数据挖掘关于Kmeans算法的研究(含数据集)
毕业设计(论文)-基于k-means算法的平面点集聚类系统[管理资料]
![毕业设计(论文)-基于k-means算法的平面点集聚类系统[管理资料]](https://img.taocdn.com/s3/m/06dadde8964bcf84b8d57b82.png)
(6)高维性:一个数据库可能含有若干维或者属性。很多聚类算法擅长处理低维数据,一般只涉及两到三维。通常最多在三维的情况下能够很好地判断聚类的质量。聚类数据对象在高维空间是非常有挑战性的,尤其是考虑到这样的数据可能高度偏斜,非常稀疏;
(7)处理噪声数据的能力:在现实应用中绝大多数的数据都包含了孤立点,空缺、未知数据或者错误的数据。有些聚类算法对于这样的数据敏感,将会导致质量较低的聚类结果;
人们已经提出了很多聚类算法,比如有基于划分的K-MEANS算法、CLARANS算法;基于层次的BIRCH算法、CURE算法;基于网格的STING算法、WaveCluster算法等。但是这些算法都存在着不足,所以就存在如何选择参数的问题,不适当的选择将会大大影响算法的结果。
2.2.1
给定类的个数k,随机挑选k个对象为初始聚类中心,利用距离最近的原则,将其余数据集对象分到k个类中去,聚类的结果由k个聚类中心来表达。算法采用迭代更新的方法,通过判定给定的聚类目标函数,每一次迭代过程都向目标函数值减少的方向进行。在每一轮中,依据k个参照点将其周围的点分别组成k个类,而每个类的几何中心将被作为下一轮迭代的参照点,迭代使得选取的参照点越来越接近真实的类几何中心,使得类内对象的相似性最大,类间对象的相似性最小。
kmeans 算法

kmeans 算法K-Means算法,也称为K均值聚类算法,是一种无监督机器学习方法,用于将数据集分成K个簇群。
该算法的核心思想是将数据点划分为不同的簇群,使得同一簇群内的点相似度尽可能高,而不同簇群之间的相似度尽可能低。
该算法可用于许多领域,如计算机视觉、医学图像处理、自然语言处理等。
1.工作原理K-Means算法的工作原理如下:1. 首先,从数据集中随机选择K个点作为初始簇群的中心点。
2. 接下来,计算每个数据点与K个中心点之间的距离,并将它们归入距离最近的簇群中。
这个过程称为“分配”。
3. 在所有数据点都被分配到簇群后,重新计算每个簇群的中心点,即将簇群中所有数据点的坐标取平均值得出新的中心点。
这个过程称为“更新”。
4. 重复执行2-3步骤,直到簇群不再发生变化或达到最大迭代次数为止。
2.优缺点1. 简单易懂,实现方便。
2. 可用于处理大量数据集。
1. 随机初始化可能导致算法无法找到全局最优解。
2. 结果受到初始中心点的影响。
3. 对离群值敏感,可能导致簇群数量不足或簇群数量偏多。
4. 对于非球形簇群,K-Means算法的效果可能较差。
3.应用场景K-Means算法可以广泛应用于许多领域,如:1. 机器学习和数据挖掘:用于聚类分析和领域分类。
2. 计算机视觉:用于图像分割和物体识别。
3. 自然语言处理:用于文本聚类和词向量空间的子空间聚类。
4. 财务分析:用于分析财务数据,比如信用评分和市场分析。
5. 医学图像处理:用于医学影像分析和分类。
总之,K-Means算法是一种简单有效的聚类算法,可用于处理大量数据集、连续型数据、图像和文本等多种形式数据。
但在实际应用中,需要根据具体情况选择合适的簇群数量和初始中心点,在保证算法正确性和有效性的同时,减少误差和提高效率。
利用KNIME进行数据挖掘的实验手册

数据挖掘实验手册本次实践分别用两个数据集来进一步学习如何在KNIME中对两个数据集进行分类,聚类和频繁模式挖掘算法的实践。
两个数据集均来自Kaggle网站的UCI Machine Learning。
一、蘑菇数据集蘑菇数据集来自于Mushroom Classification | Kaggle,该数据集总数据量为8124条,涉及特征包括菌盖形状、菌盖表面、气味等等22个字段,目标是对蘑菇是否有毒进行二分类,即有毒、无毒。
所有的特征都是离散分类特征,在Kaggle 上可以看到各特征的具体含义和属性取值。
本次实践使用的软件是KNIME Analytics Platform,其主界面如下:在本次实践过程主要涉及两个区域:工作区和节点选项板。
工作区放置操作节点和数据流,节点选项板则提供了不同功能的节点。
首先介绍两个基本概念:节点和数据流。
KNIME Analytics Platform进行的数据挖掘重点关注通过一系列节点运行数据的过程,我们将这一过程称为工作流。
也可以说KNIME Analytics Platform是以工作流这一系列节点代表要对数据执行的操作,而节点之间的链接指示数据的流动方向。
通常,KNIME Analytics Platform将数据以一条条记录的形式读入,然后通过对数据进行一系列操作,最后将其发送至某个地方(可以是模型,或某种格式的数据输出)。
使用KNIME Analytics Platform处理数据的三个步骤:1.将数据读入KNIME Analytics Platform。
2.通过一系列操纵运行数据。
3.将数据发送到目标位置。
在KNIME Analytics Platform中,可以通过打开新的工作流来一次处理多个数据流。
会话期间,可以在KNIME Analytics Platform窗口右上角的流管理器中管理打开的多个数据流。
接下来我们开始对数据集进行操作:第一步创建流在左上角菜单栏选择“文件”→“新建流”,创建一个新的数据流。
kmeans算法原理

kmeans算法原理K-Means算法,又叫k均值算法,是一种比较流行的数据聚类算法,它是一种迭代聚类算法,旨在将数据分为K个聚类,每个聚类具有最相似的数据点。
K-Means算法最初被使用于一些研究领域,例如音频处理和图像处理,但是在数据挖掘和机器学习领域中,K-Means 算法也被广泛使用,用于挖掘和识别隐藏的模式和结构,以及比较大型数据集的好处。
K-Means算法的基本原理K-Means算法是一种基于迭代的聚类算法,它利用距离公式将数据集分为k个不同的聚类,每个聚类具有最相似的数据点。
K-Means 算法的基本流程如下:(1)首先,确定数据集中簇的数量K。
(2)然后,将数据集中的每个数据点分配到K个不同的聚类。
(3)最后,按照每个聚类的平均值更新每个聚类的中心点,并将每个数据点根据距离新的聚类中心点的距离重新分配到新的聚类中。
K-Means算法的优点(1)K-Means算法的计算容易,它的时间复杂度较低,可以在大数据集上应用。
(2)可以用来快速对大型数据集进行聚类,可以轻松发现隐藏在数据中的模式和结构。
(3)K-Means算法也可以用来进行压缩,K-Means算法可以确定数据元素的聚类,从而减少数据集的大小。
(4)K-Means算法也可以用来发现预测模型,K-Means可以用来挖掘和识别隐藏的模式和结构,从而发现预测模型。
K-Means算法的缺点(1)K-Means算法为聚类选择的K值敏感,只有当K值适当时,K-Means算法才能得到最佳结果。
(2)K-Means算法在处理非球形数据集时效果不佳,K-Means算法会将数据分配到最近的聚类中心,但是对于非球形数据集来说,最近的聚类中心并不能很好的表示数据。
(3)K-Means算法在选择聚类中心的时候也有一定的局限性,K-Means算法选择的聚类中心受到初始值的影响,因此算法的结果受初始值的影响。
结论K-Means算法可以有效的将大型数据集分割成不同的聚类,是聚类分析中一种最常用的算法。
kmeans的聚类算法

kmeans的聚类算法K-means是一种常见的聚类算法,它可以将数据集划分为K个簇,每个簇包含相似的数据点。
在本文中,我们将详细介绍K-means算法的原理、步骤和应用。
一、K-means算法原理K-means算法基于以下两个假设:1. 每个簇的中心是该簇内所有点的平均值。
2. 每个点都属于距离其最近的中心所在的簇。
基于这两个假设,K-means算法通过迭代寻找最佳中心来实现聚类。
具体来说,该算法包括以下步骤:二、K-means算法步骤1. 随机选择k个数据点作为初始质心。
2. 将每个数据点分配到距离其最近的质心所在的簇。
3. 计算每个簇内所有数据点的平均值,并将其作为新质心。
4. 重复步骤2和3直到质心不再变化或达到预定迭代次数。
三、K-means算法应用1. 数据挖掘:将大量数据分成几组可以帮助我们发现其中隐含的规律2. 图像分割:将图像分成几个部分,每个部分可以看做是一个簇,从而实现图像的分割。
3. 生物学:通过对生物数据进行聚类可以帮助我们理解生物之间的相似性和差异性。
四、K-means算法优缺点1. 优点:(1)简单易懂,易于实现。
(2)计算效率高,适用于大规模数据集。
(3)结果可解释性强。
2. 缺点:(1)需要预先设定簇数K。
(2)对初始质心的选择敏感,可能会陷入局部最优解。
(3)无法处理非球形簇和噪声数据。
五、K-means算法改进1. K-means++:改进了初始质心的选择方法,能够更好地避免陷入局部最优解。
2. Mini-batch K-means:通过随机抽样来加快计算速度,在保证精度的同时降低了计算复杂度。
K-means算法是一种常见的聚类算法,它通过迭代寻找最佳中心来实现聚类。
该算法应用广泛,但也存在一些缺点。
针对这些缺点,我们可以采用改进方法来提高其效果。
数据挖掘实验报告结论(3篇)

第1篇一、实验概述本次数据挖掘实验以Apriori算法为核心,通过对GutenBerg和DBLP两个数据集进行关联规则挖掘,旨在探讨数据挖掘技术在知识发现中的应用。
实验过程中,我们遵循数据挖掘的一般流程,包括数据预处理、关联规则挖掘、结果分析和可视化等步骤。
二、实验结果分析1. 数据预处理在实验开始之前,我们对GutenBerg和DBLP数据集进行了预处理,包括数据清洗、数据集成和数据变换等。
通过对数据集的分析,我们发现了以下问题:(1)数据缺失:部分数据集存在缺失值,需要通过插补或删除缺失数据的方法进行处理。
(2)数据不一致:数据集中存在不同格式的数据,需要进行统一处理。
(3)数据噪声:数据集中存在一些异常值,需要通过滤波或聚类等方法进行处理。
2. 关联规则挖掘在数据预处理完成后,我们使用Apriori算法对数据集进行关联规则挖掘。
实验中,我们设置了不同的最小支持度和最小置信度阈值,以挖掘出不同粒度的关联规则。
以下是实验结果分析:(1)GutenBerg数据集在GutenBerg数据集中,我们以句子为篮子粒度,挖掘了林肯演讲集的关联规则。
通过分析挖掘结果,我们发现:- 单词“the”和“of”在句子中频繁出现,表明这两个词在林肯演讲中具有较高的出现频率。
- “and”和“to”等连接词也具有较高的出现频率,说明林肯演讲中句子结构较为复杂。
- 部分单词组合具有较高的置信度,如“war”和“soldier”,表明在林肯演讲中提到“war”时,很可能同时提到“soldier”。
(2)DBLP数据集在DBLP数据集中,我们以作者为单位,挖掘了作者之间的合作关系。
实验结果表明:- 部分作者之间存在较强的合作关系,如同一研究领域内的作者。
- 部分作者在多个研究领域均有合作关系,表明他们在不同领域具有一定的学术影响力。
3. 结果分析和可视化为了更好地展示实验结果,我们对挖掘出的关联规则进行了可视化处理。
通过可视化,我们可以直观地看出以下信息:(1)频繁项集的分布情况:通过柱状图展示频繁项集的分布情况,便于分析不同项集的出现频率。
数据挖掘实验报告

数据挖掘实验报告数据挖掘是一门涉及发现、提取和分析大量数据的技术和过程,它可以揭示出隐藏在数据背后的模式、关系和趋势,对决策和预测具有重要的价值。
本文将介绍我在数据挖掘实验中的一些主要收获和心得体会。
实验一:数据预处理在数据挖掘的整个过程中,最重要的一环就是数据预处理。
数据预处理包括数据清洗、数据集成、数据转换和数据规约等步骤,目的是为了提高数据的质量和可用性。
首先,我对所使用的数据集进行了初步的观察和探索。
发现数据集中存在着一些缺失值和异常值。
为此,我使用了一些常见的缺失值处理方法,如均值替代、中值替代和删除等。
对于异常值,我采用了离群值检测和修正等方法,使得数据在后续的分析过程中更加真实可信。
其次,我进行了数据集成的工作。
数据集合并是为了整合多个来源的数据,从而得到更全面和综合的信息。
在这个过程中,我需要考虑数据的一致性和冗余情况。
通过采用数据压缩和去重等技术,我成功地完成了数据集成的工作。
接着,我进行了数据转换的处理。
数据转换是为了将原始的数据转换成适合数据挖掘算法处理的形式。
在这个实验中,我采用了数据标准化和归一化等方法,使得不同属性之间具备了可比性和可计算性,从而便于后续的分析过程。
最后,我进行了数据规约的操作。
数据规约的目的在于减少数据的维数和复杂度,以提高数据挖掘的效果。
在这个阶段,我采用了主成分分析和属性筛选等方法,通过压缩数据集的维度和减少冗余属性,成功地简化了数据结构,提高了挖掘效率。
实验二:关联规则挖掘关联规则挖掘是数据挖掘中常用的一种方法,它用于发现数据集中项集之间的关联关系。
在这个实验中,我使用了Apriori算法来进行关联规则的挖掘。
首先,我对数据进行了预处理,包括数据清洗和转换。
然后,我选择了适当的最小支持度和最小置信度阈值,通过对数据集的扫描和频繁项集生成,找出了数据集中的频繁项集。
接着,我使用了关联规则挖掘算法,从频繁项集中挖掘出了具有一定置信度的关联规则。
在实验过程中,我发现挖掘出的关联规则具有一定的实用性和可行性。
基于最小生成树的多层次k-Means聚类算法及其在数据挖掘中的应用

基于最小生成树的多层次k-Means聚类算法及其在数据挖掘中的应用金晓民;张丽萍【摘要】针对传统聚类算法存在挖掘效率慢、准确率低等问题,提出一种基于最小生成树的多层次k-means聚类算法,并应用于数据挖掘中.先分析聚类样本的数据类型,根据分析结果设计聚类准则函数;再通过最小生成树对样本数据进行划分,并选取初始聚类中心,将样本的数据空间划分为矩形单元,在矩形单元中对样本对象数据进行计算、降序和选取,得到有效的初始聚类中心,减少数据挖掘时间.实验结果表明,与传统算法相比,该算法可快速、准确地挖掘数据,且挖掘效率提升约50%.【期刊名称】《吉林大学学报(理学版)》【年(卷),期】2018(056)005【总页数】6页(P1187-1192)【关键词】最小生成树;多层次k-means聚类算法;数据挖掘【作者】金晓民;张丽萍【作者单位】内蒙古大学交通学院,呼和浩特010021;内蒙古自治区桥梁检测与维修加固工程技术研究中心,呼和浩特010070;内蒙古师范大学计算机科学技术学院,呼和浩特010022【正文语种】中文【中图分类】TP301数据挖掘就是从大量随机的、模糊的、有噪声的、不完全的数据中, 提取潜在的、未知的、隐含的、有应用价值的模式或信息的过程[1-3]. 数据挖掘中重要的步骤是聚类[4], 聚类将数据分为多个簇或类, 使相似度较高的对象在一个类中, 不同类别中的数据相似度较低[5]. 对稀疏和密集区域的识别通过聚类完成, 并通过聚类发现数据属性和分布模式间存在的关系[6]. 数据聚类广泛应用于医疗图像自动检测、客户分类、卫星照片分析、基因识别、空间数据处理和文本分类等领域[7].在低维情况下, 数据挖掘方法通过人眼进行模式识别及SOM(self organizing maps)可视化功能确定聚类的数目, 完成数据的挖掘, 该方法存在挖掘时间长和挖掘结果不准确的问题[8]. Means算法是数据聚类分析中常用的划分方法, 以准则函数和误差平方作为数据聚类的准则, 可快速、有效地完成大数据集的处理. MFA算法是一个优先考虑边权值进行社团划分的算法, 同时也继承了通过优化Q值进行社团划分的特点. 文献[9]提出了一种基于改进并行协同过滤算法的大数据挖掘方法, 通过分析协同过滤算法的执行流程, 针对传统协同过滤算法的不足, 从生成节点评分向量、获取相邻节点、形成推荐信息等方面对传统协同过滤算法进行改进, 得到了从运行时间、加速率和推荐精度三方面均运行效率较高的改进并行协同过滤算法. k-means算法依赖于数据输入的顺序和初始值的选择, 通过准则函数和误差平方对聚类效果进行测度, 各类的大小和形状差别较大[10]. 为了优化挖掘过程, 本文提出一种基于最小生成树的多层次k-means聚类算法对数据进行挖掘.1 数据类型与聚类准则函数设计1.1 聚类分析中的矩阵类型选取1) 数据矩阵. 数据矩阵表示一个对象的属性结果, 是数据之间的关系表, 每列都表示对象的一类属性, 每行表示数据对象, 如通过m个属性对数据对象进行描述, 属性一般为种类、高度等. n个对象中存在m个属性可通过n×m矩阵表示为(1)2) 差异矩阵. 数据对象之间的差异性用差异矩阵进行储存, 差异矩阵用n×n维矩阵表示, 其中d(i,j)为差异矩阵中的元素, 表示数据对象i和j之间存在的差异程度, 表达式为(2)差异矩阵中的元素d(i,j)≥0, 数据对象间的相似度越高, 该数据越接近于0;数据对象之间的相似度越低, 该数据越大.1.2 聚类准则和加权平均平方距离计算函数设计1) 误差平方和准则函数设计. 设X={x1,x2,…,xn}表示混合样本集, 通过相似性度量将混合样本集聚类成C个子集X1,X2,…,XC, 每个子集都表示一个数据的类型, 分别存在n1,n2,…,nC种样本. 采用准则函数和误差平方对数据聚类的质量进行衡量, 表达式为(3)其中: mj表示数据样本在类中的均值; JC表示准则函数, 是聚类中心和样本的函数, JC值越大, 表示聚类过程中存在的误差越大, 得到的聚类结果较差.2) 加权平均平方距离计算. 数据聚类过程中的加权平均平方距离和准则的表达式为(4)其中表示样本在数据类中的平均平方距离, 计算公式为(5)用数据的类间距离和准则Jb2及类间距离和准则Jb1对聚类结果类间存在的距离分布状态进行描述, Jb1和Jb2的计算公式为其中: mj表示样本在数据类别中的均值向量; m表示数据样本全部的均值向量; pj 表示数据类别的先验概率[11].2 算法设计2.1 基于最小生成树的初始中心点选取各矩形单元中存在的数据对象个数用最小生成树分割, 计算公式为(8)其中: RecU表示矩形单元; DataN表示样本数据的总数; SF表示细分因子; k表示聚类数. 最小生成树分割得到的矩形单元均值计算公式为(9)其中: S表示数据对象在矩形单元中的线性和; W表示矩形单元权重. 数据对象在各矩形单元中密集程度的计算公式为(10)其中: vi表示每个矩形单元的面积; ni表示数据对象在每个矩形单元中的数量; dmin和dmax分别表示矩阵单元中最小数据和最大数据的距离值.用最小生成树对样本数据X={x1,x2,…,xn}进行划分, CenterRecU表示分割后得到的矩形单元RecU, 其反映了样本数据集的分布状况. 采用数据集X′对集合CenterRecU进行表示, 用矩形单元密度对数据集X′进行降序排序, 初始聚类中心在数据集X′中选取, 记C={C1,C2,…,Ck}, 用矩形单元中心对数据集X′进行聚类, 得到k个类, 原始样本数据集的初始中心点通过在矩形单元中进行操作获得[12]. 2.2 算法描述设X1和X2表示样本的数据集, Dist(Ci,Cj)表示样本簇与样本簇之间的距离, 函数Dist(Ci,Cj)的表达式为(11)其中: Ci和Cj分别表示含有xi和xj的两个不同聚类簇; xi和xj分别表示数据集Xi和Xj中的样本点;用欧氏距离计算函数Dist(xi,xj)中数据间的距离; n1和n2表示数据对象在两个样本簇中的个数. 平均簇间距定义为(12)其中, Ci和Cj表示两个不同的聚类簇. 如果AvgDist(C)大于两个簇间的距离, 则不处理这两个簇, 继续比较, 直到AvgDist(C)小于两个簇之间的距离为止. 算法步骤如下:1) 通过k个中心点集C={C1,C2,…,Ck}构建最小生成树.2) 设Mi表示增量数据在第i个类中的总数, Gi表示第i个类中对象数据构成的集合. 对其他对象及相应的邻近类Ci进行搜索, 将搜索得到的数据划分到相应的集合Gi中.3) 从构建的最小生成树根节点向下出发, 搜索数据, 如果分裂点的坐标大于当前的坐标, 则搜索其左侧的空间;如果分裂点的坐标小于当前的坐标, 则搜索其右侧的坐标, 直至最小生成树的叶节点终止, 并对其进行标记, 记为Nearest. 计算与叶节点之间的距离, 并记为Distance.4) 计算每个目标点与节点之间的距离, 如果Distance大于与目标点的距离, 则将该节点更新为Nearest, 距离为Distance. 将目标点作为圆心、 Distance为半径画圆, 观察节点分类轴与所做圆是否相交. 若相交, 则向该节点的子节点进行搜索;若不相交, 则继续回溯, 当回溯到最小生成树的根节点时, 完成搜索. 此时最近的目标点聚类中心为最近点Nearest, 并在最近点Nearest中加入最近数据对象的聚类中心.5) 设Ci表示搜索得到的增量数据相应的最近聚类中心, 按下式对聚类中心进行更新:(13)6) 用式(12)比较k个聚类簇之间的距离, 如果平均簇间距AvgDist(C)大于两个簇之间的距离, 则对两个簇进行合并, 直到平均簇间距AvgDist(C)小于两个簇之间的距离为止. 用最小生成树得到的增量数据与初始聚类中心建立最小生成树, 用最近邻搜索方法将增量数据依次划分到相应的聚类中, 完成数据的聚类, 并根据类间的平均距离对聚类结果进行完善和修正, 获得最优的聚类结果, 完成数据挖掘.基于最小生成树的多层次k-means聚类算法流程如图1所示.图1 多层次k-means聚类算法流程Fig.1 Flow chart of multi-level k-means clustering algorithm3 算法应用实验1 为了验证基于最小生成树的多层次k-means聚类算法对数据挖掘的有效性, 下面对该算法进行测试, 操作系统为Windows7.0. 基于聚类结果越精准得到的数据挖掘结果越准确的原则, 分别采用基于最小生成树的多层次k-means聚类算法与传统k-means算法进行测试, 对比两种不同算法对数据挖掘过程中的聚类结果, 测试结果如图2所示, 图2中不同形状表示不同类别的数据.由图2可见: 采用基于最小生成树的多层次k-means聚类算法对数据进行聚类时, 可准确地对不同类别的数据进行划分; 采用传统k-means算法对数据进行聚类时,得到的分类中存在不同类别的数据, 聚类结果不准确. 因此, 基于最小生成树的多层次k-means聚类算法可准确地对数据进行挖掘.实验2 在k-means算法中, k值决定在该聚类算法中所要分配聚类簇的多少, 同时影响算法的聚类效果和迭代次数, 因此利用Canopy算法先进行粗略的聚类, 产生簇的个数为6, 即k-means算法的k=6.图2 两种不同算法的聚类结果Fig.2 Clustering results of two different algorithms在k=6的条件下, 为进一步验证本文算法的优越性, 在分类簇的划分过程中, 可用挖掘数据对象到簇中心的距离衡量算法的优劣. 聚类过程中, 距离计算次数能很好地衡量挖掘算法的相关性能. 通过对本文改进k-means算法和传统的MFA算法的距离计算次数进行比较, 完成性能对比, 对比结果如图3所示. 由图3可见, 本文提出的改进k-means算法得到的距离计算次数比传统MFA算法少, 随着计算挖掘控制维度的不断增加, 这种优势对比越来越明显. 与MFA算法相比, 在数据维度不断增加的集合中, 本文算法的效率提升约50%. 利用本文提出的改进k-means算法和MFA算法在运行实际效率上进行实验对比, 结果如图4所示. 由图4可见, 本文算法在每次迭代过程中, 在时间效率上都优于传统MFA算法, 且维度越大, 效果越明显.图3 不同算法的数据点距离计算数比较Fig.3 Comparison of calculation number of data points distance of different algorithms图4 不同算法迭代阶段的运行时间比较Fig.4 Comparison of running time of different algorithms in iterative stages由以上分析可知, 当k=6时, 本文提出的算法在时间效率上优于传统的MFA挖掘算法.图5 不同算法的效率测试结果比较Fig.5 Comparison of efficiency test resultsof different algorithms实验3 选择初始点和聚类迭代次数在数据挖掘中均较耗时的两个阶段, 分别采用基于最小生成树的多层次k-means聚类算法、文献[9]算法及传统MFA算法对数据进行挖掘, 对比不同算法进行数据挖掘的效率, 结果如图5所示.由图5可见, 采用基于最小生成树的多层次k-means聚类算法对数据进行挖掘时, 在选择初始点阶段的迭代次数较多, 在聚类阶段中的迭代次数较低. 采用其他算法对数据进行挖掘时, 在选择初始点阶段的迭代次数较少, 但在聚类阶段中的迭代次数较多. 对比基于最小生成树的多层次k-means聚类算法其他和算法的迭代次数可知, 基于最小生成树的多层次k-means聚类算法的总体迭代次数少于其他算法的总体迭代次数, 因此基于最小生成树的多层次k-means聚类算法对数据进行挖掘时迭代次数较少, 挖掘所用时间较短.综上可见, 针对传统聚类算法挖掘数据时, 存在挖掘结果不准确、挖掘时间长的问题, 本文提出了一种基于最小生成树的多层次k-means聚类算法, 解决了目前数据挖掘效率低的问题, 可有效提高信息检索率.参考文献【相关文献】[1] 林媛. 非结构化网络中有价值信息数据挖掘研究 [J]. 计算机仿真, 2017, 34(2): 414-417. (LIN Yuan. Research on Data Mining of Valuable Information in Unstructured Network [J]. Computer Simulation, 2017, 34(2): 414-417.)[2] 何拥军, 骆嘉伟, 余爱民. 多帧CT图像数据的测序数据挖掘与规律分析 [J]. 现代电子技术, 2017, 40(14): 106-108. (HE Yongjun, LUO Jiawei, YU Aimin. Sequencing Data Mining and Rules Analysis of Multi-frame CT Image Data [J]. Modern Electronics Technique, 2017, 40(14): 106-108.)[3] 贾瑞玉, 李振. 基于最小生成树的层次K-Means聚类算法 [J]. 微电子学与计算机, 2016, 33(3):86-88. (JIA Ruiyu, LI Zhen. The Level of K-Means Clustering Algorithm Based on the Minimum Spanning Tree [J]. Microelectronics & Computer, 2016, 33(3): 86-88.)[4] 王茜, 刘胜会. 改进K-Means算法在入侵检测中的应用研究 [J]. 计算机工程与应用, 2015,51(17): 124-127. (WANG Qian, LIU Shenghui. Application Research of Improved K-Means Algorithm in Intrusion Detection [J]. Computer Engineering and Applications, 2015, 51(17): 124-127.)[5] 杨辉华, 王克, 李灵巧, 等. 基于自适应布谷鸟搜索算法的K-Means聚类算法及其应用 [J]. 计算机应用, 2016, 36(8): 2066-2070. (YANG Huihua, WANG Ke, LI Lingqiao, et al. K-Means Clustering Algorithm Based on Adaptive Cuckoo Search and Its Application [J]. Journal of Computer Applications, 2016, 36(8): 2066-2070.)[6] 李洪成, 吴晓平, 陈燕. MapReduce框架下支持差分隐私保护的K-Means聚类算法 [J]. 通信学报, 2016, 37(2): 124-130. (LI Hongcheng, WU Xiaoping, CHEN Yan. K-Means Clustering Method Preserving Differential Privacy in MapReduce Framework [J]. Journal on Communications, 2016, 37(2): 124-130.)[7] 张顺龙, 庞涛, 周浩. 针对多聚类中心大数据集的加速K-Means聚类算法 [J]. 计算机应用研究, 2016, 33(2): 413-416. (ZHANG Shunlong, PANG Tao, ZHOU Hao. Accelerate K-Means for Multi-center Clustering of Big Datasets [J]. Application Research of Computers, 2016,33(2): 413-416.)[8] 陈平华, 陈传瑜. 基于满二叉树的二分K-Means聚类并行推荐算法 [J]. 计算机工程与科学, 2015, 37(8): 1450-1457. (CHEN Pinghua, CHEN Chuanyu. A Bisecting K-Means Clustering Parallel Recommendation Algorithm Based on Full Binary Tree [J]. Computer Engineering and Science, 2015, 37(8): 1450-1457.)[9] ZHU Li, LI Heng, FENG Yuxuan. Research on Big Data Mining Based on Improved Parallel Collaborative Filtering Algorithm [J]. Cluster Computing, 2018(5): 1-10.[10] França F O D. A Hash-Based Co-clustering Algorithm for Categorical Data [J]. Expert Systems with Applications, 2016, 64(12): 24-35.[11] 张睿, 熊金虎,汪东兴, 等. 基于体素邻域信息的均值漂移聚类算法检测fMRI激活区 [J]. 江苏大学学报(自然科学版), 2016, 37(5): 556-561. (ZHANG Rui, XIONG Jinhu, WANG Dongxing, et al. Detecting fMRI Activation by Mean-Shift Clustering Method Based on Voxel Neighborhood Information [J]. Journal of Jiangsu University (Natural Science Edition), 2016, 37(5): 556-561.)[12] 王永,万潇逸,陶娅芝, 等. 基于K-medoids 项目聚类的协同过滤推荐算法 [J]. 重庆邮电大学学报(自然科学版), 2017, 29(4): 521-526. (WANG Yong, WAN Xiaoyi, TAO Yazhi, et al. Collaborative Filtering Recommendation Algorithm Based on K-medoids Item Clustering [J]. Journal of Chongqing University of Posts and Telecommunications (Natural Science Edition), 2017, 29(4): 521-526.)。
数据挖掘中的K—means算法及改进

20 0 6年 第 1 1期
福 建 电
脑
4 7
数据挖掘 中的 K m a s 法及改进 — en 算
贾 磊. 丁冠 华
( 警 工程 学 院研 究 生队 陕 西 西 安 7 0 8 ) 武 10 6
【 摘 要】 从数 据挖掘 的基本概念入手 , 步深入分析本质 , : 逐 并且 对 k m as - en 进行探讨 , 对其 中的聚类 中心的方法进行
1 数据 挖 掘 的 含 义 .
1 . 据 挖 掘 过 程 : 据 挖 掘 是 一 个 多步 骤 过 程 . 括 挖 掘 2数 数 包 数 据 . 析 结 果 和 采取 行 动 . 分 被访 问 的数 据 可 以存 在 于 一 个 或 多 个 操 作 型数 据 库 中 、 一个 数 据 仓 库 中或一 个 平 面 文 件 中
K ME N — A S算 法 是 一 个 简 单 而 有 效 的统 计 聚类 技 术 其 算 3 y 15 45 . = .0;簇 C x ( .+ .+ . /. 33 v 3,=( .+ .+1 5) 25 2:= 20 30 5o) o .3,= 3
法如下 :
( 选 择 一个 K值 . 以确 定 簇 的 总数 . 1 ) 用
i 5
45
接 受 的 均方 误 差 , 行 k m a s 法 , 到 结 果满 足条 件 执 - en 算 直 3 算 法 的 问 题 及 改进 . 31算 法存 在 的 问题 K m as 法 是 比较 容 易理 解 和实 现 . — en 算 的 。 然而 , 还有 许 多 问 题需 要 考 虑 , 别 是 : 特 A 该算 法 只对 数 值数 据 有 效 。我 们 需 要 为要 构 造 的 簇 数选 . 取一 个 值 。 当数 据 中簇 的大 小 近似 相 等 时 ,— A S算 法 的效 K ME N
数据挖掘的常用算法

数据挖掘的常用算法数据挖掘是通过对大量数据进行分析和挖掘,发现其中隐藏的模式、规律和知识的过程。
在数据挖掘中,常用的算法有很多种,每种算法都有其特点和适用场景。
本文将介绍数据挖掘中常用的算法,并对其原理和应用进行简要说明。
一、聚类算法聚类算法是将数据集中的对象分组或聚类到相似的类别中,使得同一类别的对象相似度较高,不同类别的对象相似度较低。
常用的聚类算法有K-means算法和层次聚类算法。
1. K-means算法K-means算法是一种基于距离的聚类算法,它将数据集分为K个簇,每个簇以其质心(簇中所有点的平均值)为代表。
算法的过程包括初始化质心、计算样本点到质心的距离、更新质心和重复迭代,直到质心不再变化或达到最大迭代次数。
2. 层次聚类算法层次聚类算法是一种自底向上或自顶向下的聚类方法,它通过计算样本点之间的相似度来构建聚类树(或聚类图),最终将数据集划分为不同的簇。
常用的层次聚类算法有凝聚层次聚类和分裂层次聚类。
二、分类算法分类算法是将数据集中的对象分为不同的类别或标签,通过学习已知类别的样本数据来预测未知类别的数据。
常用的分类算法有决策树算法、朴素贝叶斯算法和支持向量机算法。
1. 决策树算法决策树算法是一种基于树形结构的分类算法,它通过对数据集进行划分,构建一棵决策树来进行分类。
决策树的节点表示一个特征,分支表示该特征的取值,叶子节点表示一个类别或标签。
2. 朴素贝叶斯算法朴素贝叶斯算法是一种基于概率模型的分类算法,它假设特征之间相互独立,并利用贝叶斯定理来计算后验概率。
朴素贝叶斯算法在处理大规模数据时具有较高的效率和准确率。
3. 支持向量机算法支持向量机算法是一种基于统计学习理论的分类算法,它通过将数据映射到高维空间中,找到一个超平面,使得不同类别的样本点尽可能远离该超平面。
支持向量机算法具有较强的泛化能力和较好的鲁棒性。
三、关联规则挖掘算法关联规则挖掘算法用于发现数据集中的频繁项集和关联规则,揭示数据中的相关关系。
K-Means聚类算法的研究

K-Means聚类算法的研究周爱武;于亚飞【摘要】The algorithm of K-means is one kind of classical clustering algorithm, including both many points and also shortages.For example must choose the initial clustering number.The choose of initial clustering centre has randomness.The algorithm receives locally optimal solution easily, the effect of isolated point is serious.Mainly improved the choice of initial clustering centre and the problem of isolated point.First of all ,the algorithm calculated distance between all data and eliminated the effect of isolated point.Then proposed one new method for choosing the initial clustering centre and compared the algorithm having improved and the original algorithm using the experiment.The experiments indicate that the effect of isolated point for algorithm having improved reduces obviously, the results of clustering approach the actual distribution of the data.%K-Means算法是一种经典的聚类算法,有很多优点,也存在许多不足.比如初始聚类数K要事先指定,初始聚类中心选择存在随机性,算法容易生成局部最优解,受孤立点的影响很大等.文中主要针对K-Means算法初始聚类中心的选择以及孤立点问题加以改进,首先计算所有数据对象之间的距离,根据距离和的思想排除孤立点的影响,然后提出了一种新的初始聚类中心选择方法,并通过实验比较了改进算法与原算法的优劣.实验表明,改进算法受孤立点的影响明显降低,而且聚类结果更接近实际数据分布.【期刊名称】《计算机技术与发展》【年(卷),期】2011(021)002【总页数】4页(P62-65)【关键词】K-Means算法;初始聚类中心;孤立点【作者】周爱武;于亚飞【作者单位】安徽大学,计算机科学与技术学院,安徽,合肥,230039;安徽大学,计算机科学与技术学院,安徽,合肥,230039【正文语种】中文【中图分类】TP301.6聚类分析是数据挖掘领域中重要的研究课题,用于发现大规模数据集中未知的对象类。
kmeans 聚类系数

kmeans 聚类系数Kmeans聚类系数(K-MeansClusteringCoefficients)是一种常用的数据挖掘算法,它源于西班牙数学家Juan Carlos Martínez的研究,概括而言,Kmeans系数是一种用于在给定数据集中组合不相关的模式和特征的数据挖掘技术。
它旨在判断接近数据空间中存在的数据点之间的联系和它们差异的程度,以提升数据集的紧凑性和可解释性。
Kmeans系数可以通过一种叫做k-means的算法来实现。
输入的数据空间可以是任意大小的,但它必须包含至少两个属性,并且这些属性必须有一定的关联性。
算法就是根据属性中对于每个点之间的距离来将点分组,以实现最佳聚类。
具体而言,算法将数据集中的数据点相互比较并将其分为从小到大,不同的组。
同时,将参数称为“k-means系数”,它将每个组的大小缩小到最小。
Kmeans系数的优势在于它可以区分不同的模式与特征,因此有助于形成具有对比性的数据集,以及使数据集更容易分析。
因此,Kmeans系数可以用来处理模式分析、模式识别和其他相关任务,如聚类分析、社会网络分析、文本挖掘等等。
Kmeans系数有很多应用,在商业分析中,它可以用来分析营销渠道、客户以及品牌信息,分析客户行为模式,以确定客户忠诚度,发现客户最有可能购买的产品,甚至可以识别客户的价值。
此外,Kmeans系数在自然语言处理、机器学习和图像处理等领域也有大量应用。
Kmeans系数可以让数据科学家从大量混合数据中发现有用的信息,使用Kmeans系数可以开发出可重复使用的模式,这些模式可以在将来的分析工作中进行重用,从而使数据分析更加有效高效。
它在精确性和稳定性方面也有不错的表现,它可以以更少的计算量创建更稳定的模型,因此更加有效地处理大规模数据集。
总之,Kmeans系数是一种高效的数据挖掘技术,它可以帮助数据科学家从大量混合数据中发现有用的信息,它的应用可以极大地提高数据分析的准确性,有助于理解数据集的联系和它们的重要性,并为未来的数据分析提供基础。
K-Means聚类算法

K—means聚类算法综述摘要:空间数据挖掘是当今计算机及GIS研究的热点之一。
空间聚类是空间数据挖掘的一个重要功能.K—means聚类算法是空间聚类的重要算法。
本综述在介绍了空间聚类规则的基础上,叙述了经典的K-means算法,并总结了一些针对K-means算法的改进。
关键词:空间数据挖掘,空间聚类,K—means,K值1、引言现代社会是一个信息社会,空间信息已经与人们的生活已经密不可分。
日益丰富的空间和非空间数据收集存储于空间数据库中,随着空间数据的不断膨胀,海量的空间数据的大小、复杂性都在快速增长,远远超出了人们的解译能力,从这些空间数据中发现邻域知识迫切需求产生一个多学科、多邻域综合交叉的新兴研究邻域,空间数据挖掘技术应运而生.空间聚类分析方法是空间数据挖掘理论中一个重要的领域,是从海量数据中发现知识的一个重要手段。
K—means算法是空间聚类算法中应用广泛的算法,在聚类分析中起着重要作用。
2、空间聚类空间聚类是空间数据挖掘的一个重要组成部分.作为数据挖掘的一个功能,空间聚类可以作为一个单独的工具用于获取数据的分布情况,观察每个聚类的特征,关注一个特定的聚类集合以深入分析。
空间聚类也可以作为其它算法的预处理步骤,比如分类和特征描述,这些算法将在已发现的聚类上运行。
空间聚类规则是把特征相近的空间实体数据划分到不同的组中,组间的差别尽可能大,组内的差别尽可能小。
空间聚类规则与分类规则不同,它不顾及已知的类标记,在聚类前并不知道将要划分成几类和什么样的类别,也不知道根据哪些空间区分规则来定义类。
(1)因而,在聚类中没有训练或测试数据的概念,这就是将聚类称为是无指导学习(unsupervised learning)的原因。
(2)在多维空间属性中,框定聚类问题是很方便的。
给定m个变量描述的n个数据对象,每个对象可以表示为m维空间中的一个点,这时聚类可以简化为从一组非均匀分布点中确定高密度的点群.在多维空间中搜索潜在的群组则需要首先选择合理的相似性标准.(2)已经提出的空间聚类的方法很多,目前,主要分为以下4种主要的聚类分析方法(3):①基于划分的方法包括K—平均法、K—中心点法和EM聚类法。
k-means算法原理

k-means算法原理k-means算法是一种基本的聚类算法,其原理是根据样本间的距离,将样本分为k个簇。
k-means算法经常被用来对数据进行聚类分析、图像分割等应用。
k-means算法的过程可以分为以下几步:1. 随机选择k个样本作为初始簇的中心点。
2. 计算每个样本点和每个簇中心点的距离,并将每个样本点分配到距离最近的簇中心点所在的簇中。
3. 对每个簇重新计算中心点。
4. 重复步骤2和3,直到簇不再发生变化或达到预设的最大迭代次数。
现在我们来具体介绍一下k-means算法的原理:1. 初始化簇这里的簇是指由样本组成的集合,k指分成的簇的数量。
初始簇的中心点是随机选择的,可以是任意k个样本点。
如果簇的初始中心点选择不够好,最终聚类结果也可能不理想。
应该在不同的随机样本中进行实验,以确定最佳的初始聚类中心点。
2. 分配样本点在第二步中,我们需要计算每个样本点到各个簇中心点的距离,并将其分配到距离最近的簇中。
这里的距离可以使用欧几里得距离、曼哈顿距离、切比雪夫距离等方式来衡量。
3. 计算新的簇中心点在第三步中,我们需要重新计算每个簇的中心点。
这一步可以采用平均法来计算每个簇中样本点的坐标平均值,从而得到一个新的簇中心点。
4. 重复迭代在第四步中,我们需要重复进行步骤2和步骤3,直到簇不再发生变化或达到预设的最大迭代次数。
如果簇中新的中心点位置与原来的中心点位置相同,那么我们可以认为算法已经收敛。
5. 输出聚类结果最后一步是输出聚类结果。
可以将同一簇的样本点标记为同一类,从而得到聚类结果。
对于大规模的数据集,我们可以采用MapReduce等并行计算框架来加速计算,从而提高算法的效率和可扩展性。
总结:k-means算法是一种简单而又经典的聚类算法,可以发现数据中的分布结构,对于模式识别及数据分析等领域有着广泛的应用。
需要注意的是,k-means算法的聚类结果会受到初始簇中心点的影响,因此需要进行多次实验,从而得到最佳的聚类结果。
基于Hive的分布式K_means算法设计与研究

基于Hive的分布式K_means算法设计与研究作者:冯晓云陆建峰来源:《计算机光盘软件与应用》2013年第21期摘要:针对大数据的处理效率问题,论文主要应用Hadoop技术,探讨了分布式技术应用于大数据挖掘的编程模式。
论文以k_means算法作为研究对象,采用Hadoop的一个数据仓库工具——HIVE来实现该算法的并行化,并在结构化的UCI数据集上进行了实验,实验结果表明该方法具有优良的加速比和运行效率,适用于结构化海量数据的分析。
关键词:大数据;Hadoop;分布式;k-means中图分类号:TP393.02―大数据‖时代已经降临,在商业、经济及其他领域中,决策将日益基于数据和分析而作出,而并非基于经验和直觉[1]。
随着互联网和信息行业的发展,在日常运营中生成、累积的用户网络行为数据的规模是非常庞大的,以至于不能用G或T来衡量。
我们希望从这些结构化或半结构化的数据中学习到有趣的知识,但这些数据在下载到关系型数据库用于分析时会花费过多时间和金钱。
因此,并行化数据挖掘成为了当下的一个热门研究课题,其主要编程模式包括:数据并行模式,消息传递模式,共享内存模式以及后两种模式同时使用的混合模式[2][3]。
1 国内研究现状当前中国的云计算的发展正进入成长期,国内很多研究者正进入分布式的数据挖掘领域,利用国外的成熟平台,例如Hadoop来实现大数据的聚类等算法。
但是数据的多样性,文本多格式,造成对数据的操作有很大的难度,而如今大多数论文都利用了标准化的mapreduce方法来进行代码的编写,具有一定的通用性,但是Hadoop下还有许多的工具,能够简化m/r过程,同样对一定结构的数据具有很好的并行效果,但是这方面的研究比较少,因此本文引入了HIVE的运用,简化了数据的操作过程,利用类似标准的SQL语句对数据集进行运算,在一定程度上提高了并行化计算的效率。
2 Hadoop并行化基础数据挖掘(Data Mining)是对海量数据进行分析和总结,得到有用信息的知识发现的过程[4]。
基于k-means算法的数据挖掘与客户细分研究
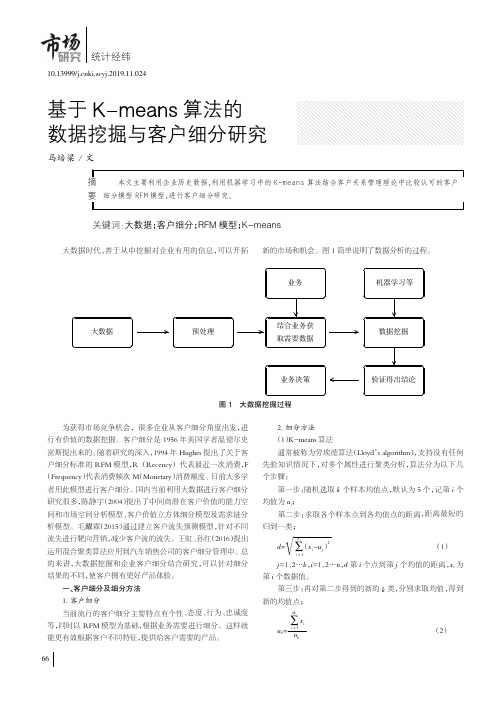
业务
机器学习等
大数据
预处理
结合业务获 取需要数据
数据挖掘
业务决策
验证得出结论
图 1 大数据挖掘过程
为获得市场竞争机会,很多企业从客户细分角度出发,进 行有价值的数据挖掘。客户细分是 1956 年美国学者温德尔史 密斯提出来的。随着研究的深入,1994 年 Hughes 提出了关于客 户细分标准的 RFM 模型,R (Recency) 代表最近一次消费,F (Frequency)代表消费频次 M(Monetary)消费额度。目前大多学 者用此模型进行客户细分。国内当前利用大数据进行客户细分 研究很多,陈静宇(2004)提出了中间商潜在客户价值的能力空 间和市场空间分析模型、客户价值立方体细分模型及需求链分 析模型。毛躍霖(2015)通过建立客户流失预测模型,针对不同 流失进行靶向营销,减少客户流的流失。王虹、孙红(2016)提出 运用混合聚类算法应用到汽车销售公司的客户细分管理中。总 的来讲,大数据挖掘和企业客户细分结合研究,可以针对细分 结果的不同,使客户拥有更好产品体验。
由于 k-means 均值算法分类 k 值随机选取,为了选取更好
的分类结果,评估最优的聚类个数,有两种方法:平均轮廓系数
和手肘法.平均轮廓系数公式表示:
Si=
xi -yi max{xi ,yi
}
(4)
xi 表示第 i 个聚类点到本类其他店的平均距离。yi 表示第 i 个聚类点到其他类中点的平均距离 Si 取值范围为(-1,1)越接 近 1 表明分类越好。
一尧客户细分及细分方法 1. 客户细分 当前流行的客户细分主要特点有个性、态度、行为、忠诚度 等,同时以 RFM 模型为基础,根据业务需要进行细分。这样就 能更有效根据客户不同特征,提供给客户需要的产品。
python_一维数据的k-means算法_概述及解释说明

python 一维数据的k-means算法概述及解释说明1. 引言1.1 概述本文将介绍K-means算法在处理一维数据上的应用。
K-means算法是一种常用的聚类分析方法,可帮助我们将数据集划分为不同的簇。
聚类分析是一种无监督学习方法,通过找到数据中的相似性来对其进行分类,从而提取出隐藏在数据背后的模式和特征。
1.2 文章结构本文共包含以下几个部分:引言、K-means算法概述、一维数据的K-means 算法解释、示例与实现讲解以及结论与展望。
在引言部分,我们将提供一个简要介绍并概括本文所要讨论的主题。
接下来,在K-means算法概述中,我们将详细解释该算法的原理、步骤说明以及适用的场景。
然后,我们会详细探讨如何在一维数据上应用K-means算法,并对其中涉及到的数据预处理、聚类中心计算与更新以及聚类结果评估与迭代调整进行解释。
紧接着,在示例与实现讲解部分,我们将通过具体示例来演示如何使用Python 编写代码实现一维数据的K-means算法,并给出结果可视化和分析解读。
最后,在结论与展望部分,我们将总结本文的主要观点和发现,并展望未来关于K-means算法在一维数据上的研究方向和应用场景的拓展。
1.3 目的本文的目标是为读者提供对K-means算法在处理一维数据时的全面了解和应用指导。
通过阅读本文,读者将了解K-means算法的基本原理、步骤说明以及适用场景,并能够根据具体需求编写代码实现该算法并进行结果分析和解释。
同时,我们还希望通过本文对一维数据的K-means算法进行详细讲解,加深读者对该算法在实际问题中的应用理解和掌握能力。
2. K-means算法概述:2.1 算法原理:K-means算法是一种基于聚类的机器学习算法,主要用于将一组数据分成k 个不同的簇。
该算法通过计算数据点与各个簇中心之间的距离来确定每个数据点所属的簇,并且不断迭代更新簇中心以优化聚类结果。
其核心思想是最小化数据点到其所属簇中心的欧氏距离平方和。
kmeans聚类算法的 步骤

一、介绍K-means聚类算法是一种常见的无监督学习算法,用于将数据集划分成多个不相交的子集,从而使每个子集内的数据点都彼此相似。
这种算法通常被用于数据挖掘、模式识别和图像分割等领域。
在本文中,我们将介绍K-means聚类算法的步骤,以帮助读者了解该算法的原理和实现过程。
二、算法步骤1. 初始化选择K个初始的聚类中心,这些聚类中心可以从数据集中随机选择,也可以通过一些启发式算法进行选择。
K表示用户事先设定的聚类个数。
2. 聚类分配对于数据集中的每个数据点,计算其与K个聚类中心的距离,并将其分配到距离最近的聚类中心所属的子集中。
3. 更新聚类中心计算每个子集中所有数据点的均值,将均值作为新的聚类中心。
4. 重复第二步和第三步重复进行聚类分配和更新聚类中心的步骤,直到聚类中心不再发生变化,或者达到预设的迭代次数。
5. 收敛当聚类中心不再发生变化时,算法收敛,聚类过程结束。
三、算法变体K-means算法有许多不同的变体,这些变体可以根据特定的场景和需求进行调整。
K-means++算法是K-means算法的一种改进版本,它可以更有效地选择初始的聚类中心,从而提高聚类的准确性和效率。
对于大规模数据集,可以使用Mini-batch K-means算法,它可以在迭代过程中随机选择一部分数据进行计算,从而加快算法的收敛速度。
四、总结K-means聚类算法是一种简单而有效的聚类算法,它在各种领域都得到了广泛的应用。
然而,该算法也存在一些局限性,例如对初始聚类中心的选择比较敏感,对异常值比较敏感等。
在实际使用时,需要根据具体情况进行调整和改进。
希望本文对读者有所帮助,让大家对K-means聚类算法有更深入的了解。
K-means聚类算法作为一种经典的无监督学习算法,在进行数据分析和模式识别时发挥着重要作用。
在实际应用中,K-means算法的步骤和变体需要根据具体问题进行调整和改进。
下面我们将进一步探讨K-means聚类算法的步骤和变体,以及在实际应用中的注意事项。
K均值算法中的数据标准化技巧及使用教程(四)

在数据挖掘和机器学习领域中,K均值算法是一种常见的聚类算法,它用于将数据集中的数据点划分到K个不同的组中。
K均值算法的核心思想是通过计算数据点之间的距离来找出最佳的聚类中心,然后将数据点分配到最近的聚类中心中。
然而,在实际应用中,数据集的不同特征可能具有不同的数值范围和方差,这就需要对数据进行标准化处理,以保证各个特征在计算距离时具有相同的权重。
下面将介绍K均值算法中的数据标准化技巧及使用教程。
数据标准化是指将具有不同量纲和方差的特征进行处理,使其具有相同的数值范围和方差。
常见的数据标准化方法包括最小-最大标准化和Z-score标准化。
最小-最大标准化通过对原始数据进行线性变换,将其缩放到一个特定的范围内,通常是[0, 1]或者[-1, 1]之间。
而Z-score标准化则是通过将原始数据进行线性变换,使其均值为0,标准差为1。
在K均值算法中,通常采用Z-score标准化方法来处理数据,因为这种方法能够保留数据的分布信息,同时消除了特征之间的量纲影响。
使用Python语言进行K均值算法的实现时,可以使用scikit-learn库中的KMeans方法来进行聚类分析。
在进行聚类分析之前,首先需要对原始数据进行Z-score标准化处理。
scikit-learn库中提供了preprocessing模块,其中包括了StandardScaler类用于数据标准化。
下面是一个简单的K均值算法的使用教程:1. 导入必要的库```pythonimport pandas as pdfromimport KMeansfromimport StandardScaler```2. 读取数据```python# 读取数据集data = _csv('')```3. 数据标准化```python# 初始化StandardScalerscaler = StandardScaler()# 对数据进行标准化处理scaled_data = _transform(data) ```4. 聚类分析```python# 初始化KMeans模型kmeans = KMeans(n_clusters=3, random_state=0)# 对标准化后的数据进行聚类分析(scaled_data)# 获取聚类结果cluster_labels = _# 将聚类结果添加到原始数据中data['cluster'] = cluster_labels```通过以上步骤,我们完成了K均值算法的实现。
K-means聚类算法簇的个数的研究

K-means聚类算法聚类个数的方法研究摘要:在数据挖掘算法中,K均值聚类算法是一种比较常见的无监督学习方法,簇间数据对象越相异,簇内数据对象越相似,说明该聚类效果越好。
然而,簇个数的选取通常是由有经验的用户预先进行设定的参数。
本文提出了一种能够自动确定聚类个数,采用SSE和簇的个数进行度量,提出了一种聚类个数自适应的聚类方法(SKKM)。
通过UCI数据集的实验,验证了SKKM可以快速的找到数据集中聚类个数。
关键字:K-means算法; 聚类个数; 初始聚类中心;近年来,随着信息技术的发展,特别是云计算、物联网、社交网络等新兴应用的产生,我们的社会正从信息时代步入数据时代。
数据挖掘就是从大量的、不完整的、有噪声的、模糊的数据中通过数据清洗、数据集成、数据选择、数据变换、数据挖掘、数据评估、知识表示等过程挖掘出隐含信息的过程。
目前,数据挖掘已经广泛的应在电信、银行、零售、公共服务、气象等多个行业与领域。
聚类是数据挖掘中一项重要的技术指标,也受到人们的重视,并且广泛的应用在多个领域中[1]。
K均值算法是一种基于划分的聚类算法。
通常是由有经验的用户对簇个数K进行预先设定,一般用户很难确定K的值,K值设定的不正确将会导致聚类算法结果的错误,因此,本文提出了一种SKKM的方法对K值进行确认。
传统的K均值聚类算法中的另外一个缺点就是初始中心点的选取问题,随机选取初始中心点将会导致局部最优解,而不是全局最优解,因此,初始中心点的研究也是聚类算法比较热门的话题。
文献[2]提出了基于划分的聚类算法,该方法对簇的个数并不是自动的获取,而是通过有经验的用户进行设定。
现有的自动确定簇的个数的聚类方法通常需要给出一些参数,然后再确定簇的个数。
如:Iterative Self organizing Data Analysis Techniques Algorithm,该方法在实践中需要过多的对参数进行设定,并且很难应用在高维数据中[3]。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
大学算法研究实验报告数据挖掘题目:K-means目录一、实验容 (5)二、实验目的 (7)三、实验方法 (7)3.1软、硬件环境说明 (7)3.2实验数据说明 (7)图3-1 (7)3.3实验参数说明/软件正确性测试 (7)四、算法描述 (9)图4-1 (10)五、算法实现 (11)5.1主要数据结构描述 (11)图5-1 (11)5.2核心代码与关键技术说明 (11)5.3算法流程图 (14)六、实验结果 (15)6.1实验结果说明 (15)6.2实验结果比较 (21)七、总结 (23)一、 实验容实现K-means 算法,其中该算法介绍如下:k-means 算法是根据聚类中的均值进行聚类划分的聚类算法。
输入:聚类个数k ,以及包含n 个数据对象的数据。
输出:满足方差最小标准的k 个聚类。
处理流程:Step 1. 从n 个数据对象任意选择k 个对象作为初始聚类中心; Step 2. 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离,并根据最小距离重新对相应对象进行划分; Step 3. 重新计算每个(有变化)聚类的均值(中心对象) Step 4. 循环Step 2到Step 3直到每个聚类不再发生变化为止;k-means 算法的工作过程说明如下:首先从n 个数据对象任意选择k 个对象作为初始聚类中心,而对于所剩下的其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类。
然后,再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值),不断重复这一过程直到标准测度函数开始收敛为止。
一般都采用均方差作为标准测度函数,具体定义如下:21∑∑=∈-=ki iiE C p m p (1)其中E 为数据库中所有对象的均方差之和,p 为代表对象的空间中的一个点,m i 为聚类C i 的均值(p 和m i 均是多维的)。
公式(1)所示的聚类标准,旨在使所获得的k 个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
重点要求:用于聚类的测试级不能仅为单独的一类属性,至少有两种属性值参与聚类。
二、实验目的通过实现K-means算法,加深对课本上聚类算法的理解,并对数据集做出较高的要求,以期锻炼我们的搜索查找能力。
最后自己实现K-means算法,可以加强我们的编程能力。
三、实验方法3.1软、硬件环境说明采用win7旗舰版(盗版)系统,用vs2010实现3.2实验数据说明实验数据,源于google的广告关键词推荐页面,在该页面输入关键词,会出现与该关键词相关的一些信息,包括月均搜索量,关键词价值等等,取出来在经过自己处理,就得到了我们需要的实验数据,包括关键词、月均搜索量、竞争力、估价以及关键词排名,包含两种属性。
部分数据如下:关键词月均搜索量竞争力建议出价排名模拟股票700.1427.89194股票交流300.1119.17160股票交易系统300.1711.46101股票交易5900.3131.86203gupiao10000.0615.94137股市投资200.29 2.8216股票趋势200.11 6.9555财经网19000.2213.38123股票书500.0689.06246图3-13.3实验参数说明/软件正确性测试我采用了各种数据对程序进行测试,出现一些数组越界bug,修改后再次测试,无问题,测试通过。
四、算法描述KMeans算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。
然后按平均法重新计算各个簇的质心,从而确定新的簇心。
一直迭代,直到簇心的移动距离小于某个给定的值。
K-Means聚类算法主要分为三个步骤:(1)第一步是为待聚类的点寻找聚类中心(2)第二步是计算每个点到聚类中心的距离,将每个点聚类到离该点最近的聚类中去(3)第三步是计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心反复执行(2)、(3),直到聚类中心不再进行大围移动或者聚类次数达到要求为止下图展示了对n个样本点进行K-means聚类的效果,这里k取2:(a)未聚类的初始点集(b)随机选取两个点作为聚类中心(c)计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去(d)计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心(e)重复(c),计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去(f)重复(d),计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心图4-1五、算法实现5.1主要数据结构描述这里我建造了一个data的结构体,如下:typedef vector<double> Tuple;//存储每条数据记录struct data{string s;//存储关键词Tuple tup;//存储属性信息};图5-15.2核心代码与关键技术说明5.2.1计算距离函数此函数用于计算两个元祖之间的距离,对于每个元祖的属性值,对于数值型的属性值(X1,X2,X3,X i,X n),我们用Y i代替X i来进行归一化处理,其中Y i计算公式如下:Y i=(X i - X min )/(X max -X min )对于序数型属性值(M 1,M 2,M 3,M i ,M n ), 我们用Q i 代替M i 进行归一化处理,其中Q i 计算公式如下:Q i=(Z(Q i )-1)/(Z (Total )-1) 其中Z (Q i )表示Q i 属于的组数,Z (Total )表示总共的组数,他们的计算规则如下:Z(Total )= kZ (Q i )= Q i/(dataNum/k )+1 (其中dataNum 为总数据量,K 为总分组数。
)归一化处理之后,在计算两个元祖之间的欧式几何距离,具体实现代码如下:double getDistXY(const data &t1, const data &t2){double sum = 0,temp1=0,temp2=0,temp3=0,temp4=0;int zuBase,zu1,zu2; //确定分组依据zuBase=dataNum/k;zu1=t1.tup[4]/zuBase+1;//确定分组zu2=t2.tup[4]/zuBase+1;temp3=(zu1-1)/6;if(temp3>1)temp3=1;temp4=(zu2-1)/6;if(temp4>1)temp4=1;//修正序数度量temp1=(t1.tup[1]-10)/367990;temp2=(t2.tup[1]-10)/367990;sum+=(temp1-temp2)*(temp1-temp2)+(temp3-temp4)*(temp3-temp4); for(int i=2; i<dimNum-1; ++i){sum += (t1.tup[i]-t2.tup[i]) * (t1.tup[i]-t2.tup[i]);}return sqrt(sum);}5.2.2重新分簇对于每个簇,算出当前每个元祖与各个质心间的距离,重新判定该元组属于哪一个簇,代码如下:int clusterOfTuple(data means[],const data& tuple){double dist=getDistXY(means[0],tuple);double tmp;int label=0;//标示属于哪一个簇for(int i=1;i<k;i++){tmp=getDistXY(means[i],tuple);if(tmp<dist) {dist=tmp;label=i;}}return label;}5.3算法流程图六、实验结果6.1实验结果说明进过归一化操作聚类效果比较明显,可以看到大家对股票的哪一方面比较关心,并且给广告投资商一些参考,帮助其决定把广告投到哪一个关键词上,进而得到的关注量最时花费最少。
同时,考虑到结果的聚类性,用户搜索某个关键词时,可以推荐给他同一个簇其他的关键词。
具体实验结果如下:第1个簇:关键词编号搜索量竞争价值估价排名股票学习网 8 20 0.11 27.19 193 股票初学 15 20 0.16 22.41 171 指数股票 16 20 0.07 26.66 191 怎样看股票 18 20 0.14 18.93 155 股票入门教程 30 20 0.11 17.5 149 购买股票 31 20 0.2 23.75 180 股票交流 35 30 0.11 19.17 160 中国股市论坛 44 30 0.16 23.98 182 股票指数 50 30 0.04 29.41 196股票开户流程 54 30 0.1 25.71 187 股票怎么看 56 30 0.1 19.84 164 股票投资入门 62 40 0.23 21.38 170 美国股票软件 67 40 0.28 20.74 168 虚拟股票 72 40 0.13 30.66 199 股票市盈率 81 50 0.07 24.42 184 股市走势 86 50 0.1 17.05 145 查股票 90 50 0.21 17.02 143 股票公式 102 70 0.07 20.73 167 如何购买股票 104 70 0.17 19.73 163 航空股票 105 70 0.12 19 157 股票买卖 109 70 0.24 22.86 173 中国远洋股票 111 70 0.05 30.55 198 模拟股票 114 70 0.14 27.89 194 股票走势 117 70 0.11 21.33 169 股票基础知识 119 70 0.11 24.16 183 股票公司 125 90 0.36 17.04 144 股票交易费用 129 90 0.13 24.47 185 中国铁建股票 131 90 0.09 19.05 158股票分析软件 132 90 0.24 22.7 172 新手股票 141 110 0.18 23.92 181 谷歌股票 142 110 0.04 20.07 165 股票网 161 140 0.2 17.47 148 中国中铁股票 164 140 0.06 27.17 192 怎么买股票 165 140 0.19 17.86 152 股票技术分析 168 140 0.07 19.37 162 中国联通股票 172 170 0.05 25.72 188 搜狐股票 173 170 0.06 19.08 159 新浪财经股票首页 174 170 0.03 23.3 176 股票查询 183 210 0.48 23.4 177股票交易时间 189 210 0.06 30.44 197 股票交易所 190 210 0.17 30.78 201 股票行 194 210 0.49 17.17 146 如何看股票 196 210 0.11 18.66 154 基金股票 197 210 0.21 18.98 156 股指 198 210 0.04 30.73 200 百度股票 202 260 0.05 32.88 204 股票行情查询 205 260 0.04 22.86 174 股票投资 212 320 0.32 25.64 186 股票網 214 320 0.38 20.35 166 股票知识 215 320 0.12 17.18 147 股票新手 228 390 0.23 23.69 179 股票交易 233 590 0.31 31.86 203 股票软件 234 590 0.2 29.04 195 新加坡股票 235 590 0.35 18.01 153 股票入门 242 880 0.15 26.05 189 中国股票 248 1300 0.11 30.84 202 炒股 250 1900 0.15 26.28 190 gushi 252 2400 0.01 19.18 161 股票 254 2400 0.46 23.26 175新浪股票 256 2900 0.05 17.71 151 港股 260 6600 0.21 23.52 178 股市 266 368000 0.01 17.51 150 第2个簇:关键词编号搜索量竞争价值估价排名股票模拟软件 24 20 0.13 75.05 237 股票自动交易软件 26 20 0.13 77.44 239 新浪股票博客 36 30 0.06 80.16 240 股票怎么买 73 40 0.21 92.89 248 股票技巧 80 50 0.23 85.53 244 新股票 89 50 0.11 68.96 235 股票书 92 50 0.06 89.06 246 联通股票 93 50 0.03 104.99 252股票基本知识 107 70 0.09 68.56 234 股票大盘 127 90 0.1 103.13 251 股票研究 133 90 0.11 80.77 241 中国重工股票 138 90 0.1 90.51 247 中国股票行情 148 110 0.07 76.05 238 股票网上开户 159 140 0.1 103.04 250 股票交易手续费 166 140 0.12 85.11 243 石油股票 191 210 0.18 93.22 249 股票 200 210 0.23 71.25 236澳洲股票 218 390 0.21 85.95 245 新浪股市 223 390 0.04 84.8 242 第3个簇:关键词编号搜索量竞争价值估价排名股票 29 20 0.1 154.15 262今日股市行情大盘 49 30 0.12 117.53 253 怎么玩股票 52 30 0.1 133.11 257 银行股票 68 40 0.11 123.23 254 股票计算器 74 40 0.1 144.89 259 股票频道 101 70 0.04 130.46 255 a股大盘 126 90 0.06 174.74 264 证券股 137 90 0.03 150.32 260 股票 158 140 0.01 142.11 258st股票 169 140 0.05 168.23 263 民生银行股票 193 210 0.06 130.61 256 招商银行股票 210 320 0.03 152.85 261 第4个簇:关键词编号搜索量竞争价值估价排名美国股票交易软件 2 10 0.32 4.65 34 股票价格查询 4 10 0.09 1.83 11 投资美国股票 5 10 0.38 0.1 1 股票书籍下载 6 10 0.12 5.8 44 股票趋势 11 20 0.11 6.95 55 股市投资 12 20 0.29 2.82 16 股票怎么开户 13 20 0.16 0.68 4 股票下载 17 20 0.2 3.4 20 世界股市行情 19 20 0.13 0.18 3 加拿大股票交易 21 20 0.17 4.29 32 怎么买美国股票 22 20 0.28 2.63 15 购买美国股票 23 20 0.18 3.42 21 股票购买 27 20 0.14 2.42 13 股票入门知识 38 30 0.12 4.35 33 股市资讯网 53 30 0.08 1.05 8 中国股指期货 58 40 0.05 5.37 42 如何买美国股票 61 40 0.26 3.51 23股票交易所 65 40 0.13 7.27 56股市场 69 40 0.21 1.39 10 股票操盘手 76 40 0.05 0.85 6 北美股票 78 50 0.22 4.75 36 股市财经 85 50 0.1 0.1 2 今日股市行情大盘走势91 50 0.13 0.97 7 股票信息 98 50 0.23 3.21 19 美国股票市场 100 70 0.29 5.36 41 怎样买股票 108 70 0.24 6.11 48 今天股票行情 110 70 0.22 6.44 51 股票基础 122 70 0.07 3.96 25 a股新股 124 90 0.05 4.07 28 股票怎么玩 130 90 0.16 2.56 14 股市指数 136 90 0.09 5.68 43 美国股票开户 144 110 0.23 6.66 53 股票行情 147 110 0.5 6.62 52投资股票 149 110 0.29 4.98 37 新加坡股票交易所 150 110 0.14 1.22 9 全球股票 151 110 0.13 2.97 18 巴菲特股票 157 110 0.07 3.48 22 a股行情 170 140 0.09 6.21 50 人民网新闻 171 170 0.2 3.97 26 股票价格 176 170 0.13 7.32 57 股票资讯 186 210 0.16 4.09 29 如何玩股票 203 260 0.14 4.7 35 股票查询 204 260 0.15 6.95 54 qq股票 206 260 0.08 5.86 45 什么是股票 207 260 0.1 3.68 24 加拿大股票 217 390 0.08 4.04 27 股票市场 220 390 0.22 4.23 31 股票型基金 226 390 0.24 4.18 30 a股基金 227 390 0.39 5.3 40 马来西亚股票 232 590 0.15 2.9 17 雅虎股票 237 720 0.15 5.88 46 股票消息 238 720 0.21 2.11 12 今日股票行情 243 880 0.2 6.19 49 美国股票 244 880 0.31 5.3 39 新浪网新闻 253 2400 0.06 0.72 5 財經網 261 8100 0.21 5.19 38 第5个簇:关键词编号搜索量竞争价值估价排名中国股市大盘 33 30 0.04 50.39 227 股票软件 39 30 0.54 40.68 219财经资讯 41 30 0.07 45.02 223 怎么炒股票 42 30 0.11 49.45 225 股票短线 43 30 0.05 33.05 205 新浪股市行情 51 30 0.04 33.96 206 股市中国 57 30 0.06 53.1 228 股票图 79 50 0.1 39.41 216 股票预测 84 50 0.04 39.11 214 同花顺股票 88 50 0.06 39.06 213 股市新闻 116 70 0.15 53.13 229 股票交易软件 128 90 0.21 38.16 211 股票学习 145 110 0.08 61.42 233 股票入门基础知识 153 110 0.14 39.81 218 中国股票市场 162 140 0.14 49.94 226 和讯股票 179 170 0.05 58.63 231 股票指数 181 210 0.06 34.19 209 tcl股票 184 210 0.04 59.64 232 股票吧 185 210 0.04 36.77 210 股价 192 210 0.05 46.88 224 网易股票 211 320 0.1 42.09 221 炒股票 216 390 0.25 41.99 220 新浪财经股票 221 390 0.12 33.99 207 中国股市行情 229 480 0.13 39.39 215 中石化股票 231 590 0.09 43.83 222 股票开户 236 590 0.17 55.28 230 苹果股票 240 720 0.06 39.59 217 证券 247 1300 0.04 38.53 212 第6个簇:关键词编号搜索量竞争价值估价排名模拟股票游戏 1 10 0.07 11.78 105 同花顺股票软件 3 10 0.1 16.73 140 买什么股票好 7 10 0.13 14.45 127 股票证券 9 20 0.13 12.9 118 新浪网股票 10 20 0.09 9.45 84 新浪财经新闻 14 20 0.05 12.35 110 上证股票 20 20 0.09 11.52 102 学股票 25 20 0.14 12.85 116 怎样炒股票 28 20 0.23 7.72 58 中国股票网 32 20 0.15 12.59 112 股票交易系统 34 30 0.17 11.46 101 今日股票行情查询 37 30 0.16 9.87 89 股票自动交易 45 30 0.08 14.92 131 买美国股票 46 30 0.5 9.26 80 如何买卖股票 47 30 0.22 8.48 69美国股票交易 48 30 0.33 8.99 78 如何购买美国股票 55 30 0.3 8.62 72 格力股票 59 40 0.08 9.82 88 股票教程 60 40 0.09 12.03 107 指数期货 63 40 0.08 12.11 108 股票代码查询 66 40 0.1 10.45 92 如何选股票 70 40 0.07 7.96 62 股票走势图 71 40 0.11 9.48 85 股票新浪 75 40 0.06 8.55 71 腾讯财经股票 77 40 0.12 14.85 129 稀土股票 82 50 0.14 13.05 119 股票行情软件 83 50 0.12 12.77 114 股票模拟 94 50 0.13 9.78 86 股票新闻 95 50 0.16 8.9 75 股票入门书籍 96 50 0.04 13.81 124 财经股票 97 50 0.66 15.39 134 股票期货 99 50 0.1 8.36 68 股票 103 70 0.13 13.17 120股票工具 106 70 0.25 10.63 94 股票游戏 112 70 0.08 14.45 128 如何炒股票 113 70 0.23 8.04 65 股票开户 115 70 0.7 10.98 96如何投资股票 118 70 0.34 9.36 82 财经新闻网 120 70 0.47 7.77 60 紫金矿业股票 121 70 0.1 13.27 121 美国股票行情 123 90 0.31 9.14 79 创业板股票 134 90 0.06 14.12 126 鸿海股票 135 90 0.07 7.74 59 新上市股票 139 110 0.18 8.83 74 建设银行股票 140 110 0.05 15.77 136 中國股票市場 143 110 0.27 16.81 141 股票走勢 146 110 0.23 8.53 70 股票估值 152 110 0.11 14.07 125 中国证券 154 110 0.03 11.29 99 股票交易所 155 110 0.52 12.22 109股票是什么 156 110 0.1 9.32 81 买股票 160 140 0.22 15.34 133 财经频道 163 140 0.02 15.96 138 股票手续费 167 140 0.12 16.67 139 如何买股票 175 170 0.18 15.22 132 股市大盘 177 170 0.07 12.88 117 股票佣金 178 170 0.37 15.56 135 股票报价 180 170 0.45 8.04 66 看股票 182 210 0.09 11.25 98股票 187 210 0.29 12.65 113股票價 188 210 0.55 11.58 103 股票推荐 195 210 0.16 13.33 122 股票代码 199 210 0.07 8.02 63 日本股票 201 260 0.17 12.36 111 今日股票 208 260 0.18 8.96 77 股票資訊 209 260 0.26 11.77 104 中國股市行情 213 320 0.07 7.88 61 股票基金 219 390 0.26 16.97 142 股票配资 224 390 0.19 8.94 76 股票论坛 225 390 0.09 12.79 115 股票 230 480 0.08 11.88 106全球股市指數 239 720 0.01 9.39 83 股市報價 241 720 0.2 8.02 64 gupiao 245 1000 0.06 15.94 137 腾讯股票 246 1000 0.05 10.86 95 财经新闻 249 1300 0.19 10.48 93 财经网 251 1900 0.22 13.38 123 今日股市行情 255 2400 0.06 8.12 67 股價 257 3600 0.08 11.08 97 股票分析 258 4400 0.06 11.38 100 财经 259 5400 0.15 10.31 91 股票行情 262 8100 0.15 10.22 90 基金 263 22200 0.41 9.81 87 美股 264 27100 0.06 8.62 73 股票 265 74000 0.27 14.87 130 第7个簇:关键词编号搜索量竞争价值估价排名股票交易平台 87 50 0.43 253.84 265 股票期权 222 390 0.05 380.25 2666.2实验结果比较拿来比较的算法用时:5600ms我的算法用时:4399ms从性能上看,我的算法好一点。