HADOOP大数据平台系统思路流程图
《Hadoop大数据技术》课程理论教学大纲

《Hadoop大数据技术》课程教学大纲一、课程基本情况课程代码:1041139083课程名称(中/英文):Hadoop大数据技术/Hadoop Big Data Technology课程类别:专业必修课学分:3.5总学时:56理论学时:32实验/实践学时:24适用专业:数据科学与大数据技术适用对象:本科先修课程:JA V A程序设计、Linux基础教学环境:课堂、多媒体、实验机房二、课程简介《Hadoop大数据技术》课程是数据科学与大数据技术专业的专业必修课程。
《Hadoop大数据技术》主要学习当前广泛使用的大数据Hadoop平台及其主要组件的作用及使用。
通过学习Hadoop 平台框架,学会手动搭建Hadoop环境,掌握Hadoop平台上存储及计算的原理、结构、工作流程,掌握基础的MapReduce编程,掌握Hadoop生态圈常用组件的作用、结构、配置和工作流程,并具备大数据的动手及问题分析能力,使用掌握的知识应用到实际的项目实践中。
课程由理论及实践两部分组成,课程理论部分的内容以介绍Hadoop平台主要组件的作用、结构、工作流程为主,对Hadoop 平台组件的作用及其工作原理有比较深入的了解;课程同时为各组件设计有若干实验,使学生在学习理论知识的同时,提高实践动手能力,做到在Hadoop的大数据平台上进行大数据项目开发。
三、课程教学目标2.课程教学目标及其与毕业要求指标点、主要教学内容的对应关系四、教学内容(一)初识Hadoop大数据技术1.主要内容:掌握大数据的基本概念、大数据简史、大数据的类型和特征、大数据对于企业带来的挑战。
了解对于大数据问题,传统方法、Google的解决方案、Hadoop框架下的解决方案,重点了解Google的三篇论文。
掌握Hadoop核心构成、Hadoop生态系统的主要组件、Hadoop发行版本的差异及如何选择;了解Hadoop典型应用场景;了解本课程内容涉及到的Java语言基础;了解本课程实验涉及到的Linux基础。
01第一章 初识Hadoop大数据技术

第1章初识Hadoop大数据技术本章主要介绍大数据的时代背景,给出了大数据的概念、特征,还介绍了大数据相关问题的解决方案、Hadoop大数据技术以及Hadoop的应用案例。
本章的主要内容如下。
(1)大数据技术概述。
(2)Google的三篇论文及其思想。
(3)Hadoop概述。
(4)Hadoop生态圈。
(5)Hadoop的典型应用场景和应用架构。
1.1 大数据技术概述1.1.1 大数据产生的背景1946年,计算机诞生,当时的数据与应用紧密捆绑在文件中,彼此不分。
19世纪60年代,IT系统规模和复杂度变大,数据与应用分离的需求开始产生,数据库技术开始萌芽并蓬勃发展,并在1990年后逐步统一到以关系型数据库为主导,具体发展阶段如图1-1所示。
Hadoop 大数据技术与应用图1-1 数据管理技术在2001年前的两个发展阶段 2001年后,互联网迅速发展,数据量成倍递增。
据统计,目前,超过150亿个设备连接到互联网,全球每秒钟发送290万封电子邮件,每天有2.88万小时视频上传到YouTube 网站,Facebook 网站每日评论达32亿条,每天上传照片近3亿张,每月处理数据总量约130万TB 。
2016年全球产生数据量16.1ZB ,预计2020年将增长到35ZB (1ZB = 1百万,PB = 10亿TB ),如图1-2所示。
图1-2 IDC 数据量增长预测报告2011年5月,EMC World 2011大会主题是“云计算相遇大数据”,会议除了聚焦EMC 公司一直倡导的云计算概念外,还抛出了“大数据”(BigData )的概念。
2011年6月底,IBM 、麦肯锡等众多国外机构发布“大数据”相关研究报告,并予以积极的跟进。
19世纪60年代,IT 系统规模和复杂度变大,数据与应用分离的需求开始产生,数据库技术开始萌芽并蓬勃发展,并在1990年后逐步统一到以关系型数据库为主导1946年,计算机诞生,数据与应用紧密捆绑在文件中,彼此不分1946 1951 1956 1961 1970 1974 1979 1991 2001 … 网络型E-RSQL 关系型数据库 数据仓库 第一台 计算机 ENIAC 面世 磁带+ 卡片 人工 管理 磁盘被发明,进入文件管理时代 GE 公司发明第一个网络模型数据库,但仅限于GE 自己的主机 IBM E. F.Dodd 提出关系模型 SQL 语言被发明 ORACLE 发布第一个商用SQL 关系数据库,后续快速发展数据仓库开始涌现,关系数据库开始全面普及且与平台无关,数据管理技术进入成熟期 0.8ZB :将一堆DVD 堆起来够地球到月亮一个来回 35ZB :将一堆DVD 堆起来是地球到火星距离的一半IDC 报告“Data Universe Study ”预测:全世界数据量将从2009年的0.8ZB 增长到2020年的35ZB ,增长44倍!年均增长率>40%!1.1.2 大数据的定义“大数据”是一个涵盖多种技术的概念,简单地说,是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合。
大数据处理之 Hadoop 原理与应用介绍

Input
Input Data:
A DD BB A BB A
Map Task Map
Map
0,A 1,DD
A,1 DD,1
Reduce Task
Shuffle & Sort
Reduce
map, sort, combiner, partition, spill, merge
copy partition data A,[1, 1, 1]
1、问题:
有如下数据,字段内容分别为:url,catePath0,catePath1,catePath2,unitparams
https:///confluence 0 1 8 {"store":{"fruit":[{"weight":1,"type":"apple"},{"weight":9,"type":"pear"}],"bicycle":{"price":19.951,"color":"red1"}},"email":" amy@only_for_json_udf_","owner":"amy1"} /leejun2005/blog/83058 0 1 23 {"store":{"fruit":[{"weight":1,"type":"apple"},{"weight":2,"type":"pear"}],"bicycle":{"price":19.951,"color":"red1"}},"email":"
Chapter2-大数据技术原理与应用-第二章-大数据处理架构Hadoop-pdf

《大数据技术原理与应用》 厦门大学计算机科学系 林子雨 ziyulin@
2.1 概述
• • • • 2.1.1 2.1.2 2.1.3 2.1.4 Hadoop简介 Hadoop发展简史 Hadoop的特性 Hadoop的应用现状
《大数据技术原理与应用》
厦门大学计算机科学系
林子雨
《大数据技术原理与应用》 厦门大学计算机科学系 林子雨 ziyulin@
2.3.4 安装单机Hadoop
Hadoop版本:1.2.1 下载地址:/apache/hadoop/common/hadoop-1.2.1/ 实验步骤: 解压缩hadoop-1.2.1.tar.gz 修改hadoop-env.sh 查看hadoop版本信息:./hadoop version 运行hadoop实例
大数据工具资料收集之hadoop

1基本介绍1.1简介Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。
它支持在商品硬件构建的大型集群上运行的应用程序。
Hadoop是根据Google 公司发表的MapReduce和Google档案系统的论文自行实作而成。
Hadoop框架透明地为应用提供可靠性和数据移动。
它实现了名为MapReduce的编程范式:应用程序被分割成许多小部分,而每个部分都能在集群中的任意节点上执行或重新执行。
此外,Hadoop还提供了分布式文件系统,用以存储所有计算节点的数据,这为整个集群带来了非常高的带宽。
MapReduce和分布式文件系统的设计,使得整个框架能够自动处理节点故障。
它使应用程序与成千上万的独立计算的电脑和PB级的数据。
现在普遍认为整个Apache Hadoop“平台”包括Hadoop内核、MapReduce、Hadoop分布式文件系统(HDFS)以及一些相关项目,有Apache Hive和Apache HBase等等。
1.2主要功能组件∙HDFS: Hadoop Distributed File System,简称HDFS,是一个分布式文件系统。
HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。
而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
HDFS放宽了(relax)POSIX的要求(requirements)这样可以实现流的形式访问(streaming access)文件系统中的数据。
∙MapReduce:并行计算框架,MapReduce是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算。
概念“Map(映射)”和“Reduce(化简)”,及他们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言借来的特性。
基于Hadoop构建大数据云平台(DAAS)

Hadoop和虚拟化的差异点
虚拟化技术
CPU资源
V1
内存资源
V2 Vn
硬盘资源
切分
硬盘资源
虚拟化技术
服务器
内存资源 CPU资源 服务器
服务器
聚合
专注于企业级大数据 4200台主机
集中存储和计算的主要瓶颈
Oracle IBM
EMC存储
scale-up(纵向扩展)
➢计算能力和机器数量成正比 ➢IO能力和机器数量成非正比
VPS VPS
VPS VPS
小型机 cpu
小型机 cpu
数据移动
计算瓶颈 带宽瓶颈
存储阵列
磁盘IO瓶颈
基于共享存储和高性能计算的架构。 大型机和小型机的差别 存储阵列和普通硬盘的差别 IO,稳定性。
专注于企业级大数据
Hadoop MapReduce 提供存储和计算扩展能力
交换机 R
交换机
➢计算能力和机器数量成正比
➢IO能力和机器数量成正比
R Reduce
cpu M 服务器
cpu M
服务器
cpu M 服务器
cpu M
服务器
cpu M 服务器
cpu
MM AP 数据移动 服务器
计算瓶颈 带宽瓶颈
HDFS 存储 存储 存储 存储 存储 存储
磁盘IO瓶颈
横向扩展(scale-out)
➢移动计算而非移动数据; ➢化整为零(128m),分片处理; ➢计算和存储资源池花 ➢并行IO,本地化计算,降低网络通专注信于;企业级大数据
近线区 非结构化
归档区 文件形
OLTP交易 数据库
实时,低价 值日志数 据
Serach, OLAP分析 视频/文本数据
大数据分析技术基础教学课件3-大数据处理平台Hadoop

mapred-site.xml <configuration>
伪分布式模式 • Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件
分布式模式 • 多个节点构成集群环境来运行Hadoop
Hadoop的安装
Hadoop基本安装配置主要包括以下几个步骤:
第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其中,0.20.x最 后演化成1.0.x,变成了稳定版,而0.21.x和0.22.x则增加了NameNode HA等新的 重大特性
第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop 1.0, 是一套全新的架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x,2.x 增加了NameNode HA和Wire-compatibility两个重大特性
Pig是一个用于大数据分析的工具,包括了一个数据分析语言和其运行环 境。Pig的特点是其结构设计支持真正的并行化处理,因此适合应用于大数 据处理环境。
Ambari是一个用于安装、管理、监控hadoop集群的web界面工具。目前已 支持包括MapReduce、HDFS、HBase在内的几乎所有hadoop组件的管理。
◦ 10年后,摩尔在IEEE国际电子组件大会上将他的语言修正为半导体芯片上集成的晶体管和电阻的 数量将每两年增加1倍。
大数据平台聚类分析系统的设计与实现

DCWTechnology Analysis技术分析93数字通信世界2024.021 大数据平台聚类分析系统架构设计1.1 功能架构设计用户聚类分析系统功能架构设计首先是创建聚类任务,根据相对应的核心条件(比如圈人条件以及调度频率等),待聚类任务运行完毕后创建clu s t e r level 数据便能够予以可视化呈现。
之后在可视化呈现的基础上通过人工予以再次标注,并予以再次聚合计算,如此便可生成tribe level 指标数据并用于用户分析。
如图1所示[1]。
1.2 技术架构设计(1)前端展示:具备与用户进行交互的功能。
用户通过该页面登录进入该聚类分析系统,之后用户进行的创建聚类任务、查看聚类结果等相关操作行为均在该模块范围内[2]。
(2)后端调度:该模块的核心职责是响应前端传输至此的全部请求,同时和数据库、HDFS 、Hive大数据平台聚类分析系统的设计与实现孙雪峰(首都经济贸易大学密云分校,北京 101500)摘要:互联网领域蕴含着海量的数据信息,且这些信息呈现出多样性以及复杂性,总体而言,可以大致将这些数据划分成用户行为数据和内容数据,科学精细地分析处理这些数据,是强化用户分群治理效率、内容分类研究以及实现精细化运营的重要手段。
但现阶段尚无一站式的大数据聚类分析系统可供人们使用,因此,文章详细分析和阐述了基于大数据平台的聚类分析系统设计与实现,以此为相关工作人员提供参考。
关键词:大数据;聚类分析;系统设计;系统实现doi:10.3969/J.ISSN.1672-7274.2024.02.031中图分类号:TP 311.13 文献标志码:A 文章编码:1672-7274(2024)02-0093-03Design and Implementation of Cluster Analysis System for Big Data PlatformSUN Xuefeng(Capital University of Economics and Trade, Miyun Branch, Beijing 101500, China)Abstract: The internet field contains a vast amount of data information, which presents diversity and complexity. Overall, this data can be roughly divided into user behavior data and content data, and scientifically and meticulously analyzed and processed. It is an important means to strengthen the efficiency of user group governance, research on content classification, and achieve refined operations. However, at present, there is no one-stop big data clustering analysis system available for the public to use. Therefore, this article conducts research on this topic, analyzes and elaborates in detail on the design and implementation of clustering analysis systems based on big data platforms, in order to provide reference for relevant staff.Key words: big data; cluster analysis; system design; system implementation作者简介:孙雪峰(1980-),男,北京人,讲师,博士研究生,研究方向为计算机应用技术专业、计算机网络与应用技术、新媒体与网络传播。
基于Hadoop的大数据分析系统设计与实现

基于Hadoop的大数据分析系统设计与实现一、引言随着互联网的快速发展和智能化技术的不断进步,大数据已经成为当今信息时代的核心资源之一。
大数据分析系统作为处理和分析海量数据的重要工具,扮演着至关重要的角色。
本文将围绕基于Hadoop 的大数据分析系统的设计与实现展开讨论,探讨其在实际应用中的优势和挑战。
二、Hadoop技术概述Hadoop是一个开源的分布式计算平台,提供了可靠、高效、可扩展的分布式存储和计算能力。
其核心包括Hadoop Distributed File System(HDFS)和MapReduce计算框架。
HDFS用于存储海量数据,而MapReduce则用于并行处理这些数据。
除此之外,Hadoop生态系统还包括了各种组件,如Hive、Pig、Spark等,为大数据处理提供了丰富的选择。
三、大数据分析系统设计1. 系统架构设计基于Hadoop的大数据分析系统通常采用分布式架构,其中包括数据采集、数据存储、数据处理和数据展示等模块。
数据采集模块负责从各个数据源获取原始数据,数据存储模块使用HDFS进行数据持久化存储,数据处理模块通过MapReduce等技术进行数据处理,最终结果通过可视化工具展示给用户。
2. 数据处理流程设计在大数据分析系统中,数据处理流程至关重要。
设计合理的数据处理流程可以提高系统的效率和准确性。
通常包括数据清洗、数据转换、特征提取、模型训练等环节。
利用Hadoop平台提供的并行计算能力,可以加速这些过程,并支持更复杂的分析任务。
四、大数据分析系统实现1. 数据采集与存储在实际应用中,大数据分析系统需要从多个来源采集海量数据,并将其存储到HDFS中。
可以利用Flume、Kafka等工具进行实时数据采集,同时通过Hive建立元数据管理,方便对存储在HDFS中的数据进行查询和分析。
2. 数据处理与计算MapReduce是Hadoop中最经典的计算框架之一,通过编写Map和Reduce函数来实现并行计算任务。
云计算平台架构图
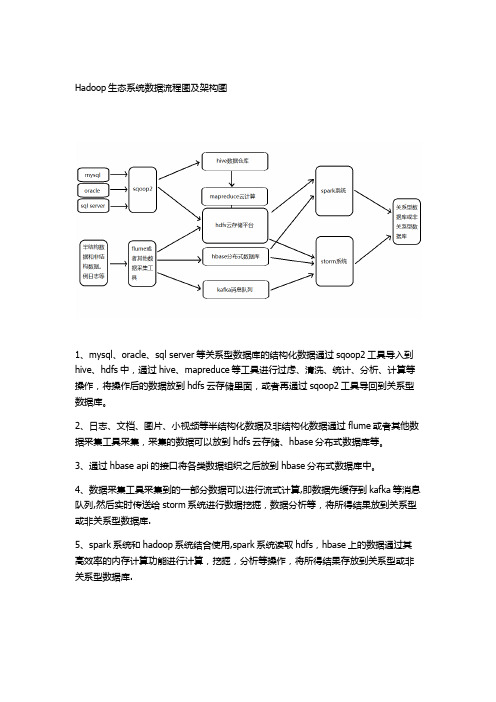
Hadoop生态系统数据流程图及架构图
1、mysql、oracle、sql server等关系型数据库的结构化数据通过sqoop2工具导入到hive、hdfs中,通过hive、mapreduce等工具进行过虑、清洗、统计、分析、计算等操作,将操作后的数据放到hdfs云存储里面,或者再通过sqoop2工具导回到关系型数据库。
2、日志、文档、图片、小视频等半结构化数据及非结构化数据通过flume或者其他数据采集工具采集,采集的数据可以放到hdfs云存储、hbase分布式数据库等。
3、通过hbase api的接口将各类数据组织之后放到hbase分布式数据库中。
4、数据采集工具采集到的一部分数据可以进行流式计算,即数据先缓存到kafka等消息队列,然后实时传送给storm系统进行数据挖掘,数据分析等,将所得结果放到关系型或非关系型数据库.
5、spark系统和hadoop系统结合使用,spark系统读取hdfs,hbase上的数据通过其高效率的内存计算功能进行计算,挖掘,分析等操作,将所得结果存放到关系型或非关系型数据库.。
大数据、云计算系统高级架构师课程学习路线图

大数据、云计算系统高级架构师课程学习路线图大数据之Linux+大数据开发篇Java Linux基础Shell编程Hadoop2.x HDFS YARN MapReduce ETL数据清洗Hive Sqoop Flume/Oozieo大数据WEB工具Hue HBase Storm Storm ScalaSpark Spark核心源码剖析CM 5.3.x管理CDH 5.3.x集群项目部分项目一:北风网用户行为分析项目二:驴妈妈离线电商平台分析平台项目三:基于Spark技术实现的大型离线电商数据分析平台大数据之阿里云企业级认证篇阿里云数据处理和分析报表场景的实现(企业案例)企业自助沙箱实验(10个)阿里云企业认证(ACP11003模块)大数据之Java企业级核心技术篇Java性能调优Tomcat、Apache集群数据库集群技术分布式技术WebLogic 企业级技术大数据之PB级别网站性能优化篇CDN镜像技术虚拟化云计算共享存储海量数据队列缓存Memcached+Redis\No-SqlLVS负载均Nginx项目部分PB级通用电商网站性能优化解决方案大数据之数据挖掘\分析&机器学习篇Lucene爬虫技术Solr集群KI分词Apriori算法Tanagra工具决策树贝叶斯分类器人工神经网络K均值算法层次聚类聚类算法SPSS Modeler R语言数据分析模型统计算法回归聚类数据降维关联规则决策树Mahout->Python金融分析项目部分项目一:地震预警分析系统项目二:文本挖掘(Mathout\中文分词)项目三:电商购物车功能实现(R语言)项目四:使用Python构建期权分析系统大数据之运维、云计算平台篇Zookeeper Docker OpenStack云计算项目部分博客WordPress、ELK、日志管理:Maven+Jenkins项目部分.了解更多详情课程体系北风大数据、云计算系统架构师高级课程大数- Hadoop阶段一、大数据、云计算据开发技术基础课程一、大数据运维之Linux基础,以便更好地学习Linux本部分是基础课程,帮大家进入大数据领域打好等众多课程。
Hadoop大数据开发基础教案Hadoop基础操作教案

一、Hadoop简介1. 教学目标(1) 了解Hadoop的定义和发展历程(2) 掌握Hadoop的核心组件及其作用(3) 理解Hadoop在大数据领域的应用场景2. 教学内容(1) Hadoop的定义和发展历程(2) Hadoop的核心组件:HDFS、MapReduce、YARN(3) Hadoop的应用场景3. 教学方法(1) 讲授(2) 案例分析(3) 互动讨论4. 教学步骤(1) 引入话题:大数据与Hadoop(2) 讲解Hadoop的定义和发展历程(3) 介绍Hadoop的核心组件及其作用(4) 分析Hadoop的应用场景(5) 总结本节课的重点内容二、HDFS操作1. 教学目标(1) 掌握HDFS的基本概念和架构(2) 学会使用HDFS客户端进行文件操作(3) 了解HDFS的配置和优化方法2. 教学内容(1) HDFS的基本概念和架构(2) HDFS客户端的使用方法(3) HDFS的配置和优化方法3. 教学方法(1) 讲授(2) 实操演示(3) 互动讨论4. 教学步骤(1) 讲解HDFS的基本概念和架构(2) 演示HDFS客户端的使用方法(3) 介绍HDFS的配置和优化方法(4) 进行实操练习(5) 总结本节课的重点内容三、MapReduce编程模型1. 教学目标(1) 理解MapReduce的编程模型和原理(2) 掌握MapReduce的基本操作和编程步骤(3) 了解MapReduce的优缺点和适用场景2. 教学内容(1) MapReduce的编程模型和原理(2) MapReduce的基本操作和编程步骤(3) MapReduce的优缺点和适用场景3. 教学方法(1) 讲授(2) 案例分析(3) 互动讨论4. 教学步骤(1) 讲解MapReduce的编程模型和原理(2) 介绍MapReduce的基本操作和编程步骤(3) 分析MapReduce的优缺点和适用场景(4) 进行案例实操(5) 总结本节课的重点内容四、YARN架构与资源管理1. 教学目标(1) 理解YARN的架构和功能(2) 掌握YARN的资源管理和调度机制(3) 了解YARN的应用场景和优势2. 教学内容(1) YARN的架构和功能(2) YARN的资源管理和调度机制(3) YARN的应用场景和优势3. 教学方法(1) 讲授(2) 案例分析(3) 互动讨论4. 教学步骤(1) 讲解YARN的架构和功能(2) 介绍YARN的资源管理和调度机制(3) 分析YARN的应用场景和优势(4) 进行案例实操(5) 总结本节课的重点内容五、Hadoop生态系统简介1. 教学目标(1) 了解Hadoop生态系统的概念和组成(2) 掌握Hadoop生态系统中常用组件的功能和应用场景(3) 理解Hadoop生态系统的发展趋势2. 教学内容(1) Hadoop生态系统的概念和组成(2) Hadoop生态系统中常用组件:Hive、HBase、Pig、Sqoop、Flume(3) Hadoop生态系统的发展趋势3. 教学方法(1) 讲授(2) 案例分析(3) 互动讨论4. 教学步骤(1) 讲解Hadoop生态系统的概念和组成(2) 介绍Hadoop生态系统中常用组件的功能和应用场景(3) 分析Hadoop生态系统的发展趋势(六、Hive大数据处理平台1. 教学目标(1) 理解Hive的概念和架构(2) 掌握Hive的基本操作和数据处理能力(3) 了解Hive的应用场景和优缺点2. 教学内容(1) Hive的概念和架构(2) Hive的基本操作:表的创建、数据的导入和导出(3) Hive的数据处理能力:查询、统计、分析(4) Hive的应用场景和优缺点3. 教学方法(1) 讲授(2) 实操演示(3) 互动讨论4. 教学步骤(1) 讲解Hive的概念和架构(2) 演示Hive的基本操作(3) 介绍Hive的数据处理能力(4) 分析Hive的应用场景和优缺点(5) 进行实操练习(6) 总结本节课的重点内容七、HBase分布式数据库1. 教学目标(1) 理解HBase的概念和架构(2) 掌握HBase的基本操作和数据管理能力(3) 了解HBase的应用场景和优缺点2. 教学内容(1) HBase的概念和架构(2) HBase的基本操作:表的创建、数据的增删改查(3) HBase的数据管理能力:数据一致性、并发控制、灾难恢复(4) HBase的应用场景和优缺点3. 教学方法(1) 讲授(2) 实操演示(3) 互动讨论4. 教学步骤(1) 讲解HBase的概念和架构(2) 演示HBase的基本操作(3) 介绍HBase的数据管理能力(4) 分析HBase的应用场景和优缺点(5) 进行实操练习(6) 总结本节课的重点内容八、Pig大数据脚本语言1. 教学目标(1) 理解Pig的概念和架构(2) 掌握Pig的基本操作和数据处理能力(3) 了解Pig的应用场景和优缺点2. 教学内容(1) Pig的概念和架构(2) Pig的基本操作:LOAD、STORE、FILTER(3) Pig的数据处理能力:数据转换、数据清洗、数据分析(4) Pig的应用场景和优缺点3. 教学方法(1) 讲授(2) 实操演示(3) 互动讨论4. 教学步骤(1) 讲解Pig的概念和架构(2) 演示Pig的基本操作(3) 介绍Pig的数据处理能力(4) 分析Pig的应用场景和优缺点(5) 进行实操练习(6) 总结本节课的重点内容九、Sqoop数据迁移工具1. 教学目标(1) 理解Sqoop的概念和架构(2) 掌握Sqoop的基本操作和数据迁移能力(3) 了解Sqoop的应用场景和优缺点2. 教学内容(1) Sqoop的概念和架构(2) Sqoop的基本操作:导入、导出数据(3) Sqoop的数据迁移能力:关系数据库与Hadoop之间的数据迁移(4) Sqoop的应用场景和优缺点3. 教学方法(1) 讲授(2) 实操演示(3) 互动讨论4. 教学步骤(1) 讲解Sqoop的概念和架构(2) 演示Sqoop的基本操作(3) 介绍Sqoop的数据迁移能力(4) 分析Sqoop的应用场景和优缺点(5) 进行实操练习(6) 总结本节课的重点内容十、Flume数据采集系统1. 教学目标(1) 理解Flume的概念和架构(2) 掌握Flume的基本操作和数据采集能力(3) 了解Flume的应用场景和优缺点2. 教学内容(1) Flume的概念和架构(2) Flume的基本操作:配置文件编写、组件部署(3) Flume的数据采集能力:日志数据十一、日志数据处理实战1. 教学目标(1) 理解日志数据处理的重要性(2) 掌握使用Hadoop生态系统工具处理日志数据的方法(3) 能够设计日志数据处理流程2. 教学内容(1) 日志数据的特点和处理需求(2) 使用Hadoop生态系统中的工具(如LogParser, Flume, Hive, Pig)处理日志数据(3) 案例分析:构建一个简单的日志数据分析流程3. 教学方法(1) 讲授(2) 实操演示(3) 案例分析(4) 互动讨论4. 教学步骤(1) 讲解日志数据的特点和处理需求(2) 演示如何使用Hadoop生态系统工具处理日志数据(3) 通过案例分析,让学生设计一个简单的日志数据分析流程(4) 学生实操练习,应用所学知识处理实际日志数据(5) 总结本节课的重点内容,强调日志数据处理的最佳实践十二、大数据可视化分析1. 教学目标(1) 理解大数据可视化的重要性(2) 掌握使用可视化工具进行大数据分析的方法(3) 能够设计有效的大数据可视化方案2. 教学内容(1) 大数据可视化的概念和作用(2) 常用的大数据可视化工具:Tableau, QlikView, D3.js等(3) 如何选择合适的可视化工具和设计原则3. 教学方法(1) 讲授(2) 实操演示(3) 案例分析(4) 互动讨论4. 教学步骤(1) 讲解大数据可视化的概念和作用(2) 演示常用的大数据可视化工具的使用方法(3) 分析如何选择合适的可视化工具和设计原则(4) 通过案例分析,让学生设计一个大数据可视化方案(5) 学生实操练习,应用所学知识创建可视化分析(6) 总结本节课的重点内容,强调大数据可视化的最佳实践十三、大数据安全与隐私保护1. 教学目标(1) 理解大数据安全的重要性(2) 掌握大数据安全和隐私保护的基本概念(3) 了解大数据安全与隐私保护的技术和策略2. 教学内容(1) 大数据安全与隐私保护的基本概念(2) 大数据安全威胁和风险分析(3) 大数据安全和隐私保护技术和策略:加密、访问控制、匿名化等3. 教学方法(1) 讲授(2) 案例分析(3) 互动讨论4. 教学步骤(1) 讲解大数据安全与隐私保护的基本概念(2) 分析大数据安全威胁和风险(3) 介绍大数据安全和隐私保护技术和策略(4) 通过案例分析,让学生了解如何实施大数据安全与隐私保护(5) 总结本节课的重点内容,强调大数据安全和隐私保护的最佳实践十四、大数据应用案例分析1. 教学目标(1) 理解大数据在不同行业的应用(2) 掌握大数据解决方案的设计思路(3) 能够分析大数据应用案例,提取经验教训2. 教学内容(1) 大数据在各行业的应用案例:金融、医疗、零售、物流等(2) 大数据解决方案的设计思路和步骤(3) 分析大数据应用案例,提取经验教训3. 教学方法(1) 讲授(2) 案例分析(3) 互动讨论4. 教学步骤(1) 讲解大数据在各行业的应用案例(2) 分析大数据解决方案的设计思路和步骤(3) 通过案例分析,让学生提取大数据应用的经验教训(4) 学生实操练习,分析特定行业的大数据应用案例(5) 总结本节课的重点内容,强调大数据应用的最佳实践十五、大数据的未来趋势与职业规划1. 教学目标(1) 理解大数据发展的未来趋势(2) 掌握大数据行业职业规划的方向(3) 能够根据个人兴趣和能力规划大数据相关职业发展路径2. 教学内容(1) 大数据发展的未来趋势:技术、应用、产业等(2) 大数据行业职业规划的方向重点和难点解析本文主要介绍了Hadoop大数据开发基础教案,包括Hadoop基础操作、HDFS 操作、MapReduce编程模型、YARN架构与资源管理、Hadoop生态系统简介、Hive大数据处理平台、HBase分布式数据库、Pig大数据脚本语言、Sqoop数据迁移工具、Flume数据采集系统、日志数据处理实战、大数据可视化分析、大数据安全与隐私保护、大数据应用案例分析以及大数据的未来趋势与职业规划等十五个章节。
Hadoop大数据平台方案

业务成本
劳动成本
软件成本
硬件成本
存储成本
降低大数据的成本
交易
台式机
本地
云
移动电话
交互作用
9
Hadoop的特点
扩容能力(Scalable)
– 能可靠地(reliably)存储和处理千兆字节(PB)数据。
成本低(Economical)
– 可以通过普通机器组成的服务器群来分发以及处理数据。这些 服务器群总计可达数千个节点。
Hadoop大数据平台建设方案
2
C时代
• 24小时在线(Connected 24 hours Era) • 全方位网络覆盖
2
C时代带来数据的爆炸性增长
3
通俗的描述:Big Data
大数据(Big Data)是大交易数据,大交互数据和大数据处理的统称。
大交易数据
在线交易处理 (OLTP) 在线分析处理 (OLAP) & 数据仓库设备
任何 DI/BI 体系结构
•
预定义转换
PIG
EDW MDM
6
大数据解决方案
业务需求
提供 分析洞见 提高业务 灵活性 改善 业务流程 提高效率& 降低成本 兼并收购& 资产剥离 获取及挽留 客户 外包 非 核心职能 治理风险 合规 提升合作伙伴 网络效率
大数据仓库 & 运营商业智能
通过数据源,将 客户、风险和投 诉等各种来源的 数据(数据仓库、 遗留数据、 30000数据集市 和10M投诉)的访 问迅速提高了5 倍,而成本仅是 之前的1/3
提高 效率 和降低 成本 合并 收购 和 剥离 赢得并 留住 客户 外包 非核心 功能 治理 风险 合规性 增加 合 作伙伴 网络 效率 提高 业务 灵活性
大数据Hadoop学习之搭建Hadoop平台(2.1)

⼤数据Hadoop学习之搭建Hadoop平台(2.1) 关于⼤数据,⼀看就懂,⼀懂就懵。
⼀、简介 Hadoop的平台搭建,设置为三种搭建⽅式,第⼀种是“单节点安装”,这种安装⽅式最为简单,但是并没有展⽰出Hadoop的技术优势,适合初学者快速搭建;第⼆种是“伪分布式安装”,这种安装⽅式安装了Hadoop的核⼼组件,但是并没有真正展⽰出Hadoop的技术优势,不适⽤于开发,适合学习;第三种是“全分布式安装”,也叫做“分布式安装”,这种安装⽅式安装了Hadoop的所有功能,适⽤于开发,提供了Hadoop的所有功能。
⼆、介绍Apache Hadoop 2.7.3 该系列⽂章使⽤Hadoop 2.7.3搭建的⼤数据平台,所以先简单介绍⼀下Hadoop 2.7.3。
既然是2.7.3版本,那就代表该版本是⼀个2.x.y发⾏版本中的⼀个次要版本,是基于2.7.2稳定版的⼀个维护版本,开发中不建议使⽤该版本,可以使⽤稳定版2.7.2或者稳定版2.7.4版本。
相较于以前的版本,2.7.3主要功能和改进如下: 1、common: ①、使⽤HTTP代理服务器时的⾝份验证改进。
当使⽤代理服务器访问WebHDFS时,能发挥很好的作⽤。
②、⼀个新的Hadoop指标接收器,允许直接写⼊Graphite。
③、与Hadoop兼容⽂件系统(HCFS)相关的规范⼯作。
2、HDFS: ①、⽀持POSIX风格的⽂件系统扩展属性。
②、使⽤OfflineImageViewer,客户端现在可以通过WebHDFS API浏览fsimage。
③、NFS⽹关接收到⼀些可⽀持性改进和错误修复。
Hadoop端⼝映射程序不再需要运⾏⽹关,⽹关现在可以拒绝来⾃⾮特权端⼝的连接。
④、SecondaryNameNode,JournalNode和DataNode Web UI已经通过HTML5和Javascript进⾏了现代化改造。
3、yarn: ①、YARN的REST API现在⽀持写/修改操作。
大数据处理平台的系统架构及其技术细节

大数据处理平台的系统架构及其技术细节随着信息技术的迅猛发展,企业乃至国家的数字化转型已经成为当今互联网领域最为热门的话题之一。
而在这一背景下,大数据处理平台的兴起成为了企业数据处理以及智能化应用的核心。
所谓大数据就是指数据量大、速度快、种类繁多、价值密度低等特征的数据,大数据处理平台是能够快速处理海量、异构和分散的数据的技术平台,它通常具备高度自动化和灵活性,提供强大的数据抽取、清洗、分析、建模、可视化等数据处理工具。
本文旨在介绍大数据处理平台的系统架构及其技术细节,主要从以下几个方面进行深入的讲解。
一、大数据处理平台的基本架构大数据处理平台主要分为以下四层架构:1.数据源层该层主要涵盖数据的采集、存储管理和访问。
数据采集:大数据处理平台的基础是数据的采集,数据可以从文件、数据库、社交平台、网站、移动端、物联网设备、传感器等各种数据源获取。
数据存储:大规模数据存储是大数据平台的核心部分之一,常见的数据存储方式包括分布式文件系统Hadoop HDFS、NoSQL数据库等。
数据访问:为了方便用户对数据的访问,需要建立方便、快速的数据访问渠道,如基于RESTful API的数据服务。
2.数据处理层该层主要涵盖数据预处理、数据分析和数据挖掘等,是整个平台最为核心的一层。
数据预处理:大数据预处理主要通过数据清洗、去噪、标准化、格式转换、数据集成等手段对海量数据进行预处理,以保证后续分析的准确性和效率。
数据分析:基于大数据平台的数据分析不仅是数据分析的工具,同时也是商业智能的应用。
分析主要应用在数据挖掘、数据建模、数据统计分析、数据可视化等方面。
数据挖掘:大数据挖掘成为了平台一个非常关键的部分。
通过机器学习、数据挖掘算法、深度学习等手段对海量数据进行探索极其重要。
3.数据集成层该层主要是对来自不同数据源的数据进行归并、整合和处理的过程。
数据归并:由于来自不同数据源的数据类型和格式不同,为了进行更好的数据分析需调权衡对这些数据进行归并,整合形成相同的格式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
执行hadoop -get命令,将运行结 果从HDFS中下载到服务器上 hadoop集群中HDFS 系统中结果文件
通过mapReduce在集群中运 行处结果输出到文件中去 hadoop集群 中HDFS系统
执行hadoop -put命令, 将文件添加到HDFS中
kettle将文件上传 到linux上去 hadoop集群中 nameNode节 点服务器
关系型数据库与hadoop集群数据交换流程图
kettle读取文件中数据 到mysql数据库中去
kettle所在的 windows本 地结果文件 kettle下载结果文件到 本地windows中
kettle将数据输出.txt文件中去 关系型数据库 数据库
.txt格式的数 据文件(不要 头部列名)
hadoop集群中 nameNode节点 服务器结果文件
通过sql实现读取、查询、操作数据
具 或 现 sq 数 据 oop 全 量 工具 、 增 (建 量 导 议使 入 和 用) 导 出 ,应
该
通过创建表时配置映射实现hbase与hive中数据实时同步
可
hbase表中数据是存储到hadoop集群中的hdfs上
通过命令可以实现HDFS中原有数 据文件与hive表中数据的交互 hive工具
存储hive的元数据信息 mysql数据库
t le
工
上传下载 数据文件
, 用) 议使 导出 建 具( 导入和 p工 跟 qo o 、增来 s 具或 全量 工 t le 现数据 ke t 通过 可以实 应该
通过kettle实现数据文件交互
过
通
数据目录
业务处理数据输出 结果到文件
ke t
hadoopMapReduc e nameNode 通过命令可以实现本地数据文 件与hive表中数据的交互
web项目与hadoop大数据平台结合思路流程图
通过jdbc方式连接,实现大数据统计分析定时查询 通过jdbc方式连接, 实现大数据实时查询 通过类sql操作hbase中表 Phoenix工具 注意: 如果使用此方式,注意 了解通过Phoenix创建 hbase表和视图的优点 缺点,再决定使用创建 表还是视图 通过java代码读取、查询、操作hbase 表中数据,实现大数据实时查询
关系型数据库
linux中存储文件 hadoop集群 管理节点、分发 读取数据文件 存储数据的文件
dataNode hive表中数据实际存储在hdfs 中的dataNode中
通过kettle工具或sqoop工具(建议使用),应该可以实现数据全量、增量导入hive表中和导出
流程说明: 黑色文字:代表过程确定可以实现; 蓝色文字:代表过程可以实现,但暂时还没有亲自尝试; 红色文字:代表过程理论上可以实现,但实际上可能会有问题,暂时还没有亲自尝试
Байду номын сангаас
平台项目系统
hmaster 管理 hbase表信息同步到z k z k管理hbase集群
leader 管理
hbase集群
z ookeeper集群
sqlDeveloper 客户端
统计分析sql
开发人员进行SQL 统计分析数据
hRegionServer
follower 连接hiveServer
以
实
通过hbaseMapReduce实现 读取hadoop集群中文件数 据到hbase表中去