Matlab训练好的BP神经网络如何保存和读取方法(附实例说明)
MATLAB神经网络工具箱的详细使用步奏
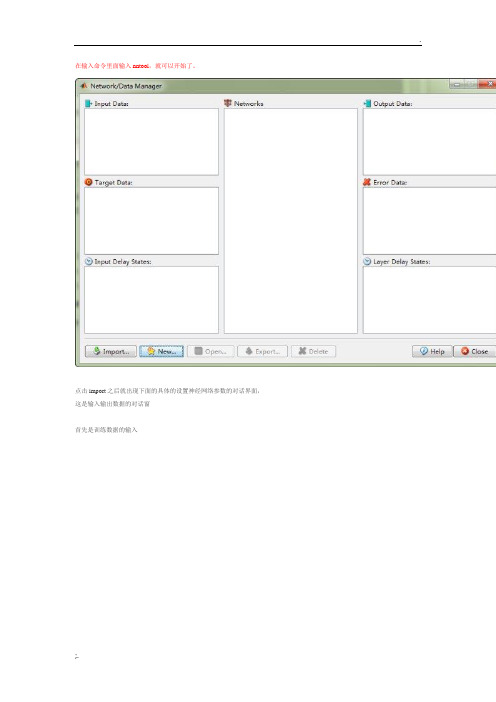
在输入命令里面输入nntool,就可以开始了。
点击import之后就出现下面的具体的设置神经网络参数的对话界面,这是输入输出数据的对话窗
首先是训练数据的输入
然后点击new,创建一个新的神经网络network1,并设置其输入输出数据,包括名称,神经网络的类型以及隐含层的层数和节点数,还有隐含层及输出层的训练函数等
点击view,可以看到这是神经网络的可视化直观表达
创建好了一个network之后,点击open,可以看到一个神经网络训练,优化等的对话框,选择了输入输出数据后,点击train,神经网络开始训练,如右下方的图,可以显示动态结果
下面三个图形则是点击performance,training state以及regression而出现的
下面就是simulate,输入的数据是用来检验这个网络的数据,output改一个名字,这样就把输出数据和误差都存放起来了
在主界面上点击export就能将得到的out结果输入到matlab中并查看
下图就是输出的两个outputs结果。
(完整版)BP神经网络matlab实例(简单而经典).doc

p=p1';t=t1';[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t); % 原始数据归一化net=newff(minmax(pn),[5,1],{'tansig','purelin'},'traingdx'); %设置网络,建立相应的BP 网络net.trainParam.show=2000; % 训练网络net.trainParam.lr=0.01;net.trainParam.epochs=100000;net.trainParam.goal=1e-5;[net,tr]=train(net ,pn,tn); %调用TRAINGDM 算法训练BP 网络pnew=pnew1';pnewn=tramnmx(pnew,minp,maxp);anewn=sim(net,pnewn);anew=postmnmx(anewn,mint,maxt); %对 BP 网络进行仿真%还原数据y=anew';1、 BP 网络构建(1)生成 BP 网络net newff ( PR,[ S1 S2...SNl],{ TF1 TF 2...TFNl }, BTF , BLF , PF ) PR :由R 维的输入样本最小最大值构成的R 2 维矩阵。
[ S1 S2...SNl] :各层的神经元个数。
{TF 1 TF 2...TFNl } :各层的神经元传递函数。
BTF :训练用函数的名称。
(2)网络训练[ net,tr ,Y, E, Pf , Af ] train (net, P, T , Pi , Ai ,VV , TV )(3)网络仿真[Y, Pf , Af , E, perf ] sim(net, P, Pi , Ai ,T ){'tansig','purelin'},'trainrp'BP 网络的训练函数训练方法梯度下降法有动量的梯度下降法自适应 lr 梯度下降法自适应 lr 动量梯度下降法弹性梯度下降法训练函数traingd traingdm traingda traingdx trainrpFletcher-Reeves 共轭梯度法traincgf Ploak-Ribiere 共轭梯度法traincgpPowell-Beale 共轭梯度法traincgb 量化共轭梯度法trainscg 拟牛顿算法trainbfg 一步正割算法trainoss Levenberg-Marquardt trainlmBP 网络训练参数训练参数net.trainParam.epochsnet.trainParam.goal net.trainParam.lrnet.trainParam.max_fail net.trainParam.min_grad net.trainParam.show net.trainParam.timenet.trainParam.mc net.trainParam.lr_inc 参数介绍最大训练次数(缺省为10)训练要求精度(缺省为0)学习率(缺省为0.01 )最大失败次数(缺省为5)最小梯度要求(缺省为1e-10)显示训练迭代过程( NaN 表示不显示,缺省为 25)最大训练时间(缺省为inf )动量因子(缺省0.9)学习率lr增长比(缺省为1.05)训练函数traingd 、traingdm 、traingda 、traingdx 、 trainrp 、 traincgf 、traincgp 、traincgb 、trainscg、trainbfg 、 trainoss、 trainlmtraingd 、traingdm 、traingda 、traingdx 、 trainrp 、 traincgf 、traincgp 、traincgb 、trainscg、trainbfg 、 trainoss、 trainlmtraingd 、traingdm 、traingda 、traingdx 、 trainrp 、 traincgf 、traincgp 、traincgb 、trainscg、trainbfg 、 trainoss、 trainlmtraingd 、traingdm 、traingda 、traingdx 、 trainrp 、 traincgf 、traincgp 、traincgb 、trainscg、trainbfg 、 trainoss、 trainlmtraingd 、traingdm 、traingda 、traingdx 、 trainrp 、 traincgf 、traincgp 、traincgb 、trainscg、trainbfg 、 trainoss、 trainlmtraingd 、traingdm 、traingda 、traingdx 、 trainrp 、 traincgf 、traincgp 、traincgb 、trainscg、trainbfg 、 trainoss、 trainlmtraingd 、traingdm 、traingda 、traingdx 、 trainrp 、 traincgf 、traincgp 、traincgb 、trainscg、trainbfg 、 trainoss、 trainlmtraingdm 、 traingdx traingda 、traingdxnet.trainParam.lr_dec 学习率 lr 下降比(缺省为 0.7) traingda 、 traingdxnet.trainParam.max_perf_inc 表现函数增加最大比(缺省traingda 、 traingdx为 1.04)net.trainParam.delt_inc 权值变化增加量(缺省为trainrp1.2)net.trainParam.delt_dec 权值变化减小量(缺省为trainrp0.5)net.trainParam.delt0 初始权值变化(缺省为 0.07) trainrpnet.trainParam.deltamax 权值变化最大值(缺省为trainrp50.0)net.trainParam.searchFcn 一维线性搜索方法(缺省为traincgf 、traincgp 、traincgb 、srchcha)trainbfg 、 trainossnet.trainParam.sigma 因为二次求导对权值调整的trainscg影响参数(缺省值 5.0e-5)mbda Hessian 矩阵不确定性调节trainscg参数(缺省为 5.0e-7)net.trainParam.men_reduc 控制计算机内存/ 速度的参trainlm量,内存较大设为1,否则设为 2(缺省为 1)net.trainParam.mu 的初始值(缺省为0.001) trainlmnet.trainParam.mu_dec 的减小率(缺省为0.1)trainlmnet.trainParam.mu_inc 的增长率(缺省为10)trainlmnet.trainParam.mu_max 的最大值(缺省为1e10)trainlm2、 BP 网络举例举例 1、%traingdclear;clc;P=[-1 -1 2 2 4;0 5 0 5 7];T=[-1 -1 1 1 -1];%利用 minmax函数求输入样本范围net = newff(minmax(P),T,[5,1],{'tansig','purelin'},'trainrp');net.trainParam.show=50;%net.trainParam.lr=0.05;net.trainParam.epochs=300;net.trainParam.goal=1e-5;[net,tr]=train(net,P,T);net.iw{1,1}%隐层权值net.b{1}%隐层阈值net.lw{2,1}%输出层权值net.b{2}%输出层阈值sim(net,P)BP 神经网络来完成非线性函数的逼近任务,其中隐层神经元个数为五个。
BP神经网络matlab教程
w
N 1 ho
w o (k )hoh (k )
N ho
2.4.2 BP网络的标准学习算法
第七步,利用隐含层各神经元的 h (k )和 输入层各神经元的输入修正连接权。
e e hih (k ) wih (k ) h (k ) xi (k ) wih hih (k ) wih w
p
i 1
h 1,2,
o 1,2,
,p
q
yio (k ) whohoh (k ) bo
o 1,2,
yoo (k ) f( yio (k ))
h 1
q
2.4.2 BP网络的标准学习算法
第四步,利用网络期望输出和实际输出, 计算误差函数对输出层的各神经元的偏导 o (k ) 数 。 ( w ho (k ) b ) e e yio yi (k )
输入样本---输入层---各隐层---输出层
判断是否转入反向传播阶段:
若输出层的实际输出与期望的输出(教师信号)不 符
误差反传
误差以某种形式在各层表示----修正各层单元 的权值
网络输出的误差减少到可接受的程度 进行到预先设定的学习次数为止
2.4.2 BP网络的标准学习算法
网络结构 输入层有n个神经元,隐含层有p个神经元, 输出层有q个神经元 变量定义 x x1, x2 , , xn 输入向量; 隐含层输入向量; hi hi1 , hi2 , , hi p 隐含层输出向量; ho ho1 , ho2 , , ho p 输出层输入向量; yi yi1 , yi2 , , yiq 输出层输出向量; yo yo1 , yo2 , , yoq 期望输出向量; d o d1 , d 2 , , d q
BP神经网络matlab实现的基本步骤

1、数据归一化2、数据分类,主要包括打乱数据顺序,抽取正常训练用数据、变量数据、测试数据3、建立神经网络,包括设置多少层网络(一般3层以内既可以,每层的节点数(具体节点数,尚无科学的模型和公式方法确定,可采用试凑法,但输出层的节点数应和需要输出的量个数相等),设置隐含层的传输函数等。
关于网络具体建立使用方法,在后几节的例子中将会说到。
4、指定训练参数进行训练,这步非常重要,在例子中,将详细进行说明5、完成训练后,就可以调用训练结果,输入测试数据,进行测试6、数据进行反归一化7、误差分析、结果预测或分类,作图等数据归一化问题归一化的意义:首先说一下,在工程应用领域中,应用BP网络的好坏最关键的仍然是输入特征选择和训练样本集的准备,若样本集代表性差、矛盾样本多、数据归一化存在问题,那么,使用多复杂的综合算法、多精致的网络结构,建立起来的模型预测效果不会多好。
若想取得实际有价值的应用效果,从最基础的数据整理工作做起吧,会少走弯路的。
归一化是为了加快训练网络的收敛性,具体做法是:1 把数变为(0,1)之间的小数主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
2 把有量纲表达式变为无量纲表达式归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量比如,复数阻抗可以归一化书写:Z = R + jωL = R(1 + jωL/R) ,复数部分变成了纯数量了,没有量纲。
另外,微波之中也就是电路分析、信号系统、电磁波传输等,有很多运算都可以如此处理,既保证了运算的便捷,又能凸现出物理量的本质含义。
神经网络归一化方法:由于采集的各数据单位不一致,因而须对数据进行[-1,1]归一化处理,归一化方法主要有如下几种,供大家参考:1、线性函数转换,表达式如下:复制内容到剪贴板代码:y=(x-MinValue)/(MaxValue-MinValue)说明:x、y分别为转换前、后的值,MaxValue、MinValue分别为样本的最大值和最小值。
智能控制MALAB神经网络BP算法

智能控制MALAB神经网络BP算法智能控制MALAB神经网络BP算法是一种基于MATLAB平台的智能控制算法,用于神经网络的训练和优化。
BP算法,即反向传播算法,是一种常用的神经网络训练算法,通过不断调整网络权值和阈值,使得网络的输出与期望输出之间的误差最小化。
在MATLAB中,可以利用自带的神经网络工具箱来实现BP算法。
具体步骤如下:一、数据准备数据准备是智能控制MALAB神经网络BP算法的第一步,它涉及到准备训练数据集和测试数据集。
以下是数据准备的详细步骤:1.收集和整理数据:首先,需要收集与问题相关的数据,并将其整理成适合神经网络输入的格式。
数据可以来自实验、观测、模拟等途径。
2.数据预处理:对收集到的原始数据进行预处理,以便更好地适应神经网络的训练和优化。
预处理步骤可能包括数据清洗、去噪、归一化、标准化等。
这些步骤有助于提高数据的质量和可靠性。
3.数据划分:将整个数据集划分为训练数据集和测试数据集。
通常,大部分数据用于训练神经网络,而少部分数据用于测试网络的泛化能力。
常见的划分方法包括随机划分、交叉验证等。
4.数据编码:对于非数值型数据,需要进行编码转换成数值型数据。
例如,可以使用独热编码将分类变量转换为二进制向量。
5.数据特征选择:根据问题的需求和特征的相关性,选择合适的特征子集。
这有助于减少数据维度,提高训练效率和模型性能。
6.数据平衡:对于不平衡的数据集,可以采取一些方法来平衡正负样本的比例,例如过采样、欠采样、SMOTE等。
数据准备是神经网络训练的重要环节,对于获得良好的训练结果和模型性能至关重要。
通过合理的数据准备步骤,可以提高神经网络的训练效率和泛化能力,从而实现智能控制任务的优化。
二、网络创建使用MATLAB的神经网络工具箱,可以创建一个BP神经网络模型。
可以选择网络的拓扑结构,包括输入层、隐藏层和输出层的节点数目,以及激活函数等参数。
以下是网络创建的详细步骤:1.确定网络的拓扑结构:首先,需要确定网络的拓扑结构,包括输入层、隐藏层和输出层的节点数目。
Matlab中的文件读写与数据存储方法

Matlab中的文件读写与数据存储方法在科学研究以及工程领域,数据的处理和存储是至关重要的。
而Matlab作为一款强大的科学计算软件,提供了丰富的文件读写和数据存储方法,为用户提供了便捷的数据处理和存储功能。
本文将从文件读写和数据存储两个方面来介绍Matlab中的相关方法,让读者可以更好地掌握和运用这些功能。
一、文件读写在Matlab中,文件读写是一项基本而重要的功能。
无论是从外部读取数据,还是将数据输出到外部,都需要用到文件读写方法。
1. 读取文本文件在Matlab中,可以使用readtable函数读取文本文件。
readtable函数可以读取CSV文件、文本文件以及其他普通的表格文件。
读取文本文件的关键是指定文件路径,并设置好相关的参数。
例如,下面的代码演示了如何读取一个名为data.txt 的文本文件:```Matlabdata = readtable('data.txt');```2. 写入文本文件与读取文本文件类似,可以使用writetable函数将数据写入文本文件。
同样,写入文本文件也需要指定文件路径和参数。
下面的代码展示了将数据写入data.txt 文件的示例:```Matlabwritetable(data, 'data.txt');```3. 读取二进制文件除了处理文本文件,Matlab也支持读取和写入二进制文件。
对于二进制文件,可以使用fread函数进行读取,使用fwrite函数进行写入。
这两个函数的使用方式和参数较为复杂,需要根据具体的文件格式和数据结构进行设置。
二、数据存储方法在Matlab中,数据存储方法包括矩阵存储、图像存储、音频存储等。
1. 矩阵存储在Matlab中,矩阵是最基本的数据结构之一,也是最常用的数据存储方式。
可以使用save函数将矩阵保存为.mat格式的文件,以便后续的读取和使用。
下面的代码演示了如何将矩阵data保存为matlab_data.mat文件:```Matlabsave('matlab_data.mat', 'data');```使用load函数可以读取.mat文件,并将其中的数据加载到工作空间中:```Matlabload('matlab_data.mat');```2. 图像存储Matlab中的图像处理功能非常强大,同时也提供了方便的图像存储功能。
bp神经网络及matlab实现

bp神经网络及matlab实现分类:算法学习2012-06-20 20:56 66399人阅读评论(28) 收藏举报网络matlab算法functionnetworkinput本文主要内容包括: (1) 介绍神经网络基本原理,(2) 实现前向神经网络的方法,(3) Matlab实现前向神经网络的方法。
第0节、引例本文以Fisher的Iris数据集作为神经网络程序的测试数据集。
Iris数据集可以在找到。
这里简要介绍一下Iris数据集:有一批Iris花,已知这批Iris花可分为3个品种,现需要对其进行分类。
不同品种的Iris花的花萼长度、花萼宽度、花瓣长度、花瓣宽度会有差异。
我们现有一批已知品种的Iris花的花萼长度、花萼宽度、花瓣长度、花瓣宽度的数据。
一种解决方法是用已有的数据训练一个神经网络用作分类器。
如果你只想用C#或Matlab快速实现神经网络来解决你手头上的问题,或者已经了解神经网络基本原理,请直接跳到第二节——神经网络实现。
第一节、神经网络基本原理1. 人工神经元( Artificial Neuron )模型人工神经元是神经网络的基本元素,其原理可以用下图表示:图1. 人工神经元模型图中x1~xn是从其他神经元传来的输入信号,wij表示表示从神经元j到神经元i的连接权值,θ表示一个阈值 ( threshold ),或称为偏置( bias )。
则神经元i的输出与输入的关系表示为:图中 yi表示神经元i的输出,函数f称为激活函数 ( Activation Function )或转移函数 ( Transfer Function ) ,net称为净激活(net activation)。
若将阈值看成是神经元i的一个输入x0的权重wi0,则上面的式子可以简化为:若用X表示输入向量,用W表示权重向量,即:X = [ x0 , x1 , x2 , ....... , xn ]则神经元的输出可以表示为向量相乘的形式:若神经元的净激活net为正,称该神经元处于激活状态或兴奋状态(fire),若净激活net为负,则称神经元处于抑制状态。
BP神经网络matlab详细参数

BP神经⽹络matlab详细参数基于matlab BP 神经⽹络参数详解(1)⽣成BP ⽹络(,[1 2...],{ 1 2...},,,)net newff PR S S SNl TF TF TFNl BTF BLF PF =PR :由R 维的输⼊样本最⼩最⼤值构成的2R ?维矩阵。
[1 2...]S S SNl :各层的神经元个数。
{ 1 2...}TF TF TFNl :各层的神经元传递函数。
BTF :训练⽤函数的名称。
(2)⽹络训练[,,,,,] (,,,,,,)net tr Y E Pf Af train net P T Pi Ai VV TV =(3)⽹络仿真[,,,,] (,,,,)Y Pf Af E perf sim net P Pi Ai T =BP ⽹络的训练函数训练⽅法训练函数梯度下降法traingd 有动量的梯度下降法 traingdm ⾃适应lr 梯度下降法traingda⾃适应lr 动量梯度下降法 traingdx 弹性梯度下降法 trainrpFletcher-Reeves 共轭梯度法traincgfPloak-Ribiere 共轭梯度法 traincgp Powell-Beale 共轭梯度法 traincgb 量化共轭梯度法trainscg拟⽜顿算法trainbfg⼀步正割算法trainoss Levenberg-Marquardt trainlmBP⽹络训练参数训练参数参数介绍训练函数net.trainParam.epochs最⼤训练次数(缺省为10)traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlm net.trainParam.goal训练要求精度(缺省为0)traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlm net.trainParam.lr学习率(缺省为0.01)traingd、traingdm、traingda、traingdx、trainrp、traincgf、trainscg、trainbfg、trainoss、trainlmnet.trainParam.max_fail最⼤失败次数(缺省为5)traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlm net.trainParam.min_grad最⼩梯度要求(缺省为1e-10)traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlmnet.trainParam.show显⽰训练迭代过程(NaN表⽰不显⽰,缺省为25)traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlmnet.trainParam.time最⼤训练时间(缺省为inf)traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlm net.trainParam.mc动量因⼦(缺省0.9)traingdm、traingdxnet.trainParam.lr_inc学习率lr增长⽐(缺省为1.05)traingda、traingdxnet.trainParam.lr_dec学习率lr下降⽐(缺省为0.7)traingda、traingdxnet.trainParam.max_perf_inc表现函数增加最⼤⽐(缺省为1.04)net.trainParam.delt_inc权值变化增加量(缺省为1.2)trainrpnet.trainParam.delt_dec权值变化减⼩量(缺省为0.5)trainrpnet.trainParam.delt0初始权值变化(缺省为0.07)trainrpnet.trainParam.deltamax权值变化最⼤值(缺省为50.0)trainrpnet.trainParam.searchFcn⼀维线性搜索⽅法(缺省为srchcha)traincgf、traincgp、traincgb、trainbfg、trainoss net.trainParam.sigma因为⼆次求导对权值trainscg调整的影响参数(缺省值5.0e-5)/doc/cd3ed4b6f5335a8102d220e4.html mbda trainscgHessian矩阵不确定性调节参数(缺省为5.0e-7)net.trainParam.men_redtrainlm控制计算机内存/速uc度的参量,内存较⼤设为1,否则设为2(缺省为1)net.trainParam.mu trainlmµ的初始值(缺省为0.001)net.trainParam.mu_dec trainlmµ的减⼩率(缺省为0.1)net.trainParam.mu_inc trainlmµ的增长率(缺省为10)net.trainParam.mu_max trainlmµ的最⼤值(缺省为1e10)。
Matlab中各种神经网络的使用示例

Matlab中各种神经网络的使用示例Matlab中各种神经网络的使用示例%通用BP神经网络 (2)%通用径向基函数网络......... 错误!未定义书签。
%广义回归神经网络 (11)%通用感应器神经网络 (14)%通用BP神经网络P=[-1 -1 2 2;0 5 0 5];t=[-1 -1 1 1];net=newff(minmax(P),[3,1],{'tansig','purelin'},'t raingd');%输入参数依次为:'样本P范围',[各层神经元数目],{各层传递函数},'训练函数'%训练函数traingd--梯度下降法,有7个训练参数.%训练函数traingdm--有动量的梯度下降法,附加1个训练参数mc(动量因子,缺省为0.9)%训练函数traingda--有自适应lr的梯度下降法,附加3个训练参数:lr_inc(学习率增长比,缺省为1.05;% lr_dec(学习率下降比,缺省为0.7);max_perf_inc(表现函数增加最大比,缺省为1.04)%训练函数traingdx--有动量的梯度下降法中赋以自适应lr的方法,附加traingdm和traingda 的4个附加参数%训练函数trainrp--弹性梯度下降法,可以消除输入数值很大或很小时的误差,附加4个训练参数:% delt_inc(权值变化增加量,缺省为1.2);delt_dec(权值变化减小量,缺省为0.5);% delta0(初始权值变化,缺省为0.07);deltamax(权值变化最大值,缺省为50.0) % 适合大型网络%训练函数traincgf--Fletcher-Reeves共轭梯度法;训练函数traincgp--Polak-Ribiere共轭梯度法;%训练函数traincgb--Powell-Beale共轭梯度法%共轭梯度法占用存储空间小,附加1训练参数searchFcn(一维线性搜索方法,缺省为srchcha);缺少1个训练参数lr%可以通过net=newrbe(P,T,spread)生成网络,且误差为0%可以通过net=newrb(P,T,goal,spread)生成网络,神经元由1开始增加,直到达到训练精度或神经元数目最多为止%GRNN网络,迅速生成广义回归神经网络(GRNN)P=[4 5 6];T=[1.5 3.6 6.7];net=newgrnn(P,T);%仿真验证p=4.5;v=sim(net,p)%PNN网络,概率神经网络P=[0 0 ;1 1;0 3;1 4;3 1;4 1;4 3]';Tc=[1 1 2 2 3 3 3];%将期望输出通过ind2vec()转换,并设计、验证网络T=ind2vec(Tc);net=newpnn(P,T);Y=sim(net,P);Yc=vec2ind(Y)%尝试用其他的输入向量验证网络P2=[1 4;0 1;5 2]';Y=sim(net,P2);Yc=vec2ind(Y)%应用newrb()函数构建径向基网络,对一系列数据点进行函数逼近P=-1:0.1:1;T=[-0.9602 -0.5770 -0.0729 0.3771 0.6405 0.6600 0.4609...0.1336 -0.2013 -0.4344 -0.500 -0.3930 -0.1647 -0.0988...0.3072 0.3960 0.3449 0.1816 -0.0312 -0.2189 -0.3201];%绘制训练用样本的数据点plot(P,T,'r*');title('训练样本');xlabel('输入向量P');ylabel('目标向量T');%设计一个径向基函数网络,网络有两层,隐层为径向基神经元,输出层为线性神经元%绘制隐层神经元径向基传递函数的曲线p=-3:.1:3;a=radbas(p);plot(p,a)title('径向基传递函数')xlabel('输入向量p')%隐层神经元的权值、阈值与径向基函数的位置和宽度有关,只要隐层神经元数目、权值、阈值正确,可逼近任意函数%例如a2=radbas(p-1.5);a3=radbas(p+2);a4=a+a2*1.5+a3*0.5;plot(p,a,'b',p,a2,'g',p,a3,'r',p,a4,'m--')title('径向基传递函数权值之和')xlabel('输入p');ylabel('输出a');%应用newrb()函数构建径向基网络的时候,可以预先设定均方差精度eg以及散布常数sceg=0.02;sc=1; %其值的选取与最终网络的效果有很大关系,过小造成过适性,过大造成重叠性net=newrb(P,T,eg,sc);plot(P,T,'*')xlabel('输入');X=-1:.01:1;Y=sim(net,X);hold onplot(X,Y);hold offlegend('目标','输出')%应用grnn进行函数逼近P=[1 2 3 4 5 6 7 8];T=[0 1 2 3 2 1 2 1];plot(P,T,'.','markersize',30)axis([0 9 -1 4])title('待逼近函数')xlabel('P')ylabel('T')%网络设计%对于离散数据点,散布常数spread选取比输入向量之间的距离稍小一些spread=0.7;net=newgrnn(P,T,spread);A=sim(net,P);hold onoutputline=plot(P,A,'o','markersize',10,'color',[1 0 0]);title('检测网络')xlabel('P')ylabel('T和A')%应用pnn进行变量的分类P=[1 2;2 2;1 1]; %输入向量Tc=[1 2 3]; %P对应的三个期望输出%绘制出输入向量及其相对应的类别plot(P(1,:),P(2,:),'.','markersize',30)for i=1:3text(P(1,i)+0.1,P(2,i),sprintf('class %g',Tc(i))) endaxis([0 3 0 3]);title('三向量及其类别')xlabel('P(1,:)')ylabel('P(2,:)')%网络设计T=ind2vec(Tc);spread=1;net=newgrnn(P,T,speard);%网络测试A=sim(net,P);Ac=vec2ind(A);%绘制输入向量及其相应的网络输出plot(P(1,:),P(2,:),'.','markersize',30)for i=1:3text(P(1,i)+0.1,P(2,i),sprintf('class %g',Ac(i))) endaxis([0 3 0 3]);title('网络测试结果')xlabel('P(1,:)')ylabel('P(2,:)')%广义回归神经网络%%GRNN神经网络,主要用于函数逼近。
bp神经网络matlab实例(bp神经网络matlab实例)

bp神经网络matlab实例(bp神经网络matlab实例)Case 1 training BP network by momentum gradient descent algorithm.Training samples are defined as follows:Input vector asP =[-1 -2 31-1 15 -3]The target vector is t = [-1 -1 1 1]Solution: the MATLAB program of this example is as follows:Close allClearEcho onCLC% NEWFF - generating a new feedforward neural network% TRAIN -- training BP neural network% SIM -- Simulation of BP neural networkPauseStart by hitting any keyCLCPercent defines training samples% P as input vectorP=[-1, -2, 3, 1; -1, 1, 5, -3];% T is the target vectorT=[-1, -1, 1, 1];Pause;CLC% create a new feedforward neural networkNet=newff (minmax (P), [3,1],{'tansig','purelin'},'traingdm')The current input layer weights and thresholds InputWeights=net.IW{1,1}Inputbias=net.b{1}The current network layer weights and thresholdsLayerWeights=net.LW{2,1}Layerbias=net.b{2}PauseCLC% set training parametersNet.trainParam.show = 50;Net.trainParam.lr = 0.05;Net.trainParam.mc = 0.9;Net.trainParam.epochs = 1000;Net.trainParam.goal = 1e-3;PauseCLC% call TRAINGDM algorithm to train BP network [net, tr]=train (net, P, T);PauseCLCSimulation of BP network by%A = sim (net, P)Calculate the simulation errorE = T - AMSE=mse (E)PauseCLCEcho offExample 2 adopts Bayesian regularization algorithm to improve the generalization ability of BP network. In this case, we used two kinds of training methods, namely L-M algorithm (trainlm) and the Bias regularization algorithm (trainbr), is used to train the BP network, so that it can fit attached to a white noise sine sample data. Among them, the sample data can be generated as follows MATLAB statements:Input vector: P = [-1:0.05:1];Target vector: randn ('seed', 78341223);T = sin (2*pi*P) +0.1*randn (size (P));Solution: the MATLAB program of this example is as follows: Close allClearEcho onCLC% NEWFF - generating a new feedforward neural network% TRAIN -- training BP neural network% SIM -- Simulation of BP neural networkPauseStart by hitting any keyCLC% define training sample vector% P as input vectorP = [-1:0.05:1];% T is the target vectorRandn ('seed', 78341223); T = sin (2*pi*P) +0.1*randn (size (P));Draw the sample data pointsPlot (P, T, +);Echo offHold on;Plot (P, sin (2*pi*P), ':');Draw sine curves without noiseEcho onCLCPauseCLC% create a new feedforward neural networkNet=newff (minmax (P), [20,1], {'tansig','purelin'});PauseCLCEcho offCLCDisp ('1. L-M optimization algorithm TRAINLM'); disp ('2. Bayesian regularization algorithm TRAINBR');Choice=input (\ "please select training algorithm (1,2): ');Figure (GCF);If (choice==1)Echo onCLC% using L-M optimization algorithm TRAINLMNet.trainFcn='trainlm';PauseCLC% set training parametersnet.trainparam.epochs = 500;net.trainparam.goal = 1e-6;NET(.NET);%重新初始化暂停中图分类号“(选择= = 2)回声中图分类号%采用贝叶斯正则化算法trainbr trainfcn = 'trainbr”网;暂停中图分类号%设置训练参数net.trainparam.epochs = 500;randn(“种子”,192736547);NET(.NET);%重新初始化暂停中图分类号结束调用相应算法训练BP网络% [净额],列车=(净额,P,T);暂停中图分类号对BP网络进行仿真%a = sim(NET,p);%计算仿真误差e = a;MSE=MSE(e)暂停中图分类号%绘制匹配结果曲线关闭所有;图(p,a,p,t,+,p,p,p(2),“,”;暂停;中图分类号回音通过采用两种不同的训练算法,我们可以得到如图1和图2所示的两种拟合结果。
(整理)BP神经网络matlab实现和matlab工具箱使用实例.

(整理)BP神经网络matlab实现和matlab工具箱使用实例.BP神经网络matlab实现和matlab工具箱使用实例经过最近一段时间的神经网络学习,终于能初步使用matlab实现BP网络仿真试验。
这里特别感谢研友sistor2004的帖子《自己编的BP算法(工具:matlab)》和研友wangleisxcc的帖子《用C++,Matlab,Fortran实现的BP算法》前者帮助我对BP算法有了更明确的认识,后者让我对matlab下BP函数的使用有了初步了解。
因为他们发的帖子都没有加注释,对我等新手阅读时有一定困难,所以我把sistor2004发的程序稍加修改后加注了详细解释,方便新手阅读。
%严格按照BP网络计算公式来设计的一个matlab程序,对BP网络进行了优化设计%yyy,即在o(k)计算公式时,当网络进入平坦区时(<0.0001)学习率加大,出来后学习率又还原%v(i,j)=v(i,j)+deltv(i,j)+a*dv(i,j); 动量项clear allclcinputNums=3; %输入层节点outputNums=3; %输出层节点hideNums=10; %隐层节点数maxcount=20000; %最大迭代次数samplenum=3; %一个计数器,无意义precision=0.001; %预设精度yyy=1.3; %yyy是帮助网络加速走出平坦区alpha=0.01; %学习率设定值a=0.5; %BP优化算法的一个设定值,对上组训练的调整值按比例修改字串9error=zeros(1,maxcount+1); %error数组初始化;目的是预分配内存空间errorp=zeros(1,samplenum); %同上v=rand(inputNums,hideNums); %3*10;v初始化为一个3*10的随机归一矩阵; v表输入层到隐层的权值deltv=zeros(inputNums,hideNums); %3*10;内存空间预分配dv=zeros(inputNums,hideNums); %3*10;w=rand(hideNums,outputNums); %10*3;同Vdeltw=zeros(hideNums,outputNums);%10*3dw=zeros(hideNums,outputNums); %10*3samplelist=[0.1323,0.323,-0.132;0.321,0.2434,0.456;-0.6546,-0.3242,0.3255]; %3*3;指定输入值3*3(实为3个向量)expectlist=[0.5435,0.422,-0.642;0.1,0.562,0.5675;-0.6464,-0.756,0.11]; %3*3;期望输出值3*3(实为3个向量),有导师的监督学习count=1;while (count<=maxcount) %结束条件1迭代20000次c=1;while (c<=samplenum)for k=1:outputNumsd(k)=expectlist(c,k); %获得期望输出的向量,d(1:3)表示一个期望向量内的值endfor i=1:inputNumsx(i)=samplelist(c,i); %获得输入的向量(数据),x(1:3)表一个训练向量字串4end%Forward();for j=1:hideNumsnet=0.0;for i=1:inputNumsnet=net+x(i)*v(i,j);%输入层到隐层的加权和∑X(i)V(i)endy(j)=1/(1+exp(-net)); %输出层处理f(x)=1/(1+exp(-x))单极性sigmiod函数endfor k=1:outputNumsnet=0.0;for j=1:hideNumsnet=net+y(j)*w(j,k);endif count>=2&&error(count)-error(count+1)<=0.0001o(k)=1/(1+exp(-net)/yyy); %平坦区加大学习率else o(k)=1/(1+exp(-net)); %同上endend%BpError(c)反馈/修改;errortmp=0.0;for k=1:outputNumserrortmp=errortmp+(d(k)-o(k))^2; %第一组训练后的误差计算enderrorp(c)=0.5*errortmp; %误差E=∑(d(k)-o(k))^2 * 1/2%end%Backward();for k=1:outputNumsyitao(k)=(d(k)-o(k))*o(k)*(1-o(k)); %输入层误差偏导字串5endfor j=1:hideNumstem=0.0;for k=1:outputNumstem=tem+yitao(k)*w(j,k); %为了求隐层偏导,而计算的∑endyitay(j)=tem*y(j)*(1-y(j)); %隐层偏导end%调整各层权值for j=1:hideNumsfor k=1:outputNumsdeltw(j,k)=alpha*yitao(k)*y(j); %权值w的调整量deltw(已乘学习率)w(j,k)=w(j,k)+deltw(j,k)+a*dw(j,k);%权值调整,这里的dw=dletw(t-1),实际是对BP算法的一个dw(j,k)=deltw(j,k); %改进措施--增加动量项目的是提高训练速度endendfor i=1:inputNumsfor j=1:hideNumsdeltv(i,j)=alpha*yitay(j)*x(i); %同上deltwv(i,j)=v(i,j)+deltv(i,j)+a*dv(i,j);dv(i,j)=deltv(i,j);endendc=c+1;end%第二个while结束;表示一次BP训练结束double tmp;tmp=0.0; 字串8for i=1:samplenumtmp=tmp+errorp(i)*errorp(i);%误差求和endtmp=tmp/c;error(count)=sqrt(tmp);%误差求均方根,即精度if (error(count)<precision)%另一个结束条件< p="">break;endcount=count+1;%训练次数加1end%第一个while结束error(maxcount+1)=error(maxcount);p=1:count;pp=p/50;plot(pp,error(p),"-"); %显示误差然后下面是研友wangleisxcc的程序基础上,我把初始化网络,训练网络,和网络使用三个稍微集成后的一个新函数bpnet %简单的BP神经网络集成,使用时直接调用bpnet就行%输入的是p-作为训练值的输入% t-也是网络的期望输出结果% ynum-设定隐层点数一般取3~20;% maxnum-如果训练一直达不到期望误差之内,那么BP迭代的次数一般设为5000% ex-期望误差,也就是训练一小于这个误差后结束迭代一般设为0.01% lr-学习率一般设为0.01% pp-使用p-t虚拟蓝好的BP网络来分类计算的向量,也就是嵌入二值水印的大组系数进行训练然后得到二值序列% ww-输出结果% 注明:ynum,maxnum,ex,lr均是一个值;而p,t,pp,ww均可以为向量字串1% 比如p是m*n的n维行向量,t那么为m*k的k维行向量,pp为o*i的i维行向量,ww为o* k的k维行向量%p,t作为网络训练输入,pp作为训练好的网络输入计算,最后的ww作为pp经过训练好的BP训练后的输出function ww=bpnet(p,t,ynum,maxnum,ex,lr,pp)plot(p,t,"+");title("训练向量");xlabel("P");ylabel("t");[w1,b1,w2,b2]=initff(p,ynum,"tansig",t,"purelin"); %初始化含一个隐层的BP网络zhen=25; %每迭代多少次更新显示biglr=1.1; %学习慢时学习率(用于跳出平坦区)litlr=0.7; %学习快时学习率(梯度下降过快时)a=0.7 %动量项a大小(△W(t)=lr*X*ん+a*△W(t-1))tp=[zhen maxnum ex lr biglr litlr a 1.04]; %trainbpx[w1,b1,w2,b2,ep,tr]=trainbpx(w1,b1,"tansig",w2,b2,"purelin", p,t,tp);ww=simuff(pp,w1,b1,"tansig",w2,b2,"purelin"); %ww就是调用结果下面是bpnet使用简例:%bpnet举例,因为BP网络的权值初始化都是随即生成,所以每次运行的状态可能不一样。
BP神经网络matlab详细参数

基于matlab BP 神经网络参数详解(1)生成BP网络=net newff PR S S SNl TF TF TFNl BTF BLF PF(,[1 2...],{ 1 2...},,,) PR:由R维的输入样本最小最大值构成的2R⨯维矩阵。
S S SNl:各层的神经元个数。
[1 2...]{ 1 2...}TF TF TFNl:各层的神经元传递函数。
BTF:训练用函数的名称。
(2)网络训练=net tr Y E Pf Af train net P T Pi Ai VV TV[,,,,,] (,,,,,,)(3)网络仿真=Y Pf Af E perf sim net P Pi Ai T[,,,,] (,,,,)BP网络的训练函数训练方法训练函数梯度下降法traingd有动量的梯度下降法traingdm自适应lr梯度下降法traingda自适应lr动量梯度下降法traingdx弹性梯度下降法trainrptraincgfFletcher-Reeves共轭梯度法Ploak-Ribiere共轭梯度法traincgpPowell-Beale共轭梯度法traincgb量化共轭梯度法trainscg拟牛顿算法trainbfg一步正割算法trainoss Levenberg-Marquardt trainlmBP网络训练参数训练参数参数介绍训练函数net.trainParam.epochs最大训练次数(缺省为10)traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlmnet.trainParam.goal训练要求精度(缺省为0)traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlmnet.trainParam.lr学习率(缺省为0.01)traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlmnet.trainParam.max_fail最大失败次数(缺省为5)traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlmnet.trainParam.min_grad最小梯度要求(缺省为1e-10)traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlmnet.trainParam.show显示训练迭代过程(NaN表示不显示,缺省为25)traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlmnet.trainParam.time最大训练时间(缺省为inf)traingd、traingdm、traingda、traingdx、trainrp、traincgf、traincgp、traincgb、trainscg、trainbfg、trainoss、trainlm net.trainParam.mc动量因子(缺省0.9)traingdm、traingdxnet.trainParam.lr_inc学习率lr增长比(缺省为1.05)traingda、traingdxnet.trainParam.lr_dec学习率lr下降比(缺省为0.7)traingda、traingdxnet.trainParam.max_perf_inc表现函数增加最大比(缺省为1.04)traingda、traingdxnet.trainParam.delt_inc权值变化增加量(缺省为1.2)trainrpnet.trainParam.delt_dec权值变化减小量(缺省为0.5)trainrpnet.trainParam.delt0初始权值变化(缺省为0.07)trainrpnet.trainParam.deltamax权值变化最大值(缺省为50.0)trainrpnet.trainParam.searchFcn一维线性搜索方法(缺省为srchcha)traincgf、traincgp、traincgb、trainbfg、trainossnet.trainParam.sigma因为二次求导对权值trainscg调整的影响参数(缺省值5.0e-5)mbdatrainscgHessian矩阵不确定性调节参数(缺省为5.0e-7)net.trainParam.men_redtrainlm控制计算机内存/速uc度的参量,内存较大设为1,否则设为2(缺省为1)net.trainParam.mutrainlmμ的初始值(缺省为0.001)net.trainParam.mu_dectrainlmμ的减小率(缺省为0.1)net.trainParam.mu_inctrainlmμ的增长率(缺省为10)net.trainParam.mu_maxtrainlmμ的最大值(缺省为1e10)。
BP神经网络的Matlab语法介绍

1. 数据预处理在训练神经网络前一般需要对数据进行预处理,一种重要的预处理手段是归一化处理。
下面简要介绍归一化处理的原理与方法。
(1) 什么是归一化?数据归一化,就是将数据映射到[0,1]或[-1,1]区间或更小的区间,比如(0.1,0.9) 。
(2) 为什么要归一化处理?<1>输入数据的单位不一样,有些数据的范围可能特别大,导致的结果是神经网络收敛慢、训练时间长。
<2>数据范围大的输入在模式分类中的作用可能会偏大,而数据范围小的输入作用就可能会偏小。
<3>由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域。
例如神经网络的输出层若采用S形激活函数,由于S形函数的值域限制在(0,1),也就是说神经网络的输出只能限制在(0,1),所以训练数据的输出就要归一化到[0,1]区间。
<4>S形激活函数在(0,1)区间以外区域很平缓,区分度太小。
例如S形函数f(X)在参数a=1时,f(100)与f(5)只相差0.0067。
(3) 归一化算法一种简单而快速的归一化算法是线性转换算法。
线性转换算法常见有两种形式:<1>y = ( x - min )/( max - min )其中min为x的最小值,max为x的最大值,输入向量为x,归一化后的输出向量为y 。
上式将数据归一化到 [ 0 , 1 ]区间,当激活函数采用S形函数时(值域为(0,1))时这条式子适用。
<2>y = 2 * ( x - min ) / ( max - min ) - 1这条公式将数据归一化到 [ -1 , 1 ] 区间。
当激活函数采用双极S形函数(值域为(-1,1))时这条式子适用。
(4) Matlab数据归一化处理函数Matlab中归一化处理数据可以采用premnmx , postmnmx , tramnmx 这3个函数。
<1> premnmx语法:[pn,minp,maxp,tn,mint,maxt] = premnmx(p,t)参数:pn: p矩阵按行归一化后的矩阵minp,maxp:p矩阵每一行的最小值,最大值tn:t矩阵按行归一化后的矩阵mint,maxt:t矩阵每一行的最小值,最大值作用:将矩阵p,t归一化到[-1,1] ,主要用于归一化处理训练数据集。
BP神经网络的Matlab语法.

1. 数据预处理在训练神经网络前一般需要对数据进行预处理,一种重要的预处理手段是归一化处理。
下面简要介绍归一化处理的原理与方法。
(1) 什么是归一化?数据归一化,就是将数据映射到[0,1]或[-1,1]区间或更小的区间,比如(0.1,0.9) 。
(2) 为什么要归一化处理?<1>输入数据的单位不一样,有些数据的范围可能特别大,导致的结果是神经网络收敛慢、训练时间长。
<2>数据范围大的输入在模式分类中的作用可能会偏大,而数据范围小的输入作用就可能会偏小。
<3>由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域。
例如神经网络的输出层若采用S形激活函数,由于S形函数的值域限制在(0,1),也就是说神经网络的输出只能限制在(0,1),所以训练数据的输出就要归一化到[0,1]区间。
<4>S形激活函数在(0,1)区间以外区域很平缓,区分度太小。
例如S形函数f(X)在参数a=1时,f(100)与f(5)只相差0.0067。
(3) 归一化算法一种简单而快速的归一化算法是线性转换算法。
线性转换算法常见有两种形式:<1>y = ( x - min )/( max - min )其中min为x的最小值,max为x的最大值,输入向量为x,归一化后的输出向量为y 。
上式将数据归一化到[ 0 , 1 ]区间,当激活函数采用S形函数时(值域为(0,1))时这条式子适用。
<2>y = 2 * ( x - min ) / ( max - min ) - 1这条公式将数据归一化到[ -1 , 1 ] 区间。
当激活函数采用双极S形函数(值域为(-1,1))时这条式子适用。
(4) Matlab数据归一化处理函数Matlab中归一化处理数据可以采用premnmx ,postmnmx ,tramnmx 这3个函数。
<1> premnmx语法:[pn,minp,maxp,tn,mint,maxt] = premnmx(p,t)参数:pn:p矩阵按行归一化后的矩阵minp,maxp:p矩阵每一行的最小值,最大值tn:t矩阵按行归一化后的矩阵mint,maxt:t矩阵每一行的最小值,最大值作用:将矩阵p,t归一化到[-1,1] ,主要用于归一化处理训练数据集。
BP神经网络matlab详细参数

trainbfg trainoss trainlm
参数介绍 训练函数
训练参数
net.trainParam.epochs
最大训练次数(缺省 traingd 、 traingdm 、 为 10) traingda 、 traingdx 、 trainrp 、 traincgf 、 traincgp 、 traincgb 、 trainscg 、 trainbfg 、 trainoss、trainlm
net.trainParam.deltama x net.trainParam.searchF cn
权值变化最大值(缺 trainrp 省为 50.0) 一 维 线 性 搜 索 方 法 traincgf 、 traincgp 、 (缺省为 srchcha) traincgb 、 trainbfg 、 trainoss
net.trainParam.show
显 示 训 练 迭 代 过 程 traingd 、 traingdm 、 (NaN 表示不显示, traingda 、 traingdx 、 缺省为 25) trainrp 、 traincgf 、 traincgp 、 traincgb 、 trainscg 、 trainbfg 、 trainoss、trainlm
net.trainParam.lr
学习率 (缺省为 0.01) traingd 、 traingdm 、 traingda 、 traingdx 、 trainrp 、 traincgf 、 traincgp 、 traincgb 、 trainscg 、 trainbfg 、
trainoss、trainlm
net.trainParam.time
最大训练时间(缺省 traingd 、 traingdm 、 为 inf) traingda 、 traingdx 、 trainrp 、 traincgf 、
BP神经网络实验_Matlab

计算智能实验报告实验名称:BP神经网络算法实验班级名称: 2010级软工三班专业:软件工程姓名:李XX学号: XXXXXX2010090一、实验目的1)编程实现BP神经网络算法;2)探究BP算法中学习因子算法收敛趋势、收敛速度之间的关系;3)修改训练后BP神经网络部分连接权值,分析连接权值修改前和修改后对相同测试样本测试结果,理解神经网络分布存储等特点。
二、实验要求按照下面的要求操作,然后分析不同操作后网络输出结果。
1)可修改学习因子2)可任意指定隐单元层数3)可任意指定输入层、隐含层、输出层的单元数4)可指定最大允许误差ε5)可输入学习样本(增加样本)6)可存储训练后的网络各神经元之间的连接权值矩阵;7)修改训练后的BP神经网络部分连接权值,分析连接权值修改前和修改后对相同测试样本测试结果。
三、实验原理1 明确BP神经网络算法的基本思想如下:在BPNN中,后向传播是一种学习算法,体现为BPNN的训练过程,该过程是需要教师指导的;前馈型网络是一种结构,体现为BPNN的网络构架反向传播算法通过迭代处理的方式,不断地调整连接神经元的网络权重,使得最终输出结果和预期结果的误差最小BPNN是一种典型的神经网络,广泛应用于各种分类系统,它也包括了训练和使用两个阶段。
由于训练阶段是BPNN能够投入使用的基础和前提,而使用阶段本身是一个非常简单的过程,也就是给出输入,BPNN会根据已经训练好的参数进行运算,得到输出结果2 明确BP神经网络算法步骤和流程如下:1初始化网络权值2由给定的输入输出模式对计算隐层、输出层各单元输出3计算新的连接权及阀值,4选取下一个输入模式对返回第2步反复训练直到网络设输出误差达到要求结束训练。
四、实验内容和分析1.实验时建立三层BP神经网络,输入节点2个,隐含层节点2个,输出节代码:P=[0.0 0.0 1.0 1.0;0.0 1.0 0.0 1.0];%输入量矩阵T=[0.0 1.0 1.0 0.0];%输出量矩阵net=newff(minmax(P),T,[2 1],{'tansig','purelin'},'traingd');%创建名为net的BP神经网络inputWeights=net.IW{1,1};%输入层与隐含层的连接权重inputbias=net.b{2};%输入层与隐含层的阈值net.trainParam.epochs=5000;%网络参数:最大训练次数为5000次net.trainParam.goal=0.01;%网络参数:训练精度为0.001 net.trainparam.lr=0.5;%网络参数:学习设置率为0.5net.trainParam.mc=0.6; %动量[net,tr]=train(net,P,T); %训练A=sim(net,P); %仿真E=T-A; %误差MSE=mse(E); %均方误差训练次数5000,全局误差0.0083642.输入测试样本为可见网络性能良好,输出结果基本满足识别要求。
BP神经网络matlab实例(简单而经典)(完整资料).doc

【最新整理,下载后即可编辑】p=p1';t=t1';[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t); %原始数据归一化net=newff(minmax(pn),[5,1],{'tansig','purelin'},'traingdx');%设置网络,建立相应的BP网络,minmax(pn)找到pn 矩阵的最大最小值net.trainParam.show=2000; % 训练网络net.trainParam.lr=0.01;net.trainParam.epochs=100000;net.trainParam.goal=1e-5;[net,tr]=train(net ,pn,tn); %调用TRAINGDM算法训练BP网络pnew=pnew1';pnewn=tramnmx(pnew,minp,maxp);anewn=sim(net,pnewn); %对BP网络进行仿真anew=postmnmx(anewn,mint,maxt); %还原数据y=anew';1、BP网络构建(1)生成BP网络net newff PR S S SNl TF TF TFNl BTF BLF PF=(,[1 2...],{ 1 2...},,,)PR:由R维的输入样本最小最大值构成的2R⨯维矩阵。
S S SNl:各层的神经元个数。
[ 1 2...]TF TF TFNl:各层的神经元传递函数。
{ 1 2...}BTF:训练用函数的名称。
(2)网络训练[,,,,,] (,,,,,,)=net tr Y E Pf Af train net P T Pi Ai VV TV (3)网络仿真=Y Pf Af E perf sim net P Pi Ai T[,,,,] (,,,,){'tansig','purelin'},'trainrp'BP网络训练参数举例1、%traingdclear;clc;P=[-1 -1 2 2 4;0 5 0 5 7];T=[-1 -1 1 1 -1];%利用minmax函数求输入样本范围net = newff(minmax(P),[5,1],{'tansig','purelin'},'trainrp');%minmax(P)取P的最大最小值;[5,1]第一次神经元5个,第二层1个;'tansig','purelin'神经网络第一层和第二层的转移函数;'trainrp'网络训练函数。
Matlab训练好的BP神经网络如何保存和读取方法(附实例说明)

Matlab训练好的BP神经网络如何保存和读取方法(附实例说明)看到论坛里很多朋友都在提问如何存储和调用已经训练好的神经网络。
本人前几天也遇到了这样的问题,在论坛中看了大家的回复,虽然都提到了关键的两个函数“save”和“load”,但或多或少都简洁了些,让人摸不着头脑(呵呵,当然也可能是本人太菜)。
通过不断调试,大致弄明白这两个函数对神经网络的存储。
下面附上实例给大家做个说明,希望对跟我有一样问题的朋友有所帮助。
如果只是需要在工作目录下保到当前训练好的网络,可以在命令窗口输入:save net %net为已训练好的网络然后在命令窗口输入:load net %net为已保存的网络加载net。
但一般我们都会在加载完后对网络进行进一步的操作,建议都放在M文件中进行保存网络和调用网络的操作如下所示:%% 以函数的形式训练神经网络functionshenjingwangluo()P=[-1,-2,3,1;-1,1,5,-3];%P为输入矢量T=[-1,-1,1,1,];%T为目标矢量net=newff(minmax(P),[3,1],{'tansig','purelin'},'traingdm')%创建一个新的前向神经网络inputWeights=net.IW{1,1}inputbias=net.b{1}%当前输入层权值和阀值layerWeights=net.LW{2,1}layerbias=net.b{2}net.trainParam.show=50;net.trainParam.lr=0.05;net.trainParam.mc=0.9;net.trainParam.epochs=1000;net.trainParam.goal=0.0002;%调用算法训练BP网络[net,tr]=train(net,P,T);%保存训练好的网络在当前工作目录下的aaa 文件中,net为网络名save('aaa', 'net');%也可以采用格式“save aaa net;”%若要保存到指定目录用“'save('d:\aaa.mat', 'net');”这样就保存到指定的目录下了%%调用网络,以函数的形式function jiazaiwangluo()%网络加载,注意文件名要加单引号load('-mat','aaa');%从指定目录加载“load('-mat','d:\aaa.mat'); ”P=[3;4]A=sim(net,P)%对网络进行仿真上面两个函数都已经调试成功,有需要的朋友可以试试看,希望对大家有帮助。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Matlab训练好的BP神经网络如何保存和读取方法(附实例说明)
看到论坛里很多朋友都在提问如何存储和调用已经训练好的神经网络。
本人前几天也遇到了这样的问题,在论坛中看了大家的回复,虽然都提到了关键的两个函数“save”和“load”,但或多或少都简洁了些,让人摸不着头脑(呵呵,当然也可能是本人太菜)。
通过不断调试,大致弄明白这两个函数对神经网络的存储。
下面附上实例给大家做个说明,希望对跟我有一样问题的朋友有所帮助。
如果只是需要在工作目录下保到当前训练好的网络,可以在命令窗口
输入:save net %net为已训练好的网络
然后在命令窗口
输入:load net %net为已保存的网络
加载net。
但一般我们都会在加载完后对网络进行进一步的操作,建议都放在M文件中进行保存网络和调用网络的操作
如下所示:
%% 以函数的形式训练神经网络
functionshenjingwangluo()
P=[-1,-2,3,1;
-1,1,5,-3];
%P为输入矢量
T=[-1,-1,1,1,];
%T为目标矢量
net=newff(minmax(P),[3,1],{'tansig','purelin'},'traingdm')
%创建一个新的前向神经网络
inputWeights=net.IW{1,1}
inputbias=net.b{1}
%当前输入层权值和阀值
layerWeights=net.LW{2,1}
layerbias=net.b{2}
net.trainParam.show=50;
net.trainParam.lr=0.05;
net.trainParam.mc=0.9;
net.trainParam.epochs=1000;
net.trainParam.goal=0.0002;
%调用算法训练BP网络
[net,tr]=train(net,P,T);
%保存训练好的网络在当前工作目录下的aaa 文件中,net为网络名
save('aaa', 'net');
%也可以采用格式“save aaa net;”
%若要保存到指定目录用“'save('d:\aaa.mat', 'net');”这样就保存到指定的目录下了
%%调用网络,以函数的形式
function jiazaiwangluo()
%网络加载,注意文件名要加单引号
load('-mat','aaa');
%从指定目录加载“load('-mat','d:\aaa.mat'); ”
P=[3;4]
A=sim(net,P)%对网络进行仿真
上面两个函数都已经调试成功,有需要的朋友可以试试看,希望对大家有帮助。
来源:matlab中文论坛。