数据库表标准定义
数据库命名规范(表、字段名)

数据库命名规范(表、字段名)一. 实体和属性的命名1常用单词已经进行了缩写,在命名过程当中,根据语义拼凑缩写即可。
注意,由于ORCAL数据库会将字段名称统一成大写或者小写中的一种,所以要求加上下划线举例:定义的缩写Sales: Sal 销售;Order: Ord 订单;Detail: Dtl 明细;则销售订单名细表命名为:Sal_Ord_Dtl;2.如果表或者是字段的名称仅有一个单词,那么建议不使用缩写,而是用完整的单词。
举例:定义的缩写Material Ma 物品;物品表名为:Material, 而不是Ma.但是字段物品编码则是:Ma_ID;而不是Material」。
3.所有的存储值列表的表前面加上前缀Z目的是将这些值列表类排序在数据库最后。
4.所有的冗余类的命名(主要是累计表)前面加上前缀X冗余类是为了提高数据库效率,非规范化数据库的时候加入的字段。
或者表5.关联类通过用下划线连接两个基本类之后,再加前缀R的方式命名,后面按照字母顺序罗列两个表名或者表名的缩写。
关联表用于保存多对多关系。
如果被关联的表名大于10个字母,必须将原来的表名的进行缩写。
如果没有其他原因,建议都使用缩写。
举例:表Object与自身存在多对多的关系,则保存多对多关系的表命名为:R_Object ;表Depart和Employee;存在多对多的关系;则关联表命名为R_Dept_Emp6.每一个表都将有一个自动ID作为主健,逻辑上的主健作为第一组候选主健来定义,如果是数据库自动生成的编码,统一命名为:ID;如果是自定义的逻辑上的编码则用缩写加“ID” 的方法命名。
举例:销售订单的编号字段命名:Sal_Ord」D ;如果还存在一个数据库生成的自动编号,则命名为:ID。
7.所有的属性加上有关类型的后缀,类型后缀的缩写定义见文件《类型后缀缩写定义》,注意,如果还需要其它的后缀,都放在类型后缀之前。
二•关系的命名关系的命名基本上按照;如有特殊情况,可以灵活处理.[must/may/ca n/should][verb/verb+prep][a/ma ny/exatly nu m][or a/ma ny] 的结构命名三. 域的命名四. 触发器的命名五•有关于默认的几点说明1.严格依赖关系的主细表,主表的后缀Main可以不写。
数据库表描述-概述说明以及解释

数据库表描述-概述说明以及解释1.引言1.1 概述在数据库管理系统中,表是一种结构化的数据存储单元,它由行和列组成,用于存储具有相似特性的数据。
数据库表描述着整个数据库的结构和关系,是数据存储和管理的基本单位之一。
通过对数据库表的描述,我们可以清晰地了解数据的组织结构,实现数据的高效存储和管理。
在本文中,我们将介绍数据库表的定义、作用以及相关的设计原则,以帮助读者深入了解数据库表的重要性和设计要点。
通过本文的学习,读者将能够更好地理解和应用数据库表,提高数据库系统的性能和可维护性。
1.2文章结构文章结构部分主要包括本文的组织结构和内容安排。
在本文中,我们将分为引言、正文和结论三个部分来介绍数据库表的描述。
在引言部分,我们会概述本文的主题,介绍数据库表描述的重要性和背景,以及本文的目的和结构。
在正文部分,我们将详细讨论数据库表的定义、作用、组成要素和设计原则,从而帮助读者深入了解数据库表的概念和特点。
在结论部分,我们会总结数据库表描述的重要性,强调数据库表设计的关键因素,并对数据库表描述的未来发展进行展望。
通过全面地介绍数据库表的描述和设计原则,我们希望读者可以更好地理解和应用数据库表,提高数据管理和存储的效率和质量。
1.3 目的在数据库系统中,数据库表描述是非常重要的。
它可以帮助开发人员更好地了解数据库表的结构和功能,帮助维护人员更好地管理和维护数据库表,帮助用户更好地理解数据库表中存储的数据。
因此,本文的目的是通过对数据库表描述的介绍,帮助读者了解数据库表的重要性和作用,掌握数据库表的基本概念和设计原则,以提高数据库表设计的质量和效率。
同时,希望通过本文的讨论,引发对数据库表描述的思考和讨论,推动数据库表描述在未来的进一步发展和应用。
2.正文2.1 数据库表的定义和作用数据库表是数据库中的一个重要组成部分,它是用来存储数据的结构化方式。
每个数据库表都包含了一定数量的行和列,行代表记录,列代表属性。
数据库表描述

数据库表描述全文共四篇示例,供读者参考第一篇示例:数据库表是数据库系统中的基本组成单元,用来存储特定类型的数据。
它由行和列组成,行代表数据记录,列代表数据属性。
在数据库设计中,表的结构和字段类型需要经过精心设计,以确保数据的存储和检索效率。
本文将探讨数据库表的描述和设计方法。
一、数据库表的描述1. 表名:数据库表需要有一个唯一的名称来区分不同的表。
表名应该简洁明了,能够清晰地表达表所存储的数据类型。
一般来说,表名采用复数形式,并使用下划线或驼峰命名规则。
2. 字段(列):数据库表由多个字段组成,每个字段代表数据的一个属性。
字段的命名应该具有描述性,能够清晰地表达该字段存储的数据内容。
常见的字段类型包括整型、字符型、日期型等。
3. 数据类型:字段的数据类型决定了字段可以存储的数据范围和格式。
常见的数据类型包括整型(INT)、字符型(VARCHAR)、日期型(DATE)等。
选择合适的数据类型可以提高数据库的存储效率和数据完整性。
4. 主键:主键是表中用来唯一标识每条记录的字段,通常是一个或多个字段的组合。
主键的值必须唯一且不能为空,可以通过主键索引来加快数据检索速度。
主键的选择应该遵循唯一性和稳定性原则。
5. 外键:外键是表与表之间建立关联关系的依据。
外键是指在一个表中存在的另一个表的主键,用来确保数据的一致性和完整性。
外键约束可以在数据库设计时设置,以确保引用表的数据不会出现错误或不一致。
6. 索引:索引是一种提高数据检索效率的数据结构,可以加速查询操作。
在数据库表中设置适当的索引可以减少搜索时间,并提高数据库的性能。
常见的索引类型包括主键索引、唯一索引、组合索引等。
7. 约束:约束是用来确保数据完整性和一致性的规则。
常见的约束包括主键约束、唯一约束、外键约束、默认值约束等。
在设计数据库表时,应该根据业务需求和数据关系来设置适当的约束。
二、数据库表的设计方法1. 标识表的对象:在设计数据库表时,首先需要确定要存储的数据对象和关系,然后根据需求来设计表的结构和字段。
数据库标准规范(两篇)2024

数据库标准规范(二)引言:数据库是当代信息系统中关键的存储和管理数据的工具,数据库标准规范的制定对于确保数据的一致性、完整性和可靠性至关重要。
本文将详细阐述数据库标准规范的五个大点,包括数据库设计、数据模型、数据操作、数据存储和数据安全。
概述:在数据库标准规范中,数据库设计是基础,决定了整个数据库系统的架构和功能。
数据模型定义了数据的结构和属性,数据操作确定了对数据库的增删改查操作,数据存储指定了数据的物理存储方式,数据安全保证了数据库的安全性和可用性。
正文内容:一、数据库设计1. 定义数据库设计的目标和要求,包括数据的一致性、可扩展性和易用性。
2. 建立数据库的概念模型,包括实体关系模型、关系模型和层次模型。
3. 制定数据库设计的规范和准则,确保数据库结构的一致性和易维护性。
4. 设计数据库的表结构,包括表的字段、属性和约束等。
5. 定义数据库的索引和视图,提高数据库的查询和操作效率。
二、数据模型1. 介绍常用的数据模型,包括层次模型、网络模型、关系模型和面向对象模型。
2. 选择合适的数据模型,根据数据库的特点和应用需求进行权衡。
3. 设计数据模型的实体和属性,确保数据的准确性和完整性。
4. 定义数据模型之间的关系,包括一对一、一对多和多对多关系。
5. 使用标准的建模工具和方法,对数据模型进行建模和验证。
三、数据操作1. 定义数据操作的目标和要求,包括数据的增加、删除、修改和查询。
2. 设计数据操作的接口和功能,提供简单易用的操作方式。
3. 制定数据操作的规范和约束,确保数据的一致性和安全性。
4. 优化数据操作的性能,提高查询和更新的效率。
5. 实现数据操作的事务管理和并发控制,确保数据的一致和可靠。
四、数据存储2. 设计数据的物理存储结构,包括数据文件、表空间和数据块等。
3. 制定数据存储的规范和准则,确保数据的安全和可靠。
4. 实施数据存储的备份和恢复策略,保护数据的完整性和可用性。
5. 优化数据存储的性能,提高数据访问的效率和响应速度。
软件工程-数据库--如何设计数据库表

关系型数据库理论可能是20世纪60年代和70年代存储系统先锋的救星,但是从那是开始它就成了许多数据开发人员的毒药,就是因为现代数据库系统发展得如此之好,以至于它将其关系型支柱对开发人员隐藏了。
设计良好的关系型数据库很容易使用、很灵活,并且能够保护数据的有效性。
而设计不良的数据相反仍然能够发挥相当的作用,但是最终可能会导致数据的无效、错误或者丢失。
开发人员有一些专用的规则,叫做范式(normal forms),他们根据这些规则来创建设计良好的数据库。
在这里,我将通过创建一个用于保存书籍信息的简单数据库来探讨一下范式。
确定实体和元素设计数据库的第一步是做你的家庭作业并确定你所需要的实体。
实体是数据一种类型的概念集。
通常只从一两个实体开始,再随着你数据的规范化而增加列表。
对于我们的示例数据库,它看上去就好像我们只需要一个实体——书。
在确定了所需要实体的清单之后,你下一步就需要为每个实体创建数据元素(也就是说,你需要保存的信息)的清单。
收集这样的信息有多种途径,但是最有效的可能就是依赖你的用户了。
向你的用户询问他们日常工作的情况,要求查看当前完成他们工作所需要的各种表格和报告。
例如,订单上可能会列出你创建销售应用程序所需要的许多数据元素。
我们的书籍实体没有书面表格和报告可用,但是下列元素清单将有助于我们开始设计这个数据库:{Title, Author, ISBN, Price, Publisher, Category}很重要的一点是,要注意,把我们这里要用的实体移动到元素的过程并不能适用于所有状况。
你所需要的实体不会总是像我们书籍示例那样清楚,所以你可能要从数据元素的一长串清单开始,在后面你会根据实体来划分元素。
正规化的头几步一旦有了实体清单(表格)和数据元素(字段),你就准备好让关系型数据库理论运作了。
这个理论的主要推动力是规范化——删除任何重复的组和冗余的数据,并把它们放到两个或者更多相关表里的过程。
小神探巡检管理系统数据库主要表格结构定义
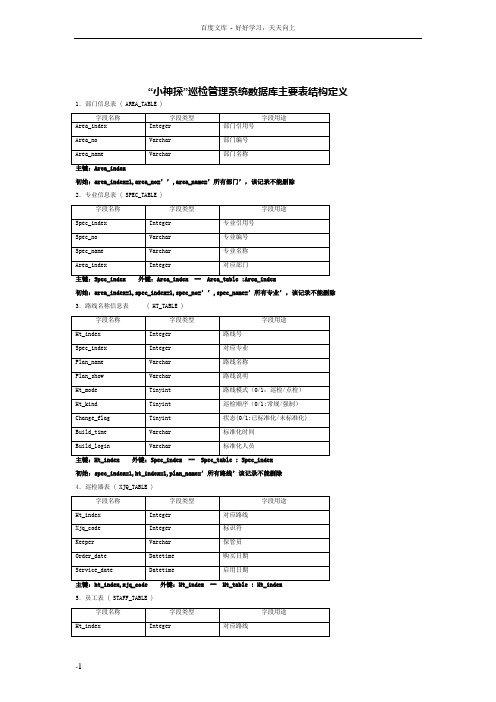
“小神探”巡检管理系统数据库主要表结构定义1.部门信息表 ( AREA_TABLE )初始:area_index=1,area_no=’’,area_name=’所有部门’,该记录不能删除2.专业信息表 ( SPEC_TABLE )初始:area_index=1,spec_index=1,spec_no=’’,spec_name=’所有专业’,该记录不能删除3.路线名称信息表( HT_TABLE )初始:spec_index=1,ht_index=1,plan_name=’所有路线’该记录不能删除4.巡检器表 ( XJQ_TABLE )5.员工表 ( STAFF_TABLE )6.ID表 ( ID_TABLE )初始:ht_index=1,id_index=1,id_code=’0000000000000000’,position=’待定’,该记录不能删除7.测温ID表 ( TID_TABLE )8.代码表 ( CODE_TABLE )9.异常程度定义表(elevel_table)10.处理措施定义表(emeasure_table)11.路线默认值标 (ht_default)12.设备信息表 ( DEVICE_TABLE )初始:ht_index=1,dev_index=1,dev_no=’’,dev_name=’所有设备’,该记录不能操作13.部件信息表 ( PART_TABLE )初始:dev_index=1,part_index=1,part_no=’’,part_name=’所有部件’,该记录不能操作14.项目信息表 (ITEM_TABLE )初始:part_index=1,item_index=1,item_no=’’,item_name=’所有项目’,该记录不能操作15.用户组表( USERGROUP )初始:ug_id=1,ug_name=’管理员组’,ug_level=’33333’,该记录不能删除16.用户表( USERLOGIN )初始:ug_id=1,ul_id=1,ul_name=’管理员’,ul_login=’manager’…该记录不能删除17.计划表( PLAN_TABLE )外键:Area_index – Area_table:Area_index Spec_index – Spec_table:Spec_indexHt_index -- Ht_table: Ht_indexDev_index -- Device_table:Dev_indexPart_index – Part_table: Part_indexItem_index – Item_table: Item_indexID_index -- ID_table: ID_inde 18.观察类结果表(DATA_TABLE)19.时间段定义表( TIME_TABLE )20.计量单位表( UNIT_TABLE )21.统计表( COUNT_TABLE )22.公共信息表(COMMON_INFO)初始:company_name=’上海鸣志自动控制设备有限公司’,此表只有且只能有一条记录,该记录不能删除23.路线基础设置默认值定义表(default_table)主键:无24.路线强制检查的ID钮次序表(idsort_table)–id_table:id_index 25.计划标准化表(planmap)26.出勤统计表(abstotal_table)27.启停状态表(srstatus_table)28.临时输入记录表(titable)29.工时表( STYYYYMM)30.结果表( RYYYYYMM)31.异常表( ER000000 ) ( ERYYYYMM )32.漏检表( ARYYYYMM )附录周期代码A)次/天:短周期类型B)次/周:长周期类型,允许或,在DAY_LIST中表示成“W|W/W|W/”格式,其中W表示周次,|表示或,/表示一次结束C)次/月:长周期类型,允许或,分为按日期和按两种按天:在DAY_LIST中表示成“DD|DD/DD|DD/”格式,其中DD表示天,|表示或,/表示一次结束按周:在DAY_LIST中表示成“NW|NW/NW|NW/”格式,其中N表示第几周,W表示周次,|表示或,/表示一次结束D)次/年:长周期类型,允许或,分为按日期和按两种按天:在DAY_LIST中表示成“MMDD|MMDD/MMDD|MMDD/”格式,其中MM表示月份,DD表示天,|表示或,/表示一次结束按周:在DAY_LIST中表示成“MMNW|MMNW/MMNW|MMNW/”格式,其中MM表示月份,N表示第几周,W表示周次,|表示或,/表示一次结束E)次%天:短周期类型变体,在DAY_LIST中保存起始日期以及间隔天数量,格式为YYYY-MM-DDNNN, 其中YYYY表示年份,MM表示月份,DD表示天,NNN表示间隔天数。
数据库标准

数据库标准
数据库标准是数据库管理系统 (DBMS) 开发和使用过程中的规范。
它们定义了数据库系统的架构、数据存储、数据检索和数据操作等方面的标准,以确保不同的数据库系统可以互相兼容和互操作。
以下是一些常见的数据库标准:
1. 关系数据库标准 (SQL):SQL 是关系数据库管理系统的标准查询语言,定义了对关系数据库进行数据查询、插入、更新、删除等操作的语法和命令规范。
2. 数据库模型标准:数据库模型标准定义了数据库的结构和组织方式,包括层次模型、网状模型和关系模型等。
关系模型是最常用的数据库模型,它基于关系和关系之间的联系建立了数据库表格的概念。
3. 数据库管理系统标准:数据库管理系统标准定义了数据库系统的功能和特性,包括数据存储、数据安全、事务处理、并发控制和数据恢复等方面的标准。
4. 数据库编程接口标准:数据库编程接口标准定义了用于开发数据库应用程序的接口和方法,例如ODBC (Open Database Connectivity)和 JDBC (Java Database Connectivity)等。
5. 数据库安全标准:数据库安全标准定义了数据库系统的安全性要求和控制措施,包括用户认证、访问控制、数据加密和审
计等方面的标准。
通过使用数据库标准,开发人员和用户可以更容易地理解、使用和交换不同数据库系统之间的数据,提高了数据的一致性和互操作性。
数据库——基本概念

数据库——基本概念⼀、概述(了解) 数据库(Database,简称DB) 数据库技术是计算机应⽤领域中⾮常重要的技术,它产⽣于20世纪,60年代末,是数据管理的最新技术,也是软件技术的⼀个重要分⽀。
简单的说,数据库就是⼀个存放数据的仓库,这个仓库是按照⼀定的数据结构(数据结构是指数据的组织形式或数据之间的联系)来组织、存储的,我们可以通过数据库提供的多种⽅法来管理数据库⾥的数据。
更简单的形象理解,数据库和我们⽣活中存放杂物的仓库性质⼀样,区别只是存放的东西不同。
数据库表(table) 数据表是关系数据库中⼀个⾮常重要的对象,是其他对象的基础,也是⼀系列⼆维数组的集合,⽤来存储、操作数据的逻辑结构。
根据信息的分类性情。
⼀个数据库中可能包含若⼲个数据表,每张表是由⾏和列组成,记录⼀条数据,数据表就增加⼀⾏,每⼀列是由字段名和字段数据集合组成,列被称之为字段。
每⼀列还有⾃⼰的多个属性,例如是否允许为空、默认值、长度、类型、存储编码、注释等。
例如: 数据(data) 存储在表中的信息就叫做数据。
数据库系统有3个主要的组成部分 1.数据库(Database System):⽤于存储数据的地⽅ 2.数据库管理系统(Database Management System,DBMS):⽤户管理数据库的软件。
3.数据库应⽤程序(Database Application):为了提⾼数据库系统的处理能⼒所使⽤的管理数据库的软件补充。
数据库的发展史(五个阶段) 1.⽂件系统 数据库系统的萌芽阶段,通过⽂件来存取数据.⽂件系统是数据库系统的萌芽阶段,出现在上世纪五六⼗年代,可以提供简单的数据存取功能,但⽆法提供完整、统⼀的数据管理功能,例如复杂查询等。
所以在管理较少、较简单的数据或者只是⽤来存取简单数据,没有复杂操作的情况下, 2.层次型数据库 数据库系统真正开始阶段,数据的存储形式类似树形结构,所以也叫树型数据库. 3.⽹状数据库 数据的存储形式类似⽹状结构.从⼆⼗世纪六⼗年代开始,第⼀代数据库系统(层次模型数据库系统、⽹状模型数据库系统)相继问世,它们为统⼀管理和共享数据提供了有⼒的⽀撑在这个阶段,⽹状模型数据库由于它的复杂、专⽤性,没有被⼴泛使⽤。
数据库基础数据表的创建与管理

数据库基础数据表的创建与管理
数据库是现代计算机系统中用于存储和管理数据的重要工具。
在数据库中,数据表是存储数据的基本单位。
本文将介绍数据库基础数据表的创建与管理。
1. 创建数据表
要创建一个数据表,需要定义数据表的名称、每个字段的名称、数据类型和约束条件。
在定义数据表之前,必须确定数据表存储的数据类型和数据结构。
2. 管理数据表
对于已经创建的数据表,需要对数据表进行管理。
管理数据表包括以下方面:
①. 修改数据表结构:需要在数据表已有数据的前提下,对数据表进行结构修改。
例如新增字段、删除字段、修改字段数据类型等。
②. 约束条件管理:对于数据表中的约束条件,需要进行管理和维护。
例如,对于主键和外键约束,需要对其进行管理和维护,保证数据的完整性和一致性。
③. 数据表备份和恢复:为了保证数据的安全性,需要对数据表进行备份和恢复。
备份可以保证数据的安全性,恢复可以保证数据的完整性。
3. 数据表的性能优化
对于大型数据库,需要对数据表进行性能优化。
性能优化包括以下方面:
①. 索引优化:对于经常进行数据检索的数据表,需要对其进行索引优化,提高数据检索的效率。
②. 分区管理:对于大型数据表,可以进行分区管理,将数据表分成多个区域,减少数据操作的压力,提高数据操作的效率。
总之,数据库基础数据表的创建与管理是数据库管理中的重要步骤。
只有对数据表进行良好的管理和维护,才能保证数据库的稳定性和安全性。
数据库设计规范_编码规范

数据库设计规范_编码规范数据库设计规范包括数据库表结构的设计原则和数据库编码规范。
数据库表结构的设计原则包括表的命名规范、字段的命名规范、主键和外键的设计、索引的使用、约束的定义等。
数据库编码规范包括SQL语句的书写规范、存储过程和函数的命名规范、变量和参数的命名规范、注释的使用等。
1.表的命名规范-表名使用有意义的英文单词或短语,避免使用拼音或缩写。
- 使用下划线(_)作为单词之间的分隔符,如:user_info。
- 表名使用单数形式,如:user、order。
2.字段的命名规范-字段名使用有意义的英文单词或短语,避免使用拼音或缩写。
- 字段名使用小写字母,使用下划线(_)作为单词之间的分隔符,如:user_name。
- 字段名要具有描述性,可以清楚地表示其含义,如:user_name、user_age。
3.主键和外键的设计-每张表应该有一个主键,用于唯一标识表中的记录。
- 主键字段的命名为表名加上“_id”,如:user_id。
- 外键字段的命名为关联的表名加上“_id”,如:user_info_id,指向user_info表的主键。
4.索引的使用-对于经常用于查询条件或连接条件的字段,可以创建索引,提高查询性能。
-索引的选择要权衡查询性能和写入性能之间的平衡。
-不宜为每个字段都创建索引,避免索引过多导致性能下降。
5.约束的定义-定义必要的约束,保证数据的完整性和一致性。
-主键约束用于保证唯一性和数据完整性。
-外键约束用于保证数据的一致性和关联完整性。
6.SQL语句的书写规范-SQL关键字使用大写字母,表名和字段名使用小写字母。
-SQL语句按照功能和逻辑进行分行和缩进,提高可读性。
-使用注释清晰地描述SQL语句的功能和用途。
7.存储过程和函数的命名规范-存储过程和函数的命名要具有描述性,可以清楚地表示其功能和用途。
-使用有意义的英文单词或短语,避免使用拼音或缩写。
- 使用下划线(_)作为单词之间的分隔符,如:get_user_info。
数据库中的表

第10章数据库表在这一章中,我们将讨论各种类型的数据库表,并介绍什么情况下想用哪种类型的数据库表(也就是说,在哪些情况下某种类型的表比其他类型更适用)。
我们会强调表的物理存储特征:即数据如何组织和存储。
从前只有一种类型的表,这千真万确,原先确实只有一种“普通”表。
管理这种表就像管理“一个堆”一样(下一节会给出有关的定义)。
后来,Oracle又增加了几类更复杂的表。
如今,除了堆组织表外,还有聚簇表(共有3种类型的聚簇表)、索引组织表、嵌套表、临时表和对象表。
每种类型的表都有不同的特征,因此分别适用于不同的应用领域。
10.1表类型在深入讨论细节之前,我们先对各种类型的表给出定义。
Oracle中主要有9种表类型:q 堆组织表(heap organized table):这些就是“普通”的标准数据库表。
数据以堆的方式管理。
增加数据时,会使用段中找到的第一个能放下此数据的自由空间。
从表中删除数据时,则允许以后的INSERT和UPDATE重用这部分空间。
这就是这种表类型中的“堆”这个名词的由来。
堆(heap)是一组空间,以一种有些随机的方式使用。
528 / 976q 索引组织表(index organized table):这些表按索引结构存储。
这就强制要求行本身有某种物理顺序。
在堆中,只要放得下,数据可以放在任何位置;而索引组织表(IOT)有所不同,在IOT中,数据要根据主键有序地存储。
q 索引聚簇表(index clustered table):聚簇(cluster)是指一个或多个表组成的组,这些表物理地存储在相同的数据库块上,有相同聚簇键值的所有行会相邻地物理存储。
这种结构可以实现两个目标。
首先,多个表可以物理地存储在一起。
一般而言,你可能认为一个表的数据就在一个数据库块上,但是对于聚簇表,可能把多个表的数据存储在同一个块上。
其次,包含相同聚簇键值(如DEPTNO=10)的所有数据会物理地存储在一起。
数据库定义表之间关系(带图)

如何定义数据库表之间的关系特别说明数据库的正规化是关系型数据库理论的基础。
随着数据库的正规化工作的完成,数据库中的各个数据表中的数据关系也就建立起来了。
在设计关系型数据库时,最主要的一部分工作是将数据元素如何分配到各个关系数据表中。
一旦完成了对这些数据元素的分类,对于数据的操作将依赖于这些数据表之间的关系,通过这些数据表之间的关系,就可以将这些数据通过某种有意义的方式联系在一起。
例如,如果你不知道哪个用户下了订单,那么单独的订单信息是没有任何用处的。
但是,你没有必要在同一个数据表中同时存储顾客和订单信息。
你可以在两个关系数据表中分别存储顾客信息和订单信息,然后使用两个数据表之间的关系,可以同时查看数据表中每个订单以及其相关的客户信息。
如果正规化的数据表是关系型数据库的基础的话,那么这些数据表之间的关系则是建立这些基础的基石。
出发点下面的数据将要用在本文的例子中,用他们来说明如何定义数据库表之间的关系。
通过Boyce-Codd Normal Form(BCNF)对数据进行正规化后,产生了七个关系表:Books: {Title*, ISBN, Price}Authors: {FirstName*, LastName*}ZIPCodes: {ZIPCode*}Categories: {Category*, Description}Publishers: {Publisher*}States: {State*}Cities: {City*}现在所需要做的工作就是说明如何在这些表之间建立关系。
关系类型在家中,你与其他的成员一起存在着许多关系。
例如,你和你的母亲是有关系的,你只有一位母亲,但是你母亲可能会有好几个孩子。
你和你的兄弟姐妹是有关系的——你可能有很多兄弟和姐妹,同样,他们也有很多兄弟和姐妹。
如果你已经结婚了,你和你的配偶都有一个配偶——这是相互的——但是一次只能有一个。
在数据表这一级,数据库关系和上面所描述现象中的联系非常相似。
数据库指标表设计

数据库指标表设计数据库指标表设计是为了满足企业或组织对数据的需求,以便更好地进行管理和决策。
在设计数据库指标表时,需要考虑以下几个方面:指标的定义、指标的计算方法、指标的数据类型、指标的来源、指标的更新方式、指标的时间粒度、指标的维度、指标的归类方式。
首先,指标的定义是数据库指标表设计的首要任务。
指标应该明确反映企业或组织所关注的具体问题或目标。
例如,如果企业关注销售收入,那么可以定义一个名为“销售收入”的指标。
其次,指标的计算方法也是一个关键问题。
不同的指标有不同的计算方法,例如求和、平均值、比例等。
在设计指标表时,需要明确指标的计算方法,以保证数据的准确性和一致性。
第三,指标的数据类型是指标表设计的另一个重要方面。
指标的数据类型可以是数值型、文本型、日期型等。
根据实际需要,选择合适的数据类型可以提高数据的存储效率和查询效率。
第四,指标的来源是指标表设计中需要考虑的一个问题。
指标的来源可以是企业内部生成的数据,也可以是外部获取的数据。
对于企业内部的数据,可以直接从其他数据库中获取;对于外部的数据,可以通过数据接口进行获取。
第五,指标的更新方式是指标表设计中需要考虑的另一个问题。
指标的更新方式可以是手动更新,也可以是自动更新。
对于手动更新的指标,需要人工进行数据录入或导入;对于自动更新的指标,可以通过编写程序或脚本来实现。
第六,指标的时间粒度是指标表设计中需要考虑的另一个重要问题。
时间粒度可以是小时、天、周、月、季度、年等不同的时间单位。
根据实际需要,选择合适的时间粒度可以满足不同的数据需求。
第七,指标的维度是指标表设计中需要考虑的另一个重要方面。
维度可以是产品、地区、部门等不同的角度。
通过添加维度,可以从不同的角度分析指标的变化情况,帮助企业或组织进行决策。
最后,指标的归类方式是指标表设计中需要考虑的最后一个问题。
根据指标的性质和方向,可以将指标进行分类,以便更好地进行管理和分析。
例如,可以将销售相关的指标进行归类,将财务相关的指标进行归类,将生产相关的指标进行归类等。
数据库命名设计规范

一、数据库表及字段1.数据库表的命名规范:表的前缀应该用系统或者模块的英文名的缩写(全部大写)。
如果系统功能简单,没有划分为模块,则可以以系统英文名称的缩写作为前缀,否则以各模块的英文名称缩写作为前缀。
例如:如果有一个模块叫做 BBS(缩写为 BBS),那末你的数据库中的所有对象的名称都要加之这个前缀: BBS_ + 数据库对象名称, BBS_CustomerInfo 标示论坛模块中的客户信息表。
表的名称必须是易于理解,能表达表的功能的英文单词或者缩写英文单词,无论是完整英文单词还是缩写英文单词,单词首字母必须大写。
如果当前表可用一个英文单词表示的,请用完整的英文单词来表示;例如:系统资料中的客户表的表名可命名为:SYS_Customer。
如果当前表需用两个或者两个以上的单词来表示时,尽量以完整形式书写,如太长可采用两个英文单词的缩写形式;例如:系统资料中的客户物料表可命名为:SYS_CustItem。
表名称不应该取得太长(普通不超过三个英文单词)。
表名长度不能超过 30 个字符,表名中含有单词全部采用单数形式,单词首字母必须大写。
在命名表时,用单数形式表示名称。
例如,使用 Employee,而不是 Employees。
对于有主明细的表来说。
明细表的名称为:主表的名称 + 字符 Dts。
例如:采购定单的名称为: PO_Order,则采购定单的明细表为:PO_OrderDts;对于有主明细的表来说,明细表必须包含两个字段:主表关键字、 SN,SN 字段的类型为 int 型,目的为与主表关键字联合组成明细表的关键字,以及标示明细记录的先后顺序,如1,2,3……。
表必须填写描述信息,后台表名尽量与前台表名相同,后台独有的表应以_b 作为后缀。
如 r_gggd_b。
数据库表的命名采用如下规则:1)表名用模块名_开头,表名长度不能超过 30 个字符,表名中含有单词全部采用单数形式,单词首字母必须大写。
2)多个单词间用下划线(_)进行连接。
数据库中表的概念和作用

数据库中表的概念和作用
数据库表是用于存储数据的结构化的数据组织形式。
它由多个列和行组成,每一行代表一条数据记录,每一列代表一个数据字段。
在数据库中,表用于存储数据,并通过数据挖掘技术获取有用信息。
数据库表的作用是提供一种结构化的数据存储形式,使数据库可以更加有效地管理,以及更加有效地进行查询、检索、统计和分析。
表还可以用来指定数据的约束,比如定义字段长度、设置主键约束、唯一性约束等。
另外,表还可以用来描述两个表之间的关系,通过这种关系实现数据的联合查询、联合修改和联合删除等功能。
- 1 -。
数据库设计 标准有哪些

数据库设计标准有哪些
1. 第一范式(1NF):确保每个列只包含原子值,不允许多个
值的组合。
2. 第二范式(2NF):确保每个非主键列完全依赖于所有主键,避免部分依赖。
3. 第三范式(3NF):确保每个非主键列不传递依赖于其他非
主键列,避免传递依赖。
4. 实体完整性:确保表中每一行都包含必要的信息,并且没有重复的实体。
5. 参照完整性:确保外键只引用已经存在的主键值。
6. 数据表关系定义:在设计多个表之间的关系时,使用合适的关系类型,如一对一、一对多、多对多。
7. 数据类型选择:选择适当的数据类型来存储数据,避免浪费空间和提高查询性能。
8. 数据一致性:确保数据的一致性和准确性,使用事务和约束来管理数据更新和删除操作。
9. 数据库范式化:通过归一化设计来减少数据冗余,并提高数据的可维护性和性能。
10. 数据库安全性:实施适当的安全措施,如访问权限控制、数据加密和备份等,以保护数据的机密性和完整性。
这些是在数据库设计中常用的一些标准,但实际上,数据库设计还受到具体应用需求和实际情况的影响,因此,在设计数据库时需要综合考虑这些标准和实际情况。
数据库表结构设计

第一范式(1NF) 确保每列保持原子性,即每列不 可再分。
第二范式(2NF) 在第一范式的基础上,消除部分 函数依赖,将数据表分解为更小 的表,并建立适当的关联。
反规范化设计
反规范化设计的定义
反规范化设计是通过引入冗余数据来改进查询 性能和简化数据操作的设计方法。
反规范化设计的好处
提高查询性能、减少JOIN操作、降低数据不一 致的风险。
反规范化设计的注意事项
避免过度冗余、维护数据一致性和完整性、定期更新冗余数据。
第三范式与多范式设计
第三范式与多范式设计的定义
01
第三范式是满足第三范式的数据库表结构,而多范式设计是指
同时满足多个范式的数据库表结构。
第三范式与多范式设计的优势
数据模型设计
概念设计
根据需求文档,设计出满足业务需求的 概念模型,如实体关系图(ER图)。
VS
逻辑设计
将概念模型转换为逻辑模型,如关系模型 ,确定每个数据表的字段和数据类型。
表结构设计
表结构设计
根据逻辑模型,设计出具体的数据库表结构,包括字段名、数据类型、长度、约束等。
索引优化
根据查询需求,合理设计索引,提高数据查询效率。
数据库表结构设计
目录
• 数据库表结构设计概述 • 数据库表的要素 • 数据库表结构设计方法 • 数据库表结构设计实践 • 数据库表结构优化 • 数据库表结构设计案例分析
01
数据库表结构设计概述
数据库表的概念
数据库表是数据库中存储数据的结构 化组织,由行和列组成,类似于电子 表格。
每列定义了数据的属性或字段,如姓 名、地址等,而每行则包含具体的数 据记录。
数据库标准表

数据库标准表
数据库标准表是一种在数据库中定义数据结构和关系的方式,它是根据某个标准(例如SQL 或其他相关标准)来创建的。
这些标准通常是为了确保数据的一致性和可移植性,并使不同数据库系统之间的数据交换变得更容易。
常见的数据库标准表有以下几种:
1.关系数据库:如SQL Server、Oracle、MySQL、PostgreSQL 等中的表。
这些表通常包含行和列,并使用特定的数据类型来定义列。
它们可以定
义主键、外键等关系,以及触发器、存储过程等数据库对象。
2.层次数据库:如IBM 的IMS(Information Management System)。
在这
种类型的数据库中,数据存储在一个层次结构中,每个节点都有一个父
节点和多个子节点。
3.键-值存储:如Redis。
在这种类型的数据库中,数据存储在键-值对中,
其中每个键都映射到一个值。
4.文档存储:如MongoDB。
在这种类型的数据库中,数据存储在类似文
档的结构中,每个文档都是一个独立的实体,包含一系列键-值对。
5.列存储:如Apache Cassandra。
在这种类型的数据库中,数据按列存储,
而不是按行存储。
这使得查询和聚合操作更加高效。
6.图形数据库:如Neo4j。
在这种类型的数据库中,数据以图形形式表示,
其中每个节点代表一个实体,每个边代表一个关系。
这些只是数据库的几种类型,实际上还有更多种类的数据库和数据存储系统。
每种系统都有其自己的表和数据结构定义方式。
交通运输规划数据库标准

交通运输规划数据库标准1. 引言本文档旨在制定交通运输规划数据库的标准,以确保数据库的一致性、可靠性和可维护性。
交通运输规划数据库是用于存储和管理与交通运输规划相关的数据,包括道路、铁路、航空等交通设施的信息。
2. 数据库结构2.1 数据表定义交通运输规划数据库应包含以下数据表:- 道路表:存储道路的基本信息,包括道路名称、起点、终点、道路类型等。
道路表:存储道路的基本信息,包括道路名称、起点、终点、道路类型等。
- 铁路表:存储铁路线路的基本信息,包括线路名称、起点、终点、运营状态等。
铁路表:存储铁路线路的基本信息,包括线路名称、起点、终点、运营状态等。
- 航空表:存储航空线路的基本信息,包括航空公司、起飞地点、降落地点、航班号等。
航空表:存储航空线路的基本信息,包括航空公司、起飞地点、降落地点、航班号等。
2.2 数据字段定义每个数据表应包含以下基本数据字段:- ID:唯一标识每条数据的编号。
ID:唯一标识每条数据的编号。
- 名称:用于描述道路、铁路或航空线路的名称。
名称:用于描述道路、铁路或航空线路的名称。
- 起点:描述道路、铁路或航空线路的起点位置。
起点:描述道路、铁路或航空线路的起点位置。
- 终点:描述道路、铁路或航空线路的终点位置。
终点:描述道路、铁路或航空线路的终点位置。
- 类型:描述道路、铁路或航空线路的类型,如高速公路、城市道路、高铁、普速铁路、国内航班、国际航班等。
类型:描述道路、铁路或航空线路的类型,如高速公路、城市道路、高铁、普速铁路、国内航班、国际航班等。
- 运营状态:描述铁路线路或航空线路的运营状态,如运营中、停运等。
运营状态:描述铁路线路或航空线路的运营状态,如运营中、停运等。
- 航班号:描述航班的航班号。
航班号:描述航班的航班号。
2.3 数据库关联关系交通运输规划数据库中的数据表应建立适当的关联关系,以便进行查询和分析。
例如,道路表和铁路表可以通过起点和终点位置进行关联,以确定交通运输的连通性。
mysql大表的定义

mysql大表的定义MySQL大表是指在MySQL数据库中具有大量数据行的表,通常具有数百万甚至数十亿条记录。
这些大表在处理和查询数据时会面临一些特殊的挑战和性能问题。
本文将从多个方面讨论MySQL大表的定义及相关内容。
一、什么是MySQL大表MySQL大表是指在MySQL数据库中具有大量数据行的表。
具体来说,当一个表的数据行数量达到数百万条甚至更多时,我们就可以称之为MySQL大表。
大表的出现是由于数据量的增长和业务需求的变化所致。
二、MySQL大表的特点1. 数据量庞大:MySQL大表通常包含数百万到数十亿条记录,数据量非常庞大。
2. 查询复杂:由于数据量大,查询操作会变得相对复杂,需要考虑性能优化和索引的使用。
3. 写入延迟:对于大表的写入操作可能会存在一定的延迟,因为需要对大量数据进行插入、更新或删除。
4. 索引维护:大表的索引维护也是一个挑战,需要合理设计索引以提高查询性能。
三、MySQL大表的性能优化1. 合理设计表结构:在创建大表时,应根据实际业务需求合理设计表结构,避免冗余字段和多余的索引。
2. 使用合适的数据类型:选择合适的数据类型对于大表的性能至关重要。
应尽量使用较小的数据类型来减少存储空间和提高查询性能。
3. 使用合理的索引:为大表创建合理的索引,可以大幅提高查询性能。
需要根据实际查询需求来选择合适的索引类型和字段。
4. 分区表:对于大表,可以考虑将其分成多个分区,以减轻查询和维护的压力。
可以按照时间、地区等维度进行分区。
5. 数据库分库分表:当数据量非常庞大时,可以考虑将数据库进行分库分表,将数据分散到多个物理机上,以提高查询性能。
6. 批量操作:对于大表的写入操作,可以考虑使用批量操作,如批量插入、批量更新等,以减少数据库的负载。
7. 缓存机制:对于经常查询的数据,可以使用缓存机制,将查询结果缓存起来,提高查询性能。
四、MySQL大表的维护和管理1. 定期备份:对于大表的数据,需要定期进行备份,以防止数据丢失。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据库标准定义注:1.本文档中标注为红色的字段为在国网规范规定的表基础上扩展的字段2.标注为蓝色的字段为相似字段中应正确使用的(如单位分为管理单位、产权单位、所在单位,优先使用管理单位,不使用产权单位,会将管理单位标注为蓝色)3.标注为浅橙色的字段为153号文件中包含但在验收文档中不包含的字段4.根据153号文中对主题域的规定,目前已确定规范中涉及的9个域的字母符号,如有新增数据表的情况,请按照规定进行命名,如有需要新增主题域的情况,请提前与MIS 开发组联系。
已确定的主题域如下:域名代号域说明所覆盖的主要实体/数据备注组织域(Orgnization)O 定义了与营销业务应用密切相关的组织与人员信息。
供电单位、部门、人员及管理等。
电网域(Grid)G 定义了电网基础资料及其关系信息。
变电站、线路、台区等。
客户档案域(Customer)C 定义了客户基础数据资料。
客户、用电客户、计量点、客户用电设备、客户档案等。
采集设备域(Device)D 定义了营销设备资产信息。
采集终端、集中器、采集器、电能表、互感器。
终端参数域(Parameter)P 定义了终端运行的各项参数配置信息。
终端基本参数、测量点参数、总加组参数、模拟量参数、脉冲量参数、控制参数。
采集任务域(Assignment)A 定义了采集任务、自动抄表任务等任务配置及执行信息。
采集任务、任务执行明细、任务执行信息、抄表计划。
有序用电域(Market)M 定义了有序用电业务涉及的数据。
有序用电基本信息、错避峰方案信息、限电信息、有序用电执行情况。
运行控制域(Run Control)R 定义了用电采集终端的运行信息、通过用电采集终端进行催费、营业报停控信息。
用电异常信息、设备运行工况、催费控制、营业报停控制、预购电控。
采集数据域(ElementsData)E 定义了用电信息采集主站采集回的用电信息元数据。
实时数据、历史数据、曲线数据、事件数据。
统计数据域(StatisticsData) T 定义了用电信息采集主站统计分析后的数据。
电量数据、功率电流电压数据、损耗数据。
规范未规定,自有域系统公共域(System) S 定义了系统参数、公共数据。
系统参数、主站配置信息等。
规范未规定,自有域1.组织与人员1.1. 供电单位(O_ORG)字段描述新字段名字段类型备注供电单位编号ORG_NO V ARCHAR2(16) 主键长度不足(100)供电单位名称ORG_NAME V ARCHAR2(256)P_ORG_NO V ARCHAR2(16)上级供电单位编号供电单位类别ORG_TYPE V ARCHAR2(8) 单位类别:国网公司、省公司、地市公司、区县公司、分公司、供电所等。
01 国网公司、02 省公司、03 地市公司、04 区县公司、05分公司、06 供电所。
排序序号SORT_NO NUMBER(5) 在同级中的排列顺序的序号,用自然数标识,如,1、2、3。
操作员编号SYS_USER_NO V ARCHAR2(16)经办日期HANDL_DA TE DA TE助记符MNEMONIC V ARCHAR2(256)ORG_NO_MIS V ARCHAR2(16)营销MIS供电单位编号机构编号AGENC_NO V ARCHAR2(16)1.2. 部门(O_DEPT)字段描述新字段名字段类型备注部门编号DEPT_NO V ARCHAR2(16) 主键供电单位编号ORG_NO V ARCHAR2(16)简称ABBR V ARCHAR2(256)部门名称NAME V ARCHAR2(256)部门类型TYPE_CODE V ARCHAR2(8) 部门的类型,可以提供给部门选择使用,方便部门过滤。
属于枚举类属性,主要包括:01抄表班、02营业厅、03 核算班、04 电费班、05 计量班。
上级部门编号P_DEPT_NO V ARCHAR2(16)显示序号DISP_SN NUMBER(5)操作员编号SYS_USER_NO V ARCHAR2(16)经办日期HANDL_DA TE DA TE助记符MNEMONIC V ARCHAR2(256)营销MIS部门编号DEPT_NO_MIS V ARCHAR2(16)机构编号AGENC_NO V ARCHAR2(16)1.3. 人员(O_STAFF)字段描述新字段名字段类型备注人员编号EMP_NO V ARCHAR2(16) 主键部门编号DEPT_NO V ARCHAR2(16)工号STAFF_NO V ARCHAR2(16) 工号,营销业务人员的服务工号。
姓名NAME V ARCHAR2(64)性别GENDER V ARCHAR2(8) 性别。
01 男、02 女相片PHOTO BLOB职位POS_NAME V ARCHAR2(256)岗位POSITION V ARCHAR2(8)工种WORK_TYPE_CODE V ARCHAR2(8) 工作分工种类:01 检定人员、02 修校人员、03 装表接电。
技术等级TECH_LEVEL_CODEV ARCHAR2(8) 出生年月YMD DA TE文化程度DEGREE_CODE V ARCHAR2(8) 文化程度。
01 专科、02 本科、03 研究生、04 博士、05 博士后。
手机号码MOBILE V ARCHAR2(32) 办公电话OFFICE_TEL_NOV ARCHAR2(32)服务等级SRV_LEVEL_CODE V ARCHAR2(8) 服务人员的服务等级设置。
01 一级、02 二级、03 三级、04 四级、05 五级。
持证标志CERT_FLAG V ARCHAR2(8)定编标志FIXED_FLAG V ARCHAR2(8)在岗标志ON_POS_FLAG V ARCHAR2(8)专业PROFESSION_CODEV ARCHAR2(8)本专业工作日期PROFESSION_BGN_DATEDA TE 本人在该业务专业工作的开始日期工作日期JOIN_DA TE DA TE职称TITEL V ARCHAR2(256)政治面貌POLITICAL_STATUS_CODE V ARCHAR2(8) 政治面貌,如01 普通02 团员03 党员职称级别TITLE_LEVEL_CODE V ARCHAR2(8) 职称级别,如01 初级02 中级03 高级及以上调退亡STA TUS_CODE V ARCHAR2(8) 人员调离、退休、死亡标识。
备注REMARK V ARCHAR2(256)操作员编号SYS_USER_NO V ARCHAR2(16)经办日期HANDL_DA TE DA TE助记符MNEMONIC V ARCHAR2(256)营销MIS人员编号EMP_NO_MIS V ARCHAR2(16)机构编号AGENC_NO V ARCHAR2(16)2.电网2.1. 变电站(G_SUBS)字段描述新字段名字段类型备注变电站标识SUBS_ID NUMBER(16) 主键变电站名称SUBS_NAME V ARCHAR2(256)变电站编码SUBS_NO V ARCHAR2(16) 变电站编号变电站电压等级VOLT_CODE V ARCHAR2(8) 变电站电压等级,引用生产标准代码变电站地址SUBS_ADDR V ARCHAR2(256)主变台数MT_NUM NUMBER(5)主变容量MT_CAP NUMBER(15)变电站管理单位ORG_NO V ARCHAR2(16)入线标识INLINE_ID V ARCHAR2(16)变点站变更时间CHG_DATE DA TE变电站运行状态RUN_STATUS_CODE V ARCHAR2(8) 标识变电站当前状态:运行、停用、拆除。
操作员SYS_USER_NO V ARCHAR2(16) 经办日期HANDL_DA TE DA TE助记符MNEMONIC V ARCHAR2(256)营销MIS变电站标识SUBS_ID_MIS NUMBER(16) 机构编号AGENC_NO V ARCHAR2(16)变电站类型SUBS_TYPE_CODE V ARCHAR2(8) 1:变电站,3:地方公用电厂,6:企业自备电厂营销MIS变电站编码SUBS_NO_MIS V ARCHAR2(16)2.2. 变电站线路关系(G_SUBS_LINE_RELA)字段描述新字段名字段类型备注变电站线路关系标识RELA_ID NUMBER(16) 主键变电站标识SUBS_ID NUMBER(16)线路标识LINE_ID NUMBER(16) 线路的系统内部唯一标识当前变电站线路关系标志RELA_FLAG V ARCHAR2(8) 标志当前生效的变电站线路关系2.3. 线路(G_LINE)字段描述新字段名字段类型备注线路标识LINE_ID NUMBER(16) 主键线路编码LINE_NO V ARCHAR2(16) 线路的编码线路名称LINE_NAME V ARCHAR2(256)线路管理单位ORG_NO V ARCHAR2(16)线路电压VOLT_CODE V ARCHAR2(8)导线规格WIRE_SPEC_CODEV ARCHAR2(32)导线长度WIRE_LEN NUMBER(12,4) 导线长度, 量纲单位:米支线标志SUBLINE_FLAGV ARCHAR2(8) 标识是否支线:是、否线路变更时间CHG_DATE DA TE有损无损标志LN_FLAG V ARCHAR2(8) 有损无损标志:是、否农网标志RURAL_GRID_FLAGV ARCHAR2(8) 农网标志:是、否线路运行状态RUN_STATUS_CODE V ARCHAR2(8) 标识线路当前状态:运行、停用、拆除。
用户标识CONS_ID NUMBER(16) 用电客户的内部唯一标识线损计算方式LL_CALC_MODE V ARCHAR2(8) 引用国家电网公司营销管理代码类集:5110.34 线损计算方式分类与代码0 不计算1 按定比2 按定量3 按标准公式有功线损计算值AP_LL_V ALUE NUMBER(12,4) 当线路按定量或定比计算有功线损时,使用此属性。
有功线损计算方式为定量时,则此值需为大于 1 的整数,为定比时此值为大于0 小于1 的小数,其他有功线损计算方式此值无效,统一填写0无功线损计算值RP_LL_VALUE NUMBER(12,4) 当线路按定量或定比计算无功线损时,使用此属性。
按定量计算则此值需为大于1 的整数,按定比值时此值为大于0小于1 的小数单位长度线路电阻UNIT_RESI NUMBER(12,4) 单位长度线路电阻,按照公式计算线损用, 计量单位:欧姆单位长度线路电抗UNIT_REAC NUMBER(12,4) 单位长度线路电抗,按照公式计算线损用, 单位: 欧姆操作员SYS_USER_NO V ARCHAR2(16)经办日期HANDL_DA TE DA TE助记符MNEMONIC V ARCHAR2(256)营销MIS线路标识LINE_ID_MIS NUMBER(16)机构编号AGENC_NO V ARCHAR2(16)营销MIS线路编码LINE_NO_MIS V ARCHAR2(16)母线标志BUG_BAR_FLAGV ARCHAR2(8)2.4. 线路关系(G_LINE_RELA)字段描述新字段名字段类型备注线路关系标识LINE_RELA_ID NUMBER(16) 主键线路标识LINE_ID NUMBER(16) 线路的系统内部唯一标识相关线路标识LINK_LINE_ID NUMBER(16) 上级线路标识当前线路关系标志CASCADE_FLAGV ARCHAR2(8) 标明当前生效的线路级联关系,0.是, 1. 否2.5. 线路台区关系(G_LINE_TG_RELA)字段描述新字段名字段类型备注线路台区关系标识LINE_TQ_ID NUMBER(16) 主键线路标识LINE_ID NUMBER(16) 线路的系统内部唯一标识台区标识TG_ID NUMBER(16)当前线路台区关系标志RELA_FLAG V ARCHAR2(8) 当前线路与台区间是多对多关系,但当前生效的只有一个,0.否, 1.是2.6. 台区(G_TG)字段描述新字段名字段类型备注台区标识TG_ID NUMBER(16) 主键台区管理单位编号ORG_NO V ARCHAR2(16)台区编码TG_NO V ARCHAR2(16)台区名称TG_NAME V ARCHAR2(256)容量TG_CAP NUMBER(16,6) 台区容量, 为可并列运行的变压器容量之和安装地址INST_ADDR V ARCHAR2(256)变更时间CHG_DATE DA TE 台区新装、拆除、变更的时间公变专变标志PUB_PRIV_FLAGV ARCHAR2(8) 台区是0. 公变或者1. 专变运行状态RUN_STATUS_CODEV ARCHAR2(8)操作员SYS_USER_NO V ARCHAR2(16)经办日期HANDL_DA TE DA TE助记符MNEMONIC V ARCHAR2(256)营销MIS台区标识TG_ID_MIS NUMBER(16)机构编号AGENC_NO V ARCHAR2(16)营销MIS台区编码TG_NO_MIS V ARCHAR2(16)2.7. 变压器(G_TRAN)主键:EQUIP_ID字段描述新字段名字段类型备注设备标识EQUIP_ID NUMBER(16) 设备的唯一标识,变更的时候用于对应线损模型中的变压器唯一标识台区标识TG_ID NUMBER(16)变压器管理单位编号ORG_NO V ARCHAR2(16)用户标识CONS_ID NUMBER(16) 用电客户的内部唯一标识设备类型TYPE_CODE V ARCHAR2(8) 区分是变压器还是高压电动机01 变压器,02 高压电动机变更说明CHG_REMARK V ARCHAR2(8) 设备的变更说明01 新装、02 停用、03 启用、04 拆除,05 减容,06减容恢复名称TRAN_NAME V ARCHAR2(256)安装地址INST_ADDR V ARCHAR2(256)安装日期INST_DA TE DA TE铭牌容量PLATE_CAP NUMBER(16,6)首次运行日期FRST_RUN_DATEDA TE实际启用日期ACTUAL_START_DA TEDA TE实际停用日期ACTUAL_STOP_USE_DA TEDA TE计划恢复日期PLAN_RESUME_DA TE DA TE 设备申请的计划恢复日期,如暂停或临时减容业务时,指本条设备的计划恢复的日期变压器主备性质MS_FLAG V ARCHAR2(8) 引用国家电网公司营销管理代码类集:5110.17 电源用途分类与代码运行状态RUN_STATUS_CODE V ARCHAR2(8) 本次变更前的运行状态01 运行、02 停用、03 拆除公变专变标志PUB_PRIV_FLAGV ARCHAR2(8) 台区是0.公变或者1.专变变动容量CHG_CAP NUMBER(16,6) 减容期满后的用户以及新装、增容用户,二年内不得申办减容或暂停。