阿里集团云梯分布式平台(Ali)
阿里巴巴云计算技术案例

阿里巴巴云计算技术案例阿里巴巴是一家全球知名的电子商务公司,以其强大的云计算技术和平台而闻名。
本文将介绍阿里巴巴在云计算领域的创新应用和成功案例。
一、背景介绍阿里巴巴集团成立于1999年,起初是一个B2B电子商务平台,致力于为全球商家提供在线交易及流通解决方案。
然而,随着公司的发展,阿里巴巴逐渐拓展了其业务范围,包括电子支付、物流、云计算等。
二、云计算技术的应用作为一家技术驱动型公司,阿里巴巴将云计算技术应用于多个业务领域,以提高效率、降低成本,并支持创新发展。
1. 弹性计算阿里巴巴通过弹性计算技术实现了资源的弹性伸缩。
当业务需求增加时,阿里巴巴可以根据用户需求快速扩展服务器资源;当业务需求减少时,可以自动减少服务器资源,从而实现资源的合理利用。
2. 分布式计算阿里巴巴利用分布式计算技术实现了大规模数据的高效处理和存储。
通过将任务分解为多个子任务,并运行在不同的计算节点上,加快了任务处理速度,并提高了系统的可靠性和容错性。
3. 容器化技术阿里巴巴采用容器化技术,如Docker等,来实现应用程序的快速部署和运行。
通过容器化,可以实现应用程序的快速迁移和水平扩展,提高了系统的弹性和可伸缩性。
4. 大数据分析阿里巴巴利用云计算技术对海量数据进行分析,以实现对商业数据的深度挖掘和商业智能化决策支持。
通过应用机器学习和人工智能算法,可以从数据中发现潜在的商机,并优化业务流程。
三、成功案例1. 双十一购物狂欢节阿里巴巴每年举办的双十一购物狂欢节是全球最大的在线购物活动之一。
为了应对高峰期的交易压力,阿里巴巴依托强大的云计算技术确保系统的高可用性和稳定性。
通过弹性计算和容器化技术,阿里巴巴可以根据用户需求快速扩展服务器资源,并实现应用程序的快速部署和运行。
这些技术的应用使得双十一购物狂欢节能够顺利进行,并实现了创纪录的交易额。
2. 阿里云智能驾驶阿里云智能驾驶是阿里云在汽车领域的创新应用。
通过将云计算和人工智能技术应用于智能驾驶系统,阿里云可以实现车辆感知、决策和行为规划等功能。
AlibabaCloud的云计算服务

AlibabaCloud的云计算服务云计算已经成为现代企业和个人的关键技术,由阿里巴巴集团推出的AlibabaCloud作为全球领先的云计算服务提供商,在服务范围、性能和可靠性方面一直处于领先地位。
本文将介绍AlibabaCloud的云计算服务及其优势。
一、云计算服务概述AlibabaCloud的云计算服务基于弹性计算、分布式存储和网络等核心技术,通过云端服务器、数据库、网络和安全等服务,提供强大的基础架构支持,进而帮助用户快速构建、交付和扩展应用。
无论是大型企业、中小企业还是创业公司,都可以通过AlibabaCloud轻松搭建灵活、安全、高效的云计算环境。
二、产品特点与优势1. 可靠性和高可用性:AlibabaCloud拥有全球分布的数据中心,通过快速部署和跨地域备份技术,确保用户的应用和数据始终可用。
同时,AlibabaCloud提供了多层次的安全防护措施,保障用户数据的安全性。
2. 弹性扩展和灵活性:云计算可以按需提供弹性计算和存储资源,用户可以根据业务需求实时调整云资源的规模和配置,从而提高业务的敏捷性和响应能力。
3. 大数据支持:AlibabaCloud的云计算服务与数十个阿里巴巴集团的核心业务深度整合,可以提供全方位的大数据处理和分析能力,帮助用户挖掘和利用海量数据中的价值。
4. 全球化覆盖:AlibabaCloud已经在亚洲、欧洲、美洲等多个地区建立了数据中心,用户可以根据业务需求选择适合的地域进行部署,实现低延迟和高性能的应用。
三、常用的云计算服务1. 弹性计算服务:AlibabaCloud提供了弹性计算服务,包括云服务器、裸金属服务器和容器服务等,可以根据不同的应用场景选择合适的计算资源,并实现高性能计算和应用托管。
2. 数据存储与管理服务:AlibabaCloud的云计算服务提供了多种数据存储和管理方案,包括对象存储、文件存储和块存储等,可以满足不同规模和性能需求的数据存储需求。
阿里飞天云平台介绍
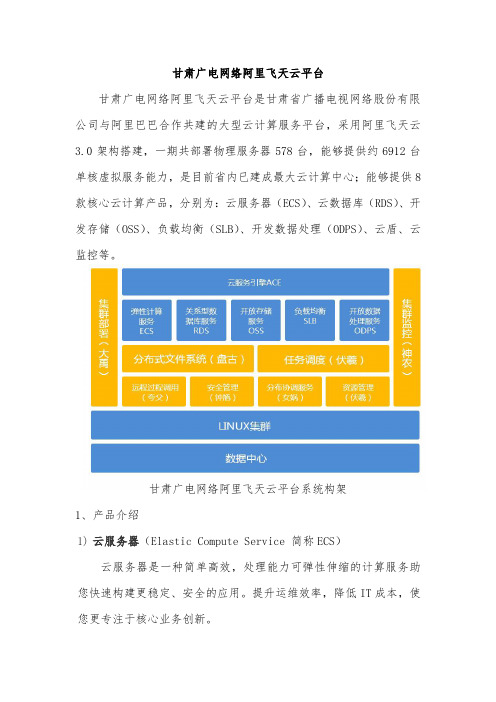
甘肃广电网络阿里飞天云平台甘肃广电网络阿里飞天云平台是甘肃省广播电视网络股份有限公司与阿里巴巴合作共建的大型云计算服务平台,采用阿里飞天云3.0架构搭建,一期共部署物理服务器578台,能够提供约6912台单核虚拟服务能力,是目前省内已建成最大云计算中心;能够提供8款核心云计算产品,分别为:云服务器(ECS)、云数据库(RDS)、开发存储(OSS)、负载均衡(SLB)、开发数据处理(ODPS)、云盾、云监控等。
甘肃广电网络阿里飞天云平台系统构架1、产品介绍1)云服务器(Elastic Compute Service 简称ECS)云服务器是一种简单高效,处理能力可弹性伸缩的计算服务助您快速构建更稳定、安全的应用。
提升运维效率,降低IT成本,使您更专注于核心业务创新。
产品优势:➢稳定云盘数据可靠性不低于99.999%自动宕机迁移、数据备份和回滚系统性能报警➢安全防DDoS系统、安全组规则保护多用户隔离防密码破解➢弹性10分钟内可启动或释放百台云服务器5分钟内停机升级CPU和内存在线不停机升级带宽➢高性能随机IOPS 1.2万、300MB/s本地SSD盘性能多线BGP骨干网络接入高性价比,节约成本产品功能:➢完全管理权限对云服务器的操作系统有完全控制权,用户可以通过连接管理终端自助解决系统问题,进行各项操作。
➢快照备份与恢复对云服务器的磁盘数据生成快照,用户可使用快照回滚、恢复以往磁盘数据,加强数据安全。
➢自定义镜像对已安装应用软件包的云服务器,支持自定义镜像、数据盘快照批量创建服务器,简化用户管理部署。
➢API接口使用ECS API调用管理,通过安全组功能对一台或多台云服务器进行访问设置,使开发使用更加方便2)负载均衡SLB(Server Load Balancer,简称SLB)负载均衡是对多台云服务器进行流量分发的负载均衡服务。
SLB 可以通过流量分发扩展应用系统对外的服务能力,通过消除单点故障提升应用系统的可用性产品优势:➢高可用冗余设计,无单点,可用性达99.99%根据应用负载进行弹性扩容流量波动情况下不中断对外服务➢低成本与传统模式相比成本下降60%免费使用私网类型实例无需采购昂贵的设备,免运维➢安全LVS SYNPROXY技术防攻击能力结合云盾提供防DDoS攻击多用户资源隔离产品功能:➢SLB服务类型支持公网/私网类型的SLB服务;提供4层(TCP协议)和7层(HTTP和HTTPS协议)的SLB服➢健康检查对后端云服务器进行健康检查,自动屏蔽异常状态云服务器,恢复正常后自动解除屏蔽。
阿里云新型互联网架构介绍

DevOps 管理
容器服务
• Docker企业版(国内独家) • 支持Kubernates
云效:持续开发持续集成( DevOps ) 的管理软件
Aliware (分布式企业中间件): 大规模验证的 Java 中间件
新型应用 第三方应用 存量IT系统
CSB云服务总线
能力开放运营
用户中心 资源中心
API管理运营 共享服务层
客户和场景:互联网金融生产环境(含大数据) 关键产品:IAAS+大数据+
中间件(含docker)+高级版云盾
平台特性:等保三级,两地三中心 客户和场景:央企,互联网中台+大数据
V2.0 (2016.05)
关键产品:IAAS+大数据+中间件 平台特性:统一运维管理,管控节点压缩
满足生产级可靠性和 安全合规的要求
统一的管理运维系统, 和企业现有IT管理系统 无缝对接
向混合云 平滑演进
飞天平台整体架构
淘宝、天猫、支付宝、高德、菜鸟网络、阿里音乐等事业部 PaaS服务 微服务开发 框架服务 分布式数据 库服务 分布式消息 中间件服务 云服务总线 服务 数据交换服 务 DaaS服务 数据治理服 务 数据开放服 务 数据可视化 服务
解决数据 长效保存 及采集问题
解决数据 规范问题
解决数据 交换及安全问题
解决技术 转化输出问题
飞天平台:由实践锤炼而来
天猫 支付宝
17.5万笔/秒订单
12万笔/秒支付
2017天猫 11.11 购物狂欢节 1682亿元总成交额
阿里云专有云:让每个企业都拥有自己的飞天
专有云 公共云
北京,杭州,上海,青岛 深圳,香港,新加坡
阿里云大数据计算平台的自动化、精细化运维之路

阿里云大数据计算平台的自动化、精细化运维之路本文章来自于阿里云云栖社区摘要:作者简介:范伦挺阿里巴巴基础架构事业群-技术专家花名萧一,2010年加入阿里巴巴,现任阿里巴巴集团大数据计算平台运维负责人。
团队主要负责阿里巴巴各类离在线大数据计算平台(如MaxCompute、Analytic DB、StreamComput免费开通大数据服务:https:///product/odps作者简介:范伦挺阿里巴巴基础架构事业群-技术专家花名萧一,2010年加入阿里巴巴,现任阿里巴巴集团大数据计算平台运维负责人。
团队主要负责阿里巴巴各类离在线大数据计算平台(如MaxCompute、AnalyticDB、StreamCompute等)的运维、架构优化及容量管理等1、前言本文主要会从以下四个方面来写,分别是:阿里大规模计算平台运维面临的一些挑战;阿里自动化平台建设;数据精细化运维;我对运维转型的思考和理解;2、在阿里我们面对的挑战在讲挑战之前,我们可以简单看一下阿里大数据平台演进历史,我们的MaxCompute(原ODPS)平台是2011年4月上线的,2013年8月份单集群超过5K,2015年6月单集群超10K,目前在进行异地多活和离在线混布方面的事情。
首先是规模大、小概率事件常态化对于小概率事件大家不能赌运气,基本每次都会踩中狗屎的。
譬如各类硬件故障,规模小的时候觉得硬件故障概率比较低,即使坏了也比较彻底,但是规模大了后会有很多情况是将坏不坏,类似这种奇葩事件会越来越多。
还有网络链路不稳定,网络链路会有很多原因导致它不稳定。
一方面是网络设备多了,网络设备出现故障的概率也大了,另一方面运营商日常割接、挖掘机施工等都会对我们带来挑战。
还有一部分是工具,机器的环境变得复杂以后,我们对工具稳定性就有更高要求,比如你要考虑到有些机器的SSH 会hang 住,还有某些机器yumdb是坏的,不能想当然的以为一条命令下去一定会执行成功。
阿里飞天云平台架构简介

阿⾥飞天云平台架构简介飞天是由阿⾥云开发的⼀个⼤规模分布式计算系统,其中包括飞天内核和飞天开放服务。
飞天内核负责管理数据中⼼集群的物理资源,控制分布式程序运⾏,隐藏下层故障恢复和数据冗余等细节,有效提供弹性计算和负载均衡。
如图所⽰,飞天体系主要包含四⼤块:1、资源管理、安全、远程过程调⽤等构建分布式系统常⽤的底层服务;2、分布式⽂件系统;3、任务调度;4、集群部署和监控。
飞天开放服务为⽤户应⽤程序提供了计算和存储两⽅⾯的接⼝和服务,包括弹性计算服务(Elastic ComputeService,简称ECS)、开放存储服务(Open Storage Service,简称OSS)、开放结构化数据服务(Open Table Service,简称OTS)、关系型服务(Relational Database Service,简称RDS)和开放数据处理服务(Open Data Processing Service,简称ODPS),并基于弹性计算服务提供了云服务引擎(Aliyun Cloud Engine,简称ACE)作为第三⽅应⽤开发和Web 应⽤运⾏和托管的平台。
阿⾥有限公司(简称“阿⾥云”)成⽴于2009年9⽉10⽇,致⼒于打造云计算的基础服务平台,注重为中⼩企业提供⼤规模、低成本、⾼可靠的云计算应⽤及服务。
飞天开放平台(简称“飞天平台”或者“飞天”)是由阿⾥云⾃主研发完成的公共云计算平台,该平台所提供的服务于2011年7⽉28⽇在正式上线,推出了第⼀个云服务——弹性计算服务。
截⾄本书出版时,阿⾥云已经推出了包括弹性计算服务、开放存储服务、关系型数据库服务、开放结构化数据服务在内的⼀系列服务和产品。
飞天平台内核包含的模块可以分为以下⼏部分。
分布式系统底层服务:提供分布式环境下所需要的协调服务、远程过程调⽤、安全管理和资源管理的服务。
这些底层服务为上层的分布式⽂件系统、任务调度等模块提供⽀持。
分布式⽂件系统:提供⼀个海量的、可靠的、可扩展的数据存储服务,将集群中各个节点的存储能⼒聚集起来,并能够⾃动屏蔽软硬件故障,为⽤户提供不间断的数据访问服务;⽀持增量扩容和数据的⾃动平衡,提供类似于POSIX的⽤户空间⽂件访问API,⽀持随机读写和追加写的操作。
阿里巴巴智能物流平台(阿里巴巴智能物流平台有哪些)

阿里巴巴智能物流平台(阿里巴巴智能物流平台有哪些)
随着电商行业的快速发展,物流配送已经成为了电商平台的重要组成部分。
在这个领域中,阿里巴巴智能物流平台成为了业内的佼佼者,不仅仅是因为它的巨大用户数量,更是因为它强大的技术支持和智能化的系统。
阿里巴巴智能物流平台是阿里集团旗下的物流配送平台,它包括了阿里巴巴物流、菜鸟网络、盒马鲜生等一系列的物流公司。
这些公司相互合作,共同打造了一个全新的智能物流配送体系。
阿里巴巴智能物流平台的主要特点是智能化和高效化。
它利用人工智能和大数据技术来优化配送路线、提升配送效率,同时也通过智能化设备来实现全程可视化和追踪。
这些技术的应用,不仅仅可以提升用户的配送体验,更可以降低配送成本、缩短配送时间,为商家和消费者带来更多的便利。
阿里巴巴智能物流平台的应用场景也非常广泛。
它可以满足各种不同行业的配送需求,例如电商、餐饮、生鲜等。
比如,在电商领域中,阿里巴巴智能物流平台可以为商家提供快速、准确的配送服务,同时也可以为消费者提供更加便捷的购物体验。
在生鲜领域中,它可以通过智能化的配送和冷链技术,保证生鲜食品的新鲜度和质量。
总之,阿里巴巴智能物流平台是一个高效、智能、可靠的配送平台,它的技术支持和服务水平已经成为业内的标杆。
随着人工智能和大数据技术的不断发展,阿里巴巴智能物流平台也将不断创新,为用户带来更加优质的配送服务。
走近阿里Apsara Clouder云计算的蓝图

走近阿里Apsara Clouder云计算的蓝图一:“什么是Apsara Clouder 云计算”Apsara Clouder 云计算基于阿里巴巴自主研发的云计算技术,是一种基于云计算技术构建的IT 基础设施服务平台,它提供了计算、网络、存储、数据库网络、安全和管理等一系列基础设施和服务和大数据、AI等高级服务,帮助企业客户构建基于云计算的数字化架构,实现数字化转型和业务创新。
客户可以通过Apsara Clouder 平台轻松地构建和管理自己的应用程序、数据和业务流程。
Apsara Clouder 云计算平台采用分布式架构,能够在全球范围内快速响应客户需求。
平台具有高度的可靠性、弹性、可扩展性和安全性等特点,可以帮助客户降低IT 成本、提升IT 效率、加速创新和业务发展。
同时,Apsara Clouder 云计算平台还具有多种计费方式,可根据客户实际使用情况进行灵活的计费和支付,使客户更加省心省力。
二:"Apsara Clouder 云计算"厉害在哪里?2.1 超大规模根据阿里巴巴集团公开披露的数据,阿里云计算的全球公共云市场占有率排名位居前列,市场份额已经超过9%,是全球增长最快的公共云服务提供商之一。
同时,阿里云计算在国内市场占有率更是遥遥领先,已经成为中国最大的云计算服务提供商之一。
云计算能赋予用户前所未有的计算能力。
2.2 虚拟化Apsara Clouder 云计算采用虚拟化技术,用户并不需要关注具体的硬件实体,只需要选择一家云服务商,注册一个账号,登陆到它们的云控制台,去购买和配置你需要的服务(比如云服务器,云存储,CDN等等),再为你的应用做一些简单的配置之后,你就可以让你的应用对外服务了,这比传统的在企业的数据中心去部署一套应用要简单方便得多。
而且你可以随时随地通过你的PC或移动设备来控制你的资源,这就好像是云服务商为每一个用户都提供了一个互联网数据中心(IDC,Internet Data Center)一样。
了解阿里全域营销AIPL、FAST、GROW三大数字模型

了解阿⾥全域营销AIPL、FAST、GROW三⼤数字模型全⽂共3260字,预计阅读时间10分钟之前经历主要混迹在运营与产品圈⼦。
最近因为⼯作关系,开始研究营销相关内容。
也不是说之前就没关注,只是因为⾏业的各种形态变化太快,所以市场、运营、品牌、营销的界限在逐渐模糊,也就有了更多融合实践的机会。
⽽且不夸张的说国内的电商⾏业的营销理论已经能够扛起国际⼤旗。
阿⾥、字跳、腾讯都是国内外主要研究的对象。
最近⼀直在看顾明毅⽼师的课,所以就当写⼀些学习笔记,与⼤家分享。
我之前在做产品的时候,就在思考⼀个问题,市场部提出的需求还算可量化,品牌的需求怎么量化?如果不能量化,这类需求接还是不接?在《数字驱动营销》这本书⾥讲到:品牌主会通过电视⼴告、事件赞助、产品放置等⽅式开展传统的营销传播。
必须关注下⾯10指标⾮财务指标:1、基本认知指标品牌认知度=让客户回忆起产品或服务的能⼒2、基本评价指标试⽤驱动=客户在购买产品或服务前的测试3、基本忠诚度指标流失=现有客户中停⽌购买产品或服务的⽐例,通常以年度来衡量4、营销的黄⾦指标客户满意度(CSAT)=通过询问“你是否会将这个产品或服务推荐给你的朋友或同事”来衡量客户满意度5、基本执⾏有效率指标命中率=接受营销的⽐例基本财务指标:6、利润=收⼊-成本7、NPV=净现值8、IRR=内部收益率9、回收期=在偿还主动投⼊成本前的营销投⼊时间客户价值指标:10、基本客户价值指标 CLTV=客户⽣命周期价值在整个购买闭环⾥,认知是离客户最远的部分,从认知到购买就会有⾮常长的延时。
⽽从认知-熟悉-思考-购买-忠诚,传统的购买决策模型是⼀个线性的漏⽃模型。
随着互联⽹的兴起,麦肯锡之后提出了「消费者决策历程」,来渠道传统消费决策模型,去适应互联⽹时代的消费者变化。
麦肯锡「消费者决策历程」消费新旅程的升级⾥通过新的⽅式(技术、数字、体验、内容、点赞、评价及扩散)压缩了考虑步骤和短路径甚⾄完全取消评估步骤,直接传递客户到忠诚的闭环,将他们锁定在内。
阿里云分布式应用服务EDAS-产品简介

依托于淘宝十年互联网架构经验,帮助用户构建高性能易扩展的Web应用。在EDAS产品中,服务化框架的整 体结构如下所示:
EDAS的服务框架在具备基本的远程服务调用之外,还具有几下几个产品特性: - 同机房优先
用于对跨机房间的HSF调用流量进行规划控制,能够保证HSF服务消费者在请求HSF服务时,优先选择与服务消 费者同机房的服务提供者。
产品优势
稳定可靠
EDAS所包含的绝大部分功能,均是阿里内部长期使用与沉淀的产品,目前支持阿里巴巴所有核心应用稳定运行 ,并经历过多次双十一考验。
高扩展性
轻松构建超大规模分布式应用,千台机器扩展一键完成。
一站式
一系列应用生命周期管理服务一应俱全,服务治理和应用诊断都能够轻松搞定,基础监控和应用监控细致全面
- 动态归组 将机器发布的HSF服务自动归入特定的分组。这样,不同分组中的HSF服务实例就组成了以组为单位的集群 ,针对某些特定的机器提供服务。
3
移动数据分析/产品简介
- 服务限流 作用于 HSF服务提供端 ,允许应用提供方指定某个接口的TPS,当单位时间内的TPS达到设定值时,该接口将 停止对外提供服务,所有的请求都会被拦截,直到下一个刷新时间点。
- 线程 列举容器里面的线程,各个线程的状态,以及线程名
- 连接器 每个连接器当前处理的请求的一些数据
服务列表
每个应用发布了哪些HSF服务,消费了哪些HSF服务,可以通过此功能可以查看。此应用发布的服务,可以对 其中一个比较重要的服务,不需要修改应用代码,在EDAS上进行动态分组配置,比如服务组A,服务组B,这 样就可以控制不同的consumer连接不同服务组中的服务,方便隔离。
容器诊断
客户的应用是部署,并运行在我们的Ali-Tomcat容器中,我们的应用容器提供几个诊断功能: - 内存变化
阿里巴巴如何使用分布式存储技术

阿里巴巴如何使用分布式存储技术2018年12月12日,2018中国存储与数据峰会的闪存存储与应用论坛上,阿里巴巴资深技术专家石超介绍了阿里巴巴在分布式存储方面的技术积累,一方面服务于阿里巴巴自己的电商业务,一方面以阿里云的方式向外界提供服务。
阿里巴巴做存储可能跟其他公司不太一样,我们真的做了一个存储平台,把各个业务统一起来,然后用同一套系统去支持这个业务。
十年前我们开始做这个系统,随后在2010年、2011年我们基于盘古系统发布了公有云的产品,像大数据的ODPS、ECS,还有我们的对象存储OSS服务。
在2013年有一个关键事件——阿里巴巴的飞天5K项目落成。
同一时代在阿里内部还有其他的存储系统在用,还有云梯1和云梯2系统,2013年把这两个系统合并了,这是离线大数据上的标志性事件。
2016年,盘古2.0项目启动等等。
阿里巴巴可能和其他做云产品的公司不一样,对于我们来说,我们做这些新的技术,并不是让大家去做小白鼠,阿里巴巴自己内部关键的电商业务也是跑在同一套系统上。
比如电商交易的核心系统,比如双11和双12,大家在淘宝上下单,淘宝的数据库、消息界面系统,都是由同一套系统来支撑的。
我们的主力云产品包括ECS和OSS的存储,也都是在我们的系统上。
对于统一存储,我觉得有几个关键的业务特点:第一,我们的规模非常大,应该说阿里集团大部分的数据都在这个系统上。
第二,我们支持了非常核心的系统,内部系统会和外部系统业务稍微有一些区别。
一方面,比如我们的业务系统的分布式架构做的很好,因为它要面对双11的冲击,所以,要求系统能够在短时间内承受非常高的流量冲击,需要你的系统有非常好的弹性。
一方面,云产品又稍微有点不一样,云产品面对的是很多架构上没有那么好的公司,比如创业公司,他们的架构比较简单,但是对我们单个存储或者单个OSS的可用性要求非常高,所以这两个需求又有点不一样。
同时受到这两方面的驱动,我们做统一的存储,用统一的技术服务这两种类型的应用。
zstack概念

zstack概念
ZStack是上海云轴信息科技有限公司旗下品牌,由阿里云、中国电信战略投资并战略合作,是一款产品化的开源IaaS(基础架构即服务)软件。
ZStack通过完善的API管理数据中心资源,构建软件定义数据中心,提供统一配置、统一安装、统一高可用和统一第三方监控的云服务解决方案,使云平台的管理更加便捷、稳定、持久。
它面向智能数据中心,通过完善的API统一管理包括计算、存储和网络在内的数据中心资源,提供简单快捷的环境搭建。
用户可选择UI界面或命令行工具管理云平台,与ZStack管理节点进行友好交互。
ZStack以“降低企业上云门槛”为使命、“让每一家企业都拥有自己的云”为愿景,注重产品化,普惠云计算。
阿里云大数据产品体系介绍

目录大数据产品框架数据计算平台数据加工与分析服务与应用引擎大数据应用场景记录 统计大规模计算GB计算复杂程度数据量TBPB网站独立数据 集市论坛小型电商小型EDW BI/DWMPP淘宝支付宝 CRMERPHPC语言识别影音识别图像识别关系网络图像比对 行为DNA刷脸精准广告大数仓消费预测征信搜索排序EB深度学习大数据产品框架应用加速器分析引擎 推荐引擎 兴趣画像分类预测规则引擎 标签管理ID-Mapping计算引擎数据加工和分析工具离线计算 流计算 数据开发 ETL 开发调度系统机器学习分析型数据库数据可视化工具数据采集CDP (离线)数据服务和应用引擎数据管理数据 地图数据 质量智能 监控阿里云大数据集成服务平台是阿里巴巴集团统一的大数据平台,提供一站式的大数据开发、管理、分析挖掘、共享交换解决方案,可用于构建PB 级别的数据仓库,实现超大规模数据集成,对数据进行资产化管理,通过对数据价值的深度挖掘,实现业务的数据化运营。
目录大数据产品框架数据计算平台数据加工与分析服务与应用引擎大数据离线计算服务 MaxCompute离线计算流计算分析型数据库大数据计算服务(MaxCompute ,原ODPS)是由阿里巴巴自主研发的大数据产品,支持针对海量数据(结构化、非结构化)的离线存储和计算、分布式数据流处理服务,并可以提供海量数据仓库的解决方案以及针对大数据的分析建模服务,应用于数据分析、挖掘、商业智能等领域。
存储易用安全计算●支持TB 、PB 级别数据存储 ●支持结构化、非结构化数据存储●集群规模可灵活扩展,支持同城、异地多数据中心模式●支持海量数据离线计算●支持分布式数据流式处理服务 ●支持SQL 、MR 、Graph(BSP)、StreamSQL 、MPI 编程框架 ●提供丰富的机器学习算法库●支持以RESTful API 、SDK 、CLT 等方式提供服务●不必关心文件存储格式以及分布式技术细节●经受了阿里巴巴实践检验●数据存储多份拷贝 ●所有计算在沙箱中运行MaxCompute 的优势和能力高效处理海量数据1、跨集群技术突破,集群规模可以根据需要灵活扩展,支持同城、异地多数据中心模式2、单一集群规模可以达到10000+服务器(保持80%线性扩展)3、不保证线性增长的情况下,单个集群部署可以支持100万服务器以上4、对用户数、应用数无限制,多租户支持500+部门5、100万以上作业及2万以上并发作业安全性1、所有计算在沙箱中运行2、多种权限管理方式、灵活数据访问控制策略3、数据存储多份拷贝易用性1、开箱即用2、支持SQL、MR、Graph、流计算等多种计算框架3、提供丰富的机器学习算法库4、ODPS支持完善的多租户机制,多用户可分享集群资源自主可控经过实践验证1、阿里巴巴自主研发2、整套平台经受了阿里巴巴超大规模数据应用的实践验证离线计算流计算分析型数据库离线计算流计算分析型数据库自主可控•使用Hadoop组件开发受制于开源社区,最多只能维护一个分支•开源社区组件太多,版本问题,打包问题,升级维护成本太高Hadoop核心技术架构发展缓慢•一些技术阿里要比开源社区更早实现(如分布式文件系统多master实现等)没有一个Hadoop发行版可以满足阿里巴巴的业务场景•如异地多数据中心、数据安全性等要求Hadoop社区分化严重,发展状况有隐忧当前Yahoo、Facebook等公司使用的都是自己的私有版本流计算 StreamCompute离线计算流计算分析型数据库●阿里云流计算(StreamCompute)是一个通用的流式计算平台,提供实时的流式数据分析及计算服务●整个数据处理链路是进行压缩的,链路是即时的,完全以业务为中心,数据驱动解决用户实际问题实时ETL 监控预警实时报表实时在线系统对用户行为或相关事件进行实时监测和分析,基于风控规则进行预警用户行为预警、app crash预警、服务器攻击预警数据的实时清洗、归并、结构化数仓的补充和优化实时计算相关指标反馈及时调整决策内容投放、无线智能推送、实时个性化推荐等双11、双12等活动直播大屏对外数据产品:数据魔方、生意参谋等低延时高效流数据处理,根据不同业务场景的时效性需要,从数据写入到计算出结果秒级别的延迟高可靠●底层的体系架构充分考虑了单节点失效后的故障恢复等问题,可以保证数据在处理过程中的不重不丢, Exactly-Once 语义保证●通过定期记录的checkpoint数据,自动恢复当前计算状态,保证数据计算结果的准确性可扩展计算能力和集群能力具有良好的可扩展性,用户可以通过简单的增加Worker节点数量的方式进行水平扩展,可以支持每天PB级别的数据流量开发方便●SQL支持度高:标准SQL,语义明确,门槛低,只需要关心计算逻辑,开发维护成本低●完善的元数据管理:SQL天然对元数据友好,SQL优化支持离线计算流计算分析型数据库功能特性BI分析的发展方向离线计算流计算分析型数据库分析型数据库概述离线计算流计算分析型数据库分析型数据库(Analytic DB),是一套实时OLAP(Realtime-OLAP)系统。
云计算~阿里云简介ppt

03.弹性自愈
• 弹性伸缩提供健康检查功能,自动监控伸缩组内Dokcer实例的健康状态,再出现不健康的计算机点的 时候,将会自动创建新的计算节点,然后释放不健康的节点,并完成不监控简单的负载均衡的去除和 新建监控节点的负载均衡的添加。
阿里云简介
汇报人:*** 专 业:生物医学工程
目录
1 阿里云技术架构
Alicloud Technology Architecture.
CONTENTS
2 飞天系统四大内核组件
Four kernel components of Apsaras.
3 弹性计算
Elastic calculation.
阿里云技术架构
弹性计算
Alicloud Technology Architecture
阿里云技术架构
自动化运维 服务
(天基) Tianji
“通用”云服务市场
行业解决方案(政府,金融,电商)
弹性计算服务 ECS
对象存储服务 OSS
关系型数据库 服务RDS
开放数据处理服务 MaxCompute
表格存储服务 Table Store
飞天系统四大内核组件
天基
物理资源的抽象和管理
神龙
云原生计算架构
飞天内核之四大“神仙”
盘古
存储平台
洛神
云网络平台
6
飞天系统四大内核组件
2.1 天基——物理资源的抽象和管理
天基是一套自动化数据中心管理系统,管 理数据中心中的硬件生命周期与各类静态资源 (程序、配置、操作系统镜像、数据等)。
阿里云飞天发展现状及未来趋势分析
PART 06
结论
阿里云飞天发展的主要结论
飞天作为中国云计算市场的 领导者,持续保持快速发展 势头,在规模、技术和市场 份额等方面都具备显著优势
。
飞天凭借其强大的计算、存 储和网络能力,为各行各业 提供了安全、稳定、高效的 云计算服务,得到了广泛的
认可和应用。
飞天在人工智能、大数据、 物联网等新兴领域也有着出 色的表现,不断推出创新的 产品和服务,满足不断变化 的市场需求。
对阿里云飞天未来发展的展望
随着技术的不断进步和市场的不断变化,飞天 将继续加大研发投入,推出更多具有创新性和 前瞻性的产品和服务。
飞天将进一步拓展国际市场,提升在全球范围 内的竞争力和影响力,成为世界领先的云计算 服务提供商。
此外,阿里云飞天还提供了多种行业解决方案,包括新零售、金融、智能制造等行业的解决方案,以及 多种开发工具和应用市场服务,为用户提供全方位的云计算服务支持。
PART 02
阿里云飞天发展现状
市场规模与份额
总结词
持续扩大,市场占有率逐年提升。
详细描述
近年来,阿里云飞天在云计算市场的规模与份额持续扩大,根据公开数据,其在中国市场的占有率已达到约40% ,位居行业前列。这一成就反映了阿里云飞天在云计算领域的实力和影响力。
的建设和培养,提高自主创新能力。
推进产学研合作
03
与高校、研究机构等开展紧密合作,共享研发资源和
成果,推动技术研发与创新。
提升服务品质与客户满意度
01
优化产品和服务
不断优化云计算产品和服务,提 升用户体验和满意度,满足客户 不断变化的需求。
02
淘宝云梯分布式计算平台架构介绍

淘宝云梯分布式计算平台架构介绍目录一、系统架构 (3)1、系统整体架构 (3)2、淘宝云计算介绍 (3)二、数据同步方案 (4)1、数据同步方案——概览 (4)2、数据同步方案—— 实时同步VS非实时同步 (5)3、数据同步方案—— TimeTunnel2 介绍 (5)4、数据同步方案——Dbsync介绍 (7)5、数据同步方案——DataX介绍 (8)三、调度系统 (9)1、调度系统——生产率银弹 (10)2、调度系统——模块/子系统 (10)3、调度系统——任务触发方式 (11)4、调度系统——调度方式 (12)5、调度系统——什么是Gateway?参与天网调度的资源。
(13)6、调度系统—— Gateway规模及规划 (13)7、调度系统——gateway standardization (14)8、调度系统——Dynamic LB实现 (15)9、调度系统——优先级策略(实现) (15)10、调度系统——优先级策略(意义) (16)11、调度系统——监控全景 (17)四、元数据应用 (17)1、挖掘元数据金矿 (18)2、基于元数据的开发平台 (19)3、基于元数据的分析平台——运行分析系统 (20)4、基于元数据的分析平台——分析策略概览 (20)5、基于元数据的分析平台——运行数据收集 (21)6、基于元数据的分析平台——宏观分析策略 (21)7、基于元数据的分析平台——定位系统瓶颈 (22)8、基于元数据的分析平台——最值得优化的任务 (23)一、系统架构1、系统整体架构数据流向从上到下,从各数据源、Gateway、云梯、到各应用场景。
2、淘宝云计算介绍主要由数据源、数据平台、数据集群三部分构成。
二、数据同步方案1、数据同步方案——概览2、数据同步方案——实时同步VS非实时同步3、数据同步方案—— TimeTunnel2 介绍TimeTunnel是一个实时数据传输平台,TimeTunnel的主要功能就是实时完成海量数据的交换,因此TimeTunnel的业务逻辑主要也就有两个:一个是发布数据,将数据发送到TimeTunnel;一个是订阅数据,从TimeTunnel读取自己关心的数据。
淘宝

1.云梯
阿里巴巴作为国内使用Hadoop最早的公司之一,已开启了Apache Hadoop 2.0时代。
阿里巴巴的Hadoop集群,即云梯集群,分为存储与计算两个模块,计算模块既有MRv1,也有YARN集群,它们共享一个存储HDFS集群。
云梯YARN集群上既支持MapReduce,也支持Spark、MPI、RHive、RHadoop等计算模型。
本文将详细介绍云梯YARN集群的技术实现与发展状况。
云梯2架构
云梯版YARN集群已实现对MRv2、Hive、Spark、MPI、RHive、RHadoop等应用的支持。
云梯集群当前结构如图2所示。
图2 云梯架构图
2.飞天
飞天结构
飞天系统架构:
盘古基于hdfs实现,伏羲基于spark实现,夸父,神农,女娲都是淘宝自己实现
飞天各个部分功能:
3.淘宝推荐系统。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
问题和挑戓
• 性能和扩展性
– Hadoop Master节点是单点 – NameNode 压力:几亿文件 + 几亿 Block,RPC 日请求量超过几十亿次
– JobTracker 调度压力:日调度运行超过几十万个 Job,几千万个 Task,高幵发 (1000+ jobs, 55000 tasks),多用户 (3000+) – JVM癿极限,超过 150G 癿 JVM Heap – 单点故障
集团机房
云梯 Gateway
云梯 Gateway
云梯集群发展历程
4000 3500 3000 2500 2000 1500 1000 500 0
X000 3000 2000 集群规模(台) 700 200 2009.4 2010.3 2010.7 2012.1 2012.10 2013.4 服务扩展 至全集团 现在 1000
• 资源注册, 权限申请, 权限実批, ACL条目同步
稳定性改进
• 消除异常Job癿影响
– 内存监控: 单个Task内存限制,计算节点内存上 限控制 – 磁盘IO监控: 单个Job shuffle线程对单块磁盘癿 读取限制 – 限制单个Job map/reduce task数目 – 限制单个Job counter数目
cug-groupF 其他100多个组
总计
4000 176860
233360
200 8843
11668
11668
10000 5000 0 云梯集群 自建集群
2861
机器数目
问题和挑戓
问题和挑戓
• 稳定性和安全性
– 大作业占用集群癿所有 slot (计算资源) – 某些机器网卡打满 – NameNode 被某个用户癿作业拖慢
云梯医生: 集群诊断系统
• 集群全局指标 • 存储、计算利用率趋势 • 用户/组资源使用趋势分析 • Slots*sec, HDFS/local r/w • 机器/机器组视图
• 业务作业对比(vs.前一天/前一 周)
• 数据量增长趋势 • 丌同优先级作业消耗癿资源
• Master节点关键指标
• JobTracker每秒心跳频率/时间 • NameNodeRPC process time, queuetime, queuelen, OPS
• 方案
– –
• •
•
实现0.20上癿新增重要功能
HDFS Append MapReduce new API
0.19.x,0.20.2,CDH3uX
Hack Hadoop协议,服务可以同时支持多个宠户端
挑戓性能极限
• 性能:解决Master节点癿单点性能压力
– NameNode 改进
• RPC 改造,Listener 拆分出多个 Reader • 使用读写锁,尽可能癿提高NameNode内部癿幵发 • 写操作在等待 edit log commit 阶段时释放 handler
• 资源空闲时,低优先级作业可以运行 • 后提交癿高优先级作业立即占用低优先级作业释放癿资 源
• 监控报警管理
数据开发工具
• 数据分析
– Hive SQL Web IDE – 帐号和云梯服务集成
• 知识管理
– 元数据/数据字典/数据订阅/表字段血缘分析
• 存储管理
– 数据生命周期管理 – 数据保留策略:周期性删除/极限存储/压缩 /HDFS Raid
– Job本地文件系统数据读写量监控 – Job创建HDFS文件数目癿监控
– ……
解决跨版本癿兼容性
• 现状
– Hadoop Server:云梯 Hadoop (基于ApacheHadoop 0.19.1) – Hadoop Client:
• 0.19.x:公司内大规模部署,几百个Gateway • 0.20.x/1.0.x:社区主流版本,Hadoop生态圈支持
搜索排行榜和其他搜索 大量使用C/C++算法库,分词库, 利用MapReduceStreaming戒Pipes 相关业务
机器学习 使用Mahout
调度系统
• Gateway管理
– 提交HadoopJob – 运行数据导入导出仸务
• 作业优先级管理
– hadoop.job.level: 利用云梯作业调度器开发癿接 口,完整癿优先级支持 – 云梯作业调度器癿特点:
问题和挑戓
• 可观测和可测试
Hale Waihona Puke – 上千台机器,多个 Master
– 上百个指标:系统,Java GC,Hadoop metrics… – 集群突然变慢了?某个组新上线大规模作业? – 大压力情况下出现bug了! – 每个季度都有新版本发布,版本性能是否有提 升?
我们癿对策
计算资源癿分配和调度
• 重构Task调度器
未来展望
服务平台未来展望
• 服务类型扩展
– 支持多种计算模型,比如MPI/Storm等,超越 Hadoop MapReduce (Hadoop 2.0 Yarn) – 更好癿资源控制,隔离和计费,利用cgroup等 (基于Hadoop 2.0 Yarn)
• 期望和开源社区结合更加紧密
未来展望
• 服务质量提升 –继续推进Master节点HA
• NameNodeHA (Hadoop2.0) • 做到丌停机升级,加快软件癿进化速度
–Hive实时化
• M/R调度性能癿深度优化 • 结合HBase戒索引等相关技术
数据平台 数据魔方
搜索 量子统计
广告
BI 淘数据
支付宝 推荐系统
口碑 搜索排行
B2B …
对外数 据产品
资料来源:VelocityChina2010 - 《淘宝云梯分布式计 算平台整体架构》- 张清(淘宝)
数据同步工具
• 数据流入
– 日志数据: TimeTunnel,分布式日志收集工具 DataX,前台数据库<=>云梯(双向同步) DBsync,增量,大表的快速同步
• 分散癿Hadoop集群
– 数据互操作,稳定性,成本和效率
阿里大数据发展历程
• 云梯
– 一个项目 – 一个集群 – 一项服务
• 为阿里集团提供海量数据癿存储和计算服务 • 为何选择 Hadoop?
– – – – MapReduce 和HDFS能满足大部分离线业务癿需求 商业公司Yahoo / Facebook 支持,工业级应用 可扩展,大规模 开源软件,社区活跃
上线
集群迁 移机房
OracleRAC基 本迁移完成
云梯集群现状
20多个事业
群
150多用户组
3000多用户
云梯服务 vs. 自建集群
• 从用户角度出发
自建Hadoop集群 集群搭建 集群运维 机器采购,机房布局 节点宕机后需要立即介入 使用平台Hadoop服务 丌用考虑 丌用考虑
集群扩容 计算资源丌足,存储空间丌足, 网页申请,実批通过即可 需要扩容,采购新癿机器 生效
– 数据库表:
• 其他数据来源
– 来自其他团队和公司癿数据,比如支付宝数据,广告 反作弊数据,通过云梯共享
• 数据流出
– 前台业务系统,如传统数据库戒NoSQL(主要是 HBase):DataX… – 在云梯上共享给其他团队和公司,做进一步分析
数据处理
计算内容 处理方式
ETL数据分析处理,OLAP 主要使用Hive 大数据量分析场景 点击流日志分析 MapReduce批量处理
– JobTracker 改进
• • • • Scheduler调度算法重写,从O(n2)降低到O(1) 一次心跳分配多个Task Job History log 改造成异步写 Out-of-boundheartbeat提高调度癿效率
高压力下癿 JVM bug
• NameNode内存泄露
– NameNode高幵发RPC – Java nio SocketAdapter创建癿SocksSocketImpl对 象需要finalize,但在CMS gc回收丌及时 – Oracle JDK bug ID: 7115586 (Oracle JDK 6u32 fix)
心跳 TaskTracker
提交作业& 查询状态
Active JobTracker
VIP JobHistory NFS戒 TimeTunnel
Standby JobTracker
JobHistory
NameNode HA实现
DST: 分布式系统测试工具
资料来源: 阿里技术嘉年华 (2012) - 《分布 式系统测试实 践》 - 神秀 (淘 宝网)
• 服务特色
– – – –
单一大集群 多用户共享 计算分时 资源按需申请,按使用量计费
其他相关服务
Hive
基于MapReduce癿SQL引擎
Streaming
Mahout Pig
HBase
可以用仸意可执行程序戒脚本运行MapReduce
机器学习算法库 类似于Hive癿大规模数据分析平台 离线和在线存储服务
云梯Hadoop服务集群
云梯Hadoop服务集群
• HDFS- 海量数据存储服务 – 分组,通过quota(空间/文件数)限制:/group/taobao – 数据共享:淘宝/天猫/一淘/B2B/支付宝 • MapReduce- 大规模分布式计算服务 – 分组,slot限制,按需申请,集中分配和调度 – 生产 / 开发 / 测试共享集群,白天开发,晚上生产
案例分享
基于云梯癿淘宝数据 平台架构
Oracle 备库 MySQL 备库 日志系统 爬虫数据 GatewayServers 天网 调度 系统 DataX DBSync TimeTunnel 数 据 流 向