Memcached缓存分布式架构设计
8种缓存框架介绍

8种缓存框架介绍缓存框架是一种用于存储和管理缓存数据的软件工具或库。
它们用于提高应用程序的性能,减少数据库或其他远程资源的访问次数。
在本文中,我们将介绍8种流行的缓存框架,包括Redis、Memcached、Ehcache、Guava Cache、Caffeine、Hazelcast、Infinispan和Apache Geode。
1. Redis: Redis是一个基于内存的缓存框架,提供了丰富的数据结构和灵活的功能,包括缓存、消息队列和数据持久化。
Redis的性能出色,并且具有高可用性和扩展性。
2. Memcached: Memcached是另一个流行的基于内存的缓存框架,广泛用于提高Web应用程序的性能。
它具有简单的架构和易于使用的API。
Memcached可以在多台服务器上进行水平扩展,以提供更高的负载能力。
3. Ehcache: Ehcache是一个Java缓存框架,可以用于将缓存添加到应用程序中。
它具有简单易用的API,并提供了多种缓存策略,如LRU (最近最少使用)和FIFO(先进先出)。
Ehcache还支持磁盘持久化和分布式缓存。
4. Guava Cache: Guava Cache是Google开发的一个轻量级缓存库,可以在本地JVM中实现缓存功能。
它具有内存敏感的淘汰策略和异步加载机制,可以优化资源利用和应用程序响应时间。
5. Caffeine: Caffeine是另一个基于本地内存的缓存库,由Google开发。
它被设计为高性能、无锁的缓存框架,并且具有比Guava Cache更高的吞吐量和更低的延迟。
6. Hazelcast: Hazelcast是一个分布式缓存框架和数据网格,可以在多个服务器上共享缓存数据。
它提供了分布式数据结构和分布式计算功能,并支持高可用性和容错性。
7. Infinispan: Infinispan是另一个开源的分布式缓存框架,用于构建高性能和高可靠性的应用程序。
分布式缓存设计

分布式缓存设计缓存是提高系统性能的关键组件之一,而分布式缓存则在分布式系统的环境下实现了数据的共享和高效访问。
本文将介绍分布式缓存的设计原理和实践,以及一些常见的分布式缓存方案。
一、缓存的作用缓存是将计算结果、数据库查询结果等常用数据存储在高速读写的存储介质中,以提高系统的性能和响应速度。
在分布式系统中,缓存的作用尤为重要,可以减轻后端数据库的压力,提高系统的可扩展性和可用性。
二、分布式缓存的设计原则1. 数据一致性:分布式缓存需要保证数据的一致性,即缓存中的数据和后端存储中的数据保持同步。
常见的解决方案包括使用缓存更新策略、缓存伪装技术等。
2. 高可用性:分布式缓存需要保证在各种异常情况下都能够正常工作,如节点故障、网络分区等。
常见的解决方案包括使用数据复制、故障检测与恢复机制等。
3. 高性能:分布式缓存需要具备快速读写的能力,以满足系统对高并发读写的需求。
常见的解决方案包括使用缓存预热、数据分片、分布式存储等。
4. 可扩展性:分布式缓存需要支持系统的水平扩展,以应对日益增长的数据访问需求。
常见的解决方案包括使用分布式哈希、一致性哈希等。
三、常见的分布式缓存方案1. Redis:Redis 是一个开源的高性能分布式缓存系统,支持多种数据结构和丰富的功能,如持久化、发布订阅、事务等。
它通过将数据存储在内存中,提供了非常快速的读写性能。
2. Memcached:Memcached 是一个免费的、高性能的分布式内存对象缓存系统,适用于访问模式相对简单的场景。
它通过缓存的方式,将数据存储在内存中,从而提供快速的数据访问速度。
3. Hazelcast:Hazelcast 是一个开源的分布式缓存和计算平台,支持多种数据结构和分布式计算模型。
它可以无缝地集成到 Java 应用中,提供快速的数据访问和计算能力。
四、分布式缓存的设计实践1. 数据划分:根据业务需求和数据访问特点,将数据划分到不同的缓存节点中。
可以采用按数据分片方式,将数据均匀地分布在不同的节点上,提高并发读写能力。
Memcache分布式内存缓存系统

Memcache是什么?memcached是高性能的,分布式的内存对象缓存系统,用于在动态应用中减少数据库教程负载,提升访问速度。
Memcache是的一个项目,目前全世界不少人使用这个缓存项目来构建自己大负载的网站,来分担数据库的压力。
它可以应对任意多个连接,使用非阻塞的网络IO。
由于它的工作机制是在内存中开辟一块空间,然后建立一个HashTable,Memcached自管理这些HashTable。
Memcache官方网站:/memcached,更多详细的信息可以来这里了解关于Memcache和memcached其实应该说这不是个问题,但网上有很多地方用着这两个不同的单词。
Memcache是这个项目的名称,Memcached是这个项目的主程序的文件名,就这么简单。
工作原理:首先 memcached 是以守护程序方式运行于一个或多个服务器中,随时接受客户端的连接操作,客户端可以由各种语言编写,目前已知的客户端 API 包括 Perl/PHP/Python/Ruby/Java/C#/C 等等。
客户端在与 memcached 服务建立连接之后,接下来的事情就是存取对象了,每个被存取的对象都有一个唯一的标识符 key,存取操作均通过这个 key 进行,保存到 memcached 中的对象实际上是放置内存中的,并不是保存在 cache 文件中的,这也是为什么 memcached 能够如此高效快速的原因。
注意,这些对象并不是持久的,服务停止之后,里边的数据就会丢失。
与许多 cache 工具类似,Memcached 的原理并不复杂。
它采用了C/S的模式,在 server 端启动服务进程,在启动时可以指定监听的 ip,自己的端口号,所使用的内存大小等几个关键参数。
一旦启动,服务就一直处于可用状态。
Memcached 的目前版本是通过C实现,采用了单进程,单线程,异步I/O,基于事件 (event_based) 的服务方式.使用 libevent 作为事件通知实现。
Java中的分布式缓存框架有哪些

Java中的分布式缓存框架有哪些随着互联网应用的快速发展,分布式缓存已经成为了提高系统性能和扩展性的关键技术之一。
在Java开发领域,也涌现了许多优秀的分布式缓存框架。
本文将介绍几个Java中常用的分布式缓存框架,并分析它们的特点和适用场景。
一、EhcacheEhcache是一个开源的Java缓存框架,被广泛应用于各种Java应用中。
它提供了基于内存和磁盘的缓存机制,支持分布式部署,能够满足大规模应用的缓存需求。
Ehcache具有轻量级、易于使用和快速的特点,适合用于小型和中型的应用系统。
二、RedisRedis是一种高性能的内存数据存储系统,支持多种数据结构,可以用作分布式缓存的解决方案。
Redis提供了持久化和复制机制,可以实现高可用性和数据持久化。
同时,Redis还具有丰富的功能,如发布订阅、事务管理等,使得它不仅可以作为缓存系统,还可以用于其他用途,如消息队列等。
Redis适用于各种规模的应用系统。
三、MemcachedMemcached是一个简单的高性能分布式内存对象缓存系统。
它使用键值对的方式存储数据,提供了多种API,支持分布式部署。
Memcached具有高速的读写性能和可扩展性,通常被用于缓存数据库查询结果、页面内容等。
它适用于大规模应用和高并发场景,但需要注意的是,Memcached不提供数据持久化功能。
四、HazelcastHazelcast是一个基于Java的开源分布式缓存框架,它提供了分布式数据结构和集群管理功能。
Hazelcast采用了集中式架构,能够实现多节点之间的数据共享和同步。
它具有简单易用的特点,并提供了多种数据结构和并发算法的支持。
Hazelcast适用于构建复杂的分布式应用系统。
五、CaffeineCaffeine是一个在Java中最受欢迎的缓存库之一,它提供了高性能、无锁的内存缓存解决方案。
Caffeine采用了分片策略来管理缓存对象,提供了各种缓存策略和配置选项,可以根据实际需求进行灵活配置。
Memcached开源高性能分布式内存对象缓存系统教程说明书

About the T utorialMemcached is an open source, high-performance, distributed memory object caching system.This tutorial provides a basic understanding of all the relevant concepts of Memcached needed to create and deploy a highly scalable and performance-oriented system.AudienceThis tutorial is designed for software professionals who wish to learn and apply the concepts of Memcached in simple and easy steps.PrerequisitesBefore proceeding with this tutorial, you need to know the basics of data structures.Copyright & DisclaimerCopyright 2018 by Tutorials Point (I) Pvt. Ltd.All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher.We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. If you discover any errors on our website or inthistutorial,******************************************T able of ContentsAbout the Tutorial (i)Audience (i)Prerequisites (i)Copyright & Disclaimer (i)Table of Contents (ii)PART 1 BASICS (1)1.Memcached ─ Overview (2)2.Memcached ─ Environment (3)Installing Memcached on Ubuntu (3)Memcached Java Environment Setup (3)3.Memcached ─ Connection (4)Connection from Java Application (4)PART 2 STORAGE COMMANDS (6)4.Memcached ─ Set Data (7)Set Data Using Java Application (8)5.Memc ached ─ Add Data (9)Add Data Using Java Application (10)6.Memcached ─ Replace Data (11)Replace Data Using Java Application (12)7.Memcached ─ Append Data (14)Append Data Using Java Application (15)8.Memcached ─ Prepend Data (17)Prepend Data Using Java Application (18)9.Memcached ─ CAS Command (20)CAS Using Java Application (21)PART 3 RETRIEVAL COMMANDS (23)10.Memcached ─ Get Data (24)Get Data Using Java Application (24)11.Memcached ─ Get CAS Data (26)Get CAS Data Using Java Application (26)12.Memcached ─ Delete Data (28)Delete Data Using Java Application (28)13.Memcached ─ Increment Decrement Data (30)Incr/Decr Using Java Application (31)PART 4 STATISTICAL COMMANDS (33)14.Memcached ─ Stats (34)Stats Using Java Application (35)15.Memcached ─ Stats Items (37)16.Memcached ─ Stats Slabs (38)17.Memcached ─ Stats Sizes (39)18.Memcached ─ Clear Data (40)Clear Data Using Java Application (40)MemcachedPart 1Basics4Memcached5Memcached is an open source, high-performance, distributed memory caching system intended to speed up dynamic web applications by reducing the database load. It is a key-value dictionary of strings, objects, etc., stored in the memory, resulting from database calls, API calls, or page rendering.Memcached was developed by Brad Fitzpatrick for LiveJournal in 2003. However, it is now being used by Netlog, Facebook, Flickr, Wikipedia, Twitter, and YouTube among others The key features of Memcached are as follows:∙ It is open source.∙ Memcached server is a big hash table. ∙ It significantly reduces the database load.∙ It is perfectly efficient for websites with high database load.∙ It is distributed under Berkeley Software Distribution (BSD) license. ∙It is a client-server application over TCP or UDP.Memcached is not:∙ a persistent data store ∙ a database∙ application-specific ∙ a large object cache∙ fault-tolerant or highly available1. Memcached ─ OverviewInstalling Memcached on UbuntuTo install Memcached on Ubuntu, go to terminal and type the following commands:$sudo apt-get update$sudo apt-get install memcachedConfirming Memcached InstallationTo confirm if Memcached is installed or not, you need to run the command given below. This command shows that Memcached is running on the default port11211.$ps aux | grep memcachedTo run Memcached server on a different port, execute the command given below. This command starts the server on the TCP port 11111 and listens on the UDP port 11111 as a daemon process.$memcached -p 11111 -U 11111 -dYou can run multiple instances of Memcached server through a single installation. Memcached Java Environment SetupTo use Memcached in your Java program, you need to download spymemcached-2.10.3.jar and setup this jar into the classpath.6To connect to a Memcached server, you need to use the telnet command on HOST and PORT names.SyntaxThe basic syntax of Memcached telnet command is as shown below:$telnet HOST PORTHere,HOST and PORT are machine IP and port number respectively, on which the Memcached server is executing.ExampleThe following example shows how to connect to a Memcached server and execute a simple set and get command. Assume that the Memcached server is running on host 127.0.0.1 and port 11211.$telnet 127.0.0.1 11211Trying 127.0.0.1...Connected to 127.0.0.1.Escape character is '^]'.// now store some data and get it from memcached serverset tutorialspoint 0 900 9memcachedSTOREDget tutorialspointVALUE tutorialspoint 0 9memcachedENDConnection from Java ApplicationTo connect the Memcached server from your java program, you need to add the Memcached jar into your classpath as shown in the previous chapter. Assume that the Memcached server is running on host 127.0.0.1 and port 11211.7MemcachedExampleimport net.spy.memcached.MemcachedClient;public class MemcachedJava {public static void main(String[] args) {// Connecting to Memcached server on localhostMemcachedClient mcc = new MemcachedClient(newInetSocketAddress("127.0.0.1", 11211));System.out.println("Connection to server sucessfully");//not set data into memcached serverSystem.out.println("set status:"+mcc.set("tutorialspoint", 900,"memcached").done);//Get value from cacheSystem.out.println("Get from Cache:"+mcc.get("tutorialspoint"));}}OutputOn compiling and executing the program, you get to see the following output:Connection to server successfullyset status:trueGet from Cache:memcached8MemcachedPart 2Storage Commands9Memcached 10Memcached set command is used to set a new value to a new or existing key. SyntaxThe basic syntax of Memcached set command is as shown below: set key flags exptime bytes [noreply]valueThe keywords in the syntax are as described below:∙ key: It is the name of the key by which data is stored and retrieved from Memcached. ∙flags: It is the 32-bit unsigned integer that the server stores with the data provided by the user, and returns along with the data when the item is retrieved. ∙exptime: It is the expiration time in seconds. 0 means no delay. If exptime is more than 30 days, Memcached uses it as UNIX timestamp for expiration. ∙bytes: It is the number of bytes in the data block that needs to be stored. This is the length of the data that needs to be stored in Memcached. ∙ noreply (optional): It is a parameter that informs the server not to send any reply. ∙ value: It is the data that needs to be stored. The data needs to be passed on the new line after executing the command with the above options.OutputThe output of the command is as shown below:STORED∙STORED indicates success. ∙ERROR indicates incorrect syntax or error while saving data.4. Memcached ─ Set DataMemcachedEnd of ebook previewIf you liked what you saw…Buy it from our store @ https://11。
存储系统高可扩展性设计

存储系统高可扩展性设计存储系统的高可扩展性设计,是指系统在面对不断增长的数据量和不断变化的业务需求时,能够保持高效的性能和可靠性。
在当今数据爆炸式增长的时代,高可扩展性设计成为存储系统不可或缺的要素。
本文将从多方面探讨存储系统高可扩展性设计的关键要点。
一、架构设计1. 分布式架构高可扩展性的存储系统应采用分布式架构,通过将数据和计算任务分布到多个节点,实现对数据的并行处理和存储。
分布式架构能够提高系统的吞吐量和处理能力,并且具备良好的横向扩展性,能够根据需求灵活添加新的节点。
2. 数据分片和负载均衡将数据按照某种规则进行分片,将每个片段分布到不同的节点上,实现数据的分布式存储。
同时,通过负载均衡算法,合理地将读写请求分发到各个节点上,避免单个节点负载过高,保证系统整体的性能稳定。
3. 异步处理和消息队列在存储系统中,可以将一些耗时和资源消耗较大的操作进行异步处理,通过消息队列的方式实现任务的解耦和异步执行。
这样可以提高系统的响应速度和吞吐量,降低对实时性要求较高的业务操作的延迟。
二、存储设计1. 分布式文件系统采用分布式文件系统可以将大规模数据分布式存储在多个节点上,并通过元数据管理实现数据的一致性和高可靠性。
常见的分布式文件系统有Hadoop HDFS和GlusterFS等,它们能够提供高可扩展性和高容错性。
2. 数据冗余和备份为了保证数据的安全性和可靠性,存储系统应该进行数据冗余和备份。
通过将数据多次复制到不同的节点或数据中心,即使某个节点或数据中心发生故障,系统仍能继续提供服务,并能够快速恢复数据。
3. 数据压缩和归档随着数据规模的不断增长,存储系统需要考虑对数据进行压缩和归档,以节省存储空间和降低存储成本。
采用有效的压缩算法和归档策略,可以在不降低查询性能的前提下,大幅度减少存储空间的占用。
三、性能优化1. 缓存设计通过合理的缓存设计,可以降低对后端存储的访问压力,提高系统的读写性能。
常见的缓存技术包括内存缓存和分布式缓存,如Redis、Memcached等。
Java分布式缓存使用Redis和Memcached进行缓存管理

Java分布式缓存使用Redis和Memcached进行缓存管理随着互联网应用的快速发展,对于高并发请求的支持成为了一个重要的挑战。
为了提高应用程序的性能和稳定性,缓存是一种常见的解决方案。
本文将介绍如何通过使用Redis和Memcached 进行缓存管理来实现Java分布式缓存。
一、Redis缓存管理Redis是一个开源的内存键值数据库,它支持持久化、集群和事务等特性,非常适合用作缓存存储。
下面是一个使用Redis进行缓存管理的示例代码:1. 引入Redis客户端依赖在pom.xml文件中添加以下依赖项:```<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.10.2</version></dependency>```2. 初始化Redis连接池在应用程序启动时,初始化Redis连接池并创建一个Redis连接对象。
以下是示例代码:```JedisPool redisPool = new JedisPool("localhost", 6379);Jedis jedis = redisPool.getResource();```3. 设置和获取缓存数据使用Redis进行缓存管理时,可以使用set和get方法来设置和获取缓存数据。
以下是示例代码:```// 设置缓存数据jedis.set("key", "value");// 获取缓存数据String value = jedis.get("key");```4. 缓存失效设置为了避免缓存数据过期而导致的脏数据访问问题,可以为每个缓存数据设置一个失效时间。
以下是示例代码:```// 设置缓存数据,并设置失效时间为60秒jedis.setex("key", 60, "value");```二、Memcached缓存管理Memcached是一个高性能的分布式内存对象缓存系统,它以键值对的形式存储数据,并且可以通过哈希算法将数据分布到多个节点上。
缓存设计方案

采用分布式缓存架构,提高系统并发处理能力,确保缓存高可用。
五、详细设计
1.架构设计
-缓存层:负责存储热点数据,减少数据库访问压力。
-服务层:处理业务逻辑,与缓存层交互获取数据。
-数据源:提供原始数据,可以是数据库或其他数据存储服务。
2.数据一致性
-双写策略:在数据更新时同时更新数据库和缓存。
2.缓存架构
采用分布式缓存架构,主要包括以下组件:
(1)缓存服务器:选用成熟稳定的缓存服务器,如Redis、Memcached等。
(2)缓存客户端:集成缓存客户端库,负责与缓存服务器进行通信。
(3)应用服务器:部署缓存策略,实现数据缓存和查询。
3.缓存数据一致性
为确保缓存数据的一致性,采用以下措施:
-动态缓存:针对实时性要求较高的数据,采用动态缓存策略,结合数据更新频率和应用场景选择合适的缓存算法。
2.缓存算法
- LRU(Least Recently Used):对于访问模式稳定、热点数据明显的场景,采用LRU算法。
- LFU(Least Frequently Used):对于访问模式不固定、数据更新频繁的场景,采用LFU算法。
第2篇
缓存设计方案
一、引言
在当前互联网服务日益依赖于大数据处理的背景下,提升数据访问速度、降低系统响应时间成为技术架构设计的重要考量。缓存技术作为提升系统性能的有效手段,其重要性不言而喻。本方案旨在制定一套详细、合规的缓存设计方案,以优化系统性能,提升用户体验。
二、设计原则
1.性能优化:确保缓存机制能够显著降低数据访问延迟,提升系统吞吐量。
5.监控与优化:上线后持续监控,根据反馈优化缓存策略。
七、总结
memcached参数

memcached参数Memcached是一种高性能的分布式内存对象缓存系统,常用于提高Web应用程序的性能和扩展性。
Memcached的设计目标是提供一个简单、快速、可扩展的缓存解决方案,而其参数配置则对其性能和稳定性至关重要。
以下是一些常见的Memcached参数及其作用:2. -U,--udp:启用UDP监听功能。
默认情况下,Memcached使用TCP进行通信,但也可以选择启用UDP。
使用UDP可以提高性能,但同时也可能会导致数据丢失。
3. -l,--listen:指定绑定的IP地址。
默认情况下,Memcached会绑定到所有可用的IP地址上,但可以通过此参数来指定要绑定的特定IP地址。
4. -u,--user:指定运行Memcached进程的用户。
可以使用此参数来提高服务器的安全性,限制只有指定用户才能运行Memcached。
5. -m,--memory:指定Memcached使用的内存大小(以MB为单位)。
这个参数非常重要,它决定了可以缓存的对象数量和大小。
应根据预期的负载和可用内存来调整此参数。
6. -c,--connections:指定Memcached服务器能够处理的最大并发连接数。
默认情况下,这个值是1024,但在高并发情况下,可能需要增加这个值来处理更多的连接。
7. -t,--threads:指定Memcached使用的线程数量。
默认情况下,Memcached会根据可用的处理器核心数量来自动配置线程数,但也可以通过此参数来手动设置线程数量。
9. -R,--max-reqs-per-event:指定每个事件处理器循环中处理的最大请求数。
默认情况下,Memcached每次处理一个请求,但这个参数可以用来限制每个事件处理器循环中处理的请求数,以提高其他连接的响应速度。
以上是一些常用的Memcached参数,通过对这些参数的配置,可以根据实际需求来优化Memcached的性能和稳定性。
Memcached分布式缓存简介

一.什么是MemcachedMemcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。
它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提供动态、数据库驱动网站的速度。
相信很多人都用过缓存,在.net 中也有内置的缓存机制,还有很多第三方工具如apache,nginx等可以做静态资源的缓存,同时我们也可以制定自己的缓存机制,缓存数据库查询的数据以减少对数据库的频繁操作。
但是很多时候我们总是感觉这些缓存总不尽人意,Memcached可以解决你不少的烦恼问题。
最少在我的学习中解决了我不少问题,所以决定记录下来分享。
Memcached基于一个存储键/值对的hashmap。
其守护进程是用C写的,但是客户端可以用任何语言来编写(本文使用C#作为例子),并通过memcached协议与守护进程通信。
可能这些东西都太高深了,我们暂不做研究。
二.分布式缓存其实 Memcached作为一个分布式缓存数据服务,但是每个服务之间根本没有进行相互通信,这里可能与我理解的分布式有点区别,可能是我才疏学浅,也可能是每个人思考问题的角度不同。
Memcached 客户端就是通过一种分布式算法将数据保存到不同的Memcached服务器上,将数据进行缓存。
分布式缓存,可以而知memcached可以进行大数据量的缓存。
这点可以弥补我们之前很多人都遇到的将数据缓存到应用服务器上,而且只能缓存少量数据,否则对应用服务器的影响非常大。
Memcached应用机制图:这个图是有点简陋了,但是问题还是能够描述的清楚的,缓存机制的基本原理就是先查询数据保存到memcached中,地址在此请求就直接从Memcached缓存中取数据,这样就可以减少对服务器请求压力。
三.Memcached 特征(1)协议简单: 不使用复杂的xml格式,而是使用文本格式(2)基于libevent的事件处理机制 (不懂)(3)内置内存存储方式: 数据存在在内存中,所以重启机器会导致数据丢失(4)Memcached相互不通信的分布式: Memcached 服务器之间不会进行通信,数据都是通过客户端的分布式算法存储到各个服务器中四.Memcached的安装首先这里是在windows系统上做测试,Memcached在linux等非windows平台上性能会更高。
使用Docker容器部署和管理Memcached缓存

使用Docker容器部署和管理Memcached缓存随着互联网的快速发展,大量的数据处理和存储需求逐渐涌现。
为了提高应用程序的性能和响应速度,缓存成为了不可或缺的一部分。
而Memcached作为一种高性能的分布式内存对象缓存系统,被广泛应用于各类网站和应用程序中。
本文将探讨使用Docker容器来部署和管理Memcached缓存的方法和优势。
Docker是一个开源的容器化平台,可以将应用程序及其依赖打包成轻量级、可移植的容器,并进行部署和管理。
相较于传统的虚拟机技术,Docker提供了更快速、更高效的部署和资源利用方式。
对于Memcached这种高性能的缓存系统,使用Docker进行部署和管理是一个理想的解决方案。
首先,在部署Memcached缓存之前,我们需要在本地安装Docker。
安装完成后,可以通过Docker Hub来获取Memcached的Docker镜像。
Docker Hub是一个存储和分享Docker镜像的在线平台,用户可以在其中找到各种基础镜像和应用程序镜像。
在命令行中执行以下命令,即可从Docker Hub上下载Memcached镜像:```docker pull memcached```下载完成后,可以通过以下命令来创建一个Memcached容器:```docker run -d -p 11211:11211 --name my_memcached memcached```上述命令的含义是以后台模式运行一个Memcached容器,将容器内部的11211端口映射到本地的11211端口,并将容器命名为my_memcached。
接下来,我们可以使用telnet命令来测试是否成功部署了Memcached缓存:```telnet localhost 11211```如果成功连接上了Memcached服务器,则说明容器已经正确部署并且可以正常访问了。
使用Docker部署和管理Memcached缓存的好处不仅仅在于简化了部署过程,还包括了以下几个优势:1. 资源隔离:每个Docker容器都有自己独立的进程空间和文件系统,不会相互影响。
memcached 构建分布式缓存
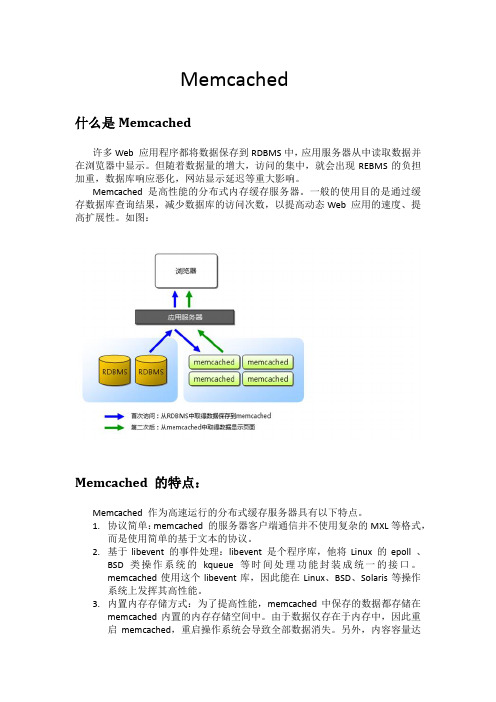
Memcached什么是Memcached许多Web 应用程序都将数据保存到RDBMS中,应用服务器从中读取数据并在浏览器中显示。
但随着数据量的增大,访问的集中,就会出现REBMS的负担加重,数据库响应恶化,网站显示延迟等重大影响。
Memcached是高性能的分布式内存缓存服务器。
一般的使用目的是通过缓存数据库查询结果,减少数据库的访问次数,以提高动态Web 应用的速度、提高扩展性。
如图:Memcached的特点:Memcached作为高速运行的分布式缓存服务器具有以下特点。
1.协议简单:memcached的服务器客户端通信并不使用复杂的MXL等格式,而是使用简单的基于文本的协议。
2.基于libevent的事件处理:libevent是个程序库,他将Linux 的epoll、BSD类操作系统的kqueue等时间处理功能封装成统一的接口。
memcached使用这个libevent库,因此能在Linux、BSD、Solaris等操作系统上发挥其高性能。
3.内置内存存储方式:为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。
由于数据仅存在于内存中,因此重启memcached,重启操作系统会导致全部数据消失。
另外,内容容量达到指定的值之后memcached回自动删除不适用的缓存。
4.Memcached不互通信的分布式:memcached尽管是“分布式”缓存服务器,但服务器端并没有分布式功能。
各个memcached不会互相通信以共享信息。
他的分布式主要是通过客户端实现的。
Memcached的内存管理最近的memcached默认情况下采用了名为Slab Allocatoion的机制分配,管理内存。
在改机制出现以前,内存的分配是通过对所有记录简单地进行malloc 和free来进行的。
但是这中方式会导致内存碎片,加重操作系统内存管理器的负担。
Slab Allocator的基本原理是按照预先规定的大小,将分配的内存分割成特定长度的块,已完全解决内存碎片问题。
分布式系统架构 技术栈详解

分布式系统架构技术栈详解分布式系统架构是一种通过将系统的不同组件分布在不同的节点上来实现高可用性、可伸缩性和容错性的系统设计方法。
它是一种将任务分解成多个子任务,并通过网络进行通信和协作的系统架构。
在分布式系统架构中,技术栈是指用于构建和管理分布式系统的各种技术和工具的集合。
下面将介绍几个常用的技术栈。
1. 分布式存储技术:分布式存储技术是分布式系统中的核心技术之一。
它将数据分布到多个节点上,实现数据的高可用性和容错性。
常见的分布式存储技术包括分布式文件系统(如HDFS)、分布式数据库(如Cassandra和MongoDB)等。
2. 分布式计算技术:分布式计算技术用于将计算任务分布到多个节点上并进行并行计算。
常见的分布式计算技术包括MapReduce(如Hadoop)和Spark等。
这些技术通过将大规模的计算任务分解成多个小任务,并在多个节点上并行执行,从而实现高效的计算。
3. 分布式消息队列技术:分布式消息队列技术用于在分布式系统中实现异步通信和解耦。
它通过提供可靠的消息传递机制来实现系统间的解耦和异步通信。
常见的分布式消息队列技术包括Kafka和RabbitMQ等。
4. 分布式缓存技术:分布式缓存技术用于在分布式系统中提高数据访问性能。
它将数据缓存在多个节点上,以减轻数据库的负载和提高系统的响应速度。
常见的分布式缓存技术包括Redis和Memcached等。
5. 分布式服务框架技术:分布式服务框架技术用于实现分布式系统中的服务调用和管理。
它提供了服务注册、发现和负载均衡等功能,简化了分布式系统的开发和维护。
常见的分布式服务框架技术包括Dubbo和Spring Cloud等。
以上是几个常用的分布式系统架构技术栈。
在实际应用中,根据具体的需求和场景,还可以选择其他技术和工具来构建和管理分布式系统。
分布式系统架构的设计和实现是一个复杂而关键的任务,需要综合考虑系统的可靠性、性能和可扩展性等方面的需求。
系统缓存架构设计

系统缓存架构设计全文共四篇示例,供读者参考第一篇示例:系统缓存在软件开发中起着至关重要的作用,它能够大大提高系统的性能和响应速度。
设计一个高效的系统缓存架构是至关重要的。
在本文中,将探讨系统缓存架构的设计原则、常见的缓存类型、缓存技术选型以及系统缓存的性能优化等方面。
一、系统缓存架构的设计原则1. 数据一致性:系统缓存中的数据必须保持与数据库中的数据一致。
在进行数据更新操作时,必须及时同步更新缓存中的数据。
2. 高性能:系统缓存应该具有高性能的特点,即能够快速响应请求,提高系统的处理速度。
3. 可扩展性:系统缓存应该具有良好的扩展性,能够随着系统规模的增加而灵活扩展。
4. 高可用性:系统缓存应该能够保证高可用性,即在系统故障或网络异常的情况下能够正常运行。
5. 容错性:系统缓存应该具有容错能力,能够处理各种异常情况下的数据同步和恢复操作。
二、常见的缓存类型1. 本地缓存:本地缓存是指将数据缓存在本地服务器内存中,以减少数据库访问,提高系统的性能。
3. 内存数据库:内存数据库是指将数据存储在内存中的数据库系统,能够提供高速的数据读写操作,适合于对实时数据进行处理。
4. 网络缓存:网络缓存是指将数据缓存在网络节点上,以提高数据的访问速度和响应时间。
三、缓存技术选型1. Redis:Redis是一款开源的内存数据库系统,具有高性能、高可用和可扩展性等特点,适合于构建高效的系统缓存架构。
2. Memcached:Memcached是一款开源的分布式内存缓存系统,能够实现数据的分布式存储和访问,提高系统的性能和可扩展性。
3. Ehcache:Ehcache是一款Java开源的本地缓存系统,能够提供高速的缓存操作,适合于在本地服务器上缓存数据。
四、系统缓存的性能优化1. 缓存命中率优化:通过优化缓存的命中率,能够减少数据库访问次数,提高系统的性能和响应速度。
2. 缓存同步策略优化:通过优化缓存的同步策略,能够及时更新缓存中的数据,保证数据的一致性。
缓存设计方案

缓存设计方案缓存设计方案概述缓存是一种将数据存储在临时内存中的技术,目的是提高数据访问速度和系统性能。
在大多数应用程序中,缓存通常用来存储频繁访问的数据,以减少对底层数据存储系统的负载。
本文将介绍缓存的设计方案,包括缓存的选择、缓存数据的更新和失效策略,以及缓存的一些最佳实践。
缓存选择在选择缓存方案时,我们需要根据应用程序的特点和需求来做出合适的选择。
以下是一些常用的缓存方案:1.本地缓存本地缓存是将数据存储在应用程序所在的服务器或客户机上的缓存方案。
它的优点是速度快、使用简单,适合存储小规模的数据。
然而,本地缓存的容量有限,且在分布式系统中无法共享数据。
2.分布式缓存分布式缓存是将数据存储在多台服务器上的缓存方案。
它的优点是容量大、可扩展性强,适合存储大规模的数据。
另外,分布式缓存可以通过网络访问,实现数据的共享和协作。
3.内存缓存内存缓存是将数据存储在内存中的缓存方案。
它的优点是读写速度极快,适合存储频繁访问的数据。
然而,由于内存容量有限,内存缓存可能导致数据丢失和系统崩溃的风险。
4.磁盘缓存磁盘缓存是将数据存储在磁盘上的缓存方案。
它的优点是容量大、持久化性强,适合存储大量的数据。
然而,由于磁盘读写速度相对较慢,磁盘缓存可能导致数据访问速度的下降。
根据应用程序的特点和需求,可以选择合适的缓存方案或结合多种缓存方案来满足不同的需求。
缓存数据的更新和失效策略在设计缓存方案时,我们需要考虑缓存数据的更新和失效策略,以保证缓存数据的准确性和有效性。
1.更新策略- 手动更新:手动更新缓存数据,适用于数据变动较少的情况。
可以通过定时任务或手动触发来进行更新。
- 自动更新:自动更新缓存数据,适用于数据变动频繁的情况。
可以通过监听数据变动事件或使用缓存代理来实现自动更新。
2.失效策略- 基于时间的失效策略:设置缓存数据的过期时间,当数据过期时自动失效。
适用于数据更新频率较低的情况。
- 基于事件的失效策略:监听数据变动事件,当数据发生变化时自动失效。
分布式缓存系统Memcached入门指导

分布式缓存系统Memcached入门指导摘要:这篇Memcached入门介绍涵盖的主题包括安装、配置、memcached 客户机命令和评估缓存效率,主要讨论与 memcached 服务器的直接交互,其目的是为您提供监控memcahed 实例所需的工具。
首先介绍一下,memcached 是由 Danga Interactive 开发并使用 BSD 许可的一种通用的分布式内存缓存系统Memcached示意图(来自)Danga Interactive 开发 memcached 的目的是创建一个内存缓存系统来处理其网站 的巨大流量。
每天超过 2000 万的页面访问量给 LiveJournal 的数据库施加了巨大的压力,因此 Danga 的 Brad Fitzpatrick 便着手设计了 memcached。
memcached 不仅减少了网站数据库的负载,还成为如今世界上大多数高流量网站所使用的缓存解决方案。
本文首先全面概述memcached,然后指导您安装memcached 以及在开发环境中构建它。
我还将介绍 memcached 客户机命令(总共有 9 个)并展示如何在标准和高级 memcached 操作中使用它们。
最后,我将提供一些使用 memcached 命令测量缓存的性能和效率的技巧。
如何将 memcached 融入到您的环境中?在开始安装和使用 using memcached 之前,我们需要了解如何将 memcached 融入到您的环境中。
虽然在任何地方都可以使用 memcached,但我发现需要在数据库层中执行几个经常性查询时,memcached 往往能发挥最大的效用。
我经常会在数据库和应用服务器之间设置一系列 memcached 实例,并采用一种简单的模式来读取和写入这些服务器。
图 1 可以帮助您了解如何设置应用程序体系结构:图 1. 使用 memcached 的示例应用程序体系结构体系结构相当容易理解。
常见缓存方案

常见缓存方案缓存是提高系统性能的重要手段之一,通过预先加载数据或计算结果,可以减少系统对繁重和耗时的操作的依赖。
在现代计算机系统中,有许多常见的缓存方案可供选择。
本文将讨论一些常见的缓存方案,包括内存缓存、数据库缓存和分布式缓存。
一、内存缓存内存缓存是最常见的缓存方案之一,它利用系统的内存资源来存储经常使用的数据。
通过将数据存储在内存中,可以大大提高访问速度,从而加快系统的响应时间。
内存缓存一般使用键值对的方式存储数据,通过键来快速查找和获取对应的值。
常见的内存缓存实现包括Memcached和Redis。
1. MemcachedMemcached是一个高性能的内存对象缓存系统,它可以用来存储任意类型的数据。
Memcached将数据存储在内存中,并使用哈希表来快速查找数据。
它支持分布式架构,可以在多台服务器上部署,实现数据的分布式存储。
由于其高效的性能和可扩展性,Memcached被广泛应用于大规模网站和应用程序中。
2. RedisRedis是一个开源的内存数据结构存储系统,它支持多种数据类型,包括字符串、哈希、列表和有序集合等。
Redis也是基于键值对的存储方式,并提供了丰富的命令集合来操作数据。
与Memcached相比,Redis 具有更丰富的功能,例如支持持久化、事务和发布订阅等特性。
因此,Redis在许多场景下被用作高性能缓存解决方案。
二、数据库缓存数据库缓存是指在应用程序和数据库之间增加一个中间层,用来缓存数据库查询结果。
通过将热数据存储在数据库缓存中,可以大大减少对数据库的访问次数,提高系统的响应速度和并发能力。
常见的数据库缓存实现包括Query Cache和第三方缓存组件。
1. Query CacheQuery Cache是MySQL数据库自带的缓存功能,它可以缓存查询语句的结果集。
当应用程序执行相同的查询语句时,MySQL会首先检查Query Cache中是否存在该查询的缓存结果,如果存在则直接返回缓存结果,而不会再次执行查询。
memcache分布式原理

Memcache是一种分布式内存缓存系统,它的分布式原理主要包括以下几个方面:1. 数据分片:Memcache将数据分成多个片段,每个片段存储在不同的服务器上。
这样可以将数据均匀地分布在不同的节点上,提高系统的并发处理能力和数据存储容量。
2. 一致性哈希算法:为了确定数据应该存储在哪个节点上,Memcache使用一致性哈希算法。
该算法将数据的键值通过哈希函数映射到一个固定的哈希环上,然后根据节点的位置在环上进行分配。
这样可以保证当节点增加或减少时,只有少量的数据需要重新分配。
3. 节点间通信:在Memcache中,各个节点之间通过网络进行通信。
当一个节点接收到一个请求时,它会首先检查本地是否有所需的数据,如果没有则会向其他节点发送请求。
节点之间的通信可以通过TCP/IP协议进行,也可以使用UDP 协议进行更快的数据传输。
4. 数据一致性:在分布式系统中,数据一致性是一个重要的问题。
Memcache通过使用复制和失效机制来保证数据的一致性。
当一个节点接收到一个写请求时,它会将数据写入本地缓存,并将数据复制到其他节点上。
当一个节点接收到一个读请求时,它会首先检查本地缓存是否有所需的数据,如果没有则会向其他节点请求数据。
5. 负载均衡:为了提高系统的性能和可扩展性,Memcache 使用负载均衡算法将请求均匀地分配到不同的节点上。
常用的负载均衡算法包括轮询、随机和最少连接等。
总的来说,Memcache通过数据分片、一致性哈希算法、节点间通信、数据一致性和负载均衡等机制实现了分布式的存储和访问。
这些机制使得Memcache能够处理大量的并发请求,并提供高性能的缓存服务。
Memcache分布式部署方案

前言应该是很久之前,我开始研究Memcache,写了一系列的学习心得,比如《Discuz!的Memcache缓存实现》等。
后面的好几十条回复也让这篇文章成为了此博客中颇受关注的一员。
同时在百度和Google,关键词Memcache在长达一年多的时间里占据着第二位(第一位是官方),为很多需要了解或者应用Memcache的朋友提供了一些信息,但是我始终觉着还不够,于是本文诞生。
唠唠叨叨说了半天,如果你觉着前面啰嗦,请直接看最后一大段,那是本文的重点。
基础环境其实基于PHP扩展的Memcache客户端实际上早已经实现,而且非常稳定。
先解释一些名词,Memcache是的一个开源项目,可以类比于MySQL 这样的服务,而PHP扩展的Memcache实际上是连接Memcache的方式。
首先,进行Memcache被安装具体可查看:Linux下的Memcache安装:/257.htmlWindows下的Memcache安装:/258.html;其次,进行PHP扩展的安装,官方地址是/package/memcache最后,启动Memcache服务,比如这样/usr/local/bin/memcached -d -p 11213 -u root -m 10 -c 1024 -t 8 -P /tmp/memcached.pid/usr/local/bin/memcached-d -p 11214-u root -m 10-c 1024-t 8-P/tmp/memcached.pid/usr/local/bin/memcached-d -p 11215-u root -m 10-c 1024-t 8-P/tmp/memcached.pid启动三个只使用10M内存以方便测试。
分布式部署PHP的PECL扩展中的memcache实际上在2.0.0的版本中就已经实现多服务器支持,现在都已经2.2.5了。
请看如下代码$memcache = new Memcache;$memcache->addServer('localhost', 11213);$memcache->addServer('localhost', 11214);$memcache->addServer('localhost', 11215);$memStats = $memcache->getExtendedStats();print_r($memStats);通过上例就已经实现Memcache的分布式部署,是不是非常简单。