python爬虫抓去google图片搜索结果的图片
python爬虫之requests爬取页面图片的url,并将图片下载到本地

python爬⾍之requests爬取页⾯图⽚的url,并将图⽚下载到本地⼤家好我叫hardy需求:爬取某个页⾯,并把该页⾯的图⽚下载到本地思考: img标签⼀个有多少种类型的src值?四种:1、以http开头的⽹络链接。
2、以“//”开头⽹络地址。
3、以“/”开头绝对路径。
4、以“./”开头相对路径。
当然还有其他类型,不过这个不做考虑,能⼒有限呀。
使⽤什么⼯具?我⽤requests、xpth 都有那些步骤:1、爬取⽹页 2、分析html并获取img中的src的值 3、获取图⽚ 4、保存具体实现import requestsfrom lxml import etreeimport timeimport osimport rerequests = requests.session()website_url = ''website_name = '''''爬取的页⾯'''def html_url(url):try:head = set_headers()text = requests.get(url,headers=head)# print(text)html = etree.HTML(text.text)img = html.xpath('//img/@src')# 保存图⽚for src in img:src = auto_completion(src)file_path = save_image(src)if file_path == False:print('请求的图⽚路径出错,url地址为:%s'%src)else :print('保存图⽚的地址为:%s'%file_path)except requests.exceptions.ConnectionError as e:print('⽹络地址⽆法访问,请检查')print(e)except requests.exceptions.RequestException as e:print('访问异常:')print(e)'''保存图⽚'''def save_image(image_url):if not image_url:return Falsesize = 0number = 0while size == 0:try:img_file = requests.get(image_url)except requests.exceptions.RequestException as e:raise e# 不是图⽚跳过if check_image(img_file.headers['Content-Type']):return Falsefile_path = image_path(img_file.headers)# 保存with open(file_path, 'wb') as f:f.write(img_file.content)# 判断是否正确保存图⽚size = os.path.getsize(file_path)if size == 0:os.remove(file_path)# 如果该图⽚获取超过⼗次则跳过number += 1if number >= 10:breakreturn (file_path if (size > 0) else False)'''⾃动完成url的补充'''def auto_completion(url):global website_name,website_url#如果是http://或者https://开头直接返回if re.match('http://|https://',url):return urlelif re.match('//',url):if'https://'in website_name:return'https:'+urlelif 'http://'in website_name:return'http:' + urlelif re.match('/',url):return website_name+urlelif re.match('./',url):return website_url+url[1::]'''图⽚保存的路径'''def image_path(header):# ⽂件夹file_dir = './save_image/'if not os.path.exists(file_dir):os.makedirs(file_dir)# ⽂件名file_name = str(time.time())# ⽂件后缀suffix = img_type(header)return file_dir + file_name + suffix'''获取图⽚后缀名'''def img_type(header):# 获取⽂件属性image_attr = header['Content-Type']pattern = 'image/([a-zA-Z]+)'suffix = re.findall(pattern,image_attr,re.IGNORECASE)if not suffix:suffix = 'png'else :suffix = suffix[0]# 获取后缀if re.search('jpeg',suffix,re.IGNORECASE):suffix = 'jpg'return'.' + suffix# 检查是否为图⽚类型def check_image(content_type):if'image'in content_type:return Falseelse:return True#设置头部def set_headers():global website_name, website_urlhead = {'Host':website_name.split('//')[1],'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',}return headif __name__ == '__main__':#当前的url,不包含⽂件名的⽐如index.html,⽤来下载当前页的页⾯图⽚(./) website_url = 'https:///kindroid/article/details'#域名,⽤来下载"/"开头的图⽚地址#感兴趣的朋友请帮我完善⼀下这个⾃动完成图⽚url的补充website_name = 'https://'url = 'https:///kindroid/article/details/52095833'html_url(url)。
Python图片检索之以图搜图

Python图⽚检索之以图搜图⽬录⼀、待搜索图⼆、测试集三、new_similarity_compare.py四、image_similarity_function.py五、结果⼀、待搜索图⼆、测试集三、new_similarity_compare.py# -*- encoding=utf-8 -*-from image_similarity_function import *import osimport shutil# 融合相似度阈值threshold1 = 0.70# 最终相似度较⾼判断阈值threshold2 = 0.95# 融合函数计算图⽚相似度def calc_image_similarity(img1_path, img2_path):""":param img1_path: filepath+filename:param img2_path: filepath+filename:return: 图⽚最终相似度"""similary_ORB = float(ORB_img_similarity(img1_path, img2_path))similary_phash = float(phash_img_similarity(img1_path, img2_path))similary_hist = float(calc_similar_by_path(img1_path, img2_path))# 如果三种算法的相似度最⼤的那个⼤于0.7,则相似度取最⼤,否则,取最⼩。
max_three_similarity = max(similary_ORB, similary_phash, similary_hist)min_three_similarity = min(similary_ORB, similary_phash, similary_hist)if max_three_similarity > threshold1:result = max_three_similarityelse:result = min_three_similarityreturn round(result, 3)if __name__ == '__main__':# 搜索⽂件夹filepath = r'D:\Dataset\cityscapes\leftImg8bit\val\frankfurt'#待查找⽂件夹searchpath = r'C:\Users\Administrator\Desktop\cityscapes_paper'# 相似图⽚存放路径newfilepath = r'C:\Users\Administrator\Desktop\result'for parent, dirnames, filenames in os.walk(searchpath):for srcfilename in filenames:img1_path = searchpath +"\\"+ srcfilenamefor parent, dirnames, filenames in os.walk(filepath):for i, filename in enumerate(filenames):print("{}/{}: {} , {} ".format(i+1, len(filenames), srcfilename,filename))img2_path = filepath + "\\" + filename# ⽐较kk = calc_image_similarity(img1_path, img2_path)try:if kk >= threshold2:# 将两张照⽚同时拷贝到指定⽬录shutil.copy(img2_path, os.path.join(newfilepath, srcfilename[:-4] + "_" + filename)) except Exception as e:# print(e)pass四、image_similarity_function.py# -*- encoding=utf-8 -*-# 导⼊包import cv2from functools import reducefrom PIL import Image# 计算两个图⽚相似度函数ORB算法def ORB_img_similarity(img1_path, img2_path):""":param img1_path: 图⽚1路径:param img2_path: 图⽚2路径:return: 图⽚相似度"""try:# 读取图⽚img1 = cv2.imread(img1_path, cv2.IMREAD_GRAYSCALE)img2 = cv2.imread(img2_path, cv2.IMREAD_GRAYSCALE)# 初始化ORB检测器orb = cv2.ORB_create()kp1, des1 = orb.detectAndCompute(img1, None)kp2, des2 = orb.detectAndCompute(img2, None)# 提取并计算特征点bf = cv2.BFMatcher(cv2.NORM_HAMMING)# knn筛选结果matches = bf.knnMatch(des1, trainDescriptors=des2, k=2)# 查看最⼤匹配点数⽬good = [m for (m, n) in matches if m.distance < 0.75 * n.distance]similary = len(good) / len(matches)return similaryexcept:return '0'# 计算图⽚的局部哈希值--pHashdef phash(img):""":param img: 图⽚:return: 返回图⽚的局部hash值"""img = img.resize((8, 8), Image.ANTIALIAS).convert('L')avg = reduce(lambda x, y: x + y, img.getdata()) / 64.hash_value = reduce(lambda x, y: x | (y[1] << y[0]), enumerate(map(lambda i: 0 if i < avg else 1, img.getdata())), 0)return hash_value# 计算两个图⽚相似度函数局部敏感哈希算法def phash_img_similarity(img1_path, img2_path):""":param img1_path: 图⽚1路径:param img2_path: 图⽚2路径:return: 图⽚相似度"""# 读取图⽚img1 = Image.open(img1_path)img2 = Image.open(img2_path)# 计算汉明距离distance = bin(phash(img1) ^ phash(img2)).count('1')similary = 1 - distance / max(len(bin(phash(img1))), len(bin(phash(img1))))return similary# 直⽅图计算图⽚相似度算法def make_regalur_image(img, size=(256, 256)):"""我们有必要把所有的图⽚都统⼀到特别的规格,在这⾥我选择是的256x256的分辨率。
Python如何利用正则表达式爬取网页信息及图片

Python如何利⽤正则表达式爬取⽹页信息及图⽚⼀、正则表达式是什么?概念:正则表达式是对字符串操作的⼀种逻辑公式,就是⽤事先定义好的⼀些特定字符、及这些特定字符的组合,组成⼀个“规则字符串”,这个“规则字符串”⽤来表达对字符串的⼀种过滤逻辑。
正则表达式是⼀个特殊的字符序列,它能帮助你⽅便的检查⼀个字符串是否与某种模式匹配。
个⼈理解:简单来说就是使⽤正则表达式来写⼀个过滤器来过滤了掉杂乱的⽆⽤的信息(eg:⽹页源代码…)从中来获取⾃⼰想要的内容⼆、实战项⽬1.爬取内容获取上海所有三甲医院的名称并保存到.txt⽂件中2.访问链接3.正则表达式书写的灵感进⼊⽹站查看本页⾯的源代码发现:医院的名称都是放在⼀个<div class="province-box"> ...... </div>盒⼦⾥我们只需要直接把这个盒⼦⾥⾯的数据过滤⼀下就⾏正则表达式:法⼀:1.⼀级过滤 :<div class="province-box">(.*)<div class="wrap-right">开头是:<div class="province-box"> (.*) 结尾是:<div class="wrap-right">2.⼆级过滤:title="(.*[院⼼部])*)" 获取title=" " ⾥⾯的信息法⼆:优化后⼀次性过滤:<li><a href="/[^/].*/" rel="external nofollow" rel="external nofollow" target="_blank" title="(.*)">贴图⽚开头是:结尾是:4.项⽬源代码import requestsimport reurl = "https:///sanjia/shanghai/"# 模拟浏览器的访问headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:87.0) ''Gecko/20100101 Firefox/87.0'}res = requests.get(url,headers=headers)if res.status_code == 200:#1.获取⽹页源代码raw_text = res.text#2.正则表达式书写:#2.2注意:正则表达式默认匹配的是⼀⾏我们的源代码是多⾏匹配的要加另⼀个参数 re.DOTALL#2.3正则法⼀:#re.findall() 返回的是lsit集合⼀次过滤re_res = re.findall(r'<div class="province-box">(.*)<div class="wrap-right">', raw_text,re.DOTALL)#re_res[0] 获取下标是的数据⼆次过滤res=re.findall(r'title="(.*[院⼼部])*)"',re_res[0])#检查打印获取到的信息print(res)#2.4正则法⼆:#(优化)不⽤⼆次过滤⼀次过滤就解决了# re_list = re.findall(r'<li><a href="/[^/].*/" rel="external nofollow" rel="external nofollow" target="_blank" title="(.*)">', res.text)#print(re_list)# 写⼊⽂件中read = open("上海医院名单", "w", encoding='utf-8')for i in res:read.write(i)read.write("\n")read.close()else:print("error")项⽬⽬录:部分结果:python 正则表达式-提取图⽚地址import os,sys,time,json,timeimport socket,random,hashlibimport requests,configparserimport json,refrom datetime import datetimefrom multiprocessing.dummy import Pool as ThreadPooldef getpicurl(url):url = "/zipai/comment-page-352"html = requests.get(url).textpic_url = re.findall('img src="(.*?)"',html,re.S)for key in pic_url:print(key + "\r\n")#print(pic_url)getpicurl("/zipai/comment-pag.e-352")输出结果:总结到此这篇关于Python如何利⽤正则表达式爬取⽹页信息及图⽚的⽂章就介绍到这了,更多相关Python正则表达式爬取内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
Python爬虫之网页图片抓取的方法

Python爬⾍之⽹页图⽚抓取的⽅法⼀、引⼊这段时间⼀直在学习Python的东西,以前就听说Python爬⾍多厉害,正好现在学到这⾥,跟着⼩甲鱼的Python视频写了⼀个爬⾍程序,能实现简单的⽹页图⽚下载。
⼆、代码__author__ = "JentZhang"import urllib.requestimport osimport randomimport redef url_open(url):'''打开⽹页:param url::return:'''req = urllib.request.Request(url)req.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.75 Safari/537.36')# 应⽤代理'''proxyies = ["111.155.116.237:8123","101.236.23.202:8866","122.114.31.177:808"]proxy = random.choice(proxyies)proxy_support = urllib.request.ProxyHandler({"http": proxy})opener = urllib.request.build_opener(proxy_support)urllib.request.install_opener(opener)'''response = urllib.request.urlopen(url)html = response.read()return htmldef save_img(folder, img_addrs):'''保存图⽚:param folder: 要保存的⽂件夹:param img_addrs: 图⽚地址(列表):return:'''# 创建⽂件夹⽤来存放图⽚if not os.path.exists(folder):os.mkdir(folder)os.chdir(folder)for each in img_addrs:filename = each.split('/')[-1]try:with open(filename, 'wb') as f:img = url_open("http:" + each)f.write(img)except urllib.error.HTTPError as e:# print(e.reason)passprint('完毕!')def find_imgs(url):'''获取全部的图⽚链接:param url: 连接地址:return: 图⽚地址的列表'''html = url_open(url).decode("utf-8")img_addrs = re.findall(r'src="(.+?\.gif)', html)return img_addrsdef get_page(url):'''获取当前⼀共有多少页的图⽚:param url: ⽹页地址:return:'''html = url_open(url).decode('utf-8')a = html.find("current-comment-page") + 23b = html.find("]</span>", a)return html[a:b]def download_mm(url="/ooxx/", folder="OOXX", pages=1):'''主程序(下载图⽚):param folder:默认存放的⽂件夹:param pages: 下载的页数:return:'''page_num = int(get_page(url))for i in range(pages):page_num -= ipage_url = url + "page-" + str(page_num) + "#comments"img_addrs = find_imgs(page_url)save_img(folder, img_addrs)if __name__ == "__main__":download_mm()三、总结由于代码中访问的⽹址已经运⽤了反爬⾍的算法。
python爬虫爬取图片的简单代码

python爬⾍爬取图⽚的简单代码Python是很好的爬⾍⼯具不⽤再说了,它可以满⾜我们爬取⽹络内容的需求,那最简单的爬取⽹络上的图⽚,可以通过很简单的⽅法实现。
只需导⼊正则表达式模块,并利⽤spider原理通过使⽤定义函数的⽅法可以轻松的实现爬取图⽚的需求。
1、spider原理spider就是定义爬取的动作及分析⽹站的地⽅。
以初始的URL**初始化Request**,并设置回调函数。
当该request**下载完毕并返回时,将⽣成**response ,并作为参数传给该回调函数。
2、实现python爬⾍爬取图⽚第⼀步:导⼊正则表达式模块import re # 导⼊正则表达式模块import requests # python HTTP客户端编写爬⾍和测试服务器经常⽤到的模块import random # 随机⽣成⼀个数,范围[0,1]第⼆步:使⽤定义函数的⽅法爬取图⽚def spiderPic(html, keyword):print('正在查找 ' + keyword + ' 对应的图⽚,下载中,请稍后......')for addr in re.findall('"objURL":"(.*?)"', html, re.S): # 查找URLprint('正在爬取URL地址:' + str(addr)[0:30] + '...')# 爬取的地址长度超过30时,⽤'...'代替后⾯的内容try:pics = requests.get(addr, timeout=100) # 请求URL时间(最⼤10秒)except requests.exceptions.ConnectionError:print('您当前请求的URL地址出现错误')continuefq = open('H:\\img\\' + (keyword + '_' + str(random.randrange(0, 1000, 4)) + '.jpg'), 'wb')# 下载图⽚,并保存和命名fq.write(pics.content)fq.close()到此这篇关于python爬⾍爬取图⽚的简单代码的⽂章就介绍到这了,更多相关python爬⾍怎么爬取图⽚内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
Python爬虫学习总结-爬取某素材网图片
Python爬⾍学习总结-爬取某素材⽹图⽚ Python爬⾍学习总结-爬取某素材⽹图⽚最近在学习python爬⾍,完成了⼀个简单的爬取某素材⽹站的功能,记录操作实现的过程,增加对爬⾍的使⽤和了解。
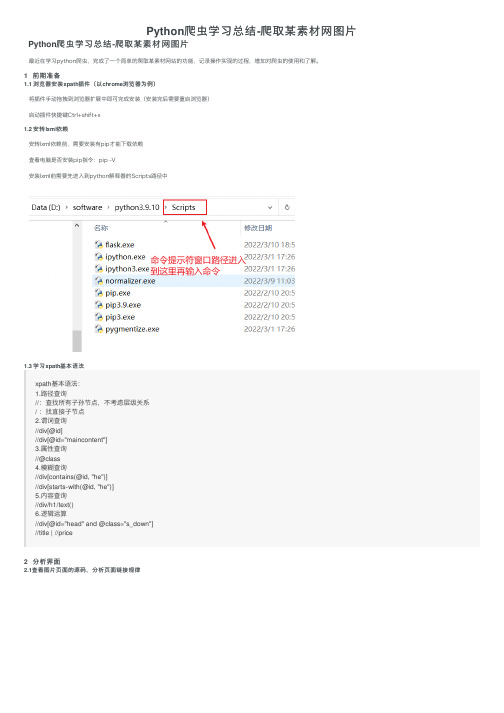
1 前期准备1.1 浏览器安装xpath插件(以chrome浏览器为例)将插件⼿动拖拽到浏览器扩展中即可完成安装(安装完后需要重启浏览器)启动插件快捷键Ctrl+shift+x1.2 安转lxml依赖安转lxml依赖前,需要安装有pip才能下载依赖查看电脑是否安装pip指令:pip -V安装lxml前需要先进⼊到python解释器的Scripts路径中1.3 学习xpath基本语法xpath基本语法:1.路径查询//:查找所有⼦孙节点,不考虑层级关系/ :找直接⼦节点2.谓词查询//div[@id]//div[@id="maincontent"]3.属性查询//@class4.模糊查询//div[contains(@id, "he")]//div[starts‐with(@id, "he")]5.内容查询//div/h1/text()6.逻辑运算//div[@id="head" and @class="s_down"]//title | //price2 分析界⾯2.1查看图⽚页⾯的源码,分析页⾯链接规律打开有侧边栏的风景图⽚(以风景图⽚为例,分析⽹页源码)通过分析⽹址可以得到每页⽹址的规律,接下来分析图⽚地址如何获取到2.2 分析如何获取图⽚下载地址⾸先在第⼀页通过F12打开开发者⼯具,找到图⽚在源代码中位置: 通过分析源码可以看到图⽚的下载地址和图⽚的名字,接下来通过xpath解析,获取到图⽚名字和图⽚地址2.3 xpath解析获取图⽚地址和名字调⽤xpath插件得到图⽚名字://div[@id="container"]//img/@alt图⽚下载地址://div[@id="container"]//img/@src2注意:由于该界⾯图⽚的加载⽅式是懒加载,⼀开始获取到的图⽚下载地址才是真正的下载地址也就是src2标签前⾯的⼯作准备好了,接下来就是书写代码3 代码实现3.1 导⼊对应库import urllib.requestfrom lxml import etree3.2 函数书写请求对象的定制def create_request(page,url):# 对不同页⾯采⽤不同策略if (page==1):url_end = urlelse:#切割字符串url_temp = url[:-5]url_end = url_temp+'_'+str(page)+'.html'# 如果没有输⼊url就使⽤默认的urlif(url==''):url_end = 'https:///tupian/fengjingtupian.html'# 请求伪装headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39' }# 请求对象的定制request = urllib.request.Request(url = url_end,headers=headers)# 返回伪装后的请求头return request获取⽹页源码def get_content(request):# 发送请求获取响应数据response = urllib.request.urlopen(request)# 将响应数据保存到contentcontent = response.read().decode('utf8')# 返回响应数据return content下载图⽚到本地def down_load(content):# 下载图⽚#urllib.request.urlretrieve('图⽚名称','⽂件名字')# 解析⽹页tree = etree.HTML(content)# 获取图⽚姓名返回的是列表img_name = tree.xpath('//div[@id="container"]//a/img/@alt')img_add = tree.xpath('//div[@id="container"]//a/img/@src2')# 循环下载图⽚for i in range(len(img_name)):# 挨个获取下载的图⽚名字和地址name = img_name[i]add = img_add[i]# 对图⽚下载地址进⾏定制url = 'https:'+add# 下载到本地下载图⽚到当前代码同⼀⽂件夹的imgs⽂件夹中需要先在该代码⽂件夹下创建imgs⽂件夹urllib.request.urlretrieve(url=url,filename='./imgs/'+name+'.jpg')主函数if __name__ == '__main__':print('该程序为采集站长素材图⽚')url = input("请输⼊站长素材图⽚第⼀页的地址(内置默认为风景图⽚)")start_page = int(input('请输⼊起始页码'))end_page = int(input('请输⼊结束页码'))for page in range(start_page,end_page+1):#请求对象的定制request = create_request(page,url)# 获取⽹页的源码content = get_content(request)# 下载down_load(content)完整代码# 1.请求对象的定制# 2.获取⽹页源码# 3.下载# 需求:下载前⼗页的图⽚# 第⼀页:https:///tupian/touxiangtupian.html# 第⼆页:https:///tupian/touxiangtupian_2.html# 第三页:https:///tupian/touxiangtupian_3.html# 第n页:https:///tupian/touxiangtupian_page.htmlimport urllib.requestfrom lxml import etree# 站长素材图⽚爬取下载器def create_request(page,url):# 对不同页⾯采⽤不同策略if (page==1):url_end = urlelse:#切割字符串url_temp = url[:-5]url_end = url_temp+'_'+str(page)+'.html'# 如果没有输⼊url就使⽤默认的urlif(url==''):url_end = 'https:///tupian/fengjingtupian.html'headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36 Edg/99.0.1150.39' }request = urllib.request.Request(url = url_end,headers=headers)return requestdef get_content(request):response = urllib.request.urlopen(request)content = response.read().decode('utf8')return contentdef down_load(content):# 下载图⽚#urllib.request.urlretrieve('图⽚名称','⽂件名字')tree = etree.HTML(content)# 获取图⽚姓名返回的是列表img_name = tree.xpath('//div[@id="container"]//a/img/@alt')img_add = tree.xpath('//div[@id="container"]//a/img/@src2')for i in range(len(img_name)):name = img_name[i]add = img_add[i]# 对图⽚下载地址进⾏定制url = 'https:'+add# 下载到本地urllib.request.urlretrieve(url=url,filename='./imgs/'+name+'.jpg')if __name__ == '__main__':print('该程序为采集站长素材图⽚')url = input("请输⼊站长素材图⽚第⼀页的地址(内置默认为风景图⽚)")start_page = int(input('请输⼊起始页码'))end_page = int(input('请输⼊结束页码'))for page in range(start_page,end_page+1):#请求对象的定制request = create_request(page,url)# 获取⽹页的源码content = get_content(request)# 下载down_load(content)4 运⾏结果总结此次案例是基于尚硅⾕的python视频学习后的总结,感兴趣的可以去看全套视频,⼈们总说兴趣是最好的⽼师,⾃从接触爬⾍后我觉得python⼗分有趣,这也是我学习的动⼒,通过对⼀次案例的简单总结,回顾已经学习的知识,并不断学习新知识,是记录也是分享。
Python3直接爬取图片URL并保存示例

Python3直接爬取图⽚URL并保存⽰例有时候我们会需要从⽹络上爬取⼀些图⽚,来满⾜我们形形⾊⾊直⾄不可描述的需求。
⼀个典型的简单爬⾍项⽬步骤包括两步:获取⽹页地址和提取保存数据。
这⾥是⼀个简单的从图⽚url收集图⽚的例⼦,可以成为⼀个⼩⼩的开始。
获取地址这些图⽚的URL可能是连续变化的,如从001递增到099,这种情况可以在程序中将共同的前⾯部分截取,再在最后递增并字符串化后循环即可。
抑或是它们的URL都保存在某个⽂件中,这时可以读取到列表中:def getUrls(path):urls = []with open(path,'r') as f:for line in f:urls.append(line.strip('\n'))return(urls)保存图⽚在python3中,urllib提供了⼀系列⽤于操作URL的功能,其中的request模块可以⾮常⽅便地抓取URL内容,也就是发送⼀个GET请求到指定的页⾯,然后返回HTTP的响应。
具体细节请看注释:def requestImg(url, name, num_retries=3):img_src = url# print(img_src)header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) \AppleWebKit/537.36 (KHTML, like Gecko) \Chrome/35.0.1916.114 Safari/537.36','Cookie': 'AspxAutoDetectCookieSupport=1'}# Request类可以使⽤给定的header访问URLreq = urllib.request.Request(url=img_src, headers=header)try:response = urllib.request.urlopen(req) # 得到访问的⽹址filename = name + '.jpg'with open(filename, "wb") as f:content = response.read() # 获得图⽚f.write(content) # 保存图⽚response.close()except HTTPError as e: # HTTP响应异常处理print(e.reason)except URLError as e: # ⼀定要放到HTTPError之后,因为它包含了前者print(e.reason)except IncompleteRead or RemoteDisconnected as e:if num_retries == 0: # 重连机制returnelse:requestImg(url, name, num_retries-1)其他捕获异常以下是批量爬取⽹页时可能需要捕获的异常,同时可以看出,urllib2库对应urllib库,⽽httplib库对应http.client:Python2Pyhton3urllib2.HTTPError urllib.error.HTTPErrorurllib2.URLError urllib.error.URLError (HTTPError被包含其中)httplib.IncompleteRead http.client.IncompleteRead httplib.RemoteDisconnected http.client.RemoteDisconnected重连机制在函数参数中设置⼀个参数num_retries并对其进⾏初始化,即默认参数。
用python爬取图片

⽤python爬取图⽚声明:全过程没有任何违法操作背景这周闲的⽆聊,到某个不⽤FQ就能上P站的⽹站上欣赏图⽚,但是光欣赏也不够,我得下载下来慢慢欣赏,于是便写了个爬⾍(批量)下载图⽚(因为在这个⽹站上下载需要⼀张⼀张下载,⿇烦)。
分析下载单张图⽚⾸先打开,然后F12寻找我需要的⽬标⽂件,然后再爬⾍上运⾏⼀下看看状态是什么import requestsurl = 'https://pixiv-image.pwp.link/img-original/img/2018/12/08/03/57/33/72014282_p0.jpg'headers = {'Origin': 'https://pixiviz.pwp.app','Referer': 'https://pixiviz.pwp.app/pic/72014282','Sec-Fetch-Dest': 'empty','User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Mobile Safari/537.36' }response = requests.get(url, headers=headers)print(response)结果显⽰是200,说明可以下载下载可以使⽤如下代码filename = str('图⽚')+".png"with open(filename,"wb") as code:code.write(response.content)print('⽂件下载成功!')如图,图⽚下载成功注意:这个下载的⽂件的请求头必须写完整,否则图⽚是⽆法爬取到的批量下载其实批量下载有多种⽅法,我只讲⼀种,还有⼀种我会在最后说思路在我们所要爬取的⽹页中的作品集⼀共有15张图⽚,于是我们可以尝试吧url中的"p0"中的数字进⾏修改然后再看看效果图⽚会更改,于是我们可以设计⼀个循环来实现图⽚批量爬取,设计如下import requestsimport timei = 0while i < 15:url = 'https://pixiv-image.pwp.link/img-original/img/2018/12/08/03/57/33/72014282_p{}.jpg'.format(i)headers = {'Origin': 'https://pixiviz.pwp.app','Referer': 'https://pixiviz.pwp.app/pic/72014282','Sec-Fetch-Dest': 'empty','User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Mobile Safari/537.36' }response = requests.get(url, headers=headers)filename = str('图⽚{}'.format(i))+".png"with open(filename,"wb") as code:code.write(response.content)print('图⽚{}下载成功!'.format(i))i += 1time.sleep(0.5)这⾥的time.sleep是⽤来减慢爬取速度,防⽌⽹站识别爬⾍⽽禁ip访问上图是第15张图⽚这是我们爬到的第15张图⽚于是这样我们就实现了图⽚的批量爬取批量下载的另种设计思路在这个⽹站(⽹站url我不会给出)上可以进⼊画师主页,然后F12可以寻找到对应的作品集⽂件,然后发送请求返回⽂件中的数据(json⽂件),最后利⽤循环就能设计出批量爬取图⽚的程序了,下⾯我就放⼀张⾃⼰设计的程序运⾏图⽚⾄于本⼈欣赏什么类型的图⽚,⼤伙⼉就不⽤知道了。
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码

Python使⽤Scrapy爬⾍框架全站爬取图⽚并保存本地的实现代码⼤家可以在Github上clone全部源码。
基本上按照⽂档的流程⾛⼀遍就基本会⽤了。
Step1:在开始爬取之前,必须创建⼀个新的Scrapy项⽬。
进⼊打算存储代码的⽬录中,运⾏下列命令:scrapy startproject CrawlMeiziTu该命令将会创建包含下列内容的 tutorial ⽬录:CrawlMeiziTu/scrapy.cfgCrawlMeiziTu/__init__.pyitems.pypipelines.pysettings.py middlewares.pyspiders/__init__.py...cd CrawlMeiziTuscrapy genspider Meizitu /a/list_1_1.html该命令将会创建包含下列内容的 tutorial ⽬录:CrawlMeiziTu/scrapy.cfgCrawlMeiziTu/ __init__.pyitems.pypipelines.pysettings.py middlewares.pyspiders/ Meizitu.py__init__.py...我们主要编辑的就如下图箭头所⽰:main.py是后来加上的,加了两条命令,from scrapy import cmdlinecmdline.execute("scrapy crawl Meizitu".split())主要为了⽅便运⾏。
Step2:编辑Settings,如下图所⽰BOT_NAME = 'CrawlMeiziTu'SPIDER_MODULES = ['CrawlMeiziTu.spiders']NEWSPIDER_MODULE = 'CrawlMeiziTu.spiders'ITEM_PIPELINES = {'CrawlMeiziTu.pipelines.CrawlmeizituPipeline': 300,}IMAGES_STORE = 'D://pic2'DOWNLOAD_DELAY = 0.3USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'ROBOTSTXT_OBEY = True主要设置USER_AGENT,下载路径,下载延迟时间Step3:编辑Items.Items主要⽤来存取通过Spider程序抓取的信息。
python爬虫10例经典例子

python爬虫10例经典例子当谈到Python爬虫,经典的例子可能包括以下几种:1. 爬取静态网页数据,使用库如requests或urllib来获取网页内容,然后使用正则表达式或者BeautifulSoup来解析页面,提取所需数据。
2. 爬取动态网页数据,使用Selenium或者PhantomJS等工具模拟浏览器行为,获取JavaScript渲染的页面内容。
3. 爬取图片,通过爬虫下载图片,可以使用requests库发送HTTP请求,获取图片的URL,然后使用openCV或者PIL库来处理图片。
4. 爬取视频,类似图片爬取,但需要考虑视频文件的大小和格式,可能需要使用FFmpeg等工具进行处理。
5. 爬取特定网站,例如爬取新闻网站的新闻内容,或者爬取电商网站的商品信息,需要根据网站的结构和特点编写相应的爬虫程序。
6. 爬取社交媒体数据,可以通过API或者模拟登录的方式爬取Twitter、Facebook等社交媒体平台的数据。
7. 数据存储,将爬取的数据存储到数据库中,可以使用MySQL、MongoDB等数据库,也可以将数据保存为CSV、JSON等格式。
8. 数据清洗和分析,对爬取的数据进行清洗和分析,去除重复数据、处理缺失值,进行数据可视化等操作。
9. 自动化爬虫,编写定时任务或者事件触发的爬虫程序,实现自动化的数据采集和更新。
10. 反爬虫策略,了解和应对网站的反爬虫机制,如设置请求头、使用代理IP、限制访问频率等,以确保爬虫程序的稳定运行。
以上是一些Python爬虫的经典例子,涵盖了静态网页、动态网页、多媒体文件、特定网站、社交媒体等不同类型的数据爬取和处理方法。
希望这些例子能够帮助你更好地理解Python爬虫的应用和实现。
python爬取图集谷妹子图片,按自己喜好抓取一页图片,有兴趣二次开发抓全站

python爬取图集⾕妹⼦图⽚,按⾃⼰喜好抓取⼀页图⽚,有兴趣⼆次开发抓全站# -*- coding: utf-8 -*-import requests, time, osfrom lxml import etreefrom urllib import requestname_url = {} # 创建⼀个字典def sort():req = requests.get('https:///') # ⾸页req.encoding = 'utf-8'# 中⽂出现乱码,调整编码req_xp = etree.HTML(req.text) # 装换为xp,text是为了变成字符串形式,不然会报错text_list = req_xp.xpath('//*[@class="menu"]/li/a/text()|//*[@id="tag_ul"]/li/a/text()') # 读取分类名href_list = req_xp.xpath('//*[@class="menu"]/li/a/@href|//*[@id="tag_ul"]/li/a/@href') # 获取⽹址for href, text in zip(href_list, text_list):name_url[text] = href # 已分类名做为key,⽹址作为值return text_list # 返回分类名列表,好为后⾯打印分类名def dow(url, name):if not os.path.exists("图集⾕"): # 检查并创建⽂件夹,强迫症~~~os.mkdir('图集⾕')if not os.path.exists("图集⾕/{}".format(name)): # 同上,创建分类os.mkdir('图集⾕/{}'.format(name))atlas = requests.get(url) # get你选择的⽹址atlas.encoding = 'utf-8'# 同上,乱码问题atlas_xp = etree.HTML(atlas.text)text_list = atlas_xp.xpath('//*[@class="biaoti"]/a/text()') # 获取图集名href_list = atlas_xp.xpath('//*[@class="biaoti"]/a/@href')for text, href in zip(text_list, href_list):req = requests.get(href)req.encoding = 'utf-8'req_xp1 = etree.HTML(req.text)src_list = req_xp1.xpath('//*[@class="content"]/img/@src')num = 1 # 创建图⽚名,美观# 下⾯是为了删除⼀些图集中包含了⽂件夹不能创建的符号text = text.replace('\n', '').replace('/', '').replace('\\', '').replace(':', '').replace('*', '').replace('"','').replace('<', '').replace('>', '').replace('|', '').replace('?', '')if not os.path.exists("图集⾕/{}/{}".format(name, text)): # 检测此图集是否下载过os.mkdir("图集⾕/{}/{}".format(name, text))for src in src_list:request.urlretrieve(src, "图集⾕/{}/{}/{}.jpg".format(name, text, num)) # 保存图⽚num += 1print('{}-------------成功下载'.format(text))else:print('{}--------------内容已下载'.format(text))def get():while 1:text_list = sort() # 从⾸页获取分类信息和urli = 1 # 序号for text in text_list[2:-1]: # 从2到-1是为了去除没⽤的分类print('%02d.{}'.format(text) % i) # 打印分类信息i += 1opt = input('输⼊您要爬取的内容(⾸页为默认)>>>>> ')if not opt.isdigit(): # 判断输⼊内容print('傻X输⼊中⽂懂么')time.sleep(3)continueopt = int(opt)if not 0 < opt < len(text_list) - 3: # 判断输⼊内容print('输⼊范围错误')time.sleep(3)continueopt += 1 # 以为删除了⾸页,所以+1才能正确选择分类url = name_url[text_list[opt]] # 获取你选择的地址name = text_list[opt] # 分类的名字,好创建⼀个⽂件夹放⼊print('{}====开始爬取'.format(name))dow(url, name) # 开始运⾏下载程序input('爬取完成,按下回车重新开始')if__name__ == '__main__':get() # 开始运⾏主程序安装好库,选择⾃⼰喜好,就可以了。
python爬虫抓取图片

python爬⾍抓取图⽚⼀、什么是爬⾍ 什么是爬⾍?爬⾍是蜘蛛么?是⼋⽖鱼么?nonono。
爬⾍是指请求⽹站并获取数据的⾃动化程序,⼜称⽹页蜘蛛或⽹络机器,最常⽤领域是搜索引擎,最常⽤的⼯具是⼋⽖鱼。
它的基本流程分为以下五部分,依次是: 明确需求——发送请求——获取数据——解析数据——存储数据。
爬⾍的三⼤特点:⽹页都有唯⼀的URL(统⼀资源定位符,也就是⽹址)进⾏定位⽹页都使⽤HTML(定位超⽂本标记语⾔)来描述页⾯信息⽹页都使⽤HTTP/HTTPS(超⽂本传输协议)协议来传输HTML数据 爬⾍可以由什么编写呢: 编写爬⾍的语⾔有很多,但⽤的最多最⼴的还应该是Python,并且也诞⽣了很多优秀的库和框架,如scrapy、BeautifulSoup 、pyquery、Mechanize等。
但是⼀般来说,搜索引擎的爬⾍对爬⾍的效率要求更⾼,会选⽤c++、java、go(适合⾼并发)。
⼆、爬⾍前期准备⼯作1、准备⼀台性能良好的电脑 电脑要求:windows7以上,内存四核8G以上2、安装python环境 python官⽹下载地址: https:///downloads/release/python-395/ 安装流程: 请⾃⾏百度。
3、安装所需要的扩展 咱们主要使⽤以下四个扩展:import os # python⾃带扩展不需要安装import requests # pip install requestsfrom urllib import request # python⾃带扩展不需要安装from bs4 import BeautifulSoup # 安装命令:pip install bs44、查找⼀个可读取源码的图⽚⽹站注意注意:此链接仅供学习参考,请勿⾮法批量爬取,任何不听劝阻,⼀意孤⾏者,如若产⽣违法乱纪之事,请⾃⾏承担。
(开发不易,且⾏且珍惜)抓取图⽚的地址:https:///meinvtupian/meinvxiezhen/三、分析⽹站源码1、分析源码,得到获取源码的三个⽅向(编码格式、请求⽅式、header请求头)1. windows默认是gbk的编码格式,⽹页⼀般默认是utf-8的编码,所以直接⽤windows电脑抓取⽹页内容信息的时候可能会遇到乱码的问题,所以请求的时候统⼀编码格式保证数据不乱吗 2. 请求⽅式有post、get、put等⽅式校验,所以选择对的请求⽅式获取页⾯信息,如果不争取可能会出现404找不到页⾯或者500服务器错误 3. header请求头包含很多阴性信息,如果我们常见的,如:反爬机制、token校验、cookie校验等等2、查找列表页的唯⼀节点3、根据图⽚排版,查找源码规律(相同的li标签获取节点)4、获取列表的最后⼀页,获取最后⼀页的页码(NewPages节点下的尾页,代表最后141页)根据图⽚分页的页码地址规律,我们能得到(特别注意:第⼀页不能使⽤ index_1.htm 来查询):https:///meinvtupian/meinvxiezhen/ 第⼀页没有indexhttps:///meinvtupian/meinvxiezhen/index_2.htmhttps:///meinvtupian/meinvxiezhen/index_3.htmhttps:///meinvtupian/meinvxiezhen/index_4.htmhttps:///meinvtupian/meinvxiezhen/index_5.htmhttps:///meinvtupian/meinvxiezhen/index_6.htmhttps:///meinvtupian/meinvxiezhen/index_7.htmhttps:///meinvtupian/meinvxiezhen/index_8.htmhttps:///meinvtupian/meinvxiezhen/index_9.htm......5、根据每⼀个图⽚链接,进⼊图⽚详情根据上题3可以看出,图⽚详情的地址为:https:///meinvtupian/meinvxiezhen/233941.htm6、查找图⽚详情的地址规律,获取所有的详情⼦图⽚地址根据图⽚详情可以查看出来每⼀个⼦图⽚的详情地址:https:///meinvtupian/meinvxiezhen/233941.htmhttps:///meinvtupian/meinvxiezhen/233941_2.htmhttps:///meinvtupian/meinvxiezhen/233941_3.htmhttps:///meinvtupian/meinvxiezhen/233941_4.htmhttps:///meinvtupian/meinvxiezhen/233941_5.htmhttps:///meinvtupian/meinvxiezhen/233941_6.htmhttps:///meinvtupian/meinvxiezhen/233941_7.htmhttps:///meinvtupian/meinvxiezhen/233941_8.htmhttps:///meinvtupian/meinvxiezhen/233941_9.htm7、根据地址抓取图⽚流,保留本地 根据题6获取的图⽚地址进⾏爬取图⽚信息,保存到本地,页⾯分析到此结束,废话不多说,直接上代码,赶紧抓取。
简单实现Python爬取网络图片

简单实现Python爬取⽹络图⽚本⽂实例为⼤家分享了Python爬取⽹络图⽚的具体代码,供⼤家参考,具体内容如下代码:import urllibimport urllib.requestimport re#打开⽹页,下载器def open_html ( url):require=urllib.request.Request(url)reponse=urllib.request.urlopen(require)html=reponse.read()return html#下载图⽚def load_image(html):regx='http://[\S]*jpg'pattern=pile(regx)get_image=re.findall(pattern,repr(html))num=1for img in get_image:photo=open_html(img)with open(r'E:\Photo\%s.jpg'%num,'wb') as f:print('开始下载图⽚')f.write(photo)print('正在下载第%s张图⽚'%num)f.close()num=num+1if num>1:print('下载成功')else:print('下载失败')url='/'html=open_html(url)load_image(html)执⾏结果:注意: 在运⾏之前,必须要有路径(⽂件夹):E:\Photo\ 如果⽹站是HTTPS可以将正则中的http换为HTTPS,可以再定义⼀个下载图⽚的函数 如果想要下载jpg、png、gif等多种格式的图⽚可以将正则中的jpg换为对应格式,也可以使⽤元组定义多种格式后遍历我这⾥只要jpg就可以,就不改了,⼤家可以⾃⼰改下。
python网络爬虫之使用scrapy爬取图片

python⽹络爬⾍之使⽤scrapy爬取图⽚在前⾯的章节中都介绍了scrapy如何爬取⽹页数据,今天介绍下如何爬取图⽚。
下载图⽚需要⽤到ImagesPipeline这个类,⾸先介绍下⼯作流程:1 ⾸先需要在⼀个爬⾍中,获取到图⽚的url并存储起来。
也是就是我们项⽬中test_spider.py中testSpider类的功能2 项⽬从爬⾍返回,进⼊到项⽬通道也就是pipelines中3 在通道中,在第⼀步中获取到的图⽚url将被scrapy的调度器和下载器安排下载。
4 下载完成后,将返回⼀组列表,包括下载路径,源抓取地址和图⽚的校验码⼤致的过程就以上4步,那么我们来看下代码如何具体实现1 ⾸先在settings.py中设置下载通道,下载路径以下载参数ITEM_PIPELINES = {# 'test1.pipelines.Test1Pipeline': 300,'scrapy.pipelines.images.ImagesPipeline':1,}IMAGES_STORE ='E:\\scrapy_project\\test1\\image'IMAGES_EXPIRES = 90IMAGES_MIN_HEIGHT = 100IMAGES_MIN_WIDTH = 100其中IMAGES_STORE是设置的是图⽚保存的路径。
IMAGES_EXPIRES是设置的项⽬保存的最长时间。
IMAGES_MIN_HEIGHT和IMAGES_MIN_WIDTH是设置的图⽚尺⼨⼤⼩2 设置完成后,我们就开始写爬⾍程序,也就是第⼀步获取到图⽚的URL。
我们以⽹站图⽚为例。
中⽂名称为摄图⽹。
⾥⾯有各种摄影图⽚。
我们⾸先来看下⽹页结构。
图⽚的地址都保存在<div class=“swipeboxex”><div class=”list”><a><image>中的属性data-original⾸先在item.py中定义如下⼏个结构体class Test1Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()image_urls=Field()images=Field()image_path=Field()根据这个⽹页结构,在test_spider.py⽂件中的代码如下。
Python爬虫的谷歌ChromeF12如何抓包分析?案例详解

Python爬⾍的⾕歌ChromeF12如何抓包分析?案例详解浏览器打开⽹页的过程就是爬⾍获取数据的过程,两者是⼀样⼀样的。
浏览器渲染的⽹页是丰富多彩的数据集合,⽽爬⾍得到的是⽹页的源代码htm有时候,我们不能在⽹页的html代码⾥⾯找到想要的数据,但是浏览器打开的⽹页上⾯却有这些数据。
这就是浏览器通过ajax技术异步加载(偷偷下载)了这些数据。
⼤家禁不住要问:那么该如何看到浏览器偷偷下载的那些数据呢?答案就是⾕歌Chrome浏览器的F12快捷键,也可以通过⿏标右键菜单“检查”(Inspect)打开Chrome⾃带的开发者⼯具,开发者⼯具会出现在浏览器⽹页的左侧或者是下⾯(可调整),它的样⼦就是这样的:让我们简单了解⼀下它如何使⽤:⾕歌Chrome抓包:1. 最上⾯⼀⾏菜单左上⾓箭头⽤来点击查看⽹页的元素第⼆个⼿机、平板图标是⽤来模拟移动端显⽰⽹页Elements 查看渲染后的⽹页标签元素提醒是渲染后(包括异步加载的图⽚、数据等)的完整⽹页的html,不是最初下载的那个html。
Console 查看JavaScript的console log信息,写⽹页时⽐较有⽤Sources 显⽰⽹页源码、CSS、JavaScript代码Network 查看所有加载的请求,对爬⾍很有帮助后⾯的暂且不管。
⾕歌Chrome抓包:2. 重要区域图中红框的两个按钮⽐较有⽤,编号为2的是清空请求记录;编号3的是保持记录,这在⽹页有重定向的时候很有⽤图中绿⾊区域就是加载完整个⽹页,浏览器的全部请求记录,包括⽹址、状态、类型等。
写爬⾍时,我们就要在这⾥寻找线索,提炼⾦矿。
最下⾯编号为4的红框显⽰了加载这个⽹页,⼀共请求了181次,数量是多么地惊⼈,让⼈不禁⼼疼七浏览器来。
点击⼀条请求的⽹址,右侧就会出现新的窗⼝显⽰该条请求的相信信息:图中左边红框就是点击的请求⽹址;绿框就是详情窗⼝。
详情窗⼝包括,Headers(请求头)、Preview(预览响应)、Response(服务器响应内容)和Timing(耗时)。
Python爬取网页图片详解流程

Python爬取⽹页图⽚详解流程简介快乐在满⾜中求,烦恼多从欲中来记录程序的点点滴滴。
输⼊⼀个⽹址从这个⽹址中解析出图⽚,并将它保存在本地流程图程序分析解析主⽹址def get_urls():url = '/show/35350678.html' # 主⽹址pattern = "(http.*?jpg)"header = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36' }r = requests.get(url,headers=header)r.encoding = r.apparent_encodinghtml = r.texturls = re.findall(pattern,html)return urlsurl 为需要爬的主⽹址pattern 为正则匹配header 设置请求头r = requests.get(url,headers=header) 发送请求r.encoding = r.apparent_encoding 设置编码格式,防⽌出现乱码属性说明r.encoding从http header中提取响应内容编码r.apparent_encoding从内容中分析出的响应内容编码urls = re.findall(pattern,html) 进⾏正则匹配re.findall(pattern, string, flags=0)正则 re.findall 的简单⽤法(返回string中所有与pattern相匹配的全部字串,返回形式为数组)下载图⽚并存储def download(url_queue: queue.Queue()):while True:url = url_queue.get()root_path = 'F:\\1\\' # 图⽚存放的⽂件夹位置file_path = root_path + url.split('/')[-1] #图⽚存放的具体位置try:if not os.path.exists(root_path): # 判断⽂件夹是是否存在,不存在则创建⼀个os.makedirs(root_path)if not os.path.exists(file_path): # 判断⽂件是否已存在r = requests.get(url)with open(file_path,'wb') as f:f.write(r.content)f.close()print('图⽚保存成功')else:print('图⽚已经存在')except Exception as e:print(e)print('线程名: ', threading.current_thread().name,"url_queue.size=", url_queue.qsize())此函数需要传⼀个参数为队列queue模块中提供了同步的、线程安全的队列类,queue.Queue()为⼀种先⼊先出的数据类型,队列实现了锁原语,能够在多线程中直接使⽤。
Python爬虫学习第一天--利用正则表达式爬取图片

Python爬⾍学习第⼀天--利⽤正则表达式爬取图⽚ 1#!/usr/bin/env python2# -*- coding: utf-8 -*-3# @Time : 2018/7/10 22:344# @Author : chenxiaowei5# @Email : chen1020xiaowei@6# @File : parse_meinv.py7###利⽤正则表达式匹配字符串爬取***的美⼥图⽚,保存相关数据到MongoDB并且把相关图⽚保存在本地###8from parse_config import *9import requests10import re11import json12import time13import pymongo14from requests.exceptions import RequestException15import hashlib1617 db_client = pymongo.MongoClient(mongo_url) # 初始化MongoDB数据库对象18 db = db_client[mongo_database] # 引⽤实例192021def get_responses(url): # 定义获取response函数22try:23 responses = requests.get(url, headers=headers)24if responses.status_code == 200: # 判断是否请求成功,利⽤.text⽅法返回html代码25return responses.text26else:27return None28except RequestException: # 捕获⽗类异常29print('error1')30return None313233def get_image_content(url): # 定义函数34try:35 responses = requests.get(url, headers=headers)36if responses.status_code == 200:37return responses.content # 利⽤.content⽅法返回⼆进制⽂件38else:39return None40except RequestException:41print('error2')42return None434445def download_image(content):46 filename = '{0}.{1}'.format(hashlib.md5(content).hexdigest(), 'jpg') # 字符串的通配⽅法47 with open(path_image.format(filename), 'wb')as f: # 'wb'保存图⽚48 f.write(content)49print(filename,'下载成功!')50 f.close()515253def get_url_items(html):54 pattern = pile('<li>.*?<a.*?href="(.*?)".*?class="TypeBigPics".*?src="(.*?)".*?<span>(.*?)</span>'55 + '.*?class="IcoList">(.*?)</em>.*?class="IcoTime">(.*?)</em>', re.S)56 items = re.findall(pattern, html) # 利⽤re库的compile⽅法构造正则表达式,findall⽅法获取items57for item in items:58yield {59'名称': item[2],60'壁纸': item[1],61'⽹址': item[0],62'发布⽇期': item[4],63'查看次数': item[3][3:]64 } # yield⽣成器,被调⽤时才赋值65 content = get_image_content(item[1])66 download_image(content)676869def save_to_file(filename,file_type,text): # 保存⾄本地70 with open('{}{}{}'.format(path_txt, filename,file_type), 'a', encoding='utf-8', )as wf: # 以utf-8的编码⽅式追加到⽂件71 wf.write(json.dumps(text, ensure_ascii=False) + '\n') # 解码相关json格式72print(text,'写⼊到本地成功!')73 wf.close()747576def save_to_mongo(text): # 存储到MongoDB77if db[mongo_table].insert(text):78print(text,'写⼊Mongo成功!')79return True80return False818283def main(filename, page):84 url = 'http://www.***/bizhitupian/meinvbizhi/{}.htm'.format(page)85 html = get_responses(url)86 items = get_url_items(html)87for item in items:88 save_to_file(filename,file_type, item)89 save_to_mongo(item)909192if__name__ == '__main__':93for page in range(start_page, end_page + 1):94 main(file, page)95 time.sleep(15)#等待15秒,防⽌被识别1#!/usr/bin/env python2# -*- coding: utf-8 -*-3# @Time : 2018/7/10 22:354# @Author : chenxiaowei5# @Email : chen1020xiaowei@6# @File : parse_config.py7 mongo_url = 'localhost'8 mongo_database = 'youmeiwang'9 mongo_table = 'meinv'10 headers = {11'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.15 Safari/537.36'12 }13 file = '***美⼥图⽚.txt'14 path_image = 'H:/Python_download/20180710/image/{}'15 path_txt = 'H:/Python_download/20180710/file/'16 filename = '***美⼥图⽚'17 file_type = '.txt'18 start_page = 119 end_page = 44。
Python3简单爬虫抓取网页图片代码实例

Python3简单爬⾍抓取⽹页图⽚代码实例现在⽹上有很多python2写的爬⾍抓取⽹页图⽚的实例,但不适⽤新⼿(新⼿都使⽤python3环境,不兼容python2),所以我⽤Python3的语法写了⼀个简单抓取⽹页图⽚的实例,希望能够帮助到⼤家,并希望⼤家批评指正。
import urllib.requestimport reimport osimport urllib#根据给定的⽹址来获取⽹页详细信息,得到的html就是⽹页的源代码def getHtml(url):page = urllib.request.urlopen(url)html = page.read()return html.decode('UTF-8')def getImg(html):reg = r'src="(.+?\.jpg)" pic_ext'imgre = pile(reg)imglist = imgre.findall(html)#表⽰在整个⽹页中过滤出所有图⽚的地址,放在imglist中x = 0path = 'D:\\test'# 将图⽚保存到D:\\test⽂件夹中,如果没有test⽂件夹则创建if not os.path.isdir(path):os.makedirs(path)paths = path+'\\' #保存在test路径下for imgurl in imglist:urllib.request.urlretrieve(imgurl,'{0}{1}.jpg'.format(paths,x)) #打开imglist中保存的图⽚⽹址,并下载图⽚保存在本地,format格式化字符串x = x + 1return imglisthtml = getHtml("/p/2460150866")#获取该⽹址⽹页详细信息,得到的html就是⽹页的源代码print (getImg(html)) #从⽹页源代码中分析并下载保存图⽚以上就是本⽂的全部内容,希望对⼤家的学习有所帮助,也希望⼤家多多⽀持。
python爬虫之爬取谷歌趋势数据

python爬⾍之爬取⾕歌趋势数据⼀、前⾔爬取⾕歌趋势数据需要科学上⽹~⼆、思路⾕歌数据的爬取很简单,就是代码有点长。
主要分下⾯⼏个就⾏了爬取的三个界⾯返回的都是json数据。
主要获取对应的token值和req,然后构造url请求数据就⾏token值和req值都在这个链接的返回数据⾥。
解析后得到token和req就⾏socks5代理不太懂,抄⽹上的作业,假如了当前程序的全局代理后就可以跑了。
全部代码如下import socketimport socksimport requestsimport jsonimport pandas as pdimport logging#加⼊socks5代理后,可以获得当前程序的全局代理socks.set_default_proxy(socks.SOCKS5,"127.0.0.1",1080)socket.socket = socks.socksocket#加⼊以下代码,否则会出现InsecureRequestWarning警告,虽然不影响使⽤,但看着糟⼼# 捕捉警告logging.captureWarnings(True)# 或者加⼊以下代码,忽略requests证书警告# from requests.packages.urllib3.exceptions import InsecureRequestWarning# requests.packages.urllib3.disable_warnings(InsecureRequestWarning)# 将三个页⾯获得的数据存为DataFrametime_trends = pd.DataFrame()related_topic = pd.DataFrame()related_search = pd.DataFrame()#填⼊⾃⼰打开⽹页的请求头headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36','x-client-data': 'CJa2yQEIorbJAQjEtskBCKmdygEI+MfKAQjM3soBCLKaywEI45zLAQioncsBGOGaywE=Decoded:message ClientVariations {// Active client experiment variation IDs.repeated int32 variation_id = [3300118, 3300130, 3300164, 3313321, 331877 'referer': 'https:///trends/explore','cookie': '__utmc=10102256; __utmz=10102256.1617948191.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); __utma=10102256.889828344.1617948191.1617948191.1617956555.3; __utmt=1; __utmb=10102256.5.9.1617956603932; SID=8AfEx31goq255 }# 获取需要的三个界⾯的req值和token值def get_token_req(keyword):url = 'https:///trends/api/explore?hl=zh-CN&tz=-480&req={{"comparisonItem":[{{"keyword":"{}","geo":"US","time":"today 12-m"}}],"category":0,"property":""}}&tz=-480'.format(keyword)html = requests.get(url, headers=headers, verify=False).textdata = json.loads(html[5:])req_1 = data['widgets'][0]['request']token_1 = data['widgets'][0]['token']req_2 = data['widgets'][2]['request']token_2 = data['widgets'][2]['token']req_3 = data['widgets'][3]['request']token_3 = data['widgets'][3]['token']result = {'req_1': req_1, 'token_1': token_1, 'req_2': req_2, 'token_2': token_2, 'req_3': req_3,'token_3': token_3}return result# 请求三个界⾯的数据,返回的是json数据,所以数据不⽤解析,完美def get_info(keyword):content = []keyword = keywordresult = get_token_req(keyword)#第⼀个界⾯req_1 = result['req_1']token_1 = result['token_1']url_1 = "https:///trends/api/widgetdata/multiline?hl=zh-CN&tz=-480&req={}&token={}&tz=-480".format(req_1, token_1)r_1 = requests.get(url_1, headers=headers, verify=False)if r_1.status_code == 200:try:content_1 = r_1.contentcontent_1 = json.loads(content_1.decode('unicode_escape')[6:])['default']['timelineData']result_1 = pd.json_normalize(content_1)result_1['value'] = result_1['value'].map(lambda x: x[0])result_1['keyword'] = keywordexcept Exception as e:print(e)result_1 = Noneelse:print(r_1.status_code)#第⼆个界⾯req_2 = result['req_2']token_2 = result['token_2']url_2 = 'https:///trends/api/widgetdata/relatedsearches?hl=zh-CN&tz=-480&req={}&token={}'.format(req_2, token_2)r_2 = requests.get(url_2, headers=headers, verify=False)if r_2.status_code == 200:try:content_2 = r_2.contentcontent_2 = json.loads(content_2.decode('unicode_escape')[6:])['default']['rankedList'][1]['rankedKeyword']result_2 = pd.json_normalize(content_2)result_2['link'] = "https://" + result_2['link']result_2['keyword'] = keywordexcept Exception as e:print(e)result_2 = Noneelse:print(r_2.status_code)#第三个界⾯req_3 = result['req_3']token_3 = result['token_3']url_3 = 'https:///trends/api/widgetdata/relatedsearches?hl=zh-CN&tz=-480&req={}&token={}'.format(req_3, token_3)r_3 = requests.get(url_3, headers=headers, verify=False)if r_3.status_code == 200:try:content_3 = r_3.contentcontent_3 = json.loads(content_3.decode('unicode_escape')[6:])['default']['rankedList'][1]['rankedKeyword']result_3 = pd.json_normalize(content_3)result_3['link'] = "https://" + result_3['link']result_3['keyword'] = keywordexcept Exception as e:print(e)result_3 = Noneelse:print(r_3.status_code)content = [result_1, result_2, result_3]return contentdef main():global time_trends,related_search,related_topicwith open(r'C:\Users\Desktop\words.txt','r',encoding = 'utf-8') as f:words = f.readlines()for keyword in words:keyword = keyword.strip()data_all = get_info(keyword)time_trends = pd.concat([time_trends,data_all[0]],sort = False)related_topic = pd.concat([related_topic,data_all[1]],sort = False)related_search = pd.concat([related_search,data_all[2]],sort = False)if __name__ == "__main__":main()到此这篇关于python爬⾍之爬取⾕歌趋势数据的⽂章就介绍到这了,更多相关python爬取⾕歌趋势内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。