OLTP数据库优化方案
基于Oracle的OLTP与OLAP数据库优化差异之内存设计

基于Oracle的OLTP与OLAP数据库优化差异之内存设计要进行数据库优化,首先应该弄清数据库类型及其特点。
从数据处理角度分类,数据库可分为两大类:联机事务处理OLTP(on-line transaction processing)和联机分析处理OLAP(On-Line Analytical Processing),OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易,电信业务等。
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
两类系统处理的数据量不同,技术的使用也是不一样的,在OLTP系统中,oracle、db2等是主流数据库产品,数据量在几个TB甚至更小。
在OLAP系统中,除了传统的数据库外,有越来越多的其他数据库产品出现,如sysbase IQ,GP,国产数据库GBase 8a,达梦7等,数据量大多在几十TB甚至更高,数据处理主要集中在查询统计分析、大数据量的导入导出等。
在这里,我们主要讨论的还是最通用的ORACLE数据库的两类系统的优化思路和方式的差异。
数据库具体是OLTP还是OLAP取决于你的业务类型。
OLTP和OLAP两类系统对数据库要求截然不同。
除了系统本身自有的特点之外,在技术方面也存在巨大的差别,所带来的优化技术和理念也不太一样。
OLTP主要是交易型数据库,其事务特征为高并发而数据量小,大部分情况都要求瞬间出结果,系统要求的实时性、稳定性、安全性较高。
这类数据库的系统瓶颈主要在CPU和内存上,在优化思路上,更加关注CPU的利用率;各种命中率指标,譬如SHARED POOL, BUFFER CACHE的命中率;SQL语句绑定变量等。
由于数据量相对比较小,因此OLTP大部分都是集中式的。
OLAP主要是分析型数据库,并发量比较小,但单个sql消耗巨大,大部分查询需要处理海量数据,用户对响应时间的要求远不如OLTP用户。
优化数据库查询的六种方法

优化数据库查询的六种方法数据库查询是开发过程中常见的操作,对于大型系统来说,查询的性能优化至关重要。
本文将介绍六种常用的优化数据库查询的方法,帮助开发人员提升系统的性能。
一、合理设计数据库结构良好的数据库结构是查询性能优化的基础。
在设计数据库时,需要合理划分表和字段,遵循范式原则,避免冗余数据和不必要的连接。
另外,可以使用索引来加速查询,选择适当的数据类型,减小存储空间,提高查询效率。
二、减少查询数据量优化查询的关键是减少查询的数据量。
通过精确的条件筛选和投影查询可以减少返回的数据条目,提高查询速度。
合理使用WHERE子句、GROUP BY子句和HAVING子句,尽量避免全表扫描和排序操作。
三、使用适当的索引索引是提高查询效率的重要手段。
在选择索引时,需要考虑查询的频率和字段的选择性。
高频率的查询字段和选择性较高的字段适合创建索引,而低频率的查询字段和选择性较差的字段则可以不考虑。
同时,需要定期维护索引,避免过多的无效索引对性能造成影响。
四、避免跨表查询和多重连接跨表查询和多重连接通常导致性能下降,应尽量避免使用。
可以通过合理的数据库设计和多表关联查询来减少跨表查询的次数。
此外,可以使用子查询、联合查询和视图等方式代替多重连接,提高查询效率。
五、使用缓存技术缓存技术是提高查询性能的有效手段。
可以使用缓存存储查询结果,当有相同查询请求时,直接从缓存中读取数据,避免重复查询数据库。
同时,需要合理设置缓存的过期时间和更新策略,保证数据的及时性和准确性。
六、定期优化数据库定期优化数据库是保证查询性能持续稳定的重要措施。
可以通过数据库性能分析工具来监控查询的执行计划和性能指标,及时发现和解决潜在问题。
另外,可以进行数据库的分区、拆分和归档,优化数据库的管理和维护。
综上所述,优化数据库查询是提升系统性能的关键步骤。
通过合理设计数据库结构、减少查询数据量、使用适当的索引、避免跨表查询和多重连接、使用缓存技术以及定期优化数据库,可以有效提高查询的效率和性能,提升用户的体验和系统的可用性。
数据库查询优化中的列存储与行存储选型讨论(五)

数据库查询优化是提高数据库性能和查询效率的重要手段之一。
在数据库查询优化中,存储方式的选择是一个关键的决策,其中最常见的选择是列存储和行存储。
本文将就列存储和行存储两种存储方式进行讨论,并比较它们在不同场景下的优劣之处。
一、背景介绍数据库查询优化的目标是尽可能减少查询的时间和资源消耗,提高查询的效率。
存储方式的选型是数据库查询优化中的重要一环。
传统的存储方式采用的是行存储,即将一条记录的所有字段以行的形式存储在磁盘上。
而列存储则是将同一列的数据连续地存储在磁盘上。
二、列存储的优势1. 压缩效果好:列存储可以针对每一列的数据进行独立的压缩,因此相比行存储,节省了更多的存储空间。
这也意味着在数据传输和磁盘I/O时,可以减少数据的读取量和传输量,提高查询的速度。
2. 列式处理优化:由于列存储将同一列的数据存放在一起,这样在对某一列进行查询、过滤、聚合等操作时,可以将同一列数据的处理集中在一起,减少了不必要的IO操作和数据的读取量,提高了查询的效率。
3. 多维度查询的高效性:在涉及到多维度查询的情况下,列存储能够更加高效地支持这种查询。
例如,在数据仓库或分析系统的场景中,经常需要对大量的数据进行多个维度的统计和查询,列存储的数据组织方式更加符合这种需求,可以减少不必要的IO和数据的读取量。
三、行存储的优势1. 更新操作效率高:由于行存储将一条记录的所有字段信息存储在一起,因此在更新操作时,只需要操作特定的一行数据,可以减少不必要的数据移动和复制操作,提高更新的效率。
2. 事务处理的支持:行存储对于事务处理的支持更加友好。
事务处理通常需要操作多个字段和多条记录,行存储的存储方式更容易支持事务的原子性、一致性和隔离性。
3. 高并发读写操作:由于行存储将一条记录的所有字段信息存储在一起,这样在并发读写操作时,可以减少数据块的冲突和互斥,提高并发读写的效率。
四、选型讨论在实际的应用场景中,选择列存储还是行存储需要根据具体的需求来确定。
数据库oltp与olap 通俗理解

数据库oltp与olap 通俗理解
通俗理解来讲,OLAP是个有分析师的仓库,OLTP则是个进出货很快的仓库。
OLAP与OLTP数据库由于关注的业务不同,所以软件在工作方式和优化方法会有一些不同。
OLTP 系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;OLAP 系统则强调数据分析,强调SQL 执行市场,强调磁盘I/O,强调分区等。
OLTP业务主要业务场景是交易记录的准确性,因此需要写入具有唯一性,所以传统针对OLTP数据库的优化方法将负责写入的“一夫”节点性能大幅提升,如使用更快的CPU,增加更多的内存,使用将内存当做磁盘用的傲腾存储,使用IB网络(InfiniBand network)等。
但个体设备的配置提升,会遇到天花板。
于是近年来有人提出将数据库进行分库分表,增加写入节点的数量而提升写入能力。
通过将数据复制到多个只读节点,提升数据读的能力。
比如对于一个记录用户名数据库,按姓名拼音的第一个字母拆成26个数据库,这样就可以将原来只能由一个库来写,变成分别由26个库来写入,从而提升写入能力。
但每个分开的库还是只能有一个写入,还是有种“一夫当关,万夫莫开”的意思。
数据库系统中的多维数据分析与查询优化研究

数据库系统中的多维数据分析与查询优化研究随着互联网时代的到来,数据量急剧增长,如何高效管理和利用数据成为了每个企业不可缺少的部分。
而数据库系统就是为了满足这一需求而被广泛应用的一种计算机软件。
但是,仅仅实现数据的存储和管理远远不能满足实际需求,多维数据分析和查询优化的研究就成为了当下数据库系统中的热门研究方向。
一、多维数据分析所谓多维数据分析,是指将数据从不同的角度进行分析和展示,以便更好地挖掘数据之间的关系和规律,从而为企业的决策提供有效的支持。
多维数据分析一般分为OLAP(Online Analytical Processing)和OLTP(Online Transaction Processing)两种方式。
OLAP在数据仓库中应用广泛, OLAP分析使用多维数据模型,使用不同的维度和度量对数据进行分析、计算、统计和查询,从而能够得到更多的洞察力。
OLAP可以更快速地回答如“销售额最高的五名客户”这类复杂的问题,同时也可以支持各种多维和交互式分析。
利用OLAP,企业可以更好的分析顾客需求、市场变化和销售模型,从而更好的进行业务决策。
相比于OLAP,OLTP更专注于实时的事务处理。
OLTP的目的是使数据处理更快、更稳定和更可靠,在处理每个来自不同事务的条目时,要始终保持一致。
OLTP是许多应用程序的核心,如电子商务平台和在线银行服务。
能够快速将交易数据从源到目的地传输,并能够处理大量并发请求,对于企业开展商业活动是至关重要的。
二、查询优化查询优化是数据库系统的核心之一,其主要目的就是优化查询语句的性能,缩短响应时间,提高整个系统的效率,并减轻服务器资源的负担。
常见的优化方式有查询重构、索引优化、统计信息优化等。
在查询优化中,查询重构是最基础的优化技术之一。
查询重构可以消除对于系统来说重复的查询,减少开销,提高效率。
例如,将一个子查询嵌入主查询中,大大地降低了查询的开销。
另外,索引优化也是查询优化中非常关键的一部分。
OLAP OLTP优化

Oracle决策支持系统下的性能调整和优化原则DSS 系统的特征是从大量的数据中产生有意义的报告。
DSS 应用可能会经常与OLTP 一起使用,但因为它们的设计要求差异很大,把OLTP 系统用于决策支持不是好的主意。
OLTP 的用户一般很多,而DSS 系统的用户一般较少。
决策支持系统的例子有与定单录入系统(OLTP系统)一起工作的现金流预测工具,该工具可以帮助决定需要多大的现金储备。
另一个决策支持的例子是客户需求分析工具,该工具可以找出某个地域客户对哪个产品购买量最大。
决策支持系统的主要特征是:读取大容量的数据,经常使用全表扫描作为存取数据的方法。
极少量地更新数据。
一般而言,从OLTP 系统的数据(也可能是其它的数据源)会以批的方式流向DDS 系统,用户自己极少会更新DSS 的数据。
下图反映了DSS系统的特征:DSS系统在运行时,有如下的一些要求:合理的响应时间。
结果是准确的。
可以在白天使用。
为了满足上面的要求,应当从以下几个方面考虑调节数据库DSS应用系统。
1. 在使用应用逻辑和声明约束来维护完整性方面,切记声明完整性约束的代价要小。
在DSS系统中,相关完整性约束和表的check 约束是主要使用的约束形式。
2. 尽量要使代码被存储过程对象共享。
3. 即使一条SQL语句在不同的运行环境下捆绑变量(bind variable)取了不同的值,Oracle认为他们是同样的SQL语句。
因此,要使分析SQL语句的工作减少到最抵,应当使用捆绑变量,而不是将这些不同的值直接放到SQL语句中(使用literal)(如果这样做了,Oracle 认为它们之间是不同的SQL,需要重新分析)。
但是,这样做会有如下的损失:优化器无法知道列的可选择性。
而完全写出来的SQL 语句(使用literal),可使基于成本的Oracle优化器使用直方图统计(histogram)。
4. 无论如何,对DSS系统来说,分析SQL 用的时间要比执行SQL语句用的时间要少的多。
基于现代通用处理器的数据库优化综述

到稿日期:2008—09—02返修日期:2008—12—04 本文受国家高技术研究发展计划863重点项目(2007AAl20400)资助。 邓亚丹(1981一),男,博士生,主要研究方向为数据库内核优化、空间数据库,E-mail:dengyadan2008@yahoo.corfL cn;曩宁(1963--),男,博士, 教授,博士生导师,主要研究力向为地理信息系统与数据库技术;熊伟(1976--),男,博士,副教授,主要研究方向为空间数据库。
预取分为硬件预取和软件预取。前者为通过处理器自身 的预取部件完成,只能针对顺序访问等简单的数据访问,对数 据库复杂的数据访问的优化效果不明显;后者主要分为两种 实现方式:(1)编译器在生成可执行文件时,将预取指令插入 可执行代码中;(2)本文所指的预取优化,即在处理器访问某 个Cache块之前,由程序员在代码中合适位置插入处理器支 持的预取指令函数,将内存中指定的数据预取到指定的某级 Cache中。如图2所示,每次执行计算之前,都会将下一次计 算所需数据预取到L2一Cache中。由于预取一次可将多个 Cache块读人Cache中,相比较Cache不命中而言,预取可以
程序运行中,指令数据同样需要读入指令Cache或通用 Cache中,处理器才能执行该指令。因此,如果处理器访问指 令数据时Cache缺失严重,对于数据库这种代码量巨大的程
· 】8·
万方数据
序而言,数据库性能也会受到比较严重的影响。CGIx叫(Call Graph Prefetching)首先构建数据库内核函数的调用图,基于 函数调用图就能预测将要执行的指令数据,在处理器执行代 码之前将指令取到Cache中。文献[6]中提出了两种访问图 实现方法:(1)基于软件的CGP,使用Profile信息构建访问 图;(2)基于硬件的CGP,使用硬件表动态地缓存程序中函数 的调用顺序构建访问图。实验表明,通过指令预取可以减少 83%的指令Cache缺失,相比未经优化的系统,平均性能提高 了30%。 1.2 Cache-Conscious算法
数据库查询优化与执行计划评估指南

数据库查询优化与执行计划评估指南数据库查询优化是提高数据库性能和减少查询时间的重要手段。
执行计划评估则涉及查询优化的核心步骤,通过分析执行计划,我们可以了解查询语句的执行方式以及查询过程中消耗资源的情况。
本文将为您介绍数据库查询优化的基本原则以及执行计划评估的方法,帮助您更好地进行数据库查询优化。
首先,让我们了解一下数据库查询优化的基本原则。
优化查询的目的是最大限度地减少查询时间和消耗的资源,提高数据库的响应速度。
以下是一些常见的查询优化原则。
1. 选择合适的索引:索引是优化查询的基础。
通过为数据库表添加索引,可以加快数据的查找和筛选速度,提高查询效率。
在选择索引时,应考虑查询的频率、数据分布以及可用的索引类型等因素。
2. 避免全表扫描:全表扫描是一种效率较低的查询方式,尤其在数据量较大的情况下会造成严重的性能问题。
通过合理地选择索引或使用适当的查询条件,可以避免全表扫描,提高查询效率。
3. 减少查询次数:多次查询同一表或使用了多个子查询的查询语句通常性能较差。
通过改写查询语句,将多个查询合并为一个查询或使用连接查询等方式,可以减少查询次数,提高查询效率。
4. 避免使用函数和表达式:在查询语句中使用函数和表达式可以实现复杂的计算和类型转换,但会增加查询的时间和资源消耗。
若不是必要的,尽量避免使用函数和表达式,以提高查询效率。
了解了数据库查询优化的基本原则之后,让我们来看一下如何通过执行计划评估来进一步优化查询。
执行计划是数据库根据查询语句生成的查询执行计划的一种可视化表示形式。
它显示了数据库执行查询的具体方式,包括查询语句中使用的索引、查询的顺序、表之间的连接方式、用到的临时表等信息。
通过分析执行计划,我们可以了解查询的执行路径和资源的使用情况,从而找到查询的瓶颈和优化的方向。
下面是一些常用的执行计划评估方法。
1. 分析查询耗时:执行计划中通常会显示每个操作(例如表扫描、索引扫描、连接操作等)的耗时。
ORACLE数据库优化理论探讨

0RACLE数据库优化理论探讨摘要:Oracle数据库是一种具有高可靠性、高安全性、高兼容性的大型关系数据库,得到广泛应用,要使Oracle数据库满足应用需求,有效管理和利用数据,较好地为业务服务,对Oracle数据库优化显得尤为重要。
关键词:数据库优化ORACLE SQL数据库作为系统的核心,其设计和应用对系统执行的效率和稳定性具有重大影响。
因此在软件系统开发中,数据库设计应遵循必要的数据库范式理论,以减少冗余、保证数据的完整性与正确性。
只有在合适的数据库产品上设计出合理的数据库模型,才能降低整个系统的编程和维护难度,提高系统的实际运行效率。
本文主要从以下角度分析数据库性能优化技术。
1 ORACLE数据库的系统性能评估参数DBA应该根据信息系统的类型注意考虑相关的数据库参数。
1.1 在线事务处理信息系统(OLTP)系统有频繁的Insert、Update操作,需要确保数据库的并发性、可靠性和最终用户的速度,考虑以下参数:数据库回滚段是否足够?建立索引、聚集、散列的必要性?系统全局区(SGA)大小是否合适?SQL 语句是否高效?1.2 数据仓库系统(Data Warehousing)主要任务是从ORACLE的大量数据中进行查询,总结数据之间的相关规律。
涉及以下参数:是否采用B*-索引或者bitmap索引?是否采用并行SQL查询?是否采用PL/SQL函数编写存储过程?是否需要建立并行数据库提高数据库的查询效率?2 ORACLE数据库优化、参数调整2.1 设计数据结构和应用程序需要注意考虑是否应用ORACLE 数据库的分区功能;哪些频繁访问的数据库表应该建立索引;根据所需要的数据库资源决定应用程序采用Client/Server还是Browser/Web/Database体系结构2.2 应用程序最终将通过SQL语句执行,SQL语句的执行效率是ORACLE数据库性能的决定因素同一功能可以通过不同的SQL语句来实现,但是不同的SQL语句执行效率不一样。
数据库查询优化方案(百万级数据查询统计优化)

《数据库查询优化方案(百万级数据查询统计优化)》1.对查询进行优化,应尽量避免全表扫描,首先应考虑在where 及order by 涉及的列上建立索引。
2.应尽量避免在where 子句中对字段进行null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num is null可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num=03.应尽量避免在where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在where 子句中使用or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num=10 or num=20可以这样查询:select id from t where num=10union allselect id from t where num=205.in 和not in 也要慎用,否则会导致全表扫描,如:select id from t where num in(1,2,3)对于连续的数值,能用between 就不要用in 了:select id from t where num between 1 and 36. 下面的查询也将导致全表扫描:select id from t where name like '%abc%'若要提高效率,可以考虑全文检索。
7. 如果在where 子句中使用参数,也会导致全表扫描。
因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。
然而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。
如下面语句将进行全表扫描:select id from t where num=@num可以改为强制查询使用索引:select id from t with(index(索引名)) where num=@num8. 应尽量避免在where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。
OLTP 与 OLAP业务系统的Oracle优化思路
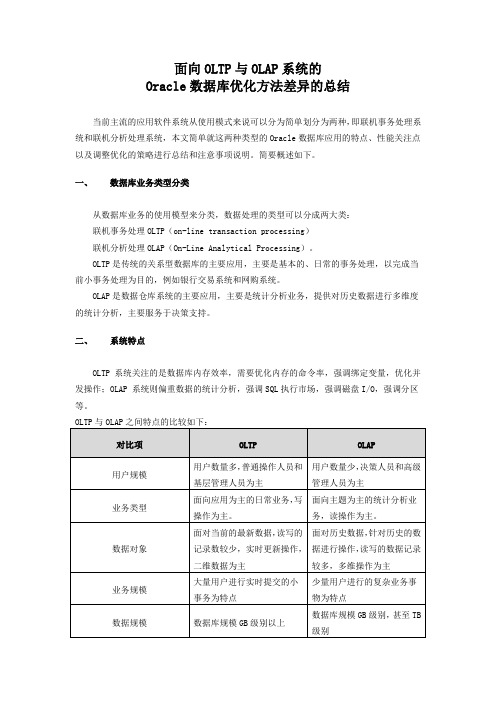
面向OLTP与OLAP系统的Oracle数据库优化方法差异的总结当前主流的应用软件系统从使用模式来说可以分为简单划分为两种,即联机事务处理系统和联机分析处理系统,本文简单就这两种类型的Oracle数据库应用的特点、性能关注点以及调整优化的策略进行总结和注意事项说明。
简要概述如下。
一、数据库业务类型分类从数据库业务的使用模型来分类,数据处理的类型可以分成两大类:联机事务处理OLTP(on-line transaction processing)联机分析处理OLAP(On-Line Analytical Processing)。
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,以完成当前小事务处理为目的,例如银行交易系统和网购系统。
OLAP是数据仓库系统的主要应用,主要是统计分析业务,提供对历史数据进行多维度的统计分析,主要服务于决策支持。
二、系统特点三、常见瓶颈问题与优化策略(一)OLTP系统1.OLTP性能关注指标OLTP,全称为联机事务处理(Online Transaction Processing),其特点是事务性非常高,一般都是高可用的在线系统,以小的事务以及小的查询为主,其每秒执行的Transaction以及Execute SQL的数量是其性能指标的主要指标。
数据库每秒处理的Transaction达到几百以上,Select 语句的执行量每秒上千至万。
典型的OLTP系统有电子商务系统和银行。
2. OLTP系统的瓶颈点OLTP系统最容易出现瓶颈的地方就是CPU资源与IO资源。
(1)CPU资源主要消耗在逻辑读总量、自定义的函数或者存储过程上这样的系统中单个语句执行速度虽然很快,但是执行次数非常多,同样会导致很大的逻辑读总量。
要减少单个语句的逻辑读,或者是减少执行次数。
自定义函数、decode等的频繁使用,也会消耗大量的CPU资源用户这些调用的解析,要尽量避免调用自定义的函数和计算过程。
数据库性能优化的五种方案

数据库性能优化的五种方案文档修订摘要目录数据库性能优化的五种方案 (1)1. 概述 (4)1.1. 目的 (4)1.2. 阅读对象 (4)1.3. 名词解释 (4)1.4. 转载出处 (4)2. 操作步骤 (4) (4)2.1. 建立索引 (5)2.1.1. Mysql索引概念 (5)2.1.2. Mysql索引主要有两种结构:B+树和hash (5)2.1.3. Mysql常见索引有:主键索引、唯一索引、普通索引、全文索引、组合索引 (5)2.1.4. Mysql各种索引区别 (6)2.1.5. INNODB与MyISAM两种表存储引擎区别 (6)2.2. 优化SQL语句 (6)2.2.1. 常用策略 (6)2.2.2. 实例案例分析 (9)2.3. 优化表结构 (9)2.4. 表的拆分 (10)2.5. 分库 (10)1.概述1.1.目的数据库性能优化1.2.阅读对象1.3.名词解释1.4.转载出处https:///csflvcxx/article/details/812790242.操作步骤关系型数据库在互联网项目中应用极为广泛,今天小编就和大家分享几个数据库优化的几种方案。
2.1.建立索引数据库优化第一步就是建立合理的索引,这也是最初级的优化,也是DBA常用的优化方案!MySql索引类型有:普通索引,主键索引,唯一索引,组合索引!2.1.1.Mysql索引概念说说Mysql索引,看到一个很少比如:索引就好比一本书的目录,它会让你更快的找到内容,显然目录(索引)并不是越多越好,假如这本书1000页,有500也是目录,它当然效率低,目录是要占纸张的,而索引是要占磁盘空间的。
2.1.2.Mysql索引主要有两种结构:B+树和hashhash:hash索引在mysql比较少用,他以把数据的索引以hash形式组织起来,因此当查找某一条记录的时候,速度非常快.当时因为是hash结构,每个键只对应一个值,而且是散列的方式分布.所以他并不支持范围查找和排序等功能.B+树:b+tree是mysql使用最频繁的一个索引数据结构,数据结构以平衡树的形式来组织,因为是树型结构,所以更适合用来处理排序,范围查找等功能.相对hash索引,B+树在查找单条记录的速度虽然比不上hash索引,但是因为更适合排序等操作,所以他更受用户的欢迎.毕竟不可能只对数据库进行单条记录的操作.2.1.3.Mysql常见索引有:主键索引、唯一索引、普通索引、全文索引、组合索引PRIMARY KEY(主键索引)ALTER TABLE table_name ADD PRIMARY KEY ( column ) UNIQUE(唯一索引) ALTER TABLE table_name ADD UNIQUE (column)INDEX(普通索引) ALTER TABLE table_name ADD INDEX index_name ( column )FULLTEXT(全文索引) ALTER TABLE table_name ADD FULLTEXT ( column )组合索引ALTER TABLE table_name ADD INDEX index_name ( column1, column2, column3 )2.1.4.Mysql各种索引区别普通索引:最基本的索引,没有任何限制。
如何进行数据库性能测试和优化

如何进行数据库性能测试和优化数据库性能测试是一项关键的任务,它可以帮助我们评估数据库的性能,并发现存在的瓶颈和问题。
而数据库性能优化旨在提高数据库的性能和响应时间,以满足用户的需求。
下面将详细介绍数据库性能测试和优化的步骤和方法。
一、数据库性能测试1.确定测试目标在进行数据库性能测试之前,首先要确定测试的目标。
这可能包括测试数据库的读写速度、并发处理能力、稳定性等。
2.设计测试用例根据测试目标,设计测试用例。
测试用例应包含各种不同的操作,如增加、查询、更新和删除等,以覆盖数据库的各个方面。
3.创建测试数据为了进行性能测试,需要创建大量的测试数据。
这些数据应具有真实性,以便更好地模拟实际使用情况。
4.配置测试环境为进行性能测试,需要在测试环境中配置数据库服务器和客户端。
确保数据库服务器的硬件、操作系统和网络设置符合实际生产环境。
5.执行性能测试执行测试用例,记录每个操作的执行时间和性能指标。
可以使用性能测试工具(如JMeter、LoadRunner等)来模拟多用户并发访问数据库的场景。
6.收集测试结果收集测试结果,包括每个操作的响应时间、吞吐量和错误率等。
这些数据可以帮助我们评估数据库的性能,并找出存在的瓶颈。
7.分析测试结果对测试结果进行分析,找出性能瓶颈和问题的根本原因。
这可能涉及到查看数据库的查询执行计划、索引使用情况、磁盘和内存使用等。
二、数据库性能优化1.优化数据库结构通过合理设计数据库表结构和关系,优化数据库的性能。
包括避免不必要的冗余和复杂的关联查询,规范字段类型和长度等。
2.创建索引通过创建适当的索引,可以加快数据库的查询速度。
需要根据实际查询需求和数据分布情况来选择索引的字段和类型。
3.优化查询语句通过优化查询语句,可以减少数据库的访问次数和响应时间。
包括合理使用查询条件、避免查询全部字段、避免使用复杂的子查询等。
4.调整系统参数根据实际情况,调整数据库服务器的相关参数,以提高数据库的性能。
数据库管理系统的设计与优化

数据库管理系统的设计与优化一、引言数据库管理系统(Database Management System,简称DBMS)是现代信息管理系统的核心技术之一。
随着信息技术的飞速发展和应用场景的不断扩展,数据库管理系统在各个行业领域的重要性日益凸显。
本文将深入探讨数据库管理系统的设计与优化方法,旨在为读者提供相关知识与经验。
二、数据库管理系统的设计数据库管理系统的设计是整个系统的基石,直接关系到系统的性能和稳定性。
设计数据库管理系统时,需要考虑以下几个方面。
1. 数据库结构设计数据库结构设计是数据库管理系统的核心问题之一。
在设计数据库结构时,需要根据具体的业务需求,合理划分数据表,建立正确的关系模型。
合理的数据库结构设计可以提高数据存取的效率,减少数据冗余,提高系统的响应速度。
2. 数据库安全设计随着互联网的普及,数据安全越来越受到人们的关注。
在设计数据库管理系统时,必须考虑到数据的机密性、完整性和可用性。
可以采取一系列的安全措施,例如加密、权限管理、备份等,以保障数据的安全。
3. 数据库性能设计数据库的性能是数据库管理系统设计的重要指标之一。
在设计数据库时,需要考虑到数据量的大小、访问的并发性、高可用性等因素,以提高系统的性能。
可以采用索引、分区、缓存等技术手段进行优化,以提升数据库的读写效率。
三、数据库管理系统的优化数据库管理系统的优化是在实际应用中不断完善和改进的过程。
数据库的优化主要包括以下几个方面。
1. 查询优化查询是数据库管理系统中最常见的操作之一。
通过优化查询语句的编写,可以提高查询的效率。
例如,可以通过合理的索引设计、避免全表扫描、合理的查询策略等手段,减少查询的时间开销。
2. 索引优化索引是提高数据库查询效率的关键。
在设计索引时,需要考虑到查询的频率和索引的维护成本。
合理的索引设计可以减少磁盘IO次数,加快查询速度。
同时,需要定期对索引进行优化和维护,以保持其有效性。
3. 存储优化存储是数据库管理系统中重要的一环。
达梦数据库的性能优化

达梦数据库的性能优化“棱镜门”、“微软XP系统停摆”的接踵而至给我国信息安全敲响了警钟,也加速了国内“去IOE”运动的进程。
达梦数据库作为连续5年国产数据库市场占有率第一的高性能、高可靠性、高安全性、高兼容性大型关系型数据库管理系统,已成功替代了Oracle,在电力、金融、电子政务、教育等行业领域得到了广泛的应用,逐渐成为国家信息化建设的重要基础平台。
为了更好地支撑业务应用,有效管理和利用信息时代不断产生并急剧膨胀的数据,对达梦数据库的优化显得尤为重要。
一、数据库参数优化1.优化内存➢公共内存池公共内存池提供了一组内存申请/释放接口,为系统中需要动态分配内存的模块提供服务。
MEMORY_POOL决定了以M为单位的公共内存池的大小,上例中40M;N_MEM_POOLS决定把内存池划分为几个独立的单元,以减少并发访问的冲突,提升并发效率;MEMORY_BAK_POOL表示系统保留的备用内存量,当常规的内存申请都失败时,从这个备用内存里分配,然后在上层模块中进行必要的容错处理。
可以在v$sysstat中查看当前公用内存池的使用情况:这里的STAT_VAL给出的是已经使用的字节数。
正常情况下,应该小于配置的池大小,否则系统不得不从池外向操作系统申请/释放内存,造成效率低下,并可能把操作系统的内存搞得很零碎。
➢系统缓冲区BUFFER为了加速数据访问,系统开辟了一个缓冲区,使用LRU算法存放经常访问的数据页,逐步淘汰不用的数据页。
使用下列参数,可配置基本的系统缓冲区的大小:其中HUGE_BUFFER 是专门用于列存表的缓存区,BUFFER是用户行存表的系统缓冲区。
BUFFER表示初始的系统缓冲区大小,单位为M。
通常情况下,如果物理数据量大于物理内存,则应该把BUFFER调到物理内存的三分之二比较合适。
当BUFFER_POOLS = 1时,系统支持缓冲区的自动扩展。
MAX_BUFFER表示最多能扩到多大。
在自动扩展后,如果系统的压力在一段时间内比较低,系统又会自动收缩缓冲区。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
OLTP数据库优化方案及案例ORACLE数据库SQL优化方案、案例Edgar Liu© 2015 Huatek CO., LTD. All Rights Reserved.2015.3.17目录1. 优化方案与基础知识1.1 问题SQL来源(现象) 1.2 数据库性能优化方案及期待效果 1.3 优化方法论及优化分析树 1.4 数据库体系结构 1.5 逻辑读 逻辑写4.索引设计与查询条件4.1 4.2 4.3 4.4 索引介绍 索引设计步骤 索引创建原则 索引失效与不足2. 执行计划分析2.1 执行计划查看方法 2.2 执行计划示例 2.3 执行计划三部分 2.4 硬解析和软解析5. 高效SQL5.1 5.2 5.3 5.4 优化规则30条 关于Hit提示优化 DML语句优化 批量读取游标数据优化3.最佳表连接方式3.1 3.2 3.3 3.4 ORACLE表介绍 RDBMS表连接方式介绍 执行计划中表连接方式介绍 执行计划中表连接方式比较6. 数据模型与SQL6.1 数据逻辑模型设计 6.2 数据库物理设计 6.3 书集推荐2/401.0 OLTP 与OLAP区别•对于Oracle数据库的数据存取,主要有四个不同的调整级别, •第一级调整是操作系统级包括硬件平台, •第三级是Oracle数据库设计级的调整, 第二级调整是Oracle RDBMS级的调整, 第四级调整级是SQL级。
通常依此四级调整级别对数据库进行调整、优化,数据库的整体性能会得到很大的改善。
3/401.1 问题SQL来源ORACLE概念: AWR=Auto Workload Repository;ASH= Active Session History, ADDM= Automatic Database Diagnostic Monitor数据标准化的必要性 AWR报告或者Statspack报告 SQL ordered by Elapsed Time SQL ordered by CPU Time SQL ordered by Gets等部分 ADDM报告 程序检查•FINDING 1::SQL statements consuming significant database time were found. •FINDING 2:Time spent on the CPU by the instance was responsible for a substantial part of database time. •Etc…4/401.4 数据库优化方法论优化方法论 方法论一Oracle里SQL优化的本质是基于对 CBO和执行计划的深刻理解;方法论二并行执行目标SQL语句”,这实际上 是以额外的资源消耗来换取执行时间 的缩短,很多情况下使用并行是针对 某些SQL的唯一优化手段。
方法论三平衡系统的资源消耗” 可以避免不 必要的资源争用所导致的目标SQL 语句执行时间的增长。
•大部分SQL优化的问题都可以通过增加或者减少索引的方式来解决,但这绝不是全部! •时刻牢记调优三板斧:索引,join顺序,join算法。
•BI数据仓库中,各子系统的同一数据,因不标准而导致重复统计,导致分析结果误差5/404.数据模型现状分析1.2数据库性能优化方案性能优化方案6/404.数据模型现状分析1.2 数据库性能优化期待效果期待效果7/40••有备而来,去了解系统一切正常的情况下性能怎么样。
搜集运行监视信息来跟踪一段时 间内系统行为的变化。
•了解整个场景,不要局限于你从ORACLE 上看到的,也要搜集并分析来自于操作系统、 存储、应用程序甚至来自用户的数据。
了解系统本身将有助于你解释监控数据。
•只调整能解释你看到的症状的参数,如果连发动机都无法启动就不要更换轮胎。
不要试 图通过降低 CPU 来解决磁盘的瓶颈。
•一次只改一个参数,在更改其他参数之前先观察效果。
4.数据模型现状分析1.4 数据库体系结构Oracle 10g,11g,12c体系结构,解决问题的利器:运用整体结构知识分析问题所在。
10/404.数据模型现状分析1.4 数据库体系结构-2Oracle 10g,11g,12c体系结构,解决问题的利器:运用整体结构知识分析问题所在。
11/404.数据模型现状分析1.5 逻辑读 逻辑写CBOOracle 10g,11g,12c体系结构,解决问题的利器:运用整体结构知识分析问题所在。
•基于代价的优化方式(Cost-Based Optimization, 简称为CBO) ;它是看语句的代价(Cost),这里的代 价主要指Cpu和内存。
优化器在判断是否用这种方式 时,主要参照的是表及索引的统计信息。
统计信息给出 表的大小、有少行、每行的长度等信息。
这些统计信 息起初在库内是没有的,是做 analyze 后才出现的, 很多的时侯过期统计信息会令优化器做出一个错误的 执行计划,因些应及时更新这些信息。
12/402.1 Oracle 生成和显示执行计划的方法执 计划 : 过工具( ):PL/SQL Developer TOAD; 种 过ORACLE 带 DBMS_XPLAN 显 执 计划。
基于Web的应用程 序一条合法的语句在执行 之后,就会在内存中至 少产生一条执行计划, 可以从视图v$sql_plan 查询。
每一条执行计划对于一 个游标。
13/402.3 执行计划示例1表部分2谓词部分3统计信息14/402.3 执行计划查看—表部分执行计划表部分序号 列名 解释这一行是这一条语句的hash值,我们知道oracle对每条语句产生的执行 1 Plan hash value 计划放在share pool里面,第一次要经过硬解析,产生hash值。
下次再 执行该语句时候比较hash值,如果相同就不要执行硬解析。
2 3 4 5Operation( 操作) Name(被操作的对象) Row Byte把sql进行分解被操作的对象 有的地方也叫Cardinality(用plsqldev里面解释计划窗口) 扫描的数据的字节数没有单位,是一个相对值,是sql文以cbo方式解析执行时,供oracle用 6 cost 来评估cbo成本,选择执行计划用的。
公式:Cost=(Single block I/O cost+ Multiblock I/O cost+ cost)/sreadtim 15/40 CPU2.3 执行计划查看– 谓词信息Predicate Information序号 列名 解释属性 属性索引(access) 非索引(filter)INDEX FULL SCAN vs INDEX FAST FULL SCAN总结 1、当select where 现 发 index f ull scan与index fast full scan 2、查询 数据 总数 据 个 10% 3、 count(*) 总 选择index fast full scan, order by 句 总 选择index full scan 4、index fast full scan 块读 读 块,产 db file scattered reads 件,读 时高 , 为 读 5、index full scan 单块读 读 块,产 db file sequential reads 件,当 该 读 扫 , 6、绝 数 况 ,index fast full scan 优 index f ull scan, order by时, 会 对读 块 过 7、index fast full scan 过牺 内 与临时 空间换 , 内 饱 状态应进 权 .16/402.3 执行计划—统计信息AUTOTRACE Statistics列解释序号 列名 解释1 2 3 4 5 6 7recursive calls db block gets consistent gets physical reads redo size sorts (memory) sorts (disk)递归调查 从buffer cache中读取的block的数量 从buffer cache中读取的undo数据的block的数 量 从磁盘读取的block的数量 DML生成的redo的大小 在内存执行的排序量 在磁盘上执行的排序量17/402.3 硬解析和软解析解析类型分类解析过程 在执行软软解析之前,首先要进行软解析,MOS上说执行3次的SQL语句 会把游标缓存到PGA,这个游标一直开着,当再有相同的SQL执行时, 则跳过解析的所有过程直接去取执行计划。
软软解析软解析1.语法、语义及权限检查; 2.将整条SQL hash后从库缓存中执行计划。
硬解析1.语法、语义及权限检查; 2.查询转换(通过应用各种不同的转换技巧,会生成语义上等同的新 的SQL语句,如count(1)会转为count(*)); 3.根据统计信息生成执行计划(找出成本最低的路径,这一步比较耗 时); 4.将游标信息(执行计划)保存到库缓存。
18/40•Oracle数据种类 :Heap Table、组织 IOTCluster。
•注意:如果使用from子句指定内、外连接,则必须要使用on子句指定连接条件;如果使用(+)操作 符指定外连接,则必须使用where子句指定连接条件。
•对于外连接, 也可以使用“(+) ”来表示。
关于使用(+)的一些注意事项: •1.(+)操作符只能出现在where子句中,并且不能与outer join语法同时使用。
•2. 当使用(+)操作符执行外连接时,如果在where子句中包含有多个条件,则必须在所有条件中都 包含(+)操作符 •3.(+)操作符只适用于列,而不能用在表达式上。
•4.(+)操作符不能与or和in操作符一起使用。
•5.(+)操作符只能用于实现左外连接和右外连接,而不能用于实现完全外连接。
Merge Join间 连 。
种:Nested Loops,Hash JoinSort Merge Join.来介绍 种连select from where/*+ ordered */ ename, dept.deptno dept, emp dept.deptno = emp.deptnoselect from where/*+ ordered */ ename, dept.deptno emp, dept dept.deptno = emp.deptno;select from where/*+ ordered */ ename, dept.deptno emp, dept dept.deptno = emp.deptno;3.4 执行计划中 执行计划中表连接方式比较表连接方式NESTED LOOP对于被连接的数据子集较小的情况, 嵌套循环连接是个较好的选择。