量的各分量得分值,具体结果如表6所示.利用表6的信用评分卡对5000个测试集样本进行评分转换,得测试集样本的最终得分情况见表7.从表7的得分情况可以看出,随着用户得分的上升,高分段的坏样本占比呈现出不断下降的趋势,这也说明了信用评分卡可以较好地识别信用风险.2.1.6 模型的效果评价对于分类模型而言,可以从分类能力和预测的准确程度来评价模型的效果.一般来说,使用AUC 和KS 来评估模型的分类能力以及F1和Accuracy 来评估模型的预测准确程度[13].通过对训练集和测试集的样本测试,得到相关的评价指标如表8所示.从表8可以看出该模型在测试集上拥有0.7294的AUC 和0.5378的KS ,这表示模型具有较好的分类能力.同时该模型在测试集上拥有0.8218的F1和0.8325的Accuracy ,这表示模型具有较高的预测准确程度.2.2 XGBoost 机器学习模型2.2.1 朴素的XGBoost 机器学习模型首先,用训练数据来建立默认参数下的XGBoost 机器学习模型;其次,对所构建的XGBoost 机器学习模型进行效果评价.具体结果如表9所示.由表9可知,在没有超参数约束的情况下,XGBoost 机器学习模型在训练集上完全拟合,而在测试集上的表现相对一般,这表明该模型的泛化能力较弱.造成这种现象的原因是XGBoost 机器学习模型是基于决策树的集成模型,如果不限制其增表3 缺失变量处理表Tab. 3 Missing variable processing table 变量名称COMMONAREA_AVGCOMMONAREA_MODE COMMONAREA_MEDINONLIVINGAPARTMENTS_AVGNONLIVINGAPARTMENTS_MODE …AMT_REQ_CREDIT_BUREAU_HOUR AMT_REQ_CREDIT_BUREAU_DAYAMT_REQ_CREDIT_BUREAU_WEEK NAME_TYPE_SUITEOBS_30_CNT_SOCIAL_CIRCLE DEF_30_CNT_SOCIAL_CIRCLE OBS_60_CNT_SOCIAL_CIRCLEDEF_60_CNT_SOCIAL_CIRCLEEXT_SOURCE_2AMT_GOODS_PRICEDAYS_LAST_PHONE_CHANGE缺失比例0.699250.699250.699250.693550.69355…0.134700.134700.134700.004150.003600.003600.003600.003600.002500.000750.00005处理方式删除变量删除变量删除变量删除变量删除变量…删除变量删除变量删除变量众数填充中位数填充中位数填充中位数填充中位数填充中位数填充中位数填充中位数填充表5 标准评分卡Table. 5 Standard score card变量基准点x 1x 2…x n WOE 分箱—12…k 112…k 2 (12)…k n分值(A -Bθ0)-(Bθ1ω11)-(Bθ1ω12)…-(Bθ1ω1k)-(Bθ2ω21)-(Bθ2ω22)-(Bθ2ω2k)…-(Bθn ωn 1)-(Bθnωn 2)…-(Bθn ωnk)表4 入模变量表Table. 4 Molding variables变量教育程度(x 1)收入(x 2)就业年数(x 3)年龄(x 4)不动产拥有情况(x 5)所在地区评级(x 6)常驻地址和工作地址匹配情况(x 7)车辆情况(x 8)家庭电话提供情况(x 9)收入类型(x 10)家庭状况(x 11)IV0.96300.92130.89760.84320.81340.75030.74180.72120.70190.68180.6745相关性检测全部变量均通过相关性检测849第 42 卷中南民族大学学报(自然科学版)长,它可以学习到适应所有训练样本的规则.但是如何提高该模型在测试集上的表现,才是我们真正所关心的,因此需要对模型进行调参优化.2.2.2 调优的XGBoost机器学习模型XGBoost的超参数可以归为三个核心部分:通用参数,Booster参数和任务参数[14].本文在通用参数、Booster参数以及学习目标参数这三类参数的具体选择如表10所示.本文使用网格搜索交叉验证得到的最优超参数为:eta为0.02,min_child_weight为2,gamma=0.2,max_depth为5,num_boost_round为110.使用该参数组合的XGBoost机器学习模型对训练数据和测试数据进行效果评价,具体结果如表11所示.从表11可以看出,该模型在测试集上拥有0.8746的AUC和0.6318的KS,这表示模型具有很好的分类能力.同时该模型在测试集上拥有0.9487的F1和0.9318的Accuracy,这表示模型具有很高的预测准确程度.将该模型与朴素的XGBoost机器学习模型在测试集上的表现进行对比,得到的结果如表12所示.从表12可知,调优的XGBoost机器学习模型相表8 模型结果评估Tab. 8 Evaluation of model results数据集训练集测试集分类能力评价AUC0.76820.7294KS0.55360.5378预测准确程度评价F10.83790.8218Accuracy0.84190.8325表9 朴素的XGBoost机器学习模型结果Tab. 9 Results of simple XGBoost machine learning model数据集训练集测试集分类能力评价AUC0.99620.8362KS0.99740.5546预测准确程度评价F10.99540.8871Accuracy0.99130.8916表6 基于逻辑回归模型的信用评分卡Tab. 6 Credit scoring card based on logistic regression model变量名称基础分值教育程度年龄常驻地址和工作地址收入类型WOE分箱—Lower secondarySecondary /secondary specialIncomplete higherHigher education20~4040~6060~80不相同相同WorkingCommercial associatePensionerState servantElse分值5576111419510133935321变量名称基础分值收入不动产拥有情况车辆情况家庭状况WOE分箱—<100000100000~200000200000~300000>300000有无无有MarriedSingle / not marriedCivil marriageSeparatedWidow分值55771013154112842431变量名称基础分值就业年数所在地区评级家庭电话提供情况WOE分箱—0~1010~2020~3030~50123否是分值5576101214491037表7 测试集样本得分情况统计Tab. 7 Statistics of sample scores of test set得分区间[599,609)[609,619)[619,629)[629,639)[639,649)[649,659)[659,669)[669,672]好样本132140645712865778712678坏样本3525535663473524总计167165698768928825747702好样本占比79%84.8%92.4%92.7%93.2%94.3%95.3%96.6%坏样本占比21%15.2%7.6%7.3%6.8%5.7%4.7%3.4%总体占比3.34%3.3%13.96%15.36%18.56%16.5%14.94%14.04%信用等级DCBA说明信用风险很高,不建议贷款有一定的信用风险,需要对资产和信誉做进一步评估后考虑是否贷款信用风险较低,需要对贷款的流向关注后考虑贷款信用风险极低,建议贷款850第 6 期张利斌,等:基于XGBoost 机器学习模型的信用评分卡与基于逻辑回归模型的对比比于朴素的XGBoost 机器学习模型,AUC 、KS 、F1和Accuracy 都有所提升,这说明调优后的XGBoost 机器学习模型更加优秀.2.2.3 信用评分卡的构建为了更加具体地观察调优的XGBoost 机器学习模型输出结果,本文考虑引入传统的信用评分机制,进而将机器学习模型输出的概率值转换为常见的信用评分值.通过对测试集样本的信用评分统计,具体的信用评分卡如表13所示.从表13可以看出,XGBoost 机器学习模型输出的概率值可以通过信用评分机制转换为信用评分值.随着得分的提高,好样本的占比逐渐提升,坏样本的占比逐渐降低,这说明所建立的信用评分卡能够较好地识别信用风险.2.3 模型对比分析根据上文的实验结果,将逻辑回归模型和调优的XGBoost 机器学习模型在测试集上的AUC 、KS 、F1和Accuracy 进行比较,如表14所示.从表14可以看出,XGBoost 机器学习模型在测试集上的AUC 、KS 、F1和Accuracy 均高于逻辑回归模型.通过对两种建模方式的比较,XGBoost 机器学习模型更加优秀的原因主要有以下三点:(1) 维度信息损失程度更低在建立逻辑回归模型,运用WOE 分箱、IV 值筛选法以及相关性检测相结合的方法从121个原始变量中挑选出11个变量来建立逻辑回归模型,该方法损失了较多的维度信息,仅列出Ⅳ最高的11个变量.然而,在建立XGBoost 机器学习模型时,将121个变量经过数据处理后全部输入到模型中,几乎没有原始数据的信息损失.单从数据维度来看,XGBoost 机器学习模型纳入更多的维度信息是机器学习模型相对于逻辑回归模型更加优秀的原因之一.(2) 缺失值的处理方式更加科学在建立逻辑回归模型时,一般删除缺失比例超表10 XGBoost 的调参参数Tab. 10 Adjusted parameters of XGBoost超参数通用参数Booster 参数学习目标参数参数标签booster=tree etamin_child_weight gamma max_depth num_boost_roundobject=binary :logisticeval_metric :auc ,ks ,f1,accuracy参数含义决策树学习率最小叶节点样本权值gamma 值基决策树最大深度迭代轮数逻辑回归算法误差评判标准参数作用使用决策树作为基学习器控制基学习器的特征权重更新大小控制基学习器的叶子节点分裂情况控制基学习器的叶子节点总数控制基学习器的最大深度控制算法的迭代次数控制每次迭代的目标损失函数评估模型的分类性能表12 朴素的XGBoost 与调优的XGBoost 机器学习模型对比结果Tab. 12 Comparison results of simple XGboost and optimizedXGboost machine learning models模型朴素的XGBoost 机器学习模型调优的XGBoost 机器学习模型AUC0.83620.8746KS0.55460.6318F10.88710.9487Accuracy 0.89160.9318表11 调优的XGBoost 机器学习模型结果Tab. 11 Results of optimized XGboost machine learning model 数据集训练集测试集分类能力评价AUC0.88690.8746KS0.65280.6318预测准确程度评价F10.95380.9487Accuracy 0.94190.9318表13 基于XGBoost 机器学习模型的信用评分卡Tab. 13 Credit scoring card based on XGBoost machine learning model输出概率(0.0,0.5](0.5,0.6](0.6,0.7](0.7,0.8](0.8,0.9](0.9,1.0]得分区间(-∞,500](500,509](509,528](528,558](558,606](606,+∞)好样本528755876985728660坏样本12510397814715总体6538589731066775675好样本占比/%80.8688.0090.0392.4093.9497.78坏样本占比/%19.1412.009.977.606.042.22总体占比/%13.0617.1619.4621.3215.5013.50信用等级D C B A说明信用风险很高,不建议贷款有一定的信用风险,需要对资产和信誉做进一步评估后考虑是否贷款信用风险较低,需要对贷款的流向关注后考虑贷款信用风险极低,建议贷款表14 逻辑回归模型与调优的XGBoost 机器学习模型对比结果Tab. 14 Comparison results between logistic regression model andoptimized XGboost machine learning model模型逻辑回归模型调优的XGBoost 机器学习模型AUC0.72940.8746KS0.53780.6318F10.82180.9487Accuracy 0.83250.9318851第 42 卷中南民族大学学报(自然科学版)过10%的缺失值,同时用众数填充类别型缺失变量和中位数填充连续型缺失变量,该方法有一定的人工干预,处理缺失值方式不够严谨.然而,XGBoost 机器学习模型采用内置算法处理数据的缺失值,该方法处理缺失值更加科学.单从缺失值的处理方式来看,XGBoost机器学习模型科学地处理缺失值是该模型相对于逻辑回归模型更加优秀的原因之一.(3) 模型的算法原理考虑了正则化项在建立逻辑回归模型时,没有考虑正则化项,导致该模型复杂度较高,有过拟合的风险,评估效果一般.然而,在建立XGBoost机器学习模型时,考虑了正则化项,降低了过拟合风险,评估效果得到了有效提升.单从模型的算法原理来看,XGBoost机器学习模型考虑了正则化项是该模型相对于逻辑回归模型更加优秀的原因之一.3 结论与思考本文比较了逻辑回归模型和XGBoost机器学习模型在信用评分卡构建中的具体表现,通过对比两个模型的AUC、KS、F1和Accuracy值,得出了以下结论:(1)逻辑回归模型在测试集上的分类效果以及预测准确程度不如XGBoost机器学习模型.逻辑回归模型的AUC、KS、F1和Accuracy均低于XGBoost 机器学习模型,这表明XGBoost机器学习模型在分类效果以及预测准确程度上均表现更优.(2)逻辑回归模型建模过程较XGBoost机器学习模型更易于理解.在建立逻辑回归模型时,通过特征筛选从121个变量中筛选出11个变量建立逻辑回归模型,该方法建模过程透明,易于理解.然而,XGBoost机器学习模型以编程和调整参数的形式来建立模型,具有一定的不透明性,不易于理解.(3)维度信息损失程度更低、缺失值的处理方式更加科学以及模型的算法原理更加科学(考虑了正则化项)是XGBoost机器学习模型相较于逻辑回归模型在分类效果以及预测准确程度上更加优秀的原因.如何融合逻辑回归模型和XGBoost机器学习模型,使其两者在风控领域可以优势互补,在提高模型效果的同时又增强解释能力?是值得我们下一步深入研究的问题.参考文献[1]WIGINTON,J C. A note on the comparison of logit and discriminant models of consumer credit behavior[J]. TheJournal of Financial and Quantitative Analysis, 1980, 15(3): 757-770.[2]涂艳,王翔宇. 基于机器学习的P2P网络借贷违约风险预警研究——来自“拍拍贷”的借贷交易证据[J]. 统计与信息论坛, 2018, 33(6): 69-76.[3]毛毅,陈稳霖,郭宝龙,等. 基于密度估计的逻辑回归模型[J]. 自动化学报, 2014, 40(1): 62-72.[4]COSTA S E, LOPES I C, CORREIA A, et al. A logistic regression model for consumer default risk[J]. Journal ofApplied Statistics, 2020, 47(13-15): 2879-2894.[5]周毓萍,陈官羽. 基于机器学习方法的个人信用评价研究[J]. 金融理论与实践, 2019(12): 1-8.[6]CHEN T,GUESTRIN C. XGBoost:A scalable tree boosting system[J]. IEICE Transactions on Fundamentalsof Electronics, Communications and Computer Sciences,2016:785-794.[7]严武,冯凌秉,蒋志慧,等. 基于机器学习模型的P2P 网贷平台风险预警研究[J]. 金融与经济, 2019 (9):18-25.[8]黄卿,谢合亮. 机器学习方法在股指期货预测中的应用研究——基于BP神经网络、SVM和XGBoost的比较分析[J]. 数学的实践与认识, 2018, 48(8): 297-307.[9]WANG Kui,LI Meixuan,CHENG Jingyi;et al.Research on personal credit risk evaluation based onXGBoost[J]. Procedia Computer Science Volume, 2022,199: 1128-1135.[10]洪文洲,王旭霞,冯海旗. 基于Logistic回归模型的上市公司财务报告舞弊识别研究[J]. 中国管理科学,2014,22(S1):351-356.[11]王重仁,韩冬梅. 基于超参数优化和集成学习的互联网信贷个人信用评估[J]. 统计与决策, 2019,35(1):87-91.[12]刘志惠,黄志刚,谢合亮. 大数据风控有效吗——基于统计评分卡与机器学习模型的对比分析[J]. 统计与信息论坛, 2019, 34(9): 18-26.[13]张佳倩,李伟阮,素梅. 基于机器学习的贷款违约风险预测[J]. 长春理工大学学报(社会科学版). 2021,34(4):105-111.[14]周庆岸. 基于遗传XGBoost模型的个人网贷信用评估研究[D]. 南昌:江西财经大学,2019.(责编&校对雷建云)852。
基于Xgboost的心血管疾病预测模型和指标分析研究

958
现代医院 2021年 6月第 21卷第 6期 ModernHospitalsJun2021Vol21No6
基于 Xgboost的心血管疾病预测模型和指标分析研究
陈洞天 单 杰 周文丹
【摘 要】 目的 建立一种基于 Xgboost机器学习算法的心血管疾病预测模型,并分析各指标对于最终预测结果的 影响。方法 采集诊断为冠心病、心肌梗塞等心血管疾病的病例和未诊断为心血管疾病的患者,合计 1000病例数据,通 过 Xgboost机器学习算法训练得出心血管疾病风险预测模型,并对模型进行可解释性分析。结果 该风险预测模型的准 确率在 765%,预测结果相对可靠;此外,模型的可解释性分析结果得出了各指标的影响规律。结论 Xgboost对以心血 管疾病为例的疾病预测具有较好的效果,并且通过可解释性分析能直观地总结各指标的影响规律。 【关键词】 机器学习;Xgboost;心血管疾病;可解释性;特征重要性 中图分类号:TP181;R54 文献标志码:A doi:10.3969/j.issn.1671-332X.2021.06.044
表 2 部分样本数据
患者编号 95 96 97 98 99
年龄 21076 19258 18410 21860 17363
性别 1 2 1 2 1
《2024年结合SVM与XGBoost的链式多路径覆盖测试用例生成》范文

《结合SVM与XGBoost的链式多路径覆盖测试用例生成》篇一一、引言在软件测试领域,确保软件的完整性和功能正确性是至关重要的。
链式多路径覆盖测试用例生成方法是一种有效的测试策略,能够更全面地测试软件中的不同路径和逻辑组合。
随着机器学习技术的快速发展,特别是支持向量机(SVM)和极端梯度提升树(XGBoost)等算法的崛起,为测试用例生成提供了新的思路。
本文将探讨如何结合SVM与XGBoost进行链式多路径覆盖测试用例生成,以提高测试效率和准确性。
二、SVM与XGBoost在测试用例生成中的应用SVM是一种有监督学习算法,能够根据已知的输入和输出数据,找到一个最优的决策边界来对数据进行分类。
而XGBoost是一种集成学习算法,通过集成多个决策树来提高分类和预测的准确性。
在测试用例生成中,这两种算法可以相互配合,提高测试的全面性和效率。
具体而言,SVM可以通过对历史测试数据的学习,找到输入和输出之间的潜在关系和规律。
而XGBoost则可以在SVM的基础上,进一步分析这些关系和规律,从而生成更加精确和全面的测试用例。
三、结合SVM与XGBoost的链式多路径覆盖测试用例生成方法1. 数据准备:收集历史测试数据,包括输入数据和输出数据。
这些数据应涵盖软件的各种功能和逻辑路径。
2. 数据预处理:对收集到的数据进行清洗、去重、归一化等处理,以便于后续的算法学习和分析。
3. SVM模型训练:使用预处理后的数据训练SVM模型,找到输入和输出之间的潜在关系和规律。
4. XGBoost模型训练:在SVM模型的基础上,使用XGBoost算法对数据进行进一步的分析和预测。
通过集成多个决策树,提高预测的准确性和全面性。
5. 生成测试用例:根据SVM和XGBoost的预测结果,结合链式多路径覆盖的思路,生成新的测试用例。
这些测试用例应涵盖软件的各种功能和逻辑路径,以确保软件的完整性和功能正确性。
6. 测试执行与评估:将生成的测试用例进行执行,并评估软件的性能和功能正确性。
机器学习实验报告完整

机器学习实验报告完整摘要:本实验报告旨在探究机器学习算法在数据集上的表现,并评估不同算法的性能。
我们使用了一个包含许多特征的数据集,通过对数据进行预处理和特征选择,进行了多个分类器的比较实验。
实验结果显示,不同的机器学习算法在不同数据集上的表现存在差异,但在对数据进行适当预处理的情况下,性能可以有所改善。
引言:机器学习是一种通过计算机程序来自动学习并改善性能的算法。
机器学习广泛应用于各个领域,例如医学、金融和图像处理等。
在本实验中,我们比较了常用的机器学习算法,并评估了它们在一个数据集上的分类性能。
方法:1. 数据集我们使用了一个包含1000个样本和20个特征的数据集。
该数据集用于二元分类任务,其中每个样本被标记为正类(1)或负类(0)。
2. 预处理在进行实验之前,我们对数据集进行了预处理。
预处理的步骤包括缺失值填充、异常值处理和数据归一化等。
缺失值填充使用常用的方法,例如均值或中位数填充。
异常值处理采用了离群点检测算法,将异常值替换为合理的值。
最后,我们对数据进行了归一化处理,以确保不同特征的尺度一致。
3. 特征选择为了提高分类性能,我们进行了特征选择。
特征选择的目标是从原始特征中选择出最相关的特征子集。
我们使用了常见的特征选择方法,如相关性分析和特征重要性排序。
通过这些方法,我们选取了最具判别能力的特征子集。
4. 算法比较在本实验中,我们选择了四种常见的机器学习算法进行比较:决策树、逻辑回归、支持向量机(SVM)和随机森林。
我们使用Python编程语言中的机器学习库进行实验,分别训练了这些算法,并使用交叉验证进行评估。
评估指标包括准确率、召回率、F1值和ROC曲线下方的面积(AUC)。
结果与讨论:通过对比不同算法在数据集上的性能,我们得出以下结论:1. 决策树算法在本实验中表现欠佳,可能是由于过拟合的原因。
决策树算法可以生成高度解释性的模型,但在处理复杂数据时容易陷入过拟合的状态。
2. 逻辑回归算法表现较好,在数据集上获得了较高的准确率和F1值。
基于xgboost的特征筛选

基于xgboost的特征筛选基于XGBoost的特征选择是一种利用集成学习方法来选择最重要特征的技术。
XGBoost是一种基于梯度增强决策树的机器学习算法,它通过迭代地训练多个弱学习器来提高整体预测性能。
特征选择是机器学习中非常重要的一个环节,它可以帮助我们减少模型复杂度、提高模型泛化能力,并且能够提供更好的解释性。
在大数据时代,我们经常会面对成千上万个特征的问题,但其中很多特征并不一定对模型的预测结果有任何帮助,甚至可能会引入噪声和过拟合的风险。
因此,选择最重要的特征对于提升模型性能是非常关键的。
XGBoost通过自带的特征重要性评估方法来进行特征选择。
在XGBoost中,特征重要性是通过计算每个特征在决策树中分裂节点时,对模型目标函数的贡献来衡量的。
贡献越大,说明该特征对目标函数的预测有更强的能力。
具体而言,XGBoost的特征选择过程可以分为以下几个步骤:1. 训练初始模型:首先,我们需要使用所有特征训练初始的XGBoost模型。
这个模型可能并不是最优的,但它可以提供一个基准性能。
2. 评估特征重要性:使用训练好的模型,我们可以通过XGBoost自带的特征重要性方法评估每个特征的重要性。
这个重要性指标可以衡量每个特征对目标函数的贡献。
3.移除重要性低的特征:根据特征重要性得分,我们可以按照一定的阈值筛选掉重要性较低的特征。
通常情况下,我们会选择一个合理的阈值来保留重要性较高的特征,而移除重要性较低的特征。
4. 重新训练模型:在移除低重要性特征后,我们需要使用保留下来的特征重新训练XGBoost模型。
这个新模型会考虑到特征选择的结果,从而提供更好的性能。
5.重复上述步骤:我们可以多次重复上述步骤,直到达到我们的要求。
每次迭代时,特征重要性的评估和特征筛选都会发生改变,从而可能得到更好的特征选择结果。
需要注意的是,特征重要性的评估结果可能受到许多因素的影响,比如输入数据、参数设置等。
因此,在进行特征选择时,我们需要进行交叉验证或者使用其他稳定性评估方法来确保结果的可靠性。
xgboost算法原理

xgboost算法原理XGBoost(ExtremeGradientBoosting)是近几年比较流行的机器学习算法,可以用于分类和回归预测。
XGBoost是基于梯度提升决策树(Gradient Boosting Decision Tree)的可扩展的、高效的、开源的实现,它具有快速的训练时间,自动处理数据不平衡,自动选择合适的特征等优点。
本文将介绍XGBoost算法的原理,分析它的优势,以及它在实际应用中的经验。
第二部分:基本概念XGBoost是一种基于梯度提升决策树(GBDT)的机器学习算法,它以树模型为基础,使用不同的正则化技术来处理过拟合和建立初步结构。
XGBoost算法通过在弱学习器(weak learners)之间构建一个有序而又复杂的集成模型,从而实现得到较强的预测精度。
XGBoost 算法使用了目标函数(objective function)、正则化项(regularization term)和损失函数(loss function)来训练模型,能够自动学习各个特征的权重,并且具有很高的准确率。
第三部分:算法原理XGBoost算法是一种基于梯度提升的机器学习算法,它的基本原理如下:(1)目标函数(Objective Function):XGBoost算法的目标函数是为了提升模型的性能而定义的。
它包含三项:损失函数(Loss Function)、正则化(Regularization)和其他项(Other Items)。
(2)损失函数(Loss Function):XGBoost算法使用常见的损失函数,如二分类损失函数、多分类损失函数以及回归损失函数。
(3)正则化(Regularization):XGBoost算法使用L1和L2正则化,以及自动学习率(auto-learn rate)来防止过拟合。
(4)其他项(Other Items):XGBoost算法还有一些其他参数,例如行深度(row depth)、叶子数量(leaf number)、最小叶子样本数量(minimum leaf sample number)等,这些参数可以在算法训练过程中通过超参数调优来提高性能。
xgb原理

xgb原理XGBoost(eXtreme Gradient Boosting)是一种高效的机器学习算法,它在数据科学领域得到了广泛的应用。
本文将介绍XGBoost的原理和工作原理,以帮助读者更好地理解这一强大的算法。
XGBoost是一种集成学习算法,它通过组合多个弱分类器来构建一个强分类器。
在XGBoost中,每个弱分类器都是一棵决策树,这些决策树通过集成学习的方式来提高整体模型的准确性。
XGBoost的核心思想是不断地迭代训练决策树模型,然后将每棵树的预测结果相加,得到最终的预测结果。
在训练过程中,XGBoost通过最小化损失函数来优化模型参数,从而使模型在训练数据上达到最佳拟合效果。
XGBoost的训练过程可以分为两个阶段,第一阶段是初始化模型,第二阶段是迭代优化模型。
在初始化阶段,XGBoost会根据训练数据的分布初始化模型参数,然后通过迭代优化模型参数来最小化损失函数。
在每一轮迭代中,XGBoost都会计算每个样本的梯度和二阶导数,然后根据这些信息来更新模型参数,直到达到停止迭代的条件为止。
XGBoost的优点之一是它能够处理大规模的数据集,并且具有很高的准确性。
这得益于XGBoost采用了一系列的优化技术,如特征分裂算法、稀疏感知算法和缓存感知算法等。
这些技术使XGBoost在训练和预测过程中能够高效地利用计算资源,从而加速模型的训练和预测速度。
此外,XGBoost还具有很好的鲁棒性和泛化能力,它能够有效地避免过拟合和欠拟合问题,从而在实际应用中取得更好的效果。
这得益于XGBoost在模型训练过程中引入了正则化项,以防止模型过于复杂,同时也采用了特征子采样和样本子采样等技术,以增强模型的泛化能力。
总之,XGBoost作为一种高效、准确、鲁棒的机器学习算法,已经成为了数据科学领域的瑰宝。
通过本文的介绍,相信读者对XGBoost的原理和工作原理有了更深入的了解,希望本文能够对读者在实际应用中使用XGBoost算法起到一定的帮助和指导作用。
基于S-XGBoost_融合模型的中国进境快件风险水平评价研究

51
3 Smote 算法
在进境快件实际监管中, 无风险包裹是占据绝大多数的, 相对来说异常包裹数量是微乎其
微的, 反映在获取到的进境 B 类快件多维度特征数据集中, 则体现为类别不平衡, 这就会对学
习过程造成困扰。 为此, 本文提出了构建 S - XGBoost 风险评估融合模型, 即为使用 smote 算法
代快件业务开始在中国生根发芽。 改革开放后, 进出口外贸业务的蓬勃发展, 进出境快件业务
随之应运而生。 自 1985 年海关总署发布 《 海关对进出口快递物品监管办法》 , 明确进出境快件
业务的监管方式后, 随着互联网经济的飞速发展, 快件凭借网络优势和技术优势不断冲击和改
变着传统产业的发展形态, 海关业务将应纳税货物从进出境快件渠道移除, 使得进出境快件业
管与违法企业为切入点, 构建形成博弈模型, 重点围绕税率、 货值、 处罚损失、 商誉损失、 海
关奖励和查验成本等模型变量开展讨论, 观察对海关查验概率和电商企业违法概率造成的影
响, 最终提出应整合、 再造海关监管流程等对策建议。[3] Xu ( 2022) 为了加快快件通关效率,
使用 ZBAR 算法和 Tesseract -OCR 技术建立了一种快速识别方法, 帮助物流中心从数据库中准
最邻近生成异常包裹数据进而增大异常数据的比重, 从而提升 XGBoost 模型对于风险数据的敏
感度, 以期对进境快件的风险评估提供技术支持。
基于 S -XGBoost 融合模型的
中国进境快件风险水平评价研究
刘昌伟 谢 晶 邹廉青 梅云鹏 Kashif Abbass ∗
摘 要: 党的二十大报告指出要增强维护国家安全能力, 推进国家安全体系和
python机器学习库xgboost的使用

python机器学习库xgboost的使⽤1.数据读取利⽤原⽣xgboost库读取libsvm数据import xgboost as xgbdata = xgb.DMatrix(libsvm⽂件)使⽤sklearn读取libsvm数据from sklearn.datasets import load_svmlight_fileX_train,y_train = load_svmlight_file(libsvm⽂件)使⽤pandas读取完数据后在转化为标准形式2.模型训练过程1.未调参基线模型使⽤xgboost原⽣库进⾏训练import xgboost as xgbfrom sklearn.metrics import accuracy_scoredtrain = xgb.DMatrix(f_train, label = l_train)dtest = xgb.DMatrix(f_test, label = l_test)param = {'max_depth':2, 'eta':1, 'silent':0, 'objective':'binary:logistic' }num_round = 2bst = xgb.train(param, dtrain, num_round)train_preds = bst.predict(dtrain)train_predictions = [round(value) for value in train_preds] #进⾏四舍五⼊的操作--变成0.1(算是设定阈值的符号函数)train_accuracy = accuracy_score(l_train, train_predictions) #使⽤sklearn进⾏⽐较正确率print ("Train Accuary: %.2f%%" % (train_accuracy * 100.0))from xgboost import plot_importance #显⽰特征重要性plot_importance(bst)#打印重要程度结果。
深入理解XGBoost:高效机器学习算法与进阶

目录分析
1.2集成学习发展 与XGBoost提出
1.1何谓机器学习
1.3小结
2.1搭建Python机器 学习环境
2.2搭建XGBoost运 行环境
2.3示例:XGBoost 告诉你蘑菇是否有毒
2.4小结
01
3.1 KNN
02
3.2线性回 归
04
3.4决策树
06
3.6排序
03
3.3逻辑回 归
05
精彩摘录
相比深度神经络,XGBoost能够更好地处理表格数据,并具有更强的可解释性,另外具有易于调参、输入数 据不变性等优势。
Gradient Boosting也是将弱学习器通过一定方法的融合,提升为强学习器。与AdaBoost不同的是,它将损 失函数梯度下降的方向作为优化的目标,新的学习器建立在之前学习器损失函数梯度下降的方向,代表算法有 GBDT、XGBoost
读书笔记
这本书对我这个菜鸟很友好,我手机上看了三分之一后就买了纸质书仔细读了。
1)大厂工程师撰写,帮你打通高效机器学习脉络,掌握竞赛神器XGBoost 2)以机器学习基础知识做铺垫, 深入剖析XGBoost原理、分布式实现、模型优化、深度应用等。
多角度的有浅有深的讲解了XGB的基础知识,原理,优化方法和实际应用,看完后感觉对xgboost框架有了一 个整体把握,很赞;同时,对相关的知识和技术做了介绍,扩展了眼界,很不错。
Stacking的思想是通过训练集训练好所有的基模型,然后用基模型的预测结果生成一个新的数据,作为组合 器模型的输入,用以训练组合器模型,最终得到预测结果。组合器模型通常采用逻辑回归。
识别准确率仅比随机猜测高一些的学习算法为弱学习算法;识别准确率很高并能在多项式时间内完成的学习 算法称为强学习算法。
《基于XGBoost的用户投诉风险预测模型的探究与实现》范文

《基于XGBoost的用户投诉风险预测模型的探究与实现》篇一一、引言随着互联网的快速发展,用户投诉问题逐渐成为企业关注的重点。
为了有效预测和管理用户投诉风险,本文提出了一种基于XGBoost算法的用户投诉风险预测模型。
该模型通过对用户的历史行为数据和投诉信息进行分析,准确预测其投诉风险,从而为企业提供更准确的决策支持。
二、相关文献综述与现状近年来,许多学者对用户投诉风险预测进行了研究。
其中,传统的预测方法如逻辑回归、决策树等已经取得了一定的成果。
然而,这些方法在处理高维度、非线性、具有交互作用的特征时,存在局限性。
随着机器学习技术的发展,XGBoost算法作为一种优秀的梯度提升算法,在多个领域取得了显著的成果。
因此,本文选择XGBoost算法作为用户投诉风险预测模型的基础。
三、研究方法与数据来源本文采用XGBoost算法构建用户投诉风险预测模型。
首先,对数据进行预处理,包括数据清洗、特征提取等步骤。
然后,利用XGBoost算法对处理后的数据进行训练和预测。
本文所使用的数据来源包括企业内部用户行为数据、用户投诉数据等。
四、模型构建与实现4.1 特征选择与处理在构建模型之前,需要对数据进行特征选择和处理。
首先,从用户行为数据中提取出与投诉风险相关的特征,如用户活跃度、购买行为、使用时长等。
其次,对数据进行归一化处理,以消除不同特征之间的量纲差异。
最后,对数据进行编码处理,将非数值型特征转换为数值型特征。
4.2 XGBoost算法原理XGBoost算法是一种基于梯度提升决策树的集成学习算法。
它通过不断添加新的树来优化目标函数,以实现更高的预测精度。
在每一步迭代中,XGBoost算法计算目标函数的负梯度作为残差的近似值,并将其作为下一个基函数的训练目标。
通过多次迭代,最终得到一个强学习器。
4.3 模型训练与调参在模型训练过程中,需要选择合适的参数以优化模型的性能。
本文采用网格搜索和交叉验证等方法对参数进行调优。
集成XGBoost算法优化模型性能

集成XGBoost算法优化模型性能随着数据集的增加和机器学习模型的发展,算法性能成为了模型优化中不可忽视的重要部分。
而XGBoost算法,因为其高效、准确和可扩展性等优点,已成为机器学习领域中广泛应用的强有力算法。
然而,在实际应用中,我们常常需要进一步优化XGBoost算法性能,以满足不同场景和需求的应用。
下面我们将从三个方面论述如何优化XGBoost算法性能。
一、选择合适的参数和评估指标合适的参数选取对于算法的性能优化尤为重要。
XGBoost算法中较为重要的参数包括树的数量、学习率、最大深度、每个节点最少样本数等。
此外,评估指标也是一个关键因素,包括精度、召回率、F1分数、ROC曲线等。
因此,我们需要根据具体情况选择合适的参数和评估指标来优化模型性能。
在实践中,我们常常通过网格搜索等方法来选择最佳参数,并根据模型表现来选择最佳评估指标。
二、减小过拟合风险过拟合是机器学习中一个常见的问题,如果不处理过拟合,会导致模型泛化性能下降。
对于XGBoost算法,我们可以采用如下几种方法减小过拟合风险:1.提前停止:可以根据模型在验证集上的表现来停止模型的训练,避免模型在训练集上过拟合。
2.正则化参数: L1和L2正则化是减少过拟合的另一个有效方法。
通过在目标函数中加入惩罚项来限制模型的复杂度,从而降低过拟合风险。
3.使用样本子集:通过在训练过程中使用部分样本子集来训练,可以避免模型在全部训练集上过拟合。
三、集成XGBoost算法集成学习是一种有效的机器学习方法,能够利用多个模型的优势,提高模型的性能和准确性。
而对于XGBoost算法,我们也可以通过集成不同版本的XGBoost算法,或者与其他算法组合来优化模型性能。
例如,我们可以用XGBoost和LightGBM等算法进行集成,或者采用Stacking等多层次集成方法。
集成XGBoost算法能够有效地提升模型的性能,并提高模型在不同场景中的适应性。
总结XGBoost算法是机器学习领域中性能出色的算法之一,但如何优化XGBoost算法性能也是一个值得探讨的问题。
基于XGBoost算法的财务造假识别研究

基于XGBoost算法的财务造假识别研究基于XGBoost算法的财务造假识别研究摘要:财务造假在商业领域是一个严重的问题,能够对经济市场的稳定性和投资者利益产生严重影响。
本研究旨在利用XGBoost算法来识别财务造假,并比较其在财务报表指标中的效果。
通过对历史财务数据集的实证研究,结果显示XGBoost算法的识别准确性相比传统方法有所提升,具有较好的鉴别能力。
1. 引言财务造假是指企业通过刻意篡改财务报表,掩盖真实财务状况,欺骗投资者和其他利益相关者的行为。
财务造假的存在会扭曲市场的供需关系,破坏市场竞争环境,带来不公平竞争和投资者利益的损失,因此,发展一种可靠的方法来识别财务造假具有重要意义。
2. 相关研究过去的研究主要采用传统的财务报表分析法来识别财务造假,如财务比率分析、现金流分析等。
然而,这些方法往往依赖于人工选择指标和阈值,容易出现主观性和局限性。
近年来,机器学习算法在财务造假识别中得到了广泛应用,其优势在于能够自动化地发现隐藏在大量数据背后的潜在规律。
3. XGBoost算法原理XGBoost是一种基于梯度提升决策树的机器学习算法,在Kaggle等数据科学竞赛中取得了良好的成绩。
相比其他梯度提升算法,XGBoost具有更快的训练速度、更高的准确性和更好的可解释性。
4. 数据集和特征选择本研究选择了包含历史财务数据的数据集,包括财务报表指标、质量指标、市场指标等。
通过分析每个指标的相关性和重要性,筛选出了一组特征作为输入变量,并进行数据预处理和特征工程。
5. 实证研究及结果分析利用XGBoost算法对选定的数据集进行训练和测试,通过交叉验证和混淆矩阵等评价指标对算法进行评估。
结果显示,XGBoost算法在识别财务造假方面具有较高的准确性和召回率,较低的误报率和漏报率。
6. 比较分析为了验证XGBoost算法的有效性,本研究还将其与传统的财务比率分析法进行了比较。
结果显示,相比传统方法,XGBoost算法在识别财务造假方面的准确性和召回率更高,能够减少误报和漏报的情况。
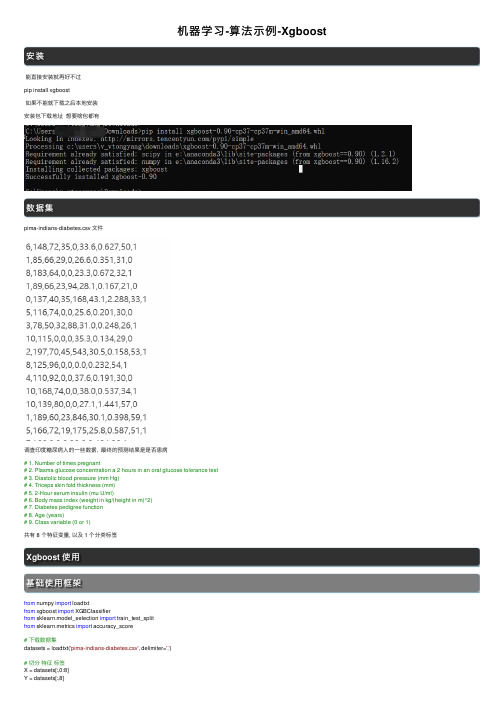
机器学习-算法示例-Xgboost
机器学习-算法⽰例-Xgboost 安装能直接安装就再好不过pip install xgboost如果不能就下载之后本地安装安装包下载地址想要啥包都有数据集pima-indians-diabetes.csv ⽂件调查印度糖尿病⼈的⼀些数据, 最终的预测结果是是否患病# 1. Number of times pregnant# 2. Plasma glucose concentration a 2 hours in an oral glucose tolerance test# 3. Diastolic blood pressure (mm Hg)# 4. Triceps skin fold thickness (mm)# 5. 2-Hour serum insulin (mu U/ml)# 6. Body mass index (weight in kg/(height in m)^2)# 7. Diabetes pedigree function# 8. Age (years)# 9. Class variable (0 or 1)共有 8 个特征变量, 以及 1 个分类标签Xgboost 使⽤基础使⽤框架from numpy import loadtxtfrom xgboost import XGBClassifierfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score# 下载数据集datasets = loadtxt('pima-indians-diabetes.csv', delimiter=',')# 切分特征标签X = datasets[:,0:8]Y = datasets[:,8]# 切分训练集测试集seed = 7test_size = 0.33X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed) # 模型创建训练model = XGBClassifier()model.fit(X_train, y_train)# 预测模型y_pred = model.predict(X_test)predictions = [round(i) for i in y_pred]# 精度计算accuracy = accuracy_score(y_test, predictions)print("Accuracy: %.2f%%" %(accuracy * 100) )Accuracy: 77.95%中间过程展⽰Xgboost 的原理是在上⼀棵树的基础上通过添加树从⽽实现模型的提升的如果希望看到中间的升级过程可以进⾏如下的操作from numpy import loadtxtfrom xgboost import XGBClassifierfrom sklearn.model_selection import train_test_splitfrom sklearn.metrics import accuracy_score# 下载数据集datasets = loadtxt('pima-indians-diabetes.csv', delimiter=',')# 切分特征标签X = datasets[:,0:8]Y = datasets[:,8]# 切分训练集测试集seed = 7test_size = 0.33X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=test_size, random_state=seed) # 模型创建训练model = XGBClassifier()eval_set = [(X_test, y_test)]model.fit(X_train, y_train, # 传⼊的训练数据early_stopping_rounds=10, # 当多少次的 lost值不在下降就停⽌模型eval_metric='logloss', # lost 评估标准eval_set=eval_set, # 构造⼀个测试集, 没加⼊⼀个就进⾏⼀次测试verbose=True # 是否展⽰出中间的详细数据打印)# 预测模型y_pred = model.predict(X_test)predictions = [round(i) for i in y_pred]# 精度计算accuracy = accuracy_score(y_test, predictions)print("Accuracy: %.2f%%" %(accuracy * 100) )打印的过程中会体现出 lost 值的变化过程[0] validation_0-logloss:0.660186Will train until validation_0-logloss hasn't improved in 10 rounds.[1] validation_0-logloss:0.634854[2] validation_0-logloss:0.61224[3] validation_0-logloss:0.593118[4] validation_0-logloss:0.578303[5] validation_0-logloss:0.564942[6] validation_0-logloss:0.555113[7] validation_0-logloss:0.54499[8] validation_0-logloss:0.539151[9] validation_0-logloss:0.531819[10] validation_0-logloss:0.526065[11] validation_0-logloss:0.519769[12] validation_0-logloss:0.514979[13] validation_0-logloss:0.50927[14] validation_0-logloss:0.506086[15] validation_0-logloss:0.503565[16] validation_0-logloss:0.503591[17] validation_0-logloss:0.500805[18] validation_0-logloss:0.497605[19] validation_0-logloss:0.495328[20] validation_0-logloss:0.494777[21] validation_0-logloss:0.494274[22] validation_0-logloss:0.493333[23] validation_0-logloss:0.492211[24] validation_0-logloss:0.491936[25] validation_0-logloss:0.490578[26] validation_0-logloss:0.490895[27] validation_0-logloss:0.490646[28] validation_0-logloss:0.491911[29] validation_0-logloss:0.491407[30] validation_0-logloss:0.488828[31] validation_0-logloss:0.487867[32] validation_0-logloss:0.487297[33] validation_0-logloss:0.487562[34] validation_0-logloss:0.487789[35] validation_0-logloss:0.487962[36] validation_0-logloss:0.488218[37] validation_0-logloss:0.489582[38] validation_0-logloss:0.489334[39] validation_0-logloss:0.490968[40] validation_0-logloss:0.48978[41] validation_0-logloss:0.490704[42] validation_0-logloss:0.492369Stopping. Best iteration:[32] validation_0-logloss:0.487297Accuracy: 77.56%详细打印特征重要性展⽰from numpy import loadtxtfrom xgboost import XGBClassifierfrom xgboost import plot_importancefrom matplotlib import pyplot# 下载数据集datasets = loadtxt('pima-indians-diabetes.csv', delimiter=',') # 切分特征标签X = datasets[:,0:8]Y = datasets[:,8]# 模型创建训练model = XGBClassifier()model.fit(X, Y)# 展⽰特征重要程度plot_importance(model)pyplot.show()参数调节Xgboost 有很多的参数可以调节常见参数学习率 learning rate ⼀般设置在 0.1 以下tree 相关参数max_depth 最⼤深度min_child_weight 最⼩叶⼦权重subsample 随机选择⽐例colsample_bytree 速记特征⽐例gamma 损失率相关的⼀个参数正则化参数lambdaalpha其他参数⽰例更详细的的参数可以参考官⽅⽂档xgb1 = XGBClassifier(learning_rate= 0.1,n_estimators=1000,max_depth=5,min_child_weight=1,gamma=0,subsample=0.8,colsample_bytree=0.8,objective='binary:logistic', # 指定出是⽤什么损失函数, ⼀阶导还是⼆阶导nthread=4, #scale_pos_weight=1,seed=27 # 随机种⼦)参数选择⽰例from numpy import loadtxtfrom xgboost import XGBClassifierfrom sklearn.model_selection import GridSearchCVfrom sklearn.model_selection import StratifiedKFold# 下载数据集datasets = loadtxt('pima-indians-diabetes.csv', delimiter=',')# 切分特征标签X = datasets[:,0:8]Y = datasets[:,8]# 模型创建训练model = XGBClassifier()# 学习率备选数据learning_rate = [0.0001, 0.001, 0.01, 0.1, 0.2, 0.3]param_grid = dict(learning_rate=learning_rate) # 格式要求转换为字典格式# 交叉验证kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=7)# 训练模型最佳学习率选择grid_serarch = GridSearchCV(model,param_grid,scoring='neg_log_loss',n_jobs=-1, # 当前所有 cpu 都跑这个事cv=kfold)grid_serarch = grid_serarch.fit(X, Y)# 打印结果print("Best: %f using %s" % (grid_serarch.best_score_, grid_serarch.best_params_)) means = grid_serarch.cv_results_['mean_test_score']params = grid_serarch.cv_results_['params']for mean, param in zip(means, params):print("%f with: %r" % (mean, param))打印结果Best: -0.483304 using {'learning_rate': 0.1}-0.689811 with: {'learning_rate': 0.0001}-0.661827 with: {'learning_rate': 0.001}-0.531155 with: {'learning_rate': 0.01}-0.483304 with: {'learning_rate': 0.1}-0.515642 with: {'learning_rate': 0.2}-0.554158 with: {'learning_rate': 0.3}。
基于XGBoost算法的社交网络链路预测

基于XGBoost算法的社交网络链路预测社交网络链路预测是指根据已知的社交网络结构和节点属性,预测社交网络中两个节点间是否存在连接。
链路预测在社交网络分析、推荐系统等领域具有重要的应用价值。
近年来,机器学习算法在社交网络链路预测中取得了许多成功的应用,其中XGBoost算法是一种常用且有效的方法。
XGBoost算法是一种基于梯度提升的决策树算法,它通过迭代训练决策树,并根据损失函数的梯度进行优化,得到最优的模型。
XGBoost算法在处理大规模数据和高维特征时有较好的性能,并且能够自动学习特征的重要性。
1. 数据准备:收集社交网络的节点数据,并提取与链路预测相关的特征。
特征可以包括节点本身的属性,例如年龄、性别等,以及节点间的关系,例如共同好友、共同兴趣等。
2. 数据划分:将数据集划分为训练集和测试集。
通常将大部分数据用于训练,少部分数据用于测试。
3. 特征工程:根据问题需求,对特征进行进一步处理。
可以进行特征选择、特征缩放、特征组合等操作,以提高模型性能。
4. 训练模型:使用训练集进行模型训练。
XGBoost算法会自动进行特征的选择和树的生成,并根据损失函数的梯度进行优化。
5. 模型评估:使用测试集对模型进行评估。
可以使用准确率、召回率、F1值等指标来评估模型的性能。
6. 模型调优:根据评估结果,对模型进行调优。
可以调整模型参数、特征选择、数据预处理等,以提高模型的性能。
7. 预测结果:使用训练好的模型对未知样本进行预测。
根据模型预测结果,可以判断两个节点之间是否存在连接。
通过以上步骤,基于XGBoost算法的社交网络链路预测模型可以被构建和应用。
这种方法在现实生活中有广泛的应用,例如在社交网络推荐系统中,可以根据用户的关系、兴趣等信息,预测用户可能感兴趣的新朋友或内容,从而提供更好的推荐体验。
在社交媒体营销中,可以根据用户的社交网络关系,预测用户之间的相互传播效应,以提高营销活动的效果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
OUTLINE:
1.BOOSTING方法的起源,背景与当前发展状况。 2.XGBOOST的介绍
3.在WINDOWS下安装与配置XGBOOST。
4.设计实验,并使用XGBOOST进行实验。 5.实验核心代码。
杜帅剑 郭振强 于海涛
6.总结与分析。
1.BOOSTING方法的起源,背景与当前发展状况。
•
• •
test_id = test.ID
test = test.drop(["ID"],axis=1) X = train.drop(["TARGET","ID"],axis=1)
•
• • • •
y = train.TARGET.values
X_train, X_test, y_train, y_test = train_test_split(X, y, \ test_size=0.2,random_state=1729) print(X_train.shape, X_test.shape, test.shape) # 我们采用默认的阈值 1e-5 进行特征选 择,那么将从 306 个特征中选出 193 个。
• • • • • •
1. 读取数据,观察数据特征,发现可能有常量列和重复列。 2. 消除常量列,29 列数据被删除,这些属性值可能是永远为 0,或者永远为 1。 3. 消除重复列,数据中只有两列重复。 4. 首先使用随机森林进行训练,训练的目标不是得到最终结果,而是期望得到 每个属性 特征的重要性,为我们后面进行特征选择做准备。 5. 将重要性>1e-5 的列选择出来,最终剩余 193 列数据。 6. 我们在 193 维度下进行预测,构建 xgboost 分类器,设置基本分类器数目为 110,使 用 auc 度量指标
2.XGBOOST的介绍
• XGBoost 算法可以有效的解决这个问题,相对于 Adaboost,XGBoost 采
用了二阶泰勒展开以使算法可以更快的收敛到全局最优。同时, XGBoost 采用 C++进行实现,运算速度 和精度都得到了大大的提升, 在实践中,XGBoost 赢得了多次机器学习竞赛的冠军,在 Kaggle 也是最 火的工具包之一。
• Boosting方法来源于两位科学家对强可学习和弱可学习的研究(弱分类器是指分类结果
仅仅比随机猜测略好的方法),之后有人证明两种分类器是等价的,也就是说弱可学 习算法可以被提升为强可学习算法。Boosting就是一种提升任意给定学习算法分类准确 度的方法,大多提升方法都是改变训练数据的概率分布,针对不同分布来调用弱学习 算法学习一系列弱分类器,组合成为 一个强分类器,这种思想被称为ensemble。
• •
# split data into train and test # 将数据分成训练集合测试集
• • • • • • • • • •
clf = Re=1729)
print("there are %d feature have a importance value more than 1e-5" % \ (np.count_nonzero(clf.feature_importances_> 1e-5))) # 根据以上的输出结果,如果我们采用默认的阈值 1e5 进行特征选择,那么将从 306 # 个特征中选出 193 个。 # 下面进行特征选择 fs = SelectFromModel(selector, prefit=True) # 按选择到的特征分别处理训练集和测试集 X_train = fs.transform(X_train) X_test = fs.transform(X_test)
•
•
test = fs.transform(test)
print(X_train.shape, X_test.shape, test.shape)
•
# 下面进行特征选择
6.总结与分析。
• 通过以上的实验,我们在 Kaggle 上得到了一个 0.83 的分数,意味着我
们在测试集上的 准确率达到了 83.9%。这个结果距离榜单上最高分数 84.3%尚有一些差距。想要更好的结果需要我们对特征和模型进行更加 细致的分析与调优。
• (3)打开命令行输入:cd到之前build的目录下; • (4)之后执行 “python setup.py install”进行安装。使用时,只需要在Python
环境下输入 “import xgboost as xgb” 即可。
4.设计实验,并使用XGBOOST进行实验。
我们使用 XGBoost 对 Kaggle 上的数据竞赛”Santander Customer Satisfaction”进行了预测。 该项目的目的是通过银行客户的历史数据训练 一个模型来预测客户对银行的满意度,数据集上包含超过 300 个属性, 经过仔细分析,我们认为其中的属性包含了存款,贷款,国籍,年龄等 等。所有的属性都是匿名的并且包含了许多空值。我们的处理思路如下:
• Adaboost是Boosting方法的第一种实用的实现,在实践中也得到了广泛的使用,它在训
练过程中生成成百上千个分类性能较弱的树在,生成每一棵树的时候采用梯度下降的思 想,以之前生成的所有树为基础,向着最小化给定目标函数的方向多走一步。在合理 的参数 设置下,我们往往要生成一定数量的树才能达到令人满意的准确率。在数据集 较大较复杂的时候,我们可能需要几千次迭代运算,耗时比较高。
• 本次实验主要使用了 Xgboost 算法进行数据竞赛,根据结果来看,
Xgboost 非常适合在大数据下进行机器学习,训练速度和精度都非常好, 简单的调整即能得出一个良好的结果。 同时,Xgboost 的分布式版本已 经发布,而且在不断的完善中。可以说,这是一个非常有潜力的工具包。
• 为了直观的观察各个特征,我们画出了特征的重要性分布图,可以发现,
大部分特征的 重要性是很低的,只有少数特征在决策中起到了重要的 作用:
图上大部分属性的重要性集中在很小的一个范围内,我们将这个范 围展开画出图形:
5.实验核心代码(#后面是注释)。 • selector = clf.fit(X_train, y_train)
3.安装与配置(WINDOWS):
• (1)首先从github下载源代码:https:///tqchen/xgboost • (2)下载成功后,打开xgboost-master源文件夹下的windows文件夹,打开
里面的VS工程。 编译生成Python使用的xgboost_wrapper.dll。