统计分析软件复习题答案
《统计分析与SPSS的应用》课后练习答案

《统计分析与SPSS的应用》课后练习答案在学习《统计分析与 SPSS 的应用》这门课程后,通过课后练习能够帮助我们更好地掌握所学知识,并将其应用到实际的数据分析中。
以下是针对部分课后练习的答案及解析。
一、选择题1、在 SPSS 中,用于描述数据集中变量分布特征的统计量是()A 均值B 标准差C 中位数D 众数答案:ABCD解析:均值、标准差、中位数和众数都是描述数据分布特征的常用统计量。
均值反映了数据的集中趋势;标准差反映了数据的离散程度;中位数是将数据排序后位于中间位置的数值;众数则是数据集中出现次数最多的数值。
2、进行独立样本 t 检验时,需要满足的前提条件是()A 样本来自正态分布总体B 两样本方差相等C 两样本相互独立D 以上都是答案:D解析:独立样本 t 检验要求样本来自正态分布总体、两样本方差相等以及两样本相互独立。
只有在这些条件满足的情况下,t 检验的结果才是可靠的。
3、以下哪种方法适用于多组数据的比较()A 单因素方差分析B 配对样本 t 检验C 相关分析D 回归分析答案:A解析:单因素方差分析用于比较三个或三个以上组别的数据是否存在显著差异。
配对样本 t 检验适用于配对数据的比较;相关分析用于研究变量之间的线性关系;回归分析用于建立变量之间的预测模型。
二、简答题1、请简述 SPSS 中数据录入的基本步骤。
答:SPSS 中数据录入的基本步骤如下:(1)打开 SPSS 软件,选择“新建数据文件”。
(2)在变量视图中定义变量的名称、类型、宽度、小数位数等属性。
(3)切换到数据视图,按照定义好的变量逐行录入数据。
(4)录入完成后,保存数据文件。
2、解释相关分析和回归分析的区别。
答:相关分析主要用于研究两个或多个变量之间的线性关系程度和方向,但它并不确定变量之间的因果关系。
相关分析的结果通常用相关系数来表示,如皮尔逊相关系数。
回归分析则不仅可以确定变量之间的关系,还可以建立数学模型来预测因变量的值。
统计分析与SPSS课后习题课后习题答案汇总(第五版)

统计分析与SPSS课后习题课后习题答案汇总(第五版)第⼀章练习题答案1、SPSS的中⽂全名是:社会科学统计软件包(后改名为:统计产品与服务解决⽅案)英⽂全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗⼝是数据编辑器窗⼝和结果查看器窗⼝。
数据编辑器窗⼝的主要功能是定义SPSS数据的结构、录⼊编辑和管理待分析的数据;结果查看器窗⼝的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:SPSS运⾏时可同时打开多个数据编辑器窗⼝。
每个数据编辑器窗⼝分别显⽰不同的数据集合(简称数据集)。
活动数据集:其中只有⼀个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进⾏分析。
4、SPSS的三种基本运⾏⽅式:完全窗⼝菜单⽅式、程序运⾏⽅式、混合运⾏⽅式。
完全窗⼝菜单⽅式:是指在使⽤SPSS的过程中,所有的分析操作都通过菜单、按钮、输⼊对话框等⽅式来完成,是⼀种最常见和最普遍的使⽤⽅式,最⼤优点是简洁和直观。
程序运⾏⽅式:是指在使⽤SPSS的过程中,统计分析⼈员根据⾃⼰的需要,⼿⼯编写SPSS命令程序,然后将编写好的程序⼀次性提交给计算机执⾏。
该⽅式适⽤于⼤规模的统计分析⼯作。
混合运⾏⽅式:是前两者的综合。
5、.sav是数据编辑器窗⼝中的SPSS数据⽂件的扩展名.spv是结果查看器窗⼝中的SPSS分析结果⽂件的扩展名.sps是语法窗⼝中的SPSS程序6、SPSS的数据加⼯和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按⼀定的概率以随机原则抽取样本,抽取样本时每个单位都有⼀定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
统计分析软件复习题答案
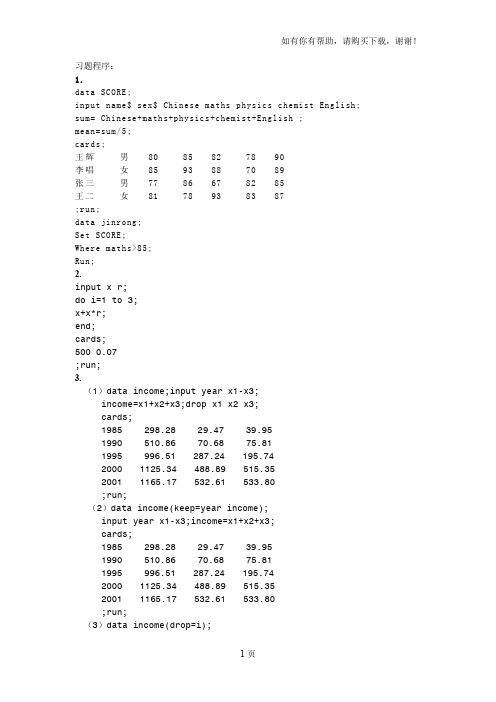
习题程序:1.data SCORE;input name$ sex$ Chinese maths physics chemist English; sum= Chinese+maths+physics+chemist+English ;mean=sum/5;cards;王辉男80 85 82 78 90李唱女85 93 88 70 89张三男77 86 67 82 85王二女81 78 93 83 87;run;data jinrong;Set SCORE;Where maths>85;Run;2.input x r;do i=1 to 3;x+x*r;end;cards;500 0.07;run;3.(1)data income;input year x1-x3;income=x1+x2+x3;drop x1 x2 x3;cards;1985 298.28 29.47 39.951990 510.86 70.68 75.811995 996.51 287.24 195.742000 1125.34 488.89 515.352001 1165.17 532.61 533.80;run;(2)data income(keep=year income);input year x1-x3;income=x1+x2+x3;cards;1985 298.28 29.47 39.951990 510.86 70.68 75.811995 996.51 287.24 195.742000 1125.34 488.89 515.352001 1165.17 532.61 533.80;run;(3)data income(drop=i);input x1-x3;array consum{3} x1-x3;do i=1 to 3;sum+consum(i);end;cards;1985 298.28 29.47 39.951990 510.86 70.68 75.811995 996.51 287.24 195.742000 1125.34 488.89 515.352001 1165.17 532.61 533.80;run;4.data group1 group2;input region$ income@@;if income>=2366.40 then do;output group1;n+1;end;else do;output group2;m+1;end;cards;beijing 5025.5 tianjin 3947.72 hebei 2603.6 shanxi 1956.05 nemenggu 1973.37 liaoning 2557.93 jilin 2182.22 heilong 2280.28 shanghai 5870.87 jiangsu 3784.71 zhejiang 4582.34 anhui 2020.04 fujian 3380.72 jiangxi 2231.6 shandong 2804.51 henan 2097.86 hubei 2352.16 hunanÏ 2299.46 guangdong 3769.79 guangxi 1944.33 hainan 2226.47 chongqing 1971.18 sichuan 1986.99 guizhou 1411.73 yunnan 1533.74 xizang 1404.01 shananxi 1490.8 gansu 1508.61 qinghai 1557.32 ningxia 1823.05 xinjiang 1710.44;proc print data=group1(drop=m);title 'group1';proc print data=group2(drop=n);title 'group2';run;5.data a;input region$ wage@@;if wage<10000 then delete;cards;beijing 19776 tianjin 15110 hebei 9139 shanxi 8618 neimenggu 8737liaoning 10609 jilin 9043 heilongjiang 8924 shanghai 21961jiangsu 12917zhejiang 19514 anhui 8501 fujian 13313 jiangxi 8346 shandong 11067henan 8573 hubei 9133 hunan 9991 guangdong 16779 guangxi 9209 hainan 8102 chongqing 10035 sichuan 10783 guizhou 9308 yunnan 10880 xizang 20112 shananxi 9440 gansu 10442 qinghai 14028 ningxia 11112 xinjiang 10145;run;6.data nongye;input xiangmu$ year85 year90 year95 year00 year01;cards;gulei 2 1 1 1 1roulei 2 1 1 1 1mianhua 1 1 1 1 1dadou 3 3 3 4 4;data gongye;input xiangmu$ year85 year90 year95 year99 year00;cards;gang 4 4 2 1 1mei 2 1 1 1 1yuanyou 6 5 5 5 5;data order;set nongye gongye;proc print;run;7.data gdp;input gdp1-gdp45 @@;cards;144 150 165 168 200 216 218 185 173 181 208 240 254 235 222 243 275 288 292 309 310 327 316 339 379 417 460 489 525 580 692 853 956 1104 1355 1512 1634 1879 2287 2939 3923 4854 5576 6053 6392;proc means data=gdp mean std cv skewness kurtosis;run;8.data gdp;input area$ gdp consumpt capital export@@;cards;beijing 2845.65 1467.71 1775.3 -397.36tianjin 1840.1 901.85 934.48 3.77hebei 5577.78 2509.3 2511.57 556.91shanxi 1787.76 1046.43 800.27 -58.94neimenggu 1545.326789 936.1894062 614.1373826 -5 liaoning 5033.08 2828.09 1625.5 579.49jilin 2087.87 1331.32 790.99 -34.44heilongjiang 3515.69982 2110.54 1130.53982 274.62shanghai 4950.84 2149.07 2294.46 507.31jiangsu 9403.3 4295.96 4239.17 868.17zhejiang 6749.18 3306.1 2891.02 552.06anhui 3290.130414 2108.09475 1185.495664 -3.46fujian 4218.31 2225.23 1939.61 53.47jiangxi 2161.75 1357.47 800.83 3.45shangdong 9438.31 4582.61 4513.32 342.38henan 5640.11 3114.13 2329.32 196.66hubei 4557.02 2408.84 1963.46 184.72hunan 3983 2553.14 1426.47 3.39gongdong 10647.71 5841.32 3860.81 945.58guangxi 2231.19 1597.05 769.04 -134.9hainan 546.62 299.86 254.79 -8.03chongqing 1769.77 1078.06 819.08 -127.37sichuan 4421.76 2691.47 1726.33 3.96guizhou 1084.9 833.87 599.95 -348.92yunnan 2074.71 1430.44 929.73 -285.46xizang 138.31 82.79 49.72 5.8shananxi 1844.27 1004.5 972.51 -132.74gansu 1081.51 674.42 444.89 -37.8qinghai 294.83 197.79 207.39 -110.35ningxia 298.38 223.52 207.69 -132.83xinjiang 1485.48 854.6 771.42 -140.54;proc sort;by gdp;proc transpose out = trans;id area;var gdp consumpt capital export;proc means sum;var gdp consumpt capital export;proc means mean max min std cv skewness kurtosis clm;run;9.d ata a;input r@@;cards;718525.4 723715.3 702236.6 37390.56 632662.2 443082.7 59706.7 17774.8 115653 558135.4 1581666 513099.3 213847.4 2917080 30368.26 1049252 32864.3 31972.76 364228.6 40924.85 30557.34 39874.46 32741.52 248281.1 98826.12 1956514 43551.33 387256.1 67158.48 238265.7 50744.47 51291.24 54995.52 157951.5 40349.33 220848.3 18309.99 20264.13 31359.99 41325.33 49634.95 51689.58 129214.6 35857.56 27680.21 58609.62 24192.69 15665.46 60003.2 53617.02 8605.78 85371.95 161167.1 24852.03 48598.58 36004.81 131046 68424.84 63149.74;proc means mean max min maxdec=2 var std cv skewness kurtosis alpha=0.1 clm n nmiss range;run;10.data a(drop=i);do i=1 to 100 by 1;x=normal(0);y=100+sqrt(30)*x;output;end;proc means alpha=0.05 clm;run;proc univariate data=a normal;run;11.data a;input b@@;cards;167.939 169.369 176.228 172.077 163.284 169.564 174.022 157.814 170.794 164.796 172.887 166.425 166.189 176.456 162.080 167.290 175.004 165.762 158.315 167.812 178.715 170.624 173.090 180.698 172.621 176.095 164.211 174.641 173.427 171.869 166.742 167.137 175.704 168.537 175.321 173.532 168.285 171.333 173.911 171.226 174.694 169.868 178.338 171.044 178.550 173.199 168.664 169.562 168.996;proc univariate plot;run;12.data a;input year r1 r2 r3 r4 r5 r6 r7@@;cards;1926 11.6 0.28 7.37 7.77 5.38 3.27 -1.49 1927 37.49 22.1 7.44 8.93 4.52 3.12 -2.08 1928 43.61 39.69 2.84 0.1 0.92 3.56 -0.97 1929 -8.42 -51.36 3.27 3.42 6.01 4.75 0.2 1930 -24.9 -38.15 7.98 4.66 6.72 2.41 -6.03 1931 -43.34 -49.75 -1.85 -5.31 -2.32 1.07 -9.52 1932 -8.19 -5.39 10.82 16.84 8.81 0.96 -10.3 1933 53.99 142.87 10.38 -0.07 1.83 0.3 0.51 1934 -1.44 24.22 13.84 10.03 9 0.16 2.03 1935 47.67 40.19 9.61 4.98 7.01 0.17 2.99 1936 33.92 64.8 6.74 7.52 3.06 0.18 1.21 1937 -35.03 -58.01 2.75 0.23 1.56 0.31 3.10 1938 31.12 32.8 6.13 5.53 6.23 -0.02 -2.78 1939 -0.41 0.35 3.97 5.94 4.52 0.02 -0.48 1940 -9.78 -5.16 3.39 6.09 2.96 0 0.96 1941 -11.59 -9 2.73 0.93 0.5 0.06 9.72 1942 20.3 44.51 2.6 3.22 1.94 0.27 9.29 1943 25.9 88.37 2.83 2.08 2.81 0.35 3.16 1944 19.75 53.72 4.73 2.81 1.8 0.33 2.111946 -8.07 -11.63 1.72 -0.1 1 0.35 18.16 1947 5.71 0.92 -2.34 -2.62 0.91 0.5 9.01 1948 5.5 -2.11 4.14 3.4 1.85 0.81 2.71 1949 18.79 19.75 3.31 6.45 2.32 1.10 -1.80 1950 31.71 38.75 2.12 0.06 0.7 1.2 5.79 1951 24.02 7.8 -2.69 -3.93 0.36 1.49 5.87 1952 18.37 3.03 3.52 1.16 1.63 1.66 0.88 1953 -0.99 -6.49 3.41 3.64 3.23 1.82 0.62 1954 52.62 60.58 5.39 7.19 2.68 0.86 -0.5 1955 31.56 20.44 0.48 -1.29 -0.65 1.57 0.37 1956 6.56 4.28 -6.81 -5.59 -0.42 2.46 2.86 1957 -10.78 -14.57 8.71 7.46 7.84 3.14 3.02 1958 43.36 64.89 -2.22 -6.09 -1.29 1.54 1.76 1959 11.96 16.4 -0.97 -2.26 -0.39 2.95 1.5 1960 0.47 -3.29 9.07 13.78 11.76 2.66 1.48 1961 26.89 32.09 4.82 0.97 1.85 2.13 0.67 1962 -8.73 -11.9 7.95 6.89 5.56 2.73 1.22 1963 22.8 23.57 2.19 1.21 1.64 3.12 1.65 1964 16.48 23.52 4.77 3.51 4.04 3.54 1.19 1965 12.45 41.75 -0.46 0.71 1.02 3.93 1.92 1966 -10.06 -7.01 0.2 3.65 4.69 4.76 3.35 1967 23.98 83.57 -4.95 -9.18 1.01 4.21 3.04 1968 11.06 35.97 2.57 -0.26 4.54 5.21 4.72 1969 -8.5 -25.05 -8.09 -5.07 -0.74 6.58 6.11 1970 4.01 -17.43 18.37 12.11 16.86 6.52 5.49 1971 14.31 16.5 11.01 13.23 8.72 4.39 3.36 1972 18.98 4.43 7.26 5.69 5.16 3.84 3.41 1973 -14.66 -30.9 1.14 -1.11 4.61 6.93 8.8 1974 -26.47 -19.95 -3.06 4.35 5.69 8 12.20 1975 37.2 52.82 14.64 9.2 7.83 5.8 7.01 1976 23.84 57.38 18.65 16.75 12.87 5.08 4.81 1977 -7.18 25.38 1.71 -0.69 1.41 5.12 6.77 1978 6.56 23.46 -0.07 -1.18 3.49 7.18 9.03 1979 18.44 43.46 -4.18 -1.23 4.09 10.38 13.31 1980 32.42 39.88 -2.76 -3.95 3.91 11.24 12.4 1981 -4.91 13.88 -1.24 1.86 9.45 14.71 8.94 1982 21.41 28.01 42.56 40.36 29.1 10.54 3.87 1983 22.51 39.67 6.26 0.65 7.41 8.8 3.8 1984 6.27 -6.67 16.86 15.48 14.02 9.85 3.95 1985 32.16 24.66 30.09 30.97 20.33 7.72 3.77 1986 18.47 6.85 19.85 24.53 15.14 6.16 1.13 1987 5.23 -9.3 -0.27 -2.71 2.9 5.47 4.41 1988 16.81 22.87 10.7 9.67 6.1 6.35 4.421990 -3.17 -21.56 6.78 6.18 9.73 7.81 6.11 1991 30.55 44.63 19.89 19.3 15.46 5.6 3.06 1992 7.67 23.35 9.39 8.05 7.19 3.51 2.9 1993 9.99 20.98 13.19 18.24 11.24 2.9 4.75 1994 1.31 3.11 -5.76 -7.77 -5.14 3.9 2.67 1995 37.43 34.46 27.2 31.67 16.8 5.6 2.54 1996 23.07 17.62 1.4 -0.83 2.1 5.21 3.32 1997 33.36 22.78 12.95 15.85 8.38 5.26 1.7 ;proc univariate normal;run;13.data gdp;input area$ gdp consumpt capital export@@;cards;beijing 2845.65 1467.71 1775.3 -397.36tianjin 1840.1 901.85 934.48 3.77hebei 5577.78 2509.3 2511.57 556.91shanxi 1787.76 1046.43 800.27 -58.94neimenggu 1545.326789 936.1894062 614.1373826 -5 liaoning 5033.08 2828.09 1625.5 579.49jilin 2087.87 1331.32 790.99 -34.44 heilongjiang 3515.69982 2110.54 1130.53982 274.62 shanghai 4950.84 2149.07 2294.46 507.31jiangsu 9403.3 4295.96 4239.17 868.17zhejiang 6749.18 3306.1 2891.02 552.06anhui 3290.130414 2108.09475 1185.495664 -3.46 fujian 4218.31 2225.23 1939.61 53.47jiangxi 2161.75 1357.47 800.83 3.45shangdong 9438.31 4582.61 4513.32 342.38henan 5640.11 3114.13 2329.32 196.66hubei 4557.02 2408.84 1963.46 184.72hunan 3983 2553.14 1426.47 3.39gongdong 10647.71 5841.32 3860.81 945.58guangxi 2231.19 1597.05 769.04 -134.9hainan 546.62 299.86 254.79 -8.03chongqing 1769.77 1078.06 819.08 -127.37sichuan 4421.76 2691.47 1726.33 3.96guizhou 1084.9 833.87 599.95 -348.92yunnan 2074.71 1430.44 929.73 -285.46xizang 138.31 82.79 49.72 5.8shananxi 1844.27 1004.5 972.51 -132.74gansu 1081.51 674.42 444.89 -37.8qinghai 294.83 197.79 207.39 -110.35ningxia 298.38 223.52 207.69 -132.83 xinjiang 1485.48 854.6 771.42 -140.54;proc means data=gdp mean var std cv skewness kurtosis alpha=0.1 t prt clm;var consumpt ;run;14.data a;input name$ sex$ region$ sales type$;select;when(sales<20000) group=10000;when(20000<=sales<40000) group=30000;when(40000<=sales<60000) group=50000;when(60000<=sales<80000) group=70000;otherwise group=90000;end;cards;Rose F East 9664 PPeter M West 22969 PStafer F West 27253 CStride F West 86432 CTopin M North 99210 PSpark F North 38928 CVetter M South 21531 PCurci M East 79345 PMarco M East 18523 PGreco F South 32914 CRyan F South 42109 PTomas M West 94329 CThalman F East 25718 CFarlow M North 64700 CSmith M South 27634 P;proc tabulate;class name sex type region;var sales group;table type,sex,region sales group; table region*sex;run;proc gchart;pie region/sumvar=sales;run;15.data density;input zhou$ country$ area renkou@@;density=renkou/area;if density>=100 then grade='a';else if density<10 then grade='c';else grade='b';cards;Asia China 960 126743Asia Japan 37.8 12687Asia India 297.4 100596Asia Philippines 30 7558Asia Mongolia 156.7 240Africa Eygpt 100.2 6398Africa Nigeria 92.4 12691Europe Germany 35.7 8215Europe UK 24.2 5974Europe France 55.2 5889Europe Italy 30.1 5769Europe Russian 1707.5 14556Northamerica US 937.3 28155NorthAmerica Canada 997.1 3075NorthAmerica Mexico 196.7 9797SouthAmerica Brazil 854.7 17041SouthAmerica Argentina 277.7 3703Oceania Australia 768.2 1918Oceania Newzealand 27.1 383;proc tabulate;title 'the table of population density';class zhou grade;var density;table zhou grade all, density*(n max min);run;16.data a;input date total@@;cards;90.1 1421 90.2 1367 90.3 1720 90.4 1760 90.5 1796 90.6 1848 90.7 1637 90.8 1671 90.9 1760 90.10 1790 90.11 1889 90.12 1981 91.1 1758 91.2 1486 91.3 1894 91.4 1970 91.5 2034 91.6 2103 91.7 1856 91.8 1915 91.9 2022 91.10 2045 91.11 2069 91.12 2136 91.1 1984 92.2 1812 92.3 2274 92.4 2329 92.5 2373 92.6 2516 92.7 2288 92.8 2312 92.9 2441 92.10 2502 92.11 2608 92.12 2823 93.1 2179 93.2 2409 93.3 2869 93.4 2917 93.5 3022 93.6 3274 3.7 2863 93.8 2864 93.9 2908 93.10 2912 93.11 3101 93.12 3664 94.1 2903 94.2 2513 94.3 3409 94.4 3500 94.5 3643 94.6 3871 94.7 3373 94.8 3463 94.9 3664 94.10 3753 94.11 3973 94.12 4469 95.1 2997 95.2 2740 95.12 3581 95.4 3746 95.5 3818 95.6 4041 95.7 3484 95.8 3511 95.9 3703 95.10 3811 95.11 4091 95.12 4651 96.1 3477 96.2 2970 96.3 3943 96.4 4068 96.5 4747 96.6 4417 96.7 3807 96.8 3746 96.9 4011 96.10 4130 96.11 4373 96.12 4992 97.1 3844 97.2 3182 97.3 4405 97.4 4520 97.5 4639 97.6 4970 97.7 4147 97.8 4199 97.9 4537 97.10 4719 97.11 5035 97.12 5546;run;proc sort;by total;proc gplot;plot total*date/vaxis=1000 to 6000 by 500;symbol v=plus i=spline c=blue;run;17.data shoping;input expend income number age hire@@;label expend='年食品支出:(千元) ' income=' 年收入'number=' 家庭人口数' age=' 收入最高者年龄'hire=' 房屋是否购买';cards;4.7 24 3 32 15.2 29 3 28 16.1 30 2 25 0 4.8 23 1 43 1 10.1 52 4 50 0 9.2 61 2 55 0 6.5 33 3 32 0 5.4 28 2 28 17.8 41 1 37 0 9.8 53 6 54 0 4.9 42 3 30 1 7.3 44 4 31 0 5.2 26 1 28 1 3.2 12 5 48 0 3.4 18 3 42 0 7.2 47 1 32 1 15.6 112 6 60 0 13.7 85 5 47 0 5.1 27 2 33 0 2.9 13 2 29 1 3.8 19 1 26 1 7.2 38 1 45 1 4.9 25 4 43 1 10.2 62 3 30 0 10 54 4 55 0 4.8 28 3 33 1 4.7 29 2 29 1 5.3 34 1 26 04.4 30 1 25 1 10.3 57 6 48 0 7.6 45 4 55 0 7.3 47 3 31 15.1 36 1 32 1 3.3 19 4 29 1 4.6 28 4 29 0 2.8 14 2 43 1 3.0 20 5 33 1 8.0 49 3 35 0 13.8 87 3 63 0 12.4 72 2 34 0 2.5 12 1 23 1 4.3 28 2 27 1 3.1 14 1 25 1 3.1 19 1 28 1 7.7 39 4 30 0 4.2 27 2 51 0 10.1 64 5 45 1 9.6 53 5 47 0 4.7 27 3 28 0 5.5 28 3 29 16.1 33 4 32 0 5.4 29 1 25 14.8 24 1 27 1 9.8 55 7 46 0 6.9 43 5 48 0 8.0 45 4 52 05.8 34 3 36 1 2.9 17 1 29 1 5.1 26 2 32 0 3.2 15 1 24 14.1 21 1 28 1 7.5 50 2 42 0 13.1 78 3 58 05.5 27 1 68 05.1 31 2 33 1 12.5 73 2 43 0 4.5 29 3 38 1 3.2 20 1 31 1 7.5 38 4 35 0 9.7 51 5 51 0 5.3 33 3 29 1 10.2 53 4 52 0 4.8 43 3 30 1 7.1 49 1 33 1 8.5 40 2 35 1 9.1 46 3 40 0 8.7 43 4 37 0 10.3 51 3 43 16.4 34 2 32 0 5.2 38 3 37 0 ;proc gplot ;plot age*income/vaxis=0 to 16 by 2;symbol v=star;run;proc tabulate;class hire;var income expend;table hire,income expend;table hire*(n pctn<hire>);run;18.data state;input first second third;cards;2763.9 4492.7 2945.63204.3 5251.6 3506.63831.0 6587.2 4510.14228.0 7278.0 5403.25017.0 7717.4 5813.55288.6 9102.2 7227.05800.0 11699.5 9138.66882.1 16428.5 11323.89457.2 22372.2 14930.011993.0 28537.9 17947.213844.2 33612.9 20427.514211.2 37222.7 23028.714552.4 38619.3 25173.514457.2 40417.9 27035.8;proc means t prt clm;var first second third;run;19.data a;input polit1 econ1 law1 cult1 polit2 econ2 law2 cult2@@;dpolit=polit1-polit2;decon=econ1-econ2;dlaw=law1-law2; dcult=cult1-cult2;cards;65 35 25 60 55 55 40 6575 50 20 55 50 60 45 7060 45 35 65 45 45 35 7575 40 40 70 50 50 50 7070 30 30 50 55 50 30 7555 40 35 65 60 40 45 6060 45 30 60 65 55 45 7555 40 25 60 50 60 35 8055 50 30 70 40 45 30 6550 55 35 75 45 50 45 70;proc means t prt clm;var dpolit decon dlaw dcult;run;20.data newhappy;input B C D E F G H I J K cards;39 1 1 1 3 3 5 1 3 143 1 3 3 1 3 1 1 3 138 1 3 1 3 1 1 5 1 132 1 3 3 3 3 3 5 1 141 3 1 1 1 3 5 5 1 130 1 1 1 3 1 1 1 1 139 3 3 3 3 3 3 3 3 3 33 1 3 3 3 3 5 3 3 3 15 1 3 5 3 3 5 5 1 5 8 3 3 3 5 3 3 3 3 5 23 1 1 1 5 3 1 3 3 5 41 3 3 3 3 3 5 1 3 3 40 1 1 1 3 1 1 1 1 3 34 1 1 3 1 1 3 3 5 1 37 1 3 1 1 1 3 3 3 1 44 1 3 3 1 3 3 3 3 1 48 1 1 3 1 1 3 1 3 1 27 3 3 1 3 3 5 1 1 1 45 1 1 1 1 1 3 5 3 1 39 1 1 3 3 1 3 3 5 3 24 3 3 1 3 3 1 3 1 3 47 1 1 1 3 3 3 3 3 3 29 1 1 3 1 1 3 5 1 146 3 3 3 3 3 1 1 1 347 1 1 1 3 3 3 3 3 3 22 3 1 1 1 1 3 5 1 3 42 1 1 1 1 3 5 5 3 1 39 3 3 1 1 1 3 3 3 3 48 1 1 3 3 1 1 1 1 3 40 1 3 3 3 1 1 1 1 1 37 1 1 1 1 1 1 3 1 1 41 1 1 1 1 3 3 3 1 1 30 3 1 1 1 1 3 3 3 7 46 1 1 1 1 1 1 1 1 1 28 1 3 3 3 3 3 1 3 7 20 1 3 1 1 1 5 3 1 7 36 1 5 1 3 1 1 3 1 7 10 3 3 5 5 3 1 3 5 3 30 3 3 3 3 3 3 3 3 3 11 3 3 5 3 3 3 5 3 3 26 3 3 3 3 1 5 5 3 5 14 3 1 5 3 3 5 5 3 3 18 1 3 3 3 3 1 5 3 3 22 1 3 1 3 3 5 5 1 3 29 1 5 3 3 3 3 3 1 3 29 3 1 3 1 3 3 3 3 1 41 3 1 5 1 1 3 3 3 1 28 1 3 3 3 1 3 3 3 3 48 1 1 3 1 1 3 5 1 146 1 1 1 1 1 1 1 1 1 42 1 1 1 1 1 5 3 1 1 32 3 1 1 1 1 3 3 3 7 32 3 3 1 3 3 3 1 3 7 47 1 1 1 1 1 3 3 3 7 31 1 3 1 3 3 5 3 1 724 3 1 1 1 3 5 1 3 725 1 1 1 3 1 5 3 1 5 23 3 3 5 3 3 3 3 5 5 44 1 3 5 1 1 3 3 1 3 16 1 1 1 5 1 1 5 3 340 3 3 3 3 3 1 5 3 341 3 3 3 3 3 3 3 3 3 35 3 3 3 5 3 5 3 1 3 42 3 1 1 3 3 5 3 3 3 22 3 1 1 3 1 5 3 5 3 36 3 3 3 3 3 5 3 5 3 28 3 1 1 1 3 3 1 3 1 47 1 1 1 1 3 1 1 3 1 34 3 3 1 3 3 5 3 5 1 36 3 1 3 1 3 5 3 3 1 38 1 1 1 1 3 3 3 3 1 37 1 1 1 1 1 1 3 3 1 35 1 1 3 1 3 1 3 1 1 41 1 1 1 1 1 5 3 1 1 30 1 1 1 1 3 1 5 1 1 47 1 1 1 1 1 1 1 1 1 28 1 3 1 1 1 1 3 3 1 34 1 1 3 3 3 1 1 1 1 36 3 1 1 1 3 3 1 1 3 48 1 1 3 1 1 3 1 3 1 41 1 1 1 1 1 1 1 1 3 33 1 1 1 5 3 5 5 1 5 40 1 1 1 1 1 1 1 5 1 40 1 1 1 1 1 3 3 1 7 40 1 1 3 3 3 5 5 3 1 37 1 1 1 3 3 1 3 3 3 29 3 1 1 1 1 5 5 3 1 33 1 1 1 5 3 5 5 1 5 27 3 1 3 3 3 5 3 3 3 37 1 3 1 3 3 3 1 1 1 39 3 1 1 1 1 5 3 3 3 43 1 1 1 1 1 3 3 1 126 5 3 1 3 3 5 5 5 738 3 1 1 3 3 5 3 3 743 1 1 1 1 1 1 1 1 745 1 1 3 1 1 1 3 1 134 1 1 1 1 1 1 1 1 137 3 3 3 3 3 3 1 3 144 1 1 1 1 1 3 1 1 142 1 1 1 3 3 1 5 5 242 3 1 1 3 1 1 1 3 316 1 1 3 1 1 1 5 1 322 3 3 5 3 3 3 3 3 342 3 1 1 1 3 1 1 1 321 3 1 3 1 3 3 1 3 7 38 3 1 3 1 3 3 5 3 1 48 3 1 3 1 1 1 1 3 147 1 1 1 1 3 1 1 3 148 1 3 1 1 3 5 3 1 1 44 3 1 3 1 1 3 3 1 1 42 1 1 1 1 1 3 3 1 1 42 3 1 3 1 1 3 1 1 1 45 1 1 1 1 1 3 1 1 1 23 3 1 3 3 3 1 3 5 542 3 1 3 1 3 1 1 1 343 1 1 3 3 3 1 1 1 3 18 1 3 3 3 3 3 3 3 3 44 1 3 1 3 3 3 3 3 1 42 3 3 1 3 1 1 1 1 3 48 3 1 1 1 1 3 1 1 1 44 1 1 1 1 1 3 1 1 1 24 3 1 3 1 1 1 1 1 139 3 3 3 1 1 1 3 3 140 1 3 3 3 3 1 3 3 3 25 1 3 5 3 3 5 5 1 3 24 3 3 3 1 3 3 3 3 1 31 1 3 3 3 3 1 1 3 1 29 3 3 1 3 3 3 5 5 1 38 1 1 1 1 3 1 3 3 1 41 1 1 1 1 1 3 5 3 1 32 3 1 3 1 1 3 1 1 1 28 1 3 1 3 3 3 5 3 1 42 3 3 1 1 1 5 1 1 1 45 3 3 3 1 1 1 1 3 1 38 1 3 3 1 1 3 3 1 147 1 1 1 1 3 3 1 3 1 16 3 1 1 1 1 1 5 5 1 48 1 1 1 1 1 1 1 1 1 40 1 3 3 3 3 5 3 3 3 30 1 3 3 3 3 5 1 3 3 40 1 1 1 1 3 1 1 3 1 38 1 3 1 3 3 3 3 3 3 10 1 5 3 5 1 5 3 1 7 26 5 1 1 1 3 3 5 5 1 45 1 3 1 1 3 1 1 1 1 ;proc corr spearman kendall;var B;with C D E F G H I J K;run;21.data engle;input area$ engle@@;cards;n 67.7 c 57.5n 61.8 c 56.9n 57.8 c 53.31n 58.8 c 54.24n 57.6 c 53.82n 57.6 c 52.86n 58.1 c 50.13n 58.9 c 49.89n 58.6 c 49.92n 56.3 c 48.6n 55.1 c 46.4n 53.4 c 44.5n 52.6 c 41.9n 49.1 c 39.2n 47.7 c 37.9;proc sort; by area;proc univariate normal;var engle;by area;proc ttest ; class area;var engle;run;22.data zichfz;input type$ sold@@;cards;如有你有帮助,请购买下载,谢谢!g 98.39 z 97.94g 97.6 z 99.01g 98.59 z 98.07g 98.44 z 94.5g 98.41 z 100.88g 98.38 z 96.7g 97.25 z 96.52g 98.58 z 92.41g 99.23 z 99.16g 98.54 z 97.66g 98.88 z 97.01g 99.16 z 98.97g 98.55 z 96.79g 98.27 z 98.03g 98.97 z 97.36g 98.45 z 96.43g 97.87 z 98g 99.2 z 98.67g 100 z 97.28g 98.27 z 96.34g 97.19 z 91.59g 99.29 z 96.64g 98.99 z 97.13g 97.46 z 98.56g 98.99 z 96.88g 89.98 z 150g 98.03 z 96.99g 97.8 z 99.86g 93.18 z 95.92g 98.14 z 91.12g 100.01 z 94.25;proc sort; by type;run;proc univariate normal;var sold;by type;run;proc npar1way wilcoxon;class type;var sold;run;23.data west;input goods00 goods01@@;dif=goods01-goods00;cards;13.47 15.36128.88 130.450.5 0.5393.31 95.29111.28 113.578.43 79.63114.57 118.396.55 9.2924 25.943.17 43.1236.71 38.1814.46 16.2450.41 53.912.81 28.92;proc univariate normal;var goods00 goods01 dif; run;24.data profit;input income salecost manacost tax profit;cards;5660515 4912868 427811 17545 287060 1725333 1542880 96734 4611 76711 1452182 1254814 82696 5705 98800 956443 802351 51391 5371 36649 440964 318268 20941 1571 21893 1953394 1658137 108810 16637 153004 867502 780569 42384 2244 31877 1025303 870530 59582 4497 75436 7262690 6259320 570936 20983 330910 4603819 3971448 268991 13730 276187 2976451 2600835 155475 8701 156487 856125 729628 47443 2556 64003 1272714 1130089 78857 5580 49723 448680 390230 22144 1728 30030 4370183 3887907 181083 9943 239310 1710652 1557867 79861 6046 56301 1685283 1455903 74866 8863 116854 1032003 857019 56693 4462 96957 5174417 4447083 394244 15381 274865 662746 566211 39927 2568 42198 130742 101912 6999 218 10078 723438 630002 46940 2508 37455 1564629 1380889 97369 4068 64524 330985 287932 20668 1336 20005 691074 592652 49185 2425 3432950305 43980 3201 323 2669 692077 594424 31157 2126 62258 387899 338440 29242 1211 17105 86227 73939 5286 242 4616 130934 110672 8413 548 11182 771256 674105 45221 2332 47192 ;proc corr spearman Pearson;var profit;with income salecost manacost tax;run;“属性数据分析与FREQ过程”后面的习题第一题:data a;input sex$ colour$ number@@;cards;m red 30 m blue 10 m green 10f red 20 f blue 10 f green 10;run;proc freq;weight number;tables sex*colour/chisq expected;run;第二题:data a;input sex$ regist$ n@@;cards;m y 3738 m n 4704f y 1494 f n 2827;proc freq;tables sex*regist/chisq;weight n;run;第三题:data a;input type$ sex$ y x@@;x1=y*x/100;x2=y-x1;cards;a m 825 62 a f 108 82b m 560 63 b f 25 68c m 325 37 c f 593 34d m 417 33 d f 375 35e m 191 28 ef 393 24g m 373 6 g f 341 7;proc freq;weight x2;tables type*sex/chisq;run;proc freq;weight x1;tables type*sex/chisq;run;第四题:data market;input ying$ pin$ yong$ wen$ number@@;cards4;软 N 用过高温 19 软 N 用过低温 57软 N 未用过高温 29 软 N 未用过低温 63软 M 用过高温 29 软 M 用过低温 49软 M 未用过高温 27 软 M 未用过低温 53中 N 用过高温 23 中 N 用过低温 47中 N 未用过高温 33 中 N 未用过低温 66中M 用过高温 47 中M 用过低温 55中M 未用过高温 23 中M 未用过低温 50硬 N 用过高温 24 硬 N 用过低温 37硬 N 未用过高温 42 硬 N 未用过低温 68硬M 用过高温 43 硬M 用过低温 52硬M 未用过高温 30 硬M 未用过低温 42;;;;proc freq;tables ying*pin yong*wen/nocol norow;weight number;run;第五题:data cancer;input health$ cigerat$ number@@;cards;cancer smoker 60cancer nsmoker 3ncancer smoker 32ncancer nsmoker 11;proc freq;tables health*cigerat/expected chisq norow nocol nopercent exact; weight number;run;第六题:data score;input score$ class sex$ number@@;cards;c 1 m 3 b 1 m 11 a 1 m 3 c 1 f 2b 1 f 14 a 1 f 2c 2 m 4 b 2 m 10a 2 m 7 c 2 f 3b 2 f 9 a 2 f 5;proc freq;tables class*score class*sex/chisq nocol norow nopercent;tables sex*score*class/ chisq expected norow nocol; tables class*score/chisq measures norow nocol nopercent; weight number;run;。
实用统计软件试题及答案

实用统计软件试题及答案一、单项选择题(每题2分,共40分)1. SPSS软件中,用于描述数据集中趋势的统计量是()。
A. 平均值B. 方差C. 标准差D. 众数答案:A2. 在R语言中,用于创建向量的函数是()。
A. vector()B. list()C. matrix()D. array()答案:A3. Excel中,计算一组数据的标准差的函数是()。
A. AVERAGEB. STDEV.PC. STDEV.SD. MEDIAN答案:B4. 在统计学中,用于衡量数据离散程度的指标是()。
A. 均值B. 方差C. 标准差D. 众数答案:C5. MATLAB中,用于生成随机数的函数是()。
A. rand()B. randn()C. randi()D. all of the above答案:D6. Python中,用于计算相关系数的函数是()。
A. corr()B. cov()C. mean()D. median()答案:A7. 在统计分析中,用于检验两个独立样本均值差异显著性的统计方法是()。
A. t检验B. 方差分析C. 卡方检验D. 回归分析答案:A8. SAS中,用于数据清洗的步骤是()。
A. PROC CONTENTSB. PROC FREQC. PROC MEANSD. PROC STANDARD答案:A9. 在统计软件中,用于创建数据框的函数是()。
A. data.frame()B. matrix()C. list()D. array()答案:A10. 用于绘制箱线图的R语言函数是()。
A. boxplot()B. hist()C. plot()D. barplot()答案:A二、多项选择题(每题3分,共30分)1. 下列哪些软件属于统计分析软件?()A. SPSSB. ExcelC. MATLABD. Photoshop答案:ABC2. R语言中,用于数据可视化的函数包括()。
A. plot()B. hist()C. boxplot()D. barplot()答案:ABCD3. Excel中,可以用于描述数据分布的函数有()。
SPSS数据统计与分析考试习题集附答案淮师

1 第三章统计假设检验二、计算题1.桃树枝条的常规含氮量为2.40%,现对一桃树新品种枝条的含氮量进行了10次测定,其结果为2.38%、2.38%、2.41%、2.50%、2.47%、2.41%、2.38%、2.26%、2.32%、2.41%,试问该测定结果与常规枝条含氮量有无差别。
单个样本显著值0.349>0.052.随机抽测了10只兔的直肠温度,其数据为:38.7、39.0、38.9、39.6、39.1、39.8、38.5、39.7、39.2、38.4(℃),已知该品种兔直肠温度的总体平均数为39.5(℃),试检验该样本平均温度与该品种兔直肠温度的总体平均数是否存在显著差异?单个样本显著值0.027<0.053.假说:“北方动物比南方动物具有较短的附肢。
”为验证这一假说,调查了如下鸟类翅长(mm)资料。
试检验这一假说。
双个样本成组这个说法不正确,差异不明显。
显著值0.581>0.054.11只60日龄的雄鼠在x射线照射前后之体重数据见下表(单位:g):检验雄鼠在照射x射线前后体重差异是否显著?双个样本成对5.用中草药青木香治疗高血压,记录了13个病例,所测定的舒张压数据如下:试检验该药是否具有降低血压的作用。
双个样本成对6.为测定A、B两种病毒对烟草的致病力,取8株烟草,每一株皆半叶接种A病毒,另半叶接种B病毒(每一株的哪半边接种哪一种病毒由抽签随机决定),以叶面出现枯斑病的多少作为致病力强弱的指标,得结果如下表。
试检验两种病毒的致病能力是否有显著差异。
0.034<0.052双个样本成对7.下表为随机抽取的国光苹果和红富士苹果果实各11个的果肉硬度(磅/cm2,1磅=0.453 6kg),问两品种的果肉硬度有无显著差异?双个样本成组苹果果实的果肉硬度(磅/cm2)8.为研究电渗处理对草莓果实中钙离子含量的影响,选用10个草莓品种来进行电渗处理与对照的对比试验,结果见下表。
实用统计软件试题及答案

实用统计软件试题及答案# 实用统计软件试题及答案一、选择题1. 在统计分析中,SPSS软件主要用于处理以下哪类数据?A. 图像数据B. 音频数据C. 定量数据D. 文本数据答案:C2. Excel中,以下哪个功能用于创建数据的频率分布表?A. 数据透视表B. 排序C. 筛选D. 条件格式答案:A3. R语言中,以下哪个命令用于安装新的包?A. `library()`B. `install.packages()`C. `require()`D. `source()`答案:B4. 在统计学中,描述数据集中趋势的度量是:A. 方差B. 标准差C. 均值D. 极差答案:C5. 以下哪个统计软件是开源的?A. SPSSB. SASC. RD. Stata答案:C二、判断题1. 在使用Excel进行数据分析时,数据透视表可以用于计算数据的中位数。
(对/错)答案:错2. R语言中,所有的数据集默认都是以列表的形式存储。
(对/错)答案:对3. 统计分析软件中,散点图可以用来展示两个变量之间的相关性。
(对/错)答案:对4. 在SPSS中,可以直接使用鼠标拖拽来完成数据的排序。
(对/错)答案:对5. 所有的统计软件都支持进行假设检验。
(对/错)答案:错三、简答题1. 描述Excel中数据透视表的基本功能。
答案:Excel中的数据透视表是一种强大的数据汇总工具,它允许用户快速地对大量数据进行分组、排序和筛选,以及执行多维度的汇总计算。
用户可以通过数据透视表来计算数据的总和、平均值、最大值、最小值、计数等,并且能够动态地改变汇总的方式和显示的数据分组,从而深入分析数据。
2. 解释R语言中数据框(data frame)的结构特点。
答案:R语言中的数据框是一种二维数据结构,类似于Excel中的表格。
数据框由多列组成,每列可以是不同的数据类型(数值、字符、逻辑等)。
数据框的行通常代表观测值,列代表变量。
数据框中的数据可以通过列名进行访问和操作,这使得数据操作和分析变得非常灵活和高效。
统计复习题及答案

1.样本均数的标准误越小说明A.观察个体的变异越小 B.观察个体的变异越大 C.抽样误差越大D.由样本均数估计总体均数的可靠性越大E.由样本均数估计总体均数的可靠性越小2.某医生开展一项科研工作,按统计工作步骤进行,不属于搜集资料的内容是A.实验 B.录入计算机 C.专题调查 D.统计报表 E.医疗卫生工作记录3.某医生开展一项科研工作,按统计工作步骤进行,分析资料包括A.对照、重复 B.随机、均衡 C.描述、推断D.计算、讨论 E.归纳、整理4.两组呈正态分布的数值变量资料,但均数相差悬殊,若比较离散趋势,最好选用的指标为A.全距B.四分位数间距 C.方差D.标准差E.变异系数5.平均数表示一组性质相同的变量值的A.集中趋势 B.精密水平 C.分布情况 D.离散趋势E.离散程度6.下列观测结果属于等级资料的是A.收缩压测量值B.脉搏数C.病情程度D.住院天数 E.四种血型7.统计工作的步骤不包括A.整理资料 B.统计设计 C.分析资料D.搜集资料 E.得出结论8.从一个数值变量资料的总体中抽样,产生抽样误差的主要原因是A.总体中的个体值存在差别 B.总体均数不等于零C.样本中的个体值存在差别 D.样本均数不等于零 E.样本只包含总体的一部分9.变异系数主要用于A.比较不同计量指标的变异度 B.衡量正态分布的变异程度 C.衡量测量的准确度D.衡量正态分布的变异程度 E.衡量抽样误差的大小10.抽样误差产生的原因是A.样本不是随机抽样 B.测量不准确 C.资料不是正态分布D.统计指标选择不当 E.个体差异11.不属于变异指标的是A.标准差 B.中位数 C.全距 D.四分位间距E.变异系数12.若计算某疫苗接种后的平均滴度应选用的指标是A.均数 B.几何均数 C.中位数 D.百分位数 E.倒数的均数13.进行假设检验时,若两组资料间差异有统计学意义,其p值为A. p<0.05B. p<0.5C. P>0.05D. p>0.5 E. p<0.114.资料为大样本时,总体均数的99%可信区间的t值为A. 2.58B. 2.326C. 1.96D.3.84 E. 6.3615.从一个呈正态分布的总体中随机抽样,x≠μ,该差别被称为A.系统误差 B.个体差异C.过失误差 D.抽样误差 E.测量误差16.“算术均数”适合的资料是:A.正态或近似正态分布的资料B.对数正态分布资料 C.偏态分布资料 D.分布类型不清的资料 E.开口资料17. 欲比较同年龄、同性别身高与体重的变异度,宜选择A.全距 B.方差 C.标准差 D.变异系数 E.标准误18. µ±1.96σ范围内的面积占正态曲线下总面积的 A. 68.27% B. 95% C .99% D.100%E.47.5%19.可以表示抽样误差大小的指标是A.全距B.方差C.标准差D.变异系数E.标准误20.两样本均数比较,自由度大小等于A.n1-1B.n2-1C.n1+n2–1D.n1+n2-2E. n1+n221.四个样本率比较,若χ2>χ20.01(3),可认为A.各总体率不同或不全相同B.各总体率均不相同 C.各样本率均不相同 D.各样本率不同或不全相同 E.各总体率相同22.χ2检验的自由度是A.n﹣1B.n﹣2C.n1﹢n2﹣1D.n1﹢n2﹣2E.(R﹣1)(C﹣1)23.两样本均数比较,经t检验,差别有显著性时,P越小,说明,A.两样本均数差别越大B.两总体均数差别越大C. 越有理由认为两样本均数不同D.越有理由认为两总体均数不同E. 以上均不对24.表示某事物因时间而变化的趋势宜选择A.百分条图B.圆图C.线图D.直条图E.直方图25.行×列表χ2检验的条件是A.不宜有1/10以上的格子的理论频数小于5B.不宜有1/8以上的格子的理论频数小于5C.不宜有1/6以上的格子的理论频数小于5D.不宜有1/5以上的格子的理论频数小于5E.不宜有1/3以上的格子的理论频数小于526.百分条图适合的资料是A.相互独立无连续关联的资料B.构成比资料C.两事物相关关系资料D.连续性资料的频数分布E.某现象随另一现象变迁的资料27.四格表中四个基本数字是A.两个样本率的分子和分母B.两个构成比的分子和分母C.两个实测阳性绝对数和阴性绝对数D.两个实测数和理论数E.以上均不对28.反映事物发生的频率和强度宜选择A.均数B.标准差C.率D.构成比E.相对比29.使用相对数时,容易犯的错误是A.把构成比做率看待B.把率作构成比看待C.把构成比做相对比看待D.把率作相对比看待E.以上均不对30.观察单位在100~400个时,频数分布表的组数一般为A.越多越好B.越少越好C.5~10组D.8~15组E.10~20组31.估计正常值范围时,样本含量一般为A.20以上B.30以上C.50以上D.100以上E.1000以上32.下列资料属于有序分类变量资料的是A.血红蛋白B.血糖C.血压D.体重E.疗效某医生随机抽取某工厂40名苯作业男工检查,其白细胞均数为5.1×109个/L,问苯作业男工白细胞均数是否与正常成人有差别?33.进行假设检验时应作A.均数u检验B.t检验C.χ2检验D. 率的u检验E.F检验34.假设检验的步骤A.建立假设B.确定检验水准C.计算统计量D.确定p值和做出统计推断结论E.以上都是35.本例的自由度为A.40B.38C.39D.30E.41 36.调查某疫苗在儿童中接种后的预防效果,在某地全部1000名易感儿童中进行接种,经一定时间后从中随机抽取300名儿童做效果测定,得阳性人数228名。
统计学-复习试题(含答案)

一. 单项选择题(每小题2分,共20分)1. 对于未分组的原始数据,描述其分布特征的图形主要有( )A. 直方图和折线图B. 直方图和茎叶图C. 茎叶图和箱线图D. 茎叶图和雷达图2. 在对几组数据的离散程度进行比较时使用的统计量通常是( ) A. 异众比率 B. 平均差 C. 标准差 D. 离散系数3. 从均值为100、标准差为10的总体中,抽出一个50=n的简单随机样本,样本均值的数学期望和方差分别为( )A. 100和2 B. 100和0.2 C. 10和1.4 D. 10和24.在参数估计中,要求通过样本的统计量来估计总体参数,评价统计量标准之一是使它与总体参数的离差越小越好。
这种评价标准称为( )A. 无偏性 B. 有效性 C. 一致性 D. 充分性5.根据一个具体的样本求出的总体均值95%的置信区间( )A. 以95%的概率包含总体均值B. 有5%的可能性包含总体均值C. 一定包含总体均值D. 可能包含也可能不包含总体均值6.在方差分析中,检验统计量F 是( )A. 组间平方和除以组内平方和B. 组间均方和除以组内均方C. 组间平方和除以总平方和D. 组间均方和除以组内均方7.在回归模型εββ++=x y 10中,ε反映的是( )A. 由于x 的变化引起的y 的线性变化部分B 由于y 的变化引起的x 的线性变化部分C. 除x 和y 的线性关系之外的随机因素对y 的影响D 由于x 和y 的线性关系对y 的影响8.在多元回归分析中,多重共线性是指模型中( )A. 两个或两个以上的自变量彼此相关B 两个或两个以上的自变量彼此无关C 因变量与一个自变量相关D 因变量与两个或两个以上的自变量相关9.若某一现象在初期增长迅速,随后增长率逐渐降低,最终则以K 为增长极限。
描述该类现象所采用的趋势线应为( )A. 趋势直线 B. 指数曲线 C. 修正指数曲线 D. Gompertz 曲线10. 消费价格指数反映了( )A. 商品零售价格的变动趋势和程度B 居民购买生活消费品价格的变动趋势和程度C 居民购买服务项目价格的变动趋势和程度D 居民购买生活消费品和服务项目价格的变动趋势和程度二. 简要回答下列问题(每小题5分,共20分)1. 解释总体与样本、参数和统计量的含义。
spss统计分析习题答案

spss统计分析习题答案SPSS统计分析习题答案在统计学中,SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件。
它提供了一系列功能强大的工具,用于数据处理、数据可视化和统计分析。
对于学习和实践统计分析的人来说,掌握SPSS的使用是非常重要的。
在学习SPSS统计分析过程中,我们常常会遇到一些习题,用以巩固和应用所学的知识。
下面,我将提供一些SPSS统计分析习题的答案,希望能对你的学习和实践有所帮助。
习题一:假设你有一份关于某个班级学生的成绩数据,包括数学成绩、语文成绩和英语成绩。
请使用SPSS计算每个学生的总分,并计算班级的平均总分。
答案:首先,打开SPSS软件并导入数据集。
然后,依次点击"Transform"、"Compute Variable"。
在弹出的对话框中,输入一个新的变量名,比如"Total_Score",然后在"Numeric Expression"框中输入数学成绩、语文成绩和英语成绩的变量名,并使用"+"符号将它们连接起来,最后点击"OK"按钮。
这样,SPSS将会计算每个学生的总分,并将结果保存在新的变量"Total_Score"中。
接下来,点击"Analyze"、"Descriptive Statistics"、"Frequencies"。
在弹出的对话框中,将"Total_Score"变量拖动到"Variables"框中,并点击"OK"按钮。
SPSS将会计算班级的平均总分,并在输出结果中显示。
习题二:假设你有一份关于某个公司员工的工资数据,包括性别、年龄和工资水平。
统计分析软件应用考试试题及答案

统计分析软件应用考试试题及答案一、选择题1. 统计分析软件是指用于处理和分析数据的计算机软件。
以下哪个软件是统计分析软件?A. PhotoshopB. ExcelC. WordD. Powerpoint答案:B2. 统计分析软件可以进行以下哪种分析?A. 文字分析B. 图像处理C. 数据分析D. 视频编辑答案:C3. 统计分析软件最常用于以下哪个领域?A. 医学研究B. 艺术设计C. 建筑工程D. 音乐制作答案:A4. 统计分析软件可以帮助用户进行哪些统计操作?A. 数据可视化B. 数据收集C. 数据存储D. 数据传输答案:A5. 统计分析软件在数据分析中的作用是什么?A. 进行数据获取B. 进行数据整理C. 进行数据分析D. 进行数据存储答案:C二、填空题1. 统计分析软件中,______是用来对数据进行描述性统计的功能。
答案:描述统计2. 统计分析软件可以根据数据的分布特征进行______分析。
答案:频率3. 统计分析软件可以使用______图来展示数据的整体情况。
答案:柱状4. 统计分析软件可以通过______来进行数据的比较和关联分析。
答案:相关性分析5. 统计分析软件可以进行______分析,对数据进行分类和归类。
答案:聚类三、简答题1. 统计分析软件在统计学研究中的应用有哪些?答:统计分析软件在统计学研究中有很多应用。
它可以帮助研究人员对大量的数据进行整理、分析和处理,提取出数据中的规律和趋势。
同时,统计分析软件还可以进行数据可视化,将复杂的数据以图表的形式呈现,帮助研究人员更直观地理解和解读数据。
2. 统计分析软件可以如何帮助企业决策?答:统计分析软件可以帮助企业进行数据分析,从而提供决策支持。
通过对企业内部数据的分析,统计分析软件可以揭示出企业的业务运行状况、市场趋势等关键信息,从而为企业的决策提供依据。
例如,在市场营销中,统计分析软件可以帮助企业分析客户的购买行为和偏好,从而有效地制定营销策略。
统计复习题(最终,有答案)

1.甲、乙两种不同水稻品种,分别在5个田块上试种,其中乙品种平均亩产量是520公斤,标准差是40.6公斤。
甲品种产量情况如下:甲品种要求:试研究两个品种的平均亩产量,以及确定哪一个品种具有较大稳定性,更有推广价值? (1)(公斤)506.355.2531甲===∑∑fxf x(公斤)44.6558.0)3.506420(....2.1)3.506600()(222甲=⨯-++⨯-=-=∑∑ffx x σ (2)%93.123.50644.65V 甲===x σσ %81.75206.40V 乙===x σσ 因为7。
81%<12。
93%,所以乙品种具有较大稳定性,更有推广价值2.已知甲、乙两个班级,乙班学生《统计学》考试平均成绩为76.50分,标准差为10。
30分,而甲的成绩如下所示:甲班要求:计算有关指标比较两个班级学生平均成绩的代表性。
(计算结果保留2位小数)(分)17.37604390甲===∑∑fxfx(分)96.13606)17.7395(....5)17.7354()(222甲=⨯-++⨯-=-=∑∑ffx x σ (2)%08.1917.7396.13V 甲===x σσ %46.1376.53.10V 乙===x σσ 因为13。
46%<19.08%,所以乙班学生平均成绩的代表性好于甲班的 3.已知甲厂职工工资资料如下:又已知乙厂职工的月平均工资为600元,标准差为120元,试比较甲乙两厂职工月平均工资的代表性大小。
(元)66010066000甲===∑∑fxf x(元)24.23310010)6601100(....15)660300()(222甲=⨯-++⨯-=-=∑∑ffx x σ (2)%34.3566024.233V 甲===x σσ %20600120V 乙===x σσ 因为20%〈35.34%,所以乙厂平均工资的代表性好于甲厂4.现已知甲企业在2007年前10个月的月平均产值为400万元,标准差为16 万元,而乙企业在2007年前10个月的各月产值如下表所示:请计算乙企业的月平均产值及标准差,并根据产值比较2007年前10个月甲乙两企业的生产稳定性。
统计软件模拟试题及答案

统计软件模拟试题及答案一、单项选择题(每题2分,共10分)1. SPSS中用于描述性统计分析的命令是:A. DESCRIPTIVESB. FREQUENCIESC. DESCRIPTIVED. DESCRIPT答案:A2. 在R语言中,用于创建数据框的函数是:A. data.frame()B. dataframe()C. data.frameD. dataframe答案:A3. Excel中,用于计算一组数据平均值的函数是:A. AVERAGEB. MEANC. AVGD. MEDIAN答案:A4. SAS中,用于输出结果的命令是:A. PRINTB. PROC PRINTC. OUTPUTD. LIST答案:B5. 在Stata中,用于进行线性回归分析的命令是:A. REGB. LINEARC. REGRESSIOND. REGRESS答案:D二、多项选择题(每题3分,共15分)1. 下列哪些软件属于统计分析软件?A. SPSSB. ExcelC. SASD. R答案:ABCD2. 在R语言中,下列哪些函数用于数据导入?A. read.csv()B. read.table()C. readRDS()D. read.xlsx()答案:ABCD3. Excel中,下列哪些函数用于数据排序?A. SORTB. RANKC. SMALLD. LARGE答案:ABC4. SAS中,下列哪些命令用于数据清洗?A. PROC MEANSB. PROC CONTENTSC. PROC FREQD. PROC SQL答案:BCD5. Stata中,下列哪些命令用于数据转换?A. reshapeB. generateC. replaceD. merge答案:ABC三、判断题(每题2分,共10分)1. 在SPSS中,可以通过“Transform”菜单进行数据转换。
(对)2. R语言中,向量的长度必须是固定的。
(错)3. Excel中,可以通过“数据”菜单进行数据透视表的创建。
R统计软件的期末试题及答案

R统计软件的期末试题及答案一、选择题1. R统计软件是一种什么类型的软件?A. 数据库软件B. 办公软件C. 统计分析软件D. 图形设计软件答案:C2. R统计软件最初由哪个计算机语言开发而来?A. PythonB. C++C. JavaD. S答案:D3. R语言中,以下哪个函数可以用于生成随机数?A. sample()B. sort()C. mean()答案:A4. 在R中,以下哪个命令可以用于读取Excel文件?A. read.csv()B. read.table()C. read.xlsx()D. read.json()答案:C5. R中的数据结构包括以下哪些类型?A. 向量、矩阵、数组、列表、数据框B. 字符串、整数、浮点数、逻辑型C. 函数、变量、数据集、图形D. 文件、文件夹、路径、日期答案:A二、填空题1. R语言中常用的数据结构是____。
答案:数据框2. 在R语言中,用于计算两个向量的相关系数的函数是____。
3. R中用于执行循环操作的函数是____。
答案:for()4. 在R中,可以使用____函数将字符转换为小写字母。
答案:tolower()5. R中用于创建直方图的函数是____。
答案:hist()三、简答题1. 请简要介绍一下R统计软件的优势和应用领域。
答:R统计软件具有以下优势:- 免费开源:R是一个免费的开源软件,可以降低用户的软件成本。
- 强大的统计分析功能:R提供了丰富的统计分析函数和算法,可以对各种类型的数据进行分析和建模。
- 多样的图形绘制功能:R具有强大的图形绘制功能,可以生成各种类型的统计图表,有助于数据的可视化和探索。
- 大型用户社区:R拥有庞大的用户社区,用户可以通过社区获取帮助、分享经验和代码。
- 可扩展性:R可以通过安装各种扩展包来扩展其功能,用户可以根据自己的需求选择合适的扩展包。
R统计软件主要应用于以下领域:- 统计分析:R具有丰富的统计分析函数和算法,可以用于各类统计分析任务,如假设检验、回归分析、时间序列分析等。
统计分析与SPSS课后习题课后习题答案汇总(第五版)

《统计分析与SPSS的应用(第五版)》课后练习答案第一章练习题答案1、SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是:Statistical Package for the Social Science.(Statistical Product and Service Solutions)2、SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
●数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;●结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、SPSS的数据集:●SPSS运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
●活动数据集:其中只有一个数据集为当前数据集。
SPSS只对某时刻的当前数据集中的数据进行分析。
4、SPSS的三种基本运行方式:●完全窗口菜单方式、程序运行方式、混合运行方式。
●完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
●程序运行方式:是指在使用SPSS的过程中,统计分析人员根据自己的需要,手工编写SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
●混合运行方式:是前两者的综合。
5、.sav是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样(probability sampling):也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
统计分析与spss的应用第三版第章课后习题详细答案(docX页)

统计分析与spss的应用(第三版)第10章课后习题详细答案1、(1)聚类分析的第1步,1号样本(广西瑶族)和3号样本(广西侗族)聚为一小类,它们的个体距离(欧氏距离)是3.722,这个小类将在下面第2步用到。
聚类分析的第2步,8号个体(贵州苗族)与第1步聚成的小类(1号和3号聚成的小类)又聚成一小类,它们的距离(个体与小类的距离,采用组间平均链锁距离)是9.970,这个小类将在下面第4步用到。
聚类分析的第3步,5号样本和7号样本聚成小类,它们的距离(个体与个体的距离)是11.556,这个小类将在第5步用到。
聚类分析的第4步,6号与第2步形成的小类(1号3号8号聚成的小类)聚为小类,它们的距离(个体与小类的距离)为18.607,这个小类将在第6步用到。
聚类分析的第5步,4号样本与第3步聚成的小类聚为小类,它们的距离(个体与小类的距离)为20.337,这个小类将在第6步用到。
聚类分析的第6步,第4步聚成的小类与第5步聚成的小类聚成小类,它们的距离(小类与小类的距离,采用组间平均链锁距离)是22.262,这个小类将在下面第7步中用到。
聚类分析的第7步,2号样本与第6步中聚成的小类聚成小类。
它们的距离(个体与小类的距离)是31.020。
经过7步,8个样本最后聚成了一大类。
(2)(3) 广西瑶族与广西侗族、贵州苗族、基诺族为一类,土家族与崩龙族、白族为一类,湖南侗族自成一类2、(1)凝聚状态表随着类数目不断减少,类间距离在逐渐增大。
3类后,聚间距离迅速增大,形成极为平坦的碎石路。
所以考虑聚成3类。
(2)北京自成一类,江苏广东上海湖南湖北聚为一类,剩余的聚省为一类。
(3)(4)通过该表可以看出,,对应P值-小于0.005,所以各指数的均值在3类中的差异是显著的。
3、答:聚类分析是以各种距离来度量个体间的“亲疏”程度的。
从各种距离的定义来看,数量级将对距离产生较大的影响,并影响最终的聚类结果。
进行层次聚类分析时,为了避免上述问题,聚类分析之前应首先消除数量级对聚类的影响,对数据进行标准化就是最常用的方法。
应用统计分析复习要点和答案

《应用统计学》复习要点(要求:每人携带具有开方功能的计算器)一、名词解释1.统计学:收集、处理、分析、解释数据并从数据中得出结论的科学。
2.方差分析:是通过分析数据的误差判断各总体均值是否相等,研究分类型自变量对数值型因变量的影响,分为单3.假设检验:是事先对总体参数或分布形式做出某种假设,然后利用样本信息来判断原假设是否成立。
分为参数假4.置信区间:是指由样本统计量所构成的总体参数的估计区间。
在统计学中,一个概率样本的置信区间是对这个样5.置信水平:是指总体参数值落在样本统计值某一区内的概率。
6.抽样分布:从已知的总体中以一定的样本容量进行随机抽样,由样本的统计数所对应的概率分布称为抽样分布。
7.方差分析:是通过分析数据的误差判断各总体均值是否相等,研究分类型自变量对数值型因变量的影响,分为单(重复啦)8.相关分析:是研究现象之间是否存在某种依存关系,并对具体有依存关系的现象探讨其相关方向以及相关程度是9.推断统计:是研究如何利用样本数据来推断总体特征的统计方法。
包含两个内容:参数估计,即利用样本信息推二、计算题1. 在某地区随机抽取按利润额分组(万元)企业数(个)300以下19300~400 30400~500 42500~600 18600以上11合计120计算120。
解:2.某银行为缩短顾客到银行办理业务等待的时间,准备了两种排队方式进行试验。
为比较哪种排队方式使顾客等待的时间更短,两种排队方式各随机抽取9名顾客,得到第一种排队方式的平均等待时间为7.2分钟,标准差为1.97分钟,第二种排队方式的等待时间(单位:分钟)如下:5.56.6 6.76.87.1 7.37.4 7.8 7.8(1)计算第二种排队时间的平均数和标准差。
(2)比较两种排队方式等待时间的离散程度。
(3)如果让你选择一种排队方式,你会选择哪一种?试说明理由。
解:3. 某大学为了解学生每天上网的时间,在全校学生中随机抽取36人,调查他们每天上网的时间(单位:小时),得到的数据如下:3.3 3.1 6.2 5.8 2.34.14.4 2.05.4 2.66.4 1.82.1 1.9 1.2 5.1 4.3 4.24.7 1.4 1.2 2.9 3.5 2.45.4 3.6 4.5 0.8 3.2 1.53.5 0.5 5.7 3.6 2.3 2.5z(0.01)统计量值分别为1.65、1.96和2.58)解:4. 利用下面的信息,构建总体均值μ的置信区间。
统计分析复习题(园艺、植保、设施)

第二章:试验设计技术1.进行园艺植物科学研究的方法有哪些主要方式?2.解释田间试验的概念,并说明为什么田间试验是进行园艺植物科学研究最主要的一种方法。
3.解释下列概念:试验方案、试验指标、试验因素、试验处理和处理组合、试验误差、试验小区、表头设计、复因素试验、综合实验4.简述园艺植物科学试验中误差的主要来源及控制误差的主要途径。
5.品种试验、栽培试验、植保试验分别是研究哪些问题的?6.按试验阶段可将田间试验分为哪几个阶段?各阶段的特点是什么?7.田间试验的基本要求是其应具有正确性、代表性、重演性,请问这“三性”分别的含义是什么?8.试验设计的三条基本原理(原则)是什么?各自的含义及其功能是什么?9.什么是区组?区组的特点是什么?10.随着小区面积的增大以及重复次数的增加,试验误差是下降的。
是否小区面积越大、重复次数越多越好呢?为什么?园艺植物试验时一般重复次数为多少?采用单株小区设计时,重复次数最低为多少?11.试验为什么要设置对照?我们对对照小区的要求是什么?12.什么是边际效应?我们对保护区和对照区的植株要求是否一样的?13.比较顺序排列设计和随机排列设计各自主要优缺点。
</SPAN14.比较完全随机设计、随机区组设计、拉丁方设计各自主要优缺点,并说明各设计方法适用范围。
第六章试验资料的整理1.解释下列概念总体与样本,参数与统计数,变数与变量,集中性与离散性,频率分布和累计频率分布2.试验数据可分为哪两类?说出各种数据的特征以及获取这些数据的主要手段。
3.调查100株某植物幼苗高度如下表,请将此资料整理成次数分布表,并绘出次数分布图。
用加权法计算该变数的平均数和标准差。
4.表示变数分布集中性和离散性常用的统计数是什么?5.算术平均数的特性是什么?请作证明。
6.说出标准差和变异系数的异同点。
7.随机抽取某个苹果品种果实10个,测定其果实重量分别为205、230、198、175、230、254、215、220、225、185克,请计算改变数的平均数、平方和、标准差、变异系数和平均数变异系数(写出计算公式),并判断该变数平均数的代表性强否?第七章试验资料的统计假设测验1. 何谓二项总体、二项分布?简述二项分布的形状特征。
spss统计试题及答案

spss统计试题及答案SPSS统计试题及答案1. 单项选择题- 1.1 SPSS中,用于进行数据描述性分析的命令是()。
- A. DESCRIPTIVES- B. FREQUENCIES- C. MEANS- D. T-TEST- 答案:A- 1.2 在SPSS中,要进行方差分析,应该使用以下哪个命令?() - A. DESCRIPTIVES- B. ANOVA- C. REGRESSION- D. CROSSTABS- 答案:B2. 多项选择题- 2.1 下列哪些选项是SPSS中的数据类型?()- A. Numeric- B. String- C. Date- D. Time- 答案:A、B、C、D- 2.2 在SPSS中,进行相关性分析可以使用以下哪些命令?()- A. CORRELATIONS- B. REGRESSION- C. CROSSTABS- D. MEANS- 答案:A、B3. 简答题- 3.1 简述SPSS中如何进行数据的导入和导出。
- 答案:在SPSS中,数据的导入可以通过“文件”菜单下的“打开”选项,选择“数据”并导入不同格式的数据文件。
数据的导出则可以通过“文件”菜单下的“另存为”选项,选择导出为SPSS、Excel、CSV等格式。
- 3.2 解释在SPSS中进行回归分析的步骤。
- 答案:在SPSS中进行回归分析的步骤包括:打开数据文件,选择“分析”菜单下的“回归”选项,选择“线性”或“逻辑”回归,指定因变量和自变量,点击“确定”进行分析。
4. 计算题- 4.1 假设有一组数据:10, 15, 20, 25, 30。
计算这组数据的平均值和标准差。
- 答案:平均值 = (10+15+20+25+30)/5 = 20;标准差 =√[(10-20)²+(15-20)²+(20-20)²+(25-20)²+(30-20)²]/5 =7.071。
《统计分析与SPSS的应用》课后练习答案

《统计分析与SPSS的应用》课后练习答案在学习《统计分析与 SPSS 的应用》这门课程后,通过课后练习,我们对所学知识有了更深入的理解和掌握。
以下是针对课后练习的详细答案及相关解释。
一、单选题1、在 SPSS 中,用于描述数据集中变量分布特征的命令是()A FrequenciesB DescriptivesC ExploreD Crosstabs答案:B解释:Descriptives 命令可以提供变量的集中趋势、离散程度等分布特征的统计量。
2、进行独立样本 t 检验时,需要满足的前提条件是()A 样本来自正态分布总体B 两样本方差相等C 以上都是D 以上都不是答案:C解释:独立样本 t 检验要求样本来自正态分布总体,且两样本方差相等。
3、用于分析两个变量之间线性关系强度的统计量是()A 相关系数B 决定系数C 方差D 标准差答案:A解释:相关系数用于衡量两个变量之间线性关系的密切程度。
二、多选题1、以下哪些是 SPSS 中的数据类型()A 数值型B 字符型C 日期型D 以上都是答案:D解释:SPSS 中的数据类型包括数值型、字符型和日期型。
2、方差分析的基本假定包括()A 正态性B 方差齐性C 独立性D 以上都是答案:D解释:方差分析需要满足正态性、方差齐性和独立性这三个基本假定。
三、简答题1、请简述 SPSS 中数据录入的基本步骤。
答:首先打开 SPSS 软件,在变量视图中定义变量的名称、类型、宽度、小数位数等属性。
然后切换到数据视图,逐行录入数据。
在录入过程中,要注意数据的准确性和完整性。
2、解释均值、中位数和众数的含义及适用情况。
答:均值是所有数据的算术平均值,反映数据的集中趋势,但容易受极端值影响。
适用于数据分布较为对称、不存在极端值的情况。
中位数是将数据从小到大排序后位于中间位置的数值,不受极端值影响,适用于数据分布偏态或存在极端值的情况。
众数是数据中出现次数最多的数值,适用于描述数据的集中趋势,尤其在类别数据中常用。
定性数据统计分析课后练习题含答案

定性数据统计分析课后练习题含答案1. 问题描述一项研究调查了 100 名学生的职业意向,结果发现54人有医生的职业意向,23人希望成为工程师,11人希望成为演员,5人有投行的意向,7人希望成为教师。
请使用适当的统计方法回答以下问题。
2. 题目1.在这100个学生中,有多少人有IT行业的职业意向?2.有多少比例的学生有医生的职业意向?3.有多少比例的学生没有教师和医生的职业意向?4.哪个职业的意向最高?3. 答案1.IT行业的职业意向人数是5人。
解析:根据题目给出的数据,5人有投行的意向,而我们知道投行常常被归类为金融或者IT行业,所以可以推断出这5人中肯定包含有IT行业的职业意向。
2.有医生职业意向的学生比例是 $\\frac{54}{100} = 0.54$。
解析:根据题目给出的数据,有医生职业意向的学生人数为 54,而总样本数为100,所以比例为54/100=0.54。
3.没有教师和医生职业意向的学生比例是 $\\frac{23+11+5}{100} =0.39$,即 $39\\%$。
解析:根据题目给出的数据,有医生职业意向的有54人,有工程师职业意向的有23人,有演员职业意向的有11人,一共这三类职业意向的学生人数为54+23+11=88,而总样本数为100,所以没有这三类职业意向的学生人数为100−88=12,所以比例为12/100=0.12,即 $12\\%$,所以没有教师和医生职业意向的学生比例为1−0.54−0.12=0.34,即$34\\%$。
4.医生职业意向的比例最高,为 $54\\%$。
解析:根据题目给出的数据,有医生职业意向的学生人数为 54,有工程师职业意向的学生人数为 23,有演员职业意向的学生人数为 11,有投行的意向的学生人数为 5,有教师职业意向的学生人数为 7。
因此,医生职业意向的人数最多,比例为 $54\\%$。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
习题程序:1.data SCORE;input name$ sex$ Chinese maths physics chemist English; sum= Chinese+maths+physics+chemist+English ;mean=sum/5;cards;王辉男80 85 82 78 90李唱女85 93 88 70 89张三男77 86 67 82 85王二女81 78 93 83 87;run;data jinrong;Set SCORE;Where maths>85;Run;2.input x r;do i=1 to 3;x+x*r;end;cards;500 0.07;run;3.(1)data income;input year x1-x3;income=x1+x2+x3;drop x1 x2 x3;cards;1985 298.28 29.47 39.951990 510.86 70.68 75.811995 996.51 287.24 195.742000 1125.34 488.89 515.352001 1165.17 532.61 533.80;run;(2)data income(keep=year income);input year x1-x3;income=x1+x2+x3;cards;1985 298.28 29.47 39.951990 510.86 70.68 75.811995 996.51 287.24 195.742000 1125.34 488.89 515.352001 1165.17 532.61 533.80;run;(3)data income(drop=i);input x1-x3;array consum{3} x1-x3;do i=1 to 3;sum+consum(i);end;cards;1985 298.28 29.47 39.951990 510.86 70.68 75.811995 996.51 287.24 195.742000 1125.34 488.89 515.352001 1165.17 532.61 533.80;run;4.data group1 group2;input region$ income@@;if income>=2366.40 then do;output group1;n+1;end;else do;output group2;m+1;end;cards;beijing 5025.5 tianjin 3947.72 hebei 2603.6 shanxi 1956.05 nemenggu 1973.37 liaoning 2557.93 jilin 2182.22 heilong 2280.28 shanghai 5870.87 jiangsu 3784.71 zhejiang 4582.34 anhui 2020.04 fujian 3380.72 jiangxi 2231.6 shandong 2804.51 henan 2097.86 hubei 2352.16 hunanÏ 2299.46 guangdong 3769.79 guangxi 1944.33 hainan 2226.47 chongqing 1971.18 sichuan 1986.99 guizhou 1411.73 yunnan 1533.74 xizang 1404.01 shananxi 1490.8 gansu 1508.61 qinghai 1557.32 ningxia 1823.05 xinjiang 1710.44;proc print data=group1(drop=m);title 'group1';proc print data=group2(drop=n);title 'group2';run;5.data a;input region$ wage@@;if wage<10000 then delete;cards;beijing 19776 tianjin 15110 hebei 9139 shanxi 8618 neimenggu 8737liaoning 10609 jilin 9043 heilongjiang 8924 shanghai 21961jiangsu 12917zhejiang 19514 anhui 8501 fujian 13313 jiangxi 8346 shandong 11067henan 8573 hubei 9133 hunan 9991 guangdong 16779 guangxi 9209 hainan 8102 chongqing 10035 sichuan 10783 guizhou 9308 yunnan 10880 xizang 20112 shananxi 9440 gansu 10442 qinghai 14028 ningxia 11112 xinjiang 10145;run;6.data nongye;input xiangmu$ year85 year90 year95 year00 year01;cards;gulei 2 1 1 1 1roulei 2 1 1 1 1mianhua 1 1 1 1 1dadou 3 3 3 4 4;data gongye;input xiangmu$ year85 year90 year95 year99 year00;cards;gang 4 4 2 1 1mei 2 1 1 1 1yuanyou 6 5 5 5 5;data order;set nongye gongye;proc print;run;7.data gdp;input gdp1-gdp45 @@;cards;144 150 165 168 200 216 218 185 173 181 208 240 254 235 222 243 275 288 292 309 310 327 316 339 379 417 460 489 525 580 692 853 956 1104 1355 1512 1634 1879 2287 2939 3923 4854 5576 6053 6392;proc means data=gdp mean std cv skewness kurtosis;run;8.data gdp;input area$ gdp consumpt capital export@@;cards;beijing 2845.65 1467.71 1775.3 -397.36tianjin 1840.1 901.85 934.48 3.77hebei 5577.78 2509.3 2511.57 556.91shanxi 1787.76 1046.43 800.27 -58.94neimenggu 1545.326789 936.1894062 614.1373826 -5 liaoning 5033.08 2828.09 1625.5 579.49jilin 2087.87 1331.32 790.99 -34.44heilongjiang 3515.69982 2110.54 1130.53982 274.62shanghai 4950.84 2149.07 2294.46 507.31jiangsu 9403.3 4295.96 4239.17 868.17zhejiang 6749.18 3306.1 2891.02 552.06anhui 3290.130414 2108.09475 1185.495664 -3.46fujian 4218.31 2225.23 1939.61 53.47jiangxi 2161.75 1357.47 800.83 3.45shangdong 9438.31 4582.61 4513.32 342.38henan 5640.11 3114.13 2329.32 196.66hubei 4557.02 2408.84 1963.46 184.72hunan 3983 2553.14 1426.47 3.39gongdong 10647.71 5841.32 3860.81 945.58guangxi 2231.19 1597.05 769.04 -134.9hainan 546.62 299.86 254.79 -8.03chongqing 1769.77 1078.06 819.08 -127.37sichuan 4421.76 2691.47 1726.33 3.96guizhou 1084.9 833.87 599.95 -348.92yunnan 2074.71 1430.44 929.73 -285.46xizang 138.31 82.79 49.72 5.8shananxi 1844.27 1004.5 972.51 -132.74gansu 1081.51 674.42 444.89 -37.8qinghai 294.83 197.79 207.39 -110.35ningxia 298.38 223.52 207.69 -132.83xinjiang 1485.48 854.6 771.42 -140.54;proc sort;by gdp;proc transpose out = trans;id area;var gdp consumpt capital export;proc means sum;var gdp consumpt capital export;proc means mean max min std cv skewness kurtosis clm;run;9.d ata a;input r@@;cards;718525.4 723715.3 702236.6 37390.56 632662.2 443082.7 59706.7 17774.8 115653 558135.4 1581666 513099.3 213847.4 2917080 30368.26 1049252 32864.3 31972.76 364228.6 40924.85 30557.34 39874.46 32741.52 248281.1 98826.12 1956514 43551.33 387256.1 67158.48 238265.7 50744.47 51291.24 54995.52 157951.5 40349.33 220848.3 18309.99 20264.13 31359.99 41325.33 49634.95 51689.58 129214.6 35857.56 27680.21 58609.62 24192.69 15665.46 60003.2 53617.02 8605.78 85371.95 161167.1 24852.03 48598.58 36004.81 131046 68424.84 63149.74;proc means mean max min maxdec=2 var std cv skewness kurtosis alpha=0.1 clm n nmiss range;run;10.data a(drop=i);do i=1 to 100 by 1;x=normal(0);y=100+sqrt(30)*x;output;end;proc means alpha=0.05 clm;run;proc univariate data=a normal;run;11.data a;input b@@;cards;167.939 169.369 176.228 172.077 163.284 169.564 174.022 157.814 170.794 164.796 172.887 166.425 166.189 176.456 162.080 167.290 175.004 165.762 158.315 167.812 178.715 170.624 173.090 180.698 172.621 176.095 164.211 174.641 173.427 171.869 166.742 167.137 175.704 168.537 175.321 173.532 168.285 171.333 173.911 171.226 174.694 169.868 178.338 171.044 178.550 173.199 168.664 169.562 168.996;proc univariate plot;run;12.data a;input year r1 r2 r3 r4 r5 r6 r7@@;cards;1926 11.6 0.28 7.37 7.77 5.38 3.27 -1.49 1927 37.49 22.1 7.44 8.93 4.52 3.12 -2.08 1928 43.61 39.69 2.84 0.1 0.92 3.56 -0.97 1929 -8.42 -51.36 3.27 3.42 6.01 4.75 0.2 1930 -24.9 -38.15 7.98 4.66 6.72 2.41 -6.03 1931 -43.34 -49.75 -1.85 -5.31 -2.32 1.07 -9.52 1932 -8.19 -5.39 10.82 16.84 8.81 0.96 -10.3 1933 53.99 142.87 10.38 -0.07 1.83 0.3 0.51 1934 -1.44 24.22 13.84 10.03 9 0.16 2.03 1935 47.67 40.19 9.61 4.98 7.01 0.17 2.99 1936 33.92 64.8 6.74 7.52 3.06 0.18 1.21 1937 -35.03 -58.01 2.75 0.23 1.56 0.31 3.10 1938 31.12 32.8 6.13 5.53 6.23 -0.02 -2.78 1939 -0.41 0.35 3.97 5.94 4.52 0.02 -0.48 1940 -9.78 -5.16 3.39 6.09 2.96 0 0.96 1941 -11.59 -9 2.73 0.93 0.5 0.06 9.72 1942 20.3 44.51 2.6 3.22 1.94 0.27 9.29 1943 25.9 88.37 2.83 2.08 2.81 0.35 3.16 1944 19.75 53.72 4.73 2.81 1.8 0.33 2.111946 -8.07 -11.63 1.72 -0.1 1 0.35 18.16 1947 5.71 0.92 -2.34 -2.62 0.91 0.5 9.01 1948 5.5 -2.11 4.14 3.4 1.85 0.81 2.71 1949 18.79 19.75 3.31 6.45 2.32 1.10 -1.80 1950 31.71 38.75 2.12 0.06 0.7 1.2 5.79 1951 24.02 7.8 -2.69 -3.93 0.36 1.49 5.87 1952 18.37 3.03 3.52 1.16 1.63 1.66 0.88 1953 -0.99 -6.49 3.41 3.64 3.23 1.82 0.62 1954 52.62 60.58 5.39 7.19 2.68 0.86 -0.5 1955 31.56 20.44 0.48 -1.29 -0.65 1.57 0.37 1956 6.56 4.28 -6.81 -5.59 -0.42 2.46 2.86 1957 -10.78 -14.57 8.71 7.46 7.84 3.14 3.02 1958 43.36 64.89 -2.22 -6.09 -1.29 1.54 1.76 1959 11.96 16.4 -0.97 -2.26 -0.39 2.95 1.5 1960 0.47 -3.29 9.07 13.78 11.76 2.66 1.48 1961 26.89 32.09 4.82 0.97 1.85 2.13 0.67 1962 -8.73 -11.9 7.95 6.89 5.56 2.73 1.22 1963 22.8 23.57 2.19 1.21 1.64 3.12 1.65 1964 16.48 23.52 4.77 3.51 4.04 3.54 1.19 1965 12.45 41.75 -0.46 0.71 1.02 3.93 1.92 1966 -10.06 -7.01 0.2 3.65 4.69 4.76 3.35 1967 23.98 83.57 -4.95 -9.18 1.01 4.21 3.04 1968 11.06 35.97 2.57 -0.26 4.54 5.21 4.72 1969 -8.5 -25.05 -8.09 -5.07 -0.74 6.58 6.11 1970 4.01 -17.43 18.37 12.11 16.86 6.52 5.49 1971 14.31 16.5 11.01 13.23 8.72 4.39 3.36 1972 18.98 4.43 7.26 5.69 5.16 3.84 3.41 1973 -14.66 -30.9 1.14 -1.11 4.61 6.93 8.8 1974 -26.47 -19.95 -3.06 4.35 5.69 8 12.20 1975 37.2 52.82 14.64 9.2 7.83 5.8 7.01 1976 23.84 57.38 18.65 16.75 12.87 5.08 4.81 1977 -7.18 25.38 1.71 -0.69 1.41 5.12 6.77 1978 6.56 23.46 -0.07 -1.18 3.49 7.18 9.03 1979 18.44 43.46 -4.18 -1.23 4.09 10.38 13.31 1980 32.42 39.88 -2.76 -3.95 3.91 11.24 12.4 1981 -4.91 13.88 -1.24 1.86 9.45 14.71 8.94 1982 21.41 28.01 42.56 40.36 29.1 10.54 3.87 1983 22.51 39.67 6.26 0.65 7.41 8.8 3.8 1984 6.27 -6.67 16.86 15.48 14.02 9.85 3.95 1985 32.16 24.66 30.09 30.97 20.33 7.72 3.77 1986 18.47 6.85 19.85 24.53 15.14 6.16 1.13 1987 5.23 -9.3 -0.27 -2.71 2.9 5.47 4.41 1988 16.81 22.87 10.7 9.67 6.1 6.35 4.421990 -3.17 -21.56 6.78 6.18 9.73 7.81 6.11 1991 30.55 44.63 19.89 19.3 15.46 5.6 3.06 1992 7.67 23.35 9.39 8.05 7.19 3.51 2.9 1993 9.99 20.98 13.19 18.24 11.24 2.9 4.75 1994 1.31 3.11 -5.76 -7.77 -5.14 3.9 2.67 1995 37.43 34.46 27.2 31.67 16.8 5.6 2.54 1996 23.07 17.62 1.4 -0.83 2.1 5.21 3.32 1997 33.36 22.78 12.95 15.85 8.38 5.26 1.7 ;proc univariate normal;run;13.data gdp;input area$ gdp consumpt capital export@@;cards;beijing 2845.65 1467.71 1775.3 -397.36tianjin 1840.1 901.85 934.48 3.77hebei 5577.78 2509.3 2511.57 556.91shanxi 1787.76 1046.43 800.27 -58.94neimenggu 1545.326789 936.1894062 614.1373826 -5 liaoning 5033.08 2828.09 1625.5 579.49jilin 2087.87 1331.32 790.99 -34.44 heilongjiang 3515.69982 2110.54 1130.53982 274.62 shanghai 4950.84 2149.07 2294.46 507.31jiangsu 9403.3 4295.96 4239.17 868.17zhejiang 6749.18 3306.1 2891.02 552.06anhui 3290.130414 2108.09475 1185.495664 -3.46 fujian 4218.31 2225.23 1939.61 53.47jiangxi 2161.75 1357.47 800.83 3.45shangdong 9438.31 4582.61 4513.32 342.38henan 5640.11 3114.13 2329.32 196.66hubei 4557.02 2408.84 1963.46 184.72hunan 3983 2553.14 1426.47 3.39gongdong 10647.71 5841.32 3860.81 945.58guangxi 2231.19 1597.05 769.04 -134.9hainan 546.62 299.86 254.79 -8.03chongqing 1769.77 1078.06 819.08 -127.37sichuan 4421.76 2691.47 1726.33 3.96guizhou 1084.9 833.87 599.95 -348.92yunnan 2074.71 1430.44 929.73 -285.46xizang 138.31 82.79 49.72 5.8shananxi 1844.27 1004.5 972.51 -132.74gansu 1081.51 674.42 444.89 -37.8qinghai 294.83 197.79 207.39 -110.35ningxia 298.38 223.52 207.69 -132.83 xinjiang 1485.48 854.6 771.42 -140.54;proc means data=gdp mean var std cv skewness kurtosis alpha=0.1 t prt clm;var consumpt ;run;14.data a;input name$ sex$ region$ sales type$;select;when(sales<20000) group=10000;when(20000<=sales<40000) group=30000;when(40000<=sales<60000) group=50000;when(60000<=sales<80000) group=70000;otherwise group=90000;end;cards;Rose F East 9664 PPeter M West 22969 PStafer F West 27253 CStride F West 86432 CTopin M North 99210 PSpark F North 38928 CVetter M South 21531 PCurci M East 79345 PMarco M East 18523 PGreco F South 32914 CRyan F South 42109 PTomas M West 94329 CThalman F East 25718 CFarlow M North 64700 CSmith M South 27634 P;proc tabulate;class name sex type region;var sales group;table type,sex,region sales group; table region*sex;run;proc gchart;pie region/sumvar=sales;run;15.data density;input zhou$ country$ area renkou@@;density=renkou/area;if density>=100 then grade='a';else if density<10 then grade='c';else grade='b';cards;Asia China 960 126743Asia Japan 37.8 12687Asia India 297.4 100596Asia Philippines 30 7558Asia Mongolia 156.7 240Africa Eygpt 100.2 6398Africa Nigeria 92.4 12691Europe Germany 35.7 8215Europe UK 24.2 5974Europe France 55.2 5889Europe Italy 30.1 5769Europe Russian 1707.5 14556Northamerica US 937.3 28155NorthAmerica Canada 997.1 3075NorthAmerica Mexico 196.7 9797SouthAmerica Brazil 854.7 17041SouthAmerica Argentina 277.7 3703Oceania Australia 768.2 1918Oceania Newzealand 27.1 383;proc tabulate;title 'the table of population density';class zhou grade;var density;table zhou grade all, density*(n max min);run;16.data a;input date total@@;cards;90.1 1421 90.2 1367 90.3 1720 90.4 1760 90.5 1796 90.6 1848 90.7 1637 90.8 1671 90.9 1760 90.10 1790 90.11 1889 90.12 1981 91.1 1758 91.2 1486 91.3 1894 91.4 1970 91.5 2034 91.6 2103 91.7 1856 91.8 1915 91.9 2022 91.10 2045 91.11 2069 91.12 2136 91.1 1984 92.2 1812 92.3 2274 92.4 2329 92.5 2373 92.6 2516 92.7 2288 92.8 2312 92.9 2441 92.10 2502 92.11 2608 92.12 2823 93.1 2179 93.2 2409 93.3 2869 93.4 2917 93.5 3022 93.6 3274 3.7 2863 93.8 2864 93.9 2908 93.10 2912 93.11 3101 93.12 3664 94.1 2903 94.2 2513 94.3 3409 94.4 3500 94.5 3643 94.6 3871 94.7 3373 94.8 3463 94.9 3664 94.10 3753 94.11 3973 94.12 4469 95.1 2997 95.2 2740 95.12 3581 95.4 3746 95.5 3818 95.6 4041 95.7 3484 95.8 3511 95.9 3703 95.10 3811 95.11 4091 95.12 4651 96.1 3477 96.2 2970 96.3 3943 96.4 4068 96.5 4747 96.6 4417 96.7 3807 96.8 3746 96.9 4011 96.10 4130 96.11 4373 96.12 4992 97.1 3844 97.2 3182 97.3 4405 97.4 4520 97.5 4639 97.6 4970 97.7 4147 97.8 4199 97.9 4537 97.10 4719 97.11 5035 97.12 5546;run;proc sort;by total;proc gplot;plot total*date/vaxis=1000 to 6000 by 500;symbol v=plus i=spline c=blue;run;17.data shoping;input expend income number age hire@@;label expend='年食品支出:(千元) ' income=' 年收入'number=' 家庭人口数' age=' 收入最高者年龄'hire=' 房屋是否购买';cards;4.7 24 3 32 15.2 29 3 28 16.1 30 2 25 0 4.8 23 1 43 1 10.1 52 4 50 0 9.2 61 2 55 0 6.5 33 3 32 0 5.4 28 2 28 17.8 41 1 37 0 9.8 53 6 54 0 4.9 42 3 30 1 7.3 44 4 31 0 5.2 26 1 28 1 3.2 12 5 48 0 3.4 18 3 42 0 7.2 47 1 32 1 15.6 112 6 60 0 13.7 85 5 47 0 5.1 27 2 33 0 2.9 13 2 29 1 3.8 19 1 26 1 7.2 38 1 45 1 4.9 25 4 43 1 10.2 62 3 30 0 10 54 4 55 0 4.8 28 3 33 1 4.7 29 2 29 1 5.3 34 1 26 04.4 30 1 25 1 10.3 57 6 48 0 7.6 45 4 55 0 7.3 47 3 31 15.1 36 1 32 1 3.3 19 4 29 1 4.6 28 4 29 0 2.8 14 2 43 1 3.0 20 5 33 1 8.0 49 3 35 0 13.8 87 3 63 0 12.4 72 2 34 0 2.5 12 1 23 1 4.3 28 2 27 1 3.1 14 1 25 1 3.1 19 1 28 1 7.7 39 4 30 0 4.2 27 2 51 0 10.1 64 5 45 1 9.6 53 5 47 0 4.7 27 3 28 0 5.5 28 3 29 16.1 33 4 32 0 5.4 29 1 25 14.8 24 1 27 1 9.8 55 7 46 0 6.9 43 5 48 0 8.0 45 4 52 05.8 34 3 36 1 2.9 17 1 29 1 5.1 26 2 32 0 3.2 15 1 24 14.1 21 1 28 1 7.5 50 2 42 0 13.1 78 3 58 05.5 27 1 68 05.1 31 2 33 1 12.5 73 2 43 0 4.5 29 3 38 1 3.2 20 1 31 1 7.5 38 4 35 0 9.7 51 5 51 0 5.3 33 3 29 1 10.2 53 4 52 0 4.8 43 3 30 1 7.1 49 1 33 1 8.5 40 2 35 1 9.1 46 3 40 0 8.7 43 4 37 0 10.3 51 3 43 16.4 34 2 32 0 5.2 38 3 37 0 ;proc gplot ;plot age*income/vaxis=0 to 16 by 2;symbol v=star;run;proc tabulate;class hire;var income expend;table hire,income expend;table hire*(n pctn<hire>);run;18.data state;input first second third;cards;2763.9 4492.7 2945.63204.3 5251.6 3506.63831.0 6587.2 4510.14228.0 7278.0 5403.25017.0 7717.4 5813.55288.6 9102.2 7227.05800.0 11699.5 9138.66882.1 16428.5 11323.89457.2 22372.2 14930.011993.0 28537.9 17947.213844.2 33612.9 20427.514211.2 37222.7 23028.714552.4 38619.3 25173.514457.2 40417.9 27035.8;proc means t prt clm;var first second third;run;19.data a;input polit1 econ1 law1 cult1 polit2 econ2 law2 cult2@@;dpolit=polit1-polit2;decon=econ1-econ2;dlaw=law1-law2; dcult=cult1-cult2;cards;65 35 25 60 55 55 40 6575 50 20 55 50 60 45 7060 45 35 65 45 45 35 7575 40 40 70 50 50 50 7070 30 30 50 55 50 30 7555 40 35 65 60 40 45 6060 45 30 60 65 55 45 7555 40 25 60 50 60 35 8055 50 30 70 40 45 30 6550 55 35 75 45 50 45 70;proc means t prt clm;var dpolit decon dlaw dcult;run;20.data newhappy;input B C D E F G H I J K cards;39 1 1 1 3 3 5 1 3 143 1 3 3 1 3 1 1 3 138 1 3 1 3 1 1 5 1 132 1 3 3 3 3 3 5 1 141 3 1 1 1 3 5 5 1 130 1 1 1 3 1 1 1 1 139 3 3 3 3 3 3 3 3 3 33 1 3 3 3 3 5 3 3 3 15 1 3 5 3 3 5 5 1 5 8 3 3 3 5 3 3 3 3 5 23 1 1 1 5 3 1 3 3 5 41 3 3 3 3 3 5 1 3 3 40 1 1 1 3 1 1 1 1 3 34 1 1 3 1 1 3 3 5 1 37 1 3 1 1 1 3 3 3 1 44 1 3 3 1 3 3 3 3 1 48 1 1 3 1 1 3 1 3 1 27 3 3 1 3 3 5 1 1 1 45 1 1 1 1 1 3 5 3 1 39 1 1 3 3 1 3 3 5 3 24 3 3 1 3 3 1 3 1 3 47 1 1 1 3 3 3 3 3 3 29 1 1 3 1 1 3 5 1 146 3 3 3 3 3 1 1 1 347 1 1 1 3 3 3 3 3 3 22 3 1 1 1 1 3 5 1 3 42 1 1 1 1 3 5 5 3 1 39 3 3 1 1 1 3 3 3 3 48 1 1 3 3 1 1 1 1 3 40 1 3 3 3 1 1 1 1 1 37 1 1 1 1 1 1 3 1 1 41 1 1 1 1 3 3 3 1 1 30 3 1 1 1 1 3 3 3 7 46 1 1 1 1 1 1 1 1 1 28 1 3 3 3 3 3 1 3 7 20 1 3 1 1 1 5 3 1 7 36 1 5 1 3 1 1 3 1 7 10 3 3 5 5 3 1 3 5 3 30 3 3 3 3 3 3 3 3 3 11 3 3 5 3 3 3 5 3 3 26 3 3 3 3 1 5 5 3 5 14 3 1 5 3 3 5 5 3 3 18 1 3 3 3 3 1 5 3 3 22 1 3 1 3 3 5 5 1 3 29 1 5 3 3 3 3 3 1 3 29 3 1 3 1 3 3 3 3 1 41 3 1 5 1 1 3 3 3 1 28 1 3 3 3 1 3 3 3 3 48 1 1 3 1 1 3 5 1 146 1 1 1 1 1 1 1 1 1 42 1 1 1 1 1 5 3 1 1 32 3 1 1 1 1 3 3 3 7 32 3 3 1 3 3 3 1 3 7 47 1 1 1 1 1 3 3 3 7 31 1 3 1 3 3 5 3 1 724 3 1 1 1 3 5 1 3 725 1 1 1 3 1 5 3 1 5 23 3 3 5 3 3 3 3 5 5 44 1 3 5 1 1 3 3 1 3 16 1 1 1 5 1 1 5 3 340 3 3 3 3 3 1 5 3 341 3 3 3 3 3 3 3 3 3 35 3 3 3 5 3 5 3 1 3 42 3 1 1 3 3 5 3 3 3 22 3 1 1 3 1 5 3 5 3 36 3 3 3 3 3 5 3 5 3 28 3 1 1 1 3 3 1 3 1 47 1 1 1 1 3 1 1 3 1 34 3 3 1 3 3 5 3 5 1 36 3 1 3 1 3 5 3 3 1 38 1 1 1 1 3 3 3 3 1 37 1 1 1 1 1 1 3 3 1 35 1 1 3 1 3 1 3 1 1 41 1 1 1 1 1 5 3 1 1 30 1 1 1 1 3 1 5 1 1 47 1 1 1 1 1 1 1 1 1 28 1 3 1 1 1 1 3 3 1 34 1 1 3 3 3 1 1 1 1 36 3 1 1 1 3 3 1 1 3 48 1 1 3 1 1 3 1 3 1 41 1 1 1 1 1 1 1 1 3 33 1 1 1 5 3 5 5 1 5 40 1 1 1 1 1 1 1 5 1 40 1 1 1 1 1 3 3 1 7 40 1 1 3 3 3 5 5 3 1 37 1 1 1 3 3 1 3 3 3 29 3 1 1 1 1 5 5 3 1 33 1 1 1 5 3 5 5 1 5 27 3 1 3 3 3 5 3 3 3 37 1 3 1 3 3 3 1 1 1 39 3 1 1 1 1 5 3 3 3 43 1 1 1 1 1 3 3 1 126 5 3 1 3 3 5 5 5 738 3 1 1 3 3 5 3 3 743 1 1 1 1 1 1 1 1 745 1 1 3 1 1 1 3 1 134 1 1 1 1 1 1 1 1 137 3 3 3 3 3 3 1 3 144 1 1 1 1 1 3 1 1 142 1 1 1 3 3 1 5 5 242 3 1 1 3 1 1 1 3 316 1 1 3 1 1 1 5 1 322 3 3 5 3 3 3 3 3 342 3 1 1 1 3 1 1 1 321 3 1 3 1 3 3 1 3 7 38 3 1 3 1 3 3 5 3 1 48 3 1 3 1 1 1 1 3 147 1 1 1 1 3 1 1 3 148 1 3 1 1 3 5 3 1 1 44 3 1 3 1 1 3 3 1 1 42 1 1 1 1 1 3 3 1 1 42 3 1 3 1 1 3 1 1 1 45 1 1 1 1 1 3 1 1 1 23 3 1 3 3 3 1 3 5 542 3 1 3 1 3 1 1 1 343 1 1 3 3 3 1 1 1 3 18 1 3 3 3 3 3 3 3 3 44 1 3 1 3 3 3 3 3 1 42 3 3 1 3 1 1 1 1 3 48 3 1 1 1 1 3 1 1 1 44 1 1 1 1 1 3 1 1 1 24 3 1 3 1 1 1 1 1 139 3 3 3 1 1 1 3 3 140 1 3 3 3 3 1 3 3 3 25 1 3 5 3 3 5 5 1 3 24 3 3 3 1 3 3 3 3 1 31 1 3 3 3 3 1 1 3 1 29 3 3 1 3 3 3 5 5 1 38 1 1 1 1 3 1 3 3 1 41 1 1 1 1 1 3 5 3 1 32 3 1 3 1 1 3 1 1 1 28 1 3 1 3 3 3 5 3 1 42 3 3 1 1 1 5 1 1 1 45 3 3 3 1 1 1 1 3 1 38 1 3 3 1 1 3 3 1 147 1 1 1 1 3 3 1 3 1 16 3 1 1 1 1 1 5 5 1 48 1 1 1 1 1 1 1 1 1 40 1 3 3 3 3 5 3 3 3 30 1 3 3 3 3 5 1 3 3 40 1 1 1 1 3 1 1 3 1 38 1 3 1 3 3 3 3 3 3 10 1 5 3 5 1 5 3 1 7 26 5 1 1 1 3 3 5 5 1 45 1 3 1 1 3 1 1 1 1 ;proc corr spearman kendall;var B;with C D E F G H I J K;run;21.data engle;input area$ engle@@;cards;n 67.7 c 57.5n 61.8 c 56.9n 57.8 c 53.31n 58.8 c 54.24n 57.6 c 53.82n 57.6 c 52.86n 58.1 c 50.13n 58.9 c 49.89n 58.6 c 49.92n 56.3 c 48.6n 55.1 c 46.4n 53.4 c 44.5n 52.6 c 41.9n 49.1 c 39.2n 47.7 c 37.9;proc sort; by area;proc univariate normal;var engle;by area;proc ttest ; class area;var engle;run;22.data zichfz;input type$ sold@@;cards;g 98.39 z 97.94 g 97.6 z 99.01 g 98.59 z 98.07 g 98.44 z 94.5 g 98.41 z 100.88 g 98.38 z 96.7 g 97.25 z 96.52 g 98.58 z 92.41 g 99.23 z 99.16 g 98.54 z 97.66 g 98.88 z 97.01 g 99.16 z 98.97 g 98.55 z 96.79 g 98.27 z 98.03 g 98.97 z 97.36 g 98.45 z 96.43 g 97.87 z 98g 99.2 z 98.67 g 100 z 97.28 g 98.27 z 96.34 g 97.19 z 91.59 g 99.29 z 96.64 g 98.99 z 97.13 g 97.46 z 98.56 g 98.99 z 96.88 g 89.98 z 150g 98.03 z 96.99 g 97.8 z 99.86 g 93.18 z 95.92 g 98.14 z 91.12 g 100.01 z 94.25 ;proc sort; by type;run;proc univariate normal;var sold;by type;run;proc npar1way wilcoxon; class type;var sold;run;23.data west;input goods00 goods01@@;dif=goods01-goods00;cards;13.47 15.36128.88 130.450.5 0.5393.31 95.29111.28 113.578.43 79.63114.57 118.396.55 9.2924 25.943.17 43.1236.71 38.1814.46 16.2450.41 53.912.81 28.92;proc univariate normal;var goods00 goods01 dif; run;24.data profit;input income salecost manacost tax profit;cards;5660515 4912868 427811 17545 287060 1725333 1542880 96734 4611 76711 1452182 1254814 82696 5705 98800 956443 802351 51391 5371 36649 440964 318268 20941 1571 21893 1953394 1658137 108810 16637 153004 867502 780569 42384 2244 31877 1025303 870530 59582 4497 75436 7262690 6259320 570936 20983 330910 4603819 3971448 268991 13730 276187 2976451 2600835 155475 8701 156487 856125 729628 47443 2556 64003 1272714 1130089 78857 5580 49723 448680 390230 22144 1728 30030 4370183 3887907 181083 9943 239310 1710652 1557867 79861 6046 56301 1685283 1455903 74866 8863 116854 1032003 857019 56693 4462 96957 5174417 4447083 394244 15381 274865 662746 566211 39927 2568 42198 130742 101912 6999 218 10078 723438 630002 46940 2508 37455 1564629 1380889 97369 4068 64524 330985 287932 20668 1336 20005 691074 592652 49185 2425 3432950305 43980 3201 323 2669 692077 594424 31157 2126 62258 387899 338440 29242 1211 17105 86227 73939 5286 242 4616 130934 110672 8413 548 11182 771256 674105 45221 2332 47192 ;proc corr spearman Pearson;var profit;with income salecost manacost tax;run;“属性数据分析与FREQ过程”后面的习题第一题:data a;input sex$ colour$ number@@;cards;m red 30 m blue 10 m green 10f red 20 f blue 10 f green 10;run;proc freq;weight number;tables sex*colour/chisq expected;run;第二题:data a;input sex$ regist$ n@@;cards;m y 3738 m n 4704f y 1494 f n 2827;proc freq;tables sex*regist/chisq;weight n;run;第三题:data a;input type$ sex$ y x@@;x1=y*x/100;x2=y-x1;cards;a m 825 62 a f 108 82b m 560 63 b f 25 68c m 325 37 c f 593 34d m 417 33 d f 375 35e m 191 28 ef 393 24g m 373 6 g f 341 7;proc freq;weight x2;tables type*sex/chisq;run;proc freq;weight x1;tables type*sex/chisq;run;第四题:data market;input ying$ pin$ yong$ wen$ number@@;cards4;软 N 用过高温 19 软 N 用过低温 57软 N 未用过高温 29 软 N 未用过低温 63软 M 用过高温 29 软 M 用过低温 49软 M 未用过高温 27 软 M 未用过低温 53中 N 用过高温 23 中 N 用过低温 47中 N 未用过高温 33 中 N 未用过低温 66中M 用过高温 47 中M 用过低温 55中M 未用过高温 23 中M 未用过低温 50硬 N 用过高温 24 硬 N 用过低温 37硬 N 未用过高温 42 硬 N 未用过低温 68硬M 用过高温 43 硬M 用过低温 52硬M 未用过高温 30 硬M 未用过低温 42;;;;proc freq;tables ying*pin yong*wen/nocol norow;weight number;run;第五题:data cancer;input health$ cigerat$ number@@;cards;cancer smoker 60cancer nsmoker 3ncancer smoker 32ncancer nsmoker 11;proc freq;tables health*cigerat/expected chisq norow nocol nopercent exact; weight number;run;第六题:data score;input score$ class sex$ number@@;cards;c 1 m 3 b 1 m 11 a 1 m 3 c 1 f 2b 1 f 14 a 1 f 2c 2 m 4 b 2 m 10a 2 m 7 c 2 f 3b 2 f 9 a 2 f 5;proc freq;tables class*score class*sex/chisq nocol norow nopercent;tables sex*score*class/ chisq expected norow nocol; tables class*score/chisq measures norow nocol nopercent; weight number;run;。