GP 常用数据库命令
gp数据库循环语句

gp数据库循环语句GP数据库是一种关系型数据库管理系统,它可以通过循环语句来实现对数据库中数据的逐行处理。
下面列举了十个基于GP数据库的循环语句的示例。
1. 使用FOR循环语句遍历表中的所有记录```sqlFOR row IN SELECT * FROM table_name LOOP-- 处理每一行数据的逻辑-- 可以使用row.column_name来访问每一列的值END LOOP;```2. 使用WHILE循环语句实现条件控制的循环```sqlDECLAREcounter integer := 0;BEGINWHILE counter < 10 LOOP-- 处理逻辑counter := counter + 1;END LOOP;END;```3. 使用CURSOR循环语句遍历游标中的结果集```sqlDECLAREcursor_name CURSOR FOR SELECT * FROM table_name; row record;BEGINOPEN cursor_name;LOOPFETCH cursor_name INTO row;EXIT WHEN NOT FOUND;-- 处理每一行数据的逻辑-- 可以使用row.column_name来访问每一列的值END LOOP;CLOSE cursor_name;END;```4. 使用RECORD类型和FOREACH循环语句遍历表中的所有记录```sqlDECLARErow RECORD;BEGINFOREACH row IN ARRAY (SELECT * FROM table_name) LOOP-- 处理每一行数据的逻辑-- 可以使用row.column_name来访问每一列的值END LOOP;END;```5. 使用LOOP语句和EXIT条件语句实现循环的控制```sqlDECLAREcounter integer := 0;BEGINLOOP-- 处理逻辑counter := counter + 1;EXIT WHEN counter >= 10;END LOOP;END;```6. 使用FOR循环语句和RAISE NOTICE语句输出循环过程中的信息```sqlFOR i IN 1..10 LOOPRAISE NOTICE '当前循环次数:%', i;-- 处理逻辑END LOOP;```7. 使用FOR循环语句和CONTINUE条件语句实现循环的跳过```sqlFOR i IN 1..10 LOOPIF i % 2 = 0 THENCONTINUE;END IF;-- 处理逻辑END LOOP;```8. 使用FOR循环语句和EXIT条件语句实现循环的中止```sqlFOR i IN 1..10 LOOPIF i = 5 THENEXIT;END IF;-- 处理逻辑END LOOP;```9. 使用LOOP语句和RETURN NEXT语句返回逐行处理的结果集```sqlCREATE OR REPLACE FUNCTION function_name() RETURNS SETOF table_name AS $$DECLARErow record;BEGINFOR row IN SELECT * FROM table_name LOOP-- 处理每一行数据的逻辑-- 可以使用row.column_name来访问每一列的值RETURN NEXT row;END LOOP;END;$$ LANGUAGE plpgsql;```10. 使用FOR循环语句和UPDATE语句批量更新表中的数据```sqlFOR row IN SELECT * FROM table_name LOOPUPDATE table_name SET column_name = new_value WHERE id = row.id;END LOOP;```以上是十个基于GP数据库的循环语句的示例,可以根据实际需求进行灵活运用。
PostgreSQL数据库常用SQL命令示例

PostgreSQL数据库常⽤SQL命令⽰例本⽂仅记录我使⽤到的部分命令⽰例。
这⾥不对命令及各种参数做详细介绍,仅列出⽰例与简单说明。
详细介绍可参考PostgreSQL官⽅发布的⼿册。
已验证环境Ubuntu 20.04PostgreSQL 12.5注意事项psql内运⾏的SQL命令末尾都会以分号作为结束标志。
如果没有带上分号,会被认为命令还未结束。
字符串要⽤单引号来包含,不是双引号。
1. 创建表命令:CREATE TABLE⽰例1:create table webpage(id serial primary key,name varchar(60) unique not null,contents text not null default '',scripts text not null default '');简单说明:其中的serial表⽰是⾃增列,primary key为主键。
unique表⽰唯⼀约束,not null表⽰不能为空,default为默认值。
2. 修改表命令:ALTER TABLE2.1 修改表名或字段名:alter table 表名 rename to 新表名;alter table 表名 rename 字段名 to 新字段名;2.2 给指定字段设置默认值与删除默认值:alter table webpage alter column contents set default '';alter table webpage alter column contents drop default;简单说明:修改默认值的命令与设置默认值的命令⼀样,即都使⽤set default来实现。
2.3 修改字段类型:alter table 表名 alter column 字段名 type 新类型;alter table webpage alter column name type char(40);alter table webpage alter column contents type text;2.4 删除约束alter table webpage drop constraint webpage_name_key;这⾥要注意的是,约束名称最好使⽤“\d 表名”命令查看,并根据查看结果来操作。
postgresql数据库简单应用命令

目录1.创建数据库: (1)2.访问数据库 (1)3.创建新表 (1)4.向表中添加行 (1)5.查询一个表 (2)6.在表间连接 (2)7.聚合函数 (3)8.更新 (3)9.删除 (4)10. 视图 (4)11. 外键 (4)12.事务 (5)13.窗口函数 (5)14.继承 (6)15.索引 (6)1.创建数据库:删除数据库:2.访问数据库psql mydb3.创建新表双划线("--") 引入注释,任何跟在它后面的东西直到该行的结尾都被忽略。
SQL 是对关键字和标识符大小写不敏感的语言,只有在标识符用双引号包围时才能保留它们的大小写属性。
4.向表中添加行所有数据类型都使用了相当明了的输入格式。
那些不是简单数字值的常量必需用单引号(')包围。
可以使用COPY从文本文件中装载大量数据。
这么干通常更快,因为COPY命令就是为这类应用优化的,只是比INSERT 少一些灵活性。
5.查询一个表6.在表间连接一般认为在连接查询里使用字段全称是很好的风格,这样,即使在将来向其中一个表里添加了同名字段也不会引起混淆。
7.聚合函数聚合和SQL的WHERE和HAVING 子句之间的关系非常重要。
WHERE和HAVING的基本区别如下:WHERE在分组和聚合计算之前选取输入行(它控制哪些行进入聚合计算),而HAVING在分组和聚合之后选取输出行。
因此,WHERE 子句不能包含聚合函数;因为试图用聚合函数判断那些行将要输入给聚合运算是没有意义的。
相反,HAVING子句总是包含聚合函数。
当然,你可以写不使用聚合的HAVING 子句,但这样做没什么好处,因为同样的条件用在WHERE阶段会更有效。
8.更新UPDATE命令更新现有的行。
假设你发现所有11 月28 日的温度计数都低了两度,那么你就可以用下面的方式更新数据:9.删除10. 视图11. 外键确保没有人可以在weather表里插入一条在cities 表里没有匹配记录的数据行。
GP 常用数据库命令
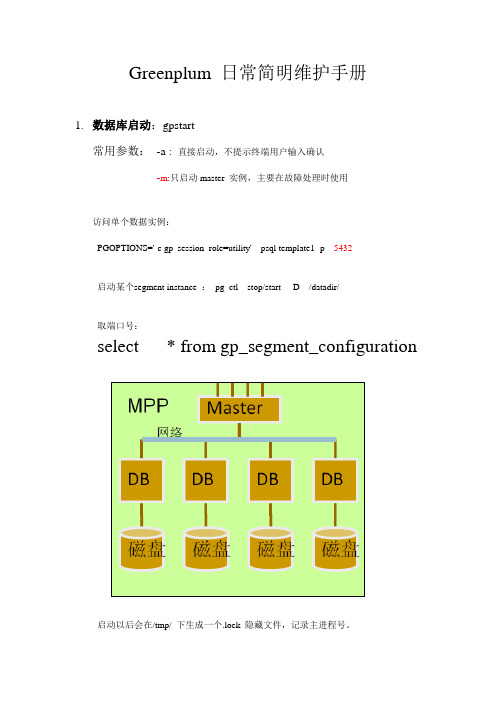
Greenplum 日常简明维护手册1.数据库启动:gpstart常用参数:-a : 直接启动,不提示终端用户输入确认-m:只启动master 实例,主要在故障处理时使用访问单个数据实例:PGOPTIONS='-c gp_session_role=utility' psql template1 -p 5432启动某个segment instance :pg_ctl stop/start -D /datadir/取端口号:select * from gp_segment_configuration 启动以后会在/tmp/ 下生成一个.lock 隐藏文件,记录主进程号。
2.数据库停止:gpstop:常用可选参数:-a:直接停止,不提示终端用户输入确认-m:只停止master 实例,与gpstart –m 对应使用-f:停止数据库,中断所有数据库连接,回滚正在运行的事务-u:不停止数据库,只加载pg_hba.conf 和postgresql.conf中运行时参数,当改动参数配置时候使用。
连接数,重启3.查看实例配置和状态select * from gp_segment_configuration order by content ;select * from pg_filespace_entry ;主要字段说明:Content:该字段相等的两个实例,是一对P(primary instance)和M(mirror Instance)Isprimary:实例是否作为primary instance 运行Valid:实例是否有效,如处于false 状态,则说明该实例已经down 掉。
Port:实例运行的端口Datadir:实例对应的数据目录4.gpstate :显示Greenplum数据库运行状态,详细配置等信息常用可选参数:-c:primary instance 和mirror instance 的对应关系-m:只列出mirror 实例的状态和配置信息-f:显示standby master 的详细信息该命令默认列出数据库运行状态汇总信息,常用于日常巡检。
postgresql 常用sql 语句

一、概述PostgreSQL是一种功能强大的开源关系型数据库管理系统,广泛应用于各种规模和类型的应用程序中。
在使用PostgreSQL时,熟练掌握常用的SQL语句是非常重要的,可以帮助用户更高效地管理和操作数据库。
本文将介绍PostgreSQL中常用的SQL语句,帮助读者更好地使用这一数据库管理系统。
二、连接数据库1. 连接到数据库使用以下命令可以连接到PostgreSQL数据库:```psql -U username -d database_name```其中,-U参数用于指定用户名,-d参数用于指定要连接的数据库名称。
2. 退出数据库在连接到数据库后,可以使用以下命令退出数据库:```\q```三、数据库管理1. 创建数据库使用以下命令可以在PostgreSQL中创建数据库: ```CREATE DATABASE database_name;```2. 删除数据库若要删除数据库,可以使用以下命令:```DROP DATABASE database_name;```四、表操作1. 创建表使用以下命令可以在数据库中创建表:```CREATE TABLE table_name (column1 datatype,column2 datatype,column3 datatype,...);```2. 删除表若要删除表,可以使用以下命令:```DROP TABLE table_name;```五、数据操作1. 插入数据使用以下命令可以向表中插入数据:```INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);```2. 查询数据查询表中的数据可以使用以下命令:```SELECT column1, column2, ...FROM table_nameWHERE condition;```3. 更新数据若要更新表中的数据,可以使用以下命令:```UPDATE table_nameSET column1 = value1, column2 = value2, ...WHERE condition;```4. 删除数据若要删除表中的数据,可以使用以下命令:```DELETE FROM table_nameWHERE condition;```六、数据过滤1. 按条件过滤使用WHERE子句可以对查询结果进行条件筛选,例如: ```SELECT *FROM table_nameWHERE column1 = value;```2. 模糊查询若要进行模糊查询,可以使用LIKE运算符,例如:```SELECT *FROM table_nameWHERE column1 LIKE 'value';```七、数据排序1. 升序排序若要按升序对查询结果进行排序,可以使用以下命令: ```SELECT *FROM table_nameORDER BY column1 ASC;```2. 降序排序若要按降序对查询结果进行排序,可以使用以下命令: ```SELECT *FROM table_nameORDER BY column1 DESC;```八、聚合函数1. 求和使用SUM函数可以对数据列进行求和操作,例如:```SELECT SUM(column1)FROM table_name;```2. 平均值若要计算数据列的平均值,可以使用AVG函数:```SELECT AVG(column1)FROM table_name;```3. 计数使用COUNT函数可以统计行数或满足条件的行数,例如: ```SELECT COUNT(*)FROM table_name;九、数据分组1. 分组统计若要对数据进行分组统计,可以使用GROUP BY子句,例如:```SELECT column1, COUNT(*)FROM table_nameGROUP BY column1;```2. 分组筛选若要对分组后的数据进行筛选,可以使用HAVING子句:```SELECT column1, COUNT(*)FROM table_nameGROUP BY column1HAVING COUNT(*) > 1;```十、连接表1. 内连接使用INNER JOIN可以连接两个表,并返回满足连接条件的行,例```SELECT *FROM table1INNER JOIN table2ON table1.column1 = table2.column2;```2. 左连接若要返回左表中所有行以及与其关联的右表中的行,可以使用LEFT JOIN:```SELECT *FROM table1LEFT JOIN table2ON table1.column1 = table2.column2;```十一、子查询1. 标量子查询若要返回单一值的子查询结果,可以使用标量子查询,例如:```SELECT column1,(SELECT MAX(column2) FROM table2) AS max_value FROM table1;```2. 列表子查询使用列表子查询可以返回一列多行结果,例如:```SELECT column1FROM table1WHERE column1 IN (SELECT column2 FROM table2); ```十二、索引1. 创建索引若要在表的一个或多个列上创建索引,可以使用以下命令: ```CREATE INDEX index_nameON table_name (column1, column2, ...);```2. 删除索引若要删除索引,可以使用以下命令:```DROP INDEX index_name;```十三、事务管理1. 开始事务使用以下命令可以开始一个事务:```BEGIN;```2. 提交事务若要将未提交的事务更改保存到数据库中,可以使用以下命令: ```COMMIT;```3. 回滚事务若要撤销未提交的事务更改,可以使用以下命令:```ROLLBACK;```十四、权限管理1. 授权若要授予用户对数据库或表的特定操作许可,可以使用GRANT命令:```GRANT permissionON object_nameTO user_name;```2. 撤销权限若要撤销用户对数据库或表的特定操作许可,可以使用REVOKE命令:```REVOKE permissionON object_nameFROM user_name;```3. 角色管理使用CREATE ROLE命令可以创建新角色,使用ALTER ROLE命令可以修改角色,使用DROP ROLE命令可以删除角色。
GP日常维护手册-常用命令

Greenp lum 日常维护手册1.数据库启动:g pstar t常用可选参数:-a : 直接启动,不提示终端用户输入ye s确认-m:只启动mas ter 实例,主要在故障处理时使用2.数据库停止:g pstop:常用可选参数:-a:直接停止,不提示终端用户输入确认-m:只停止mas t er 实例,与gpsta rt –m 对应使用-M fast:停止数据库,中断所有数据库连接,回滚正在运行的事务-u:不停止数据库,只加载pg_hba.conf 和postgresql.conf中运行时参数,当改动参数配置时候使用。
-f:强制停止数据库-r:重启数据库3.查看实例配置和状态select * from gp_con figur ation orderby 1 ;select * from gp_con figur ation_hist ory orderby 1 ;主要字段说明:Conten t:该字段相等的两个实例,是一对P(primar y instan ce)和M(mirrorInstan ce)Isprim ary:实例是否作为p rimary instan ce 运行V alid:实例是否有效,如处于fal se 状态,则说明该实例已经dow n 掉。
Port:实例运行的端口Datadi r:实例对应的数据目录注 4.0后,实例配置的数据表:gp_seg ment_confi gurat ion 、pg_fil espac e_ent ry、gp_fau lt_st rateg y;其它常用的系统表:pg_cla ss,pg_att ribute,pg_database,pg_tab l es……可以用tab来匹配表名;4.gpstat e :显示Gree n plum数据库运行状态,详细配置等信息常用可选参数:-c:primary instan ce 和mirror instan ce 的对应关系-m:只列出mir ror 实例的状态和配置信息-f:显示stan dby master的详细信息-s:查看详细状态,如在同步,可显示数据同步完成百分比--versio n,查看数据库v ersio n(也可使用pg_cont roldata查看数据库版本和p ostg r esql版本)该命令默认列出数据库运行状态汇总信息,常用于日常巡检。
PG数据库常用命令

PG数据库常⽤命令查看帮助命令DB=# help --总的帮助DB=# \h --SQL commands级的帮助DB=# \? --psql commands级的帮助按列显⽰,类似MySQL的\GDB=# \xExpanded display is on.查看DB安装⽬录(最好root⽤户执⾏)find / -name initdb查看有多少DB实例在运⾏(最好root⽤户执⾏)find / -name postgresql.conf查看DB版本cat $PGDATA/PG_VERSIONpsql --versionDB=# show server_version;DB=# select version();查看DB实例运⾏状态pg_ctl status查看所有数据库psql –l --查看5432端⼝下⾯有多少个DBpsql –p XX –l --查看XX端⼝下⾯有多少个DBDB=# \lDB=# select * from pg_database;创建数据库createdb database_nameDB=# \h create database --创建数据库的帮助命令DB=# create database database_name进⼊某个数据库psql –d dbnameDB=# \c dbname查看当前数据库DB=# \cDB=# select current_database();查看数据库⽂件⽬录DB=# show data_directory;cat $PGDATA/postgresql.conf |grep data_directorycat /etc/init.d/postgresql|grep PGDATA=lsof |grep 5432得出第⼆列的PID号再ps –ef|grep PID查看表空间select * from pg_tablespace;查看语⾔select * from pg_language;查询所有schema,必须到指定的数据库下执⾏select * from information_schema.schemata;SELECT nspname FROM pg_namespace;\dnS查看表名DB=# \dt --只能查看到当前数据库下public的表名DB=# SELECT tablename FROM pg_tables WHERE tablename NOT LIKE 'pg%' AND tablename NOT LIKE 'sql_%' ORDER BY tablename;DB=# SELECT * FROM information_schema.tables WHERE table_name='ff_v3_ff_basic_af';查看表结构查看表结构DB=# \d tablenameDB=# select * from information_schema.columns where table_schema='public' and table_name='XX';查看索引DB=# \diDB=# select * from pg_index;查看视图DB=# \dvDB=# select * from pg_views where schemaname = 'public';DB=# select * from information_schema.views where table_schema = 'public';查看触发器DB=# select * from information_schema.triggers;查看序列DB=# select * from information_schema.sequences where sequence_schema = 'public';查看约束DB=# select * from pg_constraint where contype = 'p'DB=# select a.relname as table_name,b.conname as constraint_name,b.contype as constraint_type from pg_class a,pg_constraint b where a.oid = b.conrelid and a.relname = 'cc';查看XX数据库的⼤⼩SELECT pg_size_pretty(pg_database_size('XX')) As fulldbsize;查看所有数据库的⼤⼩select pg_database.datname, pg_size_pretty (pg_database_size(pg_database.datname)) AS size from pg_database;查看各数据库数据创建时间:select datname,(pg_stat_file(format('%s/%s/PG_VERSION',case when spcname='pg_default' then 'base' else'pg_tblspc/'||t2.oid||'/PG_11_201804061/' end, t1.oid))).* from pg_database t1,pg_tablespace t2 where t1.dattablespace=t2.oid;按占空间⼤⼩,顺序查看所有表的⼤⼩select relname, pg_size_pretty(pg_relation_size(relid)) from pg_stat_user_tables where schemaname='public' order bypg_relation_size(relid) desc;按占空间⼤⼩,顺序查看索引⼤⼩select indexrelname, pg_size_pretty(pg_relation_size(relid)) from pg_stat_user_indexes where schemaname='public' order bypg_relation_size(relid) desc;查看参数⽂件DB=# show config_file;DB=# show hba_file;DB=# show ident_file;查看当前会话的参数值DB=# show all;查看参数值select * from pg_file_settings查看某个参数值,⽐如参数work_memDB=# show work_mem修改某个参数值,⽐如参数work_memDB=# alter system set work_mem='8MB'--使⽤alter system命令将修改postgresql.auto.conf⽂件,⽽不是postgresql.conf,这样可以很好的保护postgresql.conf⽂件,加⼊你使⽤很多alter system命令后搞的⼀团糟,那么你只需要删除postgresql.auto.conf,再执⾏pg_ctl reload加载postgresql.conf⽂件即可实现参数的重新加载。
gp导出表结构

gp导出表结构
在GP(Greenplum)数据库中,您可以使用以下命令导出表结构:
1. 如果您只需要导出单个表的结构,可以使用以下命令:
sql
pg_dump -t tablename -s databasename > structure.sql 其中,`tablename`是要导出结构的表名,`databasename`是包含该表的数据库名。
这将把表结构以SQL语句的形式保存到名为`structure.sql`的文件中。
2. 如果您需要导出整个数据库的所有表结构,可以使用以下命令:
sql
pg_dump -s databasename > structure.sql
这将把整个数据库的所有表结构以SQL语句的形式保存到`structure.sql`文件中。
请确保在执行上述命令之前,您具有适当的权限以及足够的磁盘空间来保存导出的结构文件。
postgres常用命令

postgresql常用命令2011-01-19 13:35:57| 分类:postgresql |字号订阅1.createdb 数据库名称产生数据库2.dropdb 数据库名称删除数据库3.CREATE USER 用户名称创建用户4.drop User 用户名称删除用户5.SELECT usename FROM pg_user;查看系统用户信息\du7.SELECT version();查看版本信息8.psql 数据库名打开psql交互工具9.mydb=> \i basics.sql\i 命令从指定的文件中读取命令。
10.COPY weather FROM '/home/user/weather.txt';批量将文本文件中内容导入到wether表11.SHOW search_path;显示搜索路径12.创建用户CREATE USER 用户名 WITH PASSWORD '密码'13.创建模式CREATE SCHEMA myschema;14.删除模式DROP SCHEMA myschema;15.查看搜索模式SHOW search_path;16.设置搜索模式SET search_path TO myschema,public;17.创建表空间create tablespace 表空间名称 location '文件路径';18.显示默认表空间show default_tablespace;19.设置默认表空间set default_tablespace=表空间名称;20.指定用户登录psql MTPS -u21.显示当前系统时间、now()22.配置plpgsql语言CREATE LANGUAGE 'plpgsql' HANDLER plpgsql_call_handler 23.删除规则DROP RULE name ON relation [ CASCADE | RESTRICT ]输入name要删除的现存的规则.relation该规则应用的关系名字(可以有大纲修饰).CASCADE自动删除依赖于此规则的对象。
postgrepsql常用命令

postgrepsql常⽤命令1、查看数据库及⽤户名./psql -l2、以oftenlin ⽤户登陆 postgres 数据库./psql -d postgres -U oftenlin3、列举表,相当于mysql的show tables\dt4、查看表结构,相当于desc tblname,show columns from tbname\d tblname5、postgresql ⽀持 gis 功能CREATE EXTENSION postgis;查看 GIS 插件是否起作⽤SELECT PostGIS_Full_Version();6、创建数据表DROP TABLE IF EXISTS "public"."link_info";CREATE TABLE "public"."link_info" ("edgeid" int8 NOT NULL,"from_node_id" int8,"to_node_id" int8,"two_way" int2,"spd" float4,"vertex_cnt" int4,"geo" geometry);ALTER TABLE "public"."link_info" OWNER TO "postgres";ALTER TABLE "public"."link_info" ADD CONSTRAINT "link_info_pkey" PRIMARY KEY ("edgeid");7、创建空间索引CREATE INDEX linkinfo_geom_idx ON public.link_info USING GIST (geom);8、python 连接 PostgreSQL使⽤ psycopg2 库 pip install安装过程中出现Error: pg_config executable not found需要把 /Library/PostgreSQL/9.6/bin 添加到环境变量安装成功后仍然没有办法使⽤,需要做动态链接库的软连接sudo install_name_tool -change libpq.5.dylib /Library/PostgreSQL/9.6/lib/libpq.5.dylib /Users/didi/anaconda2/envs/py36/lib/python3.6/site-packages/psycopg2/_psycopg.cpython-36m-darwin.sosudo install_name_tool -change libssl.1.1.dylib /Library/PostgreSQL/9.6/lib/libssl.1.1.dylib/Users/didi/anaconda2/envs/py36/lib/python3.6/site-packages/psycopg2/_psycopg.cpython-36m-darwin.sosudo install_name_tool -change libcrypto.1.1.dylib /Library/PostgreSQL/9.6/lib/libcrypto.1.1.dylib/Users/didi/anaconda2/envs/py36/lib/python3.6/site-packages/psycopg2/_psycopg.cpython-36m-darwin.so。
PostgreSQL常用命令.

PostgreSQL 常用命令\d [ table ]列出数据库中的表,或(如果声明了)表table的列/字段.如果表名是用统配符(“*”)声明的,列出所有表和表的列/字段信息.\da列出所有可用聚集.\dd object列出pg_description里对声明的对象的描述,对象可以是一个表,表中的列/字段,类型,操作符或聚集.小技巧:并非所有对象在pg_description里有描述.此后期命令在快速获取 Postgres 内部特性时很有用.\df列出函数.\di只列出索引.\do只列出操作符.\ds只列出序列.\dS列出系统表和索引.\dt只列出非系统表.\dT列出类型.\e [ filename ]编辑当前查询缓冲或文件filename的内容.\E [ filename ]编辑当前查询缓冲或文件filename的内容并且在编辑结束后执行之.\f [ separator ]设置域分隔符.缺省是单个空白.\g [ { filename | |command } ]将当前查询输入缓冲送给后端并且(可选的)将输出放到filename或通过管道将输出送给一个分离的Unix shell 用以执行command.\h [ command ]给出声明的SQL 命令的语法帮助.如果command不是一个定义的SQL 命令(或在 psql 里没有文档),或没有声明command,这时 psql将列出可获得帮助的所有命令的列表.如果命令command是一个通配符(“*”),则给出所有SQL 命令的语法帮助.\H切换 HTML3 输出.等效于 -H 命令行选项.\i filename从文件filename中读取查询到输入缓冲.\l列出服务器上所有数据库.\m切换老式监视器样的表输出,这时表周围有边界字符包围着.这是标准SQL 输出.缺省时,psql 只包括列/字段间的分隔符.\o [ { filename | |command } ]将后面的查询结果输出到文件filename或通过管道将后面结果输出到一个独立的Unix shell 里执行command.如果没有声明参数,将查询结果输出到stdout.\p打印当前查询缓冲区.\q退出 psql 程序.\r重置(清空)查询缓冲区.\s [ filename ]将命令行历史打印出或是存放到filename.如果省略filename,将不会把后继的命令存放到历史文件中.此选项只有在 psql 配置成使用输入行时才有效.\t切换输出的列/字段名的信息头和行记数脚注(缺省是开).\T table_options允许你在使用HTML 3.0 格式输出时声明放在表table ...中的标记选项.例如,border将给你的表以边框.这必须和\H后期命令一起使用.\x切换扩展行格式.当打开时,每一行将在左边打印列/字段名而在右边打印列/字段值.这对于那些不能在一行输出的超长行是很有用的.HTML 行输出模式也支持这个标记.\w filename将当前查询缓冲区输出到文件filename.\z生成一个带有正确ACL(赋予/禁止权限)的数据库中所有表的输出列表.\! [ command ]回到一个独立的Unix shell或执行一个Unix 命令command.\?获得关于反斜杠(“\”) 命令的帮助.一般选项\c[onnect] [数据库名|- [用户名称]]联接到新的数据库(当前为"test")\cd [目录名] 改变当前的工作目录\copyright 显示PostgreSQL 用法和发布信息\encoding [编码]显示或设置客户端编码\h [名字] SQL 命令的语法帮助, 用* 可以看所有命令的帮助\q 退出psql\set [名字[值]]设置内部变量, 如果没有参数就列出所有\timing 查询计时开关切换(目前是关闭)\unset 名字取消(删除)内部变量\! [命令] 在shell 里执行命令或者开始一个交互的shell信息选项\d [名字] 描述表, 索引, 序列, 或者视图\d{t|i|s|v|S} [模式] (加"+" 获取更多信息)列出表/索引/序列/视图/系统表\da [模式] 列出聚集函数\db [模式] 列出表空间(加"+" 获取更多的信息)\dc [模式] 列出编码转换\dC 列出类型转换\dd [模式] 显示目标的注释\dD [模式] 列出域\df [模式] 列出函数(加"+" 获取更多的信息)\dg [模式] 列出组\dn [模式] 列出模式(加"+" 获取更多的信息)\do [名字] 列出操作符\dl 列出大对象, 和\lo_list 一样\dp [模式] 列出表, 视图, 序列的访问权限\dT [模式] 列出数据类型(加"+" 获取更多的信息)\du [模式] 列出用户\l 列出所有数据库(加"+" 获取更多的信息)\z [模式] 列出表, 视图, 序列的访问权限(和\dp 一样)命令: ABORT描述: 终止当前事务语法:ABORT [ WORK | TRANSACTION ]命令: ALTER DATABASE描述: 改变一个数据库语法:ALTER DATABASE 名字SET 参数{ TO | = } { 值| DEFAULT } ALTER DATABASE 名字RESET 参数ALTER DATABASE 名字RENAME TO 新名字ALTER DATABASE 名字OWNER TO 新属主命令: ALTER GROUP描述: 改变一个用户组语法:ALTER GROUP 组名称ADD USER 用户名称[, ... ]ALTER GROUP 组名称DROP USER 用户名称[, ... ]ALTER GROUP 组名称RENAME TO 新名称命令: ALTER INDEX描述: 改变一个索引的定义语法:ALTER INDEX 索引名称动作[, ... ]ALTER INDEX 索引旧名称RENAME TO 索引新名称动作为以下之一:OWNER TO 新属主SET TABLESPACE indexspace_name命令: ALTER SEQUENCE描述: 改变一个序列生成器的定义语法:ALTER SEQUENCE 名字[ INCREMENT [ BY ] 递增][ MINVALUE 最小值| NO MINVALUE ] [ MAXVALUE 最大值| NO MAXVALUE ][ RESTART [ WITH ] 开始] [ CACHE 缓存] [ [ NO ] CYCLE ]命令: ALTER TABLE描述: 改变一个表的定义语法:ALTER TABLE [ ONLY ] 表名[ * ]action [, ... ]ALTER TABLE [ ONLY ] 表名[ * ]RENAME [ COLUMN ] 字段名TO 新字段名ALTER TABLE 表名RENAME TO 新表名action 为下面的一种:ADD [ COLUMN ] 字段名类型[ 字段约束[ ... ] ]DROP [ COLUMN ] 字段名[ RESTRICT | CASCADE ]ALTER [ COLUMN ] 字段名TYPE 类型[ USING 表达式]ALTER [ COLUMN ] 字段名SET DEFAULT 表达式ALTER [ COLUMN ] 字段名DROP DEFAULTALTER [ COLUMN ] 字段名{ SET | DROP } NOT NULLALTER [ COLUMN ] 字段名SET STATISTICS integerALTER [ COLUMN ] 字段名SET STORAGE { PLAIN | EXTERNAL | EXTENDED | MAIN } ADD 表约束DROP CONSTRAINT 约束名字[ RESTRICT | CASCADE ]CLUSTER ON 索引名称SET WITHOUT CLUSTERSET WITHOUT OIDSOWNER TO 新属主SET TABLESPACE 表空间名字命令: ALTER TRIGGER描述: 改变一个触发器的定义语法:ALTER TRIGGER 名字ON 表RENAME TO 新名字命令: ALTER USER描述: 改变一个数据库用户语法:ALTER USER name [ [ WITH ] option [ ... ] ]where option can be:CREATEDB | NOCREATEDB| CREATEUSER | NOCREATEUSER| [ ENCRYPTED | UNENCRYPTED ] PASSWORD 'password'| VALID UNTIL 'abstime'ALTER USER name RENAME TO newnameALTER USER name SET parameter { TO | = } { value | DEFAULT }命令: COPY描述: 在一个文件和一个表之间拷贝数据语法:COPY 表名[ ( 字段[, ...] ) ]FROM { '文件名' | STDIN }[ [ WITH ][ BINARY ][ OIDS ][ DELIMITER [ AS ] 'delimiter' ][ NULL [ AS ] 'null string' ][ CSV [ QUOTE [ AS ] 'quote' ][ ESCAPE [ AS ] 'escape' ][ FORCE NOT NULL column [, ...] ]COPY 表名[ ( 字段[, ...] ) ]TO { '文件名' | STDOUT }[ [ WITH ][ BINARY ][ OIDS ][ DELIMITER [ AS ] 'delimiter' ][ NULL [ AS ] 'null string' ][ CSV [ QUOTE [ AS ] 'quote' ][ ESCAPE [ AS ] 'escape' ][ FORCE QUOTE column [, ...] ]命令: CREATE TABLE描述: 定义一个新的表语法:CREATE [ [ GLOBAL | LOCAL ] { TEMPORARY | TEMP } ] TABLE table_name ({ column_name data_type [ DEFAULT default_expr ] [ column_constraint [ ... ] ]| table_constraint| LIKE parent_table [ { INCLUDING | EXCLUDING } DEFAULTS ] } [, ... ])[ INHERITS ( parent_table [, ... ] ) ][ WITH OIDS | WITHOUT OIDS ][ ON COMMIT { PRESERVE ROWS | DELETE ROWS | DROP } ][ TABLESPACE tablespace ]where column_constraint is:[ CONSTRAINT constraint_name ]{ NOT NULL |NULL |UNIQUE [ USING INDEX TABLESPACE tablespace ] |PRIMARY KEY [ USING INDEX TABLESPACE tablespace ] |CHECK (expression) |REFERENCES reftable [ ( refcolumn ) ] [ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ][ ON DELETE action ] [ ON UPDATE action ] }[ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]and table_constraint is:[ CONSTRAINT constraint_name ]{ UNIQUE ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] |PRIMARY KEY ( column_name [, ... ] ) [ USING INDEX TABLESPACE tablespace ] |CHECK ( expression ) |FOREIGN KEY ( column_name [, ... ] ) REFERENCES reftable [ ( refcolumn [, ... ] ) ][ MATCH FULL | MATCH PARTIAL | MATCH SIMPLE ] [ ON DELETE action ] [ ON UPDATE action ] } [ DEFERRABLE | NOT DEFERRABLE ] [ INITIALLY DEFERRED | INITIALLY IMMEDIATE ]。
postgresql常用命令讲解

1.createdb 数据库名称产生数据库2.dropdb 数据库名称删除数据库3.CREATE USER 用户名称创建用户4.drop User 用户名称删除用户5.SELECT usename FROM pg_user;查看系统用户信息\du7.SELECT version();查看版本信息8.psql 数据库名打开psql交互工具9.mydb=> \i basics.sql\i 命令从指定的文件中读取命令。
10.COPY weather FROM '/home/user/weather.txt'; 批量将文本文件中内容导入到wether表11.SHOW search_path;显示搜索路径12.创建用户CREATE USER 用户名WITH PASSWORD '密码'13.创建模式CREATE SCHEMA myschema;14.删除模式DROP SCHEMA myschema;15.查看搜索模式SHOW search_path;16.设置搜索模式SET search_path TO myschema,public;17.创建表空间create tablespace 表空间名称location '文件路径';18.显示默认表空间show default_tablespace;19.设置默认表空间set default_tablespace=表空间名称;20.指定用户登录psql MTPS -u21.显示当前系统时间、now()22.配置plpgsql语言CREATE LANGUAGE 'plpgsql' HANDLER plpgsql_call_handler 23.删除规则DROP RULE name ON relation [ CASCADE | RESTRICT ]输入name要删除的现存的规则.relation该规则应用的关系名字(可以有大纲修饰).CASCADE自动删除依赖于此规则的对象。
gp数据库建表语句

gp数据库建表语句1. 嘿,你想知道gp数据库建表语句吗?这就像盖房子打地基一样重要呢!比如说,我们要建一个存储用户信息的表。
那CREATE TABLE user_info (id SERIAL PRIMARY KEY, name VARCHAR(50), age INTEGER); 就这么简单,这就像给每个用户信息在数据库里盖了个小房间。
2. 哟,gp数据库建表语句可没那么神秘!你看啊,假如你要做个记录商品的表,就像超市里的货架管理一样。
CREATE TABLE product (product_id SERIAL, product_name VARCHAR(100), price DECIMAL(10,2)); 这么一来,每个商品的信息就有地方存放啦,多酷啊!3. 嗨呀,gp数据库建表语句不难理解啦。
想象你是个厨师,要给食材分类建个表,就像整理厨房的橱柜。
CREATE TABLE ingredients (ingredient_id SERIAL, ingredient_name VARCHAR(80), quantity INTEGER); 这就好比给每种食材都安排了个专属小格子呢。
4. 哇塞,你要是接触gp数据库建表语句,就像打开了一个神奇的魔法盒。
比如说要建一个学生成绩表,CREATE TABLE student_scores (student_id SERIAL, subject VARCHAR(60), score INTEGER); 这就像是给每个学生的成绩在数据库里打造了一个特殊的记录空间,超有趣的吧?5. 哎呀,gp数据库建表语句真的挺好玩的。
假如你是个图书管理员,要给图书建个表,CREATE TABLE books (book_id SERIAL,book_title VARCHAR(200), author VARCHAR(100)); 这就如同给每本书在图书馆的数据库里找到了一个专属的“座位”,是不是很神奇呢?6. 嘿,朋友!gp数据库建表语句就像搭积木。
postgre常用命令

initdb命令详解:
在使用数据库前,是启动数据库,启动数据库前是initdb(初始化数据库);一起来看一下initdb做了什么吧。
初始化数据库的操作为: ./initdb -D /usr/local/pgsql/data
创建数据库用户,修改密码:
useradd postgres
passwd postgres
创建数据库文件存储文件夹:mkdir /usr/local/pgsql/data
改变先前目录的文件夹的权限:chown -R postgres:postgres /usr/local/pgsql
设置环境变量1:
或:pg_dump -h localhost -U postgres(用户名) 数据库名(缺省时同用户名) >/data/dum.sql
导入整个数据库:psql -U postgres(用户名) test数据库名(缺省时同用户名) < /data/dum.sql
导出某个表:pg_dump -h localhost -U postgres(用户名) 数据库名(缺省时同用户名) -t table(表名) >/data/dum.sql
source /etcile
把 PATH=$PATH:$HOME/bin 改成 PATH=$PATH:$HOME/bin:/usr/local/pgsql/bin 保存退出
生效:source .bash_profile
切换用户:su - postgres
time int NOT NULL DEFAULT CURRENT_TIMESTAMP(),
postgreSQL常用命令

postgreSQL常⽤命令⼀、查看数据库当前连接状态1、.查看被锁定表:SELECT pg_class.relname AS table, pg_database.datname AS database, pid, mode, granted FROM pg_locks, pg_class, pg_database WHEREpg_locks.relation = pg_class.oid AND pg_locks.database = pg_database.oid;3、查看数据库⼤⼩:SELECT pg_size_pretty(pg_database_size('MTPS')) As fulldbsize;4、查看表结构:select * from information_schema.columns;5、显⽰默认表空间:show default_tablespace;6、查看Postgresql的连接状况:select * from pg_stat_activity;7、查看数据库表⼤⼩:select relname, pg_size_pretty(pg_relation_size('relname')) frompg_stat_user_tables where schemaname = 'public' order by pg_relation_size('relname') desc;查看单个表的⼤⼩:select pg_size_pretty(pg_relation_size('table_name'));8、查看主从复制状态:SELECT * from pg_stat_replication ;9、查看主从状态:SELECT * from pg_is_in_recovery();10、暂停/恢复主从复制:pg_xlog_replay_pause();pg_xlog_replay_resume();11、⼆、psql1、修改密码:alter user postgres with password 'new password'2、创建库并引⽤postgis模板:create database cetcnav template postgis;3、修改库的属主:alter database cetcnav owner to terra;4、添加索引:CREATE INDEX t_gps_20131111_idx_vehicle_id ON t1(list);5、删除索引:drop INDEX t_gps_20131111_idx_vehicle_id;6、插⼊数据:INSERT INTO t_vehicle_login (vehicle_id,password) select id,snumber from t_vehicle;7、过滤重复:SELECT distinct(vehicle_id),vnumber,snumber,warrant_code,warrant_result from t_vehicle_warrant;根据某个字段去重8、导出授权的⽤户:pg_dumpall -h localhost -U postgres -v --roles-only -f test.sql;9、创建⽤户:CREATE USER user1 WITH PASSWORD '123456';10、三、查看数据库系统参数1、设置执⾏超过指定秒数的sql语句输出到⽇志:log_min_duration_statement = 32、查看客户端编码:show client_encoding;3、。
postgresql常用命令

postgresql常⽤命令(1)⽤户实⽤程序:createdb 创建⼀个新的PostgreSQL的数据库(和SQL语句:CREATE DATABASE 相同)createuser 创建⼀个新的PostgreSQL的⽤户(和SQL语句:CREATE USER 相同)dropdb 删除数据库dropuser 删除⽤户pg_dump 将PostgreSQL数据库导出到⼀个脚本⽂件pg_dumpall 将所有的PostgreSQL数据库导出到⼀个脚本⽂件pg_restore 从⼀个由pg_dump或pg_dumpall程序导出的脚本⽂件中恢复PostgreSQL数据库psql ⼀个基于命令⾏的PostgreSQL交互式客户端程序vacuumdb 清理和分析⼀个PostgreSQL数据库,它是客户端程序psql环境下SQL语句VACUUM的shell脚本封装,⼆者功能完全相同(2)系统实⽤程序1. pg_ctl 启动、停⽌、重启PostgreSQL服务(⽐如:pg_ctl start 启动PostgreSQL服务,它和service postgresql start相同)2. pg_controldata 显⽰PostgreSQL服务的内部控制信息3. psql 切换到PostgreSQL预定义的数据库超级⽤户postgres,启⽤客户端程序psql,并连接到⾃⼰想要的数据库,⽐如说:psql template1出现以下界⾯,说明已经进⼊到想要的数据库,可以进⾏想要的操作了。
template1=#(3).在数据库中的⼀些命令:template1=# \l 查看系统中现存的数据库template1=# \q 退出客户端程序psqltemplate1=# \c 从⼀个数据库中转到另⼀个数据库中,如template1=# \c sales 从template1转到salestemplate1=# \dt 查看表template1=# \d 查看表结构template1=# \di 查看索引[基本数据库操作]========================1. *创建数据库: create database [数据库名];2. *查看数据库列表: \d3. *删除数据库: . drop database [数据库名];创建表: create table ([字段名1] [类型1] <references 关联表名(关联的字段名)>;,[字段名2] [类型2],......<,primary key (字段名m,字段名n,...)>;);*查看表名列表: \d*查看某个表的状况: \d [表名]*重命名⼀个表: alter table [表名A] rename to [表名B];*删除⼀个表: drop table [表名]; ========================================[表内基本操作]==========================*在已有的表⾥添加字段: alter table [表名] add column [字段名] [类型];*删除表中的字段: alter table [表名] drop column [字段名];*重命名⼀个字段: alter table [表名] rename column [字段名A] to [字段名B];*给⼀个字段设置缺省值: alter table [表名] alter column [字段名] set default [新的默认值];*去除缺省值: alter table [表名] alter column [字段名] drop default;在表中插⼊数据: insert into 表名 ([字段名m],[字段名n],......) values ([列m的值],[列n的值],......);修改表中的某⾏某列的数据: update [表名] set [⽬标字段名]=[⽬标值] where [该⾏特征];删除表中某⾏数据: delete from [表名] where [该⾏特征];delete from [表名];--删空整个表 ========================== ==========================(4).PostgreSQL⽤户认证PostgreSQL数据⽬录中的pg_hba.conf的作⽤就是⽤户认证,可以在/usr/local/pgsql/data中找到。
gp数据库导出建表语句

gp数据库导出建表语句如果您想要从Greenplum Database(一个基于PostgreSQL的大规模并行处理(MPP)数据库)中导出建表语句,通常可以通过以下几种方式完成:1.使用pg_dump工具:pg_dump是PostgreSQL的备份工具,可以用来导出数据库或特定的表。
如果您想要导出建表语句,可以使用以下命令:bash复制代码pg_dump -U your_username -s -t your_table_name your_database_name其中:复制代码* `-U` 指定用户名* `-s` 导出模式(只导出架构)* `-t` 指定要导出的表* `your_database_name` 是您要导出的数据库名称* `your_table_name` 是您要导出的表名称这将为指定的表生成建表语句。
2. 查询pg_catalog:您还可以查询pg_catalog来获取表的DDL。
例如,要获取名为your_table_name的表的DDL,可以执行以下查询:sql复制代码SELECT'CREATE TABLE ' || table_name || ' (' ||array_to_string(array_agg(column_name || ' ' || data_type), ', ') || ');'FROM information_schema.columnsWHERE table_name = 'your_table_name';这会为指定的表生成一个DDL字符串。
3. 使用其他第三方工具:市场上也有一些第三方工具和库,如pgloader,可以帮助您从Greenplum或其他PostgreSQL数据库中导出DDL。
无论您选择哪种方法,都请确保在生产环境中操作时采取适当的备份措施,并始终在安全的环境中测试所导出的建表语句以确保其准确性。
PostgreSQL数据库常用命令

Postgresql数据库常用命令psqlNamepsql -- PostgreSQL 交互终端Synopsispsql [option...] [dbname [username]]描述psql 是一个以终端为基础的 PostgreSQL 前端。
它允许你交互地键入查询,把它们发出给 PostgreSQL,然后看看查询的结果。
另外,输入可以来自一个文件。
还有,它提供了一些元命令和多种类 shell 地特性来实现书写脚本以及对大量任务的自动化。
选项-a--echo-all在读取行时向标准输出打印所有内容。
这个选项在脚本处理时比交互模式时更有用。
这个选项等效于设置变量ECHO 为 all。
-A--no-align切换为非对齐输出模式。
(缺省输出模式是对齐的。
)-c command--command command声明 psql 将执行一条查询字串, command,然后退出。
这一点在 shell 脚本里很有用。
command 必须是一条完全可以被服务器分析的查询字串(也就是说,它不包含 psql特有的特性),或者是一个反斜杠命令。
这样你就不会混合 SQL 和 psql 元命令。
要想混合使用,你可以把字串定向到 psql里,象这样: echo "/x // select * from foo;" | psql。
如果命令字串包含多个 SQL 命令,那么他们在一个事务里处理,除非在字串里包含了明确的 BEGIN/COMMIT 命令把他们分成多个事务。
这个和从 psql 的标准输入里给它填充相同字串不同。
-d dbname--dbname dbname声明想要联接的数据库名称。
等效于在命令行行上把 dbname 声明为第一个非选项参数。
-e--echo-queries把所有发送给服务器的查询同时也拷贝到标准输出。
等效于把变量 ECHO 设置为 queries。
-E--echo-hidden回显由/d和其他反斜杠命令生成的实际查询。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Greenplum 日常简明维护手册1.数据库启动:gpstart常用参数:-a : 直接启动,不提示终端用户输入确认-m:只启动master 实例,主要在故障处理时使用访问单个数据实例:PGOPTIONS='-c gp_session_role=utility' psql template1 -p 5432启动某个segment instance :pg_ctl stop/start -D /datadir/取端口号:select * from gp_segment_configuration启动以后会在/tmp/ 下生成一个.lock 隐藏文件,记录主进程号。
2.数据库停止:gpstop:常用可选参数:-a:直接停止,不提示终端用户输入确认-m:只停止master 实例,与gpstart –m 对应使用-f:停止数据库,中断所有数据库连接,回滚正在运行的事务-u:不停止数据库,只加载pg_hba.conf 和postgresql.conf中运行时参数,当改动参数配置时候使用。
连接数,重启3.查看实例配置和状态select * from gp_segment_configuration order by content ;select * from pg_filespace_entry ;主要字段说明:Content:该字段相等的两个实例,是一对P(primary instance)和M(mirror Instance)Isprimary:实例是否作为primary instance 运行Valid:实例是否有效,如处于false 状态,则说明该实例已经down 掉。
Port:实例运行的端口Datadir:实例对应的数据目录4.gpstate :显示Greenplum数据库运行状态,详细配置等信息常用可选参数:-c:primary instance 和mirror instance 的对应关系-m:只列出mirror 实例的状态和配置信息-f:显示standby master 的详细信息该命令默认列出数据库运行状态汇总信息,常用于日常巡检。
5.查看用户会话和提交的查询等信息select * from pg_stat_activity该表能查看到当前数据库连接的IP 地址,用户名,提交的查询等。
另外也可以在master 主机上查看进程,对每个客户端连接,master 都会创建一个进程。
ps -ef |grep -i postgres |grep -i con杀进程:Linux: kill -11 PIDSql :pg_cancel_backend(pid)ps –ef |grep – i postgre |grep –i con6.查看数据库、表占用空间select pg_size_pretty(pg_relation_size('schema.tablename'));select pg_size_pretty(pg_database_size('databasename));分区表:Select *from pg_partitions where …查某个schema 占用的空间:select pg_size_pretty(pg_relation_size(tablename))from pg_tables t inner join pg_namespace d on t.schemaname=d.nspname group by d.nspname必须在数据库所对应的存储系统里,至少保留30%的自由空间,日常巡检,要检查存储空间的剩余容量。
7.收集统计信息,回收空间定期使用Vacuum analyze tablename 回收垃圾和收集统计信息,尤其在大数据量删除,导入以后,非常重要将delete 或update 的“旧”数据放到Rollback Segment,与表分开存放。
并发事务为了保证数据一致性,需要从Rollback Segment 上恢复数据。
Greenplum:“旧数据”与表存放在一起,对旧的数据做了标志。
并发事务通过transaction ID(XID)判断数据是否可用系统表也是需要进行vaccum:#!/bin/bashDBNAME="databasename"VCOMMAND="VACUUM ANALYZE"#VCOMMAND="VACUUM FULL ANALYZE"psql -tc "select '$VCOMMAND' || ' pg_catalog.' || relname || ';' from pg_classa,pg_namespace b where a.relnamespace=b.oid and b.nspname= 'pg_catalog' anda.relkind='r'" $DBNAME | psql -a $DBNAME长期没有vaccum 的大表,使用重建表/drop 表的方式,消除垃圾空间。
Alter table xxx rename to yyyy.8.查看数据分布情况两种方式:Select gp_segment_id,count(*) from tablename group by 1 ;如数据分布不均匀,将发挥不了并行计算的优势,严重影响性能。
9.实例恢复:gprecoverseg通过gpstate 或gp_segment_configuration 发现有实例down 掉以后,使用该命令进行回复,恢复时候不需要停机,不影响应用10.查看锁信息:SELECT locktype, database, c.relname, l.relation,l.transactionid, l.transaction, l.pid, l.mode, l.granted,a.current_queryFROM pg_locks l, pg_class c, pg_stat_activity aWHERE l.relation=c.oid AND l.pid=a.procpid ORDER BY c.relname;主要字段说明:relname: 表名locktype、mode 标识了锁的类型MVCC: 读写相互不影响select / insert update delete避免死锁:delete 和update 是表级排他EXCLUSIVE锁。
11.数据库备份gp_dump, pg_dump常用参数:-s: 只导出对象定义(表结构,函数等)-n: 只导出某个schemagp_dump 默认在master 的data 目录上产生这些文件:gp_catalog_1_<dbid>_<timestamp> :关于数据库系统配置的备份文件gp_cdatabase_1_<dbid>_<timestamp>:数据库创建语句的备份文件gp_dump_1_<dbid>_<timestamp>:数据库对象ddl语句gp_dump_status_1_<dbid>_<timestamp>:备份操作的日志在每个segment instance 上的data目录上产生的文件:gp_dump_0_<dbid>_<timestamp>:用户数据备份文件gp_dump_status_0_<dbid>_<timestamp>:备份日志12.数据库恢复gp_restore pg_restore必选参数:--gp-k=key :key 为gp_dump 导出来的文件的后缀时间戳-d dbname :将备份文件恢复到dbname13.Master主机硬件故障时,如何切换至Stand by Master,切换成功后是否需要进行数据检查或恢复等HA答:在stand by master 主机上,运行gpactivatestandby -d /gpdata 进行切换。
由于Master 只存储系统元数据信息,切换成功后,一般不需要进行数据检查和恢复。
日常巡检中要检查Stand by master 是否同步,可以通过表gp_master_mirroring 确认,如果发现不同步,可以通过命令:gpinitstandby -s standby_master_hostname –n 使得master和standby 重新同步。
14.当Master主机硬件故障排除时,如何由Stand by切换至原Master主机。
答:1,在standby master运行:gpinitstandby –s original_master_hostname2,在standby master 上运行:gpstop –m,注意这里只停止master 实例3,在原来的maste上运行:gpactivatestandby -d /gpdata。
4,在原来的master上运行:gpinitstandby -s original_standby_master_hostn ame15.日志:master 和segment 上分别有日志:$DATADIR/pg_log/*.csv$DATADIR:select * from pg_filespace_entry ;使用外部表将日志导入数据库,进行分析。
使用xfs 文件系统。
后台存储目录结构:base 下每个目录,对应select oid ,* from pg_database ;select relfilenode from pg_class : ;16.gpconfig : 4.0 新增加管理工具,参数配置工具;-c | --change <param_name>-v | --value value-m | --mastervalue master_value-s | --show <param_name>gpconfig -c max_connections -v 100 -m 1017.gpcheckperf :网络:gpcheckperf -f hostfile_gpchecknet_ic1 -r N –netperf -d /tmp磁盘IOgpcheckperf -f hostfile_gpcheckperf -d /data1 -d /data2 -r d linux DD 命令:dd if=/dev/zero of=/vol2/a.test bs=256k count=161000dd if=/vol2/b.test of=/dev/null bs=256k count=16000018.gpssh: 同时登陆到多个机器上,进行操作Gpssh -h sdw1 –h sdw2 -h sdw319.gp_toolkit: 管理工具包:◆gp_bloat_diag◆gp_stats_missing更多详细信息参见GpadminGuide appendix I ;pg_stat_last_operation:Shows the last time certain database operations were performed on adatabase object, for example, the last time a table was vacuumed。