Linux下打开Emacs出现乱
astah,linux下中文输入乱码有关问题解决方案_1

astah,linux下中文输入乱码有关问题解决方案_1竭诚为您提供优质文档/双击可除astah,linux下中文输入乱码有关问题解决方案篇一:关于linux下中文乱码的完整解决方案关于linux下中文显示为乱码的完整解决方案linux,作为一款免费的操作系统,相对于高额费用的windows系列操作系统,有着更强的优势,所以,许多人也都开始学习linux操作系统的知识。
但是,由于windows系列操作系统还是当今社会的主流,所以,人们少不了在windows和linux系统之间进行文件的传输。
但是一个新问题出现了,那就是中文乱码问题,这个问题困扰着无数的linux用户,尤其是linux的初学者,对于这个问题相当的头疼。
主要问题如下:1、ssh中,中文显示为乱码:在windows 系统下,用ssh远程连接linux系统,对于在linux下显示正常的中文,在ssh中却显示为完全无法识别的乱码字符。
2、中文传输乱码:把windows中的中文文件传输到linux 操作系统中,原本在windows下显示正常的文件,到了linux 系统下,成了无法识别的乱码。
分析其原因,是因为linux和windows系统下,所用户的字符集不同,linux系统使用的是unicode字符集,而windows使用的是gb 字符集。
所以,在网上出现了两种解决方案:方法一:使用putty代替secureshellclient(ssh):在putty终端设置中,修改window-〉translation中的Receiveddataassumedtobeinwhichcharacterset值为linux 中的字符集utF-8,再连接linux,发现这时,linux中的中文可以正常显示了。
但是一个新问题出现了,把windows中的文件上传了linux中,原本在windows下显示正常的中文文件,现在却成了乱码。
所以,这个方法无法彻底解决乱码问题。
linux中显示中文乱码的问题

linux中显示中文乱码的问题/seuxiaoqi/article/details/5577195分类:linux 2010-05-11 09:154586人阅读评论(0)收藏举报由于在windows下默认是gb编码,而我的vim默认是utf-8(gedit默认也是utf-8),所以打开会成乱码。
修改了一下配置文件,使vi支持gb编码就好了。
$vi ~/.vimrclet &termencoding=&encodingset fileencodings=utf-8,gbk$:wq再次打开vi,显示就正常了。
如果你需要在linux下面用到windows下的文件,拷贝上去后经常发现中文显示乱码。
原因是Windows中默认的文件格式是 GBK(gb2312),而Linux一般都是UTF-8。
比较繁琐的方法是在windows下用程序把内容转换为utf-8编码格式的,但是相当麻烦,而且遇到一个文件转一回。
下面介绍一下,在Linux中如何一劳永逸的解决这个问题,查看文件的编码及如何进行对文件进行编码转换。
查看文件编码在Linux中查看文件编码可以通过以下几种方式:1.在Vim中可以直接查看文件编码:set fileencoding即可显示文件编码格式。
文件编码转换1.如果你只是想查看其它编码格式的文件或者想解决用Vim查看文件乱码的问题,那么你可以在~/.vimrc(在/etc目录下面)文件中添加以下内容:set encoding=utf-8 fileencodings=ucs-bom,utf-8,cp936其中encoding是vim的默认显示编码格式,fileencodings是vim打开文件时检测的编码格式,存在这种类型的编码即转换为utf-8 编码。
这样,就可以让vim自动识别文件编码(可以自动识别UTF-8或者GBK编码的文件),其实就是依照fileencodings提供的编码列表尝试,如果没有找到合适的编码,就用latin-1(ASCII)编码打开。
详解Linux中文乱码问题终极解决方法

详解Linux中⽂乱码问题终极解决⽅法初⼊linux的程序员们,经常会受到乱码的问候。
可谓“始乱终弃”。
因为乱码,并且最终放弃了linux的不在少数。
好吧,⾔归正传,下⾯来看⼀下linux乱码的具体解决办法吧。
⽅法⼀:修改/root/.bash_profile⽂件,增加export LANG=zh_CN.GB18030该⽂件在⽤户⽬录下,对于其他⽤户,也必须相应修改该⽂件。
使⽤该⽅法时putty能显⽰中⽂,但桌⾯系统是英⽂,⽽且所有的⽹页中⽂显⽰还是乱码⽅法⼆:修改/etc/sysconfig/i18n⽂件#LANG="en_US.UTF-8"#SUPPORTED="en_US.UTF-8:en_US:en"#SYSFONT="latarcyrheb-sun16"修改为:LANG="zh_CN.GB18030"LANGUAGE="zh_CN.GB18030:zh_CN.GB2312:zh_CN"SUPPORTED="zh_CN.GB18030:zh_CN:zh"SYSFONT="lat0-sun16"SYSFONTACM="8859-15"参考:Linux中⽂乱码问题最近,公司在XP系统于LINUX之间传数据时出现了中⽂乱码问题!⾸先,字符集:汉字编码:* GB2312字集是简体字集,全称为GB2312(80)字集,共包括国标简体汉字6763个。
* BIG5字集是台湾繁体字集,共包括国标繁体汉字13053个。
* GBK字集是简繁字集,包括了GB字集、BIG5字集和⼀些符号,共包括21003个字符。
* GB18030是国家制定的⼀个强制性⼤字集标准,全称为GB18030-2000,它的推出使汉字集有了⼀个“⼤⼀统”的标准。
ASCII:American Standard Code for Information Interchange,美国信息交换标准码。
linux文件乱码解决方案

Linux文件乱码解决方案一、引言在使用L in ux系统时,我们可能会遇到文件乱码的情况,这给我们的工作和学习带来了不便。
本文将为您介绍一些常见的L in ux文件乱码解决方案,帮助您解决文件乱码问题,提高您在Li nu x系统下的使用体验。
二、检查文件编码文件编码是导致文件乱码的主要原因之一。
首先我们需要检查文件的编码方式,以确定是否是编码导致了文件乱码的问题。
我们可以使用一些工具来检查文件的编码方式,例如使用`fil e`命令或者`e nc a`工具。
这些工具可以自动判断文件的编码方式,并给出相应的结果。
根据结果,我们可以采取相应的解决方案。
三、使用合适的文本编辑器使用合适的文本编辑器也是解决文件乱码问题的重要一环。
不同的文本编辑器对于文件编码的支持程度不同,选择合适的文本编辑器可以减少文件乱码的可能性。
在L in ux系统中,有很多文本编辑器可以选择,例如`V i`、`Vi m`、`E ma cs`、`S ub li me T ex t`等。
这些编辑器具有不同的特点和优势,可以根据自己的需要选择合适的编辑器来编辑文本文件。
同时,我们还需要确保文本编辑器的编码设置与文件的编码方式一致,避免出现编码不匹配的问题。
四、转换文件编码如果确定文件的编码方式与文本编辑器设置的编码方式不一致导致了文件乱码,我们可以考虑将文件的编码方式转换为与文本编辑器设置的编码方式一致。
在L in ux系统中,我们可以使用一些工具来进行文件编码转换,例如`i co nv`命令。
该命令可以将文件从一种编码方式转换为另一种编码方式,解决文件乱码的问题。
使用`i co nv`命令时,需要指定源文件的编码方式和目标文件的编码方式,通过该命令进行文件编码的转换。
五、使用合适的字体有时,文件的乱码可能是由于系统缺少相应的字体文件导致的。
我们可以尝试安装合适的字体文件来解决文件乱码问题。
L i nu x系统中,我们可以通过包管理器来安装字体文件。
Linux操作系统下linux命令乱码的终极解决方案

英文字符linux命令乱码
一般该字符linux命令乱码多出现在cat了二进制的文件时,因为二进制文件中多有控制码,会导致终端界面linux命令乱码,通常解决方法是用reset终端复位命令解决问题
其他伪终端linux命令乱码
有时是通过SSH进入远程LINUX服务器时,cat一个core文件,并且用reset命令都不能成功,怎么办?很简单,看以下试验,首先cat一个python的编译文件
以上是Linux操作系统下linux命令乱码的终极解决方案,希望对您有所acle@linux-suse:~> VT102VT102
\-bash: VT102VT102: command not found
oracle@linux-suse:~>
在SSH终端上看到是的linux命令乱码,提示符都是乱的,可以用以下命令恢复
oracle@linux-suse:~> tput sgr0
linux命令乱码问题产生的原因是SSH的问题,因为在其他终端下,cat用样一个文件,不会产生乱码,于是试验linux命令乱码产生的原因
oracle@linux-suse:~> ^N
只要用ctrl+v,ctrl+n就使用屏幕linux命令乱码,当然恢复后再试验
oracle@linux-suse:~> cat fibo.pyc
m?
{?鯡c@sd
Zd
ZdS(cCs:d\}}x'jo G }}qWdS(Nii(ii(tatbtn(RRR((tfibo.pytfibs
cCsIg}d\}}x0jo" i}}qW S(Nii(ii(tresultRRRtappend(RRRR((Rtfib2 s
linux expect syntax error

linux expect syntax error【解决Linux expect语法错误问题】简介:Linux expect是一个自动化交互脚本工具,通过模拟用户输入和对输出的响应,实现自动化任务的执行。
在使用Linux expect时,可能会遇到语法错误的问题。
本文将以解决Linux expect语法错误问题为主题,从原因分析到解决方案,一步一步回答,并提供相关案例和建议。
正文:第一步: 理解Linux expect语法错误的原因在使用Linux expect过程中,语法错误可能由多种原因引起。
常见的原因包括:1. 语法错误: 在编写expect脚本时,可能会因为拼写错误、缺少符号或使用错误的语法结构等而导致语法错误。
2. 脚本执行错误: expect脚本在执行过程中,可能会遭遇未预料到的输入或输出,从而导致语法错误。
3. 环境配置问题: Linux expect脚本依赖于正确的环境配置,如安装expect工具、设置正确的环境变量等。
如果这些配置存在问题,也可能导致语法错误。
第二步: 分析并定位语法错误一旦遇到语法错误,我们需要通过分析和定位错误来解决问题。
下面是一些常见的方法:1. 仔细检查脚本: 检查脚本中可能存在的拼写错误、符号错误以及语法结构错误等。
特别注意与引号配对使用的情况。
2. 运行脚本进行调试: 可以尝试直接运行脚本并观察错误提示信息。
根据提示信息,定位错误的具体位置。
3. 查看脚本日志: 在脚本中添加日志记录功能,以便在执行过程中输出相关信息。
通过查看日志,可以追踪错误发生的原因。
第三步: 解决语法错误一旦定位并分析了语法错误,我们可以针对具体情况采取相应的解决措施。
下面是一些常见的解决方案:1. 修正语法错误: 找到并修复脚本中存在的语法错误。
可以参考相关文档或教程提供的正确语法进行修改。
2. 调整脚本逻辑: 如果脚本在执行过程中遭遇未预料到的输入或输出,可以通过调整脚本逻辑来解决语法错误。
Oracle数据库教程 —— linux系统 重启盘符错乱问题

Oracle数据库教程—— linux系统重启盘符错乱问题linux磁盘重启乱序问题处理最近到客户那去巡检时,客户提到一个问题,他们的rac在重启的时候,原来的sda1、sdb1、sdc1会对应变成sdd1、sde1、sdf1,由于他们使用的是盘符来绑定裸设备,所以启动后,经常要手动执行以下命令[root@ractest1 ~]# raw /dev/raw/raw1 /dev/sda1[root@ractest1 ~]# raw /dev/raw/raw2 /dev/sdb1[root@ractest1 ~]# raw /dev/raw/raw3 /dev/sdc1并且,比较奇怪的事,两边有时认得的盘完全不一样,一边是sda\b\c,另一边是sdd\e\f,这样,使oracle rac的共享盘出现问题。
在了解了他们的情况后,我基本上明白是什么原因,这种盘序错乱,与linux对磁盘的扫描机制有关,所以我们只能从另一角度去规避这样的问题,使用id号去绑定,这样就没有问题。
在告诉他后,他同意我们对他原来的绑定方式进行修改,具体操作如下:[root@ractest1 ~]# fdisk -lDisk /dev/sdd: 429.4 GB, 429496729600 bytes255 heads, 63 sectors/track, 52216 cylindersUnits = cylinders of 16065 * 512 = 8225280 bytesDeviceBoot Start End Blocks Id System/dev/sdd1 1 52216 419424988+ 83 LinuxDisk /dev/sde: 209 MB, 209715200 bytes7 heads, 58 sectors/track, 1008 cylindersUnits = cylinders of 406 * 512 = 207872 bytesDeviceBoot Start End Blocks Id System/dev/sde1 1 1008 20459583 LinuxDisk /dev/sdf: 209 MB, 209715200 bytes7 heads, 58 sectors/track, 1008 cylindersUnits = cylinders of 406 * 512 = 207872 bytesDeviceBoot Start End Blocks Id System/dev/sdf1 1 1008 204595 83 Linux可以看到,刚重启的节点1是sdd/sde/sdf另一个节点的情况是:[root@ractest2 ~]# fdisk -lDisk /dev/sda: 429.4 GB, 429496729600 bytes255 heads, 63 sectors/track, 52216 cylindersUnits = cylinders of 16065 * 512 = 8225280 bytesDeviceBoot Start End Blocks Id System/dev/sda1 1 52216 419424988+ 83 LinuxDisk /dev/sdb: 209 MB, 209715200 bytes7 heads, 58 sectors/track, 1008 cylindersUnits = cylinders of 406 * 512 = 207872 bytesDeviceBoot Start End Blocks Id System/dev/sdb1 1 1008 204595 83 LinuxDisk /dev/sdc: 209 MB, 209715200 bytes7 heads, 58 sectors/track, 1008 cylindersUnits = cylinders of 406 * 512 = 207872 bytesDeviceBoot Start End Blocks Id System/dev/sdc1 1 1008 204595 83 Linux分别在两台机子上执行如下命令:[root@ractest2 ~] scsi_id -g -s /block/sda360080e500017ff06000004054c47bd4a[root@ractest2 ~] scsi_id -g -s /block/sdb360080e500017fdd8000004c74c6344ef[root@ractest2 ~] scsi_id -g -s /block/sdc360080e500017ff060000044f4c63446e[root@ractest1 ~] scsi_id -g -s /block/sdd360080e500017ff06000004054c47bd4a[root@ractest1 ~] scsi_id -g -s /block/sde360080e500017fdd8000004c74c6344ef[root@ractest1 ~] scsi_id -g -s /block/sdf360080e500017ff060000044f4c63446e能过对比,可以看到sda与sdd,sdb与sde,sdc与sdf是对应用的,所以我们启用udev,通过绑定id来规避这个问题![root@ractest1 ~]# cd /etc/udev/rules.d/[root@ractest1 rules.d]# ls -a. 50-udev.rules 60-pcmcia.rules 61-uinput-wacom.rules 90-hal.rules.. 51-hotplug.rules 60-raw.rules85-pcscd_ccid.rules 95-pam-console.rules05-udev-early.rules 60-libsane.rules 60-wacom.rules 90-al sa.rules 98-kexec.rules40-multipath.rules 60-net.rules 61-uinput-stddev.rules 90-dm.ru les bluetooth.rules[root@ractest1 rules.d]# vi 60-raw.rules# Enter raw device bindings here.## An example would be:# ACTION=="add", KERNEL=="sda", RUN+="/bin/raw /dev/raw/raw1 %N"# to bind /dev/raw/raw1 to /dev/sda, or# ACTION=="add", ENV{MAJOR}=="8", ENV{MINOR}=="1", RUN+="/bin/raw/dev/raw/raw2 %M %m"# to bind /dev/raw/raw2 to the device with major 8, minor 1.ACTION=="add", KERNEL=="sd*1", PROGRAM=="/sbin/scsi_id -g -u -s %p",RESULT=="360080e500017ff060000044f4c63446e", RUN+="/bin/raw /dev/raw/raw1 %N" ACTION=="add", KERNEL=="sd*1", PROGRAM=="/sbin/scsi_id -g -u -s %p",RESULT=="360080e500017fdd8000004c74c6344ef", RUN+="/bin/raw /dev/raw/raw2 %N"ACTION=="add", KERNEL=="sd*1", PROGRAM=="/sbin/scsi_id -g -u -s %p",RESULT=="360080e500017ff06000004054c47bd4a", RUN+="/bin/raw /dev/raw/raw3 %N" KERNEL=="raw[1-3]", OWNER="oracle", GROUP="dba", MODE="660"[root@ractest1 rules.d]# start_udevStarting udev: [ OK ][root@ractest1 rules.d]#[root@ractest1 rules.d]# raw -qa/dev/raw/raw1: bound to major 8, minor 81/dev/raw/raw2: bound to major 8, minor 65/dev/raw/raw3: bound to major 8, minor 49同理,在另一台机,也进行同样的操作。
doom emacs linux 基本操作

doom emacs linux 基本操作doom Emacs 是一种基于Emacs 的高度定制化编辑器,它提供了一个强大且易于使用的工作环境,可以满足开发人员和编辑器爱好者对于高效编码的需求。
在Linux 系统中使用doom Emacs,你可以利用它的诸多强大功能来提升自己的代码编辑体验。
本文将逐步指导你如何在Linux 系统中安装和配置doom Emacs,并介绍一些常用的操作技巧。
1. 安装doom Emacs1.1 安装依赖库执行以下命令来安装构建doom Emacs 所需的依赖库:sudo apt install build-essential git ripgrep fd-find1.2 克隆doom Emacs 仓库在命令行中执行以下命令来克隆doom Emacs 的仓库到本地:git clone ~/.emacs.d1.3 安装doom Emacs执行以下命令来安装doom Emacs:~/.emacs.d/bin/doom install2. 配置doom Emacs2.1 快速配置doom Emacs 提供了一套默认配置,你可以快速使用它们来开始编辑代码。
执行以下命令来使用默认配置:~/.emacs.d/bin/doom quickstart2.2 定制配置如果你想自定义doom Emacs 的配置,可以编辑`~/.doom.d/config.el` 文件,该文件包含了对doom Emacs 的个性化配置。
你可以添加或修改变量、键绑定等来满足自己的需求。
编辑完配置后,执行以下命令来加载新的配置:~/.emacs.d/bin/doom refresh3. doom Emacs 基本操作3.1 打开文件你可以通过以下命令来打开一个文件:SPC f f3.2 保存文件你可以使用以下命令来保存当前文件:SPC f s3.3 搜索文件doom Emacs 提供了强大的文件搜索功能,你可以使用以下命令搜索文件:SPC p f3.4 切换缓冲区在多个文件之间快速切换可以提高编辑效率。
linux 乱码的解决方法

linux 乱码的解决方法嘿,朋友们!咱今天来聊聊 Linux 乱码这档子事儿。
你说这乱码就像调皮的小精灵,时不时就蹦出来捣乱,让人头疼得很呐!咱先来说说为啥会出现乱码。
就好比你去一个陌生的地方,人家说的话你听不懂,那可不就懵了嘛!Linux 系统也一样,有时候它遇到一些它不太熟悉的字符编码格式,就搞不明白了,然后乱码就出现了。
那咋解决呢?嘿,这办法还不少嘞!首先啊,咱得看看系统的语言环境设置对不对。
就像你出门得先选对要穿的衣服一样,得合适才行呀!如果设置错了,那不乱码才怪呢!咱得把它调整到正确的编码格式,比如 UTF-8 啥的,这可是个常用的好东西呢!然后呢,再检查一下那些文件的编码。
哎呀,就好比你看书,要是书的印刷有问题,那你能看清内容才怪嘞!要是文件本身的编码就不对,那显示出来可不就乱套啦!得把它们转换成合适的编码。
还有啊,有些软件也可能会导致乱码哦!这就像一个团队里有个捣蛋鬼,得把它揪出来才行。
看看是不是软件的设置有问题,或者是不是该更新一下啦。
你想想看,要是你电脑上老是出现乱码,你看着不心烦呀?那感觉就像你走路老是被石头绊脚一样,多闹心呐!所以啊,咱得把这些乱码问题给解决咯,让咱的 Linux 系统顺顺畅畅的。
比如说,你正在处理一个很重要的文档,结果打开一看,全是乱码,那你不得抓狂呀!这时候你就得赶紧用咱说的这些方法去试试,把乱码赶跑。
再比如,你在看一些外文资料,结果因为乱码啥都看不清,那不就白费劲了嘛!所以说呀,学会解决 Linux 乱码问题可太重要啦!总之呢,Linux 乱码并不可怕,只要咱找对方法,就能轻松搞定。
就像打怪兽一样,找到它的弱点,一下就把它打败啦!可别让这些乱码影响了咱使用 Linux 的好心情哟!大家加油吧!让咱的 Linux 系统一直清清爽爽,没有乱码的困扰!。
关于Linux连接工具mobaxterm显示中文乱码问题
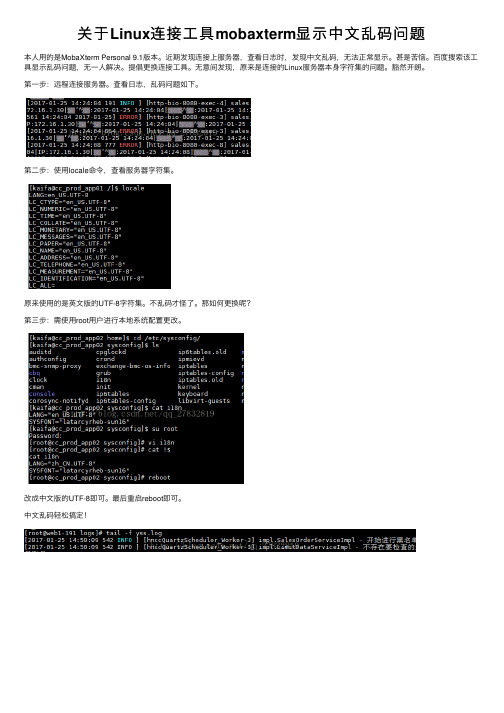
关于 Linux连接工具 mobaxterm显示中文乱码问题
本人用的是MobaXterm Personal 9.1版本。近期发现连接上服务器,查看日志时倡更换连接工具。无意间发现,原来是连接的Linux服务器本身字符集的问题。豁然开朗。 第一步:远程连接服务器。查看日志,乱码问题如下。
第二步:使用locale命令,查看服务器字符集。
原来使用的是英文版的UTF-8字符集。不Байду номын сангаас码才怪了。那如何更换呢? 第三步:需使用root用户进行本地系统配置更改。
改成中文版的UTF-8即可。最后重启reboot即可。 中文乱码轻松搞定!
Linux下文本编辑利器Emacs简介与安装过程

2012年04月第12期科技视界Science &Technology Vision1认识Emacs1.1Emacs 是一种强大的文本编辑器在程序员和其他以技术工作为主的计算机用户中广受欢迎。
EMACS,即Editor MACroS(编辑器宏)的缩写,最初由Richard Stallman(理查德·马修·斯托曼)于1975年在MIT 协同Guy Steele 共同完成。
Emacs 有两个主要分支:GNUEmacs,XEmacs。
1.2Emacs 不仅仅是一个编辑器,它是一个整合环境,或可称它为集成开发环境图1GNU Emacs这些功能如让使用者置身于全功能的操作系统中,在基于编辑器的功能基础上,Emacs 还可以:收发电子邮件通过Telnet 登录主机查看日历撰写文章大纲对多种编程语言的编辑调试程序,结合GDB,EDebug 等。
支持C/C++,Perl,Python,Lisp 等等玩游戏目录管理浏览网站为各种程序提供操作界面2Emacs 安装步骤以redhat enterprise 5为例2.1下载安装文件首先,到Emacs 的GNU 官网(/software/emacs/)去下载新版的安装文件。
我们这里下载的是2012初发布的Emacs 23.4。
解压文件$cp emacs-23.4.tar.ba2/opt $cd /opt$tar -jxvf emacs-23.4.tar.bz2这时解压生成一个emacs-23.4的目录,然后就可以进入安装步骤了。
2.2安装安装前应先切换到root 目录下。
$su输入root 密码1)进入Emacs 的解压目录,调用“configure”脚本:#cd emacs-23.4#./configure 2)当configure 指令结束,屏幕会输出一些系统配置有关的细节信息,仔细阅读这些信息查看是否有错误提示,如CPU 错误、libraries 文件缺失等。
解决Linux中Matlab中文乱码问题

解决Linux中Matlab中文乱码问题由于Linux下Matlab的图形界面是用Java写的,所以只要搞定Java的中文显示就行了。
1、我Matlab2007a的JRE目录为:/opt/Matlab/sys/java/jre /glnx86/jre1.5.0 请根据自己的安装目录和版本确定JRE的目录;2、$ cd /opt/Matlab/sys/java/jre/glnx86/jre1.5.0/lib/fonts/;3、建立目录fallback: $ mkdir fallback;4、把字体复制或链接到fallback目录:$ cp /media/disk/WINDOWS/Fonts/simsun.ttc fallback/ 我用的是Windows XP 的simsun字体,你也可以用别的支持中文的字体,[注:我选的是Ubuntu自带的文泉驿正黑,默认存放路径是/usr/share/fonts/truetype/wpy/wqy-zenhei.ttc];5、进入fallback目录,执行mkfontscale 命令;6、将上一步生成的文件添加到lib/fonts/fonts.dir文件中,可用以下命令完成,当然也可以用编辑器复制粘贴[注:我是在终端中root下执行gedit fonts.dir命令完成该操作的]:$ cat fallback/fonts.scale >> fonts.dir ,注意fonts.dir应该设为可写。
[注:我用这个命令并不成功,估计是可写权限的问题,但我不清楚如何设置文件为可写权限]7、至此Matlab的Java环境中文支持安装完了。
[注:我做到这一步,再打开Matlab时就已经可以显示中文,因此并没有进行下一步的配置Matlab,只是稍看了一下]接下来配置Matlab8、进入Matlab,选择菜单File>>Preferences>>Fonts 选择SimSun字体就行了;9、如果没有相应的(我的是SimSun)字体,请把fallback下的字体加上可读属性:$ chmod a+r fallback/*10、至此Matlab应该可以正常显示中文了。
linux python中文乱码解决方法-概述说明以及解释

linux python中文乱码解决方法-概述说明以及解释1.引言1.1 概述概述部分是文章引言的一部分,它的目的是提供一个简要的介绍,概括文章的主题和内容。
在“Linux Python中文乱码解决方法”这篇长文中,概述部分可以包括以下内容:概述:随着Linux和Python的广泛应用,中文乱码问题也逐渐成为了许多开发者和用户的关注焦点。
在日常的Linux和Python编程过程中,我们经常会遇到中文乱码的情况,这不仅给我们的工作带来了不便,还可能影响程序的正确执行。
因此,解决Linux和Python中文乱码问题成为了一个重要的任务。
本文将从两个方面详细介绍Linux 和Python 中文乱码问题的原因和解决方法。
首先,我们将探讨Linux 系统中的中文乱码问题,分析其产生的原因和对应的解决方法。
其次,我们将深入探讨Python 编程语言中出现的中文乱码问题,解释其中的原因,并提供相应的解决方案。
通过本文的阐述,读者将能够更好地理解和解决在Linux 和Python 中遇到的中文乱码问题。
总结:在本文的结论部分,我们将总结我们在解决Linux 和Python 中文乱码问题的过程中所采用的方法和技巧。
我们将讨论这些方法的有效性和适用性,并提供一些建议,帮助读者在实际的工作和学习中更好地解决中文乱码问题。
通过本文提供的解决方案,读者将能够提高工作效率,避免中文乱码带来的困扰,并更好地利用Linux 和Python 进行程序开发和日常使用。
通过本文的阅读和理解,读者将对Linux 和Python 中文乱码问题有更清晰的认识,并能够运用相应的解决方法,提高工作效率和代码质量。
同时,本文还为解决其他编程语言或操作系统中出现的中文乱码问题提供了一个思路和参考。
文章结构部分的内容:1.2 文章结构本文将分为三个主要部分:引言、正文和结论。
- 引言部分将概述整篇文章的主要内容和目的,以便读者能够了解文章的背景和意义。
[linux文件处理命令]使用chkdsk命令处理文件乱码问题
![[linux文件处理命令]使用chkdsk命令处理文件乱码问题](https://img.taocdn.com/s3/m/a04ae7cfd05abe23482fb4daa58da0116c171fb0.png)
[linux文件处理命令]使用chkdsk命令处理文件乱码问题篇一: 使用chkdsk命令处理文件乱码问题使用chkdsk命令处理文件乱码问题网上只有简短文字说明,却无详细图文教程,鉴于此我特地制作了本教程供广大网友参考:U盘文件夹名称出现乱码:佞愳亠?仠或者@?等等不一,不能删除,删除时提示:无法删除文件,无法读源文件或磁盘。
右键点击文件夹,发现乱码文件特别大,几十G。
出现了92.8G。
但是退出U盘查看大小的时候发现还是正常的,并且无法安全弹出可移动磁盘如下图所示:之前几次发现连接电脑后无法安全删除硬件,所以强行断开MP3与电脑的连接,导致内部文件出现链接错误,因而出现上面的情况第一步:打开开始菜单,点击运行,输入cmd 如图所示:第二步:在下图所示位置输入chkdsk 此命令用来检测并修复多种磁盘逻辑错误第三步:接下会出现磁盘逻辑错误检测信息如下图所示第四步:如下图所示,输入chkdsk/f第五步:在键盘上输入Y ,然后重启电脑重启电脑后会进入磁盘自检阶段,如果出现Y/N直接点Y即可,整个检测修复过程大约需要2小时附上自检过程的txt目录这个就是windows自检可移动磁盘的相关数据,它将会以BOOTEX.LOG记事本文档存储到你的可移动磁盘当中。
最后一步:自检完成电脑自动重启,打开我电脑会发现显示有两个可移动磁盘,其中一个没有文件,总容量也是0。
打开另外一个可移动磁盘,发现磁盘内乱码文件全部消失,把我的电脑文件设置为显示全部文件,则可以看到found000这个隐藏文件,按住shift+delete 删除。
还有一个BOOTEX.LOG的文件,这个也可以删除。
它的性质是windows 使用chkdsk/f命令检测修复的记录。
注:本方法适合各种移动硬盘,MP3,MP4,u盘文件乱码问题。
篇二: 10条思科IOS文件管理命令10条思科IOS文件管理命令本文中,作者David Davis将列举出我们常用的Cisco IOS文件管理命令,帮助我们巩固如何管理好Cisco路由器上flash, nvram或其它文件系统里的文件,并教大家如何简单快速的备份路由器配置,升级路由器,或者仅仅是维护IOS文件系统。
Linux新手必读常见命令行错误及解决方法

Linux新手必读常见命令行错误及解决方法Linux操作系统作为一款强大且广泛应用的操作系统,其命令行界面是最为重要的一部分。
然而,对于新手来说,掌握命令行并不是一件容易的事情。
在使用过程中,经常会遇到各种错误提示,影响正常的使用体验。
本文将介绍一些常见的命令行错误以及解决方法,帮助Linux新手更好地应对各种情况。
错误一:命令找不到或不存在(Command not found)这是一个非常常见的错误,意味着输入的命令在当前的环境中没有找到。
这通常是由于命令不存在或者命令没有被正确地安装所致。
解决方法:1. 确保所输入的命令正确无误,检查是否拼写错误。
2. 使用适当的命令进行搜索。
例如,使用`which`命令可以查找某个命令的路径,例如`which command_name`。
3. 检查命令是否被正确地安装。
可以尝试使用`apt-get`或者`yum`等包管理器进行命令的安装。
4. 如果命令仍然无法找到,可能需要手动安装命令或者检查环境变量设置。
错误二:权限不足(Permission denied)Linux系统中,每个用户都有相应的权限来访问和执行文件。
当遇到权限不足的错误提示时,说明当前用户没有执行该命令的权限。
解决方法:1. 使用`sudo`命令,该命令可以提升当前用户的权限并执行命令。
例如,`sudo command_name`。
2. 如果当前用户没有sudo权限,则需要使用管理员账户来执行命令。
错误三:文件或目录不存在(No such file or directory)当输入的文件或者目录不存在时,就会出现这个错误提示。
这可能是由于输入错误的文件名或者目录路径所致。
解决方法:1. 确认输入的文件或者目录路径是否正确,并检查拼写错误。
2. 使用`ls`命令来查看当前目录下的文件和目录,确认所要操作的文件或目录是否存在。
错误四:命令语法错误(Syntax error)当输入的命令语法错误时,系统会提示命令的用法或者提供一些错误信息。
linux下多串口错乱的一般解决方案

linux下多串口错乱的一般解决方案在Linux下,当使用多个串口时可能出现错乱的情况。
以下是一般的解决方案:1. 检查串口设置:首先,确保每个串口的设置正确。
使用stty命令可以查看和修改串口的设置,如波特率、数据位数等。
确保每个串口的设置相同,并与设备连接的设备一致。
2. 避免串口冲突:多个串口设备可能会使用相同的IRQ(中断请求)或IO地址。
这可能导致冲突和错乱。
使用lspci或lsusb命令可以查看设备的IRQ和IO地址,确保它们不会冲突。
如果存在冲突,可以通过重新分配IRQ或IO地址来解决。
3. 禁用串口自动检测:有些Linux发行版可能会自动检测和配置串口设备。
这可能会导致错乱和冲突。
在启动时,可以通过修改内核参数或配置文件来禁用串口自动检测。
具体方法请参考相应发行版的文档。
4. 使用适当的串口驱动程序:确保使用适当的串口驱动程序。
有些串口设备需要特定的驱动程序才能正常工作。
使用lsmod命令可以查看已加载的模块,确保正确的驱动程序已加载。
5. 使用流控制:在串口通信中,使用流控制可以避免数据丢失和错乱。
流控制可以通过硬件流控制(使用RTS/CTS信号)或软件流控制(使用XON/XOFF字符)来实现。
确保流控制已启用,并正确配置。
6. 更换串口线和设备:有时,串口线或设备本身可能存在问题,导致数据错乱。
尝试更换线缆和设备,并确保它们是可靠的。
7. 使用串口调试工具:在调试时,可以使用串口调试工具(如minicom、screen等)来检测和解决错乱问题。
这些工具可以查看串口的输入输出,并帮助识别问题所在。
以上是一般的解决方案,具体解决方法可能因系统和硬件而异。
如果问题仍然存在,请参考相关文档和资源,或向相应的技术支持寻求帮助。
linux中eclipse!message frameworkevent error

linux中eclipse!message frameworkeventerror在Linux中使用Eclipse时,可能会遇到"!Message FrameworkEvent ERROR"的错误。
本文将详细讨论该错误的原因、解决方案以及一些额外的技巧,旨在帮助读者解决这个问题。
该错误通常出现在启动或运行Eclipse时,提示"!Message FrameworkEvent ERROR"并附带一些特定的错误信息。
这可能会导致Eclipse无法正常工作,影响开发者的效率和体验。
造成这个错误的原因可能有多种,下面我将逐一介绍并提供相应的解决方案。
1. 插件冲突:插件(也称为扩展或插件)是Eclipse的核心组件之一,它们提供了额外的功能和特性。
但是,有时安装的插件可能不兼容或相互冲突,导致错误出现。
在这种情况下,您可以尝试以下解决方案: - 禁用冲突插件:在Eclipse的"插件"或"扩展"管理器中,禁用或卸载可能引起冲突的插件。
- 更新插件版本:检查插件的最新版本是否可用,并尝试更新到最新版本。
新版本通常修复了已知的冲突问题。
- 暂时移除插件:如果无法确定哪个插件引起了错误,您可以尝试暂时移除所有安装的插件,并逐个重新添加,以确定问题所在。
2. 缓存和配置问题:Eclipse在运行时会生成和使用各种配置文件和缓存,以提供更快的启动和更好的性能。
但是,这些文件有时可能损坏或变得不一致,从而导致错误。
您可以尝试以下解决方案:- 清除Eclipse缓存:定期清除Eclipse的缓存文件夹(通常位于用户目录下的".eclipse"或".metadata"文件夹)。
- 重置Eclipse配置:将Eclipse恢复到默认状态,通过删除或重命名工作区目录(位于用户目录下的"workspace"文件夹)来实现。
linux php乱码解决方法

linux php乱码解决方法Linux和PHP是常用的开源软件,它们在Web开发中被广泛使用。
然而,有时候在使用Linux服务器上运行PHP程序时会出现乱码的问题。
乱码问题会导致网页显示出错,影响用户的体验。
本文将介绍几种解决Linux和PHP乱码问题的方法。
一、检查字符编码我们需要确保服务器和PHP程序使用的字符编码一致。
常见的字符编码有UTF-8、GBK等。
可以通过在PHP程序中设置字符编码来解决乱码问题。
在程序的开头加入以下代码:```phpheader('Content-Type:text/html;charset=utf-8');```这样可以确保网页以UTF-8编码输出,解决大部分乱码问题。
二、检查文件编码乱码问题有可能是由于文件本身的编码问题导致的。
可以使用文本编辑器打开PHP文件,查看文件编码。
常见的编码有UTF-8、GBK、ISO-8859-1等。
如果文件编码与服务器和PHP程序使用的编码不一致,就会出现乱码。
可以尝试将文件编码修改为与服务器和PHP 程序一致的编码,然后重新保存文件。
三、检查数据库编码如果PHP程序使用了数据库,还需要检查数据库的编码设置。
常见的数据库编码有UTF-8、GBK等。
可以登录数据库管理工具,查看数据库的编码设置。
如果数据库编码与服务器和PHP程序使用的编码不一致,也会导致乱码问题。
可以尝试修改数据库的编码设置,使其与服务器和PHP程序一致。
四、检查PHP扩展有时候乱码问题还可能是由于缺少相应的PHP扩展引起的。
可以通过检查php.ini文件来确认是否加载了需要的扩展。
可以搜索以下几个扩展,看是否被注释掉:```iniextension=mbstring.soextension=iconv.soextension=mysqli.so```如果这些扩展没有被加载,可以去掉前面的分号,并重启服务器。
五、检查环境变量在Linux系统中,还需要检查环境变量是否正确设置。
Linux中文显示乱码问题解决方法(编码查看及转换)

Linux中⽂显⽰乱码问题解决⽅法(编码查看及转换)Linux中⽂显⽰乱码问题解决⽅法(编码查看及转换)1,⽰例图中名为⼀个.sql⽂件的⼀段内容,是⼀个数据库⽂件。
其在windows中打开显⽰正常,在Linux中,中⽂部分显⽰为乱码。
注意:这个与数据库乱码的情况不同,属于⽂件内容的乱码。
2,分析Linux系统与windows系统在编码上有显著的差别。
Windows中的⽂件的格式默认是GBK(gb2312),⽽Linux系统中⽂件的格式默认是UTF-8。
这两个系统就好⽐是中国和⽇本。
⽂件就好⽐是⼀个⼈,如果要在另外的国家居住就要办理居住许可证,使⽤他国的证件(编码和字符集),否则是不被允许的⿊户。
因此,解决中⽂乱码问题要从编码和字符集着⼿。
⽂件出现编码错误的原因:当前系统的字符集有问题某个⽂件的编码有问题3,解决⽅案3.1⽅案⼀:从系统的字符集处理当系统中多个⽂件的内容出现乱码问题,或者中⽂⽂件名显⽰乱码时,就先从系统的字符集处理。
常⽤字符集:中⽂LANG=“zh_CN.UTF-8”英⽂LANG=“en_US.UTF-8”或LANG=C1,查看字符集<1>查看当前系统默认采⽤的字符集locale<2>查看系统当前字符集echo $LANG<3>查看系统是否安装中⽂字符集出现zh开头的,即为安装了中⽂字符集如未安装,需执⾏: yum -y groupinstall chinese-supportlocale -a |grep zh2,修改系统字符集<1>修改系统字符集为中⽂如果前⾯查看到的系统当前的字符集是英⽂,通常修改系统字符集为中⽂即可成功。
临时修改(当前终端⽣效):export LANG="zh_CN.UTF-8"永久修改:echo"export LANG="zh_CN.UTF-8" >> /etc/proflilesource /etc/profile<2>查看echo $LANG3.2 解决⽅法⼆:从⽂件的编码处理当系统的字符集为中⽂,⽂件的中⽂部分仍然显⽰乱码,就从⽂件的编码格式处理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• Jjhl7684dggds如果你想学到更多的电脑知 识请随时关注系统114,记住我们的官方网 站:系统之家下载站 /zhuti/
系统之家下载站 /
Linux下打开Emacs出现编辑器之一, 很多用户在Linux系统下使用Emacs。不过 由于默认编码跟文档编码不同会导致 Emacs经常出现乱码,下面就来介绍一下 Linux下打开Emacs出现乱码怎么解决
• 方法一: • 只需C-x 《RET》 r ( M-x revertbuffer-with-coding-system) 来用指定的编 码重新读入这个文件即可。一般乱码都是 因为emacs下使用latin或者utf8,而打开的 文档是gb2312编码。如果不记得编码类型 就试一下,基本上gb2312都能解决。询问 编码时记得用tab补齐比较方便。或则也可 以通过file 文件名或者enca文件名来查看。
• •
方法二: 使用unicad插件下载unicad.el保存到相 应目录(如.emacs中配置my-elisp文件夹为 存放目录),然后在.emacs中声明 (require ‘unicad)即可。这样下次打开文 档时会自动判断编码类型。
• 以上就是Linux下打开Emacs出现乱码的解 决方法了,如果您也遇到Emacs乱码的问 题,不妨尝试使用上文的方法解决。