搜狗微信公众号采集方法
搜狗微信搜索不用关注公众号就能在电脑查看图文消息

搜狗微信搜索不⽤关注公众号就能在电脑查看图⽂消息
搜狗微信搜索开通了,不得不说⽅便了许多,⽤户可在搜狗搜索结果页可浏览到与查询词相关的微信公众号及全部⽂章。
地址
是。
就像之前说的,在⽅便⼤多数⼈的同时也⽅便了采集者,如果他们不加修改地直接发布的话也会造成信息的泛滥。
对于搜狗微信搜索,微信官⽅称:“微信公众平台搜索功能核⼼为,⽤户获取、查询微信公众平台的内容信息更简单、⽅便,为微信增加了⼀个⾮常好的内容查询⼊⼝。
” 微信称,这次与搜狗合作意义在于三点:⼀是公众号可以从搜索引擎获得更多流量与阅读量;其次公众号获取⽤户的成本降低,⽤户可直接在搜索引擎中加关注,便捷易操作;最后,⾃媒体的玩法会发⽣变化,如何借⽤搜索引擎扩⼤关注和影响⼒,需要业内共同探讨。
搜狗微信搜索可以解决不能查看微信订阅号历史消息的烦恼【搜狗微信搜不到公众号怎么办?可以直接在⼿机微信上添加公众号,因为搜狗微信搜索暂时⽆法直接搜索微信号,⽐如下图的公众号如果你直接搜索xmyanke是找不到的】
搜狗和微信的合作本意是好的,但那些搜索结果很容易成为采集者的⽬标,采集规则应该也不难写,不反对采集,但要有⾃⼰的元素,修修改改,加上⾃⼰的观点、精彩点评,才能留住访客,千篇⼀律,信息过剩,客户瞄个⼏秒就跳出了,对搜索引擎也不友好。
所以说某些东西要⽤之有道。
,最新上线的“微信互动区”将企业微信公众号相关内容全⾯接⼊品专,除了基本延续了品牌专区的现有页⾯格局和搜索逻辑外,还提供了微信公众号 “扫描⼆维码加关注”。
搜狗将充分利⽤优质⼤数据资源和多平台⼊⼝,为企业微信公众号提供更多⽤户的精准触达,提⾼微信公众号的关注度,增强与⽤户互动沟通的机会。
采集文本素材的主要方法

采集文本素材的主要方法
文本素材的采集是指从线上或线下资源中收集文本信息,进行记录并存储,以便进行文本内容分析。
文本素材采集的主要方法如下:
一、搜索引擎采集
搜索引擎采集是指利用搜索引擎爬取相关信息,包括百度、Google、360等多种搜索引擎,通过设置关键词和类型爬取相关的文本素材,如微博、微信等。
二、社交媒体采集
社交媒体采集是指在社交媒体上收集文本素材,如在微博、微信、QQ等社交平台上收集信息,通过设置关键词和类型爬取。
三、数据库采集
数据库采集是指从数据库中抓取文本素材,如MySQL、Oracle等数据库,可以根据不同的表结构进行检索,获取想要的文本素材。
四、文件采集
文件采集是指从文件里获取文本素材,如word、txt、pdf等,可以使用相应的工具来解析文件,然后提取出文本素材。
五、API采集
API采集是指利用第三方提供的API接口来获取所需的文本素材,如果接口支持,可以抓取接口提供的数据,获取文本素材。
六、网站采集
网站采集是指从网站上抓取文本素材,这种方式最常用,可以根据不同的网站设置不同的规则,抓取网站上的相应数据,然后提取出文本素材。
以上就是采集文本素材的主要方法,文本素材采集的方式不仅仅局限于以上这些,也可以根据实际情况选择不同的采集方式,以获取更加准确的文本素材。
搜狗正式上线微信搜索

昨天,搜狗搜索宣布正式接入微信公众号数据,用户将在搜狗搜索页面查找和浏览微信公众号内容 。
据悉,“搜狗微信搜索”平台二级域名为。在搜狗搜索框中输入微信公众号或者文章 标题,即可搜索出相关的公众账号或者相关文章。此外,用户不仅可以检索微信公众账号看到文章 ,还能通过二维码关注该账号。通过公众号搜索,可以查询到所有包含该关键词的微信公众号,搜 索结果包含有微信号、功能介绍、认证信息、二维码等信息。
此次,微信对搜狗开放公众账号数据,说明双方合作正在快速展开。 人人都是产品经理()中国最大最活跃的产品经理学习、交流、分享平台
微信文章采集器使用方法详解
微信文章采集器使用方法详解对于某些用户来说,直接自定义规则可能有难度,所以在这种情况下,我们提供了网页简易模式,本文介绍八爪鱼简易采集模式下“微信文章采集”的使用教程以及注意要点。
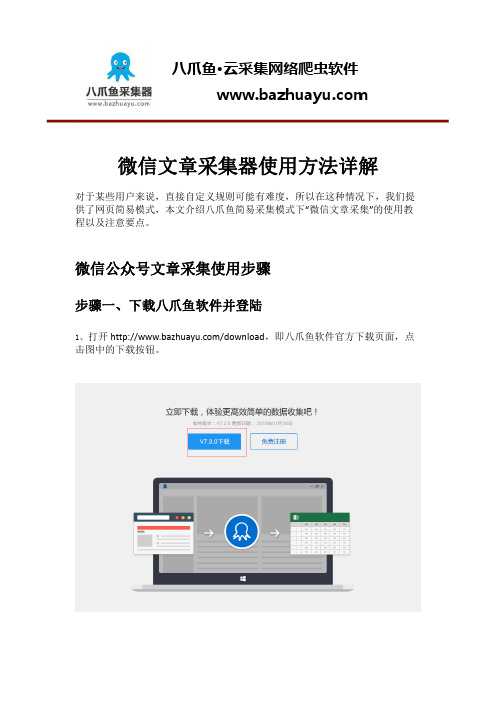
微信公众号文章采集使用步骤步骤一、下载八爪鱼软件并登陆1、打开/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆步骤二、设置微信文章爬虫规则任务1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集微信公众号内容的,这里选择搜狗即可。
3、找到搜狗公众号这条爬虫规则,点击即可使用。
4、搜狗公众号简易采集模式任务界面介绍查看详情:点开可以看到示例网址任务名:自定义任务名,默认为搜狗公众号任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组公众号URL列表填写注意事项:提供要采集的网页网址,即搜狗微信中相关公众号的链接。
多个公众号输入多个网址即可。
采集数目:输入希望采集的数据条数示例数据:这个规则采集的所有字段信息。
5、微信文章爬虫规则设置示例例如要采集相关旅游、美食的公众号文章在设置里如下图所示:任务名:自定义任务名,也可以不设置按照默认的就行任务组:自定义任务组,也可以不设置按照默认的就行商品评论URL列表:/weixin?type=1&s_from=input&query=电影&ie=utf8&_sug_=n&_sug_type_=/weixin?type=1&s_from=input&query=美食&ie=utf8&_sug_=n&_sug_type_=一行一个,使用回车(Enter)进行换行。
采集数目:可根据自身需求选填(当前默认)注意事项:URL列表中建议不超过2万条步骤三、保存并运行微信文章爬虫规则1、设置好爬虫规则之后点击保存。
微信公众号内容采集方法详解

微信已成为大多数人每天生活工作的一部分,所以会花不少的时间浏览微信公众号的文章内容,里面的精品以及爆款文章不少,如果想把这些文章都采集下来,怎么办在手机上一篇一篇下载有不方便,这是不得不用一下科学高效的采集方法了。
下面介绍一个微信公众号内容采集的神奇方法。
很多时候,我们有采集网页文章正文的需求。
本文以搜狗微信文章为例,介绍使用八爪鱼采集网页文章正文的方法。
文章正文里一般包括文本和图片两种。
本文仅演示采集正文中本文的方法,图文采集会在另一篇教程中讲到。
本文将采集以下字段:文章标题、时间、来源和正文(正文中的所有文本,将合并到一个excel单元格中,将使用到“自定义数据合并方式”功能,请大家注意)。
以下为“自定义数据合并方式”详解教程,大家可先了解一下:/tutorialdetail-1/zdyhb_7.html采集网站:/使用功能点:分页列表信息采集 1)进入主界面,选择“自定义模式”微信公众号文章正文采集步骤12)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址” 微信公众号文章正文采集步骤2步骤2:创建翻页循环1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
网页打开后,默认显示“热门”文章。
下拉页面,找到并点击“加载更多内容”按钮,在操作提示框中,选择“更多操作”微信公众号文章正文采集步骤32)选择“循环点击单个元素”,以创建一个翻页循环微信公众号文章正文采集步骤4由于此网页涉及Ajax技术,我们需要进行一些高级选项的设置。
选中“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”微信公众号文章正文采集步骤5注:AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
表现特征:a、点击网页中某个选项时,大部分网站的网址不会改变;b、网页不是完全加载,只是局部进行了数据加载,有所变化。
信息收集的渠道和方法

信息收集的渠道和方法信息收集是获取所需信息的过程,而信息收集的渠道和方法是指获取信息的途径和方式。
本文将介绍一些常用的信息收集渠道和方法,帮助读者更好地了解如何获取所需信息。
一、在线搜索引擎在线搜索引擎是目前最常用的信息收集渠道之一。
通过输入关键词,搜索引擎会返回与关键词相关的网页、文档、图片等信息资源。
谷歌、百度、必应等搜索引擎都可以提供丰富的信息资源,但需要注意选择可靠的搜索引擎,以避免获取错误信息。
二、网络论坛和社交媒体网络论坛和社交媒体是人们交流和分享信息的重要平台。
在相关论坛上发布问题或参与讨论,可以获得其他用户的经验和见解。
而社交媒体上的用户分享的信息也可以作为参考。
但需要注意,论坛和社交媒体上的信息可能存在主观性和不准确性,需要进行筛选和核实。
三、专业网站和数据库针对特定领域的信息需求,可以选择访问专业网站和数据库。
例如,学术研究可以使用学术搜索引擎和学术数据库;市场调研可以使用商业数据库和行业报告;医学领域可以使用医学数据库和医学期刊等。
这些专业资源提供了更精准、可靠的信息,但有些需要付费或订阅。
四、图书馆和档案馆图书馆和档案馆是传统的信息收集渠道。
通过借阅图书、期刊、报纸、文献等,可以获取丰富的信息。
同时,图书馆和档案馆也收藏了很多历史资料和文化遗产,对于一些特殊领域的信息需求也是重要的来源。
五、采访和调查采访和调查是直接获取信息的方法之一。
通过与专家、从业者、用户等进行交流,可以了解他们的意见、经验和观点。
采访和调查可以通过面对面、电话、邮件等方式进行,但需要注意保护被采访者的隐私和权益,并确保信息的准确性和可靠性。
六、实地调研和观察实地调研和观察是获取实际情况和数据的重要手段。
通过亲自前往研究对象所在地,进行实地考察和观察,可以获取更真实、全面的信息。
实地调研和观察可以通过实地考察、实验、观察等方式进行,但需要注意保护研究对象的权益和遵守相关规定。
七、数据分析和统计对于大量数据的信息收集,可以使用数据分析和统计方法。
怎么搜集行业公众号资料

怎么搜集行业公众号资料搜集行业公众号资料是一项对于从业者而言非常重要的任务。
随着移动互联网的快速发展,公众号已经成为了人们获取信息、交流和娱乐的重要渠道之一。
不论是对于企业还是个人来说,了解行业公众号的动态和趋势,对于提高竞争力和谋求发展都具有重要意义。
本文将从两个角度,即通过搜索引擎和通过社交媒体平台,来探讨如何更好地搜集行业公众号资料。
首先,通过搜索引擎是最为常用和直接的方式之一。
搜索引擎如百度、谷歌等提供了强大的检索功能,通过输入关键词即可找到相关的行业公众号。
搜索引擎还会根据搜索者的兴趣和搜索历史,推荐相关的公众号,方便用户快速找到感兴趣的内容。
此外,搜索引擎还提供了“相关搜索”和“人们还搜索”等功能,可以进一步拓展搜索范围,发现更多有价值的行业公众号。
然而,通过搜索引擎搜集行业公众号资料也存在一定的局限性。
首先,搜索结果的排序可能受到搜索引擎算法的影响,有些优质的公众号可能会被遗漏或排在较后面。
其次,由于搜索引擎的广告推广和SEO优化等因素,搜索结果中可能会出现一些与行业公众号无关的内容。
因此,需要用户进行筛选和鉴别,选择真正与行业相关、权威可信的公众号。
除了搜索引擎,社交媒体平台也是搜集行业公众号资料的重要渠道之一。
大多数行业公众号都会在社交媒体平台上进行宣传和推广,通过关注这些平台的官方账号,可以及时了解到公众号的更新和最新动态。
在微博、微信等平台上,有许多专门推荐和推广公众号的账号或专栏,可以通过关注这些账号来获取更多行业公众号的信息。
此外,一些行业博主和专家也会在社交媒体上分享有关公众号的推荐和评价。
他们通常会在自己的账号上推荐一些在某个领域内有影响力和质量较高的公众号,这对于搜集行业公众号资料是非常有帮助的。
然而,由于社交媒体平台的信息泛滥和劣质内容泛滥的问题,需要用户保持警惕,辨别真伪,选择可信赖的来源。
除此之外,一些行业资讯网站和专业论坛也是搜集行业公众号资料的宝贵资源。
微信内容,搜狗一下!

微信内容,搜狗一下!微信内容,搜狗一下。
7月23日,因上线“微信公众平台搜索”而备受关注的搜狗公司举办了媒体发布会,就搜狗搜索现有发展与未来布局发布了战略计划。
搜狗搜索作为国内独家将数百万微信公众号资源数据接入的搜索引擎,将更多高质量的文章“开放”到整个中文互联网世界当中,极大丰富了用户获取优质内容的渠道和方式。
借此,搜狗搜索成为了唯一一家能够提供“通用搜索”和“微信公众平台搜索”服务、全面覆盖网页、微信等媒体形态的搜索引擎,差异化优势得到进一步的提升。
此前,搜狗“微信公众平台搜索”Beta版上线试运行,在业内外引发强烈关注。
世界杯期间,其更因成为用户获取独家资讯的重要平台而广受好评。
获取微信优质内容就上搜狗搜索,即将成为新的流行。
“微信公众平台搜索的上线,是搜狗与腾讯合作不断深化的结晶。
”搜狗CEO 王小川表示,微信公众平台搜索目前已经成为搜狗搜索的独有标志。
接下来,他们还结合手机QQ等各类产品进行场景整合创新,给用户带来更丰富的体验。
当天,搜狗还同时上线了搜狗搜索iOS版APP,微信公众平台搜索也成为亮点之一。
评论认为,搜狗此举是迈向“社会化搜索”的重要一步,也是其全面发力移动搜索市场的重要标志。
自全面入驻腾讯版图以来,搜狗搜索已经全面接入QQ、QZone、手机QQ浏览器等各种应用场景,并逐步将腾讯社交关系链融入相关产品,推动搜索引擎向人机智能共通的形态进化。
而与用户使用频率最高的微信合作深入推进,也进一步打开了搜狗搜索的想象空间。
值得留意的是,日前更新的搜狐新闻客户端也深度融合搜狗搜索,为2亿用户提供搜狗独家的微信公众平台搜索服务,吸引了不少关注。
借力腾讯、搜狐全产品链的移动资源,搜狗搜索着力打造的“无处不在”的搜索体验已初见端倪。
目前,随着移动搜索用户规模急剧扩大超过5亿,市场环境逐渐成熟,各大搜索公司纷纷加速进军移动搜索布局的步伐。
而得益于PC市场的良好基础和差异化发展策略,加上腾讯、搜狐的强大资源支持,搜狗移动搜索在市场份额、网友覆盖、用户好评等方面,均已位于行业前列。
微信爬虫如何采集数据

微信爬虫如何采集数据微信公众号已经成为我们日常获取信息的一个非常重要的方式,很多人也希望能把优质的信息抓取出来,却苦于不会使用爬虫软件。
下面教大家一个不用会打代码也能轻松采集数据的软件工具:八爪鱼是如何采集微信文章信息的抓取的内容包括:微信文章标题、微信文章关键词、微信文章部分内容展示、微信所属公众号、微信文章发布时间、微信文章URL等字段数据。
采集网站:/步骤1:创建采集任务1)进入主界面,选择“自定义模式”微信爬虫采集数据步骤12)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址” 微信爬虫采集数据步骤2步骤2:创建翻页循环1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”微信爬虫采集数据步骤32)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮微信爬虫采集数据步骤43)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮”微信爬虫采集数据步骤54)页面中出现了“八爪鱼大数据”的文章搜索结果。
将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”微信爬虫采集数据步骤6步骤3:创建列表循环并提取数据1)移动鼠标,选中页面里第一篇文章的区块。
系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”微信爬虫采集数据步骤72)继续选中页面中第二篇文章的区块,系统会自动选中第二篇文章中的子元素,并识别出页面中的其他10组同类元素,在操作提示框中,选择“选中全部”微信爬虫采集数据步骤83)我们可以看到,页面中文章区块里的所有元素均被选中,变为绿色。
右侧操作提示框中,出现字段预览表,将鼠标移到表头,点击垃圾桶图标,可删除不需要的字段。
字段选择完成后,选择“采集以下数据”微信爬虫采集数据步骤94)由于我们还想要采集每篇文章的URL,因而还需要提取一个字段。
使用fiddler抓取微信公众号文章的阅读数、点赞数、评论数

使⽤fiddler抓取微信公众号⽂章的阅读数、点赞数、评论数1 设置fiddler⽀持https打开fiddler,在菜单栏中依次选择 [Tools]->[Options]->[HTTPS],勾上如下图的选项:单击Actions,选择Export Root Certificate to Desktop(导出证书到桌⾯)选项:安装证书:在桌⾯上找到FiddlerRoot.cer⽂件,双击进⾏安装直到导⼊成功。
2 配置fiddler抓取规则在菜单栏中依次选择 [Rules]->[Customize Rules] 弹出Fiddler ScriptEditor界⾯找到OnBeforeRequest⽅法和OnBeforeResponse⽅法修改OnBeforeRequest⽅法内容如下:static function OnBeforeRequest(oSession: Session) {//加在⽅法末尾if (oSession.fullUrl.Contains("")){var fso;var file;fso = new ActiveXObject("Scripting.FileSystemObject");//⽂件保存路径,可⾃定义file = fso.OpenTextFile("c:\\Sessions.txt",8 ,true, true);file.writeLine("Request url: " + oSession.url);file.writeLine("Request header:" + "\n" + oSession.oRequest.headers);file.writeLine("Request body: " + oSession.GetRequestBodyAsString());file.writeLine("\n");file.close();}}修改OnBeforeResponse⽅法内容如下:static function OnBeforeResponse(oSession: Session) {//加在⽅法末尾if (oSession.HostnameIs("") && oSession.uriContains("https:///mp/getappmsgext")){var filename = "C:/fiddler-token.log";var curDate = new Date();var logContent = "[" + curDate.toLocaleString() + "] " + oSession.PathAndQuery + "\r\n"+oSession.GetResponseBodyAsString()+"\r\n";var sw : System.IO.StreamWriter;if (System.IO.File.Exists(filename)){sw = System.IO.File.AppendText(filename);sw.Write(logContent);}else{sw = System.IO.File.CreateText(filename);sw.Write(logContent);}sw.Close();sw.Dispose();}}修改后保存⽂件。
轻轻松松教会你网站提取(抓取搜狗微信文章为例)

轻轻松松教会你网站提取(抓取搜狗微信文章为例)互联网时代,各种各样的网站上充斥着丰富的数据资源。
很多时候,你可能有抓取这些数据的需求,却没有找到一个简单高效的方法。
针对目标网站写一个抓取程序?网站结构往往十分复杂且不尽相同,同时还需要一定的硬件环境支持——基于这两点,自写抓取程序成本较大。
今天分享的是网站数据提取的一个简单方法——借助于合适的爬虫工具进行网站数据提取。
目前市面上有很多良莠不齐的爬虫工具。
本文选择的是容易上手,第小白用户十分友好的八爪鱼。
以下是一个使用八爪鱼采集网站数据的完整示例,示例中采集的是在搜狗微信这个网站上,搜索关键词“八爪鱼大数据”后出现的结果文章的标题、文章关键词、文章部分内容展示、所属公众号、发布时间、文章URL等字段数据。
采集网站:/步骤1:创建采集任务1)进入主界面,选择“自定义模式”轻轻松松教会你网站提取图12)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”轻轻松松教会你网站提取图2步骤2:创建翻页循环1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”轻轻松松教会你网站提取图32)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮轻轻松松教会你网站提取图43)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮” 轻轻松松教会你网站提取图54)页面中出现了“八爪鱼大数据”的文章搜索结果。
将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”轻轻松松教会你网站提取图6步骤3:创建列表循环并提取数据1)移动鼠标,选中页面里第一篇文章的区块。
系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”轻轻松松教会你网站提取图72)继续选中页面中第二篇文章的区块,系统会自动选中第二篇文章中的子元素,并识别出页面中的其他10组同类元素,在操作提示框中,选择“选中全部”轻轻松松教会你网站提取图8 3)我们可以看到,页面中文章区块里的所有元素均被选中,变为绿色。
微信公众平台搜索引擎上线 扒开历史的污垢

微信公众平台搜索引擎上线扒开历史的污垢作为域名。
搜狗微信搜索的功能搜狗微信搜索主要提供两个方向的搜索,一个是微信公众号搜索,一个是文章搜索。
根据我测试发现,在用户搜索微信公众号时,通过微信认证的微信公众号会被优先展示,在展示结果中,依次为微信号、功能介绍、认证信息,在右侧则会显示统一样式的二维码,用户通过微信扫描即可关注。
用户搜索微信公众号文章时采用的是图文展示结果,在右侧会显示文章的图片,结果页依次展现的是标题、简介、文章的微信公众号名称、认证图标、大概发布时间,每页的展示结果为 10 条,搜索结果最多会展示 100 页。
用户对微信公众平台搜索呼之欲出封闭的微信在其内容体系上依然是走的是封闭路线,订阅者和运营者两者形成封闭的空间,非订阅关系的用户之间是无法通过内容进行流传的,而社交则根本无法形成。
所以,用户对于内容的「开放」呼之欲出,希望微信官方能将微信公众平台的内容通过搜索引擎展现出来。
搜狗微信搜索的推出满足了这部分用户的需求,搜索微信公众号、搜索微信公众号的文章,一方面让微信公众号的展现量更大,另一方面则让运营者的内容能够开放呈现,用户通过搜索即可查看相关文章,再也不用在密闭的信息罐里乱窜。
用户对搜狗微信搜索的三点惶恐忧患意识的人总是如此之多,亦或许他们天生就是忧虑的,习惯性的从事情不好的一面去看。
所以,当搜狗微信搜索产品推出之际,运营者反倒是习惯了的发出了惶恐的声音,他们会担心哪几个方面呢?(1)竞价排名。
类似于 PC 端的搜索引擎一样,用户搜索微信公众号时,官方会推出竞价排名系统,比如搜索「郭静的互联网圈」时,付费的用户会通过系统给出的竞价工具,让非官方的「郭静的互联网圈」公众号优先展现,这样微信公众平台官方就能够通过此种方式获益,这种情况不是不可能。
2014 年 5 月 6 日,腾讯宣布成立微信事业群,由张小龙担任微信事业群总裁,微信的作用被提升到高位,而微信在商业化的道路上并不是特别顺利,所以尝试对微信公众号搜索进行竞价排名,并不是没有可能。
微信公众号素材来源渠道及重要性

微信公众号素材来源渠道及重要性我想,我们大多数人中都错过了2003年开淘宝的机遇,又错过了微博营销,在2013年微信公众号火起来的时候大家似乎没有放过这次机遇,于是一头扎进微信营销的浪潮中。
腾讯公布的数据是现在有上百万公众号,而且每天以8000个的速度在增加。
那么我们怎样才能从这里打下自己的一片天地呢?其实我们要想增长自己的粉丝量除了外部推广以外,还有一个重要的途径,那就是我们的内容所形成的转发收藏带来的粉丝。
那么我们应该怎么去获取这些优质的内容呢?那下面我就给大家说说具体的途径有哪些。
1.搜狗搜索利用搜狗搜索的前提是我们对自己公众号的定位,比如我的微信公众号是:被震惊了(beizhenjingle)那么我就可以在搜狗里面搜索与震惊有关的微信文章或者公众号,如图:通过搜索我们就可以找到用户搜索最多的是什么,喜欢什么类型的文章,那么我们就可以根据这个找一篇你觉得价值比较高的内容发到自己的微信里面。
这样有个坏处就是我们只是自己觉得内容好,并不代表粉丝也认可你的内容,所以说找内容的时候一定要结合粉丝的心里去寻找内容。
2.微信搜索榜微信搜索榜就是根据当日搜索量高的内容和当日比较热门的内容展现在前三,通过微信搜索榜我们就可以很快的找的大家喜欢什么样的话题,如图:这里展现了8个搜索量比较高的内容,前三是这两天都比较热门的,我们知道二月二龙抬头,大家都去理发,这是一个习俗,那么我们发这样的内容可能就会有很多的人感兴趣,毕竟还是有很多人不知道有这么个习俗,我也是在网上看到了才知道的,之前一直不知道,那么这样的文章就会形成高转发收藏,分享到朋友圈让好友也记住这个日子。
3.微信热门推荐微信热门内容都是大号展现出来的,这些号有很多方面都是值得我们去学习的,比如他们的内容,排版,引导,封面,如图:我们可以看到,这些号都是大号,一两个小时的时间阅读量就达到了十几万,这说明什么?1.粉丝多 2.内容好 3.引导关注好在热门这个栏目里面都是当日比较热门阅读量高的内容,我们要是想发这样的内容话,我们可以选择一条与自己相关的内容进行推送。
微信搜索,终于被搜狗拿下了

微信搜索,终于被搜狗拿下了自2013年腾讯投资搜狗后,双方在搜索方面的合作还真没怎么被提及。
但今天(6月9日),我们终于看到腾讯与搜狗搜索的合作——搜狗搜索宣布正式接入微信公众号数据,从此使用搜狗搜索可以浏览或查询到相关公众号以及全部文章。
不画大饼,单说现在。
从双方的合作内容以及方式来看,微信终于让公众账号资源可以被分类检索到,对碎片化的信息进行梳理,一定程度上帮助微信从封闭走向开放,让微信公众号中产生的内容可以得到更广泛的传播;另一方面,对搜狗来说,能利用“自家人”优势整合目前已受大众认可的微信公众号内容,说不定真能为搜狗在移动搜索竞争中破局贡献一份#力量#。
搜狗微信搜索的两个关键词:全面聚合、检索订阅全面的聚合让用户可以全面找到相关的账号和文章(包括历史文章)。
目前来看按照认证账号向非认证账号排列;搜索文章也会先展示认证账号发布的文章。
另外,搜狗微信搜索既可以使用PC端也可以使用移动端,方便用户按关键字大规模查找和阅读文章,一定程度上解决信息“碎片化”问题,也是为微信产生的信息提供了一个聚合平台。
(#这绝对不是广告!但是你也可以打开微信扫扫看嘛#)检索订阅的功能目前来看是PC端独有的:每个搜索到的账号旁边带有二维码,方便用户订阅;而移动端虽然没有二维码,但打开文章后作者名字处已经显示为#看起来可以跳转#的超链接字体,只是目前还无法实现跳转。
这也为日后搜狗微信搜索的发展埋下伏笔,作为一个检索工具(目前来看是这样),未来公众账号排序的机制是否会采用竞价排名还不可知,但对于被动搜索来说,竞价排名和广告确实是两个最成熟的商业模式。
其实在PC端(还有移动端)做微信公众账号的聚合检索平台早就应该有,但直到现在才由搜狗推出,除了感慨微信沉得住气外,也该恭喜搜狗获得了一个相当好的入口。
唱唱反调只是在一片叫好声中,也有媒体提醒到,2013年7月,360搜索页也曾上线过一个名为“自媒体百科频道”,试图做一个微博/微信公众号的导航平台,内容囊括数千个新浪微博与腾讯微信平台上加V或不加V的自媒体及大号(同一账号下整合微博与微信内容),并按照账号内容或属性分类罗列,同时也提供通过搜索直达相关页面或二维码直接加关注服务。
微信公众号网页授权获取用户信息

微信公众号⽹页授权获取⽤户信息微信公众号⽹页授权获取⽤户信息近期做过微信公众号这块的对接及业务,梳理下其中的点,有需要的⼩伙伴可以参考下。
⽤户在微信客户端中访问第三⽅⽹页,公众号可以通过微信⽹页授权机制,来获取⽤户基本信息,进⽽实现业务逻辑。
关于⽹页授权回调域名的说明3、如果公众号登录授权给了第三⽅开发者来进⾏管理,则不必做任何设置,由第三⽅代替公众号实现⽹页授权即可。
关于⽹页授权的两种scope的区别说明1、以snsapi_base为scope发起的⽹页授权,是⽤来获取进⼊页⾯的⽤户的openid的,并且是静默授权并⾃动跳转到回调页⾯的。
⽤户感知的就是直接进⼊了回调页⾯(配置在⾃定义菜单中的⼀长串地址中redirect_uri 对应的回调⽅法)2、以snsapi_userinfo为scope发起的⽹页授权,是⽤来获取⽤户的基本信息的。
但这种授权需要⽤户⼿动同意,并且由于⽤户同意过,所以⽆须关注,就可在授权后获取该⽤户的基本信息,下图为⼿动授权的参考:scope等于snsapi_userinfo时的授权页⾯。
3、⽤户管理类接⼝中的“获取⽤户基本信息接⼝”,是在⽤户和公众号产⽣消息交互或关注后事件推送后,才能根据⽤户OpenID来获取⽤户基本信息。
这个接⼝,包括其他微信接⼝,都是需要该⽤户(即openid)关注了公众号后,才能调⽤成功的。
关于UnionID机制1、请注意,⽹页授权获取⽤户基本信息也遵循UnionID机制。
即如果开发者有在多个公众号,或在公众号、移动应⽤之间统⼀⽤户帐号的需求,需要前往微信开放平台()绑定公众号后,才可利⽤UnionID机制来满⾜上述需求。
2、UnionID机制的作⽤说明:如果开发者拥有多个移动应⽤、⽹站应⽤和公众帐号,可通过获取⽤户基本信息中的unionid来区分⽤户的唯⼀性,因为同⼀⽤户,对同⼀个微信开放平台下的不同应⽤(移动应⽤、⽹站应⽤和公众帐号),unionid是相同的。
通过微信公众平台获取公众号文章的方法示例

通过微信公众平台获取公众号⽂章的⽅法⽰例我之前⾃⼰维护了⼀个公众号,但因为个⼈关系很久没有更新了,今天上来缅怀⼀下,却偶然发现了⼀个获取微信公众号⽂章的⽅法。
之前获取⽅法有很多,通过搜狗、清博、⽹页端、客户端等等都还可以,这个可能并没有其他的优秀,但是操作简单,很容易理解。
so、⾸先需要有⼀个微信公众平台的账号登陆之后,进⼊⾸页,点击新建群发。
选择⾃建图⽂:似乎像是公众号运营教学了进⼊编辑页⾯之后,点击超链接弹出选择框,我们在框中输⼊对应的公众号名字,即可出现对应的⽂章列表是不是很惊奇,可以打开控制台,查看⼀下请求的接⼝打开response,⾥⾯就是我们需要的⽂章链接确定了数据以后,我们需要分析⼀下这个接⼝。
感觉很简单,⼀个GET请求,携带⼀些参数。
fakeid是公众号的独有ID,所以想通过名字直接获取⽂章列表,还需要先获取⼀下fakeid。
当我们输⼊公众号名字后,点击搜索。
可以看到触发了搜索接⼝,返回了fakeid。
这个接⼝所需参数也不多。
接下来,我们可以⽤代码来模拟以上的操作了。
但是还需要使⽤现有Cookie避免登陆。
⽬前Cookie的有效期,我还没有测试。
可能需要及时更新Cookie。
测试代码:import requestsimport jsonCookie = '请换上⾃⼰的Cookie,获取⽅法:直接复制下来'url = "https:///cgi-bin/appmsg"headers = {"Cookie": Cookie,"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36' }keyword = 'pythonlx' # 公众号名字:可⾃定义token = '你的token' # 获取⽅法:如上述直接复制下来search_url = 'https:///cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)doc = requests.get(search_url,headers=headers).textjstext = json.loads(doc)fakeid = jstext['list'][0]['fakeid']data = {"token": token,"lang": "zh_CN","f": "json","ajax": "1","action": "list_ex","begin": 0,"count": "5","query": "","fakeid": fakeid,"type": "9",}json_test = requests.get(url, headers=headers, params=data).textjson_test = json.loads(json_test)print(json_test)这样就能获取最新的10篇⽂章了,如果想要获取更多的历史⽂章,可以修改data中的"begin"参数,0是第⼀页,5是第⼆页,10是第三页(以此类推)但是如果想要⼤规模抓取的话:请给⾃⼰安排⼀个稳定的代理,降低爬⾍的速度,准备多个账号,来减少被封禁的可能性。
搜狗语音助手微信版贴心教程

更多请访问—武汉网站建设—/★搜狗语音助手微信版贴心教程微信自开放第三方接口后,已经逐步成为了一个万能工具,而不再只是一个单纯的聊天工具。
如果你想让微信(手机版)变成一个生活万事通,如果你希望你说出问题就能马上得到一个答案,那么赶紧在微信上关注搜狗语音助手的微信公众账号(sogouzhushou)吧,目前搜狗语音助手是微信4.5版上唯一一个智能语音公众账号。
只要在微信4.5版上关注了搜狗语音助手,手机上的微信便可立刻万事通,无论你向他询问什么,都能得到一个比较满意的答案。
例如,问天气、问汇率、问附近哪里有好吃的等等问题,都难不倒强大的搜狗语音助手微信版。
今天,小编就为大家准备了一份搜狗语音助手微信版使用教程,图文并茂,方便大家更便捷更畅快地使用搜狗语音助手微信版一、如何关注搜狗语音助手微信版公众账号方法一:打开微信之后,在通讯录那里直接搜索“搜狗”,然后再点击“你可能感兴趣的公众账号”,就可以看到搜狗语音助手,最后直接点“关注”即可。
方法二:打开微信后,进入“朋友们”,点击“添加朋友”,进入“查找微信公众账号”,输入搜索搜狗语音助手ID:sougouzhushou,后,即可添加关注。
关注搜狗语音助手公众账号之后,就可以在通讯录的公众账号里直接找到搜狗语音助手,点击就可以进行语音聊天。
二、教你玩转搜狗语音助手微信版如同直接使用搜狗语音助手客户端一样,也可以直接向搜狗语音助手微信版进行语音提问,无需使用键盘输入。
在首次打开搜狗语音助手微信版的时候,会提供“小助手使用对话指南”帮助用户更好地体验小助手。
接下来,小编就直接进入语音互动体验环节,带你一起感受小助手的精彩表现,教你玩转搜狗语音助手微信版。
首先语音提问小助手“帮我找美女图片”和“播放中国好声音视频”。
再连续提问四个问题:“你是谁”、“现在几点”、“广州天气”、“来个冷笑话”。
向小助手提问“黄金每克多少钱”、“白金每克多少钱”、“白银每克多少钱”、“广州油价”四个问题。
如何使用搜狗微信搜索寻找公众号文章?
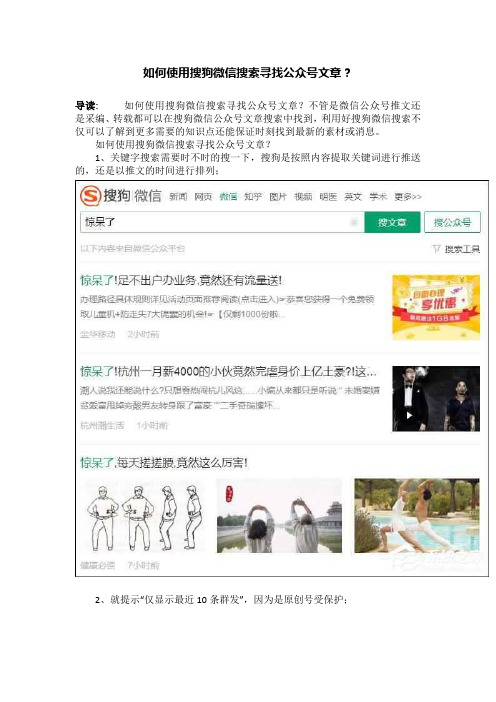
如何使用搜狗微信搜索寻找公众号文章?
导读:如何使用搜狗微信搜索寻找公众号文章?不管是微信公众号推文还是采编、转载都可以在搜狗微信公众号文章搜索中找到,利用好搜狗微信搜索不仅可以了解到更多需要的知识点还能保证时刻找到最新的素材或消息。
如何使用搜狗微信搜索寻找公众号文章?
1、关键字搜索需要时不时的搜一下,搜狗是按照内容提取关键词进行推送的,还是以推文的时间进行排列;
2、就提示“仅显示最近10条群发”,因为是原创号受保护;
3、公众号助手的原创文章可以转载或查看而不被举报,会自动标识来源公众号不支持修改;
4、根据热点推荐来找素材也不错;
5、或者看看有什么新的素材爆文。
以上便是关于使用搜狗微信搜索寻找公众号文章的一些搜索技巧,按照需要,使用不同的搜索习惯,可以搜索到尽可能多的参考资料。
怎么复制公众号内容

怎么复制公众号内容
第一种方法是使用截图工具。
当我们看到公众号上的内容想要保存下来时,可以使用手机自带的截图功能或者下载一些截图软件来进行截图。
通过截图,我们可以将公众号上的文字、图片等内容保存下来,方便日后查看或者分享。
第二种方法是使用复制粘贴功能。
虽然公众号的内容不能直接复制,但是我们可以通过一些小技巧来实现复制粘贴。
首先,我们可以将公众号的内容分享到自己的朋友圈或者微博,然后在朋友圈或者微博中进行复制粘贴操作,将内容复制到自己的笔记或者文档中保存下来。
第三种方法是使用第三方工具。
现在市面上也有一些针对公众号内容复制的第三方工具,通过这些工具,我们可以轻松地将公众号上的内容复制下来。
当然,在使用第三方工具时,我们需要注意选择正规、安全的工具,以免造成信息泄露或者其他安全问题。
除了以上几种方法,我们还可以通过订阅公众号的方式来获取内容。
有些公众号会提供订阅功能,我们可以通过订阅公众号来获取最新的内容,方便我们随时查看。
总的来说,虽然公众号的内容不能直接复制,但是通过一些小技巧或者工具,我们还是可以实现复制公众号内容的目的。
当然,在复制公众号内容时,我们也需要尊重原作者的版权,不要进行恶意抄袭或者未经授权的转载,做一个遵纪守法的互联网公民。
希望以上方法对大家有所帮助,让我们可以更方便地获取和分享有用的信息。
公众号没有标题怎么搜索

公众号没有标题怎么搜索众所周知,微信公众号是一个非常重要的信息传播平台,许多人都会关注各种公众号获取资讯,了解最新动态。
然而,有时我们会遇到没有标题的公众号文章,无法通过关键词搜到目标文章的问题。
本文将介绍如何在没有公众号文章标题的情况下进行搜索。
搜索公众号名称首先,我们可以通过搜索公众号名称来寻找我们所需的文章。
首先打开微信,进入“发现”栏目,然后点击“搜索”,输入公众号名称即可。
如果您已关注该公众号,您可以在微信首页下拉,点击右下角的“我”,找到已关注的公众号进行查看。
如果您不知道公众号名称,您可以通过搜索相应的关键词,筛选出相关公众号,再一个个尝试查看是否有您需要的文章。
虽然这种方法会比较费时间,但是一般来说,可以找到我们所需的文章。
使用微信搜索功能其次,您可以利用微信搜索功能进行搜索。
在微信搜索框内输入您所需的关键词,再通过筛选选项选择“文章”,即可搜索出符合您需求的文章。
如果您知道公众号名称,也可以在微信搜索框中输入公众号名称进行查找。
值得注意的是,由于微信搜索算法的原因,也有可能会误判您所需的文章。
如果通过关键词搜索不到您所需的文章,建议您尝试其他方法进行查找。
利用第三方工具除了微信自带的搜索功能,还有许多针对微信公众号文章的第三方工具,如搜狗搜索、百度指数、360指数、神马指数等。
这些第三方工具可以帮助您更准确、更快速地查找到相关的公众号文章。
需要注意的是,在使用这些第三方工具时,要注意防范网络安全风险,尽可能选择正规可靠的第三方工具进行使用。
总结以上是在没有公众号文章标题的情况下进行搜索的方法。
虽然这种情况出现的几率并不高,但是当我们真正需要查看某篇文章时,却可能因为找不到标题而错失良机。
希望这些方法可以帮助您更好地利用微信公众号获取所需信息。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
本文介绍使用八爪鱼采集搜狗微信文章(以采集搜索“八爪鱼大数据”出现的文章为例)的方法
采集网站:/
使用功能点:
●分页列表信息采集
/tutorial/fylb-70.aspx?t=1
●URL
/faq/url.aspx
相关采集教程:
58同城信息采集
豆瓣电影短评采集
步骤1:创建采集任务
1)进入主界面,选择“自定义模式”
2)将要采集的网址URL 复制粘贴到网站输入框中,点击“保存网址”
步骤2:创建翻页循环
1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”
(搜狗微信公众号采集方法图3)
2)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮
(搜狗微信公众号采集方法图4)
3)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮”
(搜狗微信公众号采集方法图5)
4)页面中出现了“八爪鱼大数据”的文章搜索结果。
将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”
(搜狗微信公众号采集方法图6)
步骤3:创建列表循环并提取数据
1)移动鼠标,选中页面里第一篇文章的区块。
系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”
2)继续选中页面中第二篇文章的区块,系统会自动选中第二篇文章中的子元素,并识别出页面中的其他10组同类元素,在操作提示框中,选择“选中全部”
(搜狗微信公众号采集方法图8)
3)我们可以看到,页面中文章区块里的所有元素均被选中,变为绿色。
右侧操作提示框中,出现字段预览表,将鼠标移到表头,点击垃圾桶图标,可删除不需要的字段。
字段选择完成后,选择“采集以下数据”
(搜狗微信公众号采集方法图9)
4)由于我们还想要采集每篇文章的URL,因而还需要提取一个字段。
点击第一篇文章的链接,再点击第二篇文章的链接,系统会自动选中页面中的一组文章链接。
在右侧操作提示框中,选择“采集以下链接地址”
5)字段选择完成后,选中相应的字段,可以进行字段的自定义命名。
完成后,点击左上角的“保存并启动”,启动采集任务
(搜狗微信公众号采集方法图11)
6)选择“启动本地采集”
(搜狗微信公众号采集方法图12)
步骤4:数据采集及导出
1)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的搜狗微信文章的数据导出
2)这里我们选择excel作为导出为格式,数据导出后如下图
(搜狗微信公众号采集方法图14)
八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。
配置好采集任务后可关机,任务可在云端执行。
庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。