信息论大作业
(完整word版)信息论习题集

信息论习题集第一章、判断题1、信息论主要研究目的是找到信息传输过程的共同规律,提高信息传输的可靠性、有效性、保密性和认证性,以达到信息传输系统的最优化。
(√)2、同一信息,可以采用不同的信号形式来载荷;同一信号形式可以表达不同形式的信息。
(√)3、通信中的可靠性是指使信源发出的消息准确不失真地在信道中传输;(√)4、有效性是指用尽量短的时间和尽量少的设备来传送一定量的信息。
(√)5、保密性是指隐蔽和保护通信系统中传送的消息,使它只能被授权接收者获取,而不能被未授权者接收和理解。
(√)6、认证性是指接收者能正确判断所接收的消息的正确性,验证消息的完整性,而不是伪造的和被窜改的。
(√)7、在香农信息的定义中,信息的大小与事件发生的概率成正比,概率越大事件所包含的信息量越大。
(×)第二章一、判断题1、通信中获得的信息量等于通信过程中不确定性的消除或者减少量。
(√)2、离散信道的信道容量与信源的概率分布有关,与信道的统计特性也有关。
(×)3、连续信道的信道容量与信道带宽成正比,带宽越宽,信道容量越大。
(×)4、信源熵是信号符号集合中,所有符号的自信息的算术平均值。
(×)5、信源熵具有极值性,是信源概率分布P的下凸函数,当信源概率分布为等概率分布时取得最大值。
(×)6、离散无记忆信源的N次扩展信源,其熵值为扩展前信源熵值的N倍。
(√)7、互信息的统计平均为平均互信息量,都具有非负性。
(×)8、信源剩余度越大,通信效率越高,抗干扰能力越强。
(×)9、信道剩余度越大,信道利用率越低,信道的信息传输速率越低。
(×)10、信道输入与输出之间的平均互信息是输入概率分布的下凸函数。
(×)11、在信息处理过程中,熵是不会增加的。
(√)12、熵函数是严格上凸的。
(√)13、信道疑义度永远是非负的。
(√)14、对于离散平稳信源,其极限熵等于最小平均符号熵。
信息论期末大作业

《信息论与编码》课程期末大作业题目及评分标准
1、以下面方向为题,写一份论文报告:
a) 信息理论方法的应用
b) 信息率失真函数与有损数据压缩技术
c) 信源编码及其发展动态
d) 论信源编码与信道编码
e) 论现代密码体制
f) 论通信与香农三大定理的关系
2、论文格式要求
a)按题目、名字学号、摘要、关键词、正文、结论、参考文献进行书写,
格式要统一规范,图表要完备;
b)字体小四、宋体、1.5行距;
c)任意两个同学的论文不能相同,如相同20%以上则视为零分;
3、论文内容要求
1)论文不能写成综述性文章,必须是对技术的探讨与分析,研究并提出自己的论点;
2)论文中要有图形、框图等。
4、大作业分数评定标准
1)符合选题要求10分;
2)格式规范10分;
3)内容论述正确、图表完备、分析深入60分;
4)有自己见解及技术上的创新性20分。
5、期末总成绩评分标准
1)平时成绩30% (由4次考勤、1次实验成绩综合构成);
2)期末大作业成绩70%。
信息论与编码大作业

广西科技大学大作业课程名称:信息论与编码题目:信道编码对通信系统性能的影响学院:电气与信息工程学院专业:电子信息工程班级:学号:成绩:姓名:电话号码:信道编码对通信系统性能的影响[摘要] 简述信道编码理论,详细说明分组码的编译原理、实现方法及检错纠错能力,用MATLAB仿真有无信道编码条件下对通信系统性能的影响及信道编码在不同信道下对通信系统性能的影响,如AWGN信道和深衰落信道。
[关键词] 信道编码、分组码、MATLAB仿真、性能一、引言提高信息传输的有效性和可靠性始终是通信技术所追求的目标,而信道编码能够显著的提升信息传输的可靠性。
1948年,信息论的奠基人C.E.Shannon在他的开创性论文“通信的数学理论”中,提出了著名的有噪信道编码定理.他指出:对任何信道,只要信息传输速率R不大于信道容量C, 就一定存在这样的编码方法:在采用最大似然译码时,其误码率可以任意小.该定理在理论上给出了对给定信道通过编码所能达到的编码增益的上限,并指出了为达到理论极限应采用的译码方法.在信道编码定理中,香农提出了实现最佳编码的三个基本条件:(1 )采用随机编译码方式;(2 )编码长度L→∞ , 即分组的码组长度无限;(3)译码采用最佳的最大似然译码算法。
二、信道编码理论1、信道编码的概念与目的进行信道编码是为了提高信号传输的可靠性,改善通信系统的传输质量,研究信道编码的目标是寻找具体构造编码的理论与方法。
从原理上,构造信道码的基本思路是根据一定的规律在待发送的信息码元中人为的加入一定的多余码元,以引入最小的多余度为代价来换取最好的抗干扰性能。
信道编码是通过信道编码器和译码器实现的用于提高信道可靠性的理论和方法,是信息论的内容之一。
信道编码大致分为两类:①信道编码定理,从理论上解决理想编码器、译码器的存在性问题,也就是解决信道能传送的最大信息率的可能性和超过这个最大值时的传输问题。
②构造性的编码方法以及这些方法能达到的性能界限。
信息论作业答案
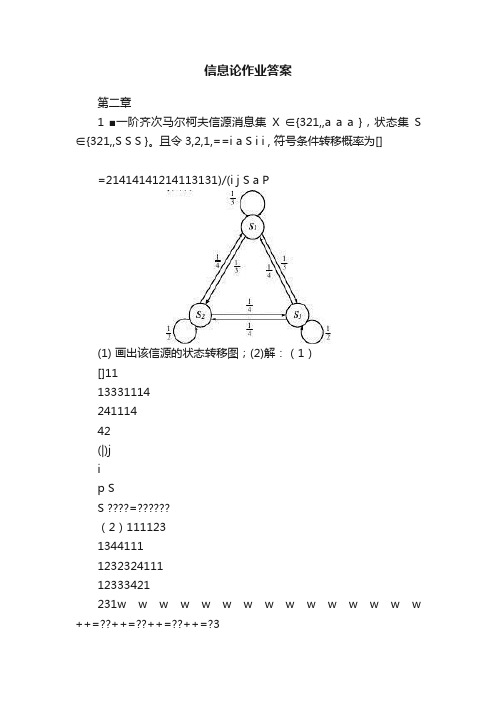
信息论作业答案第二章1 ■一阶齐次马尔柯夫信源消息集X ∈{321,,a a a },状态集S ∈{321,,S S S }。
且令3,2,1,==i a S i i , 符号条件转移概率为[]=21414141214113131)/(i j S a P(1) 画出该信源的状态转移图;(2)解:(1)[]111333111424111442(|)jip SS =??(2)1111231344111123232411112333421231w w w w w w w w w w w w w w w ++=??++=??++=??++=?311142114311w w w =??=??=?H(X|S 1)=H (1/3,1/3,1/3)=1.58bit/符号H(X|S 2)=H (1/4,1/2,1/4)=1.5bit/符号= H(X|S 3)33411111()(|) 1.58 1.52 1.52i i i H X w H X S ∞===?+??=∑bit/符号2 如果你确定你的朋友是6月的生日,但是不知道具体是哪一天。
那么你问你的朋友“你的生日是6月哪一天?”,则答案中含有的信息量为4.91bit ;3p42 2-12 4 p42 2-13 5 p43 2-19 6 p44 2-29第三章1. ■设信道的转移概率矩阵为P =0.90.10.10.9??(1)若p(x 0)=0.4,p(x 1)=0.6,求H(X ),H(Y ),H(Y|X )和I(X ;Y );(2)求该信道的信道容量及其达到信道容量时输入符号的概率分布。
(3)设该信道以1800个二元符号/秒的速度传输输入符号。
现有一消息序列共有10000个二元符号,在p(x 0)=1/2,p(x 1)=1/2情况下,从信息传输的角度来考虑,10秒内能否将这消息序列无失真地传送完?解:(1)[]0.360.04(,)0.060.54p x y ??=?, [p(y)]=[0.42 0.58] H(X)(0.4,0.6)0.97H ==bit/符号H(Y)(0.42,0.58)0.98H ==bit/符号 H(Y|X)(0.9,0.1)0.47H ==bit/符号I(X;Y)= H(Y)-H(Y|X)=0.51bit/符号(2)C=1-H(ε)=1-H(Y|X)=0.53bit/符号 p 0=p 1=0.5(3)H(X)×104=104 bit1800×C ×10=9540 bit < 104 所以不能无失真传送完。
信息论与编码大作业

二
当前信息论发展日新月异,目前,世界正在谈论三种前沿科学,即生命科学、材料科学和信息科学。信息论是信息科学的理论基础,现在的人们虽然不通晓信息论,但是,在日常生活中的谈话、书信、报纸、书籍、电影、电话、电报、电视、电子计算机……都是信息传输和处理的方式。随着信息革命和信息科学的发展,信息技术(指通信、计算机和控制)的研究和使用,信息论研究范畴远远超出了通信及类似的学科,从一般认为“信息论即通信理论”的认识延伸到像生物学、生理学、人类学、物理学、化学、电子学、语言学、经济学和管理学等学科。人类社会正在走向一个以充分发挥人的创造力和创新精神,以智能、知识为核心的高度发展的信息社会。
左分支表示字符'0',右分支表示字符'1',则可以根结点到叶结点的路径上分支字符组成的串作为该叶结点的字符编码。因此可得到字符A、B、C、D的二进制前缀编码分别:0、10、110、111。假设每种字符在电文中出现的次数为Wi,编码长度为Li,电文中有n种字符,则电文编码总长为∑WiLi。若将此对应到二叉树上,Wi为叶结点的权,Li为根结点到叶结点的路径长度。那么,∑WiLi恰好为二叉树上带权路径长度。因此,设计电文总长最短的二进制前缀编码,就是以n种字符出现的频率作权,构造一棵霍夫曼树,此构造过程称为霍夫曼编码。
信息论大作业

信息论大作业信息论大作业电子工程学院班号编码1.Huffman 编码原理:①将信源符号按概率从大到小的顺序排列,令p(x1)≥ p(x2)≥?≥ p(xn) ②给两个概率最小的信源符号p(xn-1)和p(xn)各分配一个码位“0”和“1”,将这两个信源符号合并成一个新符号,并用这两个最小的概率之和作为新符号的概率,结果得到一个只包含(n-1)个信源符号的新信源。
称为信源的第一次缩减信源,用S1表示。
③将缩减信源S1的符号仍按概率从大到小顺序排列,重复步骤2,得到只含(n -2)个符号的缩减信源S2。
④重复上述步骤,直至缩减信源只剩两个符号为止,此时所剩两个符号的概率之和必为1。
然后从最后一级缩减信源开始,依编码路径向前返回,就得到各信源符号所对应的码字。
2. 霍夫曼编码优缺点:1) 编出来的码都是异字头码,保证了码的唯一可译性。
2) 于编码长度可变。
因此译码时间较长,使得霍夫曼编码的压缩与还原相当费时。
3) 编码长度不统一,硬件实现有难度。
4) 对不同信号源的编码效率不同,当信号源的符号概率为2的负幂次方时,达到100%的编码效率;若信号源符号的概率相等,则编码效率最低。
5) 于0与1的指定是任意的,故上述过程编出的最佳码不是唯一的,但其平均码长是一样的,故不影响编码效率与数据压缩性能。
3.编码流程:读入一幅图像的灰度值; 1. 将矩阵的不同数统计在数组c的第一列中; 2. 将相同的数占站整个数组总数的比例统计在数组p中; 3. 找到最小的概率,相加直到等于1,把最小概率的序号存在tree第一列中,次小放在第二列,和放在p像素比例之后; 4. C数组第一维表示值,第二维表示代码数值大小,第三维表示代码的位数; 5. 把概率小的值为1标识,概率大的值为0标识; 6. 计算信源的熵;7. 计算平均码长;8. 计算编码效率’;9. 计算冗余度。
源程序:p=input(‘请输入数据:’); n=length(p); for i=1:n if p(i) fprintf(‘\\n 提示:概率值不能小于0!\\n’); p=input(‘请重新输入数据:’);end end if abs(sum(p))>1 fprintf(‘\\n 哈弗曼码中概率总和不能大于1!\\n’); p=input(‘请重新输入数据:’);end q=p; a=zeros(n-1,n); %生成一个n-1 行n 列的数组for i=1:n-1[q,l]=sort(q); a(i,:)=[l(1:n-i+1),zeros(1,i-1)];q=[q(1)+q(2),q(3:n),1];end for i=1:n-1 c(i,1:n*n)=blanks(n*n); end c(n-1,n)=‘0’;c(n-1,2*n)=‘1’; for i=2:n-1 c(n-i,1:n-1)=c(n-i+1,n*(find(a(n-i+1,:)==1 ))-(n-2):n*(find(a(n-i+1,:)==1))) ; c(n-i,n)=‘0’ ; c(n-i,n+1:2*n-1)=c(n-i,1:n-1) ; c(n-i,2*n)=‘1’ ;for j=1:i-1c(n-i,(j+1)*n+1:(j+2)*n)=c(n-i+1,n*(find( a(n-i+1,:)==j+1)-1)+1:n*find(a(n-i+1,:)==j +1)); end end%完成huffman 码字的分配for i=1:n h(i,1:n)=c(1,n*(find(a(1,:)==i)-1)+1:find(a (1,:)==i)*n);ll(i)=length(find(abs(h(i,:))~=32)); %计算每一个huffman 编码的长度end l=sum(p.*ll);%计算平均码长fprintf(‘\\n Huffman编码结果为:\\n’);h fprintf(‘\\n 编码的平均码长为:\\n’); l hh=sum(p.*(-log2(p))); %计算信源熵fprintf(‘\\n 信源熵为:\\n’);hh fprintf(‘\\n 编码效率为:\\n’); t=hh/l%计算编码效率运行结果为:请输入数据:[,,,,,,,] Huffman编码结果为: h = 1100 1101010111011 00010001 编码的平均码长为: l = 3 信源熵为: hh = 编码效率为: t = 编码:Fano 码: 费诺编码属于概率匹配编码,但它不是最佳的编码方法。
信息论作业

熵1. 从大量统计资料知道,男性中红绿色盲的发病率为7%,女性发病率为0.5 %,如果你问一位男同志:“你是否是红绿色盲?”他的回答可能是“是”,可 能是“否”,问这二个答案中各含多少信息量?平均每个回答中含有多少信息 量?如果你问一位女同志,则答案中含有的平均自信息量是多少?2.. 设有一概率空间,其概率分布为{1p ,2p ,…,q p },并有1p >2p 。
若取'1p =1p ε-,'2p =2p ε+,其中1202p p ε<≤-,其他概率不变。
试证明由此所得新的概率空间的熵是增加的,并用熵的物理意义加以解释。
3.(1)为了使电视图像获得良好的清晰度和规定的适当的对比度,需要用5×105个像素和10个不同的亮度电平,求传递此图像所需的信息率(比特/秒)。
并设每秒要传送30帧图像,所有像素独立变化,且所有亮度电平等概率出现。
(2)设某彩电系统,除了满足对于黑白电视系统的上述要求外,还必须有30个不同的色彩度,试证明传输这彩色系统的信息率约是黑白系统的信息率的2.5倍。
4. 为了传输一个由字母A 、B 、C 、D 组成的符号集,把每个字母编码成两个二元码脉冲序列,以00代表A ,01代表B ,10代表C ,11代表D 。
每个二元脉冲宽度为5ms 。
(1)不同字母等概率出现时,计算传输的平均信息速率; (2)若每个字母出现的概率分别为1111,,,2488A B C D p p p p ====,试计算传输的平均信息速率。
5. 证明:1212()()()()N N H X X X H X H X H X ⋅⋅⋅≤++⋅⋅⋅+6 设有扰离散信道的输入端是以等概率出现的A 、B 、C 、D 四个字母。
该信道的正确传输概率为0.5,错误传输概率平均分布在其他三个字母上。
验证在该信道上每个字母传输的平均信息量为0.21比特。
压缩编码1. 有一信源,它有六种可能的输出,其概率分布如下表所示,表中给出了对应的六种编码12345C C C C C 、、、、和6C 。
信息论与编码课程大作业

信息论与编码课程大作业
一、信源与信源编码
1、若信源包含N 个符号,在什么情况下熵最大?(10分)
最大的熵值是多少?(10分)
2、简述信源编码的两个作用。
(10分)
3、已知离散无记忆信源中各符号的概率空间为
X = 符号u1 u2 u3 u4
概率:1/2 1/4 1/8 1/8
(1)求信源的熵(10分);
(2)对其进行哈夫曼编码(要求码方差较小),写出过程(10分);
(3)求出平均码长和编码效率(10分)。
4、举出学过的无失真与限失真编码方法,各1种。
(10分)
并选择一种,阐述其在实际中的应用(不少于200字)。
(10分)
5、编程题(20分)
二、信道与信道编码
1、 对称信道容量公式?(10分)
在信源如何分布时达到信道容量?(10分)
2、信道编码的基本原理是什么?(10分)
3、对一个(4,2)码,其生成矩阵为
(1)写出伴随式译码表(10分);
(2)接收序列R=1100,估算发码(10分);
(3)判断码的检错能力(10分)。
4、举出两种常用的纠错码,(10分)
并选择一种,阐述其在实际中的应用(不少于200字)。
(10分)
5、编程题(20分)
说明:(1)按学号排列前30名同学完成信源与信源编码方面的作业,其余同学
完成信道与信道编码方面的作业。
(2)第5题编程题另付题目与具体要求,可在20道编程题中任选一道;
自己编写课程相关的其他程序也可以。
(3)第4题和第5题,任意两个同学不能雷同,否则均不能通过。
10010111G ⎡⎤=⎢⎥⎣⎦。
信息论第2章作业(DOC)

2.居住在某地区的女孩中有25%是大学生,在大学生中有75%是身高1.6以上的,而女孩中身高1.6米以上的占总数一半.假如我们得知“身高1.6米以上的某女孩是大学生”的消息,问获得多少信息量?
解:
信息量:比特
有一信源输出X∈{0,1,2},其概率为p0=1/4,p1=1/4,p2=1/2。
设计两个独立实验去观察它,其结果为Y1∈{0,1}和Y2∈{0,1}。
已知条件概率为
P(Y1|X) 0 1 P(Y2|X) 0 1
0 1 0 0 1 0
1 0 1 1 1 0
2 1/2 1/2 2 0 1 求:
1)I(X;Y1)和I(X;Y2),并判断哪一个实验好些。
2)I(X;Y1,Y2),并计算做Y1和Y2两个实验比做Y1或Y2中的一个实验各可多得多少关
于X的信息。
3)I(X;Y1/Y2)和I(X;Y2/Y1),并解释它们的含义。
H(X)=
.若有二个串接的离散信道,它们的信道矩阵都是
00
10001⎡⎤⎢⎥
11.有一个一阶平稳马尔可夫链X1,X2,……X r……,各X r取值于集合A={a1,a2,a3}。
已知起始概率p(X r)为p1=1/2,p2=p3=1/4,转移概率如下。
j
1 2 3
21.0585
.1251
.11100=-=-
=∞H H R。
信息论与编码课程大作业

《信息论与编码》课程大作业——正交多项式拟合的信息熵学院班级姓名学号阅读文献名称:Information entropy of orthogonal polynomials中文名称:正交多项式拟合的信息熵文章摘要:主要讲了Boltzmann–Shannon的经典正交多项式拟合的信息熵的定义式:以及从这个公式和雅克比行列式的推导出来的一个很明确的公式:文章的第一部分是介绍部分,主要介绍了熵的来历,熵的引入,熵的概念的解释:是一种种类性,同时带有组的概念,动态性不确定性等等的一种表征,是描述随机性、杂乱性和不确定性的一种标志。
同时文章的介绍部分引入了位置空间和动量空间的两个表达式,,并同时给出了它们与Boltzmann–Shannon 的关系即推导公式:以及由这些公式得到的一些结论和这些对这个学科的贡献和不足之处,在第一部分的最后介绍了一些基本的分析和推导要用到的公式和定理:1、第一类切比雪夫多项式:2、第二类切比雪夫多项式:3、盖根保多项式:4、厄密多项式:5、拉盖尔多项式:6、紧凑正交多项式拟合的间隔问题:其中:文章的第二部分是一些概念和符号的说明和介绍,其中包括:1、雅克比行列式简介:2、Zeta矩阵函数:以及泰勒分解后的表达式:3、权重的概念以及几何学的方程:权重定义:在推导过程中用到了微分方程:还有皮尔森方程:第三部分是正交信息熵的提出,同时也提出了一些辅助定理以及证明:1、2、其中:3、文章总结以及心得体会:这篇文章介绍的是一种信息熵的新的求解方法,就是基于正交拟合的方法,文章还介绍了要用到的一些矩阵以及在推导过程中的矩阵的变换和一些基本又经典的方程,比如泰勒级数的展开等等。
解决了以前求熵的复杂问题,提出了简明的计算公式,以及从基本的Boltzmann–Shannon熵的表达式推导出简明计算公式的方法和推导出来的理论依据和数学支持,最终达到了解决在摘要中提出的问题的目的。
信息论大作业2课件

一、实验目的1、通过实验进一步理解霍夫曼编码、算术编码和LZ编码原理和方法2、熟悉matlab编程和GUI界面的设计二、实验原理1、赫夫曼(Huffman )编码是1952年提出的,是一种比较经典的信息无损熵编码,该编码依据变长最佳编码定理,应用Huffman 算法而产生。
Huffman 编码是一种基于统计的无损编码。
设信源X 的信源空间为:⎩⎨⎧∙)()()()(:)(::][32121N N x P x P x P x P X P x x x X P X 其中,1)(1=∑=Ni i x P ,现用二进制对信源X 中的每一个符号i x (i=1,2,…N)进行编码。
根据变长最佳编码定理,Huffman 编码步骤如下:(1)将信源符号xi 按其出现的概率,由大到小顺序排列。
(2)将两个最小的概率的信源符号进行组合相加,并重复这一步骤,始终将较大的概率分支放在上部,直到只剩下一个信源符号且概率达到1.0为止;(3)对每对组合的上边一个指定为1,下边一个指定为0(或相反:对上边一个指定为0,下边一个指定为1);(4)画出由每个信源符号到概率1.0处的路径,记下沿路径的1和0;(5)对于每个信源符号都写出1、0序列,则从右到左就得到非等长的Huffman 码。
Huffman 编码的特点是:(1)Huffman 编码构造程序是明确的,但编出的码不是唯一的,其原因之一是两个概率分配码字“0”和“1”是任意选择的(大概率为“0”,小概率为“1”,或者反之)。
第二原因是在排序过程中两个概率相等,谁前谁后也是随机的。
这样编出的码字就不是唯一的。
(2)Huffman 编码结果,码字不等长,平均码字最短,效率最高,但码字长短不一,实时硬件实现很复杂(特别是译码),而且在抗误码能力方面也比较差。
(3)Huffman 编码的信源概率是2的负幂时,效率达100%,但是对等概率分布的信源,产生定长码,效率最低,因此编码效率与信源符号概率分布相关,故Huffman 编码依赖于信源统计特性,编码前必须有信源这方面的先验知识,这往往限制了哈夫曼编码的应用。
信息论大作业

信息论大作业电子工程学院班号1.huffman编码1.哈夫曼编码原理:①将信源符号按概率从大到小的顺序排列,令p(x1)≥p(x2)≥?≥p(xn)②给两个概率最小的信源符号p(xn-1)和p(xn)各分配一个码位“0”和“1”,将这两个信源符号合并成一个新符号,并用这两个最小的概率之和作为新符号的概率,结果得到一个只包含(n-1)个信源符号的新信源。
称为信源的第一次缩减信源,用s1表示。
③ 简化源S1的符号仍然按照从大到小的概率顺序排列,并且重复步骤2以获得仅包含(n-2)个符号的简化源S2。
④ 重复上述步骤,直到精简源中只剩下两个符号。
此时,剩余两个符号的概率之和必须为1。
然后,从最后一个减少的信源开始,根据编码路径向前返回,得到每个信源符号对应的码字。
2.霍夫曼编码优缺点:1)编译的代码是不同的前缀代码,这确保了代码的唯一可翻译性。
2)由于编码长度可变。
因此译码时间较长,使得霍夫曼编码的压缩与还原相当费时。
3)编码长度不统一,硬件实现困难。
4)对不同信号源的编码效率不同,当信号源的符号概率为2的负幂次方时,达到100%的编码效率;若信号源符号的概率相等,则编码效率最低。
5)由于0和1的指定是任意的,因此通过上述过程编译的最佳代码不是唯一的,但其平均代码长度相同,因此不会影响编码效率和数据压缩性能。
3.编码过程:读入一幅图像的灰度值;1.计算数组C第一列中矩阵的不同数;2.将相同的数占站整个数组总数的比例统计在数组p中;3.找到最小概率,将其相加,直到它等于1,并将最小概率的序列号存储在树的第一列中两次小放在第二列,和放在p像素比例之后;4.C数组的第一维表示值,第二维表示代码的值,第三维表示代码的位数;5.低概率值标注为1,高概率值标注为0;6.计算源的熵;7.计算平均码长;8.计算“编码效率”;9.计算冗余度。
源程序:P=输入('请输入数据:');n=长度(p);fori=1:nifp(i)<0fprintf('\\n提示:概率值不能小于0!\\n');P=输入('请重新输入数据:';结束ifabs(sum(p))>1Fprintf('\\n哈夫曼码中的概率之和不能大于1!\\n');P=输入('请重新输入数据:';endq=P;a=zeros(n-1,n);%生成一个n-1行n列的数组fori=1:n-1[q,l]=sort(q);a(i,:)=[l(1:n-i+1),零(1,i-1)];q=[q(1)+q(2),q(3:n),1];终止fori=1:n-1c(i,1:n*n)=空格(n*n);终止c(n-1,n)='0';c(n-1,2*n)='1';fori=2:n-1c(n-i,1:n-1)=c(n-i+1,n*(find(a(n-i+1,:)=1))-(n-2):n*(find (a(n-i+1,:)=1));c(n-i,n)='0';c(n-i,n+1:2*n-1)=c(n-i,1:n-1);c(n-i,2*n)='1';forj=1:i-1c(n-i,(j+1)*n+1:(j+2)*n)=c(n-i+1,n*(find(a(n-i+1,:)==j+1)-1)+1:n*find(a(n-i+1,:)==j+1));end结束%i=1:n分配哈夫曼码字h(i,1:n)=c(1,n*(find(a(1,:)==i)-1)+1:find(a(1,:)==i)*n);ll(i)=长度(find(abs(h(i,:)~=32));%计算每个哈夫曼代码的长度l=sum(p.*ll);%计算平均码长fprintf('\\nhuffman编码结果为:\\n');hfprintf('\\n编码的平均码长为:\\n');lhh=sum(p.*(-log2(p)));%计算信源熵fprintf('\\n信源熵为:\\n');hhFprintf('\\n编码效率:\\n');T=HH/L%计算编码效率运行结果为:请输入数据:[0.1,0.1,0.1,0.2,0.1,0.1,0.2,0.1]哈夫曼编码结果:H=1100110101011101100010001代码的平均代码长度为:l=3,源熵为:HH=2.9219编码效率为:t=零点九七四零2.fano编码:法诺代码:费诺编码属于概率匹配编码,但它不是最佳的编码方法。
10-11第二学期信息论作业题参考答案

第1讲2、信息论创始人是谁?香农。
3、信息和消息、信号有什么联系与区别?从信息理论角度上看,信号是消息的载体,信息含藏在消息之中,有信号有消息不一定有信息。
4、通信系统的主要性能指标是什么? 有效性、可靠性和安全性。
5、举例说明信息论有哪些应用?为信息传送和处理系统提供数学模型和评估方法,在通信和信息处理领域是一门基础理论,在其它领域如语言学、生物学、医学、神经网络、经济学方面的应用也很成功。
具体应用实例有:语音、图像和数据信息的压缩,通信信道有效性和可靠性的提高,或信道传输功率指标要求的降低,通信或计算机系统可靠性和安全性的提高,信息处理领域的信号重建和模式识别等。
2.4 (求车牌自信息量)某车牌号的概率是(1/26)3×(1/10)3,24bit/牌,后一种概率为(1/36)6,31bit/牌, 第2讲设二元对称信道的传递矩阵(条件概率矩阵)为⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡32313132若P(0) = 3/4, P(1) = 1/4,求H(X), H(Y), H(X/Y), H(Y/X)和I(X;Y);先求P(Y)=∑X P(XY)和P(XY)=P(X)P(Y|X),再得各种熵和互信息。
H(X)=H(3/4,1/4), H(Y)=H(7/12,5/12);H(XY)=H(1/2,1/4,1/12,1/6); H(X/Y)=H(XY)-H(Y)H(Y/X)=H(XY)-H(X);或H(Y/X)=∑P(X=a)H(Y/a)=H(3/4,1/4) I(X;Y)=H(X)-H(X/Y)=H(X)+H(Y)-H(XY); 2.2(求条件信息量)1.6米以上女孩是条件,某个1.6米以上的女大学生是概率事件,得条件概率为:P=0.25×0.75/0.5=0.375=3/8,信息量为I= -log0.375=1.42比特。
2.52.10(1)(2)(由联合概率分布求熵、联合熵和条件熵)(1)思路:先求出X 、Y 、Z 、XZ 、YZ 、XYZ 的概率或联合分布,再求其熵。
信息论大作业

信息论在语音识别中的应用
• 基于相对熵的语音识别 • 基于相对熵的声音控制系统 • ……
信息论在图像识别中的应用
• • • • • 基于相对熵的人脸识别 基于相对熵的指纹识别 基于相对熵的汉字识别 基于相对熵的汽车车牌识别 ……
信息论的最新进展及其它
• 基于相对熵/互信息的门禁系统 • 基于相对熵/互信息的防盗系统 • ……
信道模拟与信息测度
实验目的:
了解信道和信道测度的概念、方法等,加深对信道的认 识; 熟悉并掌握信道转移概率矩阵、互信息的计算方法; GUI界面的设计。
实验原理: 实验内容: 实验结论: 实验感想与收获:
二元Huffman编码
实验目的:
了解信源编码的目的、方法等,加深对编码的认识; 熟悉并掌握Huffman编码的原理和方法,会进行简单的计 算; GUI界面的设计。
信息论实验内容
信LZ编码
信息的获取与测度
实验目的:
了解信息获取、信源测度的概念、方法等,加深对信源 的认识; 熟悉并掌握信息熵、互信息、相对熵的原理和方法,会 进行简单的计算; GUI界面的设计。
实验原理: 实验内容: 实验结论: 实验感想与收获:
实验原理: 实验内容: 实验结论: 实验感想与收获:
LZ编码
实验目的:
了解信源编码的目的、方法等,加深对编码的认识; 了解通用编码LZ码的原理和方法; GUI界面的设计。
实验原理: 实验内容: 实验结论: 实验感想与收获:
信息论大作业
要求
大作业格式要求:
• • • • • • • 题目 学生姓名,班级,学号 摘要 引言 方法 实验结果 参考文献
阅读不少于10篇的参考文献; 三至四人一组,也可一人一组; 每组负责一个题目; 实验部分要有完整的数据描述、GUI界面、源代码、 结果; 公式用公式编译器输入; 源代码要有说明。
信息论大作业

信息理论与编码大作业报告课题:算术编码班级:通信1211姓名:学号:1220119127一、实验原理1.编码过程:算术编码方法是将被编码的一则消息或符号串(序列)表示成0和1之间的一个间隔(Interval),即对一串符号直接编码成[0,1]区间上的一个浮点小数。
符号序列越长,编码表示它的间隔越小,表示这一间隔所需的位数就越多。
信源中的符号序列仍然要根据某种模式生成概率的大小来减少间隔。
可能出现的符号概率要比不太可能出现的符号减少范围小,因此,只正加较少的比特位。
算术编码进行编码时,从实数区间[0,1)开始。
按照符号的频度将当前的区间分割成多个子区间。
根据当前输入的符号选择对应的子区间,然后从选择的子区间中继续进行下一轮的分割。
不断的进行这个过程,直到所有符号编码完毕。
对于最后选择的一个子区间,输出属于该区间的一个小数。
这个小数就是所有数据的编码。
现在来举个例子。
假设一份数据由“A”、“B”、“C”三个符号组成。
现在要编码数据“BCCB”,编码过程如下图所示。
观察上图可以发现算术编码的过程。
首先,算术编码是从区间[0,1)开始的。
这时三个符号的概率都是1/3,按照这个概率分割区间。
第一个输入的符号是“B”,所以我们选择子区间[0.3333,0.6667)作为下一个区间。
输入“B”后更新频度,根据新的概率对区间[0.3333,0.6667)进行分割。
这时输入的符号是“C”,我们可以选择子区间[0.5834,0.6667)。
继续更新频度、分割区间、选择子区间,直到符号全部编码完成。
我们最后得到的区间是[0.6390,0.6501)。
输出属于这个区间的一个小数,例如0.64。
那么经过算术编码的压缩,数据“BCCB”最后输出的编码就是0.64。
2.解码过程:算术编码进行解码时仅输入一个小数。
解码前首先需要对区间[0,1)按照初始时的符号频度进行分割。
然后观察输入的小数位于那个子区间。
输出对应的符号,选择对应的子区间,然后从选择的子区间中继续进行下一轮的分割。
信息论第三章作业

第三章作业1、将某六进制信源进行二进制编码,如表所示,求: (1)哪些是唯一可译码? (2)哪些是非延长码(即时码)?(3)所有唯一可译码的平均码长和编码效率。
解:(1)C1,C2,C3,C6是唯一可译码。
(2)C1, C3,C6是即时码。
(3)H(X)=2bit/符号,符号码元/31=l ,%7.6632)(11===l X H η 符号码元/125.2)(612==∑=i i i l u p l ,%1.94125.22)(22===l X H η 符号码元/125.2)(613==∑=i i i l u p l ,%1.94125.22)(33===l X H η 符号码元/5.2)(616==∑=i i i l u p l ,%805.22)(66===l X H η 2、某信源有8个符号{x 1,x 2,…,x 8},概率分别为1/2,1/4,1/8,1/16,1/32,1/64,1/128,1/128,编成这样的码:000,001,010,011,100,101,110,111。
求: (1)信源的符号熵; (2)出现一个1或0的概率; (3)这种码的编码效率; (4)相应的香农码和费诺码; (5)该码的编码效率。
解:(1)符号/98.1)(log )()(bit x p x p X H iii=-=∑(2)8.03/)1*12811*6412*3211*1612*812*413*21()0()0(=++++++==l l p 2.0)0(1)1(=-=p p(3)%66398.1)(===l X H η费诺码:(码字不唯一)(5)符号码元/98.1)(81==∑=ii i lx p l ,因此香农码和费诺码的编码效率均为:%10098.198.1)(===l X H η 4、设有离散无记忆信源p(X)={0.37,0.25,0.18,0.10,0.07,0.03}。
(1)求信源符号熵(2)用霍夫曼编成二元变长码,计算编码效率。
信息论作业

2.1 试问四进制、八进制脉冲所含信息量是二进制脉冲的多少倍?解:四进制脉冲可以表示4个不同的消息,例如:{0, 1, 2, 3}八进制脉冲可以表示8个不同的消息,例如:{0, 1, 2, 3, 4, 5, 6, 7}二进制脉冲可以表示2个不同的消息,例如:{0, 1}假设每个消息的发出都是等概率的,则:四进制脉冲的平均信息量symbol bit n X H / 24log log )(1===八进制脉冲的平均信息量symbol bit n X H / 38log log )(2===二进制脉冲的平均信息量symbol bit n X H / 12log log )(0===所以:四进制、八进制脉冲所含信息量分别是二进制脉冲信息量的2倍和3倍。
2.2 居住某地区的女孩子有25%是大学生,在女大学生中有75%是身高160厘米以上的,而女孩子中身高160厘米以上的占总数的一半。
假如我们得知“身高160厘米以上的某女孩是大学生”的消息,问获得多少信息量?解:设随机变量X 代表女孩子学历X x 1(是大学生) x 2(不是大学生)P(X) 0.25 0.75设随机变量Y 代表女孩子身高Y y 1(身高>160cm ) y 2(身高<160cm )P(Y) 0.5 0.5已知:在女大学生中有75%是身高160厘米以上的即:bit x y p 75.0)/(11=求:身高160厘米以上的某女孩是大学生的信息量即2.6 设信源⎭⎬⎫⎩⎨⎧=⎥⎦⎤⎢⎣⎡17.016.017.018.019.02.0)(654321x x x x x x X P X ,求这个信源的熵,并解释为什么H(X) > log6不满足信源熵的极值性。
解:585.26log )(/ 657.2 )17.0log 17.016.0log 16.017.0log 17.018.0log 18.019.0log 19.02.0log 2.0( )(log )()(26=>=+++++-=-=∑X H symbolbit x p x p X H i i i不满足极值性的原因是107.1)(6>=∑i ix p :bit y p x y p x p y x p y x I 415.15.075.025.0log )()/()(log )/(log )/(11111111=⨯-=-=-= 2.10 一阶马尔可夫信源的状态图如下图所示。
信息论作业

1、设二元对称信道的输入概率分布分别为]4/14/3[][=X P ,转移矩阵为[]⎥⎦⎤⎢⎣⎡=3/23/13/13/2|X Y P , 求信道的输入熵,输出熵,平均互信息量;求信道容量和最佳输入分布;求信道剩余度。
解:(1)信道的输入熵4log 4/1)3/4(log 4/3)(22+=X H ;⎥⎦⎤⎢⎣⎡=6/112/14/12/1][XY P ]12/512/7[][=Y P)5/12(log 12/5)7/12(log 12/7)(22+=Y H)6/1,12/1(4/1)4/1,2/1(4/3)|(H H X Y H +=)|()();(X Y H Y H Y X I -=2)最佳输入分布为]2/12/1[][=X P ,此时信道的容量为)3/1,3/2(1H C -=(3)信道的剩余度:);(Y X I C -2、(10分)计算机终端发出A.B.C.D.E 五种符号,出现概率分别为1/16,1/16,1/8,1/4,1/2.通过一条带宽为18KHz 的信道传输数据,假设信道输出信噪比为2047,试计算:1)香农信道容量;2)无误码传输的最高符号速率。
(1) 22log 118log 2048198/t S C B kbit s N ⎛⎫=+== ⎪⎝⎭(2)()()max t B C R H x =,()1111115,,,,16168428H x H ⎛⎫== ⎪⎝⎭ ()5198max 1.05610158B k R Baud ==⨯ 3、设二元对称信道的传递矩阵为21331233⎛⎫ ⎪ ⎪ ⎪ ⎪⎝⎭(1) 若(0)3/4,(1)1/4P P ==,求(),(|),(|)H X H X Y H Y X 和(;)I X Y ;(2) 求该信道的信道容量及其达到信道容量时的输入概率分布。
解:(1)已知二元对称信道的传递矩阵,又已知输入的概率分布(0)3/4,(1)1/4P P ==,可以求得输出Y 的概率分别和后验概率。
信息论作业

信息是事物运动状态或存在方式的不确 定性的描述
不仅仅是形式上的消息或情报,而且包 括消息或情报所含的对事物状态或不确 定性的描述
信息论
1948年,香农发表了 “通信的数学理论”(A Mathematicsl Theory of Communication), 创立了信息论,开始对 信息的数量化研究。
香农信息论也称为狭义信息论,研究从 通信系统引出的基础理论问题。归纳起 来其研究内容包括: ①信息熵、信道容量和信息率失真函数; ②无失真信源编码定理、信道编码定理和 保真度准则下的信源编码定理; ③信源编码、信道编码理论与方法。
一般信息论的研究内容
几乎在香农创立信息论的同时,另一位 美国科学家、控制论(Control Theory, Cybernetics)的奠基人维纳(N.Wiener) 将人或机器与外部环境所进行的交换看 成广义的通信,将信息理解为广义通信 的对象。
在这个意义上,人们更愿意将广义信息 论称为信息科学。
信息科学的研究内容
信息科学是由一般信息论发展起来的, 目前它已渗透到通信与电子、计算机、 自动化、微电子与材料、光学与光电子 等工程学科以及经济、管理、心理、生 物、社会、哲学等非工程学科。 可见,信息科学的研究内容极为广泛, 是目前最活跃的技术科学之一
信息论
主要内容:
1、信息的定义 2、什么是信息论 3、信息论的研究内容和目的 4、信息论的形成与发展
信息论大作业

fuzzy
comprehensive
evaluation
enterprise
management and project management technique by using Shannon entropy and mutual information principle, which made the evaluation is more objective, accurate and reliable in the determination of weight vector, and made the method of fuzzy comprehensive evaluation model have self learning and adaptive functions.
H ( XY ) p ( xi y j )I ( xi y j ) p ( xi y j ) log 2 p ( xi y j )
i 1 j 件熵:由于不同的xi,H (Y / xi )是变化的,对H (Y / xi )的所有可能值进行统计平均,
07121001
古国宝
信息论在企业管理中的应用
第一章 绪 论
纵观全球, 科学技术的进步、 知识经济的崛起、 经济全球化和网络化的发展, 正引发着一场从宏观领域到微观领域的巨大变革。在这场变革中,将抛弃许多传 统的管理概念和模式,创新出一大批新的管理概念和管理模式。比如:伙伴关系 取代了雇用关系; 从管理物发展到管理人、 进一步发展到管理人才; 从重视资本、 劳动的投入到重视知识的创新: 从信息管理发展到知识管理;从鼓励知识保密到 鼓励知识公开, 进而实现隐性知识的共享;从单纯的竞争发展到竞争与合作并存 等等。这一切,都对企业的管理和管理者提出了严峻的挑战。从全球范围来看, 当然包括中国, 管理问题依然是制约企业发展的重大问题。关于企业发展战略问 题,麦肯锡公司曾作过一个统计:在全球,大约仅有 33%企业的并购是成功的。 而通过并购进入新工业部门的一半以上的企业, 进入全新经营领域的 69%的企业 和进入完全无关经营领域的 74%的企业的并购最终以失败告终。 可以这样说, 企 业的每一次成功与失败,都与经营决策息息相关。也有人说,管理就是决策。决 策和评价问题贯穿于整个企业经营管理的全过程。尤其是世界经济处于动荡不 安、跨国公司兼并浪潮风起云涌的今天,综合评价更应处于企业管理的核心地位, 它是执行企业的各种管理职能、 保证管理工作顺利进行的基础。如果评价失误或 所作的不是最好的评价,轻则影响到企业的效率和效益,重则影响到企业的生死存 亡。对于市场经济机制尚未根本完善、各类企业融入国际大市场尚未站稳脚跟、 企业的生产力和管理水平存在明显地域、行业和所有制结果间的差别的中国说, 这决不仅仅意味着几个企业的破产倒闭。 信息论的理论定义是由当代伟大的数学家美国贝尔实验室杰出的科学家香 农在他 1948 年的著名论文《通信的数学理论》所定义的,它为信息论奠定了理 论基础。后来其他科学家,如哈特莱、维纳、朗格等人又对信息理论作出了更加 深入的探讨。使得信息论到现在形成了一套比较完整的理论体系。 信息论将信息的传递作为一种统计现象来考虑, 给出了估算通信信道容量的 方法。 信息传输和信息压缩是信息论研究中的两大领域。这两个方面又由信息传 输定理、信源-信道隔离定理相互联系。香农被称为是“信息论之父”。人们通 常将香农于 1948 年 10 月发表于 《贝尔系统技术学报》 上的论文 《A Mathematical Theory of Communication》(通信的数学理论)作为现代信息论研究的开端。这 -1-
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
信息论大作业电子工程学院班号1.Huffman编码1. Huffman 编码原理:①将信源符号按概率从大到小的顺序排列,令p(x1)≥ p(x2)≥…≥ p(xn)②给两个概率最小的信源符号p(xn-1)和p(xn)各分配一个码位“0”和“1”,将这两个信源符号合并成一个新符号,并用这两个最小的概率之和作为新符号的概率,结果得到一个只包含(n-1)个信源符号的新信源。
称为信源的第一次缩减信源,用S1表示。
③将缩减信源S1的符号仍按概率从大到小顺序排列,重复步骤2,得到只含(n -2)个符号的缩减信源S2。
④重复上述步骤,直至缩减信源只剩两个符号为止,此时所剩两个符号的概率之和必为1。
然后从最后一级缩减信源开始,依编码路径向前返回,就得到各信源符号所对应的码字。
2. 霍夫曼编码优缺点:1)编出来的码都是异字头码,保证了码的唯一可译性。
2) 由于编码长度可变。
因此译码时间较长,使得霍夫曼编码的压缩与还原相当费时。
3) 编码长度不统一,硬件实现有难度。
4) 对不同信号源的编码效率不同,当信号源的符号概率为2的负幂次方时,达到100%的编码效率;若信号源符号的概率相等,则编码效率最低。
5) 由于0与1的指定是任意的,故由上述过程编出的最佳码不是唯一的,但其平均码长是一样的,故不影响编码效率与数据压缩性能。
3.编码流程:读入一幅图像的灰度值;1.将矩阵的不同数统计在数组c的第一列中;2.将相同的数占站整个数组总数的比例统计在数组p中;3.找到最小的概率,相加直到等于1,把最小概率的序号存在tree第一列中,次小放在第二列,和放在p像素比例之后;4.C数组第一维表示值,第二维表示代码数值大小,第三维表示代码的位数;5.把概率小的值为1标识,概率大的值为0标识;6.计算信源的熵;7.计算平均码长;8.计算编码效率';9.计算冗余度。
源程序:p=input('请输入数据:');n=length(p);for i=1:nif p(i)<0fprintf('\n 提示:概率值不能小于0!\n');p=input('请重新输入数据:');endendif abs(sum(p))>1fprintf('\n 哈弗曼码中概率总和不能大于1!\n');p=input('请重新输入数据:');endq=p;a=zeros(n-1,n); %生成一个n-1 行n 列的数组for i=1:n-1[q,l]=sort(q);a(i,:)=[l(1:n-i+1),zeros(1,i-1)];q=[q(1)+q(2),q(3:n),1];endfor i=1:n-1c(i,1:n*n)=blanks(n*n);endc(n-1,n)='0'; c(n-1,2*n)='1';for i=2:n-1c(n-i,1:n-1)=c(n-i+1,n*(find(a(n-i+1,:)==1))-(n-2):n*(find(a(n-i+1,:)==1))) ;c(n-i,n)='0' ;c(n-i,n+1:2*n-1)=c(n-i,1:n-1) ;c(n-i,2*n)='1' ;for j=1:i-1c(n-i,(j+1)*n+1:(j+2)*n)=c(n-i+1,n*(find(a(n-i+1,:)==j+1)-1)+1:n*find(a(n-i+1,:)==j+1));endend %完成huffman 码字的分配for i=1:nh(i,1:n)=c(1,n*(find(a(1,:)==i)-1)+1:find(a(1,:)==i)*n);ll(i)=length(find(abs(h(i,:))~=32)); %计算每一个huffman 编码的长度endl=sum(p.*ll); %计算平均码长fprintf('\n Huffman编码结果为:\n'); hfprintf('\n 编码的平均码长为:\n'); lhh=sum(p.*(-log2(p))); %计算信源熵fprintf('\n 信源熵为:\n'); hhfprintf('\n 编码效率为:\n'); t=hh/l%计算编码效率运行结果为:请输入数据:[0.1,0.1,0.1,0.2,0.1,0.1,0.2,0.1]Huffman编码结果为:h =1100110101011101100010001编码的平均码长为:l =3信源熵为:hh =2.9219编码效率为:t =0.97402.fano编码:Fano码:费诺编码属于概率匹配编码,但它不是最佳的编码方法。
不过有时也可以得到紧致码的性能。
信源符号以概率递减的次序排列进来,将排列好的信源符号划分为两大组,使第组的概率和近于相同,并各赋于一个二元码符号”0”和”1”.然后,将每一大组的信源符号再分成两组,使同一组的两个小组的概率和近于相同,并又分别赋予一个二元码符号.依次下去,直至每一个小组只剩下一个信源符号为止.这样,信源符号所对应的码符号序列则为编得的码字。
费诺码编码的一般步骤如下:(1)将信源消息符号按其出现的概率大小依次排列排列:n p p p ≥≥≥ 21。
(2)将依次排列的信源符号按概率值分为两大组,使两个组的概率之和近似相同,并且对各组赋予一个二进制码元“0”和“1”。
(3)将每一大组的信源符号再分成两组,使划分后的两个组的概率之和近似相同,并且对各组赋予一个二进制符号“0”和“1”。
以上两部分在程序中。
(4)如此重复,直到每个组只剩下一个信源符号为止。
在程序中本部分采用递归思想。
信源符号所对应的码字即为费诺编码。
费诺编码特点 费诺编码,它编码后的费诺码要比香农码的平均码长小,消息传输速率达,编码效率高,但它属于概率匹配编码它不是最佳的编码方法。
源程序:A=input('input the A:');A=fliplr(sort(A));%降序排列[m,n]=size(A);for i=1:nencoding(i,1)=A(i);%生成B 的第1列end%生成B 第2列的元素a=sum(encoding(:,1))/2;for k=1:n-1if abs(sum(encoding(1:k,1))-a)<=abs(sum(encoding(1:k+1,1))-a)break;endendfor i=1:n%生成B第2列的元素if i<=kencoding(i,2)=0;elseencoding(i,2)=1;endend%生成第一次编码的结果CODE=encoding(:,2)';CODE=sym(CODE);%生成第3列及以后几列的各元素j=3;while (j~=0)p=1;while(p<=n)x=encoding(p,j-1);for q=p:nif x==-1break;elseif encoding(q,j-1)==xy=1;continue;elsey=0;break;endendendif y==1q=q+1;endif q==p|q-p==1encoding(p,j)=-1;elseif q-p==2encoding(p,j)=0;CODE(p)=[char(CODE(p)),'0'];encoding(q-1,j)=1;CODE(q-1)=[char(CODE(q-1)),'1'];elsea=sum(encoding(p:q-1,1))/2;for k=p:q-2if abs(sum(encoding(p:k,1))-a)<=abs(sum(encoding(p:k+1,1))-a);break;endendfor i=p:q-1if i<=kencoding(i,j)=0;CODE(i)=[char(CODE(i)),'0'];elseencoding(i,j)=1;CODE(i)=[char(CODE(i)),'1'];endendendendp=q;endC=encoding(:,j);D=find(C==-1);[e,f]=size(D);if e==nj=0;elsej=j+1;endendencodingACODEfor i=1:n[u,v]=size(char(CODE(i)));L(i)=v;endavlen=sum(L.*A)运行结果:input the A:[0.3,0.1,0.2,0.3,0.1]encoding =0.3000 0 0 -1.0000 -1.00000.3000 0 1.0000 -1.0000 -1.00000.2000 1.0000 0 -1.0000 -1.00000.1000 1.0000 1.0000 0 -1.00000.1000 1.0000 1.0000 1.0000 -1.0000A =0.3000 0.3000 0.2000 0.1000 0.1000CODE =[ 00, 01, 10, 110, 111]avlen =2.2000对于这次的大作业做的大体上没有什么差错,可是我感觉过于简洁。
这次作业,使我对信息论2种编码有了更多的了解。
同样,我感觉自己存在了太多的不足。
对于课本知识,我未能够有全局的了解。
对于接下来的考试,也未能有十足的把握。
这使我更加的抓紧时间好好复习信息论的知识。
感谢老师的平时的辛苦的教学,学生在此表示深深的感谢。