尚硅谷大数据技术之数仓开发规范
数据仓库开发设计流程

数据仓库开发设计流程
数据仓库开发设计流程如下:
1.分析业务需求,确定数据仓库主题:需要全面了解企业业务和数据。
2,构建逻辑模型:通常使用维度建模技术,包括维度表和事实表来描述数据。
3.数据仓库技术选型。
4.逻辑模型转换为物理模型。
5.数据源分析:识别和分析所有可用的数据源,包括内部和外部系统。
6.数据抽取、转换和加载(ETL):确定如何从不同的数据源中提取数据,并将其转换为适合数据仓库的格式。
包括数据清洗、数据集成和数据转换等过程。
7.数据仓库架构设计:确定数据仓库的整体架构,考虑到数据仓库的可伸缩性、性能和可用性等方面。
8.数据仓库实施:根据设计的数据模型和架构来实施数据仓库。
包括创建数据库表、索引、视图等。
9.数据质量管理。
10.开发数据仓库的分析应用。
11.数据仓库管理和维护。
尚硅谷大数据之hive

尚硅谷大数据之hive尚硅谷大数据之hive》是一本关于Hive技术的书籍。
它旨在全面介绍Hive的主要内容和应用,并针对不同的读者群体提供有用的信息和指导。
Hive是一个开源的数据仓库基础设施工具,它构建在Hadoop 之上,用于处理大规模数据集。
通过使用Hive,用户可以使用类似于SQL的查询语言来访问和分析存储在Hadoop分布式文件系统中的数据。
这使得非技术背景的用户也能够利用Hive进行数据分析和查询。
本书主要包括以下内容:Hive基础知识:介绍Hive的基本概念、架构和组件。
读者将了解Hive如何与Hadoop生态系统中的其他工具集成,并研究如何安装和配置Hive。
Hive数据模型:详细解释Hive的数据模型,包括数据表、分区和桶等概念。
读者将研究如何创建、修改和管理Hive数据表,并了解如何利用分区和桶来提高查询性能。
Hive查询语言:深入介绍HiveQL,这是Hive的查询语言。
读者将研究如何编写各种类型的查询,包括基本的选择、过滤和聚合查询,以及复杂的连接和子查询。
Hive优化和性能调优:提供有关如何优化Hive查询性能的实用技巧和建议。
读者将研究如何使用索引、分区和桶来改善查询速度,以及如何使用适当的配置参数来优化Hive性能。
Hive高级特性:介绍Hive的一些高级特性和扩展,例如动态分区、外部表、UDF和UDAF等。
读者将了解如何利用这些功能来处理具有更复杂需求的数据分析场景。
本书适合各种读者群体,包括数据分析师、数据工程师、数据库管理员和对Hive技术感兴趣的研究者。
无论您是初学者还是有一定经验的专业人士,本书都将为您提供全面且易于理解的Hive研究资源。
2.简要介绍HiveHive是一个基于Hadoop的数据仓库基础架构,用于处理和分析大数据。
它提供了一个类似于SQL的查询语言,称为HiveQL,使用户能够对存储在Hadoop集群中的大规模数据进行查询和分析。
Hive的重要性在于它简化了大数据处理和分析的过程。
数据仓库开发规范

01数据层次的划分具体仓库的分层情况需要结合业务场景、数据场景、系统场景进行综合考虑,下面我们看一下常见的分层•ODS:Operational Data Store,操作数据层,在结构上其与源系统的增量或者全量数据基本保持一致。
它相当于一个数据准备区,同时又承担着基础数据的记录以及历史变化。
其主要作用是把基础数据引入到数仓。
•CDM:Common Data Model,公共维度模型层,又细分为DWD和DWS。
它的主要作用是完成数据加工与整合、建立一致性的维度、构建可复用的面向分析和统计的明细事实表以及汇总公共粒度的指标。
▪DWD:Data Warehouse Detail,明细数据层。
▪DWS:Data Warehouse Summary,汇总数据层。
•ADS:Application Data Service,应用数据层。
02数据分类架构该数据分类架构在ODS层分为三部分:数据准备区、离线数据和准实时数据区。
在进入到CDM层后,由以下几部分组成:•公共维度层:基于维度建模理念思想,建立整个企业的一致性维度。
•明细粒度事实层:以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。
您可以结合企业的数据使用特点,将明细事实表的某些重要维度属性字段做适当的冗余,即宽表化处理。
•公共汇总粒度事实层:以分析的主题对象为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段来物理化模型。
03数据划分及命名约定请根据业务划分数据并约定命名,建议针对业务名称结合数据层次约定相关命名的英文缩写,这样可以给后续数据开发过程中,对项目空间、表、字段等命名做为重要参照。
数据划分•按业务划分:命名时按主要的业务划分,以指导物理模型的划分原则、命名原则及使用的ODS project。
•按数据域划分:命名时按照CDM层的数据进行数据域划分,以便有效地对数据进行管理,以及指导数据表的命名。
数据库开发规范

数据库开发规范数据库开发规范指的是在进行数据库开发工作时,要遵循的一系列规范和准则,以确保数据库的设计合理性、效率和稳定性。
以下是一个包括约1000字的数据库开发规范:一、命名规范1. 表名、字段名、视图名、存储过程名、函数名、触发器名等应该使用有意义的英文单词或词组来命名,且使用下划线作为单词之间的分隔符。
例如,表名可以命名为“students”,字段名可以命名为“student_id”。
2. 表名应该使用单数形式,例如“student”而不是“students”。
二、数据类型规范1. 在选择数据类型时,应尽量使用最简单的数据类型,避免使用过于复杂的数据类型。
2. 需要存储精确浮点数时应使用 DECIMAL 或 NUMERIC 数据类型,避免使用浮点型数据类型,例如 FLOAT 或DOUBLE。
3. 需要存储日期和时间时应分别使用 DATE 和 TIMESTAMP数据类型。
三、主键规范1. 每个表都应该有一个主键,用于唯一标识每一条记录。
2. 主键应该是简单、稳定和不可更改的。
一般情况下,可以使用自增长的整数作为主键。
3. 主键的命名应该统一,并且在命名时应遵循表名加上“_id”的规则。
四、索引规范1. 对于经常被查询或用于连接的字段,应该添加索引,以提高查询性能。
2. 除非有特殊需要,不要在较小的表上创建索引,因为索引会增加查询和更新的开销。
3. 在创建索引时,应该根据具体的查询需求选择合适的索引类型,包括唯一索引、非唯一索引、聚集索引、非聚集索引等。
五、约束规范1. 应该使用外键约束来确保数据的完整性和一致性。
2. 外键约束应该定义在子表上,并且应该指向主表的主键。
3. 在删除或更新主表的数据时,应该采取合适的措施来处理与之相关的子表数据,例如设置级联删除或级联更新。
六、存储过程和函数规范1. 存储过程和函数应该使用有意义的名称,以描述其功能。
2. 存储过程和函数应该尽量简短,并且只处理一个具体的业务逻辑。
数据仓库规范

数据仓库规范一.数据仓库层次结构规范1.1 基本分层结构系统的信息模型从存储的内容方面可以分为,STAGE接口信息模型、ODS/DWD信息模型,MID信息模型、DM信息模型、元数据信息模型。
在各个信息模型中存储的内容如下描述:1) SRC接口层信息模型:提供业务系统数据文件的临时存储,数据稽核,数据质量保证,屏蔽对业务系统的干扰,对于主动数据采集方式,以文件的方式描述系统与各个专业子系统之间数据接口的内容、格式等信息。
与该模型对应的数据是各个专业系统按照该模型的定义传送来的数据文件。
STAGE是生产系统数据源的直接拷贝,由ETL过程对数据源进行直接抽取,在格式和数据定义上不作任何改变。
与生产系统数据的唯一不同是,STAGE层数据具有时间戳。
STAGE层存在的意义在于两点:(1)对数据源作统一的一次性获取,数据仓库中其他部分都依赖于STAGE层的数据,不再重复进行抽取,也不在生产系统上作运算,减小生产系统的压力;(2)在生产系统数据已经刷新的情况下,保存一定量的生产系统的历史数据,以便在二次抽取过程中运算出错的情况下可以进行回溯。
2) ODS/DWD层(对应原模型的ODS和DW层)信息模型:简称DWD层是数据仓库的细节数据层,是对STAGE层数据进行沉淀,减少了抽取的复杂性,同时ODS/DWD的信息模型组织主要遵循企业业务事务处理的形式,将各个专业数据进行集中。
为企业进行经营数据的分析,系统将数据按分析的主题的形式存放,跟STAGE层的粒度一致,属于分析的公共资源。
3) MID 信息模型:轻度综合层是新模型增加的数据仓库中DWD层和DM层之间的一个过渡层次,是对DWD层的生产数据进行轻度综合和汇总统计。
轻度综合层与DWD的主要区别在于二者的应用领域不同,DWD的数据来源于生产型系统,并为满足一些不可预见的需求而进行沉淀;轻度综合层则面向分析型应用进行细粒度的统计和沉淀。
4) DM信息模型:为专题经营分析服务,系统将数据按分析的专题组织成多维库表的形式存放,属于分析目标范畴的数据组织与汇总,属于分析的专有资源。
03_尚硅谷大数据之Kafka工作流程分析

第3章Kafka工作流程分析Kafka核心组成Producer A Producer BTopic APartition 0Topic APartition 1Broker1Leader FollowerReplicationA/0ReplicationA/1Topic APartition 0Topic APartition 1Broker2LeaderFollowerConsumer AConsumer BKafka ClusterBroker3Partition0message0message1Consumer CZookeeperConsumer groupmessage to A-0 message to A-1 message to B-0message from A-0 message from A-1message from B-0生产者生产消息Kafka集群管理消息消费者消费消息Zookeeper注册消息3.1 Kafka生产过程分析3.1.1 写入方式producer采用推(push)模式将消息发布到broker,每条消息都被追加(append)到分区(patition)中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障kafka吞吐率)。
3.1.2 分区(Partition)消息发送时都被发送到一个topic,其本质就是一个目录,而topic是由一些Partition Logs(分区日志)组成,其组织结构如下图所示:我们可以看到,每个Partition中的消息都是有序的,生产的消息被不断追加到Partition log上,其中的每一个消息都被赋予了一个唯一的offset值。
1)分区的原因(1)方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;(2)可以提高并发,因为可以以Partition为单位读写了。
数据仓库开发规范

数据仓库设计与开发规范1概述2数据仓库设计规范2.1命名规范数据仓库库表的命名规范命名规范➢RAW表:RAW+源表名称➢中间表:MID+源表名称➢如果表名字符长度超过32位,则在源表名称中英文字母缩写替换英文单词表字段命名规范命名规范数据库字段的命名必须遵循以下规范:➢采用有意义的字段名。
字段的名称必须是易于理解,能表达字段功能的英文单词或缩写英文单词,无论是完整英文单词还是缩写英文单词,单词首字母必须大写。
➢系统中属于是业务范围内的编号的字段,其代表一定的业务信息,这样的字段建议命名为:代表当前这字段含意的英文单词+ “ID”➢尽量遵守第三范式的标准(3NF)。
✧表内的每一个值只能被表达一次✧表内的每一行都应当被唯一的标示✧表内不应该存储依赖于其他键的非键信息存储过程命名规范命名规范➢存贮过程的命名请遵循以下命名规范:P_ MID_+ 业务逻辑(英文单词或缩写)如:P_MID_PUB_TRADE_BUY设计规范在存贮过程中必须说明以下内容:➢名称:存贮过程。
➢描述:描述存储过程的作用➢创建者:首次创建此存贮过程的人的姓名。
在此请使用中文全名,不允许使用英文简称。
➢修改者、修改日期、修改原因:如果有人对此存贮过程进行了修改,则必须在此存贮过程的前面加注修改者姓名、修改日期及修改原因。
➢对存贮过程各参数及变量的中文注解。
示例如下:-- =============================================-- procedurename: P_MID_PUB_TRADE_BUY-- description : 公募交易表-- author : 张三-- create date : 2015-07-17--source_table : raw_tp_dis_trade_app_rec--target_table : MID_PUB_TRADE_BUY--modified :修改日期:2015-07-20 修改原因及内容-- =============================================视图命名规范命名规范➢视图的命名请遵循以下命名规范:V_ +_操作的表名(不带前缀)或功能的英文单词或英文单词缩写。
08_尚硅谷大数据之压缩和存储

第8章压缩和存储8.1 Hadoop源码编译支持Snappy压缩8.1.1 资源准备1)CentOS联网配置CentOS能连接外网。
Linux虚拟机ping 是畅通的注意:采用root角色编译,减少文件夹权限出现问题2)jar包准备(hadoop源码、JDK8 、maven、protobuf)(1)hadoop-2.7.2-src.tar.gz(2)jdk-8u144-linux-x64.tar.gz(3)snappy-1.1.3.tar.gz(4)apache-maven-3.0.5-bin.tar.gz(5)protobuf-2.5.0.tar.gz8.1.2 jar包安装0)注意:所有操作必须在root用户下完成1)JDK解压、配置环境变量JAVA_HOME和PATH,验证java-version(如下都需要验证是否配置成功)[root@hadoop101 software] # tar -zxf jdk-8u144-linux-x64.tar.gz -C /opt/module/ [root@hadoop101 software]# vi /etc/profile[root@hadoop101 software]#source /etc/profile验证命令:java -version2)Maven解压、配置 MAVEN_HOME和PATH。
[root@hadoop101 software]# tar -zxvf apache-maven-3.0.5-bin.tar.gz -C /opt/module/[root@hadoop101 apache-maven-3.0.5]# vi /etc/profile[root@hadoop101 software]#source /etc/profile验证命令:mvn -version8.1.3 编译源码1)准备编译环境[root@hadoop101 software]# yum install svn[root@hadoop101 software]# yum install autoconf automake libtool cmake[root@hadoop101 software]# yum install ncurses-devel[root@hadoop101 software]# yum install openssl-devel[root@hadoop101 software]# yum install gcc*2)编译安装snappy[root@hadoop101 software]# tar -zxvf snappy-1.1.3.tar.gz -C /opt/module/[root@hadoop101 module]# cd snappy-1.1.3/[root@hadoop101 snappy-1.1.3]# ./configure[root@hadoop101 snappy-1.1.3]# make[root@hadoop101 snappy-1.1.3]# make install# 查看snappy库文件[root@hadoop101 snappy-1.1.3]# ls -lh /usr/local/lib |grep snappy3)编译安装protobuf[root@hadoop101 software]# tar -zxvf protobuf-2.5.0.tar.gz -C /opt/module/[root@hadoop101 module]# cd protobuf-2.5.0/[root@hadoop101 protobuf-2.5.0]# ./configure[root@hadoop101 protobuf-2.5.0]# make[root@hadoop101 protobuf-2.5.0]# make install# 查看protobuf版本以测试是否安装成功[root@hadoop101 protobuf-2.5.0]# protoc --version4)编译hadoop native[root@hadoop101 software]# tar -zxvf hadoop-2.7.2-src.tar.gz[root@hadoop101 software]# cd hadoop-2.7.2-src/[root@hadoop101 software]# mvn clean package -DskipTests -Pdist,native -Dtar -Dsnappy.lib=/usr/local/lib -Dbundle.snappy执行成功后,/opt/software/hadoop-2.7.2-src/hadoop-dist/target/hadoop-2.7.2.tar.gz即为新生成的支持snappy压缩的二进制安装包。
02_尚硅谷大数据技术之Hadoop(入门)

02_尚硅⾕⼤数据技术之Hadoop(⼊门)尚硅⾕⼤数据技术之 Hadoop(⼊门)(作者:尚硅⾕⼤数据研发部)版本:V3.3第 1 章 Hadoop 概述1.1 Hadoop 是什么1) Hadoop是⼀个由Apache基⾦会所开发的分布式系统基础架构。
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3)⼴义上来说,Hadoop通常是指⼀个更⼴泛的概念——Hadoop⽣态圈。
1.2 Hadoop 发展历史(了解)1)Hadoop创始⼈Doug Cutting,为了实现与Google类似的全⽂搜索功能,他在Lucene框架基础上进⾏优化升级,查询引擎和索引引擎。
2)2001年年底Lucene成为Apache基⾦会的⼀个⼦项⽬。
3)对于海量数据的场景,Lucene框架⾯对与Google同样的困难,存储海量数据困难,检索海量速度慢。
4)学习和模仿Google解决这些问题的办法:微型版Nutch。
5)可以说Google是Hadoop的思想之源(Google在⼤数据⽅⾯的三篇论⽂)GFS --->HDFSMap-Reduce --->MRBigTable --->HBase6)2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Doug Cutting等⼈⽤了2年业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。
7)2005 年Hadoop 作为 Lucene的⼦项⽬ Nutch的⼀部分正式引⼊Apache基⾦会。
8)2006 年 3 ⽉份,Map-Reduce和Nutch Distributed File System (NDFS)分别被纳⼊到 Hadoop 项⽬中,Hadoop就此正式诞⽣,标志着⼤数据时代来临。
9)名字来源于Doug Cutting⼉⼦的玩具⼤象1.3 Hadoop 三⼤发⾏版本(了解)Hadoop 三⼤发⾏版本:Apache、Cloudera、Hortonworks。
大数据开发流程与规范

大数据开发流程与规范随着互联网技术的发展和应用范围的扩大,大数据技术逐渐成为各行业十分重要的技术之一。
大数据技术的应用可以为企业带来更多商机和价值,并且能够帮助企业更好地理解市场和用户需求。
但是,大数据技术的开发和应用也面临着一系列挑战,如数据量大、数据多样性、数据更新快、数据处理复杂等。
为了高效地开发和应用大数据技术,需要建立一套完善的开发流程和规范。
本文将介绍大数据开发流程与规范的相关内容,希望能够帮助读者更好地理解和应用大数据技术。
一、大数据开发流程大数据开发流程是指在开发大数据应用过程中,从需求分析到系统上线的一系列流程和环节。
大数据开发流程的设计合理与否直接影响到开发工作的效率和质量。
一个完整的大数据开发流程应包括以下几个阶段:1. 需求分析阶段需求分析是大数据开发的第一步,也是最为关键的一步。
在这个阶段,需要和业务部门沟通,了解业务需求,明确数据分析的目标和方向,确定数据来源和数据清洗策略。
2. 数据采集阶段数据采集是大数据分析的基础,数据质量直接影响到分析结果的准确性。
在数据采集阶段,需要考虑数据的来源、数据的结构、数据的格式等问题,同时需要选择合适的数据采集工具和技术。
3. 数据清洗阶段数据清洗是大数据分析的一个重要环节,数据清洗的目的是保证数据的质量和完整性。
在数据清洗阶段,需要处理数据的脏数据、缺失数据、重复数据等问题,同时需要对数据进行标准化和规范化处理。
4. 数据存储阶段数据存储是大数据分析的另一个关键环节,数据存储的设计将直接影响到数据的查询和分析效率。
在数据存储阶段,需要选择合适的数据库和存储技术,设计合理的数据表结构,同时考虑数据的安全性和备份策略。
5. 数据分析阶段数据分析是大数据开发的核心环节,通过数据分析可以发现隐藏在数据中的规律和趋势。
在数据分析阶段,需要选择合适的数据分析工具和算法,进行数据挖掘和模型建立,最终得出有效的分析结果。
6. 数据可视化阶段数据可视化是将数据分析结果以图表、报表等形式展示出来,以便用户更直观地理解和使用数据。
尚硅谷大数据课程大纲

尚硅谷大数据课程大纲
尚硅谷的大数据课程大纲主要包括以下几个部分:
1. Java SE:学习Java的基础语法和面向对象编程思想,以及常用的Java
开发工具。
2. MySQL:学习关系型数据库管理系统MySQL,包括数据库设计、SQL
语言、存储过程、触发器等。
3. Linux:学习Linux操作系统的基本命令和常用工具,以及在Linux环境
下部署和配置应用程序。
4. Maven:学习使用Maven进行项目管理和构建,了解Maven的依赖管理、项目构建、项目报告等功能。
5. Shell:学习Shell脚本编程,以及在Linux环境下使用Shell脚本来自动化管理任务。
6. Hadoop:学习使用Hadoop进行大数据处理和分析,了解Hadoop的分布式文件系统、MapReduce编程模型、Hive、HBase等组件。
7. Zookeeper:学习使用Zookeeper进行分布式系统的一致性协调和管理。
8. Hive:学习使用Hive进行数据仓库建设和管理,以及Hive的数据建模
和SQL查询。
9. Flume:学习使用Flume进行大数据采集和传输,了解Flume的数据采集、数据清洗、数据传输等功能。
10. 大数据实践项目:通过实际的大数据项目,综合运用所学知识解决实际问题,提升大数据处理和分析能力。
以上是尚硅谷大数据课程大纲的简要介绍,具体内容可能会根据不同的版本和讲师有所差异。
05_尚硅谷大数据之DML数据操作

第5章DML数据操作5.1 数据导入5.1.1 向表中装载数据(Load)1)语法hive> load data [local] inpath '/opt/module/datas/student.txt' [overwrite] into table student [partition (partcol1=val1,…)];(1)load data:表示加载数据(2)local:表示从本地加载数据到hive表;否则从HDFS加载数据到hive表(3)inpath:表示加载数据的路径(4)overwrite:表示覆盖表中已有数据,否则表示追加(5)into table:表示加载到哪张表(6)student:表示具体的表(7)partition:表示上传到指定分区2)实操案例(0)创建一张表hive (default)> create table student(id string, name string) row format delimited fields terminated by '\t';(1)加载本地文件到hivehive (default)> load data local inpath '/opt/module/datas/student.txt' into table default.student;(2)加载HDFS文件到hive中上传文件到HDFShive (default)> dfs -put /opt/module/datas/student.txt /user/atguigu/hive;加载HDFS上数据hive (default)> load data inpath '/user/atguigu/hive/student.txt' into table default.student;(3)加载数据覆盖表中已有的数据上传文件到HDFShive (default)> dfs -put /opt/module/datas/student.txt /user/atguigu/hive;加载数据覆盖表中已有的数据hive (default)> load data inpath '/user/atguigu/hive/student.txt' overwrite into table default.student;5.1.2 通过查询语句向表中插入数据(Insert)1)创建一张分区表hive (default)> create table student(id int, name string) partitioned by (month string) row format delimited fields terminated by '\t';2)基本插入数据3)基本模式插入(根据单张表查询结果)hive (default)> insert overwrite table student partition(month='201708')select id, name from student where month='201709';4)多插入模式(根据多张表查询结果)hive (default)> from studentinsert overwrite table student partition(month='201707')select id, name where month='201709'insert overwrite table student partition(month='201706')select id, name where month='201709';5.1.3 查询语句中创建表并加载数据(As Select)详见4.5.1章创建表。
数据仓库开发规范

数据仓库开发规范Schema定义ODS层ods_业务系统名_业务系统⾥的schema名(如ods_lps_kkb_cloud_passport)DM层应⽤层DWD层数据清洗层,去重,标准化,数据补齐。
可以基于ER建模和维度建模。
DWS层数据汇总与过程表维度表TEMP层临时表DIM表公共维度EXT层外部导⼊表,短期或长期使⽤,由该表负责⼈⾃⼰维护开发环境:DEV_DMDEV_DWDDEV_DWSDEV_TEMPDEV_EXTDEV_DIM表的定义采⽤26个英⽂字母(区分⼤⼩写)和0-9的⾃然数(经常不需要)加上下划线''组成,命名简洁明确,多个单词⽤下划线''分隔(特殊符号以及-严格要求不准使⽤)。
全部⼩写命名,禁⽌出现⼤写表名称命名禁⽌使⽤数据库关键字,如:name,time ,datetime,password,tmp,ext等⽤单数形式表⽰名称,例如,使⽤ employee,⽽不是 employees单词单词分割⽤_分割表名称的通⽤命名规则:表名类型_主题域名称_业务名称1_业务名称2_后缀类型备注:表名类型:DIM 维度表FCT 事实表,事件表,关系表RPT 报表类表APP 数据产品类模型或其他服务宽表MID 中间表SMY 数据汇总表后缀类型:H 0-23 颗粒度快照表D 天颗粒度快照表M ⽉颗粒度快照表Y 年颗粒度快照表P 累计表或者过程表V 视图表_di是⽇快照,增量抽数,昨天的数据。
_f(a)是⽇快照,全量抽数,历史到昨天的数据。
表存储形式:⽆分区表和分区表,分区表⼀般以时间维度做分区列DW层表经常使⽤的表类型DIM和FCT类型表DM层经常使⽤的表类型RPT表表创建其他项⽬组成员如需要创建临时⾃⽤表,需要通过外部表的⽅式进⾏创建,数据⽂件创建在⾃⼰的⽂件系统中如create external table test(id int,name string,age int,tel string)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','STORED AS TEXTFILElocation '/user/liudaipeng/data/test';如创建⼀个临时的外部表test到/user/liudaipeng/data/test⽬录下。
尚硅谷数据仓库实战之3数仓搭建

尚硅谷数据仓库实战之3数仓搭建数仓笔记数据仓库和数据集市详解:ODS、DW、DWD、DWM、DWS、ADS:尚硅谷数仓实战之1项目需求及架构设计:尚硅谷数仓实战之2数仓分层+维度建模:尚硅谷数仓实战之3数仓搭建:B站直达:百度网盘:,提取码:yyds 阿里云盘:,提取码:335o第4章数仓搭建-ODS层1)保持数据原貌不做任何修改,起到备份数据的作用。
2)数据采用LZO压缩,减少磁盘存储空间。
100G数据可以压缩到10G以内。
3)创建分区表,防止后续的全表扫描,在企业开发中大量使用分区表。
4)创建外部表。
在企业开发中,除了自己用的临时表,创建内部表外,绝大多数场景都是创建外部表。
4.2 ODS层(业务数据)ODS层业务表分区规划如下在这里插入图片描述ODS层业务表数据装载思路如下在这里插入图片描述4.2.1 活动信息表第5章数仓搭建-DIM层5.1 商品维度表(全量)1.建表语句2.分区规划在这里插入图片描述3.数据装载在这里插入图片描述5.6 用户维度表(拉链表)5.6.1 拉链表概述1)什么是拉链表在这里插入图片描述2)为什么要做拉链表在这里插入图片描述3)如何使用拉链表在这里插入图片描述4)拉链表形成过程在这里插入图片描述5.6.2 制作拉链表1.建表语句2.分区规划在这里插入图片描述3.数据装载在这里插入图片描述1)首日装载拉链表首日装载,需要进行初始化操作,具体工作为将截止到初始化当日的全部历史用户导入一次性导入到拉链表中。
目前的ods_user_info表的第一个分区,即2023-06-14分区中就是全部的历史用户,故将该分区数据进行一定处理后导入拉链表的9999-99-99分区即可。
2)每日装载(1)实现思路在这里插入图片描述第6章数仓搭建-DWD层1)对用户行为数据解析。
2)对业务数据采用维度模型重新建模。
6.1 DWD层(用户行为日志)6.1.1 日志解析思路1)日志结构回顾(1)页面埋点日志在这里插入图片描述(2)启动日志在这里插入图片描述2)日志解析思路在这里插入图片描述6.1.2 json_object函数使用Mysql中也有响应的JSON处理函数,不过性能没有hive高。
大数据开发规范

大数据开发规范大数据开发规范是指在进行大数据开发过程中,遵循的一系列规范和标准,以确保开发过程高效、可靠,并且最终的产品符合预期。
1. 数据准备规范- 数据源选择:选择高质量、真实可靠的数据源,确保数据的准确性和完整性。
- 数据清洗和预处理:对原始数据进行去重、去噪、填充缺失值等预处理操作,以提高后续分析的准确性。
- 数据采集和存储:选择合适的采集工具和存储格式,确保数据的高效获取和存储。
2. 编码规范- 统一命名规范:采用有意义且易于理解的命名方式,遵循驼峰命名法等编码规范。
- 代码风格规范:采用统一的代码风格,包括缩进、空格、注释等规范,以提高代码的可读性和可维护性。
- 模块化和可重用性:采用模块化的设计思想,将代码拆分成独立的功能模块,以便于重复利用和维护。
3. 安全规范- 敏感数据保护:对于包含个人隐私等敏感数据,需要加密和权限控制,以确保数据的安全性。
- 访问控制和身份认证:对于敏感数据和系统资源,需要实施访问控制和身份认证,确保只有授权人员可以访问。
- 防止数据泄露和漏洞利用:加强系统的安全性,防止黑客攻击和数据泄露。
4. 性能优化规范- 数据分区和索引设计:将数据按照合适的规则进行分区和索引,以提高查询效率。
- 数据压缩和存储优化:对于大数据量的数据,采用合适的压缩算法和存储方式,以减小存储空间和提高读写性能。
- 并行计算和任务调度:利用并行计算和任务调度的特性,提高数据处理和计算的效率。
5. 监控和日志规范- 异常处理和报警:编写健壮的代码,处理异常情况,并设置相应的报警机制,及时发现和解决问题。
- 系统监控和日志记录:对系统进行监控,定期记录系统运行日志和错误日志,以便于问题追踪和系统优化。
总结起来,大数据开发规范包括数据准备规范、编码规范、安全规范、性能优化规范和监控和日志规范等多方面的规范。
通过遵循这些规范,可以提高大数据开发的效率和质量,并确保最终的产品符合预期。
尚硅谷大数据项目之电商数仓(2业务数据采集平台)

尚硅谷大数据项目之电商数仓(系统业务数据仓库)(作者:尚硅谷大数据研发部)版本:V6.1.2第1章电商业务简介1.1 电商业务流程1.2 电商常识(SKU、SPU)SKU=Stock Keeping Unit(库存量基本单位)。
现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的SKU号。
SPU(Standard Product Unit):是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息集合。
例如:iPhoneX手机就是SPU。
一台银色、128G内存的、支持联通网络的iPhoneX,就是SKU。
SPU 表示一类商品。
好处就是:可以共用商品图片,海报、销售属性等。
1.3 电商业务表结构电商表结构订单表order_info商品评论表comment_info 加购表cart_info 商品收藏表favor_info用户表user_info 支付流水表payment_info优惠卷领用表coupon_use优惠卷表coupon_info 活动表Activity_info 活动订单表Activity_order优惠规则表Activity_rule参与活动商品表Activity_sku省份表base_province地区表base_region订单详情表order_detailSKU 商品表sku_info商品三级分类表base_category3商品二级分类表base_category2商品一级分类表base_category1SPU 商品表spu_info品牌表base_trademark退单表order_redund_info订单状态表order_status_log编码字典表base_dic1.3.1 订单表(order_info )标签 含义 id 订单编号 consignee 收货人 consignee_tel 收件人电话 final_total_amount 总金额 order_status 订单状态 user_id用户id delivery_address 送货地址 order_comment 订单备注out_trade_no 订单交易编号(第三方支付用)trade_body 订单描述(第三方支付用) create_time 创建时间operate_time 操作时间expire_time 失效时间tracking_no 物流单编号parent_order_id 父订单编号img_url 图片路径province_id 地区benefit_reduce_amount 优惠金额original_total_amount 原价金额feight_fee 运费1.3.2 订单详情表(order_detail)标签含义id 订单编号order_id 订单号sku_id 商品idsku_name sku名称(冗余)img_url 图片名称(冗余)order_price 商品价格(下单时sku价格)sku_num 商品数量create_time 创建时间1.3.3 SKU商品表(sku_info)标签含义id skuIdspu_id spuidprice 价格sku_name 商品名称sku_desc 商品描述weight 重量tm_id 品牌idcategory3_id 品类idsku_default_img 默认显示图片(冗余) create_time 创建时间1.3.4 用户表(user_info)标签含义id 用户idlogin_name 用户名称nick_name 用户昵称passwd 用户密码name 姓名phone_num 手机号email 邮箱head_img 头像user_level 用户级别birthday 生日gender 性别M男,F女create_time 创建时间operate_time操作时间1.3.5 商品一级分类表(base_category1)标签含义id idname 名称1.3.6 商品二级分类表(base_category2)标签含义id idname 名称category1_id 一级品类id1.3.7 商品三级分类表(base_category3)标签含义id idname 名称Category2_id 二级品类id1.3.8 支付流水表(payment_info)标签含义id 编号out_trade_no 对外业务编号order_id 订单编号user_id 用户编号alipay_trade_no 支付宝交易流水编号total_amount 支付金额subject 交易内容payment_type 支付类型payment_time 支付时间1.3.9 省份表(base_province)标签含义id idname 省份名称region_id 地区IDarea_code 地区编码iso_code 国际编码1.3.10 地区表(base_region)标签含义id 大区idregion_name 大区名称1.3.11 品牌表(base_trademark)标签含义tm_id 品牌idtm_name 品牌名称1.3.12 订单状态表(order_status_log)标签含义id 编号order_id 订单编号order_status 订单状态operate_time 操作时间1.3.13 SPU商品表(spu_info)标签含义id 商品idspu_name spu商品名称description 商品描述(后台简述)category3_id 三级分类idtm_id 品牌id1.3.14 商品评论表(comment_info)标签含义id 编号user_id 用户idsku_id 商品idspu_id spu_idorder_id 订单编号appraise 评价 1 好评 2 中评 3 差评comment_txt 评价内容create_time 创建时间1.3.15 退单表(order_refund_info)标签含义id 编号order_id 订单编号sku_id sku_idrefund_type 退款类型refund_amount 退款金额refund_reason_type 原因类型refund_reason_txt 原因内容create_time 创建时间1.3.16 加购表(cart_info)标签含义id 编号user_id 用户idsku_id SKU商品cart_price 放入购物车时价格sku_num 数量img_url 图片文件sku_name sku名称 (冗余)create_time 创建时间operate_time 修改时间is_ordered 是否已经下单order_time 下单时间1.3.17 商品收藏表(favor_info)标签含义id 编号user_id 用户名称sku_id 商品idspu_id spu_idis_cancel 是否已取消 0 正常 1 已取消create_time 创建时间cancel_time 修改时间1.3.18 优惠券领用表(coupon_use)标签含义id 编号coupon_id 购物券IDuser_id 用户IDorder_id 订单IDcoupon_status 购物券状态get_time 领券时间using_time 使用时间used_time 支付时间expire_time 过期时间1.3.19 优惠券表(coupon_info)标签含义id 购物券编号coupon_name 购物券名称coupon_type 购物券类型 1 现金券 2 折扣券 3 满减券 4 满件打折券condition_amount 满额数condition_num 满件数activity_id 活动编号benefit_amount 减金额benefit_discount 折扣create_time 创建时间range_type 范围类型 1、商品 2、品类 3、品牌spu_id 商品idtm_id 品牌idcategory3_id 品类idlimit_num 最多领用次数operate_time 修改时间expire_time 过期时间1.3.20 活动表(activity_info)标签含义id 活动idactivity_name 活动名称activity_type 活动类型activity_desc 活动描述start_time 开始时间end_time 结束时间create_time 创建时间1.3.21 活动订单关联表(activity_order)标签含义id 编号activity_id 活动idorder_id 订单编号create_time 发生日期1.3.22 优惠规则表(activity_rule)标签含义id 编号activity_id 活动idcondition_amount 满减金额condition_num 满减件数benefit_amount 优惠金额benefit_discount 优惠折扣benefit_level 优惠级别1.3.23 编码字典表(base_dic)标签含义dic_code 编号dic_name 编码名称parent_code 父编号create_time 创建日期operate_time 修改日期1.3.24 活动参与商品表(activity_sku)(暂不导入)标签含义id 编号activity_id 活动idsku_id sku_idcreate_time 创建时间1.4 时间相关表1.4.1 时间表(date_info)标签含义date_id 日期idweek_id 周idweek_day 周day 日month 月quarter 季度year 年is_workday 是否是周末holiday_id 假期id1.4.2 假期表(holiday_info)标签含义holiday_id 假期idholiday_name 假期名称1.4.3 假期年表(holiday_year)标签含义holiday_id 假期idholiday_name 假期名称start_date_id 假期开始时间end_date_id 假期结束时间第2章 业务数据采集模块Flume 消费MySQL 业务数据Nginx业务日志数据(后端埋点数据)Web/App 前端埋点日志服务器(Springboot)Nginx业务服务器(Springboot)日志服务器(Springboot)logFilelogFile业务服务器(Springboot)生产Flume生产FlumeKafkaKafka KafkaSparkSt reamingHbaseHDFSHive (ods dwd dws ads)消费FlumeMysql数据可视化SqoopWeb/App 业务交互PrestoKylin实时指标分析业务交互数据:业务流程中产生的登录、订单、用户、商品、支付等相关的数据,通常存储在DB 中,包括Mysql 、Oracle 埋点用户行为数据:用户在使用产品过程中,与客户端产品交互过程中产生的数据,比如页面浏览、点击、停留、评论、点赞、收藏等2.1 MySQL 安装 2.1.1 安装包准备1)卸载自带的Mysql-libs (如果之前安装过mysql ,要全都卸载掉)[atguigu@hadoop102 software]$ rpm -qa | grep -i-Emysql\|mariadb | xargs -n1 sudo rpm -e --nodeps 2)将安装包和JDBC 驱动上传到/opt/software ,共计6个01_mysql-community-common-5.7.29-1.el7.x86_64.rpm 02_mysql-community-libs-5.7.29-1.el7.x86_64.rpm03_mysql-community-libs-compat-5.7.29-1.el7.x86_64.rpm 04_mysql-community-client-5.7.29-1.el7.x86_64.rpm 05_mysql-community-server-5.7.29-1.el7.x86_64.rpm mysql-connector-java-5.1.48.jar2.1.2 安装MySQL1)安装mysql 依赖[atguigu@hadoop102 software]$ sudo rpm -ivh 01_mysql-community-common-5.7.29-1.el7.x86_64.rpm[atguigu@hadoop102 software]$ sudo rpm -ivh 02_mysql-community-libs-5.7.29-1.el7.x86_64.rpm[atguigu@hadoop102 software]$ sudo rpm -ivh 03_mysql-community-libs-compat-5.7.29-1.el7.x86_64.rpm 2)安装mysql-client[atguigu@hadoop102 software]$ sudo rpm -ivh 04_mysql-community-client-5.7.29-1.el7.x86_64.rpm 3)安装mysql-server[atguigu@hadoop102 software]$ sudo rpm -ivh 05_mysql-community-server-5.7.29-1.el7.x86_64.rpm4)启动mysql[atguigu@hadoop102 software]$ sudo systemctl start mysqld5)查看mysql密码[atguigu@hadoop102 software]$ sudo cat /var/log/mysqld.log | grep password2.1.3 配置MySQL配置只要是root用户+密码,在任何主机上都能登录MySQL数据库。
尚硅谷大数据之实时数仓_FlinkCDC
硅谷大数据技术之Flink-CDC()版本:V2.0第1章CDC简介1.1什么是CDCCDC是Change Data Capture(变更数据获取)的简称。
核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
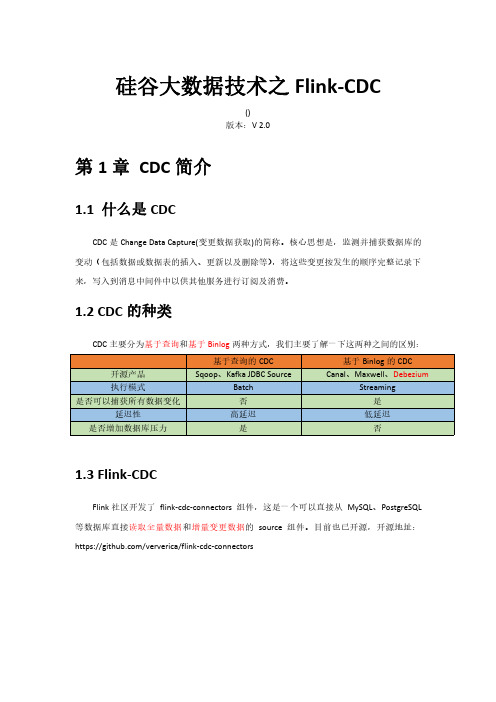
1.2CDC的种类CDC主要分为基于查询和基于Binlog两种方式,我们主要了解一下这两种之间的区别:1.3Flink-CDCFlink社区开发了flink-cdc-connectors组件,这是一个可以直接从MySQL、PostgreSQL 等数据库直接读取全量数据和增量变更数据的source组件。
目前也已开源,开源地址:https:///ververica/flink-cdc-connectors第2章FlinkCDC案例实操2.1DataStream方式的应用2.1.1导入依赖<dependencies><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>1.12.0</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.49</version></dependency><dependency><groupId>com.alibaba.ververica</groupId><artifactId>flink-connector-mysql-cdc</artifactId><version>1.2.0</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.75</version></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>2.1.2编写代码import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema; import mon.restartstrategy.RestartStrategies;import org.apache.flink.runtime.state.filesystem.FsStateBackend;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.CheckpointConfig;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import java.util.Properties;public class FlinkCDC{public static void main(String[]args)throws Exception{//1.创建执行环境StreamExecutionEnvironment env= StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//2.Flink-CDC将读取binlog的位置信息以状态的方式保存在CK,如果想要做到断点续传,需要从Checkpoint或者Savepoint启动程序//2.1开启Checkpoint,每隔5秒钟做一次CKenv.enableCheckpointing(5000L);//2.2指定CK的一致性语义env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);//2.3设置任务关闭的时候保留最后一次CK数据env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckp ointCleanup.RETAIN_ON_CANCELLATION);//2.4指定从CK自动重启策略env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,2000L));//2.5设置状态后端env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flinkCDC"));//2.6设置访问HDFS的用户名System.setProperty("HADOOP_USER_NAME","atguigu");//3.创建Flink-MySQL-CDC的Source//initial(default):Performs an initial snapshot on the monitored database tables upon first startup,and continue to read the latest binlog.//latest-offset:Never to perform snapshot on the monitored database tables upon first startup,just read from the end of the binlog which means only have the changes since the connector was started.//timestamp:Never to perform snapshot on the monitored database tables upon first startup,and directly read binlog from the specified timestamp.The consumer will traverse the binlog from the beginning and ignore change events whose timestamp is smaller than the specified timestamp.//specific-offset:Never to perform snapshot on the monitored database tables upon first startup,and directly read binlog from the specified offset.DebeziumSourceFunction<String>mysqlSource=MySQLSource.<String>builder().hostname("hadoop102").port(3306).username("root").password("000000").databaseList("gmall-flink").tableList("gmall-flink.z_user_info")//可选配置项,如果不指定该参数,则会读取上一个配置下的所有表的数据,注意:指定的时候需要使用"db.table"的方式.startupOptions(StartupOptions.initial()).deserializer(new StringDebeziumDeserializationSchema()).build();//4.使用CDC Source从MySQL读取数据DataStreamSource<String>mysqlDS=env.addSource(mysqlSource);//5.打印数据mysqlDS.print();//6.执行任务env.execute();}}2.1.3案例测试1)打包并上传至Linux2)开启MySQL Binlog并重启MySQL3)启动Flink集群[atguigu@hadoop102flink-standalone]$bin/start-cluster.sh4)启动HDFS集群[atguigu@hadoop102flink-standalone]$start-dfs.sh5)启动程序[atguigu@hadoop102flink-standalone]$bin/flink run-c com.atguigu.FlinkCDC flink-1.0-SNAPSHOT-jar-with-dependencies.jar6)在MySQL的gmall-flink.z_user_info表中添加、修改或者删除数据7)给当前的Flink程序创建Savepoint[atguigu@hadoop102flink-standalone]$bin/flink savepoint JobIdhdfs://hadoop102:8020/flink/save8)关闭程序以后从Savepoint重启程序[atguigu@hadoop102flink-standalone]$bin/flink run-s hdfs://hadoop102:8020/flink/save/...-c com.atguigu.FlinkCDC flink-1.0-SNAPSHOT-jar-with-dependencies.jar2.2FlinkSQL方式的应用2.2.1添加依赖<dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.12</artifactId><version>1.12.0</version></dependency>2.2.2代码实现import mon.restartstrategy.RestartStrategies;import org.apache.flink.runtime.state.filesystem.FsStateBackend;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.environment.CheckpointConfig;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;public class FlinkSQL_CDC{public static void main(String[]args)throws Exception{//1.创建执行环境StreamExecutionEnvironment env= StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);StreamTableEnvironment tableEnv=StreamTableEnvironment.create(env);//2.创建Flink-MySQL-CDC的SourcetableEnv.executeSql("CREATE TABLE user_info("+"id INT,"+"name STRING,"+"phone_num STRING"+")WITH("+"'connector'='mysql-cdc',"+"'hostname'='hadoop102',"+"'port'='3306',"+"'username'='root',"+"'password'='000000',"+"'database-name'='gmall-flink',"+"'table-name'='z_user_info'"+")");tableEnv.executeSql("select*from user_info").print();env.execute();}}2.3自定义反序列化器2.3.1代码实现import com.alibaba.fastjson.JSONObject;import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema; import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;import io.debezium.data.Envelope;import mon.restartstrategy.RestartStrategies;import mon.typeinfo.TypeInformation;import org.apache.flink.runtime.state.filesystem.FsStateBackend;import org.apache.flink.streaming.api.CheckpointingMode;import org.apache.flink.streaming.api.datastream.DataStreamSource;import org.apache.flink.streaming.api.environment.CheckpointConfig;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.util.Collector;import org.apache.kafka.connect.data.Field;import org.apache.kafka.connect.data.Struct;import org.apache.kafka.connect.source.SourceRecord;import java.util.Properties;public class Flink_CDCWithCustomerSchema{public static void main(String[]args)throws Exception{//1.创建执行环境StreamExecutionEnvironment env= StreamExecutionEnvironment.getExecutionEnvironment();env.setParallelism(1);//2.创建Flink-MySQL-CDC的SourceProperties properties=new Properties();//initial(default):Performs an initial snapshot on the monitored database tables upon first startup,and continue to read the latest binlog.//latest-offset:Never to perform snapshot on the monitored database tables upon first startup,just read from the end of the binlog which means only have the changes since the connector was started.//timestamp:Never to perform snapshot on the monitored database tables upon first startup,and directly read binlog from the specified timestamp.The consumer will traverse the binlog from the beginning and ignore change events whose timestamp is smaller than the specified timestamp.//specific-offset:Never to perform snapshot on the monitored database tables upon first startup,and directly read binlog from the specified offset.DebeziumSourceFunction<String>mysqlSource=MySQLSource.<String>builder().hostname("hadoop102").port(3306).username("root").password("000000").databaseList("gmall-flink").tableList("gmall-flink.z_user_info")//可选配置项,如果不指定该参数,则会读取上一个配置下的所有表的数据,注意:指定的时候需要使用"db.table"的方式.startupOptions(StartupOptions.initial()).deserializer(new DebeziumDeserializationSchema<String>(){//自定义数据解析器@Overridepublic void deserialize(SourceRecord sourceRecord,Collector<String> collector)throws Exception{//获取主题信息,包含着数据库和表名mysql_binlog_source.gmall-flink.z_user_infoString topic=sourceRecord.topic();String[]arr=topic.split("\\.");String db=arr[1];String tableName=arr[2];//获取操作类型READ DELETE UPDATE CREATEEnvelope.Operation operation=Envelope.operationFor(sourceRecord);//获取值信息并转换为Struct类型Struct value=(Struct)sourceRecord.value();//获取变化后的数据Struct after=value.getStruct("after");//创建JSON对象用于存储数据信息JSONObject data=new JSONObject();for(Field field:after.schema().fields()){Object o=after.get(field);data.put((),o);}//创建JSON对象用于封装最终返回值数据信息JSONObject result=new JSONObject();result.put("operation",operation.toString().toLowerCase());result.put("data",data);result.put("database",db);result.put("table",tableName);//发送数据至下游collector.collect(result.toJSONString());}@Overridepublic TypeInformation<String>getProducedType(){return TypeInformation.of(String.class);}}).build();//3.使用CDC Source从MySQL读取数据DataStreamSource<String>mysqlDS=env.addSource(mysqlSource);//4.打印数据mysqlDS.print();//5.执行任务env.execute();}}。
尚硅谷大数据项目之实时项目5(灵活分析需求)

尚硅谷大数据项目之实时分析系统--灵活分析(作者:尚硅谷大数据研发部)版本:V 1.6第1章需求分析1.1 灵活查询的场景数仓中存储了大量的明细数据,但是hadoop存储的数仓计算必须经过mr ,所以即时交互性非常糟糕。
为了方便数据分析人员查看信息,数据平台需要提供一个能够根据文字及选项等条件,进行灵活分析判断的数据功能。
2.2 需求详细输入参数返回结果第2章架构分析2.1 T+1 模式2.1.1 实现步骤1)利用sqoop等工具,从业务数据库中批量抽取数据;2)利用数仓作业,在dws层组织宽表(用户购买行为);3)开发spark的批处理任务,把dws层的宽表导入到ES中;4)从ES读取数据发布接口,对接可视化模块。
2.1.2 特点优点:可以利用在离线作业处理好的dws层宽表,直接导出一份到ES进行快速交互的分析。
缺点:因为要用离线处理的后的结果在放入ES,所以时效性等同于离线数据。
2.2 T+0 模式2.2.1 实现步骤1)利用canal抓取对应的数据表的实时新增变化数据,推送到Kafka;2)在spark-streaming中进行转换,过滤,关联组合成宽表的结构;3)保存到ES中;4)从ES读取数据发布接口,对接可视化模块。
2.2.2 特点优点:实时产生数据,时效性非常高。
缺点:因为从kafka中得到的是原始数据,所以要利用spark-streaming要进行加工处理,相对来说要比批处理方式麻烦,比如join操作。
第3章实时采集数据3.1 在canal 模块中增加要追踪的表代码public class CanalHandler {private List<CanalEntry.RowData> rowDatasList;String tableName;CanalEntry.EventType eventType;public CanalHandler(List<CanalEntry.RowData> rowDatasList, String tableName, CanalEntry.EventType eventType) {this.rowDatasList = rowDatasList;this.tableName = tableName;this.eventType = eventType;}//根据不同业务的类型发送不同主题public void handle(){if(eventType.equals(CanalEntry.EventType.INSERT)&&tableName.equals("order_info")){sendRowList2Kafka(GmallConstants.KAFKA_TOPIC_ORDER); }elseif((eventType.equals(CanalEntry.EventType.INSERT)||eventType.equals(CanalEntry.EventType.UPDATE))&&tableName.equals("user_info")){ sendRowList2Kafka(GmallConstants.KAFKA_TOPIC_USER); }elseif(eventType.equals(CanalEntry.EventType.INSERT)&&tableName.equals("order_detail")){sendRowList2Kafka(GmallConstants.KAFKA_TOPIC_ORDER_DETAIL);}}// 统一处理发送kafkaprivate void sendRowList2Kafka(String kafkaTopic){for (CanalEntry.RowData rowData : rowDatasList) {List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();JSONObject jsonObject = new JSONObject();for (CanalEntry.Column column : afterColumnsList) {System.out.println(column.getName()+"--->"+column.getValue());jsonObject.put(column.getName(),column.getValue()); }try {Thread.sleep(new Random().nextInt(5)*1000);} catch (InterruptedException e) {e.printStackTrace();}MyKafkaSender.send(kafkaTopic,jsonObject.toJSONString());}}}第4章实时数据处理4.1 数据处理流程4.2 双流join(难点)4.2.1 程序流程图4.2.2 代码4.2.2.1 样例类OrderDetailcase class OrderDetail( id:String ,order_id: String,sku_name: String,sku_id: String,order_price: String,img_url: String,sku_num: String) SaleDetailimport java.text.SimpleDateFormatimport java.utilcase class SaleDetail(var order_detail_id:String =null, var order_id: String=null,var order_status:String=null,var create_time:String=null,var user_id: String=null,var sku_id: String=null,var user_gender: String=null,var user_age: Int=0,var user_level: String=null,var sku_price: Double=0D,var sku_name: String=null,var dt:String=null) {def this(orderInfo:OrderInfo,orderDetail: OrderDetail) {thismergeOrderInfo(orderInfo)mergeOrderDetail(orderDetail)}def mergeOrderInfo(orderInfo:OrderInfo): Unit ={if(orderInfo!=null){this.order_id=orderInfo.idthis.order_status=orderInfo.order_statusthis.create_time=orderInfo.create_timethis.dt=orderInfo.create_dateer_id=er_id}}def mergeOrderDetail(orderDetail: OrderDetail): Unit ={if(orderDetail!=null){this.order_detail_id=orderDetail.idthis.sku_id=orderDetail.sku_idthis.sku_name=orderDetail.sku_namethis.sku_price=orderDetail.order_price.toDouble}}def mergeUserInfo(userInfo: UserInfo): Unit ={if(userInfo!=null){er_id=userInfo.idval formattor = new SimpleDateFormat("yyyy-MM-dd")val date: util.Date = formattor.parse(userInfo.birthday) val curTs: Long = System.currentTimeMillis()val betweenMs= curTs-date.getTimeval age=betweenMs/1000L/60L/60L/24L/365Ler_age= age.toInter_gender=userInfo.genderer_level=er_level}}}UserInfocase class UserInfo(id:String ,login_name:String,user_level:String,birthday:String,gender:String)4.2.2.2 SaleAppdef main(args: Array[String]): Unit = {val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sale_app")val ssc = new StreamingContext(sparkConf,Seconds(5))val inputOrderDstream: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(GmallConstant.KAFKA_TOPIC_ORDER,ssc)val inputOrderDetailDstream: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(GmallConstant.KAFKA_TOPIC_ORDER_DETAIL ,ssc)//整理转换val orderInfoDstream: DStream[OrderInfo] = inputOrderDstream.map { record =>val jsonString: String = record.value()// 1 转换成case classval orderInfo: OrderInfo = JSON.parseObject(jsonString, classOf[OrderInfo])// 2 脱敏电话号码 1381*******val telTuple: (String, String) = orderInfo.consignee_tel.splitAt(4)orderInfo.consignee_tel = telTuple._1 + "*******"// 3 补充日期字段val datetimeArr: Array[String] = orderInfo.create_time.split(" ")orderInfo.create_date = datetimeArr(0) //日期val timeArr: Array[String] = datetimeArr(1).split(":")orderInfo.create_hour = timeArr(0) //小时orderInfo}val orderDetailDStream: DStream[OrderDetail] = inputOrderDetailDstream.map { record =>val jsonString: String = record.value()val orderDetail: OrderDetail = JSON.parseObject(jsonString, classOf[OrderDetail])orderDetail}// 双流join 前要把流变为kv结构val orderInfoWithKeyDstream: DStream[(String, OrderInfo)] = orderInfoDstream.map(orderInfo =>(orderInfo.id,orderInfo))val orderDetailWithKeyDstream: DStream[(String, OrderDetail)] = orderDetailDStream.map(orderDetail=>(orderDetail.order_id,orderDe tail))//为了不管是否能够关联左右,都要保留左右两边的数据采用full joinval fullJoinDStream: DStream[(String, (Option[OrderInfo], Option[OrderDetail]))] = orderInfoWithKeyDstream.fullOuterJoin(orderDetailWithKeyDstream) val saleDetailDstream: DStream[SaleDetail] =fullJoinDStream.mapPartitions { partitionItr =>val jedis: Jedis = RedisUtil.getJedisClientimplicit val formats = org.json4s.DefaultFormatsval saleDetailList = ListBuffer[SaleDetail]()for ((orderId, (orderInfoOption, orderDetailOption)) <- partitionItr) {if (orderInfoOption != None) {println(" 主表有数据!")val orderInfo: OrderInfo = orderInfoOption.get// 1 组合关联if (orderDetailOption != None) {println(" 主表有数据!且从表有数据成功关联")val orderDetail: OrderDetail = orderDetailOption.get//组合成一个SaleDetailval saleDetail = new SaleDetail(orderInfo, orderDetail)// 存放到sale集合中saleDetailList += saleDetail}//2写缓存key 类型: string key名[order_info:order_id] value -> orderinfoJsonprintln(" 主表有数据!写入缓存")val orderInfoKey = "order_info:" + orderId// fastjson无法转换 case class 为json// val orderInfoJson: String = JSON.toJSONString(orderInfo) // json4sval orderInfoJson: String = Serialization.write(orderInfo)jedis.setex(orderInfoKey, 300, orderInfoJson)// 3 查询缓存val orderDetailKey = "order_detail:" + orderIdval orderDetailJson: String = jedis.get(orderDetailKey)val orderDetailSet: util.Set[String] = jedis.smembers(orderDetailKey)import collection.JavaConversions._for ( orderDetailJson <- orderDetailSet ) {println(" 查询到从表缓存数据进行关联")val orderDetail: OrderDetail = JSON.parseObject(orderDetailJson, classOf[OrderDetail])val saleDetail = new SaleDetail(orderInfo, orderDetail)saleDetailList += saleDetail}} else if (orderDetailOption != None) { //主表没有数据从表有数据 println("主表没有数据从表有数据 ")val orderDetail: OrderDetail = orderDetailOption.get//1 查询缓存查询主表println("查询主表缓存")val orderInfoKey = "order_info:" + orderIdval orderInfoJson: String = jedis.get(orderInfoKey)if (orderInfoJson != null && orderInfoJson.size > 0) {val orderInfo: OrderInfo = JSON.parseObject(orderInfoJson, classOf[OrderInfo])val saleDetail = new SaleDetail(orderInfo, orderDetail)saleDetailList += saleDetail}// 2 从表写缓存 // 从表缓存设计问题 //要体现一个主表下多个从表的结构1:n keytype: set key order_detail:order_id members -> 多个order_detailjsonprintln("写从表缓存")val orderDetailKey = "order_detail:" + orderIdval orderDetailJson: String = Serialization.write(orderDetail)jedis.sadd(orderDetailKey,orderDetailJson)jedis.expire(orderDetailKey,300)//jedis.setex(orderDetailKey, 300, orderDetailJson)}}jedis.close()saleDetailList.toIterator}saleDetailDstream.foreachRDD{rdd=>println(rdd.collect().mkString("\n"))}ssc.start()ssc.awaitTermination()}4.2.2.3 样例类转换成为JSON字符串pom.xml<dependency><groupId>org.json4s</groupId><artifactId>json4s-native_2.11</artifactId><version>3.5.4</version></dependency>import org.json4s.native.Serializationimplicit val formats=org.json4s.DefaultFormatsval orderInfoJson: String = Serialization.write(orderInfo)4.3 采集userInfo进入缓存val inputUserDstream: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(GmallConstants.KAFKA_TOPIC_USER,ssc)// 把userInfo 保存到缓存中inputUserDstream.map{record=>val userInfo: UserInfo = JSON.parseObject(record.value(), classOf[UserInfo])userInfo}.foreachRDD{rdd:RDD[UserInfo]=>val userList: List[UserInfo] = rdd.collect().toListval jedis: Jedis = RedisUtil.getJedisClientimplicit val formats=org.json4s.DefaultFormatsfor (userInfo <- userList ) { // string set list hash zset//设计user_info redis type hash key user_info , fielduser_id ,value user_info_jsonval userkey="user_info"val userJson: String = Serialization.write(userInfo)jedis.hset(userkey,userInfo.id,userJson)}jedis.close()}4.4 反查缓存并关联userInfoval fullSaleDetailDstream: DStream[SaleDetail] = saleDetailDstream.mapPartitions { saleIter =>val jedis: Jedis = RedisUtil.getJedisClientval userList: ListBuffer[SaleDetail] = ListBuffer[SaleDetail]() for (saleDetail <- saleIter) {val userInfoJson: String = jedis.hget("user_info", er_id)val userinfo: UserInfo = JSON.parseObject(userInfoJson, classOf[UserInfo])saleDetail.mergeUserInfo(userinfo)userList += saleDetail}jedis.close()userList.toIterator}4.5 保存购买明细进入ES中4.5.1 ES索引建立PUT gmall190408_sale_detail{"mappings" : {"_doc" : {"properties" : {"order_detail_id" : {"type" : "keyword"},"order_id" : {"type" : "keyword"},"create_time" : {"type" : "date","format" : "yyyy-MM-dd HH:mm:ss"},"dt" : {"type" : "date"},"order_status" : {"type" : "keyword"},"sku_id" : {"type" : "keyword"},"sku_name" : {"type" : "text","analyzer": "ik_max_word"},"sku_price" : {"type" : "float"},"user_age" : {"type" : "long"},"user_gender" : {"type" : "keyword"},"user_id" : {"type" : "keyword"},"user_level" : {"type" : "keyword","index" : false}}}}}4.5.2 保存ES代码fullSaleDetailDstream.foreachRDD{rdd=>val saleDetailList: List[SaleDetail] = rdd.collect().toListval saleDetailWithKeyList: List[(String, SaleDetail)] = saleDetailList.map(saleDetail=>(saleDetail.order_detail_id,saleDe tail))MyEsUtil.insertBulk(GmallConstants.ES_INDEX_SALE_DETAIL,saleDetai lWithKeyList)}第5章灵活查询数据接口开发5.1 传入路径及参数5.2 返回值5.3 编写DSL语句GET gmall190408_sale_detail/_search {"query": {"bool": {"filter": {"term": {"dt": "2019-02-14"}},"must": [{"match":{"sku_name": {"query": "小米手机","operator": "and"}}}]}} ,"aggs": {"groupby_age": {"terms": {"field": "user_age"}}},"from": 0,"size": 2,}5.4 代码开发5.4.1 代码清单5.4.2 pom.xml<!--- ES依赖包--><dependency><groupId>io.searchbox</groupId><artifactId>jest</artifactId><version>5.3.3</version></dependency><dependency><groupId>net.java.dev.jna</groupId><artifactId>jna</artifactId><version>4.5.2</version></dependency><dependency><groupId>org.codehaus.janino</groupId><artifactId>commons-compiler</artifactId><version>2.7.8</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency>5.4.3 配置application.properties#esspring.elasticsearch.jest.uris=http://hadoop102:92005.4.4 PublisherServiceImpl@Overridepublic Map getSaleDetail(String date, String keyword, int pageSize, int pageNo) {SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();//过滤匹配BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();boolQueryBuilder.filter(new TermQueryBuilder("dt",date));boolQueryBuilder.must(newMatchQueryBuilder("sku_name",keyword).operator(MatchQueryBuilder. Operator.AND));searchSourceBuilder.query(boolQueryBuilder);// 性别聚合TermsBuilder genderAggs = AggregationBuilders.terms("groupby_user_gender").field("user_gend er").size(2);searchSourceBuilder.aggregation(genderAggs);// 年龄聚合TermsBuilder ageAggs =AggregationBuilders.terms("groupby_user_age").field("user_age").s ize(100);searchSourceBuilder.aggregation(ageAggs);// 行号= (页面-1) * 每页行数searchSourceBuilder.from((pageNo-1)*pageSize);searchSourceBuilder.size(pageSize);System.out.println(searchSourceBuilder.toString());Search search = new Search.Builder(searchSourceBuilder.toString()).addIndex(GmallCons tant.ES_INDEX_SALE_DETAIL).addType("_doc").build();Map resultMap=new HashMap(); //需要总数,明细,2个聚合的结果try {SearchResult searchResult = jestClient.execute(search);//总数Long total = searchResult.getTotal();//明细List<SearchResult.Hit<Map, Void>> hits = searchResult.getHits(Map.class);List<Map> saleDetailList=new ArrayList<>();for (SearchResult.Hit<Map, Void> hit : hits) {saleDetailList.add(hit.source) ;}//年龄聚合结果Map ageMap=new HashMap();List<TermsAggregation.Entry> buckets = searchResult.getAggregations().getTermsAggregation("groupby_user_ age").getBuckets();for (TermsAggregation.Entry bucket : buckets) {ageMap.put(bucket.getKey(),bucket.getCount());}//性别聚合结果Map genderMap=new HashMap();List<TermsAggregation.Entry> genderbuckets = searchResult.getAggregations().getTermsAggregation("groupby_user_ gender").getBuckets();for (TermsAggregation.Entry bucket : genderbuckets) {genderMap.put(bucket.getKey(),bucket.getCount());}resultMap.put("total",total);resultMap.put("list",saleDetailList);resultMap.put("ageMap",ageMap);resultMap.put("genderMap",genderMap);} catch (IOException e) {e.printStackTrace();}return resultMap;}5.4.5 Bean@Data@AllArgsConstructorpublic class Option {String name;Double value;}@Data@AllArgsConstructorpublic class Stat {String title;List<Option> options;}需要pom.xml增加依赖<dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency>5.4.6 PublisherController@GetMapping("sale_detail")public String getSaleDetail(@RequestParam("date")String date ,@RequestParam("startpage") int startpage,@RequestParam("size") int size,@RequestParam("keyword")String keyword){Map saleMap = publisherService.getSaleDetail(date, keyword, startpage, size);Long total = (Long)saleMap.get("total");List<Map> saleDetailList = (List)saleMap.get("detail");Map ageMap =(Map) saleMap.get("ageMap");Map genderMap =(Map) saleMap.get("genderMap");// genderMap 整理成为 OptionGroupLong femaleCount =(Long) genderMap.get("F");Long maleCount =(Long) genderMap.get("M");double femaleRate = Math.round(femaleCount * 1000D / total) / 10D;double maleRate = Math.round(maleCount * 1000D / total) / 10D; List<Option> genderOptions = new ArrayList<>();genderOptions.add( new Option("男", maleRate));genderOptions.add( new Option("女", femaleRate));OptionGroup genderOptionGroup = new OptionGroup("性别占比", genderOptions);// ageMap 整理成为 OptionGroupLong age_20Count=0L;Long age20_30Count=0L;Long age30_Count=0L;for (Object o : ageMap.entrySet()) {Map.Entry entry = (Map.Entry) o;String agekey =(String) entry.getKey();int age = Integer.parseInt(agekey);Long ageCount =(Long) entry.getValue();if(age <20){age_20Count+=ageCount;}else if(age>=20&&age<30){age20_30Count+=ageCount;}else{age30_Count+=ageCount;}}Double age_20rate=0D;Double age20_30rate=0D;Double age30_rate=0D;age_20rate = Math.round(age_20Count * 1000D / total) / 10D;age20_30rate = Math.round(age20_30Count * 1000D / total) / 10D; age30_rate = Math.round(age30_Count * 1000D / total) / 10D;List<Option> ageOptions=new ArrayList<>();ageOptions.add(new Option("20岁以下",age_20rate));ageOptions.add(new Option("20岁到30岁",age20_30rate));ageOptions.add(new Option("30岁以上",age30_rate));OptionGroup ageOptionGroup = new OptionGroup("年龄占比", ageOptions);List<OptionGroup> optionGroupList=new ArrayList<>();optionGroupList.add(genderOptionGroup);optionGroupList.add(ageOptionGroup);SaleInfo saleInfo = new SaleInfo(total, optionGroupList, saleDetailList);return JSON.toJSONString(saleInfo);}5.5 对接可视化模块。
数据仓库开发规范

数据仓库开发规范目录数据仓库开发规范 (1)数据仓库框架 (2)数据库命名规范 (3)数据仓库框架数据据仓库框架为便于跟踪数据的处理过程、数据加载效率等方面因素的考虑,如数据仓库框架图所示,在报表平台及驾驶舱页面指标更新时,可以在对DW层及MID 层数据进行调整。
数据仓库框架采用ODS、DW、MID三层框架结构:1.ODS层ODS层获取从OA、EAS、流向、填报、EXCEL采集的数据,区分维表和事实表数据分类。
2.DW层DW层对ODS层的数据进行加工处理,该层处于ODS与MID层之间,在该层主要实现:1)联和主数据(日期、组织架构、产品、产品类型等维度)实现指标的数据归类处理;2)为MID层提供数据分类的梳理,主要根据建设主体的应用。
3.MID层(数据集市)数据集市层面向BI平台展示应用,指标逻辑计算实现在该层实现。
根据系统建设需要区分为客户档案、流向分析、财务经营效果表三个数据集市,目的在数据加载时根据数据应用主题能加快数据的加载效率。
数据库命名规范基本原则采用26个英文字母和0-9这十个自然数,加上下划线_组成,共36个字符,不出现其他字符。
采用英文单词或英文短语(包括缩写)作为名称,参照字典表给出的基础命名,没有的去翻译,不使用无意义的字符或汉语拼音。
英文字母全部大写。
一套系统中英文使用同一单词,并使用单数形式。
数据库对象命名规范数据库表命名规范数据库表字段命名基于基本原则,字段命名新增原则有:无意义的编码列如自增列、UUID等采用表名+ID 如DIM_CUSTOMER_ID 有业务意义的编码列如员工工号、机台编号等采用字段义+CODE 如EMPLOYEE_CODE标志字段统一采用字段义+FLAG,如CHECK_FLAG。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1.背景
为了避免底层业务变动对上层需求影响过大,屏蔽底层复杂的业务逻辑,尽可能简单、完整的在接口层呈现业务数据,建设高内聚松耦合的数据组织,使数据从业务角度可分割,显得尤为重要。
从整个集团业务条线出发,形成数据仓库总体概念框架,并对整个系统所需要的功能模块进行划分,明确各模块技术细节,建设一套完整的开发规范。
2.分层规范
ODS(原始数据层):ODS层是数据仓库准备区,为DWD层提供基础原始数据。
DWD(明细数据层):和ODS粒度一致的明细数据,对数据进行去重,脏数据过滤,空处理,保证数据质量。
DWS(服务数据层):轻度汇总数据及建宽表(按主题)存放数据。
ADS(应用数据层):存放应用类表数据。
3.表规范
3.1 命名
维表命名形式:dim_描述
事实表命名形式:fact_描述_[AB]
临时表命名形式:tmp_ 正式表名_ [C自定义序号]
宽表命名形式:dws_主题_描述_[AB]
备份表命名形式:正式表名_bak_yyyymmdd
表命名解释:
1)表名使用英文小写字母,单词之间用下划线分开,长度不超过40个字符,命名一般控制在小于等于6级。
2)其中ABC第一位"A"时间粒度:使用"c"代表当前数据,"h"代表小时数据,"d"代表天
数据,"w"代表周数据,"m"代表月数据,"q"代表季度数据, "y"代表年数据。
3)其中ABC的第二位"B"表示对象属性,用"t"表示表,用"v"表示视图。
4)其中ABC的第三位"C"自定义序号用于标识多个临时表的跑数顺序。
3.2 注释
注释要结合表的英文名,要求注释简洁明了,体现出表的业务出处、主题和用途。
3.3 存储格式
所谓的存储格式就是在Hive建表的时候指定的将表中的数据按照什么样子的存储方式,如果指定了方式,那么在向表中插入数据的时候,将会使用该方式向HDFS中添加相应的数据类型。
在数仓中建表默认用的都是PARQUET存储格式,相关语句如下所示:STORED AS INPUTFORMAT
‘org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat’
OUTPUTFORMAT
‘org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat’
3.5 字符集
Hadoop和hive 都是用utf-8编码的,在建表时可能涉及到中文乱码问题,所以导入的文件的字符编码统一为utf-8格式。
3.6 约定
理论上在数仓落地的表不应该出现null未知类型,对于可能出现null的字段,如果为字符型统一为空字符串,如果是数值则给0。
4.字段规范
4.1 命名
1)使用英文小写字母,单词之间用下划线分开,长度不超过30个字符,命名一般控制在小于等于4级;
2)和源数据ods层表字段名一致,如为新增字段,尽量言简意赅;
3)英文名尽量专业,符合业界要求,不得使用汉语拼音;
4)尽量避免使用关键字。
如无法避免,使用”`”转义;
5)指标字段能使用缩写的尽量使用统一的缩写,如申请金额统计apply_amt_sum。
4.2 注释
注释本着简洁、详实、完整的原则,对于有业务含义的字段,在注释中需要枚举并解释其业务含义,如ods_loan_apidata_order_info.order_status 订单状态:1待支付,2支付不成功,3支付成功;
4.3 类型
日期时间等格式统一用string类型,字符串也是用string,数值的话,会根据字段定义来确定,对于有小数点要求的,比如某些金额、利率,需要用到decimal类型,无小数点要求的用浮点类型double和整数类型(int,bigint)。
5.代码规范
5.1 sql编码
1)关键字右对齐,代码注释详尽,查询字段时每行不超过三个字段,缩进时空四格等相关书写规范。
2)明细数据层依赖于ods层,应用数据层依赖于服务数据层,原则上,不允许跨层查询。
3)如果SQL语句连接多表时,应使用表的别名来引用列。
4)WHERE条件中参数与参数值使用的类型应当匹配,避免进行隐式类型转化。
5)在SELECT语句中只获取实际需要的字段。
5.2 shell脚本
调度脚本主要是通过跑shell脚本,shell脚本的注意点:
1)命名与所跑的目标表名相同,注释要完善,后缀以.sh结尾。
2)脚本头需要加上分割线、作者、日期、目的、描述等信息。