在UltraEdit使用技巧及其中的正则表达式
UltraEdit 中替换部分字符串的正则表达式

UltraEdit 中替换部分字符串的正则表达式UltraEdit 中替换部分字符串的正则表达式 <CITE </CITE>替换为目标串:bcscpy(_resdetail.accno,FmRechk->txtAccount->Text);在UE中可以以下面的方式替换:FIND:strcpy^(*^)Text.c_str()REPLACE:bcscpy^1Text说明:^(*^)表示取strcpy之后Text之前的内容,结果存在^1中。
这样就可以将希望保留的内容存下来,而将其他内容替换掉。
example 2:原字符串:split(o_num, rulestr, is_any_of(valid_delim));要替换成:o_num = split(rulestr, valid_delim);UE替换的正则表达式为:对于UNIX 样式正则表达式如何编写可以查看相关文档,在此列出帮助参考:表1.常用的特殊代码代码/语法说明. 匹配除换行符以外的任意字符\w 匹配字母或数字\s 匹配任意的空白符\d 匹配数字\b 匹配单词的开始或结束^ 匹配字符串的开始$ 匹配字符串的结束表2.常用的量词代码/语法说明* 重复零次或更多次+ 重复一次或更多次? 重复零次或一次{n} 重复n次{n,} 重复n次或更多次{n,m} 重复n到m次表3.常用的反义代码代码/语法说明\W 匹配任意不是字母和数字的字符\S 匹配任意不是空白符的字符\D 匹配任意非数字的字符\B 匹配不是单词开头或结束的位置[^x] 匹配除了x以外的任意字符[^aeiou] 匹配除了aeiou这几个字母以外的任意字符案例:某文件中有相当多"/1231,60983.html" 形式的链接,需要将该形式中的news1改为news2,其它形式的不去改变。
替换方法:在UltraEdit“搜索”菜单中选择“替换”,勾选上“正则表达式”,在“查找”输入框中输入 /(\d+),(\d+).html在“替换”输入框中输入 /\1,\2.html 点“全部替换”即可对文档中所有此形式的字串全部替换。
UltraEditor使用正则表达式

常用删除空行:替换%[^t]++^p为空串删除行尾空格:替换[^t]+$为空串删除行首空格:替换%[^t]+为空串每行设置为固定的4个空格开头:替换%[^t]++^([~^t^p]^)为"^1"每段设置为固定的4个空格开头:替换%[^t]+为""(如果一行是以空格开始的,则视之为一段的开始行)将一段合并为一行:替换[^t]++^p^([~^t^p]^)为^1(注意:此处假定文本是以DOS方式回车换行-CR/LF)去掉HTMLTAG:替换^{<*>^}^{<*^p*>^}为空串删除HTML中的所有:替换<[]++a*[]++href[]++=*>为空串删除文本中指定的前2列字符:替换%??为空串在第4列后插入2列空白字符:替换%^(????^)^(?^)为"^1^2"查找所有的数字:[0-9]+[.]++[0-9]+查找所有的单词:[a-z]+查找所有的网址:http://[a-z0-9^~`_./^-^?=&]+注意:替换的时候需要勾选使用正则表达式选项基础很多朋友都用过或者正在用UltraEdit,这个编辑器陪伴我也好几年了,从很多地方影响着我写代码的快捷键习惯,Ul traedit提供了非常丰富的编辑功能,其中非常重要的查找和替换功能一定大家都用过,Ultraedit提供的查找替换功能非常方便和强大,可以在单独文件里面查找替换,也可以在多个文件、多个目录里面进行查找替换。
而我们在使用这些查找替换功能的时候,一般都是针对某个字符串进行,前两天我要对一个目录下(包含子目录)所有的html文件中某一段代码进行查找替换,一下子不知道怎么操作了,由于长期写程序用到正则表达式,于是猜想具备如此强大功能的Ultraedit一定也有这样类似的匹配功能,于是点击Help一看,果然不出所料,Ultraedit支持基本的正则表达式匹配查找和替换功能,这能满足我们几乎全部的需要了。
(完整word版)UltraEdit使用小技巧

UltraEdit使用技巧UltraEdit 是每天必用的工具之一.但想想看,实际使用到的功能只是这个工具强大功能的极小的一部分.灵活使用这个工具有的时候能起到事半功倍的效果.记录并收集一些小技巧对自己对别人都有帮助.因为我在使用"列编辑”这样的编辑方式还令我的一个同事看到之后很惊讶,之前他从来不知道有这个用法.这也是写这个备忘文档的目的之一.Tip 1: Alt+C 列模式可以说最初选择使用这个文本编辑软件,原因很简单,就是因为“她"具有列编辑模式。
如果您还不知道什么是列编辑模式的话,我想您应该好好研究一下啦。
这是一个超级“赞”的功能.在对大文本进行批量的列编辑时候非她莫属(如果您是Windows平台上另外一个强大的文本编辑软件gVim 的使用者除外).快实验一下这个功能吧。
Tip 2:Ctrl+W 切换自动换行这个快捷键您用过么?您一定有过查看一行文字超级长,不得不拖动下面的滚动条进行阅读的时候,这样非常的不符合我们的阅读习惯。
这时Ctrl+W快捷键就派上用场啦.切换回原模式方法:再一次键击Ctrl+WTip 3:Ctrl+F2 切换书签我个人认为这个功能很人性,在您想要在某一行做标记以便快速定位这一行的时候很实用。
如您想要反复定位之前书写的一个表的创建语句时等等。
我在这里强烈推荐的是另外一个使用技巧:在您使用Ctrl+F进行查找,在查找界面中选中“列出包含字符串的行",在“查找内容”框中输入关键字,如“create table”,点击“查找下一个”,这时您看到是“行包含查找字符串”对话框,点击一下“全部书签标记”后看看效果,是不是很激动人心(尤其是在包含大量建表语句的文本中操作时)?所有包含“create table"的行都标记了书签。
这里您有要问啦,那我这么向上和向下查看书签标记呢?不要着急,您试试F2和Alt+F2,F2是查看下一个书签标记,Alt+F2是查看上一个书签标记。
ultraedit正则表达式

UltraEdit是一款功能强大的文本编辑器,它支持正则表达式的使用。
以下是一些常用的UltraEdit正则表达式的示例:
查找和替换:
查找匹配的字符串:在查找框中输入正则表达式,例如\d+ 可以匹配一个或多个数字。
替换文本:在替换框中使用正则表达式来匹配和替换文本。
行操作:
删除空白行:使用正则表达式\s*^$\s* 来匹配空白行,并删除它们。
去除行尾空格:使用正则表达式\s+$ 来匹配行尾的空格,并替换为空。
提取信息:
提取邮箱地址:使用正则表达式[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,} 可以匹配并提取邮箱地址。
提取电话号码:使用正则表达式(\+\d{1,2}\s?)?(\(\d{1,3}\)\s?)?(\d{1,4}[-\.\s]?)+\d{1,9} 可以匹配并提取电话号码。
文件操作:
批量重命名文件:使用正则表达式来匹配和替换文件名中的特定部分,例如将所有文件名中的空格替换为下划线。
文件搜索:在UltraEdit中使用正则表达式来进行高级文件搜索,可以更灵活地定位目标文件。
ultraedit 正则提取数字 到单独文件

UltraEdit 正则提取数字到单独文件UltraEdit 是一款强大的文本编辑器,支持正则表达式搜索和替换功能。
要使用UltraEdit 的正则表达式功能提取数字并将其保存到单独的文件中,你可以按照以下步骤操作:1.打开文件:首先,在UltraEdit 中打开你想要提取数字的源文件。
2.正则表达式搜索:o按下Ctrl + F打开“查找”对话框。
o在“查找”框中,输入你的正则表达式。
如果你想提取所有的数字,你可以使用正则表达式\d+,其中\d表示任何数字,+表示一个或多个。
o确保“正则表达式”选项是选中的。
o点击“查找下一个”按钮开始搜索。
3.提取匹配项:o每次找到匹配的数字时,你可以使用UltraEdit 的剪贴板功能(如“复制到剪贴板”或“复制到新文件”)来提取它。
o为了更高效地提取所有数字,你可以使用UltraEdit 的列模式(Column Mode)来一次性选择所有匹配的数字。
要做到这一点,首先找到第一个匹配项,然后按住Alt键并拖动鼠标选择所有其他匹配项。
之后,你可以将这些选定的数字复制到剪贴板或新文件中。
4.保存到单独的文件:o创建一个新文件,并将之前提取的数字粘贴到这个新文件中。
o保存这个新文件到你想要的位置。
5.重复搜索:如果你想继续查找和提取更多的数字,可以重复步骤2 和3。
请注意,根据你的具体需求和源文件的复杂性,可能需要对上述步骤进行一些调整。
正则表达式是一种强大的工具,可以非常灵活地匹配和提取文本中的模式。
因此,根据你的具体需求,可能需要调整或优化你使用的正则表达式。
UE正则式详解

UE正则式详解很好2009-12-11 14:32转:/wwp0726/blog/item/0247f97f4814ef0f28388ab2.htmlUltraEdit 允许在搜索菜单下面列出的大多数搜索和替换功能中使用正则表达式。
正则表达式允许在一次操作中执行多个组合搜索和替换功能。
这里有两个可以使用的语法集。
下面的第一个表显示用于早期 UltraEdit 的原始UltraEdit 语法。
第二个表显示可选的“Unix”样式的正则表达式。
这可以从配置段启用。
正则表达式 (UltraEdit 语法):符号功能%匹配行首 - 表示搜索字符串必须在行首,但不包括任何选定的结果字符中的行终止字符。
$匹配行尾 - 表示搜索字符串必须在行尾,但不包括任何选定的结果字符中的行终止字符。
?匹配任何除换行符的字符。
*匹配任何除换行符外所出现的任意数量的字符。
+匹配一个或多个前面的字符/表达式。
必须找到至少一个出现的字符。
不匹配重复的换行符。
++0 次或多次匹配前面的字符/表达式。
不匹配重复的换行符。
^b匹配一个分页符。
^p匹配一个换行符 (CR/LF) (段落) (DOS 文件)^r匹配一个换行符 (仅 CR) (段落) (MAC 文件)^n匹配一个换行符 (仅 LF) (段落) (UNIX 文件)^t匹配一个制表符[ ]匹配任何括号中的单个字符或范围^{A^}^{B^}匹配表达式 A 或 B^忽略其后的正则表达式字符^(*^)在表达式加上括号或标签在替换命令中使用。
正则表达式中可以有 9 个表达式标签,数字根据它们在正则表达式中的次序确定数字。
相应的替换表达式是 ^x,x 的范围是 1-9。
例如: 如果 ^(h*o^) ^(f*s^) 匹配“hello folks”,那么^2 ^1 表示将用“folks hello”替换它。
注意 - ^ 这里涉及的字符“^”不是控制键 + 值。
例如:m?n 匹配“man”、“men”、“min”,但不匹配“moon”。
Emeditor正则表达式教程

EmEdit or 正则表达式应用专题1在工作中,经常用到Em Edito r来编辑纯文本文档。
最近接触了正则表达式,感受到其功能非常强大。
我现在想要实现这样一个功能,还没有比较好的解决办法:在一篇中英文混排的文档中,删除中文字符(包括标点)之间的空格,但英文单词之间及英文单词与字母之前的空格不能删除;仅删除全角或半角空格,不删除制表符。
求高人试一下。
以下是一些比较有用的正则表达式:^[\t]*\n这个正则表达式代表所有的空行,指含有零个或零个以上空格或制表符、以换行符结尾、不含其它字符的行。
(^|(?<=中国)).*?(?=中国|$)用正则表达式匹配特定字符串外的所有字符。
指除“中国”外的所有其它字符,类似于反选功能。
^[ \t]+查找以上字符,并替换为空,可删除行首空白(包括全半角空格和制表符)。
[ \t]+$查找以上字符,并替换为空,可删除行末空白(包括全半角空格和制表符)。
^[ \t]+|[ \t]+$ 查找以上正则表达式,并替换为空,可删除行首和行末所有空白(包括全半角空格和制表符)。
匹配中文字符的正则表达式: [\u4e00-\u9fa5]评注:匹配中文还真是个头疼的事,有了这个表达式就好办了匹配双字节字符(包括汉字在内):[^\x00-\xff]评注:可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1)匹配空白行的正则表达式:\n\s*\r评注:可以用来删除空白行匹配HTM L标记的正则表达式:< (\S*?)[^>]*>.*?|<.*? />评注:网上流传的版本太糟糕,上面这个也仅仅能匹配部分,对于复杂的嵌套标记依旧无能为力匹配首尾空白字符的正则表达式:^\s*|\s*$评注:可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式匹配Em ail地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*评注:表单验证时很实用匹配网址UR L的正则表达式:[a-zA-z]+://[^\s]*评注:网上流传的版本功能很有限,上面这个基本可以满足需求匹配帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$评注:表单验证时很实用匹配国内电话号码:\d{3}-\d{8}|\d{4}-\d{7}评注:匹配形式如 0511-4405222 或 021-87888822匹配腾讯QQ号:[1-9][0-9]{4,}评注:腾讯QQ号从10000开始匹配中国邮政编码:[1-9]\d{5}(?!\d)评注:中国邮政编码为6位数字匹配身份证:\d{15}|\d{18}评注:中国的身份证为15位或18位匹配ip地址:\d+\.\d+\.\d+\.\d+评注:提取ip地址时有用匹配特定数字:^[1-9]\d*$//匹配正整数^-[1-9]\d*$ //匹配负整数^-?[1-9]\d*$ //匹配整数^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$//匹配正浮点数^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$//匹配负浮点数^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$//匹配浮点数^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$ //匹配非负浮点数(正浮点数 + 0)^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$//匹配非正浮点数(负浮点数 +0)评注:处理大量数据时有用,具体应用时注意修正匹配特定字符串:^[A-Za-z]+$//匹配由26个英文字母组成的字符串^[A-Z]+$//匹配由26个英文字母的大写组成的字符串^[a-z]+$//匹配由26个英文字母的小写组成的字符串^[A-Za-z0-9]+$//匹配由数字和26个英文字母组成的字符串^\w+$//匹配由数字、26个英文字母或者下划线组成的字符串评注:最基本也是最常用的一些表达式^.*John.*$ 匹配包括“John”的整行。
UltraEdit 使用说明及技巧(大全)——经典整合版
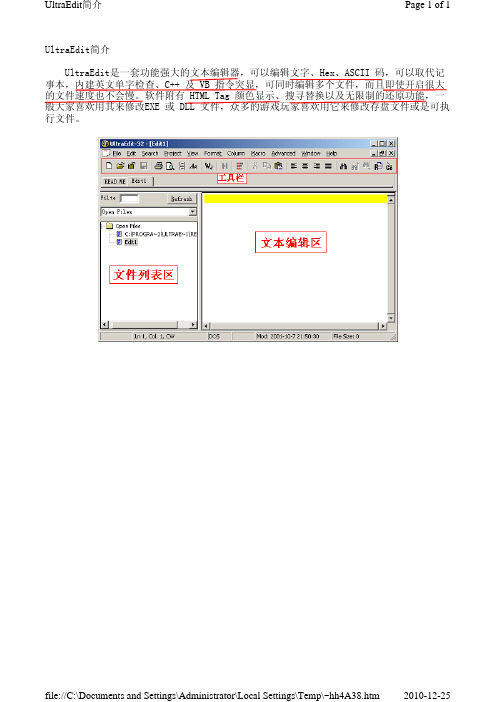
也可以通过桌面上的快捷方式打开 UltraEdit-32,如果你没有注册,每次运行时都会有 一个注册窗口,上面显示你还可以试用的天数 45 天,等一会这个窗口就会自动消失。
现在你就可以看到UltraEdit完整的界面了。
file://C:\Documents and Settings\Administrator\Local Settings\Temp\~hhB97C.htm 2010-12-25
(一)普通功能 普通功能就是指它作为一个文本工具所应该具有的功能。
Edit 菜单:恢复/重复操作、剪切和拷贝及粘贴、多项选择、多项删除等全面的编辑 功;Date/Time 能在文章中自动加入日期;Toggle Word-Wrap 是类似 Word 的自动换行功 能。
Search 菜单:提供了查找、替换功能,换行定位、书签标记、字数统计功能。 Window 菜单:可以将多个编辑框进行有序排列,并在它们之间随意切换,也可通过直接 点击编辑框上的标签在各个文本间切换;Show File In Browser 将直接启动默认浏览器,查 看用 HTML 语言所编辑的网页的实际效果;直接拖放、文件长度不限制等常规功能。
documentssettingsadministratorlocalsettingstemphh45behtmultraedit如何对文件按列排序有时我们需要对文件的内容按照某列进行排序比如对一些报表或者数字资料具体操作步骤如下选择菜单filesortadvancedsort选中removeduplicates表示删除掉重复的行内容保证每行都是唯一的内在startingcolumn处设置按哪一列进行排序既可以指定列的数目也可以按照光标所在的列进行排序在sortorder处选择递增或者递减排序方式单击start按钮开始执行排序ultraedit如何查找关键字有时候我们需要在打开的文件中查找一个关键字而这个关键字可能在文件中的不同地方出现许多次利用下面的步骤可以很好地显示操作查找的内容
UltraEdit正规表达式通配符

Ulteredit正则表达式通配符删除空行:替换%[^t]++^p为空串删除行尾空格:替换[^t]+$为空串删除行首空格:替换%[^t]+为空串每行设置为固定的4个空格开头:替换%[^t]++^([~^t^p]^)为"^1"每段设置为固定的4个空格开头:替换%[^t]+为""(如果一行是以空格开始的,则视之为一段的开始行)将一段合并为一行:替换[^t]++^p^([~^t^p]^)为^1(注意:此处假定文本是以DOS方式回车换行-CR/LF)去掉HTMLTAG:替换^{<*>^}^{<*^p*>^}为空串删除HTML中的所有:替换<[]++a*[]++href[]++=*>为空串删除文本中指定的前2列字符:替换%??为空串在第4列后插入2列空白字符:替换%^(????^)^(?^)为"^1^2"查找所有的数字:[0-9]+[.]++[0-9]+查找所有的单词:[a-z]+查找所有的网址:http://[a-z0-9^~`_./^-^?=&]+注意:替换的时候需要勾选使用正则表达式选项UltraEdit支持的通配符--------------------------------------------------------------------------------% 匹配行的开始 - 显示搜索字符串必须在行的开始,但是在所选择的结果字符串中不包括任何行终止字符$ 匹配行尾 - 显示搜索字符串必须在行尾,但是在所选择的结果字符串中不包括任何行终止字符? 除了换行符以外匹配任何单个的字符* 除了换行符匹配任何数量的字符和数字+ 前一字符匹配一个或多个,但至少要出现一个++ 前一字符匹配零个或多个,但至少要出现一个^b 匹配一个分页^p 匹配一个换行符(CR/LF)(段)(DOS文件)^r 匹配一个换行符(CR 仅仅)(段)(MAC 文件)^n 匹配一个换行符 ( LF 仅仅 )( 段)( UNIX 文件 )^t 匹配一个标签字符TAB[] 匹配任何单个的字符,或在方括号中的范围^{A^}^{ B^} 匹配表达式A或B^ 重载其后的正规表达式字符^(^) 括或标注为用于替换命令的表达式例如:m?n 匹配“man”、“men”、“min”,但不匹配“moon”。
ultraedit 正则表达式 汉字

ultraedit 正则表达式汉字问题:如何使用UltraEdit中的正则表达式来匹配汉字?正则表达式是一种强大的文本匹配工具,可以帮助我们在文本中进行高级搜索和替换操作。
在UltraEdit中,我们可以使用正则表达式来匹配汉字和其他字符。
下面,我将带您一步一步了解如何使用UltraEdit中的正则表达式来匹配汉字。
第一步:启动UltraEdit首先,您需要启动UltraEdit编辑器。
您可以从官方网站下载和安装UltraEdit,然后在您的计算机上打开该程序。
第二步:打开文件在UltraEdit编辑器中,打开包含您想要匹配汉字的文本文件。
您可以选择“文件”菜单中的“打开”选项,然后导航并选择您的文件。
第三步:打开查找对话框在UltraEdit编辑器中,您可以通过按下“Ctrl + F”键来打开“查找”对话框。
您也可以选择“搜索”菜单中的“查找”选项。
第四步:设置查找选项在“查找”对话框中,呈现给您一个文本框,您可以输入要查找的内容。
在此步骤中,我们将输入正则表达式以匹配汉字。
第五步:编写正则表达式要匹配汉字,可以使用Unicode字符编码范围。
Unicode汉字范围为“\u4e00-\u9fff”。
因此,我们可以编写以下正则表达式来匹配汉字:[\u4e00-\u9fff]这个正则表达式使用中括号包含Unicode字符编码范围,表示匹配从“\u4e00”到“\u9fff”之间的任何字符。
第六步:执行匹配操作在“查找”对话框中,您可以点击“查找下一个”按钮来执行匹配操作。
UltraEdit 会在您的文本文件中查找并高亮显示匹配的汉字。
第七步:进一步操作一旦您找到了匹配的汉字,您可以选择在UltraEdit编辑器中进行进一步的操作。
您可以选择替换操作来修改或去除这些汉字,或者您可以选择复制、删除或其他操作。
总结:使用UltraEdit中的正则表达式来匹配汉字是一种高效而强大的文本操作。
只需简单的几个步骤,您就可以找到并处理所需的汉字。
UltraEdit使用技巧

UltraEdit使用技巧1:ctrl+b写代码的时候,括号一般要一一对应的,但是如果嵌套太多,看花眼了,怎么办?你把光标放在括号开始的地方,按ctrl+b,UE会帮你找到相对应的括号结尾的地方。
你还可以试试连着多按几次ctrl+b。
2:如何去掉所编辑文本中包含特定字符串的行?这则技巧是在UltraEdit的帮助文件里提到.CTRL+R调出来替换(Replace)窗口,选中"使用正则表达式";然后用查找%*你的字符串*^p替换成空内容即可。
如,我当前有个文本文件,需要去掉所有包含DBABlog这个字符串的行,查找%*DBABlog*^p替换成空即可.注意,^p是DOS文件类型的换行符.如果是Unix类型文件,则用^n。
3:F3默认情况下,当你按F3的时候UltraEdit可以查找现在选中的内容,F3是下一个符合的内容,ctrl+f3是上一个符合的内容。
4:如何在行末添加特定字符,比如逗号?CTRL+R调出来替换(Replace)窗口,选中"使用正则表达式",然后可以查找^p(或者^n,如果是Unix文件),用,^p(或者,^n)进行"全部替换"。
5:删除空行?查找^p$然后替换为空即可6:ctrl+f2代码会有很多行你当然可以记得你要到的行数,然后用ctrl+g,然后输入行号,到所在的行。
但是用ctrl+f2我觉得更方便。
比如说你要频繁在多个function中切换。
可以在function开始的地方,按一下ctrl+f2,给这一行加一个书签。
然后再另外的function开始的地方,也来一下ctrl+f2,有书签的地方,字的背景色会不同。
当你想换到下一个书签的时候,就按f2,但是想到上一个标签怎么办?ctrl+f2?不对,再按就是加书签或者取消当前行的书签了。
应该是alt+f2。
7:ctrl+tab多个文件中切换,用鼠标点,麻烦。
8:删除整行定位光标要删除的行,然后用ctrl+e即可。
UE中常用正则表达式

UltraEdit UE 中的正则表达式。
一直在用ue,不过都是当记事本来用的。
大才小用了。
最近总是要用到查找替换,一般都是在网上搜一些来用,今天看了一下ue自己的帮助文件。
原来说明的很详细。
发来上,记录一下。
UltraEdit允许在搜索菜单下面列出的大多数搜索和替换功能中使用正则表达式。
正则表达式允许在一次操作中执行多个组合搜索和替换功能。
这里有两个可以使用的语法集。
下面的第一个表显示用于早期UltraEdit的原始UltraEdit语法。
第二个表显示可选的“Unix”样式的正则表达式。
这可以从配置段启用。
正则表达式 (UltraEdit语法):注意– ^ 这里涉及的字符“^”不是控制键 + 值。
例如:m?n匹配“man”、“men”、“min”,但不匹配“moon”。
t*t 匹配“test”、“tonight”和“tea time”中的“tea t”部分,但不匹配“tea time” (“tea ”和“time”之间有换行)。
Te+st匹配“test”、“teest”、“teeeest”等,但不匹配“tst”。
[aeiou] 匹配每个元音小写字母[,.?] 匹配文字“,”、“.”或“?”。
[0-9a-z] 匹配任何数字或小写字母[~0-9] 匹配除数字外的任何字符 (~ 表示不匹配其后的内容)你可以搜索象下面一样的表达式 A 或 B:“^{John^}^{Tom^}这将搜索 John 或 Tom。
在两个表达式之间应该没有任何其它内容。
你可以在同一次搜索象下面一样组合 A 或 B 和 C 或 D: “^{John^}^{Tom^} ^{Smith^}^{Jones^}”这将搜索后面跟随了 Smith 或 Jones 的 John 或 Tom。
下面的表显示“Unix”样式的正则表达式语法。
正则表达式 (Unix 语法):注意– ^ 这里所涉及的字符“^”不是控制键 + 值。
例如:m.n匹配“man”、“men”、“min”,但不匹配“moon”。
ultraedit正则表达式多行注释符号

ultraedit正则表达式多行注释符号在UltraEdit 中,可以使用正则表达式进行多行注释。
通常,多行注释的符号是/*和*/,但如果你想使用正则表达式来匹配这些符号,可以使用以下模式:regex复制代码/\*([^*]|[\r\n]|(\*+([^*/]|[\r\n])))*\*\/这个正则表达式可以匹配多行注释的开始和结束符号,并捕获注释内容。
其中,\用于转义特殊字符,*表示匹配星号字符,[^*]表示匹配除星号之外的任意字符,[\r\n]表示匹配回车或换行符,(\*+([^*/]|[\r\n]))表示匹配一个或多个星号,后面跟着除星号、除号、回车或换行符之外的任意字符。
在UltraEdit 中使用这个正则表达式时,可以选择要注释的文本,然后使用Ctrl+H打开查找和替换对话框,选择正则表达式选项,输入正则表达式和替换内容,最后点击替换或全部替换按钮即可。
在UltraEdit 中使用正则表达式进行多行注释的步骤如下:1.打开UltraEdit 软件,并打开需要编辑的文本文件。
2.选择需要注释的文本,可以使用鼠标拖动或键盘上的方向键来选择。
3.按下Ctrl+H快捷键,打开查找和替换对话框。
4.在查找和替换对话框中,选择“正则表达式”选项。
5.在“查找内容”框中输入正则表达式,例如:/\*([^*]|[\r\n]|(\*+([^*/]|[\r\n])))*\*\/。
6.在“替换为”框中输入注释符号,例如:/* $1 */,其中$1表示匹配到的内容。
7.点击“替换”或“全部替换”按钮,即可将选中的文本替换为注释符号。
注意:在使用正则表达式时,需要特别小心,确保正则表达式的语法正确,否则可能会导致意外的结果。
建议在使用之前先进行测试。
ultraedit技巧

ultraedit技巧Ultra edit的一些应用小技巧1、ctrl+b写程序的时候,括号一般要一一对应的。
如果嵌套太多,结构太负责,就很容易使人看的眼花缭乱。
这时,可以这样处理,把光标放在括号开始的地方,按ctrl+b,UE会自动找到对应的另一半括号的地方,并加亮括号中间的内容。
连续多按几次ctrl+b,可以自动向外层扩展加亮。
2、F3默认情况下,当你按F3的时候UE可以查找现在选中的内容,F3是下一个符合的内容,ctrl+f3是上一个符合的内容.。
3、ctrl+g当文件很大的时候,要托到具体某一行是很费劲的事,而且也浪费时间,ctrl+g 可以帮助我们快速找到我们想要到达的地方。
(其实很多工具都可以用这个组合键)4、ctrl+F2可以给文件行打标签,打标签的行颜色会改变,然后就可以按F2来切换到不同的标签了。
这个在多个函数之间切换出来还是很有用的,比ctrl+g要好用些。
按F2可以到达下一个书签,按alt+F2返回前一个书签,再按ctrl+F2可以取消书签。
5、简单的用正则表达式的查找替换有时候会有一些简单文本处理的工作。
比如你手头有一个文本,需要给所有行后边添加一个";"。
用查找替换(ctrl+r)来完成可以帮助我们减少很多工作量。
按ctrl+r,查找内容是'^p',替换为'^p;',这里记得要选上正则表达式这一项。
然后选replace all(alt+a),或者点开始,一个一个的查找,替换,很快搞定。
6、UE很多功能都可以自定义快捷键,我前面工作中有一次就是要对代码中的枚举定义全部改成小写,先在advanced/configuration/key mapping在commands里面找到要用的FormatToLower命令定义一个快捷键,结合列选择模式(Alt+C非常好用),几千行的代码一下子就搞定了,超级爽。
7、计算选中区域数字的和比如如下文本223a14 1.156先选中,然后Column/(sum column/Selection),UE会弹出一个窗口,让你选择一个忽略的符合,然后计算出结果。
UE使用技巧

都是些很简单的技巧,不过是自己摸索出来,记录一下。
我用的版本是 UltraEdit-32 13.00a 简 体中文版。
1、去重 如果文本中的数据是一行一行的,有重复的内容,去重的方法是:文件——排序——高 级排序/选项,选中“删除重复”。
2、查找后乱码将文件另存为“UTF - 16”格式的文本。
代码页要设置成: 高级——设置代码页/本地,“系统中已安装的代码页”,选择“936(ANSI/OEM-简体中 文 GBK ) ” ;“ 系统已安装的地区”选择 " 中文(中国)中国人们共和国 " 。
3、查找任意汉字选择 Unix 风格的正则表达式,查找 “[^一-龥]”。
代码页设置如上。
4、使用正则表达式,去除空行、行尾空格UltraEdit 有两种传统形式的正则表达式:UltraEdit 风格、Unix 风格。
设置在:高级——去除空行: ^[ ]* 替换为 空白去除行尾空格: [ ]+$替换为 空白 5、在UltraEdit 风格正则表达式中,有个星号(*),功能是匹配任何除换行符外所出现的 任意数量的字符。
但在 Unix 形式正则表达式6、如果一些操作是重复性的,可以用 UltraEdit 的宏来完成。
我常用的是查找后删除、 或者复制。
6.1 查找后删除InsertMode ColumnModeOffHexOffUnixReOnTopLoop配置——搜索——正则表达式引擎。
UltraEdit 风格正则表达式: 去除空行: %[ ^t]++^p 去除行尾空格: [ ^t]+$ Unix 风格正则表达式: 替换为 空白(就是什么也不输入)替换为 空白Find RegExp "要查询的内容"IfFoundDeleteLineEndLoopTopEndIf6.2 查找后复制InsertModeColumnModeOffHexOffUnixReOnNewFilePreviousWindowTopClearClipboardLoopFind RegExp "要查询的内容IfFoundCopyNextWindowPasteInsertLinePreviousWindowEndLoopEndIf/2007-10/119380902036855.html我在windows 下用得最多的编辑器就是UltraEdit 了,使用频率几乎和Firefox 差不多,特记下一些使用技巧,以备忘(随时添加新的技巧)。
ultra edit 技巧

Ultra edit的一些应用小技巧1、ctrl+b写程序的时候,括号一般要一一对应的。
如果嵌套太多,结构太负责,就很容易使人看的眼花缭乱。
这时,可以这样处理,把光标放在括号开始的地方,按ctrl+b,UE会自动找到对应的另一半括号的地方,并加亮括号中间的内容。
连续多按几次ctrl+b,可以自动向外层扩展加亮。
2、F3默认情况下,当你按F3的时候UE可以查找现在选中的内容,F3是下一个符合的内容,ctrl+f3是上一个符合的内容.。
3、ctrl+g当文件很大的时候,要托到具体某一行是很费劲的事,而且也浪费时间,ctrl+g 可以帮助我们快速找到我们想要到达的地方。
(其实很多工具都可以用这个组合键)4、ctrl+F2可以给文件行打标签,打标签的行颜色会改变,然后就可以按F2来切换到不同的标签了。
这个在多个函数之间切换出来还是很有用的,比ctrl+g要好用些。
按F2可以到达下一个书签,按alt+F2返回前一个书签,再按ctrl+F2可以取消书签。
5、简单的用正则表达式的查找替换有时候会有一些简单文本处理的工作。
比如你手头有一个文本,需要给所有行后边添加一个";"。
用查找替换(ctrl+r)来完成可以帮助我们减少很多工作量。
按ctrl+r,查找内容是'^p',替换为'^p;',这里记得要选上正则表达式这一项。
然后选replace all(alt+a),或者点开始,一个一个的查找,替换,很快搞定。
6、UE很多功能都可以自定义快捷键,我前面工作中有一次就是要对代码中的枚举定义全部改成小写,先在advanced/configuration/key mapping在commands里面找到要用的FormatToLower命令定义一个快捷键,结合列选择模式(Alt+C非常好用),几千行的代码一下子就搞定了,超级爽。
7、计算选中区域数字的和比如如下文本223a14 1.156先选中,然后Column/(sum column/Selection),UE会弹出一个窗口,让你选择一个忽略的符合,然后计算出结果。
ultraedit替换多个字符串的方法

ultraedit替换多个字符串的方法
在UltraEdit中替换多个字符串,可以通过使用正则表达式(Regex)来实现。
以下是具体的步骤:
1. 打开UltraEdit软件。
2. 在菜单栏上选择“搜索”选项。
3. 在弹出的对话框中选择“替换”选项。
4. 在“查找”框中输入你想要查找的字符串或字符串模式。
5. 在“替换”框中输入你想要替换成的字符串。
6. 如果你希望在查找时匹配整个单词,可以勾选“匹配单词”选项。
7. 点击“全部替换”按钮即可完成替换操作。
需要注意的是,UltraEdit中的正则表达式使用的是POSIX 风格的正则表达式,如果需要使用其他风格的正则表达式,可以在“搜索”菜单下的“正则表达式”中进行选择。
UltraEdit使用正则表达式(通配符)进行查找和替换

二. 正则表达式替换423 660 678xujie1322A替换的统配符采用的是UltraEdit风格通配符,因此格式上与查找通配符有些不同。
“^(*^)”代表替换时匹配任意长度字符,“^(?^)”代表替换时匹配一个长度的字符。
UltraEdit是目前使得比较多的记事本替代方案。
其对记事本的优势是不言而喻的。
下面演示一下在UltraEdit中如何使用正则表达式(通配符)进行常用的查找和替换。
准备工作:在使用正则表达式前,先需要进行一些设置。
1. 高级-> 配置-> 搜索-> 正则表达式引擎,勾选UltraEidt风格正则表达式2. 在查找及替换框中,均需勾选“正则表达式”。
某文本文件包含如下内容【2012-01-29T00:00:09】【N】: ****************************************#### total packets num 5584921854#### total un-packets num 4645790779@@@@ unpack rate: 1.29598/s[API_FH_0] packets left: 0[API_FH_1] packets left: 0[API_FH_2] packets left: 0[API_FH_3] packets left: 0[API_FH_4] packets left: 0[API_FH_5] packets left: 0[API_SS_0] packets left: 0[API_SS_1] packets left: 0[API_SS_2] packets left: 0[API_SS_3] packets left: 0[API_SS_4] packets left: 0[API_S_5] packets left: 0FH Unpack rate: 100%SS Unpack rate: 100%Mem: 290.8 MB, Virtual Mem: 429.8 MB, Total: 720.6 MB.一. 正则表达式查找“*”代表匹配任意长度的字符,“?”代表匹配一个长度的字符。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
去掉HTML TAG: 替换 ^{<*>^}^{<*^p*>^} 为 空串
删除HTML中的所有: 替换 <[ ]++a *[ ]++href[ ]++=*> 为 空串
删除文本中指定的前2列字符: 替换 %?? 为 空串
m?n 匹配“man”、“men”、“min”,但不匹配“moon”。
t*t 匹配“test”、“tonight”和“tea time”中的“tea t”部分,但不匹配“tea
time” (“tea ”和“time”之间有换行)。
Te+st 匹配“test”、“teest”、“teeeest”等,但不匹配“tst”。
替换成空内容即可.如,我当前有个文本文件,需要去掉所有包含 /
这个字符串的行,查找 %*/*^p 替换成空即可.注意,^p 是 DOS 文件类型的换行符.如果是 Unix
类型文件,则用 ^n.
Tip 2: 如何在行末添加特定字符,比如逗号?
Te*st 匹配“test”、“teest”、“teeeest”等,还有“tst”。
[aeiou] 匹配每个元音小写字母
[,.?] 匹配文字“,”、“.”或“?”。
[0-9a-z] 匹配任何数字或小写字母
[^0-9] 匹配除数字外的任何字符 (~ 表示不匹配其后的内容)
你可以象下面一样的表达式 A 或 B 进行搜索:
符号功能
\表示下一个字符有特殊含义。“n”表示匹配字符“n”,“\n”匹配一换行符。看下面的例子 (\d、\f、\n 等)。
^匹配/停驻行首。
$匹配/停驻行尾。
*匹配前面的字符 0 次或多次。
+匹配前面的字符一次或多次。不匹配重复的换行符。
参考上面两个例子,查找 ^p$ 然后替换为空即可.
看来,正则表达式需要学习一下喽.
Tip 4: 编辑文件如何加入时间戳 ?
F7 快捷键即可.你试试看?
Tip 5: 为何 拷贝(Copy)/粘贴(Paste)功能不能用了?
不怕大家笑话,我有几次使用 UltraEdit
的过程中发现拷贝与粘贴的内容是不匹配的.不知所以然,干脆重新启动了笔记本.今天翻看手册才恍然大悟:UltraEdit有10个剪切板(clipboard),分别用Ctrl+0
本站大部分内容从网上收集,收集目的仅供研究、学习。涉及版权或不希望收录您的文章请您及时与我联系。
本站IM群,请自行选择。请各位朋友按照自己喜好加入。加入群后请及时发言,防止被清理。谢谢您的合作!!! Tip 1: 如何去掉所编辑文本中包含特定字符串的行?
这则技巧是在UltraEdit的帮助文件里提到.CTRL+R 调出来替换(Replace)窗口,选中"使用正则表达式";然后用查找 %*你的字符串*^p
在第4列后插入2列空白字符: 替换 %^(????^)^(?^) 为 "^1 ^2"
查找所有的数字: [0-9]+[.]++[0-9]+
查找所有的单词: [a-z]+
查找所有的网址: http://[a-z0-9^~`_./^-^?=&]+
%1 搜索以1开头的行
. 匹配任何除换行符之外的单个字符。不匹配重复的换行符。
(表达式)在表达式加上括号或标签在替换命令中使用。正则表达式中可以有 9 个表达式标签,数字根据它们在正则表达式中的次序确定数字。
相应的替换表达式是 ^x,x 的范围是 1-9。例如: 如果 ^(h*o^) ^(f*s^) 匹配“hello folks”,那么^2 ^1
- Ctrl+9 切换. Ctrl+0 是 Windows 的,其他则为用户自定义的.我在使用的过程中错调用了 CTRL+n, 结果内容就有问题了.你遇到过没?
Tip 6: 即使是打开小文件也有迟延?
这是我遇到过的问题.每次打开文件的时候总有几秒钟的耽搁.我的机器性能可不算差.怎么回事? 网络打印机搞得鬼!
+匹配一个或多个前面的字符/表达式。必须找到至少一个出现的字符。不匹配重复的换行符。
++0 次或多次匹配前面的字符/表达式。不匹配重复的换行符。
^b匹配一个分页符。
^p匹配一个换行符 (CR/LF) 段落) (DOS 文件)
^r匹配一个换行符 (仅 CR) (段落) (MAC 文件)
相应的替换表达式是 ^x,x 的范围是 1-9。例如: 如果 ^(h*o^) ^(f*s^) 匹配“hello folks”,那么^2 ^1
表示将用“folks hello”替换它。
注意 - ^ 这里涉及的字符“^”不是控制键 + 值。
例如:
1$ 搜索以1为结尾的行
? 匹配单字符
* 匹配多字符
Te+st 匹配"test", "teest", "teeeest" 等. 但不匹配 "tst".
te++st 匹配"test", "teest", "teeeest","tst" 等. 但不匹配 .
^p 新行 (DOS Files格式)
^r 新行 (MAC Files格式)
^n 新行 (UNIX Files格式)
^t tab键
[1-9] 匹配1-9的数字
QQ群:Y①WEB开发()号码:7351660 QQ群:Y②WEB开发(ASP+.NET)号码:11864905
QQ群:Y③WEB开发(DIV+CSS)号码:16610506 QQ群:Y④WEB开发(JS+AJAX)号码:16143998
QQ群:Y⑤WEB开发(新手)号码:12777715 MSN群:yaosansi[at]
表示将用“folks hello”替换它。
[xyz]字符集,匹配任何括号间的字符。.
[^xyz]排除字符集。匹配任何不在括号间的字符。
\d匹配一个数字字符。等同于 [0-9]。
\D匹配一个非数字字符,等同于 [^0-9]。
\f匹配一个换页符。
\W匹配任何非词语的字符。
\p匹配 CR/LF (等同于 \r\n),用来匹配 DOS 行终止符。
注意 - ^ 这里所涉及的字符“^”不是控制键 + 值。
例如:
m.n 匹配“man”、“men”、“min”,但不匹配“moon”。
Te+st 匹配“test”、“teest”、“teeeest”等,但不匹配“tst”。
[linux] 匹配linux中任何一个单词
[~0-9] 除数字外任何一个词
"^{John^}^{Tom^}" 搜索john和tom 如john sdfasdf tom被选种,当然不包括sdfasdf,其中^{和^}是分割符
正则表达式 (UltraEdit 语法):
符号功能
%匹配行首 - 表示搜索字符串必须在行首,但不包括任何选定的结果字符中的行终止字符。
$匹配行尾 - 表示搜索字符串必须在行尾,但不包括任何选定的结果字符中的行终止字符。
?匹配任何除换行符的字符。
*匹配任何除换行符外所出现的任意数量的字符。
在UltraEdit (UEStudio)使用技巧及其中的正则表达式 - SoftWare - yaosansi's Blog导航
首页 AJAX ASP C#|.Net DataBase JavaScript Video XHTML+CSS others 给我留言
繁體中文 yaosansi's Blog
"(John|Tom)"
这将搜索 John 或 Tom。在两个表达式之间应该没有任何其它内容。
你可以在同一次搜索象下面一样组合 A 或 B 和 C 或 D:
"(John|Tom) (Smith|Jones)"
这将搜索 Smith 或 Jones 以及跟随在后面的 John 或 Tom。
当你背向太阳的时候,你只会看到自己的阴影!能力是有限的,努力无限的!« 一步到位,下载Windows Vista的所有语种MUIjQuery入门[1]-构造函数
»在UltraEdit (UEStudio)使用技巧及其中的正则表达式2008年2月29日 17:46:53 发布:yaosansi
打开"高级"->"设置"->"编辑器"->"高级",看看是不是选中了"载入/恢复打印机设置"?如果是的话,去掉(不同的版本/汉化与否可能该位置所在有差别).
Tip 7: 删除当前行内容 CTRL+e
正则表达式
删除空行: 替换 %[ ^t]++^p 为 空串
删除行尾空格: 替换 [ ^t]+$ 为 空串
你可以在同一次搜索象下面一样组合 A 或 B 和 C 或 D:
"^{John^}^{Tom^} ^{Smith^}^{Jones^}"
这将搜索后面跟随了 Smith 或 Jones 的 John 或 Tom。
下面的表显示“Unix”样式的正则表达式语法。
正则表达式 (Unix 语法):
\n匹配一个换行符。
\r匹配一个回车符。