memcache、redis、tair性能对比测试报告材料
ehcache、memcache、redis三大缓存比较

ehcache、memcache、redis三⼤缓存⽐较最近项⽬组有⽤到这三个缓存,去各⾃的官⽅看了下,觉得还真的各有千秋!今天特意归纳下各个缓存的优缺点,仅供参考!Ehcache在项⽬⼴泛的使⽤。
它是⼀个开源的、设计于提⾼在数据从RDBMS中取出来的⾼花费、⾼延迟采取的⼀种缓存⽅案。
正因为Ehcache具有健壮性(基于java开发)、被认证(具有apache 2.0license)、充满特⾊(稍后会详细介绍),所以被⽤于⼤型复杂分布式web application的各个节点中。
什么特⾊?1. 够快Ehcache的发⾏有⼀段时长了,经过⼏年的努⼒和不计其数的性能,Ehcache终被设计于large, high concurrency systems.2. 够简单开发者提供的接⼝⾮常简单明了,从Ehcache的搭建到运⽤运⾏仅仅需要的是你宝贵的⼏分钟。
其实很多开发者都不知道⾃⼰⽤在⽤Ehcache,Ehcache被⼴泛的运⽤于其他的开源项⽬⽐如:3.够袖珍关于这点的特性,官⽅给了⼀个很可爱的名字small foot print ,⼀般Ehcache的发布版本不会到2M,V 2.2.3 才 668KB。
4. 够轻量核⼼程序仅仅依赖slf4j这⼀个包,没有之⼀!5.好扩展Ehcache提供了对的内存和硬盘的存储,最近版本允许多实例、保存对象⾼灵活性、提供LRU、LFU、FIFO淘汰,基础属性⽀持热配置、⽀持的插件多6.监听器缓存管理器监听器(CacheManagerListener)和缓存监听器(CacheEvenListener),做⼀些统计或数据⼀致性⼴播挺好⽤的如何使⽤?够简单就是Ehcache的⼀⼤特⾊,⾃然⽤起来just so easy!贴⼀段基本使⽤代码CacheManager manager = CacheManager.newInstance("src/config/ehcache.xml");Ehcache cache = new Cache("testCache", 5000, false, false, 5, 2);cacheManager.addCache(cache);name:缓存名称。
Memcached vs. Redis不同key大小性能测试报告_v1.0_20130123_廖诚
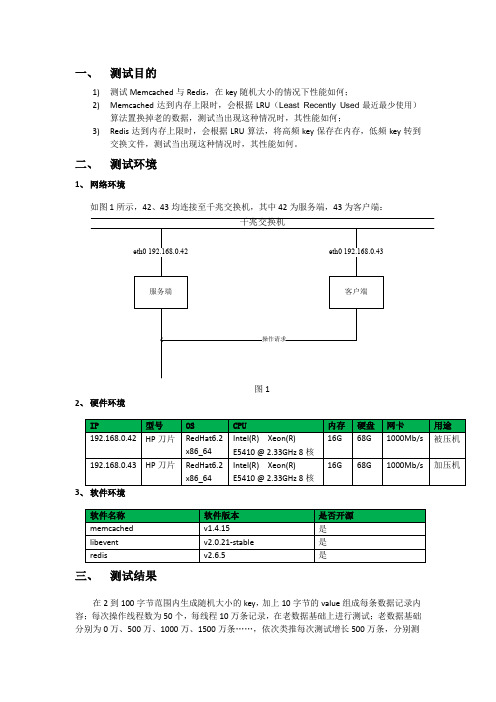
一、测试目的1)测试Memcached与Redis,在key随机大小的情况下性能如何;2)Memcached达到内存上限时,会根据LRU(Least Recently Used最近最少使用)算法置换掉老的数据,测试当出现这种情况时,其性能如何;3)Redis达到内存上限时,会根据LRU算法,将高频key保存在内存,低频key转到交换文件,测试当出现这种情况时,其性能如何。
二、测试环境1、网络环境如图1所示,42、43均连接至千兆交换机,其中42为服务端,43为客户端:图12、硬件环境3、软件环境三、测试结果在2到100字节范围内生成随机大小的key,加上10字节的value组成每条数据记录内容;每次操作线程数为50个,每线程10万条记录,在老数据基础上进行测试;老数据基础分别为0万、500万、1000万、1500万条……,依次类推每次测试增长500万条,分别测试insert、select、update情况;因为Redis在写入8千万条时,开始启动虚拟内存,此时意味着物理内存不够用,再加上受快照持久化子进程同时抢占系统资源的影响性能出现拐点,在此拐点前其性能都与7千500万的情况差不多,所以性能曲线图将只描述7千500万后的测试情况;Redis快照持久化过程如下:1)达到持久化条件,Redis调用fork创建一子进程;2)父进程继续维护自己的内存空间并同时处理client端的请求,而子进程负责将fork时刻整个数据库的一个快照写入到临时文件;3)当子进程将快照写入临时文件结束后,会用这个临时文件替换原来的快照文件,然后子进程退出;注:每次快照持久化都是将内存数据完整的写入磁盘一次,并不是增量的同步数据;1、insert操作性能对比1)在老数据基础上,进行50个客户端并发,每客户端操作100,000次写,平均用时如图2-1、图2-2示:图2-1图2-2说明:纵轴为平均用时(单位:次/秒),横轴为老数据基础(单位:千万);图3-2说明:纵轴为平均占用单个CPU百分比,横轴为老数据基础(单位:千万);图4-2说明:纵轴为占用内存平均百分比,横轴为老数据基础(单位:千万);图5-2说明:纵轴为每秒产生的页面错误数,横轴为老数据基础(单位:千万);图6-2说明:纵轴为磁盘IO读的数量(单位:kB/s),横轴为老数据基础(单位:千万);图7-2说明:纵轴为磁盘IO写的数量(单位:kB/s),横轴为老数据基础(单位:千万);2、select操作性能对比1)在老数据基础上,进行50个客户端并发,每客户端操作100,000次读,平均用时如图8-1、图8-2示:图8-2说明:纵轴为平均用时(单位:次/秒),横轴为老数据基础(单位:千万);图9-2说明:纵轴为平均占用单个CPU百分比,横轴为老数据基础(单位:千万);图10-2说明:纵轴为占用内存平均百分比,横轴为老数据基础(单位:千万);图11-2说明:纵轴为每秒产生的页面错误数,横轴为老数据基础(单位:千万);图12-2说明:纵轴为磁盘IO读的数量(单位:kB/s),横轴为老数据基础(单位:千万);图13-1图13-2说明:纵轴为磁盘IO写的数量(单位:kB/s),横轴为老数据基础(单位:千万);3、update操作性能对比1)在老数据基础上,进行50个客户端并发,每客户端操作100,000次改,平均用时如图14-1、图14-2示:图14-1图14-2说明:纵轴为平均用时(单位:次/秒),横轴为老数据基础(单位:千万);图15-1图15-2说明:纵轴为平均占用单个CPU百分比,横轴为老数据基础(单位:千万);图16-2说明:纵轴为占用内存平均百分比,横轴为老数据基础(单位:千万);图17-2说明:纵轴为每秒产生的页面错误数,横轴为老数据基础(单位:千万);图18-2说明:纵轴为磁盘IO读的数量(单位:kB/s),横轴为老数据基础(单位:千万);图19-2说明:纵轴为磁盘IO写的数量(单位:kB/s),横轴为老数据基础(单位:千万);四、分析及结论1、insert操作性能对比1)相同的数据模型,Memcached能保存的热数据要比Redis高些,如Memcached在13G的限定内存下大概能保存1亿条数据,而Redis大概保存了8千万条;2)相同服务器环境,Memcached写性能要比Redis高些,前者约10万条每秒,后者约7万条秒;3)达到内存上限时,Memcached插入性能除了在临界点有些抖动,大概降到7万条每秒,之后其性能跟临界点之前一样,而Redis性能急剧下降,一度降到396条每秒,之后其性能受子进程dump数据及每秒产生大量页面错误影响而持续下降;4)Memcached平均占用单个CPU百分比,除了在内存上限临界点达约300%外,其他一直稳定在150%左右;Redis在达到内存上限前一直稳定在90%左右,之后受子进程dump数据及每秒产生大量页面错误影响,CPU使用率并不高,一度降到1%;5)二者内存占用都随着写入数据的逐渐增多而增大,其中Memcached在达到内存上限后就不再变化,而此时Redis内存占用率因受子进程dump数据竞争而持续下降;6)Memcached由于是纯内存操作,所以没有产生页面错误,而Redis在达到内存上限后,由于需要把部分数据转到虚拟内存,再加上受子进程dump数据竞争系统资源影响会产生大量的页面错误;7)Redis在达到内存上限前没有明显的磁盘IO读操作,有明显的磁盘IO写操作,而在达到内存上限之后,有明显的磁盘IO读操作,磁盘IO写操作反而不明显;2、select操作性能对比1)相同服务器环境,Memcached读性能要比Redis高些,前者约10万条每秒,后者约8万条秒;2)达到内存上限时,Memcached读性能并没有变化,而Redis性能急剧下降,一度降到1,100条每秒,之后其性能受子进程dump数据及每秒产生大量页面错误影响而非常不稳定;3)Memcached平均占用单个CPU百分比,一直稳定在120%左右;Redis在达到内存上限前一直稳定在90%左右,之后受子进程dump数据及每秒产生大量页面错误影响,CPU使用率并不高,一度降到2%;4)二者内存占用都随着写入数据的逐渐增多而增大,其中Memcached在达到内存上限后就不再变化,而此时Redis内存占用率因受子进程dump数据竞争而下降,且非常不稳定;5)Memcached由于是纯内存操作,所以没有产生页面错误,而Redis在达到内存上限后,由于需要把部分数据转到虚拟内存,再加上受子进程dump数据竞争系统资源影响会产生大量的页面错误,且非常不稳定;6)Redis在达到内存上限前没有明显的磁盘IO读操作,有少许的磁盘IO写操作,而在达到内存上限之后,有明显的磁盘IO读操作,此时依然只有少许的磁盘IO写操作;3、update操作性能对比1)相同服务器环境,Memcached改性能不受内存上限影响,一直稳定在每秒5万条左右;2)达到内存上限前,Redis改性能要比Memcached高些,约6万条每秒;但达到内存上限后,其性能就急剧下降,一度降到14,000条每秒,其性能受子进程dump数据及每秒产生大量页面错误影响而非常不稳定;3)Memcached平均占用单个CPU百分比,一直稳定在120%左右;Redis在达到内存上限前一直稳定在90%左右,之后受子进程dump数据及每秒产生大量页面错误影响,CPU使用率并不高,一度降到20%,且非常不稳定;7)二者内存占用都随着写入数据的逐渐增多而增大,其中Memcached在达到内存上限后就不再变化,而此时Redis内存占用率因受子进程dump数据竞争而持续下降;4)Memcached由于是纯内存操作,所以没有产生页面错误,而Redis在达到内存上限后,由于需要把部分数据转到虚拟内存,再加上受子进程dump数据竞争系统资源影响会产生大量的页面错误,且非常不稳定;5)Redis在达到内存上限前没有明显的磁盘IO读操作,有明显的磁盘IO写操作,而在达到内存上限之后,有明显的磁盘IO读操作且非常不稳定,有少许的磁盘IO写操作且非常不稳定;五、后续测试及开发建议1、测试建议1)是否可以加入删除情况测试;2)是否可以测试一下Redis主从热备的性能;2、开发建议1)Memcached在达到内存上限时,会根据LRU算法丢弃老数据;2)在达到内存上限前,Redis读、写性能比Memcached低些,但改性能比后者高些,在达到内存上限后Redis读、写、改性能均比Memcached低很多;3)Redis能实现Memcached现有所有功能;4)Redis增加了数据持久化功能,但打开此功能后其性能会急剧下降;5)Redis增加了数据主从热备功能;6)并能对这个链表进行丰富的操作,举例如下:redis 127.0.0.1:6379> LPUSH students "Jeremy"(integer) 1redis 127.0.0.1:6379> LPUSH students "Anne"(integer) 2redis 127.0.0.1:6379> LPUSH students "Jimmy"(integer) 3redis 127.0.0.1:6379> LLEN students(integer) 3redis 127.0.0.1:6379> LRANGE students 0 21) "Jimmy"2) "Anne"3) "Jeremy"redis 127.0.0.1:6379> LPOP students"Jimmy"redis 127.0.0.1:6379> LLEN students(integer) 2redis 127.0.0.1:6379> LRANGE students 0 11) "Anne"2) "Jeremy"redis 127.0.0.1:6379> LREM students 1 "Anne"(integer) 1redis 127.0.0.1:6379> LLEN students(integer) 1redis 127.0.0.1:6379> LRANGE students 0 01)"Jeremy "也支持很多修改操作:redis 127.0.0.1:6379> LINSERT students BEFORE "Jeremy" "Anne"(integer) 2redis 127.0.0.1:6379> LRANGE students 0 11) "Anne"2) "Jeremy"redis 127.0.0.1:6379> LTRIM students 1 2OKredis 127.0.0.1:6379> LLEN students(integer) 1redis 127.0.0.1:6379> LRANGE students 0 01)"Jeremy"redis 127.0.0.1:6379> LREM students 1 "Jeremy"(integer) 1redis 127.0.0.1:6379> LLEN students(integer) 07)Redis增加了集合(Sets)数据类型,其能够将一系列不重复的值存储成一个集合,如下:并能对这个集合进行丰富的操作,举例如下:redis 127.0.0.1:6379> SADD birds crow(integer) 1redis 127.0.0.1:6379> SADD birds pigeon(integer) 1redis 127.0.0.1:6379> SADD birds bat(integer) 1redis 127.0.0.1:6379> SADD mammals dog(integer) 1redis 127.0.0.1:6379> SADD mammals cat(integer) 1redis 127.0.0.1:6379> SADD mammals bat(integer) 1redis 127.0.0.1:6379> SMEMBERS birds1) "pigeon"2) "bat"3) "crow"redis 127.0.0.1:6379> SMEMBERS mammals1) "cat"2) "bat"3) "dog"也支持相应的修改操作:redis 127.0.0.1:6379> SREM mammals cat(integer) 1redis 127.0.0.1:6379> SMEMBERS mammals1) "bat"2) "dog"redis 127.0.0.1:6379> SADD mammals human(integer) 1redis 127.0.0.1:6379> SMEMBERS mammals1) "bat"2) "human"3) "dog"还支持对集合的子、交、并、补等操作:redis 127.0.0.1:6379> SINTER birds mammals1)"bat"redis 127.0.0.1:6379> SUNION birds mammals1) "pigeon"2) "bat"3) "dog"4) "human"5) "crow"redis 127.0.0.1:6379> SDIFF birds mammals1) "pigeon"2) "crow"8)写入时就按这个score排好序,举例如下:redis 127.0.0.1:6379> ZADD days 0 mon(integer) 1redis 127.0.0.1:6379> ZADD days 1 tue(integer) 1redis 127.0.0.1:6379> ZADD days 2 wed(integer) 1redis 127.0.0.1:6379> ZADD days 3 thu(integer) 1redis 127.0.0.1:6379> ZADD days 4 fri(integer) 1redis 127.0.0.1:6379> ZADD days 5 sat(integer) 1redis 127.0.0.1:6379> ZADD days 6 sun(integer) 1redis 127.0.0.1:6379> ZCARD days(integer) 7redis 127.0.0.1:6379> ZRANGE days 0 61) "mon"2) "tue"3) "wed"4) "thu"5) "fri"6) "sat"7) "sun"redis 127.0.0.1:6379> ZSCORE days sat"5"redis 127.0.0.1:6379> ZCOUNT days 3 6(integer) 4redis 127.0.0.1:6379> ZRANGEBYSCORE days 3 61) "thu"2) "fri"3) "sat"4) "sun"9)redis 127.0.0.1:6379> HSET students name "Jeremy"(integer) 1redis 127.0.0.1:6379> HSET students age 30(integer) 1redis 127.0.0.1:6379> HSET students sex "male"(integer) 1redis 127.0.0.1:6379> HKEYS students1) "name"2) "age"3) "sex"redis 127.0.0.1:6379> HVALS students1) "Jeremy"2) "30"3) "male"redis 127.0.0.1:6379> HGETALL students1) "name"2) "Jeremy"3) "age"4) "30"5) "sex"6) "male"redis 127.0.0.1:6379> HDEL students sex(integer) 1redis 127.0.0.1:6379> HGETALL students1) "name"2) "Jeremy"3) "age"4) "30"还支持批量修改和获取:redis 127.0.0.1:6379> HMSET kid name Anne age 25 sex FemaleOKredis 127.0.0.1:6379> HMGET kid name age sex1) "Anne"2) "25"3) "Female"10)Redis支持Publish/Subscribe数据模型,你可以将数据推到某个信息管道中,然后其它人可以通过订阅这些管道来获取推送过来的信息,举例如下:用一个客户端订阅管道:redis 127.0.0.1:6379> SUBSCRIBE channeloneReading messages... (press Ctrl-C to quit)1) "subscribe"2) "channelone"3) (integer) 1另一个客户端往这个管道推送信息:redis 127.0.0.1:6379> PUBLISH channelone hello(integer) 1redis 127.0.0.1:6379> PUBLISH channelone world(integer) 1然后第一个客户端就能获取到推送的信息:redis 127.0.0.1:6379> SUBSCRIBE channeloneReading messages... (press Ctrl-C to quit)1) "subscribe"2) "channelone"3) (integer) 11) "message"2) "channelone"3) "hello"1) "message"2) "channelone"3) "world"11)Redis还支持按一定的模式批量订阅,举例如下:订阅所有channel开头的信息通道:redis 127.0.0.1:6379> PSUBSCRIBE channel*Reading messages... (press Ctrl-C to quit)1) "psubscribe"2) "channel*"3) (integer) 1在另一个客户端对两个推送信息:redis 127.0.0.1:6379> PUBLISH channelone hello(integer) 1redis 127.0.0.1:6379> PUBLISH channeltwo world(integer) 1然后在第一个客户端就能收到推送的信息:redis 127.0.0.1:6379> PSUBSCRIBE channel*Reading messages... (press Ctrl-C to quit)1) "psubscribe"2) "channel*"3) (integer) 11) "pmessage"2) "channel*"3) "channelone"4) "hello"1) "pmessage"2) "channel*"3) "channeltwo"4) "world"12)Redis还支持按key设置过期时间,过期后值将被删除,举例如下:用TTL命令可以获取某个key值的过期时间(-1表示永不过期):redis 127.0.0.1:6379> SET name "Jeremy"OKredis 127.0.0.1:6379> TTL name(integer) -1下面命令先用EXISTS命令查看key值是否存在,然后设置了5秒的过期时间:redis 127.0.0.1:6379> EXISTS name(integer) 1redis 127.0.0.1:6379> EXPIRE name 5(integer) 15秒后再查看:redis 127.0.0.1:6379> EXISTS name(integer) 0redis 127.0.0.1:6379> GET name(nil)设置在某个时间点过期,如设置在2013年1月18日17:23:00过期:redis 127.0.0.1:6379> SET name "Jeremy"OKredis 127.0.0.1:6379> EXPIREAT name 1358500980(integer) 1redis 127.0.0.1:6379> EXISTS name(integer) 013)Redis支持一些简单的事务性,比如以NX结尾命令都是判断在这个值没有时才进行某个命令,举行如下:redis 127.0.0.1:6379> SET name "Jeremy"OKredis 127.0.0.1:6379> SETNX name "Anne"(integer) 0redis 127.0.0.1:6379> GET name"Jeremy"redis 127.0.0.1:6379> GETSET name "Anne""Jeremy"redis 127.0.0.1:6379> GET name"Anne"通过MULTI和EXEC,将几个命令组合起来执行:redis 127.0.0.1:6379> SET counter 0OKredis 127.0.0.1:6379> MULTIOKredis 127.0.0.1:6379> INCR counterQUEUEDredis 127.0.0.1:6379> INCR counterQUEUEDredis 127.0.0.1:6379> INCR counterQUEUEDredis 127.0.0.1:6379> EXEC1) (integer) 12) (integer) 23) (integer) 3redis 127.0.0.1:6379> GET counter"3"还可以用DICARD命令来中断执行中的命令序列:redis 127.0.0.1:6379> SET newcounter 0OKredis 127.0.0.1:6379> MULTIOKredis 127.0.0.1:6379> INCR newcounter QUEUEDredis 127.0.0.1:6379> INCR newcounter QUEUEDredis 127.0.0.1:6379> INCR newcounte QUEUEDredis 127.0.0.1:6379> DISCARDOKredis 127.0.0.1:6379> GET newcounter"0"。
memcached&redis性能测试

一、Memcached1.1、memcached简介Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web 应用以减轻数据库负载。
它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提供动态、数据库驱动网站的速度。
Memcached基于一个存储键/值对的hashmap。
其守护进程(daemon )是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信。
但是它并不提供冗余(例如,复制其hashmap条目);当某个服务器S停止运行或崩溃了,所有存放在S上的键/值对都将丢失。
Memcached由Danga Interactive开发,其最新版本发布于2010年,作者为Anatoly Vorobey和Brad Fitzpatrick。
用于提升LiveJournal . com访问速度的。
LJ每秒动态页面访问量几千次,用户700万。
Memcached将数据库负载大幅度降低,更好的分配资源,更快速访问。
1.2、Memcached是如何工作的Memcached的神奇来自两阶段哈希(two-stage hash)。
Memcached就像一个巨大的、存储了很多<key,value>对的哈希表。
通过key,可以存储或查询任意的数据。
客户端可以把数据存储在多台memcached上。
当查询数据时,客户端首先参考节点列表计算出key的哈希值(阶段一哈希),进而选中一个节点;客户端将请求发送给选中的节点,然后memcached节点通过一个内部的哈希算法(阶段二哈希),查找真正的数据(item)。
举个列子,假设有3个客户端1, 2, 3,3台memcached A, B, C:Client 1想把数据”tuletech”以key “foo”存储。
Client 1首先参考节点列表(A, B, C),计算key “foo”的哈希值,假设memcached B被选中。
Memcache,Redis,MongoDB(数据缓存系统)方案对比与分析

Memcache,Redis,MongoDB(数据缓存系统)方案对比与分析一、问题:数据库表数据量极大(千万条),要求让服务器更加快速地响应用户的需求。
二、解决方案:1.通过高速服务器Cache缓存数据库数据2.内存数据库(这里仅从数据缓存方面考虑,当然,后期可以采用Hadoop HBase Hive等分布式存储分析平台)三、主流解Cache和数据库对比:上述技术基本上代表了当今在数据存储方面所有的实现方案,其中主要涉及到了普通关系型数据库(MySQL/PostgreSQL),NoSQL数据库(MongoDB),内存数据库(Redis),内存Cache(Memcached),我们现在需要的是对大数据表仍保持高效的查询速度,普通关系型数据库是无法满足的。
而MongoDB其实只是一种非关系型数据库,其优势在于可以存储海量数据,具备强大的查询功能,因此不宜用于缓存数据的场景。
从以上各数据可知,对于我们产品最可行的技术方案有两种:1.Memcached 内存Key-Value Cache2.Redis 内存数据库四、下面重点分析Memcached和Redis两种方案:4.1 Memcached介绍Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。
它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提供动态、数据库驱动网站的速度,现在已被LiveJournal、hatena、Facebook、Vox、LiveJournal等公司所使用。
4.2 Memcached工作方式分析许多Web应用都将数据保存到RDBMS中,应用服务器从中读取数据并在浏览器中显示。
但随着数据量的增大、访问的集中,就会出现RDBMS的负担加重、数据库响应恶化、网站显示延迟等重大影响。
Memcached是高性能的分布式内存缓存服务器,通过缓存数据库查询结果,减少数据库访问次数,以提高动态Web等应用的速度、提高可扩展性。
Ehcache-Redis-Tair缓存性能对比

Ehcache/Redis/Tair缓存性能对比后面介绍的不同方式都有测试数据,这些测试数据都是在同一的测试环境下得出的测试结果:测试机器的配置如下:64位5核CPU, E5620 @ 2.40GHz,内存8GCDN端缓存由于计数器的价值并不在,具体的值是多少,尤其是对一些大访问量的商品来说个位或者十位的数据并没有什么意义,所以对这些热门商品的计数器访问可以采用定时更新的办法,可以将计数器的值直接缓存在CDN上或者后端Nginx的缓存中,定时再到数据库服务器上获取最新的计数器的值,这样能够大量减少对后端服务器的访问请求,而且计数器的数据量很小对缓存服务器的空间需求也不大。
改进的结构图如下:直接在Nginx中利用Cache策略缓存住热门计数器的值,利用http协议的cache+max age来失效缓存的方式更新计数器的值。
优点:实现方式简单,改动小,能够挡住热门商品的计数器访问请求,采用这种方式对查询请求来说,能达到类似于静态服务器的性能,如Nginx能达到2w的QPS缺点:没有解决同一商品的计数器合并请求的问题,数据量会增大一倍对更新请求没有办法缓存,只能减少查询请求的压力基于Java的存储方式由于目前采用Nginx模块的方法开发,每次修改要重新编译Nginx服务器,所以想采用基于Java的方式,使得维护要容易一些。
选用Ehcache作为数据存储服务器,Ehcache也是基于内存存储,支持定时持久化功能,非常适合存储像计数器这种小数据类型。
处理Http请求使用Tomcat容器,结构图如下:处理逻辑采用一个servlet实现,并且在这个servlet中通过一致性Hash从Ehcache中获取计数器值。
在实际的部署结构中,可以将Tomcat和Ehcache部署在同一台机器上。
基于这种模式的测试结果如下:Qps能达到1.3w左右,性能瓶颈是在Tomcat处理Http连接的请求上,Tomcat较Apache和Nginx处理请求性能较差。
redis简介及与memcached比较

redis简介及与memcached⽐较
概述
redis使⽤场景:
1. 登录会话存储:存储在redis中,与memcached相⽐,数据不会丢失。
2. 排⾏版/计数器:⽐如⼀些秀场类的项⽬,经常会有⼀些前多少名的主播排名。
还有⼀些⽂章阅读量的技术,或者新浪微博的点赞数
等。
3. 作为消息队列:⽐如celery就是使⽤redis作为中间⼈。
4. 当前在线⼈数:还是之前的秀场例⼦,会显⽰当前系统有多少在线⼈数。
5. ⼀些常⽤的数据缓存:⽐如我们的BBS论坛,板块不会经常变化的,但是每次访问⾸页都要从mysql中获取,可以在redis中缓存起来,不
⽤每次请求数据库。
6. 把前200篇⽂章缓存或者评论缓存:⼀般⽤户浏览⽹站,只会浏览前⾯⼀部分⽂章或者评论,那么可以把前⾯200篇⽂章和对应的评论
缓存起来。
⽤户访问超过的,就访问数据库,并且以后⽂章超过200篇,则把之前的⽂章删除。
7. 好友关系:微博的好友关系使⽤redis实现。
8. 发布和订阅功能:可以⽤来做聊天软件。
redis和memcached的⽐较:
memcached redis
类型纯内存数据库内存磁盘同步数据库
数据类型在定义value时就要固定数据类型不需要
虚拟内存不⽀持⽀持
过期策略⽀持⽀持
存储数据安全不⽀持可以将数据同步到dump.db中
灾难恢复不⽀持可以将磁盘中的数据恢复到内存中
分布式⽀持主从同步
订阅与发布不⽀持⽀持。
redis与mysql性能对比、redis缓存穿透、缓存雪崩

redis与mysql性能对⽐、redis缓存穿透、缓存雪崩
写在开始
redis是⼀个基于内存hash结构的缓存型db。
其优势在于速读写能⼒碾压mysql。
由于其为基于内存的db所以存储数据量是受限的。
redis性能
redis读写性能测试redis官⽹测试读写能到10万左右
redis读写能⼒为2W/s
mysql读能⼒5K/s、写能⼒为3K/s
数据上看redis性能碾压mysql
redis缓存穿透
缓存穿透是指查询⼀个⼀定不存在的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写⼊缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
在流量⼤时,可能DB就挂了。
解决办法就是将从db过来的返回值进⾏缓存,根据实际情况重新加热,若db返回是空则缓存⼏分钟就可以了。
redis缓存雪崩
在我们设置缓存时采⽤了相同的过期时间或者缓存服务器因某些原因⽆法使⽤时,导致缓存在某⼀时刻同时失效,请求全部转发到DB,DB 瞬时压⼒过重雪崩。
解决办法过期时间上增加⼀个范围的随机值,使⽤Redis Sentinel 和 Redis Cluster 实现⾼可⽤,另增设⼀个寿命更短的本机缓存来解决redis分布缓存抢修时的问题。
在发⽣⽆论是缓存穿透还是缓存雪崩,都建议使⽤队列来排队、拒绝⼤量请求涌⼊和分布式互斥锁来避免后端数据服务被冲击,防⽌已有的数据出现问题。
性能测试报告

性能测试报告性能(压力)测试报告一、引言性能测试是软件测试中的一种重要测试方法,旨在评估系统在特定条件下的稳定性、可扩展性和可靠性。
本次测试以一个具体的软件系统为例,对其进行了性能测试,本报告将对测试结果进行分析和总结。
二、测试目标本次测试的主要目标是评估系统在正常负载和峰值负载情况下的性能表现。
具体而言,我们希望通过测试找出系统在高并发访问、大数据量负载和长时间运行等情况下的性能问题,并确定系统所能处理的最大访问量。
三、测试环境1.软件环境:- 操作系统:Windows Server 2024-数据库:MySQL8.0- Web服务器:Apache Tomcat 9.0- 浏览器:Chrome 87.02.硬件环境:-内存:16GB-硬盘:SSD256GB四、测试方法1. 负载生成:使用性能测试工具Apache JMeter对系统进行高并发操作模拟。
2.测试场景:-登录场景:模拟1000个用户同时登录系统并进行操作。
-数据查询场景:模拟100个用户同时进行数据查询操作。
-数据插入场景:模拟100个用户同时进行大数据量插入操作。
-长时间运行场景:模拟持续高并发操作,持续时间为1小时。
五、测试结果1.登录场景:系统对1000个用户同时登录的响应时间平均为2秒,无明显延迟,登录成功率达到100%。
2.数据查询场景:系统对100个用户同时进行数据查询的响应时间平均为3秒,查询完成率达到99%。
3.数据插入场景:系统对100个用户同时进行大数据量插入的响应时间平均为5秒,插入成功率达到98%。
4.长时间运行场景:系统在持续高并发操作下表现稳定,无明显内存泄漏或性能下降的情况。
六、问题分析1.登录响应时间略高:系统登录场景下的响应时间为2秒,稍稍超出了我们的预期。
经过分析,发现登录操作时有大量的数据库查询和权限验证,可以优化查询和权限验证的算法以提升登录的响应速度。
2.数据查询完成率不达标:数据查询场景下完成率为99%,仍有1%的查询未能成功。
内存缓存服务器(memcached)客户端比较报告

内存缓存服务器技术调研报告系列客户端性能比较分析报告2011年4月21日目录前言 (2)测试方案 (2)测试结果 (3)结论 (5)图目录图表1 简单对象查询Key对应Value(get操作)对比图 (3)图表2 简单对象设置Key-Value(set操作)对比图 (4)图表3 复杂对象查询Key对应Value(get操作)对比图 (5)图表4复杂对象设置Key-Value(set操作)对比图 (5)前言目前几乎所有主流的互联网站都引入内存对象缓存系统(key-value)来对常用对象进行内存缓存,目前应用最广泛的就是memcached开源软件。
关于Memcached的介绍可以参考下面百科的内容:Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。
它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提供动态、数据库驱动网站的速度。
Memcached基于一个存储键/值对的hashmap。
其守护进程(daemon )是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信。
借助memcached作为缓存,可以实现更为灵活“云”化的分布式系统,而抛弃掉传统以JGroups为代表的底层消息通信为基础的集群架构。
预期在Portal个性化架构调整中引用这种架构来探索新的分布式系统。
Memcached主流的Java客户端中,目前流行的主要是Spymemcached和Xmemcached 两种。
为了验证memcached的使用、开发和性能,以及对客户端进行选型,特进行性能对比测试。
测试方案选择自己编写的Java方法并发测试框架,分别测试简单对象、复杂对象两种对象的保存和读取两种操作,采用集合点的模式分别验证单线程、100、200、500、1000、2000、3000、5000并发。
其中:简单对象的Key和Value均为当前时间的毫秒数;复杂对象的Key为当前时间的毫秒数、Value为Portal中用户对象的属性值映射出来的HashMap。
memcache和redis缓存对比及我为什么选择redis

memcache和redis缓存对比及我为什么选择redis对比结论1. 性能上:性能上都很出色,具体到细节,由于Redis只使用单核,而Memcached可以使用多核,所以平均每一个核上Redis在存储小数据时比Memcached性能更高。
而在100k以上的数据中,Memcached性能要高于Redis,虽然Redis最近也在存储大数据的性能上进行优化,但是比起 Memcached,还是稍有逊色。
2. 内存空间和数据量大小:MemCached可以修改最大内存,采用LRU算法。
Redis增加了VM的特性,突破了物理内存的限制。
Memcached单个key-value大小有限,一个value最大只支持1MB,而Redis最大支持512MB。
3. 操作便利上:MemCached数据结构单一,仅用来缓存数据,而Redis支持更加丰富的数据类型,也可以在服务器端直接对数据进行丰富的操作,这样可以减少网络IO次数和数据体积。
4. 可靠性上:MemCached不支持数据持久化,断电或重启后数据消失,但其稳定性是有保证的。
Redis支持数据持久化和数据恢复,允许单点故障,但是同时也会付出性能的代价。
5. 存储数据类别上的区别:redis支持很存储表:key-value、hash表、list表等memcache只支持key-value,不过memcache可以在内存中缓存图片、视频等。
6. 应用场景:Memcached:动态系统中减轻数据库负载,提升性能;做缓存,适合多读少写,大数据量的情况。
Redis:适用于对读写效率要求都很高,数据处理业务复杂和对安全性要求较高的系统。
我为什么选择redis其实redis也支持cas,而且最新的redis支持分布式集群,即使100k以上的流量性能不及memcache高,但是我自己的网站没有那么高的并发量啊,O(∩_∩)O哈哈~上个博客测试我sso登录的并发量2000反应3s,所以达不到那么高的并发,其次个人的服务器也存在不稳定情况,docker没有配置k8s管理,容易出现进程失效问题,所以redis还能很好的保护我的数据,故,我选择redis,欢迎大神指教也希望能结交大神,能带着我学习。
JMeter测试报告

JMeter测试报告
1、使用memcache缓存的压测结果(并发600,持续时间60秒)
2、使用redis缓存
并发400,持续60秒
并发500,持续60秒
并发600,持续60秒
并发1000,持续60秒
Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值
Samples:表示你这次测试中一共发出了多少个请求,如果模拟10个用户,
每个用户迭代10次,那么这里显示100
Average:平均响应时间——默认情况下是单个 Request 的平均响应时间,当
使用了 Transaction Controller 时,也可以以Transaction 为单位显示平均响应
时间
Median:中位数,也就是 50%用户的响应时间
90% Line:90%用户的响应时间
Min:最小响应时间
Max:最大响应时间
Error%:本次测试中出现错误的请求的数量/请求的总数
Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second),当使用了 Transaction Controller 时,也可以表示类
似 LoadRunner 的 Transaction per Second 数
KB/Sec:每秒从服务器端接收到的数据量,相当于LoadRunner中的Throughput/Sec。
redis和memcached的区别(总结)

redis和memcached的区别(总结)观点⼀:1、Redis和Memcache都是将数据存放在内存中,都是内存数据库。
不过memcache还可⽤于缓存其他东西,例如图⽚、视频等等;2、Redis不仅仅⽀持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储;3、--Redis当物理内存⽤完时,可以将⼀些很久没⽤到的value 交换到磁盘;4、过期策略--memcache在set时就指定,例如set key1 0 0 8,即永不过期。
Redis可以通过例如expire 设定,例如expire name 10;5、分布式--设定memcache集群,利⽤magent做⼀主多从;redis可以做⼀主多从。
都可以⼀主⼀从;6、存储数据安全--memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化);7、--memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复;8、Redis⽀持数据的备份,即master-slave模式的数据备份;观点⼆:如果简单地⽐较Redis与Memcached的区别,⼤多数都会得到以下观点:1 Redis不仅仅⽀持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
2 Redis⽀持数据的备份,即master-slave模式的数据备份。
3 Redis⽀持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进⾏使⽤。
在Redis中,并不是所有的数据都⼀直存储在内存中的。
这是和Memcached相⽐⼀个最⼤的区别(我个⼈是这么认为的)。
Redis 只会缓存所有的key的信息,如果Redis发现内存的使⽤量超过了某⼀个阀值,将触发swap的操作,Redis根据“swappability =age*log(size_in_memory)”计算出哪些key对应的value需要swap到磁盘。
redis和memcached选择,对比分析

redis和memcached选择,对⽐分析memcache和redis是互联⽹分层架构中,最常⽤的KV缓存。
不少同学在选型的时候会纠结,到底是选择memcache还是redis?memcache提供的功能是redis提供的功能的⼦集,不⽤想太多,选redis准没错?redis倾向:复杂的数据结构:value是哈希,列表,集合,有序集合这类复杂的数据结构时,会选择redis,因为mc⽆法满⾜这些需求。
⽤户订单列表,⽤户消息,帖⼦评论列表等。
持久化: mc⽆法满⾜持久化的需求,只得选择redis。
但是千万不要把redis真的做数据库⽤a. redis的定期快照不能保证数据不丢失b.redis的AOF会降低效率,并且不能⽀持太⼤的数据量c.不要期望redis做固化存储会⽐mysql做得好,不同的⼯具做各⾃擅长的事情d.redis挂掉重启后能够快速恢复热数据,但是如果着期间有数据修改,可能导致数据不⼀致,因此,只读场景,或者允许⼀些不⼀致的业务场景,可以尝试开启redis的固化功能⾃带⾼可⽤集群: redis⾃⾝⽀持集群,实现主从读写分离功能,官⽅也提供sentinal哨兵的集群管理⼯具,实现主从监控,故障转移,memcached实现集群需要⼆次开发了但是很多时候需要考虑,真的需要⾼可⽤么?缓存很多时候是运⾏cache miss的,cache挂了可以读db的存储的内容⽐较⼤: macache 单个value最⼤存储 1M,超过1M只能⽤redis了。
注意:纯的k-v ⽽且数据量特别⼤,并发也很⼤或许使⽤memcache更合适a.内存分配:memcache使⽤预分配内存池的烦事管理内存,更节省内存分配时间,redis使⽤临时申请的⽅式,kennel导致碎⽚。
对⽐看memcache更快⼀点b.memcache把所有的数据存储在物理内存⾥。
redis有⾃⼰的VM机制,理论上能够存储⽐物理内存更多的数据,当数据超量时,会引发swap,把冷数据刷到磁盘上。
cache实验报告

cache实验报告《cache实验报告》在计算机科学领域中,cache(缓存)是一种用于存储临时数据的高速存储器,用于加快数据访问速度。
在本次实验中,我们对cache进行了一系列的实验,以探究其对计算机系统性能的影响。
首先,我们设计了一个简单的计算机系统模型,包括CPU、内存和cache。
我们使用了不同大小和结构的cache,并对其进行了性能测试。
通过比较不同cache结构下的数据访问速度和命中率,我们发现了cache大小和关联度对性能的影响。
较大的cache和更高的关联度可以显著提高数据访问速度和命中率,从而提升整个系统的性能。
接着,我们对cache的替换策略进行了实验。
我们比较了最常见的替换策略,如LRU(最近最少使用)、FIFO(先进先出)和随机替换。
通过实验结果,我们发现不同的替换策略会对cache的性能产生显著影响。
在某些情况下,合适的替换策略可以提高cache的命中率,从而提高系统的整体性能。
最后,我们对cache的一致性和一致性维护进行了实验。
我们测试了不同的一致性协议,如MESI(修改、独占、共享、无效)协议和MOESI(修改、独占、共享、无效、所有者)协议。
通过实验,我们发现一致性协议的选择对cache的性能和系统的稳定性有着重要影响。
合适的一致性协议可以有效减少数据访问的冲突和错误,提高系统的可靠性和性能。
综上所述,本次实验对cache进行了全面的性能测试和分析,探究了cache对计算机系统性能的影响。
通过实验结果,我们得出了一些重要结论,为优化计算机系统性能提供了重要的参考和指导。
希望本次实验结果能够对相关领域的研究和应用产生积极的影响。
redis和memcache对比

redis和memcache对⽐1、性能⽅⾯:没有必要过多的关⼼性能,因为⼆者的性能都已经⾜够⾼了。
由于Redis只使⽤单核,⽽Memcached可以使⽤多核,所以在⽐较上,平均每⼀个核上Redis在存储⼩数据时⽐Memcached性能更⾼。
⽽在100k以上的数据中,Memcached性能要⾼于Redis,虽然2、Redis最近也在存储⼤数据的性能上进⾏优化,但是⽐起Memcached,还是稍有逊⾊。
说了这么多,结论是,⽆论你使⽤哪⼀个,每秒处理请求的次数都不会成为瓶颈。
(⽐如瓶颈可能会在⽹卡)3、内存使⽤效率:使⽤简单的key-value存储的话,Memcached的内存利⽤率更⾼,⽽如果Redis采⽤hash结构来做key-value存储,由于其组合式的压缩,其内存利⽤率会⾼于Memcached。
当然,这和你的应⽤场景和数据特性有关。
4、数据持久化:如果你对数据持久化和数据同步有所要求,那么推荐你选择Redis,因为这两个特性Memcached都不具备。
即使你只是希望在升级或者重启系统后缓存数据不会丢失,选择Redis也是明智的。
5、数据结构:当然,最后还得说到你的具体应⽤需求。
Redis相⽐Memcached来说,拥有更多的数据结构和并⽀持更丰富的数据操作,通常在Memcached⾥,你需要将数据拿到客户端来进⾏类似的修改再set回去。
这⼤⼤增加了⽹络IO的次数和数据体积。
在Redis中,这些复杂的操作通常和⼀般的GET/SET⼀样⾼效。
所以,如果你需要缓存能够⽀持更复杂的结构和操作,那么Redis会是不错的选择。
⽹络IO模型⽅⾯:Memcached是多线程,分为监听线程、worker线程,引⼊锁,带来了性能损耗。
Redis使⽤单线程的IO复⽤模型,将速度优势发挥到最⼤,也提供了较简单的计算功能6、内存管理⽅⾯:Memcached使⽤预分配的内存池的⽅式,带来⼀定程度的空间浪费并且在内存仍然有很⼤空间时,新的数据也可能会被剔除,⽽Redis使⽤现场申请内存的⽅式来存储数据,不会剔除任何⾮临时数据 Redis更适合作为存储⽽不是cache7、数据的⼀致性⽅⾯:Memcached提供了cas命令来保证.⽽Redis提供了事务的功能,可以保证⼀串命令的原⼦性,中间不会被任何操作打断总结:如果简单地⽐较Redis与Memcached的区别,⼤多数都会得到以下观点:1 、Redis不仅仅⽀持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
tair与redis比较总结

tair与redis比较总结1. Tair总述1.1 系统架构一个Tair集群主要包括3个必选模块:configserver、dataserver和client,一个可选模块:invalidserver。
通常情况下,一个集群中包含2台configserver及多台dataServer。
两台configserver互为主备并通过维护和dataserver之间的心跳获知集群中存活可用的dataserver,构建数据在集群中的分布信息(对照表)。
dataserver负责数据的存储,并按照configserver的指示完成数据的复制和迁移工作。
client在启动的时候,从configserver 获取数据分布信息,根据数据分布信息和相应的dataserver 交互完成用户的请求。
invalidserver主要负责对等集群的删除和隐藏操作,保证对等集群的数据一致。
从架构上看,configserver的角色类似于传统应用系统的中心节点,整个集群服务依赖于configserver的正常工作。
但实际上相对来说,tair的configserver是非常轻量级的,当正在工作的服务器宕机的时候另外一台会在秒级别时间内自动接管。
而且,如果出现两台服务器同时宕机的最恶劣情况,只要应用服务器没有新的变化,tair依然服务正常。
而有了configserver这个中心节点,带来的好处就是应用在使用的时候只需要配置configserver的地址(现在可以直接配置Diamond key),而不需要知道内部节点的情况。
1.1.1 ConfigServer的功能1) 通过维护和dataserver心跳来获知集群中存活节点的信息2) 根据存活节点的信息来构建数据在集群中的分布表。
3) 提供数据分布表的查询服务。
4) 调度dataserver之间的数据迁移、复制。
1.1.2 DataServer的功能1) 提供存储引擎2) 接受client 的put/get/remove等操作3) 执行数据迁移,复制等4) 插件:在接受请求的时候处理一些自定义功能5) 访问统计1.1.3 InvalidServer的功能1) 接收来自client的invalid/hide等请求后,对属于同一组的集群(双机房独立集群部署方式)做delete/hide操作,保证同一组集群的一致。
memcache,redis分布式缓存详解

memcache,redis分布式缓存详解本答应⼤家这⼀篇⽂章讲解AutoMapper,但是为了满⾜旁边同事⼩法师的强烈要求,就先写⼀篇关于分布式缓存的⽂章吧。
⼀、问题⼀:为什么要有分布式缓存?什么时候⽤分布式缓存?答:举个例⼦,当你的⽹站随着业务的扩⼤,访问量会很⼤,很有可能在同⼀时间有⼏个⼈,共同操作⼀条数据,但是数据库锁机制,有可能会造成死锁,简单点就是服务器卡死,宕机(cpu 100%)!先普及⼀下数据库锁机制:select * from table1//此时会给这个表加上S锁(共享锁)update table1 set colum="somedata"//此时给table1加上X锁T1:begin transelect * from table (holdlock) (holdlock意思是加共享锁,直到事物结束才释放)update table set column1='hello'T2:begin transelect * from table(holdlock)update table set column1='world'假设T1和T2同时达到select,T1对table加共享锁,T2也对加共享锁,当T1的select执⾏完,准备执⾏update时,根据锁机制,T1的共享锁需要升级到排他锁才能执⾏接下来的update.在升级排他锁前,必须等table上的其它共享锁释放,但因为holdlock这样的共享锁只有等事务结束后才释放,所以因为T2的共享锁不释放⽽导致T1等(等T2释放共享锁,⾃⼰好升级成排他锁),同理,也因为T1的共享锁不释放⽽导致T2等。
死锁产⽣了。
⼀个表上可以有很多个s锁,但是⼀个表上只会有⼀个X锁存在,也就是说,在Update的时候这条数据只能被⼀个⽤户使⽤,别⼈是⽆法查询或者修改的。
随着访问量的增⼤,并发⼏率就会增⾼,所谓并发就是同意时间操作同⼀个数据。
memcache、redis、tair性能对比测试报告材料

memcache、redis、tair性能对比测试报告第1章限制条件前一周所做的分布缓存技术预言中有包括ehcache、memcache、redis、tair,还包括了基于MongoDB的分布式技术。
测试中,考虑到各自功能的差异化特点,其中选择了memcache、redis、tair功能特性相近的缓存服务器进行性能对比,所以ehcache、MongoDB将不做为本次测试的规范,其原因如下:1)Ehcache是组件级别的缓存,要搭建一个独立的缓存服务器,需要用到ehcache server 模块,这是个war包,能运行在web 容器中,决定整个缓存服务器性能的好坏因素太多,比如web服务器,集群方式等。
跟memcache、redis、tair没有对比性。
2)MongoDB是面向文档的数据库,跟缓存没有可比性。
第2章测试场景概述性能测试包括单机环境和分布式环境,主要针对memcache、redis、tair各缓存服务器在缓存了不同级别的数据下,多个线程并发操作向缓存set/get缓存数据,考虑到网络方面的负载,又将每次set/get操作的缓存数据的大小分为三个不同的级别:1KB,10KB,100KB,通过对上述的条件进行排列,取得以下的测试场景。
第3章单机环境测试3.1.测试场景:1.当各缓存的数据库空时,以单线程通过各缓存客户端set调用向服务端推送数据,比较10000操作所消耗的时间,以上动作通过使用不同大小的单个缓存对象重复三次。
2.在场景一完成的情况下,以单线程通过各缓存客户端get调用向服务端获取数据,比较10000操作所消耗的时间,以上动作通过使用不同大小的单个缓存对象重复三次。
3.并发200个线程通过缓存软件的客户set调用向服务端推送数据,每个线程完成10000次的操作,比较服务器的tps大小,以上动作通过使用不同大小的单个缓存对象重复三次。
4.并发200个线程通过缓存软件的客户get调用向服务端获取数据,每个线程完成10000次的操作,比较服务器的tps大小,以上动作通过使用不同的key取不同大小的数据,重复三次。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
memcache、redis、tair性能对比测试报告
第1章限制条件
前一周所做的分布缓存技术预言中有包括ehcache、memcache、redis、tair,还包括了基于MongoDB的分布式技术。
测试中,考虑到各自功能的差异化特点,其中选择了memcache、redis、tair功能特性相近的缓存服务器进行性能对比,所以ehcache、MongoDB将不做为本次测试的规范,其原因如下:
1)Ehcache是组件级别的缓存,要搭建一个独立的缓存服务器,需要用到ehcache server 模块,这是个war包,能运行在web 容器中,决定整个缓存服务器性能的好坏因素太多,比如web服务器,集群方式等。
跟memcache、redis、tair没有对比性。
2)MongoDB是面向文档的数据库,跟缓存没有可比性。
第2章测试场景概述
性能测试包括单机环境和分布式环境,主要针对memcache、redis、tair各缓存服务器在缓存了不同级别的数据下,多个线程并发操作向缓存set/get缓存数据,考虑到网络方面的负载,又将每次set/get操作的缓存数据的大小分为三个不同的级别:1KB,10KB,100KB,通过对上述的条件进行排列,取得以下的测试场景。
第3章单机环境测试
3.1.测试场景:
1.当各缓存的数据库空时,以单线程通过各缓存客户端set调用向服务端推送数据,比较
10000操作所消耗的时间,以上动作通过使用不同大小的单个缓存对象重复三次。
2.在场景一完成的情况下,以单线程通过各缓存客户端get调用向服务端获取数据,比较
10000操作所消耗的时间,以上动作通过使用不同大小的单个缓存对象重复三次。
3.并发200个线程通过缓存软件的客户set调用向服务端推送数据,每个线程完成10000
次的操作,比较服务器的tps大小,以上动作通过使用不同大小的单个缓存对象重复三
次。
4.并发200个线程通过缓存软件的客户get调用向服务端获取数据,每个线程完成10000
次的操作,比较服务器的tps大小,以上动作通过使用不同的key取不同大小的数据,重复三次。
3.2.测试环境
3.3.测试结果
1.当各缓存的数据库空时,以单线程通过各缓存客户端set调用向服务端推送数据,比较
10000操作所消耗的时间,以上动作通过使用不同大小的单个缓存对象重复三次。
2.在场景一完成的情况下,以单线程通过各缓存客户端get调用向服务端获取数据,比较
10000操作所消耗的时间,以上动作通过使用不同大小的单个缓存对象重复三次。
3.在场景一完成的情况下,缓存服务器有数据,并发1000个线程通过缓存软件的客户set
调用向服务端推送数据,每个线程完成10000次的操作,比较各服务器的tps大小,以上动作通过使用不同大小的单个缓存对象重复三次。
4.在场景三完成的情况下,缓存服务器有数据,并发1000个线程通过缓存软件的客户get
调用向服务端获取数据,每个线程完成10000次的操作,比较各服务器的tps大小,以上动作通过使用不同的key取不同大小的数据,重复三次。
第4章分布式环境测试
4.1.测试场景:
1.当各缓存的数据库空时,以单线程通过各缓存客户端set调用向服务端推送数据,比较
10000操作所消耗的时间,以上动作通过使用不同大小的单个缓存对象重复三次。
2.在场景一完成的情况下,以单线程通过各缓存客户端get调用向服务端获取数据,比较
10000操作所消耗的时间,以上动作通过使用不同大小的单个缓存对象重复三次。
3.在场景一完成的情况下,缓存服务器有数据,并发1000个线程通过缓存软件的客户set
调用向服务端推送数据,每个线程完成10000次的操作,比较各服务器的tps大小,以上动作通过使用不同大小的单个缓存对象重复三次。
4.在场景三完成的情况下,缓存服务器有数据,并发1000个线程通过缓存软件的客户get
调用向服务端获取数据,每个线程完成10000次的操作,比较各服务器的tps大小,以上动作通过使用不同的key取不同大小的数据,重复三次。
4.2.分布式环境
memcache
tair configserver
tair dataserver
redis
4.3.测试结果
1.当各缓存的数据库空时,以单线程通过各缓存客户端set调用向服务端推送数据,比较
10000操作所消耗的时间,以上动作通过使用不同大小的单个缓存对象重复三次。
2.在场景一完成的情况下,以单线程通过各缓存客户端get调用向服务端获取数据,比较
10000操作所消耗的时间,以上动作通过使用不同大小的单个缓存对象重复三次。
3.在场景一完成的情况下,缓存服务器有数据,并发1000个线程通过缓存软件的客户set
调用向服务端推送数据,每个线程完成10000次的操作,比较各服务器的tps大小,以上动作通过使用不同大小的单个缓存对象重复三次。
4.在场景三完成的情况下,缓存服务器有数据,并发1000个线程通过缓存软件的客户get
调用向服务端获取数据,每个线程完成10000次的操作,比较各服务器的tps大小,以上动作通过使用不同的key取不同大小的数据,重复三次。