第三节 排序和查找
第三章汉字编码原理

㈣标调拼音码
• 汉语是有声调的语言,汉语的声调是一 个重要的“音位”,具有重要的辨义功 能。有一种乐器叫做“雷琴”,可以只 用“音高”就能模拟汉语的句子。这个 例子足以说明汉语声调的重性。
• 拼音码为了降低重码率,采用标调的办法,这 样的拼音码,我们称之为“标调拼音码”。 • 汉语的音节是有数的:不加声调只有412个, 加声调则有1300个左右。 • 汉字共有6万个。收在《基本集》中的有67 63个。 • 不加声调平均每个音节约有15个重码,加上 重码分布的不平衡,个别的音节就有几十甚至 上百个; • 如果加上声调,平均每个音节只有不到4个重 码了。
拼音编码的瓶颈
• 同音字繁多,影响输入 • 《新华字典》中,读SHI音的字有72个, • 《汉语词典》中,读YI音的字有164个。
• • • • • • • •
同音词也影响编码输入 Shi-shi的词就有如下的24条: 失实、失时、诗史、失事、 失势、施事、实施、时时、 事事、时事、时势、时世、 时式、史诗、史实、试试、 誓师、事实、适时、事势、 逝世、世事、视事、实时
• 一般的编码方案多采用26个英文字母 作码元, • 也有的在这个基础上再增加10个数目 字,使码元数增加到36个的方案, • 还有的把字母键盘区的其它功能键也利 用上的。 • 这种需要增加码元数的方案多数是形码 方案。
3、确定编码规则
• 理想的规则是“字码意义对应” 、规则简单, 好学易记,没有复杂的条件限制或特例情况。 • 实际上最难做到。 • 比如按形排序,同笔画数的字很多,同笔画的 字当中,起笔相同的也不少,甚至笔顺相同的 也有。究竟谁先谁后,难以给出一个标准。 • 按音排序也有个同音字的先后问题。同音、同 调、同笔画数的汉字再按什么条件排先后,都 是难题。 • 人为地增加许多规定,势必增加用户的学习量。
《C程序设计》课程标准

《C程序设计》课程标准一、课程说明:1.本课程的性质:C程序设计是近年来在国内外得到迅速推广应用的一种现代程序设计语言,它以丰富灵活的控制和数据结构,简洁而高效的语句表达、良好的移植性,已被广泛的应用于系统软件和应用软件的开发中。
2.本课程教学目的及任务:教学目的:通过学习C程序设计课程,使学生掌握 C语言的基本内容及程序设计的算法思想与编程技巧,了解进行科学计算的一般思路,培养学生应用计算机解决和处理实际问题的思维方法与基本能力,为以后学习数据结构、操作系统等后继课程创造必备的条件,并为今后从事软件开发打下良好基础。
教学任务:通过理论学习和编程训练,使学生了解C语言特点,理解C语言的基本概念,掌握C语言的语法规则和结构化程序设计的特点、方法及开发工具的使用,激发学生底层编程方向的兴趣,培养学生的编程能力。
3.本课程教学与其他课程的关系:先修课程:《计算机文化基础》后继课程:《数据结构》、《操作系统》、《数据库原理及应用》4.教学时数分配:总学时72,理论52,实验20。
教学时数分配表5.建议教材与参考书谭浩强·《C程序设计》(第三版)·清华大学出版社谭浩强·《C语言程序设计》(第二版)·清华大学出版社·2008主要参考书:谭浩强·《C程序设计》(第三版)·清华大学出版社谭浩强·《C语言程序设计》(第二版)·清华大学出版社谭浩强·《C程序设计题解与上机指导》(第三版)清华大学出版社谭浩强·《C程序设计教程实习指导与模拟试题》6.考核模式:考试二、课程内容:第一章 C语言概述【教学要求】:熟悉TURBO C2.0/VisualC++6.0集成环境的使用了解用计算机解决实际问题的基本步骤掌握C程序的构成和C程序的运行过程。
【本章重点】:C程序的构成和C程序的运行过程【本章难点】:用计算机解决实际问题的基本步骤【教学内容】:第一节:C语言出现的历史背景第二节:C语言的特点第三节:简单的C程序介绍第四节:C程序的上机步骤和方法【参考书目】:谭浩强·《C语言程序设计》(第二版)·清华大学出版社第二章数据类型、运算符与表达式【教学要求】:掌握C语言中的各种数据类型及变量的定义方法。
第11章 数据表的排序和索引

单关键字排序
例2:将表rsda中的记录以“性别”为第一关键字段,按 将表rsda中的记录以“性别”为第一关键字段, rsda中的记录以 递增排序; 性别”相同, 递增排序;若“性别”相同,以“基本工资为第二关 键字段,按递减排序. 键字段,按递减排序.并将排序后的结果存入表 xbgz.dbf中 xbgz.dbf中。
例3:对表rsda按基本工资和出生日期建立索引, 对表rsda按基本工资和出生日期建立索引, rsda按基本工资和出生日期建立索引 索引的顺序是先按基本工资升序排列, 索引的顺序是先按基本工资升序排列,若基本工 资相同再按出生日期升序排列,并显示结果。 资相同再按出生日期升序排列,并显示结果。
若想表示:先按照某个字 段的值索引,对于此字段 值相同的记录,再按照另 一个字段的值索引。 则,这两个字段必须是字 符型的(不是字符型的通 过函数将其转换成字符型)
例1:将表rsda中的记录以“基本工资”为关键字 将表rsda中的记录以“基本工资” rsda中的记录以 段递减排序,并将排序后的结果存入表rsdat.dbf rsdat.dbf中 段递减排序,并将排序后的结果存入表rsdat.dbf中。
1、排序的结果放在了表 文件rsdat.dbf中。要想看 到排序结果,需打开 rsdat.dbf。 2 2、在rsdat.dbf中,记录 rsdat.dbf 的记录号发生了改变。
本题表示按照 基本工资字段 与奖金字段的 “和”建立索 引,升序排列。
二、排序与索引的区别
(1)前者改变了记录的物理位置,后者则没有。 (2)前者只能是字段名进行排序,后者还可以是关键字 段表达式。 (3)排序后文件是一新的表文件,可以离开原表文件而 单独使用,而索引文件不能离开原表文件而单独使 用。 (4)索引文件中存放的是按升序排列的索引关键字及必 要的链指针,其存储容量比排序产生的数据库文件 的容量要小得多,因此,索引很快,查找也快。
文献检索方法与技术3 第三节

检索实例
课题名称:氧化法处理工业废水 目的:了解国内该课题最新动态
1.分析研究课题,明确检索需求
主题: 主题:氧化 处理 废水 检索年代: 检索年代:2004-2007 学科: 学科:化学工程 语种: 语种:中文
关键词: 关键词:直接从文献的篇名或文摘或全文中抽取出来的非规范化检索词 如:《分子农业—— 一个大有发展前途的农业领域》 《分子农业 一个大有发展前途的农业领域》 关键词:分子农业;转基因植物;医用蛋白质;生物多聚体 关键词:分子农业;转基因植物;医用蛋白质;
3、作者检索 、
作者检索是从文献的作者姓名出发来检索其文献。 “作者” 作者检索是从文献的作者姓名出发来检索其文献。 作者” 广义上还应包括:汇编者、编者、主办者、译者等,此外, 广义上还应包括:汇编者、编者、主办者、译者等,此外,还有 代表机构、单位的团体作者,包括作者所在单位。 代表机构、单位的团体作者,包括作者所在单位。
4、名称检索 、 名称检索点是从各种事物的名称出发来检索文献信息。 名称检索点是从各种事物的名称出发来检索文献信息。 这些名称包括:书名、刊名、资料名、出版物名、出版社名、 这些名称包括:书名、刊名、资料名、出版物名、出版社名、会议 物质名称等等,也包括人名和机构名。 名、物质名称等等,也包括人名和机构名。 书名目录、馆藏目录普遍使用书名、 书名目录、馆藏目录普遍使用书名、刊名等出版物名称作为其检索 而论文、文章篇名一般不用作检索点。 点,而论文、文章篇名一般不用作检索点。 而在一些期刊全文数据库中,刊名,文章篇名都是检索点。 而在一些期刊全文数据库中,刊名,文章篇名都是检索点。
Excel教案
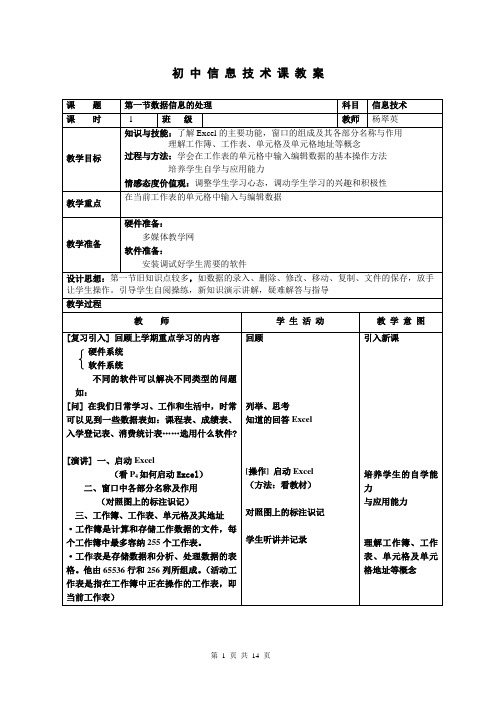
对于这个任务,书上给出了比较详细的讲解,请同学们看书完成它。
任务二:修饰日历
学生可以在小组内交流,完成。
三、教师小结:
1、修饰工作表的简单方法是:设置表格中数据的对齐方式、添加边框线、设置表格背景、修饰文本及插入图片、页面设置、打印预览。
·一个工作簿中可以包括多张工作表,工作表是以单元格组成的
·在单元格中可以输入各种数据、公式
·Excel窗口与Windows应用软件的窗口大体相同
[布置任务]将演示文稿保存
[操作]输入编辑数据
(方法:看教材)
看书自行处理
将记录内容保存
培养学生自学能力
作业设计:自阅复习第6章第二、三节
预习第5章第二节
课题
教师
学生活动
教学意图
引入:我们看“奥运风云”工作表“奥运奖牌榜”,今天我们要来计算各国家的奖牌总数。
新课:
一、新课
学生启动Excel软件,打开“奥运风云”工作表,激活“奥运奖牌榜”
1、请学生说说计算美国的奖牌总数用什么方法。金牌数+银牌数+铜牌数又可以写成c3+d3+e3
2、我们再看看下面其他国家奖牌总数的计算方法也是金牌数+银牌数+铜牌数
IF函数的格式如下:=IF(条件表达式,条件成立的结果,条件不成立的结果)
用在计算我们这个例子中的公式写成:
=if(c3>=27,”第一军团”,”第一军团”)
其中,逗号和双引号使用英文半角输入
请学生修改自己的操作
思考题:观众要求对“奥运奖牌榜”中的金牌数按照3个层次自动标注等级,金牌数不小于27的为“第一军团”,金牌数不小于9并且小于27的为“第二军团”,其他为第三军团。
信息技术互联网搜索教案《排序和筛选》

《排序和筛选》教案设计一、教案背景1,面向学生:中学 2,学科:七年级信息技术2,课时:13,学生课前准备:预习课文,排序和筛选二、教学课题通过“心灵旅游”这一活动主题,引出利用网络设计旅游路线,并进行综合考虑进行筛选。
让学生在“心灵旅游”这一任务活动过程中,通过教师的讲解、学生的自主探究、师生交流、小组内的生生交流、全班内的生生交流,掌握以下知识与技能:1、什么是排序,它有什么特点?2、什么是筛选,它有什么特点?3、排序筛选在生活中的运用?三、教材分析本节课是江苏科技出版社《初中信息技术》上册第4课“数据统计与分析”中的第三节后半节内容。
主要讲述排序和筛选的应用操作。
本人认为在网络已成为生活的一部分的今天,而七年级学生已经掌握一定的在网络中查找知识的能力,对学生而言,还不太习惯于利用网络为自己的生活服务时,这节课利用网络资源就有可能是一大推力,所以根据教材以及学生的实际情况,特制定如下教学目标:知识与技能:1.能对生活实例中的数据进行排序、筛选的实际运用;2.利用排序筛选解决实际问题。
过程与方法:体验自主、合作、探究的学习方法。
情感目标:能借助网络平台,利用排序筛选解决生活中的问题。
教学重难点:重点:掌握数据排序与筛选的基本操作。
难点:排序与筛选的灵活应用。
四、教学方法本节课将运用探究式教学法、合作学习法、行为导向教学法等多种教学方法与手段,以培养学生发现问题、解决问题为主线,设有讲练结合、小组学习、互帮互学等环节,既注重学生间的直观演示,又重视学生的自主学习,保证在整个教学中学生都有比较充分的时间进行实践操作,在做中学,在学中做。
重视学生学习方法与策略的引导,努力创设便于开展探究性学习、协作性学习、主动性学习的信息技术教学环境。
五、教学过程<一>激情导入(10分钟)【教师活动】同学们,五一就快要到了,你们想出去玩玩吗?(提问导入)最近肖晓很烦恼,是高兴的烦恼。
原因是爸爸妈妈答应五一带她出去玩,但是爸爸妈妈和他的意见却不统一,原来爸爸希望到自然风景的地方去,时间长点,而妈妈却又要求花钱不能太多,肖晓呢,想到游乐园疯玩一天。
第三节 文字处理软件word 2021的功能及基本操作

第三节文字处理软件word 2021的功能及基本操作第三节文字处理软件word2021的功能及基本操作一、word2021文字处理软件microsoftword软件就是office系统软件中的一款,word2021就是一个功能强大的文字处理软件,用以处置文字的打印、修正、排印和输入等一整套的文字处理工作,将文字女团后变为新建、单位公函、学术论文、书记、报刊等。
具体内容可实现以下功能:排印列印、图文混排、制作表格和特定文档处置。
考虑到word2021在消防工作中的实际应用,本节重点介绍了word2021的文字和段落处理的操作。
二、word2021的详述(一)启动软件方法一:执行【开始】/【程序】/【microsoftoffice】/【microsoftofficeword2021】命令,即可启动word2021。
方法二:页面鼠标右键/在菜单中选择【新建】/页面【microsoftword文档】/即可启动word2021。
(二)界面介绍word2021的工作界面主要由标题栏、菜单栏、工具栏、标尺、文档编辑区、滚动条、任务窗格以及状态栏八个部分。
标题栏:位于界面最上方的蓝色长条区域,分为两个部分。
左边用来显示文件的名称和软件名称,右边是最小化/向下还原/退出三个按钮。
菜单栏:就是命令菜单的子集,用作表明和调用程序命令的。
涵盖【文件】、【编辑】、【视图】、【填入】、【格式】、【工具】、【表格】、【窗口】和【协助】9项。
工具栏:word2021提供了多个工具栏,通常在窗口中显示的只是常用的部分。
执行菜单栏中的【视图】/【工具栏】命令,会弹出工具栏菜单。
在该命令菜单中,可以看到一些命令前面都有“√”标记,则表明该命令按钮已在工具栏中显示。
标尺:坐落于文本编辑区的上边和左边,分后水平标尺和横向标尺两种。
文档编辑区:坐落于窗口中央,用以输出、编辑文本和绘制图形的地方。
滚动条:位于文档编辑区的右端和下端,调整滚动条可以上下左右的查看文档内容。
第2章 第3节 网上查找信息(01409)

二、利用搜索引擎搜索信息
搜索引擎是设计人员为了帮助用户在网络海洋里快 速找到所需信息而开发的检索系统。工作原理是根据一 定的策略运用特定的程序从因特网上搜集信息,且对信 息进行提炼、组织和管理,并能快速地把检索到的相关 信息展示给用户。 因特网发展早期,以雅虎为代表的分类目录查询网 站非常流行。网站中的分类目录由人工整理维护,精选 互联网上的优秀网站,并进行简要的描述,分类放置不 同目录下。用户查询时,通过一层层的点击来查找自己 的网站,过去也有人把这种基于目录的检索服务网站称 为搜索引擎。随着技术的进步,搜索引擎发展出了多种 模式,如全文搜索引擎、元搜索引擎、垂直搜索引擎等。
2.佐意综合搜索(chinazss): 佐细分了不同的搜索类别,如软件搜索,游戏搜索,视频搜索
,新闻搜索,网页搜索,地图搜索,音乐搜索,企业搜索等。看似页面 简单,却搜索功能却很强大。佐意综合搜索可以说是元搜索中的一 个典范。 该搜索引擎还可直接查询手机号码归属地,IP查询等。
三、在当前页中查找信息(P30)
如果打开的网页文字内容过多,可以通过IE“编辑” 菜单上的“查找(在当前页)”功能来快速定位 到要查找的字,词位置。
以新浪网为例操作如下:
四、对获取的信息进行评价 (P30-31)
因特网是个开放性的平台,信息来源极为广泛,任 何人都可以随时在因特网上自由发表言论和信息, 因此,真话和谎言同时并存于因特网上。眼见的 并不一定为真实,有图也未必是真相。我们既要 自我约束,不在网络上制造谎言、传播谣言,也 要努力提升自己鉴别信息的能力。
1、全文搜索引擎(P27-28)
平常我们用得最为索引 擎的使用方法。
2、垂直搜索引擎(P29)
垂直搜索引擎是相对于通用搜索引擎的信息 量大、查向不准确、深度不够等提出来的新 的搜索引擎模式,是通过针对某一特定领域、 某一特定人群或某一特定需求提供的有一定 价值的信息和相关服务,与一般全文搜索相 比,垂直搜索引擎显得更加专注、具体和深 入,如餐饮、旅游、购物等。
数据结构与算法教学大纲
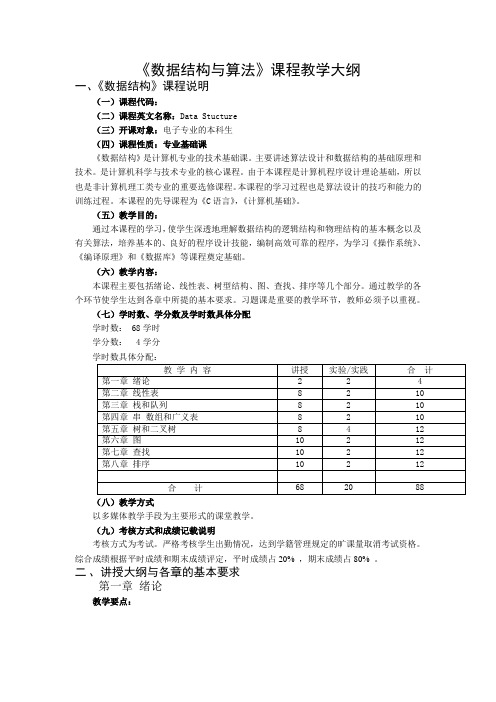
《数据结构与算法》课程教学大纲一、《数据结构》课程说明(一)课程代码:(二)课程英文名称:Data Stucture(三)开课对象:电子专业的本科生(四)课程性质:专业基础课《数据结构》是计算机专业的技术基础课。
主要讲述算法设计和数据结构的基础原理和技术。
是计算机科学与技术专业的核心课程。
由于本课程是计算机程序设计理论基础,所以也是非计算机理工类专业的重要选修课程。
本课程的学习过程也是算法设计的技巧和能力的训练过程。
本课程的先导课程为《C语言》,《计算机基础》。
(五)教学目的:通过本课程的学习,使学生深透地理解数据结构的逻辑结构和物理结构的基本概念以及有关算法,培养基本的、良好的程序设计技能,编制高效可靠的程序,为学习《操作系统》、《编译原理》和《数据库》等课程奠定基础。
(六)教学内容:本课程主要包括绪论、线性表、树型结构、图、查找、排序等几个部分。
通过教学的各个环节使学生达到各章中所提的基本要求。
习题课是重要的教学环节,教师必须予以重视。
(七)学时数、学分数及学时数具体分配学时数: 68学时学分数: 4学分(八)教学方式以多媒体教学手段为主要形式的课堂教学。
(九)考核方式和成绩记载说明考核方式为考试。
严格考核学生出勤情况,达到学籍管理规定的旷课量取消考试资格。
综合成绩根据平时成绩和期末成绩评定,平时成绩占20% ,期末成绩占80% 。
二、讲授大纲与各章的基本要求第一章绪论教学要点:通过本章的教学使学生初步了解《数据结构》的内容和目的,掌握数据结构的概念以及分类、抽象数据类型的表示与实现、算法的概念、算法的特性、算法的目标、算法效率的度量、算法的存储空间需求。
1、使学生准确掌握数据结构的概念。
2、使学生领会抽象数据类型的表示与实现。
3、使学生充分理解算法的概念。
4、明确算法的特性。
5、明确算法的目标。
6、熟练地掌握算法效率的度量。
7、掌握算法的存储空间需求。
教学时数:4学时教学内容:第一节数据结构概述第二节数据结构的概念一、基本概念二、数据结构及分类三、数据结构课程的内容第三节数据类型和抽象数据类型一、数据类型二、抽象数据类型第四节算法和算法分析考核要求:1、数据结构概述(识记)2、数据结构的概念2.1基本概念(识记)2.2数据结构及分类(识记)2.3数据结构课程的内容(识记)3、数据类型和抽象数据类型3.1数据类型(领会)3.2抽象数据类型(领会)4、算法和算法分析(应用)第二章线性表教学要点:通过本章的教学使学生初步了解线性表的结构特点;掌握顺序的和链式的存储结构各自特色;熟练掌握线性表的操作,以及链表的指针运算和各种链表的操作;理解循环链表以及双向链表。
《大学计算机基础》教学课件 第3章 文字处理软件Word2016

3.2 文档编辑
第三章 文字处理软件Word2016
(5)查找与替换文本
查找 利用查找功能可以方便快速地在文档中找到指定的文本 简单查找 查找选项 高级查找
替换 替换操作是在查找的基础上进行的 ,可以将查找到的文本按要求进
行替换(文字、格式)
13
3.2 文档编辑
第三章 文字处理软件Word2016
第三章 文字处理软件Word2016
3.3.1 字符格式设置
对字符格式的设置决定了字符在屏幕上显示和打印输出的样式
通过功能区进行设置 通过对话框进行设置 通过浮动工具栏进行设置
17
3.3 文档排版
3.3.2 段落格式设置
段落对齐方式 左对齐 右对齐 居中对齐 两端对齐 分散对齐
段落缩进 左缩进 右缩进 首行缩进 悬挂缩进
32
3.4 表格制作
3.4.6 表格排序与数字计算
表格中数据的计算 表格中数据的排序
第三章 文字处理软件Word2016
33
第三章
第三章 文字处理软件Word2016
内容导航
第一节 新建、打开及保存文档 第二节 文本基本操作 第三节 字符及段落排版 第四节 创建及美化表格 第五节 图形与图像处理 第六节 页面设置与打印
3.6.1 设置页眉与页脚 3.6.2 设置纸张大小与方向 3.6.3 设置页边距 3.6.4 设置文档封面 3.6.5 稿纸设置 3.6.6 打印预览与打印
26
3.4 表格制作
3.4.1 创建表格 3.4.2 表格内容输入 3.4.3 编辑表格 3.4.4 美化表格 3.4.5 表格转换为文本 3.4.6 表格排序与数字计算
第三章 文字处理软件Word2016
第三节:价值排序

第三节:你好,我是Angie张丹茹,欢迎收听我的副业赚钱课。
今天我们一起来学习,想要做好副业的,其中一个重要的思维认知:也是据我了解,那些财富自由的人,都知道的一个公式:思维>注意力>时间>金钱我们先来简单的解释一下公式里四个关键词所代表的意思。
第一个关键词,思维。
所谓思维是指当你面对一个状况时你是怎么想。
比如说你身边原本比你发展得差的同学,因为自己的不断学习和精进,现在变得越来越优秀了。
你是觉得哇,我要向她学习,她究竟是怎么办到的?如果你是这么想的,你一定会越来越优秀,这个世界一定会善待一个有着开放的态度、爱学习的人。
还是觉得,这有什么了不起的,我要是努力起来,肯定不会比她差。
如果你是这么想的,那你大概率会成为一个固执而不愿意改变的人。
不同的思维习惯,会让一个人在面对同样的情况下,做出完全不同的反应,最终导致完全不同的结果。
思维还有另外一层意思,你有没有建立起对一个问题产生质疑和思考的习惯。
很多人看完书、听完课就算了,别说行动,记都记不住。
但养成思考和记笔记的习惯,会让你对问题有更深刻的理解和吸收。
第二个关键词,注意力。
注意力是指你在做一件事时,是否全身心投入去做,还是只是看起来很努力而已。
举个例子,你在听我在讲的这堂课的同时,还和同事在聊天。
或者一边听我讲课,一边开小差想着今天晚上要不要约同事去逛街。
你看似在听课,但完全不知道自己听了什么内容,只是看起来在听课而已。
你的注意力完全不在自己正在做的事情上,而是走神到外太空去了。
第三个关键词,时间。
时间简单来说是指,你花多少时间去做一件事。
在这里我更想要表达的是,重视自己的时间价值,把时间花在有价值的事情上。
我们有很多小伙伴,每天的时间很多,但都拿来浪费掉了,刷手机啊、无聊啊、和同事瞎聊天啊。
也有些小伙伴,每天都很忙碌,都一日下来却发现自己什么事都没有干成。
我们要学会重视自己的时间及其价值。
第四个关键词,金钱。
金钱简单来说是指,你愿意花多少钱去做一件事。
《数据结构》课程教案

《数据结构》课程教案课程类别:专业基础课合用专业:计算机应用技术授课学时:32 学时课程学分:4 学分一、课程性质、任务课程性质:《数据结构》是计算机应用技术专业的必修课程,也是研究如何对数据进行组织和设计、如何编制高效率的处理程序的一门基础学科。
课程任务:1、学习计算机程序编写中的数据组织和设计;2、数据的物理结构和逻辑结构;3、经典算法的设计和算法效率的分析。
二、课程培养目标:(一)知识目标通过理论学习和程序的编写,使学生系统地掌握程序中数据的组织、数据的物理结构和逻辑结构,在重要算法的实现上逐步提高编程能力。
(二)技能目标通过课程的学习,让学生掌握重要的数据结构,对数据的逻辑结构和物理结构有深入的理解,同时能编写出使用重要算法知识的程序,并运用所学知识编写程序解决实际中的问题。
(三)素质目标通过课程的学习,让学习学会自学,培养学生的自学能力、克服学习艰难的能力,同时让学生掌握计算机编程中数据结构的学习方法,并养成严谨、认真、子细、塌实、上进的好习惯。
三、选用教材与参考资料教材版本信息《数据结构与算法简明教程(Java 语言版)》清华大学出版社叶小平陈瑛主编教材使用评价本教材经过两年的使用,得到了读者一致认可,同时也在不断改进,适合高职高专教学使用,内容基础、重难点突出,符合高职高专“理论够用、注重实践”的要求。
选用的参考资料严蔚敏.吴伟民《数据结构(C 语言版)》.清华大学出版社.2022 年版殷人昆. 《数据结构》 .清华大学出版社.1999 年版《C 语言程序设计》 .石油大学出版社《C 语言程序设计》 .中国石油大学出版社.2022 年版四、本课程与其他课程的联系与分工先修课程《离散数学》、《程序设计基础》后续课程《面向对象技术》、《操作系统》与其他课程配合与取舍情况《数据结构》与《离散数学》知识点结合较多,《离散数学》讲求逻辑思维能力的培养和训练,《数据结构》中逻辑结构的学习也需要逻辑思维能力做铺垫。
算法设计与分析4第三部分第三章

第三部分第三章 蛮力法
分析该算法的效率: 分析该算法的效率: S1:确定输入规模的参数为n S1:确定输入规模的参数为n S2:基本操作是内层循环体中的比较运算 S2: S3:基本操作次数的计算:外层循环执行次数为N S3:基本操作次数的计算:外层循环执行次数为N-1 内层循环执行次数为N 我们可以用求和公式给出: 次,内层循环执行次数为N-i-1次,我们可以用求和公式给出: =n(nC(n)= n − 2 n −1 =n(n-1)/2∈θ(n2)
第三部分第三章 蛮力法
排序问题是我们经常见到的,当前, 排序问题是我们经常见到的,当前,人们已经开 发出了几十种排序方法。 发出了几十种排序方法。 1、选择排序 排序思想:首先从要排序的数中选择最小的数与 排序思想: 第一个数交换位置, 第一个数交换位置,然后再从乘下的数中再 找出最小的数与第二个数交换位置, 找出最小的数与第二个数交换位置,直到剩 下两个数, 下两个数,我们选择较小的数放到倒数第二 个位置,经过n 轮这样的操作后, 个位置,经过n-1轮这样的操作后,数就按 从小到大的顺序排好了。 从小到大的顺序排好了。
第三部分第三章 蛮力法
第三,如果要解决的问题实例不多, 第三 , 如果要解决的问题实例不多 , 而且蛮力法可 以用一种能够接受的速度对实例求解,那么, 以用一种能够接受的速度对实例求解 , 那么 , 设 计一个更高效算法所花费的代价很可能是不值得 的。 第四,即使效率通常很低, 第四 , 即使效率通常很低 , 仍然可以用蛮力算法解 决一些小规模的问题实例。 决一些小规模的问题实例。 最后,一个蛮力算法可以为研究或教学目的服务, 最后 , 一个蛮力算法可以为研究或教学目的服务 , 可以用它来恒量同样问题的更高效的算法。 可以用它来恒量同样问题的更高效的算法。
信息检索技术(1)

第十三页,共61页。
截词符用来对检索词(干)进行扩展。在不同的检索系统中,截词符有不同的表示方 法,通常用(chánɡ yònɡ) “?”或者“*”来表示。 截词方式: 按截断的位置来分共有三种:后截断、中间截断、前截断; 按截断的字符数量来分:有限截词(limited truncation)、无限截词(unlimited truncation)。 平时用得较多的是后截断(无限截词和有限截词)和中间截断(仅允许有限截词)。 (1)后截断 后截断即前方一致检索,是最常用(chánɡ yònɡ)的检索技术。将截词符放在一个词干 的后边,以表示其后可有无限或有限个字符。
第七页,共61页。
(2)逻辑(luó jí)“或”:用“OR”或“+”表示
在检索中,你也可以用逻辑“或”(OR)连接关键词。检索 式(A OR B )可以检索到包含A或者B或者A和B同时出现的文 献。OR最好用于针对一个(yī ɡè)概念的同义词检索。很显然, 使用OR可以扩大检索范围。
第八页,共61页。
第二十三页,共61页。
信息检索的基本(jīběn)流程
分析(fēnxī)检索要求 选择(xuǎnzé)数据库
确定检索词
修改检索式Biblioteka 不满意第二十四页,共61页。
构成检索式
第十一页,共61页。
图(a)
图(b)
图(c)
第十二页,共61页。
1.2 截词算符( truncation )
Comput*er
截词符就是用一个符号来代替单词的一部分或某个字母。截词符只用于英文检 索(jiǎn suǒ)。 截词检索(jiǎn suǒ)的作用是减少检索(jiǎn suǒ)词的输入而保 证相关检索(jiǎn suǒ)概念的涵盖,同时也方便解决语言文字拼写方面的差异 (如美式英语和英式英语),避免漏检。这样可以扩大检索(jiǎn suǒ)范围, 提高查全率,节省检索(jiǎn suǒ)时间。 看看下面这些例子:
语句排序及其答题技巧

【解析】②③⑤④①。该题的 第⑤句特别需要关注,因为它 的开头‚这想象的喜悦‛起到 了‚勾前‛的作用——紧承③句 末尾的‚而是依据这种想象‛; 它的结尾‚悟性的陶醉‛起到 了‚连后‛的作用——连接着④ 句的开头‚我们的感动‛。这 样,③⑤④就形成了一个近似 顶真修辞格的勾前连后的句群。
二、层次分解法
【解析】B。供排序的句子分为三 个层次:⑤句为第一层次,总提 ‚中国最早的区域地理著作‛—— “《山经》和《禹贡》”;③①句为 第二层次,分述‚《山经》”和 ‚《禹贡》”;②④句为第三层次, 总说‚中国区域地理著作‛此后的 发展情况,而④句则是对②句的例 证。这样,五句话就形成了‚总— 分—总‛三个鲜明的层次。据此, 横线上的五句话应排列为⑤③①② ④,故选B。
第三节 语句排序型试题 的答题方法
事物的联系具有普遍性,孤立的单个句子在片段中是不存在的,它必然 会与文章整体、所在片段、前后句发生某种必然的联系。同时,从语言 连贯的要求来看,它也要求前后句子保持某种关系。因此,我们就可以 抓住这些联系来分析语句排序型试题的规律,从而探索出科学实用的答 题方法。
ቤተ መጻሕፍቲ ባይዱ
①《禹贡》主要以山脉、河流和海 洋为自然分界,把所描述的地区分 为九州,不受当时诸侯割据形势的 局限,把广大地区作为一个整体来 研究,分别阐述九州的山川、湖泽、 土壤、物产等,是自然区划思想的 萌芽。 ②此后,主要论述疆域、政区建制 沿革的著作不断涌现,除正史有地 理志外,各省、府、州、县也多编 有地方志。 ③《山经》以山为纲,综述远及黄 河和长江流域之外的广大地区的自 然条件。 ④班固所著《汉书•地理志》是中 国第一部疆域地理著作。 ⑤中国最早的区域地理著作是战国 前后出现的《山经》和《禹贡》。 A.⑤③①④② B.⑤③①②④ C.④②③⑤① D.④②③①⑤
40 第三节 排列活动顺序

三、排列活动顺序的工具与技术
前导图法包括活动之间存在的4种类型的依赖关系 (1)结束-开始的关系(F-S型) (2)结束-结束的关系(F-F型) (3)开始-开始的关系(S-S型) (4)开始-结束的关系(S-F型)
三、排列活动顺序的工具与技术
通常,每个节点的活动会有如下几个时间: (1)最早开始时间(ES),某项活动能够开始的最早时间。 (2)最早结束时间(EF),某项活动能够完成的最早时间。 (3)最迟结束时间(LF)。为了使项目按时完成,某项活 动必须完成的最迟时间。 (4)最迟开始时间(LS)。为了使项目按时完成,某项活 动必须开始的最迟时间。
三、排列活动顺序的工具与技术
4、提前量与滞后量 在活动之间加入时间提前量与滞后量,可以更准确
地表达活动之间的逻辑关系。
提前量是相对于紧前活动,紧后活动可以提前的时 间最。例如,对一个大型技术文档,技术文件编写小组 可以在写完文件初稿(紧前活动)之前15天着手第二稿 (紧后活动)。在进度规划软件中,提前量往往表示为负 数。
滞后量足相对于紧前活动,紧后活动需要推迟的刚 间量。例如,为了保证混凝土有10天养护期,可以在两道 工序之间加入10天的滞后时间。在进度规划软件中,滞后 量往往表示为正数。
四、排列活动顺序的输出
(1)项目进度网络图 (2)项目文件更新:活动清单、活动属性、里程碑清单、 风险登记册等。
典型真题
1、(2015.11)活动排序是指识别与记载计划活动之间的 逻辑关系,项目经理对所管理的项目进行活动排序。( ) 是在活动过程中所需的信息和资料。
C.外部依赖关系
D.网络图
A.项目进度网络图
B.请求的变更
C.项目范围说明书
D.更新的活动清单
5个圆点不同的排序教案

5个圆点不同的排序教案教案标题:五个圆点不同的排序教案I. 教学目标1. 理解排序的概念和重要性;2. 掌握五种不同的排序算法:冒泡排序、选择排序、插入排序、快速排序和归并排序;3. 能够分析和比较不同排序算法的时间复杂度和空间复杂度;4. 能够编写简单的排序算法代码。
II. 教学准备1. 讲义和习题册;2. 白板、黑板或投影仪;3. 笔记本电脑或计算机。
III. 教学过程第一节:介绍排序的概念和重要性(15分钟)A. 引入话题:请学生举例说明为什么需要进行排序。
B. 讲解概念:解释什么是排序以及为什么它在计算机科学中如此重要。
C. 探索应用场景:让学生思考并讨论在现实生活中需要使用到排序的场景,并列举一些例子。
第二节:冒泡排序(20分钟)A. 演示过程:通过示意图或代码演示冒泡排序的过程。
B. 讲解原理:详细解释冒泡排序是如何工作的,包括比较和交换元素。
C. 时间复杂度分析:讨论冒泡排序的时间复杂度,并与其他排序算法进行比较。
D. 编写代码:指导学生编写冒泡排序的代码并进行测试。
第三节:选择排序(20分钟)A. 演示过程:通过示意图或代码演示选择排序的过程。
B. 讲解原理:详细解释选择排序是如何工作的,包括查找最小值和交换元素。
C. 时间复杂度分析:讨论选择排序的时间复杂度,并与其他排序算法进行比较。
D. 编写代码:指导学生编写选择排序的代码并进行测试。
第四节:插入排序(20分钟)A. 演示过程:通过示意图或代码演示插入排序的过程。
B. 讲解原理:详细解释插入排序是如何工作的,包括将元素插入已排好序的子数组中。
C. 时间复杂度分析:讨论插入排序的时间复杂度,并与其他排序算法进行比较。
D. 编写代码:指导学生编写插入排序的代码并进行测试。
第五节:快速排序(25分钟)A. 演示过程:通过示意图或代码演示快速排序的过程。
B. 讲解原理:详细解释快速排序是如何工作的,包括选取基准值和分割数组。
C. 时间复杂度分析:讨论快速排序的时间复杂度,并与其他排序算法进行比较。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第三节排序和查找
一、教材分析
排序和查找算法是一种数据处理问题最常用的算法思想,在日常生活和学习过程中,经常需要对各种数据进行查找,而且总是希望要查找的数据井然有序,这样可以节约时间和精力,其实就是排序问题,在绝大多数情况下,查找是和排序紧密结合在一起的。
本节在编写上力求前面体现排序和查找算法的基本思想,设计了一个典型的“运动员比赛成绩管理问题”,本节在设计上,就是让学生通过经历一个充分体现查找和排序的活动的算法分析设计过程,体验和感受相对比较简单的冒泡排序法和顺序查找法的基本思想,了解排序和查找的应用场合。
在实践示例中通过与基本排序查找算法对比引入改良的算法选择排序法和二分查找法,让学生深入理解和掌握排序和查找算法的基本思想。
通过运动会管理程序不同模块对数组的引用,让学生了解变量的作用范围。
通过课堂三个教学活动的分析设计,让学生深入理解和体会模块化程序设计思想。
排序和查找算法的原理与解析法和穷举法相比复杂了一些,如果通过大量的实践应用,也是很容易掌握的,在学习指引中有明确的描述。
在活动设计上,用到了两个“分析”和一个“实现”,旨在让学生重点关注冒泡法的分析过程和顺序查找法的分析过程,并在程序实现的过程中,体会变量的作用范围和两个分析子程序的调用过程,在宏观上渗透模块化程序设计思想。
1.教学活动一分析:分析比赛成绩排序算法并编写程序
3.教学活动三分析:实现运动会管理的应用程序
4.选择排序算法及示例分析:
选择排序算法是对冒泡排序算法的改进,通过下面的活动分析,旨在让学生在对比分析过程中掌握排序的基本思想。
熟练掌握两种排序算法的使用过程及关键问题的处理过程,尤其是不同排序算法之间的排序原理的区别,决定了学生在今后解决实际问题中选择何种排序算法的重要依据,是学生算法分析素养的提升的关键环节。
示例:寻找一个数列中最小数的方法
查询过程:采用循环和选择程序结构,按顺序逐一比较数列中相邻的两个数,通过交换位置或记忆位置的方式,找到最小数。
5.二分查找算法及示例分析:
二分查找算法是对顺序查找算法的改进,通过下面的活动分析,旨在让学生在对比分析过程中掌握不同的查询思想。
熟练掌握两种查询算法的使用过程及关键问题的处理过程,尤其是不同查询算法之间的查询分析过程的区别,决定了学生在今后解决实际问题中选择何种查询算法的重要依据,是学生算法分析素养的提升的关键环节。
示例:在有序数列A{3,16,20,27,35,39,46,48,55,73}中查找20和71
6.变量的作用范围
DIM的意思是声明的意思,而PRIV A TE是私有的意思,DIM只用于声明变量,由于变量的默认声明是私有的,所以DIM和PRIV A TE在声明变量上基本上是一样。
而private和public是指对变量,过程、函数的访问类型。
它不仅仅用于变量,还用于对象、过程、函数。
如:private function find2(k as Integer) as integer
……
end function
则find2函数只能在定义的模块中被调用。
理解和掌握两种排序和查找方法的基本思想是本节的重点内容,熟练运用排序和查找算法的基本思想分析实际问题和实现程序设计过程是本节的难点所在。
二、教学建议
建议本节分成三课时完成。
第一课时完成教学活动一和“学习指引”中的“排序算法”;第二课时完成教学活动二和“学习指引”中的“查找算法”;第三课时完成教学活动三和“学习指引”中的“变量的作用范围”。
1.为了满足一些基础较好和想要深入了解排序和查找算法法的学生需求,教师在课前整理一些用排序和查找算法实现的典型程序设计过程,供他们选择探究和体验。
2.教师可以提供一些关于排序和查找算法应用的网站供学生自主学习使用。
1.开始活动一:比赛成绩排序
(1)提出问题:对运动会比赛成绩进行排序,教师可以使用电子表格软件让学生体会排序前后数据发生的变化。
同时,让学生了解不同类型数据的升序
和降序有什么规则?
(2)分组讨论:教师可以先不提出计算机排序的方法,而是让学生充分发挥自己的想象力,寻找排序的方案,用自然语言记录排序的过程,并讨论哪种
方案能更快地完成排序
(3)提示:在讨论排序方案的时候,学生往往会忽略一些细节问题,比如数据如何互换位置等,所以教师要在学生记录排序过程的时候适时地提出这个
问题
2.分析排序算法:在自然语言所描述的排序过程的基础上,总结出排序算法
(1)如果学生提出类似冒泡排序的算法,可以直接引入下面的讨论,否则,由教师演示“冒泡排序”的过程,完成活动一的步骤1~2
(2)分组讨论:“冒泡排序”算法的原理
(3)思考:数组在排序算法中的作用是什么?数组的下标在排序算法中的作用是什么?
(4)根据算法编写程序,完成活动一的步骤3
3.介绍“学习指引”中的“排序算法”
排序算法的本节教学的一个重点,主要是让学生了解冒泡排序和选择排序的过程,在教学中,教师可以用对比的方法比较这两种排序方法,从而达到深入理解的目的。
其中,选择排序要涉及数组,教师应该复习关于数组的知识,而选择排序中最值的获得要涉及数组的值和数组的下标,这些关系比较容易混淆,是学生理解上的难点,教师可以通过实验(比如学生按照高矮排序等),让学生亲身体会。
4.思考:算法是如何实现升序和降序的?
5.开始活动二:查找运动员比赛成绩
教材的活动二引用了查找试卷的活动,但为了保持一致,建议用查找某个参赛号的运动员是否存在来代替。
(1)提问:如果只知道某运动员的参赛号,要求确认该运动员的资料是否存在(2)分组讨论:如果人工查找,该如何操作,请用自然语言描述你的查找过程(3)思考:运动员的参赛号和运动员的资料是如何关联起来的?
(4)设计算法
(5)编写程序
6.介绍“学习指引”中的“查找算法”
查找算法是本节的另一重点,包括顺序查找和二分法查找两种,其中二分法查找是教学的难点,首先要让学生理解二分法查找的前提条件是有序数列,教师可以通过对比有序数列的查抄和无序数列的查找让学生理解这一点,而二分法查找更关键的内容在于如何获得中间位置,这是一个难点,教师并不一定要忙着提供答案,可以让学生提出取中间位置的算式,然后用实验数据代入,最后确定正确的算式。
7.开始活动三:实现运动会管理的应用程
(1)复习第二章第一节VB可视化开发环境的相关内容,为下面的学习打好基础
(2)建立运动会管理的应用程序框架
(3)建立工程和窗体
(4)实现排序运动员成绩窗体的功能
(5)实现两种排序方式的选择
(6)实现根据运动员的参赛号码查询运动员成绩窗体的功能
8.介绍“学习指引”中的“变量的作用范围”
9.总结:
本节是对算法和程序设计的综合运用,从功能模块的划分、界面设计到程序实现,充分体现模块化程序设计的思想。
1.学生对比分析冒泡和选择排序算法的过程中,教师要结合活动分析引导学生把握两种方法各自的特点和区别等。
2.在分组时,要把具有不同层次基础的学生进行合理组合,把基础好的同学分开,这样有利于学生协作、共同进步。
3.教师在指导学生实践的过程中,重点在于问题分析,尤其是模块化程序设计思想的渗透,让学生认识到任何知识和技能的学习和研究都不是孤立的,而是彼此相互联系,不可分割的,这一点在算法和程序化设计中体现得尤为明显,比如本节每两种算法得改进关系等。
4.本过程仅供参考,希望广大教师结合实际发挥自己的创意,进行更加合理有效的课堂教学处理,并反馈给我们。
让学生分组分模块设计完成这个大型程序,在设计过程中,理解和掌握排序和查找算法,根据学生的理解程度,教师可以采取独立完成、阅读理解和功能填充三种方式开展教学工作。
其中,独立完成是要求学生在教师的指导下,基本独立地完成从模块划分、算法设计到程序实现的所有工作;阅读理解是由教师完成上述工作,而学生阅读算法和程序代码,采取回答问题和编写代码注释的方式完成学习;功能填充则是由教师完成一部分算法和程序代码的设计,而要求学生填写其中一些比较关键的步骤。