矢量字库文件组织方式(英文)
第22章emWin(UCGUI)TrueType矢量字体

第22章TrueType矢量字体本期教程跟大家讲解矢量字体的相关知识,矢量字体最大的好处就是可以任意放大或者缩小字体,而且字体的显示效果不失真。
矢量字体的缺点就是不适合用在小型嵌入式系统中,极其消耗内存。
22. 1 XBF格式字体生成方法22. 2 移植到开发板显示22. 3 总结22.1矢量字体介绍下面的内容来自百度百科和wiki百科(两个内容居然一模一样),讲的非常好,特此转载过来。
目前主流的矢量字体格式有3种:Type1,TrueType和OpenType,这三种格式都是与平台无关的。
Type1全称PostScript Type1,是1985年由Adobe公司提出的一套矢量字体标准,由于这个标准是基于PostScript Description Language(PDL),而PDL又是高端打印机首选的打印描述语言,所以Type1迅速流行起来。
但是Type1是非开放字体,Adobe对使用Type1的公司征收高额的使用费。
TrueType是1991年由Apple公司与Microsoft公司联合提出另一套矢量字标准。
Type1使用三次贝塞尔曲线来描述字形,TrueType则使用二次贝塞尔曲线来描述字形。
所以Type1的字体比TrueType字体更加精确美观。
一个误解是,Type1字体比TrueType字体占用空间多。
这是因为同样描述一个圆形,二次贝塞尔曲线只需要8个关键点和7段二次曲线;而三次贝塞尔曲线则需要12个关键点和11段三次曲线。
然而实际情况是一般来说 Type1比TrueType要小10%左右。
这是因为对于稍微复杂的字形,为了保持平滑,TrueType必须使用更多的关键点。
由于现代大部分打印机都是使用PDL作为打印描述语言,所以Type1字体打印的时候不会产生形变,速度快;而TrueType则需要翻译成PDL,由于曲线方程的变化,还会产生一定的形变,不如Type1美观。
这么说来,Type1应该比TrueType更具有优势,为什么如今的计算机上TrueType反而比Type1使用更广泛呢?这是因为第一:Type1由于字体方程的复杂,所以在屏幕上渲染的时候,花费的时间多,解决方案是大部分Type1字体嵌入了点阵字体,这样渲染快,但是边缘不光滑,比较难看。
ESRI的三大矢量数据格式
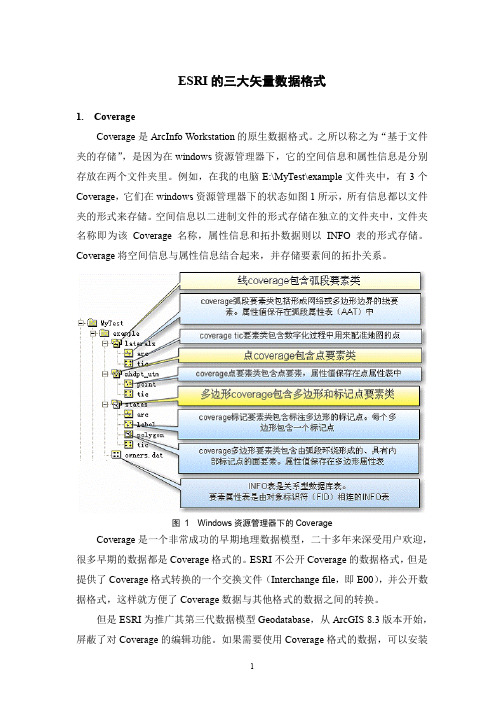
ESRI的三大矢量数据格式1.CoverageCoverage是ArcInfo Workstation的原生数据格式。
之所以称之为“基于文件夹的存储”,是因为在windows资源管理器下,它的空间信息和属性信息是分别存放在两个文件夹里。
例如,在我的电脑E:\MyTest\example文件夹中,有3个Coverage,它们在windows资源管理器下的状态如图1所示,所有信息都以文件夹的形式来存储。
空间信息以二进制文件的形式存储在独立的文件夹中,文件夹名称即为该Coverage名称,属性信息和拓扑数据则以INFO表的形式存储。
Coverage将空间信息与属性信息结合起来,并存储要素间的拓扑关系。
图 1 Windows资源管理器下的CoverageCoverage是一个非常成功的早期地理数据模型,二十多年来深受用户欢迎,很多早期的数据都是Coverage格式的。
ESRI不公开Coverage的数据格式,但是提供了Coverage格式转换的一个交换文件(Interchange file,即E00),并公开数据格式,这样就方便了Coverage数据与其他格式的数据之间的转换。
但是ESRI为推广其第三代数据模型Geodatabase,从ArcGIS 8.3版本开始,屏蔽了对Coverage的编辑功能。
如果需要使用Coverage格式的数据,可以安装ArcInfo workstation,或者将Coverage数据转换为其他可编辑的数据格式。
Coverage是一个集合,它可以包含一个或多个要素类。
2.ShapefileShapefile是ArcView GIS 3.x的原生数据格式,属于简单要素类,用点、线、多边形存储要素的形状,却不能存储拓扑关系,具有简单、快速显示的优点。
一个Shapefile是由若干个文件组成的,空间信息和属性信息分离存储,所以称之为“基于文件”。
每个Shapefile,都至少有这三个文件组成,其中:*.shp 存储的是几何要素的的空间信息,也就是XY坐标*.shx 存储的是有关*.shp存储的索引信息。
常见的矢量文件格式

常见的矢量文件格式包括:
SVG(Scalable Vector Graphics):SVG是一种基于XML 的矢量图形格式,支持矢量图形的描述和展示,可以在网页上进行缩放而不失真。
AI(Adobe Illustrator):AI是Adobe Illustrator软件使用的专有矢量文件格式,常用于存储和交换矢量图形和插图。
EPS(Encapsulated PostScript):EPS是一种通用的矢量图形文件格式,支持各种矢量图形软件的使用,常用于印刷和出版领域。
PDF(Portable Document Format):PDF是一种跨平台的文档格式,可以包含矢量图形、文本和图片等内容,广泛应用于电子文档和打印输出。
DXF(Drawing Exchange Format):DXF是由AutoCAD开发的一种矢量文件格式,常用于CAD软件之间的数据交换。
CDR(CorelDRAW):CDR是CorelDRAW软件使用的专有矢量文件格式,适用于CorelDRAW软件的图形设计和编辑。
EMF(Enhanced Metafile):EMF是一种Windows系统下的矢量图形文件格式,支持图像的缩放和编辑,常用于Windows 应用程序和打印输出。
这些矢量文件格式具有可伸缩性、保真度高、可编辑性强的特点,适用于需要保持图像质量和可调整大小的应用,如图形设计、插图、CAD绘图、印刷和出版等领域。
常用文件名后缀

1、.eot文件:是一种压缩字库,目的是解决在网页中嵌入特殊字体的难题。
2、.svg文件:是一种图形文件格式,它的英文全称为Scalable Vector Graphics,意思为可缩放的矢量图形。
3、.ttf文件:(TrueTypeFont)是Apple公司和Microsoft公司共同推出的字体文件格式,随着windows的流行,已经变成最常用的一种字体文件表示方式。
4、.woff文件:Web开放字体格式(Web Open Font Format,简称WOFF)是一种网页所采用的字体格式标准。
此字体格式发展于2009年,现在正由万维网联盟的Web字体工作小组标准化,以求成为推荐标准。
此字体格式不但能够有效利用压缩来减少档案大小,并且不包含加密也不受DRM(数位著作权管理)限制。
5、.doc文件:是电脑文件常见文件扩展名的一种,自Word 2007之后为docx6、.xls文件:是一种非常常用的电子表格文件,使用Microsoft Excel 可以将XLS格式的表格转换为多种格式:XML表格、XML数据、网页、使用制表符分割的文本文件(*.txt)、使用逗号分隔的文本文件(*.csv)等。
7、.txt文件:是微软在操作系统上附带的一种文本格式,是最常见的一种文件格式,早在DOS时代应用就很多,主要存文本信息,即为文字信息,现在的操作系统大多使用记事本等程序保存,大多数软件可以查看,如记事本,浏览器等等。
8、.pdf文件:PDF是Portable Document Format的简称,意为“可携带文档格式”,是由Adobe Systems用于与应用程序、操作系统、硬件无关的方式进行文件交换所发展出的文件格式。
PDF文件以PostScript语言图象模型为基础,无论在哪种打印机上都可保证精确的颜色和准确的打印效果,即PDF会忠实地再现原稿的每一个字符、颜色以及图象。
9、.ppt文件:由微软公司推出的一款图形演示文稿软件,全称为“PowerPoint”,简称PPT。
矢量字体

矢量字体矢量字体是与点阵字体相对应的一种字体。
矢量字体的每个字形都是通过数学方程来描述的,一个字形上分割出若干个关键点,相邻关键点之间由一条光滑曲线连接,这条曲线可以由有限个参数来唯一确定。
矢量字的好处是字体可以无级缩放而不会产生变形。
目前主流的矢量字体格式有3种:Type1,TrueType和OpenType,这三种格式都是平台无关的。
Type1全称PostScript? Type1,是1985年由Adobe公司提出的一套矢量字体标准,由于这个标准是基于PostScript Description Language(PDL),而PDL又是高端打印机首选的打印描述语言,所以Type1迅速流行起来。
但是Type1是非开放字体,Adobe对使用Type1的公司征收高额的使用费。
TrueType是1991年由Apple公司与Microsoft公司联合提出另一套矢量字标准。
Typ1使用三次贝塞尔曲线来描述字形,TrueType则使用二次贝塞尔曲线来描述字形。
所以Type1的字体比TrueType字体更加精确美观。
一个误解是,Type1字体比TrueType字体占用空间多。
这是因为同样描述一个圆形,二次贝塞尔曲线只需要8个关键点和7段二次曲线;而三次贝塞尔曲线则需要12个关键点和11段三次曲线。
然而实际情况是一般来说Type1比TrueType要小10%左右。
这是因为对于稍微复杂的字形,为了保持平滑,TrueType 必须使用更多的关键点。
由于现代大部分打印机都是使用PDL作为打印描述语言,所以True1字体打印的时候不会产生形变,速度快;而TrueType则需要翻译成PDL,由于曲线方程的变化,还会产生一定的形变,不如Type1美观。
这么说来,Type1应该比TrueType更具有优势,为什么如今的计算机上TrueType反而比Type1使用更广泛呢?这是因为第一:Type1由于字体方程的复杂,所以在屏幕上渲染的时候,花费的时间多,解决方案是大部分Type1字体嵌入了点阵字体,这样渲染快,但是边缘不光滑,比较难看。
GUI原理4 - 矢量字体

说起矢量字体,不得不说一下多边形填充原理。
本来是想将多边形填充作为单独的一节内容,可惜说得太细我累大家也累。
多边形填充最需要关注的就是斜率,计算每条边的斜率,从而得到每条边在每一行上的切点。
然后从左到右,将各切点连接起来,逐行进行。
多边形有两种填充方式,Alternate和Winding。
矢量字体主要用的前一种方式,而winding会将所有的切点都连接起来,没有了中间的分隔区域。
比如,在Alternate模式下,从最左边的切点1,会连接切点2,然后从切点3连接到切点4,而2到3是不连接的。
这样就形成了一个空洞,也是矢量字的奥秘所在。
Winding模式会将所有的切点都连接起来,即从最左边的一直画到最右边。
FillMode多边形组——PolyPolygon将多个多边形组合成一个组,从而形成复杂的多边形组。
同样,这个组也依赖于FillMode的填充模式。
下面我们来看一下中文的“口”是如何写出来的。
“口”由两条多边形组合而成,根据FillMode为Alternate,相重叠的部分不显示。
用笔在字的中央画一条横线,就可以找到4个交点,而交点2到3是不连接的,这样就形成了“口”中间的洞。
微软Arial字体中“S”的曲线微软的Arial字体中存储的“S”,就是多个Bezier3点组成的。
点41是锚点,而40和42是控制点,来控制通过41的曲线的张力。
在点的定义上,有on curve和not on curve两种,通常将在曲线上的点定为锚点,而不在曲线上的点为控制点。
这是我年初的时候,为了研究矢量字体,将字母P用微软的方式输出后,再读取字库点阵数据,使用红叉画出字库中所有的点。
P是由两条Bezier曲线包围而成的,第二条起着切割的目的,已形成P中间的圆洞。
看看字母“B”的填充。
字体是如何保证对齐的呢?原来在字库内部,有一个基准线,就好像信纸的虚线,用来水平方向对齐的,同样,也有个垂直方向的基准线。
每个字都有上浮和下沉的高度,这也是该字的最上和最下的点所处的位置。
矢量小字库制作

矢量小字库制作步骤1.建立一个test.txt文档,其中输入创建小字库需要的中文字(英文默认添加),去掉重复的汉字,请保持汉字唯一性。
示例:函数常用于再分配一个以存在构2.用UE打开该testx.txt文档,使用Ctrl+H键,切换成16进制显示。
选择“文件---转换---ASCII Unicode”按钮,既得出这些汉字的Unicode索引。
(FF FE 是Unicode编码的标识符,有效数据从第三位开始,两个字节表示一个汉字)3.打开FontCreator,选择“File---Open---Font file”,查找并打开FontSTB.ttf文件,里面包含了基础的英文和数字。
再次选择“File---Open---Installed Font”,会出现windows里的字库文件,选择你需要的字体文件打开,(我们现在选择的是楷体-GB2312:SIMKAI.TTF).4.选择FontSTB.ttf页卡,选择“Insert—Characters”,会出现Insert Characters卡,在Font选项中选择刚才添加Windows的那个字库(我们现在选择的是楷体-GB2312:SIMKAI.TTF),在最下面一条输入行里(Add these characters and/or character ranges….)依次输入test.txt 中字符的Unicode编码,输入格式$xxxx(注意字符Unicode编码输入顺序,参考图1中顺序)比如字符”函数”,$51FD, $6570.添加完成后,点击OK。
5.这样会在刚才的FontSTB.ttf页卡中增加N个空白的字符框,N等于你要添加的字符个数。
点击其中一个字符框,右键,选择“Caption—Symbol Chars“,所有的字符框头上显示的数字就是这个字符所对应的Unicode码,也就是刚才你输入的数字,如果输入错误,需要改变,点击右键,选择”Properties---Mappings“,在Mappings选项框内选择对应的数值,点击右边的”Delete”,然后在上面的V alue中输入正确的Unicode码,点击Add,最好点击OK,完成修改。
gml矢量格式

gml矢量格式
GML(Geography Markup Language)是一种基于XML的地理信息编码、传输、存储的规范。
它提供了一个开放的框架,用于定义地理空间数据,使得用户能够开发基于XML规范的应用子集。
GML常用于描述矢量数据,包括点、线、面等几何对象。
在GML中,矢量数据可以采用几何集合的方式来表示不同维度的几何对象,例如点(Point)、多点(MultiPoint)、线(LineString)、多线(MultiLineString)、面(Polygon)和多面(MultiPolygon)等。
这些
几何对象可以通过GML的XML语法进行定义和描述,包括几何特征和属
性特征。
通过使用GML规范,可以实现地理空间数据的互操作性和共享。
不同GIS
软件之间可以交换和共享GML格式的地理数据,从而方便了地理信息系统
的集成和应用。
在Surfer中输出矢量汉字的方法

在Surfer中输出矢量汉字的方法/在sur中输出矢量汉菡蘑曩Il(f2脯舡系;l鋈.柳utsteplessoo*/~Suffer/AbstractTpaperprovidethemethodtooutputsteplesszoomcharacte rto关键词矢量汉字HGL绘图仪P/^一^卅册一1fhis对于地质类的应用软件来说,内存永远也不会"过剩".大的内存可以保证装人地质上的海量数据,并且运算速度快,所以在各个油田生产单位仍然继续推出基于DOS的软件包.DOS下的Suffer绘图包由于支持多达84种的绘图仪和打印机…,占用内存少.绘图方便,以及国内许多技术人员二次开发做的函数库,使得现在仍在油田,院校中广泛应用,但是目前图形和汉字不能很好地混合输出,大多采用先输出图,再打印汉字粘贴的方法,效率较低.矢量汉字显示速度快,任意无级缩放字体边缘光滑不失真.这正是工程图输出所需要的,但是矢量汉字库很大,而我们只在显示图名,图例中用到少量汉字,采用完整的字库会带来额外的负担,浪费计算机中的内存本文采用小字库技术,同时兼顾了节约内存和快速向绘图仪输出高质量的汉字,简单实用,实现了图文的统一自动处理,同以前的点阵汉字矢量化法相比,直接解码,速度快,任意级别放大缩小时不失真.可以同时向打印机和屏幕输出Surfer的PLT文件su_T的PLT文件类似于HPGL(惠普图形语言),是笔式绘图仪的命令语言,由于HP绘图仪的广泛使用,HPGL已经成为事实上的标准绘图语言, 在绘图仪和打印机上广泛使用,它们的独特优点是完全由可读的ASCII字符构成,使之易于产生和调试,受到广大科学技术工程人员的欢迎.graph表1HPGL命令与PLT命令对比,\文件格式毋争\HPGLPL_T落笔画线到点x1,Y1PD;PAxl,ylPAxlyl选笔SPnn定义坐标原点IPx1,y1,,y2mY旋转R0姐eP-Oangle设置比例SC,xl,y0,ylSCY抬笔移动到点x1.v1PU;PAxl,v1M^xv写出一申字符LBstringPSYhianglestring由上表可以看出,两者的命令格式基本一样,所以本文的方法同样适用于HPGL文件.Surfer软件包也提供了PLT格式自动转换到HPGL的功能. 同Suffer的PLT文件接口.也就是将以上命令写到扩展名为PLT的文本文件中.矢量汉字和矢量汉字库矢量汉字是将汉字的笔划边缘用直线段或曲线段描述成封闭的曲线,前者的代表有Ucdos3.x的矢量字库,后者有Microsoft的TrueType字库, 使用二次Brzier曲线描述字符】.矢量汉字信息中以特殊的字节表示落笔和抬笔,它是以图形方式建库的.每个汉字的图形信息因此也是不固定的.矢量汉字库采用索引的方法.矢量汉字由两部分组成,前一部分是索引信息,包括每个汉字的在字库种的地址和长度,按内码顺序存放,后一部分石油工业计算机应用3/1999是汉字的数据,包括控制信息和各点坐标信息.汉字索引信息首址=((汉字机内码高位字节一0Xa1)+(汉字机内码地位字节-0Xa1))?6显示汉字方法是:从索引信息读出汉字的地址和长度=)到相应位置读出字型数据=)解码得到轮廓多边形的各点坐标=)画出多边形=)矢量汉字. 要建立小汉字库.因为汉字顺序无规律,所以在小汉字库前加入区位码信息.这样矢量汉字的索引信息表结构是:~edefstnlct{unsignedlongaddres;/-k字型数据地址4个字节★/unsigned_mtsize;/★字型数据长度2个字节★/)小汉字库的索引信息表结构typedefStlXICC{unsignedimqwrn;/★汉字的区位码2个字节-k/unsignedlongaddres;/★字型数据地址4个字节★/umigned_mtsize;/★字型数据长度2个字节★/关键程序矸为汉字轮廓的数据pl0屯oly画汉字轮廓的多边形.plodine画线.vo/dptotV o~(fiatnut/1,intxy[256J.imsc)fimi,x2,y2,x0,yo,moveup;intm/n=1000000,m=一1000000;for(i=0;iQ?num;i++){ff(mkn>xy[iJ]ndnxyi;;if(max<xy[iJ】rnax=xy[i】;)moveup=max+mfia;moveup650;x0=xy【O]:yo:一xy[1l+moveup;riot((float)x0/sc,(float)y0/so,3);t'or(i1:i<nurn;i++){=xy[2-ki】;y2=一xyl2★i+1】+moveup; v|ot((float)x2/sc.(float)y2/sc.2):}plot((float)x0/sc,(float)'~O/sc,2):}voidploflfiae(hum,datax,dauy)imnum;floatdatax[256】,dauy[256】;f.mti=0;plot(datax[i】,datay[i】,3);for(i=0;i<num,i++)ploddaax【iJ_datayⅢi,2)}其中Plot函数的作用是画线,plodx,Y,3)为抬笔到x,y点,pl0t(x,y,2)为落笔到x,y点【1】.形式为审血审,"PA%8.3f%8.3f\n",XC,YC):实例本文提供了三个实例,左图是采油累积曲线示意图,中图是一个沉积扇顶面等值线图,右图是中图的立体图,主要用于演示矢量图中插入矢量汉字的说明和图例.B等值线BContoul圈1实倒演示C立体罔CSuffer●考文tf1】孙j蔓曩,揖金蛊荨计算机蛰圉理论及其应用.成都:电子科拄大学出版社,1995I2】DavidCKaymdIof.nR.Lu-w~c.柑东等译.20种位圈矢量图文件格式与实践.北京:学苑出版社.1994I3】董有积利用C语盲缩程实现小型矢量设字库的剖建及调用电脑蝙程技巧与堆护.1998(9):28—31【4】孙隶广,橱长贵计葬机圉形学.北京:清华大学出艋杜.1995 '。
矢量字库文件组织方式英文

矢量字库文件组织方式(英文)INF: Font-File Format [P_WinSDK]WINDOWSPSSONLY | Windows 3 Developer 's Notes summary ENDUSER Summary:Note: This article is part of a set of seven articles, collectivelycalled theof both raster and vector versions ofWindows font files is shown in the following list:Field Description----- -----------dfVersion 2 bytes specifying the version (0200H or 0300H) ofthe file.dfSize 4 bytes specifying the total size of thefile inbytes.dfCopyright 60 bytes specifying copyright information.dfType 2 bytes specifying the type of font file.The low-order byte is exclusively for GDI use. If the low-order bit of the WORD is zero, it is a bitmap(raster) font file. If the low-order bit is 1, it is avector font file. The second bit is reserved and mustbe zero. If no bits follow in the file and the bits arelocated in memory at a fixed address specified indfBitsOffset, the third bit is set to 1; otherwise, thebit is set to 0 (zero). The high-order bit of the lowbyte is set if the font was realized by a device. Theremaining bits in the low byte are reserved and set tozero.The high byte is reserved for device use and will always be set to zero for GDI-realized standard fonts.Physical fonts with the high-order bit of the low byteset may use this byte to describe themselves. GDI willnever inspect the high byte.dfPoints 2 bytes specifying the nominal point size at whichthis character set looks best.dfVertRes 2 bytes specifying the nominal vertical resolution(dots-per-inch) at which this character set wasdigitized.dfHorizRes 2 bytes specifying the nominal horizontal resolution(dots-per-inch) at which this character set wasdigitized.dfAscent 2 bytes specifying the distance from the top of acharacter definition cell tothe baseline of thetypographical font. It is useful for aligning thebaselines of fonts of different heights.dfInternalLeadingSpecifies the amount of leading inside the bounds setby dfPixHeight. Accent marks may occur in this area.This may be zero at the designer 's option.dfExternalLeadingSpecifies the amount of extra leading that the designerrequests the application add between rows. Since thisarea is outside of the font proper, it contains nomarks and will not be altered by text output calls ineither the OPAQUE or TRANSPARENT mode. This may be zeroat the designer 's option.dfItalic 1 (one) byte specifying whether or not the characterdefinition data represent an italic font. The low-orderbit is 1 if the flag is set. All the other bits arezero.dfUnderline 1 byte specifying whether or not the characterdefinition data represent an underlined font. Thelow-order bit is 1 if the flag is set. All the otherbits are 0 (zero).dfStrikeOut 1 byte specifying whether or not the characterdefinition data represent a struckout font. The low-order bit is 1 if the flag is set. All the other bitsare zero.dfWeight 2 bytes specifying the weight of the characters in thecharacter definition data, on a scale of 1 to 1000. AdfWeight of 400 specifies a regular weight.dfCharSet 1 byte specifying the character set defined by thisfont.dfPixWidth 2 bytes. For vector fonts, specifies the width of thegrid on which the font was digitized. For raster fonts,if dfPixWidth is nonzero, it represents the width forall the characters in the bitmap; if it is zero, the font has variable width characters whose widths are specified in the dfCharTable array.dfPixHeight 2 bytes specifying the height of the character bitmap(raster fonts), or the height of the grid on which avector font was digitized.dfPitchAndFamilySpecifies the pitch and font family. The low bit is setif the font is variable pitch. The high four bits givethe family name of the font. Font families describe ina general way the look of a font. They are intended forspecifying fonts when the exact face name desired isnot available. The families are as follows:Family Description------ -----------FF_DONTCARE (0 < <4) Don 't care or don 't know.FF_ROMAN (1 < <4) Proportionally spaced fontswith serifs.FF_SWISS (2 < <4) Proportionally spaced fontswithout serifs.FF_MODERN (3 < <4) Fixed-pitch fonts.FF_SCRIPT (4 < <4)FF_DECORATIVE (5 < <4)dfAvgWidth 2 bytes specifying the width of characters in the font.For fixed-pitch fonts, this is the same as dfPixWidth.For variable-pitch fonts, this is the width of thecharacteret.dfLastChar 1 byte specifying the last character code defined bythis font. Note that all the characters with codesbetween dfFirstChar and dfLastChar must be present inthe font character definitions.dfDefaultChar 1 byte specifying the character to substitutewhenever a string contains a character out of therange. The character is given relative to dfFirstCharso that dfDefaultChar is the actual value of thecharacter, less dfFirstChar. The dfDefaultChar shouldindicate a special character that is not a space.dfBreakChar 1 byte specifying the character that will define wordbreaks. This character defines word breaks for wordwrapping and word spacing justification. The characteris given relative to dfFirstChar so that dfBreakChar isthe actual value of the character, less that ofdfFirstChar. The dfBreakChar is normally (32 -dfFirstChar), which is an ASCII space.dfWidthBytes 2 bytes specifying the number of bytes in each row ofthe bitmap. This is always even, so that the rows starton WORD boundaries. For vector fonts, this field has no meaning.dfDevice 4 bytes specifying the offset in the file to the stringgiving the device name. For a generic font, this valueis zero.dfFace 4 bytes specifying the offset in the file to thenull-terminated string that names the face.dfBitsPointer 4 bytes specifying the absolute machine address ofthe bitmap. This is set by GDI at load time. ThedfBitsPointer is guaranteed to be even.dfBitsOffset 4 bytes specifying the offset in the file to thebeginning of the bitmap information. If the 04H bit inthe dfType is set, then dfBitsOffset is an absoluteaddress of thebitmap (probably in ROM).For raster fonts, dfBitsOffset points to a sequence of bytes that make up the bitmap of the font, whose height is the height of the font, and whose width is the sumof the widths of the characters in the font rounded upto the next WORD boundary.For vector fonts, it points to a string of bytes or words (depending on the size of the grid on which thefont was digitized) that specify the strokes for eachcharacter of the font. The dfBitsOffset field must beeven.dfReserved 1 byte, not used.dfFlags 4 bytes specifying the bits flags, which are additionalflags that define the format of the Glyph bitmap, asfollows:DFF_FIXED equ 0001h ; font is fixed pitch DFF_PROPORTIONAL equ 0002h ; font is proportional; pitchDFF_ABCFIXED equ 0004h ; font is an ABC fixed ; fontDFF_ABCPROPORTIONAL equ 0008h ; font is an ABC pro- ; portional fontDFF_1COLOR equ 0010h ; font is one colorDFF_16COLOR equ 0020h ; font is 16 colorDFF_256COLOR equ 0040h ; font is 256 colorDFF_RGBCOLOR equ 0080h ; font is RGB color dfAspace 2 bytes specifying the global A space, if any. ThedfAspace is the distance from the current position tothe left edge of the bitmap.dfBspace 2 bytes specifying the global B space, if any. ThedfBspace is the width of the character.dfCspace 2 bytes specifying the global C space, ifany. ThedfCspace is the distance from the right edge of thebitmap to the new current position. The increment of acharacter is the sum of the three spaces. These applyto all glyphs and is the case for DFF_ABCFIXED.dfColorPointer4 bytes specifying the offset to the color table forcolor fonts, if any. The format of the bits is similarto a DIB, but without the header. That is, thecharacters are not split up into disjoint bytes.Instead, they are left intact. If no color table isneeded, this entry is NULL.[NOTE: This information is different from that in thehard-copy Developer 's Notes and reflects a correction.] dfReserved1 16 bytes, not used.[NOTE: This information is different from that in thehard-copy Developer 's Notes and reflects a correction.]dfCharTable For raster fonts, the CharTable is an array of entrieseach consisting of two 2-byte WORDs for Windows and three 2-byte WORDs for Windows . The first WORD ofeach entry is the character width. The second WORD of each entry is the byte offset from the beginning of the FONTINFO structure to the character bitmap. For Windows , the second and third WORDs are used for theoffset.There is one extra entry at the end of this table that describes an absolute-space character. This entrycorresponds to a character that is guaranteed to beblank; this character is not part of the normalcharacter set.The number of entries in the table is calculated as ((dfLastChar - dfFirstChar) + 2). This includes aspare, the sentinel offset mentioned in the following paragraph.For fixed-pitch vector fonts, each 2-byte entry in this array specifies the offset from the start of the bitmapto the beginning of the string of stroke specificationunits for the character. The number of bytes or WORDs to be used for a particular character is calculated bysubtracting its entry from the next one, so that thereis a sentinel at the end of the array of values.For proportionally spaced vector fonts, each 4-byte entry is divided into two 2-byte fields. The firstfield gives the starting offset from the start of thebitmap of the character strokes. The second field givesthe pixel width of the character.An ASCII character string specifying the name of thefont face. The size of this field is the length of thestring plus a NULL terminator.An ASCII character string specifying the name of the device if this font file is for a specific device. Thesize of this field is the length of the string plus aNULL terminator.This field contains the character bitmap definitions.Each character is stored as a contiguous set of bytes.(In the old font format, this was not the case.)The first byte contains the first 8 bits of the first scanline (that is, the top line of the character). Thesecond byte contains the first 8 bits of the secondscanline. This continues until a firstrow, each scanlineis covered by 1 byte, with bits set to zero asnecessary for padding. If the glyph is very wide, athird or even fourth set of bytes can be present.Note: The character bitmaps must be storedcontiguously and arranged in ascending order.The following is a single-character example, in which are given the bytes for a 12 x 14 pixel character, asshown here schematically..................**.........*..*.......*....*.....*......*....*......*....*......*....********....*......*....*......*....*......*......................................The bytes are given here in two sets, because the character is less than 17 pixels wide.00 06 09 10 20 20 20 3F 20 20 20 00 00 0000 00 00 80 40 40 40 C0 40 40 40 00 00 00Note that in the second set of bytes, the second digit of each is always zero. It would correspond to the 13th through 16th pixels on the right side of the character,if they were present.The Windows version of dfCharTable has a GlyphEntry structure withthe following format:GlyphEntry strucgeWidth dw ; width of character bitmap in pixelsgeOffset dw ; pointer to the bitsGlyphEntry endsThe Windows version of the dfCharTable is dependent on the formatof the Glyph bitmap.Note: The only formats supported in Windows will be DFF_FIXEDand DFF_PROPORTIONAL.DFF_FIXEDDFF_PROPORTIONALGlyphEntry strucgeWidth dw; width of character bitmap in pixelsgeOffset dd ; pointer to the bitsGlyphEntry endsDFF_ABCFIXEDDFF_ABCPROPORTIONALGlyphEntry strucgeWidth dw ; width of character bitmap in pixelsgeOffset dd ; pointer to the bitsgeAspace dd ; A space in fractional pixels geBspace dd ; B space in fractional pixels geCspace dw ; C space in fractional pixels GlyphEntry endsThe fractional pixels are expressed as a 32-bit signed number with animplicit binary point between bits 15 and 16. This is referred to as a(相关文档:••••••••••更多相关文档请访问:。
矢量字体

矢量字体简介矢量字体(Vector font)中每一个字形是通过数学曲线来描述的,它包含了字形边界上的关键点,连线的导数信息等,字体的渲染引擎通过读取这些数学矢量,然后进行一定的数学运算来进行渲染。
这类字体的优点是字体实际尺寸可以任意缩放而不变形、变色。
矢量字体主要包括 Type1 、TrueType、OpenType等几类。
又叫Outline font,通常使用贝塞尔曲线,绘图指令和数学公式进行绘制。
这样可以在对字体进行任意缩放的时候保持字体边缘依然光滑,字体色素不会丢失。
编辑本段分类目前主流的矢量字体格式有3种:Type1,TrueType和OpenType,这三种格式都是平台无关的。
Type1全称PostScript Type1,是1985年由Adobe公司提出的一套矢量字体标准,由于这个标准是基于PostScript DescriptionLanguage(PDL),而PDL又是高端打印机首选的打印描述语言,所以Type1迅速流行起来。
但是Type1是非开放字体,Adobe对使用Type1的公司征收高额的使用费。
TrueType是1991年由Apple公司与Microsoft公司联合提出另一套矢量字标准。
Type1使用三次贝塞尔曲线来描述字形,TrueType则使用二次贝塞尔曲线来描述字形。
所以Type1的字体比TrueType字体更加精确美观。
一个误解是,Type1字体比TrueType字体占用空间多。
这是因为同样描述一个圆形,二次贝塞尔曲线只需要8个关键点和7段二次曲线;而三次贝塞尔曲线则需要12个关键点和11段三次曲线。
然而实际情况是一般来说 Type1比TrueType要小10%左右。
这是因为对于稍微复杂的字形,为了保持平滑,TrueType必须使用更多的关键点。
由于现代大部分打印机都是使用PDL作为打印描述语言,所以True1字体打印的时候不会产生形变,速度快;而TrueType则需要翻译成PDL,由于曲线方程的变化,还会产生一定的形变,不如Type1美观。
教你制作属于自己的字体库FontCreatorProgram工具字体文件制作

教你制作属于自己的字体库Font Creator Program工具字体文件制作上次发布了一篇直接用CorelDRW制作字体文件的文章,但是CorelDRW毕竟只是一个设计软件,对于它制作的字体文件应付一般的应用是没有问题的,如果要制作更专业点的字体就需要配合其他的软件使用了,一个好汉三个帮嘛~一、字体基本知识平时我们常见的字体格式主要有以下几种:1.光栅字体(.FON)这种字体是针对特定的显示分辨率以不同大小存储的位图,用于Windows系统中屏幕上的菜单、按钮等处文字的显示。
它并不是以矢量描述的,放大以后会出现锯齿,只适合屏幕描述。
不过它的显示速度非常快,所以作为系统字体而在Windows中使用。
2.矢量字体(.FON)虽然扩展名和光栅字体一样,但是这种字体却是由基于矢量的数学模型定义的,是Windows系统字体的一类,一些windows应用程序会在较大尺寸的屏幕显示中自动使用矢量字体来代替光栅字体的显示。
3.PostScript字体(.PFM)这种字体基于另一种矢量语言(Adobe PostScript)的描述,常用于PostScript 打印机中,不过Windows并不直接支持这类字体,要在Windows使用这类字体需要安装";Adobe Type Manger";(ATM)软件来进行协调。
4.TrueType字体(.TTF)这是我们日常操作中接触得最多的一种类型的字体,其最大的特点就是它是由一种数学模式来进行定义的基于轮廓技术的字体,这使得它们比基于矢量的字体更容易处理,保证了屏幕与打印输出的一致性。
同时,这类字体和矢量字体一样可以随意缩放、旋转而不必担心会出现锯齿。
我们下面要制作的字体就属于这一类型。
一个完整的TTF字体有基本拉丁文(字母A-Z大小写、常用符号)、扩展拉丁文(音标、注音符号)、图形符号、控制符号以及其他很多部分组成,不过我们可以制作只包含基本拉丁文区的字体。
envi中文说明

envi中文说明预览说明:预览图片所展示的格式为文档的源格式展示,下载源文件没有水印,内容可编辑和复制e n v i3.5使用说明(t h a n k s s u p e r s of t)1.数据输入输出格式1.1数据输入格式通用图像格式TIFF,t f w(T I F F w o r l d file),G E O T I F F,J P E G,B M P,H D F/H D F1-D,P I C T,S R F,X W DN L A P S,P D S(P l a n e t a r y D a t a S y s t e m),MrSid 矢量格式A R C I n t e r c h a n g e F o r m a t(u n c o m p r e s s e d)A R C/In f o Images(.bil)A r c V i e w S h a p e (.s h p)A D R GA u t o C A D D X FD X FM a p I n f o(及相应的.mid文件的属性)M i c r o s t a t i o n .D G NU S G S S D T S&D L G遥感数据格式L a n d s a t T M:F a s t,G e o T I F,H D F,N L A P S,M R L C,A C R E S C C R S,E S A C E O SS P O T:S P O T,G e o S P O T,A C R E S SPOT,Veg e t a t i o nI K O N O S: G e o T I F F,N I T FI R S: F a s tA V H R R: K L M/L e v e l1b,S H A R P(E S A's A V H R R f o rm a t)S e a W I F S: Level 1B H D F,C E O S(E R S-1,E R S-2,J E R S-1)D M S P(N O A A)T h e r m a l:TIMS,M A S T E RR a d a r:R A D A R S A T,E R S ,J E R S,JPL T O P S A R&P O L S A R,SIR -C,A I R S A R(JPL)SIR-C/X-S A R S P O T(1A, 1B,2A,C A P) Military: AD R G,C A D R G,CIB,N I T FD i g i t a lE l e v a t i o n:D T E D,U S G S D E M ,U S G S S D T S D E MU S G S: D R G,D O Q,DEM,S D T S D E MMODIS S i m u l a t o r(M A S-50H D F)A V I R I S,C A S IA T S RC AD R GCIB其它遥感软件格式P C I (.p i x) FilesE R M a p p e rE R D A S7.5&IMAGINE8.X(包括其投影信息)其它数据格式A S C I IDMA D T E D&A D R GD M S PD O QE N V I/I D L C o m m a n d-line VariablesFlat B i n a r y FilesGeneric BIP,B I L,B S QNo P r o p r i e t a r y F o r m a t sO n-t h e-Fly D at a C o n v e r s i o n sU s e r-D e f i n a b l e D a t a F o r m a t sU S G S D E M &D O QU S G S S D T S D E M X,Y,Z A S C I I1.2数据输出格式ARC/INFO I m a g e s(.b i l)A r c V i e w S h a p e f i l e sASCII (R O I区可以ASCII输出)BMP(图像可以BMP格式输出,目前有24比特图和8比特灰度图两种)Direct O u t p u t t o P r i n t e r (先输出到P o s tscript格式上,则用户可进行大小/掩膜等设置)ERDAS 7.5(.l a n)E R M A P P E RG E O T I F FGIFP C I(.p i x)P I C TP o s tscript(可把掩膜输出到i m a g e或Postscript格式上)RGB F i l e sSRFT I F F(如有地理坐标信息,则可另输出成G e o T I F F文件或.t f w T I F F文件)X W D可在I D L命令行将E N V I的波段/文件/子集,及绘图窗口的显示数据输出成I D L变量E N V IMPEG(允许将3D曲面飞行动画序列输出为MPEG文件)N I T F02.00 (MIL-STD-2500A)或02.10 (MIL-STD-2500B)2.交互式分析2.1感兴趣区(R O I):可交互定义R O I:P o l y g o n s,P o l y l i n e s,P i x e l s允许多个R O I s合并成一个R O I可以将整个R O I区转换成点可将一幅图像里的R O I s通过地理座标转换到另一幅图像里可通过输入带有像元位置或地理坐标的ASCII文件来定义R O I ?可使图像中的R O I s和从地理坐标来定义的R O I s协调一致可用2-D散点图曲线或n-D散度分析器来定义R O I可用区域生长来定义R O I把ASCII文件转变成多边形R O I s,可将R O I s以ASCII文件输出在注记中采用T r u e T y p e字体作为注记的位置矢量图,能保持输出到P R I N T E R或POST script上(注:不会显示在输出的图像上)新增R O I类型——M u l t i Part,用户可实现“d o n u t”R O I s ?ROI分析功能增强:可以计算多个感兴趣区(R O I)的交集,并用计算结果定义新的R O I或进行掩膜2.2n-维散度可视化分析:给散点窗口中的一类或几类散点增加不同的符号可以显示和输出任意散点或类的光谱曲线,很容易地勾圈,编辑,分离各类可视化分析的每一步都可以前进或后退,分析速度可控制可将外边的光谱曲线读入n-维分析空间和图形窗口类控制对话框可报告每类里包含的散点数,可显示或关闭每一类或每几类检索到的统计结果和光谱曲线是来自文件的整个空间维,而不是参与n-D分析的子空间维(子空间维是整个空间维的一个字集)可将可视化分析窗口与光谱分析工具(S p e c t r a l A n a l y s t)连结起来以便对可视化分析窗口中的光谱曲线和标准光谱库作比较改进的N-D散度分析功能:可用预分类结果进行N-D散度分析,交互式地进行感兴趣区的细化。
矢量图形的存储格式

矢量图形的存储格式矢量图形的存储格式矢量图形的存储格式有 swf svg eps doc 等, 按使用分类:前两种常用于网络显示,后两种主要用于印刷出版一、BMP图像文件格式BMP是一种与硬件设备无关的图像文件格式,使用非常广。
它采用位映射存储格式,除了图像深度可选以外,不采用其他任何压缩,因此,BblP文件所占用的空间很大。
BMP文件的图像深度可选lbit、4bit、8bit及24bit。
BMP文件存储数据时,图像的扫描方式是按从左到右、从下到上的顺序。
由于BMP文件格式是Windows环境中交换与图有关的数据的一种标准,因此在Windows环境中运行的图形图像软件都支持BMP图像格式。
典型的BMP图像文件由三部分组成:位图文件头数据结构,它包含BMP图像文件的类型、显示内容等信息;位图信息数据结构,它包含有BMP图像的宽、高、压缩方法,以及定义颜色等信息。
二、 PCX图像文件格式PCX这种图像文件的形成是有一个发展过程的。
最先的PCX雏形是出现在ZSOFT公司推出的名叫PC PAINBRUSH的用于绘画的商业软件包中。
以后,微软公司将其移植到Windows环境中,成为Windows系统中一个子功能。
先在微软的Windows3.1中广泛应用,随着Windows的流行、升级,加之其强大的图像处理能力,使PCX 同GIF、TIFF、BMP图像文件格式一起,被越来越多的图形图像软件工具所支持,也越来越得到人们的重视。
PCX是最早支持彩色图像的一种文件格式,现在最高可以支持256种彩色,如图4-25所示,显示256色的彩色图像。
PCX设计者很有眼光地超前引入了彩色图像文件格式,使之成为现在非常流行的图像文件格式。
PCX图像文件由文件头和实际图像数据构成。
文件头由128字节组成,描述版本信息和图像显示设备的横向、纵向分辨率,以及调色板等信息:在实际图像数据中,表示图像数据类型和彩色类型。
PCX 图像文件中的数据都是用PCXREL技术压缩后的图像数据。
点阵字库和矢量字库

点阵字库的生产原理(转)2011-05-17 15:31:45| 分类:其他技术| 标签:|字号大中小订阅点阵字库的生产原理所有的汉字或者英文都是下面的原理,由左至右,每8个点占用一个字节,最后不足8个字节的占用一个字节,而且从最高位向最低位排列。
生成的字库说明:(以12×12例子)一个汉字占用字节数:12÷8=1····4也就是占用了2×12=24个字节。
编码排序A0A0→A0FE A1A0→A2FE依次排列。
以12×12字库的“我”为例:“我”的编码为CED2,所以在汉字排在CEH-AOH=2EH区的D2H-A0H=32H个。
所以在12×12字库的起始位置就是[{FE-A0}*2EH+32H]*24=104976开始的24个字节就是我的点阵模。
其他的类推即可。
英文点阵也是如此推理。
在DOS程序中使用点阵字库的方法首先需要理解的是点阵字库是一个数据文件,在这个数据文件里面保存了所有文字的点阵数据.至于什么是点阵,我想我不讲大家都知道的,使用过"文曲星"之类的电子辞典吧,那个的液晶显示器上面显示的汉子就能够明显的看出"点阵"的痕迹.在 PC 机上也是如此,文字也是由点阵来组成了,不同的是,PC机显示器的显示分辨率更高,高到了我们肉眼无法区分的地步,因此"点阵"的痕迹也就不那么明显了.点阵、矩阵、位图这三个概念在本质上是有联系的,从某种程度上来讲,这三个就是同义词.点阵从本质上讲就是单色位图,他使用一个比特来表示一个点,如果这个比特为0,表示某个位置没有点,如果为1表示某个位置有点.矩阵和位图有着密不可分的联系,矩阵其实是位图的数学抽象,是一个二维的阵列.位图就是这种二维的阵列,这个阵列中的 (x,y) 位置上的数据代表的就是对原始图形进行采样量化后的颜色值.但是,另一方面,我们要面对的问题是,计算机中数据的存放都是一维的,线性的.因此,我们需要将二维的数据线性化到一维里面去.通常的做法就是将二维数据按行顺序的存放,这样就线性化到了一维.那么点阵字的数据存放细节到底是怎么样的呢.其实也十分的简单,举个例子最能说明问题.比如说 16*16 的点阵,也就是说每一行有16个点,由于一个点使用一个比特来表示,如果这个比特的值为1,则表示这个位置有点,如果这个比特的值为0,则表示这个位置没有点,那么一行也就需要16个比特,而8个比特就是一个字节,也就是说,这个点阵中,一行的数据需要两个字节来存放.第一行的前八个点的数据存放在点阵数据的第一个字节里面,第一行的后面八个点的数据存放在点阵数据的第二个字节里面,第二行的前八个点的数据存放在点阵数据的第三个字节里面,…,然后后面的就以此类推了.这样我们可以计算出存放一个点阵总共需要32个字节.看看下面这个图形化的例子:| |1| | | | | | | | | | |1| | | || | |1|1| |1|1|1|1|1|1|1|1|1| | || | | |1| | | | | | | | |1| | | ||1| | | | | |1| | | | | |1| | | || |1|1| | | |1| | | | | |1| | | || | |1| | | |1| | | | |1| | | | || | | | |1| | |1| | | |1| | | | || | | |1| | | |1| | |1| | | | | || | |1| | | | | |1| |1| | | | | ||1|1|1| | | | | | |1| | | | | | || | |1| | | | | |1| |1| | | | | || | |1| | | | |1| | | |1| | | | || | |1| | | |1| | | | | |1| | | || | |1| | |1| | | | | | |1|1|1| || | | | |1| | | | | | | | |1| | || | | | | | | | | | | | | | | | |可以看出这是一个"汉"字的点阵,当然文本的方式效果不是很好.根据上面的原则,我们可以写出这个点阵的点阵数据:0x40,0x08,0x37,0xfc,0x10,0x08,…, 当然写这个确实很麻烦所以我不再继续下去.我这样做,也只是为了向你说明,在点阵字库中,每一个点阵的数据就是按照这种方式存放的.当然也存在着不规则的点阵,这里说的不规则,指的是点阵的宽度不是8的倍数,比如12*12 的点阵,那么这样的点阵数据又是如何存放的呢?其实也很简单,每一行的前面8个点存放在一个字节里面,每一行的剩下的4点就使用一个字节来存放,也就是说剩下的4个点将占用一个字节的高4位,而这个字节的低4位没有使用,全部都默认的为零.这样做当然显得有点浪费,不过却能够便于我们进行存放和寻址.对于其他不规则的点阵,也是按照这个原则进行处理的.这样我们可以得出一个 m*n 的点阵所占用的字节数为 (m+7)/8*n.在明白了以上所讲的以后,我们可以写出一个显示一个任意大小的点阵字模的函数,这个函数的功能是输出一个宽度为w,高度为h的字模到屏幕的 (x,y) 坐标出,文字的颜色为color,文字的点阵数据为 pdata 所指:/*输出字模的函数*/void _draw_model(char *pdata, int w, int h, int x, int y, int color){int i; /* 控制行 */int j; /* 控制一行中的8个点 */int k; /* 一行中的第几个"8个点"了 */int nc; /* 到点阵数据的第几个字节了 */int cols; /* 控制列 */BYTE static mask[8]={128, 64, 32, 16, 8, 4, 2, 1}; /* 位屏蔽字 */w = (w + 7) / 8 * 8; /* 重新计算w */nc = 0;for (i=0; i<h; i++){cols = 0;for (k=0; k<w/8; k++){for (j=0; j<8; j++){if (pdata[nc]&mask[j])putpixel(x+cols, y+i, color);cols++;}nc++;}}}代码很简单,不用怎么讲解就能看懂,代码可能不是最优化的,但是应该是最易读懂的.其中的 putpixel 函数,使用的是TC提供的 Graphics 中的画点函数.使用这个函数就可以完成点阵任意大小的点阵字模的输出.接下来的问题就是如何在汉子库中寻址某个汉子的点阵数据了.要解决这个问题,首先需要了解汉字在计算机中是如何表示的.在计算机中英文可以使用 ASCII 码来表示,而汉字使用的是扩展 ASCII 码,并且使用两个扩展 ASCII 码来表示一个汉字.一个 ASCII 码使用一个字节表示,所谓扩展 ASCII 码,也就是 ASCII 码的最高位是1的 ASCII 码,简单的说就是码值大于等于 128 的 ASCII 码.一个汉字由两个扩展 ASCII 码组成,第一个扩展ASCII 码用来存放区码,第二个扩展 ASCII 码用来存放位码.在 GB2312-80 标准中,将所有的汉字分为94个区,每个区有94个位可以存放94个汉字,形成了人们常说的区位码,这样总共就有 94*94=8836 个汉字.在点阵字库中,汉字点阵数据就是按照这个区位的顺序来存放的,也就是最先存放的是第一个区的汉字点阵数据,在每一个区中有是按照位的顺序来存放的.在汉字的内码中,汉字区位码的存放实在扩展 ASCII 基础上存放的,并且将区码和位码都加上了32,然后存放在两个扩展 ASCII 码中.具体的说就是:第一个扩展ASCII码 = 128+32 + 汉字区码第二个扩展ASCII吗 = 128+32 + 汉字位码如果用char hz[2]来表示一个汉字,那么我可以计算出这个汉字的区位码为:区码 = hz[0] - 128 - 32 = hz[0] - 160位码 = hz[1] - 128 - 32 = hz[1] - 160.这样,我们可以根据区位码在文件中进行殉职了,寻址公式如下:汉字点阵数据在字库文件中的偏移 = ((区码-1) * 94 + 位码) * 一个点阵字模占用的字节数在寻址以后,即可读取汉字的点阵数据到缓冲区进行显示了.以下是实现代码:/* 输出一个汉字的函数 */void _draw_hz(char hz[2], FILE *fp, int x, int y, int w, int h, int color){char f ON tbuf[128]; /* 足够大的缓冲区,也可以动态分配 */int ch0 = (BYTE)hz[0]-0xA0; /* 区码 */int ch1 = (BYTE)hz[1]-0xA0; /* 位码 *//* 计算偏移 */long offset = (long)pf->_hz_buf_size * ((ch0 - 1) * 94 + ch1 - 1);fseek(fp, offset, SEEK_SET); /* 进行寻址 */ fread(fontbuf, 1, (w + 7) / 8 * h, fp); /* 读入点阵数据 */ _draw_model(fontbuf, w, h, x, y, color); /* 绘制字模 */}以上介绍完了中文点阵字库的原理,当然还有英文点阵字库了.英文点阵字库中单个点阵字模数据的存放方式与中文是一模一样的,也就是对我们所写的 _draw_model 函数同样可以使用到英文字库中.唯一不同的是对点阵字库的寻址上.英文使用的就是 ASCII 码,其码值是0到127,寻址公式为:英文点阵数据在英文点阵字库中的偏移 = 英文的ASCII码 * 一个英文字模占用的字节数可以看到,区分中英文的关键就是,一个字符是 ASCII 码还是扩展 ASCII 码,如果是ASCII 码,其范围是0到127,这样是使用的英文字库,如果是扩展 ASCII 码,则与其后的另一个扩展 ASCII 码组成汉字内码,使用中文字库进行显示.只要正确区分 ASCII 码的类型并进行分别的处理,也就能实现中英文字符串的混合输出了.点阵字库和矢量字库的差别我们都只知道,各种字符在电脑屏幕上都是以一些点来表示的,因此也叫点阵.最早的字库就是直接把这些点存储起来,就是点阵字库.常见的汉字点阵字库有 16x16, 24x24 等.点阵字库也有很多种,主要区别在于其中存储编码的方式不同.点阵字库的最大缺点就是它是固定分辨率的,也就是每种字库都有固定的大小尺寸,在原始尺寸下使用,效果很好,但如果将其放大或缩小使用,效果就很糟糕了,就会出现我们通常说的锯齿现象.因为需要的字体大小组合有无数种,我们也不可能为每种大小都定义一个点阵字库.于是就出现了矢量字库.矢量字库矢量字库是把每个字符的笔划分解成各种直线和曲线,然后记下这些直线和曲线的参数,在显示的时候,再根据具体的尺寸大小,画出这些线条,就还原了原来的字符.它的好处就是可以随意放大缩小而不失真.而且所需存储量和字符大小无关.矢量字库有很多种,区别在于他们采用的不同数学模型来描述组成字符的线条.常见的矢量字库有 Type1字库和Truetype字库.在点阵字库中,每个字符由一个位图表示(如图2.5所示),并把它用一个称为字符掩膜的矩阵来表示,其中的每个元素都是一位二进制数,如果该位为1表示字符的笔画经过此位,该像素置为字符颜色;如果该位为0,表示字符的笔画不经过此位,该像素置为背景颜色.点阵字符的显示分为两步:首先从字库中将它的位图检索出来,然后将检索到的位图写到帧缓冲器中.在实际应用中,同一个字符有多种字体(如宋体、楷体等),每种字体又有多种大小型号,因此字库的存储空间十分庞大.为了减少存储空间,一般采用压缩技术.矢量字符记录字符的笔画信息而不是整个位图,具有存储空间小,美观、变换方便等优点.例如:在AutoCAD中使用图形实体-形(Shape)-来定义矢量字符,其中,采用了直线和圆弧作为基本的笔画来对矢量字符进行描述. 对于字符的旋转、放大、缩小等几何变换,点阵字符需要对其位图中的每个象素进行变换,而矢量字符则只需要对其几何图素进行变换就可以了,例如:对直线笔画的两个端点进行变换,对圆弧的起点、终点、半径和圆心进行变换等等.矢量字符的显示也分为两步.首先从字库中将它的字符信息.然后取出端点坐标,对其进行适当的几何变换,再根据各端点的标志显示出字符.轮廓字形法是当今国际上最流行的一种字符表示方法,其压缩比大,且能保证字符质量.轮廓字形法采用直线、B样条/Bezier曲线的集合来描述一个字符的轮廓线.轮廓线构成一个或若干个封闭的平面区域.轮廓线定义加上一些指示横宽、竖宽、基点、基线等等控制信息就构成了字符的压缩数据.如何使用Windows的系统字库生成点阵字库?我的程序现在只能预览一个汉字的不同字体的点阵表达.界面很简单: 一个输出点阵大小的选择列表(8x8,16x16,24x24等),一个系统中已有的字体名称列表,一个预览按钮,一块画图显示区域.得到字体列表的方法:(作者称这一段是用来取回系统的字体,然后添加到下拉框中) //取字体名称列表的回调函数,使用前要声明一下该方法int CALLBACK MyEnumF ON tProc(ENUMLOGFONTEX* lpelf,NEWTEXTMETRICEX* lpntm,DWORD nFontType,long lParam){CFontPeekerDlg* pWnd=(CFontPeekerDlg*) lParam;if(pWnd){if( pWnd->m_combo_sfont.Find ST ring(0, lpelf->elfLogFont.lfFaceName) <0 )pWnd->m_combo_sfont.AddString(lpelf->elfLogFont.lfFaceName);return 1;}return 0;}//说明:CFontPeekerDlg 是我的dialog的类名, m_combo_sfont是列表名称下拉combobox关联的control变量//调用的地方 (******问题1:下面那个&lf怎么得到呢……){::EnumFontFamiliesEx((HDC) dc,&lf, (FONTENUMPROC)MyEnumFontProc,(LPARAM) this,0);m_combo_sfont.SetCurSel(0);}字体预览:如果点阵大小选择16,显示的时候就画出16x16个方格.自定义一个类CMyStatic继承自CStatic,用来画图.在CMyStatic的OnPaint()函数中计算并显示.取得字体:常用的方法:用CreateFont创建字体,把字TextOut再用GetPixel()取点存入数组. 缺点:必须把字TextOut出来,能在屏幕上看见,不爽.我的方法,用这个函数:GetGlyphOutline(),可以得到一个字的轮廓矢量或者位图.可以不用textout到屏幕,直接取得字模信息函数原型如下:DWORD GetGlyphOutline(HDC hdc, //画图设备句柄UINT uChar, //将要读取的字符/汉字 UINT uFormat, //返回数据的格式(字的外形轮廓还是字的位图) LPGLYPHMETR ICS lpgm, // GLYPHMETRICS结构地址,输出参数DWORD cbBuffer, //输出数据缓冲区的大小LPVOID lpvBuffer, //输出数据缓冲区的地址CO NS T MAT2 *lpmat2 //转置矩阵的地址);说明:uChar字符需要判断是否是汉字还是英文字符.中文占2个字节长度.lpgm是输出函数,调用GetGlyphOutline()是无须给lpgm 赋值.lpmat2如果不需要转置,将 eM11.value=1; eM22.value=1; 即可.cbBuffer缓冲区的大小,可以先通过调用GetGlyphOutline(……lpgm, 0, NULL, mat); 来取得,然后动态分配lpvBuffer,再一次调用GetGlyphOutline,将信息存到lpvBuffer. 使用完毕后再释放lpvBuffer.程序示例:(***问题2:用这段程序,我获取的字符点阵总都是一样的,不管什么字……)……前面部分省略……GLYPHMETRICS glyph;MAT2 m2;memset(&m2, 0, sizeof(MAT2));m2.eM11.value = 1;m2.eM22.value = 1;//取得buffer的大小DWORD cbBuf = dc.GetGlyphOutline( nChar, GGO_BITMAP, &glyph,0L, NULL, &m2);BYTE* pBuf=NULL;//返回GDI_ERROR表示失败.if( cbBuf != GDI_ERROR ){pBuf = new BYTE[cbBuf];//输出位图GGO_BITMAP 的信息.输出信息4字节(DWORD)对齐dc.GetGlyphOutline( nChar, GGO_BITMAP, &glyph, cbBuf, pBuf, &m2);}else{if(m_pFont!=NULL)delete m_pFont;return;}编程中遇到问题:一开始,GetGlyphOutline总是返回-1,getLastError显示是"无法完成的功能",后来发现是因为调用之前没有给hdc设置Font.后来能取得pBuf信息后,又开始郁闷,因为不太明白bitmap的结果是按什么排列的.后来跟踪汉字"一"来调试(这个字简单),注意到了 glyph.gmBlackBoxX 其实就是输出位图的宽度,glyph.gmBlackBoxY就是高度.如果gmBlackBoxX=15,glyph.gmBlackBoxY=2,表示输出的pBuf中有这些信息:位图有2行信息,每一行使用15 bit来存储信息.例如:我读取"一":glyph.gmBlackBoxX = 0x0e,glyph.gmBlackBoxY=0x2; pBuf长度cbBuf=8 字节pBuf信息: 00 08 00 00 ff fc 00 00字符宽度 0x0e=14 则第一行信息为: 0000 0000 0000 100 (只取到前14位)第二行根据4字节对齐的规则,从0xff开始 1111 1111 1111 110看出"一"字了吗?呵呵直到他的存储之后就可以动手解析输出的信息了.我定义了一个宏#define BIT(n) (1<<(n)) 用来比较每一个位信息时使用后来又遇到了一个问题,就是小头和大头的问题了.在我的机器上是little endian的形式,如果我用unsigned long *lptr = (unsigned long*)pBuf;//j from 0 to 15if( *lptr & BIT(j) ){//这时候如果想用j来表示写1的位数,就错了}因为从字节数组中转化成unsigned long型的时候,数值已经经过转化了,像上例中,实际上是0x0800 在同BIT(j)比较.不多说了,比较之前转化一下就可以了if( htonl(*lptr) & BIT(j) )Unicode中文点阵字库的生成与使用点阵字库包含两部分信息.首先是点阵字库文件头信息,它包含点阵字库文字的字号、多少位表示一个像素,英文字母与符号的size、起始和结束 unicode编码、在文件中的起始偏移,汉字的size、起始和结束unicode编码、在文件中的起始偏移.然后是真实的点阵数据,即一段段二进制串,每一串表示一个字母、符号或汉字的点阵信息.要生成点阵字库必须有文字图形的来源,我的方法是使用ttf字体.ttf字体的显示采用的是SDL_ttf库,这是开源图形库SDL的一个扩展库,它使用的是libfreetype以读取和绘制ttf字体.它提供了一个函数,通过传入一个Unicode编码便能输出相应的文字的带有alpha 通道的位图.那么我们可以扫描这个位图以得到相应文字的点阵信息. 由于带有alpha通道,我们可以在点阵信息中也加入权值,使得点阵字库也有反走样效果.我采用两位来表示一个点,这样会有三级灰度(还有一个表示透明).点阵字库的显示首先需要将文件头信息读取出来,然后根据unicode编码判断在哪个区间内,然后用unicode编码减去此区间的起始unicode编码,算出相对偏移,并加上此区间的文件起始偏移得到文件的绝对偏移,然后读出相应位数的数据,最后通过扫描这段二进制串,在屏幕的相应位置输出点阵字型.显示点阵字体需要频繁读取文件,因此最好做一个固定大小的缓存,采用LRU置换算法维护此缓存,以减少磁盘读取.。
the 基于freetype 嵌入式矢量字体引擎的研究guide download

第23卷第4期宁波大学学报(理工版) V ol.23No.4 2010年10月JOURNAL OF NINGBO UNIVERSITY ( NSEE ) Oct. 2010文章编号:1001-5132(2010)04-0056-06基于FreeType嵌入式矢量字体引擎的研究黄秀珍, 何加铭*, 邰晓英(宁波大学信息科学与工程学院, 浙江宁波 315211)摘要: 提出了一种嵌入式矢量字体引擎的开发和实现方法. 首先剖析了FreeType开源引擎的体系结构和渲染流程, 然后针对TrueType矢量字体对其裁剪, 包括去掉不相关字体解释器及宏、对轮廓分解算法优化等, 最终在大小和速度上进行优化, 开发出新的字体引擎. 该引擎能很好地适用于存储空间小、运算能力不高的嵌入式系统, 并在MTK平台下测试通过.关键词: FreeType; TrueType矢量字体; 嵌入式平台中图分类号: TP317 文献标识码: A随着嵌入式系统的发展和应用, 在嵌入式系统中使用高质量的汉字字库已成为关注的热点. 尤其是在与人们生活关系日益密切的移动通信设备中, 高效地显示出美观大方的汉字已成为当前主要的市场需求. 目前, 嵌入式系统的字库还是以点阵字为主. 由于点阵字库不能缩放, 因此对于高分辨率屏幕而言, 显示数据量大, 其显示速度比普通的TrueType矢量字库慢[1]. 而在嵌入式系统中使用矢量字体可以实现较好的显示效果, 并且矢量字体可以对字体风格、字体大小、字体的颜色等进行动态渲染. 与传统使用的点阵字库相比, TrueType字库可以高质量地实现字符的无级放大或缩小, 并实现字符的旋转、倾斜等操作, 方便地实现“所见即所得”.在嵌入式系统中使用矢量字体需要相应的字体引擎. 在PC机上, 通常可以使用FreeType字体引擎来渲染TrueType矢量字库. FreeType库是一个开源字体引擎[2], 它支持单色位图、反走样位图的渲染, 并且提供统一的接口来访问多种字体格式文件, 包括TrueType、OpenType、Type1、CID、CFF、Windows FON/FNT、X11 PCF等. 少数嵌入式系统可以直接支持FreeType字体引擎[3]. 而对大多数嵌入式系统来说, 由于存储空间和运算能力的限制, 并不能直接使用FreeType字体引擎, 并且在移植时需要对其裁剪优化[4].1FreeType字体引擎和TrueType矢量字体1.1TrueType矢量字体TrueType字体格式是由美国Apple公司和Microsoft公司联合提出的一种新型数字化矢量字体格式, 它采用几何学中的二次B样条曲线及直线来描述字体的外形轮廓. 二次B样条曲线具有一阶连续性和正切连续性. 抛物线可由二次B样条曲线来精确表示, 而更为复杂的字体外形可用B收稿日期:2010-03-24. 宁波大学学报(理工版)网址: 基金项目:科技部创新基金(60472099); 浙江省科技计划项目(2009C31107).第一作者:黄秀珍(1983-), 女, 江西永修人, 在读硕士研究生, 主要研究方向: 网络与终端软件技术. E-mail: hxzjxsd1983@ *通讯作者:何加铭(1949-), 男, 浙江杭州人, 博导/教授, 主要研究方向: 网络与终端软件技术. E-mail: hejiaming@第4期黄秀珍, 等: 基于FreeType嵌入式矢量字体引擎的研究 57样长曲线的数学特性以数条相接的二次B样条曲线及直线来表示.描述TrueType字体的文件(内含TrueType字体描述信息、指令集、各种标记表格等)可以通用于MAC和PC平台. 在Mac平台上, 它以“Sfnt”资源的形式存放, 而在Windows平台上以TTF文件出现. 为保证TrueType的跨平台兼容性, 字体文件的数据格式采用Motorola式数据结构(高位在前, 低位在后)存放. 所有Intel平台的TrueType解释器在执行之前, 只要进行适当的预处理即可. Windows的TrueType解释器已包含在其GDI(图形设备接口)中, 所以任何Windows支持的输出设备都能用TrueType字体输出.1.2FreeType字体引擎FreeType库使用ANSI C开发的开源字体引擎, 因此, FreeType的用户可以灵活地对它进行裁剪, 并且, 它可以被用在诸如图像库、展出服务器、字体转换工具、图像文字产生工具等多种产品上. 移动通信平台中引入FreeType字体引擎有以下优势: (1)占用的存储容量小, FreeType库文件通过裁剪定制可减少存储大小和运行时间; (2)渲染字体清晰美观, 字体大小和风格可变.为了使FreeType字体引擎定制到嵌入式系统, 需要对其进行裁剪. 在32位嵌入式系统下, 存储容量的大小是嵌入式系统处理矢量字库的一个瓶颈, 这就需要我们深入研究其体系结构及渲染流程, 以做进一步的裁剪优化.2FreeType体系结构和渲染流程在使用FreeType字体引擎显示字符时, 需要调用其模块化函数, 其中的每个函数都是封装一个功能模块的组件.其具体步骤如下: 首先建立初始化类库, 装载Face信息, 然后设置字体大小, 并设置轮廓信息, 最后将轮廓渲染为位图信息. 其具体流程图如图1所示.对应流程图的步骤说明如下:(1) 首先对FreeType库进行初始化, 并且读取矢量字库文件.FT_Init_FreeType(&library);FT_New_Face(library,filename,0,&face);这里的library是个全局变量, 而filename是矢量字库的路径, 通过以上2个步骤首先建立了1个FreeType库的实例. 通过FT_New_Face加载1个TrueType矢量字库, 得到字体的face对象接口.(2) 设置当前像素尺寸.使用函数FT_Set_Pixel_Size(face,0,size)来完成设置当前像素尺寸, 也可以使用函数FT_Set_ Char_Size(), 但要注意后面的函数设置的大小不是以像素为单位的.(3) 设置字符的轮廓信息.由于在TrueType文件格式中, 每个字符的轮廓信息是根据字形索引来存放的, 所以首先需要根据字符的编码来得到字形索引, 代码如下: FT_Get_Char_Index(face,charcode);从face中来得到字符对应的字形后, 需要读取到字形槽中才能使用.FT_Load_Glyph(face,glyph_index,FT_LOAD_ DEFAULT);Get_Glyph(face->glyph,&glyph);最后提取字形槽中的字形图, 即点阵信息.FT_Glyph_To_Bitmap(&glyph,FT_RENDER_MODE_NORMAL,0,1);图1 FreeType字符显示流程58 宁波大学学报(理工版) 2010bitmap_glyph = (FT_BitmapGlyph)glyph;经过上述过程转化之后, 字符的位图信息就存放在bitmap_glyph的参数里面, 嵌入式系统GDI就可以把这个字符显示出来.(4) 改变字体风格.粗体的显示直接调用FT_GlyphSlot_Embolden (face->glyph). 由于FreeType中没有直接对斜体的支持, 所以需要自己对矢量的字形轮廓进行变换, 定义变换矩阵后进行如下变换:error = FT_Set_Transform(face, /* 目标face对象 */&matrix, /* 指向2×2矩阵的指针 */&delta ); /* 指向2维矢量的指针 */此函数将对指定的face对象设置变换. 它的第2个参数是1个指向FT_Matrix结构的指针. 该结构描述了1个2×2仿射矩阵. 第3个参数是1个指向FT_Vector结构的指针, 该结构描述了1个简单的二维矢量, 该矢量用来在2×2变换后对字形图像平移.3裁剪与优化由于FreeType库中的API都是封装好的组件, 其中的具体实现细节只在源码中才能查看到. 通过对源码的分析, 笔者去除了一些无关的定义及步骤, 裁剪和改进了一些算法.首先, 在对FreeType库进行初始化时, 去除FT_Library和FT_Face等复杂的类对象. 由于FreeType中采用了面对对象的思想编程, 因此其包含了TrueType、Type1、CID、CFF、Windows FON/ FNT、X11 PCF等多个字体驱动的抽象接口, 并使用抽象的类来统一所有字体驱动初始化过程. 而这里我们只需用到格式TrueType矢量字体, 不需要对字体驱动进行判断, 可直接使用TrueType字体driver.在对TrueType字体进行初始化时, 首先要载入其各个表项. 将Library对象、face对象的创建和初始化以及对字体平台驱动的判断都简化为TrueType中各个重要表项的载入, 以对应初始化字体的相关参数.设置字体大小部分比较简单. 主要是根据指定的字体大小, 确定缩放的规模及缩放后字体的规格参数: 如额定的宽度和高度、EM正方形的像素宽度和高度等. 而此部分也不用face对象等结构体.取得字符轮廓是字符渲染的关键步骤. 在FreeType中有多种字体, 也有多种字符轮廓, 这里我们只用TrueType字符轮廓的载入方法. 首先用函数FT_Get_Char_Index取得字符索引, 查找方法为有线性查找和二分查找. 对有序数据使用二分法查找字符索引, 然后根据字符索引和local表中偏移量得到glyf表中的图元信息. 载入图元信息时, 首先载入图元头, 然后载入简单图元, 最后再处理图元信息.最后轮换的图元数据为点阵信息时, 可选择使用smooth渲染器. 它能生成256色位图信息, 字体边缘并且有渐变的效果. 在进行渲染时, 先将作平移操作, 以调整到相对目标窗口的位置. 然后计算出Control Box的值, 最后将轮廓分解、光栅化填充.3.1读取字库去除不相关的字体driver初始化, 直接使用TrueType字体driver初始化. 首先是打开字库文件, 读取初始化信息. 由于TrueType矢量字体是以多个表的形式来包含组成字体轮廓的数据, 因此字体引擎需要各表的信息来渲染其字体. 接着读取表目录. 每个表都有1个tableentry结构项, 而tableentry结构包含了资源标记、校验和、偏移量和每个表的大小. 由于TrueType字体中的每个表都保存了不同的逻辑信息, 如图元中数据、字符到图元的映射、字距调整信息等等. 因此, 有些表是必须的, 而有些是可选的. 然后依次读取常用表的第4期 黄秀珍, 等: 基于FreeType 嵌入式矢量字体引擎的研究 59信息, 包括: head, maxp, cmap, hhea, vhea, hmtx, vmtx, loca 等. 3.2 设置字体大小主要是对函数FT_Set_Pixel_Sizes 的实现部分做了优化. 原函数实现部分主要在FT_Request_ Size 的几个函数, 主要是按照设置的字体高度和宽度取得字体缩放的各个参数, 用到数学中的除法函数FT_DivFix 、FT_MulFix 及取整函数FT_PIX_ CEIL 等.3.3 取得字符轮廓信息首先取得字符的字形索引, 函数FT_Get_ Char_Index()中主要使用的是二分法查找cmap 表中字形索引, 而不使用线性查找法.然后根据字形索引和偏移查找字符对应的图元信息. 图元数据(glyf 表)是TrueType 字体的核心信息, 通常它是最大的表. 因为, 位置索引是张单独的表, 而图元数据表则完全只是图元的序列而已; 每个图元以图元头结构开始, 简单图元中保存了当前图元的轮廓线的数目, 合成图元的轮廓线总数必须基于组成该合成图元的所有图元的数据计算得到. 对于简单图元而言, 图元的描述紧跟在图元头结构之后. 图元的描述由几部分信息组成: 所有轮廓线结束点的索引、图元指令和一系列的控制点. 每个控制点包括1个以x 和y 坐标的标志. 概念上来讲, 控制所需的信息和GDI 函数PolyDraw 函数所需的信息相同, 都是1组标志和1组点的坐标. 图元可以包含1条或多条轮廓线. 比如, 汉字“宋”有3条轮廓线和若干控制点, 图2为其控制点的显示.图2 宋体的“宋”字的控制点信息TrueType 字体中的图元轮廓是用二阶Bezier曲线定义的, 具体有3个点: 1个曲线上的点, 1个曲线外的点和另1个曲线上的点. 多个连续的不在曲线上的点是允许的. 3.4 轮换图元数据为点阵信息在3.3小节中, 主要是从字库中提取图元信息, 而本节则根据图元信息进行作图和填充. 作图是根据关键点画直线和贝塞尔曲线, 然后是光栅填充, 此时, 以将填充后的字模提取并缩小保存(字模一般是2048×2048).FreeType 缺省带了2个渲染器: raster 支持从向量轮廓(由FT_Outline 对象描述)到单色位图的转换; smooth 支持同样的轮廓转换到高质量反走样的象素图, 其使用256级灰度. smooth 渲染器也支持直接生成span. 在此, 由于我们需要得到是高质量反走样的位图, 所以使用的是smooth 渲染器.首先, 进行轮廓曲线分解. 1个轮廓是2D 平面上一系列封闭的轮廓线, 每个轮廓线由一系列线段和Bezier 弧组成. 应用如下规则于将轮廓点分解成线段和弧.2个相邻的“on ”点表示1条线段; 1个conic off 点在2个on 点之间表示1个conic Bezier 弧, off 点是控制点, on 点是起点和终点; 2个相邻的cubic off 点在2个on 点之间表示1个cubic Bezier 弧, 它必须有2个cubic 控制点和2个on 点. 最后, 强制在2个相邻的conic off 点的正中间创建1个虚拟的on 点.装入或变换过的轮廓必须在渲染成目标位图之前作平移操作, 以调整到相对目标窗口的位置.4 实验与讨论首先, 在MTK 模拟器上测试. 运行环境如下: PC 机CPU 2.17GHz, 内存1GB, 相应软件平台为VC 6.0. 图3中MTK 平台为已有的点阵字体显示. 而在模拟器上, 字体显示效果如图4和图5所示.图4和图5中显示的字体为TrueType 矢量字60 宁波大学学报(理工版) 2010体黑体和行楷, 使用的字体引擎为制作的新引擎. 在已有点阵字体显示时, 如换种字体就要在平台中加入相应的点阵资源再烧机, 然而使用矢量字体后, 只需在手机中加入1种字体文件即可, 不需要修改操作系统. 矢量字体引擎显示的字体为256色灰度级, 具有边缘渐变效果, 字体风格也可以进行动态设置.笔者测试了150个汉字, 并分别在FreeType 引擎和新引擎上测试其平均显示时间, 测试数据见表1.表1 FreeType 引擎和新引擎测试汉字平均显示时间比较测试方法 FreeType 引擎平均显示时间/ms新引擎平均显示时间/ms利用MTK 显示150个汉字32.075 15.675由表1数据可见, 在VC 编译器下, 新引擎运行时间只占原引擎时间的50%左右, 新引擎在运行时间上有明显的优势.同时, 笔者也在MTK 平台手机真机上进行实验. MTK25平台手机内核小. MTK25平台默认的是128Mbit flash memory 和32Mbit SRAM, 因为1Byte 等于8bit, 所以也就是我们通常所说的是16M ROM 和4M RAM, 其中, 文件系统占用2M. 未裁剪优化的FreeType 字体在引擎移植入后, 会因为存储运算空间不足而死机黑屏. 而经过我们对FreeType 的裁剪和优化之后, 新引擎能顺利在MTK 平台中运行. 运行时的参数如下:字体引擎: 代码大小11K; 加载后占用手机ROM 大小: 39K; 运行时占用手机RAM 大小: 139K. 由于新引擎存储和运算时占用空间小, 加载后, 速度几乎没有变慢, 因此没有出现字符显示延迟现象.5 结语提出了一种嵌入式矢量字体引擎的开发和实现方法. 该方法首先剖析了FreeType 开源引擎的体系结构和渲染流程, 然后针对TrueType 矢量字体对其裁剪, 包括去掉不相关字体解释器及宏、对轮廓分解算法优化等, 最终在大小和速度上进行优化, 开发出新的字体引擎. 在MTK 平台下测试结果表明, 采用本算法得到字体引擎与FreeType 字体引擎的显示的字体都具有256色灰度级, 具有边缘渐变效果, 可以动态设置字体风格, 但新引擎显示速度明显加快、存储空间明显减少. 新引擎能很好的适用于存储空间小、运算能力不高的嵌入式系统. 由于新引擎使用的是ANSI C 编写, 适合移植到各类有文字显示要求的嵌入系统中,如手机、图3 MTK 平台点阵字体显示图4 MTK 平台中矢量字体黑体显示图5 MTK 平台中矢量字体行楷显示第4期黄秀珍, 等: 基于FreeType嵌入式矢量字体引擎的研究 61PDA等. 下一步就可以把此引擎移植于他嵌入式系统中. 移植时, 只需要连接字体引擎和嵌入式系统GDI即可, 且此项工作与各个嵌入式系统相关.参考文献:[1]Microsoft typograph. What is TrueType[EB/OL]. (1997-06-30) [2009-01-13]. /typogra- phy/WhatIsTrueType.mspx.[2]Werner Lemberg. The freetype project: A free,high-quality and portable font engine[EB/OL]. (2009-01-14) [2009-1-14]. .[3]孙晓辉, 陈晓, 王春, 等. 在嵌入式浏览器中使用TrueType矢量字库[J]. 电视技术, 2007, 31(8):120-122. [4]Wang Yuanyuan, Gao Mingyu, Zeng Yu. Chinese displaytechnology on embedded platform using simple direct- media layer (SDL)[C]//Shanghai, 21ETT and GRS, 2008: 3563-3566.[5]万明磊, 刘卫忠, 李泉, 等. 矢量字体在顶盒上的实现与应用[J]. 数字电视, 2004(16):46-48.Design and Implementation of Vector Font EngineBased on FreeType in Embedded SystemHUANG Xiu-zhen, HE Jia-ming*, TAI Xiao-ying( Faculty of Information Science and Technology, Ningbo University, Ningbo 315211, China )Abstract: A method to develop and implement the font engine in the embedded system is introduced. First, we analyze the system architecture and rending process of open source font engine of FreeType. Then we tailor and optimize it for TrueType vector font by removing irrelevant font interpreter and macro, as well as optimizing the glyph decomposition algorithm. Finally we develop a new font engine which is optimized in size and display speed. The new engine features in lower storage space and higher arithmetic speed for the embedded system. The test on MTK platform proves its efficiency and practicality.Key words: FreeType; TrueType vector font; embedded platformCLC number: TP317 Document code: A(责任编辑 章践立)。
基于potrace算法的中文矢量字库生成方法

基于potrace算法的中文矢量字库生成方法(最新版4篇)篇1 目录一、引言二、Potrace 算法简介三、基于 Potrace 算法的中文矢量字库生成方法四、实验与结果分析五、结论篇1正文一、引言随着计算机技术的发展,中文字库在信息处理、印刷、广告设计等领域发挥着越来越重要的作用。
为了满足各种应用场景的需求,研究者们一直在探索更高效、精确的中文字库生成方法。
矢量字库具有字形美观、放大不失真、存储空间小等优点,因此,研究基于 Potrace 算法的中文矢量字库生成方法具有重要意义。
二、Potrace 算法简介Potrace 算法是一种基于轮廓提取和简化的矢量字形生成方法,起初用于英文字符的矢量化处理。
它通过对原始点阵字形进行边缘检测、去噪、轮廓提取和简化等操作,生成简洁、美观的矢量字形。
三、基于 Potrace 算法的中文矢量字库生成方法本文提出了一种基于 Potrace 算法的中文矢量字库生成方法,主要包括以下几个步骤:1.数据预处理:收集大量中文字符的点阵图像,并将其转换为适合Potrace 算法处理的格式。
2.轮廓提取:使用 Potrace 算法对预处理后的点阵图像进行轮廓提取,得到一系列的中文矢量字形。
3.轮廓简化:为了得到简洁、美观的矢量字形,本文采用基于梯度的轮廓简化方法对提取的矢量字形进行简化。
4.字形优化:根据实际应用需求,对简化后的矢量字形进行进一步的优化,使其满足特定领域的字形规范。
四、实验与结果分析本文选取了多种中文字符进行实验,通过对比实验,验证了所提出的基于 Potrace 算法的中文矢量字库生成方法的有效性。
实验结果表明,本文提出的方法生成的矢量字形具有较高的精度和美观度,且存储空间较小。
五、结论本文提出了一种基于 Potrace 算法的中文矢量字库生成方法,实验结果表明,该方法具有较高的字形精度和美观度,且存储空间较小,具有较好的应用前景。
篇2 目录一、引言二、Potrace 算法的原理和应用三、基于 Potrace 算法的中文矢量字库生成方法四、实验结果与分析五、结论篇2正文一、引言随着计算机技术的不断发展,中文字库在信息处理、印刷排版和数字媒体等领域的需求日益增长。
矢量图都有保存格式

矢量图都有保存格式.psMIME类型:application/postscript固有名称:PostScript描述:属于基于矢量页面描述语言,由Adobe研制和拥有。
Postscript是强大的stack-based编程语言。
受很多激光打印机支持。
.eps固有名称:Encapsulated PostScript描述:一个描述小型矢量图的PostScript文件,对比与描述整页的文件格式.pdfMIME类型:application/pdf固有名称:可携式文件格式描述:一个简化的PostScript版本,允许包含有多页和链接的文件。
于Adob e Acrobat Reader或Adobe eBook Reader配合使用。
.aiMIME类型:application/illustrator固有名称:Adobe Illustrator Document描述:Adobe Illustrator使用的矢量格式。
.fh固有名称:Macromedia Freehand Document描述:Macromedia Freehand使用的矢量格式。
.swfMIME类型:application/x-shockwave-flash固有名称:Flash描述:Flash是用来播放包含在SWF文件中的矢量动画的浏览器插件。
有几中应用程序可以创建SWF文件,包括由Macromedia发布的Flash。
.fla固有名称:Flash Source File S描述:hockwave Flash源文件,只能使用与Macromedia Flash软件。
.svgMIME类型:image/svg+xml固有名称:Scalable Vector Graphics描述:一个基于XML的矢量图格式,由World Wide Web Consortium为浏览器定义的标准。
.wmfMIME类型:image/x-wmf固有名称:Windows图元文件格式描述:作为微软操作系统存储矢量图和光栅图的格式。
点阵字库和矢量字库
点阵字库的生产原理(转)2011-05-17 15:31:45| 分类:其他技术| 标签:|字号大中小订阅点阵字库的生产原理所有的汉字或者英文都是下面的原理,由左至右,每8个点占用一个字节,最后不足8个字节的占用一个字节,而且从最高位向最低位排列。
生成的字库说明:(以12×12例子)一个汉字占用字节数:12÷8=1····4也就是占用了2×12=24个字节。
编码排序A0A0→A0FE A1A0→A2FE依次排列。
以12×12字库的“我”为例:“我”的编码为CED2,所以在汉字排在CEH-AOH=2EH区的D2H-A0H=32H个。
所以在12×12字库的起始位置就是[{FE-A0}*2EH+32H]*24=104976开始的24个字节就是我的点阵模。
其他的类推即可。
英文点阵也是如此推理。
在DOS程序中使用点阵字库的方法首先需要理解的是点阵字库是一个数据文件,在这个数据文件里面保存了所有文字的点阵数据.至于什么是点阵,我想我不讲大家都知道的,使用过"文曲星"之类的电子辞典吧,那个的液晶显示器上面显示的汉子就能够明显的看出"点阵"的痕迹.在 PC 机上也是如此,文字也是由点阵来组成了,不同的是,PC机显示器的显示分辨率更高,高到了我们肉眼无法区分的地步,因此"点阵"的痕迹也就不那么明显了.点阵、矩阵、位图这三个概念在本质上是有联系的,从某种程度上来讲,这三个就是同义词.点阵从本质上讲就是单色位图,他使用一个比特来表示一个点,如果这个比特为0,表示某个位置没有点,如果为1表示某个位置有点.矩阵和位图有着密不可分的联系,矩阵其实是位图的数学抽象,是一个二维的阵列.位图就是这种二维的阵列,这个阵列中的 (x,y) 位置上的数据代表的就是对原始图形进行采样量化后的颜色值.但是,另一方面,我们要面对的问题是,计算机中数据的存放都是一维的,线性的.因此,我们需要将二维的数据线性化到一维里面去.通常的做法就是将二维数据按行顺序的存放,这样就线性化到了一维.那么点阵字的数据存放细节到底是怎么样的呢.其实也十分的简单,举个例子最能说明问题.比如说 16*16 的点阵,也就是说每一行有16个点,由于一个点使用一个比特来表示,如果这个比特的值为1,则表示这个位置有点,如果这个比特的值为0,则表示这个位置没有点,那么一行也就需要16个比特,而8个比特就是一个字节,也就是说,这个点阵中,一行的数据需要两个字节来存放.第一行的前八个点的数据存放在点阵数据的第一个字节里面,第一行的后面八个点的数据存放在点阵数据的第二个字节里面,第二行的前八个点的数据存放在点阵数据的第三个字节里面,…,然后后面的就以此类推了.这样我们可以计算出存放一个点阵总共需要32个字节.看看下面这个图形化的例子:| |1| | | | | | | | | | |1| | | || | |1|1| |1|1|1|1|1|1|1|1|1| | || | | |1| | | | | | | | |1| | | ||1| | | | | |1| | | | | |1| | | || |1|1| | | |1| | | | | |1| | | || | |1| | | |1| | | | |1| | | | || | | | |1| | |1| | | |1| | | | || | | |1| | | |1| | |1| | | | | || | |1| | | | | |1| |1| | | | | ||1|1|1| | | | | | |1| | | | | | || | |1| | | | | |1| |1| | | | | || | |1| | | | |1| | | |1| | | | || | |1| | | |1| | | | | |1| | | || | |1| | |1| | | | | | |1|1|1| || | | | |1| | | | | | | | |1| | || | | | | | | | | | | | | | | | |可以看出这是一个"汉"字的点阵,当然文本的方式效果不是很好.根据上面的原则,我们可以写出这个点阵的点阵数据:0x40,0x08,0x37,0xfc,0x10,0x08,…, 当然写这个确实很麻烦所以我不再继续下去.我这样做,也只是为了向你说明,在点阵字库中,每一个点阵的数据就是按照这种方式存放的.当然也存在着不规则的点阵,这里说的不规则,指的是点阵的宽度不是8的倍数,比如12*12 的点阵,那么这样的点阵数据又是如何存放的呢?其实也很简单,每一行的前面8个点存放在一个字节里面,每一行的剩下的4点就使用一个字节来存放,也就是说剩下的4个点将占用一个字节的高4位,而这个字节的低4位没有使用,全部都默认的为零.这样做当然显得有点浪费,不过却能够便于我们进行存放和寻址.对于其他不规则的点阵,也是按照这个原则进行处理的.这样我们可以得出一个 m*n 的点阵所占用的字节数为 (m+7)/8*n.在明白了以上所讲的以后,我们可以写出一个显示一个任意大小的点阵字模的函数,这个函数的功能是输出一个宽度为w,高度为h的字模到屏幕的 (x,y) 坐标出,文字的颜色为color,文字的点阵数据为 pdata 所指:/*输出字模的函数*/void _draw_model(char *pdata, int w, int h, int x, int y, int color){int i; /* 控制行 */int j; /* 控制一行中的8个点 */int k; /* 一行中的第几个"8个点"了 */int nc; /* 到点阵数据的第几个字节了 */int cols; /* 控制列 */BYTE static mask[8]={128, 64, 32, 16, 8, 4, 2, 1}; /* 位屏蔽字 */w = (w + 7) / 8 * 8; /* 重新计算w */nc = 0;for (i=0; i<h; i++){cols = 0;for (k=0; k<w/8; k++){for (j=0; j<8; j++){if (pdata[nc]&mask[j])putpixel(x+cols, y+i, color);cols++;}nc++;}}}代码很简单,不用怎么讲解就能看懂,代码可能不是最优化的,但是应该是最易读懂的.其中的 putpixel 函数,使用的是TC提供的 Graphics 中的画点函数.使用这个函数就可以完成点阵任意大小的点阵字模的输出.接下来的问题就是如何在汉子库中寻址某个汉子的点阵数据了.要解决这个问题,首先需要了解汉字在计算机中是如何表示的.在计算机中英文可以使用 ASCII 码来表示,而汉字使用的是扩展 ASCII 码,并且使用两个扩展 ASCII 码来表示一个汉字.一个 ASCII 码使用一个字节表示,所谓扩展 ASCII 码,也就是 ASCII 码的最高位是1的 ASCII 码,简单的说就是码值大于等于 128 的 ASCII 码.一个汉字由两个扩展 ASCII 码组成,第一个扩展ASCII 码用来存放区码,第二个扩展 ASCII 码用来存放位码.在 GB2312-80 标准中,将所有的汉字分为94个区,每个区有94个位可以存放94个汉字,形成了人们常说的区位码,这样总共就有 94*94=8836 个汉字.在点阵字库中,汉字点阵数据就是按照这个区位的顺序来存放的,也就是最先存放的是第一个区的汉字点阵数据,在每一个区中有是按照位的顺序来存放的.在汉字的内码中,汉字区位码的存放实在扩展 ASCII 基础上存放的,并且将区码和位码都加上了32,然后存放在两个扩展 ASCII 码中.具体的说就是:第一个扩展ASCII码 = 128+32 + 汉字区码第二个扩展ASCII吗 = 128+32 + 汉字位码如果用char hz[2]来表示一个汉字,那么我可以计算出这个汉字的区位码为:区码 = hz[0] - 128 - 32 = hz[0] - 160位码 = hz[1] - 128 - 32 = hz[1] - 160.这样,我们可以根据区位码在文件中进行殉职了,寻址公式如下:汉字点阵数据在字库文件中的偏移 = ((区码-1) * 94 + 位码) * 一个点阵字模占用的字节数在寻址以后,即可读取汉字的点阵数据到缓冲区进行显示了.以下是实现代码:/* 输出一个汉字的函数 */void _draw_hz(char hz[2], FILE *fp, int x, int y, int w, int h, int color){char f ON tbuf[128]; /* 足够大的缓冲区,也可以动态分配 */int ch0 = (BYTE)hz[0]-0xA0; /* 区码 */int ch1 = (BYTE)hz[1]-0xA0; /* 位码 *//* 计算偏移 */long offset = (long)pf->_hz_buf_size * ((ch0 - 1) * 94 + ch1 - 1);fseek(fp, offset, SEEK_SET); /* 进行寻址 */ fread(fontbuf, 1, (w + 7) / 8 * h, fp); /* 读入点阵数据 */ _draw_model(fontbuf, w, h, x, y, color); /* 绘制字模 */}以上介绍完了中文点阵字库的原理,当然还有英文点阵字库了.英文点阵字库中单个点阵字模数据的存放方式与中文是一模一样的,也就是对我们所写的 _draw_model 函数同样可以使用到英文字库中.唯一不同的是对点阵字库的寻址上.英文使用的就是 ASCII 码,其码值是0到127,寻址公式为:英文点阵数据在英文点阵字库中的偏移 = 英文的ASCII码 * 一个英文字模占用的字节数可以看到,区分中英文的关键就是,一个字符是 ASCII 码还是扩展 ASCII 码,如果是ASCII 码,其范围是0到127,这样是使用的英文字库,如果是扩展 ASCII 码,则与其后的另一个扩展 ASCII 码组成汉字内码,使用中文字库进行显示.只要正确区分 ASCII 码的类型并进行分别的处理,也就能实现中英文字符串的混合输出了.点阵字库和矢量字库的差别我们都只知道,各种字符在电脑屏幕上都是以一些点来表示的,因此也叫点阵.最早的字库就是直接把这些点存储起来,就是点阵字库.常见的汉字点阵字库有 16x16, 24x24 等.点阵字库也有很多种,主要区别在于其中存储编码的方式不同.点阵字库的最大缺点就是它是固定分辨率的,也就是每种字库都有固定的大小尺寸,在原始尺寸下使用,效果很好,但如果将其放大或缩小使用,效果就很糟糕了,就会出现我们通常说的锯齿现象.因为需要的字体大小组合有无数种,我们也不可能为每种大小都定义一个点阵字库.于是就出现了矢量字库.矢量字库矢量字库是把每个字符的笔划分解成各种直线和曲线,然后记下这些直线和曲线的参数,在显示的时候,再根据具体的尺寸大小,画出这些线条,就还原了原来的字符.它的好处就是可以随意放大缩小而不失真.而且所需存储量和字符大小无关.矢量字库有很多种,区别在于他们采用的不同数学模型来描述组成字符的线条.常见的矢量字库有 Type1字库和Truetype字库.在点阵字库中,每个字符由一个位图表示(如图2.5所示),并把它用一个称为字符掩膜的矩阵来表示,其中的每个元素都是一位二进制数,如果该位为1表示字符的笔画经过此位,该像素置为字符颜色;如果该位为0,表示字符的笔画不经过此位,该像素置为背景颜色.点阵字符的显示分为两步:首先从字库中将它的位图检索出来,然后将检索到的位图写到帧缓冲器中.在实际应用中,同一个字符有多种字体(如宋体、楷体等),每种字体又有多种大小型号,因此字库的存储空间十分庞大.为了减少存储空间,一般采用压缩技术.矢量字符记录字符的笔画信息而不是整个位图,具有存储空间小,美观、变换方便等优点.例如:在AutoCAD中使用图形实体-形(Shape)-来定义矢量字符,其中,采用了直线和圆弧作为基本的笔画来对矢量字符进行描述. 对于字符的旋转、放大、缩小等几何变换,点阵字符需要对其位图中的每个象素进行变换,而矢量字符则只需要对其几何图素进行变换就可以了,例如:对直线笔画的两个端点进行变换,对圆弧的起点、终点、半径和圆心进行变换等等.矢量字符的显示也分为两步.首先从字库中将它的字符信息.然后取出端点坐标,对其进行适当的几何变换,再根据各端点的标志显示出字符.轮廓字形法是当今国际上最流行的一种字符表示方法,其压缩比大,且能保证字符质量.轮廓字形法采用直线、B样条/Bezier曲线的集合来描述一个字符的轮廓线.轮廓线构成一个或若干个封闭的平面区域.轮廓线定义加上一些指示横宽、竖宽、基点、基线等等控制信息就构成了字符的压缩数据.如何使用Windows的系统字库生成点阵字库?我的程序现在只能预览一个汉字的不同字体的点阵表达.界面很简单: 一个输出点阵大小的选择列表(8x8,16x16,24x24等),一个系统中已有的字体名称列表,一个预览按钮,一块画图显示区域.得到字体列表的方法:(作者称这一段是用来取回系统的字体,然后添加到下拉框中) //取字体名称列表的回调函数,使用前要声明一下该方法int CALLBACK MyEnumF ON tProc(ENUMLOGFONTEX* lpelf,NEWTEXTMETRICEX* lpntm,DWORD nFontType,long lParam){CFontPeekerDlg* pWnd=(CFontPeekerDlg*) lParam;if(pWnd){if( pWnd->m_combo_sfont.Find ST ring(0, lpelf->elfLogFont.lfFaceName) <0 )pWnd->m_combo_sfont.AddString(lpelf->elfLogFont.lfFaceName);return 1;}return 0;}//说明:CFontPeekerDlg 是我的dialog的类名, m_combo_sfont是列表名称下拉combobox关联的control变量//调用的地方 (******问题1:下面那个&lf怎么得到呢……){::EnumFontFamiliesEx((HDC) dc,&lf, (FONTENUMPROC)MyEnumFontProc,(LPARAM) this,0);m_combo_sfont.SetCurSel(0);}字体预览:如果点阵大小选择16,显示的时候就画出16x16个方格.自定义一个类CMyStatic继承自CStatic,用来画图.在CMyStatic的OnPaint()函数中计算并显示.取得字体:常用的方法:用CreateFont创建字体,把字TextOut再用GetPixel()取点存入数组. 缺点:必须把字TextOut出来,能在屏幕上看见,不爽.我的方法,用这个函数:GetGlyphOutline(),可以得到一个字的轮廓矢量或者位图.可以不用textout到屏幕,直接取得字模信息函数原型如下:DWORD GetGlyphOutline(HDC hdc, //画图设备句柄UINT uChar, //将要读取的字符/汉字 UINT uFormat, //返回数据的格式(字的外形轮廓还是字的位图) LPGLYPHMETR ICS lpgm, // GLYPHMETRICS结构地址,输出参数DWORD cbBuffer, //输出数据缓冲区的大小LPVOID lpvBuffer, //输出数据缓冲区的地址CO NS T MAT2 *lpmat2 //转置矩阵的地址);说明:uChar字符需要判断是否是汉字还是英文字符.中文占2个字节长度.lpgm是输出函数,调用GetGlyphOutline()是无须给lpgm 赋值.lpmat2如果不需要转置,将 eM11.value=1; eM22.value=1; 即可.cbBuffer缓冲区的大小,可以先通过调用GetGlyphOutline(……lpgm, 0, NULL, mat); 来取得,然后动态分配lpvBuffer,再一次调用GetGlyphOutline,将信息存到lpvBuffer. 使用完毕后再释放lpvBuffer.程序示例:(***问题2:用这段程序,我获取的字符点阵总都是一样的,不管什么字……)……前面部分省略……GLYPHMETRICS glyph;MAT2 m2;memset(&m2, 0, sizeof(MAT2));m2.eM11.value = 1;m2.eM22.value = 1;//取得buffer的大小DWORD cbBuf = dc.GetGlyphOutline( nChar, GGO_BITMAP, &glyph,0L, NULL, &m2);BYTE* pBuf=NULL;//返回GDI_ERROR表示失败.if( cbBuf != GDI_ERROR ){pBuf = new BYTE[cbBuf];//输出位图GGO_BITMAP 的信息.输出信息4字节(DWORD)对齐dc.GetGlyphOutline( nChar, GGO_BITMAP, &glyph, cbBuf, pBuf, &m2);}else{if(m_pFont!=NULL)delete m_pFont;return;}编程中遇到问题:一开始,GetGlyphOutline总是返回-1,getLastError显示是"无法完成的功能",后来发现是因为调用之前没有给hdc设置Font.后来能取得pBuf信息后,又开始郁闷,因为不太明白bitmap的结果是按什么排列的.后来跟踪汉字"一"来调试(这个字简单),注意到了 glyph.gmBlackBoxX 其实就是输出位图的宽度,glyph.gmBlackBoxY就是高度.如果gmBlackBoxX=15,glyph.gmBlackBoxY=2,表示输出的pBuf中有这些信息:位图有2行信息,每一行使用15 bit来存储信息.例如:我读取"一":glyph.gmBlackBoxX = 0x0e,glyph.gmBlackBoxY=0x2; pBuf长度cbBuf=8 字节pBuf信息: 00 08 00 00 ff fc 00 00字符宽度 0x0e=14 则第一行信息为: 0000 0000 0000 100 (只取到前14位)第二行根据4字节对齐的规则,从0xff开始 1111 1111 1111 110看出"一"字了吗?呵呵直到他的存储之后就可以动手解析输出的信息了.我定义了一个宏#define BIT(n) (1<<(n)) 用来比较每一个位信息时使用后来又遇到了一个问题,就是小头和大头的问题了.在我的机器上是little endian的形式,如果我用unsigned long *lptr = (unsigned long*)pBuf;//j from 0 to 15if( *lptr & BIT(j) ){//这时候如果想用j来表示写1的位数,就错了}因为从字节数组中转化成unsigned long型的时候,数值已经经过转化了,像上例中,实际上是0x0800 在同BIT(j)比较.不多说了,比较之前转化一下就可以了if( htonl(*lptr) & BIT(j) )Unicode中文点阵字库的生成与使用点阵字库包含两部分信息.首先是点阵字库文件头信息,它包含点阵字库文字的字号、多少位表示一个像素,英文字母与符号的size、起始和结束 unicode编码、在文件中的起始偏移,汉字的size、起始和结束unicode编码、在文件中的起始偏移.然后是真实的点阵数据,即一段段二进制串,每一串表示一个字母、符号或汉字的点阵信息.要生成点阵字库必须有文字图形的来源,我的方法是使用ttf字体.ttf字体的显示采用的是SDL_ttf库,这是开源图形库SDL的一个扩展库,它使用的是libfreetype以读取和绘制ttf字体.它提供了一个函数,通过传入一个Unicode编码便能输出相应的文字的带有alpha 通道的位图.那么我们可以扫描这个位图以得到相应文字的点阵信息. 由于带有alpha通道,我们可以在点阵信息中也加入权值,使得点阵字库也有反走样效果.我采用两位来表示一个点,这样会有三级灰度(还有一个表示透明).点阵字库的显示首先需要将文件头信息读取出来,然后根据unicode编码判断在哪个区间内,然后用unicode编码减去此区间的起始unicode编码,算出相对偏移,并加上此区间的文件起始偏移得到文件的绝对偏移,然后读出相应位数的数据,最后通过扫描这段二进制串,在屏幕的相应位置输出点阵字型.显示点阵字体需要频繁读取文件,因此最好做一个固定大小的缓存,采用LRU置换算法维护此缓存,以减少磁盘读取.。
矢量图的扩展名是什么格式的?与JPG有什么不同?有什么作用?

矢量图的扩展名是什么格式的?与JPG有什么不同?有什么作
用?
bmp和jpg都为位图
同等情况下bmp的图像质量要好于jpg
jpg是有损压缩而bmp是基本无损的
但打印要和分辨率关系更大一点
同样的格式一样有图像的优略之差的:)
常用的矢量图格式
*.bw是包含各种像素信息的一种黑白图形文件格式。
*.cdr (CorelDraw)
*.cdr是CorelDraw中的一种图形文件格式。
它是所有CorelDraw 应用程序中均能够使用的一种图形图像文件格式。
*.col(Color Map File)
*.col是由Autodesk Animator、Autodesk Animator Pro等程序创建的一种调色板文件格式,其中存储的是调色板中各种项目的RGB值。
*.dwg
*.dwg是AutoCAD中使用的一种图形文件格式。
*.dxb(drawing interchange binary)
*.dxb是AutoCAD创建的一种图形文件格式。
*.dxf(Autodesk Drawing Exchange Format)
*.dxf是AutoCAD中的图形文件格式,它以ASCII方式储存图形,在表现图形的大小方面十分精确,可被CorelDraw、3DS等大型软件调用编辑。
*.wmf(Windows Metafile Format)
*.wmf是Microsoft Windows中常见的一种图元文件格式,它具有文件短小、图案造型化的特点,整个图形常由各个独立的组成部分拼。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
located in memory at a fixed address specified in
the character glyphs. Typically, device drivers use the Windows 3.00
version of a font only when both of these conditions are true.
the keyword FONTFMT or S12687.
More Information:
Formats for Microsoft Windows font files are defined for both raster
with future versions of Windows, these fields should be set to zero.
All device drivers support the Windows 2.x fonts. However, not all
(raster) font file. If the low-order bit is 1, it is a
vector font file. The second bit is reserved and must
dFlags, dfAspace, dfBspace, dfCspace, dfColorPointer, and dfReserved1.
These fields are not used in Windows 3.00. To ensure compatibility
byte is set if the font was realized by a device. The
remaining bits in the low byte are reserved and set to
zero.
The high byte is reserved for device use and will
always be set to zero for GDI-realized standard fonts.
dfVersion 2 bytes specifying the version (0200H or 0300H) of
the file.
dfSize 4 bytes specifying the total size of the file in
Windows 3.00 font files is shown in the following list:
Field Description
----- -----------
dfBitsOffset, the third bit is set to 1; otherwise, the
bit is set to 0 (zero). The high-order bit of the low
more frequently used by GDI itself than by support modules.
Both raster and vector font files begin with information that is
The Windows 3.00 Developer 's Notes " (Q65260).
This article can be found in the Software/Data Library by searching on
consists of structures that describe the bits for characters in the
font file. This version enables fonts to exceed 64K in size, the size
The low-order byte is exclusively for GDI use. If the
low-order bit of the WORD is zero, it is a bitmap
device drivers support the Windows 3.00 version.
Windows 3.00 font files include the glyph table in dfCharTable, which
common to both, and then continue with information that differs for
each type of file.
For Windows 3.00, the font-file header includes six new fields:
INF: Font-File Format [P_WinSDK]
3.00
WINDOWS
PSSONLY | Windows 3 Developer 's Notes summary ENDUSER
Physical fonts with the high-order bit of the low byte
set may use this byte to describe themselves. GDI will
3.00 in protected (standard or 386 enhanced) mode with an 80386 (or
higher) processor where the processor 's 32-bit registers can access
Font files are stored with an .FNT extension of the form NAME.FNT. The
information at the beginning of both raster and vector versions of
the contents of the other articles, and procedures for ordering a
hard-copy set, can be found in the knowledge base article titled "Ie: This article is part of a set of seven articles, collectively
called the "Windows 3.00 Developer 's Notes. " More information about
bytes.
dfCopyright 60 bytes specifying copyright information.
dfType 2 bytes specifying the type of font file.
Because of the 32-bit offsets and their potentially large size, these
fonts are designed for use on systems that are running Windows version
limit of Windows 2.x fonts. This is made possible by the use of 32-bit
offsets to the character glyphs in dfCharTable.
and vector fonts. These formats can be used by smart text generators
in some GDI support modules. The vector formats, in particular, are