SAS建立时间序列模型
sas绘制时序图

SAS软件绘制时序图—平稳性的检验方法之一PROC GPLOT过程proc gplot过程用于作出高分辨率的散点图或曲线图。
其主要语句形式为:proc gplot options;plot yvariable*xvariable/ options;symbol options;命令说明:(1)proc gplot options;此语句中的options主要指定SAS数据集的名称。
(2)plot y variable*x variable/options;此语句画出y变量与x变量的(y,x)图,options主要选项有:Cframe:给定图的底色,如黄色(yellow)、红色(red)、蓝色(blue)、灰色(gray)、浅灰色(ligr)等。
默认的颜色为白色。
Overlay:若要将两个以上的图形画在同一坐标系中,可用”overlay”选项。
(3)symbol options;此语句定义绘图的符号、颜色、是否连线以及线条的粗细等等。
Options主要选项有:c为点或线的颜色;v为定义点的表示符号,可以取dot(大点),point(小点),plus(加号),star(星号),circle(圆圈),square(方形),triangle(三角),diamond(菱形)等;i为确定散点之间连线的形状,可以取join(直线),spline(光滑线),needle(向水平轴的垂线);w=n确定线的粗细。
n为线的粗细的号。
n越大,线条越粗。
默认时为1。
L=n,n为线型的序号。
1表示实线,2表示虚线,等等。
例如:下列数据为y1与y2变量的取值,绘制其时序图(time=intnx('month','01jul2004'd,_n_-1);)。
12.85 15.2113.56 14.2315.36 17.3614.53 18.2513.50 15.33解答:data example1;input y1 y2;time=intnx('month','01jul2004'd,_n_-1);format time date.;cards;12.85 15.2113.56 14.2315.36 17.3614.53 18.2513.50 15.33;proc gplot data=example1;plot y1*time=1 y2*time=2/overlay;symbol1c=black v=star i=join;symbol2c=red v=circle i=spline;run;y1191817161514131201JU L0401A U G0401S E P0401O C T0401N O V0401D E C04t i m eplot y1*time y2*time/overlay;symbol1c=black v=star i=join w=2;symbol2c=red v=circle i=spline w=3;run;y1191817161514131201JU L0401A U G0401S E P0401O C T0401N O V0401D E C04t i m eproc gplot data=example1;plot y1*time y2*time/overlay cframe=yellow;symbol1c=black v=star i=join w=2;symbol2c=red v=circle i=spline w=3;run;y1191817161514131201JU L0401A U G0401S E P0401O C T0401N O V0401D E C04t i m eplot y1*time y2*time/overlay cframe=yellow;symbol1c=black v=star i=join l=1w=2;symbol2c=red v=circle i=spline l=2w=3;run;y1191817161514131201JU L0401A U G0401S E P0401O C T0401N O V0401D E C04t i m e。
基于SAS软件的时间序列实验的代码

基于SAS软件的时间序列实验的代码实验指南目录实验一分析太阳黑子数序列 (3)实验二模拟AR模型 (4)实验三模拟MA模型和ARMA模型 (6)实验四分析化工生产量数据 (8)实验五模拟ARIMA模型和季节ARIMA模型 (10)实验六分析美国国民生产总值的季度数据 (13)实验七分析国际航线月度旅客总数数据 (16)实验八干预模型的建模 (19)实验九传递函数模型的建模 (22)实验十回来与时序相结合的建模 (25)太阳黑子年度数据 (28)美国国民收入数据 (29)化工生产过程的产量数据 (30)国际航线月度旅客数据 (30)洛杉矶臭氧每小时读数的月平均值数据 (31)煤气炉数据 (35)芝加哥某食品公司大众食品周销售数据 (37)牙膏市场占有率周数据 (39)某公司汽车生产数据 (44)加拿大山猫数据 (44)实验一分析太阳黑子数序列实验目的:了解时刻序列分析的差不多步骤,熟悉SAS/ETS软件使用方法。
二、实验内容:分析太阳黑子数序列。
三、实验要求:了解时刻序列分析的差不多步骤,注意各种语句的输出结果。
四、实验时刻:2小时。
五、实验软件:SAS系统。
六、实验步骤1、开机进入SAS系统。
创建名为exp1的SAS数据集,即在窗中输入下列语句:data exp1;input a1 @@;year=intnx(‘year’,’1jan1742’d,_n_-1);format year year4.;cards;输入太阳黑子数序列(见附表)run;储存此步骤中的程序,供以后分析使用(只需按工具条上的储存按钮然后填写完提咨询后就能够把这段程序储存下来即可)。
绘数据与时刻的关系图,初步识别序列,输入下列程序:proc gplot data=exp1;symbol i=spline v=star h=2 c=green;plot a1*year;run;提交程序,在graph窗口中观看序列,能够看出此序列是均值平稳序列。
SAS与时间序列预测

第三章 时间序列模型实现过程(SAS)
• 模型识别
利用最小信息准则进行模型识别:
SAS 语句:
模型识别
参数估计
模型预测
Identify var=sales(1) minic p=(0:6) q=(0:6); /*对sales 一阶差分进行minic识别,指定p和q的最小值均为0,最 大值均为6*/ 结果:BIC信息指数和最优选择
间内表现为一种近似直线的持续向上或持续向下或平稳的趋势。
(2) 季节变动因素(S):是经济现象受季节变动影响所形成的一种长度和幅度固定的周期波动。 (3) 周期变动因素(C):周期变动因素也称循环变动因素,它是受各种经济因素影响形成的上下起 伏不定的波动。 (4) 不规则变动因素(I):不规则变动又称随机变动,它是受各种偶然因素影响所形成的不规则变动。
• IDENTIFY选项(2/2)
• OUTCOV=:指定存储自相关系数、偏自相关系数等统计量 的数据集。 • P=(pmin,pmax):指定ARMA模型中参数p的最小值和最大值, 通常与MINIC和SCAN选项搭配使用。 • Q=(qmin,qmax):指定ARMA模型中参数q的最小值和最大值, 通常与MINIC和SCAN选项搭配使用。 • SCAN:计算典型相关系数平方的估计值,并用来确定ARMA 中的参数p和q的值。 • STATIONARITY=:进行实践序列的平稳性检验
• 模型
(1)加法模型:Y=T+S+C+I (2)乘法模型:Y=T*S*C*I
第二章 时间序列模型建模步骤
第一步,模型识别
时间序列平稳性检验:如果一个时间序列的概率分布与时间无关,则成为平稳序列。
SAS经济时间序列分 各种模型分析

目录实验一分析太阳黑子数序列 (3)实验二模拟AR模型 (4)实验三模拟MA模型和ARMA模型 (6)实验四分析化工生产量数据 (8)实验五模拟ARIMA模型和季节ARIMA模型 (10)实验六分析美国国民生产总值的季度数据 (13)实验七分析国际航线月度旅客总数数据 (16)实验八干预模型的建模 (19)实验九传递函数模型的建模 (22)实验十回归与时序相结合的建模 (25)太阳黑子年度数据 (28)美国国民收入数据 (29)化工生产过程的产量数据 (30)国际航线月度旅客数据 (30)洛杉矶臭氧每小时读数的月平均值数据 (31)煤气炉数据 (35)芝加哥某食品公司大众食品周销售数据 (37)牙膏市场占有率周数据 (39)某公司汽车生产数据 (44)加拿大山猫数据 (44)实验一分析太阳黑子数序列一、实验目的:了解时间序列分析的基本步骤,熟悉SAS/ETS软件使用方法。
二、实验内容:分析太阳黑子数序列。
三、实验要求:了解时间序列分析的基本步骤,注意各种语句的输出结果。
四、实验时间:2小时。
五、实验软件:SAS系统。
六、实验步骤1、开机进入SAS系统。
2、创建名为exp1的SAS数据集,即在窗中输入下列语句:3、保存此步骤中的程序,供以后分析使用(只需按工具条上的保存按钮然后填写完提问后就可以把这段程序保存下来即可)。
4、绘数据与时间的关系图,初步识别序列,输入下列程序:ods html;ods listing close;5、run;提交程序,在graph窗口中观察序列,可以看出此序列是均值平稳序列。
6、识别模型,输入如下程序。
7、提交程序,观察输出结果。
初步识别序列为AR(2)模型。
8、估计和诊断。
输入如下程序:9、提交程序,观察输出结果。
假设通过了白噪声检验,且模型合理,则进行预测。
10、进行预测,输入如下程序:11、提交程序,观察输出结果。
12、退出SAS系统,关闭计算机。
总程序:data exp1;infile "D:\exp1.txt";input a1 @@;year=intnx('year','1jan1742'd,_n_-1);format year year4.;;proc print;run;ods html;ods listing close;proc gplot data=exp1 ;symbol i=spline v=dot h=1 cv=red ci=green w=1;plot a1*year/autovref lvref=2 cframe=yellow cvref=black ;title "太阳黑子数序列";run;proc arima data=exp1;identify var=a1 nlag=24 minic p=(0:5) q=(0:5); estimate p=3; forecast lead=6 interval=year id=year out=out; run; proc print data=out; run;选取拟合模型的规则:1.模型显着有效(残差检验为白噪声)2.模型参数尽可能少3.结合自相关图和偏自相关图以及minic 条件(BIC 信息量最小原则),选取显着有效的参数实验二 模拟AR 模型一、 实验目的:熟悉各种AR 模型的样本自相关系数和偏相关系数的特点,为理 论学习提供直观的印象。
SAS学习系列39.时间序列分析Ⅲ—ARIMA模型

39. 时间序列分析Ⅱ—-ARIMA 模型随着对时间序列分析方法的深入研究,人们发现非平稳序列的确定性因素分解方法(如季节模型、趋势模型、移动平均、指数平滑等)只能提取显著的确定性信息,对随机性信息浪费严重,同时也无法对确定性因素之间的关系进行分析。
而非平稳序列随机分析的发展就是为了弥补确定性因素分解方法的不足。
时间序列数据分析的第一步都是要通过有效手段提取序列中所蕴藏的确定性信息。
Box 和Jenkins 使用大量的案例分析证明差分方法是一种非常简便有效的确定性信息的提取方法。
而Gramer 分解定理则在理论上保证了适当阶数的差分一定可以充分提取确定性信息。
(一)ARMA 模型即自回归移动平均移动模型,是最常用的拟合平稳时间序列的模型,分为三类:AR 模型、MA 模型和ARMA 模型。
一、AR(p )模型——p 阶自回归模型 1。
模型:011t t p t p t x x x φφφε--=+++其中,0p φ≠,随机干扰序列εt 为0均值、2εσ方差的白噪声序列(()0t s E εε=, t ≠s ),且当期的干扰与过去的序列值无关,即E (x t εt )=0.由于是平稳序列,可推得均值011pφμφφ=---. 若00φ=,称为中心化的AR (p )模型,对于非中心化的平稳时间序列,可以令01(1)p φμφφ=---,*t t x x μ=-转化为中心化。
记B 为延迟算子,1()p p p B I B B φφΦ=---称为p 阶自回归多项式,则AR (p )模型可表示为:()p t t B x εΦ=.2. 格林函数用来描述系统记忆扰动程度的函数,反映了影响效应衰减的快慢程度(回到平衡位置的速度),G j 表示扰动εt —j 对系统现在行为影响的权数。
例如,AR(1)模型(一阶非齐次差分方程),1, 0,1,2,j j G j φ==模型解为0t j t j j x G ε∞-==∑.3。
时间序列分析讲义(下)

;
run;
格式2
Data 数据集名; input 变量名1 变量名2@@;
cards; 数据
;
run;
4
例1-1 录入数据 3.41 3.45 3.42 3.53 3.45 方法1 data example1_1;input price;
cards; 3.41 3.45 3.42 3.53 3.45 ; run;
48
proc gplot data= example3_1; plot x*time=1; symbol1 c=red,i=join,v=star; run; proc arima data=example3_1; identify var=x ; run;
49
50
51
本例IDENGTIFY得到的信息:
29
30
31
32
33
叫白噪声检验,这个检验着
SAS建模中至关重要,有两方面的作用: 对于待建模的时序,若检验结果为白噪声,则该
时序可不可以建模,一个白噪声序列是不能建立任 何模型的。
对于建模的后的残差序列,若检验结果为白噪声, 模型通过检验,若残差不是白噪声则模型不通过。
11
可以在数据库WORK看见数据集ex1_2数据集中有两个 变量t和price。
12
13
format t monyy.指定时间的输出格式
此处monyy.指定时间的输出格式为月-年。
14
3、 外部数据的读取
15
16
17
1.2 数据的处理 1、序列变换
data example1_3;input price@@; t=intnx('month','1jan2005'd,_n_-1); logp=log(price); format t monyy.; cards; 3.41 3.45 3.42 3.53 3.45 ; run;
SAS经济时间序列分-各种模型分析

目录实验一分析太阳黑子数序列··3实验二模拟AR模型··4实验三模拟MA模型和ARMA模型··6实验四分析化工生产量数据··8实验五模拟ARIMA模型和季节ARIMA模型··10 实验六分析美国国民生产总值的季度数据··13实验七分析国际航线月度旅客总数数据··16实验八干预模型的建模··19实验九传递函数模型的建模··22实验十回归与时序相结合的建模··25太阳黑子年度数据··28美国国民收入数据··29化工生产过程的产量数据··30国际航线月度旅客数据··30洛杉矶臭氧每小时读数的月平均值数据··31煤气炉数据··35芝加哥某食品公司大众食品周销售数据··37牙膏市场占有率周数据··39某公司汽车生产数据··44加拿大山猫数据··44实验一分析太阳黑子数序列一、实验目的:了解时间序列分析的基本步骤,熟悉SAS/ETS软件使用方法。
二、实验内容:分析太阳黑子数序列。
三、实验要求:了解时间序列分析的基本步骤,注意各种语句的输出结果。
四、实验时间:2小时。
五、实验软件:SAS系统。
六、实验步骤1、开机进入SAS系统。
2、创建名为exp1的SAS数据集,即在窗中输入下列语句:3、保存此步骤中的程序,供以后分析使用(只需按工具条上的保存按钮然后填写完提问后就可以把这段程序保存下来即可)。
4、绘数据与时间的关系图,初步识别序列,输入下列程序:ods html;ods listing close;5、run;提交程序,在graph窗口中观察序列,可以看出此序列是均值平稳序列。
SAS时间序列实验指南

实验指南广东商学院统计系数量经济教研室编制二00一年六月二十八日目录实验一分析太阳黑子数序列 (3)实验二模拟AR模型 (4)实验三模拟MA模型和ARMA模型 (6)实验四分析化工生产量数据 (8)实验五模拟ARIMA模型和季节ARIMA模型 (10)实验六分析美国国民生产总值的季度数据 (13)实验七分析国际航线月度旅客总数数据 (16)实验八干预模型的建模 (19)实验九传递函数模型的建模 (22)实验十回归与时序相结合的建模 (25)太阳黑子年度数据 (28)美国国民收入数据 (29)化工生产过程的产量数据 (30)国际航线月度旅客数据 (30)洛杉矶臭氧每小时读数的月平均值数据 (31)煤气炉数据 (35)芝加哥某食品公司大众食品周销售数据 (37)牙膏市场占有率周数据 (39)某公司汽车生产数据 (44)加拿大山猫数据 (44)实验一 分析太阳黑子数序列一、 实验目的:了解时间序列分析的基本步骤,熟悉SAS/ETS软件使用方法。
二、实验内容:分析太阳黑子数序列。
三、实验要求:了解时间序列分析的基本步骤,注意各种语句的输出结果。
四、实验时间:2小时。
五、实验软件:SAS系统。
六、实验步骤1、开机进入SAS系统。
2、创建名为exp1的SAS数据集,即在窗中输入下列语句:data exp1;input a1 @@;year=intnx(‘year’,’1jan1742’d,_n_-1);format year year4.;cards;输入太阳黑子数序列(见附表)run;3、保存此步骤中的程序,供以后分析使用(只需按工具条上的保存按钮然后填写完提问后就可以把这段程序保存下来即可)。
4、绘数据与时间的关系图,初步识别序列,输入下列程序:proc gplot data=exp1;symbol i=spline v=star h=2 c=green;plot a1*year;run;5、提交程序,在graph窗口中观察序列,可以看出此序列是均值平稳序列。
时间序列分析试验1-SAS简介

目录
• SAS简介 • 时间序列分析基本概念 • SAS在时间序列分析中的应用 • 时间序列分析试验流程 • SAS在时间序列分析中的优势和不
足 • 时间序列分析试验案例展示
01
SAS简介
SAS的发展历程
1976年,SAS软件创始人创立公司 SAS研究所,推出SAS1.0版本。
了解时间序列分析的基本概念,掌握SAS软件的 基本操作,能够独立完成时间序列数据的处理和 分析。
试验步骤和方法
步骤一:数据准备
2. 数据清洗:对数据进行 预处理,如缺失值填充、 异常值处理等。
1. 数据收集:收集时间序 列数据,确保数据准确、 完整。
试验步骤和方法
步骤二
数据导入和整理
2. 数据整理
试验结果分析和讨论
结果分析
对试验结果进行详细分析,包括模型的拟合效果、预测准确性等。
结果讨论
根据试验结果进行讨论,总结时间序列分析的优缺点和应用场景。
SAS在时间序列分析中的优
05
势和不足
SAS在时间序列分析中的优势
01
强大的数据处理能 力
SAS拥有强大的数据处理能力, 可以高效地处理大规模的时间序 列数据。
自动化和定制化
SAS提供自动化和定制化的功 能,可以根据用户需求定制报 表和数据分析流程。
SAS与其他软件的比较
与Excel相比
SAS在数据管理、统计分析等方面比Excel更加强大和 灵活。
与SPSS相比
SAS在数据处理和分析方面更加全面和灵活,同时提 供了更多的可视化功能。
与Python相比
SAS在数据分析和可视化方面相对较弱,但SAS提供 了更加易用的界面和更加全面的统计分析功能。
SAS建立时间序列模型

SAS系统 是由美国SAS软件研究所开发的用于 决策支持的大型集成信息系统,是数 据处理和统计领域的国际标准软件之 一,广泛应用于金融、医药卫生、生 产、运输、通讯、政府、教育和科研 等领域。
应用SAS软件建立时间序列模型
• 准备工作:建立一个时间序列数据集 SAS语句: Data 数据集名; Input 序号(year or month)变量名 @@; Cards;/(输入数据,按input格式逐个输入数 据,以分号结束); Proc print data=数据集名;/输出数据表 Run;
白噪声检验——卡方检验
• H0 :直到某一给定时间间隔的样本自相关系数没 有显著不为零的.(Xt为白噪声,独立的随机扰动) • 如果对所有时间间隔,该零假设成立,则没有需要 建模的信息,也不需要建立ARIMA模型. • 被检查的时间间隔个数依赖于=选项 • 对前N-2个自相关系数的检验P值。 P<=0.005 拒绝 H0 (拒绝为白噪声,P=0时, Xt高度自相关) P<=0.005 接受 H0 (即对所有时间间隔,自相关 系数为零,说明没有建模信息,不必要做下去了)
如果序列的样本自相关系数在q步后截尾,则是MA 序列,如果偏相关系数在p步后截尾,则是AR序列。如 果都不截尾,只是按负指数衰减或以阻尼正弦波形式趋 于零(即是拖尾的),则应判断为ARMA序列,但是不 能确定阶次。
若序列的样本自相关和偏相关系数都不截尾,而且 至少有一个不是拖尾,即下降趋势很慢,不能被负指数 函数所控制,或是不具有下降的趋势而是周期变化,那 么我们便认为序列具有增长趋势或季节性变化,是非平 稳序列。可应用提取趋势性和季节性的方法,对数据进 行处理,就是主要通过差分等变换将非平稳序列变成一 个平稳序列。
基于SAS系统的时间序列建模应用

技术创新41基于SAS系统的时间序列建模应用◊广州民航职业技术学院人文社科学院徐燕SAS系统是国际公认的统计分析标准软件,具有强大的统计分析和统计建模功能,其SAS/ETS模块对时间序列数据编程语言简洁,分析结果可靠。
本文以2019年全国大学生数学建模竞赛D题为例,简述SAS系统在数学建模竞赛中的应用实践,进行统计描述,以空气质量检测数据为时间序列建立ARIMA模型,并给出了预测和误差分析,结果表明数据的校准效果良好,提高了数据精度。
1引言SAS系统(Statistical Analysis System)是由美国Northcarolina 州立大学于1966年开发的统计分析软件,被誉为统计分析的标准软件,在各个领域得到了广泛的应用。
21世纪大数据时代,由于数据体量巨大、数据类型繁多、非结构化等特点,实时高效处理是个难题。
传统工具如Excel、SPSS等的表现捉襟见肘。
SAS系统被誉为“大数据分析领域的重镇”,其优越性获得了市场的认可。
SAS将数据的存储、管理、分析和呈现有机的融为一体,功能强大,统计方法齐、全、新。
SAS系统主要包括四大部分:SAS数据库、SAS分析核心、SAS开发呈现工具、SAS对分布处理模式的支持及其数据库设计。
其中,Base SAS是其整个系统的核心,负责数据管理、交互应用、用户语言处理、调用其他模块等。
它还可以进行基本的描述性统计及相关系数的计算等工作。
SAS/ETS提供了丰富的时间序列分析方法,是研究复杂系统和进行预测的有利工具,它提供了方便的模型设定手段和多样的参数估计方法。
近年来,大数据在全国大学生数学建模竞赛中频频现身,也印证了大数据时代的市场需求。
为例更好的实现数据的分析和处理,我们近年来也致力于SAS系统在数学建模竞赛中的培训和应用实虹作。
2019年全国大学生数学建模竞赛D题提供的空气污染物浓度数据,监测数据往往具有随机性,并随着时间的推移而具有某些统计规律。
SAS学习系列40.-时间序列分析Ⅳ—GARCH模型

40. 时间序列分析Ⅲ—GARCH模型(一)GRACH模型即自回归条件异方差模型,是金融市场中广泛应用的一种特殊非线性模型。
1982年,R.Engle在研究英国通货膨胀率序列规律时提出ARCH模型,其核心思想是残差项的条件方差依赖于它的前期值的大小。
1986年,Bollerslev在ARCH模型基础上对方差的表现形式进行了线性扩展,并形成了更为广泛的GARCH模型。
一、金融时间序列的异方差性特征金融时间序列,无恒定均值(非平稳性),呈现出阶段性的相对平稳的同时,往往伴随着出现剧烈的波动性;具有明显的异方差(方差随时间变化而变化)特征:尖峰厚尾:金融资产收益呈现厚尾和在均值处呈现过度波峰;波动丛聚性:金融市场波动往往呈现簇状倾向,即波动的当期水平往往与它最近的前些时期水平存在正相关关系。
杠杆效应:指价格大幅度下降后往往会出现同样幅度价格上升的倾向。
因此,传统线性结构模型(以及时间序列模型)并不能很好地解释金融时间序列数据。
二、ARCH(p)模型考虑k 变量的回归模型011t t k kt t y x x γγγε=++++若残差项t ε的均值为0,对y t 取基于t -1时刻信息的期望:1011()t t t k kt E y x x γγγ-=+++该模型中,y t 的无条件方差是固定的。
但考虑y t 的条件方差:22110111var(|)()t t t t t k kt t t y Y E y x x E γγγε---=----=其中,1var(|)t t y Y -表示基于t -1时刻信息集合Y t -1的y t 的条件方差,若残差项t ε存在自回归结构,则y t 的条件方差不固定。
假设在前p 期所有信息的条件下,残差项平方2t ε服从AR(p )模型:22211t t p t p t εωαεαεν--=++++ (*)其中t ν为0均值、2νσ方差的白噪声序列。
则残差项t ε服从条件正态分布:()2211~0,t t p t p N εωαεαε--+++残差项t ε的条件方差: 22211var()t t t p t p εσωαεαε--==+++由两部分组成:(1)常数项ω; (2)ARCH 项——变动信息,前p 期的残差平方和21pi t i i αε-=∑注:未知参数01,,,p ααα和01,,,k γγγ利用极大似然估计法估计。
SAS操作—时间序列

cards; ; proc arima data=li; identify var=x nlag=18 minic p=(0:5) q=(0:5);
estimate p=2; forecast lead=5 id=t;
对数据集temp进行arima分析 对变量x进行识别,计算最优BIC 估计模型AR(p)的参数 预测
input x y format x y cards ; proc arima proc anova identify
identify Var=x nlag=8 minic p=(0;5) q=(0:5) 参数估计方法 Method=ml Method=uls Method=cls 最大似然估计 最小二乘估计 条件最小二乘估计
/*,*/
run;
data ar
指令系统,建立一个名为“ar”的临时数据集 输入两个变量“x y”的数据,“@@”为变量类型 指出变量的输出格式 开始输入数据 对数据集“ar”进行“arima”分析 对数据集“ar”进行“方差分析” 对变量“x, y”的性质进行识别,给出5个方面的信息: 1、描述统计量; 2、样本自相关函数 3、样本偏相关函数; 4、样本逆自相关函数; 5、白噪声检验。
§1
菜单操作
一、绘制自相关、偏相关和逆函数图
1、先要激活库文件。 2、进入“时间序列”窗口 solutions analysis time series forecasting systቤተ መጻሕፍቲ ባይዱm
3、指定数据集 Browse 4、指定时间ID变量 选择t作t时间ID变量 5、观察样本自相关、偏相关函数 点击图标“Views Serise Grahpicaly” 指定变量“y” 点击“Grahp”。 6、模型估计
SAS时间序列分析

SAS时间序列分析SAS是一种强大的统计分析软件,广泛应用于各个领域的数据分析。
在时间序列分析中,SAS提供了丰富的功能和工具,可以对时间序列数据进行处理、建模和预测。
本文将介绍SAS在时间序列分析中的一些常用功能和使用方法。
首先,SAS提供了多种时间序列数据的导入和导出方式。
可以通过SAS的数据步骤或导入过程将外部数据文件导入到SAS中,例如CSV文件、Excel文件等。
同时,SAS还支持直接从数据库中读取时间序列数据,如Oracle、MySQL等。
导入数据后,可以使用SAS的数据步骤或SQL语句进行数据预处理和数据转换。
在时间序列分析中,最常用的方法是基于ARMA模型的建模和预测。
SAS提供了ARIMA过程(PROCARIMA)来实现ARMA模型的估计和预测。
首先,可以使用PROCARIMA拟合ARIMA模型。
可以通过估计过程估计ARMA(p,q)模型的参数,其中p表示自回归系数的阶数,q表示滞后误差项的阶数。
估计过程还可以估计模型的常数项。
估计过程还提供了残差检验和拟合优度检验,以评估模型的拟合效果。
在拟合ARIMA模型后,可以使用PROCARIMA进行预测。
可以使用FORECAST语句进行单步或多步预测。
单步预测可以预测下一个时间点的值,而多步预测可以预测未来一段时间的值。
预测过程还提供了预测准确度的评估指标,如均方根误差(RMSE)和平均绝对误差(MAE)。
除了ARIMA模型,SAS还支持其他的时间序列模型,如季节ARIMA模型(SARIMA)、指数平滑模型(ETS)等。
SAS提供了相应的过程(PROC)和语句,用于拟合和预测这些模型。
例如,可以使用ETS过程(PROCESM)拟合指数平滑模型,使用SPECTRA过程(PROCSPECTRA)拟合谱分析模型等。
此外,SAS还提供了一些可视化工具,如SGPLOT、SGTIME、SGPANEL 等,用于绘制时间序列图。
可以使用这些工具绘制原始时间序列、拟合值和预测值的图表,以便更直观地了解数据的趋势和周期性。
第28章如何用SAS实现时间序列分析

第28章如何⽤SAS实现时间序列分析第28章如何⽤SAS实现时间序列分析所谓时间序列,就是将某⼀指标在不同时间上的不同数值,按照时间先后次序排列⽽成的数列,这种数列由于受到各种偶然因素的影响,往往表现出某种随机性,彼此之间存在统计上的依赖关系。
因此,可以通过对时间序列的研究来认识所研究系统的结构特征(如波动的周期、振幅、趋势的种类),揭⽰其运⾏规律,进⽽⽤以预测、控制未来⾏为,修正和重新设计系统。
时间序列分析是⼀种重要的现代统计学⽅法,主要有确定性时间序列分析和随机时间序列分析⽅法。
另外,在实际问题中会遇到这样的情况,⼀个时间序列⽬前的表现,不仅受过去⾏为的影响,⽽且与另⼀个时间序列相关。
某地区经济增长的情况,不仅与过去有关,还受到投资、政策等因素的影响,进⾏多个因素对结果变量的影响要进⾏多重时间序列分析。
28.1求和⾃回归滑动平均模型(integratedautoregressivemovingaver agemodel,ARIMA)原理概述在SAS软件中,采⽤ARIMA过程进⾏分析和预测等间隔的时间序列。
ARIMA过程提供了⼀个综合的⼯具包来进⾏模型的识别、参数估计及预测。
ARIMA模型通过其⾃⾝的过去值、过去误差、其他时间序列的当前值和过去值的线性组合来预测响应时间序列。
其中,差分具有强⼤的确定性信息提取能⼒,许多⾮平稳序列差分后会显⽰出平稳序列的性质,称该⾮平稳序列为差分平稳序列。
对该种序列常⽤的⽅法就是本章介绍的齐次⾮平稳序列,简记为ARIMA(p,d,q)模型。
ARIMA(p,d,q)模型的结构为:对d阶齐次⾮平稳序列⽽⾔,{}是⼀个平稳序列,设其适合ARIMA(p,q)模型,即或表达为其ARIMA模型的构建由3个阶段组成:(1)模型的识别阶段:在识别阶段,可通过identify语句识别差分数、计算⾃相关、偏⾃相关、逆相关、互相关系数。
还可进⾏平稳性检验和模型阶数的识别。
另外,还可同时写多个identify语句,⽤以寻找模型的适合形式。
广东省H1N1(甲流)~sas~时间序列模型~拟合和预测
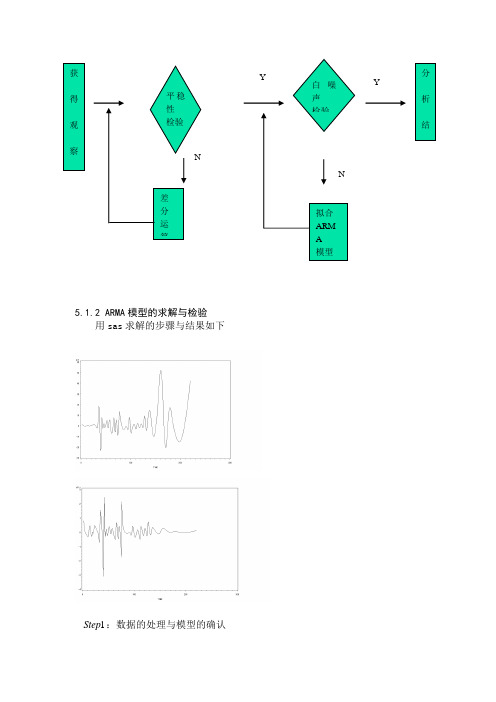
5.1.2 ARMA模型的求解与检验用sas求解的步骤与结果如下1Step:数据的处理与模型的确认拟合ARM A模型差分运算N N获得观察平稳性检验白噪声检验分析结YYH1n1人数增加的趋势,该时间序列不平稳。
原始数据一阶差分之后,方差随着时间不断地变大。
但是,对该序列取自然对数并进行一阶差分后所的序列Z 如图2,转换后数据比较平稳了。
对序列Z,绘制自相关函数和偏自相关函数图(图3),AutocorrelationsLag Covariance Correlation -1 9 8 7 6 5 4 3 2 1 0 1 2 3 4 5 6 7 8 9 1 Std Error0 0.307143 1.00000 | |********************| 01 0.0027340 0.00890 | . | . | 0.1856952 -0.075321 -.24523 | . *****| . | 0.1857103 -0.030560 -.09950 | . **| . | 0.1965604 0.018122 0.05900 | . |* . | 0.1982895 -0.013303 -.04331 | . *| . | 0.1988936 0.027612 0.08990 | . |** . | 0.1992187 -0.015125 -.04924 | . *| . | 0.200612Partial AutocorrelationsLag Correlation -1 9 8 7 6 5 4 3 2 1 0 1 2 3 4 5 6 7 8 9 11 0.00890 | . | . |2 -0.24533 | . *****| . |3 -0.10066 | . **| . |4 -0.00144 | . | . |5 -0.09838 | . **| . |6 0.09997 | . |** . |7 -0.08299 | . **| . |白噪声检查Autocorrelation Check for White NoiseTo Chi- Pr >Lag Square DF ChiSq --------------------Autocorrelations--------------------6 2.86 6 0.8264 0.009 -0.245 -0.099 0.059 -0.0430.090符合白噪声过程H1n1对数的自相关和偏相关图AutocorrelationsLag Covariance Correlation -1 9 8 7 6 5 4 3 2 1 0 1 2 3 4 5 6 7 8 9 1 Std Error0 1.658396 1.00000 | |********************| 01 1.372274 0.82747 | . |***************** | 0.1825742 1.066174 0.64289 | . |************* | 0.2810353 0.796524 0.48030 | . |********** . | 0.3263974 0.628184 0.37879 | . |******** . | 0.3491625 0.446300 0.26912 | . |***** . | 0.3626016 0.313281 0.18891 | . |**** . | 0.3691987 0.212290 0.12801 | . |*** . | 0.372406"." marks two standard errorsPartial AutocorrelationsLag Correlation -1 9 8 7 6 5 4 3 2 1 0 1 2 3 4 5 6 7 8 9 11 0.82747 | . |***************** |2 -0.13261 | . ***| . |3 -0.04033 | . *| . |4 0.08262 | . |** . |5 -0.11815 | . **| . |6 0.02544 | . |* . |7 0.00290 | . | . |从图3中可初步确定,此序列符合AR(1)。
SAS在时间序列分析中的应用

SAS在时间序列分析中的应用
SAS是一款多功能的软件,可以用来分析和预测数据和事件的发展。
时间序列分析是指在指定的时间长度内,对事件走势、趋势、周期、规律
进行深入研究和分析,以便对未来趋势和发展趋势有所预测。
本文主要讨
论SAS在时间序列分析中的应用。
一、数据准备
时间序列分析需要准备大量的历史数据,比如时间序列数据、时间序
列因子分析等。
SAS可以进行数据准备,进行数据预处理,并且可以进行
多指标的抽样分析,将数据转换成可以进行分析的标准格式,以确保分析
的准确性和可靠性。
二、时间序列分析
通过SAS的数据准备,可以对时序数据进行分析,SAS拥有时间序列
分析功能,可以使用ARIMA模型(自回归移动平均模型)、ARIMAX模型(自回归移动平均模型和外生变量)等等,可以进行模型参数的优化,以
此构建最优系统预测模型,对于小样本数据,可以进行多维时间序列分析,对于大量数据,可以进行回归分析,可以将时间序列转换为事件走势,从
而给出未来发展趋势的预测结果。
三、数据可视化
可以将SAS分析的数据可视化,使分析结果更加直观。
基于SAS软件的时间序列分析在GDP预测中的应用

基于SAS软件的时间序列分析在GDP预测中的应用作者:郑岩岩来源:《金融经济·学术版》2013年第09期摘要:国内生产总值(GDP)是国民经济核算的核心指标,GDP预测的准确与否直接关系到就业、收入分配等许多国计民生的重大问题。
根据1982年~2001年GDP数据,利用SAS统计软件,建立时间序列ARMA模型来预测未来5年的GDP的数值。
通过比较模型预测数据与实际数据,证明模型预测精度较高。
该结论不仅为GDP的预测提供了可靠信息,也可以在一定程度上作为政府决策的依据和参考。
关键词:GDP;SAS软件;时间序列;ARMA模型引言国内生产总值(Gross Domestic Product,GDP)是一个国家(地区)所有常住单位在一定时期内生产活动的最终成果。
GDP是国民经济核算的核心指标,也是衡量一个国家或地区经济状况和发展水平的重要指标。
影响GDP的因素众多,有确定性因素,还有许多随机因素,即便是确定性因素,也会由于统计过程中的人为过失或者误差使得许多参数的定量指标与实际情况之间存在较大的差异。
正是由于GDP计算过程中不可避免的随机性和复杂性,因此引入时间序列分析工具将十分有益。
时间序列分析方法可以避开统计过程中容易忽视的因素,通过对历史数据建立动态数据模型,并以此对GDP进行预测。
文中应用时间序列分析模型分析GDP随时间变化的情况,结果表明模型很好地预测未来5年乃至以后的GDP。
1. 时间序列分析简介为探索事物发展变化的规律,我们常常需要把反应事物变化特征的一定数值指标按时间顺序排列,然后研究其变化特征,即为时间序列分析[1]。
在时间序列分析中,需要建立时间序列模型,用于定量检测数据的变化规律。
常用的时间序列模型有自回归模型(AR模型)、滚动平均模型(MA模型)和自回归滚动模型(ARMA模型)。
(1)模型[2]对于p阶的自回归模型(AR(p)),其模型表达式为:(2)MA模型对于p阶的自回归模型(MA(p)),其模型表达式为:(3)ARMA模型对于p阶自回归模型--q阶滑动平均模型,其模型表达式为:2、实例分析根据1952年--2001年的中国50年的国内生产总值[3]统计情况,在SAS系统中建立ARMA模型并对未来的GDP情况进行预测,建模过程基本分为4个步骤:数据预处理(平稳化)、模型识别、模型诊断以及预测。
SAS学习系列39 时间序列分析Ⅲ—ARIMA模型

39. 时间序列分析Ⅱ——ARIMA 模型随着对时间序列分析方法的深入研究,人们发现非平稳序列的确定性因素分解方法(如季节模型、趋势模型、移动平均、指数平滑等)只能提取显著的确定性信息,对随机性信息浪费严重,同时也无法对确定性因素之间的关系进行分析。
而非平稳序列随机分析的发展就是为了弥补确定性因素分解方法的不足。
时间序列数据分析的第一步都是要通过有效手段提取序列中所蕴藏的确定性信息。
Box 和Jenkins 使用大量的案例分析证明差分方法是一种非常简便有效的确定性信息的提取方法。
而Gramer 分解定理则在理论上保证了适当阶数的差分一定可以充分提取确定性信息。
(一)ARMA 模型即自回归移动平均移动模型,是最常用的拟合平稳时间序列的模型,分为三类:AR 模型、MA 模型和ARMA 模型。
一、AR(p )模型——p 阶自回归模型 1. 模型:011t t p t p t x x x φφφε--=+++其中,0p φ≠,随机干扰序列εt 为0均值、2εσ方差的白噪声序列(()0t s E εε=, t ≠s ),且当期的干扰与过去的序列值无关,即E(x t εt )=0.由于是平稳序列,可推得均值011pφμφφ=---. 若00φ=,称为中心化的AR (p )模型,对于非中心化的平稳时间序列,可以令01(1)p φμφφ=---,*t t x x μ=-转化为中心化。
记B 为延迟算子,1()p p p B I B B φφΦ=---称为p 阶自回归多项式,则AR (p )模型可表示为:()p t t B x εΦ=.2. 格林函数用来描述系统记忆扰动程度的函数,反映了影响效应衰减的快慢程度(回到平衡位置的速度),G j 表示扰动εt -j 对系统现在行为影响的权数。
例如,AR(1)模型(一阶非齐次差分方程),1, 0,1,2,j j G j φ==模型解为0t j t j j x G ε∞-==∑.3. 模型的方差对于AR(1)模型,2221()()1t jt j j Var x G Var εσεφ∞-===-∑. 4. 模型的自协方差对中心化的平稳模型,可推得自协方差函数的递推公式:用格林函数显示表示:200()()i j t j t k j j kj i j j k G G E GG γεεσ∞∞∞---+=====∑∑∑对于AR(1)模型,21121()(0)1k k k εσγφγφφ==- 5. 模型的自相关函数 递推公式:对于AR(1)模型,11()(0)k k k ρφρφ==.平稳AR(p )模型的自相关函数有两个显著的性质: (1)拖尾性指自相关函数ρ(k)始终有非零取值,不会在k 大于某个常数之后就恒等于零;(2)负指数衰减随着时间的推移,自相关函数ρ(k)会迅速衰减,且以负指数k iλ(其中i λ为自相关函数差分方程的特征根)的速度在减小。
基于SAS软件的时间序列实验的代码

实验指南目录实验一分析太阳黑子数序列 (3)实验二模拟AR模型 (4)实验三模拟MA模型和ARMA模型 (6)实验四分析化工生产量数据 (8)实验五模拟ARIMA模型和季节ARIMA模型 (10)实验六分析美国国民生产总值的季度数据 (13)实验七分析国际航线月度旅客总数数据 (16)实验八干预模型的建模 (19)实验九传递函数模型的建模 (22)实验十回归与时序相结合的建模 (25)太阳黑子年度数据 (28)美国国民收入数据 (29)化工生产过程的产量数据 (30)国际航线月度旅客数据 (30)洛杉矶臭氧每小时读数的月平均值数据 (31)煤气炉数据 (35)芝加哥某食品公司大众食品周销售数据 (37)牙膏市场占有率周数据 (39)某公司汽车生产数据 (44)加拿大山猫数据 (44)实验一分析太阳黑子数序列一、实验目的:了解时间序列分析的基本步骤,熟悉SAS/ETS软件使用方法。
二、实验内容:分析太阳黑子数序列。
三、实验要求:了解时间序列分析的基本步骤,注意各种语句的输出结果。
四、实验时间:2小时。
五、实验软件:SAS系统。
六、实验步骤1、开机进入SAS系统。
2、创建名为exp1的SAS数据集,即在窗中输入下列语句:data exp1;input a1 @@;year=intnx(‘year’,’1jan1742’d,_n_-1);format year year4.;cards;输入太阳黑子数序列(见附表)run;3、保存此步骤中的程序,供以后分析使用(只需按工具条上的保存按钮然后填写完提问后就可以把这段程序保存下来即可)。
4、绘数据与时间的关系图,初步识别序列,输入下列程序:proc gplot data=exp1;symbol i=spline v=star h=2 c=green;plot a1*year;run;5、提交程序,在graph窗口中观察序列,可以看出此序列是均值平稳序列。
6、识别模型,输入如下程序。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
例1 磨轮剖面资料 data li; input x @@; cards; 13.5 4.0 4.0 4.5 3.0 3.0 10.0 10.2 9.0 10.0 8.5 7.0 10.5 7.5 7.0 10.5 9.5 7.0 12.0 13.5 12.5 15.0 13.0 11.0 9.0 10.5 10.5 11.5 10.5 9.0 8.2 8.5 9.2 8.5 10.0 14.5 13.0 2.0 6.0 6.0 11.0 9.5 12.5 13.8 12.0 12.0 12.0 13.0 12.0 14.0 14.5 13.5 12.3 7.0 7.0 7.0 6.5 12.5 15.0 12.5 11.6 11.0 10.0 8.5 3.0 11.5 11.5 11.5 11.0 9.0 2.5 7.0 6.0 6.6 14.0 11.0 9.0 6.5 4.0 6.0 12.0 11.0 12.0 12.5 12.5 13.6 13.0 8.0 6.5 6.8 6.0 7.2 10.2 8.0 7.5 11.0 11.8 11.8 6.5 8.0 9.0 8.0 8.0 9.0 9.5 10.0 9.0 12.0 13.5 13.8 15.0 12.5 11.0 11.5 14.5 11.5 11.8 13.0 15.0 14.5 13.0 9.0 11.0 9.0 10.0 14.0 13.5 3.0 2.2 6.0 8.0 9.0 9.0 9.0 7.0 6.0 6.5 7.0 7.5 8.5 9.0 9.5 10.0 11.5 11.2 12.5 11.6 8.0 7.0 6.0 6.0 6.0 9.0 12.0 13.5 13.0 3.5 1.8 1.6 7.5 8.0 7.9 11.6 12.5 10.5 8.0 9.0 11.6 11.8 12.6 10.2 10.0 5.0 7.0 -1.0 0.0 0.0 3.0 11.0 12.0 12.2 11.0 8.0 7.0 5.5 10.0 11.5 7.0 4.0 7.0 7.0 10.0 9.0 8.0 10.0 13.0 10.0 6.5 11.0 13.0 13.0 14.0 13.0 12.5 12.0 9.0 8.5 7.0 8.5 10.0 8.0 4.0 3.0 10.0 13.0 13.0 13.0 12.0 11.0 11.0 11.0 14.5 14.0 14.0 13.5 10.0 9.5 10.0 12.5 10.0 9.0 9.0 4.0 3.0 6.0 5.0 7.0 6.0 5.0 8.5 10.5 11.1 11.0 10.0 11.2 8.0 2.5 5.0 13.2 14.0; Proc print data=li; run;
例2 国航客票数(Airline)数据
data seriesg; input x @@; xlog=log(x); date=intnx('month','31dec1948'd,_n_); format date monyy.; cards;
112 118 132 129 121 135 148 148 136 119 104 118 115 126 141 126 126 149 170 170 158 133 114 140 145 150 178 163 172 178 199 199 184 162 146 166 171 180 193 181 183 218 230 242 209 191 172 194 196 196 236 235 229 243 264 272 237 211 180 201 204 188 235 227 234 264 302 233 259 229 203 229 242 233 267 269 270 316 364 347 312 274 237 278 284 277 317 313 318 374 413 405 355 306 271 306 315 301 356 348 356 422 465 467 404 347 305 336 340 318 362 348 363 435 491 505 404 359 310 337 360 342 406 396 420 472 548 559 463 407 362 405 417 391 419 461 472 535 622 606 508 461 390 432 ; Proc print data= seriesg; run;
白噪声检验——卡方检验
• H0 :直到某一给定时间间隔的样本自相关系数没 有显著不为零的.(Xt为白噪声,独立的随机扰动) • 如果对所有时间间隔,该零假设成立,则没有需要 建模的信息,也不需要建立ARIMA模型. • 被检查的时间间隔个数依赖于=选项 • 对前N-2个自相关系数的检验P值。 P<=0.005 拒绝 H0 (拒绝为白噪声,P=0时, Xt高度自相关) P<=0.005 接受 H0 (即对所有时间间隔,自相关 系数为零,说明没有建模信息,不必要做下去了)
SAS软件简介
SAS系统 是由美国SAS软件研究所开发的用于 决策支持的大型集成信息系统,是数 据处理和统计领域的国际标准软件之 一,广泛应用于金融、医药卫生、生 产、运输、通讯、政府、教育和科研 等领域。
应用SAS软件建立时间序列模型
• 准备工作:建立一个时间序列数据集 SAS语句: Data 数据集名; Input 序号(year or month)变量名 @@; Cards;/(输入数据,按input格式逐个输入数 据,以分号结束); Proc print data=数据集名;/输出数据表 Run;
如果序列的样本自相关系数在q步后截尾,则是MA 序列,如果偏相关系数在p步后截尾,则是AR序列。如 果都不截尾,只是按负指数衰减或以阻尼正弦波形式趋 于零(即是拖尾的),则应判断为ARMA序列,但是不 能确定阶次。
若序列的样本自相关和偏相关系数都不截尾,而且 至少有一个不是拖尾,即下降趋势很慢,不能被负指数 函数所控制,或是不具有下降的趋势而是周期变化,那 么我们便认为序列具有增长趋势或季节性变化,是非平 稳序列。可应用提取趋势性和季节性的方法,对数据进 行处理,就是主要通过差分等变换将非平稳序列变成一 个平稳序列。
ESTIMATE的输出
• 参数估计表:
– 估计方法:METHOD=选择不同的估计方法(条件最 小二乘法估计,极大似然估计,条件、无条件估计, 线性或非线性估计) 参数估计值(提供:估计值,标准差,t比值) t比值:关于参数估计值的显著性检验(近似值)。 当观测序列的长度很短,并且被估计参数的个数相 对于序列昌都很长时,t统计量的近似效果很差。 均值项MU 常数项:Constant Estimate 模型的常数项可以表 示为均值项MU和自回归参数的函数。
SAS的建模步骤
• SAS建模根据Box―Jenkins建模方法, 主要包括三个阶段: 模型识别阶段(包括模型定阶) 模型参数估计阶段(包括模型检验) 模型的预测阶段
第一阶段: 模型的识别
• 平稳性模型识别 首先判定时间序列数据是否为平稳随机数 据, (一)通过时间序列数据趋势图判别。
Sas语句: symbol1 i=join v=star; proc gplot data=seriesg; plot x*date=1/haxis='1jan49'd to '1jan61'd by year; run;
X M n ( n 2)
2 M
rk
2
R 1
(n k )
rk
t 1 n t 1
nk
t
t
tR
Байду номын сангаас
2
每个卡方值对于指定 的所有时间间隔进行计 算,并不独立于前面的 卡方值。若滞后m 期的 卡方统计量所对应的值 均小于临界值,即 p值 均小于置信水平, 则残 差卡方检验未通过.
(二)通过自相关函数和偏自相关函数的截 尾性识别模型
“IDENTIFY”语句 通过SAS软件,运行程序如下: proc arima data=数据集 identify var=变量名 nlag=时间间隔个数 run; 计算出自相关系数ACF, 逆自相关系数 SIACF, 偏自相关系数PACF和互相关系数。 根据样本自相关系数ACF和偏相关系数 PACF的形态来识别模型类别。
例2 国航客票数(Airline)数据 proc arima data=seriesg; identify var=xlog(1,12) nlag=15; run; 差分不仅影响用于IDENTIFY语句输出的 序列,而且应用于任何随后的ESTIMATE和 FORECAST语句。ESTIMATE语句对差分序 列拟模型,FORECAST语句预测差分并自动 把差分加起来以取消有IDENTIFY语句指定的 差分操作。
非平稳序列的平稳化
若序列是非平稳的,下面是通过差分变换变成一个平稳 序列。 SAS的程序为一阶差分 变量名(1) identify var=变量(1) nlog=N ; run; 若一阶差分是平稳的,对差分序列建模,观测ACF、 PACF的变化趋势,初步给出的阶数。因为输入数据是序 列的有限样本,所以由输入序列计算出样本自相关系数是 逼近产生序列的理论自相关系数。这意味着样本自相关系 数不能够恰好等于任何模型的理论自相关系数,并且可能 会具有一种或多种不同的模型的理论自相关系数相似的类 型。若一阶差分序列仍不平稳,重复以上过程,(二阶差 分,三阶差分等等)直到差分序列平稳。
第二阶段:估计和诊断检验阶段
• 时间序列Wt由IDENTIFY语句识别并且由 ESTIMATE语句处理, 即在完成可能的模型 识别后,开始估计和诊断检查阶段.
估计模型AR(P) estimate p=?; (根据偏相关系数的截尾点) run; ESTIMATE语句的功能是用模型拟合数据,并打印 出参数估计值和诊断统计量,指出模型对数据的 拟合优度。