利用SPSS 19.0剔除异常值
SPSS数据的预处理

SPSS数据的预处理SPSS是研究社会科学数据和其他统计分析领域中常用的软件之一。
在进行分析之前,我们需要进行预处理来准备我们的数据集。
数据的清理在进行数据分析之前,我们需要了解数据集中的每个变量并确保它们是正确的,并且符合我们的需要。
在数据清理过程中,我们需要进行以下操作:处理缺失值在数据集中,某些变量可能会缺乏部分值,我们需要进行缺失值处理,以便于数据的分析和处理。
填补缺失值的方法主要有以下几种:1.删除缺失值:删除含有缺失值的行或者列,但是需要注意删除的行和列如果数据量较大,可能会对后续的分析产生影响。
2.插补法:使用其他观测下的变量的平均值、中位数,众数等来填补缺失值。
在SPSS中,我们可以通过Transform->Replace Missing Values来进行缺失值的填补。
其中的缺失值可以设置被替换的数值类型,如我们可以用平均数代替缺失值,也可以用最近邻样本的替换策略等。
处理异常值当数据集中存在异常值时,需要使用删除或替换方法对其进行去除或更正。
异常值是指由于测量、数据输入或其他原因导致的不合理的数据值。
对于极端的异常数据值,删除数据可能是最好的解决方案。
在SPSS中,我们可以使用Analyze->Descriptive Statistics->Explore来寻找异常值,它会检查所有数据和变量,并给我们提供总体统计、中心趋势度量和分布度量等描述。
数据的转换在进行分析之前,我们还需要对数据进行转换来满足分析的要求。
最常见的转换包括下列几种:变量归一化某些变量或变量的值可能存在不同的测量单位,为了能够在同等条件下进行比较,需要对数据进行标准化处理。
在SPSS中,我们可以使用Transform->Recode Into Same Variables来进行数据的归一化操作。
例如,我们可以将数值变量转换为区间变量或类别变量。
变量离散化连续型数据为了进行分析常需要将其转换为类别变量。
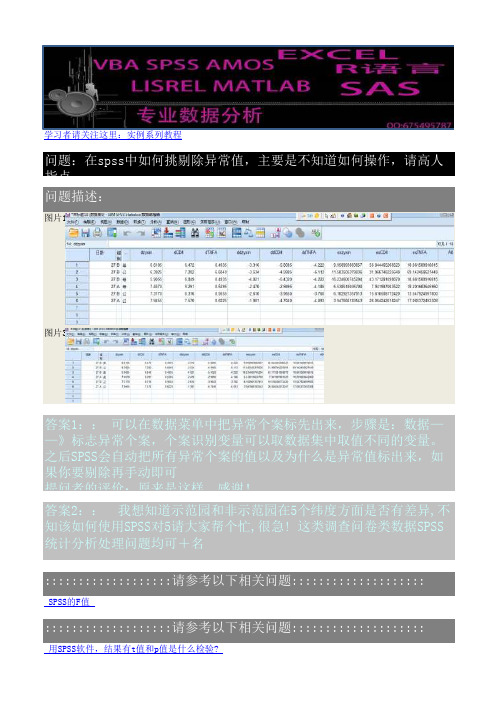
在spss中如何挑剔除异常值,主要是不知道如何操作,请高人指点
banner
学习者请关注这里:实例系列教程
问题:在spss中如何挑剔除异常值,主要是不知道如何操作,请高人指点_
问题描述:
图片1
图片3
答案1:: 可以在数据菜单中把异常个案标先出来,步骤是:数据——》标志异常个案,个案识别变量可以取数据集中取值不同的变量。
之后SPSS会自动把所有异常个案的值以及为什么是异常值标出来,如果你要剔除再手动即可
提问者的评价:原来是这样,感谢!
答案2:: 我想知道示范园和非示范园在5个纬度方面是否有差异,不知该如何使用SPSS对5请大家帮个忙,很急! 这类调查问卷类数据SPSS 统计分析处理问题均可+名:::::::::::::::::::请参考以下相关问题::::::::::::::::::::
SPSS的F值
:::::::::::::::::::请参考以下相关问题::::::::::::::::::::
用SPSS软件,结果有t值和p值是什么检验?
spss 异常值剔除 用什么方法 求助spss 中关于值标签的设置 spss数据录入时缺失值怎么处理。
如何用SPSS探测及检验异常值

异常值SS探测及检验如何用SP 一、采用数据探索过程探测异常值–>“Analyze”–>“Descriptive 菜单程序为: 主现SPSS菜单实中选>–>“Statistics”按钮–Statistics”–>“Explore……”选项个最小值作为异常5“Outliers”复选框。
输出结果中将列出5个最大值和的嫌疑值。
)探测异常值二、采用箱线图(boxplot箱线图比较直观、形象,易于理解,因此它在统计分析中占有非常重要的地位。
利用上述的数据探测过程,在“Explore”对话框中单击“Plots”,出1.通过“Boxplots”方框可以确定箱线图的生成方式。
现如图2所示的对话框,“Factor levels together”复选框表示将要为每个因变量创建一个箱线图,“Dependent together”复选框表示将为每个分组变量水平创建箱线图,“None”复选框表示不创建箱线图。
一种给出了两种箱线图,SPSS2. 直接利用SPSS中的画图功能实现箱线图,点:是基本箱线图,另一种是交互式箱线图。
基本箱线图的SPSS菜单实现为击主菜单中的“Graphs”选项,在弹出的一级菜单中选择“Boxplot……”点击主菜单中的“Graphs”选项,SPSS菜单实现为:选项。
交互式箱形图的在弹出的一级菜单中点击“Interactive”选项,在弹出的二级菜单中选择公司雇员分工种的开始工资为例构造基“Boxplot……”选项。
下面仍以A。
箱线图中的“○”表示可疑的异常值,此处异常值的确3)(本箱线图如图百分位点上25百分位点和75变量值超过第:,即定采用的是“五数概括法”百分位点上变75百分位点和25变量值之差的倍(箱体上方)或变量值小于第的点对应的值。
箱体下方)量值之差的倍( 。
:???如何设置。
后的新功能 Data –> Validation三、SPSS 14法):±3δ以外的数据为高度异常值,应予剔除。
利用SPSS 19.0剔除异常值
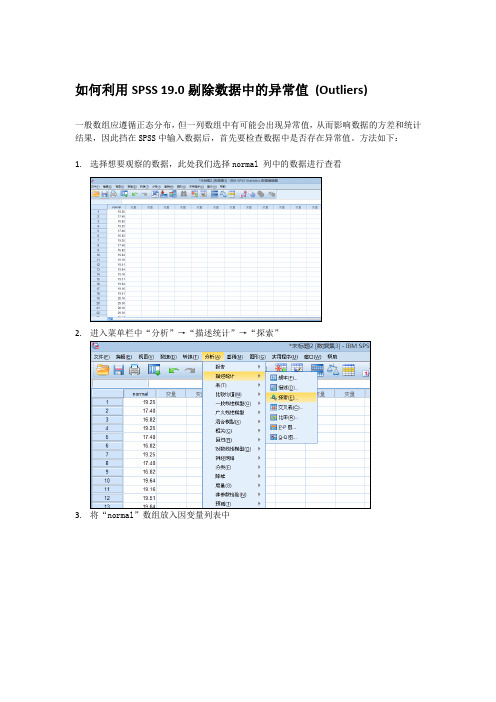
如何利用SPSS 19.0剔除数据中的异常值(Outliers)一般数组应遵循正态分布,但一列数组中有可能会出现异常值,从而影响数据的方差和统计结果,因此挡在SPSS中输入数据后,首先要检查数据中是否存在异常值。
方法如下:1.选择想要观察的数据,此处我们选择normal 列中的数据进行查看2.3.将“normal”数组放入因变量列表中4.点击“探索”窗口中的“统计量”,点掉“描述性”,选择“界外值”和“百分位数”5.点击“探索”窗口中“绘制”,选择“直方图”,去掉“茎叶图”6.选择结束后点击“探索”窗口“确定”查看结果:(1)百分位数图:(2)以50%左右两个百分位数(即四分位数25和75下方的加权平均值)的加权平均值计算最高和最低临界值,使用计算公式如下:Upper=Q3+(2.2*(Q3-Q1))Lower=Q1-(2.2*(Q3-Q1))此处Q3=26.0281, Q1=17.8396计算后,Upper=44.0428,Lower=-0.1751(3)查看“极值”表格:极值案例号值normal最高12029.3022229.3032429.3044629.3054729.30a最低18116.8227816.8237516.8245716.8255416.82ba. 上限值表中仅显示一部分具有值 29.30 的案例。
b. 下限值表中仅显示一部分具有值 16.82 的案例。
如果有最高值查过Upper,或最低值小于Lower值,则被视为Outliers, 即异常值。
由图中看,此列数组并无异常值(注:专业文档是经验性极强的领域,无法思考和涵盖全面,素材和资料部分来自网络,供参考。
可复制、编制,期待你的好评与关注)。
利用SPSS进行数据处理和分析的技巧

利用SPSS进行数据处理和分析的技巧数据是一个有用的工具,它可以帮助我们了解问题并做出更好的决策。
然而,对于大多数人来说,数据处理和分析可能会让人望而却步。
幸运的是,有一些工具可以帮助我们更轻松地处理和分析数据,其中最常用的工具之一是SPSS。
SPSS是一个广泛用于数据分析的软件包,可以轻松地进行描述性统计、假设检验、回归分析、因子分析和聚类分析等等。
在本文中,我们将探讨利用SPSS进行数据处理和分析的一些技巧。
第一步:数据的输入和清理在使用SPSS进行数据分析之前,首先需要将数据输入到SPSS 中。
数据可以来自Excel或其他电子表格程序,也可以手动输入。
在输入数据时,要注意数据类型,例如文本、数字和日期等。
要确保数据以正确的格式输入,以便进行后续的分析。
一旦数据已经输入到SPSS中,接下来需要对数据进行清理。
数据清理的目的是修复数据中的错误或缺失值,以确保数据的质量和正确性。
SPSS提供了一些工具来帮助用户对数据进行清理。
例如,可以使用SPSS Data Editor中的查找替换功能,通过查找敏感字词或错误数据,减少数据清理的负担。
SPSS还提供了插件程序,如Validate命令、Codebook等等,它们可以在清洗数据方面提供有用的支持。
第二步:描述性统计分析描述性统计分析可以帮助我们了解数据集的基本特征,例如中位数、众数、平均数、标准差和范围等等。
在SPSS中,进行描述性统计分析非常简单。
首先,选择“Analyze”菜单中的“Descriptive Statistics”选项,然后选择要分析的变量。
SPSS将生成一个报告,其中包含描述性统计信息。
在生成描述性统计报告之后,可以将其保存在SPSS的输出窗口中,以便之后参考。
此外,还可以使用SPSS的导入导出功能将描述性统计结果导出到其他程序中,例如Word或Excel。
第三步:假设检验假设检验可以帮助我们确定实际观察结果与预期结果之间是否存在显著差异。
spssau异常值处理

异常值,也称离群值,是指样本中的个别值,其数值明显偏离所属样本的绝大部分观测值。
不论什么研究数据,如果数据中存在可能的异常值,均应在分析之前处理,防止异常值带来的干扰,比如异常值会扭曲X和Y之间的相关关系,回归关系等,异常错误的结论;当然其它研究方法基本均会受到异常值的干扰,异常值较多或者异常稍大时,此时会直接扭曲结论。
通常异常值出现的原因有以下几种:1.数据收集过程出现问题,录入错误2.数据测量误差(人为、测量仪器)3.数据随机误差(数据自身)异常值处理步骤针对异常值,常见的步骤有三步:第一步是异常值检测;第二步是异常值判定;第三步是异常值处理。
第一步:异常值检测异常值的检验有很多种方法,最常见的是图示法,也有使用分析方法进行探索,如下说明。
箱盒图:实验研究时经常使用,非常直观的展示出异常数据;散点图:研究X和Y的关系时,可直观展示查看是否有异常数据;描述分析:可通过最大最小值等各类指标大致判断数据是否有异常;其它:比如结合正态分布图,频数分析等判断是否有异常值。
第二步:异常值判定上述已经说明异常值会带来严重的影响,扭曲数据结论等。
那么首先需要设定异常值的标准,然后再对其进行处理。
异常值的判定标准并不统一,更多是通过人为标准进行设定,SPSSAU提供以下几类判定规则缺失数字小于设定标准的数字大于设定标准的数字大于3个标准差图片来源:SPSSAU“异常值介绍”帮助手册第三步:异常值处理完成异常值的判定之后,接着需要进行处理;SPSSAU提供两类处理方式,分别为:1、设置为Null值;此类处理最简单,而且绝大多数情况下均使用此类处理;直接将异常值“干掉”,相当于没有该异常值。
如果异常值不多时建议使用此类方法;2、填补;如果异常值非常多时,则可能需要进行填补设置,SPSSAU共提供平均值,中位数,众数和随机数共四种填补方式。
建议使用平均值填补方式。
平均值填补:将不满足判断标准外(即正常数据)数据取平均值,对异常数据填补;中位数填补:将不满足判断标准外(即正常数据)数据取中位数,对异常数据填补;众数填补:将不满足判断标准外(即正常数据)数据取众数,对异常数据填补;随机数填补:将不满足判断标准外(即正常数据)数据取随机数(最小和最大值之间),对异常数据填补;异常值设置注意事项:首先需要选中处理的标题,请谨慎操作,一旦操作无法还原数据;异常值是针对原始数据进行修改;无法还原,建议处理之前先进行“备份数据”,防止处理出错时无法还原。
利用SPSS 190剔除异常值
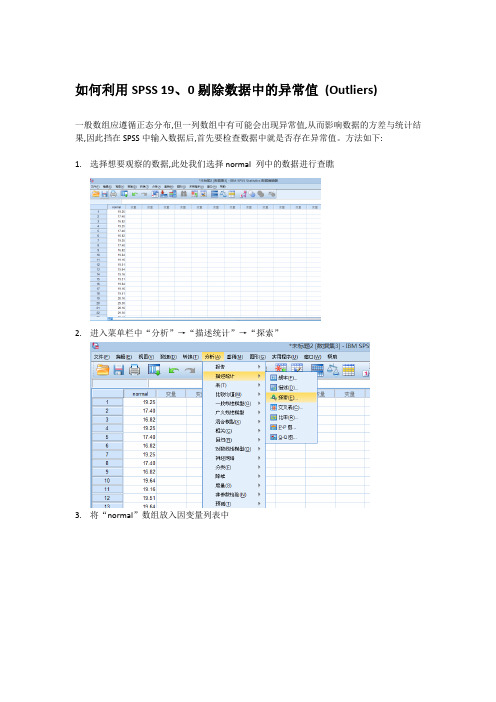
如何利用SPSS 19、0剔除数据中的异常值(Outliers)一般数组应遵循正态分布,但一列数组中有可能会出现异常值,从而影响数据的方差与统计结果,因此挡在SPSS中输入数据后,首先要检查数据中就是否存在异常值。
方法如下:1.选择想要观察的数据,此处我们选择normal 列中的数据进行查瞧2.进入菜单栏中“分析”→“描述统计”→“探索”3.将“normal”数组放入因变量列表中4.点击“探索”窗口中的“统计量”,点掉“描述性”,选择“界外值”与“百分位数”5.点击“探索”窗口中“绘制”,选择“直方图”,去掉“茎叶图”6.选择结束后点击“探索”窗口“确定”查瞧结果:(1)百分位数图:(2)以50%左右两个百分位数(即四分位数25与75下方的加权平均值)的加权平均值计算最高与最低临界值,使用计算公式如下:Upper=Q3+(2、2*(Q3-Q1))Lower=Q1-(2、2*(Q3-Q1))此处Q3=26、0281, Q1=17、8396计算后,Upper=44、0428,Lower=-0、1751(3)查瞧“极值”表格:极值案例号值normal 最高 1 20 29、302 22 29、303 24 29、304 46 29、305 47 29、30a最低 1 81 16、822 78 16、823 75 16、824 57 16、825 54 16、82ba、上限值表中仅显示一部分具有值 29、30 的案例。
b、下限值表中仅显示一部分具有值 16、82 的案例。
如果有最高值查过Upper,或最低值小于Lower值,则被视为Outliers, 即异常值。
由图中瞧,此列数组并无异常值。
全自动发光免疫定量分析项目室内质量控制靶值确定方法的比较

全自动发光免疫定量分析项目室内质量控制靶值确定方法的比较程实;王涛;张亮;陆军;张雅莹;安成【摘要】目的:比较全自动发光免疫定量分析项目确立室内质量控制靶值的不同方法,评估该实验室内简易方法的可行性。
方法收集2016年1月1日至2016年3月31日,中国中医科学院广安门医院检验科免疫室全自动免疫发光分析仪上22个检测项目的质控数据,模拟2种方法(传统方法、简易方法)确定室内质量控制的暂定靶值。
比较2种方法确立暂定靶值的差异。
同时按照即刻法累积靶值与传统方法进行比较。
结果除 E2(40862)、FPSA、2GTesto (40881/2)、TT3(40861/2,40881)以及 FT4(40881)外,其他项目经2种方法所得均值差异无统计学意义(P>0.05)。
Levey‐Jennings质控图对失控的检出能力差异无统计学意义(P>0.05)。
即刻法相对于传统方法,易造成结果假在控或假失控。
结论在该实验室内,应用简易方法确定室内质量控制暂定靶值能够代替传统方法确定的暂定靶值,满足临床需求,保证室内质控的正常进行,缩短靶值累积时间,降低成本,并且可以避免即刻法造成的假失控或假在控现象。
%Objective To compare the different methods of determining the target value of the internal quality control (IQC) and evaluate the feasibility of the simple method in our laboratory .Methods The quality control data of the 22 items on siemens IM‐MULITE 2000 ,Abbott ARCHITECT I2000 ,Roche Cobas E601 in our laboratory ,during January 1 ,2016 to March 31 ,2016 .We simulated two methods(traditional method and simple method) to establish the provisional target value of IQC with these data .The differences between the two methods were compared .At the sametime ,the data was processed with instant technique quality con‐trol ,and then compared with the traditional methods .Results The mean values of the simple method and the traditional method hadnostatisticaldifference(P> 0.05),inadditiontoE2(40862),FPSA,2GTesto(40881/2),TT3(40861/2,40881)an dFT4 (40881)outside .And there was no significant difference in monitoring the warming points and the out of control points in the Levey‐Jennings quality control chart between the two methods (P<0 .05) .Compared with the traditional method ,the instant tech‐nique quality control was easy to cause false results in control or false out of control .Conclusion In our laboratory ,the simple method could replace traditional method with a stable detection system .It can meet the clinical needs ,ensure the normal operation of IQC ,shorten the time of establishing a target value .And the simple method can avoid the false in control and out of control ,com‐pared with the instant technique quality control .【期刊名称】《检验医学与临床》【年(卷),期】2017(014)002【总页数】4页(P211-214)【关键词】免疫定量分析;室内质量控制;暂定靶值【作者】程实;王涛;张亮;陆军;张雅莹;安成【作者单位】中国中医科学院广安门医院检验科,北京100053;中国中医科学院广安门医院检验科,北京100053;中国中医科学院广安门医院检验科,北京100053;中国中医科学院广安门医院检验科,北京100053;中国中医科学院广安门医院检验科,北京100053;中国中医科学院广安门医院检验科,北京100053【正文语种】中文室内质量控制是为临床提供可重复性试验结果的重要监测手段,是临床诊断、疗效评价和疾病进展评估的重要质量保障。
SPSS回归前如何批量删除异常值
有五存”选下图SP SPSS 回归具体做法,五个菜单选项选项里面,请之后在你的
图最右边这列PSS 如归分析,要求就是利用SP 项,其中有个请把“异常指标的数据中你会
列,它说明的如何删除剔除异常值,PSS 的“数据“变量”,你标”勾选。
会看到有新的
是你的样本变除异常,比例或数量据——标识异你可以把你认内容加入,就
变异的程度—常值?
量可以自行设异常个案”,认为可能出现就是“Anomaly
——我这么理设定。
在标识异常现异常值的变量yIndex”,(我理解的)
常个案对话框量都选入,
我叫它变异指框中,在“保
指数,
(降例是即可 此时,你可
降序排列)—排完序,你是样本的2%—
可。
最后,利可以将你的S ——SPSS “数你该知道怎么做——共218个
利用删除后异PSS 数据(数据”里面有做了吧?就是个,那么将刚
异常值后的样本(添加了变异有排序,也可是将你界定的刚才排序的结
本重新分析即指数的)按该可以另存为e 的异常值删除结果中,最前即可。
该新指标的值excel 表格来除。
比如,我前面的218
个值由大到小排来排序。
我设定的异常个记录,
直接排序常值比
接删除。
剔除异常值的方法

剔除异常值的方法剔除异常值是指在数据分析中,对于偏离正常范围的极端数据进行处理或排除的方法。
异常值可能是由于测量或记录错误、无效数据、异常事件等原因导致的,如果将异常值包括在分析中,可能会对结果产生显著的偏差。
因此,剔除异常值是很重要的数据预处理步骤,下面是常用的剔除异常值的方法:1.标准差法:标准差是描述数据集合离散程度的统计量,如果一些数据点与平均值的偏离程度超过了一定的标准差范围,可以判定为异常值。
根据经验,在正态分布的情况下,采用平均值加减3倍标准差的范围内的数据是比较典型的数据集合。
2.箱线图法:箱线图是一种常用的异常值检测方法,它能够直观地显示数据的分组情况及异常值。
箱线图通过绘制数据集的上四分位数(Q3), 下四分位数(Q1)和中位数(Median)以及上下边界,可以看出数据中是否存在异常值。
根据箱线图,异常值被定义为小于Q1-1.5IQR或大于Q3+1.5IQR的数据点,其中IQR指的是四分位距。
3.3σ原则:3σ原则是指在正态分布的情况下,大约99.73%的数据位于平均值加减3倍标准差的范围之内。
因此,可以根据3σ原则剔除超出平均值加减3倍标准差范围之外的数据点。
4.多元异常值检测:多元异常值检测是指通过多个变量之间的关系检测异常值。
常用的方法有杠杆性和学生化残差。
杠杆性指的是一个数据点对回归结果的影响程度,可以使用杠杆值来判定异常值。
学生化残差是指将残差标准化后的值,可以通过学生化残差的阈值来检测异常值。
5.离群点分数法:离群点分数法是一种基于分位数的异常值检测方法,通过计算数据点相对于其他数据点的离散程度来评估异常值。
常用的离群点分数包括Z-Score、箱线图的方法以及帕累托法则。
6.局部离群点因子法:局部离群点因子(Local Outlier Factor, LOF)是一种基于密度的异常值检测方法。
LOF通过计算每个数据点相对于其邻居数据点的离散程度来评估异常值。
LOF值越大,表示越可能是异常值。
SPSS异常值剔除

倍框的长度之间的离群值(箱图/探索)3.值与框的上下边界的距离在倍框的长度到个案。
框的长度是内距。
3倍框的长度的个案。
值距离框的上下边界超过极端值(箱图).,残差有几种表示方法一般称预测值与实际值的偏差为:标准化残差在回归模型诊断里面,残差, 学生化残差等等,按照需要取一种残差,再按照某种标准取一个阀值来限定异常点,只要那个点的残差大于阀值,就可以认为它是异常点。
data下拉菜单里有define variable properties,把变量选到右边的框里,点continue,在新窗口中有变量在样本中的所有取值,要定义某个值是异常值,就把相应的missing框勾上就ok啦~~~然后再处理数据时这些值就已经被剔除,不参与分析了一、采用数据探索过程探测异常值SPSS菜单实现程序为: 主菜单-->“Analyze”-->“Descriptive Statistics”-->“Explore……”选项-->“Statistics”按钮-->选中“Outliers”复选框。
输出结果中将列出5个最大值和5个最小值作为异常的嫌疑值。
一般数组应遵循正态分布,但一列数组中有可能会出现异常值,从而影响数据的方差和统计结果,因此挡在SPSS中输入数据后,首先要检查数据中是否存在异常值。
方法如下:1.选择想要观察的数据,此处我们选择normal 列中的数据进行查看进入菜单栏中“分析”→“描述统计”→“探索”2.3.将“normal”数组放入因变量列表中4.点击“探索”窗口中的“统计量”,点掉“描述性”,选择“界外值”和“百分位数”,去掉“茎叶图”,选择“直方图”点击“探索”窗口中“绘制”5.选择结束后点击“探索”窗口“确定”查看结果:6.百分位数图:(1)百分位数百分位数9590251057550加权平均(定义)1normal的枢纽Tukey normal(2)以50%左右两个百分位数(即四分位数25和75下方的加权平均值)的加权平均值计算最高和最低临界值,使用计算公式如下:Upper=Q3+*(Q3-Q1))Lower=Q1-*(Q3-Q1))此处Q3=, Q1=计算后,Upper=,Lower=(3)查看“极值”表格:极值值案例号.最高normal201222243464475最低181278375457554a. 上限值表中仅显示一部分具有值的案例。
异常数据4种剔除方法

异常数据4种剔除方法异常数据是指与其他数据不一致或不符合预期的数据。
在数据分析和建模过程中,异常数据可能会影响统计结果和模型的准确性。
因此,为了保证分析结果的可靠性,通常需要对异常数据进行剔除或修正。
以下是常见的四种剔除异常数据的方法。
1.箱线图检测异常值箱线图是一种常用的异常值检测方法,它以数据的分位数为基础,通过上下四分位距来判断数据是否异常。
根据箱线图,我们可以判断出数据中的异常值,并将其剔除。
首先,绘制箱线图以可视化数据的分布情况。
箱线图由一个箱体和两条触须组成。
箱体表示数据的四分位数范围,上触须和下触须分别表示上四分位数和下四分位数与最大非异常值和最小非异常值之间的距离。
根据箱线图,我们可以识别出在上下触须之外的数据点,这些点通常是异常值。
然后,我们可以将这些异常值从数据集中剔除,以保证后续分析的准确性。
2.3σ原则剔除异常值3σ原则是一种基于数据的均值和标准差的统计方法,用于判断数据是否异常。
在正态分布下,大约68%的数据位于均值的±1σ范围内,95%的数据位于均值的±2σ范围内,99.7%的数据位于均值的±3σ范围内。
因此,我们可以基于3σ原则来识别并剔除数据中的异常值。
首先,计算数据的均值和标准差。
然后,根据3σ原则,识别出超出3倍标准差范围之外的数据点,并将其从数据集中剔除。
3.离群点检测算法剔除异常值离群点检测算法是一种自动化的异常值识别方法。
常用的离群点检测算法包括聚类算法(如K-means算法)、孤立森林算法、LOF(局部异常因子)算法等。
这些算法可以根据数据的特征属性来识别出异常值,并将其从数据集中剔除。
4.领域知识和业务规则剔除异常值除了基于统计和算法的方法,领域知识和业务规则同样可以用于剔除异常值。
领域专家通常对数据的特点和业务规则有深入的了解,可以根据经验判断数据是否异常。
比如,在一些业务场景下,根据实际情况设定阈值,超出阈值的数据可以被视为异常并剔除。
样本数据中异常值(Outliers)检测方法及SPSSR实现

样本数据中异常值(Outliers)检测⽅法及SPSSR实现⼀、概述异常值检验,⼜称为离群点分析或者孤⽴点挖掘。
在⼈们对数据进⾏分析处理的过程中,经常会遇到少量这样的数据,它们与数据⼀般模式不⼀致,或者说与⼤多数样相⽐有些不⼀样,我们称这样的数据为异常数据。
异常数据挖掘涉及两个基本问题。
其⼀,在对⼀个给定的数据集分析之前必须事先约定满⾜什么样的数据才是异常数据,也就是异常数据定义的问题。
其⼆,⽤什么⽅法来从给定的数据集中将异常数据提取出来。
⼆、异常数据的定义关于异常值的问题,最早可以追溯到 18 世纪中叶,当时很多学者就开始关注异常值的问题了。
1755 年,Boscovich 在确定地球椭圆率的时候,在所得到的10 个观测值中丢弃了其中的两个极端值,然后再计算剩下的 8 个观测值的平均值。
⽽最早有关异常值的定义,是 Bernoulli 于1777 年⾸先提出的,之后它的定义在⼀直变化,Hawkins 认为异常值是那些数据集中与众不同的数据,让⼈怀疑这些数据并⾮由于随机偏差产⽣的,⽽是产⽣于完全不同的机制,这在⼀定意义上揭⽰了异常值的本质;⽽ Weisberg 将异常值定义为那些与数据集中其余部分不服从相同统计模型的数据,这个定义更符合统计检验的异常数据描述;Samuels将异常值定义为“⾜够地不同于数据集中其余部分的数据”;Grubbs 将异常值定异常数据是少量的、与众不同的,与⼤多数数据相⽐是有偏差的,⽽且产⽣这种偏差的原因不是随机的,⽽是有其更深层次的必然原因,它产⽣于完全不同的机制。
张德然在吸收归纳前⼈的研究基础上,将异常值从内涵上分为⼴义异常值和狭义异常值。
⼴义异常值是指:所获统计数据与真实数据相对误差较⼤的数据,统指⼀切失真数据;狭义异常值是指:所获统计数据中部分数据与其余主体数据相⽐明显不⼀致的数据,也称离群值。
为了从数据集中识别异常数据,就必须有⼀个明确的标准。
这需要找到数据的内在规律,在⼀个可接受的误差范围内,满⾜内在规律的数据就是正常数据,⽽不满⾜内在规律的数据就是异常数据。
剔除异常值的方法

1.拉依达准则法(3δ):简单,无需查表。
测量次数较多或要求不高时用。
是最常用的异常值判定与剔除准则。
但当测量次数《=10次时,该准则失效。
如果实验数据值的总体x是服从正态分布的,则式中,μ与σ分别表示正态总体的数学期望和标准差。
此时,在实验数据值中出现大于μ+3σ或小于μ—3σ数据值的概率是很小的。
因此,根据上式对于大于μ+3σ或小于μ—3σ的实验数据值作为异常值,予以剔除。
在这种情况下,异常值是指一组测定值中与平均值的偏差超过两倍标准差的测定值。
与平均值的偏差超过三倍标准差的测定值,称为高度异常的异常值。
在处理数据时,应剔除高度异常的异常值。
异常值是否剔除,视具体情况而定。
在统计检验时,指定为检出异常值的显著性水平α=0.05,称为检出水平;指定为检出高度异常的异常值的显著性水平α=0.01,称为舍弃水平,又称剔除水平(reject level)。
标准化数值(Z-score)可用来帮助识别异常值。
Z分数标准化后的数据服从正态分布。
因此,应用Z分数可识别异常值。
我们建议将Z分数低于-3或高于3的数据看成是异常值。
这些数据的准确性要复查,以决定它是否属于该数据集。
2.肖维勒准则法(Chauvenet):经典方法,改善了拉依达准则,过去应用较多,但它没有固定的概率意义,特别是当测量数据值n无穷大时失效。
3.狄克逊准则法(Dixon):对数据值中只存在一个异常值时,效果良好。
担当异常值不止一个且出现在同侧时,检验效果不好。
尤其同侧的异常值较接近时效果更差,易遭受到屏蔽效应。
4.罗马诺夫斯基(t检验)准则法:计算较为复杂。
5.格拉布斯准则法(Grubbs):和狄克逊法均给出了严格的结果,但存在狄克逊法同样的缺陷。
朱宏等人采用数据值的中位数取代平均值,改进得到了更为稳健的处理方法。
有效消除了同侧异常值的屏蔽效应。
国际上常推荐采用格拉布斯准则法。
这些方法,都有各自的特点,例如,拉依达准则不能检验样本量较小(显著性水平为0.1时,n必须大于10)的情况,格拉布斯准则则可以检验较少的数据。
SPSS缺失值分析

SPSS缺失值分析缺失值是指数据集中的一些变量或观察值缺少了数据。
在实际的数据分析中,经常会遇到缺失值的问题,如果不对缺失值进行合理的处理,可能会导致结果的不准确甚至错误。
在SPSS中,可以使用不同的方法来处理缺失值,包括删除缺失值、替代缺失值和模型估计。
下面将详细介绍这些方法。
首先,最简单的方法是删除缺失值。
如果数据集中的一些变量存在缺失值,可以选择删除包含缺失值的观察。
删除缺失值的方法有列表删除和配对删除两种。
列表删除是指将含有缺失值的观察删除,而配对删除是指将含有缺失值的变量对应的所有观察删除。
这种方法的优点是简单易行,但缺点是可能丢失大量的有效信息,并且可能会导致样本偏差。
另一种常见的处理缺失值的方法是替代缺失值。
替代缺失值的方法包括均值替代、中位数替代、众数替代和最近邻替代等。
均值替代是将缺失值替换为该变量的平均值,中位数替代是将缺失值替换为该变量的中位数,众数替代是将缺失值替换为该变量的众数,最近邻替代是将缺失值替换为数据集中与其最相似的观察值的取值。
替代缺失值的方法可以保持样本量不变,但可能会引入估计偏差。
最后,还可以使用模型估计的方法来处理缺失值。
模型估计是指利用已有的观察值的关系来推断缺失值。
在SPSS中,可以使用EM算法、多重插补等方法进行模型估计。
EM算法是一种通过迭代来估计缺失值的方法,它通过假设每个变量都符合其中一种分布,然后根据已有数据来估计缺失值。
多重插补是指根据已有的数据生成多个完整数据集,然后分析每个完整数据集的结果,最后对多个结果进行合并得到最终结果。
模型估计的方法可以提供更准确的估计,但也比较复杂,需要一定的统计知识。
综上所述,SPSS提供了多种处理缺失值的方法,包括删除缺失值、替代缺失值和模型估计。
根据具体的研究问题和数据特点,选择合适的缺失值处理方法非常重要,可以提高数据分析的准确性和可靠性。
(最新整理)SPSS中异常值检验的几种方法介绍

(完整)SPSS中异常值检验的几种方法介绍编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望((完整)SPSS中异常值检验的几种方法介绍)的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为(完整)SPSS中异常值检验的几种方法介绍的全部内容。
SPSS中异常值检验的几种方法介绍方法具体如下所示:离群值(箱图/探索)。
值与框的上下边界的距离在1.5倍框的长度到3倍框的长度之间的个案。
框的长度是内距.极端值(箱图).值距离框的上下边界超过3倍框的长度的个案。
框的长度是内距在回归模型诊断里面,一般称预测值与实际值的偏差为”残差”,残差有几种表示方法:标准化残差,学生化残差等等,按照需要取一种残差,再按照某种标准取一个阀值来限定异常点,只要那个点的残差大于阀值,就可以认为它是异常点。
SPSS14之后新功能SPSS Data Validation能帮助您轻松地探察多个异常值,以便您可以进一步检验并确定是否把这些观测包括在您的分析中。
SPSS Data Validation异常探察程序能够基于与数据集中相似观测的偏离探察异常值,并给出偏离的原因.它使您可以通过创建新变量来标识异常值.标签:市场研究研究方法经营分析分类:经营分析 2009-11-24 18:59这段时间太忙了,一直没有静下心来。
积攒了几个朋友的问题,现在来回答或介绍一些,今天先谈谈时间序列(Time-Series Forecasting)的预测问题!预测:是对尚未发生或目前还不明确的事物进行预先的估计和推测,是在现时对事物将要发生的结果进行探讨和研究,简单地说就是指从已知事件测定未知事件.为什么要预测呢,因为预测可以帮助了解事物发展的未来状况后,人们可以在目前为它的到来做好准备,通过预测可以了解目前的决策所可能带来的后果,并通过对后果的分析来确定目前的决策,力争使目前的决策获得最佳的未来结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
如何利用SPSS 19.0剔除数据中的异常值(Outliers)
一般数组应遵循正态分布,但一列数组中有可能会出现异常值,从而影响数据的方差和统计结果,因此挡在SPSS中输入数据后,首先要检查数据中是否存在异常值。
方法如下:
1.选择想要观察的数据,此处我们选择normal 列中的数据进行查看
2.进入菜单栏中“分析”→“描述统计”→“探索”
3.将“normal”数组放入因变量列表中
4.点击“探索”窗口中的“统计量”,点掉“描述性”,选择“界外值”和“百分位数”
5.点击“探索”窗口中“绘制”,选择“直方图”,去掉“茎叶图”
6.选择结束后点击“探索”窗口“确定”查看结果:
(1)百分位数图:
(2)以50%左右两个百分位数(即四分位数25和75下方的加权平均值)的加权平均值计算最高和最低临界值,使用计算公式如下:
Upper=Q3+(2.2*(Q3-Q1))
Lower=Q1-(2.2*(Q3-Q1))
此处Q3=26.0281, Q1=17.8396
计算后,Upper=44.0428,Lower=-0.1751
(3)查看“极值”表格:
极值
案例号值
normal 最高 1 20 29.30
2 22 29.30
3 2
4 29.30
4 46 29.30
5 47 29.30a
最低 1 81 16.82
2 78 16.82
3 75 16.82
4 57 16.82
5 54 16.82b
a. 上限值表中仅显示一部分具有值 29.30 的案例。
b. 下限值表中仅显示一部分具有值 16.82 的案例。
如果有最高值查过Upper,或最低值小于Lower值,则被视为Outliers, 即异常值。
由图中看,此列数组并无异常值。