《分布式数据库》实验报告_研究生
《分布式数据库》实验报告_研究生

1)用户设置模块:客户、分店负责人、营业员以及管理人员的权限问题等。
2)图书信息模块:图书的类别、图书的基本相关的信息,以及相关的操作等。
3)员工信息模块:是对员工的信息的基本简单增删改的操作。
4)会员信息模块:包括会员的基本信息,还有订单,优惠消费等状况。
5)进货信息模块:主要是供应商的管理,记录各个分库状态,以及各个分库的销售状态以及图书的供求信息等。
任务分配:
对于前期的系统的需求分析、数据库设计包括概念设计、逻辑设计、分片和分布等都需要我们参与其中讨论合适的方案。但是对系统的开发具体的任务做如下分配:
高汉:员工和会员的模块开发以及主要的分片发布的方案。
魏宗斌:用户设置和图书信息的模块设置。
龚海晏:进货信息模块以及系统的代码测试的工作。
三、实验总结:
高汉:
魏宗斌:通过这次的课程设计让我对分布式数据库有了重新的认识,分布式数据库不是我原来所认为的那么简单。分布式数据库系统(DDBS)包含分布式数据库管理系统(DDBMS)和分布式数据库(DDB)。在分布式数据库系统中,一个应用程序可以对数据库进行透明操作,数据库中的数据分别在不同的局部数据库中存储、由不同的DBMS进行管理、在不同的机器上运行、由不同的操作系统支持、被不同的通信网络连接在一起。数据分片最常见的就是水平分片和垂直分片两种。对于数据库管理信息系统,首要要做好需求分析的工作,设计各个模块的功能以及功能之间的相互关联。因为做的是分布式数据库系统,所以系统主要是体现“分布”二字,因此使我对分布式数据库有了更深的认识。该系统前台界面的编写主要是用的vs进行开发的,后台数据库使用的是SQLServer。当在一个大企业或大部门中已建成了若干个数据库之后,为了利用相互的资源,为了开发全局应用,就要研制分布式数据库系统.分布式数据库系统虽然也要对各现存的局部数据库系统做某些改动、重构,但比起把这些数据库集中起来重建一个集中式数据库,则无论从经济上还是从组织上考虑,分布式数据库均是较好的选择.这就是分布式数据库系统的优势所在。
分布式数据库性能测试实验报告

分布式数据库性能测试实验报告引言:分布式数据库是由多个节点构成的数据库系统,每个节点都可以独立地处理查询和事务操作。
为了评估分布式数据库的性能表现,本实验进行了一系列的性能测试并得出了相应的结果和结论。
本报告旨在对分布式数据库性能进行全面的评估和分析。
实验目的:1. 通过性能测试评估分布式数据库的处理能力和并发性能。
2. 分析分布式数据库对于不同规模数据和负载的响应情况。
3. 探讨分布式数据库在扩展性和容错性方面的表现。
实验环境:- 数据库系统:分布式数据库系统XYZ- 硬件:主机配置为X GHz处理器、XGB内存、XGB磁盘空间- 软件:操作系统为X,数据库管理系统为XYZ- 数据集:使用XGB规模的数据集进行测试实验方法:1. 测试负载:使用不同类型的查询和事务操作构建测试负载,包括读操作、写操作和复杂查询操作。
2. 并发用户数:逐步增加并发用户数,从10个用户逐渐增加到100个用户。
3. 测量指标:记录每个操作的执行时间、吞吐量和响应时间。
实验结果与分析:1. 响应时间:随着并发用户数的增加,响应时间逐渐增加,但整体呈现出较好的线性扩展性。
2. 吞吐量:在低并发用户数时,吞吐量随并发用户数的增加而逐渐提高。
然而,当并发用户数达到一定阈值后,吞吐量的增加速度减缓。
3. 数据一致性:由于分布式数据库的数据分布在多个节点上,数据一致性成为一个重要的考虑因素。
实验结果表明,在正常情况下,分布式数据库能够保持数据一致性。
4. 容错性:通过模拟节点故障,实验发现分布式数据库具有较好的容错性能,能够在某些节点故障的情况下继续正常运行。
结论:1. 分布式数据库在处理大规模数据和并发操作方面表现出良好的性能。
2. 分布式数据库的吞吐量随并发用户数的增加呈现出递增趋势,但在一定阈值后增速减缓。
3. 数据一致性和容错性是分布式数据库设计和管理的重要考虑因素。
4. 开发人员和系统管理员应根据实际需求选择合适的分布式数据库,并且注意数据库的配置和优化。
分布式数据库管理实验报告

分布式数据库管理实验报告一、引言随着互联网和大数据技术的迅速发展,传统的集中式数据库管理系统已经无法满足日益增长的数据处理需求。
分布式数据库管理系统应运而生,能够将数据分散存储在不同的节点上,并实现数据的有效管理和处理。
本实验旨在通过对分布式数据库管理系统的实验操作,深入了解其工作原理和应用场景。
二、实验目的1. 了解分布式数据库管理系统的基本概念和特点;2. 掌握分布式数据库管理系统的架构和工作原理;3. 能够使用实际案例进行分布式数据库管理系统的操作。
三、实验内容1. 搭建分布式数据库管理系统的实验环境;2. 创建分布式数据库并进行数据导入;3. 进行跨节点的数据查询和更新操作;4. 测试分布式数据库管理系统的性能和扩展性。
四、实验步骤1. 搭建实验环境在实验室服务器上安装分布式数据库管理系统软件,并配置节点信息,确保各节点之间可以正常通信。
2. 创建分布式数据库使用SQL语句在不同节点上创建分布式数据库,并将数据导入到对应的表中。
3. 数据查询和更新编写SQL查询语句,可以跨节点进行数据查询操作,并测试分布式数据库系统的读写性能。
4. 性能测试模拟大量的数据操作,测试分布式数据库管理系统在高负载情况下的性能表现,并观察系统的负载均衡能力。
五、实验结果分析通过实验操作,我们成功搭建了分布式数据库管理系统的实验环境,并能够灵活操作数据库中的数据。
在性能测试中,我们发现分布式数据库系统能够有效分担数据处理压力,提高系统的稳定性和可靠性。
六、结论分布式数据库管理系统是当前大数据时代的重要组成部分,能够满足高并发、大规模数据处理的要求。
通过本次实验,我们对分布式数据库管理系统有了更深入的了解,可以更好地应用于实际的数据处理工作中。
七、参考文献1. 《分布式数据库管理系统原理与技术》2. 《大规模分布式存储系统设计与实现》3. 《分布式数据库管理系统性能优化与调优》以上是本次分布式数据库管理实验报告的具体内容,希朓能对您有所帮助。
《分布式数据库》实验报告_研究生BACKUP11

安徽工业大学
《分布式数据库》实验报告
课题名称***
学院计算机
专业计算机应用
专业班级2010班
组长刘乾
成员周松成金祥胡锦
赵起姚佳岷
指导教师戴小平
二Ο一一年月日
课程名称:《分布式数据库》课程号码:XXXXXX
实验学时:学分:
实验地点:校内实验时间:2011.3.10~2011.5.10
连锁百货商店通常由一个中心,多个远程连锁店组成。
为此我们设计了一个数据库作为主数据库,用来模拟百货商店总店数据库,同时利用另一数据库作为从数据库,用来模拟连锁百货商店分店数据库。
并分别为主数据库和从数据库设计了GUI.
我们将百货商店的数据通过分片与分配的方式,分布式的存储在主从两个不同的数据库中,并有区别的给与主从数据库不同的权限。
同时基于SQL Server 2005 数据库之间的通讯,我们设计了数据通讯模块,实现了数据库之间的相互通信,并通过发布与订阅的方式保持了数据一致性。
另外在基本数据库添加删除操作的基础上,我们添加了品牌管理的功能模。
分布式数据库实验

1.运行环境
操作系统 Solaris VM or Windows or Linux (Unix)
开发语言 JAVA JDK1.2.2以上版本 (Windows下需要Make工具)
1.运行环境
JAVA环境变量设置 Set path = …………;C:\j2sdk1.4.0_01\bin\ CLASSPATH
transaction提供了一些基本的类以帮助你完成工作, 它包含了ResourceManager的接口。请注意,你不要 修改此文件,你的RM实现要基于名为 ResourceManagerImpl的类(以及一些自己定义的新 类),这个类提供了ResourceManager的接口。你必 须自己编写接口实现代码,以替代目前提供的这个 ResourceManagerImpl.java文件中的接口实现代码。
= .;C:\j2sdk1.4.0_01\lib\tools.jar;C:\j2 sdk1.4.0_01\lib\dt.jar;C:\j2sdk1.4.0_01\ jre\lib\rt.jar;D:\project\
1.运行环境
怎样运行
javac *.java
生成 *.class 文件
make runreg
提交截止日期:2007年1月20日
参考文献
《分布式数据库系统及其应用》 《数据库系统导论》 《Java2 API 大全》 《Java编程思想》
谢 谢!
Windows下需用我们提供的makefile文件 替换part1.tar中的makefile文件。而 Linux下则不用。
基本框架结构(Part I) :C/S
Client 1
Client 2
Clie
Flights, Hotels, Cars, Customers
分布式计算机实验报告

实验二Web数据库访问一、实验目的1. 了解MVC模式的基本原理和编程方式;2. 了解DAO模式的基本原理和编程方法;2.掌握使用JDBC访问数据库的一般方法;3.掌握MySql数据库的基本操作。
二、实验内容(一)、MVC模式MVC模式是最近几年被推荐为JEE的设计平台,他主要将输入、处理和输出分开。
MVC即,M(Modle):主要是业务逻辑的处理,接受视图请求的数据,返回最终的处理结果。
V(View):表示用户交互界面,对于Web应用来说,可以是HTML界面,也可能是XHTML、XML、AppletC(Controller):从用户接受请求,将模式与视图结合在一起,共同完成用户的请求。
可以给你一段简单的代码:mvc_login.htm<form action="mvcdemo.mldn" method="POST">输入姓名:<input type="text" name="uname"><input type="submit" value="提交"></form>mvcdemo.jsp<h1>MVCDEMO</h1><h1><%=request.getAttribute("name")%></h1>mvc_success.jsp<%@page contentType="text/html;charset=gb2312"%><h1>输入成功!!!</h1><h2>欢迎:<%=request.getAttribute("name")%>光临!!!</h2>mvc_failure.jsp<%@page contentType="text/html;charset=gb2312"%><h1>输入失败!!!</h1><h2><a href="mvc_login.htm">重新登陆</a></h2>MVCCheck.javapackage cn.mldn.lxh.bean ;public class MVCCheck{private String name ;public void setName(String name){ = name ;}public String getName(){return ;}// 验证public boolean isValidate(){if(==null||"".equals()){return false ;}else{return true ;}}};MVCServlet.javapackage cn.mldn.lxh.servlet ;import java.io.* ;import javax.servlet.* ;import javax.servlet.http.* ;import cn.mldn.lxh.bean.MVCCheck ;public class MVCServlet extends HttpServlet{public void doGet(HttpServletRequest req,HttpServletResponse resp) throws IOException,ServletException{this.doPost(req,resp) ;}public void doPost(HttpServletRequest req,HttpServletResponse resp) throws IOException,ServletException{String name = req.getParameter("uname") ;MVCCheck mc = new MVCCheck() ;// 将请求内容设置到mc对象之中mc.setName(name) ;String path = null ;if(mc.isValidate()){// 保存名字在request范围之中req.setAttribute("name",mc.getName()) ;path = "mvc_success.jsp" ;}else{path = "mvc_failure.jsp" ;}// 进行跳转req.getRequestDispatcher(path).forward(req,resp) ;}};/*<servlet><servlet-name>mvc</servlet-name><servlet-class>cn.mldn.lxh.servlet.MVCServlet</servlet-class></servlet><servlet-mapping><servlet-name>mvc</servlet-name><url-pattern>/mvcdemo.mldn</url-pattern></servlet-mapping>*/要求:创建项目,建立上面的文件,调试并运行程序,记录运行结果。
分布式数据库实训报告

一、实训背景随着互联网技术的飞速发展,数据量呈爆炸式增长,传统的集中式数据库已无法满足日益增长的数据存储和处理的性能需求。
分布式数据库作为一种新型的数据库架构,通过将数据分散存储在多个节点上,提高了数据库的可扩展性、可用性和容错性。
为了更好地理解和掌握分布式数据库的原理和应用,我们开展了分布式数据库实训。
二、实训目标1. 理解分布式数据库的基本概念、架构和原理;2. 掌握分布式数据库的安装、配置和管理;3. 学会使用分布式数据库进行数据存储、查询和事务处理;4. 分析分布式数据库的优缺点,了解其在实际应用中的挑战和解决方案。
三、实训内容1. 分布式数据库基本概念分布式数据库是由多个节点组成的系统,这些节点通过网络连接在一起,共同存储和管理数据。
分布式数据库具有以下特点:(1)数据分散存储:数据分布在多个节点上,降低了单节点存储的负担;(2)高可用性:通过冗余设计,提高系统的可用性;(3)可扩展性:系统可根据需求动态增加节点,提高性能;(4)容错性:系统在部分节点故障的情况下仍能正常运行。
2. 分布式数据库架构分布式数据库架构主要包括以下几种:(1)主从复制架构:主节点负责处理数据更新,从节点负责读取数据;(2)对等复制架构:所有节点都具有读写权限,数据在节点间同步;(3)分片架构:将数据按照一定的规则划分到不同的节点上;(4)多活架构:所有节点都可以同时处理读写请求。
3. 分布式数据库安装与配置以分布式数据库HBase为例,介绍其安装与配置过程:(1)安装Java环境:HBase基于Java开发,需要安装Java环境;(2)下载HBase安装包:从Apache官网下载HBase安装包;(3)解压安装包:将安装包解压到指定目录;(4)配置HBase环境变量:在系统环境变量中添加HBase的bin目录;(5)启动HBase服务:运行hbase.sh start命令启动HBase服务;(6)创建HBase表:使用hbase shell命令创建表。
分布式数据库的最佳实践与经验总结(系列二)

分布式数据库的最佳实践与经验总结一、引言在当前大数据时代,分布式数据库成为了处理海量数据的关键技术。
而分布式数据库的设计和实践则是一个具有挑战性的任务。
本文将总结一些分布式数据库的最佳实践和经验,帮助读者更好地理解和应用分布式数据库技术。
二、理解分布式数据库分布式数据库是将数据存储和处理分布在多个节点上的数据库系统。
相比于传统的集中式数据库,分布式数据库具有更强大的横向扩展能力和高可用性。
然而,分布式数据库的设计与管理复杂度更高,需要考虑数据的一致性、容错性以及数据分片等因素。
三、数据分片与负载均衡在设计分布式数据库时,合理的数据分片策略和负载均衡机制是至关重要的。
一方面,数据分片可以将数据分布在不同的节点上,避免单点故障和性能瓶颈;另一方面,负载均衡机制能够平衡各个节点的压力,提高整体性能。
根据应用场景和数据特点,选择合适的分片键和负载均衡算法非常重要。
四、一致性与并发控制在分布式环境下,保证数据的一致性是一项具有挑战性的任务。
分布式数据库需要选择合适的一致性模型,例如强一致性、弱一致性或最终一致性。
同时,针对并发控制,可以采用乐观锁或悲观锁等机制来实现事务的隔离性和一致性。
五、容错与故障恢复分布式数据库需要具备良好的容错性,能够应对节点故障和网络中断等异常情况。
采用数据冗余和备份机制可以保证数据的可靠性和可恢复性。
此外,及时的故障检测和自动恢复机制也是分布式数据库设计的重要方面。
六、性能监控与优化为了保证分布式数据库的高性能,需要进行实时的性能监控和优化。
通过监控系统指标,例如请求响应时间,吞吐量等,可以及时发现并解决潜在的性能瓶颈。
此外,优化查询语句、索引设计和数据模型等方面也是提高性能的关键。
七、数据安全与隐私保护分布式数据库中的数据安全和隐私保护是至关重要的。
采用合适的身份认证和访问控制机制可以防止未经授权的访问和数据泄露。
另外,数据加密和数据脱敏等技术也能有效保护数据隐私。
八、云原生与容器化在云计算时代,云原生和容器化的技术越来越受到关注。
分布式数据库的最佳实践与经验总结(系列四)

分布式数据库的最佳实践与经验总结一、引言在当前的互联网时代,大数据的处理和存储成为了企业和组织面临的重要挑战。
传统的集中式数据库已经无法满足海量数据和高并发访问的需求,因此分布式数据库逐渐成为了一种重要的解决方案。
本文将探讨分布式数据库的最佳实践与经验总结。
二、分布式数据库的基本概念与原理分布式数据库是将数据库存储和处理分散到多个节点上的系统,每个节点可以独立进行数据存储和处理,同时通过网络进行通信和协调。
分布式数据库的优势在于可水平扩展和高可用性。
在设计分布式数据库时需要考虑数据分片、数据复制、数据一致性等问题。
三、数据分片的策略数据分片是将数据按照某种规则分散到不同的节点上,以实现水平扩展。
常用的数据分片策略有哈希分片和范围分片。
哈希分片将数据的关键属性进行哈希计算,并将哈希结果映射到不同的节点上;范围分片将数据按照某个范围进行划分,并将不同范围的数据分配到不同的节点上。
在选择数据分片策略时需要考虑数据的均匀分布和访问的性能。
四、数据复制与一致性数据复制是为了提高系统的可用性和容错性。
常见的数据复制策略有主从复制和多主复制。
主从复制是将一个节点作为主节点,其他节点作为从节点,主节点接收写操作并将写操作复制到从节点;多主复制则是将多个节点同时作为主节点,所有节点都可以接收写操作。
数据一致性是保证分布式数据库中数据的准确性和一致性,常用的实现方式有乐观锁和悲观锁。
五、负载均衡与容灾备份负载均衡是为了保证系统在高并发访问时能够合理分配请求到不同的节点上,以避免热点问题和单点故障。
常见的负载均衡算法有轮询、最少连接和哈希等。
容灾备份是为了保证系统在节点故障时能够继续正常运行,常用的容灾备份方案有主备复制、多活复制和分布式存储等。
六、分布式事务的处理分布式事务是分布式数据库中的一个重要问题,保证事务的一致性是保证数据的准确性和可靠性的关键。
常用的分布式事务处理方式有两阶段提交和补偿事务。
两阶段提交是在分布式系统中协调各个节点的事务,保证所有节点的操作要么都执行,要么都不执行;补偿事务则是通过补偿操作来保证分布式事务的一致性。
分布式数据库系统的实验与性能评估

分布式数据库系统的实验与性能评估分布式数据库系统是一种将数据存储在不同地理位置上的多个数据库管理系统中,并通过网络进行连接和通信的系统。
相较于传统的集中式数据库系统,分布式数据库系统更加灵活和可伸缩,并且能够提供更好的数据可用性和容错性。
然而,在实际应用中,分布式数据库系统面临着很多挑战,如数据一致性、性能与效率等问题。
本文将对分布式数据库系统的实验和性能评估进行探讨。
一、分布式数据库系统的实验1. 实验设计在进行分布式数据库系统的实验之前,我们需要首先设计实验方案。
实验设计应该包括实验目标、实验环境和实验步骤等内容。
例如,我们可以通过搭建多个数据库节点、模拟分布式场景,来测试分布式数据库系统在不同数据负载和并发访问下的性能表现。
2. 数据准备实验的数据准备是非常重要的一步。
我们可以选择合适的数据集,并将其导入到各个数据库节点中。
数据集的选择应该充分考虑到实验的需求,包括数据规模、数据类型和数据分布等。
3. 实验指标在进行实验时,我们需要选择合适的实验指标来评估分布式数据库系统的性能。
常用的实验指标包括吞吐量、延迟、并发性能等。
通过对这些指标的评估,我们可以判断分布式数据库系统的性能是否符合要求。
二、分布式数据库系统的性能评估1. 性能测试性能测试是评估分布式数据库系统性能的重要方法之一。
我们可以通过模拟真实的应用场景、设置不同的负载和并发访问情况,来测试系统的性能极限和稳定性。
通过性能测试,我们可以获得系统的吞吐量、响应时间等性能指标,并对系统的瓶颈进行分析和优化。
2. 数据一致性评估在分布式数据库系统中,数据一致性是一个重要的问题。
我们需要评估分布式数据库系统在数据复制、数据同步和数据更新等方面的数据一致性能力。
常用的评估方法包括数据一致性检查、数据冲突处理和数据恢复等。
3. 容错性评估容错性是衡量分布式数据库系统可靠性的一个重要指标。
我们需要评估系统在节点故障、网络断连和数据丢失等异常情况下的容错能力。
分布式数据库性能评估与优化实验报告

分布式数据库性能评估与优化实验报告引言:分布式数据库是一种能够将数据存储在多个节点上,实现高可用性和高性能的数据库系统。
在大数据时代,分布式数据库得到了广泛的应用和研究。
本实验旨在评估分布式数据库系统的性能,并针对性能瓶颈进行优化,从而提高数据库的整体运行效率。
一、实验目标本实验的目标是对分布式数据库系统进行性能评估,并针对性能瓶颈进行优化。
通过实验,可以更好地理解分布式数据库的工作原理,尝试解决分布式数据库中的性能问题,并提高数据库的整体性能。
二、实验环境本实验的实验环境如下:硬件:4台普通PC,每台配置为:8核CPU、16GB内存、1TB硬盘软件:分布式数据库系统DDBS v2.0实验数据:100GB大小的模拟数据三、实验步骤1. 数据准备为了模拟真实的数据情况,我们使用了100GB大小的数据集,并通过分布式方式将数据存储到4台PC的硬盘上。
这样可以保证每个节点上都有一部分数据,从而实现数据的均衡存储和访问。
2. 性能评估我们对分布式数据库进行了性能评估,测试了以下几个方面的指标:- 响应时间:测试数据库系统的读取和写入操作的响应时间。
- 吞吐量:测试数据库系统在单位时间内能处理的请求数量。
- 并发性能:测试数据库系统在并发情况下的处理能力和稳定性。
3. 优化策略根据性能评估的结果,我们确定了分布式数据库系统的性能瓶颈,并提出了以下的优化策略:- 索引优化:通过分析查询语句和数据访问模式,对数据库中的索引进行优化,提升查询性能。
- 数据分区优化:重新划分数据的分布,使得每个节点上的数据量相对均衡,减少数据访问的频率和延迟。
- 并发控制优化:采用更高效的并发控制机制,如乐观锁和MVCC,提高数据库的并发性能和事务处理能力。
四、实验结果与分析经过性能评估和优化策略的实施,我们得到了以下的实验结果和分析:1. 响应时间:优化后的分布式数据库系统的读取和写入操作的响应时间均明显降低,提高了用户的使用体验。
分布式数据库的最佳实践与经验总结(系列一)

分布式数据库的最佳实践与经验总结近年来,随着云计算和物联网技术的快速发展,大数据量、高并发和高可靠性的挑战也逐渐显现出来。
为了应对这些挑战,分布式数据库成为了当今互联网领域的一个热门话题。
分布式数据库通过将数据分散存储于多个节点上,并利用一系列复制、分片、负载均衡等技术,实现数据的高可用性、高并发和高性能。
在实践过程中,我们积累了一些分布式数据库的最佳实践和经验,现在就来总结一下。
一、定义合适的数据分片策略在分布式数据库中,数据的分片是非常重要的一个环节,直接影响到系统的可扩展性和性能。
在设计分片策略时,我们应该充分考虑数据的访问模式、负载均衡和分片负担等因素。
一种常用的策略是按照数据的哈希值进行分片,确保数据能够均匀地分布在各个节点上。
另一种策略是按照数据的某个属性进行分片,比如按照用户ID进行分片,可以将属于同一用户的数据存储在同一个节点上,提高查询效率。
二、实现数据的一致性与可用性在分布式系统中,一致性和可用性是互相矛盾的。
为了保证系统的高可用性,我们通常会采用 CAP 原则,即在网络分区时优先保证系统的可用性,而在无网络分区时追求一致性。
为了实现这一目标,可以引入副本机制,在多个节点上保存数据的副本,保证数据的冗余性和容错性。
此外,还可以采用基于时间戳或向量时钟的版本控制机制,解决并发操作引起的冲突问题。
三、优化查询性能和负载均衡在高并发的场景下,优化查询性能是一个关键问题。
首先,我们可以采用横向扩展的方式,将查询请求分发到多个节点上,提高系统的并发处理能力。
其次,可以使用缓存机制,将频繁查询的结果缓存在内存中,减少对数据库的访问。
此外,还可以对查询语句进行优化,合理设计索引,避免全表扫描和耗时的操作。
四、确保数据的安全性和一致性在分布式数据库中,数据的安全性和一致性是非常重要的,尤其对于金融、电商等对数据完整性要求较高的行业。
为了保证数据的安全性,我们可以采用密码学技术,对数据进行加密存储和传输。
分布式数据库的技术研究与应用

分布式数据库的技术研究与应用随着社会的不断发展,数据量呈现爆炸式增长,传统的单机数据库已经无法满足大规模数据处理的需求。
分布式数据库应运而生,是一种将数据存储在多个节点中,通过网络进行协调和管理的新型数据库技术。
本文将重点探讨分布式数据库的技术研究与应用。
一、分布式数据库的概念分布式数据库是将数据存储在多个节点中,通过网络进行协调和管理的新型数据库技术。
分布式数据库系统由多个节点或服务器相互协作,通过逻辑上的共享,实现数据共享,提高系统性能和可用性。
同时,它还可以横向扩展,支持大规模数据处理和并发访问。
二、分布式数据库的架构分布式数据库系统的架构主要由数据管理子系统、数据通信子系统和系统管理子系统三部分组成。
其中,数据管理子系统负责数据的存储、管理和查询;数据通信子系统负责节点间的数据传输和通信;系统管理子系统负责分布式数据库的相关管理工作和系统安全。
在分布式数据库架构中,还可以采用分区和复制等技术来实现分布式数据库的数据重复和负载均衡,从而提高系统的可靠性和性能。
三、分布式数据库的优点与传统的单机数据库相比,分布式数据库具有以下优点:1. 可扩展性分布式数据库可以通过横向扩展或纵向扩展来支持大规模数据处理和并发访问,从而支持更多的用户和更大的数据量。
2. 高可用性通过数据复制和负载均衡等技术,分布式数据库可以避免单机数据库的单点故障,提高系统的可靠性和稳定性,保证数据的安全性和完整性。
3. 高性能和并发处理能力分布式数据库可以利用多台服务器的计算能力,同时处理多个请求和任务,从而提高系统的处理能力和响应速度。
4. 统一管理和控制分布式数据库可以通过统一的管理和控制平台来管理多个数据库节点,简化了管理工作,提高了系统的管理效率。
五、分布式数据库的应用目前,分布式数据库已经广泛应用于互联网、电子商务、金融、制造业、医疗等各个领域,例如:1. 互联网分布式数据库可以支持大规模互联网应用,如电子商务、社交网站等,支持海量数据的存储和并发访问,提高用户的操作体验和交互效率。
分布式数据库的最佳实践与经验总结(系列三)

分布式数据库的最佳实践与经验总结引言:在当今的互联网时代,数据的规模不断扩大,传统的集中式数据库已经不能满足面对海量数据、高并发的需求。
分布式数据库作为一种解决方案应运而生,并且经过多年的发展和实践,已经逐渐成为大型企业和互联网公司处理大数据的首选。
本文将从架构设计、数据一致性与容错机制、性能优化以及管理与监控等四个方面,总结分布式数据库的最佳实践与经验。
一、架构设计分布式数据库的架构设计是构建一个高性能、高可用性系统的关键。
首先,需要考虑水平扩展的能力,通过将数据分散存储在多个节点上,提高系统的吞吐量和容量。
其次,选择合适的分片方式,将数据划分为不同的子集,实现负载均衡。
此外,还需要考虑节点之间的通信方式、数据的分布策略以及读写操作的路由策略等。
最后,为了保证数据的一致性,可以采用主从复制或者多主复制等方式,确保数据的同步和可用性。
二、数据一致性与容错机制数据一致性是分布式数据库中的一个重要问题。
在分布式环境中,由于网络故障或者节点故障等原因,可能会导致数据的不一致。
因此,需要采取相应的机制来确保数据的一致性。
一种常见的方式是使用分布式事务,通过将多个操作组织为一个事务来实现强一致性。
另一种方式是使用乐观并发控制(OCC),通过版本号或者时间戳等方式来实现冲突检测和解决。
此外,为了增强系统的容错能力,可以采用副本机制,将数据复制到多个节点上,当某个节点故障时,可以从其他节点上获取数据。
三、性能优化在处理海量数据和高并发请求的场景下,性能优化是至关重要的。
首先,可以通过合理的索引设计和查询优化,减少数据库的IO操作,提高查询效率。
其次,合理选择数据存储方式,可以采用列存储或者按需加载等技术,降低存储空间的消耗。
此外,还可以通过缓存技术来减少对数据库的访问,提高系统的响应速度。
最后,宿主机的选择和优化也是影响性能的重要因素,包括CPU、内存和硬盘等硬件配置以及操作系统和网络参数的调优。
四、管理与监控一个高效的分布式数据库需要有良好的管理和监控机制。
软件开发岗位实习报告:分布式数据库与一致性

软件开发岗位实习报告:分布式数据库与一致性一、实习背景与目的作为一名计算机科学专业的学生,我对软件开发领域深感兴趣,并希望通过实习经历来提升自己的实践能力。
在实习过程中,我选择了参与一个分布式数据库项目的开发,以加深对分布式系统和数据库原理的理解,特别是一致性问题。
本篇报告将详细介绍我在实习期间所参与的工作内容和所取得的成果。
二、项目背景分布式数据库是一种在多个计算机节点上存储和处理数据的系统,常用于大数据环境下的数据管理和分析。
然而,由于数据存储和处理在不同节点之间的分布,数据的一致性成为一个挑战。
一致性问题是指在分布式环境中,每个节点对数据的修改应该能够在合理的时间内同步到其他节点,以保证整个系统的数据一致性。
在实习项目中,我们的目标是设计和实现一个高性能的分布式数据库系统,其中的一致性机制是一个关键的部分。
为了保证系统的高可用性和数据一致性,我们选择了Raft一致性算法作为底层的分布式一致性协议。
三、工作内容与方法1. 系统架构设计在项目初期,我负责与团队成员一起进行系统架构设计。
我们通过分析业务需求和系统特点,设计了一个由多个节点组成的分布式数据库集群架构。
在架构设计中,我参与了系统各个组件的划分和数据通信协议的设计,确保系统能够满足高性能和高可用性的要求。
2. 一致性机制实现Raft一致性算法作为我们系统的核心一致性机制,我深入学习了该算法的原理和实现细节,并根据项目需求进行了相应的实现。
在这个过程中,我利用编程语言Java完成了分布式一致性模块的编码工作。
具体而言,我负责实现选举、日志复制和状态机等关键组件,确保分布式数据库能够按照Raft协议达成一致性。
3. 性能测试和调优为了验证我们系统的性能和一致性能力,我负责设计和执行了一系列性能测试和负载测试。
在这个过程中,我借助开源工具Simulator模拟了大规模的用户并发场景,并对系统各个组件进行了性能分析和调优。
通过优化算法、调整资源分配和优化网络通信等手段,我们成功提升了系统的性能和吞吐量。
分布式数据库的最佳实践与经验总结(系列五)

分布式数据库的最佳实践与经验总结引言如今,随着互联网和大数据的迅猛发展,分布式数据库成为了大数据处理的重要工具,为企业提供了高效可靠的数据存储和处理能力。
但是,分布式数据库的设计和实施并非容易事,需要深入理解其最佳实践和经验总结。
本文将介绍几个分布式数据库的最佳实践,包括数据分片、一致性、容灾备份以及性能优化等方面的经验总结。
数据分片与负载均衡数据分片是分布式数据库的关键之一。
通过将数据分散存储在不同的节点上,可以有效提高数据库的扩展能力和性能。
在进行数据分片时,要根据业务需求和数据模型进行合理的划分。
一般来说,可以按照数据的关键字段进行分片,确保数据的均衡访问和查询效率。
同时,为了实现负载均衡,还需要采用合适的路由策略,确保数据请求被均匀地分发到各个节点上,避免单点故障和性能瓶颈。
一致性与可用性在分布式数据库中,维护数据的一致性和可用性是非常重要的。
为了确保数据一致性,可以采用复制和同步机制。
通过在不同节点之间进行数据的复制和同步,可以提供冗余和容错能力,一旦某个节点出现故障,可以快速进行切换和恢复。
然而,数据的一致性和可用性常常是冲突的,需要根据具体业务情况进行权衡。
如果业务对数据的一致性要求较高,可以采用强一致性模型;如果对数据的可用性要求较高,可以采用弱一致性模型。
容灾备份与恢复容灾备份是分布式数据库不可或缺的一环。
在进行容灾备份时,需要考虑到数据的安全性和完整性。
可以采用多中心多活的架构,将数据备份到不同的地理位置,避免单点故障和灾难风险。
同时,还要定期进行数据的差异备份和增量备份,减少备份的时间和空间成本。
在数据恢复时,应根据备份的策略和优先级进行有序的恢复操作,确保数据能够尽快恢复到正常状态。
性能优化与扩展在分布式数据库的实施过程中,性能优化是至关重要的。
首先要对数据库的性能进行监控和诊断,及时发现和解决潜在的问题。
其次,可以采用硬件和软件的优化措施,如优化查询语句、增加索引、调整缓存配置等。
分布式数据库调研报告
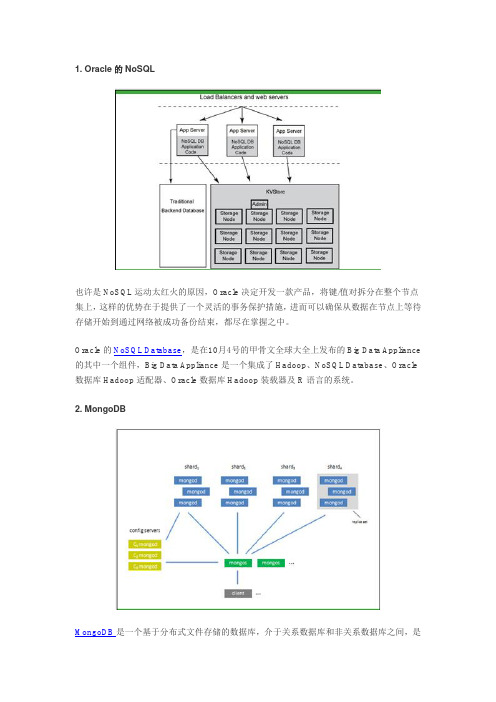
1. Oracle的NoSQL也许是NoSQL运动太红火的原因,Oracle决定开发一款产品,将键/值对拆分在整个节点集上,这样的优势在于提供了一个灵活的事务保护措施,进而可以确保从数据在节点上等待存储开始到通过网络被成功备份结束,都尽在掌握之中。
Oracle的NoSQL Database,是在10月4号的甲骨文全球大全上发布的Big Data Appliance 的其中一个组件,Big Data Appliance是一个集成了Hadoop、NoSQL Database、Oracle 数据库Hadoop适配器、Oracle数据库Hadoop装载器及R语言的系统。
2. MongoDBMongoDB是一个基于分布式文件存储的数据库,介于关系数据库和非关系数据库之间,是非关系数据库当中功能最丰富,最像关系数据库的。
MongoDB最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
MongoDB支持RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言。
MongoDB是高性能开源文档数据库,也是目前最受关注的NoSQL技术之一,以敏捷、可扩展和对企业应用友好(支持事务,一致性和数据完整性保证,有大企业应用案例)而著称。
有人甚至认为LAMP中的M应该用MongoDB取代MySQL,其火热程度可见一斑。
使用MongoDB的公司包括Foursquare, Craiglist, 迪士尼,SAP,Intuit,EA等,国内淘宝、大众点评、视觉中国等公司有应用。
(最新版MongoDB 2.2下载)3. Hadoop的HBaseHBase(Hadoop Database),是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
分布式数据库综述报告

电子科技大学研究生课程综合考核报告课程名称:数据库新技术教师姓名:胡旺学生姓名:董辉学号:201521060521 成绩:学期:2015年下学期分布式数据库综述报告摘要随着传统的数据库技术日趋成熟、计算机网络技术的飞速发展和应用范围的扩充,数据库应用已经普遍建立于计算机网络之上。
这时集中式数据库系统表现出它的不足:数据按实际需要已在网络上分布存储,再采用集中式处理,势必造成通信开销大;应用程序集中在一台计算机上运行,一旦该计算机发生故障,则整个系统受到影响,可靠性不高;集中式处理引起系统的规模和配置都不够灵活,系统的可扩充性差。
在这种形势下,集中式DB的“集中计算”概念向“分布计算”概念发展。
分布计算主要体现在客户机/服务器模式和分布式数据库体系结构两个方面。
分布式数据库系统通常使用较小的计算机系统,每台计算机可单独放在一个地方,每台计算机中都有DBMS的一份完整拷贝副本,并具有自己局部的数据库,位于不同地点的许多计算机通过网络互相连接,共同组成一个完整的、全局的大型数据库。
DDBS已成为信息处理学科的重要领域,正在迅速发展,原因基于以下几点:①它可以解决组织机构分散而数据需要相互联系的问题。
②如果一个组织机构需要增加新的相对自主的组织单位来扩充机构,则分布式数据库系统可以在对当前机构影响最小的情况下进行扩充。
③均衡负载的需要。
数据的分解采用使局部应用达到最大,这使得各处理机之间的相互干扰降到最低。
负载在各处理机之间分担,可以避免临界瓶颈。
④当现有机构中已存在几个数据库系统,而且实现全局应用的必要性增加时,就可以由这些数据库自下而上构成分布式数据库系统。
关键词:分布式数据库集群数据存储1.分布式数据库产生背景20世纪六十年代末和七十年代出现了比较成熟的数据库系统。
以IMS为代表的层次型数据库系统于1968年问世。
20世纪七十年代初,美国CODASYL的数据库任务组的提出了有名的网络数据库模型DBTG。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
龚海晏:进货信息模块以及系统的代码测试的工作。
三、实验总结:
高汉:
魏宗斌:通过这次的课程设计让我对分布式数据库有了重新的认识,分布式数据库不是我原来所认为的那么简单。分布式数据库系统(DDBS)包含分布式数据库管理系统(DDBMS)和分布式数据库(DDB)。在分布式数据库系统中,一个应用程序可以对数据库进行透明操作,数据库中的数据分别在不同的局部数据库中存储、由不同的DBMS进行管理、在不同的机器上运行、由不同的操作系统支持、被不同的通信网络连接在一起。数据分片最常见的就是水平分片和垂直分片两种。对于数据库管理信息系统,首要要做好需求分析的工作,设计各个模块的功能以及功能之间的相互关联。因为做的是分布式数据库系统,所以系统主要是体现“分布”二字,因此使我对分布式数据库有了更深的认识。该系统前台界面的编写主要是用的vs进行开发的,后台数据库使用的是SQLServer。当在一个大企业或大部门中已建成了若干个数据库之后,为了利用相互的资源,为了开发全局应用,就要研制分布式数据库系统.分布式数据库系统虽然也要对各现存的局部数据库系统做某些改动、重构,但比起把这些数据库集中起来重建一个集中式数据库,则无论从经济上还是从组织上考虑,分布式数据库均是较好的选择.这就是分布式数据库系统的优势所在。
龚海晏:通过这次的课程设计让我了解了分布式数据库设计的真正意义。在学习理论知识的时候完全是凭着自己的理解猜测所想,觉得这样是有道理的,更需要实践去检验。对于数据库管理信息系统,首要要做好需求分析的工作,而在这次设计中我们主要注重的是分布式设计内容,这对于我理解这门课程有很大的帮助。然后开始自己的系统开发的工作,前台界面的编写主要是用的vs进行开发的,感觉还是比较快速方便的,然后稍微比较麻烦的或是感到头疼的是对数据库库中表的操作,因为有的表的属性列还是比较多的,然后对其进行查询、修改等操作还是要注意一些类型之间的转换的。除此之外的就是如何实现数据库之间数据同步的问题了,上网搜了不少资料发现使用了SQLSERVER的发布和订阅的功能可以轻松的实现该功能,当然之前要做好相关的配置工作否则也是会出现让人头疼的问题的。最后开始多个数据库的连接模拟演示工作,之间可能也会出现相关的问题,其中通过和同学讨论以及自己上网搜集资料也最终解决了。这次的实验还让我更加懂得了团队之间合作的重要性,当我们共同去完成一个任务或是遇到一个问题时候,我们都会去共同的讨论。例如如何对系统进行设计,数据库表的主键字段的设计、有哪些属性等等,同时如何进行分片和分配的设计等。
数据库环境:Microsoft SQLSERVER 2008
进度安排:第6~7周,进行系统的需求分析
第7~8周,进行数据库的设计,以及系统前台的界面设计等。
第9周,进行各模块的合并完成、分布式数据库的实现功能以及
测试演示等。
第10周,完成PPT进行演示工作。
二、实验主要内容:
软件功能:该系统是图书管理信息系统。可以实现对图书的录入、修改、删除以及查询的功能,同时总店可以随时查看各个分店的图书的相关信息;实现了对员工的录入、修改、删除以及查询的功能,此功能与图书的功能相对应的;还实现了对会员的管理操作等。
安徽工业大学
《分布式数据库》实验报告
课题名称
书店管理信息系统
学院
计算机
专 业
计算机应用
专业班级
13班
组长
高汉
成员
魏宗斌
龚海晏
指导教师
戴小平
二Ο一四年五月日
课程名称:《分布式数据库》课程号码:XXXXXX
实验学时:学 分:
实验地点:校内实验时间:2014.2.17~2014.5.31
姓名
学号
贡献率(%)
5)进货信息模块:主要是供应商的管理,记录各个分库状态,以及各个分库的销售状态以及图书的供求信息等。
任务分配:
对于前期的系统的需求分析、数据库设计包括概念设计、逻辑设计、分片和分布等都需要我们参与其中讨论合适的方案。但是对系统的开发具体的任务做如下分配:
高汉:员工和会员的模块开发以及主要的分片发布的方案。
功能模块划分:根据需求分析可以将系统主要分为如下模块:
1)用户设置模块:客户、分店负责人、营业员以及管理人员的权限问题等。
2)图书信息模块:图书的类别、图书的基本相关的信息,以及相关的操作等。
3)员工信息模块:是对员工的信息的基本简单增删改的操作。
4)会员信息模块:包括会员的基本信息,还有订单,优惠消费等状况。e-mail组长高汉1320190308
850315257@
成员
魏宗斌
1320190300
810320885@
龚海晏
1320190306
811863228@
一、实验概况:
课题名称:书店管理信息系统。
开发工具:Microsoft Visual Studio 2010。
实习成绩评定:
2014年5月日