csdn博客
爬取CSDN博客保存成PDF的方法

• 144•ELECTRONICS WORLD ・技术交流爬取CSDN博客保存成PDF的方法中国电波传播研究所 刘 士中国电子科技集团公司第五十二研究所 支 浩本文阐述了一种爬取指定CSDN 账号的所有博文进行内容提并批量合并成PDF 的方法,对该方法给出了Python 语言的实现方式。
实验结果证明,该方法具有可操作性和实用性。
引言:在实际工作中常常需要对感兴趣的CSDN 博文保存成电子书,从而可以达到多设备、无网络的情况下进行阅读。
本文介绍了如何使用Chrome 浏览器和Python 语言将目标博客内容爬取后进行信息提取,然后合并成PDF 格式的方法。
除Python 自带的标准库外,所用到的Python 库为BeautifulSoup 、pdfkit 、PyPDF2。
本文一个主要成果是对爬取到的网页进行有效的数据清洗和自定义,在博客篇数较多时进行快速合并。
1.实现步骤本文的实现符合爬虫的一般步骤即:“目标爬取、数据清洗、内容整合”。
首先针对某一个感兴趣的作者爬取他的所有博文,然后进行信息提取后保存为PDF 格式,最后将所有的PDF 进行合并得到目标PDF 。
1.1 爬取原始网页(Python 3 documentation;https:///3/.)①爬取文章列表,使用chrome 浏览器打开网址“https:///用户名/article/list/页码”可以获取指定用户某一页的所有文章。
其中“用户名”为博客作者的用户名,页码为从1开始的整数。
从“页码”为1开始依次递增遍历可以获取所有页面文章列表,当页码超出范围后网页会有“空空如野”提示,可作为终止条件;②在上一步中进行网页内容解析后发现class=’article-list ’中的所有<a>链接为具体某一篇博文的地址,可使用BeautifulSoup 进行内容提取;③提取上一步中的a 链接的href 属性后使用urlopen 获取某一篇博文内容并保存到数据库。
csdn发布文章的流程

csdn发布文章的流程发布文章是一种方式,让我们可以分享我们的知识和经验,与他人进行交流和讨论。
CSDN作为一个专业的技术社区,提供了一个优秀的平台,供我们发布和分享技术文章。
本文将一步一步回答关于CSDN发布文章的流程。
1. 注册CSDN账号首先,访问CSDN官方网站,点击注册按钮进入注册页面。
填写所需的信息,如用户名、邮箱、密码等,并验证邮箱。
点击提交后,您将成功注册一个CSDN账号。
如果您已经拥有CSDN账号,可以跳过这一步。
2. 登录CSDN账号使用您的用户名和密码登录CSDN账号。
如果遇到登录问题,可以根据提示找回密码或者联系CSDN客服。
3. 创建个人博客在登录成功后,点击页面右上角的“我的博客”,进入个人博客管理页面。
如果您还没有创建个人博客,可以点击“创建博客”按钮。
按照页面提示填写相关信息,包括博客名称、博客描述等。
点击提交后,您将成功创建个人博客。
4. 点击“发表文章”在个人博客管理页面,点击“发表文章”按钮,即可进入文章编辑页面。
5. 编写文章内容在文章编辑页面,您可以输入文章的标题、正文和其他相关内容。
建议合理使用段落、标题和列表等标签,以提高文章的可读性。
同时,可以上传文章相关的图片和代码等。
6. 设置文章属性在文章编辑页面的右侧,有一栏用于设置文章属性。
您可以设置文章的分类(如技术分享、学习心得等)、标签(如Java、Python等)、阅读权限和评论权限等。
根据文章的内容和目的设置相关属性。
7. 预览和编辑文章在编辑文章的过程中,可以随时点击预览按钮,预览文章在CSDN上的展示效果。
如果需要对文章进行修改,可以点击编辑按钮,返回文章编辑页面进行相应的修改。
8. 发布文章当文章编辑完成后,可以点击发布按钮,将文章发布到CSDN上。
请确保文章的内容准确、明确,符合CSDN的发布规范和版权要求。
9. 分享和推广发布文章后,CSDN将自动为您生成文章的链接。
您可以在个人博客管理页面找到已发布的文章,并点击文章链接进行访问和分享。
CSDN博客与博客园使用对比(转载)

CSDN博客与博客园使⽤对⽐(转载)前⼀篇中写到了⼀些⾃⼰对于ITEYE的使⽤感受,现在再来看看CSDN博客与博客园——两个著名的IT博客之间的⽐较(仅仅是个⼈体会,并⽆好恶之辨)。
⾸先从基本功能来说都差不多,先从主页上来看,都是三列的分布,前两个都⼀样:分类导航、热门⽂章,第三列不太相同:CSDN是公告和其他热门⽂章,⽽博客园的那⼀列主要是搜索栏和新闻,个⼈感觉博客园的设置更合理⼀些,IT业的迅猛发展需要程序员们经常关注业内新闻,这样博客园⾸页就很⽅便了,另外其右边google搜索也很⽅便(对于我这样的初学者⽽⾔)。
再看看版⾯的设置:CSDN的论坛、资源、资讯之类的被放到了页⾯的左上⾓,⽽博客主页的导航栏上只有有关博客的“专家”“排⾏榜”等索引。
与此相对⽐:博客园的导航栏就把所有业务都显⽰出来了:⾸页新闻博问闪存⼩组⽹摘招聘专题知识库。
“博问”类似于百度知道,“闪存”很像微博发状态,“招聘”包括了各种求职、猎头信息……总体说来就是⼀站式服务。
这两种布局各有各的好处,CSDN博客保持了版⾯的纯博客形式,功能整齐划⼀,除了能被分享到微博外并未与社交⽹站有任何交集,⽽博客园则是百花齐放争取多⽅⾯服务,具体的使⽤效果还得诸位⽤户来评价。
UI⽅⾯:我觉得博客园在这⽅⾯的确与CSDN有不⼩的差距,⾸先:个⼈主页与博客园主页的上部导航栏不⼀致,⽐如在我的amazingidiot 主页上部点“新闻”就切换到主页中的新闻版块了,想再回到⾃⼰的主页只能点Backspace或是右上⾓的“我的博客”,在这⽅⾯CSDN就做得很好,⽤⼀个CSDN空间来统⼀⽤户个⼈的所有窗⼝。
其次,不同层次之间的页⾯风格也没有做到统⼀,光是logo就有三种。
这种混乱确实给新⽤户带来不⼩的压⼒。
但是,从个性化的⾓度来讲,我认为博客园优于CSDN,举例来讲:CSDN的个⼈博客只有三种⽪肤(⽪肤“炫酷⿊”还是7.21上线的…),基本不能进⾏个性化,这虽然有利于快速找到所需内容,但对于追求长时间浏览的⽤户会产⽣疲劳感,另外也不利于吸纳追求个性的博主。
csdn技术博文内容采集规则

CSDN技术博文内容采集规则随着互联网的发展,技术博客已经成为了程序员学习、交流的重要评台。
CSDN作为国内知名的技术社区,汇聚了大量的优质技术博文。
然而,对于这些博文的内容采集和使用,CSDN也有一系列的规则和要求。
为了维护技术内容的质量和保护原创作者的权益,CSDN对技术博文内容采集进行了严格的管理。
下面将详细介绍CSDN技术博文内容采集的规则:1. 原创内容优先CSDN鼓励原创内容,对原创作者给予更多的关注和支持。
在内容采集的规则中,CSDN明确规定对于非原创内容将会进行优先屏蔽或限制。
CSDN也鼓励作者注册原创声明,以便更好地保护自己的知识产权。
2. 合法合规CSDN严格要求其评台上的内容必须合法合规。
不得发布任何违法违规的技术博文,包括但不限于侵犯他人知识产权、传播色情、暴力等不良信息。
对于违规内容,CSDN将会进行严厉处罚,并保留追究其法律责任的权利。
3. 注重质量CSDN对技术博文的内容质量有着严格的要求,内容必须真实可信、原创性强、结构清晰、语言表达准确。
对于质量不合格的博文,CSDN 将有权拒绝其采集或进行下架处理。
4. 保护知识产权CSDN尊重知识产权,鼓励原创作者注册原创声明,并通过技术手段保护原创内容。
对于未经授权的内容采集、转载、引用行为,CSDN 将会追究责任,并对侵权行为进行处理。
5. 严格审核机制CSDN设立了严格的内容审核机制,对技术博文内容进行精准的筛选和审核。
只有通过审核的内容才能在评台上被采集并展示,以确保用户获取到的是高质量、有价值的技术内容。
CSDN技术博文内容采集规则严格,旨在维护技术内容的质量和保护原创作者的权益。
对于广大技术博客作者来说,应当严格遵守CSDN 的规定,积极提升内容质量,促进技术共享,共同打造良好的技术交流评台。
技术博客的发展受益于互联网的快速发展,为程序员们提供了一个交流学习的评台。
CSDN作为国内领先的技术社区,聚集了大量优质的技术博文。
csdn转载别人的博客的注意事项

csdn转载别人的博客的注意事项在使用CSDN转载别人的博客时,我们需要注意一些事项,以确保合规和尊重原作者的劳动成果。
以下是一些注意事项:1. 尊重原作者:在转载别人的博客时,我们首先要尊重原作者的权益和劳动成果。
应该在文章开头明确标注原文作者和出处,并在适当的地方表达对原作者的致谢和赞赏。
2. 转载许可:在转载他人博客之前,需要确保获得了原作者的转载许可。
可以通过与原作者联系或查看原文中是否有明确的转载授权说明来确认。
3. 不要修改原文:转载时应尽量保持原文的完整性和准确性,不要对原文进行修改。
如果需要进行一些必要的调整,比如格式调整或语言修正,应当注明并尽可能与原文保持一致。
4. 避免重复转载:在CSDN上进行转载时,应避免转载已经在其他地方广泛传播的博客,以避免信息的重复和降低原创性。
5. 内容准确性和可信度:在转载别人的博客时,我们需要确保内容的准确性和可信度。
可以通过查看原作者的资质、专业性以及其他读者的评价来评估内容的可靠性。
6. 适当修改标题和摘要:在转载时,可以根据实际情况适当修改标题和摘要,以更好地反映文章的核心内容,但不应歪曲原文的观点和主题。
7. 引用和注明:在转载时,如果需要引用原文中的某些观点或数据,应当使用恰当的引用格式,并在文中明确注明引用的来源和页码,以避免抄袭行为。
8. 不要涉及版权问题:在转载别人的博客时,要确保所转载的内容不会侵犯他人的版权。
应避免转载商业性内容、涉及专利或商标等受保护的内容。
9. 不要误导读者:在转载时,要避免对原文内容进行歪曲、误导或片面解读,应尽量保持原文的原意和观点。
10. 不要过度依赖转载:转载别人的博客只是获取信息的一种方式,不应过度依赖。
应该积极参与讨论和思考,在有需要时与原作者进行进一步的交流和深入研究。
总结起来,转载别人的博客需要尊重原作者的权益和劳动成果,确保获得转载许可并保持内容的准确性和可信度。
在转载过程中,需要遵循一些规范和原则,以确保合规和尊重原创。
CSDN CODE代码笔记用户手册

代码笔记用户手册目录1. 什么代码片笔记 (2)2. 代码笔记功能和操作介绍......................... 错误!未定义书签。
2.1功能一览 (3)2.2操作介绍 ................................... 错误!未定义书签。
3. 如何一键收藏博客中的代码片? (6)4. 如何一键引用已有代码片? (7)1.什么是代码笔记即:为所有的用户提供舒适的代码片编辑区和以目录为结构的文件管理视图。
使用户能够一目了然的管理海量代码片段,也方便用户对代码片进行分类整理,提高效率。
同时代码笔记支持编辑代码,支持一键引用和收藏代码片。
由于代码片功能是一项非常实用的重要功能,所以代码笔记的出现是希望能给大家一个关于代码片存放和整理的“云端空间”,从而不怕丢失任何信息和片段。
我们提供这样的一种服务,旨在便捷用户,从此可一键使用代码片,提高使用率和效率。
代码笔记的入口:Url地址:https:///snippets_manage代码笔记的界面:2.代码片功能一览及操作介绍功能一览代码笔记提供如下功能:提供目录结构的视图,一目了然的管理大量代码片段。
对代码片支持建立分类,能够更容易按照标签或者类别进行整理和使用。
支持一键复制代码片内容,省时省力。
提供代码编辑区域,支持按照语言分类和主题设置。
简化流程,可自动保存,无需担心丢失任何代码。
优化代码片排序功能:提供时间和文件名的方式排序。
优化搜索窗口,更方便的定位到您需要的代码片段里。
针对CSDN博客,代码笔记做了如下升级:针对CSDN博客,代码笔记做了如下升级:您可以一键保存所有文章内的代码片,无需复制粘贴,即可永久保存云端,方便及时查看。
在写博文时,您可以一键调用已收藏/已存在的代码片,采用按钮操作,无需调用代码片地址。
操作介绍对分类进行操作:●点击下图中新建分类即可进行操作。
●对已有分类,点击右上角下拉箭头可实现:重命名/新建分类/下载/删除等功能对于代码片段,点击详情后,可以完成以下操作:●修改代码片资料:名称/标签/代码片属性●对代码片进行操作:移动/复制/下载/删除筛选操作:新建代码片的两个入口:3.如何一键收藏博客中的代码片?在CSDN博客中,您可以一键保存所有文章内的代码片,无需复制粘贴,即可永久保存云端,方便及时查看。
csdn博客的写作方式

csdn博客的写作方式摘要:一、CSDN博客简介二、CSDN博客的写作方式1.选择合适的标题2.明确文章结构3.编写引人入胜的开头4.注意内容排版和图片使用5.结尾总结和引导读者评论三、CSDN博客的优势和不足四、如何提高CSDN博客的阅读量1.关注热门技术和话题2.定期更新和保持活跃3.与其他博主互动和交流4.善于学习和借鉴优秀博主的作品五、撰写CSDN博客的注意事项1.保持原创性和真实性2.避免抄袭和侵权行为3.尊重他人知识产权和隐私4.遵循博客平台规定和道德规范正文:CSDN(China Software Developer Network)是中国最大的IT技术社区,拥有众多注册会员和丰富的技术资源。
在CSDN平台上,博客作为一种重要的知识分享形式,被广大程序员和技术爱好者所喜爱。
本文将为您介绍CSDN博客的写作方式,帮助您更好地利用这个平台分享技术和经验。
一、CSDN博客简介CSDN博客是一个供程序员和技术人员发布、分享技术文章和心得的平台。
用户可以在博客中撰写关于编程、软件开发、互联网、IT硬件等方面的原创文章,以图文并茂的形式与读者交流。
CSDN博客的特点包括:1.丰富的内容:涵盖了各行各业的IT技术领域,让用户可以随时了解到最新的技术动态和应用实例。
2.便捷的发表:支持markdown语法和在线编辑器,让用户可以轻松地撰写和排版文章。
3.活跃的社区:众多技术大牛和专家在此分享经验,用户可以向他们请教问题,互相学习。
二、CSDN博客的写作方式1.选择合适的标题:标题应简洁明了,突出文章主题,同时具有一定的吸引力。
可以使用数字、疑问句等形式增加点击率。
2.明确文章结构:一篇好的CSDN博客应该有清晰的结构,方便读者阅读。
可以分为引言、正文、结论等部分,其中引言用于概述文章主题,结论用于总结全文。
3.编写引人入胜的开头:开头部分可以通过讲述故事、提出问题、引用名言等方式吸引读者的注意力。
在CSDN开通博客专栏后如何发布文章(图文)

在CSDN开通博客专栏后如何发布⽂章(图⽂)
今天打开电脑登上CSDN发现⾃⼰授予了专栏勋章,有必要了解如何在专栏发布⽂章。
在CSDN写博客已经有⼀段时间了,看到很多朋友的博客上有个博客专栏的图标,昨天也申请了⼀下并且通过了审核。
接下来怎么在博客专栏下发⽂章呢?
⼀开始找了半天也没找到门道,搜索也没有相关的结果,最终找到了发布的地⽅,分享⼀下这个可能没有⼏个⼈找不到的知识点吧希望也能为CSDN改进做点⼩⼩贡献。
博客专栏开通后,会收到CSDN的内部短消息提⽰。
可是在发布⽂章的时候并没有选项说哪个⽂章发布到博客专栏,后台还是⼀样的功能界⾯。
可以先通过博客专栏找到⾃⼰的专栏。
在打开我的专栏的⼀个隐蔽的地⽅,找到“管理专栏”。
打开“管理专栏”后,在最下⾯就是添加⽂章的地⽅了,这⾥直接把之前写的博客url地址复制粘贴进去,就会⾃动获取⽂章信息了。
接下来,打开博客管理后台,在“博客栏⽬”中启⽤“博客专栏”栏⽬,会直接在博客⾸页上显⽰博客专栏,并且有⽂章数量、访问量的统计,如果直接加链接的⽅式也可以,但是就不会有统计信息了。
qos优先级phbexp浅解-ddzhu的专栏-csdn博客

QOS 优先级PHB,EXP,浅解- ddzhu的专栏- CSDN博客QOS 优先级PHB,EXP,浅解收藏这两天在看QOS内容,其中涉及到PHB到EXP的映射,以及EXP到PHB的映射,有点不懂PHB是指哪一段,于是上网查找,结果找到:PHB是指IP包内原TOS字段(现DSCP字段),到PHB的映射关系,具体见下,而EXP当然是指MPLS包内的优先级,COS指的就是8100VLAN中的PRI字段;但是我组的人又说,我们只处理二层的内容,宏定义上的PHB指的是三层的,而我们这里单盘配置中的PHB指的就是宏定义上的COS,如果业务是基于端口的,无COS的话,则具体指的就是芯片中的队列优先级~~于是我有点晕了。
将PHB,EXP,COS的相关内容(我认为有用的)贴上。
最早,用IPv4中的TOS字段来实现QoS,TOS字段一共8bit,最高bit固定为0,最低3bit代表优先级,中间的四个bit分别是DTRC,分别表示延迟、吞吐量、可靠兴和花费,路由器在实施QoS时只检查优先级字段,其余bit均不做检查。
随后,RFC2474对IPv4的TOS字段进行了重新定义即DSCP:最高2bit保留,最高2bit表示CSCP(是一类DSCP)。
DSCP一共64个代码空间,其中XXXXX0是标准操作,其余代码点未开放使用。
PHB(Per-hop Behavior),是路由器作用于数据流的行为。
四种标准的PHB如下:类选择码CS,对应DSCP为XXX000加速转发EF确保转发AF,分为AF1、AF2、AF3和AF4尽力而为BEDSCP和PHB的映射关系(由运营商自己指定?)BE DSCP=000000EF DSCP=101110AF1 DSCP=001XXXAF2 DSCP=010XXXAF3 DSCP=011XXXAF4 DSCP=111XXXIPv4优先级和DSCP以及PHB的对应关系IP优先级DSCP PHB0 000000 BE1 001000 AF12 010000 AF23 011000 AF34 100000 AF45 101000 EF6 110000 EF7 111000 EFQoS使用的字段:MPLS中的EXP字段、VLAN中的COS(PRI)字段和IP中的DSCP字段或优先级字段1. 分类和标记Qos分类是一种标识流量并将流量归类为不同类别的Qos 处理过程或机制。
Makefile中用宏定义进行条件编译-CSDN博客

Makefile中用宏定义进行条件编译-CSDN博客在源代码里面如果这样是定义的:#ifdef MACRONAME//可选代码#endif那在makefile里面gcc -D MACRONAME=MACRODEF或者gcc -D MACRONAME这样就定义了预处理宏,编译的时候可选代码就会被编译进去了。
对于GCC编译器,有如下选项:-D macro=string,等价于在头文件中定义:#define macro string。
例如:-D TRUE=true,等价于:#define TRUE true-D macro,等价于在头文件中定义:#define macro 1,实际上也达到了定义:#define macro的目的。
例如:-D LINUX,等价于:#define LINUX 1(与#define LINUX作用类似)。
--define-macro macro=string与-D macro=string作用相同。
如:TEST.C 文件#include <stdio.h>#include <stdlib.h>main(){#ifdef p1 printf('Hello p1');#else printf('Hello p2');#endif }1.编译: gcc -o test test.c运行: ./test输出: Hello p22.编译: gcc -o test test.c -D p1运行: ./test输出: Hello p1还有另外一种使用方式:Makefile写法:$(SERVER_NAME):$(SERVER_OBJ) $(COM_OBJS) $(CC) -Wall -pthread -D KRC_SERVER_NAME=$(SERVER_NAME)_FLAG C代码中用法:#if KRC_SERVER_NAME == krc_search_FLAG#elif KRC_SERVER_NAME == krc_feedback_FLAG#else#endif注意:其中的两个参数为宏定义,不能使用常量定义,因为需要在预编译阶段就要确定其值!#define krc_search_FLAG 1#define krc_feedback_FLAG 2这种用法也能实现条件编译的作用,而且更好!。
调用阿里云接口实现短信消息的发送源码——CSDN博客

调⽤阿⾥云接⼝实现短信消息的发送源码——CSDN博客在调⽤阿⾥云接⼝之前⾸先需要购买接⼝,获得accessKeySecret,然后使⽤下列代码就可以直接调⽤了!!/*** @Title: TestPhoneVerification.java* @Package org.test* @Description: TODO该⽅法的主要作⽤:* @author A18ccms A18ccms_gmail_com* @date 2017-7-1 下午8:19:35* @version V1.0*/package org.test;import java.util.Random;import com.aliyuncs.DefaultAcsClient;import com.aliyuncs.IAcsClient;import com.aliyuncs.dysmsapi.model.v20170525.SendSmsRequest;import com.aliyuncs.dysmsapi.model.v20170525.SendSmsResponse;import com.aliyuncs.exceptions.ClientException;import com.aliyuncs.exceptions.ServerException;import com.aliyuncs.profile.DefaultProfile;import com.aliyuncs.profile.IClientProfile;/**** 项⽬名称:facephoto2* 类名称:TestPhoneVerification* 类描述:* 创建⼈:Mu Xiongxiong* 创建时间:2017-7-1 下午8:19:35* 修改⼈:Mu Xiongxiong* 修改时间:2017-7-1 下午8:19:35* 修改备注:* @version**/public class TestPhoneVerification {public static void main(String[] args) throws ServerException, ClientException {// 设置超时时间-可⾃⾏调整System.setProperty(".client.defaultConnectTimeout", "20000");System.setProperty(".client.defaultReadTimeout", "20000");// 初始化ascClient需要的⼏个参数final String product = "Dysmsapi";// 短信API产品名称final String domain = "";// 短信API产品域名// 替换成你的AKfinal String accessKeyId = "LTAIXhKAji7WzEFx";// 你的accessKeyId,参考本⽂档步骤2final String accessKeySecret = "7mYMnzCGZ";// 你的accessKeySecret,参考本⽂档步骤2// 初始化ascClient,暂时不⽀持多regionIClientProfile profile = DefaultProfile.getProfile("cn-hangzhou",accessKeyId, accessKeySecret);DefaultProfile.addEndpoint("cn-hangzhou", "cn-hangzhou", product,domain);IAcsClient acsClient = new DefaultAcsClient(profile);// 组装请求对象SendSmsRequest request = new SendSmsRequest();// 必填:待发送⼿机号。
jquerySelect2学习笔记之中文提示-CSDN博客

if (resp.products)
18.
{
19.
for (var i = 0; i < resp.products.length; i++)
20.
{
21.
var product = resp.products[i];
22.
array.push({id:product.productId, text: product.productName});
23.
}பைடு நூலகம்
24.
}
25.
var ret = new Object();
26.
ret.results = array;
27.
return ret;
28.
},
29.
cache: true
30.
},
31.
minimumInputLength: 2,
32.
language: "zh-CN",
33. }); </span>
您使用的浏览器不受支持建议使用新版浏览器
jquerySelect2学习笔记之中文提示 -CSDN博客
首先学习这个东西呢,还是看官网比较全面
要select2中文显示:必须要引入中文包,且一定要放在select2.js之后
[javascript] 1. <link type="text/css" rel="stylesheet" href="/css/select2.css">
10.
var param = new Object();
11.
= params.term;
对博客园和CSDN的简要分析

对博客园和CSDN的简要分析⼀:主页⾯:1.最左边的索引栏:两个⽹站都给出了索引的种类,但是博客园的索引栏提供了每⼀个分类的数量。
CSDN只提供了相应的索引种类。
在⿏标向下滑动时,csdn的索引会随着光标跟着向下滑动,它们的最左边分类只设计了类别(这点csdn胜),⽽博客园的最左边淡紫⾊列⽐较宽(除了分类功能,还提供了其他的功能,如下图),博客园的整体布局占据了整个页⾯,csdn则左右均有空出。
2.再观察上⾯的按钮建:博客园分区⽐较明显猪功能键也⽐较多,给⼈感觉⽐较直观;csdn则没有那么明显的感觉。
3.主页⾯的搜索框:csdn有默认的⽂字,点上去后必须删除默认的关键字信息才能搜索⾃⼰想要的,⽽且默认的关键字偏⼴告性质。
博客园这⾥做的⽐较明确,在主页⾯⽐较明显的地⽅,⽽且提供了两种搜索形式。
搜索过程:csdn会提供相应的关键词索引博客园则中规中矩,等⽤户输⼊全部的关键字之后才能展⽰对应页⾯进⼊搜索页⾯后:博客园能够清晰地展现每篇博客的阅读量,发布时间,以及博主等(根据⽤户需求,⼀般都是先点开阅读量⾼的),两个⽹站都是根据阅读量进⾏排序;csdn每⼀篇博客之间没有那么明显的界限,⽽且⽐较商业化,开始就展⽰了课程以及中间会有些⼴告(⼴告的关闭窗⼝与⼴告提⽰字设置的太⼩,不⽅便⽤户直接点击)。
两个⽹站都对关键字进⾏了标红,但是csdn只是对题⽬进⾏了红⾊醒⽬处理,⽽博客园也对⽂章⾥⾯的关键字进⾏了红⾊显⽰处理,在浏览、评论也进⾏了⼩图标的显⽰(有更好的体验)⼆:进⼊我的博客页⾯1.csdn是通过主页⾯有⼀个⽤户图标进⾏指引,使⽤户找到我的博客页⾯;博客园在右上⾓点击我的博客就可以直接进⼊⾃⼰的博客页⾯,但是字体设置较⼩(⼤⼀点就更好了)(根据⽤户常⽤的两个属性,我认为我的博客键应该在主页⾯就有快捷按钮直接进⼊,博客园在这⼀块做的相对较好。
)2.进⼊到我的博客页⾯之后:博客园偏向于时间的分类,倾向于让⽤户知道⾃⼰在什么时间段内发的⽂章内容;csdn偏向是否为⾃⼰原创,⽐较注重版权;都对评论数与阅读数做了显⽰,更偏向csdn的显⽰⽅式,在⾏数开头,与⽂章并齐的⽅式,博客园则在右下⾓。
为什么csdn名声不好

为什么csdn名声不好
1、混乱不堪的广告
2、打赏和关注占据了博客的主要板位
3、搜索的精准率越来越低
4、外链跳转居然要确认
不知道该产品是怎么想的,这种设计往往是社交类app才需要的东西避免同质化竞争,csdn这样做只能是影响程序员的效率
5、某些博文必须打赏或者关注才能查看
6、版权意识淡薄,搜索出的文章相似度极高,很难找到有用的信息
7、排版设计越来越丑陋,毕竟这是博客有不是购物网站,这里面向的是专业人士
8、对于搜索不到的问题给的是集合页签并不是相似度较高的文章,这种行为只是为了流量。
CSDN博客文章被删申述文本

CSDN博客文章被删申述文本CSDN博客文章被删申诉文本尊敬的CSDN客服部门:我是一名CSDN博客的用户,我的博客文章《XXXX》在最近被删,我对此感到非常不满和失望。
本文是我凭借自己的经验和研究写成的,旨在分享给广大读者。
然而,没有得到任何事先的通知或解释,我的文章就被删除了。
首先,我理解CSDN作为一个内容分享平台,需要执行一定的审核机制,以维护良好的阅读环境和内容质量。
但是,在删除我的文章之前,CSDN是否对内容进行了全面、准确的评估和审核呢?如果有,我希望能够得到具体的评估结果和删除依据,以便我了解并改进文章的不足之处。
如果没有,那么删除我的文章是否太过随意和任性了呢?其次,作为一个开放、自由的平台,CSDN应该尊重用户的创作权和言论自由。
我在文章中没有违反任何法律法规,也没有发布任何不良信息。
我本着分享和帮助他人的初衷创作文章,而不是恶意攻击或散播虚假信息。
所以,删除我的文章是否是出于某种误解或误判呢?此外,删除对我的努力和投入构成了巨大的打击和伤害。
我花费了大量时间和精力编写和整理这篇文章,以便为读者提供有价值的内容,同时也提升了我个人的知名度和专业形象。
然而,凭空的删除让我觉得这一切都没有意义和价值了,对我个人和职业发展带来了非常不利的影响。
基于以上的原因,我诚恳地请求CSDN的相关部门重新审核并恢复我的博客文章。
如果我的文章确实存在一些不当之处,我也将会根据CSDN的规定和要求进行修改和优化。
同时,我也希望CSDN能提供更加透明和明确的审核标准和流程,以便更好地满足广大用户的需求和期望。
期待能够得到您的理解和支持。
谢谢!此致,XXX。
逆序数的求法-csdn博客

逆序数的求法-csdn博客⾸先介绍⼀下逆序数。
对于⼀个序列,它的逆序数就是指这个序列的其中两个数前后位置和⼤⼩顺序相反。
例如序列14532,其中5、 3是⼀对逆序数,5、 2也是⼀对逆序数。
等等解法1. n^2复杂度的暴⼒直接暴⼒枚举即可```c++int s[inf],sum=0;for(int i=0;i<n;i++)for(int j=i+1;j<n;j++)if(s[i]>s[j])sum++;```2. 树状数组( nlog(n) )树状数组是先确定每个值在所有序有序情况下的序列中所在的位置(离散化)。
列如序列:5 1 4 3 。
离散化后的值为:4 1 3 2。
从最左端开始建⽴树状数组,每创建⼀个就执⾏⼀次 i - query( x ) (x 为离散化的值) 类加到ans上。
最后的 ans即为所求的答案。
离散化的实质就是把所有的数都变成从1到n-1的连续的数。
思想实质:其实就是没针对当下⼀个序列最后的位置n,维护⼀个树状数组,这个数组记录值值的个数,然后求出这个序列最后⼀个数的前⾯有⼏个数和这个数组成逆序数,然后⼀次递推。
由于可能每个数出现的次数可能不⽌⼀次,或者不连续,此时⽤离散化预处⼀下。
( 初学者可以从连续的⽆重复的序列理清⼀下思路 )#include <iostream>#include <algorithm>using namespace std;const int inf = 1e5;struct node{int val,i;bool operator<(node x)const {return val<x.val;}}sn[inf];int tree[inf],b[inf],n;void add(int i,int x){while(i<=n){tree[i]+=x;i+=i&-i;}}int query(int i){int sum=0;while(i>=1){sum+=tree[i];i-=i&-i;}return sum;}int main(){cin>>n;for(int i=1;i<=n;i++){cin>>sn[i].val;sn[i].i=i;}sort(sn+1,sn+n+1);int cnt=1;for(int i=1;i<=n;i++){if(i>1&&sn[i].val>sn[i-1].val)cnt++;b[sn[i].i]=cnt;}int ans=0;for(int i=1;i<=n;i++){add(b[i],1);ans+=i-query(b[i]);}cout<<ans<<endl;return 0;}3. 归并排序法( nlog(n) )这种⽅法是利⽤了归并排序的过程,在排序中进⾏计数。
CSDN博客文章必须要登录才能查看解决办法
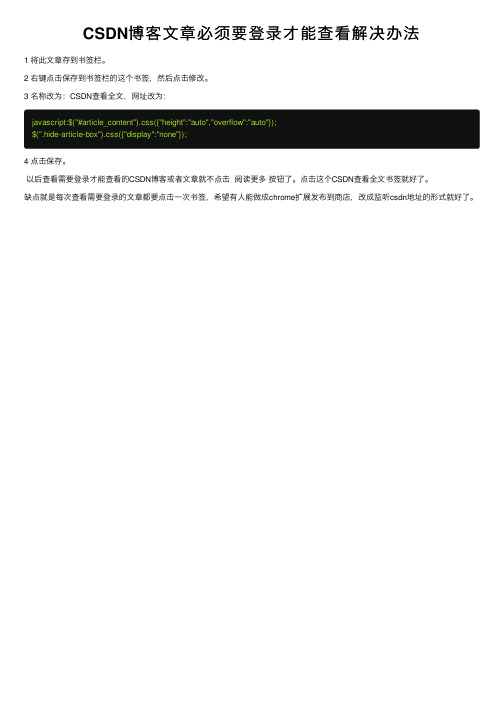
CSDN博 客 文 章ຫໍສະໝຸດ 必 须 要 登 录 才 能 查 看 解 决 办 法
1 将此文章存到书签栏。 2 右键点击保存到书签栏的这个书签,然后点击修改。 3 名称改为:CSDN查看全文,网址改为:
javascript:$("#article_content").css({"height":"auto","overflow":"auto"}); $(".hide-article-box").css({"display":"none"});
4 点击保存。 以后查看需要登录才能查看的CSDN博客或者文章就不点击 阅读更多 按钮了。点击这个CSDN查看全文书签就好了。 缺点就是每次查看需要登录的文章都要点击一次书签,希望有人能做成chrome扩展发布到商店,改成监听csdn地址的形式就好了。
经典算法研究系列:七、深入浅出遗传算法,透析GA本质-结构之法算法之道-CSDN博客

经典算法研究系列:七、深⼊浅出遗传算法,透析GA本质-结构之法算法之道-CSDN博客深⼊浅出遗传算法,透析GA本质收藏经典算法研究系列:七、遗传算法初探透析GA本质---深⼊浅出、深⼊浅出、透析作者:July ⼆零⼀⼀年⼀⽉⼗⼆⽇。
本⽂参考:维基百科华南理⼯⼤学电⼦讲义互联⽹-------------------------------------------------------------------------------⼀、初探遗传算法Ok,先看维基百科对遗传算法所给的解释:遗传算法是计算数学中⽤于解决最优化的搜索算法,是进化算法的⼀种。
进化算法最初是借鉴了进化⽣物学中的⼀些现象⽽发展起来的,这些现象包括遗传、突变、⾃然选择以及杂交等。
遗传算法通常实现⽅式为⼀种计算机模拟。
对于⼀个最优化问题,⼀定数量的候选解(称为个体)的抽象表⽰(称为染⾊体)的种群向更好的解进化。
传统上,解⽤⼆进制表⽰(即0和1的串),但也可以⽤其他表⽰⽅法。
进化从完全随机个体的种群开始,之后⼀代⼀代发⽣。
在每⼀代中,整个种群的适应度被评价,从当前种群中随机地选择多个个体(基于它们的适应度),通过⾃然选择和突变产⽣新的⽣命种群,该种群在算法的下⼀次迭代中成为当前种群。
光看定义,可能思路并不清晰,咱们来⼏个清晰的图解、步骤、公式:基本遗传算法的框图:所以,遗传算法基本步骤是:1)初始化 t←0进化代数计数器;T是最⼤进化代数;随机⽣成M个个体作为初始群体 P(t);2)个体评价计算P(t)中各个个体的适应度值;3)选择运算将选择算⼦作⽤于群体;4)交叉运算将交叉算⼦作⽤于群体;5)变异运算将变异算⼦作⽤于群体,并通过以上运算得到下⼀代群体P(t + 1);6)终⽌条件判断 t≦T:t← t+1 转到步骤2;t>T:终⽌输出解。
好的,看下遗传算法的伪代码实现:▲Procedures GA:伪代码begininitialize P(0);t = 0; //t是进化的代数,⼀代、⼆代、三代...while(t <= T) dofor i = 1 to M do //M是初始种群的个体数Evaluate fitness of P(t); //计算P(t)中各个个体的适应度end forfor i = 1 to M doSelect operation to P(t); //将选择算⼦作⽤于群体end forfor i = 1 to M/2 doCrossover operation to P(t); //将交叉算⼦作⽤于群体end forfor i = 1 to M doMutation operation to P(t); //将变异算⼦作⽤于群体end forfor i = 1 to M doP(t+1) = P(t); //得到下⼀代群体P(t + 1)end fort = t + 1; //终⽌条件判断 t≦T:t← t+1 转到步骤2end whileend⼆、深⼊遗传算法1、智能优化算法概述智能优化算法⼜称现代启发式算法,是⼀种具有全局优化性能、通⽤性强且适合于并⾏处理的算法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1./**
2. * 获取手机信息
3. */
4.public void getPhoneInfo()
5. {
6. TelephonyManager tm = (TelephonyManager) this.getSystemService(TELEP
HONY_SERVICE);
7. String mtyb = android.os.Build.BRAND;// 手机品牌
8. String mtype = android.os.Build.MODEL; // 手机型号
9. String imei = tm.getDeviceId();
10. String imsi = tm.getSubscriberId();
11. String numer = tm.getLine1Number(); // 手机号码
12. String serviceName = tm.getSimOperatorName(); // 运营商
13. tvPhoneInfo.setText("品牌: " + mtyb + "\n" + "型
号: " + mtype + "\n" + "版
本: Android " + android.os.Build.VERSION.RELEASE + "\n" + "IMEI: " + imei
14. + "\n" + "IMSI: " + imsi + "\n" + "手机号
码: " + numer + "\n" + "运营商: " + serviceName + "\n");
15. }
[java]view plaincopy
1./**
2. * 获取手机内存大小
3. *
4. * @return
5. */
6.private String getTotalMemory()
7. {
8. String str1 = "/proc/meminfo";// 系统内存信息文件
9. String str2;
10. String[] arrayOfString;
11.long initial_memory = 0;
12.try
13. {
14. FileReader localFileReader = new FileReader(str1);
15. BufferedReader localBufferedReader = new BufferedReader(localFil
eReader, 8192);
16. str2 = localBufferedReader.readLine();// 读取meminfo第一行,系统总
内存大小
17.
18. arrayOfString = str2.split("\\s+");
19.for (String num : arrayOfString)
20. {
21. Log.i(str2, num + "\t");
22. }
23.
24. initial_memory = Integer.valueOf(arrayOfString[1]).intValue() *
1024;// 获得系统总内存,单位是KB,乘以1024转换为Byte
25. localBufferedReader.close();
26.
27. }
28.catch (IOException e)
29. {
30. }
31.return Formatter.formatFileSize(getBaseContext(), initial_memory);//
Byte转换为KB或者MB,内存大小规格化
32. }
[java]view plaincopy
1./**
2. * 获取当前可用内存大小
3. *
4. * @return
5. */
6.private String getAvailMemory()
7.{
8. ActivityManager am = (ActivityManager) getSystemService(Context.ACTIVITY
_SERVICE);
9. MemoryInfo mi = new MemoryInfo();
10. am.getMemoryInfo(mi);
11.return Formatter.formatFileSize(getBaseContext(), mi.availMem);
12.}
[java]view plaincopy
2. * 获取手机CPU信息
3. *
4. * @return
5. */
6.public String[] getCpuInfo()
7. {
8. String str1 = "/proc/cpuinfo";
9. String str2 = "";
10. String[] cpuInfo = { "", "" };
11. String[] arrayOfString;
12.try
13. {
14. FileReader fr = new FileReader(str1);
15. BufferedReader localBufferedReader = new BufferedReader(fr, 8192
);
16. str2 = localBufferedReader.readLine();
17. arrayOfString = str2.split("\\s+");
18.for (int i = 2; i < arrayOfString.length; i++)
19. {
20. cpuInfo[0] = cpuInfo[0] + arrayOfString[i] + " ";
21. }
22. str2 = localBufferedReader.readLine();
23. arrayOfString = str2.split("\\s+");
24. cpuInfo[1] += arrayOfString[2];
25. localBufferedReader.close();
26. }
27.catch (IOException e)
28. {
29. }
30. tvHardwareInfo.append("CPU型号 " + cpuInfo[0] + "\n" + "CPU频
率: " + cpuInfo[1] + "\n");
31.return cpuInfo;
32. }
[java]view plaincopy
1./**
2. * 获取CPU核心数
3. *
4. * @return
5. */
6.private int getNumCores()
8.// Private Class to display only CPU devices in the directory listing
9.class CpuFilter implements FileFilter
10. {
11.@Override
12.public boolean accept(File pathname)
13. {
14.// Check if filename is "cpu", followed by a single digit number
15.if (Pattern.matches("cpu[0-9]", pathname.getName()))
16. {
17.return true;
18. }
19.return false;
20. }
21. }
22.
23.try
24. {
25.// Get directory containing CPU info
26. File dir = new File("/sys/devices/system/cpu/");
27.// Filter to only list the devices we care about
28. File[] files = dir.listFiles(new CpuFilter());
29.// Return the number of cores (virtual CPU devices)
30.return files.length;
31. }
32.catch (Exception e)
33. {
34. e.printStackTrace();
35.// Default to return 1 core
36.return1;
37. }
38.}。