(哈希查表法)通过学号找身份证号
关于学生信息采集系统快速查找身份证重复的方法[5篇材料]
![关于学生信息采集系统快速查找身份证重复的方法[5篇材料]](https://img.taocdn.com/s3/m/45fc1cfca48da0116c175f0e7cd184254b351ba8.png)
关于学生信息采集系统快速查找身份证重复的方法[5篇材料]第一篇:关于学生信息采集系统快速查找身份证重复的方法关于学生信息采集系统快速查找身份证重复的方法使用以下方法之前确认你的电脑安装了ACCESS数据库软件或有绿色版。
1、进入学生基本信息管理系统(区县级)安装目录下,默认在D盘,找到QxStudent2012.mdb数据库文件。
双击打开,或从ACCESS中选择打开文件。
2、这时提示要求输入密码,密码是illwl。
出现阻止代码之类的提示,选择否,再选择打开。
(切记不要去改动数据库中表的字段结构,否则会影响程序的运行。
)3、这时大家会看到两张表,我们接下来操作的student这张表,另一张是相关的统计数据记录。
4、接下来请选择查询菜单。
5、新建查询。
在设计视图中创建查询,点击新建。
随便选择一种类型。
这时,选择关闭。
再选择视图菜单中的SQL视图。
将以下语句复制进去:SELECT *FROM student AS AAWHERE(Sfzh IN(SELECT sfzh FROM student AS BB WHERE AA.ID <> BB.ID));6、再点击运行图标。
在工具中去找。
接下来马上就出现一个窗口,如果窗口没有出现相关的数据,只出现字段名的话,恭喜你,你的数据库中没有身份证号重复的记录。
否则的出现你的数据就是身份证号码重复的。
7、把数据导出成EXCEL。
选择文件—保存,要求你取一个名称(随便取一个)。
再选择文件—导出,选择文件保存类型,选择好文件保存的位置,取好文件名,点击导出。
8、再打开刚刚导出的EXCEL文件,选择第一张,再选择数据=筛选=自动筛选。
现sfzh一列选择升序或者降序排列。
身份证重复的信息应该很明显了。
查询出生年月不对的信息的SQL语句:SELECT *FROM studentWHERE left(csrq,4)>2012 or mid(csrq,5,2)>12 or right(csrq,2)>31;2012其实也可以改的。
Excel技巧,在大量人员信息中找到指定人员的身份证号

工作中,经常会遇到这样的问题,要在全公司的人员信息表中,找到那么几个人的身份证信息之类的,我们最先想到的解决方案就是,CTRL+F,查找这几个人的信息并一一复制粘贴到想要的地方。
如果两三个人,还好说,如果是从上千条数据中找一百人的信息,这个工作量就非常大了。
其实,用VLookup函数,可以轻松找到自己想要的数据。
请先看演示
VLOOKUP函数应用实例1
解析:
=VLOOKUP(lookup_valuetable_arraycol_index_numrange_lookup)
翻译=Vlookup(找谁,在哪里找?,排第几列,精确查找还是模糊查找)
lookup_value-找谁,我们这次要找的是左边姓名栏的姓名
table_array-在哪里找?这里我们的数据所在区域在A列到B列
col_index_num-排第几列,这里不是说表格的第几列,而是我们选定查找区域的第几列
range_lookup-精确查找还是模糊查找,一般我们输入到这里的时候,电脑会有自动提示,我们选择即可
做完这些工作,只需要按住黑十字往下拉,hoho,所有人的身份证号码都找到了。
拷贝进新表,发给领导交差!!!。
任务表:探索身份证号的秘密
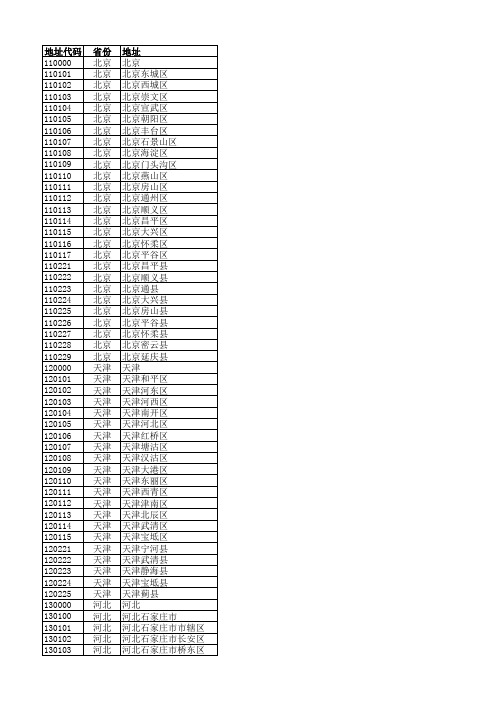
河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北 河北
地址 北京 北京东城区 北京西城区 北京崇文区 北京宣武区 北京朝阳区 北京丰台区 北京石景山区 北京海淀区 北京门头沟区 北京燕山区 北京房山区 北京通州区 北京顺义区 北京昌平区 北京大兴区 北京怀柔区 北京平谷区 北京昌平县 北京顺义县 北京通县 北京大兴县 北京房山县 北京平谷县 北京怀柔县 北京密云县 北京延庆县 天津 天津和平区 天津河东区 天津河西区 天津南开区 天津河北区 天津红桥区 天津塘沽区 天津汉沽区 天津大港区 天津东丽区 天津西青区 天津津南区 天津北辰区 天津武清区 天津宝坻区 天津宁河县 天津武清县 天津静海县 天津宝坻县 天津蓟县 河北 河北石家庄市 河北石家庄市市辖区 河北石家庄市长安区 河北石家庄市桥东区
130400 130401 130402 130403 130404 130405 130406 130421 130422 130423 130424 130425 130426 130427 130428 130429 130430 130431 130432 130433 130434 130435 130481 130500 130501 130502 130503 130521 130522 130523 130524 130525 130526 130527 130528 130529 130530 130531 130532 130533 130534 130535 130581 130582 130600 130601 130602 130603 130604 130621 130622 130623 130624 1河北沧州市东光县 河北沧州市海兴县 河北沧州市盐山县 河北沧州市肃宁县 河北沧州市南皮县 河北沧州市吴桥县 河北沧州市献县 河北沧州市孟村回族自治县 河北沧州市泊头市 河北沧州市任丘市 河北沧州市黄骅市 河北沧州市河间市 河北廊坊市 河北廊坊市市辖区 河北廊坊市安次区 河北廊坊市广阳区 河北廊坊市三河县 河北廊坊市固安县 河北廊坊市永清县 河北廊坊市香河县 河北廊坊市大城县 河北廊坊市文安县 河北廊坊市霸县 河北廊坊市大厂回族自治县 河北廊坊市霸州市 河北廊坊市三河市 河北衡水市 河北衡水市市辖区 河北衡水市桃城区 河北衡水市枣强县 河北衡水市武邑县 河北衡水市武强县 河北衡水市饶阳县 河北衡水市安平县 河北衡水市故城县 河北衡水市景县 河北衡水市阜城县 河北衡水市冀州市 河北衡水市深州市 河北邯郸地区 河北邯郸地区邯郸市 河北邯郸地区大名县 河北邯郸地区魏县 河北邯郸地区曲周县 河北邯郸地区丘县 河北邯郸地区鸡泽县 河北邯郸地区肥乡县 河北邯郸地区广平县 河北邯郸地区成安县 河北邯郸地区临漳县 河北邯郸地区磁县 河北邯郸地区武安县
身份证号码的规则及验证原理

⾝份证号码的规则及验证原理【⾝份证号码的规则】1、15位⾝份证号码组成:ddddddyymmddxxs共15位,其中:dddddd为6位的地⽅代码,根据这6位可以获得该⾝份证号所在地。
yy为2位的年份代码,是⾝份证持有⼈的出⾝年份。
mm为2位的⽉份代码,是⾝份证持有⼈的出⾝⽉份。
dd为2位的⽇期代码,是⾝份证持有⼈的出⾝⽇。
这6位在⼀起组成了⾝份证持有⼈的出⽣⽇期。
xx为2位的顺序码,这个是随机数。
s为1位的性别代码,奇数代表男性,偶数代表⼥性。
2、18位⾝份证号码组成:ddddddyyyymmddxxsp共18位,其中:其他部分都和15位的相同。
年份代码由原来的2位升级到4位。
最后⼀位为校验位。
校验规则是:(1)⼗七位数字本体码加权求和公式S = Sum(Ai * Wi), i = 0, ... , 16 ,先对前17位数字的权求和Ai:表⽰第i位置上的⾝份证号码数字值Wi:表⽰第i位置上的加权因⼦Wi: 7 9 10 5 8 4 2 1 6 3 7 9 10 5 8 4 2(2)计算模Y = mod(S, 11)(3)通过模得到对应的校验码Y: 0 1 2 3 4 5 6 7 8 9 10校验码: 1 0 X 9 8 7 6 5 4 3 2也就是说,如果得到余数为1则最后的校验位p应该为对应的0.如果校验位不是,则该⾝份证号码不正确。
以下为js版本的校验实例。
<script language="javascript"><!--var powers=new Array("7","9","10","5","8","4","2","1","6","3","7","9","10","5","8","4","2");var parityBit=new Array("1","0","X","9","8","7","6","5","4","3","2");var sex="male";//校验⾝份证号码的主调⽤function validId(obj){var _id=obj.value;if(_id=="")return;var _valid=false;if(_id.length==15){_valid=validId15(_id);}else if(_id.length==18){_valid=validId18(_id);}if(!_valid){alert("⾝份证号码有误,请检查!");obj.focus();return;}//设置性别var sexSel=document.getElementById("sex");var options=sexSel.options;for(var i=0;i<options.length;i++){if(options[i].value==sex){options[i].selected=true;break;}}}//校验18位的⾝份证号码function validId18(_id){_id=_id+"";var _num=_id.substr(0,17);var _parityBit=_id.substr(17);var _power=0;for(var i=0;i< 17;i++){//校验每⼀位的合法性if(_num.charAt(i)<'0'||_num.charAt(i)>'9'){return false;break;}else{//加权_power+=parseInt(_num.charAt(i))*parseInt(powers[i]);//设置性别if(i==16&&parseInt(_num.charAt(i))%2==0){sex="female";}else{sex="male";}}}//取模var mod=parseInt(_power)%11;if(parityBit[mod]==_parityBit){return true;}return false;}//校验15位的⾝份证号码function validId15(_id){_id=_id+"";for(var i=0;i<_id.length;i++){//校验每⼀位的合法性if(_id.charAt(i)<'0'||_id.charAt(i)>'9'){return false;break;}}var year=_id.substr(6,2);var month=_id.substr(8,2);var day=_id.substr(10,2);var sexBit=_id.substr(14);//校验年份位if(year<'01'||year >'90')return false;//校验⽉份if(month<'01'||month >'12')return false;//校验⽇if(day<'01'||day >'31')return false;//设置性别if(sexBit%2==0){sex="female";}else{sex="male";}return true;}//--></script><input type="text"onblur="validId(this)"maxlength=18 size=18> <select id="sex"><option value="male">男</option><option value="female">⼥</option>。
(WPS表格)解读居民身份证号码

(WPS表格)解读居民身份证号码15位,在18位,其编码规则按排列顺序从左至右依次为:15位:66位数字出生日期码,3位数字顺序码。
18位:68位数字出生日期码,3位数字顺序码和1位数字校验码。
下面将向用户介绍在中如何进行身份证数据的录入和利用身份证号码进行相关操作,包括以下内容:1.身份证数据的录入;2.身份证号码位数的转换;3.从身份证号码中提取生日;4.从身份证号码中提取性别;1.身份证号码的输入居民身份证号码分别存在15位和18位数字组合(除部分身份证号码以X结尾),那么身份证号码的录入也经常使用户产生困惑。
因此提供以下两种方法供用户进行数据录入:以文本方式录入:首先,设置单元格格式为“文本”,然后进行身份证号码的录入。
前置单撇号进行录入:在输入身份证号码时,先输入单撇号“'”,再输入身份证号即可,如:在单元格中输入:'123456************。
注意:以上两种方法同样可以用于如:帐号、产品编号等长数值的数据录入。
已经录入数据的修改:如果用户直接输入身份证号码,可能用户看到的是以科学计数法来显示的数值,因为在WPS表格中,整数数值仅能保留15位有效数字,而且当用户输入超过11位数值时,系统自动以科学计数法来进行显示。
因此对于这种情况,分别有两种办法来解决:1.已经输入的15位身份证:用户需要重新在单元格格式中进行自定义设置:0,身份证可以完整显示。
2.已经输入的18位身份证:由于整数数值仅能保留15位有效数字,系统除了显示成科学计数法以外,原来录入的数据系统只能保留前15位有效数字,其他3位数字以0显示,数据精度已经丢失。
因此这种数据只能重新录入。
2.15位与18位身份证的相互转换:进入公安局新颁发的居民身份证都是18位。
某些时候用户如果需要将15位身份证和18位身份证位数进行转换(或进行校验),可以使用以下两种方法:15位转换为18位:如:A2单元格为某一15位身份证号码,{=REPLACE(A2,7,,19)&MID("10X98765432",MOD(SUM(MID(REPLACE(A2,7,,19),ROW(IND IRECT("1:17")),1)*2^(18-ROW(INDIRECT("1:17")))),11)+1,1)}利用这个公式的原理,用户还可以对18位身份证进行校验,只需要将公式中“REPLACE(A2,7,,19)”修改为“LEFT(A2,17)”即可。
最新静态查找表动态查找表哈希查找表

ST.elem[i]. Key <= ST.elem[i+1]. Key; i= 1, 2 ,…n-1 查找范围 :low(低下标)= 1;
high(高下标)= 7 (初始时为最大下标 n ); 比较对象:中点元素,其下标地址为
mid = (low+high)/ 2 =4
二分法思想: (1)用给定的k与有序表的中间位置mid上的结 点的关键字比较,若相等,查完 (2)若r[mid].key < k,则在左子表中继续进行 二分查找;若(r[mid].key > k),则执行(3 ) (3)在右子表中继续进行二分查找。
有序表的查找
查找 key = 9 的结点所在的数组元素的下标地址。
有序表的查找
mid= 4
4 8 9 10 11 13 19
0 1 23
low=1
4 5 67
high=7
mid= 4
4 8 9 10 11 13 19 20
0 1 23
low=1
4 5 678
high=8
有序表的查找
性能分析
1、最坏情况分析:
定理:在最坏情况下,二分查找法的查找有序表的最大的比较次数为
<
5 <> 45
>
7 <> 6
8
<>
78
有序表的查找
性能分析
2、平均情况分析(在成功查找的情况下):设每个 结点的查找概率相同 都为1/n。为了简单起见,设结点个数为 n = 2t -1 (t = 1,2,3 …… )。 ∴ 经过 1 次比较确定的结点个数为 1 = 20 个 ,红色标识的结点。 经过 2 次比较确定的结点个数为 2 = 21 个 ,绿色标识的结点。 经过 3 次比较确定的结点个数为 4 = 22 个 ,灰色标识的结点。
数据结构 第9章 查找4-哈希表

7、随机数法 Hash(key) = random ( key ) (random为伪随机函数)
适用于:关键字长度不等的情况。造表和查找都很方便。
小结:构造哈希函数的原则:
① ② ③ ④ ⑤ 执行速度(即计算哈希函数所需时间); 关键字的长度; 哈希表的大小; 关键字的分布情况; 查找频率。
三、冲突处理方法
14 H(14)=14%7=0
6个元素用7个 地址应该足够!
1
2
23 9
3
4
39 25 11
5
6
H(25)=25%7=4 H(11)=11%7=4
有冲突!
在哈希查找方法中,冲突是不可能避免的,只能 尽可能减少。
所以,哈希方法必须解决以下两个问题:
1)构造好的哈希函数
(a)所选函数尽可能简单,以便提高转换速度; (b)所选函数对关键码计算出的地址,应在哈希地址集中 大致均匀分布,以减少空间浪费。
讨论:如何进行散列查找?
根据存储时用到的散列函数H(k)表达式,迅即可查到结果! 例如,查找key=9,则访问H(9)=9号地址,若内容为9则成功; 若查不到,应当设法返回一个特殊值,例如空指针或空记录。
缺点:空间效率低!
若干术语
哈希方法 (杂凑法)
选取某个函数,依该函数按关键字计算元素的存储位置, 并按此存放;查找时,由同一个函数对给定值k计算地址, 将k与地址单元中元素关键码进行比较,确定查找是否成 功。
3. 乘余取整法
4. 数字分析法
5. 平方取中法
常用的哈希函数构造方法有:
6. 折叠法
7. 随机数法
1、直接定址法
(a、b为常数) 优点:以关键码key的某个线性函数值为哈希地址, 不会产生冲突. 缺点:要占用连续地址空间,空间效率低。
Excel帮你轻松获取身份证号码隐藏的信息,轻松统计人员基本信息

Excel帮你轻松获取身份证号码隐藏的信息,轻松统计人员基本信息在实际工作中,我们可能会对一些人员的基本信息进行统计,往往我们可能会一项项的输入,其实呢,在Excel中如果我们知道了身份证号,可以利用简单的公式统计出一些具体的个人信息,你比如省份,具体所在地区,出生日期,年龄,性别等。
首先呢,我们先了解一下我国身份证号的编号规律:1-2位代码是指省、自治区、直辖市代码3-4位代码是指地级市、盟、自治州代码5-6位代码是指县、县级市、区代码7-14位代码是指出生年月日15-17位为顺序号,其中第17位如果是奇数指男性,偶数指女性最后一位就是校验码知道这些之后,接下来我们看一下怎样用Excel得到相关信息一、如何得到省份信息。
首先我们需要准备好一份地区代码对照表,这个可以从网上下载,或者是私信我,我发给你们电子版。
将对照表复制到Excel表格中,添加上身份证信息。
然后在省份一栏输入公式。
=VLOOKUP(LEFT(C2,2),A:B,2)解释一下公式:首先LEFT函数是用来对单元格里的内容进行截取选择,从左边第一个字符开始截取,截取指定的长度。
这里的LEFT(C2,2) 就是从C2单元格里面的数值,从左往右截取两位。
VLOOKUP函数就是竖直查找,即列查找。
在指定竖直列区域内查找,找到指定的内容,返回指定列的数据。
这里VLOOKUP(LEFT(C2,2),A:B,2) 就是在A、B列(也就是我们提前准备好的地区代码对照表)查找省份证信息的前两位返回的值是第二列对应的值(这里的第二列就是B列了,不过要注意在使用此函数时,返回第n列的数值不一定对应相应的字母列,这需要我们从选定的区域第一列开始数一下)填完了第一个单元格,鼠标移动到单元格右下角,变成加好时双击或者往下拉就行了。
二、如何得到具体所在地区信息。
公式基本和上面一样,就是利用LEFT函数截取位数时,这次截取前六位的长度。
=VLOOKUP(LEFT(C2,6),A:B,2)三、如何得到出生年月日信息。
三年级数学身份证编码规则及各位表示含义

三年级数学身份证编码规则及各位表示含义数学作为一门科学,在考察和认识客观事物的本质和规律上具有非常重要的地位。
在数学教育过程中,数学身份证编码规则也接受了广泛的应用和推广。
本文就以三年级学生数学身份证编码规则为例,来结合实际情况,为大家解析各位表示含义。
一、三年级数学身份证编码规则三年级数学身份证编码规则是根据学生在数学方面的表现水平确定的,由18位字符组成,包括11位校园代码,6位学生编号,1位校验位。
1)11位校园代码:前六位代表校本部、校区编号,其中第一位代表家长选择就近入学;第二位代表年级,三/四年级分别用3/4表示;第三位代表班级编号;后四位表示科目类别,数学代码为1000,语文代码为1001,英语代码为1002,物理代码为1003,化学代码为1004,生物代码为1005,地理代码为1006,历史代码为1007。
2) 6位学生编号:由大写字母、数字(0-9)组成,前二位表示学生姓名,后四位表示学生出生年月,前两位表示月份,后两位表示日期。
3) 1位校验位:最后一位数字是校验位,即根据其他信息,由校方计算给出,以验证输入数据的准确性。
二、各位表示含义1) 11位校园代码:用来表示某个学生所在的学校,班级,学科类别等信息,便于校园提供信息管理和准确的考试数据分析和记录。
2) 6位学生编号:用来标识某个学生的身份,使用字母和数字混合编码,便于管理快速准确地辨别学生身份,实现更精准的管理。
3) 1位校验位:校验位使用一个数字,根据输入的信息,有效地验证输入是否正确,当校验位和计算出来的数字不一致,说明输入信息有误,需要进行核实。
三、总结以上就是关于三年级数学身份证编码规则及其各位表示含义的介绍,从中可以看出,数学身份证编码规则在校园管理中起着重要的作用,有效地提升了学校管理的准确性和效率。
希望通过本文能够对大家产生帮助,更加清楚地了解数学身份证编码规则。
详解数据结构之散列(哈希)表
详解数据结构之散列(哈希)表1.散列表查找步骤散列表,最有用的基本数据结构之一。
是根据关键码的值直接进行访问的数据结构,散列表的实现常常叫做散列(hasing)。
散列是一种用于以常数平均时间执行插入、删除和查找的技术,下面我们来看一下散列过程。
我们的整个散列过程主要分为两步:1.通过散列函数计算记录的散列地址,并按此散列地址存储该记录。
就好比麻辣鱼,我们就让它在川菜区,糖醋鱼,我们就让它在鲁菜区。
但是我们需要注意的是,无论什么记录我们都需要用同一个散列函数计算地址,然后再存储。
2.当我们查找时,我们通过同样的散列函数计算记录的散列地址,按此散列地址访问该记录。
因为我们存和取的时候用的都是一个散列函数,因此结果肯定相同。
刚才我们在散列过程中提到了散列函数,那么散列函数是什么呢?我们假设某个函数为f,使得存储位置= f (key) ,那样我们就能通过查找关键字不需要比较就可获得需要的记录的存储位置。
这种存储技术被称为散列技术。
散列技术是在通过记录的存储位置和它的关键字之间建立一个确定的对应关系 f ,使得每个关键字key 都对应一个存储位置f(key)。
见下图这里的 f 就是我们所说的散列函数(哈希)函数。
我们利用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间就是我们本文的主人公------散列(哈希)上图为我们描述了用散列函数将关键字映射到散列表。
但是大家有没有考虑到这种情况,那就是将关键字映射到同一个槽中的情况,即f(k4) = f(k3) 时。
这种情况我们将其称之为冲突,k3 和k4 则被称之为散列函数 f 的同义词,如果产生这种情况,则会让我们查找错误。
幸运的是我们能找到有效的方法解决冲突。
首先我们可以对哈希函数下手,我们可以精心设计哈希函数,让其尽可能少的产生冲突,所以我们创建哈希函数时应遵循以下规则:1.必须是一致的。
假设你输入辣子鸡丁时得到的是在看,那么每次输入辣子鸡丁时,得到的也必须为在看。
第九章哈希表

对增量 di 有三种取法:
• 1) • 2) • 3) • 线 平 随 性 方 机 探 探 探 测 测 测 再 再 再 散 散 散 列 列 列 di = c× i 最简单的情况 c=1 di = 12, -12, 22, -22, …, di 是一组伪随机数列 或者 伪随机数列 di=i×H2(key) (又称双散列函数探测 又称双散列函数探测) 又称双散列函数探测
二、构造哈希函数的方法 构造哈希函数的方法
对数字 数字的关键字可有下列构造方法: 数字
1. 直接定址法 2. 数字分析法 3. 平方取中法
4. 折叠法 5. 除留余数法 6. 随机数法
若是非数字关键字 非数字关键字,则需先 需先对其进行 进行 非数字关键字 需先 数字化处理。 数字化处理
1. 直接定址法
注意: 应具有“完备性” 注意:增量 di 应具有“完备性”
即:产生的 Hi 均不相同,且所产生的 s(m-1)个 Hi 值能覆盖 覆盖哈希表中所有 个 覆盖 地址。则要求: ※ 平方探测时的表长 m 必为形如 4j+3 的素数(如: 7, 11, 19, 23, … 等); ※ 随机探测时的 m 和 di 没有公因子。
示例: 示例: 有一个关键码 key = 962148,散列表大小 , m = 25,即 HT[25]。取质数 p= 23。散列函数 , 。 。 hash ( key ) = key % p。则散列地址为 。
hash ( 962148 ) = 962148 % 23 = 12。 12。
6.随机数法 随机数法
例如:为每年招收的 1000 名新生建立
一张查找表,其关键字为学号,其值的 范围为 xx000 ~ xx999 (前两位为年份)。 若以下标为 以下标为000 ~ 999 的顺序表 的顺序表表示之。 以下标为 则查找过程可以简单进行:取给定值 (学号)的后三位,不需要经过比较 不需要经过比较便 不需要经过比较 可直接从顺序表中找到待查关键字。
哈希表的查找

1
2 3
4
2)算法思想: 设n 个记录存放在一个有序顺序表 L 中,并按其关键 码从小到大排好了序。查找范围为l=0, r=n-1; 求区间中间位置mid=(l+r)/2; 比较: L[mid].Key = x,查找成功,返回mid,结束; L[mid].Key > x,r=mid-1; L[mid].Key < x,l=mid+1; 若l<=r 转2,否则查找失败,返回 0;
对查找表常用的操作有哪些?
查询某个“特定的”数据元素是否在表中; 查询某个“特定的”数据元素的各种属性; 在查找表中插入一元素; 从查找表中删除一元素。
9.1 基本概念
如何评估查找方法的优劣? 查找的过程就是将给定的值与文件中各记录的关 键字逐项进行比较的过程。所以用比较次数的平均值 来评估算法的优劣,称为平均查找长度(ASL: average search length)。i 1 i Ci ASL P
考虑对单链表结构如何折半查找? ——无法实现!
2)算法实现:
int Search_Bin ( SSTable ST, KeyType key ) { // 在有序表ST中折半查找其关键字等于key的数据元素。 // 若找到,则函数值为该元素在表中的位置,否则为0。 low = 1; high = ST.length; // 置区间初值 while (low <= high) { mid = (low + high) / 2; if (key == ST.elem[mid].key) return mid; // 找到待查元素 else if ( key < ST.elem[mid].key) high = mid - 1; // 继续在前半区间进行查找 else low = mid + 1; // 继续在后半区间进行查找 } return 0; // 顺序表中不存在待查元素 } // Search_Bin
哈希表的应用快速查找和去重操作

哈希表的应用快速查找和去重操作哈希表的应用:快速查找和去重操作哈希表(Hash Table)是一种常用的数据结构,它通过散列函数将数据存储在数组中,以实现快速的查找和去重操作。
本文将介绍哈希表的原理和应用,以及如何利用哈希表实现快速查找和去重。
一、哈希表的原理哈希表是由键(Key)和值(Value)组成的键值对(Key-Value)结构。
其核心思想是通过散列函数将键映射为数组的索引,然后将值存储在对应索引的位置上。
这样,在进行查找或者去重操作时,只需计算键的散列值即可定位到对应的存储位置,从而实现常数时间复杂度的操作。
二、哈希表的应用1. 快速查找哈希表在快速查找中发挥了重要的作用。
由于其根据键计算散列值后直接定位到存储位置,所以查找的时间复杂度为O(1)。
这在处理大量数据时,能够显著提高查找效率。
例如,我们可以利用哈希表存储学生的学号和对应的成绩,当要查询某个学生的成绩时,只需通过学号计算散列值,并在哈希表中查找即可,无需遍历整个数组。
2. 去重操作哈希表还可以用于去除重复元素。
在需要对一组数据进行去重时,可以利用哈希表的特性,将元素作为键,将值设为1(或其他常数),并将其存储在哈希表中。
这样,在插入元素时,通过计算散列值即可判断元素是否已存在。
举例来说,假设我们有一个包含大量文章标题的列表,我们希望去除重复的标题。
可以使用哈希表存储已出现过的标题,并在插入新标题时判断是否已存在。
若已存在,则不加入哈希表,从而实现快速、高效的去重操作。
三、哈希表的实现实现哈希表通常需要解决以下几个问题:1. 散列函数的设计散列函数是哈希表实现的核心。
一个好的散列函数能够将键均匀地映射到不同的散列值,以尽量避免冲突。
2. 冲突的处理由于哈希表的存储位置是有限的,不同的键可能会映射到相同的索引位置上,即发生冲突。
常见的解决方法有拉链法(Chaining)和开放地址法(Open Addressing)。
3. 哈希表的动态扩容当哈希表中的元素数量超过存储容量时,需要进行动态扩容,以保证操作的性能。
利用EXCEL公式鉴别身份证号码 共16页

9
2 EXCEL鉴别公式简介
身份证校验码的计算方法
1、将前面的身份证号码17位数分别乘以不同的系数。第i位对应的数为[2^(18i)]mod11。从第一位到第十七位的系数分别为:7 9 10 5 8 4 2 1 6 3 7 9 10 5 842;
谢谢聆听
15
谢谢你的阅读
知识就是财富 丰富你的人生
IF(LEN(身份证)=18,MID("10X98765432",MOD(SUMPRODUCT(MID(身份证, ROW(INDIRECT("1:17")),1)*2^(18ROW(INDIRECT("1:17")))),11)+1,1)=RIGHT(身份证), IF(LEN(身份证)=15,ISNUMBER(--TEXT(19&MID(身份证,7,6),"#-00-00"))))
利用EXCEL公式鉴别 身份证号码正误
1
目录
1 一二代身份证简介 23 EXCEL鉴别公式简介
3
工作相关改善
2
自1984年为中华人民共和国公民颁发的身 份证明性证件,第一阶段采用印刷和照相翻拍技术塑封而成,为聚酯 薄膜密封、单页卡式,15位编码。2019年7月1日起启用新的防伪居 民身份证,采用全息透视塑封套防伪。2019年10月1日起,建立和实 行公民身份号码制度,身份代码是唯一的、终身不变的18位号码。 2019年1月1日,第二代居民身份证开始换发 。
6
目录
1 一二代身份证简介
23 EXCEL鉴别公式简介
3
工作相关改善
【最新】帮我找个身份证号码-word范文模板 (8页)

本文部分内容来自网络整理,本司不为其真实性负责,如有异议或侵权请及时联系,本司将立即删除!== 本文为word格式,下载后可方便编辑和修改! ==帮我找个身份证号码篇一:身份证号查找图片并重命名在一个点在表格中,有学生的学号,身份证号,姓名等信息,另外有一个以身份证号命名的图片文件夹,现在需要将电子表格中有身份证号的学生的照片筛选出来并需要用学籍号重命名图片文件夹如下:D盘中有一个名为学籍号的文件夹,里面有很多以学生身份证号命名的照片学生信息表入下:现在要把以上同学身份证号对应的照片找出来并存放到另外一个文件夹中(本例子以存放在D盘目录下的xuejihao文件夹为例)第一步,建立好文件夹xuejihao第二步,在电子表格中第一条记录后面的空白单元格中输入="copy d:\学籍号\"&E2&".jpg d:\xuejihao\",在表格中显示如下图所示:第三步,按住F2的填充柄将需要筛选照片的换充满,如图所示:第四步,新建一个txt格式文档,并将F列的数据复制到新建的文档中保存,然后将这个文档的后缀名改为 .bat 文件名可以是任意的,合法即可第五步:双击重命名后的文件即可,这时就会在xuejihao文件夹中出现所需要的照片重命名第一步:在excel中仿照以上步骤输入公式 ="ren "&E2&".jpg "&C2&".jpg",(G2单元格中)按填充柄充满,结果如下:第G列第二步:在xuejihao文件夹中新建一个文本文档,讲G列的数据复制到该文本文档中保存,然后将后缀名改为.bat第三步,双击该文件即可将所有的文件以学号重命名。
(结果入下)篇二:查找身份证重复号码函数查找身份证重复号码函数=and(countif(H:H,H7&”*”)>1,H7<>””)篇三:(哈希查表法)通过学号找身份证号/*本C语言例程实现了一个简单的哈希查表算法:使用随机函数生成100个学生std[100]的学号与身份证号,分别为studentNum 与idNum 通过一个最大能容纳1024个学生的哈希表mHashTable来存储这100个学生的身份资料利用第i个学生独立的学号生成的索引号indexNum =Hash(std[i].studentNum),把对应这个学生的资料存储进哈希表mHashTable.std[indexNum] = std[i];如果需要通过某个学生的学号查询他的身份证号(抑或其他数据比如名字年龄性别什么的),就不需要遍历查询100个学生的学号,只需要利用学号生成索引号indexNum,再把对应mHashTable.std[indexNum] 学生结构体里的数据都拿出来就行了.哈希查表算法的关键在于:1. int Hash(int key) 哈希函数的设计,如何利用特定的数据算出一个索引号,下面是常用算法,需要根据关键字长度,哈希表大小,哈希函数计算时间,记录查找频率等因素来确定使用什么算法.(key是关键字,在本程序中指代studentNum 中的关键数据,我懒了就直接用这个studentNum当关键字)1.1直接定址法: return a*key + b;1.2数字分析法:1.3平方取中法: return (int)(((key*key)>>16)&0x000000ff) 平方后使用中间12位的数据1.4 折叠法:1.5 取模法:return key%512 本程序采用这种方法1.6 随机数法:rand() 函数等2. 索引号冲突的处理算法,比如我有学号311422与311934 ,两者通过取模法生成的索引号都是 126,由于311422的资料已占据了mHashTable.std[126] ,该如何得出新的索引号以防止311934的资料复写到mHashTable.std[126]里,下面是常用的算法:2.1 开放定址法: indexNum = indexNum + di , di可以是1,2,3到k(k<MAX)或者1,-1,4,-4,9,-9,16,-16,25,-25到k^2 (k^2<MAX) 抑或者是随机数2.2 再哈希法: indexNum = R*Hash(indexNum);2.3 链地址法:所有同索引号的成员资料都存进同一个线性链表里2.4 公共溢出区:把所有冲突者的资料悉数放入另一张哈希表*/#include <stdio.h>#include <stdlib.h>#include <time.h>#define MAX 1024#define EMPTY 0#define EXIST -1#define FULL -2typedef struct {int studentNum;int idNum;}Student;typedef struct{Student *std;int sizeIndex;。
(哈希查表法)通过学号找身份证号

/*本C语言例程实现了一个简单的哈希查表算法:使用随机函数生成100个学生std[100]的学号与身份证号,分别为studentNum与idNum 通过一个最大能容纳1024个学生的哈希表mHashTable来存储这100个学生的身份资料利用第i个学生独立的学号生成的索引号indexNum = Hash(std[i].studentNum),把对应这个学生的资料存储进哈希表mHashTable.std[indexNum] = std[i];如果需要通过某个学生的学号查询他的身份证号(抑或其他数据比如名字年龄性别什么的),就不需要遍历查询100个学生的学号,只需要利用学号生成索引号indexNum,再把对应mHashTable.std[indexNum] 学生结构体里的数据都拿出来就行了.哈希查表算法的关键在于:1.int Hash(int key) 哈希函数的设计,如何利用特定的数据算出一个索引号,下面是常用算法,需要根据关键字长度,哈希表大小,哈希函数计算时间,记录查找频率等因素来确定使用什么算法.(key是关键字,在本程序中指代studentNum 中的关键数据,我懒了就直接用这个studentNum当关键字)1.1直接定址法: return a*key + b;1.2数字分析法:1.3平方取中法: return (int)(((key*key)>>16)&0x000000ff) 平方后使用中间12位的数据1.4 折叠法:1.5 取模法:return key%512 本程序采用这种方法1.6 随机数法:rand() 函数等2.索引号冲突的处理算法,比如我有学号311422与311934 ,两者通过取模法生成的索引号都是126,由于311422的资料已占据了mHashTable.std[126] ,该如何得出新的索引号以防止311934的资料复写到mHashTable.std[126]里,下面是常用的算法:2.1 开放定址法: indexNum = indexNum + di , di可以是1,2,3到k(k<MAX)或者1,-1,4,-4,9,-9,16,-16,25,-25到k^2 (k^2<MAX) 抑或者是随机数2.2 再哈希法: indexNum = R*Hash(indexNum);2.3 链地址法:所有同索引号的成员资料都存进同一个线性链表里2.4 公共溢出区:把所有冲突者的资料悉数放入另一张哈希表*/#include<stdio.h>#include<stdlib.h>#include<time.h>#define MAX 1024#define EMPTY 0#define EXIST -1#define FULL -2typedef struct {int studentNum;int idNum;}Student;typedef struct{Student *std;int sizeIndex;int studentCount;}HashTable;int Hash(int studentNum){return studentNum%(MAX/2);}void InitHash(HashTable *H){int i;H->std = (Student*)malloc(MAX*sizeof(Student));H->sizeIndex = MAX;H->studentCount = 0;for(i=0;i<MAX;i++){H->std[i].studentNum = 0;H->std[i].idNum = 0;}}int SearchHash(HashTable H,int studentNum,int *indexHash){int count;*indexHash = Hash(studentNum);for(count = 0; count < MAX, *indexHash < MAX; count+=1){ if(H.std[*indexHash].studentNum == 0)return EMPTY;if(H.std[*indexHash].studentNum == studentNum)return EXIST;*indexHash = *indexHash + 1;}return FULL;}int InsertHash(HashTable *H,Student std){int indexHash;int ret = SearchHash(*H,std.studentNum,&indexHash);switch(ret){case EXIST:return EXIST;case EMPTY:H->std[indexHash] = std;H->studentCount ++;break;case FULL:return FULL;}return ret;}void PrintHash(HashTable *H){int i;printf("Start print HashTable:\n");for(i=0;i<MAX;i++){if(H->std[i].studentNum!=0)printf("Hash : std[%d].studentNum = %d , idNum = %d \n",i,H->std[i].studentNum,H->std[i].idNum);}printf("End of HashTable\n");return;}Student* InitStudent(int num){int i;Student *std;std = (Student *)malloc(num*sizeof(Student));for(i=0;i<num;i++){srand((unsigned int )(time(0)*i));std[i].studentNum = rand();srand((unsigned int )(time(0)*std[i].studentNum));std[i].idNum = rand();}return std;}void PrintStudent(Student* std,int num){int i;for(i=0;i<num;i++)printf("std[%d].studentNum = %d, idNum = %d\n",i,std[i].studentNum,std[i].idNum);}int main(){int i;int studentNum;int indexHash;Student *std;HashTable mHashTable;std = InitStudent(100);InitHash(&mHashTable);std[20].studentNum=std[10].studentNum+(MAX/2);i=10;printf("std[%d].studentNum = %d, idNum = %d\n",i,std[i].studentNum,std[i].idNum);i=20;printf("std[%d].studentNum = %d, idNum = %d\n",i,std[i].studentNum,std[i].idNum);//PrintStudent(std,100);for(i=0;i<100;i++)InsertHash(&mHashTable,std[i]);PrintHash(&mHashTable);printf("student count = %d \n",mHashTable.studentCount);while(1){printf("Please use the \"student number\" to find the \"id numer\" :");scanf("%d",&studentNum);if(mHashTable.std[Hash(studentNum)].studentNum == 0)printf("Student number error!\n");if(EXIST == SearchHash(mHashTable,studentNum,&indexHash))printf("\nStudent number %d 's id number is %d \n\n",mHashTable.std[indexHash].studentNum,mHashTable.std[indexHash].idNum);}PrintHash(&mHashTable);return 0;}。
用Excel校验身份证号码的方法

用Excel校验身份证号码的方法威远县东联镇小学校·罗斌身份证号码中的校验码是身份证号码的最后一位,是根据〖中华人民共和国国家标准GB 11643-1999〗中有关公民身份号码的规定,根据相应的规定计算出来的。
公民身份号码是特征组合码,由十七位数字本体码和一位数字校验码组成。
排列顺序从左至右依次为:六位数字地址码,八位数字出生日期码,三位数字顺序码,最后一位是数字校验码。
最后一位的数字校验码是由前17位唯一确定的,随便乱填的身份证号就不能通过校验。
下面分步详细介绍一下用Excel校验身份证号码的一种方法:1.在D1到T1这17个单元格中依次输入1到17这17个数。
2.在D2中输入公式:=2^(18-D1)。
单击D2拖动鼠标向右填充到T2。
3.在D3中输入公式:=MOD(D2,11)以得到身份证第一位的校验系数。
单击D3拖动鼠标向右填充至T3可以得到前17位中每一位的校验系数。
4.在B5至B14中输入要校验的身份证号码(这里选择的是10个身份证号码),实际选择的身份证号码数可以自定。
5.在D5中输入公式:=MID($B5,D$1,1)*1以提取身份证的第一个数字,乘1的目的是将第一个数字由文本格式转为数字格式,便于后续的计算。
单击D5拖动鼠标向右填充至T5可以得到身份证号的前17位的每个数字。
6.在U5中输入公式:=SUMPRODUCT($D$3:$T$3,D5:T5)计算出前十七位数字和相应的校验系数的乘积之和。
7.在V5中输入公式:=MOD(1-U5,11)以得到该身份证的校验数。
8.在W5中输入公式:=IF(V5=10,"X",V5)以得到该身份证的校验码。
9.在X5中输入公式:=MID(B5,1,17)&W5得到由前17位计算出的正确的身份证号码。
10.在C5 中输入公式:=IF(B5=X5,"校验正确","号码错误!")以得到第一个身份证的校验结果。
字典表的使用

字典表的使用字典表是一种数据结构,主要用于存储键值对形式的信息,其中每个键都对应一个唯一的值。
字典表的使用在现代计算机科学中非常广泛,针对不同的应用场景,有着不同的实现方式和优化策略。
本文将从字典表的基础概念、常见实现方法、使用场景和实际应用等方面,介绍字典表的使用。
一、基础概念1.1 键值对键值对是字典表中最基本的数据单元,它由两部分组成:键和值。
键用于唯一标识一个数据单元,值则是与该键相对应的具体数据内容。
例如,在一个学生信息系统中,学生的学号就可以作为键,而学生的姓名、年龄、班级等信息则可以作为相应的值。
1.2 哈希表哈希表是实现字典表最常用的数据结构之一,它是由一组桶(Bucket)构成的数组,每个桶中又保存着一个链表。
当需要存储键值对时,哈希表首先根据键的哈希值(Hash Value),找到相应的桶,然后再在该桶所对应的链表中查找指定的键。
如果该键已经存在,则直接修改相应的值;否则,就在链表的末尾插入一个新节点,完成键值对的添加。
1.3 二叉搜索树二叉搜索树是另一种常用的数据结构,它是由一组节点构成的树形结构,且每个节点最多只有两个子节点。
二叉搜索树的特点是,左子树上的所有节点的键值均小于根节点的键值,而右子树上的所有节点的键值均大于根节点的键值。
当需要查找一个键值对时,就可以根据比较大小的原则,快速地定位该节点所在的位置。
二、常见实现方法2.1 哈希表哈希表的实现方法主要有两个关键点:哈希函数(Hash Function)和冲突解决方法。
哈希函数是将任意长度的输入数据(例如一个字符串或对象)映射为固定长度输出的函数,通常采用取模运算等方法实现。
冲突解决方法则是处理由于哈希函数产生的哈希冲突(即两个键被映射到同一个桶上的现象),常见的方法有链表法、开放地址法等。
2.2 二叉搜索树二叉搜索树的实现方法主要有两种:一种是普通的二叉搜索树,每个节点仅保存一个键和值;另一种是平衡二叉搜索树,它可以保证搜索树的左右子树高度差不超过1,从而达到快速查找和插入的效果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
/*本C语言例程实现了一个简单的哈希查表算法:使用随机函数生成100个学生std[100]的学号与身份证号,分别为studentNum与idNum 通过一个最大能容纳1024个学生的哈希表mHashTable来存储这100个学生的身份资料利用第i个学生独立的学号生成的索引号indexNum = Hash(std[i].studentNum),把对应这个学生的资料存储进哈希表mHashTable.std[indexNum] = std[i];如果需要通过某个学生的学号查询他的身份证号(抑或其他数据比如名字年龄性别什么的),就不需要遍历查询100个学生的学号,只需要利用学号生成索引号indexNum,再把对应mHashTable.std[indexNum] 学生结构体里的数据都拿出来就行了.哈希查表算法的关键在于:1.int Hash(int key) 哈希函数的设计,如何利用特定的数据算出一个索引号,下面是常用算法,需要根据关键字长度,哈希表大小,哈希函数计算时间,记录查找频率等因素来确定使用什么算法.(key是关键字,在本程序中指代studentNum 中的关键数据,我懒了就直接用这个studentNum当关键字)1.1直接定址法: return a*key + b;1.2数字分析法:1.3平方取中法: return (int)(((key*key)>>16)&0x000000ff) 平方后使用中间12位的数据1.4 折叠法:1.5 取模法:return key%512 本程序采用这种方法1.6 随机数法:rand() 函数等2.索引号冲突的处理算法,比如我有学号311422与311934 ,两者通过取模法生成的索引号都是126,由于311422的资料已占据了mHashTable.std[126] ,该如何得出新的索引号以防止311934的资料复写到mHashTable.std[126]里,下面是常用的算法:2.1 开放定址法: indexNum = indexNum + di , di可以是1,2,3到k(k<MAX)或者1,-1,4,-4,9,-9,16,-16,25,-25到k^2 (k^2<MAX) 抑或者是随机数2.2 再哈希法: indexNum = R*Hash(indexNum);2.3 链地址法:所有同索引号的成员资料都存进同一个线性链表里2.4 公共溢出区:把所有冲突者的资料悉数放入另一张哈希表*/#include<stdio.h>#include<stdlib.h>#include<time.h>#define MAX 1024#define EMPTY 0#define EXIST -1#define FULL -2typedef struct {int studentNum;int idNum;}Student;typedef struct{Student *std;int sizeIndex;int studentCount;}HashTable;int Hash(int studentNum){return studentNum%(MAX/2);}void InitHash(HashTable *H){int i;H->std = (Student*)malloc(MAX*sizeof(Student));H->sizeIndex = MAX;H->studentCount = 0;for(i=0;i<MAX;i++){H->std[i].studentNum = 0;H->std[i].idNum = 0;}}int SearchHash(HashTable H,int studentNum,int *indexHash){int count;*indexHash = Hash(studentNum);for(count = 0; count < MAX, *indexHash < MAX; count+=1){ if(H.std[*indexHash].studentNum == 0)return EMPTY;if(H.std[*indexHash].studentNum == studentNum)return EXIST;*indexHash = *indexHash + 1;}return FULL;}int InsertHash(HashTable *H,Student std){int indexHash;int ret = SearchHash(*H,std.studentNum,&indexHash);switch(ret){case EXIST:return EXIST;case EMPTY:H->std[indexHash] = std;H->studentCount ++;break;case FULL:return FULL;}return ret;}void PrintHash(HashTable *H){int i;printf("Start print HashTable:\n");for(i=0;i<MAX;i++){if(H->std[i].studentNum!=0)printf("Hash : std[%d].studentNum = %d , idNum = %d \n",i,H->std[i].studentNum,H->std[i].idNum);}printf("End of HashTable\n");return;}Student* InitStudent(int num){int i;Student *std;std = (Student *)malloc(num*sizeof(Student));for(i=0;i<num;i++){srand((unsigned int )(time(0)*i));std[i].studentNum = rand();srand((unsigned int )(time(0)*std[i].studentNum));std[i].idNum = rand();}return std;}void PrintStudent(Student* std,int num){int i;for(i=0;i<num;i++)printf("std[%d].studentNum = %d, idNum = %d\n",i,std[i].studentNum,std[i].idNum);}int main(){int i;int studentNum;int indexHash;Student *std;HashTable mHashTable;std = InitStudent(100);InitHash(&mHashTable);std[20].studentNum=std[10].studentNum+(MAX/2);i=10;printf("std[%d].studentNum = %d, idNum = %d\n",i,std[i].studentNum,std[i].idNum);i=20;printf("std[%d].studentNum = %d, idNum = %d\n",i,std[i].studentNum,std[i].idNum);//PrintStudent(std,100);for(i=0;i<100;i++)InsertHash(&mHashTable,std[i]);PrintHash(&mHashTable);printf("student count = %d \n",mHashTable.studentCount);while(1){printf("Please use the \"student number\" to find the \"id numer\" :");scanf("%d",&studentNum);if(mHashTable.std[Hash(studentNum)].studentNum == 0)printf("Student number error!\n");if(EXIST == SearchHash(mHashTable,studentNum,&indexHash))printf("\nStudent number %d 's id number is %d \n\n",mHashTable.std[indexHash].studentNum,mHashTable.std[indexHash].idNum);}PrintHash(&mHashTable);return 0;}。