excel表格计算概率的教程
如何使用excel计算概率论一些题目

如何使用excel 计算概率论一些题目简单介绍一些1.1.1 t 分布Excel 计算t 分布的值(查表值)采用TDIST 函数,格式如下:TDIST (变量,自由度,侧数)其中:变量(t ):为判断分布的数值;自由度(v ):以整数表明的自由度;侧数:指明分布为单侧或双侧:若为1,为单侧;若为2,为双侧.范例:设T 服从t (n-1)分布,样本数为25,求P (T >1.711).已知t =1.711,n =25,采用单侧,则T 分布的值:=TDIST(1.711,24,1)得到0.05,即P (T >1.711)=0.05.若采用双侧,则T 分布的值:=TDIST(1.711,24,2)得到0.1,即()1.7110.1P T >=. 1.1.2 t 分布的反函数Excel 使用TINV 函数得到t 分布的反函数,格式如下:TINV (双侧概率,自由度)范例:已知随机变量服从t (10)分布,置信度为0.05,求t 205.0(10).输入公式=TINV(0.05,10)得到2.2281,即()2.22810.05P T >=.若求临界值t α(n ),则使用公式=TINV(2*α, n ).范例:已知随机变量服从t (10)分布,置信度为0.05,求t 0.05 (10).输入公式=TINV(0.1,10)得到1.812462,即t 0.05 (10)= 1.812462.1.1.3 F 分布Excel 采用FDIST 函数计算F 分布的上侧概率1()F x -,格式如下:FDIST(变量,自由度1,自由度2)其中:变量(x ):判断函数的变量值;自由度1(1n ):代表第1个样本的自由度;自由度2(2n ):代表第2个样本的自由度.范例:设X 服从自由度1n =5,2n =15的F 分布,求P (X >2.9)的值.输入公式=FDIST(2.9,5,15)得到值为0.05,相当于临界值α.1.1.4 F 分布的反函数Excel 使用FINV 函数得到F 分布的反函数,即临界值12(,)F n n α,格式为:FINV(上侧概率,自由度1,自由度2)范例:已知随机变量X 服从F (9,9)分布,临界值α=0.05,求其上侧0.05分位点F 0.05(9,9).输入公式=FINV(0.05,9,9)得到值为3.178897,即F 0.05(9,9)= 3.178897.若求单侧百分位点F 0.025(9,9),F 0.975(9,9).可使用公式=FINV(0.025,9,9)=FINV(0.975,9,9)得到两个临界值4.025992和0.248386.若求临界值F α(n 1,n 2),则使用公式=FINV(α, n 1,n 2).1.1.5 卡方分布Excel 使用CHIDIST 函数得到卡方分布的上侧概率1()F x -,其格式为:CHIDIST(数值,自由度)其中:数值(x ):要判断分布的数值;自由度(v ):指明自由度的数字.范例:若X 服从自由度v =12的卡方分布,求P (X >5.226)的值.输入公式=CHIDIST(5.226,12)得到0.95,即1(5.226)F -=0.95或(5.226)F =0.05.1.1.6 卡方分布的反函数Excel 使用CHIINV 函数得到卡方分布的反函数,即临界值2()n αχ.格式为:CHIINV (上侧概率值α,自由度n )范例:下面的公式计算卡方分布的反函数:=CHIINV(0.95,12)得到值为5.226,即20.95(12)χ=5.226.若求临界值2αχ(n),则使用公式=CHIINV(α, n). 1.1.7 泊松分布计算泊松分布使用POISSON 函数,格式如下:POISSON(变量,参数,累计)其中:变量:表示事件发生的次数;参数:泊松分布的参数值;累计:若TRUE ,为泊松分布函数值;若FALSE ,则为泊松分布概率分布值. 范例:设X服从参数为4的泊松分布,计算P {X =6}及P {X ≤6}.输入公式=POISSON(6,4,FALSE)=POISSON(6,4,TRUE)得到概率0.104196和0.889326.在下面的实验中,还将碰到一些其它函数,例如:计算样本容量的函数COUNT ,开平方函数SQRT ,和函数SUM ,等等.关于这些函数的具体用法,可以查看Excel 的关于函数的说明,不再赘述.2 区间估计实验计算置信区间的本质是输入两个公式,分别计算置信下限与置信上限.当熟悉了数据输入方法及常见统计函数后,变得十分简单.2.1 单个正态总体均值与方差的区间估计:2.1.1σ2已知时μ的置信区间 置信区间为22x u x u αα⎛⎫-+ ⎝. 例1 随机从一批苗木中抽取16株,测得其高度(单位:m )为:1.14 1.10 1.13 1.151.20 1.12 1.17 1.19 1.15 1.12 1.14 1.20 1.23 1.11 1.14 1.16.设苗高服从正态分布,求总体均值μ的0.95的置信区间.已知σ =0.01(米).步骤:(1)在一个矩形区域内输入观测数据,例如在矩形区域B3:G5内输入样本数据.(2)计算置信下限和置信上限.可以在数据区域B3:G5以外的任意两个单元格内分别输入如下两个表达式:=average(b3:g5)-normsinv(1-0.5*α)*σ/sqrt(count(b3:g5))=average(b3:g5)+normsinv(1-0.5*α)*σ/sqrt(count(b3:g5))上述第一个表达式计算置信下限,第二个表达式计算置信上限.其中,显著性水平α和标准差σ是具体的数值而不是符号.本例中,α =0.05, 0.01σ=,上述两个公式应实际输入为=average(b3:g5)-normsinv(0.975)*0.01/sqrt(count(b3:g5))=average(b3:g5)+normsinv(0.975)*0.01/sqrt(count(b3:g5))计算结果为(1.148225, 1.158025).2.1.2 σ2未知时μ的置信区间置信区间为22((x t n x t n αα⎛⎫--+- ⎝. 例2 同例1,但σ未知.输入公式为:=average(b3:g5)-tinv(0.05,count(b:3:g5)-1)*stdev(b3:g5)/sqrt(count(b3:g5))=average(b3:g5)-tinv(0.05,count(b:3:g5)-1)*stdev(b3:g5)/sqrt(count(b3:g5))计算结果为(1.133695, 1.172555).2.1.3 μ未知时σ2的置信区间:置信区间为 2222122(1)(1),(1)(1)n n n n s s ααχχ-⎛⎫ ⎪-- ⎪-- ⎪⎝⎭. 例3 从一批火箭推力装置中随机抽取10个进行试验,它们的燃烧时间(单位:s)如下:50.7 54.9 54.3 44.8 42.2 69.8 53.4 66.1 48.1 34.5试求总体方差2σ的0.9的置信区间(设总体为正态).操作步骤:(1)在单元格B3:C7分别输入样本数据;(2)在单元格C9中输入样本数或输入公式=COUNT(B3:C7);(3)在单元格C10中输入置信水平0.1.(4)计算样本方差:在单元格C11中输入公式=V AR(B3:C7)(5)计算两个查表值:在单元格C12中输入公式=CHIINV(C10/2,C9-1),在单元格C13中输入公式=CHIINV(1-C10/2,C9-1)(6)计算置信区间下限:在单元格C14中输入公式=(C9-1)*C11/C12(7)计算置信区间上限:在单元格C15中输入公式=(C9-1)*C11/C13.当然,读者可以在输入数据后,直接输入如下两个表达式计算两个置信限:=(count(b3:c7)-1)*var(b3:c7)/chiinv(0.1/2, count(b3:c7)-1)=(count(b3:c7)-1)*var(b3:c7)/chiinv(1-0.1/2, count(b3:c7)-1)2.2 两正态总体均值差与方差比的区间估计2.2.1 当σ12 = σ22 = σ2但未知时μ1-μ2的置信区间置信区间为 ()1212211(2)w x y t n n S n n α⎛⎫-±+-+ ⎪ ⎪⎝⎭. 例4 在甲,乙两地随机抽取同一品种小麦籽粒的样本,其容量分别为5和7,分析其蛋白质含量为甲:12.6 13.4 11.9 12.8 13.0乙:13.1 13.4 12.8 13.5 13.3 12.7 12.4蛋白质含量符合正态等方差条件,试估计甲,乙两地小麦蛋白质含量差μ1-μ2所在。
如何使用excel进行概率统计

数理统计实验1Excel基本操作1.1单元格操作1.1.1单元格的选取Excel启动后首先将自动选取第A列第1行的单元格即A1(或a1)作为活动格,我们可以用键盘或鼠标来选取其它单元格.用鼠标选取时,只需将鼠标移至希望选取的单元格上并单击即可.被选取的单元格将以反色显示.1.1.2选取单元格范围(矩形区域)可以按如下两种方式选取单元格范围.(1) 先选取范围的起始点(左上角),即用鼠标单击所需位置使其反色显示.然后按住鼠标左键不放,拖动鼠标指针至终点(右下角)位置,然后放开鼠标即可.(2) 先选取范围的起始点(左上角),即用鼠标单击所需位置使其反色显示.然后将鼠标指针移到终点(右下角)位置,先按下Shift键不放,而后点击鼠标左键.1.1.3选取特殊单元格在实际中,有时要选取的单元格由若干不相连的单元格范围组成的.此类有两种情况.第一种情况是间断的单元格选取.选取方法是先选取第一个单元格,然后按住[Ctrl]键,再依次选取其它单元格即可.第二种情况是间断的单元格范围选取.选取方法是先选取第一个单元格范围,然后按住[Ctrl]键,用鼠标拖拉的方式选取第二个单元格范围即可.1.1.4公式中的数值计算要输入计算公式,可先单击待输入公式的单元格,而后键入=(等号),并接着键入公式,公式输入完毕后按Enter键即可确认..如果单击了“编辑公式”按钮或“粘贴函数”按钮,Excel将自动插入一个等号.提示:(1) 通过先选定一个区域,再键入公式,然后按CTRL+ENTER 组合键,可以在区域内的所有单元格中输入同一公式.(2) 可以通过另一单元格复制公式,然后在目标区域内输入同一公式.公式是在工作表中对数据进行分析的等式.它可以对工作表数值进行加法、减法和乘法等运算.公式可以引用同一工作表中的其它单元格、同一工作簿不同工作表中的单元格,或者其它工作簿的工作表中的单元格.下面的示例中将单元格B4 中的数值加上25,再除以单元格D5、E5 和F5 中数值的和.=(B4+25)/SUM(D5:F5)1.1.5公式中的语法公式语法也就是公式中元素的结构或顺序.Excel 中的公式遵守一个特定的语法:最前面是等号(=),后面是参与计算的元素(运算数)和运算符.每个运算数可以是不改变的数值(常量数值)、单元格或区域引用、标志、名称,或工作表函数.在默认状态下,Excel 从等号(=)开始,从左到右计算公式.可以通过修改公式语法来控制计算的顺序.例如,公式=5+2*3的结果为11,将2 乘以3(结果是6),然后再加上5.因为Excel 先计算乘法再计算加法;可以使用圆括号来改变语法,圆括号内的内容将首先被计算.公式=(5+2)*3的结果为21,即先用5 加上2,再用其结果乘以3.1.1.6单元格引用一个单元格中的数值或公式可以被另一个单元格引用.含有单元格引用公式的单元格称为从属单元格,它的值依赖于被引用单元格的值.只要被引用单元格做了修改,包含引用公式的单元格也就随之修改.例如,公式“=B15*5”将单元格B15 中的数值乘以5.每当单元格B15 中的值修改时,公式都将重新计算.公式可以引用单元格组或单元格区域,还可以引用代表单元格或单元格区域的名称或标志.在默认状态下,Excel 使用A1 引用类型.这种类型用字母标志列(从A 到IV ,共256 列),用数字标志行(从1 到65536).如果要引用单元格,请顺序输入列字母和行数字.例如,D50 引用了列D 和行50 交叉处的单元格.如果要引用单元格区域,请输入区域左上角单元格的引用、冒号(:)和区域右下角单元格的引用.下面是引用的示例.1.1.7工作表函数Excel 包含许多预定义的,或称内置的公式,它们被叫做函数.函数可以进行简单的或复杂的计算.工作表中常用的函数是“SUM”函数,它被用来对单元格区域进行加法运算.虽然也可以通过创建公式来计算单元格中数值的总和,但是“SUM”工作表函数还可以方便地计算多个单元格区域.函数的语法以函数名称开始,后面是左圆括号、以逗号隔开的参数和右圆括号.如果函数以公式的形式出现,请在函数名称前面键入等号(=).当生成包含函数的公式时,公式选项板将会提供相关的帮助.使用公式的步骤:A. 单击需要输入公式的单元格.B. 如果公式以函数的形式出现,请在编辑栏中单击“编辑公式”按钮.C. 单击“函数”下拉列表框右端的下拉箭头.D. 单击选定需要添加到公式中的函数.如果函数没有出现在列表中,请单击“其它函数”查看其它函数列表.E. 输入参数.F. 完成输入公式后,请按ENTER 键.1.2几种常见的统计函数1.2.1均值Excel计算平均数使用AVERAGE函数,其格式如下:AVERAGE(参数1,参数2,…,参数30)范例:AVERAGE(12.6,13.4,11.9,12.8,13.0)=12.74如果要计算单元格中A1到B20元素的平均数,可用AVERAGE(A1:B20).1.2.2标准差计算标准差可依据样本当作变量或总体当作变量来分别计算,根据样本计算的结果称作样本标准差,而依据总体计算的结果称作总体标准差.(1)样本标准差Excel计算样本标准差采用无偏估计式,STDEV函数格式如下:STDEV(参数1,参数2,…,参数30)范例:STDEV(3,5,6,4,6,7,5)=1.35如果要计算单元格中A1到B20元素的样本标准差,可用STDEV(A1:B20).(2)总体标准差Excel 计算总体标准差采用有偏估计式STDEVP 函数,其格式如下:STDEVP (参数1,参数2,…,参数30)范例:STDEVP (3,5,6,4,6,7,5)=1.251.2.3 方差方差为标准差的平方,在统计上亦分样本方差与总体方差.(1)样本方差S 2=1)(2--∑n x x iExcel 计算样本方差使用VAR 函数,格式如下:VAR (参数1,参数2,…,参数30)如果要计算单元格中A1到B20元素的样本方差,可用 VAR(A1:B20). 范例:VAR (3,5,6,4,6,7,5)=1.81(2)总体方差S 2=n x x i ∑-2)(Excel 计算总体方差使用VARP 函数,格式如下:VARP (参数1,参数2,…,参数30)范例:VAR (3,5,6,4,6,7,5)=1.551.2.4 正态分布函数Excel 计算正态分布时,使用NORMDIST 函数,其格式如下:NORMDIST(变量,均值,标准差,累积)其中:变量(x):为分布要计算的x值;均值(μ):分布的均值;标准差(σ):分布的标准差;累积:若为TRUE,则为分布函数;若为FALSE,则为概率密度函数.范例:已知X服从正态分布,μ=600,σ=100,求P{X≤500}.输入公式=NORMDIST(500,600,100,TRUE)得到的结果为0.158655,即P{X≤500}=0.158655.1.2.5正态分布函数的反函数Excel计算正态分布函数的反函数使用NORMINV函数,格式如下:NORMINV(下侧概率,均值,标准差)范例:已知概率P=0.841345,均值μ=360,标准差σ=40,求NORMINV函数的值.输入公式=NORMINV(0.841345,360,40)得到结果为400,即P{X≤400}=0.841345.注意:(1) NORMDIST函数的反函数NORMINV用于分布函数,而非概率密度函数,请务必注意;(2) Excel 提供了计算标准正态分布函数NORMSDIST(x),及标准正态分布的反函数NORMSINV(概率).Φ=P{X<2}.输入公式范例:已知X~N(0,1), 计算(2)=NORMSDIST(2)Φ=0.97725.得到0.97725,即(2)范例:输入公式=NORMSINV(0.97725) ,得到数值2.若求临界值uα(n),则使用公式=NORMSINV(1-α).1.2.6t分布Excel计算t分布的值(查表值)采用TDIST函数,格式如下:TDIST(变量,自由度,侧数)其中:变量(t):为判断分布的数值;自由度(v):以整数表明的自由度;侧数:指明分布为单侧或双侧:若为1,为单侧;若为2,为双侧.范例:设T服从t(n-1)分布,样本数为25,求P(T>1.711).已知t=1.711,n=25,采用单侧,则T分布的值:=TDIST(1.711,24,1)得到0.05,即P(T>1.711)=0.05.若采用双侧,则T分布的值:=TDIST(1.711,24,2)得到0.1,即()1.7110.1P T >=. 1.2.7 t 分布的反函数Excel 使用TINV 函数得到t 分布的反函数,格式如下:TINV (双侧概率,自由度)范例:已知随机变量服从t (10)分布,置信度为0.05,求t 205.0(10).输入公式=TINV(0.05,10)得到2.2281,即()2.22810.05P T >=.若求临界值t α(n ),则使用公式=TINV(2*α, n ).范例:已知随机变量服从t (10)分布,置信度为0.05,求t 0.05 (10).输入公式=TINV(0.1,10)得到1.812462,即t 0.05 (10)= 1.812462.1.2.8 F 分布Excel 采用FDIST 函数计算F 分布的上侧概率1()F x -,格式如下:FDIST(变量,自由度1,自由度2)其中:变量(x ):判断函数的变量值;自由度1(1n ):代表第1个样本的自由度;自由度2(2n ):代表第2个样本的自由度.范例:设X 服从自由度1n =5,2n =15的F 分布,求P (X >2.9)的值.输入公式=FDIST(2.9,5,15)得到值为0.05,相当于临界值α.1.2.9 F 分布的反函数Excel 使用FINV 函数得到F 分布的反函数,即临界值12(,)F n n α,格式为:FINV(上侧概率,自由度1,自由度2)范例:已知随机变量X 服从F (9,9)分布,临界值α=0.05,求其上侧0.05分位点F 0.05(9,9).输入公式=FINV(0.05,9,9)得到值为3.178897,即F 0.05(9,9)= 3.178897.若求单侧百分位点F 0.025(9,9),F 0.975(9,9).可使用公式=FINV(0.025,9,9)=FINV(0.975,9,9)得到两个临界值4.025992和0.248386.若求临界值F α(n 1,n 2),则使用公式=FINV(α, n 1,n 2).1.2.10 卡方分布Excel 使用CHIDIST 函数得到卡方分布的上侧概率1()F x -,其格式为:CHIDIST(数值,自由度)其中:数值(x ):要判断分布的数值;自由度(v ):指明自由度的数字.范例:若X 服从自由度v =12的卡方分布,求P (X >5.226)的值.输入公式=CHIDIST(5.226,12)得到0.95,即1(5.226)F -=0.95或(5.226)F =0.05.1.2.11 卡方分布的反函数Excel 使用CHIINV 函数得到卡方分布的反函数,即临界值2()n αχ.格式为:CHIINV (上侧概率值α,自由度n )范例:下面的公式计算卡方分布的反函数:=CHIINV(0.95,12)得到值为5.226,即20.95(12)χ=5.226.若求临界值2αχ(n),则使用公式=CHIINV(α, n). 1.2.12 泊松分布计算泊松分布使用POISSON 函数,格式如下:POISSON(变量,参数,累计)其中:变量:表示事件发生的次数;参数:泊松分布的参数值;累计:若TRUE ,为泊松分布函数值;若FALSE ,则为泊松分布概率分布值.范例:设X服从参数为4的泊松分布,计算P {X =6}及P {X ≤6}.输入公式=POISSON(6,4,FALSE)=POISSON(6,4,TRUE)得到概率0.104196和0.889326.在下面的实验中,还将碰到一些其它函数,例如:计算样本容量的函数COUNT ,开平方函数SQRT ,和函数SUM ,等等.关于这些函数的具体用法,可以查看Excel 的关于函数的说明,不再赘述.2 区间估计实验计算置信区间的本质是输入两个公式,分别计算置信下限与置信上限.当熟悉了数据输入方法及常见统计函数后,变得十分简单.2.1 单个正态总体均值与方差的区间估计:2.1.1 2已知时的置信区间 置信区间为22x u x u n n αα⎛⎫-+ ⎝. 例1 随机从一批苗木中抽取16株,测得其高度(单位:m )为:1.14 1.10 1.131.15 1.20 1.12 1.17 1.19 1.15 1.12 1.14 1.20 1.23 1.11 1.141.16.设苗高服从正态分布,求总体均值μ的0.95的置信区间.已知σ =0.01(米). 步骤:(1)在一个矩形区域内输入观测数据,例如在矩形区域B3:G5内输入样本数据.(2)计算置信下限和置信上限.可以在数据区域B3:G5以外的任意两个单元格内分别输入如下两个表达式:=average(b3:g5)-normsinv(1-0.5*α)*σ/sqrt(count(b3:g5))=average(b3:g5)+normsinv(1-0.5*α)*σ/sqrt(count(b3:g5))上述第一个表达式计算置信下限,第二个表达式计算置信上限.其中,显著性水平α和标准差σ是具体的数值而不是符号.本例中,=0.05, 0.01σ=,上述两个公式应实际输入为=average(b3:g5)-normsinv(0.975)*0.01/sqrt(count(b3:g5))=average(b3:g5)+normsinv(0.975)*0.01/sqrt(count(b3:g5))计算结果为(1.148225, 1.158025). 2.1.2 2未知时的置信区间置信区间为 22((x t n x t n n n αα⎛⎫--+- ⎝. 例2 同例1,但σ未知.输入公式为:=average(b3:g5)-tinv(0.05,count(b:3:g5)-1)*stdev(b3:g5)/sqrt(count(b3:g5)) =average(b3:g5)-tinv(0.05,count(b:3:g5)-1)*stdev(b3:g5)/sqrt(count(b3:g5)) 计算结果为(1.133695, 1.172555).2.1.3未知时2的置信区间:置信区间为2222122(1)(1),(1)(1)n nn ns sααχχ-⎛⎫ ⎪--⎪--⎪⎝⎭.例3从一批火箭推力装置中随机抽取10个进行试验,它们的燃烧时间(单位:s)如下:50.7 54.9 54.3 44.8 42.2 69.8 53.4 66.1 48.1 34.5试求总体方差2σ的0.9的置信区间(设总体为正态).操作步骤:(1)在单元格B3:C7分别输入样本数据;(2)在单元格C9中输入样本数或输入公式=COUNT(B3:C7);(3)在单元格C10中输入置信水平0.1.(4)计算样本方差:在单元格C11中输入公式=VAR(B3:C7)(5)计算两个查表值:在单元格C12中输入公式=CHIINV(C10/2,C9-1),在单元格C13中输入公式=CHIINV(1-C10/2,C9-1)(6)计算置信区间下限:在单元格C14中输入公式=(C9-1)*C11/C12(7)计算置信区间上限:在单元格C15中输入公式=(C9-1)*C11/C13.当然,读者可以在输入数据后,直接输入如下两个表达式计算两个置信限:=(count(b3:c7)-1)*var(b3:c7)/chiinv(0.1/2, count(b3:c7)-1)=(count(b3:c7)-1)*var(b3:c7)/chiinv(1-0.1/2, count(b3:c7)-1)2.2 两正态总体均值差与方差比的区间估计2.2.1 当12 =22 =2但未知时1-2的置信区间置信区间为 ()1212211(2)w x y t n n S n n α⎛⎫-±+-+ ⎪ ⎪⎝⎭.例4 在甲,乙两地随机抽取同一品种小麦籽粒的样本,其容量分别为5和7,分析其蛋白质含量为甲:12.6 13.4 11.9 12.8 13.0乙:13.1 13.4 12.8 13.5 13.3 12.7 12.4蛋白质含量符合正态等方差条件,试估计甲,乙两地小麦蛋白质含量差μ1-μ2所在的范围.(取α=0.05)实验步骤:(1)在A2:A6输入甲组数据,在B2:B8输入乙组数据;(2)在单元格B11输入公式=AVERAGE(A2:A6),在单元格B12中输入公式=AVERAGE(B2:B8),分别计算出甲组和乙组样本均值.(3)分别在单元格C11和C12分别输入公式=VAR(A2:A6),=VAR(B2:B8),计算出两组样本的方差.(4)在单元格D11和D12分别输入公式=COUNT(A2:A6),=COUNT(B2:B8),计算各样本的容量大小.(5)将显著性水平0.05输入到单元格E11中.(6)分别在单元格B13和B14输入=B11-B12-TINV(0.025,10)*SQRT((4*C11+6*C12)/10)*SQRT(1/ 5+1/7)和=B11-B12+TINV(0.025,10)*SQRT((4*C11+6*C12)/10)*SQRT(1/ 5+1/7)计算出置信区间的下限和上限.2.2.21和未知时方差比σ21/σ22的置信区间置信区间为22 112221221212211,(1,1)(1,1)s ss F n n s F n nαα-⎛⎫⎪⎪----⎪⎝⎭.例5有两个化验员A、B,他们独立地对某种聚合物的含氯量用相同的方法各作了10次测定.其测定值的方差分别是SA=0.5419,SB=0.6065.设σ2A和σ2B分别是A、B所测量的数据总体(设为正态分布)的方差.求方差比σ2A/σ2B的0.95置信区间.操作步骤:(1)在单元格B2,B3输入样本数,C2,C3输入样本方差,D2输入置信度.(2)在B4和B5利用公式输入=C2/(C3*FINV(1-D2/2,B2-1,B3-1))和=C2/(C3*FINV(D2/2,B2-1,B3-1))计算出A组和B组的方差比的置信区间上限和下限.2.3练习题1. 已知某树种的树高服从正态分布,随机抽取了该树种的60株林木组成样本.样本中各林木的树高资料如下(单位:m)22.3, 21.2, 19.2, 16.6, 23.1, 23.9, 24.8, 26.4, 26.6, 24.8, 23.9, 23.2, 23.3, 21.4,19.8, 18.3, 20.0, 21.5, 18.7, 22.4, 26.6, 23.9, 24.8, 18.8, 27.1, 20.6, 25.0, 22.5,23.5, 23.9, 25.3, 23.5, 22.6, 21.5, 20.6, 25.8, 24.0, 23.5, 22.6, 21.8, 20.8, 19.5,20.9, 22.1, 22.7, 23.6, 24.5, 23.6, 21.0, 21.3, 22.4,18.7, 21.3, 15.4, 22.9, 17.8,21.7, 19.1, 20.3, 19.8试以0.95的可靠性,对于该林地上全部林木的平均高进行估计.2. 从一批灯泡中随机抽取10个进行测试,测得它们的寿命(单位:100h)为:50.7,54.9,54.3,44.8,42.2,69.8,53.4,66.1,48.1,34.5.试求总体方差的0.9的置信区间(设总体为正态).3. 已知某种玉米的产量服从正态分布,现有种植该玉米的两个实验区,各分为10个小区,各小区的面积相同,在这两个实验区中,除第一实验区施以磷肥外,其它条件相同,两实验区的玉米产量(kg)如下:第一实验区:62 57 65 60 63 58 57 60 60 58第二实验区:56 59 56 57 60 58 57 55 57 55试求出施以磷肥的玉米产量均值和未施以磷肥的玉米产量均值之差的范围(α=0.05)3假设检验实验实验内容:单个总体均值的假设检验;两个总体均值差的假设检验;两个正态总体方差齐性的假设检验;拟合优度检验.实验目的与要求:(1)理解假设检验的统计思想,掌握假设检验的计算步骤;(2)掌握运用Excel进行假设检验的方法和操作步骤;(3)能够利用试验结果的信息,对所关心的事物作出合理的推断.3.1单个正态总体均值μ的检验3.1.12已知时μ的U检验例1 外地一良种作物,其1000m2产量(单位:kg)服从N(800, 502),引入本地试种,收获时任取5块地,其1000m2产量分别是800,850,780,900,820(kg),假定引种后1000m2产量X也服从正态分布,试问:=800kg 有无显著变化.(1)若方差未变,本地平均产量μ与原产地的平均产量μ0(2)本地平均产量μ是否比原产地的平均产量μ=800kg高.0=800kg低.(3)本地平均产量μ是否比原产地的平均产量μ0操作步骤:(1)先建一个如下图所示的工作表:(2)计算样本均值(平均产量),在单元格D5输入公式=AVERAGE(A3:E3);(3)在单元格D6输入样本数5;(4)在单元格D8输入U检验值计算公式=(D5-800)/(50/SQRT(D6);(5)在单元格D9输入U检验的临界值=NORMSINV(0.975);(6)根据算出的数值作出推论.本例中,U的检验值1.341641小于临界值1.959961,故接受原假设,即平均产量与原产地无显著差异.(7)注:在例1中,问题(2)要计算U检验的右侧临界值:在单元格D10输入U检验的上侧临界值=NORMSINV(0.95).问题(3)要计算U检验的下侧临界值,在单元格D11输入U检验下侧的临界值=NORMSINV(0.05).3.1.22未知时的t检验例2某一引擎制造商新生产某一种引擎,将生产的引擎装入汽车内进行速度测试,得到行驶速度如下:250 238 265 242 248 258 255 236 245 261254 256 246 242 247 256 258 259 262 263该引擎制造商宣称引擎的平均速度高于250 km/h,请问样本数据在显著性水平为0.025时,是否和他的声明抵触?操作步骤:(1)先建如图所示的工作表:(2)计算样本均值:在单元格D8输入公式=AVERAGE(A3:E6);(3)计算标准差:在单元格D9输入公式=STDEV(A3:E6);(4)在单元格D10输入样本数20.(5)在单元格D11输入t检验值计算公式=(D8-250)/(D9/(SQRT(D10)),得到结果1.06087;(6)在单元格D12输入t检验上侧临界值计算公式=TINV(0.05, D10-1).欲检验假设H0:μ=250;H:μ>250.1已知t统计量的自由度为(n-1)=20-1=19,拒绝域为t>t=2.093.由上面计算得025.0到t检验统计量的值1.06087落在接收域内,故接收原假设H0.3.2两个正态总体参数的假设检验3.2.1当12 =22 =2但未知时μ-μ的检验12在此情况下,采用t检验.例试验及观测数据同11.2中的练习题3,试判别磷肥对玉米产量有无显著影响?欲检验假设H0:μ1=μ2;H:μ1>μ2.1操作步骤:(1)建立如图所示工作表:(2)选取“工具”—“数据分析”;(3)选定“t-检验:双样本等方差假设”.(4)选择“确定”.显示一个“t-检验:双样本等方差假设”对话框;(5)在“变量1的区域”输入A2:A11.(6)在“变量2的区域”输入B2:B11.(7)在“输出区域”输入D1,表示输出结果放置于D1向右方的单元格中.(8)在显著水平“α”框,输入0.05.(9)在“假设平均差”窗口输入0.(10)选择“确定”,计算结果如D1:F14显示.得到t值为3.03,“t单尾临界”值为1.734063.由于3.03>1.73,所以拒绝原假设,接收备择假设,即认为使用磷肥对提高玉米产量有显著影响.3.2.2σ21与σ22已知时12μ-μ的U检验例3 某班20人进行了数学测验,第1组和第2组测验结果如下:第1组:91 88 76 98 94 92 90 87 100 69第2组:90 91 80 92 92 94 98 78 86 91已知两组的总体方差分别是57与53,取α =0.05,可否认为两组学生的成绩有差异?操作步骤:(1)建立如图所示工作表:(2)选取“工具”—“数据分析”;(3)选定“z-检验:双样本平均差检验”;(4)选择“确定”,显示一个“z-检验:双样本平均差检验”对话框;(5)在“变量1的区域”输入A2:A11;(6)在“变量2的区域”输入B2:B11;(7)在“输出区域”输入D1;(8)在显著水平“α”框,输入0.05;(9)在“假设平均差”窗口输入0;(10)在“变量1的方差”窗口输入57;(11)在“变量2的方差”窗口输入53;(12)选择“确定”,得到结果如图所示.计算结果得到z=-0.21106(即u统计量的值),其绝对值小于“z双尾临界”值1.959961,故接收原假设,表示无充分证据表明两组学生数学测验成绩有差异.3.2.3两个正态总体的方差齐性的F检验例5羊毛在处理前与后分别抽样分析其含脂率如下:处理前:0.19 0.18 0.21 0.30 0.41 0.12 0.27处理后:0.15 0.13 0.07 0.24 0.19 0.06 0.08 0.12问处理前后含脂率的标准差是否有显著差异?欲检验假设H0:σ21=σ22;H1:σ21≠σ22.操作步骤如下:(1)建立如图所示工作表:(2)选取“工具”—“数据分析”; (3)选定“F-检验 双样本方差”.(4)选择“确定”,显示一个“F-检验:双样本方差”对话框; (5)在“变量1的区域”输入A2:A8. (6)在“变量2的区域”输入B2:B9. (7)在显著水平“α”框,输入0.025. (8)在“输出区域”框输入D1. (9)选择“确定”,得到结果如图所示.计算出F 值2.35049小于“F 单尾临界”值5.118579,且P(F<=f)=0.144119>0.025,故接收原假设,表示无理由怀疑两总体方差相等.4 拟合优度检验拟合优度检验使用统计量221()ki i i i n np np χ=-=∑, (11.1) i i n np k 其中为实测频数,为理论频数,为分组数。
概率正态分布excel

概率正态分布excel
在 Excel 中,可以使用函数 RAND() 和 SEM() 来计算随机生成的正态分布。
RAND() 函数用于生成随机整数,而 SEM() 函数用于计算标准误差。
具体步骤如下:
1. 打开 Excel,选择“开始”选项卡上的“替换”按钮。
2. 在“查找内容”框中输入“=SEM(RAND())”,并将“替换为”框设置为空。
3. 点击“全部替换”按钮,将 RAND() 函数替换为 SEM() 函数。
4. 选择“开始”选项卡上的“编辑”按钮。
5. 在“插入函数”对话框中,选择“RAND()”函数。
6. 在“值”字段中输入期望随机数的范围,例如“=60:90”。
7. 点击“确定”按钮,Excel 将生成随机数并计算其正态分布。
例如,如果期望随机数的范围是 60 到 90 分,可以使用以下公式:
=RAND()*MAX(60,90)+60
该公式将生成 60 到 90 分之间的随机数,并将其乘以范围上限和下限的最大值,以确保其落在期望范围内。
另外,如果需要计算多个随机数的正态分布,可以使用数组公式。
例如,如果需要计算 10 个随机数的正态分布,可以使用以下公式: =RAND()*MAX(60,90)+60
该公式将生成 10 个随机数,并将其计算为正态分布。
数组公式
会自动填充,因此可以重复使用该公式来计算更多的随机数。
excel算条件概率

excel算条件概率
标题:使用Excel计算条件概率的方法
在日常生活中,我们经常需要计算一些事件发生的概率。
而条件概率则是指在已知某一事件发生的情况下,另一事件发生的概率。
使用Excel可以简化这种计算过程,让我们更加方便地得出结果。
我们需要创建一个Excel表格,用于记录事件的发生情况和计算条件概率。
我们可以将事件A和事件B的发生情况分别列在两列中。
在第三列中,我们可以使用IF函数来判断事件A和事件B是否同时发生,如果是,则为1,否则为0。
这样我们就可以得到一个包含了事件A和事件B同时发生情况的列。
接下来,我们需要计算事件A发生的概率。
我们可以使用COUNT函数来计算事件A发生的次数,并将结果除以总的实验次数,即可得到事件A发生的概率。
同样地,我们可以计算事件B发生的概率。
现在,我们可以计算条件概率了。
条件概率是指在已知事件A发生的情况下,事件B发生的概率。
我们可以使用AVERAGE函数来计算事件A和事件B同时发生的概率,并除以事件A发生的概率,即可得到条件概率。
除了使用函数来计算条件概率,我们还可以使用Excel中的筛选功能来实现。
我们可以使用筛选功能来筛选出事件A发生的情况,并统计其中同时发生事件B的次数。
然后,我们可以将这个次数除以
事件A发生的次数,即可得到条件概率。
总结一下,使用Excel计算条件概率的方法包括创建一个表格记录事件的发生情况,使用函数来计算概率,以及使用筛选功能来统计次数。
这种方法简单、方便,并且可以准确计算条件概率。
希望这个方法能够帮助大家更好地理解和应用条件概率的概念。
excel 对数分布 区间概率

excel 对数分布区间概率摘要:1.引言2.Excel对数分布概述3.计算对数分布的区间概率4.实例演示5.结论正文:【引言】在数据分析领域,Excel是一款强大的工具,可以帮助我们解决许多实际问题。
本文将介绍如何利用Excel计算对数分布的区间概率,为数据分析工作者提供实用的方法。
【Excel对数分布概述】对数分布是一种连续型概率分布,它的概率密度函数为:f(x) = (1/x) * exp(-ln(x)/λ),其中λ为正实数。
对数分布广泛应用于生物学、通信等领域。
在Excel中,我们可以利用内置的LN函数和对数函数来计算对数分布的相关参数和区间概率。
【计算对数分布的区间概率】假设我们已知对数分布的参数λ和对数函数的上下限(LN_lower,LN_upper),我们可以通过以下步骤计算区间概率:1.利用LN函数计算上限和下限对应的x值:x_upper =EXP(LN_upper),x_lower = EXP(LN_lower)。
2.计算区间长度:interval_length = x_upper - x_lower。
3.计算区间概率:probability_interval = (x_upper - x_lower) / (x_upper * x_lower)。
【实例演示】以下是一个实例,假设我们有一个对数分布的数据集,参数λ为2,数据范围为[1, 100]。
我们可以计算这个区间内的概率:1.打开Excel,创建一个新的工作表。
2.在A1单元格输入λ值,本例中为2:=2。
3.在B1单元格输入起始值,本例中为1:=1。
4.在C1单元格输入结束值,本例中为100:=100。
5.在D1单元格输入以下公式,计算对数分布的区间概率:=IF(B1>100, 0, (EXP(C1)-EXP(B1))/(EXP(C1)*EXP(B1)))。
6.按Enter键,得到区间概率。
【结论】通过以上步骤,我们可以利用Excel计算对数分布的区间概率。
excel正态分布随机概率

excel正态分布随机概率Excel是一款功能强大的电子表格软件,它不仅可以进行简单的数据输入和计算,还可以进行复杂的数据分析和统计。
其中,正态分布是Excel中非常重要和常用的概率分布之一。
正态分布(也称为高斯分布)是一种连续概率分布,其特点是对称、钟形曲线。
在Excel中,我们可以使用NORM.DIST函数来计算正态分布的概率。
该函数的语法如下所示:NORM.DIST(x, mean, standard_dev, cumulative)其中,x代表要计算概率的数值,mean代表正态分布的均值,standard_dev代表正态分布的标准差,cumulative代表累积还是非累积概率。
正态分布的随机概率在实际应用中非常广泛。
下面将从几个方面介绍正态分布随机概率在Excel中的应用。
一、随机概率的计算正态分布的随机概率可以用来计算某个数值落在某个范围内的概率。
比如,我们想要知道身高在160cm至170cm之间的人的比例,可以使用NORM.DIST函数来计算。
二、随机概率的图表展示正态分布的随机概率可以用来绘制概率密度图和累积概率图,以便更直观地了解分布情况。
在Excel中,我们可以使用数据分析工具包中的直方图和散点图来进行展示。
三、随机概率的模拟和预测正态分布的随机概率可以用来进行模拟和预测。
比如,我们可以模拟某个产品的销售量服从正态分布,然后通过随机概率来预测未来的销售情况。
四、随机概率的假设检验正态分布的随机概率可以用来进行假设检验。
比如,我们可以使用随机概率来检验某个样本的均值是否符合正态分布。
总结起来,Excel中的正态分布随机概率是一项非常重要的功能,可以用于数据分析、模拟和预测等多个领域。
通过合理地应用这一功能,我们可以更好地理解和分析数据,并做出更准确的决策。
关于正态分布随机概率的应用,上面只是简单介绍了几个方面,实际上还有很多其他的应用场景。
希望通过这篇文章的介绍,读者们能够更加全面地了解并灵活运用Excel中的正态分布随机概率功能,从而提高工作效率和数据分析能力。
常用概率函数在EXCEL中的实现

常用概率函数在EXCEL中的实现在Excel中,我们可以使用各种常见的概率函数来解决与概率相关的问题。
以下是一些常见的概率函数及其在Excel中的实现方法:1.累积分布函数(CDF):CDF函数用于计算随机变量小于或等于给定值的概率。
在Excel中,我们可以使用NORM.DIST函数来计算正态分布的累积分布函数。
该函数的语法如下:NORM.DIST(x, mean, standard_dev, cumulative)其中,x是随机变量的值,mean是正态分布的均值,standard_dev 是标准差,cumulative是一个布尔值,如果为TRUE,则计算累积分布函数;如果为FALSE,则计算概率密度函数。
2.概率密度函数(PDF):PDF函数用于计算给定随机变量取一些值的概率。
在Excel中,我们可以使用NORM.DIST函数来计算正态分布的概率密度函数。
该函数的语法与累积分布函数一样。
3.百分位数函数:百分位数函数用于计算给定分布中的一些数值的百分位数。
在Excel 中,我们可以使用PERCENTILE函数来计算一些数据集的一些百分位数。
该函数的语法如下:PERCENTILE(array, k)其中,array是数据集,k是一个介于0和1之间的小数,表示所需的百分位数。
4.期望值(均值):期望值是随机变量的平均值。
在Excel中,我们可以使用AVERAGE函数来计算一个数据集的期望值。
该函数的语法如下:AVERAGE(number1, number2, ...)其中,number1、number2等是数据集中的数值。
5.方差:方差是随机变量的离散程度的度量。
在Excel中,我们可以使用VAR函数来计算一个数据集的方差。
该函数的语法如下:VAR(number1, number2, ...)其中,number1、number2等是数据集中的数值。
6.标准差:标准差是方差的平方根,用于衡量随机变量的离散程度。
excel中的概率统计

数理统计实验1Excel基本操作1.1 单元格操作1.1.1单元格的选取Excel启动后首先将自动选取第A列第1行的单元格即A1(或a1)作为活动格,我们可以用键盘或鼠标来选取其它单元格.用鼠标选取时,只需将鼠标移至希望选取的单元格上并单击即可.被选取的单元格将以反色显示.1.1.2选取单元格范围(矩形区域)可以按如下两种方式选取单元格范围.(1) 先选取范围的起始点(左上角),即用鼠标单击所需位置使其反色显示.然后按住鼠标左键不放,拖动鼠标指针至终点(右下角)位置,然后放开鼠标即可.(2) 先选取范围的起始点(左上角),即用鼠标单击所需位置使其反色显示.然后将鼠标指针移到终点(右下角)位置,先按下Shift键不放,而后点击鼠标左键.1.1.3选取特殊单元格在实际中,有时要选取的单元格由若干不相连的单元格范围组成的.此类有两种情况.第一种情况就是间断的单元格选取.选取方法就是先选取第一个单元格,然后按住[Ctrl]键,再依次选取其它单元格即可.第二种情况就是间断的单元格范围选取.选取方法就是先选取第一个单元格范围,然后按住[Ctrl]键,用鼠标拖拉的方式选取第二个单元格范围即可.1.1.4公式中的数值计算要输入计算公式,可先单击待输入公式的单元格,而后键入=(等号),并接着键入公式,公式输入完毕后按Enter键即可确认.、如果单击了“编辑公式”按钮或“粘贴函数”按钮,Excel将自动插入一个等号.提示:(1) 通过先选定一个区域,再键入公式,然后按CTRL+ENTER 组合键,可以在区域内的所有单元格中输入同一公式.(2) 可以通过另一单元格复制公式,然后在目标区域内输入同一公式.公式就是在工作表中对数据进行分析的等式.它可以对工作表数值进行加法、减法与乘法等运算.公式可以引用同一工作表中的其它单元格、同一工作簿不同工作表中的单元格,或者其它工作簿的工作表中的单元格.下面的示例中将单元格B4 中的数值加上25,再除以单元格D5、E5 与F5 中数值的与.=(B4+25)/SUM(D5:F5)1.1.5公式中的语法公式语法也就就是公式中元素的结构或顺序.Excel 中的公式遵守一个特定的语法:最前面就是等号(=),后面就是参与计算的元素(运算数)与运算符.每个运算数可以就是不改变的数值(常量数值)、单元格或区域引用、标志、名称,或工作表函数.在默认状态下,Excel 从等号(=)开始,从左到右计算公式.可以通过修改公式语法来控制计算的顺序.例如,公式=5+2*3的结果为11,将 2 乘以3(结果就是6),然后再加上 5.因为Excel 先计算乘法再计算加法;可以使用圆括号来改变语法,圆括号内的内容将首先被计算.公式=(5+2)*3的结果为21,即先用5 加上2,再用其结果乘以 3.1.1.6单元格引用一个单元格中的数值或公式可以被另一个单元格引用.含有单元格引用公式的单元格称为从属单元格,它的值依赖于被引用单元格的值.只要被引用单元格做了修改,包含引用公式的单元格也就随之修改.例如,公式“=B15*5”将单元格B15 中的数值乘以 5.每当单元格B15 中的值修改时,公式都将重新计算.公式可以引用单元格组或单元格区域,还可以引用代表单元格或单元格区域的名称或标志.在默认状态下,Excel 使用A1 引用类型.这种类型用字母标志列(从A 到IV ,共256 列),用数字标志行(从 1 到65536).如果要引用单元格,请顺序输入列字母与行数字.例如,D50 引用了列 D 与行50 交叉处的单元格.如果要引用单元格区域,请输入区域左上角单元格的引用、冒号(:)与区域右下角单元格的引用.下面就是引用的示例.1.1.7工作表函数Excel 包含许多预定义的,或称内置的公式,它们被叫做函数.函数可以进行简单的或复杂的计算.工作表中常用的函数就是“SUM”函数,它被用来对单元格区域进行加法运算.虽然也可以通过创建公式来计算单元格中数值的总与,但就是“SUM”工作表函数还可以方便地计算多个单元格区域.函数的语法以函数名称开始,后面就是左圆括号、以逗号隔开的参数与右圆括号.如果函数以公式的形式出现,请在函数名称前面键入等号(=).当生成包含函数的公式时,公式选项板将会提供相关的帮助.使用公式的步骤:A、单击需要输入公式的单元格.B、如果公式以函数的形式出现,请在编辑栏中单击“编辑公式”按钮 .C 、 单击“函数”下拉列表框 右端的下拉箭头.D 、 单击选定需要添加到公式中的函数.如果函数没有出现在列表中,请单击“其它函数”查瞧其它函数列表.E 、 输入参数.F 、 完成输入公式后,请按 ENTER 键.1.2 几种常见的统计函数1.2.1均值 Excel 计算平均数使用A VERAGE 函数,其格式如下:A VERAGE(参数1,参数2,…,参数30)范例:A VERAGE(12、6,13、4,11、9,12、8,13、0)=12、74如果要计算单元格中A1到B20元素的平均数,可用 A VERAGE(A1:B20).1.2.2 标准差计算标准差可依据样本当作变量或总体当作变量来分别计算,根据样本计算的结果称作样本标准差,而依据总体计算的结果称作总体标准差.(1)样本标准差Excel 计算样本标准差采用无偏估计式,STDEV 函数格式如下:STDEV(参数1,参数2,…,参数30)范例:STDEV(3,5,6,4,6,7,5)=1、35如果要计算单元格中A1到B20元素的样本标准差,可用 STDEV(A1:B20).(2)总体标准差Excel 计算总体标准差采用有偏估计式STDEVP 函数,其格式如下:STDEVP(参数1,参数2,…,参数30)范例:STDEVP(3,5,6,4,6,7,5)=1、251.2.3 方差方差为标准差的平方,在统计上亦分样本方差与总体方差.(1)样本方差S 2=1)(2--∑n x x iExcel 计算样本方差使用V AR 函数,格式如下:V AR(参数1,参数2,…,参数30)如果要计算单元格中A1到B20元素的样本方差,可用 V AR(A1:B20).范例:V AR(3,5,6,4,6,7,5)=1、81(2)总体方差S 2=n x x i ∑-2)(Excel计算总体方差使用V ARP函数,格式如下:V ARP(参数1,参数2,…,参数30)范例:V AR(3,5,6,4,6,7,5)=1、551.2.4正态分布函数Excel计算正态分布时,使用NORMDIST函数,其格式如下:NORMDIST(变量,均值,标准差,累积)其中:变量(x):为分布要计算的x值;均值(μ):分布的均值;标准差(σ):分布的标准差;累积:若为TRUE,则为分布函数;若为FALSE,则为概率密度函数.范例:已知X服从正态分布,μ=600,σ=100,求P{X≤500}.输入公式=NORMDIST(500,600,100,TRUE)得到的结果为0、158655,即P{X≤500}=0、158655.1.2.5正态分布函数的反函数Excel计算正态分布函数的反函数使用NORMINV函数,格式如下:NORMINV(下侧概率,均值,标准差)范例:已知概率P=0、841345,均值μ=360,标准差σ=40,求NORMINV函数的值.输入公式=NORMINV(0、841345,360,40)得到结果为400,即P{X≤400}=0、841345.注意:(1) NORMDIST函数的反函数NORMINV用于分布函数,而非概率密度函数,请务必注意;(2) Excel 提供了计算标准正态分布函数NORMSDIST(x),及标准正态分布的反函数NORMSINV(概率).Φ=P{X<2}.输入公式范例:已知X~N(0,1), 计算(2)=NORMSDIST(2)Φ=0、97725.得到0、97725,即(2)范例:输入公式=NORMSINV(0、97725) ,得到数值2.若求临界值uα(n),则使用公式=NORMSINV(1-α).1.2.6t分布Excel计算t分布的值(查表值)采用TDIST函数,格式如下:TDIST(变量,自由度,侧数)其中:变量(t):为判断分布的数值;自由度(v ):以整数表明的自由度;侧数:指明分布为单侧或双侧:若为1,为单侧;若为2,为双侧.范例:设T 服从t (n-1)分布,样本数为25,求P (T >1、711).已知t =1、711,n =25,采用单侧,则T 分布的值:=TDIST(1、711,24,1)得到0、05,即P (T >1、711)=0、05.若采用双侧,则T 分布的值:=TDIST(1、711,24,2)得到0、1,即()1.7110.1P T >=. 1.2.7 t 分布的反函数Excel 使用TINV 函数得到t 分布的反函数,格式如下:TINV(双侧概率,自由度)范例:已知随机变量服从t (10)分布,置信度为0、05,求t 205.0(10).输入公式=TINV(0、05,10)得到2、2281,即()2.22810.05P T >=.若求临界值t α(n ),则使用公式=TINV(2*α, n ).范例:已知随机变量服从t (10)分布,置信度为0、05,求t 0、05 (10).输入公式=TINV(0、1,10)得到1、812462,即t 0、05 (10)= 1、812462. 1.2.8 F 分布Excel 采用FDIST 函数计算F 分布的上侧概率1()F x -,格式如下:FDIST(变量,自由度1,自由度2)其中:变量(x ):判断函数的变量值;自由度1(1n ):代表第1个样本的自由度;自由度2(2n ):代表第2个样本的自由度.范例:设X 服从自由度1n =5,2n =15的F 分布,求P (X >2、9)的值.输入公式=FDIST(2、9,5,15)得到值为0、05,相当于临界值α.1.2.9 F 分布的反函数Excel 使用FINV 函数得到F 分布的反函数,即临界值12(,)F n n α,格式为:FINV(上侧概率,自由度1,自由度2)范例:已知随机变量X 服从F (9,9)分布,临界值α=0、05,求其上侧0、05分位点F 0、05(9,9).输入公式=FINV(0、05,9,9)得到值为3、178897,即F 0、05(9,9)= 3、178897.若求单侧百分位点F 0、025(9,9),F 0、975(9,9).可使用公式=FINV(0、025,9,9)=FINV(0、975,9,9)得到两个临界值4、025992与0、248386.若求临界值F α(n 1,n 2),则使用公式=FINV(α, n 1,n 2).1.2.10 卡方分布Excel 使用CHIDIST 函数得到卡方分布的上侧概率1()F x -,其格式为:CHIDIST(数值,自由度)其中:数值(x ):要判断分布的数值;自由度(v ):指明自由度的数字.范例:若X 服从自由度v =12的卡方分布,求P (X >5、226)的值.输入公式=CHIDIST(5、226,12)得到0、95,即1(5.226)F -=0、95或(5.226)F =0、05.1.2.11 卡方分布的反函数Excel 使用CHIINV 函数得到卡方分布的反函数,即临界值2()n αχ.格式为:CHIINV(上侧概率值α,自由度n )范例:下面的公式计算卡方分布的反函数:=CHIINV(0、95,12)得到值为5、226,即20.95(12)χ=5、226.若求临界值2αχ(n),则使用公式=CHIINV(α, n). 1.2.12 泊松分布计算泊松分布使用POISSON 函数,格式如下:POISSON(变量,参数,累计)其中:变量:表示事件发生的次数;参数:泊松分布的参数值;累计:若TRUE,为泊松分布函数值;若FALSE,则为泊松分布概率分布值. 范例:设X服从参数为4的泊松分布,计算P {X =6}及P {X ≤6}.输入公式=POISSON(6,4,FALSE)=POISSON(6,4,TRUE)得到概率0、104196与0、889326.在下面的实验中,还将碰到一些其它函数,例如:计算样本容量的函数COUNT ,开平方函数SQRT,与函数SUM ,等等.关于这些函数的具体用法,可以查瞧Excel 的关于函数的说明,不再赘述.2 区间估计实验计算置信区间的本质就是输入两个公式,分别计算置信下限与置信上限.当熟悉了数据输入方法及常见统计函数后,变得十分简单.2.1 单个正态总体均值与方差的区间估计:2.1.1σ2已知时μ的置信区间 置信区间为22x u x u αα⎛⎫-+ ⎝. 例1 随机从一批苗木中抽取16株,测得其高度(单位:m)为:1、14 1、10 1、13 1、15 1、20 1、12 1、17 1、19 1、15 1、12 1、14 1、20 1、23 1、11 1、14 1、16.设苗高服从正态分布,求总体均值μ的0、95的置信区间.已知σ =0、01(米). 步骤:(1)在一个矩形区域内输入观测数据,例如在矩形区域B3:G5内输入样本数据.(2)计算置信下限与置信上限.可以在数据区域B3:G5以外的任意两个单元格内分别输入如下两个表达式:=average(b3:g5)-normsinv(1-0、5*α)*σ/sqrt(count(b3:g5))=average(b3:g5)+normsinv(1-0、5*α)*σ/sqrt(count(b3:g5))上述第一个表达式计算置信下限,第二个表达式计算置信上限.其中,显著性水平α与标准差σ就是具体的数值而不就是符号.本例中,α =0、05, 0.01σ=,上述两个公式应实际输入为=average(b3:g5)-normsinv(0、975)*0、01/sqrt(count(b3:g5))=average(b3:g5)+normsinv(0、975)*0、01/sqrt(count(b3:g5))计算结果为(1、148225, 1、158025).2.1.2 σ2未知时μ的置信区间置信区间为22((x t n x t n αα⎛⎫--+- ⎝.例2 同例1,但σ未知.输入公式为:=average(b3:g5)-tinv(0、05,count(b:3:g5)-1)*stdev(b3:g5)/sqrt(count(b3:g5)) =average(b3:g5)-tinv(0、05,count(b:3:g5)-1)*stdev(b3:g5)/sqrt(count(b3:g5)) 计算结果为(1、133695, 1、172555).2.1.3μ未知时σ2的置信区间:置信区间为22 22122(1)(1),(1)(1)n nn ns sααχχ-⎛⎫⎪--⎪--⎪⎝⎭.例3从一批火箭推力装置中随机抽取10个进行试验,它们的燃烧时间(单位:s)如下:50、7 54、9 54、3 44、8 42、2 69、8 53、4 66、1 48、1 34、5试求总体方差2σ的0、9的置信区间(设总体为正态).操作步骤:(1)在单元格B3:C7分别输入样本数据;(2)在单元格C9中输入样本数或输入公式=COUNT(B3:C7);(3)在单元格C10中输入置信水平0、1.(4)计算样本方差:在单元格C11中输入公式=V AR(B3:C7)(5)计算两个查表值:在单元格C12中输入公式=CHIINV(C10/2,C9-1),在单元格C13中输入公式=CHIINV(1-C10/2,C9-1)(6)计算置信区间下限:在单元格C14中输入公式=(C9-1)*C11/C12(7)计算置信区间上限:在单元格C15中输入公式=(C9-1)*C11/C13.当然,读者可以在输入数据后,直接输入如下两个表达式计算两个置信限:=(count(b3:c7)-1)*var(b3:c7)/chiinv(0、1/2, count(b3:c7)-1)=(count(b3:c7)-1)*var(b3:c7)/chiinv(1-0、1/2, count(b3:c7)-1)2.2 两正态总体均值差与方差比的区间估计2.2.1 当σ12 = σ22 = σ2但未知时μ1-μ2的置信区间置信区间为 ()1212211(2)w x y t n n S n n α⎛⎫-±+-+ ⎪ ⎪⎝⎭.例4 在甲,乙两地随机抽取同一品种小麦籽粒的样本,其容量分别为5与7,分析其蛋白质含量为甲:12、6 13、4 11、9 12、8 13、0乙:13、1 13、4 12、8 13、5 13、3 12、7 12、4蛋白质含量符合正态等方差条件,试估计甲,乙两地小麦蛋白质含量差μ1-μ2所在的范围.(取α=0、05)实验步骤:(1)在A2:A6输入甲组数据,在B2:B8输入乙组数据;(2)在单元格B11输入公式=A VERAGE(A2:A6),在单元格B12中输入公式=A VERAGE(B2:B8),分别计算出甲组与乙组样本均值.(3)分别在单元格C11与C12分别输入公式=V AR(A2:A6),=V AR(B2:B8),计算出两组样本的方差.(4)在单元格D11与D12分别输入公式=COUNT(A2:A6),=COUNT(B2:B8),计算各样本的容量大小.(5)将显著性水平0、05输入到单元格E11中.(6)分别在单元格B13与B14输入=B11-B12-TINV(0、025,10)*SQRT((4*C11+6*C12)/10)*SQRT(1/ 5+1/7)与=B11-B12+TINV(0、025,10)*SQRT((4*C11+6*C12)/10)*SQRT(1/ 5+1/7)计算出置信区间的下限与上限.2.2.2μ1与μ2未知时方差比σ21/σ22的置信区间置信区间为22 112221221212211,(1,1)(1,1)s ss F n n s F n nαα-⎛⎫⎪⎪----⎪⎝⎭.例5有两个化验员A、B,她们独立地对某种聚合物的含氯量用相同的方法各作了10次测定.其测定值的方差分别就是SA=0、5419,SB=0、6065.设σ2A与σ2B分别就是A、B所测量的数据总体(设为正态分布)的方差.求方差比σ2A/σ2B的0、95置信区间.操作步骤:(1)在单元格B2,B3输入样本数,C2,C3输入样本方差,D2输入置信度.(2)在B4与B5利用公式输入=C2/(C3*FINV(1-D2/2,B2-1,B3-1))与=C2/(C3*FINV(D2/2,B2-1,B3-1))计算出A组与B组的方差比的置信区间上限与下限.2.3 练习题1、已知某树种的树高服从正态分布,随机抽取了该树种的60株林木组成样本.样本中各林木的树高资料如下(单位:m)22、3, 21、2, 19、2, 16、6, 23、1, 23、9, 24、8, 26、4, 26、6, 24、8, 23、9, 23、2, 23、3, 21、4, 19、8, 18、3, 20、0, 21、5, 18、7, 22、4, 26、6, 23、9, 24、8, 18、8, 27、1,20、6, 25、0, 22、5, 23、5, 23、9, 25、3, 23、5, 22、6, 21、5, 20、6, 25、8, 24、0, 23、5, 22、6, 21、8, 20、8, 19、5, 20、9, 22、1, 22、7, 23、6, 24、5, 23、6, 21、0, 21、3,22、4,18、7, 21、3, 15、4, 22、9, 17、8, 21、7, 19、1, 20、3, 19、8试以0、95的可靠性,对于该林地上全部林木的平均高进行估计.2、从一批灯泡中随机抽取10个进行测试,测得它们的寿命(单位:100h)为:50、7,54、9,54、3,44、8,42、2,69、8,53、4,66、1,48、1,34、5.试求总体方差的0、9的置信区间(设总体为正态).3、已知某种玉米的产量服从正态分布,现有种植该玉米的两个实验区,各分为10个小区,各小区的面积相同,在这两个实验区中,除第一实验区施以磷肥外,其它条件相同,两实验区的玉米产量(kg)如下:第一实验区: 62 57 65 60 63 58 57 60 60 58第二实验区: 56 59 56 57 60 58 57 55 57 55试求出施以磷肥的玉米产量均值与未施以磷肥的玉米产量均值之差的范围(α=0、05) 3假设检验实验实验内容:单个总体均值的假设检验;两个总体均值差的假设检验;两个正态总体方差齐性的假设检验;拟合优度检验.实验目的与要求:(1)理解假设检验的统计思想,掌握假设检验的计算步骤;(2)掌握运用Excel进行假设检验的方法与操作步骤;(3)能够利用试验结果的信息,对所关心的事物作出合理的推断.3.1 单个正态总体均值μ的检验3.1.1 2已知时μ的U检验例1 外地一良种作物,其1000m2产量(单位:kg)服从N(800, 502),引入本地试种,收获时任取5块地,其1000m2产量分别就是800,850,780,900,820(kg),假定引种后1000m2产量X也服从正态分布,试问:=800kg 有无显著变化.(1)若方差未变,本地平均产量μ与原产地的平均产量μ0(2)本地平均产量μ就是否比原产地的平均产量μ=800kg高.0(3)本地平均产量μ就是否比原产地的平均产量μ=800kg低.0操作步骤:(1)先建一个如下图所示的工作表:(2)计算样本均值(平均产量),在单元格D5输入公式=A VERAGE(A3:E3);(3)在单元格D6输入样本数5;(4)在单元格D8输入U检验值计算公式=(D5-800)/(50/SQRT(D6);(5)在单元格D9输入U检验的临界值=NORMSINV(0、975);(6)根据算出的数值作出推论.本例中,U的检验值1、341641小于临界值1、959961,故接受原假设,即平均产量与原产地无显著差异.(7)注:在例1中,问题(2)要计算U检验的右侧临界值:在单元格D10输入U检验的上侧临界值=NORMSINV(0、95).问题(3)要计算U检验的下侧临界值,在单元格D11输入U检验下侧的临界值=NORMSINV(0、05).3.1.2σ2未知时的t检验例2某一引擎制造商新生产某一种引擎,将生产的引擎装入汽车内进行速度测试,得到行驶速度如下:250 238 265 242 248 258 255 236 245 261254 256 246 242 247 256 258 259 262 263该引擎制造商宣称引擎的平均速度高于250 km/h,请问样本数据在显著性水平为0、025时,就是否与她的声明抵触?操作步骤:(1)先建如图所示的工作表:(2)计算样本均值:在单元格D8输入公式=A VERAGE(A3:E6);(3)计算标准差:在单元格D9输入公式=STDEV(A3:E6);(4)在单元格D10输入样本数20.(5)在单元格D11输入t检验值计算公式=(D8-250)/(D9/(SQRT(D10)),得到结果1、06087;(6)在单元格D12输入t检验上侧临界值计算公式=TINV(0、05, D10-1)、欲检验假设H0:μ=250;H1:μ>250.=2、093.由上面计算得到t检已知t统计量的自由度为(n-1)=20-1=19,拒绝域为t>t.0025验统计量的值1、06087落在接收域内,故接收原假设H0.3.2 两个正态总体参数的假设检验μ-μ的检验3.2.1当σ12 = σ22 = σ2但未知时12在此情况下,采用t检验.例试验及观测数据同11、2中的练习题3,试判别磷肥对玉米产量有无显著影响?欲检验假设H0:μ1=μ2;H1:μ1>μ2.操作步骤:(1)(2)(3)选定“t-检验:双样本等方差假设”.(4)选择“确定”.显示一个“t-检验:双样本等方差假设”对话框;(5)在“变量1的区域”输入A2:A11.(6)在“变量2的区域”输入B2:B11.(7)在“输出区域”输入D1,表示输出结果放置于D1向右方的单元格中.(8)在显著水平“α”框,输入0、05.(9)在“假设平均差”窗口输入0.(10)选择“确定”,计算结果如D1:F14显示.得到t值为3、03,“t单尾临界”值为1、734063.由于3、03>1、73,所以拒绝原假设,接收备择假设,即认为使用磷肥对提高玉米产量有显著影响.3.2.2σ21与σ22已知时12μ-μ的U检验例3 某班20人进行了数学测验,第1组与第2组测验结果如下:第1组: 91 88 76 98 94 92 90 87 100 69第2组: 90 91 80 92 92 94 98 78 86 91已知两组的总体方差分别就是57与53,取α =0、05,可否认为两组学生的成绩有差异?操作步骤:(1)建立如图所示工作表:(2)选取“工具”—“数据分析”;(3)选定“z-检验:双样本平均差检验”;(4)选择“确定”,显示一个“z-检验:双样本平均差检验”对话框;(5)在“变量1的区域”输入A2:A11;(6)在“变量2的区域”输入B2:B11;(7)在“输出区域”输入D1;(8)在显著水平“α”框,输入0、05;(9)在“假设平均差”窗口输入0;(10)在“变量1的方差”窗口输入57;(11)在“变量2的方差”窗口输入53;(12)选择“确定”,得到结果如图所示.计算结果得到z=-0、21106(即u统计量的值),其绝对值小于“z双尾临界”值1、959961,故接收原假设,表示无充分证据表明两组学生数学测验成绩有差异.3.2.3两个正态总体的方差齐性的F检验例5羊毛在处理前与后分别抽样分析其含脂率如下:处理前:0、19 0、18 0、21 0、30 0、41 0、12 0、27处理后:0、15 0、13 0、07 0、24 0、19 0、06 0、08 0、12问处理前后含脂率的标准差就是否有显著差异?欲检验假设H0:σ21=σ22; H1:σ21≠σ22.操作步骤如下:(1)建立如图所示工作表:(2)选取“工具”—“数据分析”; (3)选定“F-检验 双样本方差”.(4)选择“确定”,显示一个“F-检验:双样本方差”对话框; (5)在“变量1的区域”输入A2:A8. (6)在“变量2的区域”输入B2:B9. (7)在显著水平“α”框,输入0、025. (8)在“输出区域”框输入D1.(9)选择“确定”,得到结果如图所示.计算出F 值2、35049小于“F 单尾临界”值5、118579,且P(F<=f)=0、144119>0、025,故接收原假设,表示无理由怀疑两总体方差相等.4 拟合优度检验拟合优度检验使用统计量221()ki i i in np np χ=-=∑, (11、1) i i n np k 其中为实测频数,为理论频数,为分组数。
excel均匀分布函数计算概率

一、概述Excel是一款功能强大的电子表格软件,广泛应用于数据分析、统计计算等领域。
在使用Excel进行数据分析时,经常需要计算概率分布,以便进行概率统计和决策分析。
Excel提供了多种函数来计算不同类型的概率分布,其中包括均匀分布函数。
本文将详细介绍如何使用Excel 的均匀分布函数来计算概率,帮助读者更好地掌握Excel在统计计算中的应用。
二、均匀分布概念及特点1. 均匀分布概念均匀分布是概率论中常见的一种连续概率分布,它的概率密度函数在一定区间内具有相同的取值,即概率密度函数呈现为水平的直线。
均匀分布的特点是在给定区间内各个取值的概率是相等的,因此也被称为等概率分布。
2. 均匀分布特点- 概率密度函数在一定区间内呈水平直线,各取值的概率相等;- 均匀分布的期望值等于区间的中点,方差等于区间长度的平方除以12。
三、Excel中均匀分布函数在Excel中,可以使用UNIFORM.DIST函数来计算均匀分布的概率。
UNIFORM.DIST函数的语法如下:UNIFORM.DIST(x, min, max, cumulative)- x:表示要计算概率的数值;- min:表示区间的下限;- max:表示区间的上限;- cumulative:表示是否计算累积概率,可以为TRUE或FALSE。
四、使用Excel计算均匀分布概率1. 计算概率密度要使用Excel计算均匀分布的概率密度,可以利用UNIFORM.DIST函数。
以下是一个示例:假设区间是[3, 7],要计算x=5的概率密度,可以使用以下公式: =UNIFORM.DIST(5, 3, 7, FALSE)函数的返回值为0.25,表示在区间[3, 7]中取值为5的概率密度为0.25。
2. 计算累积概率如果需要计算均匀分布的累积概率,可以将UNIFORM.DIST函数的cumulative参数设置为TRUE。
以下是一个示例:假设区间是[3, 7],要计算x小于等于6的累积概率,可以使用以下公式:=UNIFORM.DIST(6, 3, 7, TRUE)函数的返回值为0.75,表示在区间[3, 7]中取值小于等于6的累积概率为0.75。
用EXCEL计算二项分布概率值的操作步骤

⽤EXCEL计算⼆项分布概率值的操作步骤⽤Excel计算⼆项分布概率值的操作步骤1、进⼊Excel界⾯,单击某⼀单元格。
2、选择【插⼊】——【函数】选项从【选择类别】窗⼝中选择“统计”从【选择函数】窗⼝中选择“BINOMDIST”,单击【确定】3、当【BINOMDIST】对话框出现时:在【Number-s】中输⼊2(成功的次数X)在【trials】中输⼊3(实验的总次数n)在【Probability-s】中输⼊0.05(每次实验成功的概率p)在【Cumulative】中输⼊0(或False),表⽰计算成功次数恰好等于制定数值的概率(输⼊1或True表⽰计算成功次数⼩于或等于制定数值的累计概率值)。
选择【完成】即可得到结果。
计算超⼏何分布概率的步骤与上述过程类似,只不过在第2步【选择函数】窗⼝中选择“HYPGEOMDIST”函数,在第3步中输⼊相应的值即可。
如下在【sample-s】中输⼊成功的次数在【Number-sample】输⼊样本量在【population-s】中输⼊总体中成功的次数在【Number-pop】中输⼊总体中的个体总数单击【确定】即可。
⽤Excel计算泊松分布概率值的操作步骤1、进⼊Excel界⾯,单击某⼀单元格2、选择【插⼊】——【函数】选项从【选择类别】窗⼝中选择“统计”从【选择函数】窗⼝中选择“POISSON”,单击【确定】3、当【POISSON】对话框出现时在【x】中输⼊事件出现的次数在【Mean】中输⼊泊松分布的均值在【Cumulative】中输⼊0或(False),表⽰计算事件出现次数恰好等于指定数值的概率(输⼊1或True表⽰计算成功次数⼩于或等于制定数值的累计概率值)。
只需在【X】选项中,分别填⼊1,2,3即可计算出相应概率。
excel标准正态分布概率

excel标准正态分布概率Excel标准正态分布概率。
Excel是一款功能强大的电子表格软件,除了常见的数据处理和分析功能外,它还可以进行统计学计算,包括正态分布的计算。
正态分布是统计学中非常重要的一种分布,也称为高斯分布,它在自然界和社会现象中都有着广泛的应用。
在Excel中,我们可以利用一些内置的函数来计算标准正态分布的概率,本文将介绍如何在Excel中进行这一计算。
首先,我们需要了解一下标准正态分布。
标准正态分布是均值为0,标准差为1的正态分布,其概率密度函数可以用数学公式表示为:f(x) = (1/√(2π)) e^(-x^2/2)。
其中,x为随机变量的取值,e为自然对数的底,π为圆周率。
在Excel中,我们可以利用内置的函数NORM.DIST来计算标准正态分布的概率。
具体来说,NORM.DIST函数的语法为:NORM.DIST(x, mean, standard_dev, cumulative)。
其中,x为随机变量的取值,mean为分布的均值,standard_dev为分布的标准差,cumulative为一个逻辑值,用于指定计算累积分布函数还是概率密度函数。
如果cumulative为TRUE,则计算累积分布函数;如果cumulative为FALSE,则计算概率密度函数。
下面我们通过一个实例来演示如何在Excel中计算标准正态分布的概率。
假设我们要计算标准正态分布随机变量取值小于1的概率。
首先,在Excel的一个单元格中输入随机变量的取值1,比如A1单元格。
然后,在另一个单元格中输入NORM.DIST函数的公式:=NORM.DIST(A1, 0, 1, TRUE)。
按下回车键,即可得到随机变量取值小于1的概率。
除了NORM.DIST函数外,Excel还提供了NORM.S.DIST和NORM.INV函数,用于计算标准正态分布的累积分布函数和反函数。
NORM.S.DIST函数的语法与NORM.DIST函数类似,用于计算标准正态分布的累积分布函数;NORM.INV函数则用于计算标准正态分布的反函数,即给定概率值,求对应的随机变量取值。
常用概率函数在EXCEL中实现

常用概率函数在EXCEL中实现在Excel中实现常用概率函数非常简单,Excel提供了一系列内置的概率函数,可以帮助我们计算概率、分布函数以及反函数。
下面将介绍常用的概率函数和它们在Excel中的实现。
1.正态分布函数(NORM.DIST)正态分布函数用于计算给定均值和标准差的随机变量的概率。
可以使用Excel的NORM.DIST函数来计算正态分布。
语法:NORM.DIST(x,mean,standard_dev,cumulative)其中,x是要计算概率的随机变量的值,mean是均值,standard_dev 是标准差,cumulative是一个逻辑值,用于指定计算概率密度函数(FALSE) 还是累积分布函数 (TRUE)。
例子:假设一个随机变量的均值为5,标准差为2、我们想要计算随机变量取值为6的概率密度函数和累积分布函数。
使用Excel的NORM.DIST函数,可以在单元格中输入以下公式:```=NORM.DIST(6,5,2,FALSE)=NORM.DIST(6,5,2,TRUE)```第一个公式计算概率密度函数,第二个公式计算累积分布函数。
2.标准正态分布函数(NORM.S.DIST)标准正态分布函数是一种特殊的正态分布函数,其均值为0,标准差为1、在Excel中,可以使用NORM.S.DIST函数来计算标准正态分布。
语法:NORM.S.DIST(x,cumulative)其中,x是要计算概率的随机变量的值,cumulative是一个逻辑值,用于指定计算概率密度函数 (FALSE) 还是累积分布函数 (TRUE)。
例子:假设想要计算标准正态分布的概率密度函数和累积分布函数,可以在单元格中输入以下公式:```=NORM.S.DIST(1,FALSE)=NORM.S.DIST(1,TRUE)```第一个公式计算概率密度函数,第二个公式计算累积分布函数。
3.反正态分布函数(NORM.INV)反正态分布函数是正态分布函数的反函数。
excel中的概率统计(非常好的资料)

excel中的概率统计(⾮常好的资料)数理统计实验1 Excel 基本操作1.1 单元格操作1.1.1 单元格的选取Excel启动后⾸先将⾃动选取第A列第1⾏的单元格即A1(或a1)作为活动格,我们可以⽤键盘或⿏标来选取其它单元格.⽤⿏标选取时,只需将⿏标移⾄希望选取的单元格上并单击即可.被选取的单元格将以反⾊显⽰.1.1.2选取单元格范围(矩形区域)可以按如下两种⽅式选取单元格范围.(1)先选取范围的起始点(左上⾓),即⽤⿏标单击所需位置使其反⾊显⽰.然后按住⿏标左键不放,拖动⿏标指针⾄终点(右下⾓)位置,然后放开⿏标即可.(2)先选取范围的起始点(左上⾓),即⽤⿏标单击所需位置使其反⾊显⽰.然后将⿏标指针移到终点(右下⾓)位置,先按下Shift 键不放,⽽后点击⿏标左键.1.1.3选取特殊单元格在实际中,有时要选取的单元格由若⼲不相连的单元格范围组成的.此类有两种情况.第⼀种情况是间断的单元格选取.选取⽅法是先选取第⼀个单元格,然后按住[Ctrl] 键,再依次选取其它单元格即可.第⼆种情况是间断的单元格范围选取.选取⽅法是先选取第⼀个单元格范围,然后按住[Ctrl]键,⽤⿏标拖拉的⽅式选取第⼆个单元格范围即可.1.1.4公式中的数值计算要输⼊计算公式,可先单击待输⼊公式的单元格,⽽后键⼊=(等号),并接着键⼊公式,公式输⼊完毕后按Enter键即可确认..如果单击了“编辑公式”按钮或“粘贴函数”按钮,Excel 将⾃动插⼊⼀个等号.提⽰:(1)通过先选定⼀个区域,再键⼊公式,然后按CTRL+ENTER 组合键,可以在区域内的所有单元格中输⼊同⼀公式.(2)可以通过另⼀单元格复制公式,然后在⽬标区域内输⼊同⼀公式.公式是在⼯作表中对数据进⾏分析的等式.它可以对⼯作表数值进⾏加法、减法和乘法等运算.公式可以引⽤同⼀⼯作表中的其它单元格、同⼀⼯作簿不同⼯作表中的单元格,或者其它⼯作簿的⼯作表中的单元格.下⾯的⽰例中将单元格B4 中的数值加上25,再除以单元格D5、E5 和F5 中数值的和.=(B4+25)/SUM(D5:F5)1.1.5公式中的语法公式语法也就是公式中元素的结构或顺序.Excel 中的公式遵守⼀个特定的语法:最前⾯是等号(=),后⾯是参与计算的元素(运算数)和运算符?每个运算数可以是不改变的数值(常量数值)、单元格或区域引⽤、标志、名称,或⼯作表函数.在默认状态下,Excel从等号(=)开始,从左到右计算公式?可以通过修改公式语法来控制计算的顺序?例如,公式=5+2*3的结果为11,将2乘以3 (结果是6),然后再加上5 ?因为Excel先计算乘法再计算加法;可以使⽤圆括号来改变语法,圆括号内的内容将⾸先被计算?公式=(5+2)*3的结果为21,即先⽤5加上2,再⽤其结果乘以3.1.1.6 单元格引⽤⼀个单元格中的数值或公式可以被另⼀个单元格引⽤. 含有单元格引⽤公式的单元格称为从属单元格,它的值依赖于被引⽤单元格的值?只要被引⽤单元格做了修改,包含引⽤公式的单元格也就随之修改.例如,公式“=B15*5 ”将单元格B15中的数值乘以5 ?每当单元格B15中的值修改时,公式都将重新计算.公式可以引⽤单元格组或单元格区域,还可以引⽤代表单元格或单元格区域的名称或标志.在默认状态下,Excel使⽤A1引⽤类型?这种类型⽤字母标志列(从A到IV , 共256列),⽤数字标志⾏(从1到65536)?如果要引⽤单元格,请顺序输⼊列字母和⾏数字.例如,D50引⽤了列D和⾏50交叉处的单元格.如果要引⽤单元格区域,请输⼊区域左上⾓单元格的引⽤、冒号(:)和区域右下⾓单元格的引⽤?下⾯是引⽤的⽰例.1.1.7 ⼯作表函数Excel包含许多预定义的,或称内置的公式,它们被叫做函数?函数可以进⾏简单的或复杂的计算?⼯作表中常⽤的函数是“SUM”函数,它被⽤来对单元格区域进⾏加法运算?虽然也可以通过创建公式来计算单元格中数值的总和,但是“SUM ”⼯作表函数还可以⽅便地计算多个单元格区域.函数的语法以函数名称开始,后⾯是左圆括号、以逗号隔开的参数和右圆括号. 如果函数以公式的形式出现,请在函数名称前⾯键⼊等号(=)?当⽣成包含函数的公式时,公式选项板将会提供相关的帮助.使⽤公式的步骤:A.单击需要输⼊公式的单元格.B.如果公式以函数的形式出现,请在编辑栏中单击“编辑公式”按钮C.单击“函数”下拉列表框右端的下拉箭头.D.单击选定需要添加到公式中的函数. 如果函数没有出现在列表中,请单击“其它函数”查看其它函数列表.E.输⼊参数.F.完成输⼊公式后,请按ENTER键.1.2⼏种常见的统计函数1.2.1均值Excel计算平均数使⽤AVERAGE函数,其格式如下:AVERAGE (参数1,参数2,…,参数30)范例:AVERAGE (12.6,13.4,11.9,12.8,13.0) =12.74如果要计算单元格中A 1到B20元素的平均数,可⽤AVERAGE(A1:B20).1.2.2标准差计算标准差可依据样本当作变量或总体当作变量来分别计算,根据样本计算的结果称作样本标准差,⽽依据总体计算的结果称作总体标准差.(1)样本标准差Excel计算样本标准差采⽤⽆偏估计式,STDEV函数格式如下:STDEV (参数1,参数2,…,参数30)范例:STDEV (3, 5, 6, 4, 6, 7, 5)= 1.35如果要计算单元格中A 1到B20元素的样本标准差,可⽤STDEV(A1:B20).(2)总体标准差Excel计算总体标准差采⽤有偏估计式STDEVP函数,其格式如下:STDEVP (参数1,参数2,…,参数30)范例:STDEVP (3, 5, 6, 4, 6, 7, 5)= 1.251.2.3⽅差⽅差为标准差的平⽅,在统计上亦分样本⽅差与总体⽅差.(1)样本⽅差2以x)2&=—n 1Excel计算样本⽅差使⽤VAR函数,格式如下:VAR (参数1,参数2,…,参数30)如果要计算单元格中A 1到B20元素的样本⽅差,可⽤VAR(A1:B20). 范例:VAR (3, 5, 6, 4, 6, 7, 5)= 1.81(2)总体⽅差Excel 计算总体⽅差使⽤ VARP 函数,格式如下:VARP (参数1,参数2,…,参数 30)范例:VAR (3, 5, 6, 4, 6, 7, 5)= 1.55 1.2.4正态分布函数Excel 计算正态分布时,使⽤NORMDIST 函数,其格式如下:NORMDIST (变量,均值,标准差,累积)其中:变量(x ):为分布要计算的x 值;均值(分布的均值;标准差(0):分布的标准差;累积:若为TRUE ,则为分布函数;若为 FALSE ,则为概率密度函数.范例:已知X 服从正态分布,⼫600,⼫100,求P{X W 500}.输⼊公式=NORMDIST ( 500, 600, 100, TRUE ) 得到的结果为 0.158655,即 P{X <500}=0.158655 .1.2.5正态分布函数的反函数Excel 计算正态分布函数的反函数使⽤NORMINV 函数,格式如下:NORMINV (下侧概率,均值,标准差)范例:已知概率 P = 0.841345,均值⼫360,标准差⼫40,求NORMINV 函数的值.输⼊公式=NORMINV ( 0.841345 , 360, 40) 得到结果为 400,即⼙ P{X W400}=0.841345 .注意:(1) NORMDIST 函数的反函数 NORMINV ⽤于分布函数,⽽⾮概率密度函数,请务必注意;(2) Excel 提供了计算标准正态分布函数NORMSDIST(x),及标准正态分布的反函数 NORMSINV(概率).范例:已知X ?N (0,1),计算 (2) =P{X<2}.输⼊公式=NORMSDIST(2)得到 0.97725,即 (2)=0.97725 .范例:输⼊公式=NORMSINV(0.97725),得到数值2. 若求临界值 u ?(n),则使⽤公式 =NORMSINV(1- a). 1.2.6 t 分布Excel 计算t 分布的值(查表值)采⽤ TDIST 函数,格式如下: TDIST (变量,⾃由度,侧数)其中:变量(t ):为判断分布的数值;⾃由度(v ):以整数表明的⾃由度;S=(X i x)2n侧数:指明分布为单侧或双侧:若为1,为单侧;若为2,为双侧.范例:设T服从t(n-1)分布,样本数为25,求P (T>1.711).已知t= 1.711, n=25,采⽤单侧,贝U T分布的值:=TDIST(1.711,24,1)得到0.05,即P (T>1.711) =0.05 .若采⽤双侧,则T分布的值:=TDIST(1.711,24,2)得到0.1,即⼙ P T 1.711 0.1.1.2.7t分布的反函数Excel使⽤TINV函数得到t分布的反函数,格式如下:TINV (双侧概率,⾃由度)范例:已知随机变量服从t(10)分布,置信度为0.05,求t 0.05 (10).输⼊公式""2"=TINV(0.05,10)得到 2.2281,即 P T 2.2281 0.05 .若求临界值t?(n),则使⽤公式 =TINV(2* a n).范例:已知随机变量服从t(10)分布,置信度为0.05,求t0.05 (10).输⼊公式=TINV(0.1,10)得到 1.812462,即t0.05 (10)= 1.812462 .1.2.8F分布Excel采⽤FDIST函数计算F分布的上侧概率1 F(x),格式如下:FDIST(变量,⾃由度1,⾃由度2)其中:变量(x):判断函数的变量值;⾃由度1( nJ:代表第1个样本的⾃由度;⾃由度2 (门2):代表第2个样本的⾃由度.范例:设X服从⾃由度n 1=5, n2=15的F分布,求P(X>2.9)的值.输⼊公式=FDIST(2.9,5,15)得到值为0.05,相当于临界值 a.1.2.9 F 分布的反函数Excel 使⽤FINV 函数得到 F 分布的反函数,即临界值F (n1,n2) ,格式为:。
excel 2019 t分布 概率 和 分位数

Excel 2019 中的 t 分布概率和分位数一、t 分布的概念和特点1.1 t 分布的概念t 分布是由英国统计学家威廉·塞利德出版的“学生”(Student)的笔名所命名,是统计学中常用的一种概率分布。
它是正态分布的一种推广,常用于对小样本数据进行参数估计和假设检验。
1.2 t 分布的特点t 分布的形状和自由度相关,自由度越大,t 分布趋近于正态分布。
在实际应用中,t 分布常用于估计总体均值、总体均值之差以及总体标准差等参数。
二、Excel 2019 中 t 分布的概率计算2.1 使用 T.DIST 函数计算 t 分布的概率在 Excel 2019 中,可以使用 T.DIST 函数来计算 t 分布的概率。
T.DIST 函数的语法为:T.DIST(x, degrees_freedom, cumulative)。
其中,x 为 t 值,degrees_freedom 为自由度,cumulative 为累积分布函数的标志。
若要求 t 分布在 t 值为1时的概率,自由度为10,则可以使用以下公式:=T.DIST(1, 10, TRUE)2.2 使用 T.DIST.RT 函数计算 t 分布的右尾概率在 Excel 2019 中,还可以使用 T.DIST.RT 函数来计算 t 分布的右尾概率。
T.DIST.RT 函数的语法为:T.DIST.RT(x, degrees_freedom)。
其中,x 为 t 值,degrees_freedom 为自由度。
若要求 t 分布在 t 值为1时的右尾概率,自由度为10,则可以使用以下公式:=T.DIST.RT(1, 10)2.3 t 分布的概率计算实例假设某研究人员对一批产品的尺寸进行抽样检验,假设总体均值为100,样本容量为15,样本平均值为98,样本标准差为5。
现需计算样本均值的 t 值,并确定在自由度为14的情况下,t 分布在该 t 值时的概率及右尾概率。
常用概率函数在EXCEL中的实现

常用概率函数在EXCEL中的实现在Excel中,有多种常用的概率函数可以进行实现。
这些函数可以帮助我们计算和分析随机事件的概率。
下面是一些常用的概率函数及其在Excel中的实现方式:1.NORM.DIST函数-正态分布函数NORM.DIST函数可用于计算给定值的正态分布的概率密度函数值。
该函数有四个参数:x(要计算其概率密度函数值的值)、mean(正态分布的平均值)、standard_dev(正态分布的标准差)和cumulative(一个逻辑值,表示是否计算累积分布函数)。
以下是一个示例:=NORM.DIST(A2,B2,C2,TRUE)其中,A2为要计算概率密度函数值的数值,B2为正态分布的平均值,C2为正态分布的标准差,TRUE表示计算累积分布函数值。
2.BINOM.DIST函数-二项分布函数BINOM.DIST函数可用于计算二项分布的概率密度函数值。
该函数有四个参数:x(要计算其概率密度函数值的值)、n(试验的次数)、p(每次试验成功的概率)和cumulative(一个逻辑值,表示是否计算累积分布函数)。
以下是一个示例:=BINOM.DIST(A2,B2,C2,TRUE)其中,A2为要计算概率密度函数值的数值,B2为试验的次数,C2为每次试验成功的概率,TRUE表示计算累积分布函数值。
3.POISSON.DIST函数-泊松分布函数POISSON.DIST函数可用于计算泊松分布的概率密度函数值。
该函数有三个参数:x(要计算其概率密度函数值的值)、mean(平均发生率)和cumulative(一个逻辑值,表示是否计算累积分布函数)。
以下是一个示例:=POISSON.DIST(A2,B2,TRUE)其中,A2为要计算概率密度函数值的数值,B2为平均发生率,TRUE 表示计算累积分布函数值。
4.GEOMEAN函数-几何平均数GEOMEAN函数可用于计算一组数的几何平均数。
以下是一个示例:=GEOMEAN(A2:A5)其中,A2:A5为要计算几何平均数的数据范围。
excel 累积概率曲线

在Excel中制作累积概率曲线,可以按照以下步骤进行:
1.建立数据表格:在Excel中创建一个新的工作表,并输入需要的数据。
假设数据在A列,从A1
单元格开始输入数据。
2.添加辅助列:在B列添加辅助列,用于计算累积概率。
在B1单元格中输入“累积概率”,然后在
B2单元格中输入公式“=SUM(A$1:A2)”。
3.复制公式:将B2单元格中的公式复制到B列的其他单元格中,以计算每个数据的累积概率。
4.添加图表:选择A列和B列的数据,然后选择“插入”菜单中的“图表”选项。
在图表类型中选择“线
图”,然后选择“累积概率曲线”。
5.调整图表格式:可以根据需要调整图表的格式,例如更改图表标题、坐标轴标签等。
完成以上步骤后,就可以在Excel中制作出累积概率曲线了。
常用分布概率计算的Excel应用

上机实习常用分布概率计算的Excel 应用利用Excel 中的统计函数工具,中的统计函数工具,可以计算二项分布、可以计算二项分布、可以计算二项分布、泊松分布、泊松分布、正态分布等常用概率分布的概率值、累积(分布)布的概率值、累积(分布)概率等。
这里我们主要介绍如何用概率等。
这里我们主要介绍如何用Excel 来计算二项分布的概率值与累积概率,其他常用分布的概率计算等处理与此类似。
§3.1 二项分布的概率计算一、二项分布的(累积)概率值计算用Excel 来计算二项分布的概率值P n (k)、累积概率F n (k),需要用BINOMDIST 函数,其格式为:BINOMDIST (number_s ,trials, probability_s, cumulative) 其中其中 number_s number_s number_s::试验成功的次数k ;trials trials::独立试验的总次数n ;probability_s probability_s::一次试验中成功的概率p ;cumulative cumulative::为一逻辑值,若取0或FALSE 时,计算概率值P n (k);若取1或TRUE 时,则计算累积概率F n (k),。
即对二项分布B(n,p)的概率值P n (k)和累积概率F n (k),有P n (k)=BINOMDIST(k,n,p,0)BINOMDIST(k,n,p,0);;F n (k)= BINOMDIST(k,n,p,1)现结合下列机床维修问题的概率计算来稀疏现象(小概率事件)发生次数说明计算二项分布概率的具体步骤。
例3.1某车间有各自独立运行的机床若干台,设每台机床发生故障的概率为0.010.01,,每台机床的故障需要一名维修工来排除,试求在下列两种情形下机床发生故障而得不到及时维修的概率:(1)一人负责15台机床的维修;(2)3人共同负责80台机床的维修。
如何在Excel中使用EXPONDIST函数计算指数分布的概率密度

如何在Excel中使用EXPONDIST函数计算指数分布的概率密度在Excel中使用EXPONDIST函数计算指数分布的概率密度Excel是一款强大的电子表格软件,广泛应用于各个领域的数据分析和计算中。
其中,EXPONDIST函数是用来计算指数分布的概率密度的重要函数之一。
本文将介绍如何在Excel中使用EXPONDIST函数来计算指数分布的概率密度。
一、指数分布概述指数分布是一种常见的概率分布,常用于描述连续事件之间的时间间隔。
它的概率密度函数为:f(x) = λ * exp(-λ * x)其中,x为随机变量的取值,λ为指数分布的均值参数。
二、Excel中的EXPONDIST函数EXPONDIST函数是Excel中用来计算指数分布概率密度的函数,其语法如下:EXPONDIST(x,λ,cumulative)其中,x为要计算概率密度的随机变量的值,λ为指数分布的均值参数,cumulative为一个逻辑值,表示是否计算累积概率密度。
当cumulative为FALSE时,EXPONDIST函数计算的是概率密度函数;当cumulative为TRUE时,EXPONDIST函数计算的是累积概率密度函数。
三、使用EXPONDIST函数计算指数分布的概率密度在Excel中,使用EXPONDIST函数计算指数分布的概率密度非常简单。
首先,在一个单元格中输入EXPONDIST函数的公式,例如=EXPONDIST(A2, 1, FALSE),其中A2表示要计算概率密度的随机变量的值,1表示指数分布的均值参数(可以根据实际情况调整),FALSE表示计算概率密度函数。
然后,将需要计算概率密度的随机变量的值填入相应单元格,即可得到指数分布的概率密度。
可以通过拖动单元格的填充手柄来一次性计算多个随机变量的概率密度。
四、使用EXPONDIST函数计算指数分布的累积概率密度除了计算概率密度函数,EXPONDIST函数还可以用来计算累积概率密度函数。
Excel中怎样计算概率
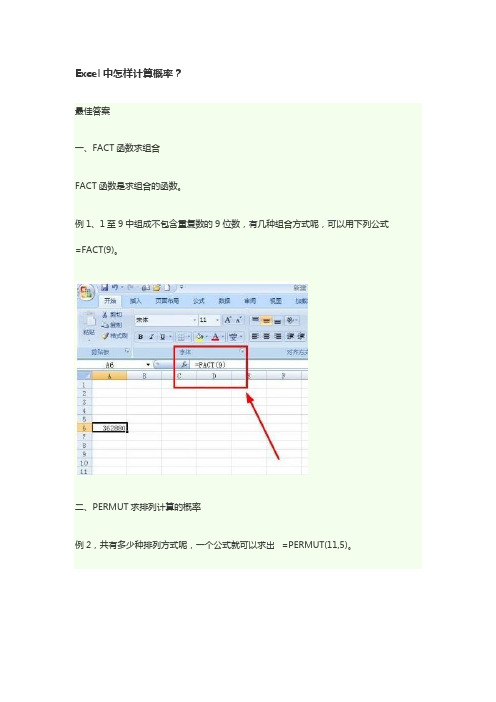
Excel中怎样计算概率?
最佳答案
一、FACT函数求组合
FACT函数是求组合的函数。
例1、1至9中组成不包含重复数的9位数,有几种组合方式呢,可以用下列公式=FACT(9)。
二、PERMUT求排列计算的概率
例2,共有多少种排列方式呢,一个公式就可以求出=PERMUT(11,5)。
也可以用FACT函数求得这个结果,公式为=FACT(11)/FACT(11-5)。
三、计算中头奖概率
当中有33个红球,16个蓝球,要在红球中选择6个,蓝球中选择1个,因此中头奖的概率用公式表示就是=1/COMBIN(33,6)/COMBIN(16,1)。
要在单元格中设置一下小数点的显示数。
四、结果就出来了。
五、那么要中头奖要花多少钱呢,用公式表示就是=COMBIN(33,6)*COMBIN(16,
1)*2,结果需要花费35442176 元才能中头奖。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
excel表格计算概率的教程
excel表格计算概率的教程:
计算概率步骤1:FACT函数求组合
FACT函数是求组合的函数。
例1、1至9中组成不包含重复数的9位数,有几种组合方式呢,可以用下列公式=FACT(9)。
计算概率步骤2:PERMUT求排列计算11选5的概率
例2,11选5共有多少种排列方式呢,一个公式就可以求出
=PERMUT(11,5)。
计算概率步骤3:也可以用FACT函数求得这个结果,公式为
=FACT(11)/FACT(11-5)。
三、COMBIN函数计算福彩双色球中头奖概率
计算概率步骤4:福彩双色球当中有33个红球,16个蓝球,要
在红球中选择6个,蓝球中选择1个,因此中头奖的概率用公式表
示就是=1/COMBIN(33,6)/COMBIN(16,1)。
要在单元格中设置一下小数点的显示数。
计算概率步骤5:结果就出来了。
计算概率步骤6:那么要中头奖要花多少钱呢,用公式表示就是
=COMBIN(33,6)*COMBIN(16,1)*2,结果需要花费35442176元才能
中头奖。