递归下降分析算术表达式
实验3 算术表达式递归下降法

简单算术表达式的递归下降语法分析法一、实验任务完成以下描述算术表达式的递归下降分析程序构造。
G[E]:E→TE1E1→+TE1|εT→FT1T1→*FT1|εF→(E)|i说明:终结符号i为用户定义的简单变量,即标识符的定义。
要求具有如下功能:(1) 从文件读入算术表达式/或者从终端输入。
(2) 总控函数分析算术表达式。
(3) 根据分析结果正误,分别给出不同信息。
二、实验目的和要求通过设计、编制、调试一个递归下降语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,掌握常用的语法分析方法。
通过本实验,应达到以下目标:(1)掌握从源程序文件中读取有效字符的方法和产生源程序的内部表示文件的方法。
(2)掌握语法分析的实现方法。
(3)上机调试编出的语法分析程序。
三、实验背景知识递归下降法是语法分析中最易懂的一种方法。
它的主要原理是,对每个非终结符按其产生式结构构造相应语法分析子程序,其中终结符产生匹配命令,而非终结符则产生过程调用命令。
因为文法递归,相应子程序也递归,所以称这种方法为递归下降法。
其中子程序的结构与产生式结构几乎是一致的。
递归下降分析程序的实现思想是:识别程序由一组子程序组成。
每个子程序对应于一个非终结符号。
每一个子程序的功能是:选择正确的右部,扫描完相应的字。
在右部中有非终结符号时,调用该非终结符号对应的子程序来完成。
自上向下分析过程中,如果带回溯,则分析过程是穷举所有可能的推导,看是否能推导出待检查的符号串,分析速度慢;而无回溯的自上向下分析技术,可根据输入串的当前符号以及各产生式右部首符,选择某非终结符的产生式,效率高,且不易出错。
无回溯的自上向下分析技术可用的先决条件是:无左递归和无回溯。
即:假设A的全部产生式为A->α1|α2|……|αn ,则必须满足如下条件才能保证可以唯一的选择合适的产生式First(αi )∩First(αj)=Φ,当i≠j.无左递归:既没有直接左递归,也没有间接左递归。
四则运算递归下降法

四则运算递归下降法递归下降法是一种常用于编写表达式解析器的技术,它将一个复杂的问题分解为一系列简单的子问题。
对于四则运算,可以通过递归下降法来解析表达式,例如,一个简单的表达式可以包含加法、减法、乘法和除法。
下面是一个简单的 Python 代码示例,演示了如何使用递归下降法来解析四则运算表达式:class Parser:def __init__(self, expression):self.tokens = self.tokenize(expression)self.current_token = 0def tokenize(self, expression):# 将表达式分解为标记(tokens)# 这里简单地将操作符和数字作为标记,实际的解析可能更复杂return expression.replace(' ', '').replace('+', ' + ').replace('-', ' - ').replace('*', ' * ').replace('/', ' / ').split()def parse_expression(self):return self.parse_addition_subtraction()def parse_addition_subtraction(self):left_expr = self.parse_multiplication_division()while self.current_token < len(self.tokens):operator = self.tokens[self.current_token]if operator in ('+', '-'):self.current_token += 1right_expr = self.parse_multiplication_division()if operator == '+':left_expr += right_exprelse:left_expr -= right_exprelse:breakreturn left_exprdef parse_multiplication_division(self):left_expr = self.parse_number()while self.current_token < len(self.tokens):operator = self.tokens[self.current_token] if operator in ('*', '/'):self.current_token += 1right_expr = self.parse_number()if operator == '*':left_expr *= right_exprelse:if right_expr != 0:left_expr /= right_exprelse:raise ValueError("Division by zero")else:breakreturn left_exprdef parse_number(self):if self.current_token < len(self.tokens):token = self.tokens[self.current_token]self.current_token += 1if token.isdigit() or (token[0] == '-' and token[1:].isdigit()):return int(token)else:raise ValueError(f"Invalid token: {token}")else:raise ValueError("Unexpected end of expression")# 示例用法expression = "3 + 5 * ( 2 - 8 ) / 4"parser = Parser(expression)result = parser.parse_expression()print(f"Result: {result}")在这个示例中,parse_expression是最顶层的解析函数,它调用parse_addition_subtraction来解析加法和减法,而后者又调用parse_multiplication_division来解析乘法和除法,依此类推。
实验二 递归下降分析法的实现
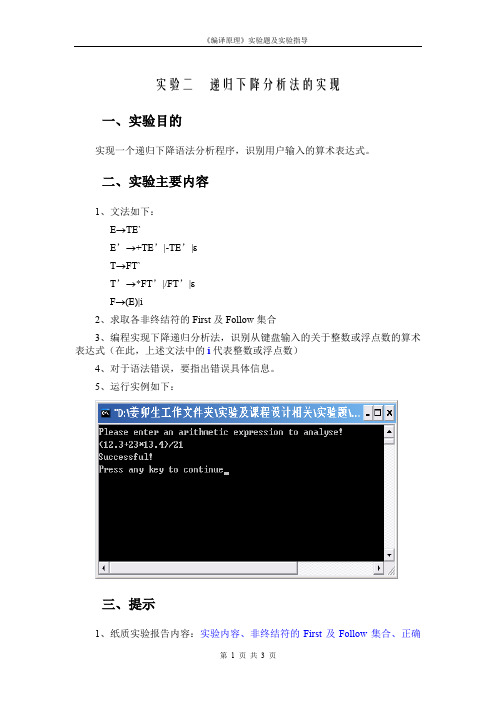
实验二递归下降分析法的实现一、实验目的实现一个递归下降语法分析程序,识别用户输入的算术表达式。
二、实验主要内容1、文法如下:E→TE`E’→+TE’|-TE’|εT→FT`T’→*FT’|/FT’|εF→(E)|i2、求取各非终结符的First及Follow集合3、编程实现下降递归分析法,识别从键盘输入的关于整数或浮点数的算术表达式(在此,上述文法中的i代表整数或浮点数)4、对于语法错误,要指出错误具体信息。
5、运行实例如下:三、提示1、纸质实验报告内容:实验内容、非终结符的First及Follow集合、正确表达式与错误表达式各举一例进行测试并给出结果、核心源代码。
2、将本次实验代码(.c、.cpp、.java等代码文件,删除编译产生的所有其他文件,不要打包)在规定时间内以作业附件(不可在线编辑、粘贴代码)的形式提交至网站,自己保存以备课程设计(本部有毕业设计要求的学生)参考。
3、纸质实验报告提交时间:临时要求。
实验指导(参考)一、实验步骤1、求取各非终结符的First及Follow集合;2、设计几个函数E(); Ep(); T(); Tp(); F();运用First集合进行递归函数选择,运用Follow集合进行出错情况判断;3、设计主函数:从键盘接受一个算术表达式串;在串尾添加尾部标志’#’;调用函数E()进行递归下降分析。
二、如何识别整数与浮点数在函数F()中要涉及到如何识别整数与浮点数。
识别的方法是:只要碰到‘0’~‘9’之间的字符就一直循环,循环到不是数字字符与小数点字符’.’为止,其间要运用一个标志变量来保证最多只能出现一个小数点,否则应该报错。
上述循环结束即表示识别了一个数,也即表达式文法中的i。
用递归下降方法实现算术表达式解析器

⽤递归下降⽅法实现算术表达式解析器对于形如2*2+2/1+3的算术表达式,如果不将优先级顺序考虑进去的话,那么解析如上的表达式⼗分容易,1 2 3 4 5 6a = get first operand while(operand present){ op = get operatorb = get second operand a = a op b} 如果将优先级考虑进去的话,⽽且还使⽤上述算法,那么复杂度可想⽽知.在此,我⽤递归下降的⽅式实现解析有优先级的算术表达式. 在此解析的算术表达式,由如下元素组成: 数字运算符+ - * / % 运算符的优先级如下 % / * > + - 优先级相等的运算符从左向右顺序计算 在使⽤递归向下解析器时,表达式被视为递归的数据结构,那么所有的表达式可以由如下的规则⽣成 表达式 ->项 [+项][-项] 项 -> 因数 [*因数][/因数][%因数] 因数 -> 数字或表达式 注意,上⾯的⽣成规则是以表达式中只包含+-*/%运算符且⽆变量为前提的,⽽且⽣成规则也包含了运算优先级,下⾯举例说明表达式的解析过程 2*3+2 有两个项,分别为2*3和2,前者包含两个因素2,3 下⾯以⼀个例⼦跟踪递归向下解析过程 2*3+3*41. 获得第⼀项2*32. 计算得到63. 获得第⼆项3*44. 计算得到125. 从第⼆项递归计算过程返回6. 6+12计算得到18 为计算表达式的值,需要对表达式进⾏分解,例如2*3-4可以分解成2,*,3,-,4四个元素,这些元素在解析器术语中称为标识符,是⼀个不能再分的独⽴单元.为了将表达式分解⼀独⽴的元素单元,需要设计⼀个过程,该过程能从头⾄尾扫描整个表达式,顺序地返回每个元素,并且能够识别每个元素的,在本解析器,实现该功能的函数称为getToken. 本⽂的解析器封装在⼀个Parser的类中,为对getToken功能有个更好的理解,现说明它的第⼀部分1 //解析器2 class Parser{3 //标识符的类型种类4 final int NONE = 0;5 final int NUMBER= 1;6 final int DELIMITER = 2;78 //异常的类型9 final int NOEXP = 0;10 final int SYNTAX = 1;11 final int DIVBYZERO = 2;1213 final String EOE = "\0";//标明表达式结尾14 private int tokType;//⽤于存放标识符类型15 private String token;//⽤于存放标识符16 private String exp;//⽤于存放表达式17 private int expIdx;//在表达式中的当前位置 解析器解析表达式时,每个标识符必须有与之关联的标识符,本解析器只⽤到2种类型,分别为NUMBER,DELIMITER.此外NONE类型只是当标识符未定义时的⼀个占位符. 此外,Parser类还定义⼏个异常,其中NOEXP是当解析器解析时没有表达式,SYNTAX代表表达式不符合规则的错误,DIVBYZERO代表除数为0时的错误. final变量EOE表⽰解析器⼰达到表达式的结尾. 被解析的表达式⼰字符串形式保存,exp保存该字符串的⼀个引⽤,exIdx保存下⼀个标识符在exp中的索引,初始值为0.当前标识符保存在token中,其类型则保存在tokType.这些变量都是private型,只允许解析器⾃⼰访问⽽不能被外部代码修改. 下⾯列出getToken函数的完整代码,每调⽤⼀次getToken(),将得到表达式的下⼀个标识,也就是exp[expIdx]后的⼀个标识.getToken()将标识符保存在token中,标识符类型则保存在tokType之中.//获得下⼀个标识符private void getToken(){token = "";tokType = NONE;//检查表达式是否到达末尾if(expIdx == exp.length()){token = EOE;return;}//去掉空格while(expIdx < exp.length() && Character.isWhitespace(exp.charAt(expIdx))) expIdx++;//当表达式以空格结束if(expIdx >= exp.length()){token = EOE;return;}if(isDelim(exp.charAt(expIdx))){//是运算符token += exp.charAt(expIdx));tokType = DELIMITER;expIdx ++;} else if(Character.isDigit(exp.charAt(expIdx))){//是数字while(!isDelim(exp.charAt(expIdx))){token += exp.charAt(expIdx);expIdx ++;if(expIdx >= exp.length())break;}tokType = NUMBER;} else {//不知名的字符结束字符串token = EOE;return;}}private boolean isDelim(char c){//判断字符是否是运算符if((" +-*/%").indexOf(c) != -1)return true;return false;}} 下⾯简单分析下getToken().getToken()⾸先做初始化⼯作,然后查看expIdx是否等于表达式的.由于expIdx保存的是解析器解析表达当前的进度,如果expIdx和exp.length(),那么表明解析器完成了表达式的解析. 如果解析器还能找到未处理的标识符,则解析过程继续进⾏.⾸先跳过下⼀个标识符之前所有的空格,如果表达式以空格结尾,则返回EOE结尾.根据exp[expIdx]后的⼀个字符的类型不同,getToken()对当前标识符的处理过程不同.如果⼀个字符为运算符,那么getToken()将当前标识符保存在token中,并将tokType设置为DELIMITER.若下⼀个字符为数字,token保存当前标识符,并将tokType设为NUMBER.如果下⼀个字符不为以上两种之⼀,则token保存EOE返回. 下⾯为解析器的代码,这个解析器只能解析由数字和运算符组成的表达式,其中运⾏符只包含+-*/%.class ParserException extends Exception{private String error;public ParserException(String error){this.error = error;}public String toString(){return error;}}class Parser {final int NONE = 0;final int NUMBER = 1;final int DELIMITER = 2;final int NOEXP = 0;final int SYNTAX = 1;final int DIVBYZERO = 2;final String EOE = "\0";private String exp;private String token;private int expIdx;private int tokType;//解析⼊⼝public double evaluate(String expStr) throws ParserException{this.exp = expStr;this.expIdx = 0;double result;getToken();if(token.equals(EOE)){handleErr(NOEXP);}result = evalExp1();if(!token.equals(EOE)){handleErr(SYNTAX);}return result;}//加或减private double evalExp1() throws ParserException{double result;double partialResult;char op;result = evalExp2();while((op = token.charAt(0)) == '+'|| op == '-'){getToken();partialResult = evalExp2();switch(op){case'+':result += partialResult;break;case'-':result -=partialResult;break;}}return result;}//乘或除或取余private double evalExp2() throws ParserException{double result;double partialResult;char op;result = atom();while((op = token.charAt(0)) == '*'|| op == '/'|| op == '%'){getToken();partialResult = atom();switch(op){case'*':result *= partialResult;break;case'/':if(partialResult == 0.0) handleErr(DIVBYZERO);result /=partialResult;break; case'%':result %= partialResult;break;}}return result;}//获得数的值private double atom() throws ParserException{double result = 0.0;switch(tokType){case NUMBER:try{result = Double.parseDouble(token);getToken();}catch(NumberFormatException exc){handleErr(SYNTAX);}break;default:handleErr(SYNTAX);}return result;}//错误处理private void handleErr(int error) throws ParserException{String[] errs = {"表达式不存在","表达式不符合规则","除数为0"};throw new ParserException(errs[error]);}//获得下⼀个标识符private void getToken(){token = "";tokType = NONE;//检查表达式是否到达末尾if(expIdx == exp.length()){token = EOE;return;}//去掉空格while(expIdx < exp.length() && Character.isWhitespace(exp.charAt(expIdx))) expIdx++; //当表达式以空格结束if(expIdx >= exp.length()){token = EOE;return;}if(isDelim(exp.charAt(expIdx))){//是运算符token += exp.charAt(expIdx);tokType = DELIMITER;expIdx ++;} else if(Character.isDigit(exp.charAt(expIdx))){//是数字while(!isDelim(exp.charAt(expIdx))){token += exp.charAt(expIdx);expIdx ++;if(expIdx >= exp.length())break;}tokType = NUMBER;} else{//不知名的字符结束字符串token = EOE;return;}}private boolean isDelim(char c){//判断字符是否是运算符if((" +-*/%").indexOf(c) != -1)return true;return false;}} 在代码最开始部分声明了⼀个ParserException类,这是⼀个异常类,当解析器解析表达式时就会根据异常类抛出特定的,该异常的处理需要使⽤该解析器的主程序处理.使⽤该解析器的⽅法是先实例化⼀个Parser,然后将⼀个表达式字符串传⼊该实例的evaluate⽅法,该⽅法返回最终的结果.下⾯的代码说明解析器的使⽤⽅法.import java.io.*;public class PDemo{public static void main(String[] args){String expr;BufferedReader br = newBufferedReader(new InputStreamReader(System.in));Parser p = new Parser();System.out.println("Enter an empty expression to stop");for(;;){System.out.print("Enter expression:");expr = br.readLine();if(expr.equals("")) break;try{System.out.println("Result :"+p.evaluate(expr));System.out.println();}catch(ParserException exc){System.out.println(exc);}}}}。
递归下递语法分析

递归下递语法分析递归下降语法分析是一种自上而下的分析方法,基于产生式规则和递归函数的方式来进行语法分析。
在递归下降语法分析中,每个非终结符对应一个递归函数,该函数负责对该非终结符所对应的产生式进行分析。
这种分析方法的优点是简单易懂,容易实现,但是对于左递归、回溯以及二义性文法的处理较为困难。
递归下降语法分析的核心思想是根据当前输入符号和预测分析表,选择适当的递归函数进行调用,直到遇到终结符或无法继续推导为止。
下面我们将详细介绍递归下降语法分析的步骤。
1.定义语法产生式规则:首先需要定义待分析的文法的产生式规则。
产生式规则由左部和右部组成,左部表示非终结符,右部表示由终结符和非终结符组成的字符串。
例如,对于表达式文法E->E+T,T,E为非终结符,+为终结符,T为非终结符,表示一个表达式可以是一个表达式加一个项,或者仅仅是一个项。
2.构建预测分析表:根据产生式规则,构建一个预测分析表。
预测分析表是一个二维表,由非终结符和终结符构成,表中的每个元素表示哪个产生式规则应该被应用。
例如,对于表达式文法,预测分析表可能如下所示:, + , * , id , ( , ) ,---,---,---,---,---,---,--E,-,-,T,T,-,T,F,-,F,F,-,F , - , - , id , (E), - ,表中的'-'代表无动作。
3.实现递归函数:根据预测分析表中的产生式规则,实现对应的递归函数。
每个非终结符对应一个递归函数,函数的实现根据当前输入符号和预测分析表中选择对应的产生式规则进行推导。
例如,对于表达式文法,可以定义如下的递归函数:```pythondef E(:if symbol == '+':match('+')TEelif symbol == 'id' or symbol == '(':TEelse:# Errordef T(:if symbol == '+':FTelif symbol == 'id' or symbol == '(':FTelse:# Errordef F(:if symbol == 'id':match('id')elif symbol == '(':match('(')Ematch(')')else:# Error```在每个递归函数中,首先需要判断当前输入符号与预测分析表的元素是否匹配,如果匹配则进行相应的操作(例如推导产生式、移动指针等),如果不匹配则报错。
自顶向下分析——递归下降法

假设有文法
Z→aBa
B→bB |c
则相应的递归子程序可如下:
ReadToken
procedure Z( )
procedure B ( )
begin
begin
if token=a then Match(a);
B;
ReadToken
Match(a)
else err( )
end;
if token = b then Match(b); B;
else if token = c then Match(c); else err( )
end;
主程序:Begin ReadToken; Z end
产生式A→被选择的条件是: 当前的输入符属于predict(A→)。
至多一个产生式被选择的条件是: predict(A→k) predict(A→j )=,当k j
if tokenPredict(A2) then (2) else …… if tokenPredict(An) then (n) else err( )
end 其中对i=X1X2…Xn,(i) = ’(X1);’(X2);…;’(Xn); 如果XVN,’(X)= X 如果XVT,’(X)= Match(X) 如果X= , () = skip(空语句)
自顶向下分析——递归下降法
递归下降法(Recursive-Descent Parsing) 对每个非终极符按其产生式结构产生相应 语法分析子程序. 终极符产生匹配命令 非终极符则产生调用命令 文法递归相应子程序也递归,所以称这种 方法为递归子程序方法或递归下降法。
例:Stm→ while Exp do Stm 则对应产生式右部的语法分析程序部 分如下: begin Match($while); Exp; Match($do); Stm end
编译原理---递归下降分析法

编译原理---递归下降分析法所谓递归下降法 (recursive descent method),是指对⽂法的每⼀⾮终结符号,都根据相应产⽣式各候选式的结构,为其编写⼀个⼦程序 (或函数),⽤来识别该⾮终结符号所表⽰的语法范畴。
例如,对于产⽣式E′→+TE′,可写出相应的⼦程序如下:exprprime( ){if (match (PLUS)){advance( );term( );exprprime( );}}其中:函数match()的功能是,以其实参与当前正扫视的符号 (单词)进⾏匹配,若成功则回送true,否则回送false;函数advance()是⼀个读单词⼦程序,其功能是从输⼊单词串中读取下⼀个单词,并将它赋给变量Lookahead;term则是与⾮终结符号T相对应的⼦程序。
诸如上述这类⼦程序的全体,便组成了所需的⾃顶向下的语法分析程序。
应当指出,由于⼀个语⾔的各个语法范畴 (⾮终结符号)常常是按某种递归⽅式来定义的,此种特点也就决定了这组⼦程序必然以相互递归的⽅式进⾏调⽤,因此,在实现递归下降分析法时,应使⽤⽀持递归调⽤的语⾔来编写程序。
所以,通常也将上述⽅法称为递归⼦程序法。
例4 2对于如下的⽂法G[statements]:statements→expression; statements |εexpression→term expression′expression′→+term expression′ |εterm→factor term′term′→*factor term′ |εfactor→numorid | (expression)通过对其中各⾮终结符号求出相应的FIRST集和FOLLOW集 (计算FIRST集和FOLLOW集的⽅法后⾯再做介绍),可以验证,此⽂法为⼀LL(1)⽂法,故可写出递归下降语法分析程序如程序41所⽰(其中,在⽂件lex.h⾥,将分号、加号、乘号、左括号、右括号、输⼊结束符及运算对象分别命名为SEMI,PLUS,TIMES,LP,RP,EOI及NUMORID,并指定了它们的内部码;此外,还对外部变量yytext,yyleng及yylineno进⾏了说明)。
递归下降程序实验报告

一、实验目的1. 理解递归下降分析法的原理和实现方法。
2. 掌握递归下降分析程序的设计和调试。
3. 加深对编译原理中语法分析部分的理解。
二、实验环境1. 操作系统:Windows 102. 编程语言:C++3. 开发环境:Visual Studio 2019三、实验内容1. 递归下降分析法原理介绍2. 递归下降分析程序的设计与实现3. 递归下降分析程序的调试与测试四、实验步骤1. 递归下降分析法原理介绍递归下降分析法是一种自顶向下的语法分析方法,它将文法中的非终结符对应为分析过程中的递归子程序。
当遇到一个非终结符时,程序将调用对应的递归子程序,直到处理完整个输入串。
2. 递归下降分析程序的设计与实现(1)定义文法以一个简单的算术表达式文法为例,文法如下:E -> E + T| TT -> T F| FF -> ( E )| id(2)消除左递归由于文法中存在左递归,我们需要对其进行消除,消除后的文法如下:E -> T + E'E' -> + T E' | εT -> F T'T' -> F T' | εF -> ( E ) | id(3)设计递归下降分析程序根据消除左递归后的文法,设计递归下降分析程序如下:```cpp#include <iostream>#include <string>using namespace std;// 定义终结符const char PLUS = '+';const char MUL = '';const char LPAREN = '(';const char RPAREN = ')';const char ID = 'i'; // 假设id为'i'// 分析器状态int index = 0;string input;// 非终结符E的分析程序void E() {T();while (input[index] == PLUS) {index++;T();}}// 非终结符T的分析程序void T() {F();while (input[index] == MUL) {index++;F();}}// 非终结符F的分析程序void F() {if (input[index] == LPAREN) {index++; // 跳过左括号E();if (input[index] != RPAREN) {cout << "Error: Missing right parenthesis" << endl; return;}index++; // 跳过右括号} else if (input[index] == ID) {index++; // 跳过标识符} else {cout << "Error: Invalid character" << endl;return;}}// 主函数int main() {cout << "Enter an arithmetic expression: ";cin >> input;index = 0; // 初始化分析器状态E();if (index == input.size()) {cout << "The expression is valid." << endl;} else {cout << "The expression is invalid." << endl;}return 0;}```3. 递归下降分析程序的调试与测试将以上代码编译并运行,输入以下表达式进行测试:```2 +3 (4 - 5) / 6```程序输出结果为:```The expression is valid.```五、实验总结通过本次实验,我们了解了递归下降分析法的原理和实现方法,掌握了递归下降分析程序的设计与调试。
递归下降分析程序(语法分析)

递归下降分析程序(语法分析)1. ⽂法 G(S):(1)S -> AB(2)A ->Da|ε(3)B -> cC(4)C -> aADC |ε(5)D -> b|ε验证⽂法 G(S)是不是 LL(1)⽂法?FIRST集FIRST(Da)={b,a}FIRST(ε)={ε}FIRST(cC)={c}FIRST(aADC)={a}FIRST(b)={b}FOLLOW集FOLLOW(A)={c,b,a,#}其中#是FOLLOW(A)=FOLLOW(C)=FOLLOW(B)=FOLLOW(S)FOLLOW(B)={#}FOLLOW(C)={#}FOLLOW(D={a,#}SELECT集SELECT(A->Da)=FIRST(Da)={b,a}SELECT(A->ε)=FOLLOW(A)={c,b,a,#}SELECT(C->aADC)=FIRST(aADC)={a}SELECT(C->ε)=FOLLOW(C)={#}SELECT(D->b)=FIRST(b)={b}SELECT(D->ε)=FOLLOW(D)={a,#}因为SELECT(A->Da)∩SELECT(A->ε)≠∅SElECT(C->aADC)∩SELECT(C->ε)=∅SELECT(D->b)∩SELECT(D->ε)=∅所以G(S)不是LL(1)⽂法。
2.(上次作业)消除左递归之后的表达式⽂法是否是LL(1)⽂法?消除左递归得:E->TE’E’->+TE’|εT->FT’T’->*FT’|εF->(E)|iFIRST集:FIRST(TE’)={ (, i }FIRST(+TE')={+,ε}FIRST(FT’)={(,i}FIRST(*FT')={ *,ε}FIRST((E))={ (}FIRST(i)={ i }FOLLOW集:FOLLOW(E)={ ),# }FOLLOW(E')={ ),# }FOLLOW(T)={+,),#}FOLLOW(T')={+,),#}FOLLOW(F)={*,+,),#}SELECT集:SELECT (E -> TE’) = FIRST(TE’) = { ( , i }SELECT(E’ -> +TE’) = FIRST(+TE’) = { + }SELECT(E’ -> ε) = FIRST(ε) - {ε} U FOLLOW(E’) = FOLLOW(E’) = { ) , # } SELECT(T -> FT’) = FIRST(FT’) = { ( , i }SELECT(T’ -> *FT’) = FIRST(*FT’) = { * }SELECT(T’ -> ε) = FIRST(ε) - {ε} U FOLLOW(T’) = FOLLOW(T’) = { + , ) ,# } SELECT(F -> (E)) = FIRST((E)) = { ( }SELECT(F -> i) = FIRST(i) = { i }SELECT(E’ -> +TE’) = FIRST(+TE’) = { + } ∩ SELECT(E’ -> ε) = FOLLOW(E’) = { ) , # }=∅SELECT(T’ -> *FT’) = FIRST(*FT’) = { * } ∩ SELECT(T’ -> ε) =FOLLOW(T’) = { + , ) ,# }=∅SELECT(F -> (E)) = FIRST((E)) = { ( } ∩ SELECT(F -> i) = FIRST(i) = { i }=∅所以该⽂法为LL(1)⽂法。
编译原理:算术表达式递归下降分析程序设计

实验二:算术表达式递归下降分析程序设计LD1、实验目的:(1)掌握自上而下语法分析的要求与特点。
(2)掌握递归下降语法分析的基本原理和方法。
(3)掌握相应数据结构的设计方法。
2、实验内容:编程实现给定算术表达式的递归下降分析器。
算术表达式文法如下:E→E+T | TT→T*F | FF→(E) | i3、设计分析题目所给的文法不为LL(1)文法,应改写成如下文法:E →TE2E2→+TE2 |∑T →FT2T2→*FT2 | ∑F →(E) | i采用递归下降分析法时,需要求出E2和T2 的FOLLOW集:FOLLOW(E2)={),#}FOLLOW(T2)={+,),#}递归下降分析法是确定的自上而下分析法,基本思想是,对文法中的每个非终结符编写一个函数,每个函数的功能是识别由该非终结符所表示的语法成分。
因此需要分别构造E,E2,T,T2,F函数来执行自己的识别功能,根据文法的内容顺序决定函数的识别功能。
advance函数用于字符串的推进,input函数用于字符串的输入。
4、程序代码#include <iostream>using namespace std;char a[80]; // 字符串的存入char sym; // 单个的判断字符int i=0; // 字符串下标void E(); // 功能识别函数void E2(); // 功能识别函数void T(); // 功能识别函数void T2(); // 功能识别函数void F(); // 功能识别函数void input(); // 输入函数void advance(); // 字符串小标进一函数void main(){while(1){input();advance();E(); // 从首个推导式E开始if (sym=='#')cout<<"success"<<endl;elsecout<<"fail"<<endl;i=0; // 重新输入时,下标置0 }}void E(){T();E2();}void E2(){if(sym=='+'){advance();T();E2();}else if (sym != ')' && sym != '#'){cout<<"error!"<<endl;exit(0);}}void T(){F();T2();}void T2(){if(sym=='*'){advance();F();T2();}else if(sym!='+'&&sym!=')'&&sym!='#'){cout<<"error!"<<endl;exit(0);}}void F(){if(sym=='('){advance();E();if(sym==')')advance();else{cout<<"error!"<<endl;exit(0);}}else if(sym=='i'){advance();}else{cout<<"error!"<<endl;exit(0);}}void input(){cout<<"请输入需识别的句子:";cin>>a;}void advance(){sym=a[i];i++;}5、测试用例(1)只含有一个字符的形式:iaA(2) 含有‘+’的形式:i+ii+i+ii++++(3) 含有‘*’的形式:i*ii*i*ii***(4) 含有‘(’‘)’的形式:(i)()((i))(5) 综合形式:(i+i)*i(i+i)*(i+i)i+i*ii++i*(*i+(i+iii6、实验总结通过本次试验实践掌握了自上而下语法分析法的特点。
递归下降分析算法

数学与计算机学院编译原理实验报告年级09软工学号姓名成绩专业软件工程实验地点主楼指导教师湛燕实验项目递归下降分析算法实验日期2012.6.10一、实验目的和要求使用递归子程序法设计一个语法分析程序,理解自顶向下分析方法的原理,掌握手工编写语法分析程序的方法。
重点和难点:本实验的重点是理解自顶向下分析方法的原理;难点是如何把文法改写成EBNF形式。
二、实验内容1、使用递归下降分析算法分析表达式文法:exp ::= expaddop term | termaddop ::= + | -term ::= term mulop factor | factormulop ::= * | /factor ::= (exp) | number其中number可以是多位的十进制数字串(整数即可),因此这里还需要一个小的词法分析器来得到number的值。
2、该词法分析器以子程序形式出现,当需要进行词法分析时进行调用;3、能够识别正确和错误的表达式;4、在进行语法分析的过程中,计算输入表达式的值。
三、程序设计主要变量有:boolIsDigit(char ch);//判断字符是否是数字static string s;//staticinti=0;//staticint flag=0;//staticint result;//主要函数有:staticintexp();//staticint exp1(int temp);//staticint term();//staticint term1(int temp);//staticint factor();//static intReadNum();//提取数字递归下降的主要原理是:对每个非终结符按其产生结构构造相应语法分析子程序,其中终结符产生匹配命令,而非终结符则产生过程调用命令。
因为文法递归相应子程序也递归,所以称这种方法为递归子程序下降法或递归下降法。
五、代码和截图自己写程序如下:#include<stdio.h>#include<conio.h>#include<cstdlib>#include<string>#include <iostream>#include <fstream>#include <stdlib.h>using namespace std;staticintexp();staticint exp1(int temp);staticint term();staticint term1(int temp);staticint factor();staticintReadNum();boolIsDigit(char ch);static string s;staticinti=0;staticint flag=0;staticint result;int main(){cout<<"请输入一个语句,以“#”结束,输入“#”退出"<<endl;while(1){cin>>s;s+='#';if(s[0]=='#')return 0;result = exp();if (flag == 0){cout<<"结果是"<<endl<<result<<endl;}}return 1;}staticboolIsDigit(char ch){if (ch>= 48 &&ch<= 57)return true;elsereturn false;}staticintReadNum(){int add = 0;stringstr = "";while (s[i]!= '#'){if (s[i] == '+'||s[i] =='-'||s[i]=='*'||s[i]=='/'||s[i]==')'){break;}else if (s[i]>= 48&&s[i]<=57){str +=s[i];}else{flag= 1;cout<<"输入了错误的字符!"<<endl;return -1;}i++;}str += "!";int n = 0;while (str[n] != '!'){cout<<str<<"(数字)"<<endl;n++;}int m = 0;while (str[m] != '!'){add += (int)(str[m] - 48);add *= 10;m++;}add = add / 10; cout<<add<<endl;return add;}staticintexp(){int temp;temp = term();temp = exp1(temp);return temp;}staticint exp1(int temp) {if(s[i]=='+'){++i;temp += term(); temp = exp1(temp);}else if(s[i]=='-'){++i;temp -= term(); temp = exp1(temp);}return temp;}staticint term(){int temp;temp = factor();temp = term1(temp); return temp;}staticint term1(int temp) {if(s[i]=='*'){++i;temp *= factor();temp = term1(temp);}else if(s[i]=='/'){++i;temp /= factor();temp = term1(temp);}return temp;}staticint factor(){int temp = 0;if (IsDigit(s[i])){temp = ReadNum();}else if(s[i]=='('){++i;temp=exp();if(s[i]==')')++i;else{flag = 1;cout<<"缺少右括号!"<<endl;}}else{flag = 1;cout<<"请输入正确的格式!"<<endl;}return temp;}输入的句子不正确时,提示,如下图:输入了正确的句子后,分析如下图:。
递归下降程序

递归下降分析程序实验报告1.实验内容编程实现给定算术表达式的递归下降分析器。
算术表达式文法如下:E→E+T | TT→T*F | FF→(E) | i2.实验分析(1 ) 对所给表达式进行分析,如果是左递归则对算术表达式进行改写消除其左递归。
改写的算术表达式如下:E→TE’E’→+TE’| εT→FT’T’→*FT’ | εF→(E) | i( 2) 写出上面表达式的FIRST集和FOLLOW集,然后对有多个规则的FIRST集求并集,看是否等于空集;对规则右部出现空串的FIRST集与FOLLOW集求并集,看是否等于空集。
对E’:FIRST(+TE′) ∩FOLLOW(E′)={+,ε} ∩{#, )}=Φ对T’:FIRST(*FT′) ∩FOLLOW(T′)={*,ε} ∩{+,#, )}=Φ对F:FIRST(i) ∩FIRST( (E) )={i} ∩{ ( }=Φ故由上面可知此改写后的文法是LL(1)文法。
(3)对上述LL(1)文法编程。
编程规则如下:①当遇到终结符a时,则编写语句If(当前读来的输入符号==a)读下一个输入符号②当前遇到非终结符A时,则编写语句调用A()。
③当前遇到A→ε规则时,则编写语句If(当前读来的输入符号不属于FOLLOW(A))error()④当某个非终结符的规则有多个候选式时,按LL(1)文法的条件能惟一地选择一个侯选式进行推导。
3.源程序代码#include<iostream>using namespace std;#include<string>#define n 100char ch[n];int k=0;void scaner(); void E();void E1();void T();void T1();void F();void Error();void scaner(){k++;}void E(){T();E1();}void E1(){if (ch[k]=='+'){scaner();T();E1();}else if(ch[k]!=')'&&ch[k]!='#') Error();}void T(){F();T1();}void T1(){if(ch[k]=='*'){ scaner();F();T1();}else if(ch[k]=='+'&&ch[k]!=')'&&ch[k]=='#')Error();}void F(){if(ch[k]=='('){scaner();E();if(ch[k]==')')scaner();else Error();}else if(ch[k]=='i'){scaner();}else Error();}void Error(){cout<<"语法错误 !!!"<<endl;cout<<"分析失败"<<endl;exit(0);}void main(){ k=0;cout<<"请输入表达式:";cin>>ch;E();if (ch[k]=='#'){cout<<"分析成功!"<<endl;}else{cout<<"分析失败"<<endl;}}4.测试用例1.图1:输入i时成功图1 输入i匹配成功2.图2:输入i+i*i时成功图2 输入i+i*i匹配成功3.图3:输入(i)时成功图 3 输入(i)匹配成功4.图4:输入(i+(i*i))时成功图 4 输入(i+(i*I))匹配成功5.图5:输入i+i时成功图 5 输入i+i匹配成功6.图6:输入i*i时成功图6 输入i*i匹配成功7.图7:输入(i*i)时成功图7 输入(i*i)时匹配成功8.图8:输入(i+i)时成功图8 输入(i+i)时匹配成功9.图9:输入i+i+i+i+i+i时成功图9 输入i+i+i+i+i+i时匹配成功10.图10:输入i*i*i*i*i*i*i*i时成功图10 输入i*i*i*i*i*i*i时匹配成功11.图11:输入+i时失败图11 输入+i时匹配失败12.图12:输入ii时失败图12 输入ii时匹配失败13.图13:输入()时失败图13 输入()匹配失败5.实验总结本次实验主要是根据一个算术表达式文法构造一个识别该文法句子的递归下降分析程序。
语法分析-递归下降分析法
void scaner();//扫描函数
void factor();//因子
void term();//项
void expression();//表达式
void statement();//语句
else
{
cout<<"错误,表达式缺乏')'"<<endl;
kk=1;
}
}
else
{
cout<<"表达式错误,表达式开头不是'('"<<endl;
kk=1;
}
return;
}
//项
void term()
{
factor();
//问题---补充判断条件
while(syn==15 || syn==16)//当开头扫描的是'*'或'/'时,继续扫描
{
scaner();
factor();
}
return;
}
//表达式
void expression()
{
//问题---补充程序代码
term();
while(syn==14 || syn==13)//当开头扫描的是'+'或'-'时,继续扫描
{
scaner();
term();
}
return;
}
编译原理实验递归下降分析器的设计(含源代码和运行结果)

《编译原理》实验报告实验3 递归下降分析器的设计姓名学号班级计科1001班时间: 2012/4/15 地点:文波同组人:无指导教师:朱少林实验目的使用递归子程序法设计一个语法分析程序,理解自顶向下分析方法的原理,掌握手工编写递归下降语法分析程序的方法。
实验内容a.运用所学知识,编程实现递归下降语法分析程序。
使用递归下降分析算法分析表达式是否符合下文法:exp → exp addop term | termAddop →+ | -term→ term mulop factor | factormulop → * | /factor → (exp) | id | number其中number可以是多位的十进制数字串(整数即可),因此这里还需要一个小的词法分析器来得到id 和number的值。
b.从数据文件中读出符号串,输出表达式并给出其正误评判。
实验数据文件中应该有多个表达式,可能有正确的也应该有错误的表达式;表达式有形式简单的也应该有复杂的。
每个表达式写在一行,以回车结束。
实验环境软件:VC++6.0实验前准备1、方案设计:①准备模拟数据:本实验中使用“work..cpp”②程序思想:为了使用递归向下的分析,为每个非终结符根据其产生式写一个分析程序,由于写入读出的操作频繁。
所以程序中还有一个match(char t)函数,该函数是将字符写入文件打印输出同时从文件中读取下一个字符,而由于id和number可能是多个字符构成,故写了number()和id()来分析数字和标识符,它们的功能仅仅是把整个number或id完整的读取出来并写入文件,打印输出。
由于分析的文件中可能出现非法字符,而一旦发现非法字符就无需再接着分析,所以在每次读取一个字符时调用islegal函数判断是否是合法字符,并返回0或1.在main()函数中,while((lookahead=='\n'||lookahead==' ')&&lookahead!=EOF) fscanf(resource,"%c",&lookahead);是为了忽略分析文件中的换行或空格,之后进入分析阶段,根据返回值判断是否是合法的表达式。
附录D递归下降语法分析和语法制导翻译结合

1. 产生式是用来表达语法单位的构造规则的,这些语法单 位对应的语义是什么? 2. 如何用属性及其计算过程来表达这些语义信息?
分析4.1:为产生式添加语义规则--加法
E | T ---------- E' | | F -- T' + ---- T ------------ E' | | | | i1 ε F ---- T' ε | | i2 * ---- F ---- T' | | i3 ε E→ E'→ T→ T'→ F→ TE' +TE' ∣ε FT' *FT' ∣ε (E) ∣i
E | T ---------- E' | | F -- T' + ---- T ------------ E' | | | | i1 ε F ---- T' ε | | i2 * ---- F ---- T' | | i3 ε E→ E'→ T→ T'→ F→ TE' +TE' ∣ε FT' *FT' ∣ε (E) ∣i
E→ E'→ T→ T'→ F→
TE' +TE' ∣ε FT' *FT' ∣ε i
分析1.4.3:产生式及其对应的代码
i1 + i2 * i3
mov mov mul add i1 i2 i3 r2 r1 r2 r2 r1
E | T ---------- E' | | F -- T' + ---- T ------------ E' | | | | i1 ε F ---- T' ε | | i2 * ---- F ---- T' | | i3 ε
编译原理用递归下降法进行表达式分析报告实验报告材料

《编译原理》课程实验报告一. 实验题目 用递归下降法进行语法分析的方法二. 实验日期三. 实验环境(操作系统,开发语言)操作系统是Windows开发语言是C 语言四. 实验内容(实验要求)词法分析程序和语法分析程序已经提供。
此语法分析程序能够实现:正确的输入可以给出结果。
例:输入表达式串为:(13+4)*3则应给出结果为51。
要求:(1)读懂源代码,理解内容写入实验报告(语法分析及语法分析程序和词法分析程序的接口)(2)把语法分析中使用的yyval ,用yytext 实现。
(3)在语法分析程序用加入出错处理(尽量完整,包括出错的位置,出错的原题目 用递归下降法进行表达式分析 专业 班级学号 姓名因,错误的重定位)五. 实验步骤1.生成lex.yy.c文件:将已给的mylexer.l文件打开,先理解,然后再在DOS环境下用flex运行此文件,这时会生成一个lex.yy.c文件。
2.创建工程:打开C-Free 5.0(注:用C-Free 4.0会出错),在菜单栏中的“工程(project)”菜单下选择“新建”;在新建工程中选择“控制台程序”,添加工程名字为“myleb”和保存位置后点“确定”;第1步选择“空的程序”点“下一步”;第2步再点“下一步”;最后点击“完成”。
3.在创建的工程中添加文件:在Source files文件夹中添加之前生成的lex.yy.c文件和syn.c文件,然后找到parser.h文件,将其添加到新建工程中的Header files文件夹中,这时就能将三个文件组成一个类似于.exe文件类型的文件,最后运行。
如图:4.理解并修改syn.c文件:首先,将num = yyval.intval修改成num = atoi(yytext);将num = yyval.fval修改成num = atof(yytext)。
可以这样修改的原因:在.l文件中所写的规则中,有{DIGIT}+ { yyval.intval = atoi(yytext);return INTEGER; }和{DIGIT}+"."{DIGIT}* {yyval.fval = atof(yytext); return DOUBLE; } 这两句代码,其中yyval.intval = atoi(yytext)和yyval.fval = atof(yytext)就说明两者可以相互替代。
递归下降 (1)

南京工程学院实验报告课程名称编译原理实验名称递归下降分析技术班级学号学生姓名成绩指导教师肖年月一.实验目的:应用递归下降分析技术,关于各非终结符号构造相应子程序来识别相对于它的短语。
二.实验内容:递归下降识别程序的例1:对于文法G[E]:E::=E+T|T T::=T*F|F F::=(E)|i经消去左递归同时也就消去了回溯性后的等价文法G’[E]:E::=TE’E’::=+TE’|εT::=FT’T’::=*FT’|εF=(E)|i递归下降识别程序的例2:对于文法G[S]:S::=S;T S::=T T::=if e then S else ST::=if e then S T::=a经消去左递归同时也就消去了回溯性后的等价文法G’[S]:S::=TS’S’::=;TS’|εT::= if e then ST’|aT’::=else S |ε+三.流程图:递归下降例1的流程图递归下降例2的流程图四.实验方法:1.用C语言写出递归下降识别程序1如下:#include<iostream.h>#include<string.h>void T(); // 声明函数void F(); // 声明函数void E1(); // 声明函数void T1(); // 声明函数char sym;char str[10]; //存放输入的字符串int i=0;char GetSymbol(){ //取字符sym=str[i];i++;return sym;}void Error(){ //出错判断cout<<"error!"<<endl;}void E(){ //递归下降的入口T();E1();}void E1(){if(sym=='+'){ //判断取的字符是否为+sym=GetSymbol();T();E1();}}void T(){F();T1();}void T1(){if(sym=='*'){ //判断取的字符是否为*sym=GetSymbol();F();T1();}}void F(){if(sym=='i') { sym=GetSymbol();} //判断取的字符是否为i取下一个字符else {if(sym=='('){ //判断取的字符是否为(取下一个字符sym=GetSymbol();E();if(sym==')') { sym=GetSymbol();} //判断取的字符是否为)取下一个字符else { Error(); }}elseError();}}void main(){for(int j=0;j<10;j++){str[j]=0;}cin>>str;sym=GetSymbol();E();if(sym!=0)Error();}2.用C语言写出递归下降识别程序2如下:#include<iostream.h>#include<string.h>#include<conio.h>void T(); //声明函数void S1(); //声明函数void T1(); //声明函数char sym;char str[100]; //放输入的字符串char str1[5]; //存放取出的字符串int i=0;char GetSymbol(){ //取字符sym=str[i];i++;return sym;}void Error(){ //判断错误cout<<"error!"<<endl;}void gj() //取字符串{for(int j=0;j<5;j++){str1[j]=0;}str1[0]=sym;int k=0;sym=GetSymbol();while(sym>='a' && sym<='z'){ k++;str1[k]=sym;sym=GetSymbol();}}void S(){T();S1();}void S1(){if(sym==';'){sym=GetSymbol();T();S1();}}void T(){if(sym=='a') { sym=GetSymbol();} else {gj();if(strcmp(str1,"if")==0){ //判断是否为ifsym=GetSymbol();if(sym=='e') {sym=GetSymbol();sym=GetSymbol();gj();if(strcmp(str1,"then")==0){ //判断是否为then sym=GetSymbol();S();T1();}else Error();}else Error();}else Error();}}void T1(){if(sym!='$'){sym=GetSymbol();gj();if(strcmp(str1,"else")==0){ // 判断是否为else sym=GetSymbol();S();}}}void main(){int j;char ch;for(j=0;j<100;j++){str[j]=0;} //清空数组j=0;do{ //输入字符以$结束ch=getche();str[j]=ch;j++;}while(ch!='$');cout<<endl;sym=GetSymbol();S();if(sym!='$') //判断是否输入完Error();}五.实验结果:⒈递归下降识别程序1的结果如下:⑴.若输入i+i*i,则有结果如下:说明输入的i+i*i为该文法的句子⑵.若输入i-i,则有结果如下:说明输入的i-i不是该文法的句子⒉.递归下降识别程序2的结果如下:⑴.若输入if e then a else a$,其中$用来表示结束符,则有结果如下:说明输入的if e then a else a是该文法的句子⑵.若输入if e$,其中$用来表示结束符,则有结果如下:说明输入的if e不是该文法的句子由递归下降分析法可以看出,要是输入字符串的为该文法的句子,就没有错误,直接结束语句执行,要是不是该文法的句子就会有错误信息提示,再结束语句执行。
用递归下降分析法编写一个用于判断数学表达式是否正确的语法分析

使用递归下降算法分析数学表达式安全编程2011-01-07 23:43:50 阅读27 评论0 字号:大中小订阅国内很多编译原理的教材都过于重视理论学习而缺少实践上的指导。
本来想通过介绍一个经典的算法问题--数学表达式问题,来举例说明编译原理中一种文法分析算法的实践。
在我们学习的编译原理中有个专题叫做语法分析(文法分析)。
文法分析就是以一种固定的文法格式来解析形式语言。
在我们的编译原理的教材中都必定包含两种文法分析的算法,一个是LL算法,另外一个就是LR算法。
LL算法也叫自顶向下的分析算法,相对简单,适合于手工编码,而LR算法是自底向上的分析算法,很复杂,一般我们都通过使用工具yacc来生成其相关代码。
本文以LL(1)算法中最简单的一种形式递归下降算法来分析常规算法问题中的数学表达式问题。
同时,本文也介绍手工构造EBNF文法的分析器代码普遍方法。
希望本文的实践能对大家实现自己的语法分析器带来帮助。
数学表达式问题在学习算法的时候,四则混合运算的表达式处理是个很经典的算法问题。
比如这里有个数学表达式“122+2*(11-1)/(3-(2-0))”。
我们需要根据这个字符串的描述计算出其结果。
Input:122 + 2 * (11-1) /( 3-(2-0) )Output:142四则混合运算中还需要考虑到括号、乘除号与加减号的优先运算问题,通常的解决办法就是使用堆栈。
这种常规的算法和LL算法有异曲同工之处,两种算法其实是一样的。
传统数学表达式处理算法简介这个传统算法其实不知不觉地使用LL(1)算法的精髓。
它就是主要依靠栈式的数据结构分别保存数和符号,然后根据运算符号的优先级别进行数学计算,并将结果保存在栈里面。
传统算法中使用了两个栈。
一个是保存数值,暂时就叫值栈。
另一个是保存符号的,叫符号栈。
我们规定一个记号#,来表示栈底。
下面我们就来看看如何计算一个简单的表达式:11+2-8*(5-3)符号栈和值栈的变化是根据输入串来进行的,基本上栈的操作可以简单用下面几句话来说。
二、递归下降语法分析

实验二递归下降语法分析程序设计[实验目的]:1.了解语法分析的主要任务。
2.熟悉编译程序的编制。
[实验内容]:根据某文法,构造一基本递归下降语法分析程序。
给出分析过程中所用的产生式序列。
[实验要求]:1.构造一个小语言的文法,例如,Pascal语言子集的文法,考虑其中的算术表达式文法:G[<表达式>]:G[E]:<表达式>→<表达式>+<项>|<表达式>-<项>|<项>E→E+T|T<项>→<项>*<因式>|<项>/<因式>|<因式>T→T*F|F<因式>→<标识符>|<无符号整数>|(<表达式>)F→i|(E)2.设计语法树的输出形式,例如:产生式……3.编写递归下降语法分析程序实现基本的递归下降分析器,能够分析任给的符号串是否为该文法所定义的合法算术表达式。
实验报告中要说明分析使用的方法。
4.生成并输出分析过程中所用的产生式序列:1产生式12产生式2……[实验步骤]:1.写出一个小语言的算术表达式文法。
2.写出该小语言的算术表达式等价的LL(1)文法。
例如:G[E]:其中E→TG G为E’E→+TG|^^为εT→FS S为T’T→*FS|^F→i|(E)3.编写递归下降语法分析程序。
4.调试运行程序。
5.结果分析。
6.撰写实验报告。
[实验报告]:每位同学撰写一份试验报告,并提交电子版。
1.源程序。
2.画出流程图。
3.实验设计过程中出现的问题及解决的方法。
4.实验设计过程中的体会。
5.给出程序清单。
6.给出测试结果。
实验报告命名规则:个人:2013-14(1)医智(1)1107505101蔡菲菲实验二交各班课代表汇总后,由课代表打包后,发送至老师的邮箱班级命名规则:2013-14医智(1)实验二截止日期:第14周周五晚11点30分测试的结果举例1.一个小语言的算术表达式文法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
递归下降分析算术表达式
计算机092—07 邹芬芬
●实验目的:
(1)掌握自上而下语法分析的要求与特点。
(2)掌握递归下降语法分析的基本原理和方法。
(3)掌握相应数据结构的设计方法。
●实验内容:
编程实现给定算术表达式的递归下降分析器。
算术表达式文法如下:E→E+T | T
T→T*F | F
F→(E) | i
●设计分析
题目所给的文法不为LL(1)文法,应改写成如下文法:
E →TE2
E2→+TE2 |∑
T →FT2
T2→*FT2 | ∑
F →(E) | i
采用递归下降分析法时,需要求出E2和T2 的FOLLOW集:
FOLLOW(E2)={),#}
FOLLOW(T2)={+,),#}
递归下降分析法是确定的自上而下分析法,基本思想是,对文法中的每个非终结符编写一个函数,每个函数的功能是识别由该非终结符所表示的语法成分。
因此需要分别构造E,E2,T,T2,F函数来执行自己的识别功能,根据文法的内容顺序决定函数的识别功能。
advance函数用于字符串的推进,input函数用于字符串的输入。
●程序代码
#include <iostream>
using namespace std;
char a[80]; // 字符串的存入
char sym; // 单个的判断字符
int i=0; // 字符串下标
void E(); // 功能识别函数
void E2(); // 功能识别函数
void T(); // 功能识别函数
void T2(); // 功能识别函数
void F(); // 功能识别函数
void input(); // 输入函数
void advance(); // 字符串小标进一函数
void main()
{
while(1)
{
input();
advance();
E(); // 从首个推导式E开始
if (sym=='#')
cout<<"success"<<endl;
else
cout<<"fail"<<endl;
i=0; // 重新输入时,下标置0 }
}
void E()
{
T();
E2();
}
void E2()
{
if(sym=='+')
{
advance();
T();
E2();
}
else if (sym != ')' && sym != '#')
{
cout<<"error!"<<endl;
exit(0);
}
}
void T()
{
F();
T2();
}
void T2()
{
if(sym=='*')
{
advance();
F();
T2();
}
else if(sym!='+'&&sym!=')'&&sym!='#')
{
cout<<"error!"<<endl;
exit(0);
}
}
void F()
{
if(sym=='(')
{
advance();
E();
if(sym==')')
advance();
else
{
cout<<"error!"<<endl;
exit(0);
}
}
else if(sym=='i')
{
advance();
}
else
{
cout<<"error!"<<endl;
exit(0);
}
}
void input()
{
cout<<"请输入需识别的句子:";
cin>>a;
}
void advance()
{
sym=a[i];
i++;
}
测试用例
(1)只含有一个字符的形式:
i
E
(2) 含有‘+’的形式:
i+i
i+E
(3) 含有‘*’的形式:
i*i
i*
(4) 含有‘(’‘)’的形式:、
(i)
()
(5) 综合形式:
(i+i)*(i+i)
i*(i+i)
i*i+i
实验总结
通过本次试验实践掌握了自上而下语法分析法的特点。
掌握了递归下降语法分析的基本原理和方法。
运用递归下降分析法完成了本试验的语法分析构造,并且成功的分析出每种正确的句子和错误的句子。
函数的构造是根据文法分析的递归过程,所编写每个函数的功能,以文法的右部为函数名,对应的左部为相应分析过程。
此分析法简单,直观,易构造分析程序,但是不适于文法过于复杂的,不易检查出错误。
在试验的过程中,遇到了一些问题,都是粗心大意而造成,并非是对文法分析和编程的熟悉问题,说明了我再以后的试验中应该更细心的编写程序的每一步,对于本次试验所出现的马虎,应该牢记,以后不再犯同样的错误。