日志分析系统调研分析-ELK-EFK
日志解决方案调研

日志解决方案调研一、日志管理的挑战与重要性随着企业信息系统的规模和复杂度不断增加,传统的手工记录和分析方式已经无法满足快速变化的需求。
有效的日志管理解决方案能够帮助企业实时监控系统运行状态、快速识别潜在问题并进行响应。
例如,通过收集和分析系统的日志数据,管理员可以及时发现异常行为或安全漏洞,并采取必要的措施加以应对,从而保障信息系统的稳定运行和数据安全。
二、常见的日志解决方案类型开源日志管理工具开源日志管理工具因其免费、灵活和社区支持广泛等特点,受到了众多企业的青睐。
其中,比较知名的包括ELK(Elasticsearch、Logstash、Kibana)和Graylog。
ELK通过Elasticsearch进行高效的日志存储和检索,Logstash用于日志收集和传输,Kibana则提供了强大的可视化分析功能,使得用户可以直观地分析和理解日志数据。
Graylog则提供了类似的功能,但更专注于企业级应用场景,提供了更多的安全和可扩展性特性。
商业日志管理平台三、如何选择适合的日志解决方案需求分析和预算:明确企业的实际需求和预算限制,选择既能满足需求又不会过度投入的解决方案。
功能和性能:根据企业规模和业务特点,选择功能和性能都能够满足要求的解决方案。
集成和可扩展性:考虑解决方案与现有系统的集成能力和未来扩展的可能性,以避免日后的技术架构调整带来的额外成本和风险。
安全性和合规性:对于一些行业,如金融和医疗,安全性和合规性可能是至关重要的考虑因素,选择能够满足相关法规要求的解决方案至关重要。
五、未来日志管理的发展趋势云原生日志管理:随着企业对云计算的广泛采用,云原生日志管理解决方案正在兴起。
这些解决方案能够与云平台无缝集成,支持自动伸缩和高可用性,为企业提供更加灵活和成本效益的日志管理选项。
安全性和合规性的增强:随着数据隐私和合规性要求的提升,未来的日志管理解决方案将更加关注安全性和合规性的增强。
例如,通过数据加密、访问控制和完整性验证等技术手段,确保日志数据的安全存储和传输。
基于大数据的ELK日志分析系统研究及应用
基于大数据的ELK日志分析系统研究及应用作者:李志民孙林檀吴建军张新征来源:《科学与信息化》2019年第28期摘要基于ELK的日志分析系统研究分析是为了有效的解决当下物联网应用日志处理效率低的问题。
因此,本文首先阐述了基于ELK的日志分析平台,然后总结了对系统日记群集优化大方法,从而提高日志分析系统的运行效率和排查异常的速度。
关键词 ELK;日志分析系统;Elasticsearch日志设计信息系统的重要组成部分,是系统运行、性能分析以及故障诊断的重要来源。
随着科学技术的不断发展和互联网技术的广泛应用,不断增加了系统的日志量,随着日志的应用范围的扩大和复杂程度的增加,传统日志的分析方式和效率已经不能适信息系统对日志的需求。
为了满足信息时代的发展需要,下面就基于ELK的日志分析系统进行相关的研究分析工作。
1 基于ELK的日志分析平台随着实时分析技术的不断发展和成熟应用,在日志领域出现了新的分析系统-ELK,ELK 实时日志分析平台主要运用了Kiba-na(数据可视分析平台)、Logstash(日志采集工具)、Elasticsearch(分布式搜索引擎)[1]。
这些技术的应用可以让系统的运行维护人员在庞大的日志信息量中及时找到所需要管理和维护的信息,从而实现了对日志系统的分析。
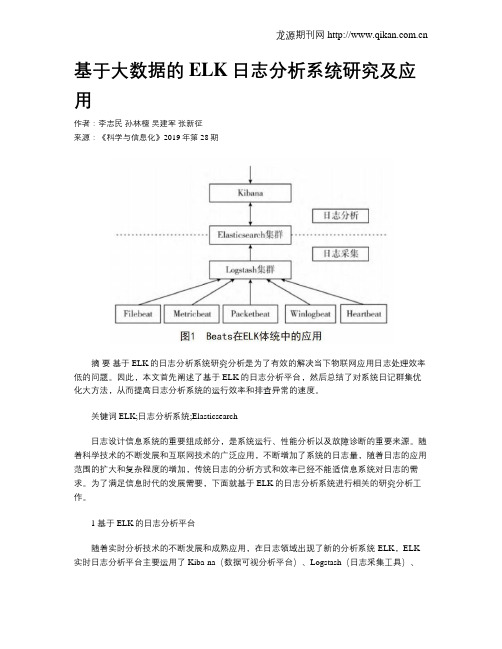
1.1 日志分析系统整体架构完整的日志系统是有日志的储存系统、采集系统、解析系统化以及可视化分析系统共同组成的。
日志采集工具是日志的主要采集器,在多台机器当中都有分布,它可以对非结构的日志进行解析,然后把解析的结果传输到分布式搜索引擎中;分布式搜索引擎可以完成全文检索的功能,属于储存日志的中央系统;而Kibana组件的存在不仅可以对分布式搜索引擎中的日志进行可视化操作[2],还可以进行统计分析和高级搜索。
但是日记采集工具及要完成对日志的采集工作又要完成解析工作,这样不仅会致系统的性能下降,严重的时候还会影响工作的进展。
而Beats的推广和应用有效解决了这一问题,图1为Beatsde在系统框架中的应用:Beats在进行信息采集和解析工作的时候可以针对不同的日志格式和来源使用不同的采集器,Beats采集器包括了5中不同种类和功能的日志采集器,分别为:Filebeat、Metricbest、Packetbeat、Winlogbeat、Heartbeat。
ELK日志分析系统

ELK⽇志分析系统⼀、ELK 概述1、ELK简介 ELK平台是⼀套完整的⽇志集中处理解决⽅案,将 ElasticSearch、Logstash 和 Kiabana 三个开源⼯具配合使⽤,完成更强⼤的⽤户对⽇志的查询、排序、统计需求。
ElasticSearch:是基于Lucene(⼀个全⽂检索引擎的架构)开发的分布式存储检索引擎,⽤来存储各类⽇志。
Elasticsearch 是⽤ Java 开发的,可通过 RESTful Web 接⼝,让⽤户可以通过浏览器与 Elasticsearch 通信。
Elasticsearch 是个分布式搜索和分析引擎,优点是能对⼤容量的数据进⾏接近实时的存储、搜索和分析操作。
Logstash:作为数据收集引擎。
它⽀持动态的从各种数据源搜集数据,并对数据进⾏过滤、分析、丰富、统⼀格式等操作,然后存储到⽤户指定的位置,⼀般会发送给 Elasticsearch。
Logstash 由JRuby 语⾔编写,运⾏在 Java 虚拟机(JVM)上,是⼀款强⼤的数据处理⼯具,可以实现数据传输、格式处理、格式化输出。
Logstash 具有强⼤的插件功能,常⽤于⽇志处理。
Kiabana:是基于 Node.js 开发的展⽰⼯具,可以为 Logstash 和 ElasticSearch 提供图形化的⽇志分析 Web 界⾯展⽰,可以汇总、分析和搜索重要数据⽇志。
Filebeat:轻量级的开源⽇志⽂件数据搜集器。
通常在需要采集数据的客户端安装 Filebeat,并指定⽬录与⽇志格式,Filebeat 就能快速收集数据,并发送给 logstash 进⾏解析,或是直接发给 Elasticsearch 存储,性能上相⽐运⾏于 JVM 上的 logstash 优势明显,是对它的替代。
2、为什么要使⽤ ELK ⽇志主要包括系统⽇志、应⽤程序⽇志和安全⽇志。
系统运维和开发⼈员可以通过⽇志了解服务器软硬件信息、检查配置过程中的错误及错误发⽣的原因。
使用ELK进行日志分析

使⽤ELK进⾏⽇志分析0x01 前⾔:前段时间做应急,总是需要溯源分析,痛点是数据量⽐较⼤,想要短时间能分析出来。
再者就是之前在调查某酒店事件的时候特别羡慕某产商有各种分析溯源⼯具。
反思过后,终于在没有那么忙的时候开始搭建平台,开始采坑0x02 ELK搭建:firewalld的基本使⽤启动: systemctl start firewalld查看状态: systemctl status firewalld停⽌: systemctl disable firewalld禁⽤: systemctl stop firewalld我安装的是⼀个精简版的centos7,所以需要安装Java环境rpm -qa | grep java*yum install java-1.8.0-openjdk* -yrpm -ivh kibana-6.4.2-x86_64.rpmrpm -ivh logstash-6.4.2.rpmrpm -ivh elasticsearch-6.4.2.rpmyum install gcc-c++修改配置⽂件vim /etc/logstash/logstash.ymlvim /etc/elasticsearch/elasticsearch.ymlvim /etc/kibana/kibana.yml启动服务systemctl start logstash.servicesystemctl start elasticsearch.servicesystemctl start kibana.service利⽤redis作为输⼊源:tar zxvf redis-5.0.0.tar.gzcd redis-5.0.0make && make install修改redis.conf。
bind 0.0.0.0protected-mode nodaemonize yesmaxclients 1000000启动redismv redis.conf /etc/redis-server /etc/redis.conf汉化:python main.py /usr/share/kibana chrome插件:。
ELK日志分析系统

ELK日志分析系统ELK日志分析系统是一种常用的开源日志管理和分析平台。
它由三个主要组件组成,即Elasticsearch、Logstash和Kibana,分别用于收集、存储、分析和可视化日志数据。
本文将介绍ELK日志分析系统的原理、特点和应用场景等。
ELK日志分析系统具有以下几个特点。
首先,它是一个开源系统,用户可以自由获取、使用和修改代码,满足各种定制化需求。
其次,它具有高度的可扩展性和灵活性,可以处理海量的日志数据,并支持实时查询和分析。
再次,它采用分布式架构,可以部署在多台服务器上,实现高可用性和负载均衡。
最后,它提供了丰富的可视化工具和功能,让用户可以直观地了解和分析日志数据,发现潜在的问题和异常。
ELK日志分析系统在各种场景下都有广泛的应用。
首先,它可以用于系统日志的监控和故障诊断。
通过收集和分析系统的日志数据,可以及时发现和解决问题,保证系统的正常运行。
其次,它可以用于应用程序的性能监控和优化。
通过分析应用程序的日志数据,可以找到性能瓶颈和潜在的问题,并采取相应的措施进行优化。
再次,它可以用于网络安全监控和威胁检测。
通过分析网络设备和服务器的日志数据,可以及时发现并应对潜在的安全威胁。
最后,它还可以用于业务数据分析和用户行为追踪。
通过分析用户的访问日志和行为日志,可以了解用户的偏好和行为模式,为业务决策提供依据。
然而,ELK日志分析系统也存在一些挑战和限制。
首先,对于大规模的日志数据,ELK系统需要消耗大量的存储和计算资源,对硬件设施和系统性能要求较高。
其次,ELK系统对日志的结构有一定的要求,如果日志数据过于复杂或不规范,可能会造成数据解析和处理的困难。
再次,ELK系统对于数据的实时性要求较高,以保证用户能够在短时间内获取到最新的数据和分析结果。
最后,对于非技术人员来说,ELK系统的配置和使用可能较为复杂,需要一定的培训和专业知识。
总之,ELK日志分析系统是一种功能强大且灵活的日志管理和分析工具,可以帮助用户实现日志数据的收集、存储、分析和可视化展示。
基于ELK架构的日志分析系统研究与实践

基于ELK架构的日志分析系统研究与实践作者:王军利杨卫中来源:《中国信息化》2020年第09期在传统的基于IOE集中架构的IT系统中,部署的主机及软件数量较少,产生的日志种类和数量也较少;随着互联网技术的快速发展,“平台+应用”的分布式架构成为主流,主机数量和软件规模急剧增加,日志分析变得日益困难。
本文主要针对基于ELK架构的日志分析系统进行研究,实现对分布式部署的主机和软件日志进行收集、分析、存储,并提供良好的UI界面进行数据展示、快速搜索、处理分析等功能,从而提升日志分析、问题定位、性能优化等工作的效率。
随着新一代BSS的上线,IT系统架构发生了巨大变化,从传统的IOE集中架构过渡为当前流行的“平台+应用”的分布式架构。
目前新一代BSS系统运行在近500台x86物理机和虚拟机上,众多的主机、组件及应用,每天合计产生TB级的日志,这些日志往往被运维人员忽略,加上日志分析工具的缺乏,这些日志远没有被有效利用起来。
因此,对各组件、各环节、各路径的日志的分析与管控,是传统业务运维走向“统一管控、智能运营”目标的重要手段,是满足IT系统开放、敏捷、智能化要求的重要保障。
在复杂的分布式的主机及应用集群中,记录日志的方式多种多样,且不易归档,以及无法提供有效的日志监控手段等,无论是开发人员还是运维人员都无法高效搜索日志内容从而快速准确定位问题,因此迫切需要一个集中的、独立的、能够收集管理各个应用和服务器上的日志,并提供良好的UI界面进行数据展示、快速搜索、處理分析等功能的工具或系统。
经过分析研究,基于开源ELK组件的日志分析系统(以下简称该系统)提供了相应的解决方案,该方案能高效、简便的满足以上场景。
(一)ELK架构及特点ELK架构主要由ElasticSearch、Logstash和Kibana等三个开源软件组成,其中E (ElasticSearch,也简称ES)是分布式搜索引擎,完成搜索、分析、存储数据等功能;L (Logstash)是收集、分析、过滤日志的工具,支持多种数据获取方式;K(Kibana)为EL提供友好的日志分析Web界面,并可以汇总、分析和搜索日志。
基于ELK的实时日志分析系统

基于ELK的实时日志分析系统ELK是一个开源的日志管理工具,它由三个独立但协作的组件组成:Elasticsearch、Logstash和Kibana。
ELK可以用于实时的日志分析,它可以帮助用户在大量的日志数据中实时、可视化和分析数据。
首先,Elasticsearch是一个分布式引擎,它可以快速地存储、和分析大规模的数据。
它使用倒排索引的方式来存储数据,并提供了灵活的全文、过滤和聚合功能。
对于实时日志分析系统来说,Elasticsearch可以作为一个集中的存储和索引引擎,用于存储和检索大量的日志数据。
其次,Logstash是一个用于数据收集、转换和发送的工具。
它可以从不同的数据源中收集日志数据,如文件、数据库、网络等,并对数据进行预处理、清洗和转换。
同时,Logstash也可以将处理后的数据发送到不同的目标,如Elasticsearch、消息队列等。
对于实时日志分析系统来说,Logstash可以负责收集应用程序生成的日志数据,并将其发送到Elasticsearch中进行索引和存储。
最后,Kibana是一个用于可视化和分析数据的工具。
它提供了一个直观的Web界面,用户可以通过查询和过滤数据来生成各种图表和图形,如柱状图、饼图、地图等。
Kibana还支持用户创建自定义的仪表板和报表,以便更方便地监控和分析日志数据。
对于实时日志分析系统来说,Kibana可以作为一个前端界面,供用户可视化和分析存储在Elasticsearch中的日志数据。
基于ELK的实时日志分析系统可以帮助用户实时地监控和分析应用程序的日志数据。
用户可以通过Kibana的查询功能,快速和过滤感兴趣的日志数据,并通过可视化工具生成图表和报表。
这样,用户可以更方便地分析日志数据,并及时发现应用程序的异常和问题。
此外,ELK还具有高可靠性和可扩展性的特点。
Elasticsearch作为一个分布式系统,可以水平地扩展以处理大规模的数据,并提供高可用性和容错性。
ELK日志分析系统

ELK日志分析系统ELK日志分析系统(Elasticsearch, Logstash, Kibana)是一种用于实时数据分析和可视化的开源工具组合。
它结合了Elasticsearch、Logstash和Kibana这三个工具,可对大量的日志数据进行收集、存储、和分析,并通过直观的可视化界面展示分析结果。
本文将对ELK日志分析系统的原理、功能和应用进行介绍。
2. 数据存储和索引:ELK日志分析系统使用Elasticsearch作为底层存储和索引引擎。
Elasticsearch是一个高性能、分布式的和分析引擎,能够实时地处理大规模的数据,并提供复杂的、聚合和分析功能。
Elasticsearch使用倒排索引来加快速度,并支持多种查询和分析方式,如全文、聚合查询、时序分析等。
3. 数据和查询:ELK日志分析系统通过Elasticsearch提供强大的和查询功能。
用户可以使用简单的关键字查询或复杂的过滤条件来和筛选数据。
同时,Elasticsearch还支持模糊、近似和正则表达式等高级方式,以便更精确地找到所需的数据。
4. 数据可视化和分析:ELK日志分析系统的另一个重要功能是数据的可视化和分析。
通过Kibana工具,用户可以创建自定义的仪表板和图表,展示日志数据的各种指标和趋势。
Kibana支持多种图表类型,如柱状图、折线图、饼图等,并提供交互式过滤和数据透视功能,以帮助用户更好地理解和分析数据。
ELK日志分析系统在实际应用中具有广泛的用途。
首先,它可以用于系统监控和故障排查。
通过收集和分析系统日志,可以实时监控系统的运行状态,并及时发现和解决潜在的问题。
其次,ELK日志分析系统可以用于安全事件检测和威胁分析。
通过分析网络和应用日志,可以识别潜在的安全威胁,提高系统的安全性。
此外,ELK日志分析系统还可以用于运营分析、业务分析和市场分析等领域,帮助企业更好地理解和利用日志数据,提升业务效率和竞争力。
总之,ELK日志分析系统是一种功能强大的实时数据分析和可视化工具组合。
详解开源日志分析管理软件--ELK架构原理与介绍

详解开源日志分析管理软件--ELK架构原理与介绍概述一般我们需要进行日志分析场景:直接在日志文件中grep、awk 就可以获得自己想要的信息。
但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。
需要集中化的日志管理,所有服务器上的日志收集汇总。
常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
而开源的集中式日志管理系统首推ELK/EFK,接下来带大家了解下这块。
ELK一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
一个完整的集中式日志系统,需要包含以下几个主要特点:•收集-能够采集多种来源的日志数据•传输-能够稳定的把日志数据传输到中央系统•存储-如何存储日志数据•分析-可以支持 UI 分析•警告-能够提供错误报告,监控机制ELK提供了一整套解决方案,并且都是开源软件,之间互相配合使用,完美衔接,高效的满足了很多场合的应用。
目前主流的一种日志系统。
ELK简介ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是开源软件。
新增了一个FileBeat,它是一个轻量级的日志收集处理工具(Agent),Filebeat占用资源少,适合于在各个服务器上搜集日志后传输给Logstash,官方也推荐此工具。
Elasticsearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。
它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。
一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
轻松玩转ELK海量可视化日志分析系统

轻松玩转ELK海量可视化日志分析系统ELK是目前行业中非常热门的一个技术,它可以用于电商网站、门户网站、企业IT系统等各种场景下,也可以用于对海量的数据进行近实时的数据分析。
到底什么是ELK?ELK呢,就是给运维提供辅助的一个应用套件。
运维工作就是对各种业务系统进行监控,发现问题,能够及时告警,然后能够迅速查到问题,进而解决问题,这是运维工作的核心。
而如果运维管理的服务器和业务系统非常多的情况下,可能无法及时、准确的了解每个业务系统和服务器的状态,如果发现业务系统有问题,那就需要登录业务系统服务器去查问题,但是如果服务器很多呢,有几百台、甚至更多情况下,不可能一个一个系统登录查看吧。
那么,问题就来了?怎么解决这种问题呢,ELK这个套件工具,就可以解决这个问题,ELK是集中对日志进行收集、过滤、分析、可视化展示的工具。
通过ELK,将运维所有的服务器日志,业务系统日志都收集到一个平台下,然后提取想要的内容,比如错误信息,警告信息等,当过滤到这种信息,就马上告警,告警后,运维人员就能马上定位是哪台机器、哪个业务系统出现了问题,出现了什么问题,都会在ELK平台有详细的描述。
ELK的功能是?这样通过这个ELK平台,就避免了运维人员登录每个机器,一台一台查看日志的麻烦,遇到问题,迅速发现,迅速定位,迅速解决问题,最终,提升运维的工作效率。
当然,ELK还有更大的功能,对大数据做分析,还可以和Hadoop大数据平台整合。
专栏解决了什么?本专栏属于从入门到应用实战性质的一个专栏,深入浅出剖析ELK在企业常见应用框架以及ZooKeeper、Kafka与ELK进行整合的方法和架构。
首选通过具体的一个应用案例介绍ZooKeeper+Kafka+ELK构建一套实时日志处理系统的过程。
然后通过对Logstash和Filebeat的对比,深入介绍Filebeat及ELK的安装配置以及日志数据可视化的实现方法。
接着,详细介绍了Logstash的各种应用插件以及具体用法。
日志分析系统调研分析-ELK-EFK

日志分析系统目录一. 背景介绍 (2)二.日志系统比较 (2)1.怎样收集系统日志并进行分析 (2)A.实时模式: (2)B.准实时模式 (2)2.常见的开源日志系统的比较 (3)A. FaceBook的Scribe (3)B. Apache的Chukwa (3)C. LinkedIn的Kafka (4)E. 总结 (8)三.较为成熟的日志监控分析工具 (8)1.ELK (9)A.ELK 简介 (9)B.ELK使用场景 (10)C.ELK的优势 (10)D.ELK的缺点: (11)2.EFK (11)3. Logstash 于FluentD(Fluentd)对比 (11)一. 背景介绍许多公司的平台每天会产生大量的日志(一般为流式数据,如,搜索引擎的pv,查询等),处理这些日志需要特定的日志系统,一般而言,这些系统需要具有以下特征:(1)构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;(2)支持近实时的在线分析系统和类似于Hadoop之类的离线分析系统;(3)具有高可扩展性。
即:当数据量增加时,可以通过增加节点进行水平扩展。
二.日志系统比较1.怎样收集系统日志并进行分析A.实时模式:1 在打印日志的服务器上部署agent2 agent使用低耗方式将日志增量上传到计算集群3 计算集群解析日志并计算出结果,尽量分布式、负载均衡,有必要的话(比如需要关联汇聚)则采用多层架构4 计算结果写入最适合的存储(比如按时间周期分析的结果比较适合写入Time Series模式的存储)5 搭建一套针对存储结构的查询系统、报表系统补充:常用的计算技术是stormB.准实时模式1 在打印日志的服务器上部署agent2 agent使用低耗方式将日志增量上传到缓冲集群3 缓冲集群将原始日志文件写入hdfs类型的存储4 用hadoop任务驱动的解析日志和计算5 计算结果写入hbase6 用hadoop系列衍生的建模和查询工具来产出报表补充:可以用hive来帮助简化2.常见的开源日志系统的比较A. FaceBook的ScribeScribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。
ELK日志分析

ELK⽇志分析⽬录1.ELK概述在规模较⼤的企业场景中,⾯临问题包括⽇志量太⼤如何归档、⽂本搜索太慢怎么办、如何多维度查询。
需要集中化的⽇志管理,所有服务器上的⽇志收集汇总。
常见解决思路是建⽴集中式⽇志收集系统,将所有节点上的⽇志统⼀收集,管理,访问。
所以企业中都会建⽴⽇志服务器,调⾼安全性、集中化管理,但是相应的⼤量的⽇志⽂件导致对⽇志分析困难。
⽽今天介绍的ELK就是为了解决这⼀问题。
1.1 ELK⽇志分析系统ELK是由Elasticsearch、Logstash、Kiban三个开源软件的组合。
在实时数据检索和分析场合,三者通常是配合共⽤,⽽且⼜都先后归于 Elastic.co 公司名下,故有此简称。
1.2 ELK中⽇志处理步骤第⼀步:将⽇志进⾏集中化管理(beats)第⼆步:将⽇志格式化(Logstash),然后将格式化后的数据输出到Elasticsearch第三步:对格式化后的数据进⾏索引和存储(Elasticsearch)第四步:前端数据的展⽰(Kibana)1.3 Elasticsearch概述Elasticsearch是⼀个基于Lucene的搜索服务器。
它基于RESTfulweb接⼝提供了⼀个分布式多⽤户能⼒的全⽂搜索引擎。
Elasticsearch是⽤Java开发的,并作为Apache许可条款下的开放源码发布,是第⼆流⾏的企业搜索引擎。
设计⽤于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使⽤⽅便。
(1)Elasticsearch的特性接近实时的搜索集群节点索引索引(库)→类型(表)→⽂档(记录)分⽚和副本(2)分⽚和副本在上述特性中,最重要的就是分⽚和副本,也是让es数据库(Elasticsearch)成为百度这些主流搜索引擎的主要原因,理论上能提升4倍的性能。
结合实际情况分析:索引存储的数据可能超过单个节点的硬件限制,如⼀个10亿⽂档需1TB空间可能不适合存储在单个节点的磁盘上,或者从单个节点搜索请求太慢了,为了解决这个问题,elasticsearch提供将索引分成多个分⽚的功能,当在创建索引时,可以定义想要分⽚的数量。
基于ELK的日志分析系统研究及应用

2018年7月计算机工程与设计July2018第 39 卷第7 期 C O M P U T E R E N G IN E E R IN G A N D D E SIG N Vol.39 No.7基于ELK的日志分析系统研究及应用姚攀123,马玉鹏12,徐春香12(1.中国科学院新疆理化技术研究所,新疆乌鲁木齐830011& 2.新疆民族语音语言信息处理实验室,新疆乌鲁木齐830011& 3.中国科学院大学,北京100049)摘要"为解决现阶段物联网应用日志处理效率低下的问题,研究一种基于E L K技术栈的开源日志解决方案。
探讨各组 件的工作原理和使用方法,提出解析日志的规则和技巧,总结优化E la s tic s e a rc h集群性能的方法,在此基础之上搭建能够 对海量日志进行实时采集和检索的分析监控系统。
实验结果表明,该方案具有配置方式灵活、集群可线性扩展、日志实时导入、检索性能高效、可视化方便等优点,能有效提高运维效率和异常排查速度。
关键词:大数据;物联网;系统监控;日志分析平台;E L K; Elasticsearch中图法分类号!T P399文献标识号:A文章编号:1000-7024(2018)07-2090-06doi:10. 16208'.is s n l000-7024. 2018. 07. 049Research and application of log analysis system based on ELK StackY A O P a n1’2’3,M A Y u-p e n g1’2,X U C h u n-x i a n g1’2(1. X in jia n g T echnical In s titu te o f Physics and C h e m is try’Chinese Academ ic o f Science’U ru m q i 830011 ’C h in a;2. X in jia n g L a b o ra to ry o f M in o rity Speech and Language In fo rm a tio n P roces3. U n iv e rs ity o f Chinese Academ y o f Sciences’B e ijing 100049’C hina)Abstract:T o solve the problem o f lo w efficiency o f In te rn e t o f things application log process’ an open source log process solution based on E L K Stack was studied. T o b u ild an analysis and m on ito rin g system fo r real-tim e collection and retrie va l o f mass lo g s’ the w o rk in g principle o f each component was discussed’ the rules o f log parsing w ere presen form ance o f Elasticsearch c luster were summ arized. E xperim ental results show th a t the solution has the advantage o f fle xib le configuration. Besides’ a ll clusters can be expanded lin e a rly’ logs can be im p orte d in real tim e’ e ffic ie n tly searched and easily visualized.L og analysis system based on E L K Stack can effe ctively im prove the maintenancetio n speedKey word s:big d a ta;In te rn e t o f th in g s;system m o n ito rin g;log analysis p la tfo rm;E L K;Elasticsearch/引言日志是系统运维、故障诊断、性能分析的重要来源’对于任何系统而言都是极其重要的组成部分。
日志分析系统调研分析_ELK_EFK

日志分析系统调研分析_ELK_EFK随着互联网的迅猛发展和系统规模的不断扩大,日志数据变得越来越庞大和复杂。
为了更方便地对日志数据进行分析和监控,出现了许多日志分析系统。
本文将对三种常见的日志分析系统进行调研分析,包括ELK (Elasticsearch、Logstash、Kibana)、EFK(Elasticsearch、Fluentd、Kibana)和Sentry。
一、ELK(Elasticsearch、Logstash、Kibana)ELK 是由 Elastic 公司开发和维护的一套日志分析系统,由三个主要组件组成:1. Elasticsearch:一个基于 Lucene 的分布式和分析引擎,用于存储和索引日志数据。
它支持实时和分析,并提供了灵活的查询语言和聚合功能。
3. Kibana:一个用于可视化和分析 Elasticsearch 数据的交互式工具。
它提供了丰富的图表、仪表盘和界面,方便用户对日志数据进行检索、统计和可视化。
ELK的优势在于其强大的和分析功能、灵活的日志数据收集和转换能力,以及直观易用的可视化界面。
它广泛用于各种场景,如运维监控、安全分析和业务分析等。
二、EFK(Elasticsearch、Fluentd、Kibana)EFK是亚马逊公司推出的一套开源日志分析系统,与ELK类似,也由三个主要组件组成:1. Elasticsearch:同样作为数据存储和索引引擎,用于存储和索引日志数据。
3. Kibana:同样用于可视化和分析 Elasticsearch 数据的交互式工具,提供了丰富的图表、仪表盘和界面。
与 Logstash 相比,Fluentd 具有更轻量级的设计和更高的吞吐量。
此外,Fluentd 还提供了丰富的插件生态系统,可以方便地进行功能扩展。
三、SentrySentry 是一个开源的实时错误日志和异常追踪系统,主要用于监控和收集应用程序发生的异常和错误信息。
它提供了丰富的报告和可视化功能,能够及时发现和解决线上问题。
ELK+Kafka日志采集分析平台

ELK+Kafka⽇志采集分析平台1. ELK 和 Kafka 介绍LK 分别是由 Logstash(收集+分析)、ElasticSearch(搜索+存储)、Kibana(可视化展⽰)组成,主要是为了在海量的⽇志系统⾥⾯实现分布式⽇志数据集中式管理和查询,便于监控以及排查故障,极⼤⽅便微服务项⽬查看⽇志;Logstash 接收应⽤系统的⽇志数据,对进⾏过滤、分析、统⼀格式等操作对接,然后将其写⼊到 ElasticSearch 中;Logstash 可以⽀持 N 种 log 渠道:Kafka ⽇志队列对接读取、和 log 硬盘⽬录对接读取、Reids 中存储⽇志队列读取等等;ElasticSearch 存储⽇志数据,是⼀种分布式搜索引擎,具有⾼可伸缩、⾼可靠、易管理等特点,可以⽤于全⽂检索、结构化检索和分析,并能将这三者结合起来;Kibana 对存放在 ElasticSearch 中⽇志数据进⾏:数据展现、报表展现,并且是实时的;单纯使⽤ ELK 做⽇志系统,由于 Logstash 消耗系统资源⽐较⼤,运⾏时占⽤ CPU 和内存资源较⾼,且没有消息队列缓存,可能存在数据丢失的风险,只能适合于数据量⼩的环境使⽤;Apache Kafka 是消息中间件的⼀种,是⼀种分布式的,基于发布/订阅的消息系统。
能实现⼀个为处理实时数据提供⼀个统⼀、每秒百万级别的⾼吞吐、低延迟的平台,且拥有分布式的,可划分的,冗余备份的持久性的⽇志服务等特点。
和采⽤ Redis 做轻量级消息队列不同,Kafka 利⽤磁盘作队列,所以也就⽆所谓消息缓冲时的磁盘问题;⽽且 Redis 作为集群使⽤时,对应的应⽤对应⼀个 Redis,在某种程度上会造成数据的倾斜性,从⽽导致数据的丢失,若对于数据量⼩的环境下使⽤ Redis 的队列替换 Kafka,效率和成本会很⼤提升;2. ELK Docker 环境搭建Docker 环境搭建可参考:(2)、讲解⼀下 docker-compose.yml;(3)、进⼊到该⽬录,在有 docker-compose.yml 的⽬录使⽤下⾯的命令进⾏下载和启动(第⼀次下载会⽐较久);#启动容器,⽅便控制台调试,第⼀次建议使⽤该命令进⾏下载和启动docker-compose up#后台启动容器docker-compose up -d#其他命令,查看 docker-compose --help#安全关闭 docker-compose#docker-compose down -v注:若出现 -bash: docker-compose: command not found 时,解决如下:# 1、先安装 pip ,检查是否已有;pip -V# 2、若已安装 pip 则忽略此步骤,若报错 -bash: pip: command not found 请安装;yum -y install epel-releaseyum -y install python-pippip install --upgrade pip# 3、安装Docker-Compose;pip install docker-compose# 4、检查是否安装成功;docker-compose -version(4)、出现绿⾊ done 则表⽰下载完成并启动;开放端⼝,我这边使⽤的是阿⾥云,所以需要去云实例的安装组配置规则开放端⼝;(5)、理解各个端⼝的作⽤,并访问 Elasticsearch 控制台和 Kibana 控制台;5000: Logstash TCP input #⽇志采集端⼝9200: Elasticsearch HTTP #控制台端⼝9300: Elasticsearch TCP transport #集群通信端⼝,作⼼跳检测5601: Kibana #控制台端⼝Elasticsearch 控制台(默认⽤户名:elastic,密码:changeme,在 docker-compose.yml 修改),如下界⾯说明服务已成功启动: Kibana 控制台(默认⽤户名:elastic,密码:changeme,在 docker-elk-master/kibana/config下 kibana.yml 修改),如下界⾯说明服务已成功启动:3. Kafka Docker 搭建(0)、本机环境 CentOS7,其他环境⼤同⼩异;安装 Docker 环境(如已安装请忽略此步骤);(1)、Github 搜索 docker kafka(下载地址如上链接),将其 clone 或下载到 linux 上,因机器问题,本⽂只安装单节点版;(2)、docker-compose.yml 会搭建多节点集群,本⽂不做演⽰,所以使⽤单节点⽂件 docker-compose-single-broker.yml;(3)、进⼊到该⽬录,在有 docker-compose.yml 的⽬录使⽤下⾯的命令进⾏下载和启动(第⼀次下载会⽐较久);#第⼀次建议使⽤该命令进⾏下载和启动docker-compose -f docker-compose-single-broker.yml up#后台启动docker-compose -f docker-compose-single-broker.yml up -d(4)、出现绿⾊ done 则表⽰下载完成并启动,查看运⾏状态;docker-compose ps4. 关联 Logstash 和 Kafka(1)、修改 logstash.conf 配置(在 docker-elk-master/logstash/pipeline ⾥);input {#tcp {# port => 5000#}kafka {id => "my_plugin_id"bootstrap_servers => "localhost:9092"topics => ["test"]auto_offset_reset => "latest"}}(2)、重新启动 Logstash;docker-compose restart logstash。
ELK(开源日志分析平台)介绍

ELK(开源日志分析平台)介绍ELK是一个开源的日志分析平台,它由三个组件:Elasticsearch、Logstash和Kibana组成。
ELK主要用于收集、存储和可视化日志数据,以便进行实时监控、分析和。
首先,让我们了解一下ELK的三个组件:1. Elasticsearch:Elasticsearch是一个分布式和分析引擎,用于存储和检索大量结构化或非结构化数据。
它能够快速地处理大规模数据,并提供实时、聚合和分析功能。
Elasticsearch使用倒排索引的方式来存储数据,它能够自动分片和复制数据,以确保高可用性和容错性。
2. Logstash:Logstash是一个用于收集、处理和转发日志数据的开源工具。
它支持多种输入源,包括文件、网络流、系统日志等。
Logstash 可以对日志数据进行过滤、转换和格式化,然后将其发送到Elasticsearch进行存储和分析。
3. Kibana:Kibana是一个基于Web的可视化工具,用于实时监控和分析Elasticsearch中的数据。
它提供了丰富的图表、图像和仪表盘,使用户能够轻松地查询和可视化数据。
Kibana还支持实时和过滤,以及导出数据和分享仪表盘。
ELK的工作流程如下:2. 数据存储:Logstash将处理后的数据发送到Elasticsearch进行持久化存储。
Elasticsearch使用其分布式架构来存储和索引数据,以支持快速和分析。
3. 数据可视化:Kibana连接到Elasticsearch,并提供直观的界面来查询和可视化数据。
用户可以自定义图表、图像和仪表盘,以满足其特定的需求。
ELK的主要优点包括:1. 强大的和分析功能:Elasticsearch能够实时和聚合大规模数据,并提供丰富的查询语言和过滤器,以便用户快速定位和分析关键数据。
2. 可扩展性和高可用性:Elasticsearch使用分布式架构和自动分片机制,以实现数据的水平扩展和高可用性。
日志收集系统对比

⽇志收集系统对⽐前⾔:efk中的f与elk中的l分别可以指代logstash、filebeat、rsyslog、Fluentd等,作为⽇志系统中的标准收集⼯具,各有优劣,本⽂将分析下各⾃的有点与不⾜。
Logstashlogstash基于JRuby实现,可以跨平台运⾏在JVM上优点主要的优点就是它的灵活性,这还主要因为它有很多插件。
然后它清楚的⽂档已经直⽩的配置格式让它可以再多种场景下应⽤。
这样的良性循环让我们可以在⽹上找到很多资源,⼏乎可以处理任何问题。
劣势Logstash 致命的问题是它的性能以及资源消耗(默认的堆⼤⼩是 1GB)。
尽管它的性能在近⼏年已经有很⼤提升,与它的替代者们相⽐还是要慢很多的。
因为logstash是jvm跑的,资源消耗⽐较⼤,所以后来作者⼜⽤golang写了⼀个功能较少但是资源消耗也⼩的轻量级的logstash-forwarder。
不过作者只是⼀个⼈,elastic.co公司以后,因为es公司本⾝还收购了另⼀个开源项⽬packetbeat,⽽这个项⽬专门就是⽤golang的,有整个团队,所以es公司⼲脆把logstash-forwarder的开发⼯作也合并到同⼀个golang团队来搞,于是新的项⽬就叫filebeat 了。
logstash 和filebeat都具有⽇志收集功能,filebeat更轻量,占⽤资源更少,但logstash 具有filter功能,能过滤分析⽇志。
⼀般结构都是filebeat采集⽇志,然后发送到消息队列,redis,kafaka。
然后logstash去获取,利⽤filter功能过滤分析,然后存储到elasticsearch中。
Filebeat使⽤go语⾔编写⼯作原理:Filebeat可以保持每个⽂件的状态,并且频繁地把⽂件状态从注册表⾥更新到磁盘。
这⾥所说的⽂件状态是⽤来记录上⼀次Harvster读取⽂件时读取到的位置,以保证能把全部的⽇志数据都读取出来,然后发送给output。
基于ELK的日志分析系统研究与实践

基于ELK的日志分析系统研究与实践谢磊张冰杨猛摘要:为解决现阶段物联网应用日志处理效率低下的问题,研究一种基于ELK技术栈的开源日志解决方案。
探讨各组件的工作原理和使用方法,提出解析日志的规则和技巧,总结优化Elasticsearch集群性能的方法,在此基础之上搭建能够对海量日志进行实时采集和检索的分析监控系统。
实验结果表明,该方案具有配置方式灵活、集群可线性扩展、日志实时导入、检索性能高效、可视化方便等优点,能有效提高运维效率和异常排查速度。
关键词:大数据;物联网;系统监控系统运行维护、诊断故障、属性分析都是通过日志数据来解析的,日志是日志分析系统的主要组成部分。
随着互联网大数据的发展和规模的扩大,系统的日志数量在不断增加,其采集规模也在不断扩大;传统的采集手段已经远远不能满足日志采集,且日志分析的方式会造成能源消耗的浪费,工作效率差,不能进行多维度的查询,也不能对复杂事件进行处理分析。
现在大数据的处理趋势主要是实时性,同时,硬件成本降低,在这种情况下出现了许多日志分析平台,其中以ELK(分布式搜索引擎Elasticsearch、日志搜集过滤工具Logstash、数据可视化分析平台Kibana)为代表的实时日志分析平台,能满足多个场合的应用和需求,可以从庞大的日志信息数据中准确及时筛选出相关的信息,对信息数据进行监控和维护,对日志可以实行统计分析。
ELK不仅提高了运维人员的工作效率和质量,还能实时地监控日志数据运行状态,并反馈处理。
1 基于ELK的日志分析系统平台1.1 系统整体结构一个完整的日志分析系统主要包括采集、解析、储存和可视化转换4个部分。
在ELK 平台运行过程中,Logstash主要是对日志数据进行采集、分析解读和过滤数据,获取大量的日志数据并按照解析规则输送至Elasticsearch。
Elasticsearch是一个开源分布式的搜索引擎,主要有搜集、分析、儲存等功能,具有对整个数据库进行检索的功能,在处理过程中Elasticsearch作为存储日志的主要系统。
微服务下,使用ELK做日志收集及分析

微服务下,使⽤ELK做⽇志收集及分析⼀、使⽤背景 ⽬前项⽬中,采⽤的是微服务框架,对于⽇志,采⽤的是logback的配置,每个微服务的⽇志,都是通过File的⽅式存储在部署的机器上,但是由于⽇志⽐较分散,想要检查各个微服务是否有报错信息,需要挨个服务去排查,⽐较⿇烦。
所以希望通过对⽇志进⾏聚合,然后通过监控,能够快速的找到各个微服务的报错信息,快速的排查。
⼆、ELK分析 对于ELK,主要是分为Elastic Search、Logstash和Kibana三部分:其中Logstash作为⽇志的汇聚,可以通过input、filter、output三部分,把⽇志收集、过滤、输出到Elastic Search中(也可以输出到⽂件或其他载体);Elastic Search作为开源的分布式引擎,提供了搜集、分析、存储数据的功能,采⽤的是restful接⼝的风格;Kibana则是作为Elastic Search分析数据的页⾯展⽰,可以进⾏对⽇志的分析、汇总、监控和搜索⽇志⽤。
本次使⽤ELK主要则是作为⽇志分析场景。
三、ELK部署 1、Elastic Search安装 本次部署的⽬录为【/data/deploy/elk】下,⾸先需要下载,下载命令为: # cd /data/deploy/elk# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.4.3.tar.gz 解压到当前⽬录:# tar -zxvf elasticsearch-6.4.3.tar.gz 相关配置:# cd elasticsearch-6.4.3/config# vim elasticsearch.yml-- 增加如下内容:network.host: 0.0.0.0http.port: 9200http.cors.enabled: truehttp.cors.allow-origin: "*" Elastic Search启动:由于ES的启动不能⽤root账号直接启动,需要新创建⽤户,然后切换新⽤户去启动,执⾏命令如下:-- 创建新⽤户及授权# groupadd elsearch# useradd elsearch -g elsearch -p elasticsearch# cd /data/deploy/elk/# chown -R elsearch:elsearch elasticsearch-6.4.3-- 切换⽤户,启动# su elsearch# cd elasticsearch-6.4.3/bin# sh elasticsearch & 启动过程中,会出现⼀些报错信息,如: 1、max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536] 2、max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] 解决问题(1):将当前⽤户的软硬限制调⼤。
Efk简介——精选推荐

Efk简介前⾔: 在没有分布式⽇志的时候,每次出问题了需要查询⽇志的时候,需要登录到Linux服务器,使⽤命令cat -n xxxx|grep xxxx 搜索出⽇志在哪⼀⾏,然后cat -n xxx|tail -n +n⾏|head -n 显⽰多少⾏,这样不仅效率低下,⽽且对于程序异常也不⽅便查询,⽇志少还好,⼀旦整合出来的⽇志达到⼏个G 或者⼏⼗G的时候,仅仅是搜索都会搜索很长时间了,当然如果知道是哪天什么时候发⽣的问题当然也⽅便查询,但是实际上很多时候有问题的时候,是不知道到底什么时候出的问题,所以就必须要在聚合⽇志中去搜索(⼀般⽇志是按照天来分⽂件的,聚合⽇志就是把很多天的⽇志合并在⼀起,这样⽅便查询),⽽搭建EFK⽇志分析系统的⽬的就是将⽇志聚合起来,达到快速查看快速分析的⽬的,使⽤EFK不仅可以快速的聚合出每天的⽇志,还能将不同项⽬的⽇志聚合起来,对于微服务和分布式架构来说,查询⽇志尤为⽅便,⽽且因为⽇志保存在Elasticsearch中,所以查询速度⾮常之快。
⼀、Efk是什么: EFK不是⼀个软件,⽽是⼀套解决⽅案,开源软件之间的互相配合使⽤,⾼效的满⾜了很多场合的应⽤,是⽬前主流的⼀种⽇志系统。
EFK是三个开源软件的缩写,分别表⽰:Elasticsearch , FileBeat, Kibana , 其中ELasticsearch负责⽇志保存和搜索,FileBeat负责收集⽇志,Kibana 负责界⾯,当然EFK和⼤名⿍⿍的ELK只有⼀个区别,那就是EFK把ELK的Logstash替换成了FileBeat,因为Filebeat相对于Logstash来说有2个好处:1、侵⼊低,⽆需修改程序⽬前任何代码和配置2、相对于Logstash来说性能⾼,Logstash对于IO占⽤很⼤ 当然FileBeat也并不是完全好过Logstash,毕竟Logstash对于⽇志的格式化这些相对FileBeat好很多,FileBeat只是将⽇志从⽇志⽂件中读取出来,当然如果你⽇志本⾝是有⼀定格式的,FileBeat也可以格式化,但是相对于Logstash来说,还是差⼀点。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
日志分析系统目录一. 背景介绍 (2)二.日志系统比较 (2)1.怎样收集系统日志并进行分析 (2)A.实时模式: (2)B.准实时模式 (2)2.常见的开源日志系统的比较 (3)A. FaceBook的Scribe (3)B. Apache的Chukwa (3)C. LinkedIn的Kafka (4)E. 总结 (8)三.较为成熟的日志监控分析工具 (8)1.ELK (9)A.ELK 简介 (9)B.ELK使用场景 (10)C.ELK的优势 (10)D.ELK的缺点: (11)2.EFK (11)3. Logstash 于FluentD(Fluentd)对比 (11)一. 背景介绍许多公司的平台每天会产生大量的日志(一般为流式数据,如,搜索引擎的pv,查询等),处理这些日志需要特定的日志系统,一般而言,这些系统需要具有以下特征:(1)构建应用系统和分析系统的桥梁,并将它们之间的关联解耦;(2)支持近实时的在线分析系统和类似于Hadoop之类的离线分析系统;(3)具有高可扩展性。
即:当数据量增加时,可以通过增加节点进行水平扩展。
二.日志系统比较1.怎样收集系统日志并进行分析A.实时模式:1 在打印日志的服务器上部署agent2 agent使用低耗方式将日志增量上传到计算集群3 计算集群解析日志并计算出结果,尽量分布式、负载均衡,有必要的话(比如需要关联汇聚)则采用多层架构4 计算结果写入最适合的存储(比如按时间周期分析的结果比较适合写入Time Series模式的存储)5 搭建一套针对存储结构的查询系统、报表系统补充:常用的计算技术是stormB.准实时模式1 在打印日志的服务器上部署agent2 agent使用低耗方式将日志增量上传到缓冲集群3 缓冲集群将原始日志文件写入hdfs类型的存储4 用hadoop任务驱动的解析日志和计算5 计算结果写入hbase6 用hadoop系列衍生的建模和查询工具来产出报表补充:可以用hive来帮助简化2.常见的开源日志系统的比较A. FaceBook的ScribeScribe是facebook开源的日志收集系统,在facebook内部已经得到大量的应用。
它能够从各种日志源上收集日志,存储到一个中央存储系统(可以是NFS,分布式文件系统等)上,以便于进行集中统计分析处理。
它为日志的“分布式收集,统一处理”提供了一个可扩展的,高容错的方案。
特点:容错性好。
当后端的存储系统crash时,scribe会将数据写到本地磁盘上,当存储系统恢复正常后,scribe将日志重新加载到存储系统中。
架构:scribe的架构比较简单,主要包括三部分,分别为scribe agent, scribe和存储系统。
(1) scribe agentscribe agent实际上是一个thrift client。
向scribe发送数据的唯一方法是使用thrift client, scribe内部定义了一个thrift接口,用户使用该接口将数据发送给server。
(2) scribescribe接收到thrift client发送过来的数据,根据配置文件,将不同topic 的数据发送给不同的对象。
scribe提供了各种各样的store,如 file, HDFS 等,scribe可将数据加载到这些store中。
(3) 存储系统存储系统实际上就是scribe中的store,当前scribe支持非常多的store,包括file(文件),buffer(双层存储,一个主储存,一个副存储),network(另一个scribe服务器),bucket(包含多个 store,通过hash的将数据存到不同store中),null(忽略数据),thriftfile(写到一个Thrift TFileTransport 文件中)和multi(把数据同时存放到不同store中)。
B. Apache的Chukwachukwa是一个非常新的开源项目,由于其属于hadoop系列产品,因而使用了很多hadoop的组件(用HDFS存储,用mapreduce处理数据),它提供了很多模块以支持hadoop集群日志分析。
需求:(1) 灵活的,动态可控的数据源(2) 高性能,高可扩展的存储系统(3) 合适的框架,用于对收集到的大规模数据进行分析架构:Chukwa中主要有3种角色,分别为:adaptor,agent,collector。
(1) Adaptor 数据源可封装其他数据源,如file,unix命令行工具等目前可用的数据源有:hadoop logs,应用程序度量数据,系统参数数据(如linux cpu使用流率)。
(2) HDFS 存储系统Chukwa采用了HDFS作为存储系统。
HDFS的设计初衷是支持大文件存储和小并发高速写的应用场景,而日志系统的特点恰好相反,它需支持高并发低速率的写和大量小文件的存储。
需要注意的是,直接写到HDFS上的小文件是不可见的,直到关闭文件,另外,HDFS不支持文件重新打开。
(3) Collector和Agent为了克服(2)中的问题,增加了agent和collector阶段。
Agent的作用:给adaptor提供各种服务,包括:启动和关闭adaptor,将数据通过HTTP传递给Collector;定期记录adaptor状态,以便crash后恢复。
Collector的作用:对多个数据源发过来的数据进行合并,然后加载到HDFS中;隐藏HDFS实现的细节,如,HDFS版本更换后,只需修改collector即可。
(4) Demux和achieving直接支持利用MapReduce处理数据。
它内置了两个mapreduce作业,分别用于获取data和将data转化为结构化的log。
存储到data store(可以是数据库或者HDFS等)中。
C. LinkedIn的KafkaKafka是2010年12月份开源的项目,采用scala语言编写,使用了多种效率优化机制,整体架构比较新颖(push/pull),更适合异构集群。
设计目标:(1) 数据在磁盘上的存取代价为O(1)(2) 高吞吐率,在普通的服务器上每秒也能处理几十万条消息(3) 分布式架构,能够对消息分区(4) 支持将数据并行的加载到hadoop架构:Kafka实际上是一个消息发布订阅系统。
producer向某个topic发布消息,而consumer订阅某个topic的消息,进而一旦有新的关于某个topic的消息,broker会传递给订阅它的所有consumer。
在kafka中,消息是按topic组织的,而每个topic又会分为多个partition,这样便于管理数据和进行负载均衡。
同时,它也使用了zookeeper进行负载均衡。
Kafka中主要有三种角色,分别为producer,broker和consumer。
(1) ProducerProducer的任务是向broker发送数据。
Kafka提供了两种producer接口,一种是low_level接口,使用该接口会向特定的broker的某个topic下的某个partition发送数据;另一种那个是high level接口,该接口支持同步/异步发送数据,基于zookeeper的broker自动识别和负载均衡(基于Partitioner)。
其中,基于zookeeper的broker自动识别值得一说。
producer可以通过zookeeper获取可用的broker列表,也可以在zookeeper中注册listener,该listener在以下情况下会被唤醒:a.添加一个brokerb.删除一个brokerc.注册新的topicd.broker注册已存在的topic当producer得知以上时间时,可根据需要采取一定的行动。
(2) BrokerBroker采取了多种策略提高数据处理效率,包括sendfile和zero copy等技术。
(3) Consumerconsumer的作用是将日志信息加载到中央存储系统上。
kafka提供了两种consumer接口,一种是low level的,它维护到某一个broker的连接,并且这个连接是无状态的,即,每次从broker上pull数据时,都要告诉broker数据的偏移量。
另一种是high-level 接口,它隐藏了broker的细节,允许consumer 从broker上push数据而不必关心网络拓扑结构。
更重要的是,对于大部分日志系统而言,consumer已经获取的数据信息都由broker保存,而在kafka中,由consumer自己维护所取数据信息。
D. Cloudera的FlumeFlume是cloudera于2009年7月开源的日志系统。
它内置的各种组件非常齐全,用户几乎不必进行任何额外开发即可使用。
设计目标:(1) 可靠性当节点出现故障时,日志能够被传送到其他节点上而不会丢失。
Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。
),Store on failure(这也是scribe采用的策略,当数据接收方crash 时,将数据写到本地,待恢复后,继续发送),Best effort(数据发送到接收方后,不会进行确认)。
(2) 可扩展性Flume采用了三层架构,分别问agent,collector和storage,每一层均可以水平扩展。
其中,所有agent和collector由master统一管理,这使得系统容易监控和维护,且master允许有多个(使用ZooKeeper进行管理和负载均衡),这就避免了单点故障问题。
(3) 可管理性所有agent和colletor由master统一管理,这使得系统便于维护。
用户可以在master上查看各个数据源或者数据流执行情况,且可以对各个数据源配置和动态加载。
Flume提供了web 和shell script command两种形式对数据流进行管理。
(4) 功能可扩展性用户可以根据需要添加自己的agent,colletor或者storage。
此外,Flume自带了很多组件,包括各种agent(file, syslog等),collector和storage (file,HDFS等)。
架构:正如前面提到的,Flume采用了分层架构,由三层组成,分别为agent,collector和storage。
其中,agent和collector均由两部分组成:source和sink,source 是数据来源,sink是数据去向。
(1) agentagent的作用是将数据源的数据发送给collector,Flume自带了很多直接可用的数据源(source)(2) collectorcollector的作用是将多个agent的数据汇总后,加载到storage中。